SISTEM REKOMENDASI BERDASARKAN MINAT DAN PERILAKU
PENGGUNA DENGAN MENGGUNAKAN ALGORITMA APPRIORITID
(STUDI KASUS GALERI WALLPAPER)
Oleh:
FAVORISEN ROSYKING LUMBANRAJA
G64101028
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
FAVORISEN ROSYKING LUMBANRAJA. Sistem Rekomendasi Berdasarkan Minat dan Perilaku Menggunakan Algoritma ApprioriTid (Studi Kasus Galeri Wallpaper). Dibimbing oleh PANJI WASMANA dan FIRMAN ARDIANSYAH.
Internet saat ini menjadi sumber informasi yang dapat diakses semua orang. Situs-situs web yang ada di dalam Internet menyediakan berbagai macam informasi kepada penggunanya. Namun dengan banyaknya informasi yang disediakan, terkadang pengguna sering menghabiskan waktu hanya untuk mencari informasi yang diinginkan. Hal ini yang menyebabkan pengguna merasa kurang nyaman dalam proses menjelajahi (browsing) sebuah situs web.
Penelitian ini mengacu pada penelitian yang telah dilakukan oleh Yong (Tsing Hua University, Taiwan) pada tahun 2001. Penelitian ini bertujuan memberikan personalisasi rekomendasi berdasarkan minat dan perilaku pengguna yang diperoleh dari data transaksi pengguna dengan studi kasus adalah koleksi walllpaper. Rekomendasi yang dihasilkan adalah koleksi yang berasal dari pengguna lain yang memiliki minat dan perilaku yang sama dan berada di dalam satu cluster yang sama pula. Proses rekomendasi dibagi menjadi lima proses, yaitu pencatatan transaksi, penentuan profil minat dan profil perilaku, pembentukan matriks vektor, clustering matriks vektor dan rekomendasi koleksi.
Penelitian dilakukan dengan menggunakan pendekatan linear sequential model yang meliputi tahap analisis, desain, pengkodean dan pengujian. Sistem Rekomendasi dibagi menjadi satu fungsi utama dan empat fungsi sistem. Keempat fungsi sistem adalah fungsi input_interest_behavior, fungsi create_vector, fungsi cluster_vekctor dan fungsi recommendation. Kompleksitas waktu algoritma sistem ini adalah O(2n2). Pada sistem ini, nilai threshold α mempengaruhi penentuan profil minat, nilai threshold β mempengaruhi penentuan profil perilaku, serta threshold δ mempengaruhi jumlah cluster yang terbentuk dan jumlah anggota cluster.
SISTEM REKOMENDASI BERDASARKAN MINAT DAN PERILAKU
PENGGUNA DENGAN MENGGUNAKAN ALGORITMA APPRIORITID
(STUDI KASUS GALERI WALLPAPER)
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh:
FAVORISEN ROSYKING LUMBANRAJA
G64101028
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul
: Sistem Rekomendasi Berdasarkan Minat dan Perilaku
Pengguna dengan Menggunakan Algoritma ApprioriTid
(Studi Kasus Galeri Wallpaper)
Nama
: Favorisen Rosyking Lumbanraja
NRP
: G64101028
Menyetujui:
Pembimbing I,
Panji Wasmana, S.Kom, M.Si
NIP.132 311 917
Pembimbing II,
Firman Ardiansyah, S.Kom, M.Si
NIP.132 311 919
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, M.S
NIP. 131 473 999
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa yang telah melimpahkan kasih dan karunia-Nya sehingga penulis dapat menyelesaikan laporan skripsi yang merupakan salah satu syarat kelulusan program sarjana pada Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Penulis mengucapkan terima kasih kepada Bapak Panji Wasmana, S.Kom, M.Si selaku pembimbing I yang telah banyak membantu dan membimbing penulis selama proses penelitian dan penyusunan skipsi ini. Penulis juga mengucapkan terima kasih kepada Bapak Firman Ardiansyah, S.Kom, M.Si selaku pembimbing II yang telah banyak memberi saran, masukan dan ide-ide kepada penulis. Terima kasih juga penulis ucapkan kepada Bapak Irman Hermadi, S.Kom, M.S selaku penguji yang telah banyak memberi saran dan masukan kepada penulis. Penulis juga mengucapkan terima kasih kepada:
1. Daddy dan Mommy yang selalu memberikan kasih sayang, semangat, doa dan nasihat tiada henti selama penulis melaksanakan studi di Institut Pertanian Bogor. Adik-adik penulis: Dede Anggita yang selalu memberikan keceriaan dan semangat, dan Eva yang tidak pernah bosan memberikan perhatian, dukungan dan bantuan setiap saat dibutuhkan.
2. Arief yang memberikan motivasi dan bantuan kepada penulis untuk mengerjakan tugas akhir. 3. Robi, Ifnu, Liesca, Abi, Nawi dan teman-teman mahasiswa ’kadal’ Lab.02 yang selalu
menemani dan memberi semangat selama penulis mengerjakan tugas akhir. 4. Teman-teman kos; Capello, Satria, Dwi, Om Asep dan Bung Tedoy.
5. Kawan-kawan ILKOM angkatan 38 yang telah membantu penulis selama menjalani waktu di IPB.
6. Departemen Ilmu Komputer, staf dan dosen yang telah banyak membantu selama masa kuliah dan selama penelitian.
Kepada semua pihak lainnya yang telah memberikan kontribusi yang besar selama pengerjaan penelitian ini yang tidak dapat disebutkan satu-persatu, penulis ucapkan terima kasih banyak.
Semoga penelitian ini dapat memberikan manfaat.
Bogor, Juli 2007
RIWAYAT HIDUP
Penulis dilahirkan di Bandar Lampung pada tanggal 10 Januari 1983 dari pasangan J. Lumbanraja dan Rosma Hasibuan. Penulis merupakan anak pertama dari tiga bersaudara.
Tahun 2001 penulis lulus dari SMU Negeri 2 Bandar Lampung dan pada tahun yang sama lulus seleksi masuk IPB melalui jalur Undangan Saringan Masuk IPB (USMI). Penulis memilih Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam IPB.
Selama mengikuti perkuliahan, penulis aktif di organisasi kemahasiswaan Ilmu Komputer (HIMALKOM) menjabat anggota Research and Development (RnD) periode 2003-2004 dan periode 2004-2005. Pada tahun 2005 penulis melakukan kegiatan praktik lapang di Balai Penelitian Bioteknologi Perkebunan Indonesia selama kurang lebih dua bulan.
