This project/internship entitled “BIG DATA, HADOOP AND ITS CHALLENGES” submitted by Waheeda Afreen, ID No to the Department of Computer Science and Engineering, Daffodil International University has been accepted as satisfactory in partial fulfillment of the requirements for the B degree .Sc. Department of Computer Science and Engineering Faculty of Information Science and Technology Daffodil International University. We declare that this project was done by us under the supervision of Asma Mariam, Lecturer - Computer Science and Engineering, Department of Daffodil International University CSE.
We also declare that neither this project nor any part of this project has been submitted elsewhere for the award of any degree or diploma. We are truly grateful and wish our deep indebtedness to Asma Mariam, Associate Professor - Computer Science and Engineering, Department of CSE, Department of CSE Daffodil International University, Dhaka. Deep knowledge and keen interest of our supervisor in “Big Data, Hadoop and its challenges” to carry out this project.
His endless patience, expert guidance, constant encouragement, constant and energetic supervision, constructive criticism, valuable advice, reading many poor drafts and correcting them at all stages made this project possible to complete. Juel Mia and Head of CSE Department for his kind help in completing our project and other faculty members and staff of CSE Department of Daffodil International University. We would like to thank our entire colleague at Daffodil International University who participated in this discussion while completing the course.
Depending on the size of the dataset and the number of cluster nodes, Hadoop Map Reduce can execute tasks in minutes.
Introduction
- Introduction
- Motivation
- Rationale of the Stud y
- Research Questions
- Expected Output
- Project Management and Finance
- Report Layout
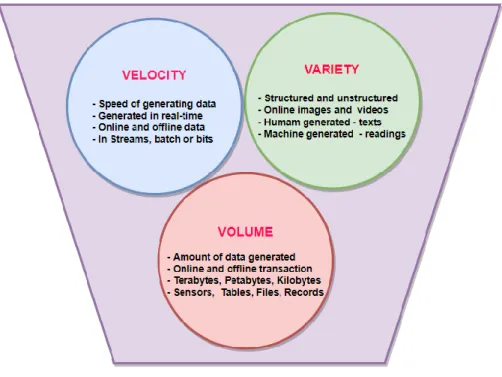
Volume: Big data is the massive amounts of word processing files that are collected and stored, including those on social networking sites such as Facebook, Messenger and Hospital. Big data can be handled with ease. Diversity: We all know that daily data will be terabytes or gigabytes in size and will not be structured. The speed at which typical big data works and the data source we work with are speed factors.
The word processing file first started to be collected when we started using social media like Facebook, YouTube and other internet services around 2005, the usage of data increased quickly. In some circumstances, the other ecosystem is preferable, while in others, Hadoop map-reduce is superior. We chose the topic because we will use an already used way to get the analysis result using a real-time analysis method.
For many business requirements and technological advances over the past three decades, the term "big data" has been very significant. I will also go over the technologies we will use to overcome the Hadoop map reduce problem. Future generations will have a greater understanding of big data, Hadoop, and its properties than in the past, according to the thesis statement.
Without the support of the group organization, we had to leave this environment and participate in a project where we had to solve the problem ourselves. Secondly, we could list names of individuals next to companies or various project-related objects to be tracked, so that traceable elements can be integrated to obtain estimated costs in particular. The authority to approve these budget changes for these financial resources is the fifth and most crucial point.
The fourth tip is to submit your application for support as soon as possible because it takes time to be approved and distributed. Depending on the organization or setting, this period may also require interaction with the government or other organizations, which may increase the delay. What we are working on, why we are working on it, and what we will learn from this paper.
Background
- Preliminaries/Terminologies
- Related Works
- Comparative Analysis and Summary
- Scope of the Problem
- Challenges
With so much data now available, it has become crucial to sort it and use it for the public good. Searching for any information like doctor names, product names, etc. seems simple for anyone. The Indian government has recently started working on big data analysis in its office to better understand people.
