L'objectif de ce projet de master est d'évaluer et de simuler analytiquement l'interface homme-machine d'un assistant contextuel à domicile (ACD), développé pour aider les personnes atteintes de troubles cognitifs à effectuer des tâches quotidiennes. Je tiens également à exprimer ma gratitude à tout le personnel de la Faculté des sciences et du Département d'informatique de l'Université de Sherbrooke.

Introduction
Problematique
En France par exemple, au moment de l'évaluation des addictions (dans le cadre du Service Dépendance Expérimentale), le coût des cas les plus lourds était estimé à plus de 12 000 F par mois (Simon et Fronteau, 1996). En effet, la maison intelligente perçoit les actions de la personne et analyse l'adéquation de ce qui a été fait et de ce qui devrait l'être.
Objectifs
Dans le cadre de l'évaluation des interfaces homme-machine conçues dans le cadre des habitats intelligents, la problématique de notre projet consiste en l'évaluation analytique des interfaces ACD en établissant l'uniphase dans le temps d'exécution des tâches requises lors de l'interaction de l'utilisateur avec ces interfaces. . Les interfaces ACD sont évaluées lors de l'exécution d'une activité spécifique de la vie quotidienne.
Structure du memoire
Aper^u sur les methodes devaluation d'interfaces homme machine
- Historique d'interaction homme machine
- Definition du terme interface
- Evaluation d'interfaces homme machine
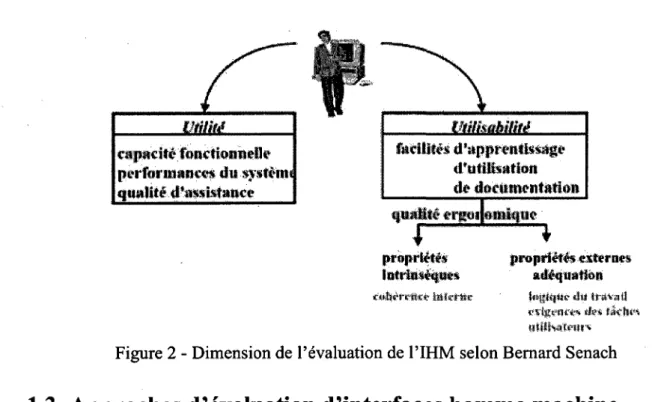
- Utilite et utilisabilite
- Approches d'evaluation d'interfaces homme machine
- Approches empiriques
- Approches analytiques
- Choix des methodes devaluation d'interfaces
- Architectures cognitives
À cette fin, la définition fournie par l'ACM semble couvrir tous les aspects du domaine de l'interaction homme-machine. La personne est vue dans l'interaction homme-machine comme un système de traitement de l'information. La composante physique de l'interaction homme-ordinateur fournit une première estimation du temps nécessaire à l'utilisateur pour interagir avec le système.
Dans notre projet, la loi de Fitts décrit clairement la composante physique ou motrice lors de l'interaction homme-machine. Ces méthodes permettent de considérer non seulement la composante physique, mais également les composantes perceptives et cognitives impliquées dans l'interaction homme-machine. Les architectures cognitives par définition ne sont pas conçues pour simuler ou évaluer des interfaces homme-machine.
Ce n'est qu'après l'intégration de la composante « utilisateur » dans l'interaction homme-machine que les spécialistes des interactions homme-machine ont eu recours aux architectures cognitives. A cet effet, de nombreuses améliorations ont été apportées aux architectures cognitives pour les adapter au domaine de l'interaction homme-machine. Par conséquent, l'architecture cognitive ACT-R nous semble la plus complète et la plus adaptée au domaine de l'interaction homme-machine en intégrant tous les composants ci-dessus.