DAFTAR ISI
Halaman
DAFTAR TABEL...vii
DAFTAR GAMBAR ...vii
PENDAHULUAN...1 Latar Belakang ...1 Tujuan...1 Ruang Lingkup ...1 Manfaat...1 TINJAUAN PUSTAKA...1
Association Mining Rule...1
Personalisasi Rekomendasi ...2
Profil Minat (Interest Profile) ...3
Profil Perilaku (Behavior Profile) ...3
Dynamic Clustering...3 Euclidean Distance...3 Web mining...3 METODE PENELITIAN ...4 Analisis...4 Desain...4 Pengkodean (Code) ...4 Pengujian (Test)...4 Pemeliharaan (Support) ...5
HASIL DAN PEMBAHASAN ...5
Rancangan Arsitektur ...5
Pembuatan Algoritma...5
Analisis Kompleksitas Waktu Algoritma ...8
Implementasi Sistem ...8
Rancangan Pengujian ...8
Hasil Pengujian...9
KESIMPULAN DAN SARAN ... 10
Kesimpulan... 10
Saran... 10
DAFTAR TABEL
Halaman 1 Notasi Algoritma ... 1 2 Tabel transaksi... 6 3 Tabel interest ... 6 4 Tabel behavior... 7 5 Koleksi wallpaper ... 96 Jumlah koleksi wallpaper yang diunduh ... 9
7 Hasil proses clustering dengan menggunakan nilai δ yang berbeda... 10
8 Tabel hit ratio berdasarkan nilai δ ... 10
DAFTAR GAMBAR
Halaman 1 Halaman koleksi wallpaper ... 52 Halaman rekomendasi koleksi wallpaper... 5
3 Arsitektur Sistem Rekomendasi (Yong 2001) ... 5
1
PENDAHULUAN
Latar Belakang
Saat ini perkembangan dan kemajuan teknologi informasi berbasis jaringan, khususnya teknologi pada jaringan Internet berlangsung dengan pesat. Berkat teknologi informasi Internet, hampir seluruh pengguna di dunia dapat mengakses informasi yang ada di dalam Internet.
Situs-situs web yang ada di dalam Internet pun mengalami perkembangan yang pesat. Informasi dan konten yang ada di dalam situs web pun semakin banyak dan beragam.
Dengan semakin banyak dan beragamnya informasi dan konten yang disediakan oleh sebuah situs web, semakin banyak waktu yang diperlukan oleh pengguna/pengunjung untuk menjelajahi (browse) seluruh isi konten yang ada di dalam situs web. Hal ini membuat pengguna merasa kurang nyaman dalam menjelajahi isi konten sebuah situs web untuk mencari informasi atau konten yang diinginkan pengguna situs web.
Oleh karena itu, diperlukan aplikasi yang dapat membantu pengunjung sebuah situs web untuk mencari konten yang sesuai dengan keinginan pengguna. Penelitian ini berusaha membantu pengguna dalam mencari konten di dalam sebuah web dengan memberikan rekomendasi konten yang cocok dengan profil pengguna.
Di dalam sebuah situs web, informasi dan konten yang diminta (request) oleh pengguna umumnya tercatat dalam browsing history. Oleh karena itu, browsing history dapat dijadikan sumber untuk mengetahui pola minat dan perilaku pengguna situs web.
Tujuan
Tujuan penelitian adalah mengembangkan sistem yang dapat memberikan rekomendasi kepada pengguna berdasarkan profil minat dan perilaku pengguna yang diambil dari data transaksi yang dilakukan oleh penggguna dalam mengakses isi informasi yang ada dalam situs web.
Ruang Lingkup
Ruang lingkup yang diteliti adalah personalisasi rekomendasi koleksi berdasarkan profil minat dan perilaku pengguna (dengan studi kasus rekomendasi koleksi wallpaper) . Koleksi-koleksi yang direkomendasikan oleh sistem adalah koleksi-koleksi yang belum diunduh oleh pengguna. Penelitian dilakukan dengan mengacu pada penelitian yang dilakukan oleh Yong (2001).
Manfaat
Hasil penelitian ini diharapkan dapat mempermudah pengguna dalam menjelajahi (browsing) isi dan informasi yang ada di dalam sebuah situs web sesuai dengan keinginan pengguna.
TINJAUAN PUSTAKA
Association Mining Rule
Jika I={i1,i2,...,im} adalah himpunan entitas
yang disebut Item. Andaikan D adalah himpunan transaksi T, di mana setiap transaksi T adalah himpunan Item di mana TI. Sebuah Identifier (pengenal) yang unik yang disebut TID, digunakan untuk mengasosiasikan setiap transaksi. Kita katakan sebuah transaksi T terdapat X, sebuah himpunan yang terdiri dari beberapa item di dalam I, jika XT. Sebuah Association Rule (aturan asosiasi) adalah sebuah implikasi dari
Y
X , di mana X I,
I
Y danXY=Ø. Aturan X Y berlaku di dalam himpunan transaksi D dengan keyakinan (confidence) c jika c% transaksi di dalam D terdapat X juga terdapat Y. Aturan
Y
X memiliki nilai support s di dalam himpunan transaksi D jika s% di dalam himpunan transaksi D terdapat
Y
X (Agrawal 1994).
Jika ada himpunan transaksi D, masalah di dalam xzAssociation Mining Rule adalah bagaimana menghasilkan aturan asosisasi yang memiliki nilai support dan nilai keyakinan (confidence) yang lebih besar daripada nilai minimum support dan nilai minimum keyakinan (confidence) yang telah ditentukan.
Algortima yang menggunakan teknik Association Mining Rule (Agrawal 1994), antara lain:
a. Algoritma Appriori
Pada Tabel 1 dapat dilihat notasi yang digunakan pada algoritma yang menggunakan teknik Association Mining Rule.
Tabel 1 Notasi Algoritma
Item k Himpunan item yang memilki item k.
k
L
Himpunan large k-items (dengan nilai minimum support) Setiap anggota himpunan memiliki dua field, yaitu itemset dan support count.k
C
Himpunan kandidat k-items (himpunan item dengan jumlah yang besar).2
Item k Himpunan item yang memilki item k.
