OPTIMASI
FUZZY INFERENCE SYSTEM
DENGAN
MENGGUNAKAN
GENETIC ALGORITHM
UNTUK
PREDIKSI JUMLAH PUBLIKASI BUKU
(STUDI KASUS DI LIPI PRESS)
SITI KANIA KUSHADIANI
PROGRAM STUDI MAGISTER ILMU KOMPUTER SEKOLAH PASCASARJANA
PERNYATAAN MENGENAI TESIS DAN SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis Optimasi Fuzzy Inference System dengan Menggunakan Genetic Algorithm untuk Prediksi Jumlah Publikasi Buku (Studi Kasus di LIPI Press) adalah karya saya dengan arahan dari komisi pebimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan mapun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, September 2012
ABSTRACT
SITI KANIA KUSHADIANI. Optimation fuzzy Inference System using Genetic Algorithm for Book Publication Amount Prediction (Case Study in LIPI Press). Under direction of Agus Buono (chairman), Aziz Kustiyo (member).
The research covers the problems in the planning of the LIPI Press publishes scholarly works LIPI, one of them is to predict the number of publications for the following year. The purpose of this study is to optimize the parameters of fuzzy inference system using a genetic algorithm, to predict the number of publications issued LIPI Press for the following year wether it is optimal with the predictors used is the number of units of work, the amount of effort and a long process. The data used is the production data from LIPI Press in five years. The method used is genetic algorithm method. K fold validation is used to split the data training and data testing. The results of this study is the achievement of the publication of an optimal prediction using genetic algorithm parameters which were composed of both population size (30), the probability of crossover (0.75), the probability of mutation (0.01) and the number of generations (150). By the achievement of optimal prediction results are then published a book planning would be better. Keywords: Fuzzy inference system, genetic algorithm, optimation, predict, LIPI
RINGKASAN
SITI KANIA KUSHADIANI. Optimasi Fuzzy Inference System Menggunakan Genetic Algorithm untuk Prediksi Jumlah Publikasi Buku (Studi Kasus di LIPI Press). Dibimbing oleh Agus Buono dan Aziz Kustiyo.
Balai Media dan Reproduksi (LIPI Press) adalah unit pelaksana teknis di bidang penerbitan ilmiah LIPI (Lembaga Ilmu Pengetahuan Indonesia). Fokus terhadap salah satu tugasnya yaitu melakukan perencanaan dalam menerbitkan hasil karya ilmiah LIPI. Terdapat permasalahan dalam melakukan perencanaan dalam menerbitkan hasil karya ilmiah LIPI. Salah satunya adalah memprediksi jumlah terbitan buku yang akan diproduksi tahun yang akan datang. Dimana perencanaan tersebut diperlukan untuk kebutuhan administrasi dalam mengusulkan anggaran yang akan datang juga untuk menentukan sumber daya yang diperlukan dalam melakukan proses produksi yang akan datang selain itu juga dapat membatu dalam penyusunan rencana kerja tahunan LIPI Press. Dimana dalam perencanaan tersebut, yang biasa dilakukan oleh LIPI Press adalah hanya hitungan perkiraan saja tanpa menggunakan model pengetahuan tertentu, sehingga penting permasalahan tersebut untuk diangkat dalam sebuah penelitian. Dengan demikian akan dilakukan penelitian memprediksi jumlah publikasi yang akan diterbitkan pada tahun yang akan datang. Dalam memprediksi tersebut dilakukan dengan menggunakan fuzzy inference system.
Tujuan Penelitian ini untuk melakukan optimasi parameter dalam fuzzy inference system dengan menggunakan genetic algorithm agar dapat memprediksi jumlah publikasi yang diterbitkan oleh LIPI Press untuk tahun yang akan datang secara optimal dengan prediktor yang digunakan adalah jumlah satuan kerja, jumlah tenaga kerja dan lama proses. Data yang digunakan adalah data sekunder yaitu data produksi dari LIPI Press tahun 2006—2010.
Fuzzy inference system digunakan untuk melakukan prediksi jumlah publikasi buku dengan fungsi keanggotaan yang diperoleh dari pakar juga fungsi keanggotaan yang telah dioptimasi. Dimana fuzzy inference system yang digunakan adalah Metode Mamdani dengan proses defuzzifikasinya menggunakan centroid. Fungsi keanggotaan yang ada dalam fuzzy inference system dioptimasi menggunakan genetic algorithm dengan parameter genetic algorithm yang digunakan adalah ukuran populasi 30, 50 dan 80, probabilitas crossover 0.75, 0.85 dan 0.95, probabilitas mutasi 0.01 dan 0.001 juga jumlah generasi 50, 100 dan 150. Crossover dilakukan dengan metode one point crossover. Metode yang digunakan untuk pembagian data menggunakan k fold cross validation dengan menggunakan strategi leave one out.
30, probabilitas crossover 0.85, probabilitas mutasi 0.01 dan jumlah generasi 100. Prediksi yang dihasilkan adalah 50, memiliki selisih dengan data observasi sebesar 10. Percobaan ketiga, data 3 merupakan data uji sedangkan data ke-1,2,4, dan 5 merupakan data latih. Hasil percobaan ketiga, nilai maksimum fitness mencapai 1 pada ukuran populasi 30, probabilitas crossover 0.75, probabilitas mutasi 0.01 dan jumlah generasi 50. Hasil prediksi sebesar 28 yakni memiliki selisih 9 dengan data observasi. Percobaan keempat, data ke-4 merupakan data uji dan data ke 1,2,3 dan 5 merupakan data latih. Hasil percobaan keempat, nilai maksimum fitness mencapai 1 pada ukuran populasi 30, probabilitas crossover 0.85, probalilitas mutasi 0.01 dan jumlah generasi 100. Hasil prediksi sebesar 37 yakni memiliki selisih dengan data observasi sebesar 3. Sedankan perobaan kelima, data ke-5 merupakan data uji dan data ke 1,2,3 dan 4 merupakan data latih. Hasil percobaan kelima, nilai maksimum fitness mencapai 1 pada ukuran populasi 30, probabilitas crossover 0.75, probabilitas mutasi 0.01 dan jumlah generasi 150. Hasil prediksi 28 yakni memiliki selisih dengan data observasi sebesar 1. Dari kelima percobaan tersebut, percobaan kelima maerupakan hasil prediksi yang lebih baik daripada percobaan lainnya. Hal ini dapat dikatakan juga bahwa pada percobaan kelima menghasilkan prediksi dengan paramater yang optimal.
Dengan tercapainya hasil prediksi secara optimal maka perencanaan dalam menerbitkan buku pun akan lebih baik. Dengan demikian dapat digunakan untuk kebutuhan administrasi dalam mengusulkan anggaran maupun dalam penyusunan rencana kerja tahunan.
©
Hak Cipta Milik IPB, tahun 2012
Hak Cipta dilindungi Undang-Undang
Dilarang mengutip sabagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan yang wajar IPB
OPTIMASI
FUZZY INFERENCE SYSTEM
DENGAN
MENGGUNAKAN
GENETIC ALGORITHM
UNTUK
PREDIKSI JUMLAH PUBLIKASI BUKU
(STUDI KASUS DI LIPI PRESS)
SITI KANIA KUSHADIANI
Tesis
Sebagai Salah Satu Syarat untuk Memperoleh Gelar Magister Komputer pada
Program Studi Ilmu Komputer
PROGRAM STUDI MAGISTER ILMU KOMPUTER SEKOLAH PASCASARJANA
Judul Penelitian : Optimasi Fuzzy Inference System dengan Menggunakan Genetic Algorithm untuk Prediksi Jumlah Publikasi Buku (Studi Kasus di LIPI Press)
Nama : Siti Kania Kushadiani
NIM : G651100281
Program Studi : Ilmu Komputer
Disetujui,
Komisi Pembimbing
Dr. Ir. Agus Buono, M.Si., M.Kom. Aziz Kustiyo, S.Si., M.Kom.
Ketua Anggota
Diketahui,
Ketua Program Studi Dekan Sekolah Pascasarjana
Ilmu Komputer
Dr. Yani Nurhadryani, S.Si., M.T. Dr. Ir Dahrul Syah, M.Sc.Agr
PRAKATA
Puji dan syukur penulis panjatkan kepada Alloh SWT atas segala karunia-Nya sehingga tesis ini berhasil diselesaikan.
Tesis ini berjudul “Optimasi Fuzzy Inference System dengan Menggunakan Genetic Algorithm untuk Prediksi Jumlah Publikasi Buku (Studi Kasus di LIPI Press)” sebagai salah satu syarat yang harus dipenuhi untuk memperoleh gelar Magister Komputer pada Program Studi Ilmu Komputer , Sekolah Pascasarjana, Institut Pertanian Bogor. Penelitian ini berlangsung selama 10 bulan, mulai bulan September 2011 sampai dengan bulan Juni 2012 bertempat di Laboratorium Computational Intelegence Pascasarjana Departemen Ilmu Komputer IPB.
Terima kasih penulis ucapkan kepada Kementerian Riset dan Teknologi yang telah memberikan beasiswa kepada penulis di Institut Pertanian Bogor, Bapak Dr. Ir. Agus Buono, M.Si., M.Kom dan Bapak Aziz Kustiyo, S.Si., M.Kom selaku pembimbing, Bapak Dr. Ir. Yandra Arkeman, M.Eng selaku penguji, serta Bapak Prof. Dr.Ir. Engkos Koswara Natakusumah, M.Sc yang telah banyak memberi saran. Di samping itu, penghargaan penulis sampaikan kepada Ibu Dra. Sarwintyas Prahastuti, M.Hum beserta staf di Balai Media dan Reproduksi (LIPI Press), yang telah membantu selama pengumpulan data. Ungkapan terima kasih juga disampaikan pada Ayahanda Kahpi, Ibunda Yayah Suryati, Suami tercinta Haedar Kusdinar, S.T serta seluruh keluarga, atas segala do’a, kasih sayang dan dukungannya, Teman-teman Sekolah Pascasarjana Ilmu Komputer angkatan 12 dan teman-teman Sarjana Ilmu Komputer angkatan 45 yang telah memberikan saran, dukungan serta diskusi bersama dalam penyelesaian tesis ini.
