PERINGKASAN DOKUMEN BAHASA INDONESIA
MENGGUNAKAN METODE
K-MEANS
MUHAMMAD RHEZA MUZTAHID
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Peringkasan Dokumen Bahasa Indonesia Menggunakan Metode K-Means adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2015
Muhammad Rheza Muztahid
ABSTRAK
MUHAMMAD RHEZA MUZTAHID. Peringkasan Dokumen Bahasa Indonesia Menggunakan Metode K-Means. Dibimbing oleh JULIO ADISANTOSO.
Membaca dokumen yang memiliki teks yang sangat panjang merupakan kegiatan yang menghabiskan banyak waktu. Perlu dilakukan peringkasan terhadap dokumen teks yang besar agar meringankan beban pengguna untuk tidak membaca dokumen secara keseluruhan. Penelitian ini mengusulkan untuk pembuatan peringkasan dokumen otomatis menggunakan fitur kata dan metode K-Means. Ringkasan dokumen otomatis dapat digunakan untuk mendapatkan ringkasan teks dengan cepat sehingga memudahkan pengguna untuk mendapatkan informasi utama dari sebuah dokumen. Penelitian ini melakukan peringkasan dokumen dengan menggunakan fitur kata dan metode k-means. Hasil penelitian yang telah dilakukan menghasilkan rata-rata akurasi 58.51%, recall 22.06%,
precision 43.84%, dan f-measure 27.88%.
Kata kunci: fitur kata, k-means, peringkasan dokumen
ABSTRACT
MUHAMMAD RHEZA MUZTAHID. Text Summarization For Indonesian Language Using K-Means Method. Supervised by JULIO ADISANTOSO.
Reading a document with very long text is a time-consuming activity. Therefore, it is necessary to summarize the documents in order to ease the burden on the reader to not read the whole document. This research proposes automatic text summarization using word features and K-Means method. Automatic text summary can be used to get a quick summary of the text by making it easier for readers to get key information from a document. The result of this research produces average accuracy 58.51%, recall 22.06%, precision 43.88%, and F-measure 27.88%.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PERINGKASAN DOKUMEN BAHASA INDONESIA
MENGGUNAKAN METODE
K-MEANS
MUHAMMAD RHEZA MUZTAHID
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Penguji:
1 Ahmad Ridha, SKom, MS
Judul Skripsi : Peringkasan Dokumen Bahasa Indonesia Menggunakan Metode K-Means
Nama : Muhammad Rheza Muztahid NIM : G64134021
Disetujui oleh
Ir Julio Adisantoso, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji syukur penulis panjatkan kehadirat Allah SWT yang telah memberikan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul “Peringkasan Dokumen Bahasa Indonesia Menggunakan Metode K-Means”. Skripsi ini disusun sebagai syarat mendapat gelar Sarjana Komputer (SKomp) pada Program Sarjana Ilmu Komputer di Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor (IPB).
Penulis mengucapkan terima kasih kepada Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing skripsi yang telah memberikan saran, arahan, serta dukungannya selama penelitian ini. Ungkapan terima kasih juga penulis sampaikan kepada orang tua tercinta, ibunda Milwani Syam, ayahanda Husen Sadim, abang Muhammad Aidil Fahmy, dan adik Muhammad Fazri Nahar, atas segala doa, kasih sayang, dukungan semangat, serta motivasi kepada penulis untuk kelancaran penelitian ini. Tak lupa juga penulis ucapkan terima kasih kepada teman-teman satu bimbingan, Lutfia dan Yozi, atas bantuan dan kerjasamanya dalam melakukan penelitian ini, serta kepada teman-teman Ekstensi Ilmu Komputer angkatan 8, atas kebersamaannya selama menjalani masa studi. Semoga skripsi ini dapat memberikan kontribusi yang bermakna bagi pengembangan wawasan para pembaca, khususnya mahasiswa dan masyarakat pada umumnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Desember 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 3
Ruang Lingkup Penelitian 3
METODE 3
Pengumpulan Dokumen 3
Pengindeksan 4
Peringkasan Teks 5
Evaluasi 9
Lingkungan Pengembangan 9
HASIL DAN PEMBAHASAN 10
Pengumpulan Dokumen 10
Pengindeksan 10
Peringkasan Teks 13
Evaluasi Hasil Ringkasan 17
SIMPULAN DAN SARAN 24
Simpulan 24
Saran 24
DAFTAR PUSTAKA 24
LAMPIRAN 26
DAFTAR TABEL
1 Matriks TFISF 7
2 Pendukung untuk menghitung recall, precision, f-measure, dan
akurasi 9
3 Record kata 12
4 Sebaran nilai IDF 13
5 Matriks hasil TFISF dokumen ke-4 16
6 Hasil clustering dokumen ke-4 17
7 Hasil ringkasan dengan tingkat peringkasan 30% 18 8 Hasil ringkasan dengan tingkat peringkasan 20% 18 9 Hasil ringkasan dengan tingkat peringkasan 10% 18 10 Suatu percobaan hasil peringkasan dokumen 91 20 11 Suatu percobaan hasil peringkasan dokumen 9 21 12 Percobaan hasil peringkasan dokumen 9 dengan fitur kata baru 22
DAFTAR GAMBAR
1 Diagram alur peringkasan teks otomatis 4
2 Skema pemisahan kalimat dan case folding 6
3 Algoritma K-Means 8
4 Proses seleksi kalimat 8
5 Statistik kalimat 100 dokumen 11
6 Perbandingan nilai akurasi peringkasan otomatis 19 7 Perbandingan nilai recall peringkasan otomatis 19 8 Perbandingan nilai precision peringkasan otomatis 20 9 Perbandingan nilai f-measure peringkasan otomatis 22
10 Perbandingan keseluruhan hasil ringkasan 22
1
PENDAHULUAN
Latar Belakang
Peningkatan teknologi informasi yang begitu pesat telah membuat terjadinya peningkatan dokumen teks digital secara besar-besaran. Riset yang dilakukan MGI
(2011) menerangkan bahwa pada tahun 2010 ada 5 milyar penggunamobile phone,
300 milyar potongan konten yang dibagikan difacebooksetiap bulannya, lebih dari
7 exabyte data baru yang disimpan oleh perusahaan global, sementara konsumen
menyimpan lebih dari 6 exabyte data baru pada perangkat seperti Personal
computer (PC) dan notebook. Data yang mengandung informasi tersebut tersebar dalam bentuk dokumen teks seperti artikel, berita, buku, makalah ilmiah, dan lain-lain. Dokumen yang banyak ini juga memiliki teks yang sangat panjang dan menyebabkan isi dokumen sulit dimengerti dengan cepat.
Mencari informasi utama dari dokumen yang besar adalah pekerjaan yang sangat sulit. Perlu dilakukan peringkasan terhadap dokumen teks tersebut agar dapat dengan cepat menghasilkan informasi bagi pengguna. Fungsi ringkasan ini adalah untuk membantu pengguna mendapatkan informasi yang relevan dengan cepat tanpa harus membaca dokumen secara keseluruhan.
Agrawal et al. (2014) menerangkan bahwa peringkasan teks adalah suatu
proses untuk menciptakan versi kompresi dari teks tertentu yang menyediakan informasi yang berguna bagi pengguna. Ringkasan dokumen dapat menghasilkan informasi inti dokumen secara singkat namun memenuhi keperluan pembaca.
Teknik untuk peringkasan dokumen dapat diklasifikasikan ke dalam dua
kategori: ekstraksi dan abstraksi (Suanmali et al. 2009). Suanmali et al. (2009)
menerangkan bahwa peringkasan dengan teknik ekstraksi adalah menyeleksi kalimat atau frasa dari teks asli dengan menghitung skor tertinggi dan menggabungkannya menjadi suatu teks pendek baru atau ringkasan tanpa mengubah teks sumber, sedangkan teknik abstraksi menggunakan metode linguistik untuk memeriksa dan menafsirkan teks.
Keuntungan menggunakan teknik ekstraksi adalah mudah untuk diterapkan dan didasarkan pada fitur-fitur statistik bukan pada hubungan semantik dalam memilih kalimat penting atau kata kunci dari dokumen. Akan tetapi, kekurangan teknik ekstraksi yaitu cenderung tidak konsisten dan informasi yang saling bertentangan tidak dapat disajikan secara akurat. Sementara itu, keuntungan dari teknik abstraksi yaitu menghasilkan rasio kompresi yang baik, serta mendapatkan ringkasan yang lebih akurat karena menggunakan hubungan semantik. Akan tetapi, teknik abstraksi lebih sulit diterapkan karena membutuhkan pemahaman teks asli (Munot dan Govilkar 2014).
Selain teknik ekstraksi dan abstraksi, terdapat pendekatan lain yaitu
berdasarkan mesin pembelajaran. Pada umumnya terdapat dua jenis algoritme
pembelajaran yaitu supervised learning algorithms dan unsupervised learning
algorithms (Wajeed dan Adilakshmi 2009). Menurut Wajeed dan Adilakshmi
(2012) supervised learning merupakan algoritme yang menyediakan data latih
2
unsupervised learningtidak memiliki data latih.
Pada umumnya proses peringkasan dokumen otomatis terdiri atas beberapa tahapan yaitu pengumpulan dokumen, pengindeksan, pemilihan fitur, pembobotan
kalimat dan pengujian. Hal yang paling penting dalam peringkasan dokumen
otomatis adalah tahap pembobotan kalimat. Tahapan inilah yang menentukan
kalimat-kalimat mana saja yang dipilih dan dimasukkan ke dalam hasil peringkasan.
