BAB IV
METODE ANALISIS DATA
4.1. METODE STATISTIKA
Pengertian statistik dan statistika seringkali dicampur-adukkan, walaupun sebenarnya kedua istilah tersebut berbeda. Statistika dapat diartikan sebagai metode ilmiah yang
digunakan untuk mengumpulkan, mengorganisasikan, meringkas, menyajikan dan menganalisis data. Tujuannya adalah untuk dapat diperoleh gambaran yang terperinci mengenai karakteristik data itu sendiri sehingga berguna bagi penarikan kesimpulan. Sedangkan statistik hanya merupakan hasil dari pada proses statistika. Statistik dipakai untuk menyatakan kumpulan data, bilangan maupun non bilangan yang disusun dalam tabel atau diagram, yang menggambarkan suatu persoalan.
berkaitan dengan pengumpulan dan penyajian suatu hasil pengamatan (data) sehingga memberikan informasi yang berguna bagi pihak-pihak yang berkepentingan terhadap data dan informasi tersebut. Yang harus mendapatkan perhatian dalam statistika deskriptif adalah hanya menyajikan atau memberikan informasi dari data yang dimiliki (data dari sampel) dan bukan memberikan kesimpulan apapun tentang data populasi. Penyampaian informasi yang dimaksud dapat berupa diagram, grafik, gambar, dan tabel. Sedangkan statistika induktif adalah mencangkup metode yang berkaitan dengan analisis sebagian data (data dari sampel) yang kemudian digunakan untuk melakukan peramalan atau penaksiran kesimpulan (generalisasi) mengenai data secara keseluruhan (populasi). Generalisasi tersebut mempunyai sifat tidak pasti karena hanya berdasarkan pada data dari sampel.
4.2. PENGUJIAN HIPOTESIS
Dalam dunia akademik, suatu masalah terlebih dahulu dijawab secara teoritik. Berdasarkan konsep teoritik tersebut maka dapat diajukan suatu hipotesis. Dengan hipotesis tersebut suatu masalah sudah dapat dijawab, namun jawaban tersebut masih bersifat teoritik dan bersifat sementara. Oleh sebab itu, diperlukan data lapangan untuk memastikan kebenaran hipotesis yang diajukan. Kebenaran hipotesis tergantung pada analisis data lapangan. Hipotesis yang diajukan dapat diterima kebenarannya jika analisis data lapangan sesuai dengan teori, sebaliknya jika analisis data lapangan bertolak belakang (berbeda) dengan teori, maka hipotesis yang diajukan dapat ditolak.
Hipotesis dapat bersifat Kuantitatif dan dapat bersifat Kualitatif. Secara statistik, hipotesis yang bersifat kualitatif tidak
dapat diuji, sedangkan yang dapat diuji adalah hipotesis yang bersifat kuantitatif. Hipotesis yang demikian, disebut Hipotesis Statistik (Statistical Hypothesis) karena selain harus disajikan dalam bentuk angka, hipotesis statistik juga merupakan pernyataan tentang bentuk fungsi yang menggambarkan hubungan antar variabel yang diteliti.
atau tidak ada hubungan antara dua variabel atau lebih. Hipotesis Alterenatif menyatakan terdapat perbedaan antara statistik sampel dengan parameter populasi atau terdapat hubungan antara dua variabel atau lebih.
Dalam merumuskan suatu hipotesis, agar hipotesis yang diajukan dapat diuji atau dianalisis maka yang perlu mendapatkan perhatian adalah bahwa hipotesis hendaknya : 1. Menyatakan hubungan antara dua variabel atau lebih;
2. Dinyatakan dalam kalimat pernyataan;
3. Dirumuskan secara jelas dan padat (sistematik); dan 4. Dapat diuji kebenarannya berdasarkan data lapangan.
Terdapat dua tipe kesalahan dalam pengujian hipotesis, yaitu Tipe Kesalahan I jika dalam pengambilan keputusan berdasarkan pada penolakan hipotesis yang benar (yang seharusnya diterima), sedangkan Tipe Kesalahan II jika kesimpulan berdasarkan pada penerimaan hipotesis yang salah (yang seharusnya ditolak).