Semoga tesis ini bermanfaat.
Bogor, September 2012
RIWAYAT HIDUP
Penulis dilahirkan di Bandung pada tanggal 04 Juni 1979 dari pasangan Kahpi dan Yayah Suryati. Penulis merupakan putri bungsu dari empat bersaudara.
DAFTAR ISI
DAFTAR ISI ... xi
DAFTAR TABEL ... xi
DAFTAR GAMBAR ... xii
DAFTAR LAMPIRAN ... xv
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan ... 3
Ruang Lingkup ... 3
Manfaat Penelitian ... 4
TINJAUAN PUSTAKA ... 5
Logika Fuzzy... 5
Himpunan Fuzzy ... 6
Fungsi Keanggotaan (Membership Function) ... 6
Fuzzy Inference System ... 8
Metode Mamdani ... 10
Optimasi Fuzzy Inference System ... 10
Genetic Algorithm... 10
Terminologi dan Operator Genetic Algorithm... 11
Representasi Kromosom ... 13
Parameter Genetic Algorithm ... 13
Perbedaan Pendekatan Genetic Algorithm dengan Metode Optimasi Konvensional ... 15
K-Fold Cross Validation ... 15
Pengertian Penerbit Buku ... 16
LIPI Press ... 17
METODE PENELITIAN ... 19
Tahapan Penelitian ... 19
Formulasi Masalah ... 20
xii
Membership Function ... 20
Rule ... 20
Desain Kromosom... 20
Setting Parameter GA... 21
Inisialisasi Populasi ... 21
Perhitungan Nilai Fitness ... 21
Seleksi ... 22
Crossover ... 22
Mutasi ... 22
k-Fold Cross Validation ... 23
Lingkup Pengembangan Sistem ... 23
Waktu Penelitian ... 24
HASIL DAN PEMBAHASAN ... 25
Identifikasi Masalah ... 25
Variable Input dan Output... 25
Membership Function ... 26
Rule ... 29
FIS Pakar ... 31
Desain Kromosom... 32
Setting Parameter Genetic Algorithm ... 32
Inisialisasi Populasi ... 33
Perhitungan Nilai Fitness ... 33
Seleksi ... 36
Crossover ... 36
Mutasi ... 37
Observasi Data Real ... 37
FIS yang Teroptimasi ... 37
Analisis ... 53
Antarmuka Grafis ... 54
SIMPULAN DAN SARAN ... 43
Simpulan ... 43
xiii
DAFTAR TABEL
1 Metode cross validation dengan menggunakan leave one out ... 23
2 Varibel input dan varibel output ... 25
3 Himpunan fuzzy pada Prediksi Publikasi Buku ... 26
4 Kombinasi rule ... 30
5 Rule yang digunakan dalam fuzzy inference system ... 31
6 Prediksi jumlah publikasi buku berdasarkan pakar ... 31
7 Range setiap variabel dan panjang kromosom ... 32
8 Hasil percobaan dengan menggunakan metode cross validation ... 33
9 Nilai fitness terbaik dengan percobaan menggunakan cross validation ... 34
10 Nilai minimum fitness dengan percobaan menggunakan cross validation ... 35
11 Hasil prediksi jumlah publikasi ... 37
DAFTAR GAMBAR
1 Logika fuzzy. ... 5
2 Contoh kurva trapesium. ... 7
3 Contoh Kurva-S ... 7
4 Contoh Kurva Bentuk Lonceng kelas Gauss. ... 8
5 Diagram Blok Sistem Inferensi Fuzzy... 9
6 Ilustrasi Diagram Blok Sistem Inferensi Fuzzy. ... 9
7 Ilustrasi cross validation dengan menggunakan leave-one-out. ... 15
8 Tahapan penelitian. ... 19
9 Proses Crossover. ... 22
10 Proses mutasi. ... 23
11 Representasi dari variabel input dan output. ... 26
12 Representasi fungsi keanggotaan untuk variabel jumlah satuan kerja. ... 27
13 Representasi fungsi keanggotaan untuk variabel jumlah tenaga kerja. ... 27
14 Representasi fungsi keanggotaan untuk variabel lama proses. ... 28
15 Representasi fungsi keanggotaan untuk variabel jumlah publikasi. ... 29
16 Desain kromosom. ... 32
17 Susunan kromosom pada setiap variabel. ... 32
18 Langkah perhitungan nilai fitness ... 34
19 Representasi maksimum fitness pada percobaan fold ke 1. ... 35
20 Representasi dari minimum fitness ... 36
21 Parameter setiap variabel yang dihasil oleh GA pada percobaan ke-1. ... 38
22 Fungsi keanggotaan dengan parameter yang dihasilkan oleh GA pada percobaan ke-1. ... 40
23 Parameter setiap variabel yang dihasil oleh GA pada percobaan ke-2. ... 41
24 Fungsi keanggotaan dengan parameter yang dihasilkan oleh GA pada percobaan ke-2. ... 43
xiv
28 Fungsi keanggotaan dengan parameter yang dihasilkan oleh GA pada
percobaan ke-4. ... 49 29 Parameter setiap varibel yang dihasil oleh GA pada percobaan ke-5. ... 50 30 Fungsi keanggotaan dengan parameter yang dihasilkan oleh GA pada
DAFTAR LAMPIRAN
1 Nilai maksimum fitnes dan minimum fitness pada Percobaan ke-1 ... 61
2 Nilai maksimum fitnes dan minimum fitness pada Percobaan ke-2 ... 63
3 Nilai maksimum fitnes dan minimum fitness pada Percobaan ke-3 ... 65
4 Nilai maksimum fitnes dan minimum fitness pada Percobaan ke-4 ... 67
5 Nilai maksimum fitnes dan minimum fitness pada Percobaan ke-5 ... 69
PENDAHULUAN
Latar Belakang
Balai Media dan Reproduksi (LIPI Press) adalah unit pelaksana teknis di bidang penerbitan ilmiah LIPI (Lembaga Ilmu Pengetahuan Indonesia). LIPI Press dibentuk dengan tujuan menjadi wadah (penerbit) untuk penanganan seluruh hasil-hasil karya ilmiah LIPI secara profesional dan terpadu, yang memberi ciri khas LIPI di bidang penerbitan dan penyebaran informasi. Tugas dan fungsi LIPI Press yaitu melaksanakan perencanaan, pelaksanaan, penyebaran, dan pemasaran hasil-hasil terbitan, tercetak dan elektronik; menjamin standar mutu terbitan, menjaga mutu ilmiah, terkait, dan sesuai dengan kebijakan yang ditetapkan Kepala LIPI menyediakan pelayanan penerbitan hasil penelitian dalam bentuk buku ilmiah kepada para peneliti LIPI khususnya dan peneliti Indonesia pada umumnya (LIPI 2011).
Fokus terhadap salah satu tugasnya yaitu melakukan perencanaan dalam menerbitkan hasil karya ilmiah LIPI. Terdapat permasalahan dalam melakukan perencanaan dalam menerbitkan hasil karya ilmiah LIPI. Salah satunya adalah memprediksi jumlah terbitan buku yang akan diproduksi tahun yang akan datang. Dimana perencanaan tersebut diperlukan untuk kebutuhan administrasi dalam mengusulkan anggaran yang akan datang juga untuk menentukan sumber daya yang diperlukan dalam melakukan proses produksi yang akan datang selain itu juga dapat membatu dalam penyusunan rencana kerja tahunan LIPI Press. Dimana dalam perencanaan tersebut, yang biasa dilakukan oleh LIPI Press adalah hanya hitungan perkiraan saja tanpa menggunakan model pengetahuan tertentu, sehingga penting permasalahan tersebut untuk diangkat dalam sebuah penelitian. Dengan demikian akan dilakukan penelitian memprediksi jumlah publikasi yang akan diterbitkan pada tahun yang akan datang. Dalam memprediksi tersebut akan dilakukan dengan menggunakan fuzzy inference system.
2
analisis data (Lubis 2007). Di dalam perkembangan logika fuzzy menunjukan bahwa pada dasarnya logika fuzzy dapat digunakan untuk memodelkan berbagai sistem, mampu untuk memetakan suatu input ke dalam suatu output tanpa mengabaikan faktor-faktor yang ada juga diyakini dapat sangat fleksibel dan memiliki toleransi terhadapat data-data yang ada (Djunaidi, Setiawan & Andista 2005).
Pada fuzzy inference system tidak mudah untuk mendapatkan parameter yang optimal. Selama ini dalam menentukan parameter tersebut dilakukan dengan cara trial dan error atau hanya diperkirakan saja. Maka untuk mengatasi hal tersebut diperlukan genetic algorithm untuk mengoptimasi fuzzy inference system dalam penentuan parameter dari fungsi keanggotaan. Salah satu artikel dalam sebuah jurnal menyebutkan bahwa sintesis dari suatu sistem fuzzy terdapat dua langkah yang umum digunakan, yaitu: identifikasi struktur dan optimasi parameter (Rojas et al 2000).
