SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
Program Strata Satu Program Studi Teknik Informatika
Fakultas Teknik dan Ilmu Komputer
Universitas Komputer Indonesia
Puji Pra Ramdhani
10108057
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA
BANDUNG
i ABSTRAK
ANALISIS PERBANDINGAN PERFORMANSI ALGORITMA ZHU-TAKAOKA DAN ALGORITMA KARP-RABIN PADA PENCARIAN
KATA DI RUMAH BACA BUKU SUNDA
Oleh
Puji Pra Ramdhani 10108057
Pada rumah baca buku sunda calon pembaca yang datang mencari buku berdasarkan judul akan tetapi terkadang calon pembaca mencari buku terbitan lama dan tidak mengingat judul buku yang akan di carinya. Hanya mengingat nama tokoh dalam buku tersebut atau kata yang sering muncul pada isi buku tersebut. Tentu saja nama tokoh atau kata yang sering muncul dalam isi buku tidak terdapat dalam katalog buku biasa. Hal tersebut mengakibatkan calon pembaca mengalami kesulitan mencari buku yang akan dibaca.
Dengan ada permasalahan tersebut perlu adanya suatu perangkat lunak pencarian kata yang dapat menyelesaikan permasalah tersebut dengan tepat dan juga cepat. Sehingga dapat membantu calon pembaca menemukan buku yang dicari. Ada sekitar 35 algoritma pencarian kata yang bisa digunakan dalam perangkat baik merupakan algoritma yang diciptakan dari awal maupun berupa pengembangan dari algoritma yang sudah ada. Dua di antaranya yaitu algoritma Karp-Rabin dan Algoritma Zhu-Takaoka.
Dengan melakukan analisis perbandingan performansi dari algoritma Karp-Rabin dan algoritma Zhu-Takaoka maka akan dapat diketahui cara kerja dan performansi dalam kecepatan dan ketepatan dari kedua algoritma tersebut. Agar selanjutnya algoritma yang lebih mangkus dapat digunakan pada perangkat lunak pencocokan kata.
.
ii
ANALYSIS OF COMPARATIVE PERFORMANCE BETWEEN ZHU-TAKAOKA AND KARP-RABIN ALGORITHMS ON WORDS SEARCHING
IN RUMAH BACA BUKU SUNDA
By
Puji Pra Ramdhani 10108057
Commonly, in the rumah baca buku sunda, readers look for a book which are wanted to be read according to its titles, but sometimes, they seek old published book and do not remember its title. Usually, they only remember names of the characters in that book or phrases which often appear to which both of them do not exist in the catalog. That matter causes them hard to find the desired book.
For handling the problem, there must be software of word searchING which can finish the problem properly and correctly. Therefore, the software can help the readers to find the desirable book. There are about 35 algorithms of word search which can be used in the software, both algorithms which were created in the beginning and algorithms which are developed form the existed algorithms. Two of them are Karp-Rabin and Zhu-Takaoka algorithms.
By doing analysis of comparative performance between Karp-Rabin and Zhu-Takaoka algorithms, it will be known a process and a performance in speed and accuracy from both algorithms. Furthermore, algorithms which are more efficient can be used on software of string matching.
iii
KATA PENGANTAR
Assalamu’alaikum, Wr.,Wb.
Yang Terucap akan lenyap, yang Tercatat akan teringat, Alhamdulillah
puji dan syukur kehadirat Allah SWT yang telah melimpahkan rahmat serta
hidayah-Nya, karena tidak lepas dari kehendak-Nya juga penulis dapat
menyelesaikan penyusunan skripsi ini. Sholawat serta salam semoga Allah SWT
limpahkan kepada junjungan alam baginda nabi besar Muhammad SAW, yang
telah membawa umat manusia dari alam kegelapan ke alam yang penuh dengan
berkah dan maghfiroh. Skripsi ini diajukan untuk memenuhi syarat dalam
menempuh ujian sidang sarjana strata satu (S1) pada Program Studi Teknik
Informatika Fakultas Teknik dan Ilmu Komputer Universitas Komputer
Indonesia. Skripsi ini berjudul: “ANALISIS PERBANDINGAN PERFORMANSI ALGORITMA ZHU-TAKAOKA DAN ALGORITMA
KARP-RABIN PADA PENCARIAN KATA DI RUMAH BACA BUKU
SUNDA”.
Sehubungan dengan telah selesainya Tugas Akhir ini, penulis yakin bahwa
tugas ini tidak akan berhasil tanpa doa, bimbingan, petunjuk dan dukungan dari
berbagai pihak yang terlibat dalam pembuatan tugas ini. Oleh karena itu penulis
iv
1. Allah S.W.T yang telah memberikan penulis nikmat dan kesehatan
sehingga dapat menyelesaikan skripsi tahun ini.
2. Kedua Orang Tua penulis yang tidak kenal leleah untuk selalu mendoakan
dan memberikan dukungan selama ini.
3. Yang terhormat Bapak Adam Mukharil Bachtiar,S.Kom. selaku Dosen
Wali sekaligus Pembimbing dan Mentor yang telah memberikan arahan
dan meluangkan waktunya dalam membantu penyusunan skripsi ini.
4. Yang terhormat Ibu Mira Kania Sabariah, S.T.,M.T. selaku Dosen Penguji
1 yang telah meluangkan waktu untuk memberikan pengarahan dan
memberikan masukan dalam penyelesaian skripsi ini.
5. Dosen-dosen Teknik Informatika yang telah mengajari berbagai hal dan
berbagai bidang ilmu pengetahuan.
6. Untuk pihak sekretariat jurusan yang telah melayani tentang
kemahasiswaan selama empat tahun ini.
7. Buat teman seperjuangan yang ngambil skripsi juga Sandi Barkah dan
Iham Andrian yang selalu ada jika penulis membutuhkan bantuan dalam
proses penyusunan skripsi ini.
8. Rekan-rekan kelas IF-02 angkatan 2008 yang selama empat tahun ini
v
9. Hilman,Helmy,Natalla dan semua pihak yang telah memberikan bantuan
dan dukungan dalam menyelesaikan skripsi.
10. Pihak-pihak lain yang tidak dapat penulis sebutkan satu persatu.
Saya menyadari bahwa Laporan penelitian tugas akhir yang penyusun buat ini masih jauh dari sempurna, seperti kata pepatah : “Tak ada gading yang tak retak”.
Oleh karenanya saran dan kritik guna kelengkapan dan kesempurnaan skripsi ini
sangat saya harapkan, serta demi peningkatan kemampuan dan pengetahuan
dimasa-masa yang akan datang.
Sebagai penutup peneliti berharap semoga penyusunan skripsi ini berguna,
khususnya bagi peneliti dan umumnya bagi kita semua. Semoga Allah SWT selalu
meridhoi kita semua, amin.
Jazakumullah Khairan Katsiran, Wassalamu alaikum, Wr., Wb.
Bandung, 26 Agustus 2012
vi
DAFTAR ISI ... vi
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... x
DAFTAR SIMBOL ... xi
DAFTAR LAMPIRAN ... xv
BAB 1 PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Perumusan Masalah ... 3
1.3. Maksud dan Tujuan ... 3
1.3.1. Maksud ... 3
1.3.2. Tujuan ... 3
1.4. Batasan Masalah ... 3
1.5. Metodologi Penelitian ... 4
1.5.1. Metode Pengumpulan Data ... 4
1.5.2. Metode Pembangunan Perangkat Lunak... 5
1.6. Sistematika Penulisan ... 7
BAB 2 LANDASAN TEORI... 9
5.1 Rumah Baca Buku Sunda ... 9
5.2 Landasan Teori ... 10
vii
2.2.5. Metode Pembangunana Perangkat Lunak ... 25
2.2.6. Object Oriented Programing (OOP) ... 26
2.2.7. JAVA ... 29
2.2.8. NetBeans IDE 6.9.1 ... 31
2.2.9. WAMP Server ... 32
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 33
3.1. Analisis Sistem ... 33
3.1.1. Analisis Masalah ... 33
3.1.2. Analisis Algoritma ... 34
3.1.3. Spesifikasi Kebutuhan Perangkat Lunak ... 57
3.2. Perancangan Sistem ... 59
3.2.1. Perancangan Arsitektural Perangkat Lunak ... 59
3.2.2. Perancangan Struktur Menu ... 59
3.2.3. Perancangan Antarmuka Perangkat Lunak ... 60
3.2.4. Perancangan Jaringan Semantik ... 64
3.2.5. Perancangan Prosedural ... 65
BAB 4 IMPLEMETASI DAN PENGUJIAN ... 67
4.1. Implementasi Sistem ... 67
4.1.1. Implementasi Perangkat Keras... 67
viii
4.2.2. Pengujian White Box ... 71
4.2.3. Pengujian Black Box ... 81
4.2.4. Kesimpulan Pengujian. ... 86
BAB 5 KESIMPULAN DAN SARAN ... 85
5.1 Kesimpulan ... 85
5.2 Saran ... 85
1
1.1. Latar Belakang
Rumah Baca Buku Sunda atau yang disingkat RBBS merupakan
perpustakaan non profit, mulai di bentuk sekitar Februari 2004 Pengunjung RBBS
beragam seperti orang tua, murid-murid sekolah (SD, SMP, atau SMA),
mahasiswa, dan masyarakat umum lainnya. Koleksi buku di RBBS berjumlah
sekitar 8000 buah dan 3000 buah diantaranya adalah karya sastra Sunda seperti
novel, kumpulan cerita pendek, kumpulan esai, kumpulan puisi dan sajak, dan ada
juga yang membahas tentang kebudayaan Sunda. Koleksi buku Sunda di RBBS
tidak hanya buku-buku tentang sastra dan kebudayaan Sunda yang berbahasa
Sunda saja. Ada juga buku-buku yang membahas hal sama tetapi disajikan dalam
bahasa Indonesia atau bahasa lain seperti bahasa Inggris. Selain itu, ada pula
buku-buku umum yang merupakan sastra Indonesia, sastra berbahasa asing seperti
bahasa Inggris, dan sastra terjemahan.
