The pronunciation dictionary is a key resource required during the development of an automatic speech recognition (ASR) system. In this thesis, we adapt a British English pronunciation dictionary to Standard South African English (SSAE), as a case study in dialect adaptation.
Context
The experiments described in the coming chapters include the steps taken towards the implementation of a Standard Pronunciation Dictionary for South African English (SSAE) for ASR purposes. Therefore, to develop a pronunciation dictionary specialized in SSAE, it would have to be adapted for the dialect.
Problem statement
A pronunciation dictionary drives the automatic speech recognition (ASR) system as it analyzes the speech data and creates acoustic patterns. The main output of this experiment will be a pronunciation dictionary that reflects the SSAE pronunciation of the phoneme KIT.
Overview of thesis
Since the main source of variation between BE and SSAE is caused by the phoneme KIT, this phoneme is selected as a case study. The sources of information used during pronunciation modeling are discussed, including both the extraction and analysis of information about pronunciation, as well as the verification of this information.
Pronunciation
Pronunciation variance origins
These include the anatomy of the speaker, whether he or she has a speech impediment or disability, how to accommodate the listener, his accent, the dialect he uses, his native language, the level of formality of his speech, the amount and importance of the information they convey (Jande, 2006), their environment (Lombard effect) and even their emotional state (Strik and Cucchiarini, 1999). Caution must also be taken when using an automatic method in the analysis of speech (such as ASR), as an automatic system does not perceive speech in the same way as a human, and thus can infer variance through its speech modeling process.
Pronunciation variance realisations
Non-native pronunciation
Standard South African English
Diphthongs in South African English
The KIT vowel in SSAE
The KIT split—the fact that words such as 'chin' and 'kit' are pronounced with a similar vowel in British English and two different vowels in SSAE—is one of SSAE's most distinctive features.
Pronunciation modelling in ASR systems
Pronunciation modelling levels
Pronunciation variance modelling
- Pronunciation dictionary
- Information representation
- Multiple and single pronunciations
- Acoustic modelling
- Language modelling
- Combination modelling
- Modelling limitations
Implementation of pronunciation variance in the pronunciation dictionary can be implemented as one of two methods, known as enumeration and formalization (Strik and Cucchiarini, 1999). Usually the formalisms take the form of rules, which are applied to the entire pronunciation dictionary.
Information sources for identifying pronunciation variants
- Data-driven analysis methods
- Phone recognisers
- Word recognisers
- Foreign data
- Phoneme confusability
- Data-driven filtering techniques
- Frequency counters
- Acoustic likelihood analysis
- Classifiers
- Knowledge based information sources
In fact, pronunciation variants can be found without manipulating the ASR system at all, but through the analysis of the existing system, as discussed in the next section. When using data-driven techniques, one must be careful in filtering the possible variants so as not to over-specialize the system based on the test set and the characteristics of the ASR system (Kessenset al., 2003).
Pronunciation dictionary verification
Filtering techniques are useful for the selection of optimal pronunciation variants for inclusion in a pronunciation dictionary for an ASR system. These formalisms can be used to manipulate a pronunciation dictionary so that an ASR system is better able to recognize natural continuous American English.
Summary
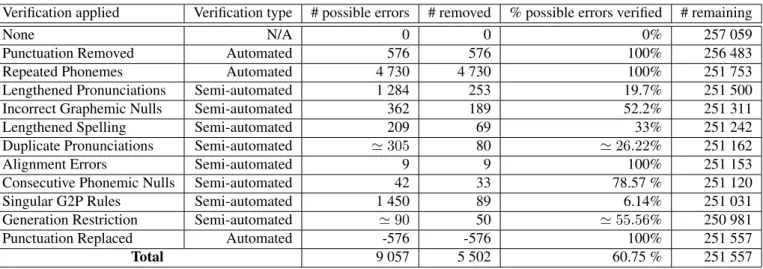
One of the results of this algorithm is that it recognizes when a grapheme maps to a phoneme that it does not regularly map to. Once dictionary verification is performed, the dictionary can be used in experiments that seek to improve the performance of an ASR system through dictionary manipulation, yielding more reliable results.
Dictionary verification techniques background
Grapheme to phoneme alignment
Viterbi alignment (Viterbi, 1967) is commonly used to obtain these mappings, where the alignment algorithm uses the probability that each grapheme maps to a particular phoneme. The probability that each grapheme maps to an invalid phoneme is conditional on the preceding phoneme.
Grapheme to phoneme rule extraction
Initial probabilities are calculated by selecting the entries in a dictionary that have the same phonemic and orthographic lengths. Phonemic nulls are consistently used to indicate that the previous phoneme is realized by more than one grapheme.
Variant modelling
Pseudophonemes are used to represent two or more phonemes which may appear in a given place in the pronunciation of a word. This ensures that if the pseudophonemes are removed again, nothing will have been added or removed from the original vocabulary.
Approach
- Written word and pronunciation length relationships
- Alignment analysis
- Grapheme to phoneme rules
- Duplicate pronunciations
- Variant analysis
The generation restriction rules accompanying words containing more than one pseudo-phoneme may allow possibly incorrect entries to be flagged in the dictionary. Once a list of generation constraint rules is obtained, the list of multiple pseudophonemes occurring in words is short enough to be evaluated manually.
