KAJIAN PENGARUH MATRIKS PEMBOBOT SPASIAL
DALAM MODEL DATA PANEL SPASIAL
TUTI PURWANINGSIH
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul “Kajian Pengaruh
Matriks Pembobot Spasial dalam Model Data panel spasial” adalah benar karya
saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2014
Tuti Purwaningsih
1
RINGKASAN
TUTI PURWANINGSIH. Kajian Pengaruh Matriks Pembobot Spasial dalam
Model Data Panel Spasial. Dibimbing oleh ERFIANI dan ANIK DJURAIDAH.
Data panel adalah kombinasi antara data deret waktu dan data lintas objek. Jika objek yang dimaksud berupa lokasi, maka perlu mengecek ada tidaknya hubungan antar lokasi. Ilmu statistika yang mengkaji mengenai hubungan antar
lokasi disebut statistika spasial. Statistika spasial mengenal adanya parameter ρ
dan yang digunakan untuk mengukur pengaruh hubungan antar lokasi. Nilai dari
ρ atau akan ikut menentukan kebaikan model, sehingga penting untuk membuat
estimasi parameter dengan baik agar diperoleh kebaikan model yang juga baik. Model yang akan dikaji dalam penelitian ini adalah model data panel spasial.
Pengaruh antar lokasi diukur dengan membuat matriks kebersinggungan (contiguity) sampai diperoleh matriks pembobot spasial (W). Beberapa W yang
dikenal diantaranya W seragam, W Biner, W Kernel Gaussian dan beberapa W
yang berasal dari kasus riil kondisi ekonomi maupun transportasi dari lokasi-lokasi yang menjadi objek penelitian.
Penelitian ini bertujuan untuk mengkaji pengaruh W dalam model data
panel spasial dengan melakukan simulasi, kemudian dari hasil simulasi akan
diketahui W terbaik yang selanjutnya digunakan untuk mengaplikasikan model
data panel spasial dari data produksi beras seluruh provinsi di Indonesia tahun 2010-2012. Simulasi dilakukan dengan membangkitkan 180 kombinasi data (3
tipe W, 3 tipe lokasi, 4 tipe waktu, 5 tipe model data panel spasial).
Masing-masing kombinasi diulangi sebanyak 1000 replikasi. Data sekunder yang digunakan pada penelitian ini berasal dari Badan Pusat Statistik (BPS). Peubah penjelas yang digunakan adalah harga beras, luas panen dan jumlah petani dari setiap provinsi di Indonesia tahun 2010-2012.
Hasil penelitian ini menunjukan bahwa W seragam memiliki nilai rataan
RMSE paling kecil dibandingkan dengan jenis W lainnya untuk hampir semua
kombinasi simulasi. W seragam juga memiliki nilai RMSE yang cukup stabil
pada nilai kecil untuk hampir semua kombinasi, kemudian setelah diaplikasikan
ke data empiris diperoleh hasil bahwa ada pengaruh spasial antar provinsi (ρ), itu
dapat dilihat dari signifikansi parameter otoregresi (ρ)dalam model dan memiliki
nilai R2 sebesar 98.9%.
2
SUMMARY
TUTI PURWANINGSIH. Analyze Influence of Spatial Weighted Matrix in Spatial Panel Data Model. Supervised by ERFIANI and ANIK DJURAIDAH.
Panel data is combining section data and time deret data. If the cross-section is locations, need to check the correlation between locations. Statistics that analyze the correlation between locations is spatial statistics. Spatial statistics
have parameter ρ and which is used to cover effect of correlation between
locations. Value of ρ or will determine the goodness of fit model, so it is
important to make parameter estimation. Model to be analyzed in this research is spatial panel data model.
The effect between locations is covered by make contiguity matrix until get
spatial weighted matrix (W). There are some type of W, it is Uniform W, Binary
W, Kernel Gaussian W and some W from real case of economics condition or
transportation condition from locations.
This research is aim to analyze influence of W in spatial panel data model
using simulation, then from the simulation result will get the best W which will be
used to apply spatial panel data model of rice production for all of provinces in Indonesia year 2010-2012. Simulation is done with generating 180 data
combinations (3 types of W, 3 types of locations, 4 types of time, 5 types of
spatial panel data model). Secondary data in this research is taken from BPS. The independent variables is rice production, rice price, harvest area, number of farmer from each provinces in Indonesia taken from 2010 to 2012.
The result in this research show that Uniform W has average of RMSE less
than another W in almost of combinations. Uniform W has stabil RMSE in small
value for all combinations, then after applied to real data then obtained result that
there are spatial correlation between provinces (ρ), it can be seen by the
significance of autoregressive parameter (ρ) in the model and has R2 equal to
98.9%.
Keywords : panel data, spatial panel data, spatial weighted matrix,
3
© Hak Cipta Milik IPB, Tahun 2014
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah, dan pengutipan tersebut tidak merugikan kepentingan IPB
4
KAJIAN PENGARUH MATRIKS PEMBOBOT SPASIAL
DALAM MODEL DATA PANEL SPASIAL
TUTI
PURWANINGSIH
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
5
6
Judul Tesis : Kajian Pengaruh Matriks Pembobot Spasial dalam Model Data
Panel Spasial
Nama : Tuti Purwaningsih
NIM : G151120061
Disetujui oleh
Komisi Pembimbing
Dr Ir Erfiani, MSi Ketua
Dr Ir Anik Djuraidah, MS Anggota
Diketahui oleh
Ketua Program Studi Statistika
Dr. Ir. Anik Djuraidah, MS
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
7
PRAKATA
Puji syukur penulis panjatkan kehadirat Allah SWT atas limpahan rahmat
dan ridho-Nya, kesempatan, dan kesehatan yang dikaruniakan-Nya sehingga tesis
yang berjudul “Kajian Pengaruh Matriks Pembobot Spasial dalam Model Data
panel spasial” ini dapat terselesaikan.
Terima kasih penulis ucapkan kepada Ibu Dr Ir Erfiani, MSi dan Ibu Dr Ir Anik Djuraidah, MS selaku pembimbing, atas kesediaan dan kesabaran untuk membimbing dan membagi ilmunya kepada penulis dalam penyusunan tesis ini. Terimakasih kepada Bapak Dr Ir Bagus Sartono, Msi selaku penguji luar komisi pembimbing atas masukan yang diberikan. Ucapan terima kasih juga penulis sampaikan sebesar-besarnya kepada seluruh Dosen Departemen Statistika IPB yang telah mengasuh dan mendidik penulis selama di bangku kuliah hingga berhasil menyelesaikan studi, serta seluruh staf Departemen Statistika IPB atas bantuan, pelayanan, dan kerjasamanya selama ini.
Ucapan terima kasih yang tulus dan penghargaan yang tak terhingga juga penulis ucapkan kepada kedua orangtuaku Bapak Puji Handoyo dan Ibu Chadimah yang telah membesarkan dan mendidik penulis disetiap langkahnya dengan penuh kasih sayang demi keberhasilan penulis selama menjalani proses pendidikan, juga kedua adikku tersayang Niki Nurhayati dan Bening Normalia Saputri serta seluruh keluargaku atas doa dan semangatnya.
Terakhir tak lupa penulis juga menyampaikan terima kasih kepada seluruh mahasiswa Pascasarjana Departemen Statistika atas segala bantuan dan kebersamaannya selama menghadapi masa-masa terindah maupun tersulit dalam menuntut ilmu, serta semua pihak yang telah banyak membantu dan tak sempat penulis sebutkan satu per satu.
Semoga tesis ini dapat bermanfaat bagi semua pihak yang membutuhkan.