Evaluation des interfaces de VACD utilisant ACT-R et la loi de Fitts
Avant-propos
Resume de l'article
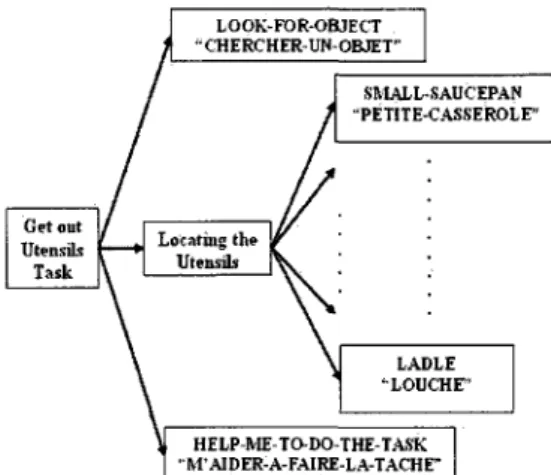
After that, the identification system identifies the name of the object and creates a piece that is located in the visual buffer. The recognition phase begins when a piece of the object is placed in the visual module. The three-step process is applied to each item displayed in the recipe's two-step interface.
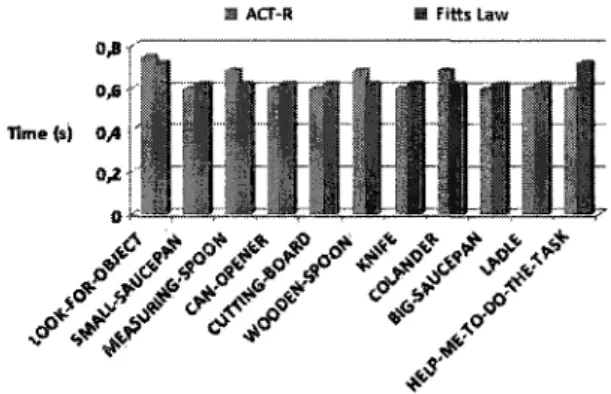
This is due to the initialization of the model such as the target buffer, the retrieval buffer and the visual buffers. The results of the ACT-R model are considered suitable and correct when compared to those obtained by the Fitts Law model. In fact, as shown in Table 2, the estimated time of the entire task in the ACT-R model (15208 ms) is very close to the Fitts Law model time estimated at 14977 ms.
The results of the ACT-R model were compared with those obtained by the Fitts Law model, developed in this study to argue and support our findings. The results of our model were consistent with the results of the Fitts Law model. The model we developed constitutes the first step in the evaluation of HMI using a contextual assistant.

Evaluation des interfaces de l'ACD utilisant ACT-R etGOMS
- Experimentation
- Ajustement du modele ACT-R
- Le modele GOMS
- Avant-propos de l'article
- Resume de 1'article
Then we use a powerful analytical method specifically based on cognitive models to evaluate the contextual assistant's interface, emphasizing the cognitive analysis of the tasks on the one hand, and the time execution of these tasks on the other lace. The analytical evaluation of HMI is based on theories and methods and the results bring a clear understanding of the way the users interact with the interface [21]. The name of the object to be retrieved is displayed on the PDA to highlight the phase of object recognition involved in the cognitive processes.
When the test begins, the subjects first look at the PDA to find out the name of the object and then press the corresponding button in the interface of the contextual assistant with their index finger. The third task is to return to the interface of the main contextual assistant to know the next step of the recipe. The recognition phase begins when the part of the object is stored in the visual buffer.
The three phases are applied to each object that appears in the interface for the two steps of the recipe. The duration of a step in the GOMS model can be defined as the sum of the production cycle duration and the duration of all actions included in the step. The same difference is observed in the predicted time for the object "LOOK-FOR-OBJECT (2)" with the GOMS model.
The main objective of our study is to build and validate models for the evaluation of the contextual assistant interface by simulating the HMI, targeting the time execution of tasks. According to these results, the two models could be used to improve the design of the contextual assistant interface and.