Experimental setup
Dictionary
If constraint rules are generated for more than three sounds, this can mean one of three things:.
Process
The rules that predict the phonemic representation of a grapheme from a single word are used to create a list of possible erroneous entries in the dictionary. The list of generation restriction rules is searched for strings of pseudo-phonemes occurring in words.
Dictionary analysis results
- Pre-processing
- Removal of systematic errors
- Spelling verification
- Lengthened pronunciations
- Graphemic null analysis
- Lengthened spelling
- Duplicate pronunciations
- Alignment
- Grapheme to phoneme rules
- Pseudo-phonemes
An example of a valid use of the phonemes is the word BESTOWER with the pronunciation / B IH S T OW AX R. The generation constraint rules used together with pseudophonemes provide insight into the relationships between the pronunciation variants of a word.

Effectiveness of error analysis
Results summary
This method has been found to have the most accurate prediction of incorrect entries due to its manual verification rate of 55.56%. The analysis of words containing several consecutive gnulls is found to be the most effective method, achieving an accuracy of 78.57.
Conclusion
Their architecture was studied and selectively implemented in the basic system used in this thesis. The results of the system are shown in Section 4.3 and concluding remarks in Section 4.5.
ASR system particulars
- Pronunciation dictionary
- Speech corpus
- Technical implementation
- Optimising system parameters
- Accuracy definition
- Word Insertion Penalty testing
- Gaussian mixture optimisation
Deletions = Number of times an entity occurs but is not recognized as itself or any other entity. Insertions = Number of times an entity is recognized as occurring, but where neither it nor any other entity occurs.
Results
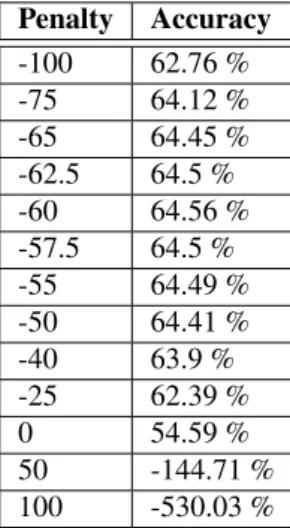
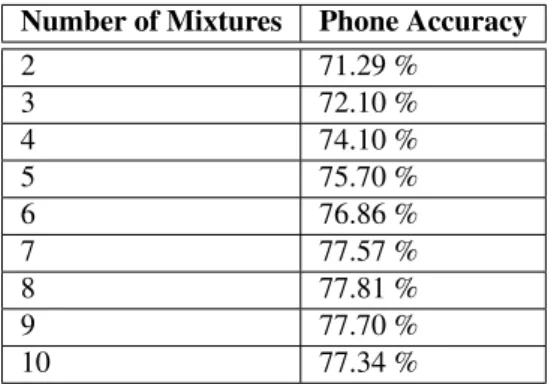
Penalty testing is performed to ensure that as the ASR system evolves, its results will be directly comparable to other iterations of the ASR system. The number of Gaussian mixtures was experimentally optimized (see Table 4.3), using phoneme accuracy as a measure of optimality.
Comparing the verified and unverified dictionaries
Conclusion
The need for diphthongs in a lexicon is evaluated by systematically replacing them with selected variants and analyzing the system results. These experiments together allow an understanding of the function of diphthongs in SSAE to be gained.
Automatic suggestion of variants
Approach
Because the diphthong has been removed, the system must now select the best option from the alternatives that remain. The phonemes in alignment B that align with the diphthong in alignment A are noted as possible alternatives to the specific diphthong.
Results
- Diphthong analysis: /AY/
- Diphthong analysis: /EY/
- Diphthong analysis: /EA/
- Diphthong analysis: /OW/
The variants selected for evaluation are all phonetically similar or identical to the standard British English definition of the diphthong /EA/. The variants selected for evaluation are all phonetically similar or identical to the standard British English definition of the diphthong /OW/.
Evaluating replacement options
Approach
It is interesting to note that all four selected main sounds are phonetically close to a definition of the diphthong /OW/. To test the diphone theory detailed in Section 5.2.1, if a diphone does not constitute one of the two final selected alternatives, the selected final alternative is run together with the diphone alternative to see if the ASR system selects the diphone. as a better model for a diphthong.
Results
- Diphthong analysis: /AY/
- Diphthong analysis: /EY/
- Diphthong analysis: /EA/
- Diphthong analysis: /OW/
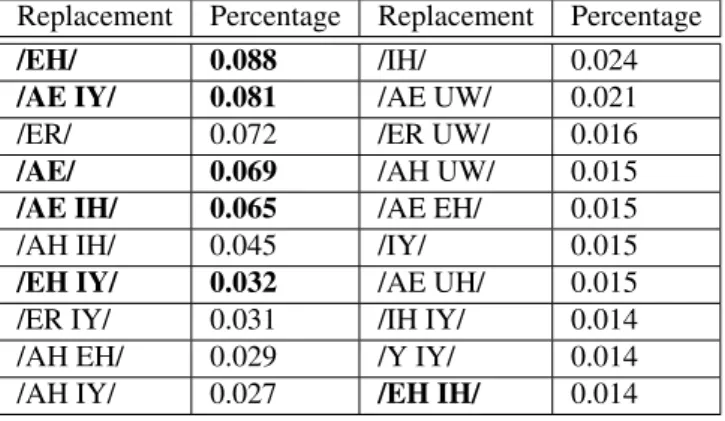
However, for the third iteration, testing the necessity of including a diphone, two of the diphones are introduced back to be tested again. Again, the highest accuracy achieved overall is for the knowledge-based linguistically suggested alternative /EH IH/.