Bogor, Juli 2014
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vii
1 PENDAHULUAN 1
1.1. Latar Belakang 1
1.2. Tujuan 2
2 TINJAUAN PUSTAKA 2
2.1. Analisis Data Panel 2
2.1.1. Model Gabungan 3
2.1.2. Model Pengaruh Tetap 3
2.1.3. Model Pengaruh Acak 4
2.1.4. Uji Chow 5
2.1.5. Uji Hausman 5
2.2. Matriks Pembobot Spasial 6
2.3. Analisis Data Panel Spasial 9
2.3.1. Uji Pengganda Lagrange 9
2.3.2. Model Otoregresi Spasial (SAR) 10
2.3.3. Model Galat Spasial (SEM) 10
3 METODE PENELITIAN 11
3.1. Data 11
3.2. Metode 11
4 HASIL DAN PEMBAHASAN 15
4.1. Tiga Jenis Matriks Pembobot Spasial 15
4.2. Hasil Simulasi Matriks Pembobot Spasial 20
4.3. Aplikasi Data Produksi Beras 24
4.3.1. Eksplorasi Data 24
4.3.2. Plot Pencaran Moran Produksi Beras antar Provinsi 25
5 SIMPULAN DAN SARAN 31
5.1. Simpulan 31
5.2. Saran 31
6 DAFTAR PUSTAKA 31
DAFTAR TABEL
1 Struktur data panel untuk satu peubah penjelas 2
2 Rincian peubah yang digunakan pada data sekunder 11
3 Nilai RMSE hasil simulasi pada kombinasi W, N, T dan model spasial 20
4 Komposisi posisi provinsi dalam plot pencaran Moran 26
5 Matriks kesesuaian posisi provinsi dalam plot pencaran Moran 26
6 Korelasi antar Peubah 27
7 Dugaan parameter model data panel (R2 =73.64%) 28
8 Model data panel dengan peubah penjelas jumlah petani (R2 =73.32%) 28
9 Model data panel dengan peubah penjelas luas panen (R2 =70.47%) 28
10 Uji LM pada SAR dan SEM 28
11 Dugaan parameter model data panel spasial 29
12 Pola galat untuk pengelompokan provinsi 30
13 Model data panel spasial kelompok 1 (R2 = 99.01%) 30
14 Model data panel spasial kelompok 2 (R2 = 99.04%) 30
15 Model data panel spasial kelompok 3 (R2 = 95.48%) 30
16 Model data panel spasial kelompok 4 (R2 = 95.92%) 30
DAFTAR GAMBAR
1 Ilustrasi model gabungan 3
2 Ilustrasi model tetap 4
3 Penghitungan matriks pembobot spasial dengan langkah ratu 7
4 Algoritma simulasi dan alur penelitian data panel spasial 13
5 Diagram alir pendugaan parameter data panel spasial 14
6 Peta Tiga Lokasi 15
7 W biner untuk tiga lokasi 16
8 W seragam untuk tiga lokasi 16
9 Peta posisi centroid 3 lokasi 17
10 W kernel gaussian untuk 3 lokasi 17
11 Peta Sembilan Lokasi 17
12 W Biner untuk sembilan lokasi 18
13 W seragam untuk sembilan lokasi 18
14 Peta posisi centroid dari 9 lokasi 18
15 Matriks pembobot kernel gaussian untuk 9 lokasi 19
16 Peta 25 lokasi 19
17 Peta posisi centroid untuk 25 lokasi 19
18 Perbandingan RMSE W Biner, W Seragam dan W Kernel
Gausian pada berbagai kombinasi N dan T 21
19 Perbandingan RMSE dari W untuk setiap model 22
20 Perbandingan RMSE pada berbagai jenis N, T & Model untuk W
2
21 Perbandingan RMSE pada berbagai jenis N, T & Model untuk W
Seragam 23
22 Perbandingan RMSE pada berbagai jenis N, T & Model untuk W
Kernel Gaussian 24
23 Produksi beras tiap provinsi tahun 2010-2012 24
24 Plot pencaran Moran Produksi Beras tahun 2010 25
25 Plot pencaran Moran Produksi Beras tahun 2011 25
26 Plot pencaran Moran Produksi Beras tahun 2012 25
27 Rataan harga beras tahunan 26
28 Fluktuasi harga beras perprovinsi tahun 2010-2012 27
29 Boxplot produksi beras masing-masing provinsi 29
DAFTAR LAMPIRAN
1 W Biner untuk 25 lokasi ... 33
2 W Seragam untuk 25 lokasi ... 34
3 W Kernel Gaussian untuk 25 lokasi ... 35
4 Plot galat model data panel spasial setiap provinsi ... 36
1
1 PENDAHULUAN
1.1. Latar Belakang
Data panel adalah kombinasi antara data deret waktu dan data lintas objek. Data deret waktu merupakan data yang diambil dari suatu objek selama periode waktu tertentu, sedangkan data lintas objek merupakan data beberapa objek untuk satu periode tertentu (Baltagi, 2005). Objek yang di maksud bisa berupa instansi pemerintah, perusahaan maupun lokasi. Dalam kehidupan sehari-hari seringkali ditemukan bahwa kondisi yang terjadi pada suatu lokasi mempengaruhi kondisi lokasi lainnya pada periode tertentu. Jika kondisi ini diamati dalam periode waktu yang cukup panjang maka kemungkinan terdapat pola tertentu pada peubah yang sedang diamati pada lokasi-lokasi tersebut. Data yang diamati selama periode waktu tertentu dari berbagai lokasi yang bertetanggaan merupakan data yang cukup kompleks, karena memiliki indeks waktu dan indeks lokasi. Data yang diambil dari suatu lokasi pada waktu tertentu kemungkinan saling berkorelasi atau saling bebas. Jika saling berkorelasi antar lokasi maka pendekatan selanjutnya perlu adanya ilmu statistika spasial yang digunakan untuk mengukur besarnya korelasi spasial pada data panel dan sebaliknya jika saling bebas, menggunakan analisis data panel.
Korelasi spasial adalah kecenderungan bahwa nilai amatan dari suatu lokasi berhubungan dengan nilai amatan lokasi lain. Model ketergantungan spasial dibagi menjadi dua, yaitu model yang mengkaji ketergantungan peubah respon
antar lokasi disebut Model Otoregresi Spasial/Spatial Auto-Regressive Model
(SAR) dan model yang mengkaji ketergantungan dari galat antar lokasi disebut
Model Galat Spasial/Spatial Error Model (SEM) (Anselin, 2009). Jika ada
pengaruh spasial tapi tidak dimasukan kedalam model maka asumsi galat bahwa antar amatan saling bebas tidak akan terpenuhi, untuk itu dibutuhkan sebuah model yang memasukan pengaruh spasial dalam analisis data panel yang akan disebut sebagai model data panel spasial.
Beberapa literatur jurnal saat ini mengenai analisis spasial dengan data
lintas objek yaitu geographically weighted regression oleh Fotheringham (2002).
Beberapa literatur jurnal mengenai data panel spasial adalah forecasting with
spatial panel data oleh Baltagi (2009) dan spatial panel models oleh Elhorst
(2011).
Pengaruh spasial dalam model diakomodir oleh matriks pembobot spasial
(W) yang merupakan komponen penting untuk menghitung besarnya pengaruh
korelasi spasial antar lokasi. Besar kecilnya nilai korelasi spasial berperan dalam prediksi dan penentuan nilai parameter spasial dalam model data panel spasial,
yang dikenal dengan notasi ρ pada SAR atau pada SEM. Beberapa jenis dari W,
yaitu W biner, W seragam,Winvers jarak, W kernel gaussian dan beberapa jenis
W yang berasal dari kasus riil seperti kondisi ekonomi atau kondisi transportasi
antar lokasi yang sedang diteliti.
Pentingnya peranan W dalam model, membuat peneliti ingin mengkaji lebih
dalammengenai W dalam model data panel spasial. Penentuan W terbaik dengan
2
menggunakan simulasi. Selanjutnya dapat diperoleh pendekatan W terbaik dari
hasil penelitian ini dan mengaplikasikannya ke data empiris.
1.2.Tujuan
Penelitian ini bertujuan untuk :
1. Mengkaji pengaruh matriks pembobot spasial dalam model data panel
spasial.
2. Menyusun model produksi beras setiap provinsi di Indonesia
2
TINJAUAN PUSTAKA
2.1. Analisis Data Panel
Ketika setiap unit lintas objek memiliki jumlah deret waktu yang sama,
maka disebut data panel seimbang (balance panel data). Sebaliknya, jika setiap
unit lintas objek memiliki jumlah deret waktu yang berbeda, maka disebut data
panel tidak seimbang (unbalance panel data). Tabel 1 menunjukkan struktur data
panel untuk satu peubah penjelas, dengan N adalah banyaknya unit lintas objek dan T adalah banyaknya unit deret waktu. Data pada peubah respon dan penjelas pada pendugaan analisis data panel ini disusun berdasarkan unit lintas objek terlebih dahulu, selanjutnya berdasarkan unit deret waktunya.
Secara umum, model regresi data panel dinyatakan sebagai berikut: [1]
i = 1,2, …, N ; t = 1,2, …, T
dengan i merupakan unit lintas objek, t merupakan unit deret waktu, α adalah
suatu nilai konstanta dan β adalah vektor berukuran , dengan K menyatakan
banyaknya peubah penjelas. Selanjutnya yit adalah respon lintas objek ke-i untuk
periode waktu ke-t dan xit adalah vektor berukuran untuk lintas objek ke-i
dan periode waktu ke-t sedangkan uit merupakan galat pada objek ke-i dan waktu
ke-t (Baltagi 2005).
Komponen sisaan satu arah dari model regresi pada persamaan [1] dapat didefinisikan sebagai berikut:
[2]
dengan µi merupakan pengaruh spesifik objek yang tidak terobservasi dan it
merupakan sisaan lintas objek ke-idan deret waktu ke-t(Baltagi 2005).
Tabel 1 Struktur data panel untuk satu peubah penjelas
i t Yit Xit
1 1 y11 y11
: : : :
1 T y1T x1T
2 1 y21 x21
: : : :
2 T y2T x2T
: : : :
N 1 yN1 xN1
: : : :
3
2.1.1. Model Gabungan
Model gabungan (Pooled Least Square) merupakan salah satu model dalam
analisis data panel. Asumsi dalam model ini adalah koefisien regresi (konstanta ataupun kemiringan) yang sama antar unit lintas objek maupun waktu. Pendugaan parameter model menggunakan metode kuadrat terkecil (MKT) (Elhorst 2010).
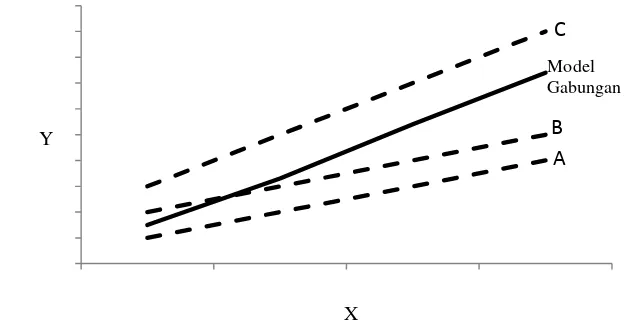
Gambar 1 Ilustrasi model gabungan
Pada Gambar 1 mengilustrasikan mengenai konsep model gabungan, ketika beberapa objek diamati selama periode waktu tertentu maka objek tersebut akan memiliki susunan data hasil amatan. Jika dimisalkan ada 3 objek, bernama A, B dan C, maka dalam model gabungan tidak lagi dilihat model masing-masing objek secara terpisah. Pada model ini diasumsikan semua objek memberikan pengaruh yang sama sehingga data semua objek dapat digabungkan untuk setiap periode waktu. Setelah data digabung, selanjutnya dimodelkan seperti regresi linier, maka didapatkanlah model gabungan yang mewakili semua objek.
