Bachelor of Information Systems (Honours) Business Information Systems Faculty of Information and Communication Technology (Kampar Campus), UTAR. It is certified that LIONG YONG XUAN (ID No: 17ACB05552) has completed this Final Year Project/Dissertation/Thesis* titled Detection and Analysis of Fake Reviews on Online Service Portal” under the supervision of Dr Ramesh Kumar Ayyasamy (Supervisor ) from the Department of Information Systems, Faculty/Institute* of Information and Communication Technology. This project helps me gain more knowledge about fake review detection techniques that I never bothered with before.
Enormous amounts of products and services are offered via online platforms, generating a considerable amount of information. This paper proposes a framework of a machine learning-based counterfeit detection model to determine which classification algorithm is most effective with the proposed framework. Bachelor of Information Systems (Honours) Business Information Systems Faculty of Information and Communication Technology (Kampar Campus), UTAR.
Introduction
- Problem Statement and Motivation
- Project Objectives
- What are the current methods using for fake reviews detection?
- Which classification algorithm is the most effective in the proposed Machine Learning based detection model?
- Contributions
- Report Organization
The purpose of this project is to research and analyze current methods of detecting fake reviews. A good method of detecting fake reviews measures the integrity value of a review, the credibility value of reviewers, and the credibility value of a product or service. The reason for researching and studying the actual methods they use to detect fake reviews is to understand how effective the detection methods are and what is the limitation of the detection methods.
If a better system is in place to detect fake reviews, there will be fewer victims. However, fake reviews will ruin the experience of users of online service portals when they have received products or services that are not up to their expectations by reading these fake reviews. The second chapter is a literature review conducted on several current false opinion detection methods and some analysis of existing false opinion detection using machine learning.
Literature Review
Current methods using for fake reviews detection
5 by Liu [12], is the practice of using machine learning technology and methods to identify meaningful information and relationships in web content. Web mining can be divided into three types of tasks: structure, usage exploitation, and content mining. Content mining applies data mining and machine learning methods to gather insights and data and categorize organizations.
Spam detection, including sentiment mining, falls under the category of content mining and takes advantage of features that are just not directly related to the content [13]. Despite the fact that most current machine learning methods are not sophisticated enough to handle spam detection, they are considered to be more effective than manual detection. Several works in literacy look at a variety of machine learning algorithms for false notification detection.
Machine Learning Based Fake Review Detection Method
7 researchers then used three algorithms, including the Support Vector Machine, the Naive Bayes method and the Decision Tree. The PU learning technique is a combination of some positive labels with unlabeled data sets, and it is described below. It is a semi-supervised approach that uses only two classifiers, one labeled as fraudulent and one classified as unlabeled, and does not use a negative as a true training example.
Then classification was performed only for unlabeled instances, and labeled instances are created as a result of applying the classifiers. After classifying the cases into positive and negative, the positive examples that were identified as dishonest evaluations are removed from the unlabeled circumstances and the remaining cases are classified as negative examples. Support Vector Machine and Naive Bayes are the two classifiers used in this PU tutorial.
The researchers investigated whether it is able to find a smaller number of events from an unlabeled set by modifying the PU learning approach. At the end of the process, only new negative instances formed by the output of the previous iteration are evaluated, and the classification is applied only to the new negative instances in that iteration. The researchers of the study discovered a way to detect both positive and negative fraudulent reviews.
Their methods included Naive Bayes and a Support Vector Machine classification that used both unigrams and bigrams functions, and the ratings were divided into two categories: fraudulent and non-fraudulent. Based on the differences in review behavior patterns, the researchers used different features depending on review data, reviewer data, and product information. In the study, the researchers used the dataset of Amazon Cell Phones and Electronics product reviews to differentiate between fraudulent and genuine reviews.
The Bayesian setup allows the researchers to represent reviewer spamicity as associated with other known behavioral traits in their Author Spamicity Model (ASM).
