SISTEM PENDUKUNG KEPUTUSAN AUTO LEARNING DENGAN ALGORITMA ITERATIVE DICHOTOMISER 3 (ID3)
(Studi Kasus: Penjurusan Siswa SMA)
Oleh: Hilman Hudaya
Jenjang pendidikan Sekolah Menengah Atas (SMA) memiliki kebijakan untuk menentukan jurusan yang akan menempatkan siswa di jurusan yang sesuai dengan minat, bakat, dan kemampuannya. Dengan mengembangkan sistem pendukung keputusan auto learning dengan algoritma Iterative Dichotomiser 3 (ID3) dapat membantu guru dalam menentukan keputusan jurusan untuk siswa. Algoritma ID3 adalah bagian dari teknik learning pada bidang ilmu kecerdasan buatan. Dengan menggunakan sample data penjurusan siswa sebelumnya sebagai data latih pada sistem pendukung keputusan, maka sistem dapat memberikan dukungan keputusan yang dapat dijadikan acuan bagi guru dalam mengambil keputusan. Untuk mendapatkan akurasi keputusan yang baik, maka dibutuhkan data latih dengan varietas yang beragam. Sistem ini dapat memproses data yang diujikan menjadi pengalaman jika data tersebut tidak sama dengan data latih. Pemrosesan pengalaman ini memungkinkan sistem menambah lebih banyak data latih. Hasil penelitian menunjukan bahwa semakin banyak data latih dengan varietas yang baik dapat membuat akurasi keputusan yang dihasilkan semakin tinggi. Selain itu algoritma ID3 yang diimplementasikan tahan terhadap data-data yang terdapat kesalahan (data noise) sehingga keputusan cenderung konsisten.
i
2.1 Sistem Pendukung Keputusan (Decision Support System) ... 7
2.2 Kecerdasan Buatan (Artificial Intelegent) ... 9
2.3 Pohon (Tree) ... 11
2.4 Decision Tree Learning ... 12
2.5 Iterative Dichotomiser 3 (ID3) ... 14
2.5.1 ID3 : Example ... 15
2.6 System Development Life Cycle (SDLC) ... 26
2.7 System Development Life Cycle (SDLC) Model Prototype ... 26
2.8 Pemrograman Berorientasi Objek ... 28
2.9 Unified Modeling Language (UML) ... 29
2.9.1 Use Case Diagram ... 30
ii
2.9.3 Class Diagram ... 32
2.9.4 Squence Diagram ... 33
2.10 Conceptual Data Model (CDM) ... 35
BAB III METODE PENELITIAN ... 36
3.1 Kerangka Konseptual Pengembangan ... 36
3.2 Alat Dan Bahan ... 39
4.3.3 Pengujian Hasil Keputusan ... 80
BAB V KESIMPULAN ... 92
5.1 Kesimpulan ... 92
1. 1 Latar Belakang
Pendidikan memegang peranan yang penting dalam menunjang kemajuan bangsa dan masyarakat, karena melalui pendidikan pengembangan berbagai potensi yang dimiliki oleh setiap orang dapat dimaksimalkan. Pendidikan juga merupakan investasi jangka panjang yang mana untuk selanjutnya dapat dimanfaatkan untuk beradaptasi dengan lingkungan sehingga pendidikan harus selalu ditingkatkan dan dijaga mutunya.
Jenjang pendidikan sekolah menengah atas (SMA) memiliki sistem yang berbeda dengan jenjang pendidikan sekolah menengah pertama (SMP) ataupun sekolah dasar (SD). SMA memiliki sistem penjurusan yang dilaksanakan oleh siswa kelas X yang akan naik ke kelas XI, dimana siswa akan ditempatkan di jurusan yang sesuai dengan minat, bakat, dan kemampuan siswa itu sendiri.
sendiri. Kurangnya konsistensi dalam menentukan keputusan oleh guru (masih bersifat subyektif) serta perbedaan keputusan antar guru menjadi kelemahan dari sistem yang sedang berjalan. Hal ini berujung pada keputusan yang bersifat tidak adil. Faktor utamanya adalah karena banyaknya siswa yang akan ditentukan jurusannya sehingga sulit untuk menganalisis jurusan yang sesuai dengan bakat, minat, dan kemampuanya. Akibatnya sebagian siswa menjadi korban yaitu mendapatkan jurusan yang tidak sesuai. Dengan demikian dibutuhkan suatu sistem yang dapat membantu para guru untuk memutuskan jurusan yang akan diambil siswa sehingga potensi yang dimiliki siswa dapat disalurkan dengan baik. Sistem pendukung keputusan (SPK) adalah salah satu sistem yang dapat dimanfaatkan untuk mendukukung suatu keputusan dari pengambil keputusan (Wibowo, 2011). Sistem pendukung keputusan (SPK) dibuat sebagai suatu cara untuk memenuhi kebutuhan seseorang dalam membuat keputusan yang spesifik dalam memecahkan permasalah yang spesifik pula. SPK dapat memperluas kemampuan pengambil keputusan dalam memproses data/informasi untuk pengambilan keputusan. SPK juga dapat menghemat waktu, tenaga, dan biaya yang dibutuhkan untuk membantu memutuskan suatu masalah. Karena luasnya bidang penerapan SPK, SPK juga dapat diaplikasikan sebagai sistem yang membantu guru dalam membuat keputusan yang spesifik untuk menentukan jurusan siswa SMA. Sehingga, guru dapat memperluas kemampuannya untuk menentukan jurusan siswa di SMA dengan waktu, tenaga, dan biaya yang efisien.
melakukan aksi secara rasional berdasarkan hasil penalaran tersebut (Suyanto, 2011). Sehingga sistem dapat sejalan dengan apa yang diinginkan pengguna. Penelitian mengenai SPK untuk penjurusan siswa telah banyak dilakukan. Pada penelitian Ariani (Ariani, 2010) SPK penjurusan siswa SMK dibuat dengan algoritma neuro-fuzzy yang memberikan dukungan keputusan berupa presentase kecocokan terhadap nilai, kemampuan, dan minat siswa. Metode yang digunakan sebenarnya masih kurang optimal. Ketika setiap jurusan memiliki presentase yang sama maka akan membingungkan bagi guru yang bersangkutaan untuk menentukan keputusan. Tetapi pada penelitian Utami (2012) SPK dibuat dengan algoritma Iterative Dichotomiser 3 dan mendapatkan hasil keputusan tidak jauh berbeda dengan yang dibuat oleh pembuat keputusan langsung yaitu dengan presentasi sekitar 70% sesuai, tetapi tahap learning hanya dilakukan sekali saat program akan dibuat. Dengan demikian sistem tidak akan menambah kepakaran sehingga tidak dapat menambah tingkat akurasi yang seharusnya bisa ditingkatkan hingga mendekati 100% sesuai berdasarkan data latih.
decision tree dari sampel-sampel yang diberikan untuk dipelajari dan dijadikan acuan untuk menentukan keputusan yang lainnya.
Dalam penelitian ini akan dibangun sistem pendukung keputusan (SPK) yang mempunyai kemampuan untuk belajar dari pengalaman yang berasal dari data yang baru diujikan menggunakan algoritma Iterative Dichotomiser 3 (ID3). Pada penelitian ini SPK akan diimplementasikan pada sistem penjurusan SMA yang diharapkan akan membantu guru dalam melakukan penjurusan siswa. ID3 pada decision tree learning menggunakan data-data valid yang digunakan sebelumnya untuk mendapatkan rule dan mencari dukungan keputusan jurusan yang diambil. SPK tersebut akan dibangun berbasiskan web sehingga dapat diakses atau digunakan oleh komputer lain tanpa harrus meng-install aplikasinya.