Kebanyakan sistem peringkasan teks otomatis dilakukan dengan teknik
ekstraksi. Suanmali et al. (2009) melakukan ekstraksi kalimat penting
menggunakan aturan fuzzy dan fuzzy set untuk pembobotan kalimat berdasarkan pada 8 fitur yaitu judul, panjang kalimat, bobot kata, posisi kalimat, kesamaan
kalimat, kata tematik, dan kata benda yang tepat. menghasilkan rata-rataprecision
sebesar 49.77%, recall 45.70%, dan f-measure 47.18%. Mustaqhfiri (2011)
menggunakan metode Maximum Marginal Relevance (MMR) untuk pembobotan
kalimat yang menghasilkan rata-rata recall 60%, precision 76% dan f-measure
65% dari evaluasi antara ringkasan otomatis dengan ringkasan manual.
Penelitian yang sudah sering dilakukan umumnya digunakan untuk dokumen yang pendek seperti dokumen artikel dan berita, sedangkan untuk dokumen yang panjang seperti dokumen karya ilmiah yang terdiri atas beberapa bab belum terlalu
banyak dilakukan. Oleh karena itu, penelitian yang akan dilakukan adalah
membuat peringkasan dokumen otomatis untuk dokumen karya ilmiah, yaitu skripsi, dengan menggunakan teknik ekstraksi dengan menggunakan metode K-Means sebagai pembobotan kalimat. Hal ini karena K-Means mempunyai kemampuan mengelompokkan data dalam jumlah yang cukup besar dengan waktu komputasi yang relatif cepat dan efisien (Arai dan Barakbah 2007).
Perumusan Masalah
Perumusan masalah dalam penelitian ini yaitu:
1 Bagaimana metode pembobotan kalimat berdasarkan fitur kata untuk keperluan peringkasan teks?
2 Apakah metodeK-Meanstepat digunakan dalam peringkasan teks?
3 Bagaimana implementasi metode K-Means untuk peringkasan dokumen
skripsi?
Tujuan Penelitian
Tujuan dari penelitian ini antara lain:
1 Mengembangkan peringkasan dokumen otomatis menggunakan pembobotan kalimat berdasarkan fitur kata.
2 Menganalisis ketepatan penggunaan metode K-Means dengan pembobotan
kalimat dalam peringkasan dokumen otomatis.
3
Manfaat Penelitian
Penelitian ini diharapkan aplikasi yang dibangun dapat menghasilkan metode peringkasan yang efektif dan memiliki kinerja yang baik.
Ruang Lingkup Penelitian
Adapun ruang lingkup dari penelitian ini antara lain:
1 Penelitian ini menggunakan dokumen skripsi Ilmu Komputer berbahasa Indonesia.
2 Pembobotan kalimat dilakukan berdasarkan fitur kata dan dengan
menggunakan metodeTerm Frequency-Inverse Sentence Frequency.
3 Pemilihan fitur kata dilakukan dengan menggunakan metode Inverse
Document Frequency.
4 Peneliti menggunakan metodeK-Meansuntuk pengelompokan kalimat.
5 Penelitian ini dilakukan dengan menggunakan tingkat peringkasan 30%, 20%, dan 10%.
6 Evaluasi dilakukan dengan membandingkan hasil ringkasan manual dan hasil
ringkasan sistem menggunakan teknikF-Measure.
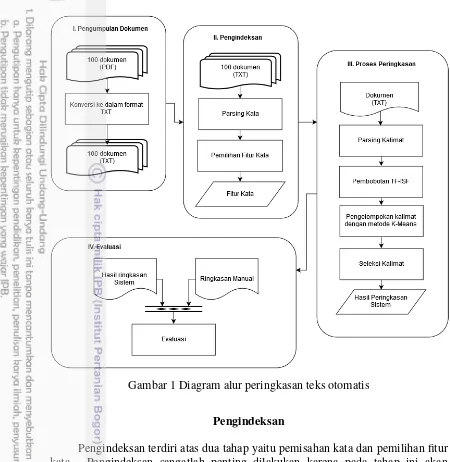
METODE
Penelitian ini dilakukan dengan beberapa tahap yaitu tahap pengumpulan dokumen, tahap pengindeksan, proses peringkasan, dan evaluasi. Diagram alur proses dapat dilihat pada Gambar 1.
Pengumpulan Dokumen
Dokumen yang digunakan dalam penelitian ini adalah 100 dokumen yang diambil dari repository.ipb.ac.id. Setiap dokumen akan dibuat ringkasan manualnya dan juga dibuat ringkasan menggunakan sistem peringkasan otomatis. kedua hasil ringkasan akan dibandingkan guna mengukur seberapa akurat sistem peringkasan otomatis yang dibuat.
Kumpulan dokumen yang didapat dari repository.ipb.ac.id adalah merupakan dokumen dengan format PDF. setiap dokumen akan diubah secara manual menjadi bentuk format TXT. Beberapa aturan yang digunakan pada tahap ini adalah:
1 Tidak melibatkan tabel, gambar, persamaan, algoritme beserta penjelasannya.
2 Bukan berupalistpendek, kecuali pada bagian kesimpulan dan saran.
3 Kutipan tidak dihilangkan.
4 Judul bab dan sub bab dihilangkan. 5 Catatan kaki dihilangkan.
4
Gambar 1 Diagram alur peringkasan teks otomatis
Pengindeksan
Pengindeksan terdiri atas dua tahap yaitu pemisahan kata dan pemilihan fitur
kata. Pengindeksan sangatlah penting dilakukan karena pada tahap ini akan
menghasilkan fitur kata untuk dijadikan bahan pembobotan kalimat.
Pemisahan Kata
Tahap pertama dalam pengindeksan yaitu memisahkan kata-kata dari teks dalam dokumen. Seluruh dokumen akan diproses untuk dijadikan kumpulan kata yang akan digunakan pada proses selanjutnya yaitu pemilihan fitur kata.
Pemisahan kata dilakukan dengan menggunakan delimiter karakter white space
pada setiap kalimat atau teks, dan juga dilakukan case folding untuk mengubah
semua huruf pada setiap kata menjadi bentuk yang seragam.
Pemilihan Fitur Kata
5
kata kunci untuk menentukan penting atau tidaknya sebuah kalimat. Untuk memilih kata kunci, seluruh kata harus memiliki bobot nilai dan diurutkan berdasarkan nilai bobot dari yang terbesar hingga terkecil.
Terdapat beberapa cara pemilihan fitur kata antara lain yaitu Mutual
Information(MI), Chi-Square(Chi-square(χ2), danInverse Document Frequency
(IDF) (Manning et al. 2008). MI dan Chi-square (χ2) baik digunakan sebagai
metode pemilihan fitur kata untuk klasifikasi teks, sedangkan metode IDF baik
digunakan untuk peringkasan teks (Manninget al.2008). Maka dari itu, penelitian
ini menggunakan metodeInverse Document Frequency(IDF).
Luthfiarta et al. (2013) menerangkan bahwa IDF adalah perhitungan
logaritma pembagian jumlah dokumen dengan frekuensi dokumen yang memuat
suatuterm. Persamaan IDF sebagai berikut:
IDFt=log( N DFt
) (1)
dengan N adalah jumlah seluruh dokumen, DFt adalah jumlah dokumen yang
mengandung katat. Jika sebuah kata muncul di banyak dokumen, maka hasil dari
IDF akan semakin kecil, begitu pula sebaliknya. Kata-kata yang sering muncul pada setiap dokumen biasanya adalah kata yang tidak penting. Beberapa contoh kata yang mungkin sering muncul di setiap dokumen ; “di”, “ke”, “pada”, “dengan”, “lalu”, dan lain sebagainya.
Peringkasan Teks
Proses peringkasan merupakan tahap inti dari penelitian ini, yang akan menghasilkan ringkasan sistem yang nantinya akan menjadi bahan pembanding
dengan hasil ringkasan manual untuk dilakukan evaluasi. Proses peringkasan
terdiri dari beberapa tahap yaitu parsing kalimat, pembobotan TF-ISF,
pengelompokan kalimat dengan menggunakan metodeK-Means, dan yang terakhir
adalah menyeleksi kalimat dari setiap kelompok untuk dijadikan sebagai ringkasan.
Pemisahan Kalimat
Tahap pertama dalam proses peringkasan adalah memisahkan dokumen menjadi kumpulan kalimat. Kalimat adalah gabungan dari dua buah kata atau lebih yang menghasilkan suatu makna tertentu dan diakhiri dengan suatu tanda titik sebagai tanda berhenti. Kalimat dapat dipisah dengan memperhatikan beberapa tanda baca seperti titik (.), tanda seru (!), dan tanda tanya (?).
Pemisahan kalimat berfungsi untuk mengumpulkan kalimat-kalimat yang
terdapat pada dokumen. Pada proses ini juga dilakukan case folding untuk
mengubah semua huruf di dalam dokumen ke dalam bentuk yang seragam. Pada
penelitian ini semua kata diseragamkan dengan huruf kecil (lower case). Contoh
6
Gambar 2 Skema pemisahan kalimat dancase folding
Pembobotan TF-ISF
PembobotanTerm frequency – inverse sentence frequency(TF-ISF) dilakukan
setelah mendapatkan fitur kata yang akan digunakan. Pada Tahap ini juga nilai TFISF dari setiap kalimat akan dijumlahkan dan dijadikan sebagai nilai dari suatu kalimat yang nantinya akan digunakan pada tahap seleksi kalimat. Persamaan ISF
dan TF-ISF dapat dilihat pada persamaan berikut: (Rinoet al.2004).