Pada penelitian sebelumnya, Tan & Tokinaga (1999) telah melakukan optimasi membership function dalam aturan fuzzy inference system dengan menggunakan genetic algorithm yang diterapkan untuk klasifikasi otomatis obligasi korporasi (peringkat obligasi) di perusahaan Jepang. Genetic algorithm digunakan untuk memilih bentuk yang lebih baik dari membership function. Dalam proses pembelajaran pada fuzzy inference system parameter ditentukan untuk meminimalkan perbedaan antara nilai yang ditentukan dan output dari sistem. Hasilnya menunjukan peningkatan sekitar 5% dari nilai obligasi dibandingkan dengan sistem konvensional fuzzy inference.
3
penentuan probabilitas crossover dan probabilitas mutasi (Setiawan, Thiang & Ferdinando 2001).
Khoiruddin (2007) telah melakukan penelitian tentang Genetic algorithm untuk menentukan jenis kurva dan parameter himpunan fuzzy. Pada penelitian tersebut genetic algorithm dilakukan untuk mengoptimasi parameter dan tipe kurva himpunan fuzzy. Dilakukan optimasi dengan menggunakan genetic algorithm karena dalam penentukan jenis kurva dan paramter dalam himpunan fuzzy dilakukan secara subjektif. Evaluasi terhadap kromosom dilakukan dengan membandingkan kedekatan hasil implementasi himpunan fuzzy-nya dengan data konsekuen. Semakin sedikit selisihnya, maka kromosom tersebut semakin tinggi fitnessnya.
Novamizanti & Vimalakirti (2010) melakukan penelitian tentang mengoptimasi logika fuzzy dengan menggunakan genetic algorithm pada identifikasi pola tanda tangan. Karena logika fuzzy dikembangkan untuk pengenalan pola huruf dan angka saja, maka Novamizanti, L. dan Vimalakirti, R. Mengembangkan aplikasi logika fuzzy yang dioptimalisasi dengan genetic algorithm. Dimana yang dioptimasikan adalah rule evaluation yaitu dengan terlebih dahulu memetakan variabel fuzzy ke dalam fungsi keanggotaannya, maka proses dilanjutkan dengan menbuat rule.
Tujuan
Tujuan Penelitian ini untuk melakukan optimasi parameter dalam fuzzy inference system (FIS) dengan menggunaka genetic algorithm (GA) agar dapat memprediksi jumlah publikasi yang diterbitkan oleh LIPI Press untuk tahun yang akan datang secara optimal.
Ruang Lingkup
4
Manfaat Penelitian
TINJAUAN PUSTAKA
Logika Fuzzy
Dalam logika matematika klasik hanya memiliki dua nilai kebenaran, yaitu benar atau salah (0 atau 1). Namun disayangkan terdapat beberapa masalah yang muncul dalam kehidupan sehari-hari yang tidak dapat dikomputasi dengan pendekatan logika klasik, terutama untuk lingkungan yang dinamis. Logika fuzzy memungkinkan suatu kebenaran menjadi lebih fleksibel dengan konsep numerik yang memiliki nilai keanggotaan antara 0 dan 1, dan konsep linguistik untuk tingkat “keabuan” antara “hitam” dan “putih”.
Penggunaan logika fuzzy dipilih karena memiliki kelebihan sebagai berikut (Kusumadewi 2002) :
1) Konsep logika fuzzy mudah dimengerti, karena konsep matematis yang mendasari penalaran fuzzy sangat sederhana dan mudah dimengerti; 2) Logika fuzzy sangat fleksibel;
3) Logika fuzzy memiliki toleransi terhadap data yang tidak tepat; 4) Logika fuzzy memodelkan fungsi nonlinier yang sangat kompleks; 5) Dengan logika fuzzy dapat dibangun dan diaplikasikan pengalaman para
pakar secara langsung tanpa melalui proses pelatihan; 6) Logika fuzzy didasarkan pada bahasa alami.
Penggambaran mengenai logika fuzzy dapat dilihat pada Gambar 1.
Gambar 1 Logika fuzzy.
Logika fuzzy dapat dipandang sebagai kotak hitam yang memetakan ruang input ke sebuah ruang output. Dalam penelitian ini, ruang input yang dimaksud adalah jumlah satuan kerja yang menggunakan jasa LIPI Press, jumlah tenaga kerja, dan lama proses produksi. Sedangkan ruang output yang dimaksud dalam
6
penelitian ini adalah jumlah publikasi buku yang akan terbit pada tahun yang akan datang.
Himpunan Fuzzy
Pada himpunan tegas (crisp), nilai keanggotaan suatu item x dalam suatu himpunan A, yang ditulis dengan A(x), memiliki dua kemungkinan nilai yaitu
satu (1), yang berarti bahwa suatu item menjadi anggota dalam suatu himpunan, atau nol (0), yg berarti bahwa suatu item tidak menjadi anggota dalam suatu himpunan. Himpunan fuzzy didasarkan pada gagasan untuk memperluas jangkauan fungsi krakteristik sedemikian hingga fungsi tersebut akan mencakup bilangan real pada interval [0,1]. Dimana nilai keanggotaannya menunjukan bahwa suatu item dalam semesta pembicaraan tidak hanya berada pada 0 atau 1, namun juga nilai yang terletak diantaranya. Dengan kata lain, kebenaran suatu item tidak hanya bernilai benar atau salah. Nilai 0 menunjukan salah, nilai 1 menunjukan benar, dan masih ada nilai-nilai yang terletak antara benar dan salah.
Fungsi Keanggotaan (Membership Function)
Fungsi keanggotaan (membership function) adalah suatu kurva yang menunjukkan pemetaan titik-titik input data ke dalam nilai keanggotaannya (sering disebut juga dengan derajat keanggotaan) yang memiliki interval antara 0 sampai 1 (Kusumadewi & Purnomo 2010).
Fungsi keanggotaan yang digunakan adalah tiga macam fungsi keanggotaan. Ketiga fungsi tersebut adalah:
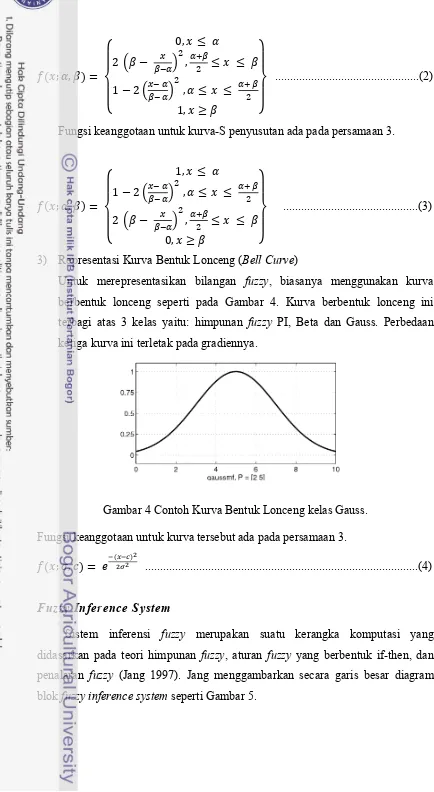
1) Representasi Kurva Trapesium
7
Gambar 2 Contoh kurva trapesium.
Fungsi keanggotaan untuk kurva trapesium ada pada persamaan 1
; , , ,
,
,
,
,
,
...(1)
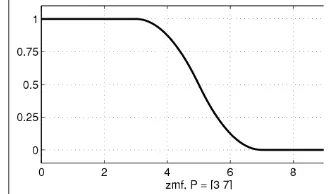
2) Representasi Kurva-S
Kurva pertumbuhan dan penyusutan merupakan kurva-S atau sigmoid yang berhubungan dengan kenaikan dan penurunan permukaan secara tak linear. Contoh kurva-s pertumbuhan dan penyusutan yang diperoleh dari matlab dapat dilihat pada Gambar 3.
Kurva-S Pertumbuhan Kurva-S Penyusutan
Gambar 3 Contoh Kurva-S.
8
Fungsi keanggotaan untuk kurva-S penyusutan ada pada persamaan 3.
; ,
3) Representasi Kurva Bentuk Lonceng (Bell Curve)
Untuk merepresentasikan bilangan fuzzy, biasanya menggunakan kurva berbentuk lonceng seperti pada Gambar 4. Kurva berbentuk lonceng ini terbagi atas 3 kelas yaitu: himpunan fuzzy PI, Beta dan Gauss. Perbedaan ketiga kurva ini terletak pada gradiennya.
Gambar 4 Contoh Kurva Bentuk Lonceng kelas Gauss. Fungsi keanggotaan untuk kurva tersebut ada pada persamaan 3.
; , ...(4)
Fuzzy Inference System
9
Gambar 5 Diagram Blok Sistem Inferensi Fuzzy.
Dengan input dan output crisp, sistem inferensi fuzzy mengimplementasikan pemetaan non linier dari ruang input. Pemetaan ini dilakukan oleh sejumlah fuzzy dengan aturan if-then, masing-masing menggambarkan prilaku lokal dalam pemetaan. Khususnya, aturan mendefenisikan sebuah daerah fuzzy dalam ruang input, sedangkan konsekuen menentukan output di daearah fuzzy.
Sebagai ilustrasi dari Gambar 5 dapat dilihat pada Gambar 6.
10
Metode Mamdani
Metode ini dikenal juga sebagai metode Max-Min. Kusumadewi dan Purnomo menjelaskan bahwa untuk mendapatkan output, diperlukan 4 tahapan yaitu:
1) Pembentukan himpunan fuzzy
2) Aplikasi fungsi implikasi. Dimana yang digunakan pada metode ini adalah Min
3) Komposisi aturan. Pada tahap ini terdapat tiga metode yang digunakan dalam melakukan inferensi sistem fuzzy,yaitu max-min, Additive dan probabilistik OR. Pada metode min-max, solusi himpunan fuzzy diperoleh dengan cara mengambil nilai maksimum aturan, kemudian menggunakannya untuk memodifikasi daerah fuzzy, dan mengaplikasikannya ke output dengan menggunakan operator OR (Union).