Dari hasil observarsi calon pembaca Rumah Baca Buku Sunda yang
datang mencari buku berdasarkan judul akan tetapi terkadang calon pembaca
mencari buku terbitan lama dan tidak mengingat judul buku yang akan di carinya.
Hanya mengingat nama tokoh dalam buku tersebut atau kata yang sering muncul
pada isi buku tersebut. Tentu saja nama tokoh atau kata yang sering muncul dalam
isi buku tidak terdapat dalam katalog buku biasa. Hal tersebut mengakibatkan
Perangkat lunak yang cepat dan tepat tergantung dari algoritma yang
digunakan, Ada sekitar 35 algoritma pencarian kata yang bisa digunakan dalam
perangkat baik merupakan algoritma yang diciptakan dari awal maupun berupa
pengembangan dari algoritma yang sudah ada [1]. Dua di antaranya yaitu algoritma Karp-Rabin dan Algoritma Zhu-Takaoka. Untuk single pattern, yaitu
ketika pattern yang dicari hanya satu atau tunggal, algoritma Karp-Rabin kalah
dibandingkan dengan Knuth-Morris-Pratt, Boyer-Moore dan algoritma
pencocokan string cepat yang lain, karena kelambatannya dalam kasus terburuk
[2]. Tetapi algoritma Rabin-Karp unggul dalam kasus pencarian string dengan
pattern yang panjang dan kasus pencarian string dengan multipattern [3]. Algoritma Zhu-Takaoka lebih cepat dibandingkan dengan algoritma Raita dan untuk pattern berupa kalimat algoritma Zhu-Takaoka lebih cepat juga dibandingkan dengan algoritma Raita [4]. Dengan melakukan analisis perbandingan performansi dari algoritma Karp-Rabin dan algoritma Zhu-Takaoka
maka akan dapat diketahui cara kerja dan performansi dalam kecepatan dan
ketepatan dari kedua algoritma tersebut. Agar selanjutnya algoritma yang lebih
mangkus dapat digunakan pada perangkat lunak pencocokan kata.
Berdasarkan permasalah yang telah dipaparkan maka dapat disimpulkan
bahwa perlu dibangun perangkat lunak pencocokan kata yang dapat membantu
menganalisis performansi algoritma Karp-Rabin dan algoritma Zhu-Takaoka.
Oleh karena itu dibangunlah perangkat lunak pencocokan kata pada pencarian
1.2. Perumusan Masalah
Berdasarkan latar belakang masalah maka dirumuskan sebuah masalah
yaitu bagaimana menganalisis performansi algoritma Zhu-Takaoka dan algoritma
Karp-Rabin pada pencarian kata dirumah baca buku sunda.
1.3. Maksud dan Tujuan
1.3.1. Maksud
Maksud dari penelitian ini adalah menganalisis performansi algoritma
Zhu-Takaoka dan algoritma Karp-Rabin pada pencarian kata di rumah baca buku
sunda.
1.3.2. Tujuan
Sedangkan tujuan yang akan dicapai dalam penelitian ini adalah untuk
mengetahui algoritma pencocokan kata mana yang lebih cepat dan tepat
dirumah buku baca sunda.
1.4. Batasan Masalah
Pembahasan permasalahan diharapkan tidak menyimpang dari pokok
permasalahan, sehingga diperlukan batasan masalah.Adapun batasan dari
penulisan tugas akhir ini adalah sebagai berikut :
1. Algoritma yang digunakan yaitu algoritma Zhu-Takaoka dan
algoritma Karp-Rabin.
2. Buku yang digunakan hanya buku berbahasa Indonesia
3. Hasil informasi data pencarian yang dihasilkan bersumber pada
4. Output pencarian dari perangkat lunak adalah judul buku,
jumlah karakter,posisi kata yang dicari, waktu pencarian dan
memori yang digunakan untuk melakukan pencarian.
5. Pattern atau kata yang dicari memiliki relevansi dengan data
buku yang ada di database.
6. Input berupa teks ASCII.
7. Pendekatan analisis pembangunan perangkat lunak
menggunakan pendekatan analisis berorientasi objek.
8. Parameter yang digunakan dalam analisis perbandingan adalah
kecepatan,ketepatan dan efesiensi dari algoritama
1.5. Metodologi Penelitian
Metodologi penelitian yang akan digunakan dalam pembuatan Skripsi ini
menggunakan metodologi Analisis Deskriptif, yaitu metode penelitaian
menggunakan studi kasus. Metodologi ini terbagi menjadi dua metode yaitu:
1.5.1. Metode Pengumpulan Data
Adapun teknik pengumpulan data yang akan digunakan terdiri dari tiga
cara pengumpulan data, diantaranya :
1. Studi literatur
Studi literatur merupakan kegiatan yang dilakukan dengan
mencari pustaka yang menunjang penelitian yang akan dikerjakan.
Pustaka tersebut dapat berupa buku, artikel, laporan akhir, dan
2. Studi lapangan
Studi lapangan merupakan kegiatan pengamatan secara langsung
di tempat penelitian untuk mengumpulkan data yang dibutuhkan.
3. Wawancara
Wawancara yaitu mendapatkan informasi dengan cara bertanya
langsung kepada responden. Tanpa wawancara, peneliti akan
kehilangan informasi yang hanya dapat diperoleh dengan jalan
bertanya langsung kepada responden. Data semacam itu
merupakan tulang punggung suatu penelitian survey.
1.5.2. Metode Pembangunan Perangkat Lunak
Tahap pengembangan perangkat lunak dalam pembuatan aplikasi ini
menggunakan classic life style atau waterfall . Tahapan pengembangan system adalah sebagai berikut :
a. Requirements analysis and definition
Tahap Requirements analysis and definition merupakan tahap pengumpulan kebutuhan secara lengkap kemudian dianalisis dan
didefinisikan kebutuhan yang harus dipenuhi oleh program yang
akan dibangun. Fase ini harus dikerjakan secara lengkap untuk bisa
menghasilkan desain yang lengkap.
Tahap System and software design merupakan tahap mendesain
perangkat lunak yang dikerjakan setelah kebutuhan selesai
dikumpulkan secara lengkap.
c. Implementation and unit testing
Tahap Implementation and unit testing merupakan tahap hasil desain program diterjemahkan ke dalam kode-kode dengan
menggunakan bahasa pemrograman yang sudah ditentukan.
Program yang dibangun langsung diuji baik secara unit.
d. Integration and system testing
Tahap Integration and system testing merupakan tahap penyatuan
unit-unit program kemudian diuji secara keseluruhan (system
testing).
e. Operation and maintenance
Tahap Operation and maintenance merupakan tahap mengoperasikan program dilingkungannya dan melakukan
pemeliharaan, seperti penyesuaian atau perubahan karena adaptasi
Requirements definition
System and Software Design
Implementation and unit testing
Integration and sytem testing
Operation and maintenance
Gambar 1.1 Model Proses Waterfall [5]
1.6. Sistematika Penulisan
Sistematika penulisan skripsi ini disusun untuk memberikan gambaran
umum tentang penelitian yang dijalankan. Adapun sistematika penulisan skripsi
ini adalah sebagai berikut :
BAB 1 PENDAHULUAN
Bab 1 merupakan proses menguraikan tentang latar belakang permasalahan,
mencoba merumuskan inti permasalahan yang dihadapi, menentukan maksud dan
tujuan penelitian, yang kemudian diikuti dengan pembatasan masalah, metodelogi
BAB 2 LANDASAN TEORI
Bab 2 membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan
topik yang diangkat dan hal-hal yang berguna dalam proses analisis permasalahan
serta tinjauan terhadap penelitian-penelitian serupa yang pernah dilakukan
sebelumnya termasuk sintesisnya.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Bab 3 berisi analisis kebutuhan untuk sistem yang akan dibangun sesuai dengan
metode pengembangan perangkat lunak yang digunakan. Selain itu, bab ini juga
berisi perancangan struktur antar muka untuk perangkat lunak yang akan
dibangun.
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab 4 berisi hasil implementasi analisis dan perancangan sistem yang dilakukan, serta hasil pengujian sistem untuk mengetahui apakah aplikasi yang dibangun sudah memenuhi kebutuhan
BAB 5 KESIMPULAN DAN SARAN
Bab 5 berisi kesimpulan hasil penelitian berdasarkan tujuan yang ingin dicapai
dan saran yang dapat diberikan untuk perangkat lunak ini untuk kemudian dapat
9
2.1 Rumah Baca Buku Sunda
Rumah Baca Buku Sunda atau yang disingkat RBBS mulai dibentuk
sekitar Februari 2004. Awalnya RBBS merupakan perpustakaan pribadi milik
Mamat Sasmita. Sebelumnya, Mamat Sasmita atau yang akrab dipanggil Uwak
Sasmita merasa koleksi bukunya sudah semakin banyak dan rasanya sayang bila
hanya dibaca sendiri. Ia pun memutuskan untuk menjadikan perpustakaan
pribadinya sebagai rumah baca buku untuk umum. Koleksi buku di RBBS
berjumlah sekitar 8000 buah dan 3000 buah diantaranya adalah karya sastra
Sunda seperti novel, kumpulan cerita pendek, kumpulan esai, kumpulan puisi dan
sajak, dan ada juga yang membahas tentang kebudayaan Sunda. Koleksi buku
Sunda di RBBS tidak hanya buku-buku tentang sastra dan kebudayaan Sunda
yang berbahasa Sunda saja. Ada juga buku-buku yang membahas hal sama tetapi
disajikan dalam bahasa Indonesia atau bahasa lain seperti bahasa Inggris. Selain
itu, ada pula buku-buku umum yang merupakan sastra Indonesia, sastra berbahasa
asing seperti bahasa Inggris, dan sastra terjemahan. Buku-buku yang ada biasanya
dibeli dari para penjual buku loak di Bandung seperti yang ada di daerah Palasari,
Dewi Sartika, Cikapundung, Cibeunying, dan Jatayu. Selain membeli sendiri,
koleksi buku juga didapatkan dari sumbangan pihak luar dan biasanya buku-buku
bertemakan sastra serta kebudayaan.
