ANALISIS PENGARUH STRUKTUR DATA TERHADAP KOMPLEKSITAS WAKTU KOMPUTASI ALGORITMA SELECTION SORT
DAN MERGE SORT
TESIS
JIJON SAGALA 117038054
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
ANALISIS PENGARUH STRUKTUR DATA TERHADAP KOMPLEKSITAS WAKTU KOMPUTASI ALGORITMA SELECTION SORT
DAN MERGE SORT
TESIS
Diajukan untuk melengkapi tugas dan memnuhi syarat memperoleh ijazah Magister Teknik Informatika
JIJON SAGALA
117038054
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul Tesis : ANALISIS PENGARUH STRUKTUR DATA TERHADAP
KOMPLEKSITAS WAKTU KOMPUTASI ALGORITMA
SELECTION SORT DAN MERGE SORT
Nama Mahasiswa : JIJON SAGALA
No. Induk Mahasiswa : 117038054
Program Studi : MAGISTER TEKNIK INFORMATIKA
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Prof. Dr. Drs. Iryanto, M.Si Prof. Drs. Tulus, Vordipl.Math, M.Si, Ph.D
Diketahui/Disetujui oleh
Program Studi S2 Teknik Informatika Ketua,
PERNYATAAN
ANALISIS PENGARUH STRUKTUR DATA TERHADAP KOMPLEKSITAS WAKTU KOMPUTASI ALGORITMA SELECTION SORT
DAN MERGE SORT
TESIS
Saya yang mengakui bahwa tesis ini adalah hasil karya tulis saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah saya sebutkan sumbernya.
Medan, 30 Oktober 2013
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai civitas akademika Universitas Sumatera Utara, saya yang bertanda tangan dibawah
ini :
Nama : Jijon Sagala
NIM : 117038054
Program Studi : S2 Teknik Informatika
Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas
Sumatera Utara Hak Bebas Royalti Non-Eksklusif ( Non-Exclusive Rayalty Free Eight )
atas tesis saya yang berjudul:
ANALISIS PENGARUH STRUKTUR DATA TERHADAP KOMPLEKSITAS
WAKTU KOMPUTASI ALGORITMA SELECTION SORT
DAN MERGE SORT
Beserta perangkat yang ada(jika diperlukan). Dengan Hak Bebas Royalti Non-Eksklusif ini,
Universitas Sumatera Utara berhak menyimpan, mengalih media, menformat, mengelola
dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari
saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang
dan/atau sebagai pemilik hak cipta
Demikian pernyataan ini dibuat dengan sebernarnya.
Medan, 30 Oktober 2013
Jijon Sagala
Telah diuji pada
Tanggal : Rabu 30 Oktober 2013
PANITIA PENGUJIAN TESIS
Ketua : Prof. Drs. Tulus, Vordipl.Math, M.Si, Ph.D
DAFTAR RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap ( Berikut Gelar ) : Jijon Sagala, S.Kom
Tempat dan Tanggal Lahir : Situnggaling, 4 September 1984
Alamat Rumah : Jln. B.W. Kusuma No.14C, Pasar 4 Padang Bulan
Telepon/Fax/HP : 081361587795
E-Mail : [email protected]
Instansi Tempat Bekerja : YPN Medicom
Alamat Kantor : Jln. Bantam No 12 Medan
DATA PENDIDIKAN
SD SD Inpres Merek TAMAT 1998
SMP SMP Negeri 1 Merek TAMAT 2001
SMA SMA Sw Dharma Pancasila Medan TAMAT 2004
D1 PABT D1 Medicom Medan TAMAT 2005
D3 AMIK D3 Medicom Medan TAMAT 2007
S1 STMIK Sisingamangaraja XII Medan TAMAT 2011
UCAPAN TERIMA KASIH
Puji dan syukur kehadirat Tuhan Yang Maha Esa atas anugerahNya dan berkatNya Penulis
dapat menyelesaikan Tesis ini, yang berjudul “ ANALISIS PENGARUH STRUKTUR DATA TERHADAP KOMPLEKSITAS WAKTU KOMPUTASI ALGORITMA
SELECTION SORT DAN MERGER SORT ”. Tesis ini merupakan Tugas Akhir pada
Program Studi Magister S2 Teknik Informatika Fakultas Ilmu Komputer dan Teknologi
Informasi, Universitas Sumatera Utara.
Dalam menyelesaikan pendidikan di Program Studi Magister S2 Teknik Informatika
Universitas Sumatera Utara ini, penulis banyak mendapat dukungan dari berbagai pihak,
maka pada kesempatan ini Penulis mengucapkan terima kasih dan penghargaan yang
sebesar-besarnya kepada:
1. Prof. Dr. dr. Syahril Pasaribu, DTM&H, M.Sc(CTM), Sp,A(K) selaku Rektor
Universitas Sumatera Utara.
2. Prof. Dr. Muhammad Zarlis selaku Dekan Fakultas Ilmu Komputer dan Teknologi
Informasi Universitas Sumatera Utara dan Ketua Program Studi Magister Teknik
Informatika dan juga sebagai pembanding pada penulisan Tesis ini dan berkat saran dan
bantuanya beliau sehingga penulisan Tesis ini dapat diselesaikan dengan baik.
3. Muhammad Andri Budiman, ST., M.Comp.Sc., selaku sekretaris Program Studi
Magister Teknik Informatika yang telah banyak memberikan bantuan dan motivasinya
selama perkuliahan sehingga Penulis dapat menyelesaikan Tesis dan Perkualiahan ini.
4. Prof. Drs. Tulus, Vordipl.Math, M.Si, Ph.D, selaku Ketua Komisi Pembimbing pada
penulisan Tesis ini, berkat dorongan dan bantuan beliau sehingga penulisan Tesis ini
dapat diselesaikan dengan baik.
5. Prof. Dr. Drs. Iryanto, M.Si, selaku Anggota Komisi Pembimbing II yang telah memberikan bimbingan dan petunjuk sehingga Tesis ini dapat diselesaikan dengan
baik.
6. Prof. Dr. Herman Mawengkang selaku pembanding, atas saran dan bantuanya untuk
7. Dr. Erna Budhiarti Nababan, M.IT selaku pembanding, atas saran dan bantuanya untuk
kesempurnaan penulisan Tesis ini serta bimbingan selama perkuliahan berlangsung.
8. Seluruh Staf pengajar pada Program Studi Magister Teknik Informatika, Fakultas Ilmu
Komputer dan Teknologi Informasi Universitas Sumatera Utara, yang telah
memberikan ilmu pengetahuan kepada penulis selama perkuliahan hingga selesai.
9. Seluruh Staf administrasi Program Studi Magister Teknik Informatika mbak Widia,
mbak Ines, bang Jawaher dan yang lainnya yang telah banyak memberikan bantuan dan
pelayanan terbaik kapada Penulis.
10.Seluruh rekan-rekan seperjuangan mahasiswa angkatan ketiga stambuk 2011 Kom B
Pak Pirmando Gultom, Bu Ertina Barus, Pak Andi Marwan, Bu Yulia Dalimunthe, Bu
Fitri Marina, Pak Arman Barus, Pak Arta Pinem, Bu Wulan, Pak Muhazir dan yang
lainnya, yang telah bersama-sama selama perkuliahan atas kerjasama, kebersamaan dan
saling pengertiannya selama ini dalam mengatasi berbagai masalah yang dihadapi
selama perkualiahan tanpa menegenal lelah sehingga tugas-tugas bersama dapat
diselesaikan dengan baik.
11.dr. Reinhard Silalahi selaku Pimpinan Yayasan Pendidikan Nasional Medicom beserta
seluruh staf yayasan dan staf pengajar yang telah memberikan dorongan dan dukungan
sehingga Penulis dengan tetap suka cita dan bersemangat untuk menyelesaikan kuliah
dengan baik.
12.Penulis menyampaikan terima kasih yang sangat luar biasa pada istri tercinta Marisa
Natarlian Br Ginting, S.Pd atas cinta dan kasih serta doa yang tulus diberikan kepada
penulis, sehingga dapat menyelesaikan Tesis dengan baik.
13.Penulis menyampaikan terima kasih yang tak terhingga kepada Bapak tercinta J. Sagala
dan Mamak Tersayang S Br Munthe, saudaraku terkasih bang Jasa Sagala & Kak
Rentina Br Sijabat, Kak Risa Br Sagala & bang Adi, Kak Riahta Br Sagala, SE, bang
Junner Sagala & Kak Erti Br Sidabuke dan Adiku Irma Sari Br Sagala, SS serta
keponakan ku Ozi, Enjel, Destri, Jesen Sagala, Jon Steven Sagala dan Jaren Sagala,
kasih sayang dan dukungan tulus dari kalian adalah semangat hidupku.
14.Penulis juga menyampaikan terima kasih yang sangat besar kepada Bapak Mertua D.
Ginting dan Ibu Mertua R Br Sebayang serta silihku Yuda Ginting & Novita Br
Ginting, Giovani Ginting dan Tercio Ginting yang telah banyak memberikan doa yang
tulus dan dukungan kepada penulis.
Kepada semua pihak yang telah turut membantu penulisan Tesis ini baik langsung
maupun tidak langsung yang penulis dapatkan selama ini. Semoga Tesis ini bermanfaat
bagi pembaca dan pihak-pihak yang membutuhkannya.