Systematic replacement of all diphthongs
Accuracy results
The first iteration, where all 3 variant options are included, achieves the highest word accuracy, even higher than the iteration that makes use of linguistic knowledge. However, phoneme accuracy increases with each iteration, reaching its peak with the use of the linguistic replacement.
Further analysis
Data limitation
Approach
Cross-validation is not implemented in this experiment, since the standard deviation of the mean in the main results is 0.13, which is low enough to accept a certain standardization between iterations of the cross-validation. To ensure comparative results between runs, a larger test set is used than for the cross-validated experiments.
Results
In this experiment, the available training data is artificially limited to determine trends during training. Both system A and system B are trained on each training list in turn and tested on the test set.
Conclusion
The stability of the knowledge-based system is also examined and appears to be good. This chapter describes the experimental procedure followed in adapting a BE pronunciation dictionary to SSAE, by adapting the KIT vowel.

The KIT vowel in SSAE
Experimental setup
Pronunciation dictionary
Approach
The results contain the initial, predicted and correct pronunciations, as well as indications of which rules apply to a particular /IH/ phoneme and whether the final result is correct or not. The results contain the initial, predicted and correct pronunciations, as well as indications of which rules apply to a particular /IH/ phoneme and whether the final result is correct or not.
KIT vowel adaptation rules
- Known adaptation rules
- Environment adaptation rules
- Rule implementation
- Selected adaptation rules
- Formulated adaptation rules
- Final adaptation rules
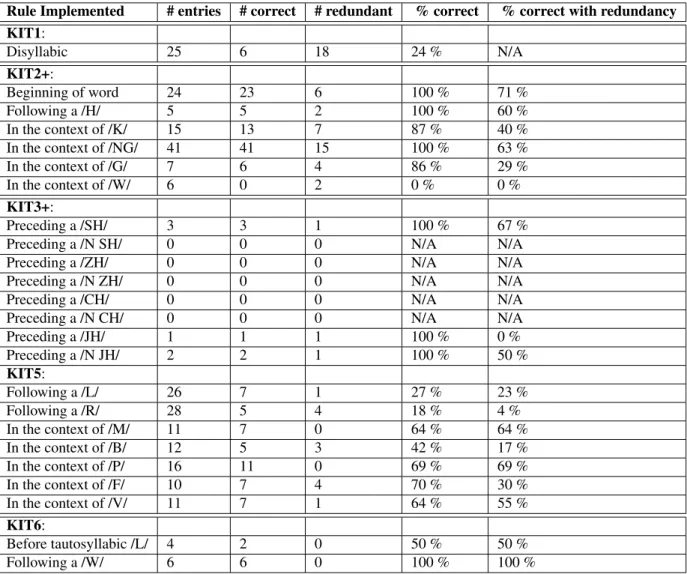
- Rule set analysis
- Analysis of errors
The accuracy and utility of the other rules are not high enough to justify implementation. When a word ends with the phoneme /IH/, the phoneme adjustment keeps it as the phoneme /IH/.
Verifying results using the validation set
Inter-speaker agreement
Results
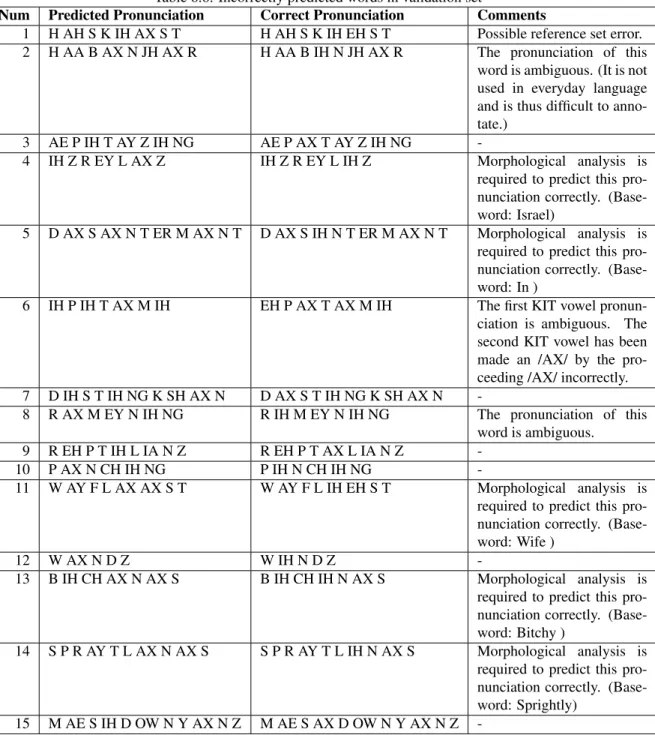
5 D AX SAX N T ER M MAX N T D AX S IH N T ER M MAX N T Morphological analysis is necessary to correctly predict this pronunciation. 14 S P RAY T L AX N AX S S P RAY T L IH N AX S A morphological analysis is required to correctly predict this pronunciation.