Probabilitas untuk terjadinya kesalahan disebut denga n “Taraf Signifikan” atau disimbolkan dengan , dimana nilai taraf
signifikan tersebut dinyatakan dalam prosentase, misalnya sebesar 5%, 10%, dan lain-lain. Lawan dari taraf signifikan
adalah tingkat keyakinan, yaitu bernilai sebesar 1 - . Misalnya
jika taraf signifikan sebesar 5% maka tingkat keyakinan sebesar 95 %, jika sebesar 10% maka tingkat keyakinan bahwa
Semakin besar atau tinggi tingkat keyakinan terhadap hipotesis (dinyatakan benar setelah diuji) maka hipo tesis tersebut semakin baik, tetapi yang harus menjadi perhatian adalah penetapan tingkat signifikan () adalah :
1. Bidang ilmu dari penelitian yang dilaksanakan. Bidang ilmu kelompok ilmu pasti, misalnya kedokteran dan teknik, penetapan tingkat kesalahan () harus sekecil mungkin karena akan berdampak sangat besar. Misalnya dalam penelitian untuk membuat obat atau mesin, maka tingkat kesalahan () pengukuran harus sekecil mungkin
2. Ruang lingkup dari penelitian yang dilaksanakan. Wilayah penelitian menjadi salah satu pertimbangan dalam penetapan tingkat kesalahan (). Jika penelitian dilakukan dalam wilayah nasional maka tingkat kesalahan akan semakin besar dibandingkan jika penelitian dilakukan hanya dalam wilayah lokal.
3. Jumlah variabel yang diteliti. Dengan semakin banyaknya jumlah variabel yang diteliti maka tingkat kesalahan akan semakin kecil dibandingkan jika penelitian hanya menggunakan sedikit variabel yang diteliti.
satu arah positif (tergantung hipotesis alternatif yang diajukan). Pengujian hipotesis tersebut dapat dijelaskan sebagai berikut: 1. Pengujian Hipotesis Satu Arah Negatif
Hipotesis Statistik : Ho : = 0 dan Ha : < 0 Keputusan penerimaan hipotesis :
Terima Ho : jika Z hitung Z atau jika T hitung T .n-1 Tolak Ho : jika Z hitung < Z atau jika T hitung < T .n-1 (lihat gambar 4.1.)
2. Pengujian Hipotesis Satu Arah Positif
Hipotesis Statistik : Ho : = 0 dan Ha : > 0 Keputusan penerimaan hipotesis :
Terima Ho : jika Z hitung Z atau jika T hitung T .n-1 Tolak Ho : jika Z hitung > Z atau jika T hitung > T .n-1 (lihat gambar 4.2.)
3. Pengujian Hipotesis Dua Arah
Hipotesis Statistik : Ho : = 0 dan Ha : 0 Keputusan penerimaan hipotesis :
Terima Ho : jika - Z ½ Z hitung Z ½ , atau jika - T ½ .n-1 T hitung T ½ .n-1 Tolak Ho : jika - Z ½ > Z hitung > Z ½ , atau
Gambar 4.1. Uji Hipotesis Satu Arah Negatif
Gambar 4.2. Uji Hipotesis Satu Arah Positif
Gambar 4.3. Uji Hipotesis Dua Arah - Z
(– T n – 1) Daerah
Penolakan Ho
Daerah Penerimaan Ho
Z (T n – 1)
Daerah Penolakan Ho
Daerah Penerimaan Ho
Z ½ (T ½ n – 1) - Z ½
(– T ½ n – 1) Daerah
Penolakan Ho
Daerah Penerimaan Ho
4.3. METODE ANALISIS DATA
4.3.1. Analisis Perbedaan
Analisis perbedaan dapat dibagi menjadi dua, yaitu Uji Beda Rata-Rata dan Uji Beda Proporsi. Data yang digunakan dalam Uji Beda Rata-Rata adalah bersifat data kontinyu, sedangkan untuk Uji Beda Proporsi adalah data dalam bentuk prosentase.
Uji Beda Rata-Rata dapat dibagi menjadi empat jenis, yaitu:
1. Uji Beda Satu Rata-Rata dengan sampel kecil (n < 30)
Rumus yang digunakan:
n SD μ X hitung
T
Keterangan:
X : Rata-Rata Statistik : Rata-Rata Parameter SD : Standart Deviasi Statistik n : Jumlah Sampel
Contoh:
wawancara diketahui bahwa rata-rata pendapatan perhari pedagang kaki lima di kota “Pn” sebesar Rp. 8.100,- dengan standat deviasi sebesar Rp. 2.300,-. Jika dalam pengujian digunakan taraf signifikan sebesar 5%, ujilah kebenaran data yang dikeluarkan lembaga tersebut.