Medan, 30 Oktober 2013
Penulis,
Jijon Sagala
ABSTRAK
Seiring berkembangnya kemajuan di bidang informatika dan komputasi, tuntutan untuk
menemukan metode pemecahan masalah secara lebih tepat, efektif dan kuat menjadi sebuah
kebutuhan, terutama untuk permasalahan klasik. Salah satu masalah klasik di bidang
informatika dan komputasi adalah pengurutan data ( sorting ). Pengurutan data ( sorting )
memegang peranan penting dalam banyak aplikasi dan persoalan yang mengacu pada
banyak data (minimal lebih dari satu), dan seringkali menjadi upa-masalah yang banyak
dipertimbangkan agar keseluruhan permasalahan dapat diselesaikan dengan lebih baik dan
cepat. Algoritma pengurutan (sorting) yang dipakai adalah algoritma Merge Sort dan
selection sort. Pada penilitian ini akan dipaparkan penjelasan singkat dan perbandingan
kecepatan dan keefektifan algoritma-algoritma pengurutan data dengan elemen integer.
DATA STRUCTURE INFLUENCE ANALYSIS TOWARDS ALGORITHM
COMPUTATION TIME COMPLEXITY SELECTION SORT
AND MERGE SORT
ABSTRACT
As the development advances in the field of informatics and computing, the demand to find
a method of solving the problem more precise, effective and powerful become a necessity,
especially for classical problems. One of the classic problems in the field of informatics and
computing are data sorting (sorting). Data sorting (sorting) plays an important role in many
applications and issues that refer to the data (at least more than one), and the ceremony is
often a problem that many considered that the whole problem can be solved with better and
faster. Sorting algorithms (sorting) is used and the Merge Sort algorithm selection sort. In
this research will be presented a brief description and comparison of the speed and
effectiveness of data sorting algorithms with integer elements.
DAFTAR ISI
UCAPAN TERIMA KASIH vii
ABSTRAK x
1.4 Tujuan Penelitian 3
BAB 2 TINJAUAN PUSTAKA 4
2.1 Pengertian Algoritma 4
2.2 Algoritma Pengurutan 5
2.3 Kompleksitas Algoritma 6
2.4 Growth Function 7
2.5 Notasi Asimptotik 8
2.6 Pengertian Selection Sort 8
2.7 Pengertian Merge Sort 9
2.8 Struktur Data 10
2.9 Penelitian Terdahulu 12
BAB 3 METODOLOGI PENELITIAN 13
3.1.1 Pseudocode Minimum Selection Sort 13
3.1.2 Pseudocode Maximum Selection Sort 14
3.1.3 Loop Invariant Minimum Selection Sort 14
3.2 Simulasi Algoritma Pengurutan Selection Sort 15
3.3 Analisis Dan Running Time Selection Sort 17
3.4 Selection Sort Model Insert(Sisip) 18
3.4.1 Pseudecode Selection Sort Model Insert 18
3.4.2 Simulasi Algoritma Pengurutan Selection Sort Model Insert 19
3.5 Selection Sort Model New List(Dua List) 20
3.5.1 Pseudecode Selection Sort Model New List 20
3.5.2 Simulasi Algoritma Pengurutan Selection Sort Model New List 20
3.6 Penjelasan Singkat Merge Sort 21
3.6.1 Pseudocode Merge Sort 21
3.6.2 Loop Invariant Pada Prosedure Merge Sot 22
3.7 Simulasi Algoritma Merge Sort 23
3.8 Analisis Dan Running Time Merge Sort 28
BAB 4 HASIL DAN PEMBAHASAN 30
4.1 Pendahuluan 30
4.2 Hasil Dan Uji Coba 30
4.2.1 Pengurutan pada Max Item = 10 30
4.2.2 Pengurutanpada Max Item = 500 35
4.2.3 Pengurutanpada Max Item = 1000 39
4.3 Pembahasan 44
4.4 Analisis Perbandingan Selection Sort dengan Merge Sort 45
BAB 5 KESIMPULAN DAN SARAN 47
DAFTAR PUSTAKA
DAFTAR TABEL
Tabel 2.1 Tabel Notasi Big O 7
Tabel 2.2 Perbedaan mendetail antara Array dan List 12
DAFTAR GAMBAR
Gambar 4.1 Item Tampilan hasil pada max item 10 danMax Value 1000 31
Gambar 4.2 Pengurutan pada Max Item 10 Max Item Value = 1000 32
Gambar 4.3 Grafik perbandingan keempat pengurutan untuk Max Item 10 Max
Item Value = 1000 32
Gambar 4.4 Tampilanhasilpada max item 10 danMax Item Value 1000000 33
Gambar 4.5 Hasil pengurutan pada Max item 10 dan Max Item Value 1000000 34
Gambar 4.6 Grafik perbandingan keempat pengurutan untuk Max Item 10 Max
Item Value = 1000000 35
Gambar 4.7 PengurutanPada Max Item 500 Max Item Value=1000 35
Gambar 4.8 Hasil pengurutan pada Max item 500 dan Max Item Value = 1000 36
Gambar 4.9 Grafik perbandingan keempat pengurutan untuk Max Item 500 Max
Item Value = 1000 37
Gambar 4.10 Pengurutan Pada Max Item 500 Max Item Value = 1000000 37
Gambar 4.11 Hasil pengurutan pada Max item 500 dan Max Item Value 1000000 38
Gambar 4.12 Grafik perbandingan keempat pengurutan untuk Max Item 500 Max
Item Value = 1000000 39
Gambar 4.13 PengurutanPada Max Item 1000 Max Item Value=1000 40
Gambar 4.14 Hasil pengurutan pada Max item 1000 dan Max Item Value 1000 41
Gambar 4.15 Grafik perbandingan keempat pengurutan untuk Max Item 1000
Max Item Value = 1000 41
Gambar 4.16 PengurutanPada Max Item 1000 Max Item Value=1000000 42
Gambar 4.17 Hasil pengurutan pada Max item 1000 dan Max Item Value 1000 43
Gambar 4.18 Grafik perbandingan keempat pengurutan untuk Max Item 1000
ABSTRAK
Seiring berkembangnya kemajuan di bidang informatika dan komputasi, tuntutan untuk
menemukan metode pemecahan masalah secara lebih tepat, efektif dan kuat menjadi sebuah
kebutuhan, terutama untuk permasalahan klasik. Salah satu masalah klasik di bidang
informatika dan komputasi adalah pengurutan data ( sorting ). Pengurutan data ( sorting )
memegang peranan penting dalam banyak aplikasi dan persoalan yang mengacu pada
banyak data (minimal lebih dari satu), dan seringkali menjadi upa-masalah yang banyak
dipertimbangkan agar keseluruhan permasalahan dapat diselesaikan dengan lebih baik dan
cepat. Algoritma pengurutan (sorting) yang dipakai adalah algoritma Merge Sort dan
selection sort. Pada penilitian ini akan dipaparkan penjelasan singkat dan perbandingan
kecepatan dan keefektifan algoritma-algoritma pengurutan data dengan elemen integer.
DATA STRUCTURE INFLUENCE ANALYSIS TOWARDS ALGORITHM
COMPUTATION TIME COMPLEXITY SELECTION SORT
AND MERGE SORT
ABSTRACT
As the development advances in the field of informatics and computing, the demand to find
a method of solving the problem more precise, effective and powerful become a necessity,
especially for classical problems. One of the classic problems in the field of informatics and
computing are data sorting (sorting). Data sorting (sorting) plays an important role in many
applications and issues that refer to the data (at least more than one), and the ceremony is
often a problem that many considered that the whole problem can be solved with better and
faster. Sorting algorithms (sorting) is used and the Merge Sort algorithm selection sort. In
this research will be presented a brief description and comparison of the speed and
effectiveness of data sorting algorithms with integer elements.
BAB 1
PENDAHULUAN
1.1Latar Belakang Masalah
Perkembangan ilmu pengetahuan dan teknologi pada saat ini sudah sangat maju dan
komputer adalah salah satu teknologi tinggi. Pengerjaan secara komputerisasi dalam
aktivitas manusia baik di sekolah, instansi, perusahaan-perusahaan maupun kalangan
masyarakat sangat membantu karena komputer bekerja lebih teliti, akurat dalam
pengolahan data.
Pengolahan data tidak dapat dilepaskan begitu saja dari kehidupan kita sehari-hari dan
komputer pada umumnya digunakan untuk mengolah data. Pengolahan data adalah
pengolahan terhadap elemen-elemen data atau kombinasinya untuk membuat data itu
berguna. Hasil dari pengolahan data adalah sebuah bentuk yang berarti bagi penerimanya
dan bermanfaat dalam pengambilan keputusan saat ini dan mendatang atau disebut dengan
informasi. Oleh karena proses pengumpulan dan pengolahan data sangat penting dilakukan
karena kemudahan dan kecepatan mendapatkan informasi merupakan suatu keinginan bagi
penerima atau yang membutuhkan.
Sejarah kemunculan algoritma sejalan dengan kemunculan teknologi komputer.