1. 2 Rumusan Masalah
Berdasarkan latar belakang tersebut, maka dapat dirumuskan suatu permasalahan dalam penelitian ini yaitu bagaimana membuat sistem pendukung keputusan yang bersifat auto learning untuk menentukan jurusan di SMA menggunakan decision tree learning dengan algoritma Iterative Dichotomiser 3 (ID3).
1. 3 Batasan Masalah
Adapun batasan masalah dalam penelitian ini adalah:
1. Teknik learning yang digunakan adalah decision tree learning dengan algoritma Iterative Dichotomiser 3 (ID3) untuk menentukan jurusan yang akan diambil oleh siswa sekolah.
3. Penjurusan dilakukan berdasarkan minat, bakat, dan kemampuan siswa 4. Input data minat siswa berupa salah satu nama jurusan yang diminati oleh
siswa tersebut (IPA/IPS/Bahasa)
5. Input data bakat siswa berupa hasil dari psikotes yang telah dilakukan yang menunjukan bakat siswa di jurusan IPA/IPS/Bahasa
6. Input data kemampuan adalah nilai-nilai rapot yang diperoleh siswa saat menjalani pendidikan kelas X semester dua adalah sebagai berikut:
a. Matematika, Fisika, Kimia, dan Biologi (IPA) b. Sejarah, Ekonomi, Geografi, dan Sosiologi (IPS)
c. Bahasa Indonesia, Bahasa Inggris, Bahasa asing (Bahasa)
7. Sistem akan mempelajari sampel data yang diperoleh dari guru SMA N 1 Way Jepara Lampung Timur.
8. Sistem yang akan dibuat adalah berbasis web.
1. 4 Tujuan
Adapun tujuan dari penelitian ini adalah memberikan metode alternatif dalam membangun SPK dengan sistem auto learning dan mengimplementasikan algoritma Iterative Dichotomiser 3 (ID3) untuk menentukan jurusan siswa di SMA.
1. 5 Manfaat
Adapun manfaat pengembangan sistem ini adalah:
1. Sekolah dapat menentukan jurusan siswanya dengan mudah dan cepat 2. Sekolah dapat konsisten dan objektif dalam menentukan jurusan terhadap
3. Sekolah dapat menerapkan aturannya sendiri dalam menentukan parameter-parameter untuk jurusan siswanya
2. 1 Sistem Pendukung Keputusan (Decision Support System)
Sistem pendukung keputusan ialah proses pengambilan keputusan dibantu menggunakan komputer untuk membantu pengambil keputusan dengan menggunakan beberapa data dan model tertentu untuk menyelesaikan beberapa masalah yang tidak terstruktur. Keberadaan SPK pada perusahaan atau organisasi bukan untuk menggantikan tugas-tugas pengambil keputusan, tetapi merupakan sarana yang membantu bagi mereka dalam pengambilan keputusan. Dengan menggunakan data-data yang diolah menjadi informasi untuk mengambil keputusan dari masalah-masalah semi-terstruktur. Dalam implementasi SPK, hasil dari keputusan-keputusan dari sistem bukanlah hal yang menjadi patokan, pengambilan keputusan tetap berada pada pengambil keputusan. Sistem hanya menghasilkan keluaran yang mengkalkulasi data-data sebagaimana pertimbangan seorang pengambil keputusan. Sehingga kerja pengambil keputusan dalam mempertimbangkan keputusan dapat dimudahkan (Wibowo, 2011).
pengambilan keputusan sampai mengevaluasi pemilihan alternatif-alternatif yang ada (Fitriani, 2012).
Karakteristik sistem pendukung keputusan menurut Wibowo (Wibowo, 2011): 1. Sistem Pendukung Keputusan dirancang untuk membantu pengambil
keputusan dalam memecahkan masalah yang sifatnya semi terstruktur ataupun tidak terstruktur dengan menambahkan kebijaksanaan manusia dan informasi komputerisasi.
2. Dalam proses pengolahannya, sistem pendukung keputusan mengkombinasikan penggunaan model-model analisis dengan teknik pemasukan data konvensional serta fungsi-fungsi pencari/interogasi informasi. 3. Sistem Pendukung Keputusan, dirancang sedemikian rupa sehingga dapat
digunakan/dioperasikan dengan mudah.
4. Sistem Pendukung Keputusan dirancang dengan menekankan pada aspek fleksibilitas serta kemampuan adaptasi yang tinggi.
Dengan berbagai karakter khusus di atas, SPK dapat memberikan berbagai manfaat dan keuntungan. Manfaat yang dapat diambil dari SPK menurut Kadarsah dalam tulisan Utami (Utami, 2012) :
1. SPK memperluas kemampuan pengambil keputusan dalam memproses data/informasi bagi pemakainya.
2. SPK membantu pengambil keputusan untuk memecahkan masalah terutama berbagai masalah yang sangat kompleks dan tidak terstruktur.
4. Walaupun suatu SPK, mungkin saja tidak mampu memecahkan masalah yang dihadapi oleh pengambil keputusan, namun SPK dapat menjadi stimulan bagi pengambil keputusan dalam memahami persoalannya, karena mampu menyajikan berbagai alternatif pemecahan.
2. 2 Kecerdasan Buatan (Artificial Intelegent)
Secara harfiah artificial intelegent adalah kecerdasan buatan, kecerdasan artifisial, intelijensia artifisial, atau intelijinsia buatan. Menurut Sutojo dkk (Sutojo dkk., 2011) cerdas adalah memiliki pengetahuan, pengalaman, dan penalaran untuk membuat keputusan dan mengambil tindakan.
Menurut Suyanto (Suyanto, 2011) para ilmuan memiliki dua cara pandang berbeda tentang AI (Artificial Intelegen/kecerdasan buatan). Yang pertama adalah memandang AI sebagai bidang ilmu yang hanya fokus pada proses berfikir. Sedangkan yang kedua adalah memandang AI sebagai bidang ilmu yang fokus pada tingkah laku. Pada cara pandang kedua memandang AI secara lebih luas karena suatu tingkah laku selalu didahului dengan proses berfikir.
Suyanto juga menambahkan definisi AI yang paling tepat saat ini adalah acting rationally dengan pendekatan relational agent. Hal ini berdasarkan pemikiran bahwa komputer bisa melakukan penalaran secara logis dan juga bisa melakukan aksi secara relasional berdasarkan hasil penalaran tersebut (Suyanto, 2011).
1. Sistem yang dapat berpikir seperti manusia (“Thinking humanly”) 2. Sistem yang dapat bertingkah laku seperti manusia (“Acting humanly”) 3. Sistem yang dapat berpikir secara rasional (“Thinking rasionally”) 4. Sistem yang dapat bertingkah laku secara rasional (“Acting rasionally”) Sejak pertama kali dikemukakan istilah AI pada tahun 1956 di konferensi Darthmouth, AI terus dikembangkan melalui berbagai penelitian mengenai teori-teori dan prinsip-prinsipnya. Perkembangan AI mengalami pasang surut mengikuti antusias para peneliti dan dana penelitian yang tersedia. Tetapi pada periode 1966 sampai 1974, perkembangan AI melambat. Tetapi sejak tahun 1980, AI menjadi sebuah industri yang besar dengan perkembangan yang sangat pesat. Banyak industri skala besar yang melakukan investasi besar-besaran dalam bidang AI (Suyanto, 2011).