2.1.2. Model Pengaruh Tetap
Pada model pengaruh tetap (fixed effect model), objek yang digunakan (N)
kebanyakan merupakan objek agregat atau hanya fokus terhadap N objek saja. Asumsi yang harus dipenuhi adalah: (1) µ diasumsikan tetap, sehingga dapat
diduga, (2) it menyebar bebas stokastik indentik Normal (0, ), (3) E(Xit, it) =0,
Xit saling bebas dengan it untuk setiap i dan t (Baltagi 2005).
Pendugaan parameter pada model pengaruh tetap, sebagai berikut: Pada persamaan regresi sederhana,
[3]
persamaan [3] ini dirata-ratakan untuk keseluruhan waktu, maka diperoleh persamaan
[4]
kemudian dengan mengurangkan persamaan [3] dengan persamaan [4], yang
disebut juga sebagai transformasi dalam (within transformation), didapatkan
4
Model [5] diduga dengan menggunakan pendekatan metode MKT. Parameter didapatkan dengan meregresikan persamaan [5]. Model pengaruh
tetap ini juga dikenal sebagai Metode Kuadrat Terkecil Peubah Boneka (Least
Square Dummy Variable/ LSDV), karena nilai pengamatan pada koefisien peubah
µi berupa peubah boneka (dummy) yang mengizinkan terjadinya perbedaan nilai
parameter yang berbeda-beda baik pada unit lintas objek maupun deret waktu (Baltagi 2005).
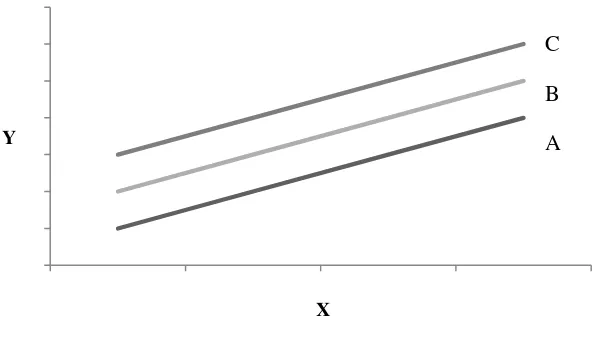
Gambar 2 Ilustrasi model tetap
Gambar 2 mengilustrasikan konsep model tetap, setiap objek memiliki model masing-masing yang berbeda nilai µ nya, selanjutnya akan mengubah nilai intersep masing-masing model. Sehingga diilustrasikan seperti Gambar 2, kemiringan yang dimiliki sama yang berarti pengaruh dari peubah penjelas terhadap peubah respon berlaku sama untuk semua objek.
2.1.3. Model Pengaruh Acak
Pada model pengaruh acak (random effect model), objek yang digunakan
biasanya merupakan objek yang dipilih secara acak dari populasi yang besar.
Asumsi yang harus dipenuhi adalah: (1) µi menyebar bsi Normal (0, σµ2), it
menyebar bsi Normal (0, ) , (2) E(Xit, µi) = 0 dan E(Xit, it) = 0, artinya Xit
saling bebas dengan µi dan it untuk setiap i dan t(Baltagi 2005).
Metode kuadrat terkecil menghasilkan penduga yang bersifat konsisten
dengan komponen galat yang dihasilkan mengalami galat baku berbias. Oleh
karena itu pendugaan dengan metode kuadrat terkecil terampat (generalized least
5
dengan 0 ≤ ≤ 1 dan simbol • menyatakan bentuk transformasi.
Bentuk persamaan [6] dan [7] diselesaikan dengan metode MKT (Elhorst 2010).
2.1.4. Uji Chow
Uji Chow digunakan untuk menguji parameter antara model gabungan dan model pengaruh tetap. Hipotesis yang di uji adalah:
Hipotesis awal (H0): =....= =0 (model gabungan)
Hipotesis tandingannya (H1): minimal ada satu i dengan , dengan
i=1,2....N
Statistik uji yang digunakan adalah:
[8]
diperoleh dari jumlah kuadrat galat hasil pendugaan model
gabungan dan diperoleh dari jumlah kuadrat galat hasil pendugaan
model pengaruh tetap. Keputusan tolak H0 jika F0 > FN-1,N(T-1)-K atau jika nilai-p<α
(Baltagi 2005).
2.1.5. Uji Hausman
Uji Hausman digunakan untuk menguji parameter antara model pengaruh
acak dengan model pengaruh tetap. Secara hipotesis bahwa pada suatu populasi,
jika objek diambil secara acak sebagai contoh maka dugaan model data panel adalah model pengaruh acak, bila objek yang digunakan merupakan keseluruhan objek dari populasi tersebut maka cenderung menggunakan model pengaruh tetap.
Lebih tepatnya, untuk mengetahui model acak dapat dibuat asumsi mengenai korelasi antara komponen galat dan peubah penjelasnya. Jika diasumsikan tidak terdapat korelasi antara galat dengan peubah penjelas maka model yang sesuai adalah model pengaruh acak dan sebaliknya adalah model tetap (Gujarati 2004).
Hipotesis digunakan pada uji ini:
Ho: (model acak)
H1 : (model tetap)
Statistik uji yang digunakan adalah:
[9]
dengan , adalah vektor koefisien peubah penjelas
dari model pengaruh acak, kemudian adalah vektor koefisien peubah
penjelas dari model pengaruh tetap. Keputusan tolak H0 jika dengan
6
2.2. Matriks Pembobot Spasial
Analisis spasial merupakan analisis yang memasukan pengaruh spasial atau ruang ke dalam model. Pada analisis spasial selalu ada korelasi antar ruang yang biasa disebut korelasi spasial. Jadi tiap amatan tidak bebas stokastik (Ward & Gleditsch 2008). Tipe data spasial antara lain data titik, data garis, data poligon dan data latis. Data titik terbagi menjadi titik diskret dan titik kontinu. Data garis misalkan peta jalan, sungai atau garis pantai. Data Poligon contohnya seperti peta kebun karena memiliki bentuk segi tidak beraturan. Kemudian data latis misalkan peta provinsi yang di dalamnya terdapat kabupaten. Ruang-ruang ini disebut sebagai lokasi.
Ada beberapa macam model spasial antara lain adalah model SAR, SEM dan GSM. Model SAR memuat informasi otoregresi spasial sedangkan model SEM memuat informasi otokorelasi antar error pada lokasi-lokasi yang menjadi objek penelitian. Ketika informasi otoregresi dan otokorelasi error antar lokasi termuat dalam satu model, maka model ini disebut model GSM. Pembentukan parameter otoregresi dan otokorelasi antar error melalui proses yang cukup kompleks karena sebelum melakukan analisa terlebih dahulu dilakukan pembentukan matriks yang berisi nilai kebersinggungan antar lokasi, matriks ini disebut dengan matriks pembobot spasial.
Matriks pembobot spasial pada dasarnya merupakan matriks yang menggambarkan hubungan antar wilayah dan diperoleh berdasarkan informasi jarak atau ketetanggaan. Diagonal dari matriks ini umumnya diisi dengan nilai nol. Karena matriks pembobot menunjukan hubungan antara keseluruhan lokasi, maka dimensi dari matriks ini adalah NxN, dimana N adalah banyaknya lokasi atau banyaknya unit lintas objek (Dubin 2009).
Beberapa pendekatan yang dapat dilakukan untuk menampilkan hubungan
spasial antar lokasi, diantaranya adalah konsep persinggungan (contiguity). Jenis
persinggungan ada 3, yaitu Rook Contiguity, Bishop Contiguity dan Queen
Contiguity (Dubin 2009).
Matriks contiguity menunjukan hubungan spasial suatu lokasi dengan lokasi
lainnya yang bertetangga. Pemberian nilai 1 diberikan jika lokasi-i bertetangga langsung dengan lokasi-j, sedangkan nilai 0 diberikan jika lokasi-i tidak bertetangga dengan lokasi-j. Lee dan Wong (2001) menyebut matriks ini dengan
biner matriks, dan juga disebut connectivity matriks, yang dinotasikan dengan C,
dan cij merupakan nilai dalam matriks baris ke-i dan kolom ke-j. Nilai cij adalah 1
jika antar lokasi-i bertetangga dengan lokasi-j dan cij bernilai 0 jika lokasi-i tidak
bertetangga dengan lokasi-j. Nilai pada matriks ini selanjutnya digunakan untuk
perhitungan matriks pembobot spasial W. Isi dari matriks pembobot spasial pada
baris ke-i dan kolom ke-j adalah wij. Nilai wij pada penelitian ini, yaitu:
wij =
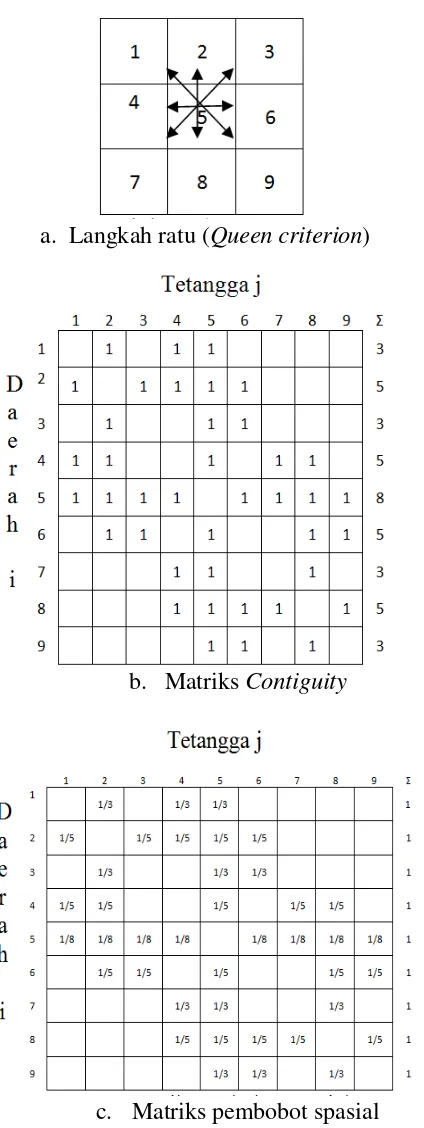
7
a. Langkah ratu (Queen criterion)
b. Matriks Contiguity
c. Matriks pembobot spasial
Gambar 3 Penghitungan matriks pembobot spasial dengan langkah ratu
Beberapa tipe Pembobot Spasial (W) yaitu W biner, W seragam, W invers
jarak dan W yang berasal dari kasus riil seperti kondisi ekonomi atau kondisi ada
8
pada lag ke-l dan pembobot non-seragam memberikan pembobotan yang tidak
sama untuk lokasi yang berbeda.