Analisis algoritma menjadi topik bahasan utama dalam disiplin ilmu komputer. Seorang
programmer komputer telah lama menggunakan algoritma untuk diterapkan pada sistem
informasi manajemen yang menjalankan fungsi-fungsi akuntansi perusahaan yang disebut
sistem pemrosesan transaksi (transaction information system) atau sistem pemrosesan data
secara elektronik (Electronic Data Processing/EDP), yang kemudian berkembang menjadi
sistem pendukung pengambilan keputusan (Decision Support System/DSS).
Algoritma adalah kumpulan instruksi yang dibuat secara jelas terhadap penyelesaian
suatu masalah. Kumpulan instruksi yang dimaksud dibangun dari suatu bahasa
pemograman yang dimengerti oleh komputer. Kumpulan instruksi tersebut berupa
suatu masalah secara lebih efektif dengan sedikit sumber daya yang dilibatkan dan lebih
efisien dengan durasi waktu yang dibutuhkan sedikit (cepat). Secara bebas, kita
menganggap algoritma kurang lebih sama dengan suatu prosedur yang sering dikerjakan
atau dilakukan sehari-hari.
Dalam analisis algoritma terdapat bagian-bagian yang dapat dianalisis, yaitu kecepatan
waktu, kapasitas biaya dan kapasitas ruang. Ketiganya menggunakan notasi θ (big θ),
dengan mengetahui Notasi θ maka notasi Big O dan Big Ω dapat diketahui. Banyak metode pada proses pengolahan data, salah satu di antaranya adalah metode pengurutan (sorting),
pengurutannya secara urut naik (ascending) dan pengurutan secara urut turun (descending).
Pengurutan (sorting) adalah proses mengatur sekumpulan obyek menurut urutan atau susunan
tertentu. Pengurutan dapat berupa nilai, objek atau nama.
Algoritma pengurutan (sorting algorithm) adalah algoritma yang menyimpan suatu list
pada suatu urutan tertentu, biasanya membesar atau mengecil, biasanya digunakan untuk
mengurutkan angka ataupun huruf. Efisiensi pada pengurutan ini diperlukan untuk
mengoptimalkan kecepatan pemrosesan. Semakin efisien suatu algoritma, maka pada saat
dieksekusi dan dijalankan akan menghabiskan waktu yang lebih sedikit dan bisa menerima
lebih banyak masukan dari user. Terdapat banyak algoritma pengurutan yang sudah dibuat
seperti selection sort, shell sort, heapsort, bubble sort, insertion sort, radix sort, quicksort,
dan mergesort.
Data yang diolah dalam pengurutan berupa data stack, vektor, tree, array, list, double
link list, maka yang di olah pada penguruan ini adalah data array dan data list. Yang
menjadi domain pada kesempatan ini adalah mencoba untuk menganalisis kecepatan waktu
dari semua algoritma sorting, dengan sekali inputan data berupa bilangan bulat (integer)
dalam suatu list atau array. Maka dari uraian tersebut diatas, penulis merasa tertarik untuk
melakukan penelitian dengan judul “ANALISIS PENGARUH STRUKTUR DATA TERHADAP KOMPLEKSITAS WAKTU KOMPUTASI ALGORITMA SELECTION
1.2 Rumusan Masalah
Rumusan masalah yang akan dibahas dalam penelitian ini adalah bagaimana menganalisis
pengaruh struktur data terhadap kempleksitas waktu komputasi secara teoritis dan
exprerimental antara metode Selection Sort dan Merge Sort.
1.3Batasan Masalah
Berdasarkan identifikasi tersebut dan menghindari cakupan masalah yang terlalu luas, maka
penulis membatasi masalah sebagai berikut :
1. Tipe struktur data yang digunakan adalah larik (array) statis dan list.
2. Data yang diinputkan bilangan positif dari 1 sampai 1.000.000 besarnya Array, data
tersebut akan diacak dengan dengan nilai batasan 1 sampai 1.000.000 nilai Array dan
boleh ada yang sama. Untuk menentukan efisiensi dari kedua metode pertukaran dilihat
dari banyaknya pertukaran terhadap elemen data.
3. Proses pengurutan (sorting) yang dilakukan secara sequential dengan melakukan
proses satu persatu.
4. Pengurutan kompleksitas(teoritikal) dengan Notasi Big θ, Big O dan Big Ω
5. Penguruan waktu (experimental) di lakukan dengan microsecond
1.4Tujuan Penelitian
Adapun tujuan yang ingin dicapai dalam penelitian ini adalah Untuk membandingkan
kesesuian nilai waktu Experimental dengan Teoritikal, untuk menganalisis pengaruh
Struktur data array dan struktur data list pada kinerja selection sort model Insert dan
selection sort model New List. Untuk menentukan mana pengurutan yang menggunakan
BAB 2
TINJAUAN PUSTAKA
2.1. Pengertian Algoritma
Algoritma adalah urutan langkah-langkah logis penyelesaian masalah yang disusun secara
sistematis dan logis. Kata Logis merupakan kata kunci dalam Algoritma. Langkah-langkah
dalam Algoritma harus logis dan harus dapat ditentukan bernilai salah atau benar (Rosa dan
Shalahuddin 2010). Kriteria Algoritma yang baik :
a. Tepat, benar, sederhana, standar dan efektif.
b. Logis, terstruktur dan sistematis.
c. Semua operasi terdefinisi.
d. Semua proses harus berakhir setelah sejumlah langkah dilakukan.
e. Ditulis dengan bahasa yang standar dengan format pemrograman agar mudah untuk
diimplementasikan dan tidak menimbulkan arti ganda.
Algoritma adalah jantung ilmu komputer atau informatika. Banyak cabang ilmu
komputer yang diacu dalam terminologi algoritma. Namun, jangan beranggapan algoritma
selalu identik dengan ilmu komputer saja. Dalam kehidupan sehari-hari pun banyak
terdapat proses yang dinyatakan dalam suatu algoritma. Cara-cara membuat kue atau
masakan yang dinyatakan dalam suatu resep juga dapat disebut sebagai algoritma. Pada
setiap resep selalu ada urutan langkah-lankah membuat masakan. Bila langkah -langkahnya
tidak logis, tidak dapat dihasilkan masakan yang diinginkan. Ibu-ibu yang mencoba suatu
resep masakan akan membaca satu per satu langkah-langkah pembuatannya lalu ia
mengerjakan proses sesuai yang ia baca. Secara umum, pihak (benda) yang mengerjakan
proses disebut pemroses (processor). Pemroses tersebut dapat berupa manusia, komputer,
robot atau alat-alat elektronik lainnya. Pemroses melakukan suatu proses dengan
melaksanakan atau mengeksekusi algoritma yang menjabarkan proses tersebut(Munir
2.2. Algoritma Pengurutan ( Sorting )
Algoritma merupakan urutan aksi-aksi yang dinyatakan dengan jelas dan tidak rancu untuk
memecahkan suatu masalah dalam rentang waktu tertentu. Sedangkan pengurutan adalah
proses pengaturan sekumpulan objek berdasarkan urutan atau susunan tertentu, dapat
berupa pengurutan menaik (ascending) atau menurun (descending). (Sharma at all 2008).
Contoh, sebuah larik atau array terdiri dari kumpulan bilangan : [3,12,1,50,33,5,28]
Hasil pengurutan menaik (ascending) : [1,3,5,12,28,33,50] Hasil pengurutan menurun (descending) : [50,33,28,12,5,3,1]
Sebuah algoritma dikatakan baik jika menghasilkan nilai yang benar, efektif dan
efisien. Efektif yaitu tepat sasaran, jelas dan tidak rancu dalam menjalankan aksi-aksinya
serta menghasilkan data yang benar. Efisien yaitu penghematan proses dari sebuah
algoritma, seperti running time dan penggunaan memori. Metode atau algoritma pengurutan
dapat diklasifikasikan menjadi :
1. Metode atau algoritma pengurutan internal, yaitu pengurutan yang dilakukan di
dalam larik itu sendiri. Datanya disimpan di dalam memori komputer.
2. Metode atau algoritma pengurutan eksternal, yaitu pengurutan yang datanya
disimpan di dalam disk storage. Metode ini disebut juga pengurutan arsip.
Sedangkan berdasarkan kestabilan (stability), algoritma pengurutan dapat dibagi
menjadi dua jenis, yaitu :
1. Metode pengurutan stabil (stable sorting algorithm), merupakan algoritma
pengurutan yang menjaga/mempertahankan (maintenance) urutan dari beberapa
elemen array yang bernilai sama.
2. Metode pengurutan tidak stabil (non stable sorting algorithm), merupakan metode
pengurutan yang tidak menjaga/mempertahankan (maintenance) urutan dari
beberapa elemen array yang bernilai sama. Dengan kata lain, urutan beberapa
Algoritma memiliki dua skema, yaitu iteratif dan rekursif. Iteratif yaitu algoritma yang
melakukan perulangan biasa, sedangkan rekursif adalah algoritma yang melakukan
perulangan dengan melakukan pemanggilan terhadap dirinya sendiri. Contoh algoritma
pengurutan yang termasuk dalam skema iteratif, yaitu pengurutan apung (bubble sort) dan
selection sort, Contoh algoritma pengurutan yang termasuk dalam skema rekursif, yaitu
pengurutan merge (merge sort), pengurutan heap (heap sort) dan pengurutan cepat (quick
sort). Tidak semua algoritma tersebut hanya memiliki satu skema, misalnya algoritma
pengurutan seleksi atau selection sort yang dapat menggunakan skema rekursif, namun di
dalam penelitian ini selection sort yang dibahas menggunakan skema iteratif (Fanani 2008).
