ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
──────── * ───────
NGUYỄN ĐỨC ĐÔNG
DỰ ĐOÁN TÁC DỤNG PHỤ CỦA THUỐC TỪ Y VĂN SỬ DỤNG MÔ HÌNH LAI DỰA TRÊN MẠNG NƠ RON
LUẬN VĂN THẠC SĨ HỆ THỐNG THÔNG TIN
HÀ NỘI 06 – 2021
2
ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
──────── * ───────
NGUYỄN ĐỨC ĐÔNG
DỰ ĐOÁN TÁC DỤNG PHỤ CỦA THUỐC TỪ Y VĂN SỬ DỤNG MÔ HÌNH LAI DỰA TRÊN MẠNG NƠ RON
NGÀNH : CÔNG NGHỆ THÔNG TIN
CHUYÊN NGÀNH : HỆ THỐNG THÔNG TIN
MÃ SỐ : 8480104.01
LUẬN VĂN THẠC SĨ HỆ THỐNG THÔNG TIN
NGƯỜI HƯỚNG DẪN KHOA HỌC: TS. ĐẶNG THANH HẢI
HÀ NỘI 06 – 2021
3
LỜI CAM ĐOAN
Với mục đích học tập, nghiên cứu để nâng cao kiến thức và trình độ chuyên môn nên tôi đã làm luận văn này một cách nghiêm túc và hoàn toàn trung thực.
Trong luận văn tôi có sử dụng một số tài liệu tham khảo của một số tác giả. Tôi đã chú thích và nêu ra trong phần tài liệu tham khảo ở cuối luận văn.
Tôi xin cam đoan và chịu trách nhiệm về nội dung và sự trung thực trong luận văn tốt nghiệp Thạc sĩ của mình.
Hà Nội, ngày 20 tháng 06 năm 2021
Nguyễn Đức Đông
4
LỜI CẢM ƠN
Lời đầu tiên, tôi xin chân thành cảm ơn các thầy cô giáo trong trường Đại Học Công Nghệ - Đại học Quốc Gia Hà Nội, đặc biệt là các thầy cô của khoa Công Nghệ Thông Tin đã truyền đạt cho tôi những kiến thức, kinh nghiệm vô cùng quý báu trong suốt thời gian học tập tại trường.
Tôi xin gửi lời cảm ơn đến TS. Đặng Thanh Hải – giảng viên khoa Công Nghệ Thông tin – Trường Đại học Công Nghệ đã tận tình giúp đỡ và hướng dẫn tận tình trong suốt quá trình làm luận văn.
Cuối cùng, tôi xin được cảm ơn đến gia đình, bạn bè đã động viên, đóng góp ý kiến và giúp đỡ trong quá trình nghiên cứu và hoàn thành luận văn.
Do thời gian, kiến thức và kinh nghiệm của tôi còn hạn chế nên khóa luận không thể tránh khỏi những sai sót. Tôi hy vọng sẽ nhận được những ý kiến nhận xét, góp ý của các thầy cô giáo và các bạn để đồ án được hoàn hiện hơn.
Tôi xin chân thành cảm ơn!
Hà Nội, ngày 20 tháng 06 năm 2021
Nguyễn Đức Đông
5
MỤC LỤC
LỜI CAM ĐOAN ... 3
LỜI CẢM ƠN... 4
MỤC LỤC ... 5
DANH MỤC CÁC KÝ HIỆU VÀ CHỮ VIẾT TẮT ... 7
DANH MỤC HÌNH VẼ ... 8
DANH MỤC BẢNG BIỂU ... 9
MỞ ĐẦU ... 10
CHƯƠNG 1: CƠ SỞ LÝ THUYẾT... 12
1.1. THUỐC VÀ QUY TRÌNH PHÁT TRIỂN THUỐC ... 12
1.1.1. Quy trình phát triển thuốc (Drug development process) ... 12
1.1.2. Tác dụng phụ của thuốc ... 14
1.2. KHAI PHÁ DỮ LIỆU VÀ CÁC THUẬT NGỮ LIÊN QUAN ... 15
1.2.1. Định nghĩa về khai phá dữ liệu ... 15
1.2.2. Bài toán phân lớp dữ liệu ... 15
1.2.3. Học sâu và mạng nơ ron ... 16
1.2.4. Đánh giá mô hình phân lớp ... 20
CHƯƠNG 2: DỰ ĐOÁN TÁC DỤNG PHỤ CỦA THUỐC ... 21
2.1. Bài toán dự đoán tác dụng phụ của thuốc từ y văn ... 21
2.1.1. Bài toán nhận dạng thực thể bệnh lý và thực thể thuốc (Named Entity Recognition – NER) [11] ... 21
2.1.2. Bài toán trích xuất mối quan hệ bệnh lý do thuốc gây ra (Chemical- Induced Disease – CID) ... 22
2.2. Bộ dữ liệu BioCreative V CDR ... 24
2.2.1. Giới thiệu về Pubmed ... 24
2.2.2. Dữ liệu quan hệ thuốc và bệnh - BioCreative V CDR ... 24
2.2.3. Cấu trúc kho dữ liệu BioCreative V CDR ... 25
2.2.4. Cách thức xử lý dữ liệu BioCreative V CDR làm đầu vào cho bài toán trích xuất quan hệ thuốc và bệnh lý ... 28
2.3. Mô hình lai dựa trên mạng nơ ron ... 31
6
2.3.1. Mô hình lai dựa trên mạng nơ ron ... 31
2.3.2. Word embedding ... 33
2.3.3. Position embedding ... 34
2.3.4. Word relation embedding ... 34
CHƯƠNG 3: THỰC NGHIỆM VÀ KẾT LUẬN ... 36
3.1. Cài đặt thực nghiệm ... 36
3.1.1. Cách thức thực hiện ... 36
3.1.2. Các tham số thiết lập mô hình ... 37
3.2. Thử nghiệm ... 38
3.2.1. Cấu hình phần cứng ... 38
3.2.2. Kết quả thực hiện khi cho mô hình học và kiểm tra trên tập dữ liệu test ... 38
3.3. Đánh giá... 40
KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN ... 41
TÀI LIỆU THAM KHẢO ... 42
7
DANH MỤC CÁC KÝ HIỆU VÀ CHỮ VIẾT TẮT
Ký hiệu viết tắt Thuật ngữ đầy đủ Giải thích
ADR Adverse drug reaction Tác dụng phụ của thuốc AI Artificial Intelligence Trí tuệ nhân tạo
CDR Chemical-Disease Relations Mối quan hệ giữa bệnh lý và thuốc
CID Chemical-Induced Disease Bệnh lý do thuốc gây ra CNN Convolutional neural network Mạng nơ ron tích chập
DL Deep Learning Học sâu
DNN Deep Neural Networks Mạng nơ ron sâu
LSTM Long Short-Term Memory Mô hình bộ nhớ ngắn hạn
ML Machine Learning Học máy
NCBI National Center for
Biotechnology Information
Trung tâm quốc gia về thông tin công nghệ sinh học
NER Named Entity Recognition Nhận dạng thực thể
NLM U.S National Library of
Medicine Thư viện Quốc gia Hoa kỳ
RNN Recurrent neural network Mạng nơ ron hồi quy
SDP Shortest Dependency Path Dường dẫn phụ thuộc ngắn nhất
WHO World Health Organization Tổ chức y tế thế giới
XML Extensible Markup Language Ngôn ngữ đánh dấu có thể mở rộng
8
DANH MỤC HÌNH VẼ
Hình 1.1 – Quy trình nghiên cứu thuốc [02] ... 13
Hình 1.2 – Mối quan hệ giữa trí tuệ nhân tạo, học máy, học sâu [01] ... 17
Hình 1.3 – Cấu trúc một nơ ron [14] ... 18
Hình 1.4 – Mô hình mạng nơ ron tích chập [14] ... 18
Hình 1.5 – Mạng nơ ron hồi quy hai chiều [14] ... 19
Hình 2.1 – Dữ liệu định dạng BioC của BioCreative V CDR ... 27
Hình 2.2 – Dữ liệu định dạng PubTator của BioCreative V CDR ... 28
Hình 2.3 – Biểu diễn các thực thể thuốc và bệnh lý được nhận dạng trong y văn và các cặp quan hệ thuốc và bệnh lý được phát hiện trong văn bản trên dữ liệu BioCreative V CDR ... 30
Hình 2.4 – Mô hình thuật toán lai dựa trên mạng nơ ron tích chập và hồi quy [20] ... 32