Menurut Suyanto (Suyanto, 2011) dalam membangun produk-produk berbasis AI, dikelompokkan kedalam empat teknik yang setiap teknik memiliki karakteristik sendiri untuk menyelesaikan suatu masalah. Teknik-teknik tersebut yaitu:
1. Teknik searching
Teknik searching (pencarian) harus mendefinisikan ruang masalah untuk suatu masalah yang dihadapi dan mendefinisikan aturan produksi yang digunakan untuk mengubah suatu keadaan (state) ke keadaan (state) lainnya, selanjutnya memilih strategi untuk menemukan solusi.
2. Teknik reasoning
3. Teknik planning
Pada teknik Planning (perencanaan) masalah dipecah kesub-sub masalah yang lebih kecil, menyelesaikan sub-sub masalah satu demi satu, kemudian menggabungkan solusi-solusi dari sub-sub masalah tersebut menjadi solusi lengkap dan tetap mengingat dan menangani interaksi yang terdapat pada sub-sub masalah tersebut.
4. Teknik learning
Teknik learning berbeda dengan teknik yang lain pada AI. Pada teknik searching, reasoning, dan planning kita harus mengetahui aturan yang berlaku untuk sistem yang akan dibangun. Tetapi, pada masalah tertentu terkadang kita tidak bisa mendefinisikan aturan secara benar dan lengkap untuk sistem yang akan kita bangun.
2. 3 Pohon ( Tree )
Sub Bab 2.3 seluruhnya diambil dari tulisan Wahyudin (Wahyudin, 2011). Pohon merupakan sebuah graf terhubung yang tidak mengandung sirkuit. konsep pohon (tree) dalam teori graf merupakan konsep yang sangat penting, karena terapannya diberbagai bidang ilmu. Oleh karenanya antara pohon (tree) sangat erat hubungannya dengan teori graf.
dari setiap simpul lainnya, maka tidak mungkin bagi sebuah lintasan untuk membentuk simpul (loop) atau siklus (cycle) yang secara berkesinambungan melalui serangkaian simpul.
Gambar 2.1 Pohon (tree) (Wahyudin, 2011)
2. 4 Decision Tree Learning
Decicion tree learning adalah suatu metode belajar yang sangat populer dan banyak
digunakan secara praktis. Metode ini merupakan metode yang berusaha menemukan fungsi-fungsi pendekatan yang bernilai diskrit dan tahan terhadap data-data yang terdapat kesalahan (noise data-data) serta mampu mempelajari ekspresi-ekspresi disjungtive (ekspresi-ekspresi OR). Iterative Dichotomiser 3 (ID3), ASSISTANT, dan C4.5 merupakan jenis dari decision tree learning. Dalam membangun decision
tree learning dibutuhkan evaluasi semua atribut yang ada menggunakan suatu ukuran statistik untuk mengukur efektifitas suatu atribut dalam mengklasifikasikan kumpulan sampel data. Dalam hal ini information gain adalah yang paling banyak digunakan (Suyanto, 2011).
1. Entropy
Dalam mengitung information gain terlebih dahulu harus memahami suatu ukuran lain yang disebut entropy. Di dalam bidang information theory, entropy sering digunakan sebagai suatu parameter untuk mengukur heterogenitas (keberagaman) dari suatu sampel data. Menurut Slocum (Slocum, 2012) entropy adalah ukuran ketidakpastian dimana semakin tinggi entropy, maka
semakin tinggi ketidakpastian. Dengan pohon keputusan, pengukuran ini digunakan untuk menentukan seberapa informatif sebuah simpul. Jika kumpulan sampel semakin heterogen, maka nilai entropy-nya semakin besar. Secara matematis entropy dirumuskan sebagai berikut:
� �� � � = ∑ −
�� �
2 ��
�
Ket:
c : Jumlah nilai yang ada pada atribut target (jumlah kelas klasifikasi) pi : Menyatakan jumlah sampel untuk kelas i.
2. Information Gain
keputusan. Ukuran efektifitas ini disebut sebagai information gain. Secara matematis, intormation gain dari suatu atribut A, dituliskan sebagai berikut:
��� �, � = � �� � � −
∑
|� |
|�| � �� � �
∈��� �� �
Ket:
A : atribut
V : menyatakan nilai yang mungkin untuk atribut A Values(A) : himpunan nilai-nilai yang mungkin untuk atribut A |Sv| : jumlah sampel untuk nilai v
|S| : jumlah sampel data
Entropy(Sv) : entropy untuk sampel-sampel yang memiliki nilai v
2. 5 Iterative Dichotomiser 3 (ID3)
ID3 adalah algoritma decision tree learning (algoritma pembelajaran pohon keputusan) yang menggunakan strategu pencarian hill-climbing, yaitu dimulai dari pohon kosong, kemudian secara progresif berusaha menemukan sebuah pohon keputusan yang mengklasifikasikan sampel-sampel data secara akurat tanpa kesalahan. Pertumbuhan cabang-cabang pohon keputusan pada lgoritma ID3 dilakukan sampai pohon tersebut mampu mengklasisifikasikan sampel data secara akurat dengan tingkat kebenaran 100 % sesuai dengan data latih (Suyanto, 2011). Adapun sample data yang digunakan oleh ID3 memiliki beberapa syarat menurut Setiawan (Setiawan, 2010), yaitu:
1. Deskripsi atribut-nilai. Atribut yang sama harus mendeskripsikan tiap contoh dan memiliki jumlah nilai yang sudah ditentukan.
3. Kelas-kelas yang diskrit. Kelas harus digambarkan dengan jelas. Kelas yang kontinu dipecah-pecah menjadi kategori-kategori yang relatif, misalnya saja metal dikategorikan menjadi “hard, quite hard, flexible, soft, quite soft”. 4. Jumlah contoh (example) yang cukup. Karena pembangkitan induktif
digunakan, maka dibutuhkan test case yang cukup untuk membedakan pola yang valid dari peluang suatu kejadian.
Gambar 2.2 adalah algoritma ID3 untuk membangun suatu pohon keputusan (Suyanto, 2011):
Gambar 2.2 Algoritma ID3
2. 5. 1 ID3 : Example
Komulatif), hasil test psikologi, dan hasil test wawancara. IPK dikelompokan menjadi tiga kategori (bagus, cukup, kurang). Hasil test psikologi dikelompokan menjadi tiga (Tinggi, Sedang, Rendah). Hasil test wawancara dikelompokan menjadi dua kategori (Baik dan Buruk). Untuk data lengkap, seharusnya terdapat 3 x 3 x 2 = 18 kombinasi sampel data. Tetapi pada Tabel 2.1 terdapat 11 data. Artinya, masih ada 7 sampel data lainya yang belum diketahui.
Tabel 2.1 Data penerimaan pegawai (Suyanto, 2011)
Pelamar IPK Psikologi Wawancara Diterima
P1 Bagus Tinggi Baik Ya
Dengan menerapkan algoritma ID3 maka didapat proses-proses sebagai berikut: 1. Rekursi level 0 iterasi ke-1
Memanggil fungsi ID3 dengan sampel training semua sampel data yaitu [8+, 3-] Untuk label training ‘Diterima’ dan atributnya adalah {IPK, Psikologi, Wawancara}. Tanda positif (+) untuk data yang keputusan diterima bernilai ‘Ya’ sebaliknya tanda negatif (-) untuk data yang keputusan diterima bernilai
‘Tidak’. Selanjutnya membuat simpul akar untuk pohon yang akan dibuat dengan mencari information gain terbesar dari setiap atribut.