Jawab:
Hipotesis Statistik : Ho : = 7.250 dan Ha : > 7.250 (Uji satu arah +)
Taraf signifikan ( = 5%), maka T . n – 1 = T 0,05 . 19 = 1,729
T hitung = 1,65
20 2.300
7.250 8.100
Jadi karena T hitung < T tabel atau 1,65 < 1,729 maka Ho diterima sehingga data dari lembaga yang menyatakan bahwa pendapatan rata-rata perhari pedagang kaki lima di kota “Pn” sebesar Rp. 7.250 adalah benar.
2. Uji Beda Satu Rata-Rata dengan sampel besar (n 30)
Rumus yang digunakan:
n SD μ X hitung
Z
Contoh:
tersebut maka diteliti kecepatan dari 200 sepeda motor yang melewati jalan dalam kota dan hasil penghitungan diketahui bahwa rata-rata kecepatannya 34 km per jam dengan standart deviasi 9,5 km per jam. Dengan menggunakan taraf signifikan sebesar 2,5% ujilah pernyataan tersebut di atas. Jawab:
Hipotesis Statistik : Ho : = 35 dan Ha : < 35 (Uji satu arah -)
Taraf signifikan ( = 2,5%) maka Z . n – 1 = Z 0,025 = - 1,960 (lihat Tabel T Student)
Z hitung = 1,49
200 9,5
35 34
Jadi karena - Z hitung > - Z tabel atau - 1,49 > - 1,960 maka Ho diterima artinya pernyataan bahwa rata-rata kecepatan sepeda motor yang melewati jalan dalam kota kurang dari 35 km per jam adalah tidak benar.
Rumus yang digunakan:
X : rata-rata statistik untuk sampel pertama
2
X : rata-rata statistik untuk sampel kedua SD1 : standart deviasi untuk sampel pertama SD1
Seorang dosen Mata Kuliah Statistika menyatakan bahwa nilai ujian mahasiswi lebih baik dari pada nilai ujian mahasiswa. Untuk membuktikan pernyataan tersebut maka diambil sampel nilai ujian dari 14 mahasiswi dan 14 mahasiswa. Setelah diteliti rata-rata nilai ujian mahasiswi 70,5 dengan standart deviasi 10,30. Sedangkan untuk mahasiswa rata-rata nilai ujianya 65,4 dengan standart deviasi 8,95. Dengan menggunakan tingkat keyakinan 95% ujilah pernyataan dosen tersebut.
Jawab:
Misalnya A : nilai mahasiswi dan B : nilai mahasiswa
(Uji satu arah +) diterima artinya pernyataan dosen tentang nilai ujian mahasiswi lebih baik dari pada nilai ujian mahasiswa adalah salah. Berdasarkan penghitungan tersebut menunjukkan bahwa rata-rata nilai ujian dari mahasiswi adalah sama dengan mahasiswa.
4. Uji Beda Dua Rata-Rata dengan sampel besar (n 30)
Rumus yang digunakan:
2
rata-rata nilai ujian adalah 70 dengan varian 38,7. Dengan menggunakan taraf signifikan 5% ujilah pernyataan dosen tersebut :
Jawab:
Hipotesis Statistik : Ho : A = B dan Ha : A B Uji dua arah dan untuk tabel lihat Tabel T Student
Taraf signifikan ( = 5%) maka Z½ .50+50-2=Z0,025;98 = 1,980
2,65
50 38,7 50
25,2 70 67 hitung
Z
Jadi karena - Z hitung < - Z tabel atau - 2,65 < - 1,980 maka Ho ditolak artinya pernyataan dosen bahwa nilai ujian statistika kelas A dan kelas B sama adalah salah. Berdasarkan penghitungan statistik tersebut di atas menunjukkan bahwa rata-rata nilai ujian statistika antara kelas A dengan kelas B adalah berbeda.
Uji Beda Proporsi akan memberikan hasil yang baik jika jumlah sampel yang digunakan cukup besar. Seperti halnya dengan Uji Beda Rata-Rata yang telah diuraikan di atas, Uji Beda Proporsi juga dibagi menjadi dua, yaitu Uji Beda Satu Proporsi dan Uji Beda Dua Proporsi.
1. Uji Beda Satu Proporsi
Rumus yang digunakan :
) q π. . (n
π) . (n X hitung Z
ˆ
Keterangan:
X : Nilai sampel yang diketahui dari pengamatan π : Proporsi dari parameter dan qˆ = 1 - π n : Jumlah sampel yang digunakan
Jika proporsi (P) dihitung dengan menggunakan rumus X / n, maka rumus tersebut dapat diubah menjadi :
n ) q .