• Kamoes Basa Sunda karangan R. Satjadibrata yang diterbitkan Bale
Poestaka pada tahun 1948.
• Kamus Sunda-Inggris yang disusun Jonathan Rigg, (anggota The
Batavia Society of Arts and Sciences) dan diterbitkan Batavia
Lange & Co pada tahun 1862.
• Buku puisi Sawer Bahasa Sunda yang diterbitkan Departemen
Pendidikan dan Kebudayaan.
• Novel Sunda Sebelum Perang karangan Yus Rusyana.
• Dipati Ukur Djilid 4 yang diterbitkan Daja Sunda Pusat.
• Jagad Carita (Kandaga Carpon Dunya) karangan Hawé Setiawan.
• Pasini Jangji di Muaraberes (Carita Mundinglaya) karangan
Rohmat Tasdik Al Garuti.
2.2 Landasan Teori
2.2.1. String Matching
String dalam ilmu komputer dapat diartikan dengan sekuens dari karakter.
Walaupun sering juga dianggap sebagai data abstrak yang menyimpan sekuens
nilai data, atau biasanya berupa bytes yang mana merupakan elemen yang
digunakan sebagai pembentuk karakter sesuai dengan encoding karakter yang
disepakati seperti ASCII, ataupun EBCDIC [
6
]. Pencocokan string atau stringmatching adalah proses pencarian semua kemunculan string pendek P[0..n-1]
yang disebut pattern di string yang lebih panjang T[0..m-1] yang disebut teks. Pencocokan string merupakan permasalahan paling sederhana dari semua
pengkompresian data, lexical analysis, dan temu balik informasi. Teknik untuk
menyelesaikan permasalahan pencocokan string biasanya akan menghasilkan
implikasi langsung ke aplikasi string lainnya [
7
].2.2.2. ASCII (American Standard Code for Information Interchange)
Kode Standar Amerika untuk Pertukaran Informasi atau ASCII (American
Standard Code for Information Interchange) merupakan suatu standar
internasional dalam kode huruf dan simbol seperti Hex dan Unicode tetapi ASCII
lebih bersifat universal, contohnya 124 adalah untuk karakter "|". Ia selalu
digunakan oleh komputer dan alat komunikasi lain untuk menunjukkan teks. Kode
ASCII sebenarnya memiliki komposisi bilangan biner sebanyak 8 bit. Dimulai
dari 0000 0000 hingga 1111 1111. Total kombinasi yang dihasilkan sebanyak
256, dimulai dari kode 0 hingga 255 dalam sistem bilangan Desimal.
Tabel 2-1 ASCII CODE
No Decimal Hex Binary Value
1 32 20 100000 (space)
2 33 21 100001 !
3 34 22 100010 "
4 35 23 100011 #
5 36 24 100100 $
6 37 25 100101 %
7 38 26 100110 &
8 39 27 100111 '
9 40 28 101000 (
No Decimal Hex Binary Value
11 42 02A 101010 *
12 43 02B 101011 +
13 44 02C 101100 ,
14 45 02D 101101 -
15 46 02E 101110 .
16 47 02F 101111 /
17 48 30 110000 0
18 49 31 110001 1
19 50 32 110010 2
20 51 33 110011 3
21 52 34 110100 4
22 53 35 110101 5
23 54 36 110110 6
24 55 37 110111 7
25 56 38 111000 8
26 57 39 111001 9
27 58 03A 111010 :
28 59 03B 111011 ;
29 60 03C 111100 <
30 61 03D 111101 =
31 62 03E 111110 >
32 63 03F 111111 ?
33 64 40 1000000 @
34 65 41 1000001 A
No Decimal Hex Binary Value
36 67 43 1000011 C
37 68 44 1000100 D
38 69 45 1000101 E
39 70 46 1000110 F
40 71 47 1000111 G
41 72 48 1001000 H
42 73 49 1001001 I
43 74 04A 1001010 J
44 75 04B 1001011 K
45 76 04C 1001100 L
46 77 04D 1001101 M
47 78 04E 1001110 N
48 79 04F 1001111 O
49 80 50 1010000 P
50 81 51 1010001 Q
51 82 52 1010010 R
52 83 53 1010011 S
53 84 54 1010100 T
54 85 55 1010101 U
55 86 56 1010110 V
56 87 57 1010111 W
57 88 58 1011000 X
58 89 59 1011001 Y
59 90 05A 1011010 Z
No Decimal Hex Binary Value
61 92 05C 1011100 \
62 93 05D 1011101 ]
63 94 05E 1011110 ^
64 95 05F 1011111 _
65 96 60 1100000 `
66 97 61 1100001 a
67 98 62 1100010 b
68 99 63 1100011 c
69 100 64 1100100 d
70 101 65 1100101 e
71 102 66 1100110 f
72 103 67 1100111 g
73 104 68 1101000 h
74 105 69 1101001 i
75 106 06A 1101010 j
76 107 06B 1101011 k
77 108 06C 1101100 l
78 109 06D 1101101 m
79 110 06E 1101110 n
80 111 06F 1101111 o
81 112 70 1110000 p
82 113 71 1110001 q
83 114 72 1110010 r
84 115 73 1110011 s
No Decimal Hex Binary Value
86 117 75 1110101 u
87 118 76 1110110 v
88 119 77 1110111 w
89 120 78 1111000 x
90 121 79 1111001 y
91 122 07A 1111010 z
92 123 07B 1111011 {
93 124 07C 1111100 |
94 125 07D 1111101 }
95 126 07E 1111110 ~
96 127 07F 1111111 DEL
2.2.3. Algoritma
Algoritma merupakan urutan langkah-langkah dalam menentukan suatu
masalah. Algoritma juga dapat didefinisikan dengan deretan langkah komputasi
yang mentransformasikan masukan menjadi keluaran
2.2.4. Algoritma String Matching
Algoritma pencocokan string dapat dibedakan atas dua cara pembacaan :
1) dari kiri ke kanan
Alogoritma pencarian dengan teknik ini sangat banyak. Hampir sebagian besar
algoritma pencarian menggunakan cara pembacaan teks dari kiri ke kanan.
2) dari kanan ke kiri
Dalam Algoritma ini, terdapat algoritma Boyer-Moore yang dianggap merupakan
salah satu algoritma yang utama dan algoritma standar dalam pencocokan string.
algoritma yang bisa digunakan, baik merupkan algoritma yang diciptakan dari
awal maupun berupa pengembangan dari algoritma yang sudah ada. [
1
].2.2.4.1Algoritma Karp-Rabin
Algoritma Rabin-Karp diperkenalkan pertama kali oleh Michael O. Rabin dan
Richard M. Karp pada tahun 1987. Algoritma ini menggunakan tabel array dan metode Hashing dalam pengoperasiannya. Metode hashing ini digunakan
terutama untuk meningkatkan kecepatan pencarian dengan meningkatkan
pengujian kesetaraan dalam teks. Pada faktanya, fungsi hash menyimpan bentuk
string dalam bentuk lain yaitu enumerasi sehingga suatu string tertentu akan
memiliki nilai enumerasinya sendiri-sendiri (unik). Karena suatu string hanya memiliki sebuah nilai enumerasi maka hal inilah yang digunakan oleh algoritma
Rabin-Karp untuk mempercepat pencarian string dalam tabel hash. Dengan menggunakan metode seperti ini, akan terdapat kebocoran pada pencarian dalam
teks yang panjang, karena pada teks yang panjang akan terjadi penomoran string
yang sama meskipun string yang dituju berbeda. Sehingga dibutuhkan verifikasi lebih lanjut terhadap isi string tersebut. Hal ini sebenarnya dapat memakan waktu
yang cukup lama apabila terjadi pada substring yang panjang. Namun fungsi hash
yang baik akan menjamin kekurang seperti ini jarang terjadi, sehingga rata-rata
waktu pencarian rata-rata menggunakan metode ini relatif baik.
Rolling hash adalah fungsi hash dengan basis. Basis biasanya adalah
bilangan prima. Berikut ini adalah penggunaan fungsi hash dengan basis.
1. Dengan menggunakan a= 2 sebagai basis lalu tentukan panjang sumber string disini ”strategi” n = 8. Sedangkan untuk pattern yang dicari ”rat”
panjangnya m = 3.
2. Selanjutnya ubah pattern yang dicari dengan menggunakan fungsi Rolling
hash. Dengan persamaan :
H = C0*am-1 + C1*am-2 + ... + C[m-1]*a0
H = nilai hash
C = nilai ASCII karakter
a = nilai basis
m = banyaknya karakter
Jadi nilai hash dari ”rat” adalah 766 didapat dari :
H = 114*22 + 97*21 + 116*20
= 456 + 194 + 116
= 766
(nilai ASCII r = 114, a = 97 , t = 116)
Percobaan ke 1 :
Hash(rat) = 766
Hash (y[0..2]) = 806
s t r a t e g i
Nilai hash dari indeks ke 0 samapai dengan 2 tidak cocok dengan nilai hash target
maka dilakukan pergeseran.