2.3. Kompleksitas Algoritma
Efisiensi sebuah algoritma tergantung dari beberapa hal, diantaranya adalah :
Kinerja CPU Kinerja Memori Kinerja Disk Kinerja Jaringan
Algoritma memiliki kompleksitas, kompleksitas merupakan acuan utama utama untuk
mengetahui kecepatan dari sebuah algoritma. Kompleksitas dibagi menjadi tiga, yaitu (Rao
and Ramesh 2012) :
1. Best case (Ω), yaitu kompleksitas algoritma dimana algoritma tersebut berjalan
dalam kondisi terbaik.
2. Average case ( ), yaitu kompleksitas algoritma dimana algoritma tersebut berjalan
dalam kondisi sedang, biasanya inputnya secara acak.
3. Worst case (Ο), yaitu kompleksitas algoritma dimana algoritma tersebut berjalan
2.4. Growth Function
Kinerja sebuah algoritma biasanya di ukur dengan mengacu pada kondisi terburuknya,
yaitu worst case yang dilambangkan dengan notasi Big O. Notasi Big O adalah fungsi yang
berkaitan dengan kelajuan proses dan kelajuan pertambahan data (Suryani 2013).
Tabel 2.1 Tabel Notasi Big O
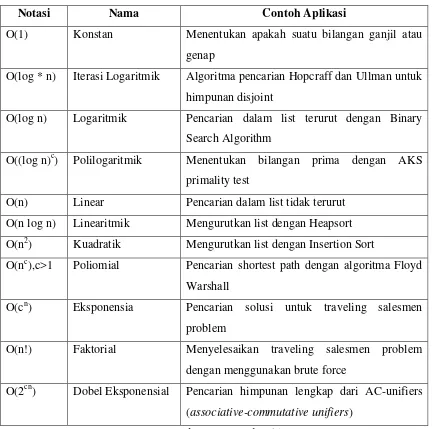
Notasi Nama Contoh Aplikasi
O(1) Konstan Menentukan apakah suatu bilangan ganjil atau
genap
O(log * n) Iterasi Logaritmik Algoritma pencarian Hopcraff dan Ullman untuk
himpunan disjoint
O(log n) Logaritmik Pencarian dalam list terurut dengan Binary
Search Algorithm
O((log n)c) Polilogaritmik Menentukan bilangan prima dengan AKS
primality test
O(n) Linear Pencarian dalam list tidak terurut
O(n log n) Linearitmik Mengurutkan list dengan Heapsort
O(n2) Kuadratik Mengurutkan list dengan Insertion Sort
O(nc),c>1 Poliomial Pencarian shortest path dengan algoritma Floyd
Warshall
O(cn) Eksponensia Pencarian solusi untuk traveling salesmen
problem
O(n!) Faktorial Menyelesaikan traveling salesmen problem
dengan menggunakan brute force
O(2cn) Dobel Eksponensial Pencarian himpunan lengkap dari AC-unifiers
(associative-commutative unifiers)
2.5. Notasi Asimptotik
Notasi asimptotik digunakan untuk menentukan kompleksitas suatu algoritma dengan
melihat waktu tempuh (running time) sebuah algoritma. Waktu tempuh algoritma
merupakan fungsi : N → R suatu algoritma dengan algoritma lainnya. Notasi asimptotik dapat dituliskan dengan beberapa simbol, yaitu :
Notasi Big O, yaitu notasi asimptotik sebuah fungsi algoritma untuk batas atas. Notasi Little o, yaitu notasi asimptotik sebuah fungsi algoritma untuk batas atas
namun tidak secara ketat terikat (not asymptotically tight).
Notasi Theta ( ), yaitu notasi asimptotik sebuah fungsi algoritma untuk batas atas
dan bawah.
Notasi Omega ( ), yaitu notasi asimptotik sebuah fungsi algoritma untuk batas
bawah, notasi ini berlawanan dengan notasi little-o.
2.6. Pengertian Selection Sort
Selection sort adalah mencari elemen yang tepat untuk diletakkan di posisi yang telah
diketahui, dan meletakkannya di posisi tersebut setelah data tersebut ditemukan. Selection
Sort Membandingkan elemen yang sekarang dengan elemen yang berikutnya sampai
dengan elemen yang terakhir. Jika ditemukan elemen lain yang lebih kecil dari elemen
sekarang maka dicatat posisinya dan kemudian ditukar(Swap) dan begitu seterusnya(Triono
2010). Dalam tesis ini penulis menambahkan 2 metode pengurutan data dengan selection
sort yang baru, yaitu:
1. Selection Sort Model Insert
2. Selection Sort Model New List
Ide dasarnya adalah melakukan beberapa kali pass untuk melakukan penyeleksian
elemen struktur data. Untuk sorting ascending (menaik), elemen yang paling kecil di antara
elemen-elemen yang belum urut, disimpan indeksnya, kemudian dilakukan pertukaran nilai
elemen dengan indeks yang disimpan tersebut dengan elemen yang paling depan yang
belum urut. Sebaliknya, untuk sorting descending (menurun), elemen yang paling besar
Algoritma selection sort memilih elemen maksimum/minimum array, lalu
menempatkan elemen maksimum/minimum itu pada awal atau akhir array (tergantung pada
urutannya ascending /descending). Selanjutnya elemen tersebut tidak disertakan pada
proses selanjutnya. Karena setiap kali selection sort harus membandingkan elemen-elemen
data, algoritma ini termasuk dalam comparison-based sorting. Seperti pada algoritma
Bubble Sort, proses memilih nilai maksimum / minimum dilakukan pada setiap pass. Jika
array berukuran N, maka jumlah pass adalah N-1 (Nugroho 2005).
Terdapat pendekatan dalam metode pengurutan dengan Selection Sort :
1. Algoritma pengurutan maksimum (maximum selection sort), yaitu memilih elemen
maksimum sebagai basis pengurutan.
2. Algoritma pengurutan minimum (minimum selection sort), yaitu memilih elemen
minimum sebagai basis pengurutan
2.7. Pengertian Merge Sort
Metode pengurutan merge sort adalah metode pengurutan lanjut, sama dengan metode
Quick Sort. Metode ini juga menggunakan konsep devide and conquer yang membagi data
S dalam dua kelompok yaitu S1 dan S2 yang tidak beririsan (disjoint). Proses pembagian
data dilakukan secara rekursif sampai data tidak dapat dibagi lagi atau dengan kata lain data
dalam sub bagian menjadi tunggal. Setelah data tidak dapat dibagi lagi, proses
penggabungan (merging) dilakukan antara sub-sub bagian dengan memperhatikan urutan
data yang diinginkan (ascending/kecil ke besar atau descending/besar ke kecil). Proses
penggabungan ini dilakukan sampai semua data tergabung dan terurut sesuai urutan yang
diiginkan. Kompleksitas algoritma merge sort adalah O(n log n)( Fenwa at all 2012).
Secara umum, algoritma merge sort dapat diimplementasikan secara rekursif. Fungsi
rekursif adalah sebuah fungsi yang didalam implementasinya memanggil dirinya sendiri.
Pemanggilan diri sendiri ini berakhir jika kondisi tertentu terpenuhi (terminated condition
is true). Pada contoh berikut ini, terminated condition dari proses rekursif mergesort akan
berakhir jika data tidak dapat dibagi lagi (data tunggal telah diperoleh). Dengan kata lain,
proses pembagian data dilakukan terus selama S.size > 1 (belum tunggal) ( Fenwa at all
Ide algoritma ini hampir mirip dengan QuickSort, yaitu melakukan partisi. Kecuali
bahwa algoritma ini melakukan partisi tanpa kriteria. Jadi, data set (X[l] ... X[r]) di partisi
langsung ke du sub data set dengan jumlah data yang sama (X[l] ... X[(l+r)/2], dan
X[(l+r)/2+1] ... X[r]). Lalu secara rekursif melakukan Merge Sort untuk masing-masing
data set. Karena kedua data set itu bisa overlapping (tidak seperti pada Quick Sort) maka
setelah kedua sub data set terurut masih memerlukan proses penggabungan (Merging).
Merging ini memerlukan ruang tambahan yaitu suatu array yang sama panjangnya dengan
panjang kedua subset untuk menyimpan hasilnya (Bhalchandra dan Deshmukh 2010).
void MergeSort(int l,int r)
{
if (l < r)
{
MergeSort(l, (l+r)/2);
MergeSort((l+r)/2,r);
Merging();
}
}
Algoritma ini memiliki kompleksitas O(n log n).