π
(
π
P hitung Z
ˆ
Contoh:
Pimpinan perusahaan komputer menyatakan bahwa 90% produk yang dihasilkan dalam kualitas standart. Untuk menguji pernyataan tersebut maka diambil sampel sebanyak 250 buah untuk diteliti kualitasnya dan ternyata terdapat sebanyak 16 buah yang dinyatakan mempunyai kualitas tidak standart. Ujilah pernyataan pimpinan tersebut dengan tingkat keyakinan 95%.
Jawab :
Hipotesis statistik Ho : π = 0,90 dan Ha : π 0,90 Uji dua arah dan untuk tabel lihat Tabel T Student
Taraf signifikan () = 5%, maka Z ½ = Z 0,025 = 1,960 X = 250 – 16 = 234 atau P = 234 / 250 = 0,936
1,897
)(0,10) (250)(0,90
) (250)(0,90 234
hitung
1,897 diterima artinya pernyataan pimpinan perusahaan komputer tentang produk yang dihasilkan sebesar 90% dalam kualitas standart adalah benar.
2. Uji Beda Dua Proporsi
Rumus yang digunakan:
X1 = nilai sampel pertama dari hasil pengamatan X2 = nilai sampel kedua dari hasil pengamatan n1 = jumlah sampel pertama
sebanyak 85 perempuan yang menyukai produk shampoo “Cl”. Dengan menggunakan tingkat keyakinan sebesar 95% ujilah pernyataan selesmen tersebut.
Jawab:
Hipotesis statistik : Ho : PL = PP Ha : PL PP Uji dua arah dan untuk tabel lihat Tabel T Student Taraf signifikan () = 5%, maka Z ½ = Z0,025 = 1,960
0,43 250 200
85 110
p
sehingga q = 1 – 0,43 = 0,57
4,47
250 1 200
1 (0,57) (0,43)
250 85 200 110
hitung Z
Jadi karena Z hitung > Z tabel atau 4,47 > 1,960 maka Ho ditolak artinya pernyataan selesmen bahwa selera laki-laki dengan perempuan terhadap shampoo “Cl” sama adalah salah. Secara statistik selera laki-laki berbeda dengan selera perempuan terhadap shampoo “Cl”.
4.3.2. Analisis Chi-Square
(disimbolkan fh) dari sampel yang terbatas merupakan perbedaan yang signifikan atau tidak. Perbedaan tersebut meyakinkan jika harga dari Chi-Square (X2) sama atau lebih besar dari suatu harga yang ditetapkan pada taraf signifikan tertentu (dari tabel X2). Dengan kata lain Ho akan diterima jika harga X2 lebih kecil dari X2 dalam tabel, sebaliknya Ho akan ditolak jika harga X2 lebih besar atau sama dengan X2 dalam tabel.
Sebagai rumus dasar dari Uji Chi-Square adalah sebagai
berikut :
h f
2 ) h f o f ( 2
X
Keterangan: f 0 : frekuensi hasil observasi f h : frekuensi yang diharapkan
Sedangkan untuk mendapatkan frekuensi yang diharapkan (fh)
adalah:
Data Jumlah
Sekolom Jumlah
x Sebaris Jumlah
h f
Uji Chi-Square dapat digunakan untuk menguji, antara lain: 1. Uji Chi-Square untuk Perbedaan. Bentuk hipotesis (Ho)
dengan kelompok sampel yang lain”. Jika banyaknya kelompok sampel dapat dibagi menjadi sebanyak k (kolom) dan sebanyak b (baris), maka untuk derajat kebebasan adalah (kolom – 1) (baris – 1) (digunakan untuk mencari nilai X2 tabel).
Contoh :
Seorang perusahaan percetakan akan membeli mesin cetak sebanyak tiga mesin cetak. Berdasarkan penawaran terdapat tiga mesin cetak, yaitu merk A, B dan C. Untuk mengetahui kualitas dari tiga merk mesin cetak tersebut maka dilakukan pengujian. Hasil pengujian menunjukkan bahwa dari mesin merk A diambil sampel sebanyak 100 lembar hasil cetakan dan ternyata yang rusak 12 lembar. Dari mesin merk B sampel hasil cetakan sebanyak 120
lembar yang rusak 15 lembar. Sedangkan mesin merk C dari sampel hasil cetakan sebanyak 100 lembar yang
rusak 13 lembar. Jika tingkat keyakinan yang digunakan sebesar 95%, apakah ketiga mesin cetak tersebut mempunyai kualitas yang sama.
