Sistem Rekomendasi Berdasarkan Minat dan Perilaku Menggunakan Algoritma ApprioriTid (Studi Kasus Galeri Wallpaper)
Teks penuh
Gambar




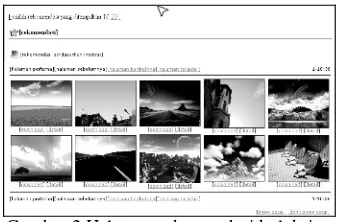
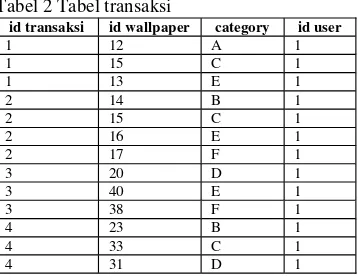
Dokumen terkait
Abstract — Sistem Rekomendasi merupakan aplikasi pemberi rekomendasi berupa informasi yang dibutuhkan oleh pengguna berdasarkan feedback dari pengguna lain.
Pada halaman sistem rekomendasi, pengguna dapat melakukan input bobot kriteria dan meminta hasil rekomendasi dimana akan dilakukan proses hitung rekomendasi dari hasil
Abstract — Sistem Rekomendasi merupakan aplikasi pemberi rekomendasi berupa informasi yang dibutuhkan oleh pengguna berdasarkan feedback dari pengguna lain.
Penelitian ini memiliki tujuan untuk merancang dan membangun sistem rekomendasi properti dengan menggunakan metode TOPSIS dan mengukur kepuasan pengguna
Pada sistem rekomendasi musik ini, hasil pencarian sistem menampilkan lagu/artis yang sering didengar oleh pengguna dilanjutkan dengan lagu/artis yang disarankan
Gambar 2 menjelaskan mengenai proses pengolahan data yang dilakukan oleh sistem hingga menghasilkan rekomendasi portofolio bagi investor.Dari gambar 2 tersebut,
Sistem Rekomendasi Berbasis Web Sistem rekomendasi sampiran berbasis web dibangun dengan dua fitur utama, yaitu: a fitur “Buat Pantun” yang memudahkan pengguna membuat pantun hanya
49 BAB V KESIMPULAN DAN SARAN 5.1 Kesimpulan Penelitian yang dilakukan pada sistem rekomendasi menu makanan menggunakan algoritma apriori pada martabak badoet dapat disimpulkan