Setelah menentukan matriks pembobot spasial yang akan digunakan, selanjutnya dilakukan normalisasi pada matriks yang pembobot spasial tersebut seperti yang sudah di ilustrasikan pada Gambar 3.c. diatas. Pada umumnya, untuk
normalisasi matriks digunakan normalisasi baris (row-normalize). Artinya bahwa
matriks tersebut ditransformasi sehingga jumlah dari masing-masing baris matriks menjadi sama dengan satu. Terdapat alternatif lain dalam normalisasi matriks ini yaitu dengan menormalisasikan kolom pada matriks sehingga jumlah tiap-tiap kolom pada matriks pembobot menjadi sama dengan satu. Selain itu, dapat juga melakukan normalisasi dengan membagi elemen-elemen dari matriks pembobot dengan akar ciri terbesar dari matriks tersebut (Dubin 2009; Elhorst 2010). Berikut adalah contoh rumusan untuk menghitung elemen matriks pembobot seragam:
wij=
adalah jumlah tetangga pada lokasi ke-i di lag ke-ℓ. Pembobot non-seragam
ada kemungkinan menjadi pembobot seragam ketika beberapa kondisi mendukung. Salah satu metode untuk membentuk pembobot non-seragam adalah metode invers jarak. Matriks pembobot spasial lag ke k diperoleh berdasarkan
invers bobot untuk lokasi ke i dan j, dengan dij merupakan jarak euklid
dengan batasan range jarak tertentu sudah ditetapkan.
Menurut Fotheringham et al. (2002), beberapa fungsi pembobot dalam
analisis spasial, antara lain:
1. untuk semua i dan j. Model spasial dengan pembobot ini akan
menghasilkan model regresi biasa, dimana setiap data pada semua lokasi diberikan pembobot yang sama yaitu 1, tanpa melihat letak atau jaraknya dengan lokasi lain.
2. , jika , dan untuk . Nilai d adalah jarak
minimal antar lokasi yang dianggap sudah tidak mempengaruhi satu sama lain.
Jika jarak lokasi-i ke lokasi-j kurang dari d ( ), maka semua data pada
lokasi tersebut digunakan dan diberi bobot yang sama yaitu 1.
3. , dengan adalah dij jarak dari lokasi-i ke lokasi-j
dan b adalah lebar jendela, yaitu suatu nilai parameter penghalus
fungsi yang nilainya selalu positif. Fungsi ini biasa disebut fungsi kernel normal (Gaussian).
4. jika , dan untuk .
Fungsi ini mengikuti bentuk kernel pembobot ganda (bi-weight) dan biasa
9
5. , dengan adalah rank (peringkat) jarak dari
lokasi-i ke lokasi ke-j. Jarak paling dekat menghasilkan nilai mendekati 1, dan akan
semakin berkurang dengan semakin bertambahnya jarak lokasi-i ke lokasi ke-j.
Lebar jendela (bandwith) merupakan nilai yang perlu ditetapkan, sebagai
gambaran jarak maksimal suatu lokasi masih mempengaruhi lokasi lainnya. Salah satu cara yang dapat digunakan sebagai kriteria untuk mendapatkan nilai lebar jendela optimum adalah dengan meminimumkan nilai koefisien validasi silang, yaitu:
CV =
Dengan adalah nilai dugaan dengan pengamatan pada lokasi ke-i
dihilangkan dari proses prediksi (Fotheringham et al. 2002). Lebar jendela
optimum dapat diperoleh dengan proses iterasi hingga didapatkan CV minimum.
2.3.Analisis Data Panel Spasial
Model regresi linear pada data panel yang terdapat interaksi diantara unit-unit spasialnya, akan memiliki peubah spasial lag pada peubah respon atau peubah spasial proses pada galat yang biasanya disebut model SAR dan SEM (Elhorst 2010). Fokus pada model otoregresi spasial berhubungan dengan korelasi spasial pada peubah respon, sedangkan pada model galat spasial fokusnya terdapat pada
bentuk sisaan (Anselin 2009).
2.3.1. Uji Pengganda Lagrange
Sebelum melakukan pemodelan terhadap data panel spasial, untuk mengetahui adanya efek interaksi spasial pada data, dapat menggunakan uji
pengganda Lagrange (Lagrange multiplier/LM). Pengujian hipotesis pengganda
Lagrange adalah:
a. Model otoregresi spasial
H0 : = 0 (tidak ada ketergantungan otoregresi spasial)
H1 : ≠ 0 (ada ketergantungan otoregresi spasial)
b. Model galat spasial
H0 : = 0 (tidak ada ketergantungan galat spasial)
H1 : ≠ 0 (ada ketergantungan galat spasial)
Statistik uji untuk LM adalah :
[10]
[11]
dan masing-masing secara berurutan adalah statistik uji pengganda
Lagrange untuk model otoregresi spasial dan model galat spasial, simbol
menyatakan perkalian Kronecker, IT menyatakan matriks identitas berukuran T ×
T, menyatakan kuadrat tengah galat dari model data panel, W adalah matriks
pembobot spasial yang telah dinormalisasi, dan e menyatakan vektor sisaan dari
10
sisaan dari model data panel dengan pengaruh tetap/acak dari spasial dan/atau
waktu. Terakhir, J dan TW didefinisikan sebagai:
[12]
[13]
[14]
[15]
dengan INT adalah matriks identitas berukuran NT × NT dan simbol “tr”
menyatakan operasi teras matriks. Keputusan tolak H0 jika nilai statistik
pengganda Lagrange lebih besar dari nilai dengan q=1 (q adalah banyaknya
parameter spasial) atau nilai-p < α (Anselin 2009; Elhorst 2010).
2.3.2. Model Otoregresi Spasial (SAR)
Model otoregresi spasial dinyatakan pada persamaan berikut:
[16]
adalah koefisien otoregresi spasial dan adalah elemen dari matriks pembobot
spasial yang telah dinormalisasi (W). Pendugaan parameter pada model ini
menggunakan penduga kemungkinan maksimum/MLE (Elhorst 2010).
2.3.3. Model Galat Spasial (SEM)
Model galat spasial dinyatakan pada persamaan berikut: ; [17]
; [18]
11
3 METODE PENELITIAN
3.1. Data
Data yang akan digunakan dalam penelitian ini adalah data dari hasil simulasi dan data sekunder untuk aplikasinya. Data sekunder yang akan digunakan adalah data mengenai peubah-peubah yang terkait dengan produksi beras diseluruh provinsi di Indonesia dari tahun 2010-2012 yang berasal dari website Badan Pusat Statistik seperti pada Tabel 2.
Tabel 2 Rincian peubah yang digunakan pada data sekunder
Nama Peubah Status Penjelasan
Produksi Peubah Respon Merupakan data produksi beras
dari 33 provinsi di Indonesia dengan satuan ton
WY Peubah Otoregresi Berasal dari perkalian kroneker
matriks I dan W yang selanjutnya dikalikan dengan vektor produksi
Harga Beras Peubah Penjelas Merupakan data harga beras dari
33 provinsi di Indonesia dengan satuan rupiah
Luas Panen Peubah Penjelas Merupakan data luas panen padi
dari 33 provinsi di Indonesia dengan satuan hektar
Jumlah Petani Peubah Penjelas Merupakan data jumlah petani dari
33 provinsi di Indonesia dengan satuan jiwa
3.2. Metode
Berikut langkah-langkah yang dilakukan untuk melakukan penelitian ini:
1. Menentukan jumlah lokasi yang akan disimulasikan yaitu N=3, N=9 dan
N=25.
2. Membuat 3 jenis Peta Lokasi dari langkah 1.
3. Membuat matriks pembobot spasial biner berdasarkan konsep
kebersinggungan queen contiguity dari masing-masing jenis peta lokasi.
Pada langkah ini, untuk peta 3 lokasi maka akan terbentuk matriks 3x3, 9 lokasi terbentuk matriks berukuran 9x9 dan 25 lokasi terbentuk matriks berukuran 25x25.
4. Membuat matriks pembobot spasial seragam berdasarkan konsep
kebersinggungan queen contiguity dari masing-masing jenis peta lokasi.