4) Penegasan (defuzzy).
Pada penelitian ini, hasil dari metode inferensi fuzzy mamdani dilakukan defuzzy. Metode defuzzy yang digunakan adalah metode centroid, yaitu cara untuk memperoleh solusi crisp dengan mengambil titik pusat( z*) daerah fuzzy.
Optimasi Fuzzy Inference System
Optimasi fuzzy dikembangkan untuk mengatasi permasalahan optimasi yang melibatkan data desain, fungsi tujuan, dan kendala lain dalam bentuk tidak tepat yang melibatkan deskripsi samar-samar dan linguistik (Rao, wiley & Sons 2009).
Dalam FIS terdapat beberapa bagian yang dapat dioptimasikan, diantaranya parameter atau bobot dalam fungsi keanggotaan, rule dan kurva membership function. Pada optimasi bobot perlu mengasumsikan temporal bentuk fungsi keanggotaan adalah tetap (Tan & Tokinaga 1999).
Genetic Algorithm
11
Inisialisasi populasi, N kromosom
Loop
Loop untuk N kromosom
Dekodekan kromosom
Evaluasi kromosom
End
Buat satu atau dua kopi kromosom terbaik (elitisme)
Loop sampai didapatkan N kromosom baru
Pilih dua kromosm
Pindah silang
Mutasi
End
End
Terminologi dan Operator Genetic Algorithm
Sivinandam dan Deepa (2008) menyatakan bahwa dalam genetic algorithm, individu merupakan digit binary atau beberapa set lain dari simbol yang diambil dari sebuah himpunan tak hingga, juga genetic algorithm dapat digunakan untuk mencari solusi yang optimal, sehingga perlu dilakukan operasi tertentu atas individu-individu. Berikut istilah dan operator dalam genetic algorithm (Sivanandam & Deepa 2008):
1) Gen, merupakan instruksi dasar dalam membangun genetic algorithm. Dimana kromosom merupakan serangkaian gen. Berikut reprensentasi dari gen,
1 0 1 0 1 1 1 0 1 1 1 1 0 1 0 1
Gen 1 Gen 2 Gen 3 Gen 4
2) Fitness merupakan alat ukur untuk mengevaluasi kulitas kromosom dalam populasi. Di mana kromosom pada setiap generasi akan melalui proses evaluasi ini. Namun demikian, fitness tidak hanya menunjukan seberapa baik solusi tersebut tetapi juga sesuai dengan seberapa dekat kromosom yang optimal.
12
4) Encoding, merupakan proses yang mewakili gen individu. Dimana proses tersebut dapat dilakukan dengan menggunakan bit, angka, tree, array, list atau objek lainnya. Encoding ini tergantung pada pemecahan masalah utamanya. Pengkodean yang digunakan dalam penelitian ini adalah Binary encoding. Yakni setiap gen hanya bisa bernilai 0 atau 1. Pada permasalahan yang membutuhkan ketelitian yang tinggi memerlukan jumlah gen yang lebih banyak dalam binary encoding. Tetapi perlu disadari bahwa jumlah gen yang terlalu banyak akan mempengaruhi kecepatan proses dari genetic algorithm secara signifikan. Untuk itu perlu dipertimbangkan jumlah gen yang sesuai. 5) Seleksi adalah proses memilih dua orangtua dari polulasi yang akan
dipindahsilangkan, yang dilakukan secara random untuk mengambil kromosom dari populasi yang sesuai dengan fungsi evaluasi kromosom tersebut, biasa yang dipilih yang memiliki nilai fitness yang tinggi. Penelitian ini metode seleksi yang digunakan adalah Roulette-wheel, dimana setiap kromosom menempati potongan lingkaran pada roulette secara proporsional sesuai dengan nilai fitnessnya. Kromosom yang memiliki nilai fitness lebih tinggi menempati potongan lingkaran yang lebih besar dibandingkan dengan kromosom bernilai fitness rendah. Untuk mengimplemetasikan metode tersebut dalam pemrograman yaitu dengan membuat interval nilai kumulatif (dalam interval [0,1]) dari nilai fitness setiap kromosom dibagi dengan total nilai fitness dari semua kromosom. Sebuah kromosom akan terpilih jika bilangan random yang dibangkitkan berada dalam interval akumulatifnya. 6) Pindah Silang (Crossover) Salah satu komponen paling penting dalam genetic
13
merupakan kasus khusus dari n-point crossover di mana n sama dengan jumlah gen dikurangi satu.
7) Mutasi, terdapat cara lain untuk mendapatkan individu yang baru, yaitu dengan cara mutasi. Konsepnya adalah semua gen yang ada, jika bilangan random yang dibangkitkan kurang dari probabilitas mutasi pmut yang
ditentukan maka ubah gen tersebut menjadi nilai kebalikannya (dalam binary encoding, 0 diubah 1, dan 1 diubah 0).
8) Elitisme, dilakukan untuk menjaga agar individu bernilai fitness tertinggi tidak hilang selama evolusi, sehingga dibuat satu atau beberapa copynya.
Representasi Kromosom
Merepresentasikan suatu solusi dalam permasalahan tertentu merupakan langkah awal dalam genetic algorithm, hal tersebut disebut dengan encoding. Pada umumnya, genetic algorithm menggunakan binary encoding dalam merepresentasikan kromosom. Sekumpulan nilai yang di encode menjadi bit string, menyatakan satu kromosom (Kantardzic 2003). Pada representasi biner sebuah kromosom terdiri dari beberapa elemen yang disimbolkan dengan angka nol (0) atau satu (1). Setiap elemen memiliki arti khusus yang menunjukkan nilai fitness kromosom yang bersangkutan.
Parameter Genetic Algorithm
Beberapa parameter yang digunakan dalam genetic algorithm adalah sebagai berikut:
1) Ukuran Populasi
Ukuran populasi merupakan jumlah individu (kromosom) yang terdapat dalam satu populasi atau satu generasi. Semakin banyak jumlah individu juga semakin beragamnya individu yang terdapat dalam populasi akan memberikan peluang yang lebih besar untuk menentukan individu yang mendekati sempurna. Ukuran populasi yang baik ditentukan dari jenis pengkodean atau bagaimana merepresentasikan kromosom, artinya jika terdapat ukuran kromosom 32 bit, ukuran populasi seharusnya juga 32, begitu pula jika ukuran kromosom 16 bit, maka ukuran populasi adalah 16 (Obitko
14
sebaiknya tidak kurang dari 30. Jika ukuran populasi terlalu kecil, genetic
algorithm akan cepat konvergen disebabkan oleh rendahnya variasi pada
kromosom-kromosom dalam populasi, tetapi ukuran populasi yang terlalu besar
akan menyebabkan proses genetic algorithm menjadi lambat (Suyanto 2005).
2) Jumlah generasi
Jumlah generasi merupakan banyaknya generasi yang akan dibangkitkan pada proses algoritme genetik. Jumlah generasi ini mempunyai andil yang besar dalam menemukan individu yang lebih baik karena semakin besar jumlah generasi maka individu yang dihasilkan akan semakin baik dan sempurna. Namun, tidak berarti semakin besar jumlah generasi maka individu yang dihasilkan selalu lebih baik karena ada suatu saat dimana nilai fitness semua individu akan menjadi sama (konvergen). Jika hal itu terjadi maka generasi-generasi selanjutnya akan cenderung mempunyai nilai fitness yang sama dengan generasi sebelumnya, kalaupun ada perubahan biasanya perubahan tersebut tidak terlalu besar. Jumlah generasi digunakan juga untuk menentukan kapan proses algoritme genetik akan berhenti dilakukan.
3) Probabilitas crossover
Probabilitas crossover (pc) ini menentukan banyaknya kemungkinan kromosom yang mengalami proses pindah silang di dalam suatu populasi. Semakin besar pc berarti semakin besar pula jumlah kromosom di dalam sebuah populasi yang mengalami proses pindah silang. Pada umumnya probabilitas pindah silang ditentukan antara 0,6 sampai 0,9 (Suyanto 2005). 4) Probabilitas mutasi
15
Perbedaan Pendekatan Genetic Algorithm dengan Metode Optimasi Konvensional
Perbedaan pendekatan genetic algorithm dengan metode optimasi konvensial,antara lain (Sivanandam & Deepa 2008):
1) Genetic algorithm bekerja pada sekumpulan solusi yang dikodekan, bukan pada solusi itu sendiri;
2) Genetic algorithm melakukan pencarian pada suatu populasi solusi, bukan pada satu solusi;
3) Genetic algorithm secara langsung memanfaatkan informasi fungsi fitness, bukan turunan atau pengetahuan tambahan lainnya;
4) Genetic algorithm menggunakan aturan-aturan transisi peluang bukan aturan deterministik.
K-Fold Cross Validation
K-fold cross validation merupakan metode untuk membagi data latih dan data uji. K-fold cross validation mengulang k-kali untuk membagi sebuah himpunan contoh secara acak menjadi k subset yang saling bebas. Setiap ulangan disisakan satu subset untuk pengujian dan subset lainnya untuk pelatihan (Fu 1994).
Dalam metode cross validation terdapat strategi leave-one out, yaitu strategi untuk mebagi data latih dan data uji dalam jumlah sample yang kecil.Dimana sebanyak k-1 buah subset digunakan sebagai data latih dan 1 buah set sebagai data uji. Sebagai ilustrasi dari cross validation dengan menggunakan strategi leave-one-out dengan 4 buah fold dapat dilihat pada Gambar 7.