Hình 2.5 – Đồ thị quan hệ phụ thuộc và đồ thị quan hệ phụ thuộc tối thiểu [20] ... 35
Hình 3.1 – Cách thức thực hiện dự đoán tác dụng phụ của thuốc ... 36
Hình 3.2 – Đồ thị biểu diễn độ chính xác trong quá trình học của thuật toán ... 39
9
DANH MỤC BẢNG BIỂU
Bảng 1.1 – Các giai đoạn phát triển thuốc [16] ... 14
Bảng 1.1 – Phân loại các tác dụng phụ khi sử dụng thuốc [13] ... 15
Bảng 2.1 – Bảng mô tả đầu vào và đầu ra đối với việc nhận dạng thực thể bệnh lý và thực thể thuốc ... 21
Bảng 2.2 – Bảng độ đo với các phương pháp nhận dạng thực thể bệnh lý và thực thể thuốc [11] ... 22
Bảng 2.3 – Bảng mô tả đầu vào và đầu ra của việc trích xuất mối quan hệ giữa thuốc và bệnh ... 22
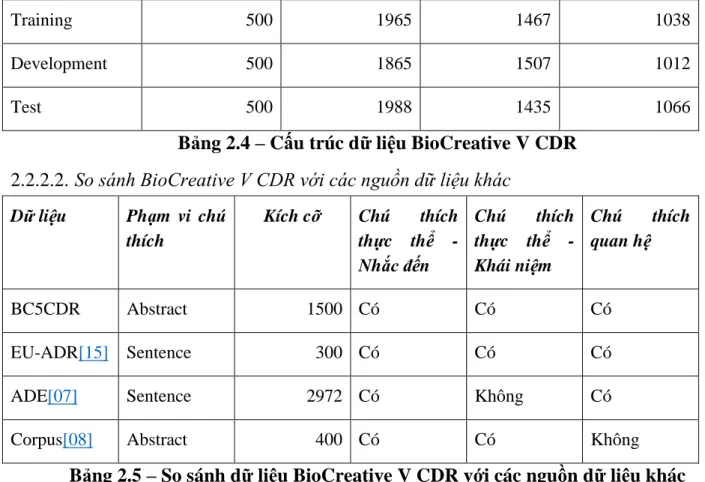
Bảng 2.4 – Cấu trúc dữ liệu BioCreative V CDR ... 25
Bảng 2.5 – So sánh dữ liệu BioCreative V CDR với các nguồn dữ liệu khác ... 25
Bảng 2.6 – Kết quả đầu ra của quá trình tiền xử lý dữ liệu BioCreative V CDR làm đầu vào cho mô hình phân lớp ... 31
Bảng 3.1 – Các tham số thiết lập mô hình chạy thuật toán ... 37
Bảng 3.2 – Cấu hình phần cứng chạy thử nghiệm thuật toán ... 38
Bảng 3.3 – Bảng độ đo kết quả thực hiện (lấy trung bình) ... 39
Bảng 3.4 – Bảng so sánh kết quả của mô hình đề xuất với một số mô hình đã được nghiên cứu trước đây ... 40
10
MỞ ĐẦU
Tác dụng phụ của thuốc là một phản ứng không mong muốn bao gồm cả có lợi và có hại khi người dùng sử dụng một hoặc một vài loại thuốc nào đó. Thông thường các nhà sản xuất thuốc sẽ có mục tác dụng không mong muốn trong hướng dẫn sử dụng thuốc để liệt kê ra danh sách các loại tác dụng phụ đã được biết đến và được xác nhận. Tuy nhiên trên thực tế có rất nhiều tác dụng phụ khác của thuốc được phát hiện trong các công trình nghiên cứu, các y văn (độ tin tưởng cao) hoặc cả trên các trang mạng xã hội (độ tin tưởng thấp hơn) nhưng chưa được liệt kê vào trong hướng dẫn sử dụng thuốc.
Ở Châu Âu, tác dụng phụ của thuốc (ADRs - Adverse drug reactions) gây ra một số lượng bệnh và tử vong đáng kể [06]. Người ta ước tính rằng khoảng 5% số bệnh nhân nhập viện nguyên nhân do tác dụng phụ của thuốc, khoảng 5% bệnh nhân đang điều trị bị ảnh hưởng bới tác dụng phụ trong thời gian chữa trị, và gây ra khoảng khoảng 197,000 ca tử vong trên toàn Châu Âu [06]. Tác dụng phụ của thuốc có thể ảnh hưởng tới 77 tỉ đô la ngân sách chăm sóc sức khỏe của Mỹ mỗi năm [20] .
Thông thường tác dụng phụ của thuốc được nhà sản xuất nghiên cứu và đưa ra trong quá trình phát triển thuốc và được tổng hợp dựa vào báo cáo trực tiếp của người dùng cho nhà sản xuất thuốc. Ngoài ra cũng còn một cách khác là nhà sản xuất sẽ chủ động phân tích các văn bản y sinh nói về thuốc của mình để tìm xem nghiên cứu đó có chỉ ra tác dụng phụ nào hay không. Nguồn văn bản đáng tin cậy nhất thường được sử dụng là những y văn, đó là những văn bản thuộc về lĩnh vực y sinh. Nhưng đây là một công việc vô cùng tốn thời gian, tốn kém và rất khó để lọc ra tất cả các dữ liệu liên quan mới nhất trong các y văn được công bố hàng ngày, hàng giờ.
Theo số lượng được công bố trên Pubmed (https://pubmed.ncbi.nlm.nih.gov/), số lượng bài báo được công bố hàng năm ngày càng tăng lên điển hình như năm 2020 có ~1,6 triệu văn bản y khoa được công bố. Đây là một nguồn tư liệu rất quý giá và mang tính khoa học cao. Nếu sử dụng được nguồn dữ liệu này để thực hiện phân tích một cách tự động sẽ mang lại lợi ích rất lớn.
Mạng nơ ron tích chập và mạng nơ ron hồi quy là 2 mạng nơ ron được sử dụng nhiều trong các bài toán trích xuất quan hệ y sinh, và mỗi mạng nơ ron đều có các điểm mạnh riêng. Bằng cách kết hợp các điểm mạnh của 2 mô hình mạng nơ ron tích chập và mạng nơ ron hồi quy để tận dụng các điểm mạnh của mỗi loại, chúng ta có thể xây dựng được các mô hình tốt hơn cho bài toán trích xuất quan hệ này.
Và đó cũng là lý do tác giả quyết định chọn đề tài “Dự đoán tác dụng phụ của thuốc từ y văn sử dụng mô hình lai dựa trên mạng nơ ron” để thực hiện phân tích các tác dụng phụ của thuốc từ y văn.
11 Luận văn có bố cục gồm 3 chương chính:
Chương 1: Cơ sở lý thuyết
Chương này giới thiệu tổng quan thuốc, quá trình chế tạo thuốc, tác dụng phụ của thuốc và cơ sở lý thuyết về các phương pháp khai phá dữ liệu văn bản.
Chương 2: Dự đoán tác dụng phụ của thuốc
Chương này sẽ mô tả một cách chi tiết về bài toán dự đoán tác dụng phụ của thuốc và việc xây dựng bộ dữ liệu tác dụng phụ của thuốc, cách thức biến đổi dữ liệu, trích chọn đặc trưng dữ liệu
Chương 3: Thực nghiệm và kết luận
Chương này sẽ trình bày việc áp dụng các mô hình phân lớp sử dụng mô hình lai dựa trên mạng nơ ron để dự tác dụng phụ của thuốc và đánh giá mô hình đạt được so với các phương pháp khác.
Cuối cùng là một số kết luận và hướng phát triển trong tương lai
12
CHƯƠNG 1: CƠ SỞ LÝ THUYẾT
1.1. THUỐC VÀ QUY TRÌNH PHÁT TRIỂN THUỐC
1.1.1. Quy trình phát triển thuốc (Drug development process)
Nghiên cứu chế tạo thuốc (Drug discovery) là một quá trình nhằm xác định một phân tử tổng hợp nhỏ hoặc một phân tử sinh học lớn để đánh giá toàn diện xem đó có phải là một ứng cử viên thuốc tiềm năng hay không. Quy trình nghiên cứu chế tạo thuốc hiện đại bao gồm việc nhận dạng căn bệnh cần điều trị và nhu cầu y tế chưa được đáp ứng của nó, lựa chọn các phân tử mục tiêu có thể tạo thành thuốc và xác nhận nó, phát triển thử nghiệm trong phòng thí nghiệm nghiệm, phát triển các hợp chất trong ống nghiệm để thể hiện khả năng và tính hiệu quả trong các mô hình sinh học.