IPK:
S = [8+, 3-], |S| = 11, Entropy(S) = 0,8454
Scukup = [3+, 1-], |Scukup|= 4, Entropy(Scukup)=0,8113
Skurang=[2+, 1-], |Skurang|= 3, Entropy(Skurang)=0,9183
Gain(S, IPK) = entropy(S) - (4/11)entropy(Sbagus) -
(4/11)entropy(Scukup) - (3/11)entropy(Skurang)
= 0,8454 – (4/11) 0,8113 – (4/11) 0,8113 – (3/11) 0,9183
Srendah=[1+, 2-], |Srendah|= 3, Entropy(Srendah)=0,9183
Gain(S, Psikologi) = entropy(S) - (4/11)entropy(Stinggi) -
(4/11)entropy(Ssedang) – (3/11)entropy(Srendah)
= 0,8454 – (3/11) 0 – (5/11) 0,7219 – (3/11) 0,9183
Gain(S, Wawancara) = entropy(S) - (4/11)entropy(Sbaik) -
(4/11)entropy(Sburuk)
= 0,8454 – (6/11) 0 – (5/11) 0,9710 = 0,4040
Dari nilai information gain di atas, gain(S,Wawancara) adalah yang paling besar maka atribut wawancara yang akan menjadi root. Untuk nilai baik pada atribut wawancara terdapat 6 sampel, berarti samplebaik tidak kosong.
Sehingga perlu memanggil fungsi ID3 dengan kumpulan sampel berupa samplebaik = [6+, 0-], atribut target = ‘diterima’ dan kumpulan atribut = {IPK,
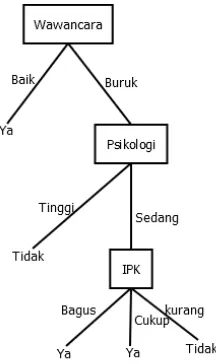
Gambar 2.3 Pohon keputusan pada rekursi level 0 iterasi ke-1 2. Rekursi level 1 iterasi ke-1
Karena semua sampel termasuk pada kelas ‘Ya’ pada sampelbaik = [6+, 0-]
maka fungsi ini akan berhenti dan mengembalikan satu simpul tunggal root dengan label ‘Ya’. Pada tahap ini menghasilkan pohon seperti Gambar 2.4.
Gambar 2.4 Pohon keputusan pada rekursi level 1 iterasi ke-1 3. Rekursi level 0 iterasi ke-2
Pada rekursi level 0 iterasi ke-1, sudah dilakukan engecekan atribut wawancara dengan nilai ‘baik’. Selanjutnya, dilakukan pengecekan untuk atribut ‘wawancara’ bernilai ‘buruk’. Sehingga memanggil fungsi ID3
dengan sampelburuk = [2+, 3-], target ‘diterima’, dan kumpulan atribut {IPK,
Psikologi}. Sehingga pada tahap ini menghasilkan pohon pada Gambar 2.5.
4. Rekursi level 1 iterasi ke-2
Dengan atribut yang sama pada tahap berikutnya maka dilakukan perhitungan information gain untuk atribut IPK dan Psikologi.
IPK:
S = Sampleburuk = [2+, 3-], |S| = 5, Entropy(S) = 0,9710
Sbagus = [1+, 1-], |Sbagus|= 2, Entropy(Sbagus)=1
Scukup = [1+, 1-], |Scukup|= 2, Entropy(Scukup)=1
Skurang=[0+, 1-], |Skurang|= 1, Entropy(Skurang)=0
Gain(S, IPK) = entropy(S) - (2/5)entropy(Sbagus) - (2/5)entropy(Scukup) -
(1/5)entropy(Skurang)
Gain(S, Psikologi) = entropy(S) - (0/5)entropy(Stinggi) -
(3/5)entropy(Ssedang) – (2/5)entropy(Srendah)
= 0,9170 – (0/5) 0 – (3/5) 0,9183 – (2/5) 0 = 0,4200
Dari dua information gain di atas, Gain(S, Psikologi) adalah yang paling besar sehingga akan dijadikan simpul berikutnya. Pada atribut Psikologi maka akan dicek nilainya satu persatu. Untuk nilai tinggi terdapat 0 sampel, berarti Sampeltinggi kosong. Sehingga dapat dibuat satu simpul daun (leaf node,
simpul yang tidak mempunyai anak) dengan nilai yang paling sering muncul pada sampelburuk yaitu ‘tidak’. Kemudian pengecekan dilanjutkan kenilai
sedang terdapat samplesedang = [2+, 1-] untuk pemanggilan fungsi ID3 dengan
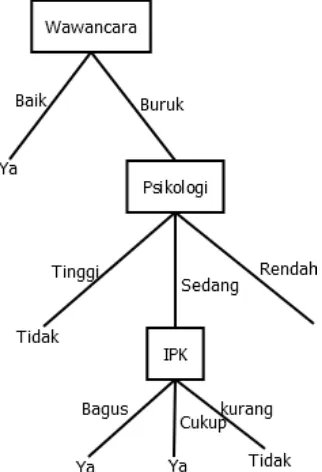
Gambar 2.6 Pohon keputusan pada rekursi level 1 iterasi ke-2 5. Rekursi level 2 iterasi ke-1
Pada pemanggilan tahap sebelumnya terdapat satu atribut yaitu atribut IPK maka secara otomatis atribut tersebut menjadi simpul berikutnya. Pada IPK bernilai ‘bagus’ pada sampesedang=[2+,1-], terdapat 1 sampel yaitu
sampelbagus=[1+, 0-]. Maka memanggil fungsi ID3 dengan sampelbagus=[1+,
0-] dengan target ‘diterima’ dan kumpulan atribut{}. Pada tahap ini menghasilkan pohon pada Gambar 2.7.
6. Rekursi level 3 iterasi ke-1
Pada pemanggilan fungsi sebelumnya pemanggilan sampelbagus=[1+,0] maka
fungsi akan berhenti dan menghasilkan daun dengan nilai ‘Ya’. Sehingga dihasilkan pohon pada Gambar 2.8. selanjutnya proses kembali ke rekursi level 2 untuk iterasi ke-2.
Gambar 2.8 Pohon keputusan pada rekursi level 3 iterasi ke-1 7. Rekursi level 2 iterasi ke-2
Pada tahap ini melanjutkan kenilai berikutnya yaitu pemanggilan fungsi ID3 dengan samplecukup = [1+, 0-], atribut target = ‘diterima’ dan kumpulan atribut
Gambar 2.9 Pohon keputusan pada rekursi level 2 iterasi ke-2 8. Rekursi level 3 iterasi ke-2
Pada pemanggilan fungsi sebelumnya pemanggilan sampelcukup=[1+,0] maka
fungsi akan berhenti dan menghasilkan daun dengan nilai ‘Ya’. Sehingga dihasilkan pohon pada Gambar 2.10. Selanjutnya proses kembali ke rekursi level 2 untuk iterasi ke-3.
9. Rekursi level 2 iterasi ke-3
Pada tahap ini melanjutkan kenilai berikutnya yaitu pemanggilan fungsi ID3 dengan samplekurang = [0+, 1-], atribut target = ‘diterima’ dan kumpulan
atribut {}. Sehingga menghasilkan pohon pada Gambar 2.11
Gambar 2.11 Pohon keputusan pada rekursi level 2 iterasi ke-3 10. Rekursi level 3 iterasi ke-3
Pada pemanggilan fungsi sebelumnya pemanggilan sampelkurang = [0+, 1-]
maka fungsi akan berhenti dan menghasilkan daun dengan nilai ‘Tidak’. Sehingga dihasilkan pohon pada Gambar 2.12. Selanjutnya proses kembali ke rekursi level 1 untuk iterasi ke-3.
