SUPPORT VECTOR BACKPROPAGATION: IMPLEMENTASI
BACKPROPAGATION SEBAGAI FEATURE REDUCTOR
PADA SUPPORT VECTOR MACHINE
SKRIPSI
ANGGI PERMANA HARIANJA
121421089
PROGRAM STUDI EKSTENSI S1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
SUPPORT VECTOR BACKPROPAGATION: IMPLEMENTASI
BACKPROPAGATION SEBAGAI FEATURE REDUCTOR
PADA SUPPORT VECTOR MACHINE
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijasah Sarjana Ilmu Komputer
ANGGI PERMANA HARIANJA 121421089
PROGRAM STUDI EKSTENSI S1 ILMU KOMPUTER FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
PERSETUJUAN
Judul : SUPPORT VECTOR BACKPROPAGATION:
IMPLEMENTASI BACKPROPAGATION SEBAGAI FEATURE REDUCTOR PADA SUPPORT VECTOR MACHINE
Kategori : SKRIPSI
Nama : ANGGI PERMANA HARIANJA
Nomor Induk Mahasiswa : 121421089
Program Studi : EKSTENSI S1 ILMU KOMPUTER
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, Agustus 2014 Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Herriyance, S.T., M.Kom Dr. Poltak Sihombing, M.Kom NIP.198010242010121002 NIP. 1961203171991031001
Diketahui/Disetujui oleh
Program Studi S1 Ilmu Komputer Ketua,
PERNYATAAN
SUPPORT VECTOR BACKPROPAGATION: IMPLEMENTASI BACKPROPAGATION SEBAGAI FEATURE REDUCTOR
PADA SUPPORT VECTOR MACHINE
SKRIPSI
Saya menyatakan bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Agustus 2014
PENGHARGAAN
Segala puji dan syukur Penulis ucapkan kepada Tuhan Yesus Kristus yang senantiasa melimpahkan rahmat dan karunia-Nya sehingga skripsi ini dapat diselesaikan.
Ucapan terima kasih Penulis sampaikan kepada semua pihak yang telah membantu Penulis dalam menyelesaikan skripsi ini baik secara langsung maupun tidak langsung, teristimewa untuk kedua orangtua terkasih. Pada kesempatan ini penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada :
1. Bapak Prof. Dr. dr. Syahril Pasaribu, DTM&H, M.Sc(CTM), Sp.A(K) selaku Rektor Universitas Sumatera Utara.
2. Bapak Prof. Dr. Muhammad Zarlis selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
3. Bapak Dr. Poltak Sihombing, M.Kom selaku Ketua Program Studi S1 Ilmu Komputer Universitas Sumatera Utara.
4. Ibu Maya Silvi Lydia, B.Sc, M.Sc selaku Sekretaris Program Studi S1 Ilmu Komputer Universitas Sumatera Utara.
5. Bapak Dr. Poltak Sihombing, M.Kom selaku Dosen Pembimbing I yang telah memberikan bimbingan, saran dan masukan kepada penulis dalam pengerjaan skripsi ini.
6. Bapak Herriyance, S.T., M.Kom selaku Dosen Pembimbing II yang telah memberikan bimbingan, saran dan masukan kepada penulis dalam pengerjaan skripsi ini.
8. Bapak Amer Sharif, S.Si, M.Si selaku Dosen Pembanding II yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
9. Semua dosen dan semua pegawai di Program Studi S1 Ilmu Komputer Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
10. Semua pihak yang terlibat langsung ataupun tidak langsung yang tidak dapat penulis ucapkan satu per satu yang telah membantu penyelesaian skripsi ini.
Penulis menyadari bahwa skripsi ini masih terdapat kekurangan. Oleh karena itu, kepada pembaca agar kiranya memberikan kritik dan saran yang bersifat membangun demi kesempurnaan skripsi ini. Sehingga dapat bermanfaat bagi kita semuanya.
Medan, Agustus 2014 Penulis,
ABSTRAK
Pada penelitian ini, diperkenalkan Support Vector Backpropagation dimana Backpropagation digunakan sebagai feature reductor pada sebuah Support Vector Machine dalam upaya mengurangi pengaruh curse of dimensionality serta menciptakan visualisasi pada high dimensional data, keduanya merupakan masalah yang dihadapi dalam real-world domain pattern recognition dan Backpropagation dipilih karena tidak ada algoritma deterministik untuk mentransformasikan sebuah high dimensional data menjadi low dimensional data. Metode ini bekerja dalam 2 fase yaitu: fase mapping oleh Backpropagation untuk men-transformasi-kan sebuah high dimensional data menjadi low dimensional data untuk kemudian menuju fase classifying yang dilakukan oleh Support Vector Machine dan output dari sistem adalah hasil analisis diskriminan beserta visualisasi data-nya. Data sample yang digunakan dalam penelitain ini didapat dari UCI Machine Learning Repository, yaitu: Wisconsin Diagnostic Breast Cancer Dataset, Cleveland Heart Disease Dataset, Fisher Iris Plants Dataset, John Hopkins University Ionosphere Dataset. Dari pengujian yang dilakukan didapat hasil bahwa Support Vector Backpropagation dapat mengurangi pengaruh curse of dimensionality, ini terbukti bahwa Support Vector Backpropagation memiliki tingkat akurasi yang sama bahkan terkadang lebih baik daripada Support Vector Machine jika menggunakan sample pelatihan yang jauh lebih sedikit serta mampu menciptakan visualisasi high dimensional data-nya pada ruang 2D secara akurat.
SUPPORT VECTOR BACKPROPAGATION: IMPLEMENTATION OF BACKPROPAGATION AS FEATURE REDUCTOR
ON SUPPORT VECTOR MACHINE
ABSTRACT
In this research, introduced Support Vector Backpropagation, where Backpropagation used as feature reductor on a Support Vector Machine in means to reduce the curse of dimensionality effect and also creating the visualization on it’s high dimensional data, both problems are always deal in real-world domain pattern recognition and Backpropagation chosen because there isn’t a deterministic algorithm to transform a high dimensional data into low dimensional data. This method works in 2 phase, which is: mapping phase by Backpropagation to transform a high dimensional data into low dimensional data and then flow into classifying phase done by Support Vector Machine and the system’s output are the result of discriminant analysis and also it’s visualization. Sample data that used in this research taken from UCI Machine Learning Repository, those are Wisconsin Diagnostic Breast Cancer Dataset, Cleveland Heart Disease Dataset, Fisher Iris Plants Dataset, John Hopkins University Ionosphere Dataset. By the test had done, got the result that Support Vector Backpropagation has same accuracy rate even better than Support Vector Machine if we use less training sample and also creating it’s high dimensional visualization in 2D space accurately.