Sau đó, các hợp chất được tối ưu hóa hơn nữa để cải thiện hiệu quả và dược động học của chúng trước khi chúng tiến tới phát triển thuốc. [17]
Quá trình phát triển thuốc (Drug development) có thể được tách biệt thành các giai đoạn phát triển tiền lâm sàng và lâm sàng. Trong quá trình phát triển tiền lâm sàng, các nghiên cứu dược lý học về độc tính và an toàn của ứng viên thuốc được thực hiện để thiết lập nồng độ an toàn tối đa ở động vật và xác định khả năng tác dụng phụ của thuốc đang phát triển. Ngoài ra, các nghiên cứu được thực hiện để hoàn thiện các quy trình hiệu quả về chi phí cần thiết để sản xuất thuốc cũng như quyết định công thức tốt nhất của nó. Nếu ứng cử viên thuốc thể hiện đủ hiệu quả và an toàn trong đánh giá tiền lâm sàng, thì cơ quan quản lý dược phẩm sẽ xin phép để bắt đầu phát triển lâm sàng trong đó tính an toàn và hiệu quả của thuốc được đánh giá trong các nghiên cứu thí điểm và then chốt. [17]
13 Nghiên cứu tiền lâm sàng
Giai đoạn thử nghiệm lâm sàng
GĐ1: Xác định mức độ an toàn
GĐ2: Xác định mức độ hiệu quả
GĐ3: Chứng minh tính ưu việt của
thuốc so với các phương pháp cơ bản GĐ4: Kiểm soát sau khi đưa vào sử dụng
Hình 1.1 – Quy trình nghiên cứu thuốc [02]
Việc khám phá và phát triển các loại thuốc cải tiến đòi hỏi nhiều thời gian và chi phí và hiện tại khoảng 12 năm và trung bình cần 1,8 tỷ đô la để tung ra một loại thuốc mới. [17]
Quá trình phát triển thuốc ở giai đoạn lâm sàng chia ra thành bốn giai đoạn như bảng 1.1 sau:
Giai đoạn Mục đích Quy mô Thời gian
Giai đoạn I: Xác định mức độ an toàn
Kiểm tra tính an toàn của thuốc trên những người khỏe mạnh
20-80 người khỏe mạnh
Vài tuần
Giai đoạn II – Xác định mức độ hiệu quả
Kiểm tra mức độ hiệu quả của thuốc trên tập nhỏ những người bệnh
>= 100 người bị bệnh
Vài tháng
Giai đoạn III – Chứng minh tính ưu việt của thuốc so với các điều kiện
So sánh tính ưu việc của thuốc mới so với các phương pháp chăm sóc tiêu chuẩn hiện tại
>= 1000 người bị bệnh, chia làm 2 nhóm
Một vài năm
14 chăm sóc cơ bản
Giai đoạn IV – Kiểm soát sau khi đưa vào sử dụng
Theo dõi hiệu quả và độ an toàn của thuốc sau khi đưa vào sử dụng
Phụ thuộc vào thực tế
Phụ thuộc vào thực tế
Bảng 1.1 – Các giai đoạn phát triển thuốc [2]
1.1.2. Tác dụng phụ của thuốc Định nghĩa
1.1.2.1.
Có rất nhiều định nghĩa về tác dụng phụ của thuốc khác nhau đã được đưa ra, nhưng trong luận văn này sử dụng định nghĩa của WHO về phản ứng có hại của thuốc, đã được sử dụng trong khoảng 30 năm, đó là “phản ứng tiêu cực và không theo ý muốn đối với một loại thuốc xảy ra ở liều lượng thường được sử dụng cho con người dùng để dự phòng, chẩn đoán hoặc điều trị bệnh, hoặc sửa đổi chức năng sinh lý” [18]
Phân loại các tác dụng phụ của thuốc 1.1.2.2.
Các phản ứng có hại của thuốc được phân thành sáu loại: liên quan đến liều lượng (Augmented), không liên quan đến liều lượng (Bizarre), liên quan đến liều lượng và liên quan đến thời gian (Chronic), liên quan đến thời gian (Delayed), liên quan sau khi ngừng thuốc (End of use), và liên quan thất bại của liệu pháp (Failure).
[13]
Loại tác dụng phụ Đặc trưng Cách thức xử lý Liên quan đến liều
lượng (Augmented)
- Phổ biến
- Liên quan đến tác dụng dược lý của thuốc
- Tỷ lệ tử vong thấp - Có thể dự đoán được
- Giảm liều hoặc dừng lại
- Xem xét tác dụng của liệu pháp đồng thời
Không liên quan đến liều lượng (Bizarre)
- Không phổ biến
- Không liên quan đến tác dụng dược lý của thuốc
- Tỷ lệ tử vong cao - Không dự đoán được
- Dừng lại và không sử dụng trong tương lai
Liên quan đến liều lượng và liên quan đến thời gian (Chronic)
- Không phổ biến
- Liên quan tới sự tích lũy liều lượng
- Giảm liều hoặc ngừng sử dụng - Việc dừng thuốc có
thể kéo dài Liên quan đến thời gian
(Delayed)
- Không phổ biến
- Thường liên quan tới liều lượng
- Thường khó chữa
15
- Xảy ra hoặc trở nên rõ ràng một thời gian sau khi sử dụng thuốc Liên quan sau khi
ngừng thuốc (End of use)
- Không phổ biến
- Xảy ra sau quá trình sử dụng thuốc
- Dùng lại thuốc và giảm dần
Liên quan thất bại của liệu pháp (Failure)
- Phổ biến
- Liên quan tới liều lượng - Thường do tương tác thuốc
- Tăng liều lượng - Xem xét các tác
dụng phụ của liệu pháp đồng thời Bảng 1.2 – Phân loại các tác dụng phụ khi sử dụng thuốc [13]
1.2. KHAI PHÁ DỮ LIỆU VÀ CÁC THUẬT NGỮ LIÊN QUAN
1.2.1. Định nghĩa về khai phá dữ liệu
Xác định một ngành khoa học luôn là một nhiệm vụ gây tranh cãi; các nhà nghiên cứu thường không đồng ý về phạm vi chính xác và giới hạn của lĩnh vực nghiên cứu của họ. Bởi vậy, có thể có những định nghĩa khác về khai phá dữ liệu, nhưng trong luận văn này sử dụng định nghĩa về khai phá dữ liệu như sau:
Khai phá dữ liệu là việc phân tích các tập dữ liệu quan sát (thường lớn) để tìm ra các mối quan hệ chính xác và tóm tắt dữ liệu theo những cách mới một cách dễ hiểu và hữu ích cho người sở hữu dữ liệu.
Các mối quan hệ và tóm tắt thu được từ một công việc khai phá dữ liệu thường được gọi là mô hình hoặc mẫu. Ví dụ như phương trình tuyến tính, quy tắc, cụm, đồ thị, cấu trúc cây và các mẫu lặp lại theo thời gian.
Định nghĩa trên đề cập đến “Dữ liệu quan sát” (Obserrvational data) trái ngược với “Dữ liệu thử nghiệm” (Experrimental data). Khai phá dữ liệu thường xử lý dữ liệu đã được thu thập cho một số mục đích khác ngoài phân tích khai phá dữ liệu (ví dụ như, đó là những dữ liệu được thu thập vì mục đích duy trì các hồ sơ về tất cả giao dịch ngân hàng luôn được cập nhật mới nhất) [10]
1.2.2. Bài toán phân lớp dữ liệu
Giới thiệu về bài toán phân lớp 1.2.2.1.
Bài toán phân lớp là một bài toán xuất hiện thường xuyên trong cuộc sống hàng ngày. Về cơ bản bài toán phân lớp là một quá trình phân chia các đối tượng để mỗi đối tượng được gán vào trong một lớp, và không bao giờ có trường hợp nào một đối tượng được gán vào trong nhiều hơn một lớp.[9]
Có nhiều bài toán phân lớp dữ liệu như
16
- Phân lớp nhị phân: Là bài toán gán nhãn dữ liệu cho đối tượng vào một trong hai lớp khác nhau. Ví dụ như bài toán phân lớp khách hàng muốn/không muốn mua một sản phẩm trong cửa hàng
- Phân lớp đa lớp: Là bài toán phân lớp dữ liệu vào số lượng lớp lớn hơn 2. Ví dụ như bài toán phân lớp chủ thể trong bức ảnh vào các nhóm cây cối, ô tô, xe đạp,…
Quá trình xây dựng mô hình phân lớp dữ liệu 1.2.2.2.