ASR system results
Conclusion
The aim of the experiments carried out in this thesis was to develop the SSAE Pronunciation Dictionary using the British Pronunciation Dictionary as a source. The steps taken to achieve this goal were checking the British Pronunciation Dictionary, analyzing phoneme distinctions in the Pronunciation Dictionary, and finally adapting the KIT vowel from British English to SSAE.
Summary of contribution
Dictionary verification
This chapter discusses each of these steps, as well as their ability to achieve the goals for which they were designed.
Diphthong analysis
KIT vowel adaptation
Future work
Conclusion
Tabel D.3: Resultaten bij het toepassen van geselecteerde aanpassingsregels (deel 3) woordpronunbasepronunpredictpronuncorrRegel2Regel3corr schuldig1GIHL-TIARGIHL-TIARGIHL-TIARG01 gyrating6”JHAY-AX-'REY-TIHNG”JHAY-AX-'REY-TIHNG01 hilt1HIHL-TIHNG01 historisch1HIH-TIHNG 01 STOH-RIH-KLHIH-”STOH- RIH-KLHIH-”STOH-RIH-KLH01 historisch6HIH-”STOH-RIH-KLHIH-”STOH-RIH-KLHIH-”STOH-RIH-KLK01 hypnotiseren1HIHP-NAX-TAYZHIHP-NAX-TAYZHIHP-NAX -TAYZH01 illusionisten0IH-'LUH- ZHAX-NIHSTSSIH-'LUH-ZHAX-NIHSTSSIH-'LUH-ZHAX-NAXSTS01 illusionisten6IH-'LUH-ZHAX-NIHSTSSIH-'LUH-ZHAX-NAXSTSIH-'LUH-ZHAX-NAXSTS001 zielloosheden0IH-'LUH-ZHAX-NIHSTSIH-'LUH -ZHAX-NAXSTS01 inanities0IH-' AE-NAX-TIHZIHN-'AE-NAX-TIHZIHN-'AE-NAX-TIHZ01 besmettelijkheid0IHN-'FEHK-SHAXS-NIHSIHN-'FEHK-SHAXS-NIHSHN-'FEHK-SHAXS-NAXS01 besmettelijkheid9IHN- 'FEHK-SHAXS-NIHSHN-' 'FEHK-SHAXS-NAXSIHN-'FEHK-SHAXS-NAXS001 infusies0IHN-'FYUH-ZHAXNZIHN-'FYUH-ZHAXNZIHN-'FYUH-ZHAXNZIHN-'FYUH-ZHAXNZ01 inner0IH-NAXRIH-NAXRIH- NAXR01 smakeloosheid0 ”IHN-SIH-'PIH-DAX-TIH”IHN -SIH-'PIH-DAX-TIH"IHN-SAX-'PAX-DAX-TIH01 smakeloosheid3"IHN-SIH-'PIH-DAX-TIH"AXN-SAX- 'PIH-DAX-TIH"IHN-SAX-'PAX -DAX-TIH001 smakeloosheid5"IHN-SIH-'PIH-DAX-TIH"AXN-SAX-'PAX-DAX-TIH"IHN-SAX-'PAX-DAX- TIH001 instrument0IHN-STRUH-MAXNTIHN-STRUH-MAXNTIHN-STRUH- MAXNT01 onderscheppingen0”IHN-TAX-'SEHP-SHAXNZ”IHN-TAX-'SEHP-SHAXNZ”IHN-TAX-'SEHP-SHAXNZ01 gemiddeld0”IHN-TAX-'MIY -DYAXT”IHN-TAX-'MIY-DYAXT”IHN -TAX-'MIY-DYAXT01 intern0IHN-TERNIHN-TERNIHN-TERN01 in0”IHN-TUH”IHN-TUH”IHN-TUH01 introspecties0”IHN-TROW-'SPEHKTS”IHN -TROW-'SPEHKTS”IHN-TROW-'SPEHKTS01 overstroomd0IH -NAHN-DEY-TIHDIH-NAHN-DEY-TIHDIH-NAHN-DEY-TAXD01 nodigt0IHN-'VAYTSIHN-'VAYTSIHN-'VYTS01 overstroomd7IH-NAHN-DEY-TIHDAX-NAHN uit -DEY-TAXDIH-NAHN-DEY-TAXD001 jiminy1JHIH-MAX -NIHJHAX-MAX-NIHJHAX-MAX-NIH001 