DAFTAR ISI
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
3.1 Pengumpulan Data Pelatihan 22
3.2 Cluster-isasi Pada Iris Plants Dataset 24 3.3 Cluster-isasi Pada Wisconsin Diagnostic Breast
Cancer Dataset
3.4 Cluster-isasi Pada Cleveland Heart Disease
Wisconsin Diagnostic Breast Cancer Dataset
44
3 Konfigurasi Support Vector Backpropagation pada Cleveland Heart Disease Dataset
45 4 Konfigurasi Support Vector Backpropagation pada John
Hopkins University Ionosphere Dataset
47
BAB 4 IMPLEMENTASI DAN PENGUJIAN
4.1 Proses Transformasi Iris Plants Dataset Oleh Support Vector Backpropagation
49
4.2 Proses Transformasi Wisconsin Diagnostic Breast Cancer Dataset Oleh Support Vector Backpropagation
57
4.3 Proses Transformasi Cleveland Heart Disease Dataset Oleh Support Vector Backpropagation
66 4.4 Proses Transformasi John Hopkins University Ionosphere
Dataset Oleh Support Vector Backpropagation
76
BAB 5 KESIMPULAN DAN SARAN
5.1 Kesimpulan 86
5.2 Saran 87
DAFTAR TABEL
Halaman
Tabel 3.1 Data Penelitian 23
Tabel 3.2 Training Sample Iris Plants Dataset 24
Tabel 3.3 Deskripsi Iris Plants Dataset 24
Tabel 3.4 Cluster Pada Iris Plants Dataset 26
Tabel 3.5 Training Sample Wisconsin Diagnostic Breast Cancer Dataset
28 Tabel 3.6 Deskripsi Wisconsin Diagnostic Breast Cancer Dataset 29 Tabel 3.7 Cluster Pada Wisconsin Diagnostic Breast Cancer Dataset 31 Tabel 3.8 Training Sample Cleveland Heart Disease Dataset 32 Tabel 3.9 Deskripsi Cleveland Heart Disease Dataset 33 Tabel 3.10 Cluster Pada Cleveland Heart Disease Dataset 35 Tabel 3.11 Training Sample John Hopkins University Ionosphere
Dataset
37
Tabel 3.12 Deskripsi John Hopkisn University Ionosphere Dataset 39 Tabel 3.13 Cluster Pada John Hopkins University Ionosphere Dataset 42 Tabel 3.14 Konfigurasi Support Vector Backpropagation Pada Iris
Plants Dataset
43 Tabel 3.15 Konfigurasi Support Vector Backpropagation Pada
Wisconsin Diagnostic Breast Cancer Dataset
44
Tabel 3.16 Konfigurasi Support Vector Backpropagation Pada Cleveland Heart Disease Dataset
46
Tabel 3.17 Konfigurasi Support Vector Backpropagation Pada John Hopkins University Ionosphere Dataset
47 Tabel 4.1 Training Sample Iris Plants Dataset Sebelum Transformasi 50 Tabel 4.2 Training Sample Iris Plants Pada Tabel 4.1 Setelah
Transformasi
52
Tabel 4.3 Training Sample Iris Plants Dataset (a) Sebelum Transformasi (b) Sesudah Transformasi
53 Tabel 4.4 Cluster-isasi Pada Iris Plants Dataset Setelah Transformasi 54 Tabel 4.5 Perbandingan Tingkat Ketelitian Classifier Pada Iris Plants
Dataset Sebelum Dan Sesudah Transformasi
55 Tabel 4.6 Training Sample Wisconsin Diagnostic Breast Cancer
Dataset Sebelum Transformasi
57
Tabel 4.7 Training Sample Wisconsin Diagnostic Breast Cancer Dataset Pada Tabel 4.6 Setelah Transformasi
Tabel 4.8 Training Sample Wisconsin Diagnostic Breast Cancer Dataset (a) Sebelum Transformasi (b) Sesudah Transformasi
61
Tabel 4.9 Cluster-isasi Pada Wisconsin Diagnostic Breast Cancer Dataset Setelah Transformasi
62
Tabel 4.10 Perbandingan Tingkat Ketelitian Classifier Pada Wisconsin Diagnostic Breast Cancer Dataset Sebelum Dan Sesudah Transformasi
63
Tabel 4.11 Training Sample Cleveland Heart Disease Sebelum Transformasi
67
Tabel 4.12 Training Sample Cleveland Heart Disease Pada Tabel 4.11 Setelah Transformasi
70 Tabel 4.13 Training Sample Cleveland Heart Disease Dataset (a)
Sebelum Transformasi (b) Sesudah Transformasi
71
Tabel 4.14 Cluster-isasi Pada Cleveland Heart Disease Dataset Setelah Transformasi
72 Tabel 4.15 Perbandingan Tingkat Ketelitian Classifier Pada Cleveland
Heart Disease Sebelum Dan Sesudah Transformasi
73
Tabel 4.16 Training Sample John Hopkins University Ionosphere Dataset Sebelum Transformasi
76
Tabel 4.17 Traning Sample John Hopkins University Ionosphere Dataset Pada Tabel 4.16 Setelah Transformasi
79 Tabel 4.18 Training Sample John Hopkins University Ionosphere
Dataset (a) Sebelum Transformasi (b) Sesudah Transformasi
80
Tabel 4.19 Cluster-isasi Pada John Hopkins University Ionosphere Dataset Setelah Transformasi
81 Tabel 4.20 Perbandingan Tingkat Ketelitian Classifier Pada John
Hopkins University Ionosphere Dataset Sebelum Dan Sesudah Transformasi
DAFTAR GAMBAR
Halaman
Gambar 2.1 Flowchart Support Vector Backpropagation 10 Gambar 2.2 Arsitektur Support Vector Backpropagation 11 Gambar 3.1 Arsitektur Support Vector Backpropagation Pada Iris Plants
Dataset
43
Gambar 3.2 Arsitektur Support Vector Backpropagation Pada Wisconsin Diagnostic Breast Cancer Dataset
45 Gambar 3.3 Arsitektur Support Vector Backpropagation Pada Cleveland
Heart Disease Dataset
46
Gambar 3.4 Arsitektur Support Vector Backpropagation Pada John Hopkins University Ionosphere Dataset
48 Gambar 4.1 Grafik Perbandingan Tingkat Ketelitian Classifier Iris Plants
Dataset Sebelum Dan Sesudah Transformasi
55
Gambar 4.2 Grafis Hasil Cluster Pada Iris Plants Dataset Sesudah Transformasi
56
Gambar 4.3 Grafik Perbandingan Tingkat Ketelitian Classifier Wisconsin Diagnostic Breast Cancer Dataset Sebelum Dan Sesudah Transformasi
63
Gambar 4.4 Grafis Hasil Cluster Pada Wisconsin Diagnostic Breast Cancer Dataset Sesudah Transformasi
64
Gambar 4.5 Grafik Perbandingan Tingkat Ketelitian Classifier Cleveland Heart Disease Dataset Sebelum Dan Sesudah Transformasi
73 Gambar 4.6 Grafis Hasil Cluster Pada Cleveland Heart Disease Dataset
Sesudah Transformasi
74
Gambar 4.7 Grafik Perbandingan Tingkat Ketelitian Classifier John Hopkins University Ionosphere Dataset Sebelum Dan Sesudah Transformasi
82
Gambar 4.8 Grafis Hasil Cluster Pada John Hopkins University Ionosphere Dataset Sesudah Transformasi
DAFTAR LAMPIRAN
Halaman
A Listing Program 90
B Dataset Description 111
ABSTRAK
Pada penelitian ini, diperkenalkan Support Vector Backpropagation dimana Backpropagation digunakan sebagai feature reductor pada sebuah Support Vector Machine dalam upaya mengurangi pengaruh curse of dimensionality serta menciptakan visualisasi pada high dimensional data, keduanya merupakan masalah yang dihadapi dalam real-world domain pattern recognition dan Backpropagation dipilih karena tidak ada algoritma deterministik untuk mentransformasikan sebuah high dimensional data menjadi low dimensional data. Metode ini bekerja dalam 2 fase yaitu: fase mapping oleh Backpropagation untuk men-transformasi-kan sebuah high dimensional data menjadi low dimensional data untuk kemudian menuju fase classifying yang dilakukan oleh Support Vector Machine dan output dari sistem adalah hasil analisis diskriminan beserta visualisasi data-nya. Data sample yang digunakan dalam penelitain ini didapat dari UCI Machine Learning Repository, yaitu: Wisconsin Diagnostic Breast Cancer Dataset, Cleveland Heart Disease Dataset, Fisher Iris Plants Dataset, John Hopkins University Ionosphere Dataset. Dari pengujian yang dilakukan didapat hasil bahwa Support Vector Backpropagation dapat mengurangi pengaruh curse of dimensionality, ini terbukti bahwa Support Vector Backpropagation memiliki tingkat akurasi yang sama bahkan terkadang lebih baik daripada Support Vector Machine jika menggunakan sample pelatihan yang jauh lebih sedikit serta mampu menciptakan visualisasi high dimensional data-nya pada ruang 2D secara akurat.
SUPPORT VECTOR BACKPROPAGATION: IMPLEMENTATION OF BACKPROPAGATION AS FEATURE REDUCTOR
ON SUPPORT VECTOR MACHINE
ABSTRACT
In this research, introduced Support Vector Backpropagation, where Backpropagation used as feature reductor on a Support Vector Machine in means to reduce the curse of dimensionality effect and also creating the visualization on it’s high dimensional data, both problems are always deal in real-world domain pattern recognition and Backpropagation chosen because there isn’t a deterministic algorithm to transform a high dimensional data into low dimensional data. This method works in 2 phase, which is: mapping phase by Backpropagation to transform a high dimensional data into low dimensional data and then flow into classifying phase done by Support Vector Machine and the system’s output are the result of discriminant analysis and also it’s visualization. Sample data that used in this research taken from UCI Machine Learning Repository, those are Wisconsin Diagnostic Breast Cancer Dataset, Cleveland Heart Disease Dataset, Fisher Iris Plants Dataset, John Hopkins University Ionosphere Dataset. By the test had done, got the result that Support Vector Backpropagation has same accuracy rate even better than Support Vector Machine if we use less training sample and also creating it’s high dimensional visualization in 2D space accurately.