Jawab:
Hipotesis Statistik:
Ho : Tidak terdapat perbedaan kualitas (mesin merk A, B, C) Ha : Terdapat perbedaan kualitas (mesin merk A, B, C)
Mencari harga frekuensi harapan (fh):
Hasil Merk Mesin Cetak Jumlah
Mesin A Mesin B Mesin C
Rusak (R) 12 1 15 2 13 3 40
Baik (B) 88 4 105 5 87 6 280
Jumlah 100 120 100 320
Untuk mencari fh masing-masing sel adalah: Sel 1 = ( 40 x 100 ) : 320 = 12,5
Sel 2 = ( 40 x 120 ) : 320 = 15,0 Sel 3 = ( 40 x 100 ) : 320 = 12,5 Sel 4 = ( 280 x 100 ) : 320 = 87,5 Sel 5 = ( 280 x 120 ) : 320 = 105 Sel 6 = ( 280 x 100 ) : 320 = 87,5
Berdasarkan hasil tersebut di atas maka untuk mencari nilai X2 adalah:
Hasil Mesin f o f h fo – f h (fo – fh)2 (fo – fh)2 : fh
Rusak
A 12 12,5 - 0,5 0,25 0,02
B 15 15,0 0 0 0
C 13 12,5 0,5 0,25 0,02
Baik
A 88 87,5 0,5 0,25 0,003
B 105 105 0 0 0
C 87 87,5 - 0,5 0,25 0,003
Dengan tingkat keyakinan sebesar 95% maka = 5% dan df = (k – 1) (b – 1) = (3 – 1) (2 – 1) = 2, maka nilai X2 tabel
sebesar = 5,99. Jadi karena X2 hitung lebih kecil dari X2 tabel atau 0,046 < 5,99 maka Ho diterima artinya ketiga
mesin cetak (mesin A, B dan C) adalah mempunyai kualitas sama.
2. Uji Chi-Square untuk Independensi
Uji Chi-Square ini pada umumnya digunakan untuk menguji apakah dua variabel yang masing-masing mempunyai beberapa kategori saling mempunyai ketergantungan atau tidak. Hipotesis nihil (Ho) menyatakan bahwa kedua variabel tidak saling tergantung atau bersifat independen. Sedangkan hipotesis alternatif (Ha) menyatakan bahwa kedua variabel saling tergantung atau mempunyai ketergantungan.
Contoh:
Nilai Matematika
Nilai Statistika
Jumlah Tinggi Sedang Rendah
Tinggi 20 1 10 2 5 3 35
Sedang 8 4 15 5 17 6 40
Rendah 0 7 4 8 21 9 25
Jumlah 28 29 43 100
Jika digunakan tingkat signifikan sebesar 5%, bagaimana kesimpulan penelitian tersebut.
Jawab:
Hipotesis Statistik:
Ho : Nilai Statistika tidak tergantung pada nilai Matematika Ha : Nilai Statistika tergantung pada nilai Matematika Mencari nilai f h masing-masing sel adalah sebagai berikut : Nilai Sel 1 = (35 x 28) : 100 = 9,8
Nilai Matematika
Nilai
Statistika fo fh fo– fh (fo – fh) 2
: fh TINGGI Tinggi 20 9,8 10,20 10,616
Sedang 10 10,15 - 0,15 0,002 Rendah 5 15,05 - 10,05 6,711 SEDANG Tinggi 8 11,2 - 3,20 0,914 Sedang 15 11,6 3,40 0,997 Rendah 17 17,2 - 0,20 0,002
RENDAH Tinggi 0 7 - 7,00 7,000
Sedang 4 7,25 - 3,25 1,457 Rendah 21 10,75 10,25 9,733
JUMLAH 100 100 0 X2 = 37,472
Nilai tabel X2 untuk = 5% dengan df = (3 – 1) (3 – 1) adalah sebesar 9,49. Jadi karena X2 hitung lebih besar dari X2 tabel atau 37,472 > 9,49 maka Ho ditolak artinya besarnya nilai mata kuliah Statistika mempunyai ketergantungan dengan besarnya nilai mata kuliah Matematika.