11. Rekursi level 1 iterasi ke-3
Telah dilakukan atribut psikologi pada nilai ‘tinggi’ dan ‘sedang’. Selanjutnya pada iterasi ini akan dilakukan pada nilai ‘rendah’. Dengan memanggil fungsi ID3 dengan sampelrendah = [0+, 2-], atribut target ‘diterima’
dan kumpulan atribut {IPK}. Pada tahap ini akan menghasilkan pohon pada Gambar 2.13. Selanjutnya ke rekursi level 2 iterasi ke-4.
Gambar 2.13 Pohon keputusan pada rekursi level 1 iterasi ke-3 12. Rekursi level 2 iterasi ke-4
Pada pemanggilan fungsi sebelumnya pemanggilan sampelrendah = [0+, 2-]
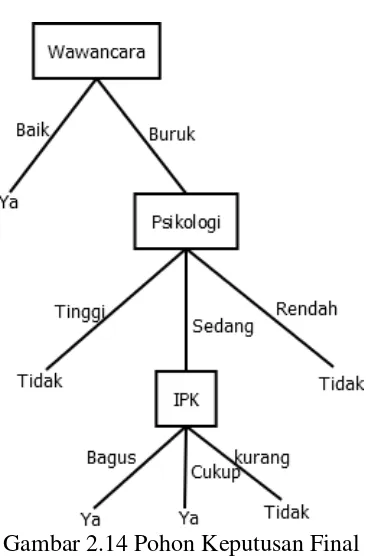
Gambar 2.14 Pohon Keputusan Final
Setelah diterapkannya algoritma ID3 maka didapatkan pohon keputusan pada Gambar 2.14. Dari pohon keputusan tersebut maka dapat disimpulkan rule-rule dalam menentukan diterima atau tidak diterimanya seorang pelamar. Maka rule-rule tersebut adalah sebagai berikut:
If (wawancara=’baik’) or ((wawancara=’buruk’) and (psikologi=’sedang’)
and (IPK=’bagus’)) or ((wawancara=’buruk’) and (psikologi=’sedang’) and
(IPK=’cukup’)) then diterima=’Ya’
Else Diterima =’tidak’
2. 6 System Devolepment Life Cycle (SDLC)
Sub bab 2.8 seluruhnya diambil dari buku tulisan Rosa dan Salahudin (Rosa dan Salahudin, 2011). SDLC atau Software Development Life Cycle atau sering disebut juga System Development life Cycle adalah proses mengembangkan atau mengubah suatu sistem perangkat lunak dengan menggunakan model-model dan metodelogi yang digunakan orang untuk mengembangkan sistem-sistem perangkat lunak sebelumnya (berdasaarkan best practice atau cara-cara yang sudah teruji baik). Terdapat banyak model yang dapat digunakan dalam membangun sistem berbasis SDLC yaitu model Waterfall, Prototype, Rapid Aplication Development (RAD), Iterative dan Spiral.
2. 7 System Devolepment Live Cycle (SDLC) model prototype
Sub Bab 2.7 seluruhnya diambil dari buku tulisan Rosa dan Salahudin (Rosa dan Salahudin, 2011). Metode System Development life cycle (SDLC) dengan model prototipe (prototype) sangat baik digunakan untuk menyelesesaikan masalah kesalahpahaman antara user dan analis yang timbul akibat user tidak mampu mendefinisikan secara jelas kebutuhannya. Prototyping adalah pengembangan yang cepat dan pengujian terhadap model kerja (prototipe) dari aplikasi baru melalui proses interaksi dan berulang-ulang yang biasa digunakan ahli sistem informasi dan ahli bisnis. Prototyping disebut juga desain aplikasi cepat (rapid application design/RAD) karena menyederhanakan dan mempercepat desain sistem.
dengan memahami kebutuhan user dan menerjemahkannya ke dalam bentuk model (prototipe). Model ini selanjutnya diperbaiki secara terus menerus sampai sesuai dengan kebutuhan user.
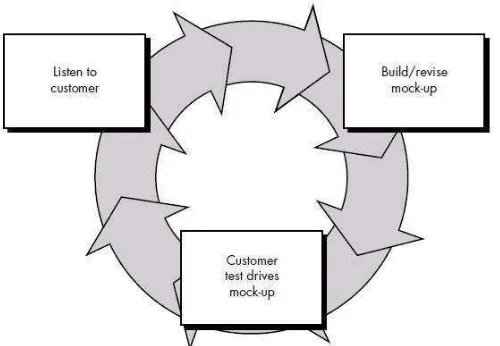
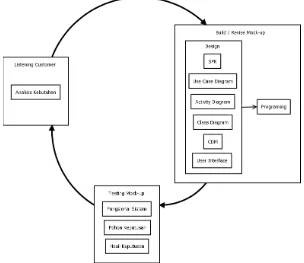
Gambar 2.15 SDLC model prototype (Rosa dan Salahudin, 2011)
Berikut adalah penjelasan dari setiap tahapan yang dilakukan saat mengembangkan sistem dengan model prototipe berdasarkan Gambar 2.1:
1. Listen to costomer
Pada tahap ini pengembang mendengarkan kebutuhan pelanggan sebagai pemakai sistem perangkat lunak (user) untuk menganalisis serta mengembangkan kebutuhan user.
2. Build/revise mock-up
3. Costomer test drives mock-up
Customer melakukan pengujian terhadap mock-up yang telah dibuat. Jika telah sesuai prototipe akan diselesaikan sepenuhnya jika masih belum sesuai kembali ketahap pertama.
2. 8 Pemrograman Berorientasi Objek
Sub Bab 2.8 seluruhnya diambil dari buku tulisan Rosa dan Salahudin (Rosa dan Salahudin, 2011). Metodologi berorientasi objek adalah suatu strategi pembangunan perangkat lunak sebagai kumpulan objek yang berisi data dan operasi yang diberlakukan terhadapnya. Metodologi berorientasi objek merupakan suatu cara bagaimana sistem perangkat lunak dibangun melalui pendekatan objek secara sistematis. Metodelogi berorientasi objek didasarkan pada penerapan prinsip-prinsip pengelolaan kompleksitas. Metode berorientasi objek meliputi rangkaian aktivitas analisis berorientasi objek, Perancangan berorientasi objek, pemrograman berorientasi objek, dan pengujian berorientasi objek.
Keuntungan menggunakan metodelogi berorientasi objek adalah sebagai berikut: 1. Meningkatkan produktivitas
Karena kelas dan objek yang ditemukan dalam suatu masalah masih dapat dipakai ulang untuk masalah lainnya yang melibatkan objek tersebut (reusable).
2. Kecepatan pengembangan
3. Kemudahan pemeliharaan
Karena dengan model objek, pola-pola yang cenderung tetap dan stabil dapat dipisahkan dan pola-pola yang mungkin sering berubah-ubah.
4. Adanya konsistensi
Karena sifat perwarisan dan penggunaan notasi yang sama pada saat analisis, perancangan, maupun pengkodean.
5. Meningkatkan kualitas
Karena pendekatan pengembangan lebih dekat dengan dunia nyata dan adanya konsistensi pada saat pengembangannya, perangkat lunak yang dihasilkan akan mampu memenuhi kebutuhan pemakai serta mempunyai sedikit kesalahan.
Saat ini sudah banyak bahasa pemrograman berorientasi objek. Banyak orang berpikir bahwa pemrograman berorientasi objek identik dengan bahasa Java. Memang bahasa Java merupakan bahasa yang paling konsisten dalam mengimplementasikan paradigma pemrograman berorientasi objek. Namun sebenarnya bahasa pemrograman yang mendukung pemrograman berorientasi objek tidak hanya bahasa Java.