Quá trình phân lớp dữ liệu bao gồm các bước sau:
- Bước 1: Tạo tập dữ liệu huấn luyện và tập dữ liệu kiểm tra: Đây là một bước rất quan trọng ảnh hướng tới độ chính xác của thuật toán
- Bước 2: Tiền xử lý dữ liệu và xác định các đặc trưng của dữ liệu sẽ được sử dụng trong mô hình phân lớp
- Bước 3: Xây dựng mô hình phân lớp
- Bước 4: Đánh giá mô hình và tối ưu hóa tham số của mô hình 1.2.3. Học sâu và mạng nơ ron
Giới thiệu 1.2.3.1.
Trí tuệ nhân tạo (Artificial Intelligence - AI) đề cập đến trí thông minh do máy móc đạt được, trái ngược với trí thông minh tự nhiên của con người. Trí tuệ nhân tạo được con người thiết kế ra để giải quyết một số công việc cụ thể.
Học máy (Machine Learning) là một tập con các phương thức bên trong AI, đặc biệt đề cập đến các thuật toán và mô hình số được thiết lập để phân tích dữ liệu và lấy hoặc học khả năng ra quyết định để đạt được một số nhiệm vụ nhất định. Mục tiêu của nó là phát hiện ra các mô hình ẩn trong dữ liệu dưới các ràng buộc dữ liệu, ví dụ như kích thước dữ liệu và chất lượng, cho phép giải quyết được các vấn đề đang được quan tâm.
Học sâu (Deep Learning - DL), được giới thiệu bởi Aizenberg và cộng sự (2000) [12] là một nhóm các phương thức trong học máy. Bởi vậy, mục đích của các phương pháp học sâu cũng tương tự như học máy.
17 Trí tuệ nhân tạo
Học máy
Học sâu
Hình 1.2 – Mối quan hệ giữa trí tuệ nhân tạo, học máy, học sâu [01]
Điểm khác biệt giữa học sâu và các phương pháp học máy khác là học sâu sử dụng mô hình phân cấp quy mô lớn với kiến trúc nhiều lớp để tự động tạo ra các biểu diễn toàn diện và tìm hiểu các mẫu phức tạp vốn có từ dữ liệu. Ngược lại các phương pháp học máy cơ bản đều phải lựa chọn các đặc trưng được trích xuất thủ công từ dữ liệu làm đầu vào và dựa vào các mô hình tương đối đơn giản để biểu diễn các mẫu dữ liệu vốn có.
Trong những năm gần đây, học sâu ngày càng trở lên phổ biến trong nghiên cứu và ứng dụng bởi vì tính khả thi với các thuật toán tiên tiến, sức mạnh tính toán cao và khả năng sẵn sàng với tập dữ liệu lớn, cũng như hiệu năng ấn tượng so với các thuật toán học máy truyền thống.
Mạng nơ ron 1.2.3.2.
Mô hình được sử dụng phổ biến nhất trong học sâu là mạng nơ ron sâu (Deep Neural Networks – DNN) [14] với một lượng lớn lớp. Thành phần cơ bản xây dựng lên DNN là các nơ ron được thiết kế dựa trên nơ ron hệ thần kinh của con người. Mỗi nơ ron nhân tạo sẽ bao gồm các thành phần chính sau: Một nhóm tín hiệu đầu vào, một hàm tuyến tính, một hàm không tuyến tính, và tín hiệu đầu ra
18
Hàm tuyến tính Hàm kích hoạt không tuyến tính
Đầu vào Đầu ra
Hình 1.3 – Cấu trúc một nơ ron [14]
Mỗi nơ ron sẽ lấy dữ liệu từ đầu vào và trước tiên sử dụng hàm tuyến tính để xử lý chúng. Kết quả sau đó được cho vào một hàm kích hoạt, thường là một hàm không tuyến tính, và trả về kết quả đầu ra.
Thông thường một mạng nơ ron học sâu bao gồm nhiều lớp. Mỗi nơ ron là một lớp sẽ nhận t hông tin từ các lớp trước đó, xử lý chúng và trả về kết quả cho các lớp tiếp theo. Bất kỳ lớp nào được nhúng giữa đầu vào của DNN và đầu ra được gọi là lớp ẩn (hidden layer)
Một số loại mạng nơ ron sâu điển hình có thể kể đến mạng nơ ron kết nối đầy đủ (Fully connected deep neural network), mạng nơ ron tích chập (Convolutional neural network – CNN), mạng nơ ron hồi quy (Recurrent neural network – RNN)
Mạng nơ ron tích chập 1.2.3.3.
Mạng nơ ron tích chập (Convolutional neural network – CNN) [14] : Mạng nơ ron tích chập bao gồm một tập hợp các lớp tích chập được chồng lên nhau và sử dụng các hàm kích hoạt không tuyến tính như ReLU hay tanh.
INPUT CNN1 Pooling CNN2 Pooling Fully
connected Output classification
cat
Hình 1.4 – Mô hình mạng nơ ron tích chập [14]
Phép tích chập sử dụng một hạt nhân và biến đổi với dữ liệu của các lớp trước để tạo ra một dữ liệu mới, gọi là các dữ liệu đặc trưng và cung cấp chúng cho các lớp tiếp theo. Các hoạt gộp, như gộp tối đa (max-pooling) hoặc là gộp trung bình (average- pooling) có thể được thêm vào sau khi tích chập để giảm kích thước của các đặc trưng.
Điều này cho phép mô hình giảm chi phí tính toán và phân tích dữ liệu ở nhiều mức độ
19
khác nhau. Ngoài các lớp này, mạng nơ ron tích chập cũng có thể kết hợp với các mạng nơ ron khác và hoạt động bình thường
Mạng nơ ron hồi quy 1.2.3.4.
Mạng nơ ron hồi quy [14] là mạng nơ ron có cơ chế phản hồi trong các lớp ẩn.
Do tính chất lặp lại, một mạng nơ ron hồi quy có thể được xem tương đương như một chuỗi các mạng sếp chồng lên nhau có cấu trúc giống nhau. Mạng nơ ron hồi quy được thiết kế để học hiệu quả từ dữ liệu tuần tự, chẳng hạn như văn bản, lời nói, dữ liệu chuỗi thời gian.
Cấu trúc ban đầu của mạng nơ ron hồi quy được phát hiện chỉ được giới hạn trong các chuỗi dữ liệu ngắn gây ra hiện tượng không ổn định trong việc truyền bộ nhớ từ các lần lặp trước. Để giảm thiếu vấn đề này, một mô hình bộ nhớ ngắn hạn (long short-term memory – LSTM) được đề xuất, bổ sung thêm các chơ chế để ghi nhớ và giải phóng các thông tin trước đây, thêm mới dữ liệu vào bộ nhớ và tính toán đầu ra mong muốn cho lần lặp đó. Với những sửa đổi này, mô hình bộ nhớ ngắn hạn có khả năng học và thực hiện trên các chuỗi dữ liệu dài hơn nhiều và đã thay thế phần lớn mạng nơ ron hồi quy cơ bản cho hầu hết các tác vụ hiện đại.
h
t-1h
th
t+1h
t-1h
th
t+1x
t-1x
tx
t+1y
t+1y
ty
t-1INPUT FORWARD BACKWARD OUTPUT
Hình 1.5 – Mạng nơ ron hồi quy hai chiều [14]
Trong khi mô hình bộ nhớ ngắn hạn là một trong những mô hình phổ biến nhất của mạng nơ ron hồi quy, một mạng khác cũng được phát triển đó là mạng nơ ron hồi quy hai chiều (Bi-directional RNN)
20 1.2.4. Đánh giá mô hình phân lớp
Khái niệm 1.2.4.1.
Để đánh giá mô hình phân lớp có hiệu quả hay không chúng ta cần phải dựa vào một số tiêu chí cơ bản như độ chính xác, độ phủ hay độ đo điều hòa F,…
Các độ đo trên thường được tính toán dựa trên tập dữ liệu kiểm định (test data).
Giả sử đầu ra của mô hình khi đầu vào là tập dữ liệu kiểm định được mô tả bởi vector vpredict và vector đầu ra đúng của tập kiểm tra là vtrue. Và để đánh giá mô hình, ta cần so sánh giữa 2 vector này với nhau. [01]
Độ chính xác & độ phủ (Precision & Recall) 1.2.4.2.