Setiap anggota himpunan memiliki dua field, yaitu itemset dan support count.
k
C
Himpunan kandidat k-items dimana TID yang dihasilkan transaksi disimpan dan diasosiasikan dengan para kandidiatPada Algoritma Appriori seperti yang tampak pada kode sumber di bawah, terjadi pemanggilan fungsi Appriori-gen yang merupakan fungsi algoritma Appriori Candidate Generation. 1) L1={large 1-itemset}; 2) for (k=2;Lk-1=Ø;k++) do begin 3) Ck=Appriori-gen(Lk-1); //Kandidat baru 4) forall transaction t
D do begin 5) Ct=subset(Ck,t); //kandidat yang terdapat pada t6) forall candidates c
Ct do 7) c.count++; 8) end 9) Lk={ c
Ck | c.count≥minsup} 10) end 11) Answer=
kL
k;Algoritma Appriori Candidate Generation Dalam alogritma Appriori diperlukan sebuah algoritma yang mengambil input Lk-1,
di dalam himpunan large (k-1) itemset dan menghasilkan himpunan superset yang terdiri dari semua himpunan large (k-1) itemset. Seperti yang tampak pada kode sumber di bawah.
1) Insert into Ck
2) select p.item1,p.item2,…,p.item k-1,q.itemk-1
3) from Lk-1p,Lk-1 q
4) where p.item1=q.item1,…,p.item k-2=q.itemk-2 ,p.itemk-1<q.itemk-1;
5) forall itemset c
Ckdo 6) forall (k-1) subset s of c do 7) If (s
L) then 8) delete c form Ck; 9) end 10) end 11) end b. Algoritma ApprioriTidPada Algoritma ApprioriTid seperti yang tampak pada kode sumber di bawah, juga terjadi pemanggilan fungsi appriori-gen yang merupakan fungsi algoritma Appriori Candidate Generation. 1) L1={large 1-itemset};. 2) C1=Database D; 3) for (k=2;Lk-1=Ø;k++) do begin 4)
C
k=Appriori-gen(Lk-1); //Kandidat baru 5)C
k=Ø; 6) forall entries t
C
k1do begin //untuk menentukan himpunan itemset di dalam Ck terdapat pada transaksi dengan identfier t.TD 7) Ct={ c
Ck |(c-c[k])
t.set-of-itemsets ^ (c-c[k-1])
t.set-of-itemsets }; 8) forall candidates c
Ct do 9) c.count++; 10) end 11) Lk={ c
Ck | c.count≥minsup} 12) end 13) Answer=
kL
k;Selain dua algortima di atas ada juga algoritma hasil modifikasinya, yaitu:
c. Algoritma Incremental mining
Algoritma ini merupakan modifikasi dari Algoritma Appriori dan Algoritma ApprioriTid yang dikembangkan oleh Yong (2001). Di mana tujuan algoritma ini adalah menentukan profil pengguna di dalam tabel Interest dan tabel Behavior.
Personalisasi Rekomendasi
Dalam menentukan rekomendasi yang akan diberikan kepada pengguna, ada dua pendekatan yang umum digunakan dalam personalisasi rekomendasi (Balabanovic 1997) yaitu:
a. Content-Based Recommendation
Pendekatan yang digunakan dalam content-based untuk menghasilkan rekomendasi berasal dari teknik temu kembali informasi. Teks dokumen direkomendasi berdasarkan perbandingan antara isi dokumen dengan profil pengguna. Rekomendasi yang akan dihasilkan berdasarkan tingkat kesesuaian isi konten suatu dokumen dengan isi konten dokumen-dokumen yang pernah diunduh oleh pengguna sebelumnya.
Ada dua kelemahan yang terdapat di dalam pendekatan content-based. Kelemahan pertama adalah bahwa sistem ini umumnya hanya dapat digunakan untuk item yang berisi teks. Untuk item yang berisikan media yang lain yang tidak menggunakan teks seperti film dan musik, pendekatan content-based tidak dapat digunakan.
3
Kelemahan yang kedua adalah sistem hanya dapat merekomendasikan item yang memiliki nilai tinggi terhadap profil pengguna, pengguna hanya dapat melihat rekomendasi item yang mirip dengan yang telah dilihat sebelumnya. Jika jumlah pengguna yang ada jauh lebih sedikit dengan volume informasi yang ada (karena ada perubahan dalam jumlah yang besar atau terlalu cepat di dalam basis data) maka akan menghasilkan rekomendasi yang terlalu luas.
b. Collaborative Recommendation
Pendekatan Collaborative Recommendation berbeda dengan Content-Based. Pendekatan Collaborative Recommendation tidak merekomendasi item yang karena kemiripan item yang diminati pengguna pada masa lalu, tetapi merekomendasikan item yang diminati pengguna yang lain.
Pendekatan inipun memiliki kelemahan. Kelemahan yang pertama adalah, jika terdapat item yang baru di dalam basis data maka tidak dapat langsung direkomendasikan sampai ada pengguna lain berminat terhadap item tersebut.