2. 9 Unified Modeling Language (UML)
Keuntungan menggunakan UML adalah:
1. Software terdesain dan terdokumentasi secara profesional sebelum dibuat. 2. Oleh karena mendesain terlebih dahulu, maka reusable code dapat dikode
dengan tingkat efisiensi yang tinggi.
3. ‘Lubang’ dapat ditemukan saat penggambaran desain. 4. Dapat melihat gambaran besar dari suatu software.
UML menjanjikan akan menghasilkan hasil dengan biaya rendah, software lebih efisien, lebih dapat dipercaya, dan hubungan antar bagian yang terlibat menjadi lebih baik.
Terdapat banyak diagram yang dapat digunakan pada UML antara lain object diagram, class diagram, component diagram, composite structure diagram,
package diagram, deployment diagram, use case diagram, activity diagram, state machine diagram, squence diagram, communication digram, timing diagram, dan
interaction overview diagram.
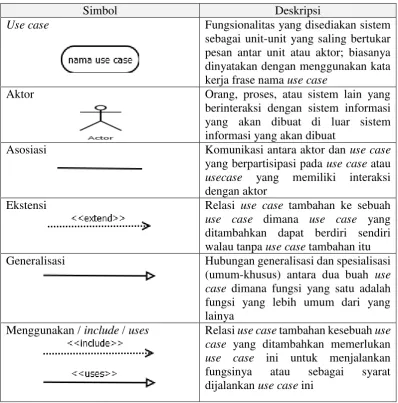
2.9.1 Use case diagram
dan dapat di pahami. Berikut adalah simbol-simbol yang digunakan pada use case diagram.
Tabel 2.2 Simbol use case
Simbol Deskripsi
Use case Fungsionalitas yang disediakan sistem
sebagai unit-unit yang saling bertukar pesan antar unit atau aktor; biasanya dinyatakan dengan menggunakan kata kerja frase nama use case
Aktor Orang, proses, atau sistem lain yang
berinteraksi dengan sistem informasi yang akan dibuat di luar sistem informasi yang akan dibuat
Asosiasi Komunikasi antara aktor dan use case
yang berpartisipasi pada use case atau usecase yang memiliki interaksi dengan aktor
Ekstensi Relasi use case tambahan ke sebuah
use case dimana use case yang ditambahkan dapat berdiri sendiri walau tanpa use case tambahan itu Generalisasi Hubungan generalisasi dan spesialisasi
(umum-khusus) antara dua buah use case dimana fungsi yang satu adalah fungsi yang lebih umum dari yang lainya
Menggunakan / include / uses Relasi use case tambahan kesebuah use case yang ditambahkan memerlukan use case ini untuk menjalankan fungsinya atau sebagai syarat dijalankan use case ini
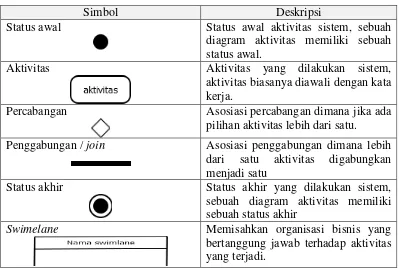
2.9.2 Activity diagram
sistem. Tabel 2.2 merupakan simbol-simbol yang terdapat pada diagram activity diagram.
Tabel 2.3 Simbol-simbol activity diagram
Simbol Deskripsi
Status awal Status awal aktivitas sistem, sebuah diagram aktivitas memiliki sebuah status awal.
Aktivitas Aktivitas yang dilakukan sistem,
aktivitas biasanya diawali dengan kata kerja.
Percabangan Asosiasi percabangan dimana jika ada
pilihan aktivitas lebih dari satu.
Penggabungan / join Asosiasi penggabungan dimana lebih dari satu aktivitas digabungkan menjadi satu
Status akhir Status akhir yang dilakukan sistem, sebuah diagram aktivitas memiliki sebuah status akhir
Swimelane Memisahkan organisasi bisnis yang
bertanggung jawab terhadap aktivitas yang terjadi.
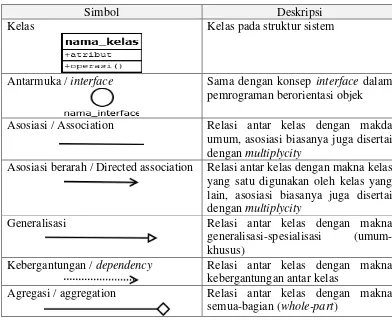
2.9.3 Class diagram
Sub bab 2.9.3 seluruhnya diambil dari buku tulisan Rosa dan Salahudin (Rosa dan Salahudin, 2011). Diagram kelas atau class diagram menggambarkan struktur sistem dari segi pendefisian kelas-kelas yang akan dibuat untuk membangun sistem. Kelas memiliki apa yang disebut atribut dan metode atau operasi.
Kelas-kelas yang ada pada struktut sistem harus dapat melakukan fungsi-fungsi sesuai dengan kebutuhan sistem. Susunan struktur kelas yang baik pada diagram kelas sebaiknya memiliki jenis-jenis kelas sebagai berikut:
1. Kelas main
2. Kelas yang menangani tampilan sistem
Kelas yang mendefinisikan dan mengatur tampilan kepemakai 3. Kelas yang diambil dari pendefinisian use case
Kelas yang menangani fungsi-fungsi yang harus ada diambil dari pendefinisian use case
4. Kelas yang diambil dari pendefinisian data
Kelas yang digunakan untuk memegang atau membungkus data menjadi sebuah kesatuan yang diambil maupun akan disimpan ke basis data.
Tabel 2.4 Simbol-simbol class diagram
Simbol Deskripsi
Kelas Kelas pada struktur sistem
Antarmuka / interface Sama dengan konsep interface dalam pemrograman berorientasi objek Asosiasi / Association Relasi antar kelas dengan makda
umum, asosiasi biasanya juga disertai dengan multiplycity
Asosiasi berarah / Directed association Relasi antar kelas dengan makna kelas yang satu digunakan oleh kelas yang lain, asosiasi biasanya juga disertai dengan multiplycity
Generalisasi Relasi antar kelas dengan makna
generalisasi-spesialisasi (umum-khusus)
Kebergantungan / dependency Relasi antar kelas dengan makna kebergantungan antar kelas
Agregasi / aggregation Relasi antar kelas dengan makna semua-bagian (whole-part)
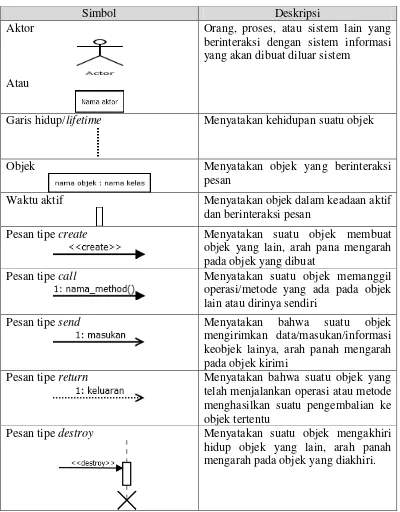
2.9.4 Squence Diagram
dengan mendeskripsikan waktu hidup objek dan message yang dikirmkan dan diterima antar objek. Banyaknya diagram sekuen yang harus digambar adalah sebanyak pendefinisian use case yang memiliki proses sendiri. Berikut adalah simbol-simbol yang pada diagram sekuen:
Tabel 2.5 Simbol-simbol squence diagram
Simbol Deskripsi
Aktor
Atau
Orang, proses, atau sistem lain yang berinteraksi dengan sistem informasi yang akan dibuat diluar sistem
Garis hidup/lifetime Menyatakan kehidupan suatu objek
Objek Menyatakan objek yang berinteraksi
pesan
Waktu aktif Menyatakan objek dalam keadaan aktif
dan berinteraksi pesan
Pesan tipe create Menyatakan suatu objek membuat objek yang lain, arah pana mengarah pada objek yang dibuat
Pesan tipe call Menyatakan suatu objek memanggil operasi/metode yang ada pada objek lain atau dirinya sendiri
Pesan tipe send Menyatakan bahwa suatu objek
mengirimkan data/masukan/informasi keobjek lainya, arah panah mengarah pada objek kirimi
Pesan tipe return Menyatakan bahwa suatu objek yang telah menjalankan operasi atau metode menghasilkan suatu pengembalian ke objek tertentu
2. 10 Conceptual Data Model (CDM)
Sub Bab 2.10 seluruhnya diambil dari buku tulisan Rosa dan Salahudin (Rosa dan Salahudin, 2011). CDM (conceptual data model) atau model konsep data merupakan konsep yang berkaitan dengan pandangan pemakai terhadap data yang disimpan dalam basis data. CDM dibuat sudah dalam bentuk tabel-tabel tanpa tipe data yang menggambarkan relasi antar tabel untuk keperluan implementasi kebasis data. CDM merupakan hasil penjabaran lebih lanjut dari ERD. Entity Relationship Diagram (ERD) salah satu bentuk pemodelan basis data yang sering digunakan dalam pengembangan sistem informasi.