junkies4JHAHNG-KIHZJHAHNG-KIHZJHAHNG-KIHZK01 schoppen1KIH-KIHNGKIH-KIHNGKIH-KIHNGK01 schoppen3KIH-KIHNGKIH-KIH NGKIH-KIHNGNG01 laminaat3LAE-MIH-NEYTLAE- MAX-NEYTLAE-MAX-NEYT001 strottenhoofd3LAE-RIHNGK-SIHZ LAE-RIHNGK-SIHZLAE-RIHNGK-SAXZNG01 strottenhoofd7LAE-RIHNGK-SIHZLAE-RIHNGK-SAXZLAE-RIHNGK-SAXZ001 licentie6LAY-SAXN-SIHNGLAY-SAXN-SIHNG LAY-SAXN-SIHNGNG01 taalkundigen1LIHNG-GWIHSLIHNG -GWIHSTSNG01 taalkundigen LIHNG-GWAXSTSLIHNG-GWAXSTS001 liquideert1LIH-KWIH -DEYTSLIH-KWIH-DEYTSLIH-KWAX-DEYTSK01 liquideert4LIH-KWIH-DEYTSLIH-KWAX-DEYTSLIH-KWAX-DEYTS001 littlest1LIH-TL-IHSTLAX-TL-IHSTLAX- TL-AXST001 littlest4LIH-TL -IHSTLAX-TL-AXSTLAX-TL-AXST001 uitziend3 ”LUH-KIHNG”LUH-KIHNG”LUH-KIHNGNG01 Lucifer3LUH-SIH-FAXRLUH-SAX-FAXRLUH-SAX-FAXR001 hoofdveren6MEYN-SPRIHNGZMEYN-SPRIHNGZMEYN-SPRIHNGZNG01 metallic1MIH-'TAE- LIHKMAX- 'TAE-LIHK001 metallic5MIH- 'TAE-LIHKMAX-'TAE-LIHKMAX-'TAE-LIHKK01 muzzily3MAH-ZIH-LIHMAH-ZAX-LIHMAH-ZAX-LIH001 smerig4NAA-STIH-LIHNAA-STAX-LIHNAA-STAX-LIH001 halsdoek5NEH-KAX- CHIHFNEH-KAX-LIH001 KAX-CHAXF001 Orangemen2OH-RIHNJH-MAXNOH-RIHNJH-MAXNOH-RIHNJH-MAXN0NJH1 overjurken7”OW-VAX-'DREH-SIHZ”OW-VAX-'DREH-SAXZ”OW-VAX-'DREH-SAXZ001 bijzonder3PAX -'TIH-KYUH -LAX-RAYZPAX-'TIH-KYUH-LAX-RAYZPAX-'TIH-KYUH-LAX-RAYZK01 pathologisch7"PAE-THAX-'LOH-JHIH-KAX-LIH"PAE-THAX-'LOH-JHIH -KAX-LIH" PAE-THAX-'LOH-JHIH-KAX-LIHK01 pauzeert3PAO-ZIHNGPAO-ZIHNGPAO-ZIHNG01 plegen3PER-PIH-TREYTPER-PAX-TREYTPER-PAX-TREYT001 volhardt3”PER-SIH-'VIAD”PER-SAX- 'VIAD” SAX-'VIAD001 heien3”PAY-LIHNG”PAY-LIHNG”PAY-LIHNGNG01 pil1PIHLPAXLPAXL001 pingpong1PIHNG-POHNGPIHNG-POHNGPIHNG-POHNGNG01 pirouette6”PIH-RUH-'EH-TIHNG”PAX-RUH-'EH-TIHNG”PIH- RUH-' EH-TIHNGNG01 pitting1PIH-TIHNGPAX-TIHNGPAX-TIHNG001 pitting3PIH-TIHNGPAX-TIHNGPAX-TIHNGNG01 planning4PLAE-NIHNGPLAE-NIHNGPLAE-NIHNGNG01 speelgoed4PLEY-THIHNGPLEY-THIHNGPLEY-THIHNGNG01 plezier8PLEH-TIHNGPL AE-NIHNGPLAE-NIHNGPLAE-NIHNGNG01 -NAXS001 dapper4PLAH-KIHPLAH-KIHPLAH - KIHK01 beleefdheid6PAX-'LAYT-NIHSPAX-'LAYT-NAXSPAX-'LAYT-NAXS001 poliepen3POH-LIHPSPOH-LAXPSPOH-LAXPS001 gepostuleerd9POHS-TYUH-LEY-TIHDPOHS-TYUH-LEY-TAXDPOHS-TYUH-LEY-TAXD001 speleologie6POHT-LIHPSPOH -LIHPSPOH- LAXPS001 ”HOE-LIHNGPOHT-”HOE-LIHNGNG01. TabelD.10:Resultatentabelvanvolledigeregelsettoegepastopvalidatieset(deel2) woordpronunbasepronunpredictuitspraakuncorrstrteb,m,n,xregel2regel3eersteendys,ies,iedvwlhrmnyaxvwlhrmnyihadjvwlhrmnyihlastphnm gecorrodeerd5KAX-'ROW-DIHDKAX-'ROW-DAXDKAX-'ROW-DAXD 000000000 kruising4KROH-S