Analysis of Existing Fake Review Detection Using Machine Learning
The biggest advantage of using an unsupervised learning strategy is that it allows researchers to distinguish between fraudulent and legitimate reviews without the need for a labeled dataset. Decision Tree (DT) - Random Forest (RF) - Gradient Enhancement Trees (GBTs). Average result with all suggested preprocessing steps).
Proposed Framework
- Proposed Framework
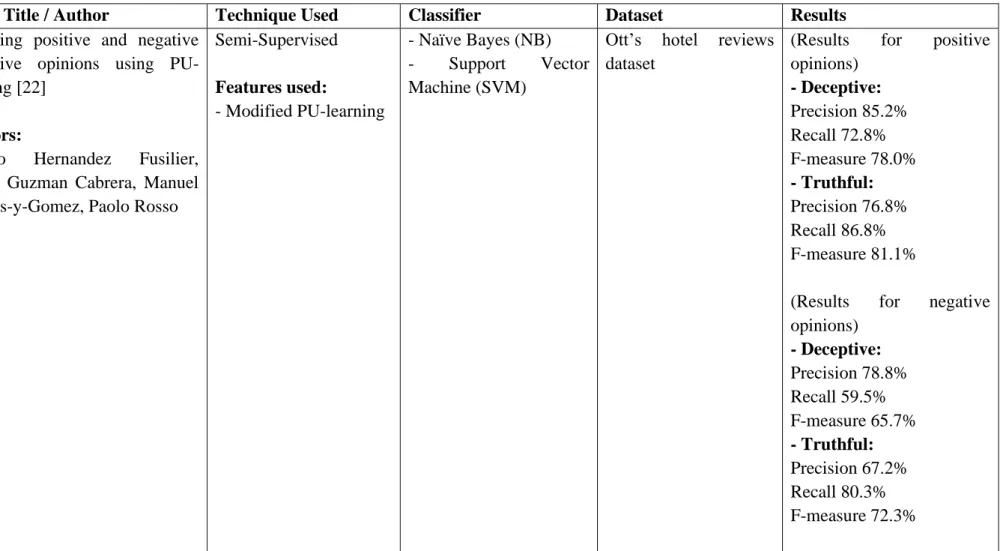
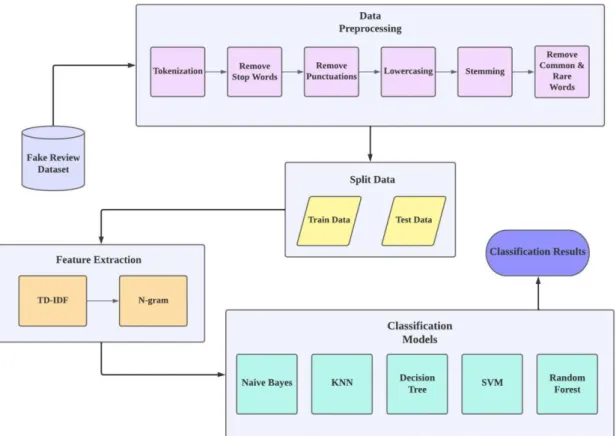
- Data Pre-processing
- Feature Extraction
- Classification Models a. Naïve Bayes (NB)
- Experiment
- Experimental Results
- Conclusion
- Conclusion
When creating NLP or machine learning models, these variations in the source text lead to redundant data. The purpose is to determine how well a machine learning model performs on new data that was not used to train the model. The purpose of feature extraction is to improve the performance of a pattern recognition system or machine learning system.
To provide more useful data for machine learning and deep learning models, feature extraction involves reducing the input to its key features. Another machine learning classifier that focuses on creating a tree to represent a judgment of training data is called Decision-Tree [29]. Successful solutions to overfitting issues arising in decision trees include Random Forest [30].