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Seperti halnya semua algoritma dalam pattern recognition pada real-world domain, Support Vector Machine juga selalu mengalami masalah pada tingginya dimensi data yang diolah atau yang biasa disebut high dimensional data. Misalnya data observasi meteorologi untuk menentukan muncul atau tidaknya kabut berkisar 26 attribut, data biomedis yang dipakai untuk memprediksi efektifitas terapi interferon pada pasien hepatitis C kronis berkisar 30 attribut ( Nugroho, 2007 ), dimensi input data hasil feature extraction pada tulisan tangan adakalanya lebih dari 700 attribut, bahkan ada yang ribuan dimensi, contohnya: gen manusia yang memiliki attribut sebanyak 22.000 attribut. Banyaknya dimensi mengakibatkan meningkatnya kebutuhan data secara signifikan, inilah yang disebut oleh Richard E. Bellman pada tahun 1957 sebagai curse of dimensionality ( Bellman, 1957 ).
maupun informasi yang telah di-ekstrak dalam sebuah low dimensional data ( Hinton, 2006 ).
“Kutukan” dan masalah visualisasi ini dianggap menarik oleh penulis, penulis merasa tertantang menemukan cara melakukan reduksi dan visualisasi terhadap dimensi data yang diolah sehingga sebuah high dimensional data tetap dapat ditemukan decision boundary-nya secara rational dalam sebuah ruang 2 Dimensi. Penulis memperkenalkan sebuah algoritma bernama Support Vector Backpropagation, sebuah algoritma hasil modifikasi kombinasi Backpropagation dan Support Vector Machine yang mampu mengubah sebuah high dimensional data menjadi sebuah low dimensional data ( hanya memiliki 2 attribut sebagai dimensi dalam ruang ) sebelum dilakukan proses analisa diskriminan-nya. Backpropagation dipilih oleh penulis dikarenakan tidak adanya algoritma deterministik yang mampu mentransformasikan sebuah high dimensional data menjadi low dimensional data. Menggunakan algoritma ini sebuah decision boundary dari sebuah high dimensional data akan mungkin diciptakan dan ditangkap secara visual.
Seperti halnya Support Vector Machine, otak manusia juga selalu terbatas pada ruang 3D. Kita tidak dapat membayangkan dan memahami apapun yang diletakkan dan digambarkan dalam ruang 4D atau lebih.
1.2. Rumusan Masalah
1. Dapatkah Support Vector Backpropagation melakukan proses cluster pada high dimensional dataset?
1.3. Batasan Masalah
Batasan masalah dalam penelitian ini adalah:
1. Perbandingan Support Vector Backpropagation hanyalah dengan metode Support Vector Machine.
2. Penelitian ini hanya menggunakan sebuah pengujian, yaitu: Accuracy Test 3. Penelitian ini menggunakan dataset dalam format *.mat dan *.txt
4. Penelitian ini menggunakan dataset yang telah tersedia dalam UCI Machine Learning Repository, yaitu: Cleveland Heart Disease, Wisconsin Diagnostic Breast Cancer Dataset, John Hopkins Univesity Ionosphere Dataset, Fisher Iris Dataset.
5. Penelitian ini menggunakan dataset yang telah mengalami pre-processing terlebih dahulu.
6. Penelitian ini bersifat eksperimental, sehingga pembuatan aplikasi bukan priorotas utama.
7. Bahasa pemrograman yang digunakan dalam penelitian ini adalah MATLAB R2010a.
1.4. Tujuan Penelitian
1.5. Manfaat Penelitian
Manfaat penelitian ini adalah:
1. Menemukan cara yang lebih efisien dalam melakukan cluster-isasi pada high dimensional data walaupun jumlah training sample yang tersedia sangat terbatas.
2. Sebagai alternatif feature reduction dalam mengatasi curse of dimensionality pada semua high dimensional data.
1.6. Metodologi Penelitian
Metodologi penelitian yang digunakan dalam penulisan tugas akhir ini adalah sebagai berikut:
a. Studi Literatur
Penulis melakukan studi kepustakan melalui penelitan berupa buku jurnal maupun artikel-artikel yang relevan mengenai Machine Learning, curse of dimensionality, Backpropagation, Support Vector Machine, high dimensional data, visualisasi.
b. Analisis dan perancangan
Analisis masalah dimulai dengan tahap mengidentifikasi masalah, memahami cara kerja sistem yang akan dibuat, menganalisis dan membuat laporan tentang hasil analisis, dan perancangan yang dimaksud adalah menggambarkan sistem menggunakan flowchart.
c. Implementasi
d. Pengujian
Metode ini dilaksanakan dengan melakukan pengujian terhadap sistem yang telah dibangun.
e. Dokumentasi
Metode ini dilaksanakan dengan membuat dokumentasi dalam bentuk laporan tugas akhir.
1.7. Sistematika Penulisan
Penulisan skripsi ini menggunakan sistematika penulisan yang membagi pembahasan skripsi dalam lima bagian utama, yang terdiri atas:
BAB 1 PENDAHULUAN
Pada bab ini merupakan pendahuluan yang berisi latar belakang, rumusan masalah, tujuan penelitian, batasan masalah, metodologi penelitian, dan sistematika penulisan skripsi.
BAB 2 LANDASAN TEORI
Pada bab ini membahas mengenai teori-teori yang digunakan untuk memahami permasalahan yang berkaitan dengan machine learning, Backpropagation, Support Vector Machine, curse of dimensionality, visualisasi data.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab ini dibahas cara kerja sistem beserta proses pengujian terhadap sistem yang telah dikembangkan
BAB 5 KESIMPULAN DAN SARAN
BAB 2
LANDASAN TEORI
Dalam bab ini dibahas teori yang digunakan sebagai landasan pengerjaan Support Vector Backpropagation. Pembahasan bertujuan untuk menguraikan teori dan algoritma yang digunakan dalam Support Vector Backpropagation dalam upaya mengurangi pengaruh curse of dimensionality dan menciptakan visualisasinya.
2.1. Data Mining
Data mining merupakan teknologi dalam menggabungkan metoda analisis tradisional dengan algoritma yang canggih untuk memproses data dengan volume besar. Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi dalam sebuah database. Data mining merupakan proses semi automatic yang menggunakan statistika, matematika, kecerdasan buatan dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang bermanfaat yang tersimpan dalam database besar.
2.2. Support Vector Machine
recognition untuk meng-investigasi potensi kemampuan Support Vector Machine secata teoritis maupun dari segi aplikasi. Dewasa ini Support Vector Machine telah berhasil diaplikasikan dalam problema dunia nyata, dan secara umum memberi solusi yang lebih baik dibandingkan metoda konvensional seperti misalnya artificial neural network.
Support Vector Backpropagation adalah pengembangan dari Support Vector Machine, digunakan untuk mengatasi curse of dimensionality yang selalu menjadi constraint dalam proses cluster sebuah high dimensional data. Support Vector Backpropagation memanfaatkan konsep jaringan syaraf tiruan dengan algoritma backpropagation untuk mentransformasikan high dimensional dataset menjadi low dimensional dataset.