Pada langkah ini, untuk peta 3 lokasi maka akan terbentuk matriks 3x3, 9 lokasi terbentuk matriks berukuran 9x9 dan 25 lokasi terbentuk matriks berukuran 25x25.
5. Membuat matriks pembobot fungsi kernel normal (Gaussian) berdasarkan
12
dan dijadikan sebagai acuan pembuatan matriks pembobot kernel normal. Fungsi pembobot kernel normal (Gaussian) sebagai berikut:
(Fotheringham et al. 2002 )
6. Menentukan jumlah deret waktu yang akan disimulasikan yaitu T=3, T=6,
T=12 dan T=36.
7. Membangkitkan y dan x berdasarkan model data panel spasial berikut:
dengan
(Elhorst 2010)
8. Membuat matriks hasil perkalian kroneker antara matriks Identitas waktu
dengan W yang akan dinamakan IW.
9. Mengalikan matriks IW dan vektor y hasil pembangkitan untuk
mendapatkan peubah WY.
10. Membangun model data panel spasial menggunakan model gabungan dan
mendapatkan nilai RMSE. Tujuan menggunakan model gabungan adalah
agar semua model yang dibentuk memiliki base model yang sama sehingga
hasil RMSE nya relevan untuk di bandingkan.
11. Mengulangi langkah 7-10 sebanyak 1000 replikasi untuk masing-masing
kombinasi jenis W, N, T, model data panel spasial ( dan berbeda)
Keterangan :
- Jenis W : W Biner, W Seragam dan W Kernel Gaussian
- Jenis N : 3, 9 dan 25 lokasi
- Jenis T : 3, 6, 12 dan 36 deret
- Jenis Model : GSM ( =0.3, 0.5, 0.8 dan =0.3, 0.5, 0.8), SAR (GSM:
=0.8 dan =0.1) dan SEM (GSM: =0.1 dan =0.8)
12. Mendapatkan nilai RMSE sebanyak 1000 replikasi dari setiap kombinasi W,
N, T dan model yang disimulasikan.
13. Menentukan W terbaik berdasarkan RMSE yang relatif kecil untuk semua
kombinasi.
14. Menggunakan W terbaik hasil simulasi untuk diaplikasikan kedalam data
empiris melalui model data panel spasial.
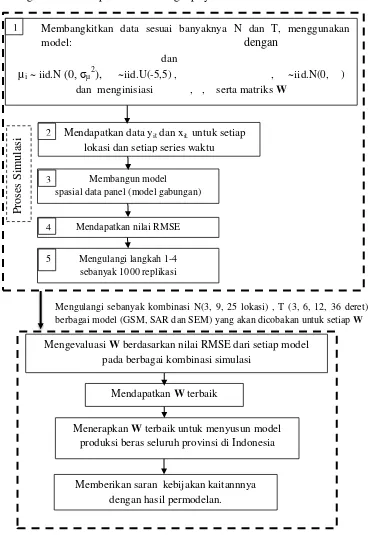
13
Membangkitkan data sesuai banyaknya N dan T, menggunakan model: dengan
dan
µi ~ iid.N (0, σµ2), ~iid.U(-5,5) , , ~iid.N(0, )
dan menginisiasi , , serta matriks W
Mendapatkan data yit dan xit. untuk setiap lokasi dan setiap series waktu
Membangun model spasial data panel (model gabungan)
Mendapatkan nilai RMSE 1
4
Mengulangi langkah 1-4 sebanyak 1000 replikasi 5
Mengevaluasi W berdasarkan nilai RMSE dari setiap model pada berbagai kombinasi simulasi
Menerapkan W terbaik untuk menyusun model produksi beras seluruh provinsi di Indonesia
Mendapatkan W terbaik
Memberikan saran kebijakan kaitannnya dengan hasil permodelan.
Berikut gambaran alur penelitian selengkapnya:
Gambar 4 Algoritma simulasi dan alur penelitian data panel spasial
P
rose
s S
im
ulasi
2
3
Mengulangi sebanyak kombinasi N(3, 9, 25 lokasi) , T (3, 6, 12, 36 deret) dan
14
Gambar 5 Diagram alir pendugaan parameter data panel spasial
Ana
Ho ditolak Ho diterima
Tidak tepenuhi
W terbaik dari hasil simulasi
15
4
HASIL DAN PEMBAHASAN
4.1. Tiga Jenis Matriks Pembobot Spasial
Matriks pembobot spasial(W) yang akan dikaji dalam penelitian ini adalah
W biner, W seragam, W kernel Gaussian berdasarkan jarak antar centroid dari
masing-masing lokasi. Matriks-matriks ini akan dibandingkan mana yang lebih baik untuk prediksi dan penentuan nilai parameter pada model data panel spasial menggunakan nilai RMSE. Penelitian ini menggunakan simulasi untuk mengkaji jenis matriks pembobot spasial manakah yang sesuai untuk berbagai kombinasi jumlah lokasi dan jumlah deret waktu yang berbeda serta pada beberapa model spasial yaitu GSM, SAR dan SEM pada keseluruhan lokasi yang menjadi amatan. Jumlah lokasi yang disimulasikan ada 3 jenis yaitu 3 lokasi, 9 lokasi dan 25 lokasi tujuannya agar amatan lokasi sedikit, sedang dan banyak terwakili, sedangkan jumlah deret waktu yang disimulasikan ada 4 jenis yaitu 3 deret, 6 deret, 12 deret dan 36 deret, tujuannya agar deret waktu sangat pendek, pendek, sedang dan lama terwakili. Masing-masing peta lokasi disajikan pada Gambar 6, 11 dan 16. Penulis mengakui bahwa mensimulasikan peta cukup tidak mudah, terutama dengan kondisi riil dilapangan. Untuk itu mencoba menggambar peta yang hampir sesuai untuk mayoritas kondisi dilapangan. Peta yang dibuat sengaja berhimpitan untuk semua lokasi karena ingin mencoba mensimulasikan matriks pembobot spasial yang pada dasarnya melihat kebertetanggaan antar lokasi dan jauh dekatnya antara lokasi (jarak). Matriks pembobot spasial dengan konsep
kebertetanggan yang dicobakan adalah matriks pembobot spasial biner (W Biner)
dan matriks pembobot spasial seragam (W Seragam), sedangkan yang
menggunakan konsep jarak dicobakan matriks pembobot spasial dengan fungsi
kernel normal (Gaussian). Penyusunan tiga jenis W ini disesuaikan dengan bentuk
peta dari masing-masing lokasi ( N=3, N=9, N=25) yang dipetakan.
Peta yang akan di cobakan ada 3 macam dengan berbagai rancangan lokasi, sebagai berikut:
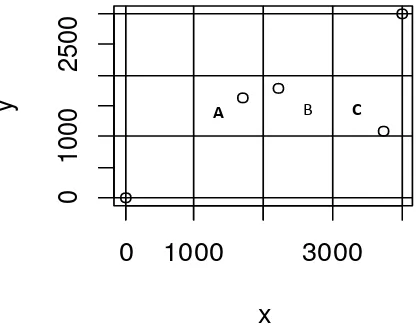
a. Jumlah lokasi sebanyak tiga
Berikut adalah ilustrasi dari peta tiga lokasi, dibuat berjajar dengan maksimal jumlah tetangga ada 2 karena lokasi hanya sebanyak 3. Kemudian akan dibuat matriks pembobot spasial biner, seragam dan kernel gaussian dari peta pada Gambar 6 dibawah ini.
A B C
Gambar 6 Peta Tiga Lokasi
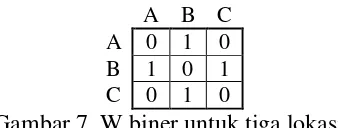
W biner dibentuk dengan menerapkan konsep queen contiguity antar lokasi
yang menjadi pusat amatan. Nilai 1 menunjukan bahwa kedua lokasi tersebut saling bertetangga sedangkan nilai 0 menunjukan kedua lokasi tersebut tidak saling bertetangga. Misalkan untuk gambar di atas antara A dan B bersinggungan maka diberi nilai 0 pada sel (A,B) sedangkan antara A dan C
tidak bersinggungan maka sel (A,C) bernilai 0. W biner yang bisa terbentuk
16
diterapkan dalam pembentukan matriks ini adalah dengan menjumlahkan baris
dari W biner, kemudian membagi nilai setiap sel dengan hasil penjumlahan
barisnya. Hal ini dimaksudkan agar nilai setiap sel mewakili konsep besaran kontribusi masing-masing tetangga dari lokasi tersebut. Misalkan untuk lokasi A yang hanya memiliki satu tetangga yaitu B maka nilai sel (A,B) adalah , maka nilai sel tersebut adalah 1. Berbeda dengan lokasi B yang
memiiki jumlah tetangga sebanyak 2 yaitu A dan C, maka nilai pada sel disetiap
baris B adalah , artinya masing-masing lokasi A dan C memiliki
kontribusi sebanyak setengah dari total kontribusi seluruh tetangga yang dimiliki