ISFt=log( N SFt
) (2)
T FISFt,s=T Ft,s×ISFt (3)
dengan T Ft,s adalah frekuensi kemunculan kata t pada kalimat s, N adalah
banyaknya kalimat dalam dokumen, dan SFt adalah banyaknya kalimat yang
mengandung katat. Nilai T FISFt,s akan tinggi jika kata t muncul beberapa kali
dalam kalimat dan jarang muncul pada kalimat lain, dan rendah jika katat muncul
hampir di seluruh kalimat (Manninget al.2008). Bobot kata ket pada kalimat kes
dalam peringkasan dokumen dapat dituliskan sebagai suatu matriksterm-sentence
seperti yang dapat dilihat pada Tabel 1.
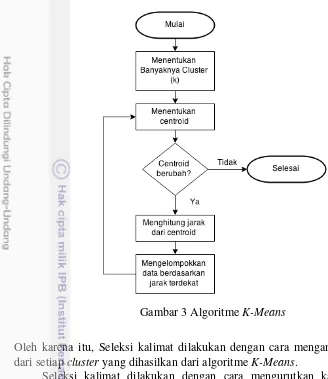
ClusteringKalimat dengan MetodeK-Means
Clustering adalah metode untuk mengatur koleksi data yang besar dengan partisi beberapa data set secara otomatis, sehingga objek yang memiliki kesamaan akan dikelompokkan ke dalam suatu kelompok yang berbeda dengan kelompok
lainnya (Muflikhah dan Baharudin 2009). K-means adalah salah satu teknik
7
melihat titik tengah (centroid) yang diberikan (Wadhvaniet al. 2013). Suatu objek
data termasuk dalam suatuclusterjika memiliki jarak terpendek terhadapcentroid
clustertersebut.
Clustering yang dilakukan pada penelitian ini digunakan untuk mengelompokan kalimat. Kalimat yang berada pada satu kelas adalah kalimat yang memiliki makna yang sama, sehingga nantinya akan dilakukan seleksi
kalimat dengan cara mengambil salah satu kalimat dari setiap cluster sebagai
perwakilan akan makna tertentu. Secara umum algoritme K-Means dapat dilihat
pada Gambar 3.
Banyaknya cluster pada penelitian ini bergantung pada tingkat peringkasan dan jumlah kalimat pada dokumen yang akan diringkas. Pada penelitian ini terdapat 3 tingkat peringkasan yaitu 30%, 20%, dan 10%. Apabila jumlah kalimat pada dokumen yang akan diringkas sebanyak 150 kalimat, dengan tingkat peringkasan
sebesar 10%, maka jumlahclusteradalah sebanyak 150 x 0.10 = 15 cluster.
Penentuan centroid awal (initial centroid) dilakukan dengan cara mengambil
data dari tabel matriks TFISF secara acak atau random. Pada pengulangan
berikutnya, centroid dihitung dengan menghitung nilai rata-rata data pada setiap
cluster. Jika centroid baru berbeda dengan centroid sebelumnya, maka proses
dilanjutkan ke langkah berikutnya. Namun Jikacentroid yang baru dihitung sama
dengan centroid sebelumnya, maka proses clustering selesai. Rumus yang
digunakan untuk menghitung jarak data dengan centroid adalah rumus euclidean
distance. Adapun rumuseuclidean distancedapat dilihat pada persamaan berikut;
d(xi,cj) =
s n
∑
j=1
(xik−cjk)2 (4)
dengan d adalah jarak data dengan centroid, j adalah banyaknya data, k adalah
dimensi, c adalah centroid, dan x adalah data. Pengelompokan data dilakukan
dengan memilih data yang memiliki jarak terpendek dengancentroid.
Seleksi Kalimat
Seleksi kalimat adalah proses akhir untuk menghasilkan ringkasan. Kalimat
8
Gambar 3 AlgoritmeK-Means
Oleh karena itu, Seleksi kalimat dilakukan dengan cara mengambil satu kalimat
dari setiapclusteryang dihasilkan dari algoritmeK-Means.
Seleksi kalimat dilakukan dengan cara mengurutkan kalimat dari nilai tertinggi hingga terendah yang didapat dari penjumlahan nilai TFISF. Pengurutan
kalimat dilakukan pada setiap cluster, sehingga pada setiap cluster akan dipilih
satu kalimat yang memiliki nilai tertinggi. Banyaknya kalimat hasil ringkasan
adalah sebanyak jumlah cluster yang bergantung pada banyaknya kalimat pada
dokumen yang akan diringkas dan besarnya tingkat peringkasan. Ilustrasinya dapat dilihat pada Gambar 4.
9
Evaluasi
Peringkasan sistem dilakukan pada seluruh dokumen dengan tingkat peringkasan 30%, 20%, dan 10%. Ada beberapa teknik evaluasi untuk mengukur
kualitas performa dari model clustering kalimat, diantaranya adalah information
metrix, misclassification index, purity, F-Measure (Luthfiarta et al. 2013).
Penelitian ini menggunakan teknikF-measureuntuk mengukur kinerja model yang
diusulkan. Pengukuran F-Measure berdasar pada nilai Precision dan Recall.
Luthfiarta et al. (2013) menerangkan bahwa, semakin tinggi nilai Precision
danRecallmaka semakin tinggi pula tingat akurasinya.
Recall adalah proporsi kalimat yang ditemukan kembali sebagai ringkasan, danPrecisionadalah proporsi jumlah kalimat yang ditemukan dan dianggap relevan
(Yanget al. 2014). Menurut Manninget al.(2008) untuk memudahkan melakukan
perhitungan, maka digunakan tabel pendukung yang dapat dilihat pada Tabel 2.
Tabel 2 Pendukung untuk menghitungrecall,precision,f-measure, dan akurasi
Relevant Non-Relevant
Retrieved tp fp
Not Retrieved fn tn
Dari Tabel 2, nilaiRecall,Precision, F-Measure, dan Akurasi dapat dihitung
menggunakan rumus sebagai berikut:
sedangkan t p (true positive) adalah jumlah kalimat relevan yang terambil, f p
(false positive) adalah jumlah kalimat yang tidak relevan yang terambil, f n(false negative) adalah jumlah kalimat relevan yang tidak terambil, dantn(true negative) adalah jumlah kalimat yang tidak relevan yang tidak terambil.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini sebagai berikut:
1 Perangkat keras berupa komputer personal dengan spesifikasi sebagai berikut:
10
• RAM 8GB
• Monitor LCD 14.0” HD
• SSD 250 GB
2 Perangkat lunak:
• Sistem Operasi Windows 8
• Bahasa pemrograman PHP
• XAMPP v1.8.0
• Sublime Text 3 digunakan sebagai editor kode program
HASIL DAN PEMBAHASAN
Pengumpulan Dokumen
Kumpulan dokumen yang didapat dari repository.ipb.ac.id adalah merupakan skripsi mahasiswa Ilmu Komputer Institut Pertanian Bogor sebanyak 100 dokumen. Pengumpulan dokumen dilakukan dengan cara mengunduh secara acak tanpa memperhatikan indikator apapun. Keseluruhan dokumen tersebut digunakan sebagai data latih untuk menentukan fitur kata dan juga sebagai data uji untuk pengujian sistem peringkasan otomatis. Setelah didapat 100 dokumen, dilakukan
konversi secara manual dengan cara melakukan copy-paste setiap kalimat pada
dokumen PDF yang sesuai dengan aturan yang telah dibuat, ke dalam file berformat TXT. Dokumen yang digunakan pada penelitian ini dapat dilihat pada Lampiran 1.
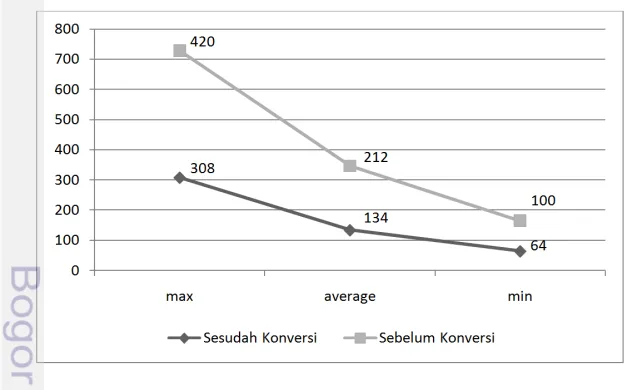
Proses pengumpulan dokumen ini memakan waktu yang cukup lama karena harus memeriksa setiap kalimat dan disesuaikan dengan aturan yang telah dibuat. Hasil konversi menghasilkan rata-rata 134 kalimat dalam setiap dokumen. Adapun perbandingan banyaknya kalimat setelah dan sebelum dilakukan konversi dapat dilihat pada Gambar 5.