2.2.1. Support Vector Backpropagation
START
Bobot x similarity function
MSE Support Vector
Machine
2.2.1.1. Aristektur Support Vector Backpropagation
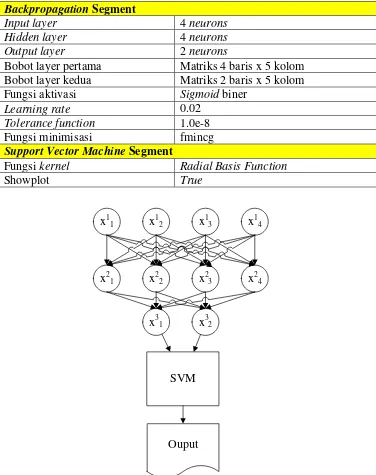
Support Vector Backpropagation memiliki arsitektur yang unik karena menggabungkan sebuah jaringan syaraf tiruan sebagai transformator yang akan meng-ubah semua dataset yang di-inputkan menjadi low dimensional dataset, penetuan jumlah neuron dan layer jaringan syaraf tiruan dalam Support Vector Backpropagation tidak memerlukan ketentuan khusus, seluruh proses yang terjadi sama halnya dengan algoritma Backpropagation biasa. Berikut gambar arsitektur Support Vector Backpropagation:
x11 x12 x13 x14
x21 x22 x23 x24
x31 x32
SVM
Ouput
2.2.1.2. Algoritma Support Vector Backpropagation
Algoritma Support Vector Backpropagation terbagi kedalam 2 fase, fase pertama adalah fase transformasi yang dilakukan oleh Backpropagation untuk kemudian di-cluster menggunakan Support Vector Machine. Berikut ini adalah algoritma Support Vector Backpropagation:
1. Proses tranformasi menggunakan Backpropagation
1. Inisialisasi bobot
Proses inisialisasi bobot pada jaringan syaraf tiruan digunakan untuk memberi nilai awal bobot berupa nilai acak dan sangat kecil, diperlukan nilai epsiloninit dalam penentuan bobot awal, nilai ini digunakan untuk
symmetry breaking yang seringkali menjadi constraint bagi jaringan syaraf tiruan dalam proses learning, nilai bobot awal yang dihasilkan akan selalu berada disekitar niali epsiloninit. Berikut adalah persamaan yang digunakan
dalam inisialisasi bobot yang digunakan dalam jaringan syaraf tiruan:
(2.1)
keterangan:
l = layer (l = 1,2,3,…,n)
2. Feedforwardpropagation
Proses selanjutnya yang dilakukan oleh Backpropagation adalah feedforwardpropagation, ini dilakukan dengan cara mengitung jumlah bobot dan nilai input pada masing-masing neuron dan kemudian dihitung nilai aktivasinya, seperti yang dijelaskan pada persamaan berikut:
keterangan:
= neuron ke -i layer ke-l (i,j = 1,2,3,…,n) = bobot neuron ke-i layer ke-l (i,j = 1,2,3,…,n) = input neuron ke-i layer ke-l (i,j = 1,2,3,…,n)
Dimana nilai fungsi aktivasi pada masing-masing neuron adalah sebagai berikut:
(2.3)
keterangan:
= nilai aktivasi neuron ke-i layer ke-l (i,j = 1,2,3,…,n)
= neuron ke -i layer ke-l (i,j = 1,2,3,…,n)
Dimana nilai fungsi aktivasi menggunakan fungsi sigmoid biner sebagai berikut:
(2.4)
keterangan:
3. Hitung nilai Mean Square Error
Setelah semua nilai aktivasi pada masing-masing neuron pada tiap layer didapat maka selanjutnya akan dihitung nilai Mean Square Error nya menggunakan learing rate (lambda), nilai Mean Square Error terkecil menandakan bahwa jaringan syaraf tiruan telah berhasil menemukan pola dan bobot yang akan digunakan dalam proses transformasi, adapun persamaan Mean Square Error adalah sebagai berikut:
(2.5)
keterangan:
= output ke-i layer ke-l (i,j = 1,2,3,…,n)
= nilai aktivasi neuron ke-i layer ke-l (i,j = 1,2,3,…,n) lambda = learning rate
m = banyaknya sample
4. Hitung nilai error
Nilai error pada output layer:
(2.6)
Nilai error pada hidden layer:
(2.7)
keterangan:
= nilai error pada output layer
= nilai aktvasi neuron ke-i pada output layer (i = 1,2,3,…,n) = nilai error pada hidden layer
= bobot neuron hidden layer
Dimana nilai sigmoidGradients didapat dengan cara turunan pertama fungsi sigmoid yaitu:
(2.7)
Dimana nilai fungsi sigmoid didapat pada persamaan (2.4)
5. Hitung nilai Thetagrad
(2.8)
keterangan:
= Thetagrad layer ke-l (l = 1,2,3,…,n)
= nilai error neuron ke-i layer ke-l (i,j = 1,2,3,…,n)
6. Update bobot jaringan syaraf tiruan
Setelah didapat nilai Thetagradmaka akan didapat bobot jaringan syaraf
terbaru yang akan di-iterasi sehingga mendapatkan bobot yang optimal menggunakan persamaan berikut:
(2.9)
keterangan:
= bobot neuron ke-i layer-l (i,l = 1,2,3,…,n)
= Thetagradneuron ke-i layer-l (i,l = 1,2,3,…,n)
2. Proses cluster menggunakan Support Vector Machine
1. Penentuan nilai kernel
Proses cluster menggunakan Support Vector Machine diawali dari proses menghitung similarity function mangunakan radial basis function, yang didapat menggunakan persamaan berikut:
(2.10)
keterangan:
= landmark x
y = feature y training sample = landmark y
= variance
2. Penentuan nilai cost
Setelah didapat nilai similarity function, maka kita akan melakukan summation pada masing input feature dengan bobot Support Vector Machine yang dihitung dengan persamaan:
(2.11)
keterangan:
= cost sample ke-i pada similarity function ke-i = sample ke-i
= similarity function ke-i
3. Perhitungan Mean Square Error Support Vector Machine
Untuk mengetahui apakah sebuah classifier telah menemukan cluster yang tepat dapat dilihat dari nilai Mean Square Error minimum yang didapat dari persamaan (2.11) dengan persamaan berikut:
(2.12)
keterangan:
= cost sample ke-i pada similarity function ke-i lambda = learning rate
m = banyaknya sample
2.3. High Dimensional Classification
Dalam aplikasi yang melibatkan klasifikasi dengan high dimensional dataset, salah satu permasalahan umum dalam tingkat praktiknya adalah kondisi yang disebut curse of dimensionality ( Bellman, 1957 ). Bagaimanapun, masalah utama ini melibatkan kondisi overfitting dan cara menyediakan jumlah training sample yang meningkat secara eksponensial. Masalah ini mudah dipahami jika kita membagi sebuah n-dimensional feature space kedalam sebuah n-n-dimensional hypercubes dengan resolusi yang konstan dalam tiap dimensi ( Bishop, 2006 ). Ketika kita melakukan ini, jumlah hypercubes akan meningkat secara eksponensial seiring jumlah dimensi. Oleh karena itu terlihat jelas bahwa persebaran data menjadi sebuah masalah dan teknik non-parametrik seperti metoda histogram menjadi tidak mungkin. Dalam banyak aplikasi, jumlah dimensi menjadi masalah yang tak terpisahkan dan terasa tidak realistis untuk menydiakan jumlah training sample yang dibutuhkan untuk mengimbangi persebaran data.
2.3.1. Curse of Dimensionality
Tools yang digunakan dalam analisis data berdasarkan pada prinsip pembelajaran dari pada pengetahuan, atau informasi dari training sample yang tersedia. Jelas sekali bahwa model yang dibangun hanya valid pada range atau volume sebanyak training sample yang tersedia. Bagaimanapun model yang dibangun, generalisasi pada data yang sangat berbeda dari semua titik pembelajaran adalah mustahil. Dengan kata lain, generalisasi yang relevan dimungkinkan dalam interpolation.
dibagian mana model tersebut adalah valid. Dapat dilihat dengan mudah bahwa jika setiap constraint yang ada tidak mengalami perubahan maka jumlah training sample akan meningkat secara eksponensial seiring dimensinya. Kenaikan jumlah training sample secara eksponensial ini adalah apa yang disebut curse of dimensionality ( Bellman, 1957) dan juga dikemukakan lagi oleh Christopher M. Bishop ( Bishop, 2006 ).
Secara umum, curse of dimensionality adalah kondisi dari semua fenomena yang muncul dalam high dimensional dataset, dan yang paling sering menjadi penghalang dalam behavior dan performa sebuah learning algorithm.
2.3.2. Feature Selection
Salah satu cara dalam mengatasi curse of dimensionality ( yang seringkali mengakibatkan kondisi overfitting dikarenakan tingginya jumlah parameter r) adalah mereduksi jumlah dimensi pada tahap preprocessing. Dalam permasalahan high dimensional dataset seringkali didapat input variable didapati redundant, jika kita dapat menghapus semua variable yang redundant, sebuah classifier dapat saja melalui proses pembelajaran dalam low dimensional dataset.
Feature selection membutuhkan pengenalan pada ukuran persebaran yang menjelaskan perbedaan nilai antara variable input yang digunakan. Ukuran persebaran data yang ideal adalah Bayes error rate dalam permasalahan klasifikasi. Sayangnya, jumlah training sample yang dibutuhkan akan selalu berubah setiap proses feature selection.
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Pada bab ini akan dijelaskan proses analisis dan perancangan sistem yang digunakan dalam penelitian ini, dimulai dari pengumpulan data serta proses cluster-isasi pada masing-masing dataset, sehingga alur sistem yang dirancang akan dapat dipahami proses pembutannya.
3.1. Pengumpulan Data Pelatihan
Langkah-langkah pengumpulan data untuk penelitian ini adalah sebagai berikut:
1. Membuat rancangan data input dan output yang akan dimasukkan sebagai data pelatihan dan pengujian. Semua sample diimplementasikan dalam tipe data numeric dan logic. Dalam penelitian ini sample dapat memiliki noise atau ketidak-lengkapan yang diharapkan Support Vector Backpropagation dapat meng-analisa sample walau terdapat noise. Pada penelitian ini akan digunakan dataset yang digunakan adalah Cleveland Heart Disease Dataset, Wisconsin Diagnosis Breast Cancer, Iris Plants Dataset, John Hopkins University Ionosphere Dataset.