B. W Seragam yang sudah dibentuk dapat dilihat pada Gambar 8.
A B C A 0 1 0 B 0.5 0 0.5 C 0 1 0
Gambar 8 W seragam untuk tiga lokasi
Matriks pembobot spasial ketiga yang disimulasikan adalah W kernel normal
(Gaussian). Konsep yang diterapkan adalah ketika ada dua lokasi saling berjauhan maka akan ada sedikit kemungkinan kedua lokasi saling mempengaruhi sedangkan jika kedua lokasi tersebut berdekatan maka akan ada besar kemungkinan kedua lokasi tersebut saling mempengaruhi. Besaran nilai pembobot dengan fungsi kernel gaussian adalah dari 0 sampai 1, jika lokasi berdekatan maka akan memiliki bobot yang relatif lebih dekat ke angka 1 sedangkan jika lokasi berjauhan maka akan memiliki nilai bobot yang cenderung dekat ke angka 0. Peta yang dibuat dengan menggambar lokasi yang memiliki luas 1000 km x 1000 km, luas sempitnya lokasi yang digambar akan menentukan besaran lebar jendela yang akan digunakan, karena penelitian ini menggunakan panjang lokasi 1000 km dan menerapkan konsep pada simulasi ini bahwa “suatu lokasi dianggap mempengaruhi jika jarak antar titik centroid masing-masing lokasi masih kurang
dari sama dengan 2000km” yang mirip dengan konsep satu tetangga, maka
mencoba menerapkan konsep lebar jendela seperti itu karena dalam simulasi sebanyak 1000 replikasi sangat sulit diterapkan mencari lebar jendela dengan ikut
mempertimbangkan minimum kovarian antar nilai yit dengan yit dugaannya
diseluruh lokasi, karena gugus data yit direplikasi sebanyak 1000 kali dengan nilai
yit pada setiap replikasi berbeda sehingga juga akan menghasilkan nilai lebar
17
lainnya sehingga lebar jendela yang digunakan adalah 2000 km. Pembobot Kernel Gaussian dibuat dengan mensimulasikan titik centroid dari masing-masing lokasi, peta lokasi dibuat dalam bidang kartesius dengan tujuan agar jarak antar centroid dapat diukur dengan akurat dan memudahkan simulasi posisi lokasi centroid. Maka didapatkan peta posisi lokasi beserta centroidnya seperti Gambar 9.
Gambar 9 Peta posisi centroid 3 lokasi
Dari posisi centroid dari masing-masing lokasi tersebut maka didapatkan jarak antar centroid kemudian membuat matriks pembobot dengan fungsi kernel Gaussian yaitu seperti Gambar 10.
A B C
A 0.000 0.965 0.572 B 0.965 0.000 0.701 C 0.572 0.701 0.000
Gambar 10 W kernel Gaussian untuk 3 lokasi
b. Jumlah lokasi sebanyak sembilan
Berikut adalah ilustrasi dari peta sembilan lokasi, kemudian akan dibuat matriks pembobot spasial biner dan seragam dari peta pada Gambar 11.
A B C D E F G H I
Gambar 11 Peta Sembilan Lokasi
W biner yang bisa terbentuk untuk sembilan lokasi seperti peta pada Gambar
11 dapat dilihat pada Gambar 12.
0 1000 3000
0
1000
2500
x
18
A B C D E F G H I
A 0 1 0 1 1 0 0 0 0
B 1 0 1 1 1 1 0 0 0
C 0 1 0 0 1 1 0 0 0
D 1 1 0 0 1 0 1 1 0
E 1 1 1 1 0 1 1 1 1
F 0 1 1 0 1 0 0 1 1
G 0 0 0 1 1 0 0 1 0
H 0 0 0 1 1 1 1 0 1
I 0 0 0 0 1 1 0 1 0
Gambar 12 W Biner untuk sembilan lokasi
Sedangkan W seragam yang bisa dibentuk berdasarkan peta pada Gambar 11
dapat dilihat pada Gambar 13.
A B C D E F G H I
A 0.000 0.333 0.000 0.333 0.333 0.000 0.000 0.000 0.000 B 0.200 0.000 0.200 0.200 0.200 0.200 0.000 0.000 0.000 C 0.000 0.333 0.000 0.000 0.333 0.333 0.000 0.000 0.000 D 0.200 0.200 0.000 0.000 0.200 0.000 0.200 0.200 0.000 E 0.125 0.125 0.125 0.125 0.000 0.125 0.125 0.125 0.125 F 0.000 0.200 0.200 0.000 0.200 0.000 0.000 0.200 0.200 G 0.000 0.000 0.000 0.333 0.333 0.000 0.000 0.333 0.000 H 0.000 0.000 0.000 0.200 0.200 0.200 0.200 0.000 0.200 I 0.000 0.000 0.000 0.000 0.333 0.333 0.000 0.333 0.000
Gambar 13 W seragam untuk sembilan lokasi
Pembobot ketiga yang akan dicobakan untuk 9 lokasi tersebut adalah pembobot kernel Gaussian seperti yang sudah dicobakan pada 3 lokasi. Peta posisi centroid dari 9 lokasi dapat dilihat pada Gambar 14.
Gambar 14 Peta posisi centroid dari 9 lokasi
0 1000 2000 3000 4000 5000
0
1000
2000
3000
4000
5000
x
y
A B C
D E F
19
Dari peta tersebut didapatkan matriks jarak antar centroid, kemudian dibentuk matriks kernel Gaussian seperti Gambar 15.
A B C D E F G H I
A 0.000 0.864 0.769 0.781 0.739 0.572 0.620 0.489 0.400 B 0.864 0.000 0.928 0.729 0.883 0.821 0.640 0.636 0.606 C 0.769 0.928 0.000 0.506 0.683 0.653 0.412 0.423 0.421 D 0.781 0.729 0.506 0.000 0.884 0.715 0.957 0.805 0.660 E 0.739 0.883 0.683 0.884 0.000 0.945 0.880 0.900 0.848 F 0.572 0.821 0.653 0.715 0.945 0.000 0.755 0.893 0.925 G 0.620 0.640 0.412 0.957 0.880 0.755 0.000 0.912 0.775 H 0.489 0.636 0.423 0.805 0.900 0.893 0.912 0.000 0.960 I 0.400 0.606 0.421 0.660 0.848 0.925 0.775 0.960 0.000
Gambar 15 Matriks pembobot kernel Gaussian untuk 9 lokasi
c. Jumlah lokasi sebanyak 25
Berikut adalah ilustrasi dari peta 25 lokasi, kemudian akan dibuat matriks pembobot spasial biner dan seragam dari peta pada Gambar 16.
A B C D E
F G H I J
K L M N O
P Q R S T
U V W X Y
Gambar 16 Peta 25 lokasi
W biner yang bisa dibentuk berdasarkan peta pada Gambar 16 bisa dilihat pada
Gambar Lampiran 1, sedangkan W seragam bisa dilihat pada Lampiran 2.
Matriks ketiga yang akan dicobakan pada 25 lokasi ini adalah matriks pembobot kernel Gaussian, dengan mensimulasikan posisi dari centroid 25 lokasi pada Gambar 16, maka didapatkan peta posisi seperti Gambar 17.
Gambar 17 Peta posisi centroid untuk 25 lokasi
Selanjutnya matriks pembobot Kernel Gaussian berdasarkan peta posisi centroid Gambar 17 dapat dilihat pada Lampiran 3.
0 1000 2000 3000 4000 5000 6000 7000
0
1000
2000
3000
4000
5000
6000
7000
x
20
Ketiga Jenis W pada tiga jenis peta berbeda tersebut (N=3, N=9, N=25)
selanjutnya juga simulasikan terhadap berbagai kombinasi jumlah waktu yang berbeda serta pada besaran nilai yang berbeda. Lama waktu yang dicobakan adalah T=3, T=6, T=12 dan T=36, sedangkan model yang dicobakan adalah GSM, SAR dan SEM.
4.2. Hasil Simulasi Matriks Pembobot Spasial
Setelah melakukan simulasi didapatkan nilai RMSE dari kombinasi jenis W,
N, T, dan berbeda, hasilnya seperti yang terlihat pada Tabel 3.
Tabel 3 Nilai RMSE hasil simulasi pada kombinasi W, N, T dan model spasial
21
Berdasarkan nilai RMSE yang dihasilkan dari semua kombinasi simulasi pada Tabel 3, terlihat bahwa rataan nilai RMSE dari W1 paling tinggi yaitu 2.314, rataan RMSE dari W2 sebesar 1.672 kemudian W3 sebesar 1.818. Jika dilihat dari
besaran rataan maka dapat disimpulkan bahwa W seragam lebih baik dari pada W
biner dan W kernel gaussian untuk hampir semua kombinasi N, T, dan karena
memiliki rataan nilai RMSE yang relatif lebih kecil.
Berdasarkan diagram batang pada Lampiran 5, untuk hampir semua jenis N
dan T, W seragam cukup stabil pada nilai RMSE yang kecil pada model GSM
(0.3), GSM (0.5) dan SAR, sedangkan pada model GSM(0.8) dan SEM nilai RMSE nya cukup tinggi. W3 (Kernel Gaussian) memiliki nilai RMSE yang tidak stabil pada lokasi berjumlah banyak (N=25) serta lokasi yang berjumlah sedikit
(N=3). W kerrnel Gaussian ini memiliki nilai rataan RMSE yang relatif kecil pada
berbagai kombinasi N dan T yaitu pada model SAR, akan tetapi nilai RMSE untuk model SAR ini cukup tinggi ketika jumlah lokasinya banyak (N=25). W1(Biner) memiliki nilai RMSE yang tidak stabil untuk semua jenis N dan T,
akan tetapi jika diperhatikan, W Biner ini memiliki nilai rataan RMSE yang
cukup kecil dan stabil pada berbagai kombinasi N dan T pada model SAR.
Kemudian berdasarkan Grafik 18 terlihat bahwa W seragam memiliki kestabilan
nilai RMSE pada berbagai kombinasi N dan T.