Resultats et discussion
Resultats
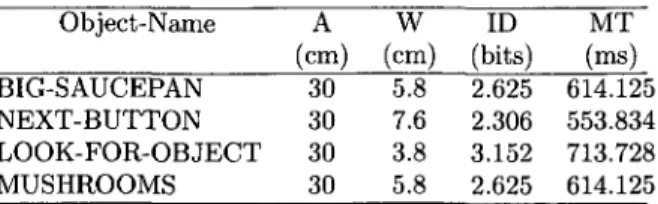
Les résultats de la loi de Fitts sont obtenus par une adaptation du premier modèle présenté au chapitre 2, en ajoutant la deuxième composante physique liée à l'interaction de l'utilisateur avec le PDA. Le temps de sélection d'un objet dans l'interface de l'assistant contextuel est calculé en additionnant le temps de reconnaissance de l'objet sur le PDA, et le temps de sélection de l'objet sur l'écran tactile selon la formule suivante. Ai : est la distance entre le point de départ et la cible sur le PDA Wi : est la largeur de la cible sur le PDA.
Discussion
- Prediction au niveau des objets
- Prediction au niveau des taches
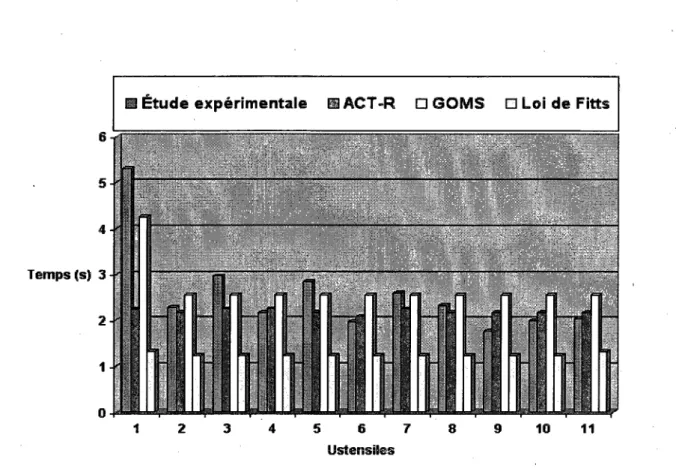
Contrairement à la loi de Fitts, les modèles ACT-R et GOMS mettent l'accent sur les processus cognitifs impliqués dans l'interaction avec l'interface ACD tels que les traitements visuels, cognitifs et manuels, et non plus sur la taille des objets. Comme présenté dans le tableau 2, l'objet « Find-an-object (1) » nécessite plus de temps pour être sélectionné avec le modèle GOMS (4,250 secondes) qu'avec le modèle ACT-R (2,230 secondes). Cette différence significative peut être interprétée par le fait que le modèle GOMS inclut un opérateur mental au début de chaque tâche, qui sert à initialiser cette tâche.
Et puisque la première tâche commence par la sélection de l'objet "Trouver-un-objet (1)", l'opérateur mental est ajouté, qui durera (1,2 secondes). La même explication s'applique à l'objet "Find-an-object (2)", qui nécessite un temps de (2 650 secondes) pour être sélectionné à l'aide du modèle GOMS. Les résultats obtenus par les trois modèles sont proches de ceux obtenus par l'étude expérimentale, et notamment les modèles ACT-R et GOMS, qui fournissent une très bonne prédiction à ce niveau, comme présenté dans le tableau 3.