IHNGKROH-SIHNGKROH-SIHNG0NG0000000 kapmessen6KAHT-LAX-SIHZKAHT-LAX - SAXZKAHT-LAX-SAXZ000000000 bedrog1DIH-'SIYTDIH-'SIYTDIH-'SIYT000000100 wijden3DEH-DIH-KEYTDEH-DIH-KEYTDEH-DIH-KEYT0K0000000 gedefalcateerd8DIY-FAEL-KEY-TIHDDIY-FAEL-KEY-TAXDDIY-FA EL-KEY-TAXD0000000 00 ontbost5 ”DIY -'FOH-RIH-STIHD”DIY-'FOH-RAX-STAXD”DIY-'FOH-RAX-STAXD00000AX000 ontbost8”DIY-'FOH-RIH-STIHD”DIY-'FOH-RAX-STAXD”DIY-' FOH- RAX-STAXD000000000 punten5DIY-'MEH-RIHTSDIY-'MEH-RAXTSDIY-'MEH-RAXTS000000000 demimondaine3”DEH-MIH-MOHN-'DEYN”DEH-MIH-MOHN-'DEYN”DEH-MIH-MOHN-'DEYN000000100 deod ars1DIH -OW -DAAZDIH-OW-DAAZDIH-OW-DAAZ000000100 verfoeilijk1DIH-'TEH-STAX-BLDIH-'TEH-STAX-BLDIH-'TEH-STAX-BL000000100 schadelijk11”DEH-TRIH-'MEHN-TAX-LIH”DEH-TRAX -' MEHN-TAX-LIH"DEH-TRIH-'MEHN-TAX-LIH000000001 schadelijk4"DEH-TRIH-'MEHN-TAX-LIH"DEH-TRIH-'MEHN-TAX-LIH"DEH-TRIH-'MEHN-TAX -LIH000000100 did1"DIHD"DAXD"DAXD000000000 dining3DAY-NIHNGDAY-NIHNGDAY-NIHNG0NG0000000 verdwijning1"DIHS-AX-'PIA-RAXNS"DAXS-AX-'PIA-RAXNS"DAXS-AX-'PIA-RAXNS000000000 opgraving1"DIHS-I HN- 'TER -MAXNT"DAXS-IHN-'TER-MAXNT"DAXS-IHN-'TER-MAXNT000000000 ontslaat1DIHS-'MIH-SIHZDAXS-'MIH-SIHZDAXS-'MAX-SAXZ000000000 ontslaat4DIHS-'MIH-SIHZDAXS-'MAX-SAXZDAXS- 'MAX -SAXZ00000AX000 verwerpt6DIHS-'MIH-SIHZDAXS-'MAX-SAXZDAXS-'MAX-SAXZ000000000 onderscheid4DIH-'STIHNGK-SHAXNDAX-'STIHNGK-SHAXNDAX-'STIHNGK-SHAXN0NG0000000 dogmatiek6DOHG-'MAE-TIHKSDOH G-'MAE E-TIHKS0K0000000 bruidsschat4DAW- AX-RIHNGDAW-AX-RIHNGDAW-AX-RIHNG0000000 economisch6”IY-KAX-'NOH-MIH-KL”IY-KAX-'NOH-MIH-KL”IY-KAX-'NOH-MIH-KL0K0000000 elektronica0”IH -LEHK -'TROH-NIHKS"IH-LEHK-'TROH-NIHKS"IH-LEHK-'TROH-NIHKS000100000 elektronica8"IH-LEHK-'TROH-NIHKS"IH-LEHK-'TROH-NIHKS"IH-LEHK-' TROH- NIHKS0K0000000 verlengend7IY-LOHNG-GEY-TIHNGIY-LOHNG-GEY-TIHNGIY-LOHNG-GEY-TIHNG0NG0000000 emotioneel0IH-'MOW-TIHVIH-'MOW-TIHVIH-'MOW-TAXV000100000 emotioneel4IH-'MOW-TIHVIH- 'MAAI-TAXVIH-' ' MOW-TAXV000000000 betoverend6IH-'NAE-MAX-RIHNGIH-'NAE-MAX-RIHNGEH-'NAE-MAX-RIHNG0NG0000000 vergroot0IHN-'LAAJHDEHN-'LAAJHDEHN-'LAAJHD100100000 betrokken0IHN-'TEYLDEHN-'TEYLD 1001 0000 entomologisch9”EHN-TAX-MAX -'LOH-JHIH-KL"EHN-TAX-MAX-'LOH-JHIH-KL"EHN-TAX-MAX-'LOH-JHIH-KL0K0000000 epitome2IH-'PIH-TAX-MIHIH-'PAX-TAX-MIHEH-' PAX-TAX-MIH00000AX000 epitome6IH-'PIH-TAX-MIHIH-'PAX-TAX-MIHEH-'PAX-TAX-MIH000000001 gelijkwaardigheid0IH-'KWIH-VAX-LAXNSIH-'KWIH-VAX-LAXNSIH-'KWAX-VAX -LAXNS0K0100000 gelijkwaardigheid3 IH -'KWIH-VAX-LAXNSIH-'KWAX-VAX-LAXNSIH-'KWAX-VAX-LAXNS00000AX000 