Gambar 18 Perbandingan RMSE W Biner, W Seragam dan W Kernel
Gausian pada berbagai kombinasi N dan T
Berdasarkan ulasan sebelumnya maka dapat disimpulkan bahwa W Seragam
merupakan W terbaik dibandingkan dengan W biner dan W kernel gaussian untuk
kasus permodelan dengan berbagai kombinasi N, T dan model spasial seperti diatas dan model spasial SAR merupakan model yang cukup kekar untuk berbagai
jenis W, dengan nilai RMSE terkecil terdapat pada W seragam untuk hampir
semua kombinasi N dan T.
22
Gambar 19 Perbandingan RMSE dari W untuk setiap model
Berdasarkan Gambar 19, dapat disimpulkan bahwa ketika dibandingkan terhadap
masing-masing model data panel spasial dengan menggunakan W berbeda akan
menghasilkan RMSE yang berbeda pula. Model GSM dengan parameter = 0.3
dan = 0.3, menghasilkan RMSE terkecil ketika menggunakan W Seragam,
model GSM dengan parameter = 0.5 dan = 0.5 memiliki RMSE terkecil ketika
menggunakan W seragam dan W Kernel Gaussian, dan seterusnya. Model SAR
menghasilkan niai RMSE terkecil ketika menggunakan W seragam, sedangkan
model SEM menghasilkan RMSE terkecil ketika menggunakan W Kernel
Gaussian.
Selanjutnya diulas sebaran nilai RMSE pada berbagai jenis N dan T untuk setiap model yang dicobakan. Grafik yang disajikan untuk masing-masing jenis matriks pembobot spasial dapat dilihat pada Gambar 20.
Gambar 20 Perbandingan RMSE pada berbagai jenis N, T & Model untuk W
Biner
23
dengan parameter spasialnya sebesar 0.8 didapatkan nilai RMSE terkecil ketika jumlah lokasi banyak (N=25) dan deret waktunya pendek (T=3). Model SAR mendapatkan nilai RMSE terkecil ketika jumlah lokasinya sedang (N=9) dan banyak (N=25) dengan deret waktu 3, 12 dan 36. Sedangkan model SEM memberikan nilai RMSE terkecil ketika jumlah lokasi banyak (N=25) dan deret waktu sedikit (T=3).
Gambar 21 Perbandingan RMSE pada berbagai jenis N, T & Model untuk W
Seragam
24 menghasilkan nilai RMSE terkecil ketika jumlah lokasi sedang (N=9) dan jumlah deret waktu sedikit (T3). Selanjutnya model GSM dengan parameter spasialnya sebesar 0.8 didapatkan nilai RMSE terkecil ketika jumlah lokasi banyak (N=9) dan deret waktunya pendek (T=3). Model SAR mendapatkan nilai RMSE terkecil ketika jumlah lokasinya sedang (N=9) dan waktu (T=3). Model SEM menghasilkan nilai RMSE terkecil ketika N=9 dan T=3.
4.3. Aplikasi Data Produksi Beras
Setelah menyelesaikan proses simulasi dan didapatkan W terbaik adalah W
seragam untuk penelitian ini, maka selanjutnya W seragam ini akan digunakan
untuk membangun model data panel spasial pada data produksi beras seluruh provinsi di Indonesia tahun 2010-2012. Berikut adalah tahapan hasil pembahasan data aplikasi.
4.3.1. Eksplorasi Data
Data yang digunakan adalah data produksi beras serta data harga beras pada setiap provinsi di Indonesia dari tahun 2010 sampai tahun 2012. Berdasarkan Diagram batang pada Gambar 23, dapat dilihat bahwa Provinsi Jawa Barat memiliki kumulatif jumlah produksi beras yang paling tinggi disusul oleh Provinsi Banten, DIY, Jawa Tengah dan Jawa Timur.
Gambar 23 Produksi beras tiap provinsi tahun 2010-2012
25
4.3.2. Plot Pencaran Moran Produksi Beras antar Provinsi
Berdasarkan hasil plot pencaran Moran antara hasil produksi beras provinsi dengan hasil produksi beras provinsi tetangga didapatkan hasil seperti Gambar 24, 25 dan 26. Jika dilihat dari plot pencaran moran dari tahun 2010 sampai tahun 2012 tidak begitu menunjukan perubahan plot yang cukup signifikan, hubungannya masih cukup stabil hanya saja ada 2 provinsi yaitu Jawa Timur dan Jawa Tengah yang mengalami penurunan jumlah produksi beras pada tahun 2011 dan 2012 sehingga posisinya digeser oleh provinsi DIY dan Banten akan tetapi pola hubungan pada plot pencaran moran secara umum masih tidak jauh berbeda dari tahun ke tahun. Detailnya dapat dilihat pada Tabel 5 dan 6.
Gambar 24 Plot pencaran Moran Produksi Beras tahun 2010
Gambar 25 Plot pencaran Moran Produksi Beras tahun 2011
Gambar 26 Plot pencaran Moran Produksi Beras tahun 2012
26
Berdasarkan hasil plot pencaran Moran di atas, terlihat bahwa plot-plot menyebar di beberapa kuadran. Detail persentase komposisi setiap kuadran dapat dilihat pada Tabel 4, Terlihat bahwa plot banyak berada pada kuadran III.
Tabel 4 Komposisi posisi provinsi dalam plot pencaran Moran
Kuadran 2010 2011 2012
I (High-High) 15.15% 12.12% 12.12%
II (Low-High) 12.12% 18.18% 18.18%
III (Low-Low) 57.58% 48.48% 54.55%
IV (Hig-Low) 6.06% 15.15% 9.09%
Untuk melihat persentase provinsi yang masih tetap berada dalam kuadran
yang sama walaupun sudah berganti tahun (masih sesuai) dapat dilihat pada Tabel
5. Terlihat bahwa ada sebanyak 54.55% provinsi yang masih dalam kuadran yang sama dari pada tahun 2010 dan 2011, ada 60.61% provinsi yang masih dalam kuadran yang sama tahun 2010 dan 2012, sedangkan pada tahun 2011 dan 2012 ada cukup banyak provinsi yang masih berada dalam kuadran yang sama yaitu sebanyak 93.94%.
Tabel 5Matriks kesesuaian posisi provinsi dalam plot pencaran Moran
Tahun 2011 2012
2010 54.55% 60.61%
2011 93.94%
4.3.3. Peubah Harga Beras
Berdasarkan diagram batang di bawah ini, dapat dijelaskan bahwa harga beras semakin lama semakin meningkat, hal ini mungkin dipengaruhi juga oleh laju inflasi.
Gambar 27 Rataan harga beras tahunan
6513 7372 8057
0 5000 10000
2010 2011 2012
Har
g
a
(R
u
p
iah
)
27
Gambar 28 Fluktuasi harga beras perprovinsi tahun 2010-2012
Besarnya korelasi antar peubah dapat dilihat pada Tabel 6, korelasi antar peubah Produksi dan peubah otoregresinya adalah positif dan cukup besar yaitu 0.226. Akan tetapi untuk melihat hubungan antara produksi dirinya dengan rataan produksi tetangganya lebih baik melihat dari plot pencaran moran pada pembahasan diatas karena lebih representatif untuk menggambarkan efek spasialnya.
Pada proses pendugaan parameter, terlebih dahulu dibangun model gabungan kemudian melakukan uji Chow untuk menguji model yang lebih cocok antara model gabungan dengan model tetap. Hipotesis awalnya adalah model gabungan dan hipotesis alternatifnya adalah model tetap. Hasil Uji Chow didapatkan nilai-p sebesar 0.000 yang berarti tolak Ho, artinya dapat dinyatakan bahwa model cocok adalah model pengaruh tetap. Selanjutnya dilakukan uji Hausman untuk membandingkan antara model acak dan model tetap. Hipotesis awalnya adalah model acak dan hipotesis alternatifnya adalah model tetap, setelah dilakukan pengujian didapatkan nilai-p sebesar 0.000 artinya Tolak Ho, maka dapat disimpulkan bahwa model yang cocok untuk data produksi pada provinsi di Indonesia tahun 2010-2012 adalah model data panel spasial dengan efek tetap.
Setelah melakukan permodelan menggunakan model pengaruh tetap, maka didapatkan hasil dugaan parameter seperti yang terlihat pada Tabel 7. Dari hasil ini peubah Harga Beras dan Luas Panen tidak berpengaruh signifikan pada taraf nyata 15%, maka dari itu mencoba mengeluarkannya dari model sehingga didapatkan model kedua dengan hasil pendugaan parameternya dapat dilihat pada
28
Tabel 8. Pada model kedua ini, R2 yang didapatkan mengalami penurunan yang
kecil sehingga tidak masalah jika dikeluarkan dari model. Penurunan yang kecil ini dimungkinkan karena korelasi antara jumlah petani dengan luas panen cukup
besar, sehingga jika salah satu saja yang digunakan maka R2 model tidak akan
jauh berbeda. Hal ini juga menyebabkan perlu ditelusuri juga bagaimanakah pengaruh dari Luas Panen terhadap Produksi, sehingga dilakukan permodelan seperti Tabel 9. Hasil tersebut menunjukan bahwa Luas Panen tidak berpengaruh signjfikan terhadap Produksi Beras, sehingga diputuskan untuk menggunakan
Model pada Tabel 8 sebagai model data panel terbaik dengan nilai R2 yang cukup
tinggi yaitu 73.32%.