2.8. Struktur Data
Struktur data adalah cara menyimpan atau merepresentasikan data di dalam komputer agar
bisa dipakai secara efisien. Sedangkan data adalah representasi dari fakta dunia nyata. Fakta
atau keterangan tentang kenyataan yang disimpan, direkam atau direpresentasikan dalam
bentuk tulisan, suara, gambar, sinyal atau simbol. Secara garis besar tipe data dapat
dikategorikan menjadi :
1. Tipe data sederhana/dasar
a. Tipe data sederhana tunggal
- Integer - Real
- Karakter
b. Tipe data sederhana majemuk misalnya string
2. Struktur data, meliputi :
a. Struktur data sederhana
- Array - Record
b. Struktur data majemuk, yang terdiri dari:
- Linier : Stack, Queue, List dan Multilist - No Linier : Pohon Biner (tree) dan Graph
Pemakaian struktur data yang tepat didalam proses pemrograman akan menghasilkan
algoritma yang lebih jelas dan tepat, sehingga menjadikan program secara keseluruhan
lebih efesien dan sederhana. Struktur data yang ′′standar′′ yang biasanya digunakan
dibidang informatika adalah List, Multilist, Stack (Tumpukan), Queue (Antrian), Tree (
Pohon ), Graph ( Graf ). Struktur data yang penulisan bahas dalam tesis ini adalah struktur
data sederhana yaitu array dan struktur data majemuk yaitu list ( Wahyudi 2004 ).
a. Array
Array (larik) adalah struktur data statik yang menyimpan sekumpulan elemen yang bertipe
sama. Setiap elemen diakses langsung melalui indeksnya. Indeks Array (larik) harus tipe
data yang menyatakan keterurutan misalnya integer atau karakter. Banyaknya elemen larik
harus sudah diketahui sebelum program dieksekusi. Array merupakan suatu struktur data
yang bersifat statis. Array harus dialokasikan terlebih dahulu di dalam memory sebelum
kita memakainya.
b. List
Merupakan suatu struktur data pengembangan dari konsep ADT (Abstrak Data Type) yang
bersifat dinamis. List dapat dimanfaatkan secara effektif sesuai dengan keperluan. List juga
dapat benar – benar dihapus / dibersihkan dari memory. List sebenarnya merupakan suatu
type data tersendiri. Di bahasa Visual Studio 2010 Ultimate, List bisa berupa suatu Class
ataupun Record. Ciri – ciri utama dari List adalah, dia mempunyai minimal dua elemen
utama. Elemen – elemen itu adalah data dan pointer untuk menunjukkan ke list berikutnya (
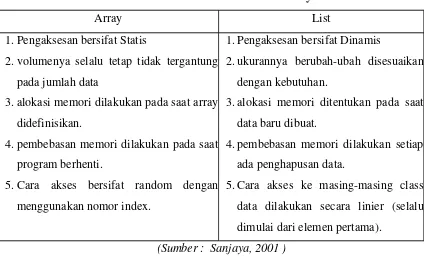
Tabel 2.2 Perbedaan mendetail antara Array dan List
Array List
1.Pengaksesan bersifat Statis
2.volumenya selalu tetap tidak tergantung
pada jumlah data
3.alokasi memori dilakukan pada saat array
didefinisikan.
4.pembebasan memori dilakukan pada saat
program berhenti.
5.Cara akses bersifat random dengan
menggunakan nomor index.
1.Pengaksesan bersifat Dinamis
2.ukurannya berubah-ubah disesuaikan
dengan kebutuhan.
3.alokasi memori ditentukan pada saat
data baru dibuat.
4.pembebasan memori dilakukan setiap
ada penghapusan data.
5.Cara akses ke masing-masing class
data dilakukan secara linier (selalu
dimulai dari elemen pertama).
(Sumber : Sanjaya, 2001 )
2.9. Penelitian Terdahulu
Penelitian yang dilakukan oleh Sareen (2013) yang berjudul Comparison of Sorting
Algorithms (On the Basis of Average Case) dimana metode merge sort dan pengurutan lain
menggunakan memori yang lebih efisien dan kompleksitas waktu terbaik dibandingkan
metode selection sort dalam proses pengurutan data, maka dilakukan penelitian untuk
menemukan sebuah algortima sorting yang dapat memberikan kompleksitas lebih baik lagi.
Penelitian yang dilakukan oleh Tjaru & Setia (2009) yang berjudul Kompleksitas
Algoritma Pengurutan Selection Sort dan Insertion Sort, yang menerengakan bahwa
algoritma pengurutan data dengan selection sort merupakan algoritma pengurutan paling
baruk dari semua metode pengurutan yang ada, maka dengan itu penulisan menambahkan 2
metode pengurutan pengembangan dari metode selection sort yaitu selection sort model
insert dan selection sort model new list untuk dilakukan perbandingan terhadap metode
yang terbaik sebelumnya yaitu metode merge sort dan juga terhadap metode selection sort.
Kedua metode yang penulis tambahkan tersebut dilakukan pengujian dengan menggunakan
bahasa pemrograman Visual Studio 2010 Ultimate terhadap 10 sampai 100000 data dengan
BAB 3
METODOLOGI PENELITIAN
3.1. Algoritma Selection Sort
Algoritma pengurutan seleksi atau selection sort dibagi menjadi dua, yaitu :
1. Algoritma pengurutan seleksi minimum atau minimum selection sort Yaitu dengan
mencari nilai terkecil dari array dan digunakan sebagai pembanding.
2. Algoritma pengurutan seleksi maksimum atau maximum selection sort Yaitu
dengan mencari nilai terbesar dari array dan digunakan sebagai pembanding.
3.1.1. Pseudocode Minimum Selection Sort
Procedure MinSelectionSort(input/output A : Larik, input n : integer)
DEKLARASI :
i, j : integer
i min : integer
temp : integer
ALGORITMA :
for I 1 to n-1 do
i min i
for j i+1 to n do
if A[j] < A[i min]
then i min j
endif
endfor
temp A [i]
A[i] A[i min]
A[i min] temp
endfor
3.1.2 Pseudocode Maximum Selection Sort
Procedure MaxSelectionSort(input/output L : Larik, input n : integer)
DEKLARASI :
i, j : integer
i maks : integer
temp : integer
DEFINISI :
for i n downto 2 do
i maks 1
for j 2 to i do
if L[j] > L[i maks]
then i maks j
endif
endfor
temp L[i]
L[i] L[i maks]
L[i maks] temp
endfor
end procedure
Algoritma pengurutan seleksi (selection sort) adalah algoritma yang tidak
stabil,karena urutan beberapa elemen yang sama berbeda antara sebelum dan sesudah
pengurutan. Algoritma ini juga termasuk algoritma pengurutan internal, karena melakukan
sorting di dalam array itu sendiri, dan menyimpan datanya di dalam memori komputer.
Yang akan dibahas kali ini adalah menggunakan pengurutan seleksi minimum(minimum
selection sort) secara menaik (ascending), yaitu selection sort dengan menggunakan nilai
3.1.3 Loop Invariant Minimum Selection Sort Statement
Saat awal algoritma dijalankan, nilai imin berisi indeks elemen terkecil dari larik
A[1...j - 1].
Initialization
Sebelum iterasi atau pass pertama dilakukan, nilai j = i + 1, i min berisi indeks elemen
terkecil dari larik A[i...i] yang merupakan indeks elemen paling pertama larik A. Maintenance
Sebelum iterasi ke- jth, i min berisi indeks elemen terkecil dari larik A[i...j - 1].
Kemudian setelah dijalankan, jika A[j] < A[i min] maka imin bernilai sama dengan j
dan menyimpan indeks terkecil larik A[i...j].
Termination
Sebelum iterasi ke- (n + 1) th, j = n + 1, i min berisi indeks terkecil dari elemen larik
A[i...n].
3.2. Simulasi Algoritma Pengurutan Selection Sort
Contoh, kita memiliki sebuah larik (array) (A) yang memiliki 7 buah elemen. Lariktersebut
akan diurutkan secara menaik (ascending) dengan mencari nilai minimum sebagai
pembanding.
26 19 38 3 9 13 21
1 2 3 4 5 6 7
1. Pass 1
Cari nilai elemen terkecil dari array (larik) A[1...7] dengan membandingkan antar
nilai elemen array, didapatkan elemen terkecil A[4]= 3.
Tukarkan dengan nilai elemen terujung (awal) yaitu A[1] Lalu elemen A[1] tersebut
sudah terurut.
3 19 38 26 9 13 21
2. Pass 2
Cari nilai elemen terkecil dari array (larik) A[2...7] dengan membandingkan antar
nilai lemen array, didapatkan elemen terkecil A[5] = 9.
Tukarkan dengan nilai elemen terujung (awal) yaitu A[2]. Lalu elemen A[2]
tersebut udah terurut.
3 9 38 26 19 13 21
1 2 3 4 5 6 7
3. Pass 3
Cari nilai elemen terkecil dari array (larik) A[3...7] dengan membandingkan antar
nilai lemen array, didapatkan elemen terkecil A[6] = 13.
Tukarkan dengan nilai elemen terujung (awal) yaitu A[3]. Lalu elemen A[3]
tersebut udah terurut.
3 9 13 26 19 38 21
4. Pass 4
Cari nilai elemen terkecil dari array (larik) A[4...7] dengan membandingkan antar nilai lemen array, didapatkan elemen terkecil A[5] = 19.
Tukarkan dengan nilai elemen terujung (awal) yaitu A[4]. Lalu elemen A[4]
tersebut udah terurut.
3 9 13 19 26 38 21
5. Pass 5
Cari nilai elemen terkecil dari array (larik) A[5...7] dengan membandingkan antar
nilai lemen array, didapatkan elemen terkecil A[7] = 21.
Tukarkan dengan nilai elemen terujung (awal) yaitu A[5]. Lalu elemen A[5] tersebut udah terurut.