Tabel 3.1 Data Penelitian
Cleveland Heart Disease
Dataset
Iris Plants Dataset
John Hopkins University
Ionosphere Dataset
Wisconsi Diagnostic Breast
Cancer Dataset
Universitas
Sumatera
3.2. Cluster-isasi Pada Iris Plants Dataset
Dataset ini adalah salah satu dataset yang paling tua dan juga paling banyak digunakan dalam banyak buku dan jurnal penelitian dalam data mining. Dataset ini merupakan hasil pekerjaan dari Sir. R. A. Fisher pada tahun 1988 yang terdiri dari 4 buah feature dari sebuah bunga iris, dataset ini terdiri dari 150 sample yang terbagi atas instance iris setosa sebanyak 50 sample, instance iris virginica sebanyak 50 sample dan instance iris versicolor sebanyak 50 sample ( Fisher, 1988 ) yang dijelaskan secara singkat dalam tabel berikut:
Tabel 3.2 Training Sample Iris Plants Dataset
sample# Sepal
Petal Width Target
1 5,1 3,5 1,4 0,2 Iris Setosa
… … … …
51 5,2 2,7 3,9 1,4 Iris Virginica
… … … …
120 6 3 4,8 1,8 Iris Versicolor
Berikut disertakan ringkasan dari masing-masing attribut dalam Iris Plants Dataset, seperti yang disajikan dalam tabel 3.3 berikut:
Tabel 3.3 Deskripsi Iris Plants Dataset
Proses cluster pada Iris Plants Dataset diawali dengan penentuan kernel yang digunakan yaitu radial basis function, pertimbangan penggunaan kernel ini adalah kenyataan bahwa dataset di cluster secara non-linear, berikut akan dijelaskan pada proses cluster pada Iris Plants Dataset:
Berikut adalah contoh proses cluster pada sebuah sample bunga iris: sepal length = 5,1
sepal width = 4,9 petal length = 4,7 petal width = 4,6
sehingga x = [5,1 4,9 4,7 4,6] akan di-cluster terhadap beberapa landmark yang ada, yaitu:
Dengan menggunakan standard deviasi = 0,8441, menggunakan persamaan (2.10) maka:
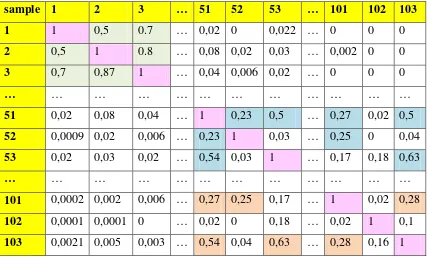
Tabel 3.4 Cluster Pada Iris Plants Dataset
sample 1 2 3 … 51 52 53 … 101 102 103
1 1 0,5 0.7 … 0,02 0 0,022 … 0 0 0
2 0,5 1 0.8 … 0,08 0,02 0,03 … 0,002 0 0 3 0,7 0,87 1 … 0,04 0,006 0,02 … 0 0 0
… … … … …
51 0,02 0,08 0,04 … 1 0,23 0,5 … 0,27 0,02 0,5 52 0,0009 0,02 0,006 … 0,23 1 0,03 … 0,25 0 0,04 53 0,02 0,03 0,02 … 0,54 0,03 1 … 0,17 0,18 0,63
… … … … …
101 0,0002 0,002 0,006 … 0,27 0,25 0,17 … 1 0,02 0,28 102 0,0001 0,0001 0 … 0,02 0 0,18 … 0,02 1 0,1 103 0,0021 0,005 0,003 … 0,54 0,04 0,63 … 0,28 0,16 1
keterangan:
= instance iris setosa
= instance iris versicolor
= instance iris virginica
= sample dengan nilai similarity function = 1
3.3. Cluster-isasi Pada Wisconsin Diagnostic Breast Cancer Dataset
Berikut disertakan ringkasan dari masing-masing attribut dalam Wisconsin Diagnostic Breast Cancer Dataset, seperti yang disajikan dalam tabel 3.6 berikut:
Tabel 3.6 Deskripsi Wisconsin Diagnostic Breast Cancer Dataset
Attribute Name
Attribute
Type Max Min Mean
Standard Deviasi
radius real 10 1 4,4500 2,8243
texture real 10 1 3,1206 3,0228
perimeter real 10 1 3,1985 2,9443
area real 10 1 2,8088 2,8557
smoothness real 10 1 3,2265 2,2328 compactness real 10 1 3,5441 3,6429 concavity real 10 1 3,4397 2,4069 concave
points
real 10 1 2,8647 3,0570
symmetry real 10 1 1,5809 1,7057
class categorical 1 0 N/A N/A
Berikut adalah contoh proses cluster pada sebuah training sample pada Wisconsin Diagnostic Breast Cancer Dataset:
radius = 5 texture = 1 perimeter = 1 area = 1 smootness = 2 compactness = 1 concavity = 3 concave points = 1 symmetry = 1
sehingga didapat x = [5 1 1 1 2 1 3 1 1] yang akan di-cluster terhadap beberapa landmark yang ada, yaitu:
Dengan menggunakan nilai standard deviasi = 2,8 maka proses perhitungan similarity function pada persamaan (2.10) adalah sebagai berikut:
Tabel 3.7 Cluster Pada Wisconsin Diagnostic Breast Cancer Dataset
Sample 1 250 455 653 … 13 280 474 531
1 1 0,77 0,29 0,86 … 0,2 0 0,66 0
250 0,77 1 0,48 0,67 … 0,18 0 0,66 0
455 0,29 0,48 1 0,35 … 0,07 0 0,56 0
653 0,86 0,67 0,35 1 … 0,24 0 0,81 0
… … … …
13 0,2 0,18 0,07 0,24 … 1 0 0,1 0,01
280 0 0 0 0 … 0 1 0 0
474 0,6 0,66 0,56 0,81 … 0 0 1 0
531 0 0 0 0 … 0 0 0 1
keterangan:
= instance benign
= sample dengan nilai similarity function = 1
Hasil cluster-isasi didapat bahwa dalam Wisconsin Diagnostic Breast Cancer Dataset terdapat 357 sample termasuk dalam class benign, dan 212 sample termasuk dalam class malignant.
3.4. Cluster-isasi Pada Cleveland Heart Disease Dataset
Berikut disertakan ringkasan dari masing-masing attribut dalam Cleveland Heart Disease Dataset, seperti yang disajikan dalam tabel 3.9 berikut:
Tabel 3.9 Deskripsi Cleveland Heart Disease Dataset
Attribute Name
Attribute
Type Max Min Mean
Standard Deviasi
age integer 77 29 54,5421 9,0497
sex logical 1 0 N/A N/A
cp integer 4 1 3,1582 0,9649
trestbps integer 200 94 131,6936 17.7628 chol integer 564 126 247,3502 51,9976
fbs logical 1 0 N/A N/A
restecg logical 2 0 N/A N/A
thalach integer 202 71 149,5993 22,9416
exang logical 1 0 N/A N/A
oldpeak real 6,2 0 1,0556 1,1661
slope categorical 3 1 N/A N/A
ca categorical 3 0 N/A N/A
thal categorical 7 0 N/A N/A
class categorical 1 0 N/A N/A
Berikut adalah contoh proses cluster pada sebuah training sample pada Cleveland Heart Disease Dataset:
age = 63 sex = 1 cp = 1
trestbps = 145 chol = 233 fbs =1 restecg = 2 thalach= 150 exang = 0 oldpeak = 2,3 slope = 3 ca = 0 thal = 6
sehingga didapat x = [63 1 1 145 233 1 2 150 0 2,3 3 0 6] yang akan di-cluster terhadap beberapa landmark yang ada, yaitu:
Dengan menggunakan nilai standard deviasi = 1,1 maka proses perhitungan similarity function pada persamaan (2.10) adalah sebagai berikut:
Untuk kemudian diolah dalam komputer menggunakan MATLAB R2010a dalam perhitungan me-minimisasi nilai pada fungsi pada persamman (2.12) untuk mendapatkan kesimpulan bahwa sample x termasuk dalam class yang dimiliki oleh , . Berikut akan disajikan dalam tabel hasil dari seluruh perhitungan proses cluster pada training sample dan landmark pada Cleveland Heart Disease Dataset:
Tabel 3.10 Cluster Pada Cleveland Heart Disease Dataset
sample 3 25 63 77 … 2 91 180 244
3 1 0,55 0,28 0,3 … 0 0 0 0
25 0,55 1 0,54 0,29 … 0 0 0 0
63 0,28 0,54 1 0,06 … 0 0 0 0
77 0,3 0,29 0,06 1 … 0 0 0 0
… … … … …
2 0 0 0 0 … 1 0,5 0,41 0,44
91 0 0 0 0 … 0,5 1 0,38 0,26
180 0 0 0 0 … 0,41 0,38 1 0,61
244 0 0 0 0 … 0,44 0,26 0,61 1
keterangan:
= instance positif sakit jantung = instance negatif sakit jantung
= sample dengan similarity function = 1
3.5. Cluster-isasi Pada John Hopkins University Ionosphere Dataset
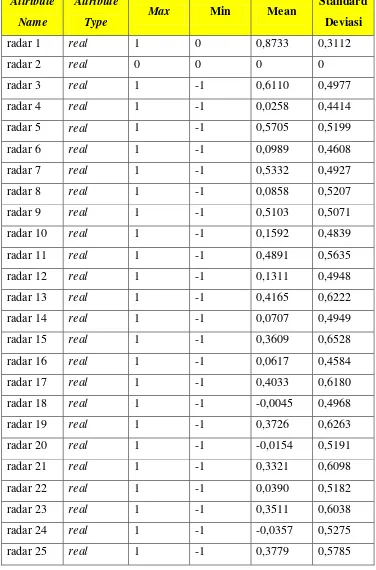
Berikut disertakan ringkasan dari masing-masing attribut dalam John Hopkins University Ionosphere Dataset, seperti yang disajikan dalam tabel 3.12 berikut:
Tabel 3.12 Deskripsi John Hopkins University Ionosphere Dataset
radar 26 real 1 -1 -0,0486 0,5085
radar 27 real 1 -1 0,53524 0,5162
radar 28 real 1 -1 -0,0533 0,5500
radar 29 real 1 -1 0,3360 0,5759
radar 30 real 1 -1 -0,0170 0,5080
radar 31 real 1 -1 0,3049 0,5715
radar 32 real 1 -1 0,0065 0,5136
radar 33 real 1 -1 0,3037 0,5227
radar 34 real 1 -1 0,0175 0,4683
class categorical 1 0 N/A N/A
Proses cluster pada John Hopkins University Ionosphere Dataset menggunakan Support Vector Machine dengan menggunakan radial basis function sebagai kernel sama seperti proses cluster pada Iris Plants Dataset yang telah dilakukan pada BAB 3, proses cluster pada John Hopkins University Ionosphere Dataset menggunakan 34 features yang akan dihitung nilai similarity nya untuk dapat menentukan apakah sebuah sample dalam kondisi baik atau buruk. Berikut disajikan proses cluster pada John Hopkins University Ionosphere Dataset:
Berikut adalah contoh proses cluster pada sebuah training sample pada John Hopkins Ionosphere Dataset:
radar1 = 1 radar8 = -0,3 radar15 = 0,6 radar22 = -0,2 radar29 =0,2 radar2 = 0 radar9 = 1 radar16 = -0,3 radar23 =0,3 radar30 =-0,3 radar3 = 0,9 radar10 = 0,03 radar17 = 0,8 radar24 =-0,4 radar31 =0,4 radar4 = -0,05 radar11 = 0,8 radar18 = -0,3 radar25 =0,5 radar32 =-0,5 radar5 = 0,8 radar12 = -0,1 radar19 = 0,5 radar26 =-0,5 radar33 =0,1 radar6 = 0,02 radar13 = 0,5 radar20 = -0,3 radar27 =0,4 radar34 =-0,4 radar7 = 0,8 radar14 = -0,4 radar21 = 0,5 radar28 =-0,4
Training sample akan di-cluster terhadap landmark menggunakan standard deviasi = 0,5 pada persamaan (2.10), sehingga akan diperoleh nilai similarity function sebagai berikut:
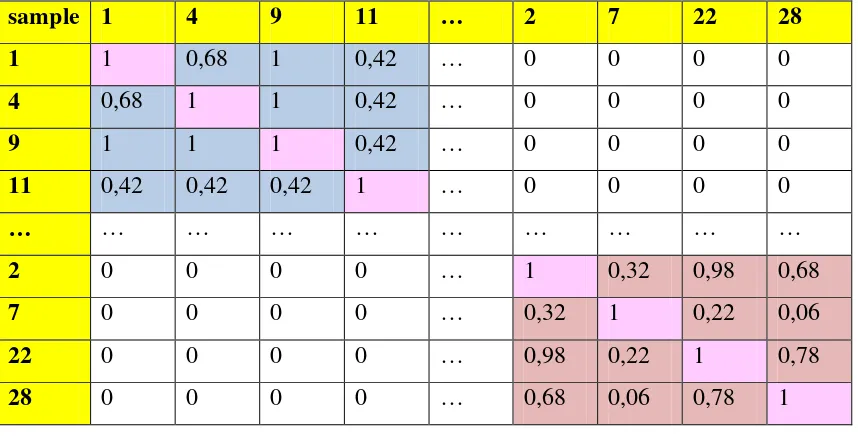
Tabel 3.13 Cluster Pada John Hopkins University Ionosphere Dataset
sample 1 4 9 11 … 2 7 22 28
1 1 0,68 1 0,42 … 0 0 0 0
4 0,68 1 1 0,42 … 0 0 0 0
9 1 1 1 0,42 … 0 0 0 0
11 0,42 0,42 0,42 1 … 0 0 0 0
… … … … …
2 0 0 0 0 … 1 0,32 0,98 0,68
7 0 0 0 0 … 0,32 1 0,22 0,06
22 0 0 0 0 … 0,98 0,22 1 0,78
28 0 0 0 0 … 0,68 0,06 0,78 1
keterangan:
= instance tidak ada electron bebas pada ionosphere = instance ada electron bebas pada ionosphere = sample dengan nilai similarity function = 1
Hasil cluster-isasi didapat bahwa dalam John Hopkins University Ionosphere Dataset terdapat 174 sample termasuk dalam class kondisi baik, dan 126 sample termasuk dalam class kondisi baik.
3.6. Konfigurasi Support Vector Backpropagation
Setelah seluruh dataset di-cluster pada masing-masing class, maka langkah selanjutnya adalah merancang konfigurasi Support Vector Backpropagation yang di-setting secara unik pada masing-masing dataset, berikut disajikan konfigurasi Support Vector Backpropagation yang digunakan dalam penelitian ini:
1. Konfigurasi Support Vector Backpropagation pada Iris Plants Dataset
layer beserta property khusus yang digunakan Support Vector Backpropagation seperti yang dijelaskan dalam tabel berikut:
Tabel 3.14 Konfigurasi Support Vector Backpropagation Pada Iris Plants Dataset
x11 x12 x13 x14
x21 x22 x23 x24
x31 x32
SVM
Ouput
Gambar 3.1 Arsitektur Support Vector Backpropagation Pada Iris Plants Dataset
Backpropagation Segment
Input layer 4 neurons
Hidden layer 4 neurons
Output layer 2 neurons
Bobot layer pertama Matriks 4 baris x 5 kolom Bobot layer kedua Matriks 2 baris x 5 kolom Fungsi aktivasi Sigmoid biner
Learning rate 0.02
Tolerance function 1.0e-8 Fungsi minimisasi fmincg Support Vector Machine Segment
Fungsi kernel Radial Basis Function
2. Konfigurasi Support Vector Backpropagation pada Wisconsin Diagnostic Breast Cancer Dataset
Konfigurasi Support Vector Backpropagation pada Wisconsin Diagnostic Breast Cancer Dataset menggunakan jaringan syaraf tiruan dengan 9 buah neuron pada input layer dan 5 buah neuron pada hidden layer dan 2 buah neuron pada output layer beserta property khusus yang digunakan dalam Support Vector Backpropagation seperti yang dijelaskan pada tabel berikut:
Tabel 3.15 Konfigurasi Support Vector Backpropagation Pada Wisconsin Diagnostic Breast Cancer Dataset
Backpropagation Segment
Input layer 9 neurons
Hidden layer 5 neurons
Output layer 2 neurons
Bobot layer pertama Matriks 5 baris x 9 kolom Bobot layer kedua Matriks 2 baris x 6 kolom Fungsi aktivasi Sigmoid biner
Learning rate 0.02
Tolerance function 1.0e-8 Fungsi minimisasi fmincg Support Vector Machine Segment
Fungsi kernel Radial Basis Function
x11 x12 x13 x14
x21 x22 x23 x24
x31 x 3
2
SVM
Ouput
x15 x17 x18 x19
x25
...