Berikut adalah simbol-simbol yang ada pada CDM: Tabel 2.6 Simbol-simbol pada CDM
Simbol Deskripsi
Entitas/Tabel Entitas/tabel yang menyimpan data dalam basis data
3. 1 Kerangka Konseptual Pengembangan
Kerangka konseptual merupakan suatu bentuk kerangka berpikir yang dapat digunakan sebagai pendekatan dalam memecahkan masalah. Biasanya kerangka penelitian ini menggunakan pendekatan ilmiah dan memperlihatkan hubungan antar variabel dalam proses analisisnya. Dalam penelitian ini kerangka konseptual dibangun berdasarkan System Development Life Cycle (SDLC) dengan model prototype dalam buku tulisan Rosa dan Salahudin (Rosa dan Salahudin, 2011). Gambar 3.1 merupakan kerangka konseptual dalam penelitian ini.
Berdasarkan Gambar 3.1, maka proses pengembangan sistem ini dibagi menjadi tiga tahap yaitu:
1. Listening customer
Listeing customer merupakan tahap awal untuk melakukan pengembangan pada sistem ini. Pada tahap ini pengembang mendengarkan kebutuhan user dengan menggunakan teknik wawancara dalam mengumpulkan data atau informasi yang dibutuhkan untuk menganalisis serta mengembangkan kebutuhan user. Pada tahap ini akan menghasilkan suatu analisis kebutuhan pada setiap iterasinya.
2. Build/revise mock-up
Build/revise mock-up merupakan tahap desain dan pengkodean (programing)
dari analisis kebutuhan pada tahap listening customer. Desain dilakukan lebih dulu sebelum pengkodean. Pada tahap ini akan menghasilkan desain dan mock-up baru pada setiap iterasinya. Dalam penelitian ini terdapat enam desain yang akan dilakukan, yaitu:
a. Sistem pendukung keputusan (SPK) b. Use case diagram
Setelah setelah melewati tahap desain, maka tahap selanjutnya adalah merubah desain tersebut melalui programing menjadi suatu mock-up. Dalam membangun mock-up dibutuhkan bahasa pemrograman sebagai berikut:
a. HTML, b. CSS,
c. PHP & MySQL, dan d. JavaScript
Dari hasil pemrograman tersebut yaitu mock-up yang nantinya akan di gunakan pada tahap selanjutnya. Mock-up yang dibangun diharapkan telah mampu mendemostrasikan sebagian besar dari fungsi perangkat lunak. 3. Testing mock-up
3. 2 Alat dan Bahan
Dalam penelitian ini menggunakan alat dan bahan sebagai berikut:
Perangkat keras berupa personal computer dengan spesifikasi sebagai berikut:
1. prosesor AMD 2.80 GHz, 2. RAM 2 GB, dan
3. HDD 250 GB. Perangkat lunak:
1. Windows 8 64 bit,
2. Adobe Dreamweaver CS 5, 3. Adobe Photoshop CS 5 64 bit, 4. Web server (Wamp server), 5. JQuery open source plugin, 6. DIA (UML maker), dan
7. Browser (Mozila Firefox dan Google Crhome)
3. 3 Tempat dan Waktu Penelitian
3. 4 Analisis Kebutuhan
a. Dalam menentukan jurusan SMA dibutuhkan suatu informasi berupa data-data sebagai input yang dibutuhkan oleh sistem. Informasi tersebut yaitu:
1. nilai matematika,
9. nilai bahasa indonesia, 10. nilai bahasa inggris, 11. nilai bahasa asing lain, 12. bakat, dan
13. minat.
b. Kebutuhan output dari sistem yang dibuat yaitu mendapatkan suatu keputusan berupa jurusan yang sesuai untuk siswa.
c. Dalam membangun suatu sistem pendukung keputusan (SPK) penentuan jurusan SMA dibutuhkan fungsi-fungsi sistem yaitu sebagai berikut:
2. Sistem dapat menjadikan setiap data yang uji yang bukan merupakan data training menjadi suatu pengalaman/exprience yang selanjutnya dapat dijadikan data training,
3. Sistem dapat memfasilitasi guru untuk memvalidasi data pengalaman/exprience menjadi data training,
4. Sistem dapat menampilkan pohon keputusan sesuai dengan data training 5. Sistem dapat memfasilitasi guru untuk dapat merubah mutu nilai yang
digunakan, dan
6. Sistem dapat melakukan pengujian data satu per satu maupun data lebih dari satu secara bersamaan.
3. 5 Desain
3. 5. 1 Sistem Pendukung keputusan (SPK)
Membangun sistem pendukung keputusan menggunakan algoritma ID3 biasanya dilakukan dengan perhitungan secara manual untuk mendapatkan aturan-aturan(rule) seperti dalam penelitian Utami (Utami, 2012). Sehingga, sulit untuk memberikan training baru kepada sistem guna menambah akurasi dari SPK itu sendiri. Tetapi, dalam penelitian ini SPK dibangun secara automatis dengan mengimplementasikan algoritma ID3 secara maksimal.
ID3 untuk mendapatkan pohon keputusan. Pohon keputusan akan menghasilkan aturan-aturan (rule) sesuai dengan data yang telah dipelajari.
Kemudian data testing yang dimasukan berupa nilai-nilai yang bernilai continue dirubah menjadi nilai-nilai yang bernilai diskrit dengan tiga level yaitu kurang, cukup, dan baik. Setiap level ketentuanya dapat diatur pada sistem. Jika data testing yang diajukan tidak sama dengan salah satu dari data training maka data
testing dimasukan dalam pengalaman yang dapat divalidasi untuk dijadikan data training untuk menambah keakuratan SPK.