11
Secara keseluruhan, rata-rata sebesar 34.33% dari isi dokumen adalah tinjauan pustaka dan kalimat yang menjelaskan tentang gambar, tabel, dan persamaan/rumus. Oleh karena itu, rata-rata hanya 65.67% dari isi dokumen yang
diikutsertakan dalam proses konversi dokumen. Selain melakukan perubahan
dokumen ke dalam bentuk TXT, juga dilakukan peringkasan manual yang nantinya akan digunakan sebagai bahan pembanding dengan hasil ringkasan sistem untuk
melakukan evaluasi. Pada penelitian ini diasumsikan bahwa hasil ringkasan
manual adalah baik.
Pengindeksan
Pengindeksan dilakukan dengan cara mengunggah satu persatu seluruh dokumen TXT ke dalam sistem. Sistem akan melakukan pemisahan kata serta
menyimpan kata-kata yang terdapat pada setiap dokumen. kata yang telah
disimpan akan digunakan untuk pembobotan kata dengan penghitungan IDF.
Pemisahan Kata
Pemisahan kata dilakukan dengan menggunakan delimiter karakter
whitespacedan dijadikan ke dalam bentukarray. adapun potongan kode algoritme pemisahan kata yang digunakan pada penelitian ini sebagai berikut:
1. $filename = ’./DATA_UPLOAD’.$path;
2. $content = strtolower(file_get_contents($filename)); 3. $wordArray = preg_split(’/[^ a-z]/’,$content, -1, PREG_SPLIT_NO_EMPTY);
4. $wordFrequencyArray = array_count_values($filteredArray); 5. arsort($wordFrequencyArray);
Penelitian ini menggunakan fungsi “array count values()” pada bahasa
pemrograman PHP untuk mendapatkan frekuensi kata dan memfilter kata agar tidak terjadi redudansi kata pada array yang telah didapat di setiap dokumen. Potongan kode di atas memisahkan kata pada dokumen dengan memperhatikan
karakter huruf yang dipisahkan oleh whitespace. Sementara itu, untuk angka
dan/atau karakter selain huruf, tidak akan dianggap sebagai kata.
Setelah mendapatkan kumpulan kata pada dokumen, kumpulan kata tersebut disimpan ke dalam database. Pemisahan kata pada 100 dokumen dalam penelitian
ini telah menghasilkanrecord sebanyak 59230 kata. Namun,record tersebut masih
mencatat seluruh kata yang keluar pada setiap dokumen. Contoh kasus; kata
‘adalah’ muncul di setiap dokumen yang artinya terdapat 100recordkata ‘adalah’.
Padarecord tersebut juga terdapat 4 kata yang hanya terdiri dari 2 karakter yaitu:
“et”, “al”, “id”, dan “ms”. jika 59230 record dilakukan teknik distinct
12
Tabel 3Recordfrekuensi kemunculan kata terhadap dokumen
Kata Frekuensi
Pada Tabel 3 dapat dilihat bahwa ada kata yang memiliki makna yang sama
sperti kata ‘sistem’ dan ‘system’. Kata ‘sistem’ muncul pada 88 dokumen,
sedangkan kata ‘system’ muncul pada 39 dokumen. Hal ini membuat bobot nilai kedua kata tersebut berbeda yang seharusnya dapat dijadikan 1 kata yang sama. Namun, pada penelitian ini kasus di atas tetap dijadikan 2 kata yang berbeda dan bobot yang berbeda karena sulitnya melakukan standarisasi kata dan bahkan mungkin merupakan suatu ungkapan atau obyek yang berbeda. Penelitian ini juga
tidak menggunakan stemming dalam proses pemisahan kata karena proses
stemming (proses untuk menemukan kata dasar dari sebuah kata) pada bahasa Indonesia lebih rumit/kompleks karena terdapat variasi imbuhan yang harus dibuang untuk mendapatkan kata dasar dari sebuah kata.
Pemilihan Fitur Kata
Pemilihan fitur kata didapat dengan menggunakan metode IDF. Pada penelitian ini, nilai IDF yang diambil sebagai fitur kata adalah nilai IDF yang
terletak pada 0.1 ≤ IDF < 2.0 . Hal ini bertujuan untuk mendapatkan fitur kata
13
IDF yang dihasilkan dapat dilihat pada Tabel 4.
Tabel 4 Sebaran nilai IDF
Frekuensi Jumlah Kata IDF
Pada Tabel 4 terlihat bahwa dari 11151 kata, terdapat 10195 kata yang memiliki frekuensi kemunculan 1-13 dokumen. Apabila fitur kata yang digunakan memiliki frekuensi kemunculan yang kecil pada dokumen, maka peluang kemunculan kata tersebut pada suatu kalimat juga semakin kecil. Hal ini akan mengakibatkan peluang kalimat bernilai nol akan semakin besar sehingga sulit untuk melakukan pembobotan kalimat. Pada Tabel 4 dapat dilihat bahwa nilai IDF
yang memenuhi persyaratan atau 0.1 ≤IDF<2.0 terdapat pada kata-kata dengan
frekuensi kemunculan di antara 14 sampai dengan 90 dokumen. Dari 11151 kata unik dari seluruh dokumen, terpilih sebanyak 894 kata yang memiliki nilai IDF
antara 0.1≤IDF<2.0.
Peringkasan Teks
Proses peringkasan otomatis dilakukan dengan cara mengunggah dokumen kedalam sistem. Sistem akan melakukan beberapa proses terhadap dokumen yang telah diunggah. Adapun proses yang akan dilakukan yaitu; pemisahan kalimat,
pembobotan TF-ISF,clusteringdengan menggunakan metodeK-Means, dan proses
terakhir adalah seleksi kalimat.
Pemisahan Kalimat
Pemisahan kalimat dilakukan dengan menggunakan beberapa indikator seperti titik (.), tanda seru (!), dan tanda tanya (?). kesulitan yang dihadapi adalah
penggunaan tanda baca seperti titik (.) tidak hanya digunakan pada saat
mengakhiri sebuah kalimat. Oleh karena itu, dilakukan perubahan karakter
menggunakan fungsi PHPstr replace()pada kasus-kasus tertentu seperti;
1 Tanda titik pada angka yang merupakan bilangan desimal. contoh 25.67 akan diubah menjadi 25*67.
14
3 Pada penulisan yang memberikan informasi format dari sebuah file. seperti .TXT, .PDF, data.sql, akan diubah menjadi *PDF yang nantinya akan diubah kembali menjadi tanda titik (.) untuk hasil peringkasan otomatis.
contoh kasus: pada dokumen ke-10 kalimat ke-4:
"Zang et al. (2001) telah menggunakan Support Vector Machine(SVM) untuk klasifikasi pada sistem temu kembali citra ciri warna."
diubah menjadi:
"Zang et al* (2001) telah menggunakan Support Vector Machine(SVM) untuk klasifikasi pada sistem temu kembali citra ciri warna."
proses ini hanya untuk menemukan tanda titik pada akhir kalimat. Setelah itu, tanda “*” akan kembali diganti menjadi tanda “.” seperti:
"Zang et al. (2001) telah menggunakan Support Vector Machine(SVM) untuk klasifikasi pada sistem temu kembali citra ciri warna."
Pada dasarnya algoritme pemrograman yang dibuat akan memisahkan kalimat menggunakan tanda titik (.), tanda seru (!), dan tanda tanya (?) yang setelahnya
diikuti dengan karakter white space kecuali pada kasus tertentu seperi penulisan
“et al.”. Hal ini berguna untuk tidak memisahkan kata yang menjelaskan suatu istilah yang memberikan informasi tertentu seperti .PDF, .TXT, menyatakan suatu url seperti http://ipb.ac.id, dan lain sebagainya.
Masalah dapat muncul apabila terdapat suatu kalimat yang diakhiri dengan
indikator berhenti namun tidak disertai karakter white space, maka kalimat tidak
akan terpisah hingga menemukan indikator yang disertai denganwhite space. Hal
ini akan terjadi apabila terdapat kesalahan penulis dalam menulis teks dokumen (human error). Namun, pada penelitian ini, dari 100 dokumen tidak terdapat kasus seperti yang dijelaskan diatas.
Pembobotan TFISF
Pembobotan TFISF dilakukan dengan menggunakan fitur kata yang telah didapat pada tahap pengindeksan. TFISF dilakukan untuk pembobotan kalimat
pada masing-masing dokumen. Adapun potongan kode program untuk
menentukan nilai TF sebagai berikut;
1. foreach($fiturkata->result() as $fit){ 2. $fitur_kata = " ".$fit->kata." "; 3. $SFkata[$fit->kata]= 0;
4. foreach($sentence->result() as $sen){ 5. $kalimat = $sen->kalimat;
6. $kalimat = str_replace(array("?", ".", "!", ","), ’ ’, $kalimat);
7. $kalimat = " ".$kalimat." ";
8. $tf[$sen->id_kalimat_sementara][$fit->id] = substr_count($kalimat, $fitur_kata);
15
10. $SFkata[$fit->kata] += 1; 11. }
12. } 13. }
Pada baris ke-6 kode program di atas, jika terdapat kata yang diikuti dengan karakter tertentu, maka karakter tersebut akan dihilangkan guna memudahkan mencari kata yang sesuai dengan fitur kata pada kalimat.