16
Pengertian Penerbit Buku
Seorang pakar dibidang penerbitan yaitu Bambang Trim menjelaskan bahwa penerbit buku merupakan lembaga atau institusi yang mengolah naskah mentah dari penulis/pengarang hingga menjadi bahan siap cetak dalam betuk dummy (prototype buku). Penerbit berbeda dengan percetakan karena modal utamanya adalah gagasan yang kemudian diolah menjadi buku siap terbit, sedangkan percetakan modal utamanya adalah mesin-mesin yang digunakan untuk menerima order cetak, termasuk buku. Tidak semua penerbit memiliki percetakan dan memang tidak diharuskan untuk memiliki percetakan.
Tugas dan fungsi penerbit adalah (Trim 2009):
1) Mengakuisisi naskah atau melakukan pengadaan naskah dengan
menghubungi penulis/pengarang atau melalui promosi pengadaan naskah. 2) Melakukan seleksi untuk menjaring naskah-naskah yang layak terbit. 3) Merencanakan waktu penerbitan naskah, termasuk menetapkan tenggat
(deadline) terbit sebuah naskah.
4) Merencanakan pengembangan naskah meliputi copyediting, desain interior (perwajahan isi), dan desain eksterior(perwajahan sampul).
5) Menghubungi percetakan untuk produksi buku secara massal
6) Mempromosikan dan memasarkan buku kepada masyarakat pembaca.
17
LIPI Press
LIPI Press terbetuk pada tahun 2002 yang merupakan unit pelaksana teknis di bidang penerbitan ilmiah, berada dibawah dan bertanggung jawab kepada Deputi Bidang Jasa Ilmiah-LIPI, dimana pembinaan sehari-harinya dilakukan oleh Kepala Pusat Dokumentasi dan Informasi Ilmiah LIPI. LIPI Press ini beralamat di Jl. Gondangdia Lama (RP Suroso) No. 39, Kelurahan Menteng, Jakarta Pusat.
Sumber daya manusia (SDM) yang ada di LIPI Press terdiri dari pegawai negeri sipil, tenaga kontrak, dan tenaga outsourching. Outsourching itu sendiri terdiri dari sekelompok pakar, penilai, penyunting, dan nara sumber serta kelompok jabatan fungsional lainnya yang berada di Biro/Puslit/UPT di lingkungan LIPI, di mana tenaga outsourching ini adalah sumber daya yang bekerja penggal waktu sesuai dengan keperluan.
18
METODE PENELITIAN
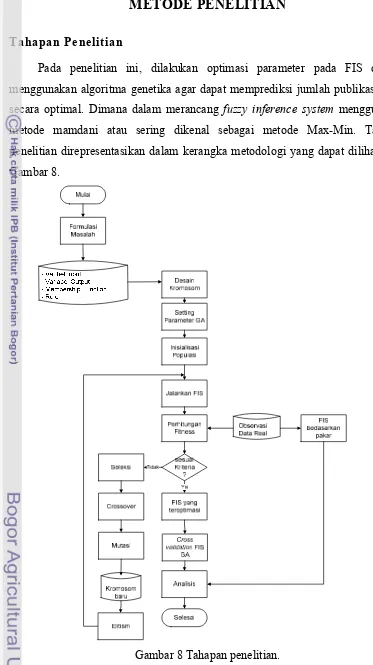
Tahapan Penelitian
Pada penelitian ini, dilakukan optimasi parameter pada FIS dengan menggunakan algoritma genetika agar dapat memprediksi jumlah publikasi buku secara optimal. Dimana dalam merancang fuzzy inference system menggunakan metode mamdani atau sering dikenal sebagai metode Max-Min. Tahapan penelitian direpresentasikan dalam kerangka metodologi yang dapat dilihat pada Gambar 8.
20
Formulasi Masalah
Pada tahap ini dilakukan identifikasi masalah yang mendasari dalam memprediksi jumlah publikasi buku untuk tahun yang akan datang.
Variabel Input dan output
Pada tahap ini ditentukan variabel input apa saja yang akan mempengaruhi jumlah publikasi, dimana jumlah publikasi ini merupakan output. Selain itu, dijelaskan juga himpunan dan definisi dari variabel-varibel tersebut.
Membership Function
Fungsi keanggotaan yang digunakan dalam FIS berdasarkan pakar adalah trapesium, sedangkan fungsi keanggotaan yang akan digunakan dalam mengoptimasi FIS dengan GA adalah
1) Kurva bentuk S penyusutan untuk himpunan sedikit. Kurva ini akan bergerak dari sisi paling kanan (nilai keanggotaan=1) ke sisi paling kiri (nilai keanggotaan = 0)
Kurva bentuk S pertumbuhan untuk himpunan banyak. Kurva ini bergerak dari sisi paling kiri (nilai keanggotaan nol) ke sisi paling kanan (nilai keanggotaan=1). Fungsi keanggotaannya akan tertumpu pada 50% nilai keanggotaan, hal ini sering disebut juga titik infleksi.
Bentuk kurva tersebut dapat dilihat pada Gambar 3.
2) Kurva PI untuk himpunan sedang. Kurva ini terdiri dari 2 parameter yaitu dan dengan derajat keanggotaan 1 dimana menunjukan nilai domain pada pusat kurva , sedangkan merupakan setengah lebar kurva. Bentuk kurva tersebut dapat dilihat pada Gambar 4.
Rule
Pembuatan rule ini terdiri dari 27 kombinasi rule. Dari 27 rule tersebut, pakar memilih 14 rule yang akan dimasukan dalam sistem fuzzy inferensi.
Desain Kromosom
21
biner, dimana setiap satu kromosom terdiri dari 4 variabel yaitu jumlah satuan kerja (x), jumlah tenaga kerja (y), lama proses (z), dan jumlah produksi (w). Masing-masing variabel tersebut memiliki 2 parameter yaitu α, dan dengan panjang kromosom (gen) sesuai dengan range setiap varibel tersebut.
Setting Parameter GA
Parameter GA yang akan digunakan dalam penelitian ini meliputi: 1) Ukuran Populasi (UkPop) : 30, 50 dan 80
2) Probabilitas crossover (Pc) : 0,75; 0,85 dan 0,95 3) Probabilitas mutasi (Pmutasi) : 0,01 dan 0,001 4) Jumlah generasi: 50, 100 dan 150
Inisialisasi Populasi
Proses inisialisasi populasi ini merupakan proses pembentukan populasi awal dalam bentuk kode biner yang dibangkitkan secara acak dalam rentang nilai sesuai dengan ukuran populasi yang ditentukan, dalam hal ini akan dilakukan percobaan dengan ukuran populasinya adalah 30, 50 dan 80.
Perhitungan Nilai Fitness
22
Seleksi
Seleksi dilakukan apabila individu tidak memenuhi kriteria. Metode yang digunakan dalam seleksi ini adalah roulette wheel yang diputar sebanyak jumlah kromosom. Dengan metode ini memungkinkan kromosom dengan nilai fitness tinggi memiliki peluang untuk terpilihnya lebih besar dari pada kromosom dengan nilai fitness rendah juga memungkinkan suatu kromosom terpilih lebih dari satu kali.
Crossover
Crossover bertujuan untuk menambah keanekaragaman individu dalam populasi dengan mengawinkan individu-individu dalam populasi sehingga menghasilkan keturunan berupa individu baru. Crossover dilakukan dengan menukarkan gen dari dua induk secara acak, juga proses crossover dilakukan pada setiap individu dengan probabilitas crossover yang ditentukan. Proses crossover ini dapat dilihat pada Gambar 9.
Gambar 9 Proses Crossover. Mutasi
23
probabilitas mutasi yang ditentukan. Proses mutasi ini dapat dilihat pada Gambar 10.
Gambar 10 Proses mutasi.
k-Fold Cross Validation
Metode yang digunakan untuk membagi data latih dan data uji adalah k-fold cross validation, dengan nilai k adalah 5 (5 fold). Data latih jumlah publikasi terdiri dari 4 data dan data ujinya adalah 1 data, dengan istilah lain strategi yang digunakan dalam cross validation adalah menggunakan leave one out. Hal tersebut dapat dilihat pada Tabel 1.
Tabel 1 Metode cross validation dengan menggunakan leave one out Percobaan Data latih Data uji
1 2,3,4,5 1
2 1,3,4,5 2
3 1,2,4,5 3
4 1,2,3,5 4
5 1,2,3,4 5
Lingkup Pengembangan Sistem
Ruang lingkup pengembangan sistem pada penelitian ini terdiri dari:
1) Software: Windows 7 Starter (32-bit), Matlab 2008, Mincrosoft Office Excel 2007
24
Waktu Penelitian
HASIL DAN PEMBAHASAN
Identifikasi Masalah
Identifikasi dari permasalahan dalam penelitian ini adalah memprediksi jumlah publikasi buku pada tahun yang akan datang. Dalam memprediksi tersebut dilakukan optimasi parameter pada setiap variabel yang mempengaruhi jumlah publikasi buku, agar hasil prediksi lebih optimal.
Variable Input dan Output
Tabel 2 berikut ini varibel input dan varibel output. Dimana varibel input ini dapat dikatakan juga sebagai predictor.