By performing big data analysis, we can find solutions to a wide range of such problems. When discussing distributed file systems, cluster computing is necessary to implement our work on verification and analysis. It can be difficult for a college student to use AWS or Google to build a meaningful cluster computing system without a lot of funding.
CHAPTER 03 Research Methodology
- Research Subject and Instrumentation
- Data Collection Procedure/Dataset Utilized
- Statistical Analysis
- Proposed Methodology/Applied Mechanism
- Implementation Requirements
- Experimental Setup
- Experimental Results & Analysis
- Discussion
In this data access flow diagram we can see how the data will arrive from our local storage. After starting the access, you should specify the local path to the storage to access the dataset. We extract the folder from the entire data set when it is fully loaded on our computer.
We have chosen to use qualitative methodology in this study to collect some relevant secondary data. Face-to-face data collection is difficult, under the current circumstances of Corvid-19. Secondary data: To ensure that I will address the research problem correctly, we feel that some secondary data is crucial.
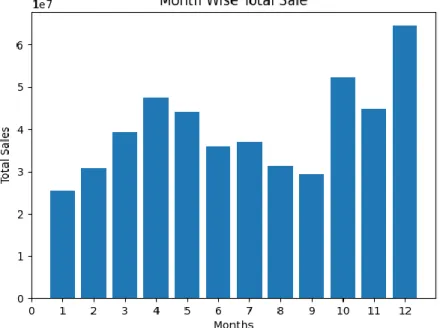
In this section, we review the diversity of our data and the other data included in it. Here, we can note that December had the largest product sales, with a total order of 24,008 and sales of USB-C and Lightning charging cables of 13% each. Month appears on the X-axis, while sales appear on the Y-axis.
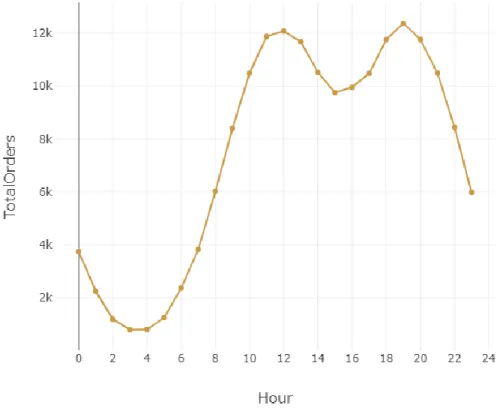
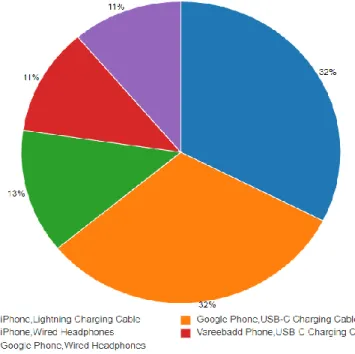
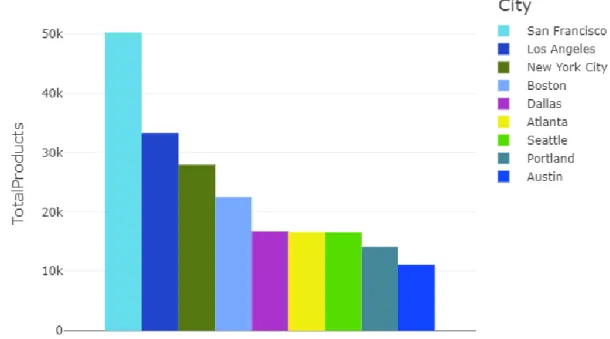
We need to pre-process our dataset after setting up the entire ecosystem and before running the study. The city with the highest volume of sales in the period is depicted below in figure 4.1. We can observe from the pie chart below that the category of products is popular and has a large sales volume.