Tabel 7 Dugaan parameter model data panel (R2 =73.64%)
Tabel 8 Model data panel dengan peubah penjelas jumlah petani (R2 =73.32%)
Tabel 9 Model data panel dengan peubah penjelas luas panen (R2 =70.47%)
Selanjutnya dilakukan pengujian pengganda Lagrange untuk melihat efek spasial pada data produksi padi untuk menentukan apakah model SAR ataukah SEM yang lebih cocok untuk permodelan ini. Pengujiannya menggunakan LM
Test, dan didapatkan hasil uji sesuai Tabel 9 sebagai berikut:
Tabel 10 Uji LM pada SAR dan SEM
SAR/SEM Uji LM Nilai Khi Kuadrat Nilai-p
LM-SAR 3.32x10-4 2.072 0.985
LM-SEM 0.128 2.072 0.721
Dari hasil uji LM, nilai-p lebih besar dari alpha 15% maka dapat disimpulkan bahwa secara uji LM tidak ada pengaruh spasial otoregresi dan galat pada data produksi beras Provinsi di Indonesia, akan tetapi jika dieksplorasi berdasarkan nilai produksi padi tahunannya yang dapat dilihat dari Gambar 24, 25 dan 26 sebaran moran scatter plot menyatakan sebaran produksi padi antar provinsi memiliki keeratan hubungan. Kemudian dilakukan ekplorasi data produksi padi terhadap masing-masing provinsi seperti Gambar 29, Gambar terlihat bahwa ragam data produksi masing-masing provinsi berbeda-beda, sehingga tetap dilakukan penelitian untuk melihat apakah ada efek spasial otoregresi produksi padi dari provinsi tetangga terhadap dirinya.
Peubah Penjelas Koefisien Galat Baku Nilai-p
Harga Beras 0.065 0.096 0.497
Luas Panen 1.123 2.164 0.605
Jumlah Petani 3.807 1.389 0.008
Konstanta 4.96x10-17 0.064 1.000
Peubah Penjelas Koefisien Galat Baku Nilai-p
Jumlah Petani 3.439 1.290 0.009
Konstanta 1.66x10-17 0.064 1.000
Peubah Penjelas Koefisien Galat Baku Nilai-p
Luas Panen 0.844 2.249 0.709
29
Gambar 29 Boxplot produksi beras masing-masing provinsi
Setelah memasukan unsur otoregresi spasial, didapatkan hasil pendugaan parameter bahwa ada pengaruh yang signifikan dari hubungan ketertetanggaan antar provinsi dari segi produksi berasnya. Terlihat nilai-p sebesar 0.000 < alpha (15%) sehingga Tolak Ho, artinya ada pengaruh yang signifikan produksi beras tetangga terhadap produksi beras dirinya pada taraf nyata 15%.
H0: = 0 (Tidak ada pengaruh produksi beras tetangga terhadap produksi beras
dirinya)
H1: (Ada pengaruh produksi beras tetangga terhadap produksi beras
dirinya)
Model pada Tabel 11 memiliki nilai R2 sebesar 98.9%, yang jauh lebih
tinggi jika dibandingkan dengan model data panel sebelumnya. Peningkatan R2 ini
dirasa cukup baik, sehingga model ini cocok sebagai model terbaik untuk menduga parameter pada data studi produksi beras di seluruh provinsi di Indonesia secara keseluruhan.
Tabel 11 Dugaan parameter model data panel spasial
Data pada Tabel 11 merupakan data hasil pembobotan dengan nilai kuadrat residual karena terdapat heteroskedastisitas pada galatnya dapat dilihat pada Lampiran 5. Hal ini menimbulkan ide untuk mencoba mengelompokkan lokasi-lokasi berdasarkan pola galatnya dengan konsep seperti yang tersaji pada Tabel 12, sehingga didapatkan model masing-masng cluster seperti Tabel 13, 14, 15 dan 16.
Peubah Penjelas Koefisien Galat Baku Nilai-p
30
Tabel 12 Pola galat untuk pengelompokan provinsi
2010 2011 2012 Kelompok Provinsi
+ + - 1 Yogyakarta, Gorontalo, Aceh, Sulawesi Selatan + - - 2 Jawa Barat, Maluku, Sulawesi Barat, Sulawesi
Tenggara, Sumatera Selatan, Sumatera Utara - + + 3 Bangka Belitung, Jawa Timur, Kalimantan Barat,
Papua, Sumatera Barat
- - + 4
Bali, Banten, Bengkulu, Jakarta, Jambi, Jawa tengah, Kalimantan Selatan, Kalimantan Tengah, Kalimantan Timur, Kep.Riau, ampung, Maluku, NTB, NTT, Papua Barat, Riau, Sulawesi Utara.
Pola galat yang terdapat pada Lampiran 4 dan kemudian dikelompokan seperti Tabel 12, menghasilkan model pada Tabel 13, 14 15 dan 16 dengan nilai
R2 masing-masing adalah 99.01%, 99.04%, 95.48% dan 95.92%. Hasil analisa
menunjukan bahwa untuk model kelompok 1 dan 2 memiliki parameter otoregresi spasial yang signifikan pengaruhnya terhadap produksi beras pada taraf nyata 15% dengan kelompok 1 bernilai negatif sedangkan kelompok 2 bernilai positif. Kelompok 3 dan 4 memiliki dugaan parameter otoregresi spasial yang tidak berpengaruh signifikan terhadap produksi beras.
Tabel 13 Model data panel spasial kelompok 1 (R2 = 99.01%)
Tabel 14 Model data panel spasial kelompok 2 (R2 = 99.04%)
Tabel 15 Model data panel spasial kelompok 3 (R2 = 95.48%)
Tabel 16 Model data panel spasial kelompok 4 (R2 = 95.92%)
Hasil ini menunjukan bahwa setiap lokasi memiliki pengaru yang berbeda-beda terhadap lokasi lainnya, sehingga pengelompokan yang dilakukan sudah cukup baik untuk menggambarkan kondisi model data panel spasial provinsi di Indonesia.
Peubah Penjelas Koefisien Galat Baku Nilai-p
WY -0.942 0.053 0.000
Jumlah Petani 4.490 1.501 0.017
Konstanta 1.573 0.469 0.010
Peubah Penjelas Koefisien Galat Baku Nilai-p
WY 0.767 0.274 0.019
Jumlah Petani 1.016 0.203 0.001
Konstanta 0.374 0.123 0.013
Peubah Penjelas Koefisien Galat Baku Nilai-p
WY 0.510 0.388 0.162
Jumlah Petani 10.749 3.167 0.009
Konstanta -6.685 2.112 0.013
Peubah Penjelas Koefisien Galat Baku Nilai-p
WY -0.045 0.068 0.514
Jumlah Petani 2.838 0.717 0.001
31
5
SIMPULAN DAN SARAN
5.1. Simpulan
Berdasarkan hasil Simulasi dan analisa data empiris, maka dapat disimpulkan bahwa:
1. Simulasi yang dilakukan terhadap 3 jenis matriks pembobot spasial yaitu W
biner, W seragam dan W kernel gaussian menghasilkan bahwa W seragam
merupakan W terbaik.
2. Model SAR data panel merupakan model terbaik untuk data produksi padi
tahun 2010-2012 dengan R2 sebesar 98.9% dan peubah penjelas yang
signifikan terhadap produksi padi adalah peubah Otoregresi Spasial dan Jumlah Petani.
5.2. Saran
Pada penelitian ini, simulasi dilakukan dengan menggunakan konsep data
panel spasial dengan data tiap deret waktunya lengkap disemua lokasi (balance
spatial panel data), sehingga penelitian selanjutnya disarankan untuk mencoba
mengkaji data panel spasial dengan data tidak lengkap (unbalance spatial panel
data). Selain itu disarankan untuk mengkaji perbedaan lag pada konsep
kebertetanggaan untuk proses pembentukan W biner dan W Seragam.
6
DAFTAR PUSTAKA
Anselin L. 2009. Spatial Regression. Fotheringham AS, PA Rogerson, editor,
Handbook of Spatial Analysis. London: Sage Publications.
Anselin L, Gallo Julie and Jayet Hubbert. 2008. The Econometrics of Panel Data.
Berlin: Springer.
Baltagi BH. 2005. Econometrics Analysis of Panel Data. Ed ke-3. England : John
Wiley and Sons, LTD.
Baltagi. 2009. Forecasting with Spatial Panel Data. Discussion Paper Deret
No.4242
Dubin R. 2009. Spatial Weights. Fotheringham AS, PA Rogerson, editor, Handbook of Spatial Analysis. London : Sage Publications.
Elhorst JP. 2010. Spatial Panel Data Models. Fischer MM, A Getis, editor,
Handbook of Applied Spatial Analysis. New York : Springer.
Elhorst. 2011. Spatial panel models. Regional Science and Urban Econometric.
Fotheringham A.S., Brunsdon C., Chartlon M. 2002. Geographically Weighted
Regression, the Analysis of Spatially Varying Relationships. John Wiley and Sons, LTD.
Fotheringham AS, Rogerson PA. 2009. Spatial Analysis. London: Sage
Publications, Inc.
Hamilton, J.D. 1994. Time Deret Analysis. New Jersey: Princeton University
Press.
Lee J, Wong DWS. 2001. Statistical Analysis ArchView GIS. New York: John
32
Lee LF, Yu J. 2009. Some Recent Developments in Spatial Panel Data Models.
Regional Science and Urban Economics Journal: REGEC-02729; No of Pages 17
Lee LF, Yu J. 2010. Estimation of Spatial Autoregressive Panel Data Models with
Fixed Effects. Journal of Econometrics 154 (2010) 165-185.
Ward MD, Gleditsch KS. 2008. Spatial Regression Models. Los Angeles: Sage
33
LAMPIRAN
Lampiran 1W Biner untuk 25 lokasi