4.3.3. Analisis Regresi dan Korelasi
jelas yang disebut variabel independen adalah variabel yang dapat mempengaruhi variabel lain, sedangkan variabel dependen adalah variabel yang dipengaruhi oleh variabel lain. Misalnya dalam persamaan konsumsi (C = a + b Y), diketahui bahwa besanya nilai konsumsi (C) dipengaruhi oleh jumlah pendapatan (Y). Dengan demikian yang disebut dengan variabel independen adalah Jumlah Pendapatan (Y) dan yang menjadi variabel dependen adalah Konsumsi (C). Yang perlu mendapatkan perhatian dalam menentukan variabel independen dan variabel dependen adalah jangan “terpaku” pada notasi dalam suatu persamaan regresi, karena masing-masing literatur menggunakan notasi sendiri-sendiri.
Analisis Korelasi digunakan untuk mengetahui tingkat keeratan dari hubungan dua variabel. Sedangkan angka yang menunjukkan kuat tidaknya hubungan antara dua variabel disebut dengan koefisien korelasi yang dinotasikan dengan “r” (khusus untuk korelasi sederhana). Nilai koefisien korelasi
adalah – 1 r 1.
Jika r = – 1, berhubungan negatif “sangat” erat Jika r = 1, berhubungan positif “sangat” erat Jika r = 0, tidak berhubungan
4.3.3.1. Analisis Regresi Sederhana
Penyebutan regresi linier sederhana karena dalam model yang diajukan hanya memasukkan satu variabel independen dan persamaannya berpangkat satu. Dengan demikian model regresi linier sederhana adalah sebagai berikut:
Y = a + b. X (dalam beberapa literatur ditulis Y = b0 + b1. X) Keterangan :
Y : Variabel Dependen (variabel terikat) X : Variabel Independen (variabel bebas) a : Konstanta
b : Koefisien Regresi
Untuk mendapatkan nilai a dan nilai b maka digunakan rumus sebagai berikut :
2 adalah sebagai berikut:Selisih antara nilai Y observasi dengan nilai Y taksiran disebut dengan Error. Berdasarkan nilai error maka dapat dihitung besarnya kekeliruan standart dari penaksiran atau Standart Error of Estimate (biasanya dinotasi dengan Sxy). Untuk menghitung besarnya nilai Sxy adalah sebagai berikut:
k Berdasarkan rumus standart error of estimate tersebut di atas, maka dapat digunakan untuk mendapatkan rumus standart error dari penaksiran konstanta (a) dan koefisien regresi (b), yaitu:
diajukan akan diuji dengan menggunakan Uji T (uji parsial), Uji F (uji serempak), dan juga memperhatikan nilai koefisien determinasinya.
membandingkan T hitung dengan T tabel. Untuk menentukan
nilai T hitung digunakan rumus =
Sb b
Keterangan:
b : Koefisien regresi
Sb : Standart error dari variabel independen
Sedangkan untuk mendapatkan nilai T tabel dapat dilihat dalam Tabel Distribusi T dengan menentukan degree of freedom (df): n – k dan nilai (jika uji satu arah digunakan dan jika uji dua arah digunakan ½). Misalnya, jika penelitian menggunakan sampel sebanyak 10 dan tingkat signifikan 5% (regresi linier
sederhana) maka nilai T tabel adalah df : 8 dan : 5% (uji satu
arah positif), yaitu sebesar 1,860. Jika uji dua arah maka df : 8 dan ½ = 2,5%, yaitu sebesar 2,306.
Uji F (Uji Serempak), digunakan untuk menguji tingkat signifikan dari pengaruh variabel independen secara serempak terhadap variabel dependen. Uji dilaksanakan dengan langkah
membandingkan nilai dari F hitung dengan F tabel. Nilai
F hitung dicari dengan rumus =
2 xy S
x2 )/(k1) 2
b (
Sedangkan untuk mengetahui nilai F tabel adalah menentukan
(regresi linier sederhana) maka nilai F tabel adalah df : k – 1 =
2 – 1 = 1 (horisontal) dan n – k = 10 – 2 = 8 dan : 5% yaitu sebesar 5,32.
Nilai koefisien korelasi digunakan rumus sebagai berikut:
)
Disamping koefisien korelasi, juga terdapat yang disebut dengan Koefisien Determinasi atau dinotasikan dengan “r2”. Yang dimaksud dengan koefisien determinasi adalah untuk menentukan seberapa besar variasi variabel dependen (Y) yang dapat dijelaskan oleh variabel independen (X). Nilai
koefisien determinasi adalah 0 r2 1. Jika r2 = 0 maka garis regresi sangat tidak dapat mencocokkan atau sangat tidak tepat dalam meramalkan nilai Y. Jika r2 = 1 maka garis regresi sangat cocok atau sangat tepat untuk meramalkan nilai Y. Dalam realita nilai r2 tidak mungkin 1 atau 100% tetapi selalu di bawah 1 atau 100%. Untuk mendapatkan nilai r2 dengan rumus:
Contoh:
Seorang peneliti ingin mengetahui pengaruh dari tinggi badan terhadap berat badan. Untuk kebutuhan penelitian tersebut diambil sampel secara acak sebanyak 10 orang untuk diteliti. Jika hipotesis penelitian menyatakan bahwa “tinggi badan seseorang berpengaruh terhadap berat badan seseorang”, ujilah hipotesis tersebut dengan menggunakan Uji T dan Uji F (tingkat keyakinan sebesar 95%) dan berapa nilai korelasi dan koefisien determinasinya.