3 9 13 19 21 38 26
6. Pass 6(n-1)
Cari nilai elemen terkecil dari array (larik) A[6...7] dengan membandingkan antar
Tukarkan dengan nilai elemen terujung (awal) yaitu A[6]. Lalu elemen A[6]
tersebut udah terurut.
3 9 13 19 21 26 38
Elemen yang tersisa yaitu elemen terakhir A[7] = 38. Elemen tersebut tidak perlu diurutkan
karena elemen tersebut berada pada posisi yang sudah terurut. Jadi array atau larik A sudah
terurut. Hasil array A yang sudah terurut yaitu :
3 9 13 19 21 26 38
3.3. Analisis dan Running Time Selection Sort
Running timealgoritma pengurutan seleksi (selectionsort) dapat dihitung dengan:
Tabel 3.1. Running Time
Selection Sort Cost Times
Keterangan :
ti,j bernilai 1 jika kondisi if benar, 0 jika salah
∑ ∑
∑
∑
∑ ( )
dapat bernilai 1 atau 0.
Ketika kondisi Best Case maka kondisi if salah, ti,j= 0. Kondisi best case terjadi jika data dalam elemen array sudah terurut.Maka :
( ) ( )
Didapatkan notasi asimptotik best case selection sort adalah T(n)=Ω( )
Ketika kondisi worst case maka kondisi if benar, ti,j= 1. Kondisi worst case terjadi jika data dalam elemen array terurut secara terbalik, Maka:
( ) ( )
Didapatkan notasi asimptotik best case selection sort adalah T(n)=O( )
Jadi baik dalam kondisi worst case, average case maupun best case didapatkan
kompleksitas waktu algoritma selection sort yaitu :T(n)=O( )
3.4. Selection Sort Model Inser ( Sisip )
Metode insert (sisip) dimana data paling kecil disisipkan ke elemen pertama (ascending)
dan data paling kecil disisip ke elemen terakhir (descending). Contoh, kita memiliki sebuah
larik (array) yang memiliki 7 buah elemen. Larik tersebut akan diurutkan secara menaik
3.4.1. Psedocode Selection sort Model insert
var int temp = data[index]
/* to change index of array item from i to index */
3.4.2. Simulasi Algoritma Pengurutan Selection Sort Model Insert
Contoh, kita memiliki sebuah Array ( larik ) (A) yang memiliki 7 buah elemen. Array(
larik ) tersebut akan diurutkan secara menaik (ascending) dengan mencari nilai minimum
sebagai pembanding.
26 19 38 3 9 13 21
1 2 3 4 5 6 7
Pass 1: Pilih data terkecil dari array dan sisipkan ke elemen pertama
3 26 19 38 9 13 21
1 2 3 4 5 6 7
Pass 2: Pilih data terkecil dari array dan sisipkan ke elemen kedua
3 9 26 19 38 13 21
1 2 3 4 5 6 7
3 9 13 26 19 38 21
1 2 3 4 5 6 7
Pass 4 :Pilih data terkecil dari array dan sisipkan ke elemen ke empat
3 9 13 19 26 38 21
1 2 3 4 5 6 7
Pass 5 :Pilih data terkecil dari array dan sisipkan ke elemen ke lima
3 9 13 19 21 26 38
1 2 3 4 5 6 7
Selesai array dan terurut secara Ascending
3.5. Selection Sort Model New List (Dua List)
Pilih data terkecil dari list pertama dan buang dari list pertama, pindahkan ke list baru dan
seterusnya. Contoh, kita memiliki sebuah list yang memiliki 7 buah elemen. List tersebut
akan diurutkan secara menaik (ascending) dengan mencari nilai minimum sebagai
pembanding.
3.5.1. Psedocode Selection sort with new list
function SelectionSortNewList(arrayList data)
/*add new item array to temporary array*/ temp.add(data(index))
/*remove item array with minimum data base on index*/
data.removeAt(index) end for
3.5.2. Simulasi Algoritma Pengurutan Selection Sort Model New List
Contoh, kita memiliki sebuah list (A) yang memiliki 7 buah elemen. List tersebut akan
diurutkan secara menaik (ascending) dengan mencari nilai minimum sebagai pembanding
List Pertama New List
26 19 38 3 9 13 21
New List sudah terurut secara Ascending
3.6. Penjelasan Singakat Merge Sort
Algoritma merge sort dirancang untuk memenuhi kebutuhan pengurutan jika data yang
diurutkan berjumlah banyak, dan tidak memungkinkan untuk ditampung dalam memori
komputer. Cara kerja atau konsep dari algoritma merge sort adalah menggunakan metode
rekursif dan teknik divide and conquer.
a. Rekurensi (Reccurence)
Merupakan sebuah fungsi atau prosedur yang digambarkan secara rekursif. Rekursif
adalah proses untuk memanggil dirinya sendiri. Dan fungsi running timenya dapat
digambarkan oleh recurrence (Rekurensi). Definisi rekursif disusun oleh dua bagian,
yaitu :
1. Basis, yaitu bagian yang berisi kasus yang terdefinisi secara eksplisit dan
berguna untuk menghentikan rekursif (memberikan sebuah nilai yang terdefinisi
pada fungsi rekursif).
2. Rekurens, yaitu bagian yang mendefinisikan objek dalam terminologi dirinya
sendiri.
Misalnya pada proses untuk menghitung faktorial dari n, maka:
Rekursi : n!=n x (n-1)! ,n>0
b. Divide and Conquer
1. Divide :Membagi sebuah array menjadi dua array, sebuah problem dipecah
menjadi sub-sub problem yang memiliki kemiripan dengan masalah semula
namun berukuran lebih kecil.
2. Conquer :Menyelesaikan masalah secara rekursif, yaitu mengurutkan setiap
array.
3. Combine : Menggabungkan solusi yaitu dua array yang sudah terurut
3.6.1. Pseudocode Merge Sort
PROCEDURE MERGESORT(A, p, r)
i ← i + 1 ELSE A[k] ← R[j]
j ← j + 1
3.6.2. Loop Invariant Pada Prosedure Merge Sort Statement
Setiap iterasi pada for (pengulang) yang terakhir, sub-array A[p...k-1] berisi nilai k-p
elemen terkecil dari array L dan R dalam keadaan yang sudah terurut. L[i] dan R[j]
merupakan elemen terkecil dari array L dan R yang tidak dicopy ke array A. Initialization
Sebelum iterasipertama dilakukan, k = p. Sub-array A[p...k-1] berisi 0 elemen terkecil
dari array L dan R. Ketika i = j = 1, L[i] dan R[j] adalah elemen terkecil dari array
yang tidak di-copy ke array A. Kedua array L dan R dalam keadaan yang terurut
Maintenance
Misalkan L[i] ≤ R[j], maka L[i] adalah elemen terkecil yang tidak di-copy ke array A. A[p...k-1] adalah k-p elemen terkecil, L[i] adalah (k–p+1)th elemen terkecil. Kemudian
L[i] di-copy ke A[k], A[p...k] berisi k–p+1 elemen terkecil. Secara berulang, nilai k + i
membuat perulangan (loop invariant). Jika L[i] > R[j], maka nilai R[j] di-copy ke array
A[k], dan nilai j + 1 agar pengulangan dapat terus dilakukan. Termination
Ketika nilai k = r + 1, A[p...k -1] = A[p...r] berisi k-p elemen terkecil dalam keadaan
yang terurut. Menghasilkan k-p = r + 1 -p elemen terkecil dalam keadaan yang erurut.
Kedua array L dan R berisi n1 + n2 + 2 = r -p + 3 elemen, dan dua buah ∞ telah di-copy
kembali ke array A.
3.7. Simulasi Algoritma Merge Sort
Contoh, kita memiliki sebuah larik (array) (A) yang memiliki 4 buah elemen. Larik
tersebut akan diurutkan secara menaik (ascending). Dengan nilai p adalah indeks elemen
awal, yaitu p = 0. Nilai r adalah indeks elemen akhir, yaitu r = 3.
1. MERGESORT(A, 0, 3)
Sesuai dengan algoritma maka nilai : n1 = q − p + 1= 1
n2 = r –q= 1.
DO R[j] ← A[q + j] nilai R[1] = A[1]= 9.
R[1]= 9
Kemudian ditambahkan L[n1 + 1] ← ∞ dan R[n2 + 1] ← ∞, sehingga
L[2] = ∞ dan R[2] = ∞. Sehingga array L dan Rberisi :
Array[1]= 12 ∞ dan array R= 9 ∞
Kedua array tersebut sudah dalam keadaan terurut.
Nilai i dan j di inisialisasi menjadi i = 1 dan j = 1. Kemudian lakukan
pengulangan pada :
FOR k ← p TO r
DO IF L[i] ≤ R[j]
THEN A[k] ← L[i] i ← i + 1 ELSE A[k] ← R[j]
j ← j + 1
Untuk menggabungkan array L dan R ke array A dalam keadaan
terurut.
Didapatkan :
o L[1] ≤ R[1], 12 ≤9 = False, maka A[0]= R[1]= 9
o L[1] ≤ R[2], 12 ≤∞= True, maka A[1]= L[1]= 12
A[0…1]= 9 12
1.2.MERGESORT(A, 2, 3)
Kemudian diperiksa apakah jika p < r, (2 < 3), jika benar maka dihitung q = (p
+ )/2 = 2.