Tabel 2 Varibel input dan varibel output
Fungsi Nama Variabel Satuan Keterangan
Input Jumlah satuan kerja Unit Jumlah satuan kerja yang
mengguna-kan jasa produksi publikasi di LIPI Press
Jumlah tenaga kerja Orang Jumlah tenaga kerja yang melakukan
proses produksi
Lama Proses Hari Lamanya proses produksi sampai
terbit
Output Jumlah produksi publikasi Publikasi Jumlah produksi publikasi
Variabel input tersebut diperoleh dari pakar, selain itu dapat juga diuraikan alasan dari penentuan variabel input tersebut berdasarkan observasi lapangan:
1. Jumlah satuan kerja
Berdasarkan kebijakan kepala LIPI bahwa menerbitkan hasil penelitian yang berada di lingkungan LIPI dilakukan secara terpusat. Artinya peneliti LIPI menerbitkan hasil penelitannya melalui LIPI Press dengan koordinasi bersama satuan kerja terkait. Dengan demikian satuan kerja dapat dijadikan predictor dalam melakukan prediksi jumlah publikasi buku di LIPI Press.
2. Jumlah tenaga kerja
26
3. Lama proses
Lama proses produksi juga menentukan jumlah publikasi, karena proses produksi publikasi buku ini terdiri dari proses pracetak dan cetak yang tentukan memerlukan waktu dalam menyelesaikan sebuah terbitan buku.
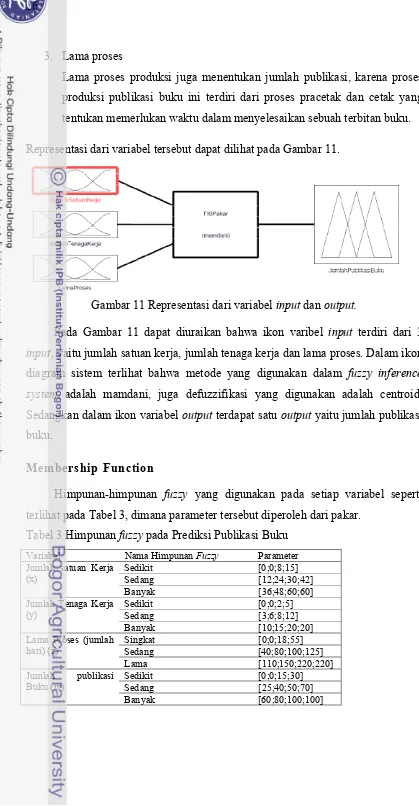
Representasi dari variabel tersebut dapat dilihat pada Gambar 11.
Gambar 11 Representasi dari variabel input dan output.
Pada Gambar 11 dapat diuraikan bahwa ikon varibel input terdiri dari 3 input, yaitu jumlah satuan kerja, jumlah tenaga kerja dan lama proses. Dalam ikon diagram sistem terlihat bahwa metode yang digunakan dalam fuzzy inference system adalah mamdani, juga defuzzifikasi yang digunakan adalah centroid. Sedangkan dalam ikon variabel output terdapat satu output yaitu jumlah publikasi buku.
Membership Function
Himpunan-himpunan fuzzy yang digunakan pada setiap variabel seperti terlihat pada Tabel 3, dimana parameter tersebut diperoleh dari pakar.
Tabel 3 Himpunan fuzzy pada Prediksi Publikasi Buku
Variabel Nama Himpunan Fuzzy Parameter
Jumlah satuan Kerja (x)
Sedikit [0;0;8;15]
Sedang [12;24;30;42]
Banyak [36;48;60;60] Jumlah Tenaga Kerja
(y)
Sedikit [0;0;2;5]
Sedang [3;6;8;12]
Banyak [10;15;20;20] Lama Proses (jumlah
hari) (z)
Singkat [0;0;18;55]
Sedang [40;80;100;125]
27
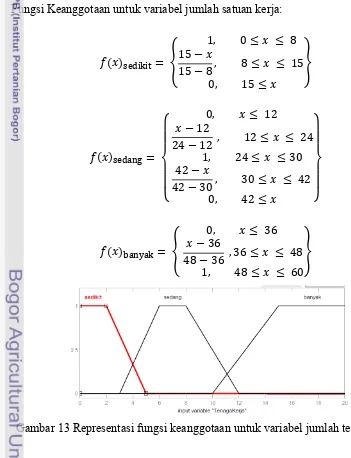
Setiap variabel direpresentasikan dengan menggunakan kurva trapesium. Representasi variabel tersebut dapat dilihat pada Gambar 12 sampai dengan Gambar 15.
Gambar 12 Representasi fungsi keanggotaan untuk variabel jumlah satuan kerja.
Fungsi Keanggotaan untuk variabel jumlah satuan kerja: ,
,
,
,
,
,
,
,
,
,
,
28
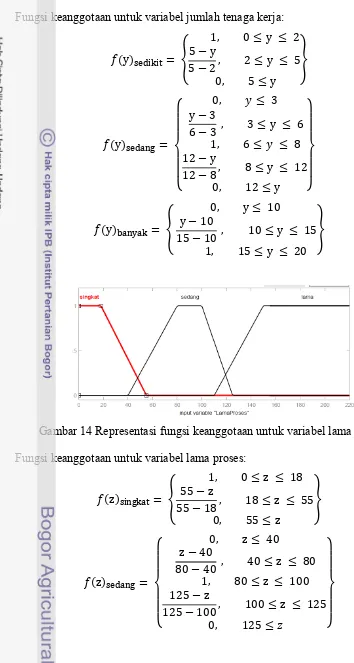
Fungsi keanggotaan untuk variabel jumlah tenaga kerja:
y
Gambar 14 Representasi fungsi keanggotaan untuk variabel lama proses. Fungsi keanggotaan untuk variabel lama proses:
29
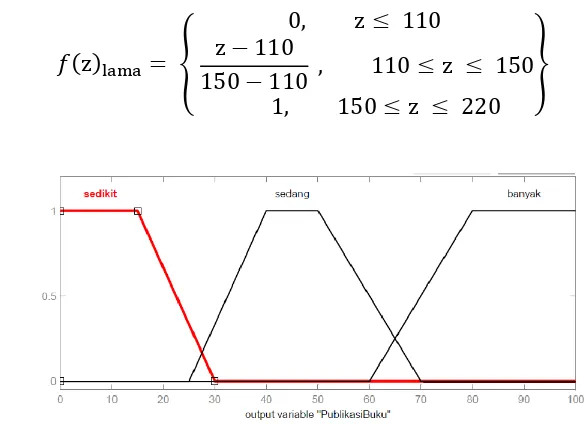
Gambar 15 Representasi fungsi keanggotaan untuk variabel jumlah publikasi. Fungsi keanggotaan untuk variabel jumlah publikasi:
w
30
Dari 27 rule tersebut, pakar memilih 14 rule yang akan dimasukan dalam sistem fuzzy inferensi dengan pertimbangan rule tersebut sering terjadi di LIPI Press.
Tabel 4 Kombinasi rule
[R1] IF Satuan kerja sedikit AND tenaga kerja sedikit AND lama proses lama THEN produksi buku sedikit
[R2] IF satuan kerja sedikit AND tenaga kerja sedikit AND lama proses sedang THEN produksi buku sedikit
[R3] IF satuan kerja sedikit AND tenaga kerja sedikit AND lama proses singkat THEN produksi buku sedikit
[R4] IF satuan kerja sedikit AND tenaga kerja sedang AND lama proses lama THEN produksi buku sedikit
[R5] IF satuan kerja sedikit AND tenaga kerja sedang AND lama proses sedang THEN produksi buku sedikit
[R6] IF satuan kerja sedikit AND tenaga kerja sedang AND lama proses singkat THEN produksi buku sedang
[R7] IF satuan kerja sedikit AND tenaga kerja banyak AND lama proses lama THEN produksi buku sedang
[R8] IF satuan kerja sedikit AND tenaga kerja banyak AND lama proses sedang THEN produksi buku sedang
[R9] IF satuan kerja sedikit AND tenaga kerja banyak AND lama proses singkat THEN produksi buku sedang
[R10] IF satuan kerja sedang AND tenaga kerja sedikit AND lama proses lama THEN produksi buku sedikit
[R11] IF satuan kerja sedang AND tenaga kerja sedikit AND lama proses sedang THEN produksi buku sedang
[R12] IF satuan kerja sedang AND tenaga kerja sedikit AND lama proses singkat THEN produksi buku sedang
[R13] IF satuan kerja sedang AND tenaga kerja sedang AND lama proses lama THEN produksi buku sedikit
[R14] IF satuan kerja sedang AND tenaga kerja sedang AND lama proses sedang THEN produksi buku sedang
[R15] IF satuan kerja sedang AND tenaga kerja sedang AND lama proses singkat THEN produksi buku sedang
[R16] IF satuan kerja sedang AND tenaga kerja banyak AND lama proses lama THEN produksi buku sedang
[R17] IF satuan kerja sedang AND tenaga kerja banyak AND lama proses sedang THEN produksi buku sedang
[R18] IF satuan kerja sedang AND tenaga kerja banyak AND lama proses singkat THEN produksi buku banyak
[R19] IF satuan kerja banyak AND tenaga kerja sedikit AND lama proses lama THEN produksi buku sedikit
[R20] IF satuan kerja banyak AND tenaga kerja sedikit AND lama proses sedang THEN produksi buku sedikit
[R21] IF satuan kerja banyak AND tenaga kerja sedikit AND lama proses singkat THEN produksi buku banyak
[R22] IF satuan kerja banyak AND tenaga kerja sedang AND lama proses lama THEN produksi buku sedikit
[R23] IF satuan kerja banyak AND tenaga kerja sedang AND lama proses sedang THEN produksi buku sedang
[R24] IF satuan kerja banyak AND tenaga kerja sedang AND lama proses singkat THEN produksi buku banyak
31
[R26] IF satuan kerja banyak AND tenaga kerja banyak AND lama proses sedang THEN produksi buku banyak
[R27] IF satuan kerja banyak AND tenaga kerja banyak AND lama proses singkat THEN produksi buku banyak
Tabel 5 Rule yang digunakan dalam fuzzy inference system
[R1] IF Satuan kerja sedikit AND tenaga kerja sedikit AND lama proses lama THEN produksi buku sedikit
[R4] IF satuan kerja sedikit AND tenaga kerja sedang AND lama proses lama THEN produksi buku sedikit
[R6] IF satuan kerja sedikit AND tenaga kerja sedang AND lama proses singkat THEN produksi buku sedang
[R9] IF satuan kerja sedikit AND tenaga kerja banyak AND lama proses singkat THEN produksi buku sedang
[R10] IF satuan kerja sedang AND tenaga kerja sedikit AND lama proses lama THEN produksi buku sedikit
[R13] IF satuan kerja sedang AND tenaga kerja sedang AND lama proses lama THEN produksi buku sedikit
[R16] IF satuan kerja sedang AND tenaga kerja banyak AND lama proses lama THEN produksi buku sedang
[R18] IF satuan kerja sedang AND tenaga kerja banyak AND lama proses singkat THEN produksi buku banyak
[R19] IF satuan kerja banyak AND tenaga kerja sedikit AND lama proses lama THEN produksi buku sedikit
[R21] IF satuan kerja banyak AND tenaga kerja sedikit AND lama proses singkat THEN produksi buku banyak
[R22] IF satuan kerja banyak AND tenaga kerja sedang AND lama proses lama THEN produksi buku sedikit
[R24] IF satuan kerja banyak AND tenaga kerja sedang AND lama proses singkat THEN produksi buku banyak
[R26] IF satuan kerja banyak AND tenaga kerja banyak AND lama proses sedang THEN produksi buku banyak
[R27] IF satuan kerja banyak AND tenaga kerja banyak AND lama proses singkat THEN produksi buku banyak
FIS Pakar
Dari parameter dan rule yang telah ditentukan oleh pakar, diperoleh prediksi jumlah publikasi buku yang dapat dilihat pada Tabel 6. Hasil prediksi berdasarkan pakar memiliki nilai yang berbeda dengan data jumlah publikasi buku.