Masalah yang kedua yang dihadapi adalah jika terdapat pengguna yang memiliki selera yang berbeda (tidak lazim), maka tidak ada pengguna yang lain yang bisa dikatakan mirip dengan pengguna tersebut, sehingga tidak dapat menghasilkan suatu rekomendasi (poor recommendation)
Profil Minat (Interest Profile)
Jika support (c) didefinisikan sebagai support atas kategori c. Kemudian, jika diberikan sebuah threshold α, maka Interest Profile (I) pengguna didefinisikan sebagai berikut:
I={c| Support (c)≥ α } ...(1) Jika count (c) didefinisikan sebagai jumlah kemunculan kategori c dalam data transaksi suatu pengguna. Kemudian, jika first (c) adalah kemunculan yang pertama kategori c di dalam himpunan transaksi pengguna. Serta jika diberikan himpunan transaksi pengguna dengan sebanyak T transaksi, maka tingkat minat pengguna terhadap kategori c (support (c)) didefinisikan sebagai berikut:
1 first(c) T count(c) Support(c) ...(2)
Profil Perilaku (Behavior Profile)
Jika support[c,d] didefinisikan sebagai support atas 2-category set [c,d]. Kemudian, jika diberikan threshold β, maka Behavior Profile (B) pengguna didefinisikan sebagai berikut:
B= {[c,d]| Support [c,d]≥ β }……….……..(3) Jika count [c,d] didefinisikan sebagai jumlah kemunculan 2-set category [c,d] dalam data transaksi suatu pengguna. Kemudian, jika first [c,d] adalah kemunculan yang pertama 2-set category [c,d] di dalam himpunan transaksi pengguna. Serta jika diberikan himpunan transaksi pengguna sebanyak T transaksi, maka tingkat perilaku pengguna terhadap kategori c dan d (support [c,d]) didefinisikan sebagai berikut: 1 d] first[c, T d] count[c, d] Support[c, ....(4) Dynamic Clustering
Dynamic Clustering dikembangkan oleh Yong (2001), di mana digunakan jarak Euclidean untuk mengukur jarak masing-masing matriks vektor. Berikut ini algoritma Dynamic Clustering:
1) forall vector matrix do 2) if cluster=Ø then 3) create new cluster; 4) centroid=vector matrix; 5) end
6) else
7) if minimal distance ≤ δ then 8) put vector matrix into cluster
with shortest distance;
9) update centroid considering the vector matrix;
10) end
11) else
12) create new cluster; 13) centroid=vektor matriks;
14) end
15) end 16) End
Euclidean distance
Jika A dan B merupakan sebuah matriks vektor, serta Ai dan Bi merupakan elemen ke-i
dari vektor A dan vektor B, maka jarak Euclidean vektor A dengan vektor B dirumuskan sebagai berikut:
n 1 i 2 i B i A B) , Distance(A ………...(5) Web MiningWeb mining adalah proses menggali dan menemukan suatu informasi (knowledge) menggunakan teknik data mining terhadap
4
dokumen, layanan, dan data pada World Wide Web (Etzoni 1996). Web mining merupakan bagian dari proses data mining yang khusus dilakukan pada sebuah situs web.
Klasifikasi web mining dapat dibagi dalam tiga kategori (Huysmans et al. 2004), yaitu:
a. Web content mining
Web content mining adalah penggalian informasi dari konten/informasi dan dokumen web untuk membantu pengunjung menemukan informasi yang diinginkannya. b. Web structure mining
Web structure mining adalah ekstraksi informasi struktur link situs web untuk mengelompokkan interkoneksi dokumen web sehingga memudahkan pencarian informasi dari situs web lain.
c. Web usage mining
Web usage mining adalah aplikasi teknik data mining untuk mengetahui pola akses pengunjung terhadap suatu situs web. Pola akses ini diolah dari data sekunder yang menyimpan aktivitas pengunjung seperti data log server, log proxy, log browser, session, cookies, dan sebagainya.
METODOLOGI
Metodologi yang digunakan dalam penelitian ini mengikuti dan mengadaptasi semua tahapan pengembangan sistem sesuai linear sequential model seperti berikut : 1. Analisis
Pada tahapan ini akan dilakukan proses analisis mengenai permasalahan yang berhubungan dengan kebutuhan sistem. Hasil analisis yang didapat adalah:
a. Sistem harus dapat menampilkan semua koleksi wallpaper dan informasi yang berkaitan dengan walllpaper tersebut yang ada dalam basis data.
b. Sistem harus dapat mencatat setiap kali pengguna mengunduh sebuah koleksi wallpaper.
c. Sistem harus dapat menghitung dan menentukan profil minat dan profil perilaku setiap pengguna berdasarkan data transaksi wallpaper yang telah diunduh. d. Sistem harus dapat membentuk matriks
vektor setiap pengguna berdasarkan profil pengguna pengguna.
e. Sistem harus dapat mengelompokkan setiap pengguna ke dalam cluster berdasarkan jarak masing-masing vektor matriks setiap pengguna.
f. Sistem harus dapat memberikan rekomendasi koleksi wallpaper yang
belum diunduh kepada pengguna dari koleksi yang sudah diunduh pengguna lain yang memiliki minat dan perilaku yang mirip dengan pengguna di dalam kelompok cluster sama.
2. Desain
Hal-hal yang akan dilakukan dan diperoleh dalam tahap ini adalah :
a. Membuat basis data yang akan berisikan informasi-informasi yang berkaitan dengan koleksi wallpaper.
b. Membuat algoritma pencatatan yang akan mencatat setiap kali pengguna mengunduh koleksi wallpaper.
c. Membuat algoritma yang akan menghitung dan menentukan profil minat dan profil perilaku setiap pengguna berdasarkan data transaksi yang telah tercatat sebelumnya. d. Membuat algoritma yang dapat
menghasilkan matriks vektor pengguna berdasarkan profil minat dan profil perilaku setiap pengguna.
e. Membuat algoritma clustering dengan menggunakan Euclidean Distance untuk mengelompokkan penguna berdasarkan jarak masing-masing vektor matriks pengguna.
f. Membuat algoritma yang dapat memberikan rekomendasi koleksi yang belum diunduh berdasarkan koleksi yang sudah diunduh pengguna lain yang memilik profil minat dan perilaku yang sama dengan pengguna di dalam satu cluster pengguna.
g. Membuat desain antarmuka pengguna yang dapat menampilkan wallpaper yang ada di dalam basis data dan informasi-informasi yang lain berkaitan dengan wallpaper tersebut serta dapat menampilkan rekomendasi koleksi untuk masing-masing pengguna.
3. Pengkodean (Code)
Pada tahap ini akan dilakukan proses implementasi pengkodean program sesuai analisis dan perancangan yang sudah dilakukan.
4. Pengujian (Test)
Pada tahap ini dilakukan proses pengujian dan percobaan terhadap terhadap sistem sesuai dengan spesifikasi yang ditentukan sebelumnya.
Faktor yang digunakan dalam percobaan adalah nilai-nilai threshold yang digunakan dalam proses perhitungan.
Hal-hal yang akan diamati selama dilakukan proses pengujian terhadap sistem yang dikembangkan:
5
b. Penentuan profil minat dan perilaku pengguna.
c. Tingkat kesesuain rekomendasi dengan yang diharapkan oleh pengguna.
5. Pemeliharaan (Support)
Tahap ini tidak dilakukan dalam penelitian ini.
HASIL DAN PEMBAHASAN
Rancangan Arsitektur
Sebelum sistem ini dijalankan, informasi-informasi yang berkaitan dengan koleksi wallpaper dikumpulkan untuk membentuk index database. Setelah itu, browsing interface akan membantu penguna melihat isi koleksi wallpaper dan informasi-informasi yang berkaitan dengan wallpaper tersebut berdasarkan kategori wallpaper. Seperti yang tampak pada Gambar 1.