Độ chính xác đối với lớp 𝑐i :
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛𝑖 = 𝑇𝑃𝑖
𝑇𝑃𝑖+𝐹𝑃𝑖 (1)
Trong đó: 𝑇𝑃𝑖 là số phần tử của lớp 𝑐i được dự đoán đúng, 𝐹𝑃𝑖 là số phần tử được dự đoán vào lớp 𝑐i nhưng bị sai
Độ phủ đối với lớp 𝑐i :
𝑅𝑒𝑐𝑎𝑙𝑙𝑖 = 𝑇𝑃𝑖
𝑇𝑃𝑖+𝐹𝑁𝑖 (2)
Trong đó: 𝑇𝑃𝑖 là số phần tử của lớp 𝑐i được dự đoán đúng, 𝐹𝑁𝑖 là số phần tử đúng của lớp 𝑐i nhưng lại được dự đoán vào lớp khác
Độ đo trung bình điều hòa F 1.2.4.3.
Độ đo trung bình điều hòa F của các tiêu chí Precision và Recall:
- Độ đo trung bình điều hòa F có xu hướng lấy giá trị gần với giá trị nào nhỏ hơn giữa hai giá trị Precision và Recall.
- Độ đo trung bình điều hòa F có giá trị lớn nếu cả hai giá trị Precision và Recall đều lớn.
Tiêu chí đánh giá là sự kết hợp của 2 tiêu chí đánh giá Precision và Recall theo công thức:
𝐹𝑖 = 2 𝑥 𝑃𝑟𝑒𝑠𝑖𝑠𝑖𝑜𝑛 𝑖 𝑥 𝑅𝑒𝑐𝑎𝑙𝑙𝑖
𝑃𝑟𝑒𝑠𝑖𝑠𝑖𝑜𝑛𝑖+𝑅𝑒𝑐𝑎𝑙𝑙𝑖 (3)
Trong đó 𝐹𝑖 là độ đo trung bình điều hòa của lớp 𝑐𝑖, 𝑃𝑟𝑒𝑠𝑖𝑠𝑖𝑜𝑛 𝑖 và 𝑅𝑒𝑐𝑎𝑙𝑙𝑖 chính là giá trị được tính bởi công thức (1) và (2)
21
CHƯƠNG 2: DỰ ĐOÁN TÁC DỤNG PHỤ CỦA THUỐC
2.1. Bài toán dự đoán tác dụng phụ của thuốc từ y văn
Thông thường bài toán dự đoán tác dụng phụ của thuốc từ y văn được chia làm hai bài toán cụ thể như sau:
- Bài toán 1: Nhận dạng thực thể bệnh lý và thực thể thuốc (Named Entity Recognition – NER)
- Bài toán 2: Trích xuất mối quan hệ bệnh lý do thuốc gây ra (Chemical- Induced Disease - CID)
2.1.1. Bài toán nhận dạng thực thể bệnh lý và thực thể thuốc (Named Entity Recognition – NER) [11]
Nhận dạng thực thể bệnh lý và thực thể thuốc là một bài toán tiền xử lý thiết yếu trong việc xử lý các y văn, và là một bài toán xử lý ngôn ngữ tự nhiên. Việc xác định được chính xác các thực thể trong tài liệu sẽ giúp việc xác định các tính chất hóa học, các đặc tính và các mối quan hệ được nêu ra trong văn bản.
Đầu vào Đầu ra
…In unanesthetized, spontaneously hypertensive rats the decrease in blood pressure and heart rate produced by intravenous clonidine, 5 to 20 micrograms/kg, was inhibited or reversed by nalozone, 0.2 to 2 mg/kg…
hypertensive – disease clonidine – chemical nalozone – chemical
Bảng 2.1 – Bảng mô tả đầu vào và đầu ra đối với việc nhận dạng thực thể bệnh lý và thực thể thuốc
Theo ví dụ trên, từ dữ liệu đầu vào chúng ta xử lý tách ra được các thực thể liên quan tới thuốc và bệnh như sau: hypertensive (bệnh lý), clonidine (thuốc), nalozone (thuốc)
Có rất nhiều phương pháp được sử dụng để thực hiện bài toán nhận dạng thực thể thuốc và bệnh lý với độ chính xác cao. Bảng 2.2 đưa ra các phương pháp đã được nghiên cứu và các độ đo cụ thể:
Hệ thống P R F
Stanford NER 82% 83% 82%
MarMoT 85% 85% 85%
22
CRF++ 74% 71% 73%
MITIE 62% 61% 62%
Glample 82% 84% 83%
Majority vote 70% 76% 73%
LSTMVoter 91% 90% 90%
Bảng 2.2 – Bảng độ đo với các phương pháp nhận dạng thực thể bệnh lý và thực thể thuốc [11]
Trong nội dung của luận văn này tác giả không đi chi tiết vào bài toán nhận diện thực thể mà chỉ đi chi tiết vào bài toán trích xuất mối quan hệ giữa thực thể bệnh lý và thực thể thuốc hay chính là tác dụng phụ khi sử dụng một loại thuốc. Các thực thể thuốc và thực thể bệnh lý sẽ được sử dụng sẵn từ dữ liệu đầu vào.
2.1.2. Bài toán trích xuất mối quan hệ bệnh lý do thuốc gây ra (Chemical-Induced Disease – CID)
Bài toán trích xuất mối quan hệ giữa bệnh lý do thuốc gây ra chính là việc xác định một loại bệnh lý xảy ra khi người dùng sử dụng một loại thuốc nào đó được viết trong y văn.
Mô tả cụ thể về bài toán chúng ta có thể xem trong ví dụ sau:
Đầu vào Đầu ra
…The 𝒉𝒚𝒑𝒐𝒕𝒆𝒏𝒔𝒊𝒗𝒆disease effect of 100 mg/kg 𝒂𝒍𝒑𝒉𝒂 − 𝒎𝒆𝒕𝒉𝒚𝒍𝒅𝒐𝒑𝒂chemical was also partially reversed by 𝒏𝒂𝒍𝒐𝒙𝒐𝒏𝒆chemical…
alpha- methyldopa (thuốc) và hypotensive (bệnh giảm huyết áp): Có quan hệ
Bảng 2.3 – Bảng mô tả đầu vào và đầu ra của việc trích xuất mối quan hệ giữa thuốc và bệnh
Như ở trong ví dụ trên, từ đầo vào của bài toán là một đoạn y văn có chứa các loại bệnh lý và thuốc (đã được nhận diện ở bài toán nhận diện thực thể), sau khi trích xuất mối quan hệ giữa thuốc và bệnh lý chúng ta có được một cặp thuốc và bênh lý có quan hệ với nhau (alpha-methyldopa + hypotensive), còn quan hệ giữa thuốc naloxone và thuốc alpha-methyldopa là mối quan hệ tương tác giữa hai loại thuốc với nhau.
Trong luận văn này chỉ làm về việc trích xuất mối quan hệ có giữa thuốc và bệnh lý, nghĩa là một thuốc có tác dụng lên một bệnh lý cụ thể. Đây là một bài toán
23
phân lớp nhị phân. Các cặp quan hệ thuốc và bệnh lý sẽ chỉ có hai tập dữ liệu đó là
“Có quan hệ” và “Không có quan hệ”.
Đặc điểm của hai tập dữ liệu này có dữ liệu không tương đồng với nhau, trong đó tập dữ liệu “Không có quan hệ” có số lượng phần tử lớn hơn rất nhiều so với tập
“Có quan hệ”. Đây chính là bài toán phân lớp nhị phân, dữ liệu đầu vào là các cặp thuốc và bệnh lý trong câu được phân vào hai lớp “Có quan hệ” và “Không có quan hệ”
Nhưng đối với bài toán trích xuất thông tin tác dụng phụ của thuốc, chúng ta chỉ quan tâm tới tập “Có quan hệ” và tập chung tối ưu việc phân lớp các cặp thuốc và bệnh lý vào tập này một cách chính xác và có hiệu quả cao. Vì vậy kết quả để đưa ra đánh giá của luận văn cũng chỉ sử dụng các độ đo chính xác, độ phủ và độ đo trung bình điều hòa F trên lớp “Có quan hệ” để đánh giá mức độ hiệu quả của mô hình.