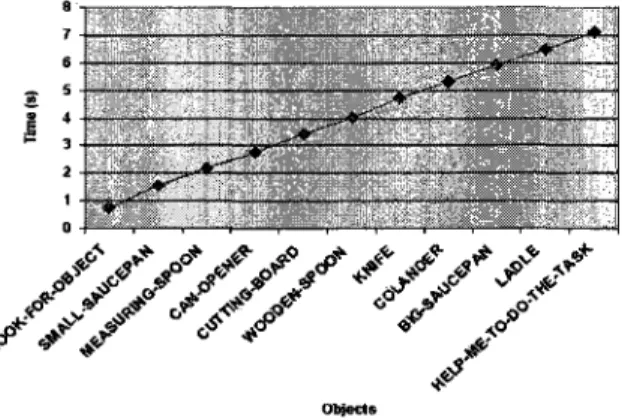
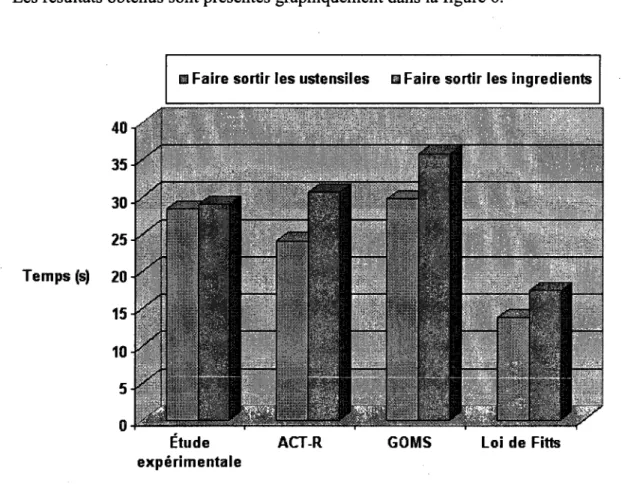
Le tableau 3 montre une observation très intéressante concernant le temps d'exécution obtenu pour les deux tâches lors de l'étude expérimentale. On remarque que le temps d'exécution nécessaire pour réaliser la première tâche (27 193 secondes) est très proche de celui nécessaire pour réaliser la seconde tâche (27 236). Certains objets de la première tâche ne sont pas faciles à identifier, et la similarité entre certains autres objets crée une lenteur d'exécution, et notamment pour la première tâche de la recette comme le montre la figure 7, ce qui explique le temps qu'il faut aux utilisateurs pour sélectionner la l'objet en question comme indiqué dans le tableau 2.
Conclusion
Dans ce premier travail de modélisation, la loi de Fitts a été utilisée pour étayer et valider les résultats obtenus par le modèle ACT-R. Pour valider les performances du premier modèle cognitif d'ACT-R, nous avons opté pour un autre modèle cognitif basé sur le modèle GOMS largement utilisé dans la littérature. Enfin, les résultats obtenus par les modèles ont été comparés à ceux obtenus par une étude expérimentale réalisée au laboratoire DOMUS auprès de personnes saines.
Les résultats obtenus ont été très satisfaisants, plus précisément les résultats obtenus avec des modèles cognitifs qui donnent de meilleures prédictions sur le temps d'exécution des tâches. Ainsi, nous pouvons conclure que si la réalisation de cette évaluation analytique illustre la cohérence et le succès des modèles développés et la réalité de l'approche adoptée, elle ne représente que la première étape d'un processus très complexe de réalisation d'activités dans un environnement intelligent. Cependant, ce travail fournit une base solide et importante pour le reste du processus d'évaluation.
Au final, les modèles développés doivent encore être pleinement améliorés, en termes d'inclusion de plusieurs aspects de la cognition humaine d'une part et de dynamisme dans l'exécution de la tâche en connectant l'environnement de l'utilisateur. Il serait intéressant de faire notre évaluation de l'ensemble de l'activité de cuisine en modélisant d'éventuelles erreurs cognitives qui pourraient être commises dans le processus d'exécution de la tâche. En parallèle de 9a et considérant que l'utilisateur interagit avec son environnement pour réaliser sa tâche, il serait très intéressant d'ajouter un modèle d'environnement qui simule les actions et mouvements de l'utilisateur dans un environnement intelligent.
Bibliographie
An Overview of the EPIC Architecture for Cognition and Performance with Human-Computer Interaction Application. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp ACM New York, NY, USA.