Percobaan ke 2 :
Hash(rat) = 766
Hash (y[1..3]) = 789
s t r a t e g i
r a t
Tidak seperti menggunakan fungsi hash biasa pada percobaan ke dua
menggunakan fungsi rolling hash tidak mengalami kecocokan nilai hash. Dengan
798 didapat dari :
H = 116*22 + 114*21 + 97*20
= 464 + 228 + 97
= 789
Maka kembali dilakukan pergeseran.
Percobaan ke 3 :
Hash(rat) = 766
Hash (y[2..4]) = 766
s t r a t e g i
Terjadi kecocokan nilai hash maka algoritma menandai lokasi penemuan dan t
melanjutkan pencarian sampai karakter pada sumber string habis.
Percobaan ke 4 :
Hash(rat) = 766
Hash (y[3..5]) = 721
s t r a t e g i
r a t
Percobaan ke 5 :
Hash(rat) = 766
Hash (y[3..5]) = 769
s t r a T e g i
R a t
Percobaan ke 6 :
Hash(rat) = 766
Hash (y[3..5]) = 715
s t r a t e g i
r a t
2.2.4.2Algoritma Zhu-Takaoka
Algoritma Zhu-Takaoka merupakan algoritma pencocokan string (String
Matching) yang dipublikasikan oleh Zhu Rui Feng dan Tadao Takaoka pada tahun
string ini sebagai BM‟ Algorithm (Boyer-Moore‟ Algorithm). BM‟ Algorithm
merupakan algoritma modifikasi dari algoritma pencocokan string Boyer-Moore
Algorithm yang dibuat oleh Boyer R.S dan Moore J.S.
Algoritma BM‟ (Algoritma Zhu-Takaoka) yang merupakan modifikasi dari
Algoritma BM mempunyai ciri-ciri yang sama dalam proses pencarian string.
Ciri-ciri tersebut yaitu adanya tahap Preprocessing, Right-to-left scan,
Bad-character rule, dan Good-suffix rule. Perbedaan antara Algoritma Boyer-Moore
dan Algoritma Zhu-Takaoka yaitu terletak pada tahap penentuan bad character
rule. Dalam Boyer-Moore, bad character hanya terdiri array satu dimensi,
sedangkan dalam Zhu-Takaoka dimodifikasi menjadi array dua dimensi. Berikut
karakteristik dari Algoritma Zhu-Takaoka.
1) Preprocessing
Prepocessing dalam algoritma Zhu-Takaoka meliputi pencarian nilai pergeseran
karakter (good-suffix shift) dan pergeseran karakter jika karakter tidak cocok
(bad-character shift). Nilai good-suffix shift ditetukan dalam good-suffix
prepocessing sedangkan nilai character shift ditentukan dalam
bad-characterprepocessing. Prepocessing dilakukan sebelum proses inti dari pencarian
pattern dalam suatu text. (Pratama, 2008)
2) Right-to-Left Scan Rule
Proses inti pencarian Algoritma Zhu-Takaoka yaitu dilakukan dengan teknik
Right-to-left scan rule. Teknik ini yaitu melakukan perbandingan antara pattern
yang dicari dengan target text secara terbalik yaitu bergerak dari kanan ke kiri.
terakhir dari pattern (karakter paling kanan) dengan target text paling kanan.
Apabila ada kecocokan maka perbandingan akan dilanjutkan dengan bergerak ke
kiri sampai karakter pertama dari pattern. Sedangkan apabila terjadi
ketidakcocokan maka akan dilakukan pergeseran, besarnya pergesaran yang
dilakukan ditentukan oleh dua fungsi pergeseran yaitu bad-character shift dan
good-suffix shift.
3) Bad-Charcter Shift Rule
Aturan bad-character shift dibutuhkan untuk menghindari pengulangan
perbandingan yang gagal dari suatu karakter dalam target text dengan pattern.
Besarnya pergeseran yang dilakukan dalam aturan bad-character shift disimpan
dalam bentuk tabel array dua dimensi, tabel ini terdiri dari beberapa kolom yaitu
kolom karakter dan kolom shift yang menunjukkan besarnya pergeseran yang
harus dilakukan.
4) Good Suffix Shift Rule
Aturan good-suffix shift dibuat untuk menangani kasus dimana terdapat
pengulangan karakter pada pattern. Contoh dibawah ini akan menjelaskan
bagaimana aturan bad-character shift gagal dalam menangani adanya perulangan
bagian dalam pattern
Langkah – langkah pencarian :
Proses inti pencarian Algoritma Zhu-Takaoka yaitu dilakukan dengan teknik
Pattern yang dicari : done
Sumber string : indonesiaindonesi
Dari hasil preproccessing maka dihasil kan tabel ztBc :
a d e i N o s a 4 3 4 4 4 4 4 d 4 3 4 4 4 2 4 e 4 3 4 4 4 4 4 i 4 3 4 4 4 4 4 n 4 3 4 4 4 4 4 o 4 3 4 4 1 4 4 s 4 3 4 4 4 4 4
bmGs:
i 0 1 2 3 X[i] d o n e bmGs 4 4 4 1
Percobaan ke 1:
Dari hasil percobaan pertama terlihat pada karakter akhir pattern yang dicari yaitu
karakter e sejajar dengan karakter o pada sumber string artinya pada percobaan
pertama terjadi ketidakcocokan, maka dilakukan pergeseran sejauh dua karakter.
Nilai pergeseran dua karakter ini diperoleh dari tabel ztBc dimana dicocokannya
dua karakter akhri pada sumber string yang sejajar dengan karakter akhir pattern.
Pada contoh ini diisi dengan karakter d dan o. maka cek pada tabel ztBc baris d
dan kolom o maka bernilai dua.
Percobaan ke 2 :
i n d o n e s i a i n d o n e s i a
d o n e
Terlihat dari hasil percobaan ke dua pattern yang dicari ditemukan pada sumber
string maka akan diberi tanda dan dilanjutkan pada pencocokan selanjutnya
dengan pergeseran berdasarkan nilai dari tabel bmGs. Dari tabel bmGs karakter d
berada pada array ke nol dan memiliki nilai pergeseran empat, maka pattern
digeser sejauh 4 karakter.
Percobaan ke 3 :
i n D O N E s I a i n d o N e s i a d O n e
Dari hasil percobaan ke tiga terlihat pada karakter akhir pattern yang dicari yaitu
karakter e sejajar dengan karakter i pada sumber string artinya pada percobaan
dari dua karakter akhri pada sumber string yang sejajar dengan karakter akhir
pattern yang kemudian dicocokan dengan tabel ztBc. Untuk percobaan ketiga diisi
dengan karakter a dan i dan setelah dicocokan baris a dan kolom i pada tabel ztBc
menghasilkan nilai pergeseran empat.
Percobaan ke 4 :
i n D O N E s i a i n d O n e s i a d o N e
pada hasil percobaan ke empat terlihat pada karakter akhir pattern yang dicari
yaitu karakter e sejajar dengan karakter n pada sumber string artinya pada
percobaan empatpun terjadi ketidakcocokan. Dengan dua karakter akhir yang
diambil yaitu o dan n maka nilai pergeseran dari ketidakcocokan adalah satu.
Percobaan ke 5 :
i n D O N E s i a i n d o n E s i a
d o n E
Terlihat dari hasil percobaan ke lima terjadi kecocokan maka pergeseran
berdasarkan tabel bmGs. Dari tabel bmGs karakter d berada pada array ke nol dan
memiliki nilai pergeseran empat, maka pattern digeser sejauh 4 karakter. Karena
panjang sumber string sudah habis maka pencocokanpun dihentikan. Dari contoh
panjang pattern yang dicari empat dilakukan lima kali percobaan dan
menghasilkan dua pola yang cocok.
i n D O N E s i a i n D O N E s i a
2.2.5. Metode Pembangunana Perangkat Lunak
Dalam proses pembangunan perangkat lunak digunakan beberapa model.
Adapun model-model tersebut yaitu [
5
]:2.2.5.1 Waterfall Model
Model proses waterfall merupakan dasar proses aktifitas pembangunan suatu perangkat lunak. Model proses waterfall mempunyai beberapa tahapan yang
berurutan seperti yang dapat dilihat pada gambar berikut ini :
Setiap tahapan mempunyai arti tersendiri dalam proses pembangunan
suatu perangkat lunak serta tahapan-tahapan tersebut harus dilakukan secara
berurutan. Berikut ini merupakan penjelasan dari setiap tahapan yang ada dalam
waterfall model
a. Requirements analysis and definition
Tahap ini adalah tahap untuk mengumpulkan kebutuhan secaralengkap
kemudian dianalisis dan didefinisikan kebutuhan yang harus dipenuhi oleh
program yang akan dibangun. Tahap ini harus dikerjakan secara lengkap
untuk bisa menghasilkan desain yang lengkap.