Pada baris ke-8 kode program menggunakan fungsi substr-count untuk
menemukan kata pada kalimat yang sesuai dengan fitur kata. Masalah yang terjadi adalah fungsi tersebut juga mengikut sertakan kata yang bukan benar-benar sesuai dengan fitur kata. contoh kasus seperti fitur kata “perlu” akan terdeteksi muncul pada kalimat yang memiliki kata “perluasan”. Untuk mengatasi masalah tersebut,
dilakukan penambahanwhite spacepada awal dan akhir dari fitur kata seperti yang
dilakukan pada baris ke-2 potongan kode program di atas. Hal ini berguna untuk menemukan fitur kata yang benar pada setiap kalimat. Oleh karena itu, fitur kata
“<spasi>perlu<spasi>” tidak akan terdeteksi pada kata “perluasan”. Potongan
kode program diatas berhasil menghasilkan penghitungan TF dengan cukup baik. Sementara itu, potongan program pembobotan TFISF sebagai berikut;
1. foreach($sentence->result() as $sen2){
Kode baris ke-9,10,dan 11 adalah kode program yang disesuaikan dengan
rumus penghitungan TFISF seperti pada Persamaan 3. Pada kode baris ke-14
dilakukan penjumlahan nilai TFISF dari setiap kalimat dan dijadikan sebagai nilai dari suatu kalimat yang nantinya akan digunakan pada tahap seleksi kalimat. Adapun hasil matriks pembobotan TFISF pada dokumen ke-4 dapat dilihat pada Tabel 5.
Pada penelitian ini pembobotan TFISF menghasilkan rata-rata matriks dengan
dimensi 134 x 894, dan pada umumnya berbentuk sparse matriks karena banyak
16
Tabel 5 Matriks hasil TFISF dokumen ke-4
Fitur Kata S1 S2 ... S72 S73 ... S119
TOTAL 30.66 10.94 ... 6.60 11.86 ... 21.65
setiap kalimat, maka TFISF akan bernilai nol.
ClusteringKalimat dengan MetodeK-Means
Banyaknya cluster pada penelitian ini bergantung pada tingkat peringkasan dan jumlah kalimat pada dokumen yang akan diringkas. adapun potongan kode program untuk menentukan banyaknya cluster sebagai berikut:
1. $BanyakCluster = ($BanyakKalimat * 30) / 100 ; 2. $BanyakCluster = floor($BanyakCluster);
Pada baris ke-2 digunakan fungsi floor untuk menghasilkan nilai bulat pada
hasil penghitungan berdasarkan tingkat peringkasan. Misalnya; pada dokumen ke-10 terdapat 119 kalimat dengan tingkat peringkasan sebesar 30%, maka jumlah clusteradalah sebanyak 119 x 0.30 = 35,70 akan menjadi 35 cluster.
Pada penelitian ini, penentuan centroid awal (initial centroid) dilakukan
dengan cara mengambil data dari matriks TFISF secara acak ataurandom. Setelah
itu, centroid berikutnya akan dilakukan penghitungan sesuai dengan Persamaan 4 sampai iterasi ke-n. Masalah yang ditemui adalah pada penghitungan dan iterasi yang dilakukan memakan waktu yang cukup lama dikarenakan besarnya dimensi
matriks TFISF yang rata-rata berdimensi 134 x 894. Rata-rata membutuhkan
waktu sekitar 10 detik untuk menyelesaikan clustering kalimat. Adapun hasil
clusteringpada dokumen ke-4 dengan tingkat peringkasan 30% dapat dilihat pada Tabel 6.
Setiap cluster dapat memiliki minimal 1 kalimat dan maksimal banyak
kalimat. Sebagai contoh pada Tabel 6, hasil dari cluster 31 (C31) pada dokumen
ke-4 terdapat 4 kalimat yaitu:
1 “dengan menggunakan time constraint 4 bulan, ternyata maksimal item yang dapat dibentuk pada sebuah sequence adalah 5 (5-sequence).” [bobot = 6.35] 2 “dengan menggunakan time constraint 2 bulan, ternyata maksimal item yang
17
3 “dengan menggunakan time constraint 20 hari, ternyata maksimal item yang dapat dibentuk pada sebuah sequence adalah 2 (2-sequence).” [bobot = 6.86] 4 “dengan menggunakan time constraint 6 bulan, ternyata maksimal item yang dapat dibentuk pada sebuah sequence adalah 6 buah (6-sequence).” [bobot = 8.43]
Jika dilihat pada kalimat-kalimat tersebut, secara keseluruhan mambahas
tentang “time constraint”. Oleh karena itu, proses clustering telah berhasil
mengelompokkan kalimat yang memiliki makna yang hampir sama.
Tabel 6 Hasilclusteringdokumen ke-4
Cluster Jumlah Kalimat
Seleksi kalimat dilakukan dengan cara mengurutkan kalimat dari nilai tertinggi hingga terendah yang telah didapat dari penjumlahan nilai TFISF pada
tahap pembobotan TFISF. Pengurutan kalimat dilakukan pada setiap cluster,
sehingga setiap cluster akan diwakilkan oleh satu kalimat yang memiliki nilai
tertinggi.
Setiap kalimat pada hasilcluster31 (C31) pada dokumen ke-4 telah memiliki
bobot nilai yang apabila dilakukan seleksi kalimat pada C31 akan terpilih kalimat ke-4 dengan bobot nilai 8.43. Kalimat “dengan menggunakan time constraint 6 bulan, ternyata maksimal item yang dapat dibentuk pada sebuah sequence adalah 6 buah (6-sequence)” akan mewakili C31 dan keluar sebagai ringkasan.
Evaluasi
Clusteringselalu memberikan hasil yang berbeda-beda. Hal ini disebabkan
karena proses clustering sangat bergantung pada penentuan centroid awal yang
18
Tabel 7 Hasil ringkasan dengan tingkat peringkasan 30%
Percobaan-1 Percobaan-2 Percobaan-3 Percobaan-4 Rata-rata
Recall 0.33 0.33 0.33 0.33 0.33
Precision 0.43 0.43 0.43 0.43 0.43
F-Measure 0.37 0.37 0.37 0.37 0.37
Akurasi 0.57 0.57 0.57 0.57 0.57
Tabel 8 Hasil ringkasan dengan tingkat peringkasan 20%
Percobaan-1 Percobaan-2 Percobaan-3 Percobaan-4 Rata-rata
Recall 0.22 0.22 0.22 0.22 0.22
Precision 0.43 0.44 0.42 0.44 0.43
F-Measure 0.29 0.29 0.28 0.29 0.29
Akurasi 0.58 0.59 0.58 0.59 0.58
Tabel 9 Hasil ringkasan dengan tingkat peringkasan 10%
Percobaan-1 Percobaan-2 Percobaan-3 Percobaan-4 Rata-rata
Recall 0.11 0.12 0.11 0.11 0.11
Precision 0.45 0.48 0.45 0.43 0.45
F-Measure 0.17 0.18 0.18 0.17 0.17
Akurasi 0.60 0.60 0.60 0.60 0.60
mengatasi hal ini, setiap dokumen dilakukan peringkasan otomatis sebanyak 4 kali pada setiap besar tingkat peringkasan dan diambil nilai rata-rata dari setiap hasilnya. Total percobaan peringkasan otomatis sistem dilakukan sebanyak 1200
kali. Adapun evaluasi hasil ringkasan sistem dengan ringkasan manual dapat
dilihat pada Tabel 7, 8, dan 9.
Nilai evaluasi hasil ringkasan sistem pada tiap percobaan dalam satu tingkat peringkasan tidak jauh berbeda walau menghasilkan keluaran ringkasan yang
berbeda. Hasil ringkasan sistem pada tingkat peringkasan 30% menghasilkan
rata-ratarecall 32.95%,Precision43.07%,f-measure36.98%, dan akurasi sebesar
57.11%. Untuk tingkat peringkasan 20% menghasilkan rata-rata recall 22.11%,
Precision43.40%,f-measure28.96%, dan akurasi sebesar 58.44%. Sementara itu,
pada tingkat peringkasan 10% hasil ringkasan sistem menghasilkan rata-ratarecall
11.13%,Precision45.06%,f-measure17.70%, dan akurasi sebesar 60%.
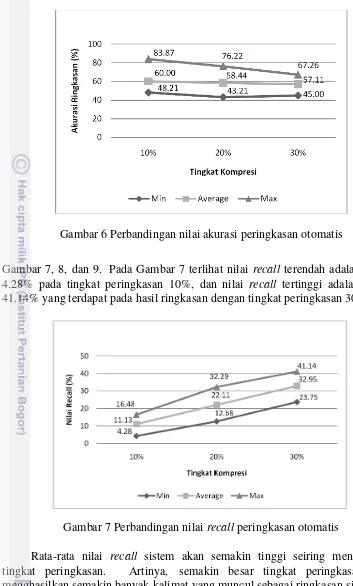
Nilai akurasi terendah adalah sebesar 43.21% pada tingkat peringkasan 20%, dan nilai akurasi tertinggi adalah sebesar 83.87% yang terdapat pada hasil ringkasan dengan tingkat peringkasan 10%. Nilai minimum, maksimum, dan rata-rata akurasi peringkasan otomatis sistem dapat dilihat pada Gambar 6.
Pada Gambar 6 dapat dilihat bahwa rata-rata nilai akurasi berbanding terbalik dengan tingkat peringkasan sistem. Rata-rata nilai akurasi sistem akan semakin rendah jika tingkat peringkasan semakin tinggi. Hal ini disebabkan karena semakin rendah tingkat peringkasan, maka akan menjadi semakin sedikit kalimat ringkasan yang dihasilkan oleh sistem dan semakin kecil pula peluang kesalahannya.