Vậy chúng ta có công thức để xác định mức độ hiệu quả của mô hình như sau:
Độ chính xác đối với lớp “Có quan hệ” : 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃
𝑇𝑃+𝐹𝑃 (4)
Trong đó: 𝑇𝑃 là số phần tử của lớp “Có quan hệ” được dự đoán đúng, 𝐹𝑃 là số phần tử được dự đoán vào lớp “Có quan hệ” nhưng bị sai
Độ phủ đối với lớp “Có quan hệ” : 𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃
𝑇𝑃+𝐹𝑁 (5)
Trong đó: 𝑇𝑃 là số phần tử của lớp “Có quan hệ”được dự đoán đúng, 𝐹𝑁 là số phần tử đúng của lớp “Có quan hệ” nhưng lại được dự đoán vào lớp khác (lớp “Không có quan hệ”)
Độ đo trung bình điều hòa F:
F = 2 𝑥 𝑃𝑟𝑒𝑠𝑖𝑠𝑖𝑜𝑛 𝑥 𝑅𝑒𝑐𝑎𝑙𝑙
𝑃𝑟𝑒𝑠𝑖𝑠𝑖𝑜𝑛+𝑅𝑒𝑐𝑎𝑙𝑙 (6)
Với Pressision và Recall được tính bởi công thức (4) và (5)
Như chúng ta đã biết, nguồn dữ liệu về y văn rất lớn, tuy nhiên trong luận văn này tác giả chỉ sử dụng nguồn văn bản là các bài báo về y sinh được đăng trên Pubmed, trong đó chỉ sử dụng các nội dung bao gồm tiêu đề và tóm tắt của y văn làm đầu vào để chạy mô hình. Ở luận văn, tác giả chỉ xét tới mối quan hệ của thuốc và bệnh lý được xuất hiện cùng nhau trong cùng một câu, vì vậy các dữ liệu tiêu đề và tóm tắt của y văn sẽ được xử lý tách câu trước khi đưa vào mô hình chạy.
Luận văn chỉ tập trung vào việc trích xuất mối quan hệ giữa thuốc và bệnh lý vì vậy tác giả sử dụng nguồn dữ liệu có sẵn đã được trích xuất các thực thể bệnh lý và
24
thuốc để làm đầu vào cho mô hình đề xuất. Đó chính là bộ dữ liệu BioCreative V CDR sẽ được mô tả cụ thể hơn ở mục 2.2.
2.2. Bộ dữ liệu BioCreative V CDR
2.2.1. Giới thiệu về Pubmed
Pubmed (https://pubmed.ncbi.nlm.nih.gov/) là một nguồn tài nguyên miễn phí hỗ trợ cho việc tìm kiếm và truy suất các tài liệu y sinh và khoa học đời sống với mục đích cải thiện sức khỏe.
Cơ sở dữ liệu của Pubmed chưa nhiều hơn 30 triệu trích dẫn và tóm tắt của tài liệu y sinh. Pubmed được mở miễn phí bắt đầu từ năm 1996 và được duy trì bởi Trung tâm quốc gia về thông tin công nghệ sinh học (National Center for Biotechnology Information – NCBI), tại Thư viện Quốc gia Hoa kỳ (U.S National Library of Medicine – NLM)
Các trích dẫn trong Pubmed chủ yếu xuất phát từ lĩnh vực y sinh và y tế, và các ngành liên quan như khoa học đời sống, khoa học hành vi, khoa học hóa học và kỹ thuật sinh học.
2.2.2. Dữ liệu quan hệ thuốc và bệnh - BioCreative V CDR Giới thiệu về BioCreative V CDR
2.2.2.1.
Xử lý dữ liệu về thuốc, bệnh và mối quan hệ giữa chúng theo cách thủ công có tầm quan trọng đáng kể đối với nghiên cứu y sinh nhưng tốn nhiều chi phí bởi sự phát triển nhanh chóng của các tài liệu y sinh.
Trong những năm gần đây, ngày càng có nhiều sự quan tâm đến việc phát triển các phương pháp tiếp cận việc trích xuất quan hệ thuốc và bệnh lý một cách tự động (Chemical Disease Relation – CDR) với nhiều đề xuất và kỹ thuật khác nhau.
Do đó các nhà khoa học đã lập ra một số các công việc thông qua BioCreative V để tự động trích xuất CDR từ tài liệu. Cụ thể hơn đó là hai công việc: Nhận dạng thực thể bệnh lý và thuốc (Named Entity Recognition - NER) và trích xuất mối quan hệ bệnh lý do thuốc gây ra (Chemical-Induced Disease - CID).
Kết quả của công việc trên là sự ra đời của kho dữ liệu BioCreative V CDR bao gồm 1.500 bài báo trên Pubmed được chú thích về 4409 loại thuốc, 5818 bệnh lý và 3116 tương tác giữa thuốc và bệnh lý.
Dữ liệu Số bài viết Bệnh lý Thuốc CID
25
Training 500 1965 1467 1038
Development 500 1865 1507 1012
Test 500 1988 1435 1066
Bảng 2.4 – Cấu trúc dữ liệu BioCreative V CDR So sánh BioCreative V CDR với các nguồn dữ liệu khác
2.2.2.2.
Dữ liệu Phạm vi chú thích
Kích cỡ Chú thích thực thể - Nhắc đến
Chú thích thực thể - Khái niệm
Chú thích quan hệ
BC5CDR Abstract 1500 Có Có Có
EU-ADR[15] Sentence 300 Có Có Có
ADE[07] Sentence 2972 Có Không Có
Corpus[08] Abstract 400 Có Có Không
Bảng 2.5 – So sánh dữ liệu BioCreative V CDR với các nguồn dữ liệu khác Như trong Bảng 2.5, kho dữ liệu EU-ADR gồm có 300 bài báo Pubmed với 739 loại thuốc, 812 bệnh lý và 300 mối quan hệ giữa thuốc và bệnh lý ở mức câu.
Kho dữ liệu ADE gồm có 2972 bài báo Pubmed ở mức câu với 5776 tác dụng phụ liên quan tới 5063 loại thuốc.
Kho dữ liệu Corpus chỉ cung cấp nhận diện tên bệnh lý và tên tác dụng phụ và không có mối quan hệ giữa bệnh lý và thuốc
2.2.3. Cấu trúc kho dữ liệu BioCreative V CDR
BioCreative V CDR được chia thành 3 tập dữ liệu: Training, Development, Test. Mỗi tập bao gồm 500 bài viết. Dữ liệu chú thích được xử lý sẵn ở cả 2 định dạng PubTator[04] và BioC [05]. Ở định dạng PubTator, các file dữ liệu được lưu dưới dạng text thông thường, câu trúc một bài viết như Hình 2.1 bên dưới. Định dạng BioC chính là định dạng XML tiêu chuẩn gần đây được đề xuất cho việc khai thác các văn bản y sinh và dữ liệu đầu ra. Cấu trúc BioC của dữ liệu BioCreative V CDR như Hình 2.2 bên dưới.
Trong mỗi tập sẽ bao gồm các thông tin: ID của bài viết trên Pubmed, Tiêu đề của bài viết, tóm tắt của bài viết, danh sách các thuốc xuất hiện trong bài viết, danh sách các bệnh lý xuất hiện trong bài viết và danh sách các quan hệ thuốc và bệnh lý xuất hiện trong bài viết.
26
<document>
<id>6504332</id>
<passage>
<infon key="type">title</infon>
<offset>0</offset>
<text>Phenobarbital-induced dyskinesia in a neurologically-impaired child.</text>
<annotation id="0">
<infon key="type">Chemical</infon>
<infon key="MESH">D010634</infon>
<location offset="0" length="13" />
<text>Phenobarbital</text>
</annotation>
<annotation id="1">
<infon key="type">Disease</infon>
<infon key="MESH">D004409</infon>
<location offset="22" length="10" />
<text>dyskinesia</text>
</annotation>
<annotation id="2">
<infon key="type">Disease</infon>
<infon key="MESH">D009422</infon>
<location offset="38" length="23" />
<text>neurologically-impaired</text>
</annotation>
</passage>
<passage>
<infon key="type">abstract</infon>
<offset>69</offset>
<text>A 2-year-old child with known neurologic impairment developed a dyskinesia soon after starting phenobarbital therapy for seizures. Known causes of movement disorders were eliminated after evaluation. On repeat challenge with phenobarbital, the dyskinesia recurred. Phenobarbital should be added to the list of anticonvulsant drugs that can cause movement disorders.</text>
<annotation id="3">
<infon key="type">Disease</infon>
<infon key="MESH">D009422</infon>
<location offset="99" length="21" />
<text>neurologic impairment</text>
</annotation>
<annotation id="4">
<infon key="type">Disease</infon>
<infon key="MESH">D004409</infon>
<location offset="133" length="10" />
<text>dyskinesia</text>
</annotation>
<annotation id="5">
<infon key="type">Chemical</infon>
<infon key="MESH">D010634</infon>
<location offset="164" length="13" />
<text>phenobarbital</text>
</annotation>
<annotation id="6">
<infon key="type">Disease</infon>
<infon key="MESH">D012640</infon>
<location offset="190" length="8" />
<text>seizures</text>
</annotation>
<annotation id="7">
27
<infon key="type">Disease</infon>
<infon key="MESH">D009069</infon>
<location offset="216" length="18" />
<text>movement disorders</text>
</annotation>
<annotation id="8">
<infon key="type">Chemical</infon>
<infon key="MESH">D010634</infon>
<location offset="294" length="13" />
<text>phenobarbital</text>
</annotation>
<annotation id="9">
<infon key="type">Disease</infon>
<infon key="MESH">D004409</infon>
<location offset="313" length="10" />
<text>dyskinesia</text>
</annotation>
<annotation id="10">
<infon key="type">Chemical</infon>
<infon key="MESH">D010634</infon>
<location offset="334" length="13" />
<text>Phenobarbital</text>
</annotation>
<annotation id="11">
<infon key="type">Disease</infon>
<infon key="MESH">D009069</infon>
<location offset="415" length="18" />
<text>movement disorders</text>
</annotation>
</passage>
<relation id="R0">
<infon key="relation">CID</infon>
<infon key="Chemical">D010634</infon>
<infon key="Disease">D004409</infon>
</relation>
</document>
6794356|t|Tricuspid valve regurgitation and lithium carbonate toxicity in a newborn infant.