Tahap ini adalah tahap mendesain sistem dan perangkat lunak yang dikerjakan
setelah kebutuhan selesai dikumpulkan secara lengkap.
c. Implementation and unit testing
Tahap ini mendesain sistem dan program maka pada tahap ini desain
diterjemahkan ke dalam kode-kode dengan menggunakan bahasa
pemrograman yang sudahditentukan.Program yang dibangun langsung diuji
baik secara unit.
d. Integration and system testing
Pada tahap ini unit-unit program disatukan kemudiandiuji secara keseluruhan
(system testing).
e. Operation and maintenance
Tahap ini program dioperasikan pada lingkungannya dan dilakukan
pemeliharaan, seperti penyesuaian atau perubahan karenaadaptasi dengan
situasi sebenarnya
2.2.6. Object Oriented Programing (OOP)
Analisis dan desain berorientasi objek adalah cara baru dalam memikirkan
suatu masalah dengan menggunkan model yang dibuat menurut konsep sekitar
dunia nyata. Dasar pembuatan adalah objek, yang merupakan kombinasi antara
struktur data dab perilaku dalam suatu entitas. Model berorientasi objek
bermanfaat untuk memahami masalah, komunikasi dengan ahli aplikasi,
pemodelan suatu organisasi, meyiapkan dokumentasi serta perancangan program
dan basis data. Pertama-tama suatu model analisis dibuat untuk menggambarkan
terdapat dalam domain aplikasi termasuk deskripsi dari keterangan objek dan
perilakunya. Secara spesifik, pengertian berorientai objek berarti bahwa
mengorganisasi perangkat lunak sebagai kumpulan dari objek tertentu yang
memiliki struktur data dan perilakunya. Hal ini yang membedakan dengan
pemograman konvensional dimana struktur data dan perilaku hanya berhubungan
secara terpisah. Terdapat beberapa cara untuk menentukan karateristik dalam
pendekatan berorientasi objek, tetapi secara umum mencakup empat hal, yaitu
identifikasi, klasifikasi, polymorphism (polimorfisme) dan inheritance
(pewarisan).
1) Karateristik dari objek
Identitas berarti bahwa data diukur mempunyai nilai tertentu yang
membedakan entitas dan disebut objek. Suatu paragraf dari dokumen, suatu
windows dari workstation, dan raja putih dari buah catur adalah contoh dari
objek. Objek dapat kongkrit, seperti halnya arsip dalam sistem, atau
konseptual seperti kebijakan penjadualan dalam multiprocessing pada sistem
operasi. Setiap objek mempunyai sifat yang melekat pada identitasnya. Dua
objek dapat berbeda walaupun bila semua atributnya identik Klasifikasi berarti
bahwa suatu kegiatan mengumpulkan data (atribut) dan perilaku (operasi)
yang mempunyai struktur data sama ke dalam satu grup yang disebut kelas.
Paragraf, window, buah catur adalah contoh dari kelas. Kelas merupakan
abstraksi yang menjelaskan sifat penting pada suatu aplikasi dan mengabaikan
yang lain. Setiap kelas menunjukan suatu kumpulan infinite yang mungkin
instans dari kelas mempunyai nilai individu untuk setiap nama atribut dan
operasi, tetapi memiliki bersama atribut dan operasi dengan instans lain dalam
kelas
2) Karateristik Metodologi Berorientasi Objek
Metodologi pengembangan sistem berorientasi objek mempunyai tiga
karateristik utama yaitu:
1) Encapsulation
Encapsulation (pengkapsulan) merupakan dasar untuk pembatasan ruang
lingkup program terhadap data yang diproses. Data dan prosedur atau
fungsi dikemas dalam bersama-sama dalam suatu objek, sehingga
prosedur atau fungsi lain dari luar tidak dapat mengaksesnya. Data
terlindung dari prosedur atau objek lain kecuali prosedur yang berada
dalam objek itu sendiri.
2) Inheritance
Inheritance (pewarisan) adalah teknik yang menyatakan bahwa anak dari
objek akan mewarisi atribut dan metoda dari induknya langsung. Atribut
dan metoda dari objek induk diturunkan kepada anak objek, demikian
seterusnya. Pendefinisian objek dipergunakan untuk membangun suatu
hirarki dari objek turunannya, sehingga tidak perlu membuat atribut dan
metoda lagi pada anaknya, karena telah mewarisi sifat induknya.
3) Polymorphism
Polymorphism (polimorfisme) yaitu konsep yang menyatakan bahwa
Polimorfisme mempunyai arti bahwa operasi yang sama mungkin
mempunyai perbedaan dalam kelas yang berbeda.
2.2.7.JAVA
Pada 1991, sekelompok insinyur Sun dipimpin oleh Patrick Naughton dan
James Gosling ingin merancang bahasa komputer untuk perangkat konsumer
seperti cable TV Box. Karena perangkat tersebut tidak memiliki banyak memori,
bahasa harus berukuran kecil dan mengandung kode yang liat. Juga karena
manufaktur – manufaktur berbeda memilih processor yang berbeda pula, maka bahasa harus bebas dari manufaktur manapun. Proyek diberi nama kode ”Green”.
Niklaus Wirth, pencipta bahasa Pascal telah merancang bahasa portabel yang
menghasilkan intermediate code untuk mesin hipotesis. Mesin ini sering disebut dengan mesin maya (virtual machine). Kode ini kemudian dapat digunakan di sembarang mesin yang memiliki interpreter. Proyek Green menggunakan mesin
maya untuk mengatasi isu utama tentang netral terhadap arsitektur mesin. Karena
orang – orang di proyek Green berbasis C++ dan bukan Pascal maka kebanyakan
sintaks diambil dari C++, serta mengadopsi orientasi objek dan bukan prosedural. Mulanya bahasa yang diciptakan diberi nama ”Oak” oleh James Gosling yang
mendapat inspirasi dari sebuah pohon yang berada pada seberang kantornya,
namun dikarenakan nama Oak sendiri merupakan nama bahasa pemrograman
yang telah ada sebelumnya, kemudian SUN menggantinya dengan JAVA. Nama
JAVA sendiri terinspirasi pada saat mereka sedang menikmati secangkir kopi di
sebuah kedai kopi yang kemudian dengan tidak sengaja salah satu dari mereka
sepakat untuk memberikan nama bahasa pemrograman tersebut dengan nama
Java. Berdasarkan white paper resmi dari SUN, Java memiliki karakteristik
berikut :
1) Sederhana (Simple)
Bahasa pemrograman Java menggunakan Sintaks mirip dengan C++ namun
sintaks pada Java telah banyak diperbaiki terutama menghilangkan penggunaan
pointer yang rumit dan multiple inheritance. Java juga menggunakan automatic
memory allocation dan memory garbage collection.
2) Berorientasi objek (Object Oriented)
Java mengunakan pemrograman berorientasi objek yang membuat program dapat
dibuat secara modular dan dapat dipergunakan kembali. Pemrograman
berorientasi objek memodelkan dunia nyata kedalam objek dan melakukan
interaksi antar objek-objek tersebut.
3) Terdistribusi (Distributed)
Java dibuat untuk membuat aplikasi terdistribusi secara mudah dengan adanya
libraries networking yang terintegrasi pada Java.
4) Interpreted
Program Java dijalankan menggunakan interpreter yaitu Java Virtual Machine
(JVM). Hal ini menyebabkan source code Java yang telah dikompilasi menjadi
Java bytecodes dapat dijalankan pada platform yang berbeda-beda.
5) Robust
Java mempuyai reliabilitas yang tinggi. Compiler pada Java mempunyai
pemrograman lain. Java mempunyai runtime-Exception handling untuk membantu
mengatasi error pada pemrograman.
6) Secure
Sebagai bahasa pemrograman untuk aplikasi internet dan terdistribusi, Java
memiliki beberapa mekanisme keamanan untuk menjaga aplikasi tidak digunakan
untuk merusak sistem komputer yang menjalankan aplikasi tersebut.
7) Architecture Neutral
Program Java merupakan platform independent. Program cukup mempunyai satu
buah versi yang dapat dijalankan pada platform berbeda dengan Java Virtual
Machine.
8) Portable
Source code maupun program Java dapat dengan mudah dibawa ke platform yang
berbeda-beda tanpa harus dikompilasi ulang.
9) Performance
Performance pada Java sering dikatakan kurang tinggi. Namun performance Java
dapat ditingkatkan menggunakan kompilasi Java lain seperti buatan
2.2.8. NetBeans IDE 6.9.1
Platform NetBeans memungkinkan aplikasi dibangun dari sekumpulan komponen perangkat lunak moduler yang disebut ‘modul’. Sebuah modul adalah
suatu arsip Java (Java archive) yang memuat kelas-kelas Java untuk berinetraksi
dengan NetBeans Open API dan file manifestasi yang mengidentifikasinya
sebagai modul. Aplikasi yang dibangun dengan modul-modul dapat
dikembangkan secara independen, aplikasi berbasis platform NetBeans dapat
dengan mudah dikembangkan oleh pihak ketiga secara mudah dan powerful.
Pengembangan NetBeans diawali dari Xelfi, sebuah proyek mahasiswa tahun
1997 di bawah bimbingan Fakultas Matematika dan Fisika Universitas Charles,
Praha. Sebuah perusahaan kemudian dibentuk untuk proyek tersebut dan
menghasilkan versi komersial NetBeans IDE hingga kemudian dibeli oleh Sun
Microsystem pada tahun 1999. Sun kemudian menjadikan NetBeans open source
pada bulan Juni tahun 2000. Sejak itu komunitas NetBeans terus berkembang.
2.2.9. WAMP Server
Wamp Server adalah paket web server yang bekerja secara pada localhost
yang dibuat secara independen dan di instal pada sistem operasi Windows.