Gambar 1 Halaman koleksi wallpaper.
Jika pengguna mengunduh sebuah koleksi wallpaper, sistem akan mencatat dan menyampaikan kategori dan identitas wallpaper tersebut ke dalam profile manager. Di dalam profile manager, sistem akan menentukan profil minat dan profil perilaku setiap pengguna berdasarkan data transaksi koleksi yang telah diunduh oleh pengguna. Pada User Cluster, akan dibentuk matriks vektor pengguna berdasarkan profil pengguna. Kemudian setiap pengguna akan dikelompokkan berdasarkan jarak masing-masing matriks vektor yang telah terbentuk sebelumnya dengan menggunakan jarak Euclidean.
Setiap kali pengguna meminta (request) rekomendasi, recommendation provider akan menampilkan rekomendasi koleksi-koleksi wallpaper yang belum pernah diunduh oleh pengguna tersebut dan berasal dari koleksi-koleksi wallpaper yang pernah diunduh pengguna-pengguna lain yang memiliki profil minat dan profil perilaku yang sama di dalam
kelompok cluster yang sama. Halaman rekomendasi tampak seperti pada Gambar 2.
Gambar 2 Halaman rekomendasi koleksi wallpaper.
Arsitektur sistem rekomendasi dapat dilihat pada Gambar 3. Index Database Recommendation Provider User Cluster user
Gambar 3 Arsitektur sistem rekomendasi (Yong 2001).
Pembuatan Algoritma
Sesuai dengan arsitektur yang telah ditentukan, maka sistem rekomendasi akan dibagi menjadi satu sistem utama dan empat fungsi sistem.
1. Sistem utama
Seperti yang tampak pada kode sumber di bawah, pada sistem utama pengguna yang baru akan dibuatkan tabel minat dan perilaku. Kemudian semua koleksi wallpaper akan ditampilkan berdasarkan kategori. Jika pengguna mengunduh sebuah koleksi wallpaper, maka identitas pengguna, identitas wallpaper dan kategori wallpaper akan dicatat pada tabel transaksi. Jika pengguna meminta rekomendasi, maka sistem akan menjalankan fungsi recommendation. Jika pengguna keluar dari sistem (logout), maka sistem akan menjalankan fungsi input_interest_behavior, fungsi create_vector dan fungsi cluster_vector.
6
1) Login user=ui;
2) if user=new user then
3) create table interest(user u);
4) create table behavior(user u);
5) end
6) show wallpaper order by kategories
7) if user downloads a wallpaper then
8) input id wallpaper,category wallpaper, id user to transaction table;
9) end
10) if user requests recommendation then
11) recommendation(user ui);
12) end
13) if user logout then
14) input_interest_behavior(user ui); 15) create_vector(user ui); 16) cluster_vector(); 17) end 2. Fungsi sistem
Terdapat empat fungsi sistem yang dijalankan di dalam sistem utama, yaitu:
a. Fungsi input_interest_behavior
Pada fungsi ini seperti yang tampak pada kode sumber di bawah, sistem akan menentukan profil minat dan profil perilaku pengguna berdasarkan kategori koleksi-koleksi wallpaper yang telah diunduh oleh pengguna sebelumnya.
1) forall transaction where user=ui do
2) forall category in
transaction where user= ui do
3) input first appearance
category to field first in interest table;
4) input last appeareance
category to field last in interest table;
5) input number of appeareance
category for each transaction to count in interest table;
6) if(count>γ) then 7) support interest= count/(Number of Transactions-first+1); 8) end 9) end
10) forall 2-set category in transaction where user= ui do
11) input first appearance
2-set category to field first in behavior tabel;
12) input last appeareance
2-set category to field last in behavior table;
13) input number of appeareance
2-set category for each
transaction to count in behavior table; 14) if (count>γ) then 15) support behavior= count/(number of transactions-first+1 16) end 17) end 18) end
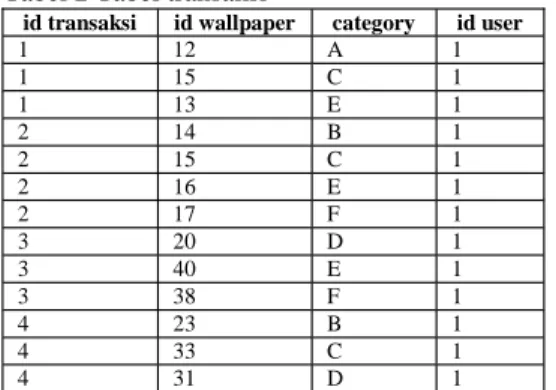
Untuk menjelaskan kode sumber di atas, akan dicontohkan suatu transaksi yang dilakukan oleh seorang pengguna seperti yang tampak pada Tabel 2.
Tabel 2 Tabel transaksi
id transaksi id wallpaper category id user
1 12 A 1 1 15 C 1 1 13 E 1 2 14 B 1 2 15 C 1 2 16 E 1 2 17 F 1 3 20 D 1 3 40 E 1 3 38 F 1 4 23 B 1 4 33 C 1 4 31 D 1
Tabel transaksi di atas memiliki empat field, yaitu id transaksi, id wallpaper, category dan id user. id transaksi merupakan identitas transaksi selama pengguna login,id wallpaper adalah identitas wallpaper yang diunduh, category adalah kategori wallpaper yang diunduh, sertaid user adalah identitas pengguna yang mengunduh wallpaper.
Fungsi input_interest_behavior akan mengisi tabel interest dan tabel behavior dari data yang ada pada Tabel 2 yang merupakan tabel transaksi.
Tabel 3 Tabel interest
Category First last count Support
A 1 1 1 N/A B 2 4 2 67% C 1 4 3 75% D 3 4 2 100% E 1 3 3 75% F 2 3 2 67%
Tabel interest di atas memiliki lima field, yaitu category, first, last, count dan support. category merupakan kategori wallpaper yang muncul pada transaksi,first adalah transaksi di mana kategori pertama kali muncul,last adalah transaksi di mana kategori terakhir kali muncul, count adalah jumlah transaksi di mana kategori muncul, serta support adalah nilai support terhadap kategori. Pada fungsi ini terdapat threshold minimal count (dilambangkan γ) yang akan menyaring kategori-kategori yang nilai kemunculannya di bawah nilai threshold γ. Kategori-kategori
7
yang nilai kemunculannya di atas nilai threshold γ (sebagai contoh, nilai γ=1) yang akan dihitung nilai support dengan menggunakan persamaan 2.