Selain perbandingan nilai akurasi, dalam evaluasi hasil ringkasan juga
19
Gambar 6 Perbandingan nilai akurasi peringkasan otomatis
Gambar 7, 8, dan 9. Pada Gambar 7 terlihat nilai recall terendah adalah sebesar
4.28% pada tingkat peringkasan 10%, dan nilai recall tertinggi adalah sebesar
41.14% yang terdapat pada hasil ringkasan dengan tingkat peringkasan 30%.
Gambar 7 Perbandingan nilairecallperingkasan otomatis
Rata-rata nilai recall sistem akan semakin tinggi seiring meningkatnya
tingkat peringkasan. Artinya, semakin besar tingkat peringkasan, akan
menghasilkan semakin banyak kalimat yang muncul sebagai ringkasan sistem, dan semakin besar pula peluang munculnya kalimat yang sesuai dengan ringkasan manual.
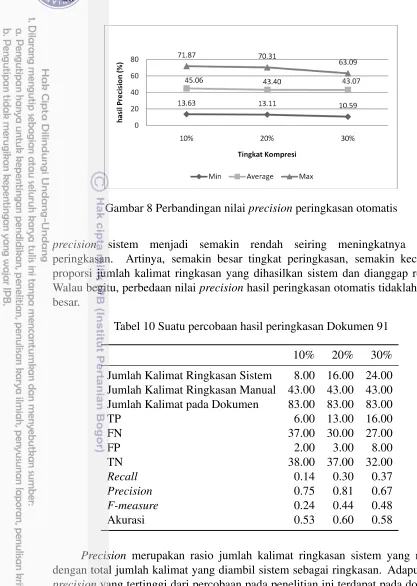
Pada Gambar 8 terlihat nilaiprecision terendah adalah sebesar 10.59% pada
tingkat peringkasan 30%, dan nilaiprecisiontertinggi adalah sebesar 71.87% yang
20
Gambar 8 Perbandingan nilaiprecisionperingkasan otomatis
precision sistem menjadi semakin rendah seiring meningkatnya tingkat
peringkasan. Artinya, semakin besar tingkat peringkasan, semakin kecil pula
proporsi jumlah kalimat ringkasan yang dihasilkan sistem dan dianggap relevan.
Walau begitu, perbedaan nilaiprecisionhasil peringkasan otomatis tidaklah begitu
besar.
Tabel 10 Suatu percobaan hasil peringkasan Dokumen 91
10% 20% 30%
Jumlah Kalimat Ringkasan Sistem 8.00 16.00 24.00
Jumlah Kalimat Ringkasan Manual 43.00 43.00 43.00
Jumlah Kalimat pada Dokumen 83.00 83.00 83.00
TP 6.00 13.00 16.00
FN 37.00 30.00 27.00
FP 2.00 3.00 8.00
TN 38.00 37.00 32.00
Recall 0.14 0.30 0.37
Precision 0.75 0.81 0.67
F-measure 0.24 0.44 0.48
Akurasi 0.53 0.60 0.58
Precision merupakan rasio jumlah kalimat ringkasan sistem yang relevan dengan total jumlah kalimat yang diambil sistem sebagai ringkasan. Adapun nilai precisionyang tertinggi dari percobaan pada penelitian ini terdapat pada dokumen 91 yaitu sebesar 0.81 dengan jumlah kalimat ringkasan yang dihasilkan sistem sebesar 16 kalimat dan terdapat 13 kalimat yang relevan dengan ringkasan manual. Nilai hasil peringkasan pada dokumen 91 dapat dilihat pada Tabel 10.
Nilai precision yang terendah terdapat pada percobaan meringkas dokumen
9 yang memberikan nilaiprecision sebesar 0.07 dengan jumlah kalimat ringkasan
21
Tabel 11 Suatu percobaan hasil peringkasan Dokumen 9
10% 20% 30%
Jumlah Kalimat Ringkasan Sistem 30.00 61.00 92.00
Jumlah Kalimat Ringkasan Manual 28.00 28.00 28.00
Jumlah Kalimat pada Dokumen 307.00 307.00 307.00
TP 2.00 7.00 9.00
dengan ringkasan manual. Nilai hasil peringkasan pada dokumen 9 dapat dilihat pada Tabel 11.
Hal ini jelas sangat bergantung dengan seberapa banyak kalimat yang relevan dan jumlah kalimat yang diambil oleh sistem sebagai hasil ringkasan. Apabila ringkasan system dibandingkan dengan ringkasan manual, maka baik atau tidaknya ringkasan manual dan atau ringkasan sistem sangatlah mempengaruhi hasil
evaluasi. Baik atau tidaknya ringkasan manual sangatlah bersifat subyektif.
Sementara itu, baik atau tidaknya hasil ringkasan sistem bergantung pada fitur kata yang digunakan. Fitur yang digunakan penelitian ini adalah kata yang memiliki
nilai 0.1≤IDF<2.0.
Pada dokumen 9 yang memilikiprecision terkecil, dicoba untuk melakukan
peringkasan dengan fitur kata 0.1 ≤ IDF < 3.5 untuk melihat apakah precision
berubah signifikan ketika fitur kata lebih banyak. Adapun hasil peringkasan
dokumen 9 dengan fitur kata 0.1≤IDF<3.5 dapat dilihat pada Tabel 12.
Pada Tabel 12 dapat dilihat peningkatan nilai precision ketika fitur kata
diubah. Namun, perubahan tersebut tidaklah begitu besar. Kecilnya nilaiprecision
pada Dokumen 9 dapat dipengaruhi oleh ringkasan manual yang merupakan acuan dari evaluasi. Jumlah ringkasan manual yang kecil dan atau kualitas ringkasan
manual yang kurang baik dapat menyebabkan peluang meningkatnya nilai f p.
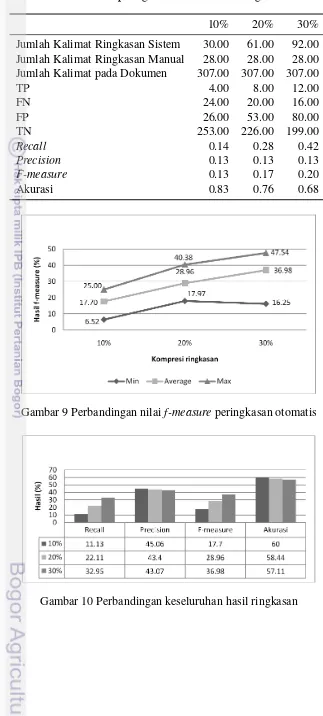
Pada Gambar 9 terlihat nilaif-measure terendah adalah sebesar 6.25% pada
tingkat peringkasan 10%, dan nilaif-measuretertinggi adalah sebesar 47,54% yang
terdapat pada hasil ringkasan dengan tingkat peringkasan 30%. Rata-rata nilai
f-measuresistem akan semakin tinggi seiring meningkatnya tingkat peringkasan.
Perbandingan keseluruhan baikrecall, precision, f-measure, maupun akurasi
dari hasil ringkasan antara tingkat peringkasan 10%, 20%, dan 30% dapat dilihat pada Gambar 10.
Nilai rata-rata recall meningkat seiring dengan meningkatnya tingkat
peringkasan. Untuk nilai rata-rata precisionmengalami penurunan seiring dengan
22
Tabel 12 Percobaan hasil peringkasan Dokumen 9 dengan fitur kata baru
10% 20% 30%
Jumlah Kalimat Ringkasan Sistem 30.00 61.00 92.00
Jumlah Kalimat Ringkasan Manual 28.00 28.00 28.00
Jumlah Kalimat pada Dokumen 307.00 307.00 307.00
TP 4.00 8.00 12.00
FN 24.00 20.00 16.00
FP 26.00 53.00 80.00
TN 253.00 226.00 199.00
Recall 0.14 0.28 0.42
Precision 0.13 0.13 0.13
F-measure 0.13 0.17 0.20
Akurasi 0.83 0.76 0.68
Gambar 9 Perbandingan nilaif-measureperingkasan otomatis
23
nilai rata-rata f-measure meningkat seiring dengan meningkatnya tingkat
peringkasan. Sementara itu, nilai rata-rata akurasi cenderung menurun seiring
dengan meningkatnya tingkat peringkasan.
Dikatakan rata-rata karena dari 100 dokumen, ada beberapa dokumen yang justru memberikan hasil yang berbeda dari perbandingan nilai rata-rata keseluruhan dokumen. Adapun hal-hal yang terjadi adalah;
1 Terdapat 7 dokumen yang nilai akurasinya berlawanan (meningkat seiring dengan meningkatnya tingkat peringkasan).
2 Terdapat 13 dokumen dengan nilai precision yang berlawanan (semakin tinggi seiring meningkatnya tingkat peringkasan).
Gambar 11 Dokumen 10.txt yang mengalami perubahan akurasi berlawanan
Pada Gambar 11 merupakan salah satu contoh dokumen yang menghasilkan nilai akurasi yang semakin tinggi seiring dengan meningkatnya tingkat
peringkasan. Evaluasi yang dilakukan pada penelitian ini sangat bergantung
kepada ringkasan manual yang dilakukan pada setiap dokumen. Sistem melakukan
dengan menggunakan fitur kata dan metode K-Means untuk menghasilkan
ringkasan. Sementara itu, ringkasan manual dilakukan oleh manusia dan
merangkum isi dokumen berdasarkan kehendak masing-masing untuk memilih kalimat mana yang dianggap baik sebagai peringkasan otomatis.