Tabel 6 Prediksi jumlah publikasi buku berdasarkan pakar
32
Setiap variabel memiliki range yang telah ditentukan. Sebagai mana terlihat pada Tabel 7. Sehingga dapat dihitung panjang kromosom pada setiap varibel.
Tabel 7 Range setiap variabel dan panjang kromosom
Variabel Range Panjang Kromosom
X [0 60] 25
Y [0 20] 20
Z [0 220] 35
W [0 100] 30
Dengan demikian desain kromosom dapat direpresentasi dalam Gambar 16
αXsedikit βXsedikit αXsedang βXsedang αXbanyak βXbanyak ... αWbanyak βWbanyak
5 bit 9 bit 11 bit ... 13 bit
110 bit
Gambar 16 Desain kromosom.
Contoh kromosom pada setiap variabel dapat dilihat pada Gambar 17
1 0 1 ... 0 1 0 0 0 ... 0 1 0 1 1 ... 1 0 0 1 1 ... 1 1
X Y Z W Gambar 17 Susunan kromosom pada setiap variabel.
Setting Parameter Genetic Algorithm
Parameter GA yang digunakan dalam penelitian ini meliputi: 1) Ukuran Populasi (UkPop) : 30, 50 dan 80
2) Probabilitas crossover (Pc) : 0,75; 0,85 dan 0,95 3) Probabilitas mutasi (Pmutasi) : 0,01 dan 0,001 4) Jumlah generasi: 50, 100 dan 150
33
percobaan sebanyak nilai k yaitu 5 percobaan. Dengan demikan jumlah kobinasi yang diperoleh ada 270.
Hasil percobaan tersebut dapat dilihat pada Tabel 8.
Tabel 8 Hasil percobaan dengan menggunakan metode cross validation
Percobaan
Paramater GA yang Optimal
Data Observasi
Hasil
Prediksi Selisih Ukuran
Dari hasil percobaan tersebut terlihat bahwa pada percobaan ke 5 memiliki selisih yang lebih kecil dari pada percobaan lainnya. Sehingga dapat dikatakan bahwa pada percobaan ke 5 dihasilkan parameter GA yang optimal.
Inisialisasi Populasi
Proses pembentukan populasi ini dalam bentuk biner yang dibangkitkan secara acak dalam rentang nilai sesuai dengan ukuran populasi yang ditentukan yaitu 30, 50 dan 80. Adapun jumlah gen adalah sebanyak 110.
Perhitungan Nilai Fitness
Maksud fitness terbaik dalam penelitian ini adalah maksimum fitness. Dimana nilai ini merupakan galat. Adapun langkah perhitungan nilai fitness yang dimaksud adalah seperti terlihat pada Gambar 18.
34
Gambar 18 Langkah perhitungan nilai fitness.
Tabel 9 Nilai fitness terbaik dengan percobaan menggunakan cross validation
Percobaan
Paramater GA yang Optimal
Maksimum
fitness
Ukuran Populasi
Probabilitas Crossover
Probabilitas Mutasi
Jumlah Generasi
1 30 0.85 0.01 150 1
2 30 0.85 0.01 100 0.5
3 30 0.75 0.01 150 1
4 30 0.95 0.01 150 1
5 30 0.75 0.01 150 1
35
Gambar 19 Representasi maksimum fitness pada percobaan fold ke 1.
Hasil percobaan diperoleh juga nilai minimum fitness dengan menggunaan cross validation dapat dilihat pada Tabel 10. Di mana nilai minimum fitness ini merupakan nilai galat yang kecil, sehingga parameter yang dihasilkan bukan merupakan parameter GA yang optimal.
Tabel 10 Nilai minimum fitness dengan percobaan menggunakan cross validation
Percobaan
Paramater GA yang Optimal
Minimum
Salah satu representasi dari hasil percobaan tersebut dapat dilihat pada Gambar 20
36
Gambar 20 Representasi dari minimum fitness. Seleksi
Pada seleksi ini menggunakan metode roulette-wheel. Adapun cara kerja metode seleksi roulette wheel yaitu diperiolehnya nilai fitness dari masing-masing individu, hitung total fitness semua individu, lalu dibangkitkan bilangan random, hitung probabilitas masing-masing individu, dari probabilitas tersebut dihitung jatah masing-masing individu. Dari bilangan random yang dihasilkan, ditentukan individu mana yang terpilih dalam proses seleksi.
Crossover
Pada proses ini dilakukan pindah silang antar kromosom induk yang terpilih sebelumnya. Pemilihan antar kromosom tersebut dilakukan dengan cara mengambil nilai acak yang bernilai lebih kecil dari probabilitas crossover (Pc). Pc yang telah ditentukan adalah 0.75; 0.85 dan 0.95. Kromosom yang akan dilakukan pindah silang menggunakan one pint crossover. Gen-gen yang dimiliki kromosom induk setelah titik potong akan dipindahsilangkan antar induk sehingga tercipta dua buah kromosom baru.
0 10 20 30 40 50 60 70 80 90 100
37
Mutasi
Proses mutasi ini mengubah nilai gen pada kromosom yang terpilih sebelumnya. Pemilihan tersebut dilakukan dengan cara mengambil nilai acak yang lebih kecil dari probabilitas mutasi yang telah ditentukan (0.01 dan 0.001). Gen yang dimutasi adalah gen yang berada diantara gen αXsedikit sampai gen
βWbanyak.
Observasi Data Real
Hasil observasi data real dibandingkan dengan hasil predeksi yang dilakukan genetic algorithm yang optimum dengan menggunakan ukuran populasi 30, probabilitas crossover 0.75, probabilitas mutasi 0.01 dan jumlah generasi 150 dapat dilihat pada Tabel 11.
Tabel 11 Hasil prediksi jumlah publikasi
Tahun
Dari tabel 11 dapat dilihat bahwa hasil prediksi jumlah publikasi sangat mendekati jumlah publikasi berdasarkan data real yang ada.
FIS yang Teroptimasi
38
Gambar 21 Parameter setiap variabel yang dihasil oleh GA pada percobaan ke-1. Dari Gambar 21 dapat diimplemetasikan pada fuzzy inference system, yaitu dengan memasukkan parameter tersebut sebagai fungsi keanggotaannya. Representasi dari fungsi keanggotaan tersebut dapat dilihat pada Gambar 22.
Fungsi keanggotaan untuk variabel jumlah satuan kerja:
Fungsi keanggotaan untuk variabel jumlah tenaga kerja:
y
Sedikit Sedang Banyak Sedikit Sedang Banyak ...
α β α β α β α β α β α β ...
0 14 2 6 9 46 0 0 4 7 15 21 ...
Lama Proses (z) Publikasi Buku (w)
singkat sedang lama sedikit sedang banyak
α β α β α β α β α β α β
39
Fungsi keanggotaan untuk variabel lama proses:
z
Fungsi keanggotaan untuk variabel jumlah publikasi buku:
40
41
Pada percobaan ke-2, populasi yang dihasilkan oleh genetic algorithm menggunakan ukuran populasi 30, probabilitas crossover 0.85, probabilitas mutasi 0.01, dan jumlah generasi 100. Parameter tersebut menghasilkan nilai maksimu m fitness 0.5. Populasi pada percobaan ke-2 tersebut dapat dilihat pada Gambar 23.