Kemudian dipanggil MERGESORT(A, 2, 2), MERGESORT(A, 3, 3) dan MERGE(A, 2, 2, 3).
A[2…3]= 24 2
Kemudian diperiksa apakah jika p < r, (2< 2), karena salah maka rekursif
pada bagian ini selesai.
1.2.2. MERGESORT(A, 3, 3)
Kemudian diperiksa apakah jika p < r, (3< 3), karena salah maka rekursif
pada bagian ini selesai.
1.2.3. MERGE(A, 2, 2, 3)
Sesuai dengan algoritma maka nilai: n1 = q − p + 1= 1
n2 = r –q= 1.
Lalu buat dua buah array bernama L dan R dengan jumlah elemen L[1 . . n1 + 1] yaitu L[1...2]
R[1 . . n2 + 1]yaitu R[1...2] Perulangan pada:
FOR i ← 1 TO n1 DO L[i] ← A[p + i − 1] nilai L[1] = A[2] = 24
L[1]= 24
Perulangan pada: FOR j ← 1 TO n2
DO R[j] ← A[q +j]
nilai R[1] = A[3] = 2
R[1]= 2
Kemudian ditambahkan L[n1 + 1] ← ∞ dan R[n2 + 1] ← ∞, sehingga L[2] = ∞ dan R[2] = ∞. Sehingga array L dan R berisi :
Array L= 24 ∞ dan array R= 2 ∞
Kedua array tersebut sudah dalam keadaan terurut.
Nilai i dan jadi inisialisasi menjadi i= 1 dan j= 1. Kemudian lakukan pengulangan pada :
DO IF L[i] ≤ R[j]
THEN A[k] ← L[i] i ← i + 1 ELSE A[k] ← R[j]
j ← j + 1
Untuk menggabungkan array L dan R ke array A dalam keadaan
terurut.
Didapatkan :
o L[1] ≤ R[1], 24≤2= False, maka A[2] = R[1]= 2
o L[1] ≤ R[2], 24≤∞= True, maka A[3] = L[1]= 24
A[2…3]= 2 24
1.3. MERGE(A, 0, 1, 3)
Sesuai dengan algoritma maka nilai : n1 = q − p + 1= 2
n2 = r – q= 2
Lalu buat dua buah array bernama L dan R dengan jumlah elemen L[1 . . n1 + 1] yaitu L[1...3]
R[1 . . n2 + 1] yaitu R[1...3] Perulangan pada:
FOR i ← 1 TO n1 DO L[i] ← A[p + i − 1]
nilai L[1] = A[0] = 9 dan L[2] = A[1] = 12.
A[1…2]= 9 12
Perulangan pada: FOR j ← 1 TO n2
DO R[j] ← A[p + j]
Nilai R[1] = A[2] = 2 dan R[2] = A[3] = 24.
Kemudian ditambahkan L[n1 + 1] ← ∞ dan R[n2 + 1] ← ∞, sehingga L[2] = ∞ dan R[2] = ∞. Sehingga array L dan R berisi :
Array L= 9 12 ∞ dan array R= 2 24 ∞
Kedua array tersebut sudah dalam keadaan terurut.
Nilai i dan jadi inisialisasi menjadi i= 1 dan j= 1. Kemudian lakukan
pengulangan pada :
FOR k ← p TO r
DO IF L[i] ≤ R[j]
THEN A[k] ← L[i] i ← i + 1 ELSE A[k] ← R[j]
j ← j + 1
Untuk menggabungkan array L dan R ke array A dalam keadaan
terurut.
Didapatkan :
o L[1] ≤ R[1],9≤2 = False, maka A[0]= R[1]= 2
o L[1] ≤ R[2], 9≤24= True, maka A[1]= L[1]= 9.
o L[2] ≤ R[2], 12≤24= True, maka A[2]= L[2]= 12
o L[3] ≤ R[2], ∞≤24= False, maka A[3]= R[2]= 24
Jika digambarkan secara sederhana maka proses eksekusi algoritma merge sort
Hasil pengurutannya adalah array A dengan elemen seperti dibawah:
A[0…3]= 2 9 12 24
3.8. Analisis Dan Running Time Merge Sort
Merge sort selalu membagi setiap array menjadi dua sub-array hingga mencapai basis,
sehingga kompleksitas dari algoritma merge sort, berlaku untuk semua kasus (Worst Case
= Best Case = Average Case).
Untuk memudahkan, kita anggap jumlah elemen array(n) adalah kelipatan 2, jadi setiap
dilakukan divide (pemecahan menjadi dua sub-array), kedua sub-array akan berukuran
n/2.
Basis : untuk n = 1, maka array tersebut sudah terurut dengan sendirinya.
Conquer : Secara rekursif menyelesaikan 2 sub-array, setiap sub-array berukuran
n/2, maka bernilai 2T(n/2)
Combine : Menggabungkan element dari sub-array ke dalam array dengan prosedur
MERGE, bernilai θ(n).
Jumlahkan semua fungsi yang dihasilkan, sehingga dihasilkan rekurens :
{ }
Dari rekurens tersebut di ubah untuk mendapatkan kompleksitas waktu algoritma merge sort, sehingga T(n)=O(n log n)
Catatan : log2n = 2log n
Kompleksitas waktu tersebut dapat dijelaskan dari recursif tree berikut :
Array awal (cn), yang memiliki dua sub-array, masing-masing bernilai T(n/2):
cn
T(n/2) T(n/2)
Kemudian sub-array tersebut di bagi lagi menjadi dua sub-sub-array, jadi bernilai
T(n/4) dan seterusya.
cn
cn/2 cn/2
T(n/4) T(n/4) T(n/4) T(n/4)
Di dapatkan tinggi pohon rekursif adalah log n, dan memiliki sebanyak log n+ 1 level.
Setiap level bernilai cn, sehingga cn log n+ cn.
Koefisien tidak perlu dimasukkan, sehingga kompleksitas waktunya menjadi: T(n)=
BAB 4
HASIL DAN PEMBAHASAN
4.1. Pendahuluan
Aplikasi ini dibangun dengan menggunakan aplikasi pemrograman Visual Studio 2010.
Adapun uji coba yang dilakukan menggunakan komputer dengan spesifikasi hardware dan
software sebagai berikut :
1. Prosesor Core i7 2 GHz 2. RAM, 2 GB
3. Aplikasi Visual Studio 2010 4. OS Win 7 ultimate
4.2. Hasil Uji Coba
Pada penelitian ini dilakukan pengamatan pada 4 metode pengurutan yaitu selection sort,
selection model insert, selection sort model new list dan merge sort. Diberikan nilai input
Max Item Value 1000 dan 1000000, sedangkan nilai Max Item pada 10, 500 dan 1000
untuk masing-masing Max Item Value tersebut. Dan data yang diberikan untuk keempat
kondisi tersebut juga sama. Berikut akan ditampilkan hasil pengamatan yang
sudahdilakukan.
4.2.1 Pengurutan pada Max Item = 10
Pengurutan pada Max Item 10 dilakukan dengan membandingkan pada 2 nilai Max
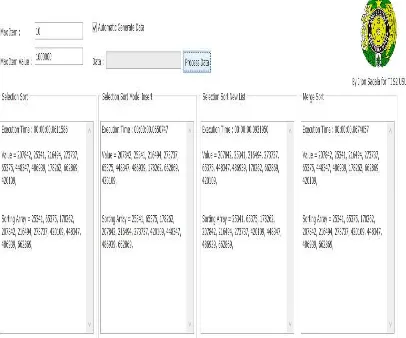
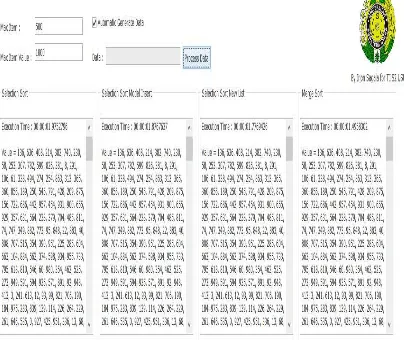
Gambar 4.1 Item Tampilan hasil pada max item 10 dan Max Value 1000
a. Max Item Value = 1000
Pada kondisi max item 10 dan Max Item Value 1000 terlihat hasil pengurutan data
seperti gambar 4.2. Dari keempat metode yang digunakan dapat diamati bahwa pada
kondisi ini waktu eksekusi yang paling cepat yaitu pada metode selection sort sebesar
0,0505 x 10-3 sec, selection model insert sebesar 0,0642x 10-3 sec, selanjutnya
selection sort new list sebesar 0,0647 x 10-3 sec dan merge sort sebesar 0,0768 x 10-3
sec. Dari keempat nilai eksekusi tersebut metode marge sort memiliki waktu eksekusi
yang paling lama untuk kondisi max item 10. Dari hasil ini terlihat bahwa metode
a.Selection Sort b Selection Sort Model Insert
b.