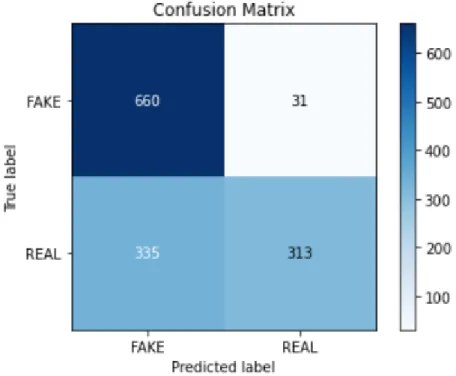
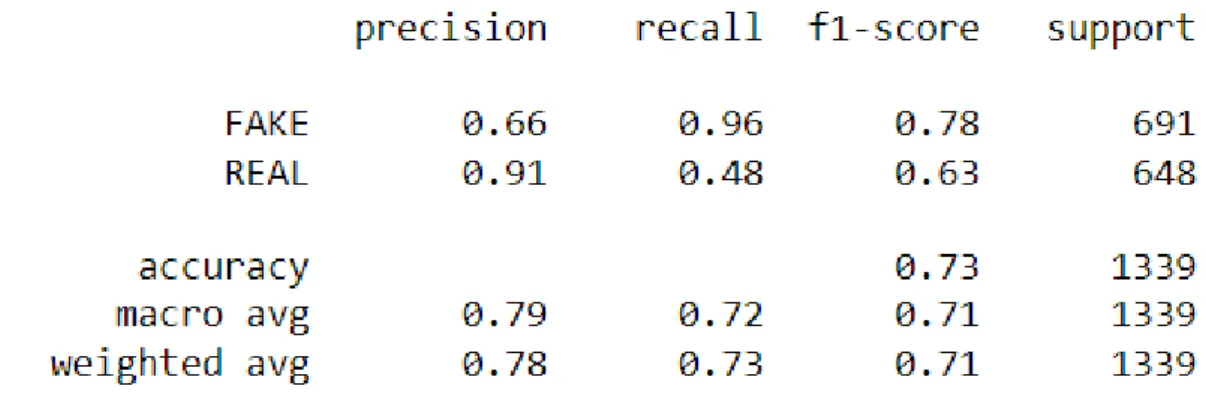
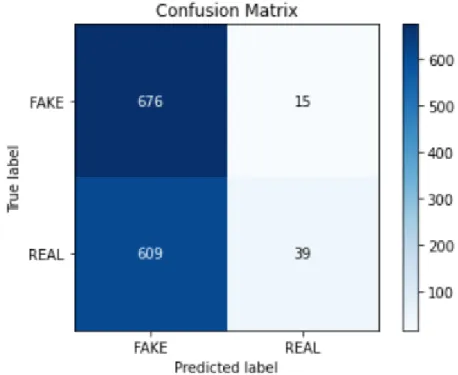
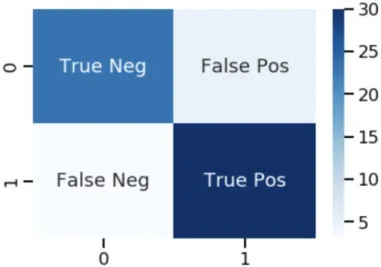
The confusion matrix from testing with the Naïve Bayes (NB) classifier is given in Figure 4.2. The fake review detection accuracy we obtained with the NB classifier is 72.66% with an average precision of 0.79, an average return of 0.72, and an average F1 score of 0.71. Using the KNN algorithm, we were able to detect fraudulent reviews with an accuracy rate of 53.39%, average precision of 0.62, average return of 0.52, and average F1 score of 0.40.
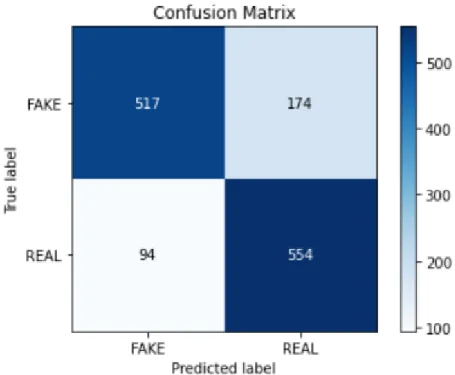
Last but not least, Figure 4.6 shows the confusion matrix from testing with Random Forest. In this paper, we have done an experiment to determine the effectiveness of the proposed framework for detecting fake reviews using Machine Learning technique. Using the Random Forest technique, we managed to get an average accuracy of 0.84, which is quite good.