Gambar 23 Parameter setiap variabel yang dihasil oleh GA pada percobaan ke-2. Dari Gambar 23 dapat diimplementasikan pada fuzzy inference system, yaitu memasukan paramter tersebut sebagau fungsi keanggotaannya. Representasi dari fungsi keanggotaan tersebut dapat dilihat pada Gambar 24.
Fungsi keanggotaan untuk variabel jumlah satuan kerja:
Sedikit Sedang Banyak Sedikit Sedang Banyak ...
α β α β α β α β α β α β ...
0 12 6 27 7 56 0 5 3 5 3 10 ...
Lama Proses (z) Publikasi Buku (w)
singkat sedang lama sedikit sedang banyak
α β α β α β α β α β α β
42
Fungsi keanggotaan untuk varibel jumlah tenaga kerja:
y
Fungsi keanggotaan untuk variabel jumlah lama proses:
z
Fungsi keanggotaan untuk variabel jumlah jumlah publikasi buku:
43
, w w
, w
w
, w
, w
44
Pada percobaan ke-3, populasi yang dihasilkan oleh genetic algorithm menggunakan ukuran populasi 30, probabilitas crossover 0.75, probabilitas mutasi 0.01, dan jumlah generasi 150. Parameter tersebut menghasilkan nilai maksimu m fitness 1. Populasi pada percobaan ke-3 tersebut dapat dilihat pada Gambar 25.
Gambar 25 Parameter setiap variabel yang dihasil oleh GA pada percobaan ke-3. Dari Gambar 25 dapat diimplemetasikan pada fuzzy inference system, yaitu dengan memasukkan parameter tersebut sebagai fungsi keanggotaannya. Representasi dari fungsi keanggotaan tersebut dapat dilihat pada Gambar 26.
Fungsi keanggotaan untuk variabel jumlah satuan kerja:
Sedikit Sedang Banyak Sedikit Sedang Banyak ...
α β α β α β α β α β α β ...
0 5 5 27 10 49 0 7 3 7 3 6 ...
Lama Proses (z) Publikasi Buku (w)
singkat sedang lama sedikit sedang banyak
α β α β α β α β α β α β
45
Fungsi keanggotaan untuk variabel jumlah tenaga kerja:
y
Fungsi keanggotaan untuk variabel jumlah lama proses:
z
Fungsi keanggotaan untuk variabel jumlah jumlah publikasi buku:
46
, w w
, w
w
, w
, w
47
Pada percobaan ke-4, populasi yang dihasilkan oleh genetic algorithm menggunakan ukuran populasi 30, probabilitas crossover 0.95, probabilitas mutasi 0.01, dan jumlah generasi 150. Parameter tersebut menghasilkan nilai maksimu m fitness 1. Populasi pada percobaan ke-3 tersebut dapat dilihat pada Gambar 27.
Gambar 27 Parameter setiap variabel yang dihasil oleh GA pada percobaan ke-4. Dari Gambar 27 dapat diimplemetasikan pada fuzzy inference system, yaitu dengan memasukkan parameter tersebut sebagai fungsi keanggotaannya. Representasi dari fungsi keanggotaan tersebut dapat dilihat pada Gambar 28.
Fungsi keanggotaan untuk variabel jumlah satuan kerja:
Sedikit Sedang Banyak Sedikit Sedang Banyak ...
α β α β α β α β α β α β ...
0 15 7 9 9 26 0 5 3 5 4 10 ...
Lama Proses (z) Publikasi Buku (w)
singkat sedang lama sedikit sedang banyak
α β α β α β α β α β α β
48
Fungsi keanggotaan untuk variabel jumlah tenaga kerja:
y
Fungsi keanggotaan untuk variabel jumlah lama proses:
z
Fungsi keanggotaan untuk variabel jumlah jumlah publikasi buku:
49
, w w
, w
w
, w
, w
50
Satuan Kerja (X) Tenaga Kerja (Y) ...
Sedikit Sedang Banyak Sedikit Sedang Banyak ...
α β α β α β α β α β α β ...
0 2 7 28 8 45 0 0 4 4 13 22 ...
Lama Proses (Z) Publikasi Buku (W)
singkat sedang lama sedikit sedang banyak
α β α β α β α β α β α β
0 56 53 100 22 155 0 24 7 32 27 64
Pada percobaan ke-5, populasi yang dihasilkan oleh genetic algorithm menggunakan ukuran populasi 30, probabilitas crossover 0.75, probabilitas mutasi 0.01, dan jumlah generasi 150. Parameter tersebut menghasilkan nilai maksimu m fitness 1. Populasi pada percobaan ke-3 tersebut dapat dilihat pada Gambar 29.
Gambar 29 Parameter setiap varibel yang dihasil oleh GA pada percobaan ke-5. Dari Gambar 29 dapat diimplemetasikan pada fuzzy inference system, yaitu dengan memasukkan parameter tersebut sebagai fungsi keanggotaannya. Representasi dari fungsi keanggotaan tersebut dapat dilihat pada Gambar 30.
51
Fungsi keanggotaan untuk variabel jumlah tenaga kerja:
, y Fungsi keanggotaan untuk variabel lama proses:
Fungsi keanggotaan untuk variabel jumlah jumlah publikasi buku:
52
54
Antarmuka Grafis
Untuk melakukan proses optimasi fuzzy inference system menggunakan genetic algorithm telah dibangun sebuah aplikasi sederhana dengan menggunakan Mathlab 7.7.0. Antramuka grafis dari aplikasi tersebut dapat dilihat pada Gambar 32.
SIMPULAN DAN SARAN
Simpulan
Dari berbagai percobaan yang telah dilakukan dalam penelitian ini, hasil penelitian menunjukan bahwa genetic algorithm dapat digunakan untuk mengoptimasi himpunan dalam fuzzy inference system pada ukuran populasi 30, probabilitas crossover 0.75, probabilitas mutasi 0.01, dan jumlah generasi 150. Dengan diperolehnya parameter genetic algorithm tersebut dihasilkan fungsi keanggotaan yang digunakan dalam fuzzy inference system untuk dilakukannya prediski jumlah publikasi. Hasil Prediksi yang dihasilkan memiliki selisih yang lebih kecil dengan data observasi dibandingkan hasil prediksi dengan menggunakan fungsi keanggotaan yang ditentukan oleh pakar.
Saran
DAFTAR PUSTAKA
Djunaidi, M., Eko Setiawan, dan Fajar Whedi Andista. 2005. Penentuan Jumlah Produksi dengan Aplikasi Metode Fuzzy – Mamdani. Jurnal Ilmiah Teknik Industri, Vol. 4, No. 2. pp 95-104. Surkarta: Jurusan Teknik Industri Universitas Muhammadiah Surakarta.
Fu L. 1994. Neural Network in Computer Intelligence. Singapura: McGraw Hill. Gallova, S., Iaeng. 2009. Genetic Algorithm as a Tool of Fuzzy Parameters and
Cutting Forces Optimization. In Proceedings of the World Congress on Engineering Vol I WCE. London., U.K.
Goldberg, David E. 1989. Genetic Algorithms in Search, Optimization & Machine Learning. Addison Wesley Longman,Inc.
Jang, Jyh-Shing Roger. 1997. Neuro Fuzzy and Soft Computing: a Computational approach to Learning and Machine Intelligent. Prentice-Hall, Inc.
Kantardzic, M. 2003. Data mining: Concept, Model, Methods, and algorithms. Wiley-Interscience.
Khoiruddin AA. 2007. Algoritma genetika untuk menentukan jenis kurva dan parameter himpunan fuzzy. Dalam seminar nasional aplikasi teknologi informasi (SNATI). Yogyakarta.
Kusumadewi, S., Purnomo, H. 2010. Aplikasi Logika Fuzzy untuk Pendukung Keputusan. Yogyakarta: Graha Ilmu.
LIPI. 2011. Tentang UPT Balai Media dan Reproduksi (LIPI Press).
www.uptbmr.lipi.go.id. [14 November 2011]
Lubis, Chairisni. 2007. Perancangan Program Aplikasi Neural-Fuzzy System untuk Menenteukan Tarif Hotel. Jurnal Teknologi dan Manajemen Informatika, Vol. 5 No.3. pp. 513–516.
Novamizanti, L., Vimalakirti, R. 2010. Optimasi Logika Fuzyy Menggunakan Algoritma Genetika pada Identifikasi Pola Tanda Tangan. Konferensi Nasional Sistem dan Informatika. Bali, November 13, 2010.
Obitko, M. 1998. Introduction to genetic Algorithm. URL:
58
Rao, S.S., Wiley, J and Sons. 2009. Engineering Optimization : Theory and Practice, 4th. New Jersey.
Rojas, I., H. Pomares, J. Ortega, and A. Prieto. 2000. Self-organized fuzzy system generation from training examples. IEEE Trans. Fuzzy Syst.,vol. 8, pp. 23–26.
Setiawan H, Thiang, Ferdinando H. 2001. Aplikasi Algoritma Genetika untuk Merancang Fungsi Keanggotaan pada Kendali Logika Fuzzy. Dalam proceeding, Seminar on Intelligent Technology and Its Aplications (SITIA). Institut Teknologi Sepuluh November, Surabaya.
Sivanandam, SN., Deepa, SN. 2008. Introduction to Genetic Algorithm. Berlin Heidelberg: Springer.
Suyanto. 2005. Algoritma Genetika dalam Matlab. Yogyakarta: Andi Yogyakarta.
Tan K, Tokinaga S. 1999. Optimization of Fuzzy Inference Rules by using the Genetic Algorithm and its Application to the Bond Rating. Journal of the Operations Research Society of Japan Vol. 42, No. 3.
Trim, B. 2009. Taktis Menyunting Buku. Bandung: Maximalis.
63
65
67
69