Gambar 3.2 Arsitektur Support Vector Backpropagation Pada Wisconsin Diagnostic Breast Cancer Dataset
3. Konfigurasi Support Vector Backpropagation pada Cleveland Heart Disease Dataset
Tabel 3.16 Konfigurasi Support Vector Backpropagation Pada Cleveland Heart Disease Dataset
x11 x
Gambar 3.3 Arsitektur Support Vector Backpropagation Pada Cleveland Heart Disease Dataset
Backpropagation Segment
Input layer 13 neurons
Hidden layer 7 neurons
Output layer 2 neurons
Bobot layer pertama Matriks 7 baris x 14 kolom Bobot layer kedua Matriks 2 baris x 8 kolom Fungsi aktivasi Sigmoid biner
Learning rate 0.02
Tolerance function 1.0e-8 Fungsi minimisasi fmincg Support Vector Machine Segment
Fungsi kernel Radial Basis Function
4. Konfigurasi Support Vector Backpropagation pada John Hopkins University Ionosphere Dataset
Konfigurasi Support Vector Backpropagation pada John Hopkins University Ionosphere Dataset menggunakan jaringan syaraf tiruan dengan 34 buah neuron pada input layer, 17 neuron pada hidden layer, dan 2 buah neuron pada output layer beserta property khusus pada Support Vector Backpropagation seperti yang disajikan dalam tabel berikut:
Tabel 3.17 Konfigurasi Support Vector Backpropagation Pada John Hopkins University Ionosphere Dataset
Backpropagation Segment
Input layer 34 neurons
Hidden layer 17 neurons
Output layer 2 neurons
Bobot layer pertama Matriks 17 baris x 35 kolom Bobot layer kedua Matriks 2 baris x 18 kolom Fungsi aktivasi Sigmoid biner
Learning rate 0.02
Tolerance function 1.0e-8 Fungsi minimisasi fmincg Support Vector Machine Segment
Fungsi kernel Radial Basis Function
x11 x12 x13 x14
x21 x 2
2 x
2
3 x
2 4
x31 x32
SVM
Ouput
x15 x132 x133 x134
x25
...
x217 ...
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Pada bab ini akan dibahas hasil proses komputasi Support Vector Backpropagation yang dilakukan menggunakan program MATLAB R2010a. MATLAB R2010a merupakan software yang cocok dipakai sebagai alat komputasi yang melibatkan penggunaan matriks dan vector. Fungsi-fungsi dalam paket perangkat lunak (toolbox) Matlab R2010a dibuat untuk memudahkan perhitungan tersebut. Banyak model jaringan syaraf tiruan dan machine learning menggunakan manipulasi matriks atau vector dalam iterasinya. Oleh karena itu MATLAB R2010a merupakan perangkat lunak yang cocok dipakai dalam penelitian ini.
4.1. Proses Transformasi Iris Plants Dataset Oleh Support Vector Backpropagation
Tabel 4.1 Training Sample Iris Plants Dataset Sebelum Transformasi
Proses transformasi yang akan dilakukan pada seluruh sample pelatihan dalam Iris Plants Dataset seperti yang diwakili oleh proses transformasi pada sample tabel 4.1 diawali dengan penentuan bobot awal dengan nilai epsilon_init = 0,002 sesuai dengan persamaan (2.1), sehingga didapat bobot awal jaringan syaraf tiruan sebagai berikut:
Setelah didapat bobot awal jaringan syaraf tiruan maka dilakukan proses pembelajaran menggunakan feedforwardpropagation pada hidden layer seperti pada persamaan (2.2), didapat hasil sebagai berikut:
Selanjutnya nilai akan dicari nilai fungsi aktivasi-nya menggunkan sigmoid biner seperti pada persamaan (2.3), didapat hasil sebagai berikut:
sepal length sepal width petal length petal width Target
Selanjutnya nilai akan melewati proses fordwardpropagation pada output layer seperti pada persamaan (2.2), sehingga didapat hasil sebagai berikut:
Untuk kemudian didapatkan nilai fungsi aktivasi menggunakan fungsi sigmoid pada output layer seperti pada persamaan (2.3), sehingga didapat hasil sebagai berikut:
Karena a3 Target, maka langkah selanjutnya adalah menghitung nilai error pada output layer seperti pada secara backpropagation persamaan (2.6), sehingga didapat hasil sebagai berikut:
Kemudian backpropagation dilanjutkan menuju hidden layer seperti pada persamaan (2.7), sehingga didapat hasil:
Kemudian hitung nilai Thetagrad sesuai dengan persamaan (2.8) pada Theta1 dan
Theta2 sehingga didapat nilai Thetagrad sebagai berikut:
Setelah didapat nilai Thetagrad maka akan dilakukan penambahan bobot jaringan syaraf
tiruan dengan learning rate ( lambda ) = 0,02 seperti pada persamaan (2.8), sehingga didapat penambahan bobot-bobot awal sebagai berikut:
Kemudian dilakukan proses update bobot-bobot jaringan syaraf tiruan untuk mengetahui nilai Mean Square Error seperti pada persamaan (2.5), setelah dilakukan proses pelatihan sebanyak epochs = 30 didapat nilai Mean Square Error terkecil=1,3814 pada bobot optimal jaringan syaraf tiruan sebagai berikut:
Tabel 4.2 Sample Iris Plants Dataset Pada Tabel 4.1 Setelah Transformasi
Feature 1 Feature 2 Target 0,4946 0,5030 Iris Virginica
Tabel 4.3 Training Sample Iris Plants Dataset (a) Sebelum Transformasi (b) Sesudah Transformasi
sample# Sepal
Petal Width Target
1 5,1 3,5 1,4 0,2 Iris Setosa
Untuk kemudian diolah dalam komputer menggunakan MATLAB R2010a dalam perhitungan me-minimisasi nilai pada fungsi pada persamaan (2.12) untuk mendapatkan kesimpulan bahwa sample x termasuk dalam class yang dimiliki oleh ,. Berikut akan disajikan dalam tabel hasil dari seluruh perhitungan proses cluster :
Tabel 4.4 Cluster-isasi Pada Iris Plants Dataset Setelah Transformasi
sample# 1 6 … 51 60 … 120
1 1 0,98 … 0,03 0 … 0,01
6 0,98 1 … 0,02 0 … 0,01
… … … … …
51 0,03 0,02 … 1 0,73 … 0,96
60 0 0 … 0,73 1 … 0,87
… … … … …
120 0,01 0,01 … 0,96 0,87 … 1
keterangan:
= instance iris setosa
= instance iris versicolor atau iris virginica = sample dengan nilai similarity function = 1
Tabel 4.5 Perbandingan Tingkat Ketelitian Classifier Pada Iris Plants Dataset Sebelum Dan Sesudah Transformasi
# training
sample # test sample
akurasi (%)
sebelum transformasi sesudah transformasi
30 10 100% 100%
60 10 40% 50%
90 10 100% 90%
120 10 100% 90%
Berikut disajikan grafik perbandingan tingkat ketelitian classifier sebelum dan sesudah transformasi pada Iris Plants Dataset:
Gambar 4.1 Grafik Perbandingan Tingkat Ketelitian Classifier Iris Plants Dataset Sebelum Dan Sesudah Transformasi
(a) (b)
(c) (d)
Gambar 4.2 Grafis Hasil Cluster Pada Iris Plants Dataset Sesudah Transformasi (a) 30 Sample (b) 60 Sample (c) 90 Sample (d) 120 Sample
yang tidak ditransformasi ( memiliki 4 features ). Pada hasil percobaan (d) diperoleh tingkat ketelitian dalam melakukan cluster-isasi pada dataset yang telah ditransformasi ( hanya memiliki 2 features ) sebesar 90% sementara pada dataset yang tidak ditransformasi ( memiliki 4 features ) diperoleh tingkat ketelitian sebesar 100%, dalam hal ini tingkat ketelitian pada dataset yang telah ditransformasi ( hanya memiliki 2 features ) 10% lebih rendah daripada tingkat ketelitian pada dataset yang tidak ditransformasi ( memiliki 4 features ). Secara keseluruhan percobaan ini menghasilkan tingkat ketelitian yang cenderung sama antara cluster-isasi pada dataset yang telah ditransformasi ( hanya memiliki 2 features ) maupun pada dataset yang tidak ditransformasi ( memiliki 4 features ).