erudiet7EH-RUH-DAYT-LIHEH-RUH-DAYT-LIHEH-RUH-DAYT-LIH000000001 essential0IH-'SEHN-SHLIH-' 'SEHN -SHLIH-'SEHN-SHL000100000 schatting3”EH-STIH-'MEY-SHAXN”EH-STAX-'MEY-SHAXN”EH-STAX-'MEY-SHAXN00000EY000 verontschuldigbaar0IHK-'SKYUH-ZAX-BLEHK-'SKYUH-ZAX -Bleed -blask0100000 ExploriviteitHxks-يпаб-راك--TaxhtiEx-'Stihg-Gwihshtea-'Stihg-Gwihshtea-'Stihg-Gwihthtea-'Stihg-Gwihthtea-'Stihg-Gwihthtea-'Stihg-Gwihthta -'strihg-Gwihthta - 'strihg-Gwihtht1k0100000 e Gedoofd4ihk- ' STIHNG-GWIHSHTEHK-'STIHNG-GWIHSHT0NG0000000 gedoofd8IHK-'STIHNG-GWIHSHTEHK-'STIHNG-GWIHSHT00SH000000 familie5”FAE-MAX-LIH”FAE-MAX-LIH”FAE-MAX-LIH000000001 violist. 1FIH-DL-AXRFAX- DL-AXRFAX-DL-AXR00000AX000 cijfers1”FIH-GAXZ”FIH-GAXZ”FIH-GAXZ0G0000000 archiveren1FIHL-CHIHNGFAXL-CHIHNGFAXL-CHIHNG000000000 archiveren4FIHL-CHIHNGFAXL-CHIHNGFAXL-CHIHNG0NG0000000 afwerking1 FIH -NIH-SHHNGFIH-NIH-SHHNGFIH-NIH- SHIHNG000000100 afwerking3FIH-NIH -SHIHNGFAX-NIH-SHIHNGFIH-NIH-SHIHNG00SH000000 afwerking5FIH-NIH-SHIHNGFAX-NIH-SHIHNGFIH-NIH-SHIHNG0NG0000000 fizzles1FIH-ZLZFAX-ZLZ00000AX000 platvissen5FLAET-FIH-ZLZFAX-ZLZ00000AX00 0 H-SHIHZFLAET-FIH-SHAXZ00SH000000 platvissen7FLAET-FIH -SHIHZFLAET-FIH- SHAXZFLAET-FIH-SHAXZ000000000 fosses3FOH-SIHZFOH-SAXZFOH-SAXZ000000000 sproeten5FREH-KLIHNGFREH-KLIHNGFREH-KLIHNG0NG0000000 frivoliteit2FRIH-VAX-LAX-NIHSFRAX-VAX-LAX-NAXSFRAX-V AX-LAX-NA XS00000AX000 lichtzinnigheid9FRIH-VAX-LAXS-NIHSFRAX -VAX-LAXS -NAXSFRAX-VAX-LAXS-NAXS000000000 glanzend2GLIH-MAXDGLAX-MAXDGLAX-MAXD00000AX000 gutsen3GAW-JHIHZGAW-JHAXZGAW-JHAXZ000000000 zwaar3HEH-VIHZHEH-VIHZHEH-VIHZ00001000 0 Hippocratisch1”HIH-POW-KRAE -TIHK”HIH-POW-KRAE-TIHK ”HIH-POW -KRAE-TIHK000000100.
Grapheme to phoneme alignment example
Results of each step involved in the verification process
Number of entries removed from the dictionary due to repeated phonemes
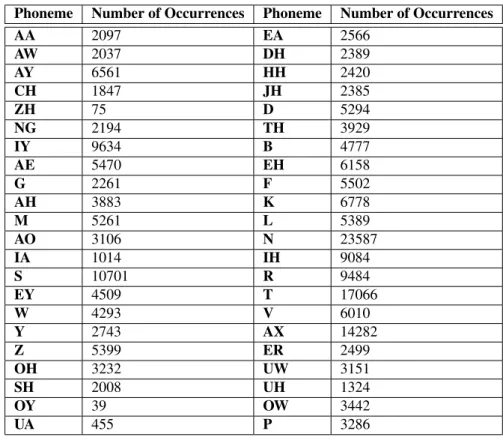
Phoneme counts for the speech corpus
Results of ASR system using selected penalties
Results of ASR system using selected Gaussian mixture quantities
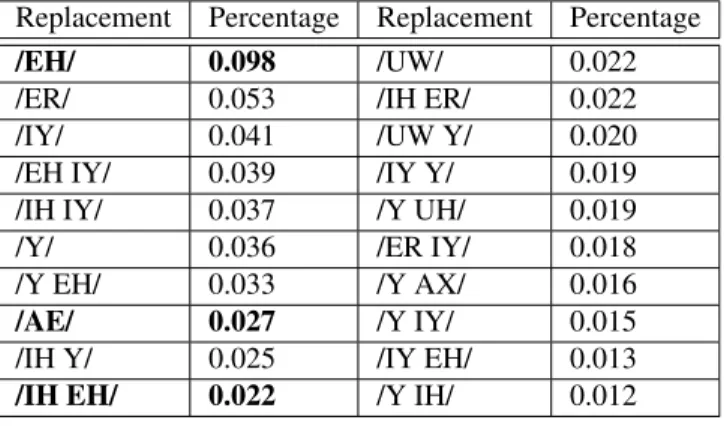
Results of the automatic variant suggestion experiment for the diphthong /AY/
Results of the automatic variant suggestion experiment for the diphthong /EY/
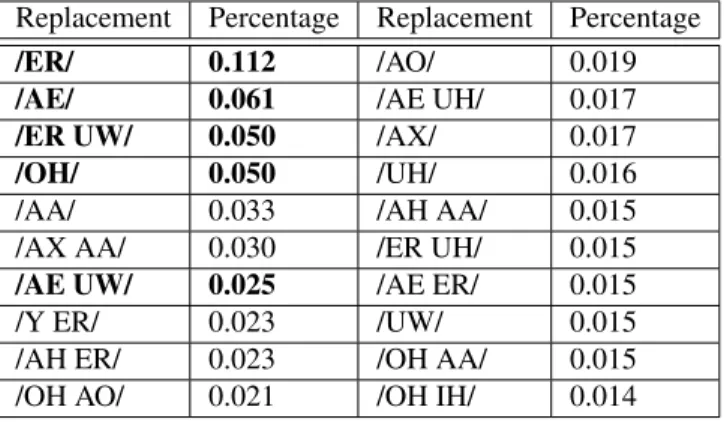
Results of the automatic variant suggestion experiment for the diphthong /EA/
Results of the automatic variant suggestion experiment for the diphthong /OW/