WAMP adalah singkatan dari dari Windows and the principal components of the
package: Apache, MySQL and PHP (or Perl or Python). Apache adalah Web
server, MySQL adalah database, PHP adalah bahasa scripting yang dapat
memanipulasi informasi yang dibuat di database dan menghasilkan halaman web
dinamis konten setiap waktu diminta oleh browser. Program lain juga dapat
dimasukkan dalam paket, seperti phpMyAdmin yang menyediakan antarmuka
pengguna grafis untuk manajer database MySQL, atau bahasa scripting Python
33
Analisis sistem dapat didefinisikan sebagai penguraian dari suatu sistem
informasi yang utuh ke dalam bagian-bagian komponennya dengan maksud untuk
mengidentifikasikan dan mengevaluasi permasalahan-permasalahan,
kesempatan-kesempatan, hambatan-hambatan yang terjadi dan kebutuhan-kebutuhan yang
diharapkan sehingga dapat diusulkan perbaikan-perbaikannya. Dalam
membangun perangkat lunak ini dilakukan beberapa tahap analisis yaitu :
1. Analisis Masalah
2. Analisis Algoritma
3. Spesifikasi kebutuhan perangkat lunak
4. Analisis Kebutuhan Non Fungsional
5. Analisis Kebutuhan Fungsional
3.1.1. Analisis Masalah
Dari hasil pengamatan diketahui bahwa rata-rata pengunjung yang datang
ke rumah baca buku sunda adalah untuk mencari buku atau bacaan dengan
terbitan lawas, karena memang rumah baca buku sunda menyediakan buku-buku
dengan terbitan lama. Timbul masalah ketika pengunjung tidak mengingat judul
buku atau pengarang buku yang akan mereka cari dan hanya mengingat nama
tokoh dalam buku tersebut atau kata yang sering muncul dalam buku sehingga
Oleh sebab itu perlu dibangunnya perangkat lunak pencarian kata yang
dapat menyelesaikan permasalah tersebut dengan tepat dan juga cepat. Sehingga
dapat membantu calon pembaca menemukan buku yang dicari. Ada sekitar 35
algoritma pencarian kata yang bisa digunakan dalam perangkat baik merupakan
algoritma yang diciptakan dari awal maupun berupa pengembangan dari algoritma
yang sudah ada [
1
]. Dua di antaranya yaitu algoritma Karp-Rabin dan AlgoritmaZhu-Takaoka. Dengan melakukan analisis perbandingan performansi dari
algoritma Karp-Rabin dan algoritma Zhu-Takaoka maka akan dapat diketahui
cara kerja dan performansi dalam kecepatan dan ketepatan dari kedua algoritma
tersebut. Agar selanjutnya algoritma yang lebih mangkus dapat digunakan pada
perangkat lunak pencocokan kata.
3.1.2. Analisis Algoritma
Pembuatan program komputer tidak terlepas dari algoritma, apalagi
program yang dibuat sangat kompleks. Analisis algoritma sangat membantu di
dalam meningkatkan efesiensi program. Kecanggihan suatu program bukan dilihat
dari tampilan program, tetapi berdasarkan efisiensi algoritma yang terdapat
didalam program tersebut. Program dapat dibuat dengan mengabaikan algoritma,
tetapi jangan heran bila ada program yang mirip tetapi memiliki akses yang lebih
cepat dan memakai memori yang sangat sedikit. Analisis algoritma adalah
bahasan utama dalam ilmu komputer. Dalam menguji suatu algoritma, dibutuhkan
beberapa kriteria untuk mengukur efisiensi algoritma. Terdapat dua tipe analisis
1. Memeriksa kebenaran algoritma dapat dilakukan dengan cara
perurutan, memeriksa bentuk logika, implementasi algoritma,
pengujian dengan data dan menggunakan cara matematika untuk
membuktikan kebenaran.
2. Penyederhanaan Algoritma Membagi algoritma menjadi bentuk yang
sederhana.
3.1.2.1.Analisis Algoritma Zhu-Takaoka
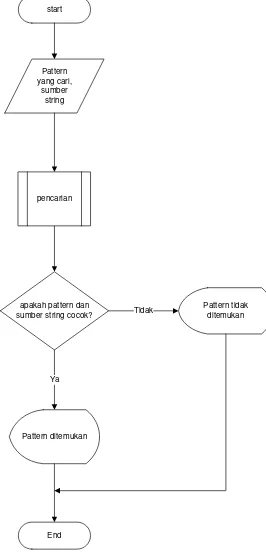
Pada Gambar 3.1 Flowchart Algoritma Zhu-Takaoka dapat dilihat alur
kerja algoritma Zhu-Takaoka.
Algoritma BM‟ (Algoritma Zhu-Takaoka) yang merupakan
modifikasi dari Algoritma Boyer Moore mempunyai ciri-ciri yang sama
dalam proses pencarian string. Ciri-ciri tersebut yaitu terbagi dua fase
yaitu fase preprocessing dan fase pencarian. Perbedaan antara Algoritma
Boyer-Moore dan Algoritma Zhu-Takaoka yaitu terletak pada tahap
penentuan bad character rule. Dalam Boyer-Moore, bad character hanya
terdiri array satu dimensi, sedangkan dalam Zhu-Takaoka dimodifikasi
menjadi array dua dimensi. Karakteristik Algoritma Zhu-Takaoka
1. Pengembangan dari algoritma Boyer-Moore
2. Menggunakan array dua dimensi untuk menghitung nilai pergeseran.
start
apakah pattern dan sumber string cocok?
End Pattern yang cari,
sumber string
pencarian
Pattern ditemukan Ya
[image:48.595.146.412.119.672.2]Pattern tidak ditemukan Tidak
Tabel 3-1 Pseudocode Algoritma Zhu-Takaoka dengan notasi Big-O
Procedure ZT(input x : array of char,input m :integer,input y :array of char , input n : integer)
{IS : pencocokan string dengan algoritma zhu-takaoka FS : keluaran yang diharapkan hasil dari pencocokan}
Kamus
i, j : integer
ztBc : array[0..ASIZE][0..ASIZE] of integer bmGs : array[0..XSIZE] of integer
algorimta
{preprocessing} preZtBc(x, m, ztBc); preBmGs(x, m, bmGs); {pencarian}
j = 0; O(1) while (j <= n - m) { O(n) i ← m - 1; O(1) while (i < m and x[i] = y[i + j]; --i) O(n) if (i < 0) { O(1) OUTPUT(j); O(1) j ← j + bmGs[0]; O(1) }
else
j ← j + MAX(bmGs[i],ztBc[y[j + m - 2]][y[j + m - 1]]); O(1)
endif endwhile endwhile Endprocedure
Perhitungan Big-O
Tabel 3-2 Perhitungan Big-O algoritma Zhu-Takaoka
Pseudocode Nilai Big-O
j = 0; O(1)
while (j <= n - m) O(n)
while (i < m and x[i] = y[i + j]; --i) O(n)
if (i < 0) O(1)
OUTPUT(j) O(1)
j ← j + bmGs[0]; O(1)
j ← j + MAX(bmGs[i],ztBc[y[j + m - 2]][y[j + m -
1]]);
O(1)
Jumlah O(n2)
Berdasarkan hasil perhitungan performansi algoritma Zhu-Takaoka menggunakan notasi Big-O didapat kompleksitas waktu dengan O(n2) dengan n adalah ukuran inputan . Yang mempengaruhi nilai kompleksitas waktu dari algoritma Zhu-Takaoka adalah nilai n karena n berpangkat dua.
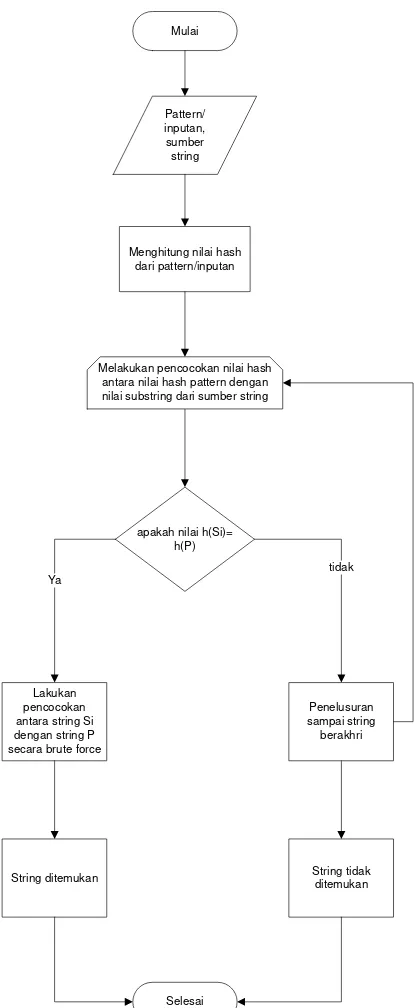
3.1.2.2.Analisis Algoritma Karp-Rarbin
Pattern/ inputan, sumber string Mulai
Menghitung nilai hash dari pattern/inputan
apakah nilai h(Si)= h(P)
Lakukan pencocokan antara string Si dengan string P secara brute force
String ditemukan Selesai Penelusuran sampai string berakhri Ya tidak String tidak ditemukan Melakukan pencocokan nilai hash
[image:51.595.199.406.109.613.2]antara nilai hash pattern dengan nilai substring dari sumber string
Gambar 3.2 Flowchart Algoritma Karp-Rabin
Algoritma Karp-Rabin ini tidak melakukan pergeseran yang rumit untuk
menyelesaikan masalah, algoritma ini mempercepat pengecekan kata pada suatu
adalah fungsi yang menerima masukan string yang panjangnya sembarang dan
mengkonversinya menjadi string keluaran yang panjangnya tetap (fixed)
umumnya berukuran jauh lebih kecil daripada ukuran string semula [
12
]. Padaalgoritma ini untaian string akan diubah menjadi integer berdasarkan bilangan
ASCII-nya. Pendekatan utamanya adalah, string yang sama akan memiliki nilai
hash yang sama.