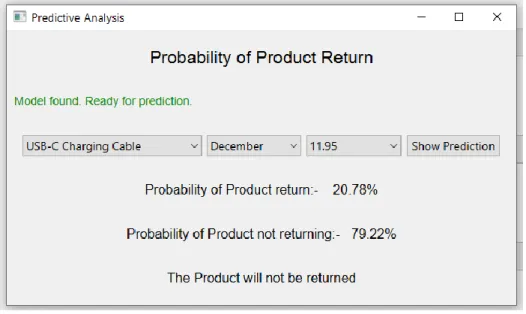
Top-selling product categories include Google Phone, USB-C Charging Cable, and iPhone, Lighting Charging Cable. Last month was the month with the highest sales, and the first month was the month with the lowest sales. Daffodil International University 19 The reason we use a naive algorithm is so we can outsource our product.
We can use this algorithm to find out how many of the products will be sold and how many will not be sold. Throughout this section, we have talked about the findings of various experiments applied to the data set.
Impact on Society, Environment and Sustainability
- Impact on Society
- Impact on Environment
- Ethical Aspects
- Sustainability Plan
Affodil International University 21 Aqueduct: Conduct analyzes of water quality and quantity and provide the public with . interactive risk maps. The strategy can outline the ideals and principles that our group has decided to uphold in relation to ethical communication. 3) Must ensure that all our communications are concise. 4) We promise to keep lines of communication open with all our stakeholders.
We will maintain our project in order to operate in the long term. This ensures that the resources used for the project are not lost in the future. The three components of our project that we should adhere to are: (A) Community Sustainability; (B) Financial Sustainability;.
Daffodil International University 22 First is the careful involvement of beneficiaries in planning and implementation from the very beginning. To ensure that the community feels invested in the project and that their wishes are realized through our project, we consult with all stakeholders whenever feasible. Second, depending on the type of project we intend to undertake, financial sustainability will look very different.
Applying for a one-time project that is expected to have almost no subsequent costs requires much less thought than applying for a project with ongoing costs that must be paid over time to be financially sustainable. Whether this is through internal resources such as income-generating activities or membership fees or external ones such as grants and long-term support, we want to achieve this. It is essential to show the donor that we are a great partner, so this component of the sustainability strategy should not be overlooked.
Summary, Conclusion, Recommendation and Implication for Future Research
Summary of the Study
Conclusions
Implication for Further Study
APPENDIX
Creating cluster, maintaining cluster and pipeline integration
Berral; Thomas Fenech, en David Carrera, The state of SQL-On-Hadoop in the Cloud, European Research Council (ERC), 2020. 3] Bijesh Dhyani; Anurag Barthwal, Big Data Analytics using Hadoop,International Journal of Computer Applications Vol 108, Desember 2014. Hemant, Strength and Accuracy Analysis of Affix Removal Stemming Algorithms,International Journal of Computer Science and Information Technologies, vol.
5] Jasmine Zakir; Tom Seymour; Kristi Berg, BIG DATA ANALYTICS, International Association for Computer Information Systems, Vol. 6] Azroual, O.; Fabre, R. Processing big data with Apache Hadoop in the current challenging era of COVID-19. Big Data Cogn. International Association for Computer Information Systems, March 2021 [7] Shaina; Dr. Sushil Kumar, Big Data Analytics using Apache Hadoop, Turkish Journal of Computer and Mathematics Education, Vol. 12, 10 May 2021.
Asim, Big Data Analytics: Predicting Academic Course Preference Using HADOOP-Inspired Map Reduce, International Journal of Research (IJR), Vol. 9] TKDas; P.Mohan Kumar, BIG Data Analytics: A Framework for Unstructured Data Analytics, International Journal of Engineering and Technology (IJET), Vol. Reyes-Ortiz; Luca Oneto; Davide Anguita, Big Data Analytics in the Cloud: Spark on Hadoop vs MPI/OpenMP on Beowulf, INNS Conference, Vol.
11] Ishawarappa; Anuradha, A Brief Introduction on Big Data 5Vs Characteristic and Hadoop Technology, International Conference on Computers Communications and Control (ICCCC), pp.