4.2. Proses Transformasi Wisconsin Diagnostic Breast Cancer Dataset Oleh Support Vector Backpropagation
Proses transformasi Wisconsin Diagnostic Breast Cancer Dataset yang memiliki 9 attributes menjadi sebuah dataset berdimensi rendah ( 2 dimensi ) mengharuskan proses transformasi memperhatikan persebaran data dalam dimensi ruang untuk menghindari overfitting penyebeb kegagalan proses cluster walaupun proses ini juga bergantung dari banyaknya sample pelatihan yang ditransformasi-kan namun diharapkan proses transformasi tetap dapat mempertahankan tingkat akurasi yang optimal, seperti proses transformasi sebuah sample pelatihan Wisconsin Diagnostic Breast Cancer yang dilakukan oleh Support Vector Backpropagation berikut ini:
Tabel 4.6 Training Sample Wisconsin Diagnostic Breast Cancer Dataset Sebelum Transformasi
rad text perim area smo comp concav conca sym Target
5 10 10 10 4 10 5 6 3 Benign
epsilon_init = 0,002 sesuai dengan persamaan (2.1), sehingga didapat bobot awal jaringan syaraf tiruan sebagai berikut:
Setelah didapat bobot awal jaringan syaraf tiruan maka dilakukan proses pembelajaran menggunakan feedforwardpropagation pada hidden layer seperti pada persamaan(2.2), didapat hasil sebagai berikut:
Selanjutnya nilai akan dicari nilai fungsi aktivasi-nya menggunkan sigmoid biner seperti pada persamaan (2.3), didapat hasil sebagai berikut:
Selanjutnya nilai akan melewati proses fordwardpropagation pada output layer seperti pada persamaan (2.2), sehingga didapat hasil sebagai berikut:
Karena a3 Target, maka langkah selanjutnya adalah menghitung nilai error pada output layer seperti pada secara backpropagation persamaan (2.6), sehingga didapat hasil sebagai berikut:
Kemudian backpropagation dilanjutkan menuju hidden layer seperti pada persamaan(2.7), sehingga didapat hasil:
Kemudian hitung nilai Thetagrad sesuai dengan persamaan (2.8) pada Theta1 dan
Theta2 sehingga didapat nilai Thetagrad sebagai berikut:
Setelah didapat nilai Thetagrad maka akan dilakukan penambahan bobot jaringan syaraf
Kemudian dilakukan proses update bobot-bobot jaringan syaraf tiruan untuk mengetahui nilai Mean Square Error seperti pada persamaan (2.5), setelah dilakukan proses pelatihan sebanyak epochs = 30 didapat nilai Mean Square Error terkecil=1,3864 pada bobot optimal jaringan syaraf tiruan sebagai berikut:
Dengan bobot optimal yang telah didapatakan maka kita dapat mentransformasikan sample pada tabel 4.6 dengan cara forwardpropagation seperti pada persamaan (2.2), sehingga didapat hasil transformasi sample pada tabel 4.1 sebagai berikut:
Tabel 4.7 Training Sample Wisconsin Diagnostic Breast Cancer Dataset Pada Tabel 4.6 Setelah Transformasi
Feature 1 Feature 2 Target 0,5002 0,5028 Benign
Tabel 4.8 Training Sample Wisconsin Diagnostic Breast Cancer Dataset (a) Sebelum Transformasi (b) Sesudah Transformasi
spl# rad text pe are smo com con conc sym Target
1 5 1 1 1 2 1 3 1 1 Malignant
… … … …
381 1 1 1 1 2 1 1 1 1 Malignant
… … … …
547 6 10 10 10 4 10 7 10 1 Benign
… … … …
671 3 10 7 8 5 8 7 4 1 Benign
(a)
sample# Feature 1 Feature 2 Target 1 0,5001 0,5023 Malignant
… … … …
381 0,5 0,5023 Malignant
… … … …
547 0,5003 0,5028 Benign
… … … …
671 0,5002 0,5027 Benign (b)
Setelah proses transformasi selesai dilakukan pada seluruh sample dalam Wisconsin Diagnostic Breast Cancer Dataset, selanjutnya akan melalui proses cluster seperti pada pada persamaan (2.10), sebagai berikut:
Untuk kemudian diolah dalam komputer menggunakan MATLAB R2010a dalam perhitungan me-minimisasi nilai pada fungsi pada persamaan (2.12) untuk mendapatkan kesimpulan bahwa sample x termasuk dalam class yang dimiliki oleh dan . Berikut akan disajikan dalam tabel hasil dari seluruh perhitungan proses cluster pada training sample dan landmark pada Wisconsin Diagnostic Breast Cancer Dataset yang telah ditransformasi:
Tabel 4.9 Cluster-isasi Pada Wisconsin Diagnostic Breast Cancer Dataset Setelah Transformasi
sample# 1 … 381 … 547 … 671
1 1 … 0,85 … 0 … 0
… … … … …
381 0,85 … 1 … 0 … 0
… … … … …
547 0 … 0 … 1 … 0,7
… … … … …
671 0 … 0 … 0,7 … 1
keterangan:
= instance Malignant = instance Benign
= sample dengan similarity function = 1
Tabel 4.10 Perbandingan Tingkat Ketelitian Classifier Pada Wisconsin Diagnostic Breast Cancer Dataset Sebelum Dan Sesudah Transformasi
# training
sample # test sample
akurasi (%)
sebelum transformasi sesudah transformasi
100 10 100% 100%
200 10 100% 0%
300 10 100% 0%
400 10 100% 0%
500 10 0% 0%
600 10 0% 0%
680 10 0% 0%
Berikut disajikan grafik perbandingan akurasi classifier sebelum dan sesudah transformasi pada Wisconsin Diagnostic Breast Cancer Dataset:
Pada gambar 4.4 berikut, disajikan visualisasi proses cluster mulai dari jumlah training sample paling sedikit yaitu 100 training sample sampai 680 training sample:
(a) (b)
(c) (d)
(e) (f)
(g)
Gambar 4.4 Grafis Hasil Cluster Pada Wisconsin Diagnostic Breast Cancer Dataset Sesudah Transformasi (a) 100 Sample (b) 200 Sample (c) 300 Sample
(d) 400 Sample (e) 500 Sample (f) 600 Sample (g) 680 Sample
dataset yang tidak ditransformasi ( memiliki 9 features ) diperoleh tingkat ketelitian sebesar 0%, dalam hal ini baik klasifikasi pada dataset yang telah ditransformasi (hanya memiliki 2 features ) maupun pada dataset yang tidak ditransformasi (memiliki 9 features ) sama-sama gagal dalam melakukan cluster-isasi pada Wisconsin Diagnostic Breast Cancer Dataset. Terlihat pada hasil yang disajikan dalam tabel 4.10 bahwa transformasi yang dilakukan pada Wisconsin Diagnostic Breast Cancer Dataset menghasilkan classifier dengan performa optimal 100% hanya pada classifier dengan 100 training sample namun classifier yang menggunakan dataset hasil transformasi sama sekali gagal dikarenakan kondisi overfitting dalam melakukan classification pada jumlah training sample 200 sampai 680 sample, sementara classifier yang menggunakan dataset yang tidak ditransformasi masih tetap mencapai akurasi 100% pada jumlah training sample dari 100 sampai 400 sample namun tetap mengalami kondisi overfitting pada jumlah training sample 500 sampai 680 sample. Kegagalan Support Vector Backpropagation dalam melakukan classification dikarenakan persebaran ( sparness ) training sample dalam feature space menjadi sangat padat mengakibatkan semua training sample yang ada dalam feature space mulai bercampur dan menyatu antar cluster mengakibatkan tidak mungkin ditemukan garis pemisah (decision boundary ) pada masing-masing class.
4.3. Proses Transformasi Cleveland Heart Disease Dataset Oleh Support Vector Backpropagation
Tabel 4.11 Training Sample Cleveland Heart Disease Dataset Sebelum Transformasi
age sex cp trest chol fbs restecg
45 1 1 110 264 0 0
thala exang oldpeak slope ca thal Target
132 0 1,2 2 0 7 Positif Sakit Jantung
Proses transformasi yang akan dilakukan pada seluruh sample pelatihan dalam Cleveland Heart Disease Dataset seperti yang diwakili oleh proses transformasi pada sample tabel 4.11 diawali dengan penentuan bobot awal dengan nilai epsiloninit=0,002
sesuai dengan persamaan (2.1), sehingga didapat bobot awal jaringan syaraf tiruan sebagai berikut:
Selanjutnya nilai akan dicari nilai fungsi aktivasi-nya menggunkan sigmoid biner seperti pada persamaan (2.3), didapat hasil sebagai berikut:
Selanjutnya nilai akan melewati proses fordwardpropagation pada output layer seperti pada persamaan (2.2), sehingga didapat hasil sebagai berikut:
Untuk kemudian didapatkan nilai fungsi aktivasi menggunakan fungsi sigmoid pada output layer seperti pada persamaan (2.3), sehingga didapat hasil sebagai berikut:
Karena a3 Target, maka langkah selanjutnya adalah menghitung nilai error pada output layer seperti pada secara backpropagation persamaan (2.6), sehingga didapat hasil sebagai berikut:
Kemudian hitung nilai Thetagrad sesuai dengan persamaan (2.8) pada Theta1 dan
Theta2 sehingga didapat nilai Thetagrad sebagai berikut:
Setelah didapat nilai Thetagrad maka akan dilakukan penambahan bobot jaringan syaraf
tiruan dengan learning rate ( lambda ) = 0,02 seperti pada persamaan (2.8), sehingga didapat penambahan bobot-bobot awal sebagai berikut:
Dengan bobot optimal yang telah didapatakan maka kita dapat mentransformasikan sample pada tabel 4.1 dengan cara forwardpropagation seperti pada persamaan (2.2), sehingga didapat hasil transformasi sample pada tabel 4.12 sebagai berikut:
Tabel 4.12 Training Sample Cleveland Heart Disease Dataset Pada Tabel 4.11 Setelah Transformasi
Feature 1 Feature 2 Target
0,5014 0,4983 Positif Sakit Jantung