6794356|a|A newborn with massive tricuspid regurgitation, atrial flutter, congestive heart ...
6794356 0 29 Tricuspid valve regurgitation Disease D014262 6794356 34 51 lithium carbonate Chemical D016651
6794356 52 60 toxicity Disease D064420
6794356 105 128 tricuspid regurgitation Disease D014262 6794356 130 144 atrial flutter Disease D001282
6794356 146 170 congestive heart failure Disease D006333 6794356 189 196 lithium Chemical D008094
6794356 265 288 tricuspid regurgitation Disease D014262 6794356 293 307 atrial flutter Disease D001282
6794356 345 360 cardiac disease Disease D006331 6794356 386 393 lithium Chemical D008094
6794356 511 528 Lithium carbonate Chemical D016651
6794356 576 600 congenital heart disease Disease D006331 6794356 651 672 neurologic depression Disease D003866 6794356 674 682 cyanosis Disease D003490
6794356 688 706 cardiac arrhythmia Disease D001145 6794356 CID D016651 D003490
Hình 2.1 – Dữ liệu định dạng BioC của BioCreative V CDR
28
6794356 CID D016651 D001145 6794356 CID D016651 D003866
Mỗi thuốc và bệnh lý sẽ bao gồm các thông tin: vị trí xuất hiện trong bài viết, tên thuốc/bệnh lý, loại (thuốc/bệnh lý) và mã định danh.
Các bản ghi thực thể thuốc và bệnh lý đã được nhận diện và tách ra thành các dòng riêng có dánh dấu vị trí của chúng xuất hiện trong y văn.
Mối quan hệ của thuốc và bệnh lý xuất hiện trong y văn được thể hiện bởi các dòng có chữ “CID”, tiếp theo là mã định danh của thuốc và mã định danh của bệnh lý.
Chúng ta hiểu được khi một cặp thuốc và bệnh lý xuất hiện tại đây là cặp thuốc và bệnh lý này “Có quan hệ” với nhau
2.2.4. Cách thức xử lý dữ liệu BioCreative V CDR làm đầu vào cho bài toán trích xuất quan hệ thuốc và bệnh lý
Do dữ liệu BioCreative V CDR được cung cấp dưới hai định dạng khác nhau là PubTator (định dạng text) và BioC (định dạng XML) nên chúng ta chỉ cần sử dụng một trong hai loại này để tiến hành xử lý dữ liệu. Ở đây tác giả chọn sử dụng định dạng PubTator để tiến hành xử lý.
Dữ liệu mỗi bài viết trong BioCreative V CDR bao gồm có tiêu đề và tóm tắt của văn bản. Dữ liệu này sẽ được đưa vào xử lý tách câu như sau:
Đầu vào:
227508|t|Naloxone reverses the antihypertensive effect of clonidine.
227508|a|In unanesthetized, spontaneously hypertensive rats the decrease in blood pressure and heart rate produced by intravenous clonidine, 5 to 20 micrograms/kg, was inhibited or reversed by nalozone, 0.2 to 2 mg/kg. The hypotensive effect of 100 mg/kg alpha-methyldopa was also partially reversed by naloxone. Naloxone alone did not affect either blood pressure or heart rate. In brain membranes from spontaneously hypertensive rats clonidine, 10(-8) to 10(-5) M, did not influence stereoselective binding of [3H]-naloxone (8 nM), and naloxone, 10(-8) to 10(-4) M, did not influence clonidine-suppressible binding of [3H]- dihydroergocryptine (1 nM). These findings indicate that in spontaneously hypertensive rats the effects of central alpha-adrenoceptor stimulation involve activation of opiate receptors. As naloxone and clonidine do not appear to interact with the same receptor site, the observed functional antagonism suggests the release of an endogenous opiate by clonidine or alpha-methyldopa and the possible role of the opiate in the central control of sympathetic tone.
Kết quả đầu ra sẽ là một danh sách các câu như sau:
Hình 2.2 – Dữ liệu định dạng PubTator của BioCreative V CDR
29
- Naloxone reverses the antihypertensive effect of clonidine
- In unanesthetized, spontaneously hypertensive rats the decrease in blood pressure and heart rate produced by intravenous clonidine, 5 to 20 micrograms/kg, was inhibited or reversed by nalozone, 0.2 to 2 mg/kg
- The hypotensive effect of 100 mg/kg alpha-methyldopa was also partially reversed by naloxone
- Naloxone alone did not affect either blood pressure or heart rate
- In brain membranes from spontaneously hypertensive rats clonidine, 10(-8) to 10(-5) M, did not influence stereoselective binding of [3H]-naloxone (8 nM), and naloxone, 10(-8) to 10(-4) M, did not influence clonidine- suppressible binding of [3H]-dihydroergocryptine (1 nM)
- These findings indicate that in spontaneously hypertensive rats the effects of central alpha-adrenoceptor stimulation involve activation of opiate receptors - As naloxone and clonidine do not appear to interact with the same receptor
site, the observed functional antagonism suggests the release of an endogenous opiate by clonidine or alpha-methyldopa and the possible role of the opiate in the central control of sympathetic tone
Tiếp theo, dựa vào danh sách các thực thể thuốc và bệnh lý đã được nhận dạng, chúng ta lọc ra các câu có chứa các cặp thuốc và bệnh lý ra như sau. Đầu vào chính là danh sách các câu đã được tách ở trên, danh sách các thực thể thuốc và bệnh lý đã được nhận dạng trong bộ dữ liệu và danh sách các cặp dữ liệu thuốc và bệnh lý có quan hệ với nhau. Sau quá trình xử lý danh sách các câu có chứa cả cặp thực thể thuốc và bệnh lý và mối quan hệ (có quan hệ/không có quan hệ) giữa hai thực thể này sẽ được sử dụng để làm đầu vào cho mô hình.
Ví dụ với danh sách các câu ở trên và cặp quan hệ đã được phân tích trong bộ dữ liệu:
30
Hình 2.3 – Biểu diễn các thực thể thuốc và bệnh lý được nhận dạng trong y văn và các cặp quan hệ thuốc và bệnh lý được phát hiện trong văn bản trên dữ
liệu BioCreative V CDR Chúng ta xử lý được bộ dữ liệu như sau:
Quan hệ Câu Thuốc Bệnh
0 In unanesthetized, spontaneously hypertensive rats the decrease in blood pressure and heart rate produced by intravenous clonidine, 5 to 20 micrograms/kg, was inhibited or reversed by nalozone, 0.2 to 2 mg/kg
clonidine hypertensive
1 The hypotensive effect of 100 mg/kg alpha-methyldopa was also partially reversed by naloxone
alpha-methyldopa hypertensive
0 The hypotensive effect of 100 mg/kg alpha-methyldopa was also partially reversed by naloxone
naloxone hypertensive
0 In brain membranes from
spontaneously hypertensive rats clonidine, 10(-8) to 10(-5) M, did not influence stereoselective binding of
clonidine hypertensive
31 [3H]-naloxone (8 nM), and naloxone, 10(-8) to 10(-4) M, did not influence clonidine-suppressible binding of [3H]-dihydroergocryptine (1 nM)
0 In brain membranes from
spontaneously hypertensive rats clonidine, 10(-8) to 10(-5) M, did not influence stereoselective binding of [3H]-naloxone (8 nM), and naloxone, 10(-8) to 10(-4) M, did not influence clonidine-suppressible binding of [3H]-dihydroergocryptine (1 nM)
[3H]-naloxone hypertensive
0 In brain membranes from
spontaneously hypertensive rats clonidine, 10(-8) to 10(-5) M, did not influence stereoselective binding of [3H]-naloxone (8 nM), and naloxone, 10(-8) to 10(-4) M, did not influence clonidine-suppressible binding of [3H]-dihydroergocryptine (1 nM)
[3H]-
dihydroergocryptine
hypertensive
Bảng 2.6 – Kết quả đầu ra của quá trình tiền xử lý dữ liệu BioCreative V CDR làm đầu vào cho mô hình phân lớp
Trong đó quan hệ bằng 1 đại diện cho việc thuốc và bệnh lý có quan hệ với nhau và bằng 0 đại diện cho việc thuốc và bệnh lý không có quan hệ với nhau. Nếu một câu có chưa nhiều cặp thuốc và bênh lý sẽ được tách ra thành nhiều dòng khác nhau, mỗi dòng đại diện cho một cặp thuốc và bệnh lý.