Tingkat peringkasan yang semakin tinggi membuat jumlah kalimat yang
keluar sebagai hasil ringkasan sistem juga meningkat. Nilai t p, f n, f p, dan tn
sangat mempengaruhi hasil precision dan akurasi. Sementara itu, banyaknya
kalimat ringkasan yang dikeluarkan oleh sistem dan baiknya ringkasan manual
yang dibuat oleh manusia juga sangat mempengaruhi nilait p, f n, f p, dantn.
Hal yang terjadi pada dokumen yang memiliki nilai akurasi yang berlawanan
adalah; karena hasil evaluasi memiliki nilai penjumlahan tn dengan t p yang
meningkat seiring dengan meningkatnya tingkat peringkasan. Sementara itu, pada
umumnya hasil penjumlahan nilai tn dengan t p akan menurun seiring
24
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan, dapat disimpulkan beberapa hal sebagai berikut:
1 Sistem peringkasan dokumen otomatis berdasarkan fitur kata telah berhasil dikembangkan.
2 Penggunaan metode K-Means dengan pembobotan kalimat berdasarkan fitur kata menghasilkan rata-rata akurasi 58.51%, recall 22.06%,
precision 43.84%, dan f-measure 27.88%.
3 Clustering menggunakan K-Means membuat hasil ringkasan mengalami perubahan disetiap kali percobaan dan membuat tingkat akurasi hasil ringkasan selalu berubah. Oleh karena itu, peringkasan dokumen dengan menggunakan metode K-Means tidak menghasilkan ringkasan yang statis.
Saran
Pembuatan ringkasan manual untuk setiap dokumen sebaiknya dibuat oleh lebih dari satu orang agar mendapatkan ringkasan yang obyektif (bersifat umum) dengan harapan akurasi yang didapatkan akan lebih baik.
DAFTAR PUSTAKA
Agrawal, Ayush, Gupta U. 2014. Extraction based approach for text summarization using K-Means clustering. IJSRP. 4 (11)
Arai K, Barakbah AR. 2007. Hierarchical K-Means: an algorithm for centroids initialization for K-Means. 1. Saga University. 25-31
Luthfiarta A, Zeniarja J, Salam A. 2013. Algoritma Latent Semantic Analysis (LSA) pada peringkas dokumen otomatis untuk proses clustering dokumen.
SEMANTIK 2013
Manning CD, Raghavan P, Schütze H. 2008. An Introduction to Information Retrieval. Cambridge (UK): Cambridge University Press
Manyika J, Chui M, Brown B, Roxburgh C, Byers AH. 2011. Big data: the next frontier for innovation, competition, and productivity. [MGI] McKinsey Global Institute.
Muflikhah L, Baharudin B. 2009. Document clustering using concept space and cosine similarity measurement. International Conference on Computer Technology and Development. 58-62
Munot N, Govilkar SS. 2014. Comparative study of text summarization methods.
International Journal of Computer Applications. 102 (12): 33-37
25 Rino LHM, Pardo THS, Silla Jr TN, Kaestner CAA, Pombo M. 2004. Advances in artificial intelligence – SBIA 2004: 17th Brazilian symposium on artificial intelligence. Ana LCB 3171. 240-241
Suanmali L, Salim N, Binwahlan MS. 2009. Fuzzy logic based method for improving text summarization. IJCSIS. 2 (1)
Wadhvani R, Pateriya RK, Roy D. 2013. A topicdriven summarization using K-Means clustering and RF-ISF sentence ranking. International Journal of Computer Applications. 79 (8)
Wajeed MA, Adilakshmi T. 2009. Text classification using machine learning.
Journal of Theoritical and Applied Information Technology. 7 (2)
Wajeed MA, Adilakshmi T. 2012. Comparison of supervised and semi-supervised fuzzy clusters in text categorization. IJFLS. 2(1)
26
Lampiran 1 Daftar dokumen skripsi yang digunakan
No File Asli Judul Skripsi
1 G06amu.pdf Pengembangan Aplikasi Data Mining Menggunakan
Fuzzy Association Rules
2 G06ede.pdf Sistem Informasi Untuk Melihat Rute Terpendek dan Jalur Angkot Berbasis SMS
3 G06fso.pdf Pengembangan Sistem Informasi Geografis Hutan Kota Propinsi DKI Jakarta
4 G06hag.pdf Penentuan Pola Sekuensial Pada Data Transaksi Perpustakaan IPB Menggunakan Algoritma Graph Search Techniques
5 G06rhs.pdf Sistem Informasi Dinas Pendidikan Berorientasi Objek dan Berbasis Web (Studi Kasus Kota Tanjung Pinang Kepulauan Riau)
6 G09apa2.pdf Sistem Informasi Geografi Asrama Putri TPB IPB Berbasis Web Menggunakan Alov Map
7 G09eap.pdf Pengenalan Wajah Dengan Citra Pelatihan Tunggal Menggunakan Algoritme VF15 Berbasis Histogram
8 G09nls.pdf Ekspansi Kueri Pada Sistem Temu Kembali Informasi Berbahasa Indonesia Menggunakan Kamus Dwibahasa 9 G09sha.pdf Perancangan Prototipe Ebook Reader Menggunakan
Usability Engineering
10 G09wsj.pdf Optimasi Query Citra Dengan Relevance Feedback dan
Support Vector Machine
11 G09yar.pdf Penentuan Tingkat Keberhasilan Mahasiswa Tingkat I IPB Menggunakan Induksi Pohon Keputusan dan Bayesian Classifier
12 G11afr.pdf Identifikasi Campuran Nada Pada Suara Piano Menggunakan Codebook
13 G11ara.pdf Klasifikasi Dokumen Bahasa Indonesia Menggunakan Metode Semantic Smoothing
14 G11hra.pdf Clustering Konsep Dokumen Berbahasa Indonesia Menggunakan Bisecting K-Means
15 G11jaz.pdf Pengenalan Iris Mata Dengan Backpropagation Neural Network Menggunakan Praproses Transformasi Wavelet
16 G11kau.pdf Data Warehouse dan Aplikasi OLAP Akademik Kurikulum Mayor-Minor Berbasis Linux
17 G11kpa.pdf Klasifikasi Dokumen Tumbuhan Obat Menggunakan Algoritma KNN Fuzzy
18 G11mrf.pdf Klasifikasi Genre Musik Menggunakan Learning Vector Quantization (LVQ)
19 G11mus.pdf Pengembangan Distribusi ILOS Multimedia (ILOSMEDIA)
20 G11pra.pdf Pengenalan Kata Berbasiskan Fenom Dengan Pemodelan
27 Lanjutan
No File Asli Judul Skripsi
21 G12kab.pdf Rancang Bangun Komunikasi Data Wireless
Mikrocontroler Menggunakan Modul Xbee Zigbee (IEEE 802.15.4)
22 G12nsa2.pdf Klasifikasi Dokumen Bahasa Indonesia Menggunakan
Semantic Smoothing Dengan Ekstraksi Ciri Chi-Square
23 G12zmu.pdf Analisis Pengaruh Dinamika Peer Pada Hierarchical Peer-To-Peer Menggunakan Topologi Superpeer
24 G13ant.pdf Penerapan Teknik Penarikan Contoh Kuota Untuk Penentuan Aplikasi Pada Distro IPB Linux Operating System (ILOS)
25 G13cpy.pdf Implementasi Jaringan Peer-To-Peer Tak Terstrukstur Menggunakan Protokol JXTA
26 G13cws.pdf Deteksi Malware Berbasis System Call Dengan Klasifikasi Support Vector Machine Pada Android
27 G13dan.pdf Perbandingan Algoritme C4.5 dan Cart Pada Data Tidak Seimbang Untuk Kasus Prediksi Risiko Kredit Debitur Kartu Kredit
28 G13dsu.pdf Pengindeksan Ontologi Dokumen Bahasa Indonesia Menggunakan Latent Semantic Analysis
29 G13eap.pdf Pencarian Teks Bahasa Indonesia Pada Mesin Pencari Berbasis Soundex
30 G13ens.pdf Identifikasi Varietas Ubi Jalar Menggunakan Metode
Decision Tree J48
31 G13esa.pdf Aplikasi Bagan Warna Daun Untuk Optimasi Pemupukan Tanaman Padi Menggunakan K-Nearest Neighbor
32 G13fam.pdf Cross Language Question Answering System
Menggunakan Pembobotan Heuristic dan Multidokumen 33 G13fdh.pdf Sistem Pendeteksi Plagiat Harfiah Pada Dokumen Teks
Berbahasa Indonesia Dengan Memanfaatkan Mesin Pencari
34 G13fir.pdf Pembangunan Framework Untuk Deteksi Perubahan dan Irisan Wilayah Pada Data Spatiotemporal
35 G13gka.pdf Sistem Pencarian Turunan Kata Pada Al-Quran Menggunakan Light Stemming dan Clustering Untuk Pembicara Bahasa Indonesia