Hal yang penting yang harus dilakukan sebelum melakukan pencocokan
dengan algoritma Karp-Rabin adalah mengubah sumber string dan pattern yang
dicari menjadi untaian integer. Karakteristik algoritma Karp-Rabin
1. Menggunakan Fungsi Rolling Hashing.
2. Melakukan pencocokan dari kiri ke kanan
3. Pergeseran dilakukan secara brute-force
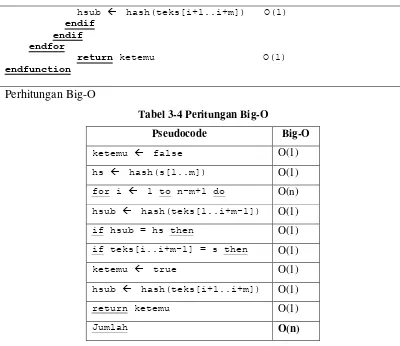
Pseudocode Algoritma Karp-Rabin
[image:52.595.80.488.518.746.2]Jika algoritma Rabin-Karp ditulis secara keseluruhan dalam pseudocode :
Tabel 3-3 Pseudocode Algoritma Karp-Rabin dengan notasi Big-O
function RabinKarp (input s: string[1..m], teks: string[1..n])
{IS : Melakukan pencarian string s pada string teks dengan algoritma Rabin Karp
FS : keluaran yang diharapkan pencarian string berhasil dilakukan}
}
Deklarasi
i : integer ketemu = boolean
Algoritma:
ketemu false O(1) hs hash(s[1..m]) O(1) for i 1 to n-m+1 do O(n) hsub hash(teks[1..i+m-1]) O(1) if hsub = hs then O(1)
if teks[i..i+m-1] = s then O(1) ketemu true O(1)
hsub hash(teks[i+1..i+m]) O(1) endif
endif endfor
return ketemu O(1)
endfunction
[image:53.595.109.509.108.454.2]Perhitungan Big-O
Tabel 3-4 Peritungan Big-O
Pseudocode Big-O
ketemu false O(1)
hs hash(s[1..m]) O(1)
for i 1 to n-m+1 do O(n)
hsub hash(teks[1..i+m-1]) O(1)
if hsub = hs then O(1)
if teks[i..i+m-1] = s then O(1)
ketemu true O(1)
hsub hash(teks[i+1..i+m]) O(1)
return ketemu O(1)
Jumlah O(n)
Berdasarkan hasil perhitungan performansi algoritma Karp-Rabin
menggunakan notasi Big-O didapat kompleksitas waktu dengan O(n) . dengan n
adalah ukuran inputan.
3.1.2.3. Perbandingan Algoritma
Sample Sinopsi yang diambil dari rumah baca buku sunda yang dijadikan
sample penelitian dalam perhitungan performansi algoritma Zhu-Takaoka dan
algoritma Karp-Rabin dikategorikan berdasarkan jumlah karakter deskripsi buku
bisa dilihat pada tabel Tabel 3-5 Data Buku dan kombinasi inputan pencarian
1. Huruf kecil , contoh : lengkong
2. Huruf besar, contoh : LENGKONG
3. Huruf besar dilanjutkan huruf kecil, contoh : Lengkong
4. Angka , contoh : 1945
5. Karakter inputan sama, contoh : dan
6. Jumlah karakter sebelum karakter ditemukan sama
Tabel 3-5 Data Buku
Buku ke Judul buku Jumlah karakter Deskripsi
1 Azab dan Sengsara 468
2 Akademi militer dan peristiwa lengkong 1858
3 Hulubalang Raja 3208
4 Salah Asuhan 3900
Untuk perhitungan waktu computer dengan arsitektur yang berbeda akan
berbeda pula lama waktu untuk setiap jenis operasinya hal ini disebabkan dalam
penjadwalan yang berbeda – beda. Untuk itu model abstrak pengukuran waktu
atau ruang besaran yang dipakai adalah kompleksitas algoritma.
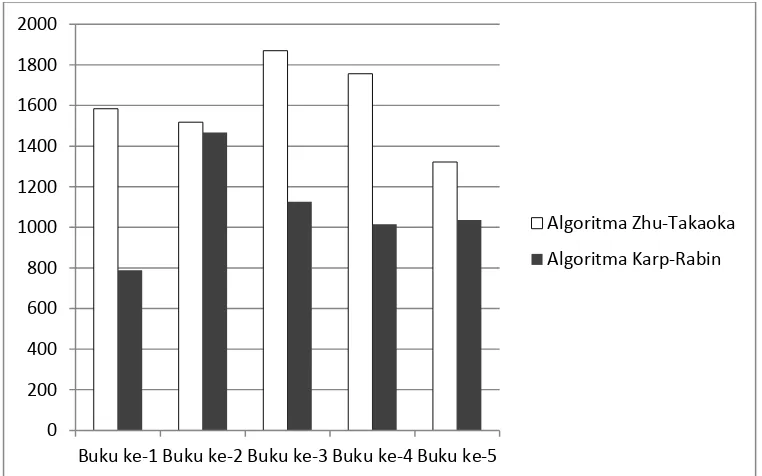
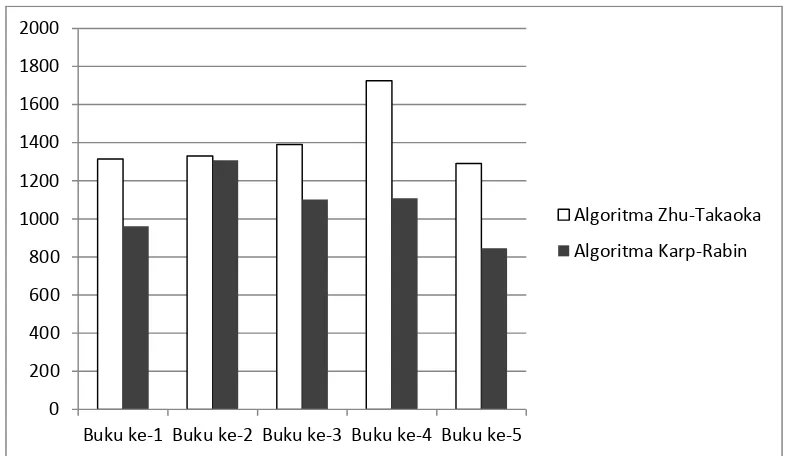
Dari hasil percobaan dengan inputan huruf kecil,untuk kecepatan dan
efesiensi algoritma Karp-Rabin lebih unggul dari pada algoritma Zhu-Takaoka
dan hal yang berpengaruh pada pencocokan yaitu posisi karakter ketika ditemukan
dan karakteristik jenis huruf sebelum diketemukan . Sedangkan dari segi
ketepatan kedua algoritma sama-sama dapat menyelesaikan pencocokan dan
[image:57.595.122.503.354.592.2]menghasilkan keluaran yang tepat.
Gambar 3.3 Grafik Waktu uji coba kedua Algoritma terhadap inputan huruf kecil(ms)
0 200 400 600 800 1000 1200 1400 1600 1800 2000
Buku ke-1 Buku ke-2 Buku ke-3 Buku ke-4 Buku ke-5
Algoritma Zhu-Takaoka
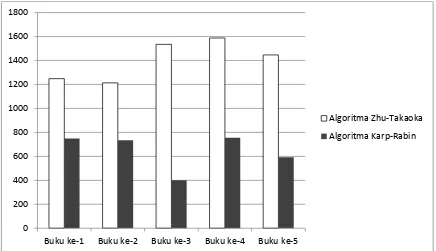
Pada percobaan dengan inputan huruf besar, dari segi waktu dan memori
yang digunakan algoritma Karp-Rabin lebih cepat dan efesien dibandingkan
dengan berpengaruh terhadap pencocokan yaitu karakteristik karakter sebelum
algoritma Zhu-Takaoka. Hal yang Sedangkan dari segi ketepatan kedua algoritma
sama-sama dapat menyelesaikan pencocokan dan menghasilkan keluaran yang
[image:60.595.86.480.214.442.2]tepat
Gambar 3.4 Grafik Waktu uji coba kedua Algoritma terhadap inputan huruf besar
0 200 400 600 800 1000 1200 1400 1600 1800 2000
Buku ke-1 Buku ke-2 Buku ke-3 Buku ke-4 Buku ke-5
Algoritma Zhu-Takaoka
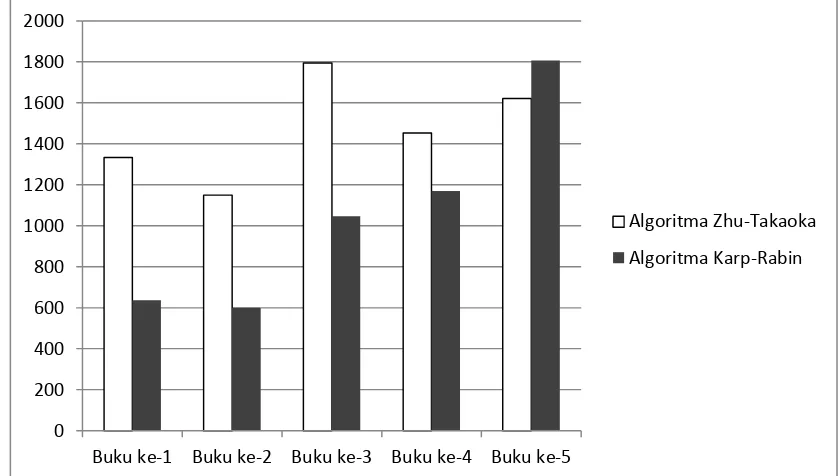
Pada percobaan dengan inputan huruf besar dilanjutkan huruf kecil, dari
segi waktu dan memori yang digunakan algoritma Karp-Rabin lebih cepat dan
efesien dibandingkan dengan berpengaruh terhadap pencocokan yaitu
karakteristik karakter sebelum ditemukan huruf capital dan huruf kecil
berpengaruh terhadap waktu pencarian algoritma Zhu-Takaoka. Hal yang
Sedangkan dari segi ketepatan kedua algoritma sama-sama dapat menyelesaikan
[image:62.595.85.521.326.577.2]pencocokan dan menghasilkan keluaran yang tepat.