Hal ini juga berlaku untuk profil perilaku, fungsi ini akan mengisi tabel behavior berdasarkan informasi yang ada pada Tabel 2.
Tabel 4 Tabel behavior
2-category set first last Count Support
[A,C] 1 1 1 N/A [A,E] 1 1 1 N/A [B,C] 2 4 2 67% [B,D] 4 4 1 N/A [B,E] 2 2 1 N/A [B,F] 2 2 1 N/A [C,D] 4 4 1 N/A [C,E] 1 2 2 50% [C,F] 2 2 1 N/A [D,E] 3 3 1 N/A [D,F] 3 3 1 N/A [E,F] 2 3 2 67%
Tabel behavior memiliki lima field, yaitu 2-category set, first, last, count dan support.2-category set merupakan himpunan dua kategori (2-category set) wallpaper yang muncul pada transaksi,first adalah transaksi di mana 2-category set pertama kali muncul, last adalah transaksi di mana 2-category set terakhir kali muncul, count adalah jumlah transaksi di mana 2-category set muncul, serta support adalah nilai support terhadap 2-category set.
Pada Tabel 4 juga dilakukan penyaringan nilai kemunculan 2-category set terhadap nilai
γ (sebagai contoh, nilai γ=1). 2-category set di atas nilai γ yang akan dihitung nilai support
dengan menggunakan persamaan 4.
Kemudian profil minat ditentukan dengan mencari nilai support yang nilainya lebih besar dari nilai threshold α, seperti yang digunakan dalam persamaan 1 (sebagai contoh, nilai
α=70%) maka profil minat={C,D,E}. Pada
profil perilaku ditentukan dengan mencari support yang nilainya lebih besar dari nilai threshold β, seperti yang digunakan di dalam
persamaan 3 (sebagai contoh, nilai β=40%)
maka profil perilaku={[B,C], [C,E],[E,F]}.
b. Fungsi create_vector
Pada fungsi create_vector sistem akan membentuk matriks vektor pengguna berdasarkan profil minat dan profil perilaku yang sudah terbentuk dari tabel interest dan tabel behavior.
1) Forall 2-set category where support
behavior>β do 2) forall category do 3) a_kat=category 4) end 5) z=0; 6) a=0; 7) n=0; 8) vector=NULL; 9) for(x=0;x<number of category;x++) do 10) for(y=n;y<number of category;y++)do 11) element=subset 2-set category; 12) if category_interest= a_kat[x]then 13) vector= vector.’1’;
14) a++;
15) end
16) else
17) if (element[0]= a_kat[x] & element[1]=a_kat[y]) then 18) vector= vector.’1’; 19) end 20) else 21) vector= vector.’0’; 22) end 23) end 24) end 25) end
26) input vektor to table user where user=ui;
27) End
Seperti disebutkan sebelumnya, bahwa fungsi ini akan membentuk matriks vektor perilaku pengguna berdasarkan profil perlaku pengguna. Sebagai contoh, jika profil minat={C,D,E} dan profil perilaku={[B,C], [C,E] ,[E,F]} maka proses pembentuk matriks dapat dilihat pada Gambar 4
0 1 1 0 0 1 0 1 0 1 0 0 0 1 0 0 0 0 0 0 0 F]} [E, E], [C, C], {[B, } , , { F E D C B A F E D C B A E D C
Gambar 4 Proses pembentukan matriks vektor.
Seperti yang tampak pada Gambar 4, maka akan diperoleh vektor matriks pengguna: 0000000100010100110.
c. Fungsi cluster_vector
Pada fungsi ini, sistem akan mengelompokkan setiap pengguna berdasarkan jarak masing-masing matriks vektor pengguna.
1) M=0;
2) forall user in user table user do 3) get user[m]; 4) get vektor_user[m]; 5) m++; 6) end 7) user_centroid[0]=user[0]; 8) vector_centroid[0]=vector_user[0]; 9) user_iteration=1; 10) sum_cluster=1; 11) id_cluster=sum_cluster; 12) k=1; 13) for(i=1;i<sum_cluster;i++)do 14) distance= euclid_distance (vector_centroid,vector_user[i]);
8
15) if(distance>δ)then 16) sum_cluster++; 17) id_cluster++; 18) user_centroid [id_cluster]= user[i]; 19) vector_centroid [id_cluster]= vector_user[i]; 20) user_is_in=id_cluster; 21) end 22) else 23) user_is_in=shortest euclid distance(vector_centroid, vector_user[i]); 24) vector_centroid [id_cluster]= average_point(cluster[id_cluster]); 25) user_is_in=id_cluster; 26) end 27) EndPada fungsi ini terdapat nilai untuk jarak minimal matriks vektor (dilambangkan dengan
δ). Pada saat fungsi dijalankan pengguna
dengan id yang paling kecil yang menjadi centriod culster dari cluster yang baru terbentuk. Pengguna seterusnya akan diperiksa jarak terpendeknya menggunakan jarak Euclidean dengan setiap cluster yang sudah terbentuk sebelumnya. Jika jarak terpendek ≤
nilai δ, maka matriks vektor masuk ke dalam
cluster yang memiliki jarak terkecil dan centroid cluster berubah berdasarkan matriks vektor yang baru di dalam cluster. Dalam hal ini penentuan nilai centroid cluster menggunakan metode Unweighted pair-group centroid. Kemudian jika jarak terpendek > nilai
δ, maka membentuk cluster baru dan matriks
vektor tersebut menjadi centroid cluster.
d. Fungsi recommendation
Pada fungsi ini, sistem akan menghasilkan rekomendasi koleksi-koleksi wallpaper yang belum pernah diunduh oleh pengguna, berdasarkan koleksi-koleski wallpaper yang telah diunduh oleh pengguna yang lain yang memiliki profil minat dan profil perilaku yang sama pada kelompok cluster yang sama.
1) forall users in the same cluster do
2) forall user which has the same interest do
3) select id wallpaper
which has not been download;
4) input into interest
recommendation;
5) end
6) forall user which has the
same behavior do
7) select id wallpaper
which has not been download;
8) input into behavior
recommendation;
9) end
10) end
Analisis Kompleksitas Waktu Algoritma
Untuk sistem utama, bisa dikatakan bahwa kompleksitas waktunya adalah O(n), karena pada baris ke-2 terjadi perulangan untuk menampilkan koleksi wallpaper. Pada sistem utama terjadi pemanggilan beberapa fungsi. Yaitu pada baris 10 terjadi pemanggilan fungsi recommendation, baris 14 terjadi pemanggilan fungsi input_interest_behavior, baris 15 terjadi pemanggilan fungsi create_vector, serta pada baris 16 terjadi pemanggilan fungsi cluster_vector.
Fungsi recommendation memiliki kompleksitas waktu O(2n2). Karena pada perulangan baris 1, terdapat perulangan pada baris 2 dan 6.
fungsi input_interest_behavior memiliki kompleksitas waktu O(2n2). Karena pada perulangan baris 1, terdapat perulangan pada baris 2 dan 10.
Untuk fungsi create_vektor, karena pada sistem ini hanya ada sepuluh kategori maka pada baris pertama hanya ada 10x9=90 kemungkinan. Pada baris 8 dan 9 terjadi perulangan berkalang 2 sebanyak 10 kali, maka waktu kompleksitasnya 90x100=9000. Karena waktu kompleksitasnya selalu tetap dan bisa dikatakan nilai skalarnya kecil, maka fungsi ini memiliki kompleksitas waktu O(1).
Fungsi cluster_vector, memiliki kompleksitas waktu O(n2). Karena pada perulangan baris 1, terdapat perulangan pada baris 13. Dengan demikian secara keseluruhan sistem rekomendasi ini memiliki kompleksitas waktu algoritma O(2n2).
Implementasi Sistem
Dalam mengembangkan sistem ini digunakan perangkat lunak dan perangkat keras sebagai berikut:
perangkat lunak:
a. Sistem Operasi Windows XP Professional SP2
b. XAMPP 1.5.5
c. Web Server Apache 2.2.3 d. Bahasa Pemrograman PHP 5.2.0 e. DBMS MySQL 5.0.2
f. Web Browser Mozilla Firefox 2.0.0.2 dan Microsoft Internet Explorer 6.0.29
dengan perangkat keras PC:
a. Prosesor Intel Pentium D 2,80Ghz b. Memori 1024MB DDR II RAM c. Harddisk 160 GB
d. VGA GeCube ATI Radeon X1650 512MB DDR II
e. Monitor 17” resolusi 1280x1024
9
Rancangan Pengujian
Pengujian sistem rekomendasi ini dilakukan secara langsung oleh pengguna awam. Dalam percobaan ini, sebanyak 517 koleksi wallpaper dikumpulkan dan dikelompokkan menjadi sepuluh kategori. Seperti yang tampak pada Tabel 5, kategori games memiliki jumlah koleksi terbanyak, yaitu 12,57% dari keseluruhan jumlah koleksi. Sedangkan kategori photo manipulated memliki koleksi yang paling sedikit, yaitu 8,12%.
Tabel 5 Koleksi wallpaper
Kategori Jumlah Koleksi %
3D 49 9.48 abstract 49 9.48 fantasy 67 12.96 fractals 47 9.09 games 65 12.57 landscape 46 8.90 minimalistic 50 9.67 PC/ Mac 49 9.48 photo manipulated 42 8.12 vector 53 10.25 TOTAL 517 100
Sistem ini diujikan kepada tujuh individu pengguna. Jika pengguna tersebut login, maka pengguna dapat melakukan proses browsing koleksi yang ada di dalam sistem berdasarkan kategori. Setiap kali pengguna mengunduh koleksi wallpaper, sistem rekomendasi akan mencatat informasi-informasi yang diperlukan untuk menghitung dan menentukan profil pengguna. Pengguna juga dapat meminta rekomendasi dari sistem. Berdasarkan wallpaper yang direkomendasikan, pengguna harus secara eksplisit menilai rekomendasi tersebut. Ada dua nilai yang digunakan untuk menilai rekomendasi yang diberikan, yaitu sesuai (hit) dan tidak sesuai (miss).
Sesuai dengan tanggapan yang dikumpulkan dari hasil percobaan, ada nilai ukur yang digunakan untuk mengevaluasi metode yang digunakan dalam sistem ini. Ng
dan Nb masing-masing adalah lambang untuk
jumlah respon baik dan respon buruk. Dalam hal ini N adalah jumlah total rekomendasi, sehingga didefinisikan bahwa hit ratio dan miss ratio, sebagai berikut:
Hit Ratio= N
Ng dan Miss Ratio = N
Nb ...(6)
Hasil Pengujian
Setelah mencatat koleksi wallpaper yang telah diunduh oleh pengguna selama masa percobaan, didapat hasil seperti yang tampak di dalam Tabel 6.
Tabel 6 Jumlah koleksi wallpaper yang diunduh
Kategori Jumlah yang diunduh %
3D 74 7.42 abstract 95 9.53 fantasy 90 9.03 fractals 95 9.53 games 49 4.91 landscape 155 15.55 minimalistic 114 11.43 PC/ Mac 57 5.72 photo manipulated 196 19.66 vektor 72 7.22 TOTAL 997 100
Seperti yang terlihat pada Tabel 6, total koleksi yang diunduh selama pengujian adalah sebanyak 997 koleksi. Di mana koleksi dari kategori photo manipulated adalah koleksi yang paling banyak diunduh, yaitu 19.66% dari jumlah koleksi yang diunduh. Sedangkan kategori games adalah kategori yang paling sedikit diunduh, yaitu 4.91%.
Untuk setiap kategori yang ada dalam profil minat dan 2-set category di dalam profil perilaku maka yang akan diproses adalah yang nilai kemunculannya harus lebih besar dari
nilai γ, di mana nilai γ=1.
Berdasarkan pengujian dan percobaan beberapa kali sebelumnya, didapat nilai threshold untuk α sebesar 0.26 dan β sebesar 0.14. Dari data transaksi yang mencatat koleksi wallpaper yang diunduh, dilakukan proses perhitungan dan penentuan matriks vektor masing-masing pengguna berdasarkan profil perilaku.
Dalam percobaan ini dilakukan percobaan dengan nilai threshold δ yang berbeda-beda, masing-masing 0.75, 1.6, 2.8 dan 3.8. Di dalam Tabel 7 ditunjukkan hasil pengelompokan berdasarkan nilai threshold δ. Di dalam tabel ini pengguna dilambangkan dengan id_user seperti 2, 3 dan seterusnya. Cluster yang terbentuk dilambangkan dengan C0, C1 dan seterusnya.
10
Tabel 7 Hasil proses clustering dengan
menggunakan nilai δ yang berbeda Cluster δ =0.75 δ =1.6 δ =2.8 δ =3.8 C0 2 2, 4 2, 4, 8 2, 3, 5, 6, 8 C1 3 3 3 4 C2 4 5 5 7 C3 5 6 6 C4 6 7 7 C5 7 8 C6 8
Dari Tabel 7 dapat dilihat pada saat nilai δ
sebesar 0.75 terdapat tujuh cluster. Kemudian,
nilai δ dinaikan menjadi 1.6 maka cluster yang
terbentuk berkurang satu dan menjadi enam cluster. Ketika nilai δ dinaikkan menjadi 2.8, ada cluster yang bergabung dengan cluster yang lain (sebagai contoh, id_user 4 bergabung dengan cluster C0). Ketika nilai δ dinaikkan lagi menjadi 3.8, beberapa cluster kembali menggabungkan diri dengan cluster yang lain sehingga jumlah cluster berkurang dua menjadi 3 cluster.
Secara umum, dengan semakin besar nilai δ
maka semakin banyak anggota yang ada di dalam cluster dan membuat semakin sedikit cluster yang terbentuk.
Dalam percobaan dilakukan juga pengamatan terhadap rekomendasi yang diminta oleh pengguna. Jika pengguna meminta rekomendasi, maka sistem akan memberikan rekomendasi wallpaper berdasarkan minat dan perilaku, serta berdasarkan cluster pengguna yang sama. Sebelum wallpaper hasil rekomendasi dapat diunduh oleh pengguna, maka sistem akan menanyakan apakah hasil yang direkomendasikan sesuai dengan keinginan pengguna. Jika sesuai, maka hasil rekomendasi dianggap sebagai hit, sebaliknya jika hasil rekomendasi tidak sesuai dengan keinginan pengguna dianggap sebagai miss.
Tabel 8 Tabel hit rasio berdasarkan nilai δ
id user δ =1.6 (%) δ=2 (%) δ=3.6 (%) 2 72.22 100.00 66.67 3 35.29 4 86.96 100.00 5 38.00 6 75.00 7 8 100.00 100.00
Pada Tabel 8 ditampilkan perbandingan hit ratio berdasarkan nilai-nilai δ yang diujikan dalam percobaan. Pada tabel nilai yang ada
memang tidak terlihat pola yang jelas, ini dikarenakan pengguna diberi kebebasan untuk meminta dan menilai rekomendasi. Jika dilihat pada Tabel 8 ada beberapa hit ratio yang nilainya kosong, hal ini dapat terjadi karena: a. Pengguna tidak meminta rekomendasi. b. Pengguna meminta rekomendasi, namun
tidak ada yang direkomendasikan. Karena pengguna sudah mengunduh koleksi wallpaper yang akan direkomendasikan. c. Pengguna meminta rekomendasi, namun
tidak ada yang direkomendasikan. Karena di dalam cluster pengguna hanya sendirian.
KESIMPULAN DAN SARAN
Kesimpulan
Sistem rekomendasi dikembangkan untuk mempermudah pengguna dalam menjelajahi (browsing) situs web untuk mencari informasi dan isi sesuai dengan keinginan pengguna. Dengan cara menentukan profil minat (interest profile) dan profil perilaku (behavior profile) pengguna yang diperoleh dari data tabel transaksi pengguna. Sistem ini dapat memberikan rekomendasi berdasarkan koleksi yang pernah diunduh oleh pengguna lain yang memiliki profil minat dan profil perilaku yang sama di dalam kelompok cluster yang sama. Nilai-nilai threshold yang ada di dalam sistem
(α, β, δ, γ) mempengaruhi penentuan profil
minat dan perilaku pengguna serta rekomendasi yang dihasilkan.
Saran
Di dalam penelitian ini masih ada yang dapat diteliti dan dikembangkan, antara lain: a. Pengembangan sistem untuk profil perilaku
N-category set, (N>2). Di dalam penelitian ini, digunakan 2-set category untuk menentukan profil perilaku pengguna. Dengan N-category set yang bernilai N>2, memungkinkan perolehan profil pengguna pengguna yang lebih kompleks, yang dapat memberikan gambaran yang lebih detail terhadap perilaku pengguna. Untuk itu diperlukan algoritma yang efisien dan efektif untuk melakukan data mining terhadap profil perilaku N-category set di mana N>2. b. Seperti dikatakan sebelumnya, nilai-nilai
threshold yang ada di dalam sistem (α, β, δ,
γ) sangat mempengaruhi penentuan profil
pengguna serta dalam proses penentuan rekomendasi. Di dalam penelitian ini,
nilai-nilai tersebut diperoleh dengan ‘trial and
error’. Perlu ada penelitian dan
pengembangan lebih lanjut untuk menentukan nilai-nilai threshold agar lebih
11
akurat, sehingga dapat ditentukan profil pengguna dengan lebih baik dan pemberian rekomendasi yang lebih tepat.
DAFTAR PUSTAKA
Agrawal R.,Srikant R. 1994. Fast Algorithms of Mining Association Rule.Proceedings of VLDB Conference:pp 487-489.
Balabanovic C, Shoham Y. 1997. Fab: Content-based Collaborative Filtering Recommendation.Communications of the ACM,35(12) :29-38.
Etzioni. 1996. The World Wide Web: Quagmire
or Gold Mine?
http://www.cs.washington.edu/homes/etzio ni/papers/cacm96.pdf [7 Mei 2007].
Han J, Kamber M. 2001. Data Mining. Concepts and Techniques. Academic Press. San Diego, USA.
Huysmans J, Beesens B, Vanthienen J. 2004. Web Usage Mining : A Practical Study. http://www.econ.kuleuven.ac.be/public/ndb ae87/publications.htm [7 Mei 2007].
[STATSOFT]. 2004. Cluster Analysis. http://www.statsoft.com/textbox/stcluan.ht ml [5 Agustus 2007].
Yong CC. 2001. Enabling Personalized Recommendation on the Web Based on User Interest and Behavior: National Tsing HuaUniversity. http:// csdl2.computer.org/persagen/DLAbsToc.js p?resourcePath=/dl/proceedings/&toc=co mp/proceedings/ride/2001/0957/00/0957to c.xml [4 September 2006].