36 G13hap.pdf Analisis Pengaruh Kecepatan Mobilitas Terhadap Kinerja Video Streaming Pada Jaringan Wireless Ad Hooc
37 G13ita.pdf Peningkatan Pelayanan Penilangan Melalui Sistem E-Violation (Studi Kasus Satuan Lalu Lintas Polres Bogor) 38 G13mam.pdf Sistem Informasi Geografis Ruang Kuliah Kampus IPB
Dramaga Berbasis Mobile Dengan Platform Android OS 39 G13mir.pdf Penerapan Algoritme Dijkstra Pada Rute Angkot Bogor
28 Lanjutan
No File Asli Judul Skripsi
40 G13mpa.pdf Optimasi Jaringan Saraf Tiruan Menggunakan Algoritme Genetika Untuk Peramalan Panjang Musim Hujan
41 G13naz1.pdf Identifikasi Kolektibilitas Kredit Menggunakan Decision Tree
42 G13nca.pdf Koreksi DNA Sequencing Error Dengan Metode Spectral Alignment
43 G13nfp.pdf Sistem Deteksi Luka Pada Otot Kaki Abalon (Haliotis Asinina) Menggunakan Metode Histogram dan Morfologi 44 G13rjs.pdf Identifikasi Varietas Kunyit Berdasarkan Ciri Fisik
Menggunakan Algoritme C4.5
45 G13rrp.pdf Peringkas Dokumen Berbahasa Indonesia Berbasis Kata Benda Dengan BM25
46 G13rsu.pdf Penentuan Jalur Tercepat dan Terpendek Berdasarkan Kondisi Lalu Lintas Di Kota Bogor Menggunakan Algoritme Dijkstra dan Algoritme Floyd-Warshall
47 G13sba.pdf Pelayanan Publik Online: Sistem Online dan SMS
Gateway Pada Pelayanan Izin Usaha Industri
48 G13sra1.pdf Pembangunan Data Warehouse dan Aplikasi OLAP Kepegawaian Institut Pertanian Bogor
49 G13swi.pdf Peringkasan Teks Bahasa Indonesia Dengan Pemilihan Fitur C4.5 dan Klasifikasi Naive Bayes
50 G14aam1.pdf Pengembangan Sistem Informasi Desain Lanskap Tanaman Obat Keluarga Pada Cloud Computing
51 G14aau.pdf Penerapan SOM Untuk Pengenalan Nada Pada Angklung Modern
52 G14ada.pdf Pengklasifikasian Genre Musik Berdasarkan Sinyal Audio Menggunakan Support Vector Machine
53 G14adn.pdf Post Pruning Pohon Keputusan Spasial Untuk Klasifikasi Kemunculan Titik Panas
54 G14afa.pdf Prediksi Panjang Musim Hujan Menggunakan Time Delay Neural Network
55 G14aha1.pdf Implementasi dan Analisis Kinerja Switch Openflow dan
Switch Konvensional Pada Jaringan Komputer
56 G14amu5.pdf Penerapan Jaringan Saraf Tiruan Untuk Pemodelan Prakiraan Curah Hujan Bulanan
57 G14apr1.pdf Penambahan Layer Google Maps Pada Spatial Data Warehouse Titik Panas Di Indonesia
58 G14ash.pdf Klasifikasi Fragmen Metagenom Menggunakan Oblique Decision Tree Dengan Optimasi Algoritme Genetika 59 G14ask.pdf Steganografi Linguistik Metode Nicetext Menggunakan
Kata dan Variasi Pola Kalimat Dasar Bahasa Indonesia 60 G14atr.pdf Aplikasi Mobile Identifikasi Penyakit Daun Kubis Dengan
29 Lanjutan
No File Asli Judul Skripsi
61 G14bsi.pdf Pengelompokan Sekuens DNA Menggunakan Metode K-Means dan Fitur N-Mers Frequency
62 G14cfr.pdf Pencarian Jarak Titik Akses Sinyal Wireless Fidelity
(WiFi) Dengan Location Based Servise (LBS) Pada Android Di Area IPB Darmaga
63 G14dam.pdf Deteksi Data Titik Api Di Provinsi Riau Menggunakan Algoritme Clustering K-Means
64 G14dfm.pdf Klasifikasi Formula Jamu Berdasarkan Khasiat Menggunakan Oblique Decision Tree Dengan Optimasi Menggunakan Algoritme Genetika
65 G14ead.pdf Analisis Sentimen Dengan Klasifikasi Naive Bayes Pada Pesan Twitter Menggunakan Data Seimbang
66 G14egp.pdf Web Log Mining Menggunakan K-Means Pada Server
Proxy Untuk Perancangan Manajemen Bandwidth IPB 67 G14esy.pdf Pengembangan Aplikasi Pertukaran SMS Rahasia
Berbasis Android Menggunakan Algoritme RSA
68 G14fam.pdf Pemodelan Biplot Pada Klasifikasi Fragmen Metagenom Dengan K-Mers Sebagai Ekstraksi Ciri dan Probabilistic Neural Network Sebagai Classifier
69 G14fap1.pdf Implementasi Bidirectional HTTP Pada Aplikasi Chat
Berbasis Web Menggunakan Protokol Bayeux
70 G14fel.pdf Klasifikasi Fragmen Metagenom Menggunakan Fitur
Spaced N-Mers dan K-Nearest Neighbour
71 G14gpr.pdf Aplikasi Mobile GIS Pencarian Tempat Olahraga Di Bogor
72 G14htr.pdf Analisis dan Perancangan Sistem Tata Kelola Kelembagaan dan Sumber Daya FMIPA IPB Menggunakan Enterprise Architecture Planning
73 G14iad.pdf Hierarchical Clustering Pada Data Time Series Hotspot
Provinsi Riau
74 G14ins.pdf Identifikasi Plat Nomor Dengan Principal Component Analysis Menggunakan Metode Jaringan Syaraf Tiruan Propagasi Balik
75 G14kil.pdf Teknik Penyisipan Informasi Pada Fitur Poligon Peta Vektor Menggunakan Reversible Watermarking
76 G14kum.pdf Optimasi Penggunaan Lahan Menggunakan Algoritme Genetika Untuk Mendukung Peningkatan Produktivitas Pertanian
77 G14lns.pdf Penerapan Learning Vector Quantization (LVQ) dan Ekstraksi Ciri Menggunakan Mel-Frequency Ceptrum Coeficients (MFCC) Untuk Transkripsi Suara Ke Teks 78 G14man.pdf Migrasi Spatial Data Warehouse Hotspot Ke Sistem
30 Lanjutan
No File Asli Judul Skripsi
79 G14mch.pdf Identifikasi Citra Luka Abalon (Haliotis Asinina) Menggunakan Gray Level Co-occurrence Matrix dan Klasifikasi Probabilistic Neural Network
80 G14mdh.pdf Klasifikasi Fragmen Metagenom Menggunakan KNN dan PNN Dengan Ekstraksi Fitur Gray Level Co-occurrence Matrix (GLCM) Pada Variasi Panjang Fragmen
81 G14mhu.pdf Integrasi Basis Data dan Pipeline Single Nucleotide Polymorphism Untuk Pemuliaan Tanaman Kedelai
82 G14mlr.pdf Pengembangan dan Implementasi Sistem Pemadaman Api Pada Fire-Fighting Robot
83 G14naf.pdf Clustering Data Indeks Pembangunan Manusia (IPM) Pulau Jawa Menggunakan Algortime ST-DBSCAN dan Bahasa Pemrograman R
84 G14nas1.pdf Clustering Dokumen Skripsi Berdasarkan Abstrak Dengan Menggunakan Bisecting K-Means
85 G14rad.pdf Penentuan Lokasi Ideal Berdasarkan Total Jarak Tempuh Terpendek Dari Berbagai Lokasi Menggunakan Algoritme Dijkstra
86 G14ref.pdf Pengembangan Sistem Informasi Tanaman Hias Lanskap Untuk Masyarakat Umum Pada Cloud Computing
87 G14rfh.pdf Pendeteksian Kemiripan Kode Program C Dengan Algoritme K-Medoids
88 G14rku.pdf Temu Kembali Informasi Dokumen XML Dengan Pembobotan Per Konteks
89 G14rku2.pdf Klasifikasi Protein Family Menggunakan Algoritme
Probabilistic Neural Network (PNN)
90 G14rma.pdf Clustering Dataset Titik Panas Dengan Algoritme DBSCAN Menggunakan Web Framework Shiny Pada Bahasa Pemrograman R
91 G14rmf.pdf Aplikasi Perangkat Uji Pupuk Berbasis Android Menggunakan Fitur Warna
92 G14rse.pdf Pengembangan Sistem Keamanan Traksaksi Peta Digital Menggunakan Teknik Kriptografi
93 G14rtr.pdf Pengelompokan Kode Program C Berdasarkan Kemiripan Struktur Menggunakan Metode Hierarchical Agglomerative Clustering
94 G14sda.pdf Pemanfaatan Citra Satelit Untuk Identifikasi Tingkat Perubahan Tutupan Lahan Dengan Menggunakan Metode
Fuzzy C-Means
95 G14sro1.pdf Transkripsi Suara Ke Teks Bahasa Indonesia Berbasis Suku Kata Menggunakan Codebook dan 2-Level Dynamic Programming
31 Lanjutan
No File Asli Judul Skripsi
97 G14yse.pdf Simulasi Master Data Untuk Data Exchange Evaluasi Kinerja Dosen Berbasis Replika Basis Data
98 G15ekd.pdf Pemodelan Support Vector Machine Untuk Klasifikasi Bakteri Patogen dan Non Patogen Berdasarkan Data Sekuens Genom
99 G15fdw.pdf Online Analytical Processing (OLAP) Berbasis Web Untuk Tanaman Holtikultura Menggunakan Palo
32