Gambar 3.5 Grafik Waktu uji coba kedua Algoritma terhadap inputan huruf Besar dilanjutkan huruf kecil
0 200 400 600 800 1000 1200 1400 1600 1800
Buku ke-1 Buku ke-2 Buku ke-3 Buku ke-4 Buku ke-5
Algoritma Zhu-Takaoka
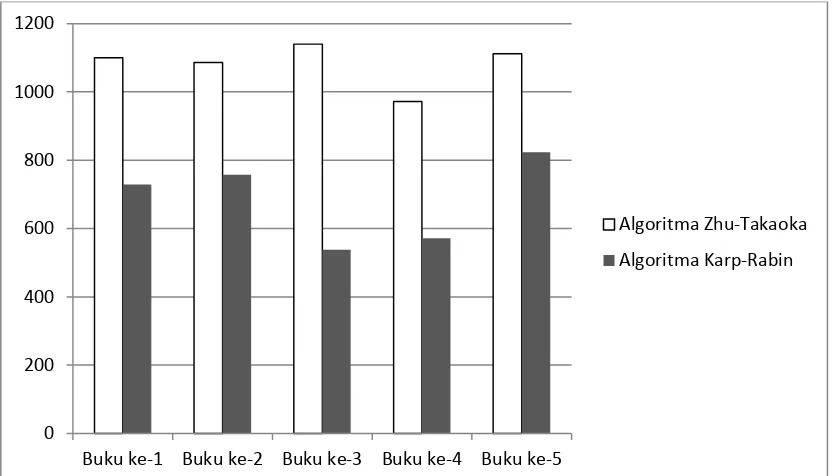
Gambar 3.6 Grafik Waktu uji coba kedua Algoritma terhadap inputan Angka
Pada percobaan dengan inputan angka, dari segi waktu dan memori yang digunakan algoritma Karp-Rabin lebih cepat dan efesien dibandingkan dengan berpengaruh terhadap pencocokan yaitu karakteristik karakter sebelum ditemukan huruf capital dan huruf kecil berpengaruh terhadap waktu pencarian algoritma Zhu-Takaoka. Hal yang Sedangkan dari segi ketepatan kedua algoritma sama-sama dapat menyelesaikan pencocokan dan menghasilkan keluaran yang tepat.
0 200 400 600 800 1000 1200 1400 1600 1800 2000
Buku ke-1 Buku ke-2 Buku ke-3 Buku ke-4 Buku ke-5
Algoritma Zhu-Takaoka
Gambar 3.7 Grafik Waktu uji coba kedua Algoritma terhadap inputan sama
Dari hasil uji coba keseluruhan terhadap kedua algoritma ,keduanya
memiliki ke akuratan yang sama-sama baik. Algoritma Karp-Rabin cendrung
lebih cepat dan efesien dalam penggunaan ruang memori, hal yang
mempengaruhi pencarian waktu dan penggunaan ruang adalah panjangnya
karakter sebelum kata pencarian ditemukan dan karakteristik karakter sebelum
kata pencarian ditemukan, huruf besar dan huruf kecil ikut dan dari hasil
perhitungan kompleksitas menggunakan metode Big –O algoritma Karp-Rabin
menghasilikan kompleksitas O(n) sedangkan untuk algoritma Zhu-Takaoka
menghasilkan kompleksitas O(n2). Maka dapat ditarik kesimpulan algoritma
Karp-Rabin cendrung lebih baik dari pada algoritma Karp-Rabin. 0
200 400 600 800 1000 1200
Buku ke-1 Buku ke-2 Buku ke-3 Buku ke-4 Buku ke-5
Algoritma Zhu-Takaoka
3.1.3. Spesifikasi Kebutuhan Perangkat Lunak
Spesifikasi kebutuhan perangkat lunak yang akan dibangun berdasarkan
kebutuhan pengguna pada jurnal dan artikel serta hasil observasi. Spesifikasi
kebutuhan perangkat lunak akan dibagi kedalam dua bagian yaitu SKPL-F (
Spesifikasi Kebutuhan Perangkat Lunak Fungsional ) dan SKPL-NF ( Spesifikasi
kebutuhan perangkata lunak non-fungsional ) Berikut ini adalah tabel Spesifikasi
kebutuhan perangkat lunak pencocokan string :
Tabel 3-11 Spesifikasi Kebutuhan Perangkat Lunak Fungsional Kode Kebutuhan
SKPL-F001 Perangkat lunak dapat malakukan inputan string atau pola
yang diinginkan oleh user
SKPL-F002 Perangkat lunak dapat memproses hasil inputan untuk
kemudian dimulai pencocokan string atau pola.
SKPL-F003 Perangkat lunak dapat mengukur waktu eksekusi ketika
memulai pencarian.
SKPL-F004 Perangkat lunak dapat menampilkan penggunaan ruang
memori saat melakukan pencocokan string.
SKPL-F005 Perangkat lunak dapat menampilkan hasil dari pencocokan
[image:69.595.148.516.327.546.2]string.
Tabel 3-12 Spesifikasi kebutuhan perangakat lunak non-fungsional Kode Kebutuhan
SKPL-NF001 Pengguna atau user yang menggunakan perangkat lunak ini
adalah user yang ingin melakukan pencarian buku.
SKPL-NF002 Perangkat lunak yang dibangun berbasis desktop
SKPL-NF003 Perangkat keras yang digunakan adalah komputer dengan
spesifikasi minimal processor Intel Pentium 4 2.6 GHz ,
memori 1024 MB,keyboard,dan mouse.
3.1.3.1. Analisis Perangkat Lunak
Rumah baca buku sunda menggunakan sistem operasi Windows 7 .
Kebutuhan perangkat lunak dalam membangun dan menerapkan sistem yang akan
dibuat di rumah baca buku sunda adalah sebagai berikut :
1. Sistem Operasi Windows XP
2. Software :
a. NetBeans IDE 6.9.1
b. Java Runtime Edition, sebagai platform untuk menjalankan sistem c. Java Development Kit versi 5 atau 6 , untuk kompilasi kode – kode
program
Spesifikasi kebutuhan perangkat lunak tersebut dipilih karena
kemudahannya, familiar dan Interaktif serta mudah dalam memahami cara kerjanya.
3.1.3.2. Analisis Perangkat pikir
Analisa dan spesifikasi kebutuhan diperlukan agar kemampuan perangkat
lunak yang dibangun menjadi jelas. Beberapa analisa dan kebutuhan yang
berkaitan dengan perangkat lunak yang akan dibangun nanti yaitu analisa dan
kebutuhan pengguna. Adapun karakteristik pengguna pada perangkat lunak
pencocokan string yang akan dibangun yaitu user sebagai berikut :
1. User dapat menggunakan komputer, minimal mampu
menggunakan keyboard sebagai sarana penginputan data dan kata
2. User dapat membaca.
3. Jenjang pendidikan dimulai dari Anak sekolah (SD,SMP dan
SMA), Mahasiswa
Berdasarkan analisis pada user, dapat diambil kesimpulan bahwa pengguna (user) yang ada cukup memenuhi syarat sebagai pengguna sistem yang akan dikembangkan, sehingga tidak diperlukan pelatihan khusus mengenai
penggunaan komputer, cukup berupa dokumen atau buku panduan untuk
membantu menjalankan perangkat lunak.
3.2. Perancangan Sistem
Perancangan merupakan penggambaran, perencanaan, dan pembuatan
sketsa atau pengaturan dari beberapa elemen yang terpisah ke dalam suatu
kesatuan yang utuh. Tahapan ini meliputi mengkonfigurasi komponen-komponen
perangkat lunak dan perangkat keras dari suatu sistem. Adapun perancangan
sistem dari sistem informasi kepegawaian yang dibuat dijelaskan sebagai berikut.
3.2.1. Perancangan Arsitektural Perangkat Lunak
Perancangan arsitektur adalah tahap yang dilakukan dalam merancang
stuktur menu , merancang antarmuka bagi pengguna, perancangan pesan dalam
perangkat lunak serta jaringan semantik.
3.2.2. Perancangan Struktur Menu
Perancangan struktur menu berisikan menu dan submenu yang berfungsi
memudahkan pengguna didalam menggunakan sistem. Pada perangkat lunak ini
perancangan struktur menu pada user menggunakan struktur menu hirarki atau
Bantuan Pencarian
Tentang
Gambar 3.8 struktur menu pada User
3.2.3. Perancangan Antarmuka Perangkat Lunak
Perancangan antarmuka merupakan sebuah penggambaran, perencanaan,
dan pembuatan sketsa atau pengaturan dari beberapa elemen yang terpisah ke
dalam satu kesatuan yang utuh dan berfungsi. Adapun perancangan antarmuka
perangkat lunak pencocokan string adalah sebagai berikut :
1. Desain Form pencarian
Form pencarian merupakan form yang digunakan sebagai tampilan user pada
saat akan mulai pencarian dimana algoritma di implementasikan. Desain
tampilan form dan deskripsi objek dari aplikasi ini dapat dilihat pada Gambar
3.9 Desain tampilan form pencarian
Gambar 3.9 Desain tampilan form pencarian Tabel 3-13 Deskripsi objek form pencarian
Objek Jenis Keterangan
Column 1,Content 2 Tabel Tempat menampilkan data buku yang telah
tersedia dari data inputan
Algoritma Combo Box Memilih algoritma yang akan digunakan
Buka Direktori Button Menginputkan data buku yang akan menjadi
sumber pencarian
Cari Button Memulai pencarian dari buku yang dipilih muncul
F06
Cari Semua Buku Button Memulai pencarian dari semua buku yang terdapat
di data base
Keluar Button Keluar aplikasi
Tentang Button Menuju F08, melihat tentang pembuat
Bantuan Button Menuju F07, melihat bantuan cara penggunaan
[image:73.5