Gambar 3.2 Diagram Blok SPK
3. 5. 2 Use Case Diagram
melakukan testing pada sistem atau meminta dukungan keputusan pada sistem. Tetapi, pada aktor guru pelatih tidak hanya dapat melakukan testing melainkan juga dapat melakukan login, training, validasi pengalaman dan melihat pohon keputusan. Guru pelatih adalah guru yang paling dipercaya sekolah dalam melakukan penjurusan siswa SMA. Setiap proses pada use case diagram ini akan dijelaskan lebih dalam pada Sub Bab 3.5.3.
Gambar 3.3 Use case diagram
3. 5. 3 Activity Diagram
pohon merupakan proses pengecekan pohon keputusan oleh guru pelatih, proses ini digambarkan pada Gambar 3.7. Proses untuk mendapatkan keputusan yang dilakukan oleh user digambarkan pada Gambar 3.8.
Gambar 3.5 Activity diagram training
Gambar 3.7 Activity Diagram view pohon keputusan
Gambar 3.8 Activity Diagram mendapatkan keputusan
3. 5. 4 Class Diagram
Gambar 3.9 Class Diagram
3. 5. 5 Squence Diagram
1. Squence Diagram: Login
Gambar 3.10 Squence diagram login
Dari Gambar 3.10 diketahui bahwa tamu (aktor) melakukan request terhadap halaman user interface untuk mendapatkan tampilan untuk melakukan pengimputan data username dan password untuk melakukan login. Selanjutnya halaman login melakukan pemanggilan method validasiLogin() pada kelas login yang digunakan untuk memproses input username dan password pada class login. Dari pemanggilan method tersebut mendapatkan pengembalian (return) berupa true atau false yang memberikan isyarat kepada halaman apakah login telah valid atau tidak valid. Penjelasan Gambar 3.10 ini serupa dengan penjelasan Gambar 3.11 dan Gambar 3.16.
2. Squence Diagram: Training
Gambar 3.11 Squence diagram tambah training
Gambar 3.12 Squence diagram edit training
Dalam melakukan edit training, objek edit pada class Training harus dibuat terlebih dahulu sehingga dalam melakukan request UI halaman training memanggil method tampil() pada class training guna menampilkan daftar training yang telah dilakukan sebelumnya. Setelah itu guru pelatih (aktor) bisa
Gambar 3.13 Squence diagram hapus training 3. Squence Diagram: Validasi Pengalaman
Gambar 3.14 Squence diagram validasi pengalaman 4. Squence Diagram: View pohon keputusan
5. Squence Diagram: Mendapatkan keputusan
Gambar 3.16 Squence diagram mendapatkan keputusan
3. 5. 6 Conceptual Data Model (CDM)
Gambar 3.10 merupakan Conceptual Data Model (CDM) dari sistem pendukung keputusan penentuan jurusan SMA.
3. 5. 7 User Interface
User interface atau halaman antarmuka pada sistem ini dibangun dan disesuaikan
berdasarkan desain usecase yang telah dibuat. Desain interface tersebut adalah sebagai berikut:
1. Interface home
Interface ini adalah interface yang pertama kali muncul saat membuka
sistem pendukung keputusan penjurusan SMA. Interface ini memiliki dua tipe yaitu halaman home sebelum melakukan login seperti pada Gambar 3.18 dan halaman home setelah melakukan login seperti Gambar 3.19. Interface home baik telah melakukan login maupun tidak melakukan login memiliki fungsi yang sama yaitu mendapatkan suatu keputusan penentuan jurusan dengan mengisi input yang disediakan.
Gambar 3.19 Interface home setelah login 2. Interface training
Interface ini dapat dibuka apabila pengguna telah melakukan login. Interface ini memiliki dua sub halaman yaitu halaman daftar training seperti Gambar 3.20 dan halaman tambah/edit training seperti Gambar 3.21.
Gambar 3.21 Interface tambah/edit training
Halaman daftar training berfungsi untuk melihat keseluruhan data training yang pernah diberikan. Halaman ini memungkinkan guru pelatih untuk melakukan tambah, edit dan hapus training. Pada halaman tambah/edit training berfungsi untuk menambah suatu data training baru atau merubah
data training yang telah dipilih. 3. Interface validasi pengalaman
Halaman ini dapat dibuka apabila pengguna telah melakukan login. Halaman ini befungsi untuk memvalidasi pengalaman menjadi data training seperti Gambar 3.22.
4. Interface view pohon keputusan
Halaman ini dapat dibuka apabila pengguna telah melakukan login. Halaman ini befungsi untuk melihat pohon keputusan yang dihasilkan oleh algoritma ID3 secara otomatis seperti Gambar 3.23.
5.1 Kesimpulan
Berdasarkan hasil penelitian yang telah dilakukan dapat disimpulkan beberapa hal sebagai berikut ;
1. Sistem pendukung keputusan telah berhasil dibangun untuk membantu guru atau sekolah dalam menentukan jurusan siswa SMA sesuai dengan kebutuhan. 2. Algoritma ID3 dapat diimplementasikan secara otomatis oleh sistem sehingga
sistem dapat melakukan learning secara otomatis.
3. Semakin banyak data latih dapat meningkatkan akurasi dari keputusan dengan tingkat komposisi keberagaman data yang baik dan menyeluruh.
4. Data latih dengan noise memiliki akurasi yang baik terhadap data uji diluar data latih.
5. Pohon keputusan yang dihasilkan oleh data latih dengan noise lebih kompleks dibandingkan dengan pohon keputusan yang dihasilkan oleh data latih tanpa noise.
5.2 Saran
Beberapa saran yang diberikan untuk pengembangan penelitian ini lebih lanjut adalah sebagai berikut ;
1. Dalam penentuan jurusan perlu juga diberi daya tampung dari setiap jurusan sebagai tambahan parameter untuk menentukan keputusan.
Ariani, Pepi Dwi. 2010. Sistem Pendukung Keputusan Pemilihan Jurusan SMK Menggunakan Neuro-Fuzzy. Undergraduate Thesis, Institut Teknologi Sepuluh Nopember: Surabaya.
Desiani, A. dan Muhammad Arhami. 2006. Konsep Kecerdasan Buatan. Palembang: ANDI
Fitriyani. 2012. Sistem Pendukung Keputusan Penjurusan Sma Menggunakan Metode AHP.Seminar Nasional Teknologi Informasi & Komunikasi Terapan 2012 (Semantik 2012). ISBN 979 - 26 - 0255 – 0. Jurusan Sistem Informasi, STMIK Atma Luhur Pangkalpinang.
Setiawan, Bambang. 2010. Perancangan Sistem Pendukung Keputusan (Spk) Untuk Menentukan Kelaiklautan Kapal : Studi Kasus Di Kantor Administrasi Pelabuhan Klas Utama Tj. Perak Surabaya. Master Thesis, Institut Teknologi Sepuluh Nopember: Surabaya.
Siswoutomo, Wiwit. 2005. PHP Undercover Mengungkap Rahasia Pemrograman PHP. Jakarta: Elex Media Komputindo.
Slocum, Mary. 2012. Decision Making Using ID3 Algorithm. Rivier Academic Journal, Volume 8, Number 2, Fall. M.S. Program in Computer Science, Rivier University.
Suyanto. 2011. Artificial Intelegent (Cetakan kedua). Informatika: Bandung. Sutojo. T, Edy Mulyanto, Vincent Suhartono. 2011. Kecerdasan Buatan. Semarang:
ANDI.
Rosa A. S dan Salahudin. 2011. Rekayasa Perangkat Lunak. Modula: Bandung. Utami, Winda Pangesti. 2012. Penerapan Algoritma Iterative Dichotomiser Three
untuk Pemilihan Dosen Pembimbing. Universitas Kristen Satya Wacana: Jawa Tengah.