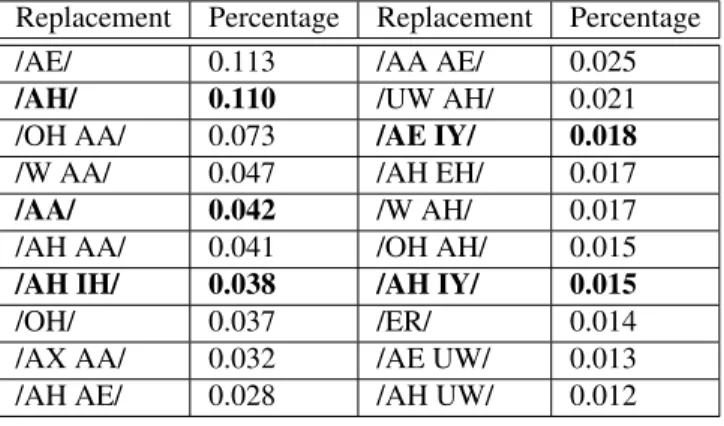
Results of the variant evaluation experiments for the diphthong /AY/
Results of the variant evaluation experiments for the diphthong /EY/
Results of the variant evaluation experiments for the diphthong /EA/
Results of the variant evaluation experiments for the diphthong /OW/
IPA based diphthong replacements
Results for data limiting experiment for baseline and knowledge-based ASR systems
Known KIT allophones identified by Webb (1983)
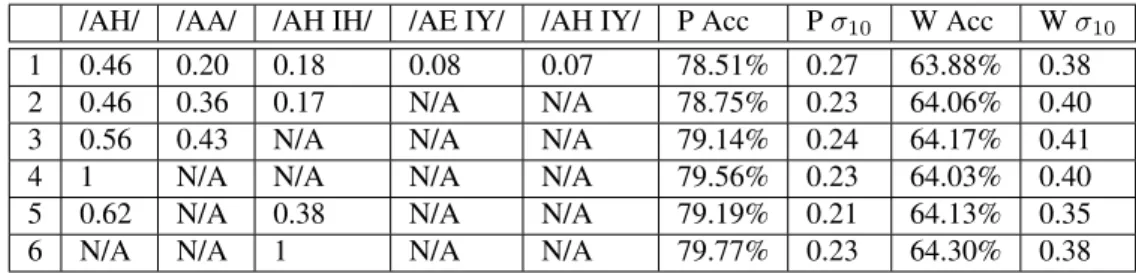
Results of /IH/ adaptation for knowledge-based rules
Results comparison of /IH/ adaptation for known, selected and final adaptation rule systems
Incorrectly predicted words in final adaptation rule system
Results of /IH/ adaptation using the final adaptation rule set
Incorrectly predicted words in validation set
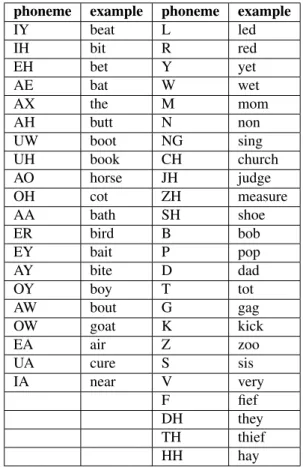
The BEEP ARPAbet phone set
Sample of removed entries in pre-processing step
Sample of removed entries during removal of repeated phonemes
Sample of removed entries during the analysis of lengthened pronunciation
Sample of removed entries during graphemic null analysis
All entries removed during the analysis of lengthened spelling
Sample of removed entries during analysis of duplicate pronunciations
All removed entries during alignment
All entries removed due to grapheme to phoneme rule analysis
Sample of removed entries during the analysis of pseudo-phonemes and generation restriction rules 66
Baseline System Confusion Matrix Part 2
Knowledge-based system confusion matrix (part 1)
Knowledge-based system confusion matrix (part 2)
Knowledge-based system confusion matrix subtracted from baseline confusion matrix (part 1)
Knowledge-based system confusion matrix subtracted from baseline confusion matrix (part 2)
Results when applying selected adaptation rules (part 1)
Results when applying selected adaptation rules (part 2)
Results when applying selected adaptation rules (part 3)
Results when applying selected adaptation rules (part 4)
Full adaptation rule system results (part 1)
Full adaptation rule system results (part 2)
Full adaptation rule system results (part 3)
Full adaptation rule system results (part 4)
Results of full rule set applied to validation set (part 1)
Results table of full rule set applied to validation set (part 2)
Results table of full rule set applied to validation set (part 3)
Results table of full rule set applied to validation set (part 4)