This is quite an effective rating for identifying fraudulent reviews, as we were able to get an average recall of 0.82 using the Random Forest algorithm, which is close to 1. Using the Random Forest algorithm, we were able to obtain an average F1 score of 0.82, indicating that the proposed model with this classification algorithm is more accurate than other models in the experiment. Precision Recall F1 Score Precision Recall F1 Score Precision Recall F1 Score Precision Recall F1 Score Precision Recall F1 Score.
Recommendation and Future Work
Recommendation and Future Work
Dwivedi, “Prediction of Helpfulness Score of Online Reviews Using Convolutional Neural Network”, Soft Computing, vol. Jansen, “Creating and Detecting Fake Reviews of Online Products,” Journal of Retailing and Consumer Services, vol. Henriques, "Revealing the Characteristics of Incentivized Online Reviews," Journal of Retailing and Consumer Services, vol.
Ester, "Detecting Single Review Spammers Using Semantic Similarity," Proceedings of the 24th International Conference on World Wide Web, 2015. Pallud, "Illusions of Truth - Experimental Insights into Human and Algorithmic Detection of Fake Online Reviews ”, Journal of Business Research, Vol. Shivashankar, “Conceptual level similarity measurement based on spam review detection”, 2010 International Conference on Signal and Image Processing, 2010.
14] Abbasi, Zhang, Zimbra, Chen og Nunamaker, "Detecting falske websteder: The bidrag of Statistical Learning theory," MIS Quarterly, vol. Liu, "Opinion spam and analysis," Proceedings of the international conference on web search and web data mining - WSDM '08, 2008. Munzel, "Assisting consumers in detecting falske anmeldelser: The role of Identity Information Disclosure and consensus," Journal of Detailhandel og forbrugerservice, vol.
Naymat, "The impact of applying different preprocessing steps on spam detection," Procedia Computer Science, vol. Spotting opinion spammers using behavioral footprints," Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, 2013. Thanushkodi, "An improved k-nearest neighbor classification using genetic algorithm," International Journal of Computer Science Issues , vol.
Brodley, "Decision tree classification of land cover based on remote sensing data", Remote sensing of environment, vol.
FINAL YEAR PROJECT WEEKLY REPORT
- WORK DONE
- WORK TO BE DONE
- PROBLEMS ENCOUNTERED
- SELF EVALUATION OF THE PROGRESS
Due to developing a machine learning system for the first time, some of the code does not work as expected. It can do Data Preprocessing for the target data frame, now proceeding to the detection part. Self-assigned tasks are completed, must be accelerated to complete the development of the model.
Interpret the test results in the report and decide which classification method is the most effective. I need to understand and learn the relationship between precision, recall, F1-socre and accuracy rate to determine which classification algorithm is the best in the proposed framework. Based on the experimental results, determine which classification algorithm is the best in the proposed framework.
The proposed framework may not be as effective due to the lack of knowledge of the new learning programming language.
POSTER
Final Year Project Title Detection and Analysis of Fake Reviews in Online Service Portal. The originality parameters required and the restrictions approved by UTAR are as follows: i) The overall similarity index is 20% and below, and. ii) Match of individual sources listed must be less than 3% each and (iii) Matching texts in continuous block must not exceed 8 words. Note: Parameters (i) – (ii) will exclude quotes, bibliography and text matching that are less than 8 words.
Note Supervisor/candidate(s) are expected to provide a soft copy of the complete set of originality report to Faculty/Institute. Based on the above results, I hereby declare that I am satisfied with the originality of the Final Year Project Report submitted by my student(s) as mentioned above. Form title: Supervisor's comments on originality report generated by Turnitin for submission of final year project report (for undergraduate programs).
UNIVERSITI TUNKU ABDUL RAHMAN