Từ dữ liệu này chúng ta sẽ sử dụng làm đầu vào cho mô hình chạy được đề xuất tại mục 2.3
2.3. Mô hình lai dựa trên mạng nơ ron
2.3.1. Mô hình lai dựa trên mạng nơ ron
Như ở phần lý thuyết chúng ta đã biết, mạng nơ ron tích chập (CNN) và mạng nơ ron hồi quy (RNN) là 2 mạng nơ ron phổ biến nhất trong mạng nơ ron học sâu.
Trong những năm gần đây, cả RNN và CNN đều đã được áp dụng thành công trong việc trích xuất quan hệ y sinh. Lưu ý rằng giữa CNN và RNN có những đặc tính khác nhau rõ rệt. Mô hình mạng nơ ron tích chập có kiến trúc mạng thần kinh phân cấp và
32
học tốt các đặc trưng từ vựng và cú pháp cục bộ. Ngược lại, mô hình mạng nơ ron hồi quy có kiến trúc mạng nơ ron tuần tư và mạn hơn trong việc nắm bắt các đặc trưng phụ thuộc liên kết nhau. Bởi vậy mô hình mạng nơ ron tích chập phù hợp để nắm bắt các đặc trưng của câu ngắn, trong khi mô hình mạng nơ ron hồi quy thích hợp hơn để xử lý các câu dài và phức tạp.
Để sử dụng các ưu điểm của mạng nơ ron tích chập và mạng nơ ron hồi quy, luận văn sử dụng một mô hình kết hợp để trích suất các quan hệ y sinh dựa trên trình tự câu, trình tự từ phụ thuộc và trình tự quan hệ phụ thuộc.
s1 s2..
..
sn..
s1 s2..
..
sn..
s1 s2..
..
sn..
Output layer
Word embed ding Position embe dding Word embed ding Position embe dding Relation embed ding
Bi-recurrent neural network Convolutional neural network 1 Convolutional neural network 2
Max-pooling Max-pooling
Softmax layer
Global max-pooling flatten
Hình 2.4 – Mô hình thuật toán lai dựa trên mạng nơ ron tích chập và hồi quy [20]
Như trong Hình 2.4, mô hình của luận văn bao gồm một Bi-RNN và hai CNN được sử dụng. Trong đó mạng nơ ron hồi quy được sử dụng chính là LSTM cho phép xử lý các câu dài và có cấu trúc phức tạp. Các đặc trưng được sử dụng trong thuật toán bao gồm word embedding (word2vector), position embedding và word relation embedding.
Mạng Bi-RNN sử dụng đầu vào là các câu với các đặc trưng word embedding và position embedding. Sau đó sử dụng một lớp flatten dùng để giảm kích thước của đầu ra cho phù hợp với đầu ra của 2 mạng CNN.
Hai mạng CNN, trong đó một mạng sử dụng đầu vào là các câu với đặc trưng word embedding và position embedding, một mạng sử dụng đầu vào là các câu với đặc trưng relation embedding. Hai mạng CNN này được kết hợp lại với nhau qua một lớp global max-pooling.
33
Cuối cùng việc kết hợp giữa mạng Bi-RNN và hai mạng CNN thông qua lớp softmax để đưa ra kết quả cuối cùng, chính là mô hình lai dựa trên mạng nơ ron được đề xuất để dự đoán tác dụng phụ của thuốc.
2.3.2. Word embedding
Word embedding là cách gọi chung của các mô hình xử lý ngôn ngữ và các phương pháp học theo đặc trưng trong xử lý ngôn ngữ tự nhiên. Trong đây, các từ hoặc các cụm từ được ánh xạ thành các vector số. Đây là một công cụ vô cùng quan trọng được sử dụng trong hầu hết các thuật toán xử lý ngôn ngữ tự nhiên (học máy, học sâu, …) vì để có thê sử dụng được các thuật toán này, các từ/cụm từ cần được biến đổi thành các số để thuật toán có thể hiểu được.
Có 2 loại Word Embedding chính đó là:
- Frequency-based embedding: Phương pháp này sử dụng tần số xuất hiện của các từ để tạo ra các vector từ.
- Prediction-based embedding: Phương pháp này xây dựng các vector từ dựa vào các mô hình dự đoán
Frequency-based embedding có 3 loại phổ biến nhất đó là:
- Count vector: Là dạng đơn giản nhất, chỉ xét đến tần số xuất hiện của từ trong một văn bản
- Tf-idf vector: Ngoài việc xét đến tần số xuất hiện của một từ trong một văn bản, tf-idf vector còn sử dụng cả tần số xuất hiện của từ trong toàn bộ tập dữ liệu. Do đó tf-idf có tính phân loại cao hơn so với Count vector
- Co-occurrence Matrix: Là phương pháp sử dụng tần số xuất hiện của các cặp từ trong một cửa sổ ngữ cảnh. Nổi bật nhất trong phương pháp này đó là GloVe (Global Vector)
GloVe (Global vector) [16] là một trong những phương pháp mới để xây dựng vector từ. Ý tưởng của phương pháp này được xây dựng từ công thức tỉ số sau:
𝑃(𝑘|𝑖) 𝑃(𝑘|𝑗) (4)
Trong đó 𝑃(𝑘|𝑖), 𝑃(𝑘|𝑗) là xác suất xuất hiện của từ k trong ngữ cảnh của từ i, j Công thức của 𝑃(𝑘|𝑖):
𝑃(𝑘|𝑖) = 𝑋𝑖𝑘
𝑋𝑖 = 𝑋𝑖𝑘
∑𝑚𝑋𝑖𝑚 (5)
Trong đó 𝑋𝑖𝑘 là số lần xuất hiện của từ k trong ngữ cảnh i. 𝑋𝑖 là số lần xuất hiện của từ i trong ngữ cảnh của toàn bộ các từ còn lại ngoại trừ i.
![Hình 1.1 – Quy trình nghiên cứu thuốc [02]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360866.0/13.893.120.783.73.569/hình-1-quy-trình-nghiên-cứu-thuốc-02.webp)
![Bảng 1.1 – Các giai đoạn phát triển thuốc [2]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360866.0/14.893.174.815.82.236/bảng-1-1-giai-đoạn-phát-triển-thuốc.webp)
![Hình 1.2 – Mối quan hệ giữa trí tuệ nhân tạo, học máy, học sâu [01]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360866.0/17.893.342.651.92.394/hình-mối-quan-tuệ-nhân-tạo-học-học.webp)
![Hình 1.3 – Cấu trúc một nơ ron [14]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360866.0/18.893.277.717.136.256/hình-1-3-cấu-trúc-nơ-ron-14.webp)
![Hình 1.4 – Mô hình mạng nơ ron tích chập [14]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360866.0/18.893.150.767.800.928/hình-mô-hình-mạng-nơ-ron-tích-chập.webp)
![Hình 1.5 – Mạng nơ ron hồi quy hai chiều [14]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360866.0/19.893.135.802.568.999/hình-mạng-nơ-ron-hồi-quy-hai-chiều.webp)

![Bảng 2.2 – Bảng độ đo với các phương pháp nhận dạng thực thể bệnh lý và thực thể thuốc [11]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360866.0/22.893.122.818.83.313/bảng-bảng-phương-dạng-thực-bệnh-thực-thuốc.webp)