Selection sort d. Merge SortGambar 4.2 Pengurutan pada Max Item 10 Max Item Value = 1000
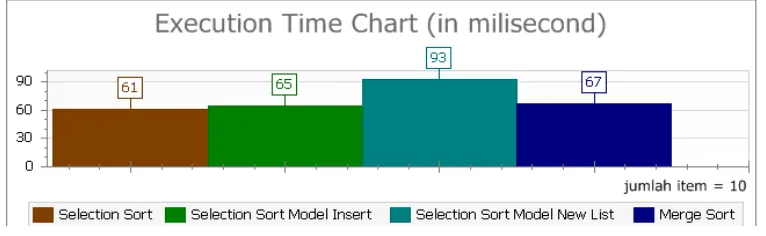
Pada gambar 4.3 jelas telihat perbedaan kompleksitas waktu dari keempat metode sorting
yang ditampilakan pada grafik, yang menujukan waktu terbaik pada selection sort dan
Gambar 4.3 Grafik perbandingan keempat pengurutan untuk
Max Item 10 Max Item Value = 1000
b. Max Item Value = 1000000
Pengurutan pada Max Item 10 dilakukan denganMax Item Value yaitu Max Item Value
= 1000000.
Pada kondisi Max item 10 dan Max Item Value 1000000 dengan data yang
diberikan pada keempat kondisi sama maka diperoleh hasil pengurutan seperti pada
gambar 4.5. Pada kondisi ini waktu eksekusi tercepat pada metode selection sort
sebesar 0,0611 x 10-3 sec, selanjutnya metode selection model insert sebesar 0,0650
x 10-3 sec, merge sort sebesar 0,0674 x 10-3 sec, metode selection sort model new
list 0,0931 x 10-3 sec. Pada kondisi ini metode selection sort model new list
memerlukan waktu paling lama untuk eksekusi bila dibandingkan dengan ketiga
metode lainnya. Dari hasil ini terlihat bahwa tidak ada perbedaan yang signifikan
antar keempat algoritma yang digunakan.
a. Selection sort b. Selection sort model insert
Gambar 4.5 Hasil pengurutan pada Max item 10 dan
Max Item Value 1000000
Grafik pada gambar 4.6 menunjukan perbedaan kompleksitas waktu untuk keempat metode
pengurutan tidak begitu signifikan, namun selection sort pada percobaan ini lebih unggul
dari ketiga pengurutan lainnya.
Gambar 4.6. Grafik perbandingan keempat pengurutan untuk Max Item 10 Max Item Value = 1000000
4.2.2 Pengurutanpada Max Item = 500
Pengurutan pada Max Item 500 dilakukan dengan membandingkan pada 2 nilai
Gambar 4.7 Pengurutan Pada Max Item 500 Max Item Value=1000
a. Max Item Value = 1000
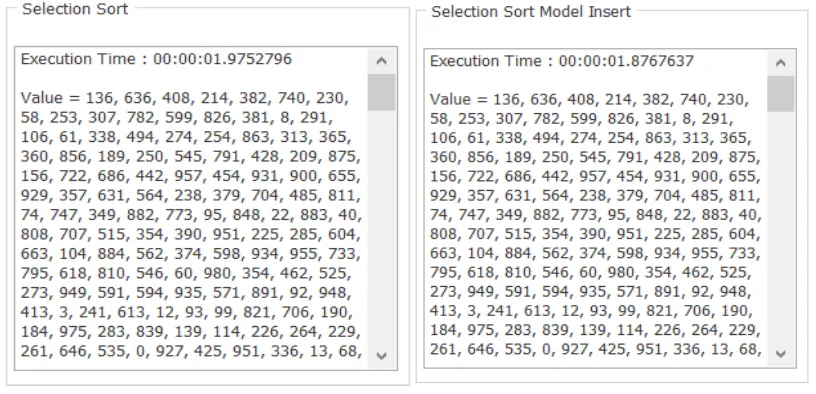
Pada kondisi Max item 500 dan Max Item Value 1000 dengan data yang diberikan
pada keempat kondisi sama maka diperoleh hasil pengurutan seperti pada gambar
4.8. Pada kondisi ini waktu eksekusi tercepat pada metode merge sort sebesar 1,495
x 10-3 sec, selanjutnya selection sort new list 1,777x 10-3 sec, metode selection
model insert sebesar 1,876 x 10-3 sec dan selection sort sebesar 1,975 x 10-3 sec.
Pada kondisi ini metode selection sort memerlukan waktu paling lama untuk
a. Selection sort b. Selection sort model insert
c. Selection sort New List d. Merge Sort.
Gambar 4.8 Hasil pengurutan pada Max item 500 dan
Max Item Value 1000
Percobaan ini memperlihatkan dominasi dari merge sort jauh lebih unggul kompleksitas
waktu dari selection sort, terlihat pada grafik pada gambar 4.9. Namun selection sort model
insert dan selection sort model new list yang penulis tambahkan memliki waktu yang tidak
Gambar 4.9 Grafik perbandingan keempat pengurutan untuk Max Item 500 Max Item Value = 1000
b. Max Item Value = 1000000
Pengurutan pada Max Item 500 dilakukan dengan Max Item Value yaitu Max Item
Value = 1000000.
Gambar 4.10 Pengurutan Pada Max Item 500 Max Item Value=1000000
Pada kondisi Max item 500 dan Max Item Value 1000000 dengan data yang
gambar 4.11. Pada kondisi ini waktu eksekusi tercepat pada metode merge sort
sebesar 1,773 x 10-3 sec, selanjutnya selection sort model insert 1,799 x 10-3 sec,
metode selection model new list sebesar 1,893 x 10-3 sec dan selection sort sebesar
2,005 x 10-3 sec. Pada kondisi ini metode selection sort memerlukan waktu paling
lama untuk eksekusi bila dibandingkan dengan ketiga metode lainnya.
a. Selection sort b. Selection sort model insert
c. Selection sort New List d. Merge Sort
Gambar 4.11 Hasil pengurutan pada Max item 500 dan
Metode pengurutan yang penulis kembangkan dari motode selection sort, memiliki waktu
yang lebih baik dari selection sort yaitu selection sort model insert dan selection sort model
new list, sehingga perbedaan kompleksitas waktu dengan merge sort tidak terlalu
signifikan, bila dibandingan merge sort dengan selection sort yang begitu jauh perbedaan
kompleksitas waktunya, dapat dilihat pada grafik dibawah ini.
Gambar 4.12 Grafik perbandingan keempat pengurutan untuk Max Item 500 Max Item Value = 1000000
4.2.3 Pengurutanpada Max Item = 1000
Pengurutan pada Max Item 1000 dilakukan dengan membandingkan pada 2 nilai
Gambar 4.13 Pengurutan Pada Max Item 1000 Max Item Value=1000
a. Max Item Value = 1000
Pada kondisi Max item 1000 dan Max Item Value 1000 dengan data yang diberikan
pada keempat kondisi sama maka diperoleh hasil pengurutan seperti pada gambar
4.14. Pada kondisi ini waktu eksekusi tercepat pada metode merge sort sebesar
3,323 x 10-3 sec, metode selection model new list sebesar 3,528 x 10-3 sec,
selanjutnya selection sort model insert 3,679 x 10-3 sec dan selection sort sebesar
3,704 x 10-3 sec. Pada kondisi ini metode selection sort memerlukan waktu paling
lama untuk eksekusi bila dibandingkan dengan ketiga metode lainnya. Terlihat
bahwa metode merge sort membutuhkan waktu semakin cepat dibandingkan dengan
metode lain dengan kondisi jumlah data yang semakin besar. Perbedaan yang
dihasilkan lebih dari 1 second dengan metode lainnya. Sedangkan untuk metode
selection sort, dari hasil terlihat bahwa dengan jumlah data yang semakin besar,
waktu yang dibutuhkan metode ini juga semakin besar dibandingkan metode
a. Selection sort b. Selection sort model insert
c. Selection sort New List d. Merge Sort
Gambar 4.14 Hasil pengurutan pada Max item 1000 dan
Max Item Value 1000
Kecepatan kompleksitas waktu yang diciptakan merge sort selalu lebih baik dibandingkan
dengan ketiga pengurutan lainnya jika max item dan max item valuenya bernilai besar.
Gambar 4.15 Grafik perbandingan keempat pengurutan untuk Max Item 1000 Max Item Value = 1000
b. Max Item Value = 1000000
Pengurutan pada Max Item 1000 dilakukan dengan Max Item Value yaitu Max Item
Gambar 4.16 Pengurutan Pada Max Item 1000 Max Item Value=1000000
Pengurutan pada Max Item = 1000 dilakukan untuk data dengan Max Item Value
100000. Sedangkan data yang diberikan kepada masing-masing kondisi adalah data
yang bentuk dan jumlahnya sama. Gambar 4.17. Merupakan hasil uji coba pada
kondisi ini. Pada kondisi ini waktu eksekusi tercepat pada metode merge sort
sebesar 2,660 x 10-3 sec, selanjutnya selection sort new list 3,510 x 10-3 sec, metode
selection model insert sebesar 3,652 x 10-3 sec dan selection sort sebesar 3,909 x
10-3 sec. Pada kondisi ini metode selection sort memerlukan waktu paling lama
untuk eksekusi bila dibandingkan dengan ketiga metode lainnya. Dengan Max Item
Value yang semakin besar, metode merge sort masih lebih baik dibandingkan
dengan metode lainnya. Dari hasil ini juga terlihat bahwa, dengan jumlah data yang
semakin besar, metode selection sort membutuhkan waktu yang semakin besar