Jawab:
Jika Y : Berat Badan Seseorang X : Tinggi Badan Seseorang
Maka untuk mendapatkan nilai a dan b untuk persamaan regersi linier sederhana:
N Y X Y 2 X 2 XY
1 68 171 4.624 29.241 11.628
2 76 180 5.776 32.400 13.680
3 51 152 2.601 23.104 7.752
4 57 159 3.249 25.281 9.063
5 77 185 5.929 34.225 14.245
6 64 172 4.096 29.584 11.008
7 71 175 5.041 30.625 12.425
8 53 157 2.809 24.649 8.321
9 67 173 4.489 29.929 11.591
10 55 155 3.025 24.025 8.525
Untuk mendapatkan nilai a dan b adalah : sebagai berikut:
2 x xy S
b
S =
1.158,9 1,881084
= 0,05525673
Berdasarkan hasil pengolahan data tersebut di atas maka
dapat dibuat persamaan regresi linier sederhana:
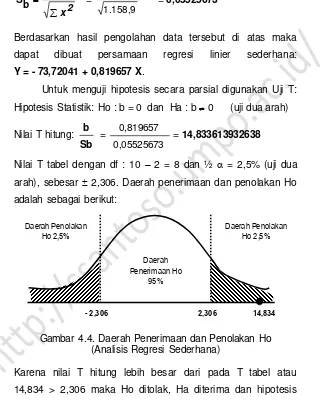
Y = - 73,72041 + 0,819657 X.
Untuk menguji hipotesis secara parsial digunakan Uji T: Hipotesis Statistik: Ho : b = 0 dan Ha : b 0 (uji dua arah)
Nilai T hitung:
Sb b
=
0,05525673 0,819657
= 14,833613932638
Nilai T tabel dengan df : 10 – 2 = 8 dan ½ = 2,5% (uji dua arah), sebesar 2,306. Daerah penerimaan dan penolakan Ho adalah sebagai berikut:
Gambar 4.4. Daerah Penerimaan dan Penolakan Ho (Analisis Regresi Sederhana)
Karena nilai T hitung lebih besar dari pada T tabel atau 14,834 > 2,306 maka Ho ditolak, Ha diterima dan hipotesis penelitian yang menyatakan bahwa Tinggi Badan berpengaruh
Daerah Penolakan Ho 2,5%
Daerah Penolakan Ho 2,5%
Daerah Penerimaan Ho
95%
2,306
terhadap Berat Badan Seseorang adalah dapat diterima (dapat dikatakan signifikan secara statistik).
Untuk melakukan pengujian secara serempak maka digunakan Uji F. Hipotesis statistik: Ho : b = 0 dan Ha : b 0
Sedangkan rumus F hitung=
2 xy S
x2 )/(k1) 2
b (
F hitung =
) 2 1,881084 (
1 / ) 1.158,9 )( 2 0,819657 (
= 220,0361
Untuk nilai F tabel dengan df : k - 1 ; n – k = 1 ; 8 dan : 5% sebesar 5,32. Karena nilai F hitung lebih besar dari F tabel atau 220,0361> 5,32 maka Ho ditolak, Ha diterima dan hipotesis penelitian yang menyatakan bahwa Tinggi Badan berpengaruh terhadap Berat Badan Seseorang adalah dapat diterima.
Untuk mendapatkan nilai koesien korelasi dan koefisien determinasi adalah:
) 2 y ( ) 2 x (
xy
r =
) 806,9 ( ) 1.158,9 (
949,9
= 0,982
independen (Tinggi Badan) terhadap naik turunnya variabel dependen (Berat Badan) sebesar 96,4% sedangkan sisanya merupakan sumbangan dari variabel lain yang tidak dimasukkan dalam model.
4.3.3.2. Analisis Regresi Berganda
Dalam analisis regresi linier sederhana jumlah variabel independen yang digunakan adalah sebanyak satu variabel. Sedangkan untuk analisis regresi dan korelasi berganda, jumlah variabel independen yang digunakan lebih dari satu variabel. Dengan demikian model persamaan regresi linier berganda menjadi : Y = a + b1 X1 + b2 X2+ … + b i X i
Keterangan:
Y : Variabel Dependen
X1 : Variabel Independen Pertama X2 : Variabel Independen Kedua X i : Variabel Independen Ke-i b1, b2, …b i : Koefisien Regresi
a : Konstanta
Analisis regresi berganda tiga variabel model persamaannya adalah sebagai berikut : Y = a + b1 X1 + b2 X2. Sedangkan untuk mendapatkan nilai a, b1 dan b2 digunakan rumus sebagai berikut:
2
adalah sebagai berikut:
Berdasarkan rumus tersebut di atas, maka untuk mendapatkan nilai kekeliruan standart dari estimasi (standart error of estimate) atau dinotasikan Syx1x2 adalah sebagai berikut:
k maka dapat dicari standar error penaksiran dari masing-masing koefisien regresi, yaitu:
signifikan dari pengaruh variabel independen secara parsial terhadap variabel dependen. Uji dilaksanakan dengan langkah membandingkan T hitung dengan T tabel.
Uji Satu Arah ( - ) Uji Satu Arah ( + ) Uji Dua Arah
Untuk menentukan nilai T hitung adalah:
1
Sedangkan untuk degree of freedom adalah n – k (dalam hal ini nilai k sebesar 3).
Uji F (Uji Serempak), digunakan untuk menguji tingkat signifikan dari pengaruh variabel independen secara serempak terhadap variabel dependen. Uji dilaksanakan dengan langkah membandingkan nilai dari F hitung dengan F tabel.
Hipotesis statistik: Ho : b1 = b2 = 0 dan Ha : b1 b2 0 (atau salah satu bernilai tidak nol).
Nilai F hitung dicari dengan rumus:
F hitung = sebesar 3, yaitu jumlah variabel yang diteliti)
2 y
) y 2 x . 2 b y 1 x . 1 b (
2
R dimana 0 R2 1
Contoh:
Suatu penelitian tentang “Pengaruh Pendapatan Keluarga per Hari (X1) dan Jumlah Anggota Keluarga (X2) terhadap Pengeluaran Konsumsi Keluarga per Hari (Y)”, menggunakan sampel sebanyak 10 keluarga. Ujilah hipotesis yang menyatakan bahwa Pendapatan Keluarga per Hari dan Jumlah Anggota Keluarga berpengaruh terhadap Pengeluaran Konsumsi Keluarga per Hari, dengan menggunakan Uji T dan Uji F pada taraf signifikan 5% dan carilah nilai R2 (koefisien determinasi).
Jawab:
N X1 X2 Y X12 X22 Y2 X1X2 X1Y X2Y
1 100 7 23 10.000 49 529 700 2.300 161
2 20 3 7 400 9 49 60 140 21
3 40 2 15 1.600 4 225 80 600 30
4 60 4 17 3.600 16 289 240 1.020 68 5 80 6 23 6.400 36 529 480 1.840 138 6 70 5 22 4.900 25 484 350 1.540 110
7 40 3 10 1.600 9 100 120 400 30
8 60 3 14 3.600 9 196 180 840 42
Dengan demikian persamaan regresi linier berganda adalah:
Uji T (uji parsial). Mencari nilai Sb1 dan Sb2 adalah sebagai berikut :
k
Dengan demikian nilai T hitung masing-masing variabel independen adalah :
2. Karena nilai T hitung X2 lebih besar dari pada T tabel atau – 0,46627 > – 2,36 (di daerah tidak arsiran) maka Ho
diterima, Ha ditolak dan hipotesis penelitian yang menyatakan bahwa Jumlah Anggota Keluarga berpengaruh terhadap Pengeluaran Konsumsi Keluarga per Hari adalah tidak dapat diterima pada taraf signifikan 5% (diterima pada taraf signifikan 40%).
Uji F (uji serempak). Nilai F hitung dengan menggunakan
rumus : maka Ho ditolak, Ha diterima dan Hipotesis Penelitian diterima, artinya Pendapatan Keluarga per Hari dan Jumlah Anggota Keluarga secara serempak atau bersama-sama mempunyai pengaruh yang signifikan terhadap Pengeluaran Konsumsi Keluarga per Hari.
R2 (koefisien determinasi) diperoleh dengan rumus: