ABSTRAK
MARIA WURI HANDAYANI Analisis Regresi Logistik untuk Menentukan Faktor-Faktor Ketertinggalan Desa di Kabupaten Bogor. Dibimbing oleh AGUS MOHAMAD SOLEH dan UTAMI DYAH SYAFITRI.
Badan Pusat Statistik (BPS) melakukan survei tentang potensi desa/kelurahan yang dilakukan setiap tiga tahun sekali dengan salah satu tujuannya yaitu untuk menghitung desa tertinggal di Indonesia. Hasil perhitungan tersebut disusun dalam bentuk daftar desa tertinggal, dimana daftar ini memiliki berbagai manfaat baik bagi instansi pemerintahan maupun masyarakat. Perhitungan desa tertinggal dengan menggunakan indikator dan metode yang digunakan oleh BPS dapat menghasilkan jumlah desa tertinggal di Kabupaten Bogor sebanyak 47 (11.06%) desa dari total 425 desa.
Analisis regresi logistik dapat digunakan untuk menentukan peubah-peubah yang berpengaruh terhadap model dan mengevaluasi hasil perhitungan dari BPS dengan melihat nilai ketepatan klasifikasi yang dihasilkan. Peubah-peubah yang berpengaruh nyata terhadap model untuk menentukan tertinggal atau tidaknya suatu desa adalah : sumber bahan bakar penduduk, jenis jamban, jalan utama dan penerangan umum di pedesaan. Model dengan peubah-peubah di atas secara keseluruhan dapat mengklasifikasikan dengan benar tertinggal tidaknya suatu desa sebesar 82.4%.
ANALISIS REGRESI LOGISTIK UNTUK MENENTUKAN
FAKTOR-FAKTOR KETERTINGGALAN DESA
DI KABUPATEN BOGOR
Oleh :
Maria Wuri Handayani
G14101019
PROGRAM STUDI STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
MARIA WURI HANDAYANI Analisis Regresi Logistik untuk Menentukan Faktor-Faktor Ketertinggalan Desa di Kabupaten Bogor. Dibimbing oleh AGUS MOHAMAD SOLEH dan UTAMI DYAH SYAFITRI.
Badan Pusat Statistik (BPS) melakukan survei tentang potensi desa/kelurahan yang dilakukan setiap tiga tahun sekali dengan salah satu tujuannya yaitu untuk menghitung desa tertinggal di Indonesia. Hasil perhitungan tersebut disusun dalam bentuk daftar desa tertinggal, dimana daftar ini memiliki berbagai manfaat baik bagi instansi pemerintahan maupun masyarakat. Perhitungan desa tertinggal dengan menggunakan indikator dan metode yang digunakan oleh BPS dapat menghasilkan jumlah desa tertinggal di Kabupaten Bogor sebanyak 47 (11.06%) desa dari total 425 desa.
Analisis regresi logistik dapat digunakan untuk menentukan peubah-peubah yang berpengaruh terhadap model dan mengevaluasi hasil perhitungan dari BPS dengan melihat nilai ketepatan klasifikasi yang dihasilkan. Peubah-peubah yang berpengaruh nyata terhadap model untuk menentukan tertinggal atau tidaknya suatu desa adalah : sumber bahan bakar penduduk, jenis jamban, jalan utama dan penerangan umum di pedesaan. Model dengan peubah-peubah di atas secara keseluruhan dapat mengklasifikasikan dengan benar tertinggal tidaknya suatu desa sebesar 82.4%.
ANALISIS REGRESI LOGISTIK UNTUK MENENTUKAN
FAKTOR-FAKTOR KETERTINGGALAN DESA
DI KABUPATEN BOGOR
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Sains pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
Maria Wuri Handayani
G14101019
PROGRAM STUDI STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul
: ANALISIS REGRESI LOGISTIK UNTUK MENENTUKAN
FAKTOR-FAKTOR KETERTINGGALAN DESA DI
KABUPATEN BOGOR
Nama
: Maria Wuri Handayani
NRP :
G14101019
Menyetujui,
Pembimbing I
Pembimbing II
Agus Mohamad Soleh, S.Si, M.T. Utami Dyah Syafitri, M.Si
NIP. 132 232 455
NIP. 132 311 922
Mengetahui,
Dekan Fakultas MIPA
Dr. Ir. Yonny Koesmaryono, MS.
NIP. 131 473 999
RIWAYAT HIDUP
Penulis dilahirkan di Wonosobo pada tanggal 22 Agustus 1982 dari ayah Fidelis Sunaswar dan
ibu Elisabet Sumarti. Penulis merupakan putri ketiga dari empat bersaudara.
Tahun 1996 Penulis menyelesaikan pendidikan dasar di SDN Kapencar II Kertek, kemudian
lulus dari SMPN I Kertek tahun 1998 dan SMUN II Wonosobo tahun 2001. Penulis diterima
sebagai mahasiswa di Departemen Statistika Fakultas Matematika dan Ilmu Pengetahuan Alam
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa atas segala karunia-Nya
sehingga karya ilmiah ini berhasil diselesaikan. Karya ilmiah ini memilih judul Analisis Regresi
Logistik untuk Menentukan Faktor-Faktor Ketertinggalan Desa di Kabupaten Bogor.
Terima kasih penulis ucapkan kepada Bapak Agus Mohamad Soleh, S.Si, M.T. dan Ibu Utami
Dyah Syafitri, M.Si selaku pembimbing yang telah banyak memberikan arahan dan saran. Penulis
juga mengucapkan terima kasih kepada :
1. Ibu dan Bapak tercinta atas segala doa dan kasih sayangnya.
2. Kakak, adek dan seluruh keluarga yang selalu mendoakan dan memberikan semangat dan
dukungan.
3. Ibu Wiwiek yang telah banyak memberikan informasi dalam pencarian literatur di
perpustakaan BPS.
4. Bapak Sudin atas bantuan terutama masalah komputer dan petuah-petuahnya.
5. Ibu Dedeh, Bapak Herman, Durrohman, Ibu Markonah, Ibu Sulis dan Pak Iyan yang telah
banyak membantu penulis selama ini.
6. STK 38 : Yanti, Santi, Elsa, Icus, Aji, Tio, Novie, Gatik, dll yang telah banyak membantu
dan memberi semangat.
7. Novia crew : Fio, Ellen, Ika, Elsa, Angel, Dhani, Dara, Mila, dll atas kebersamaannya.
8. Semua teman-teman penulis yang tidak mungkin disebutkan satu persatu, yang selalu
menjadi sumber inspirasi dan penambah pengalaman penulis.
Semoga karya ilmiah ini bermanfaat.
Bogor, September 2005
DAFTAR ISI
Halaman
DAFTAR TABEL... vi
DAFTAR LAMPIRAN... vi
PENDAHULUAN Latar Belakang... 1
Tujuan... 1
TINJAUAN PUSTAKA Podes... 1
Desa/kelurahan ... 2
Uji Khi kuadrat ... 2
Regresi Logistik... 2
Regresi Logistik Bertatar
... 2
Pendugaan Parameter Model
... 3
Pengujian Parameter Regresi Logistik ... 3
Interpretasi koefisien model regresi logistik ... 4
BAHAN DAN METODE Bahan ... 4
Metode ... 4
HASIL DAN PEMBAHASAN Perhitungan Desa Tertinggal ... 5
Penentuan Peubah Bebas ... 6
Analisis Regresi Logistik... 6
KESIMPULAN... 7
DAFTAR PUSTAKA ... 7
DAFTAR TABEL
Halaman
1. Perhitungan desa tertinggal ... 5
2. Uji Khi kuadrat ... 6
3. Matriks ketepatan model langkah 13 ... 6
4. Nilai Rasio odds regresi logistik ... 7
DAFTAR LAMPIRAN
Halaman 1. Peubah dan nilai skor perhitungan desa tertinggal ... 92. Peubah bebas analisis regresi logistik ... 11
3. Peubah dalam model dan uji koefisien dugaan ... 12
4. Uji kelayakan model ... 13
PENDAHULUAN
Latar Belakang
Pembangunan Indonesia adalah pembangunan manusia seutuhnya dan masyarakat seluruhnya. Pembangunan ini harus dapat menjangkau seluruh lapisan masyarakat baik yang ada di perkotaan maupun di pedesaan. Hasil pembangunan yang tidak merata menyebabkan perkembangan yang tidak seimbang serta kesenjangan dalam perekonomian. Akibatnya muncul kemiskinan dan ketertinggalan dalam kehidupan. Istilah tertinggal menurut Agusta (2005) merujuk pada tingkat kelengkapan prasarana sedangkan miskin mencirikan derajat ekonomi dan kelembagaan.
Badan Pusat Statistik (BPS) melakukan survei tentang potensi desa/kelurahan yang dilakukan setiap tiga tahun sekali, dengan salah satu tujuannya adalah untuk menghitung banyaknya desa tertinggal di Indonesia. Hasil perhitungan tersebut disusun dalam bentuk daftar desa tertinggal. Daftar ini memiliki berbagai manfaat baik bagi instansi pemerintahan maupun masyarakat. Manfaat tersebut antara lain dapat dengan jelas menerangkan seberapa besar ketertinggalan desa di Indonesia, dapat pula digunakan sebagai salah satu patokan pembangunan desa, serta dapat dijadikan landasan alokasi dana kompensasi pengalihan subsidi bahan bakar minyak (BBM) bagi desa tertinggal (BPS 2003).
Pengklasifikasian tertinggal tidaknya suatu desa yang dilakukan oleh BPS berdasarkan pada nilai skor yang diperoleh. Suatu desa akan disebut tertinggal apabila nilai skornya kurang dari batas nilai skor minimum desa (BPS 1994). Pendekatan statistik dapat digunakan untuk melakukan evaluasi hasil untuk melihat tingkat ketelitian dalam perhitungan.
Pada penelitian ini digunakan analisis regresi logistik untuk mengetahui faktor-faktor yang mempengaruhi tertinggal atau tidaknya suatu desa sekaligus sebagai evaluasi kategori yang digunakan untuk menentukan desa tertinggal dari BPS.
Tujuan
Penelitian ini bertujuan untuk :
1. Menentukan desa tertinggal di Kabupaten Bogor dengan menggunakan indikator serta metode yang digunakan oleh BPS.
2. Menentukan model terbaik yang dapat digunakan untuk memprediksi ketertinggalan desa dilihat dari nilai ketepatan klasifikasi yang dihasilkan.
TINJAUAN PUSTAKA
Podes
Podes (potensi desa) merupakan kemampuan atau daya/kekuatan yang memiliki kemungkinan untuk dikembangkan dalam wilayah otonomi desa. Data Podes merupakan satu-satunya data yang berurusan dengan wilayah/tata ruang dengan basis desa/kelurahan (BPS 2003). Podes pertama kali diadakan pada tahun 1980 bersamaan dengan sensus penduduk tahun 1980 (SP1980), dimana pengumpulan data Podes selalu diintegrasikan dengan kegiatan sensus dan mendahului satu tahun sebelum sensus, misal untuk Podes sensus ekonomi tahun 2006 (SE2006) dilakukan pada tahun 2005.
Tujuan dari Podes antara lain :
1. Tersedianya data tentang potensi/keadaan pembangunan di desa dan perkembangannya meliputi keadaan sosial, ekonomi, sarana dan prasarana, serta potensi yang ada di desa/kelurahan.
2. Menyediakan data untuk berbagai
keperluan khususnya yang berkaitan dengan kebutuhan perencanaan regional (spasial) di setiap daerah.
3. Melengkapi penyusunan kerangka contoh (sampling frame) untuk kegiatan statistik lebih lanjut.
4. Menyediakan informasi bagi keperluan penentuan klasifikasi/updating desa urban dan rural, desa tertinggal dan tidak tertinggal.
5. Menyediakan data pokok bagi
penyusunan statistik wilayah kecil (small area statistics).
Jenis data yang dikumpulkan pada Podes sensus pertanian tahun 2003 (ST2003) adalah :
1. Keterangan umum desa/kelurahan 2. Kependudukan dan ketenagakerjaan 3. Perumahan dan lingkungan hidup 4. Pendidikan
5. Kesehatan, gizi dan keluarga berencana 6. Sosial budaya
7. Rekreasi, hiburan, kesenian, dan olahraga 8. Angkutan
10.Penggunaan dan penguasaan lahan 11.Pertanian
12.Alat-alat pertanian 13.Perdagangan dan industri 14.Keuangan desa/kelurahan 15.Politik dan keamanan
16.Keterangan aparat desa/kelurahan
Desa/Kelurahan
Desa adalah kesatuan masyarakat hukum yang memiliki kewenangan untuk mengatur dan mengurus kepentingan masyarakat setempat berdasarkan asal usul dan adat istiadat setempat yang diakui dalam sistem pemerintahan nasional dan berada di daerah kabupaten. Sedangkan kelurahan adalah suatu wilayah lurah sebagai perangkat daerah kabupaten dan/atau daerah kota di bawah kecamatan ( UU RI No. 22 Tahun 1999 tentang Pemerintahan Daerah).
Uji Khi Kuadrat
Uji khi kuadrat digunakan untuk mengamati ada tidaknya hubungan (asosiasi) antara dua variabel kategorik. Untuk menelusuri asosiasi tersebut, biasanya sebelumnya digunakan tabulasi silang antara kedua karakteristik yang akan diuji. Bentuk tabulasi silangnya adalah sebagai berikut :
Peubah A Peubah B Total Kategori 1 … kategori q Kategori 1 O11 … O1j B1
… … …
Kategori p Oi1 … Oij Bi
Total K1 Kj N
Keterangan :
Oij = Frekuensi anggota contoh yang memiliki
kategori i pada peubah A dan kategori j pada peubah B
Bi = Total frekuensi anggota contoh yang
memiliki kategori i pada peubah A Kj = Total frekuensi anggota contoh yang
memiliki kategori j pada peubah B
Hipotesis-nya adalah:
H0 : tidak ada asosiasi antara kedua peubah
H1 : ada asosiasi antara kedua peubah
Statistik uji :
∑ ∑
= = − = p i q j ij ij ij hitung E E O 1 1 22 ( )
χ
dimana Eij merupakan frekuensi harapan
anggota contoh yang memiliki kategori i pada peubah A dan kategori j pada peubah B. Eij dapat diperoleh dengan rumus :
N K B Eij = i j
Statistik uji χ2menyebar menurut sebaran 2
χ dengan db= (p-1)(q-1) dengan asumsi bahwa kedua peubah saling bebas.Tolak H0
jika 2
) , ( 2 α χ
χhitung> db atau jika nilai-p < α (Daniel 1989).
Regresi Logistik
Menurut Hosmer dan Lemeshow (1989) metode regresi logistik adalah suatu metode analisis statistika yang menggambarkan hubungan antara peubah respon yang memiliki dua kategori atau lebih dengan satu atau lebih peubah bebas.
Model umum persamaan peluang regresi logistik dengan p peubah penjelas yaitu :
(
)
( )
( () )1
| g x
x g e e x X Y E + = Π = Dimana komponen p px x x x x
g ⎥=β +β + +β
⎦ ⎤ ⎢ ⎣ ⎡ Π − Π = ... ) ( 1 ) ( ln )
( 0 1 1
Merupakan penduga logit sebagai fungsi linear dari peubah penjelas.
Regresi Logistik Bertatar
Regresi logistik bertatar (stepwise logistic regression) digunakan untuk menentukan peubah-peubah penjelas yang bisa membedakan respon yang diamati. Prosedur ini memilih atau menghilangkan peubah-peubah satu persatu dari model sampai ditemukan peubah-peubah yang berpengaruh nyata terhadap model ( Hosmer and Lemeshow 1989).
Galat pada analisis regresi bertatar linear diasumsikan mengikuti sebaran normal sehingga digunakan uji F, sedangkan pada analisis regresi logistik bertatar galat diasumsikan mengikuti sebaran binomial dan uji signifikasi diduga dengan menggunakan uji khi kuadrat rasio likelihood (likelihood ratio chi-square test).
Analisis regresi logistik bertatar membangun model langkah demi langkah sampai ditemukan peubah yang berpengaruh nyata terhadap peubah respon (Hosmer & Lemeshow 1989). Proses diawali dengan langkah 0. Misal tersedia total peubah penjelas sebanyak p, Lj(0) merupakan
mengandung peubah Xj . Pada langkah ini uji
rasio likelihood dapat dihitung
(
0)
0 02 L L
Gj = j −
dengan nilai-p sebesar
[
]
) 0 ( 2 ) ( 0 j v r
j P G
P = χ >
. Peubah paling penting adalah peubah dengan nilai-p paling kecil atau Pei(0) =min(p(j0)). Suatu
peubah akan masuk ke model jika nilai-p untuk G < PE, dimana PE merupakan suatu nilai yang
akan menentukan berapa jumlah peubah yang akan dimasukkan kedalam model. Proses akan berlanjut ke langkah selanjutnya jika Pei <PE
) 0 (
, jika tidak proses berhenti.
Langkah satu dimulai dengan model regresi logistik yang mengandung Xei . Nilai statistik G
dihitung dengan rumus (1) 2( (1) (1)) i
ij e
e
J L L
G = − dengan
) 1 (
ij e
L merupakan model yang mengandung Xei dan
Xj ,j≠ei. Nilai-p sebesar PJ(1). Proses akan
berlanjut ke langkah berikutnya jika nilai-p < PE.
Proses akan terus berlanjut sampai ke langkah S sebelum ditemukan peubah yang nyata. Langkah S akan terjadi jika :
1. Sebanyak p peubah masih ada di dalam model.
2. Peubah didalam model memiliki nilai-p < PR dan peubah yang tidak masuk ke
dalam model memiliki nilai-p > PE, dimana
PR merupakan suatu nilai yang dapat
menunjukkan beberapa level minimal dari sumbangan peubah untuk model.
Pendugaan Parameter Model
Pendugaan parameter dalam model regresi logistik dilakukan dengan menggunakan metode kemungkinan maksimum. Jika antara amatan yang satu dengan yang lain diasumsikan bebas maka fungsi kemungkinan maksimum yang diperoleh adalah :
( ) ( ) i[ ( )] i y n i i y i x x l − =
∏
− = 1 1 1 π π β Keterangan :( )
βl = Fungsi likelihood ( )xi
π = Peluang kejadian ke-i bernilai Y=1
Parameter βi diduga dengan
memaksimumkan persamaan di atas. Untuk memudahkan perhitungan dilakukan pendekatan logaritma maka fungsi log- kemungkinan sebagai berikut :
( )β [l( )β ]
L =ln
( )
∑
{ [ ( )] ( ) [( ( ))]} = − − + = n i i ii x y x
y L 1 1 ln 1
lnπ π
β
Nilai dugaan βi dapat diperoleh dengan membuat turunan pertama L( )β terhadap βi sama dengan nol dengan i = 0, 1, 2, 3, ..., p (Freeman 1987).
Pengujian Parameter Regresi Logistik
Statistik uji-G adalah uji rasio kemungkinan maksimum (likelihood ratio test) yang digunakan untuk menguji peranan peubah bebas dalam model secara bersamaan (Hosmer dan Lemeshow 1989). Rumus umum untuk uji-G adalah :
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − = 1 0 ln 2 L L G 0
L = likelihood tanpa peubah bebas 1
L = Likelohood dengan peubah bebas Dengan hipotesis :
0 ...
: 1 2
0 = = = p =
H β β β
:
1
H minimal ada satu nilai βi≠0
dimana i =1,2,3,...,p
Statistik uji-G mengikuti sebaran χ2 dengan derajat bebas p. Kaidah keputusan yang
diambil yaitu menolak H0 jika G > 2
) (α
χp (Hosmer dan lemeshow 1989). Sedangkan untuk menguji koefisien regresi logistik secara parsial dapat menggunakan statistik uji Wald, berdasarkan hipotesis : 0 : 0 : 1 0 ≠ = i i H H β β
dimana i = 1,2,3,...,p
Rumus umum statistik uji wald sebagai berikut :
( )
i i i E S W β β ˆ ˆ ˆ = iβˆ merupakan penduga
i
β dan SE
( )
βˆimerupakan penduga galat baku dari β. Menurut Hosmer dan Lemeshow (1989) salah satu ukuran kebaikan model adalah jika memiliki peluang salah klasifikasi yang minimal.
dugaan
π
(
x
)
. Jikaπ
(
x
)
lebih besar dari c maka nilai dugaan termasuk pada respon y=1 dan selain itu y=0. Nilai c yang digunakan adalah 0.5 (Hosmer dan Lemeshow 1989). Ketepatan model dalam memprediksi kejadian gagal (y=0) dinyatakan sebagai N00/N0, proporsi nilai dugaan yang samadengan nilai amatan pada kategori nilai amatan y=0. Indikator dan pengertian yang sama juga berlaku untuk mengevaluasi kemampuan model memprediksi kejadian berhasil (y=1), yaitu N11/N1. kemampuan
model dalam memprediksi keseluruhan kejadian adalah (N00+N11)/N.. yang
mencerminkan proporsi nilai amatan yang secara tepat dapat diduga oleh model.
Dugaan Amatan
0 1 Total % tepat 0 N00 N01 N0. N00/ N0.
1 N10 N11 N1. N11/ N1.
N.0 N.1 N.. (N00+ N11)/ N..
Dengan :
N00 : Suatu amatan bernilai 0 dengan dugaan 0
N.0 : Jumlah total dugaan bernilai 0
N0. : Jumlah total amatan bernilai 0
N.. : Jumlah keseluruhan nilai yang dihasilkan
Interpretasi Koefisien Model Regresi Logistik
Interpretasi koefisien untuk model regresi logistik dapat dilakukan dengan melihat nilai rasio oddsnya. Rasio odds adalah ukuran asosiasi yang memperkirakan berapa besar kecenderungan pengaruh peubah-peubah penjelas terhadap peubah respon (Hosmer dan Lemeshow 1989).
Jika suatu peubah penjelas mempunyai tanda koefisien positif, maka nilai rasio odds akan lebih besar dari satu, sebaliknya jika tanda koefisiennya negatif maka nilai rasio oddsnya akan lebih kecil dari satu. Menurut Hosmer dan Lemeshow (1989) koefisien model logit dapat ditulis sebagai
) ( ) 1
(x g x
g
i= + −
β . Koefisien model logit
i
β mencerminkan perubahan dalam fungsi logit g(x) untuk perubahan satu unit peubah bebas yang disebut log odds, yang merupakan beda antara dua penduga logit yang dihitung pada dua nilai (misal x=a dan x=b) dinotasikan sebagai :
( )
[
,]
( ) ( )lnψ ab =g x=a −g x=b
(a b)
i −
=β
sedangkan penduga rasio oddsnya adalah :
( )ab =
[
βi(a−b)]
ψ , expsehingga jika a-b=1 maka ψ =exp
( )
βi . Interpretasi koefisien dari nilai rasio odds untuk peubah penjelas yang berskala nominal X=1, memiliki kecenderungan untuk Y=1 sebesar ψ kali dibandingkan dengan X=0 atau dapat dikatakan X=1 memiliki kecenderungan untuk Y=0 sebesar 1/ψ kali dibandingkan X=0. Sedangkan untuk peubah penjelas kontinu, jika ψ lebih besar atau sama dengan satu maka semakin besar nilai peubah X diikuti semakin besarnya kecenderungan untuk Y=1.BAHAN DAN METODE
Bahan
Data yang digunakan dalam penelitian ini adalah data sekunder tentang potensi desa/kelurahan (Podes) di Kabupaten Bogor tahun 2003 yang dilakukan oleh BPS.
Jumlah data sebanyak 425 desa dengan klasifikasi 199 desa perkotaan dan 226 untuk desa perdesaan.
Pengambilan data Podes dilakukan dengan cara sensus di seluruh desa/kelurahan, yaitu dengan cara wawancara langsung. Responden data Podes adalah kepala desa/lurah atau staf yang ditunjuk untuk mewakilinya.
Metode
Langkah-langkah yang dilakukan adalah :
1. Koding terhadap data berdasarkan
klasifikasi dan nilai skor yang digunakan oleh BPS.
2. Perhitungan desa tertinggal dengan
menggunakan indikator dan metode dari BPS.
3. Pengklasifikasian suatu desa masuk ke dalam kelompok tertinggal atau tidak tertinggal, yang nantinya akan digunakan sebagai peubah tak bebas dalam analisis regresi logistik.
4. Uji Khi kuadrat untuk menentukan
peubah-peubah yang akan digunakan sebagai peubah bebas dalam analisis regresi logistik.
5. Analisis regresi logistik untuk
membangun model tertinggal atau tidaknya suatu desa.
6. Menentukan model terbaik untuk
Indikator desa tertinggal menurut BPS : A. Desa perkotaan
1. Lapangan usaha mayoritas penduduk. 2. Fasilitas kesehatan.
3. Sarana komunikasi.
4. Kepadatan penduduk per km2. 5. Sumber bahan bakar penduduk. 6. Jenis jamban.
7. Persentase rumahtangga listrik.
8. Persentase rumahtangga yang
memiliki TV.
9. Persentase rumahtangga yang
memiliki telepon.
10. Jarak ke rumah sakit terdekat (km). 11. Jarak ke poliklinik terdekat (km). B. Desa perdesaan
1. Tipe LKMD/K (Lembaga Ketahanan Masyarakat Desa/ Kelurahan). 2. Lapangan usaha mayoritas penduduk. 3. Tenaga kesehatan.
4. Sarana komunikasi.
5. Kepadatan penduduk per km2. 6. Sumber air minun/masak penduduk. 7. Sumber bahan bakar penduduk. 8. Persentase rumahtangga listrik.
9. Persentase rumahtangga yang
memiliki TV.
10. Persentase rumahtangga yang
memiliki telepon.
12. Keberadaan rumahtangga pelanggan koran/majalah.
Metode perhitungan menurut BPS:
1. Nilai skor hasil kriteria standard deviasi yaitu : X−S
2. Nilai skor hasil kriteria range yaitu : X0 + 2I
3. Wawancara langsung
Keterangan :
X = rata-rata skor desa tingkat kabupaten
S = standard deviasi skor desa tingkat kabupaten
0
X = nilai skor terendah I = interval ( = 1/2 range ) Range = Xn−X0
Kriteria BPS :
Sebuah desa dikategorikan tertinggal apabila menurut dua dari tiga metode perhitungan yang digunakan terpenuhi (BPS 1994).
Software yang digunakan untuk analisis adalah SPSS 11.5 dan Minitab 13.
HASIL DAN PEMBAHASAN
Perhitungan Desa Tertinggal
Langkah awal yang dilakukan dalam perhitungan desa tertinggal adalah melakukan koding terhadap data asli, yaitu data hasil survei yang dilakukan oleh BPS. Pemberian nilai skor berbeda untuk desa perkotaan dan desa perdesaan (Lampiran 1). Peubah yang digunakan dalam analisis sebanyak 15, dimana nama-nama peubah tersebut dapat dilihat pada Lampiran 1.
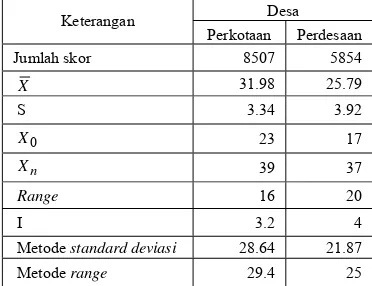
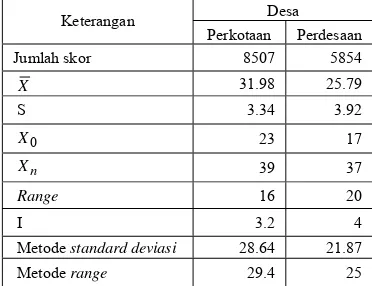
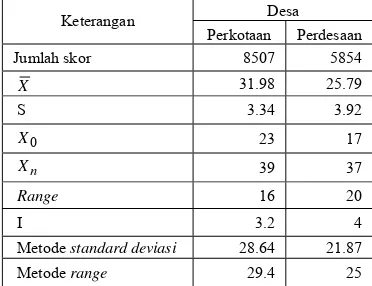
Tabel 1 Perhitungan desa tertinggal
Dari Tabel 1 dapat diketahui bahwa jumlah nilai skor untuk desa perkotaan sebesar 8507 dan rata-rata skor 31.98, diperoleh nilai skor untuk metode standard deviasi sebesar 28.64 dan metode range sebesar 29.4 sehingga dapat diketahui bahwa desa diperkotaan akan disebut tertinggal apabila nilai skor ada di bawah nilai 28.64. Sedangkan untuk desa perdesaan, jumlah nilai skor sebesar 5854 dan rata-rata skor 25.79. Nilai skor metode standard deviasi sebesar 21.87 dan metode range sebesar 25. Desa perdesaan disebut tertinggal apabila nilai skor di bawah nilai 21.87. Dari kedua metode di atas sudah didapatkan jumlah desa yang termasuk tertinggal di Kabupaten Bogor. Dilakukan wawancara langsung dengan kepala kecamatan untuk mengetahui keadaan sebenarnya dari masing-masing desa di kecamatan tersebut. Apabila dua dari tiga metode yang digunakan mengatakan tertinggal maka suatu desa akan disebut tertinggal. Hasil perhitungan di atas menghasilkan jumlah desa tertinggal untuk desa perkotaan sebanyak 8 desa dan desa perdesaan sebanyak 39 desa, sehingga di Kabupaten Bogor terdapat 47(11.06%) desa
Desa Keterangan
Perkotaan Perdesaan Jumlah skor 8507 5854
X 31.98 25.79
S 3.34 3.92
0
X 23 17
n
X 39 37
Range 16 20
I 3.2 4
Metode standard deviasi 28.64 21.87
yang tertinggal dari jumlah desa sebanyak 425 desa.
Pengklasifikasian termasuk tertinggal atau tidaknya suatu desa ini nantinya akan digunakan sebagai peubah respon (tak bebas) dalam analisis regresi logistik.
Penentuan Peubah Bebas
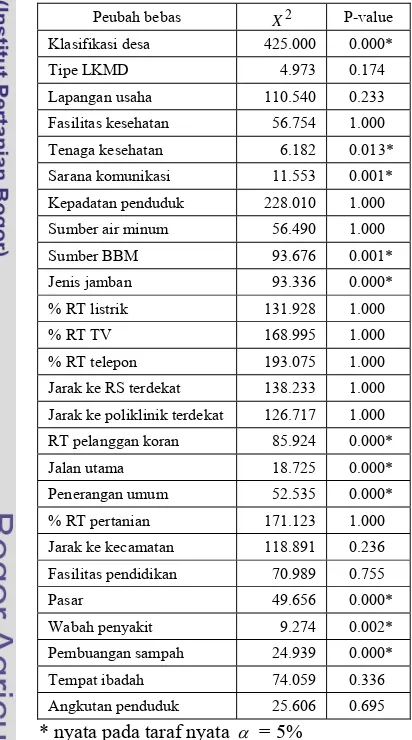
Uji Khi kuadrat digunakan untuk mengamati ada tidaknya hubungan antara peubah tak bebas dengan peubah bebas. Peubah tak bebasnya adalah desa tertinggal dan tidak tertinggal, sedangkan peubah bebas diambil dari peubah yang digunakan dalam perhitungan tertinggal tidaknya desa ditambah dengan peubah yang diambil dari data podes. Hasil uji dapat dilihat pada Tabel 2.
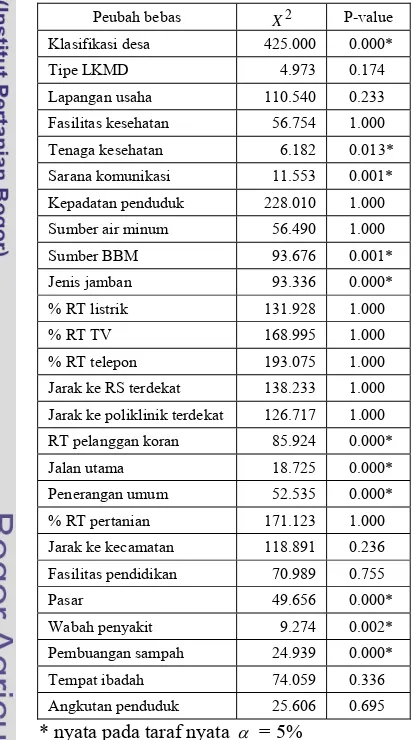
Tabel 2. Uji Khi kuadrat
Peubah bebas X2 P-value
Klasifikasi desa 425.000 0.000* Tipe LKMD 4.973 0.174 Lapangan usaha 110.540 0.233 Fasilitas kesehatan 56.754 1.000 Tenaga kesehatan 6.182 0.013* Sarana komunikasi 11.553 0.001* Kepadatan penduduk 228.010 1.000 Sumber air minum 56.490 1.000 Sumber BBM 93.676 0.001* Jenis jamban 93.336 0.000* % RT listrik 131.928 1.000 % RT TV 168.995 1.000 % RT telepon 193.075 1.000 Jarak ke RS terdekat 138.233 1.000 Jarak ke poliklinik terdekat 126.717 1.000 RT pelanggan koran 85.924 0.000* Jalan utama 18.725 0.000* Penerangan umum 52.535 0.000* % RT pertanian 171.123 1.000 Jarak ke kecamatan 118.891 0.236 Fasilitas pendidikan 70.989 0.755 Pasar 49.656 0.000* Wabah penyakit 9.274 0.002* Pembuangan sampah 24.939 0.000* Tempat ibadah 74.059 0.336 Angkutan penduduk 25.606 0.695
* nyata pada taraf nyata α = 5%
Terdapat sebelas peubah yang memiliki hubungan dengan peubah respon (tertinggal tidaknya suatu desa) yaitu peubah dengan nilai-p kurang dari α=5%. Peubah-peubah
tersebut nantinya akan digunakan sebagai peubah bebas dalam analisis regresi logistik.
Analisis Regresi Logistik
Penelitian ini hanya menggunakan model logit dalam pendugaan tertinggal atau tidaknya suatu desa. Peubah tak bebasnya adalah desa tertinggal (Y=1) dan tidak tertinggal (Y=0). Sedangkan peubah bebas/ penjelasnya ada sebanyak sebelas peubah yang dapat dilihat pada Lampiran 2.
Metode regresi logistik bertatar digunakan untuk menentukan peubah yang benar-benar berpengaruh dalam menentukan tertinggal atau tidaknya suatu desa. Pada Lampiran 3 diketahui berbagai model yang dihasilkan dari analisis regresi logistik bertatar. Analisis ini mengeluarkan satu persatu peubah yang tidak berpengaruh nyata sampai diperoleh semua peubah yang nyata. Model terakhir dihasilkan pada langkah ke tigabelas dengan peubah penjelasnya meliputi sumber bahan bakar penduduk (X4), jenis jamban (X5), jalan utama
(X7) dan penerangan umum desa (X8).
Uji kelayakan model dan kesesuaian tanda koefisien dilakukan pada model yang telah terbentuk dari analisis regresi logistik bertatar. Model pada langkah ke tigabelas memiliki nilai peluang chi-square 0.003 yang kurang dari α=5% sehingga model yang terbentuk layak atau minimal ada satu nilai
0
≠
i
β (Lampiran 4). Nilai peluang dari uji Wald untuk peubah sumber bahan bakar penduduk, jenis jamban, jalan utama dan penerangan umum pedesaan kurang dari α=10% (Lampiran 3), yang berarti bahwa peubah-peubah tersebut berpengaruh nyata terhadap tertinggal tidaknya suatu desa.
Penentuan model terbaik dari model yang telah terbentuk adalah dengan menggunakan kriteria pemotongan (penetapan batas kelompok) dengan tingkat kesalahan klasifikasi cukup berimbang antara kesalahan tipe I dan kesalahan tipe II. Penetapan nilai peluang dipilih pada nilai 0.2 karena dilihat dari proporsi desa tertinggal terhadap jumlah desa keseluruhan antara nilai 0.1 - 0.2. Matriks ketepatan dapat dilihat pada Tabel 3.
Tabel 3 Matriks ketepatan model langkah 13
Prediksi Kelompok
aktual Tidak
tertinggal Tertinggal % benar Tidak tertinggal 339 39 89.7
Tabel 3 menunjukkan bahwa dari 378 desa yang termasuk tidak tertinggal dikategorikan dengan benar sebanyak 339 (89.7%) desa dan dari 47 desa tertinggal dikategorikan dengan benar sebanyak 11 (23.4%) desa. Sehingga secara keseluruhan ketepatan prediksi dari model ini adalah sebesar 82.4% dengan pemotongan nilai peluang sebesar 0.2. Nilai ketepatan prediksi model lain dapat dilihat pada Lampiran 5.
Peubah-peubah penyusun model regresi logistik dapat diinterpretasikan dengan menggunakan nilai rasio oddsnya.
Tabel 4 Nilai rasio odds regresi logistik
Peubah Rasio odds Sumber bahan bakar penduduk (X4(1)) 1.909
Jenis jamban (X51(1)) 1.880
Jalan utama (X72(1)) 0.561
Penerangan umum (X8(1)) 2.123
Konstanta 0.079
Pada Tabel 4 diketahui bahwa untuk peubah sumber bahan bakar penduduk memiliki nilai rasio odds 1.909 yang berarti bahwa rasio peluang penduduk dengan sumber bahan bakar kayu bakar yang termasuk desa tertinggal dibandingkan dengan desa tidak tertinggal adalah 1.909 kali dibandingkan penduduk dengan bahan bakar minyak tanah. Untuk peubah jenis jamban, memiliki nilai rasio odds sebesar 1.880 artinya rasio peluang penduduk yang memiliki tempat pembuangan jenis bukan jamban yang termasuk desa tertinggal dibandingkan dengan desa tidak tertinggal adalah 1.880 kali penduduk yang memiliki jamban sendiri. Untuk peubah jalan utama, desa dengan jenis jalan diperkeras memiliki peluang lebih besar disebut desa tertinggal yaitu sebesar 1/0.561 atau 1.783 kali dibandingkan dengan desa yang memiliki jalan utama aspal. Peubah penerangan umum memiliki nilai rasio odds sebesar 2.123 yang berarti bahwa rasio peluang desa yang tidak memiliki penerangan umum yang termasuk tertinggal dibandingkan dengan desa tidak tertinggal adalah 2.123 kali dibandingkan dengan desa yang memiliki penerangan umum.
KESIMPULAN
Perhitungan desa tertinggal dengan menggunakan indikator serta metode yang digunakan oleh BPS dapat menghasilkan jumlah desa tertinggal di Kabupaten Bogor sebanyak 47 (11.06%) desa dari total sebanyak 425 desa.
Pemilihan model terbaik dilakukan dengan menggunakan analisis regresi logistik bertatar dan kriteria pemotongan nilai peluang. Peubah-peubah yang berpengaruh nyata terhadap model untuk menentukan tertinggal atau tidaknya suatu desa adalah : sumber bahan bakar penduduk, jenis jamban, jalan utama desa dan penerangan umum di pedesaan. Model dengan peubah-peubah di atas merupakan model terbaik karena secara keseluruhan dapat mengklasifikasikan dengan benar tertinggal tidaknya suatu desa sebesar 82.4%.
DAFTAR PUSTAKA
Agusta I. 2005. Desa Tertinggal dan Subsidi BBM. Http://www.kompas.com. [9 April 2005].
[BPS] Badan Pusat Statistik. 1994. Penyempurnaan Metode Penentuan Desa Tertinggal. Jakarta.
[BPS] Badan Pusat Statistik. 2003. Statistik Potensi Desa Propinsi Jawa Barat. Jakarta.
Daniel WW. 1989. Statistika Nonparametrik Terapan. Jakarta : PT Gramedia.
Freeman DH. 1987. Applied Categorical Data Analysis. New York & Basel : Marcel Dekker, Inc.
Lampiran 1Peubah dan nilai skor perhitungan desa tertinggal
Skor No Peubah Keterangan klasifikasi
Perkotaan Perdesaan
1 r305 Tipe LKMD 1. persiapan/kategori 1 1
2. kategori 2 2
3. kategori 3 3
2 r407a Lapangan usaha 1. pertanian 2 2
mayoritas 2. non pertanian 4
penduduk 3. non pertanian & jasa 3
4. jasa 4
3 r701 Fasilitas 1. maks puskesmas 2
kesehatan 2. maks RS bersalin 3
3. min ada RS 4
4 r703 Tenaga 1. maks bidan 1
kesehatan 2. maks paramedis 2
3. min ada dokter 3
5 r1102 Sarana 1. maks kantor pos 1 2
komunikasi 2. hanya telepon umum 2 3
3. kantor pos & telp umum 4 4
6 r402 Kepadatan 1. < 500 1
penduduk 2. 500-950 2
3. >=950 3
4. < 2250 2
5. 2250 - 6000 3
6. 6000 - 10000 5
7. >= 10000 4
7 r503 Sumber 1.listrik/gas 5
bahan bakar 2. minyak tanah 4
penduduk 3. kayu bakar/lainnya 2
4.gas/listrik/minyak tanah 4
5. kayu bakar/lainnya 2
8 r505 Jenis jamban 1. jamban sendiri 3
2. jamban bersama/umum 2
3. bukan jamban 1
9 r501b % RT 1. < 35 1
pemakai 2. 35 - 60 2
listrik 3. 60 - 90 3
4. >= 90 4
5. 0 - 75 1
6. 75 - 90 2
7. 90 - 97.5 3
8. >= 97.5 4
10 r709a Sumber air 1. PAM/pompa listrik 3
minum/masak 2. sumur/perigi 2
penduduk 3. hujan, lainnya 1
11 r1107 % RT 1. < 13.5 1
mempunyai 2. 13.5 - 24.5 2
TV 3. 24.5 - 35.6 3
4. >=35.6 4
5. < 50 1
6. 50 - 75 2
12 r1101 % RT 1. < 7.25 5
mempunyai 2. 7.25 - 20.00 3
telepon 3. >= 20.00 2
4. < 0.4 2
5. 0.4 - 1.4 3
6. >= 1.4 4
13 r701a3 Jarak 1. 0 4
ke RS 2. 0.01 - 3 3
terdekat (km) 3. > 3 2
14 r701c3 Jarak ke 1. 0 5
poliklinik 2. 0.01 - 2 3
terdekat (km) 3. >= 2 2
4. missing 1
15 r1109a Keberadaan RT 1. ada 3
pelanggan 2. tidak ada 2
Lampiran 2 Peubah bebas analisis regresi
logistik
X1 = klasifikasi desa
peubah bebas (1)
Perdesaan 1
Perkotaan 0
X2 = Tenaga kesehatan
peubah bebas (1) (2)
maks bidan 1 0
maks paramedis 0 1
min ada dokter 0 0
X3 = Sarana komunikasi
peubah bebas (1) (2)
maks kantor pos 1 0
hanya telepon umum 0 1
kantor pos & telp umum 0 0
X4 = Sumber bahan bakar penduduk
peubah bebas (1)
Kayu bakar 1
Minyak tanah 0
X5 = Jenis jamban
peubah bebas (1)
bukan jamban 1 0
Jamban umum/bersama 0 1
jamban sendiri 0 0
X6 = Keberadaan RT pelanggan koran/majalah
peubah bebas (1)
Tidak ada 1
Ada 0
X7 = Jalan utama
peubah bebas (1) (2)
Aspal/beton 1 0
Diperkeras 0 1
Tanah/lainnya 0 0
X8 = Penerangan umum
peubah bebas (1)
Tidak ada 1
Ada 0
X9 = Pasar
peubah bebas (1) (2)
Tanpa bangunan 1 0
Kios/pertokoan 0 1
Bangunan permanen 0 0
X10 = Wabah penyakit
peubah bebas (1)
Demam berdarah 1
Lainnya 0
X11 = Pembuangan sampah
peubah bebas (1)
Lainnya 1
Lampiran 3 Peubah dalam model dan uji koefisien dugaan
Variables in the Equation
Peubah B Wald Sig. Peubah B Wald Sig.
Step 1 X1(1) 0.613 1.675 0.196 Step 6 X1(1) 0.527 1.422 0.233
X21(1) -0.266 0.287 0.592 X21(1)
-0.290 0.350 0.554
X22(1) -0.043 0.011 0.917 X31(1) 0.295 0.185 0.667
X31(1) 0.079 0.012 0.912 X4(1) 0.849 3.964 0.046
X32(1) 0.120 0.067 0.796 X51(1) 0.715 3.042 0.081
X4(1) 0.793 3.083 0.079 X72(1)
-0.652 3.394 0.065
X51(1) 0.690 2.379 0.123 X8(1) 0.663 3.214 0.073
X52(1) 0.272 0.226 0.635 X91(1) 0.356 0.301 0.584
X6(1) -0.137 0.101 0.750 X92(1)
-0.224 0.223 0.637
X71(1) 18.781 0.000 0.999 X10(1) 1.531 2.069 0.150
X72(1) -0.570 2.418 0.120 X11(1) 0.493 0.920 0.338
X8(1) 0.655 3.053 0.081 Constant
-4.460 8.891 0.003
X91(1) 0.351 0.288 0.591 Step 7 X1(1) 0.530 1.441 0.230
X92(1) -0.228 0.218 0.640 X21(1)
-0.305 0.387 0.534
X10(1) 1.516 2.011 0.156 X4(1) 0.851 3.987 0.046
X11(1) 0.482 0.858 0.354 X51(1) 0.717 3.076 0.079
Constant -23.094 0.000 0.998 X72(1)
-0.653 3.398 0.065
Step 2 X1(1) 0.618 1.691 0.193 X8(1) 0.649 3.094 0.079
X21(1) -0.286 0.333 0.564 X91(1) 0.350 0.289 0.591
X22(1) 0.001 0.000 0.999 X92(1)
-0.156 0.120 0.729
X31(1) 0.268 0.148 0.701 X10(1) 1.554 2.136 0.144
X32(1) 0.127 0.074 0.786 X11(1) 0.499 0.943 0.332
X4(1) 0.784 3.082 0.079 Constant
-4.240 9.183 0.002
X51(1) 0.740 2.753 0.097 Step 8 X1(1) 0.570 1.802 0.179
X52(1) 0.226 0.159 0.690 X21(1)
-0.307 0.394 0.530
X6(1) -0.092 0.045 0.831 X4(1) 0.844 3.924 0.048
X72(1) -0.627 2.967 0.085 X51(1) 0.720 3.095 0.079
X8(1) 0.688 3.370 0.066 X72(1)
-0.646 3.346 0.067
X91(1) 0.368 0.319 0.572 X8(1) 0.654 3.149 0.076
X92(1) -0.250 0.264 0.607 X91(1) 0.315 0.240 0.624
X10(1) 1.490 1.945 0.163 X10(1) 1.562 2.151 0.142
X11(1) 0.481 0.863 0.353 X11(1) 0.513 0.998 0.318
Constant -4.506 8.024 0.005 Constant
-4.365 10.382 0.001
Step 3 X1(1) 0.618 1.697 0.193 Step 9 X1(1) 0.555 1.710 0.191
X21(1) -0.286 0.339 0.560 X21(1)
-0.330 0.459 0.498
X31(1) 0.268 0.149 0.699 X4(1) 0.851 3.978 0.046
X32(1) 0.127 0.074 0.785 X51(1) 0.712 3.037 0.081
X4(1) 0.784 3.093 0.079 X72(1)
X51(1) 0.740 2.766 0.096 X8(1) 0.657 3.182 0.074
X52(1) 0.226 0.160 0.689 X10(1) 1.582 2.205 0.138
X6(1) -0.092 0.045 0.831 X11(1) 0.506 0.973 0.324
X72(1) -0.627 2.969 0.085 Constant
-4.076 11.204 0.001
X8(1) 0.688 3.390 0.066
Step
10 X1(1) 0.539 1.628 0.202
X91(1) 0.368 0.319 0.572 X4(1) 0.885 4.386 0.036
X92(1) -0.250 0.272 0.602 X51(1) 0.775 3.827 0.050
X10(1) 1.490 1.950 0.163 X72(1)
-0.638 3.293 0.070
X11(1) 0.481 0.864 0.353 X8(1) 0.653 3.165 0.075
Constant -4.505 8.300 0.004 X10(1) 1.545 2.107 0.147
Step 4 X1(1) 0.606 1.652 0.199 X11(1) 0.490 0.914 0.339
X21(1) -0.291 0.352 0.553 Constant
-4.344 14.127 0.000
X31(1) 0.289 0.176 0.674
Step
11 X1(1) 0.556 1.735 0.188
X32(1) 0.153 0.117 0.733 X4(1) 0.816 3.920 0.048
X4(1) 0.804 3.418 0.065 X51(1) 0.753 3.644 0.056
X51(1) 0.747 2.834 0.092 X72(1)
-0.642 3.340 0.068
X52(1) 0.210 0.140 0.708 X8(1) 0.611 2.824 0.093
X72(1) -0.636 3.099 0.078 X10(1) 1.340 1.652 0.199
X8(1) 0.686 3.372 0.066 Constant
-4.031 13.307 0.000
X91(1) 0.359 0.304 0.581
Step
12 X1(1) 0.485 1.326 0.250
X92(1) -0.241 0.256 0.613 X4(1) 0.849 4.170 0.041
X10(1) 1.493 1.959 0.162 X51(1) 0.740 3.501 0.061
X11(1) 0.485 0.882 0.348 X72(1)
-0.625 3.194 0.074
Constant -4.578 8.987 0.003 X8(1) 0.646 3.199 0.074
Step 5 X1(1) 0.558 1.527 0.217 Constant
-2.760 39.554 0.000
X21(1) -0.295 0.361 0.548
Step
13 X4(1) 0.647 3.059 0.080
X31(1) 0.295 0.184 0.668 X51(1) 0.631 2.765 0.096
X4(1) 0.830 3.736 0.053 X72(1)
-0.579 2.797 0.094
X51(1) 0.772 3.090 0.079 X8(1) 0.753 4.687 0.030
X52(1) 0.206 0.135 0.713 Constant
-2.535 44.538 0.000
X72(1) -0.660 3.462 0.063
X8(1) 0.669 3.258 0.071
X91(1) 0.352 0.293 0.588
X92(1) -0.232 0.238 0.625
X10(1) 1.517 2.031 0.154
X11(1) 0.478 0.859 0.354
Lampiran 4 Uji kelayakan model
Chi-square df Sig.
Step 1 Step 24.304 16 .083
Block 24.304 16 .083
Model 24.304 16 .083
Step 2(a) Step -2.258 1 .133
Block 22.046 15 .107
Model 22.046 15 .107
Step 3(a) Step .000 1 .999
Block 22.046 14 .078
Model 22.046 14 .078
Step 4(a) Step -.045 1 .831
Block 22.001 13 .055
Model 22.001 13 .055
Step 5(a) Step -.116 1 .733
Block 21.884 12 .039
Model 21.884 12 .039
Step 6(a) Step -.131 1 .717
Block 21.753 11 .026
Model 21.753 11 .026
Step 7(a) Step -.195 1 .659
Block 21.558 10 .018
Model 21.558 10 .018
Step 8(a) Step -.118 1 .731
Block 21.440 9 .011
Model 21.440 9 .011
Step 9(a) Step -.256 1 .613
Block 21.184 8 .007
Model 21.184 8 .007
Step 10(a) Step -.446 1 .504
Block 20.738 7 .004
Model 20.738 7 .004
Step 11(a) Step -.857 1 .355
Block 19.882 6 .003
Model 19.882 6 .003
Step 12(a) Step -2.428 1 .119
Block 17.454 5 .004
Model 17.454 5 .004
Step 13(a) Step -1.357 1 .244
Block 16.097 4 .003
Model 16.097 4 .003
Lampiran 5 Matriks ketepatan model
Classification Table(a)
Prediksi
Kelompok aktual Tidak
tertinggal Tertinggal % benar
Step 1 Tidak tertinggal 335 43 88.6
Tertinggal 34 13 27.7
% Keseluruhan 81.9
Step 2 Tidak tertinggal 337 41 89.2
Tertinggal 34 13 27.7
% Keseluruhan 82.4
Step 3 Tidak tertinggal 338 40 89.4
Tertinggal 34 13 27.7
% Keseluruhan 82.6
Step 4 Tidak tertinggal 336 42 88.9
Tertinggal 34 13 27.7
% Keseluruhan 82.1
Step 5 Tidak tertinggal 338 40 89.4
Tertinggal 33 14 29.8
% Keseluruhan 82.8
Step 6 Tidak tertinggal 338 40 89.4
Tertinggal 34 13 27.7
% Keseluruhan 82.6
Step 7 Tidak tertinggal 338 40 89.4
Tertinggal 35 12 25.5
% Keseluruhan 82.4
Step 8 Tidak tertinggal 333 45 88.1
Tertinggal 34 13 27.7
% Keseluruhan 81.4
Step 9 Tidak tertinggal 339 39 89.7
Tertinggal 35 12 25.5
% Keseluruhan 82.6
Step 10 Tidak tertinggal 331 47 87.6
Tertinggal 35 12 25.5
% Keseluruhan 80.7
Step 11 Tidak tertinggal 334 44 88.4
Tertinggal 36 11 23.4
% Keseluruhan 81.2
Step 12 Tidak tertinggal 339 39 89.7
Tertinggal 36 11 23.4
% Keseluruhan 82.4
Step 13 Tidak tertinggal 339 39 89.7
Tertinggal 36 11 23.4
% Keseluruhan 82.4
ANALISIS REGRESI LOGISTIK UNTUK MENENTUKAN
FAKTOR-FAKTOR KETERTINGGALAN DESA
DI KABUPATEN BOGOR
Oleh :
Maria Wuri Handayani
G14101019
PROGRAM STUDI STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENDAHULUAN
Latar Belakang
Pembangunan Indonesia adalah pembangunan manusia seutuhnya dan masyarakat seluruhnya. Pembangunan ini harus dapat menjangkau seluruh lapisan masyarakat baik yang ada di perkotaan maupun di pedesaan. Hasil pembangunan yang tidak merata menyebabkan perkembangan yang tidak seimbang serta kesenjangan dalam perekonomian. Akibatnya muncul kemiskinan dan ketertinggalan dalam kehidupan. Istilah tertinggal menurut Agusta (2005) merujuk pada tingkat kelengkapan prasarana sedangkan miskin mencirikan derajat ekonomi dan kelembagaan.
Badan Pusat Statistik (BPS) melakukan survei tentang potensi desa/kelurahan yang dilakukan setiap tiga tahun sekali, dengan salah satu tujuannya adalah untuk menghitung banyaknya desa tertinggal di Indonesia. Hasil perhitungan tersebut disusun dalam bentuk daftar desa tertinggal. Daftar ini memiliki berbagai manfaat baik bagi instansi pemerintahan maupun masyarakat. Manfaat tersebut antara lain dapat dengan jelas menerangkan seberapa besar ketertinggalan desa di Indonesia, dapat pula digunakan sebagai salah satu patokan pembangunan desa, serta dapat dijadikan landasan alokasi dana kompensasi pengalihan subsidi bahan bakar minyak (BBM) bagi desa tertinggal (BPS 2003).
Pengklasifikasian tertinggal tidaknya suatu desa yang dilakukan oleh BPS berdasarkan pada nilai skor yang diperoleh. Suatu desa akan disebut tertinggal apabila nilai skornya kurang dari batas nilai skor minimum desa (BPS 1994). Pendekatan statistik dapat digunakan untuk melakukan evaluasi hasil untuk melihat tingkat ketelitian dalam perhitungan.
Pada penelitian ini digunakan analisis regresi logistik untuk mengetahui faktor-faktor yang mempengaruhi tertinggal atau tidaknya suatu desa sekaligus sebagai evaluasi kategori yang digunakan untuk menentukan desa tertinggal dari BPS.
Tujuan
Penelitian ini bertujuan untuk :
1. Menentukan desa tertinggal di Kabupaten Bogor dengan menggunakan indikator serta metode yang digunakan oleh BPS.
2. Menentukan model terbaik yang dapat digunakan untuk memprediksi ketertinggalan desa dilihat dari nilai ketepatan klasifikasi yang dihasilkan.
TINJAUAN PUSTAKA
Podes
Podes (potensi desa) merupakan kemampuan atau daya/kekuatan yang memiliki kemungkinan untuk dikembangkan dalam wilayah otonomi desa. Data Podes merupakan satu-satunya data yang berurusan dengan wilayah/tata ruang dengan basis desa/kelurahan (BPS 2003). Podes pertama kali diadakan pada tahun 1980 bersamaan dengan sensus penduduk tahun 1980 (SP1980), dimana pengumpulan data Podes selalu diintegrasikan dengan kegiatan sensus dan mendahului satu tahun sebelum sensus, misal untuk Podes sensus ekonomi tahun 2006 (SE2006) dilakukan pada tahun 2005.
Tujuan dari Podes antara lain :
1. Tersedianya data tentang potensi/keadaan pembangunan di desa dan perkembangannya meliputi keadaan sosial, ekonomi, sarana dan prasarana, serta potensi yang ada di desa/kelurahan.
2. Menyediakan data untuk berbagai
keperluan khususnya yang berkaitan dengan kebutuhan perencanaan regional (spasial) di setiap daerah.
3. Melengkapi penyusunan kerangka contoh (sampling frame) untuk kegiatan statistik lebih lanjut.
4. Menyediakan informasi bagi keperluan penentuan klasifikasi/updating desa urban dan rural, desa tertinggal dan tidak tertinggal.
5. Menyediakan data pokok bagi
penyusunan statistik wilayah kecil (small area statistics).
Jenis data yang dikumpulkan pada Podes sensus pertanian tahun 2003 (ST2003) adalah :
1. Keterangan umum desa/kelurahan 2. Kependudukan dan ketenagakerjaan 3. Perumahan dan lingkungan hidup 4. Pendidikan
5. Kesehatan, gizi dan keluarga berencana 6. Sosial budaya
7. Rekreasi, hiburan, kesenian, dan olahraga 8. Angkutan
PENDAHULUAN
Latar Belakang
Pembangunan Indonesia adalah pembangunan manusia seutuhnya dan masyarakat seluruhnya. Pembangunan ini harus dapat menjangkau seluruh lapisan masyarakat baik yang ada di perkotaan maupun di pedesaan. Hasil pembangunan yang tidak merata menyebabkan perkembangan yang tidak seimbang serta kesenjangan dalam perekonomian. Akibatnya muncul kemiskinan dan ketertinggalan dalam kehidupan. Istilah tertinggal menurut Agusta (2005) merujuk pada tingkat kelengkapan prasarana sedangkan miskin mencirikan derajat ekonomi dan kelembagaan.
Badan Pusat Statistik (BPS) melakukan survei tentang potensi desa/kelurahan yang dilakukan setiap tiga tahun sekali, dengan salah satu tujuannya adalah untuk menghitung banyaknya desa tertinggal di Indonesia. Hasil perhitungan tersebut disusun dalam bentuk daftar desa tertinggal. Daftar ini memiliki berbagai manfaat baik bagi instansi pemerintahan maupun masyarakat. Manfaat tersebut antara lain dapat dengan jelas menerangkan seberapa besar ketertinggalan desa di Indonesia, dapat pula digunakan sebagai salah satu patokan pembangunan desa, serta dapat dijadikan landasan alokasi dana kompensasi pengalihan subsidi bahan bakar minyak (BBM) bagi desa tertinggal (BPS 2003).
Pengklasifikasian tertinggal tidaknya suatu desa yang dilakukan oleh BPS berdasarkan pada nilai skor yang diperoleh. Suatu desa akan disebut tertinggal apabila nilai skornya kurang dari batas nilai skor minimum desa (BPS 1994). Pendekatan statistik dapat digunakan untuk melakukan evaluasi hasil untuk melihat tingkat ketelitian dalam perhitungan.
Pada penelitian ini digunakan analisis regresi logistik untuk mengetahui faktor-faktor yang mempengaruhi tertinggal atau tidaknya suatu desa sekaligus sebagai evaluasi kategori yang digunakan untuk menentukan desa tertinggal dari BPS.
Tujuan
Penelitian ini bertujuan untuk :
1. Menentukan desa tertinggal di Kabupaten Bogor dengan menggunakan indikator serta metode yang digunakan oleh BPS.
2. Menentukan model terbaik yang dapat digunakan untuk memprediksi ketertinggalan desa dilihat dari nilai ketepatan klasifikasi yang dihasilkan.
TINJAUAN PUSTAKA
Podes
Podes (potensi desa) merupakan kemampuan atau daya/kekuatan yang memiliki kemungkinan untuk dikembangkan dalam wilayah otonomi desa. Data Podes merupakan satu-satunya data yang berurusan dengan wilayah/tata ruang dengan basis desa/kelurahan (BPS 2003). Podes pertama kali diadakan pada tahun 1980 bersamaan dengan sensus penduduk tahun 1980 (SP1980), dimana pengumpulan data Podes selalu diintegrasikan dengan kegiatan sensus dan mendahului satu tahun sebelum sensus, misal untuk Podes sensus ekonomi tahun 2006 (SE2006) dilakukan pada tahun 2005.
Tujuan dari Podes antara lain :
1. Tersedianya data tentang potensi/keadaan pembangunan di desa dan perkembangannya meliputi keadaan sosial, ekonomi, sarana dan prasarana, serta potensi yang ada di desa/kelurahan.
2. Menyediakan data untuk berbagai
keperluan khususnya yang berkaitan dengan kebutuhan perencanaan regional (spasial) di setiap daerah.
3. Melengkapi penyusunan kerangka contoh (sampling frame) untuk kegiatan statistik lebih lanjut.
4. Menyediakan informasi bagi keperluan penentuan klasifikasi/updating desa urban dan rural, desa tertinggal dan tidak tertinggal.
5. Menyediakan data pokok bagi
penyusunan statistik wilayah kecil (small area statistics).
Jenis data yang dikumpulkan pada Podes sensus pertanian tahun 2003 (ST2003) adalah :
1. Keterangan umum desa/kelurahan 2. Kependudukan dan ketenagakerjaan 3. Perumahan dan lingkungan hidup 4. Pendidikan
5. Kesehatan, gizi dan keluarga berencana 6. Sosial budaya
7. Rekreasi, hiburan, kesenian, dan olahraga 8. Angkutan
10.Penggunaan dan penguasaan lahan 11.Pertanian
12.Alat-alat pertanian 13.Perdagangan dan industri 14.Keuangan desa/kelurahan 15.Politik dan keamanan
16.Keterangan aparat desa/kelurahan
Desa/Kelurahan
Desa adalah kesatuan masyarakat hukum yang memiliki kewenangan untuk mengatur dan mengurus kepentingan masyarakat setempat berdasarkan asal usul dan adat istiadat setempat yang diakui dalam sistem pemerintahan nasional dan berada di daerah kabupaten. Sedangkan kelurahan adalah suatu wilayah lurah sebagai perangkat daerah kabupaten dan/atau daerah kota di bawah kecamatan ( UU RI No. 22 Tahun 1999 tentang Pemerintahan Daerah).
Uji Khi Kuadrat
Uji khi kuadrat digunakan untuk mengamati ada tidaknya hubungan (asosiasi) antara dua variabel kategorik. Untuk menelusuri asosiasi tersebut, biasanya sebelumnya digunakan tabulasi silang antara kedua karakteristik yang akan diuji. Bentuk tabulasi silangnya adalah sebagai berikut :
Peubah A Peubah B Total Kategori 1 … kategori q Kategori 1 O11 … O1j B1
… … …
Kategori p Oi1 … Oij Bi
Total K1 Kj N
Keterangan :
Oij = Frekuensi anggota contoh yang memiliki
kategori i pada peubah A dan kategori j pada peubah B
Bi = Total frekuensi anggota contoh yang
memiliki kategori i pada peubah A Kj = Total frekuensi anggota contoh yang
memiliki kategori j pada peubah B
Hipotesis-nya adalah:
H0 : tidak ada asosiasi antara kedua peubah
H1 : ada asosiasi antara kedua peubah
Statistik uji :
∑ ∑
= = − = p i q j ij ij ij hitung E E O 1 1 22 ( )
χ
dimana Eij merupakan frekuensi harapan
anggota contoh yang memiliki kategori i pada peubah A dan kategori j pada peubah B. Eij dapat diperoleh dengan rumus :
N K B Eij = i j
Statistik uji χ2menyebar menurut sebaran 2
χ dengan db= (p-1)(q-1) dengan asumsi bahwa kedua peubah saling bebas.Tolak H0
jika 2
) , ( 2 α χ
χhitung> db atau jika nilai-p < α (Daniel 1989).
Regresi Logistik
Menurut Hosmer dan Lemeshow (1989) metode regresi logistik adalah suatu metode analisis statistika yang menggambarkan hubungan antara peubah respon yang memiliki dua kategori atau lebih dengan satu atau lebih peubah bebas.
Model umum persamaan peluang regresi logistik dengan p peubah penjelas yaitu :
(
)
( )
( () )1
| g x
x g e e x X Y E + = Π = Dimana komponen p px x x x x
g ⎥=β +β + +β
⎦ ⎤ ⎢ ⎣ ⎡ Π − Π = ... ) ( 1 ) ( ln )
( 0 1 1
Merupakan penduga logit sebagai fungsi linear dari peubah penjelas.
Regresi Logistik Bertatar
Regresi logistik bertatar (stepwise logistic regression) digunakan untuk menentukan peubah-peubah penjelas yang bisa membedakan respon yang diamati. Prosedur ini memilih atau menghilangkan peubah-peubah satu persatu dari model sampai ditemukan peubah-peubah yang berpengaruh nyata terhadap model ( Hosmer and Lemeshow 1989).
Galat pada analisis regresi bertatar linear diasumsikan mengikuti sebaran normal sehingga digunakan uji F, sedangkan pada analisis regresi logistik bertatar galat diasumsikan mengikuti sebaran binomial dan uji signifikasi diduga dengan menggunakan uji khi kuadrat rasio likelihood (likelihood ratio chi-square test).
Analisis regresi logistik bertatar membangun model langkah demi langkah sampai ditemukan peubah yang berpengaruh nyata terhadap peubah respon (Hosmer & Lemeshow 1989). Proses diawali dengan langkah 0. Misal tersedia total peubah penjelas sebanyak p, Lj(0) merupakan
mengandung peubah Xj . Pada langkah ini uji
rasio likelihood dapat dihitung
(
0)
0 02 L L
Gj = j −
dengan nilai-p sebesar
[
]
) 0 ( 2 ) ( 0 j v r
j P G
P = χ >
. Peubah paling penting adalah peubah dengan nilai-p paling kecil atau Pei(0) =min(p(j0)). Suatu
peubah akan masuk ke model jika nilai-p untuk G < PE, dimana PE merupakan suatu nilai yang
akan menentukan berapa jumlah peubah yang akan dimasukkan kedalam model. Proses akan berlanjut ke langkah selanjutnya jika Pei <PE
) 0 (
, jika tidak proses berhenti.
Langkah satu dimulai dengan model regresi logistik yang mengandung Xei . Nilai statistik G
dihitung dengan rumus (1) 2( (1) (1)) i
ij e
e
J L L
G = − dengan
) 1 (
ij e
L merupakan model yang mengandung Xei dan
Xj ,j≠ei. Nilai-p sebesar PJ(1). Proses akan
berlanjut ke langkah berikutnya jika nilai-p < PE.
Proses akan terus berlanjut sampai ke langkah S sebelum ditemukan peubah yang nyata. Langkah S akan terjadi jika :
1. Sebanyak p peubah masih ada di dalam model.
2. Peubah didalam model memiliki nilai-p < PR dan peubah yang tidak masuk ke
dalam model memiliki nilai-p > PE, dimana
PR merupakan suatu nilai yang dapat
menunjukkan beberapa level minimal dari sumbangan peubah untuk model.
Pendugaan Parameter Model
Pendugaan parameter dalam model regresi logistik dilakukan dengan menggunakan metode kemungkinan maksimum. Jika antara amatan yang satu dengan yang lain diasumsikan bebas maka fungsi kemungkinan maksimum yang diperoleh adalah :
( ) ( ) i[ ( )] i y n i i y i x x l − =
∏
− = 1 1 1 π π β Keterangan :( )
βl = Fungsi likelihood ( )xi
π = Peluang kejadian ke-i bernilai Y=1
Parameter βi diduga dengan
memaksimumkan persamaan di atas. Untuk memudahkan perhitungan dilakukan pendekatan logaritma maka fungsi log- kemungkinan sebagai berikut :
( )β [l( )β ]
L =ln
( )
∑
{ [ ( )] ( ) [( ( ))]} = − − + = n i i ii x y x
y L 1 1 ln 1
lnπ π
β
Nilai dugaan βi dapat diperoleh dengan membuat turunan pertama L( )β terhadap βi sama dengan nol dengan i = 0, 1, 2, 3, ..., p (Freeman 1987).
Pengujian Parameter Regresi Logistik
Statistik uji-G adalah uji rasio kemungkinan maksimum (likelihood ratio test) yang digunakan untuk menguji peranan peubah bebas dalam model secara bersamaan (Hosmer dan Lemeshow 1989). Rumus umum untuk uji-G adalah :
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − = 1 0 ln 2 L L G 0
L = likelihood tanpa peubah bebas 1
L = Likelohood dengan peubah bebas Dengan hipotesis :
0 ...
: 1 2
0 = = = p =
H β β β
:
1
H minimal ada satu nilai βi≠0
dimana i =1,2,3,...,p
Statistik uji-G mengikuti sebaran χ2 dengan derajat bebas p. Kaidah keputusan yang
diambil yaitu menolak H0 jika G > 2
) (α
χp (Hosmer dan lemeshow 1989). Sedangkan untuk menguji koefisien regresi logistik secara parsial dapat menggunakan statistik uji Wald, berdasarkan hipotesis : 0 : 0 : 1 0 ≠ = i i H H β β
dimana i = 1,2,3,...,p
Rumus umum statistik uji wald sebagai berikut :
( )
i i i E S W β β ˆ ˆ ˆ = iβˆ merupakan penduga
i
β dan SE
( )
βˆimerupakan penduga galat baku dari β. Menurut Hosmer dan Lemeshow (1989) salah satu ukuran kebaikan model adalah jika memiliki peluang salah klasifikasi yang minimal.
dugaan
π
(
x
)
. Jikaπ
(
x
)
lebih besar dari c maka nilai dugaan termasuk pada respon y=1 dan selain itu y=0. Nilai c yang digunakan adalah 0.5 (Hosmer dan Lemeshow 1989). Ketepatan model dalam memprediksi kejadian gagal (y=0) dinyatakan sebagai N00/N0, proporsi nilai dugaan yang samadengan nilai amatan pada kategori nilai amatan y=0. Indikator dan pengertian yang sama juga berlaku untuk mengevaluasi kemampuan model memprediksi kejadian berhasil (y=1), yaitu N11/N1. kemampuan
model dalam memprediksi keseluruhan kejadian adalah (N00+N11)/N.. yang
mencerminkan proporsi nilai amatan yang secara tepat dapat diduga oleh model.
Dugaan Amatan
0 1 Total % tepat 0 N00 N01 N0. N00/ N0.
1 N10 N11 N1. N11/ N1.
N.0 N.1 N.. (N00+ N11)/ N..
Dengan :
N00 : Suatu amatan bernilai 0 dengan dugaan 0
N.0 : Jumlah total dugaan bernilai 0
N0. : Jumlah total amatan bernilai 0
N.. : Jumlah keseluruhan nilai yang dihasilkan
Interpretasi Koefisien Model Regresi Logistik
Interpretasi koefisien untuk model regresi logistik dapat dilakukan dengan melihat nilai rasio oddsnya. Rasio odds adalah ukuran asosiasi yang memperkirakan berapa besar kecenderungan pengaruh peubah-peubah penjelas terhadap peubah respon (Hosmer dan Lemeshow 1989).
Jika suatu peubah penjelas mempunyai tanda koefisien positif, maka nilai rasio odds akan lebih besar dari satu, sebaliknya jika tanda koefisiennya negatif maka nilai rasio oddsnya akan lebih kecil dari satu. Menurut Hosmer dan Lemeshow (1989) koefisien model logit dapat ditulis sebagai
) ( ) 1
(x g x
g
i= + −
β . Koefisien model logit
i
β mencerminkan perubahan dalam fungsi logit g(x) untuk perubahan satu unit peubah bebas yang disebut log odds, yang merupakan beda antara dua penduga logit yang dihitung pada dua nilai (misal x=a dan x=b) dinotasikan sebagai :
( )
[
,]
( ) ( )lnψ ab =g x=a −g x=b
(a b)
i −
=β
sedangkan penduga rasio oddsnya adalah :
( )ab =
[
βi(a−b)]
ψ , expsehingga jika a-b=1 maka ψ =exp
( )
βi . Interpretasi koefisien dari nilai rasio odds untuk peubah penjelas yang berskala nominal X=1, memiliki kecenderungan untuk Y=1 sebesar ψ kali dibandingkan dengan X=0 atau dapat dikatakan X=1 memiliki kecenderungan untuk Y=0 sebesar 1/ψ kali dibandingkan X=0. Sedangkan untuk peubah penjelas kontinu, jika ψ lebih besar atau sama dengan satu maka semakin besar nilai peubah X diikuti semakin besarnya kecenderungan untuk Y=1.BAHAN DAN METODE
Bahan
Data yang digunakan dalam penelitian ini adalah data sekunder tentang potensi desa/kelurahan (Podes) di Kabupaten Bogor tahun 2003 yang dilakukan oleh BPS.
Jumlah data sebanyak 425 desa dengan klasifikasi 199 desa perkotaan dan 226 untuk desa perdesaan.
Pengambilan data Podes dilakukan dengan cara sensus di seluruh desa/kelurahan, yaitu dengan cara wawancara langsung. Responden data Podes adalah kepala desa/lurah atau staf yang ditunjuk untuk mewakilinya.
Metode
Langkah-langkah yang dilakukan adalah :
1. Koding terhadap data berdasarkan
klasifikasi dan nilai skor yang digunakan oleh BPS.
2. Perhitungan desa tertinggal dengan
menggunakan indikator dan metode dari BPS.
3. Pengklasifikasian suatu desa masuk ke dalam kelompok tertinggal atau tidak tertinggal, yang nantinya akan digunakan sebagai peubah tak bebas dalam analisis regresi logistik.
4. Uji Khi kuadrat untuk menentukan
peubah-peubah yang akan digunakan sebagai peubah bebas dalam analisis regresi logistik.
5. Analisis regresi logistik untuk
membangun model tertinggal atau tidaknya suatu desa.
6. Menentukan model terbaik untuk
dugaan
π
(
x
)
. Jikaπ
(
x
)
lebih besar dari c maka nilai dugaan termasuk pada respon y=1 dan selain itu y=0. Nilai c yang digunakan adalah 0.5 (Hosmer dan Lemeshow 1989). Ketepatan model dalam memprediksi kejadian gagal (y=0) dinyatakan sebagai N00/N0, proporsi nilai dugaan yang samadengan nilai amatan pada kategori nilai amatan y=0. Indikator dan pengertian yang sama juga berlaku untuk mengevaluasi kemampuan model memprediksi kejadian berhasil (y=1), yaitu N11/N1. kemampuan
model dalam memprediksi keseluruhan kejadian adalah (N00+N11)/N.. yang
mencerminkan proporsi nilai amatan yang secara tepat dapat diduga oleh model.
Dugaan Amatan
0 1 Total % tepat 0 N00 N01 N0. N00/ N0.
1 N10 N11 N1. N11/ N1.
N.0 N.1 N.. (N00+ N11)/ N..
Dengan :
N00 : Suatu amatan bernilai 0 dengan dugaan 0
N.0 : Jumlah total dugaan bernilai 0
N0. : Jumlah total amatan bernilai 0
N.. : Jumlah keseluruhan nilai yang dihasilkan
Interpretasi Koefisien Model Regresi Logistik
Interpretasi koefisien untuk model regresi logistik dapat dilakukan dengan melihat nilai rasio oddsnya. Rasio odds adalah ukuran asosiasi yang memperkirakan berapa besar kecenderungan pengaruh peubah-peubah penjelas terhadap peubah respon (Hosmer dan Lemeshow 1989).
Jika suatu peubah penjelas mempunyai tanda koefisien positif, maka nilai rasio odds akan lebih besar dari satu, sebaliknya jika tanda koefisiennya negatif maka nilai rasio oddsnya akan lebih kecil dari satu. Menurut Hosmer dan Lemeshow (1989) koefisien model logit dapat ditulis sebagai
) ( ) 1
(x g x
g
i= + −
β . Koefisien model logit
i
β mencerminkan perubahan dalam fungsi logit g(x) untuk perubahan satu unit peubah bebas yang disebut log odds, yang merupakan beda antara dua penduga logit yang dihitung pada dua nilai (misal x=a dan x=b) dinotasikan sebagai :
( )
[
,]
( ) ( )lnψ ab =g x=a −g x=b
(a b)
i −
=β
sedangkan penduga rasio oddsnya adalah :
( )ab =
[
βi(a−b)]
ψ , expsehingga jika a-b=1 maka ψ =exp
( )
βi . Interpretasi koefisien dari nilai rasio odds untuk peubah penjelas yang berskala nominal X=1, memiliki kecenderungan untuk Y=1 sebesar ψ kali dibandingkan dengan X=0 atau dapat dikatakan X=1 memiliki kecenderungan untuk Y=0 sebesar 1/ψ kali dibandingkan X=0. Sedangkan untuk peubah penjelas kontinu, jika ψ lebih besar atau sama dengan satu maka semakin besar nilai peubah X diikuti semakin besarnya kecenderungan untuk Y=1.BAHAN DAN METODE
Bahan
Data yang digunakan dalam penelitian ini adalah data sekunder tentang potensi desa/kelurahan (Podes) di Kabupaten Bogor tahun 2003 yang dilakukan oleh BPS.
Jumlah data sebanyak 425 desa dengan klasifikasi 199 desa perkotaan dan 226 untuk desa perdesaan.
Pengambilan data Podes dilakukan dengan cara sensus di seluruh desa/kelurahan, yaitu dengan cara wawancara langsung. Responden data Podes adalah kepala desa/lurah atau staf yang ditunjuk untuk mewakilinya.
Metode
Langkah-langkah yang dilakukan adalah :
1. Koding terhadap data berdasarkan
klasifikasi dan nilai skor yang digunakan oleh BPS.
2. Perhitungan desa tertinggal dengan
menggunakan indikator dan metode dari BPS.
3. Pengklasifikasian suatu desa masuk ke dalam kelompok tertinggal atau tidak tertinggal, yang nantinya akan digunakan sebagai peubah tak bebas dalam analisis regresi logistik.
4. Uji Khi kuadrat untuk menentukan
peubah-peubah yang akan digunakan sebagai peubah bebas dalam analisis regresi logistik.
5. Analisis regresi logistik untuk
membangun model tertinggal atau tidaknya suatu desa.
6. Menentukan model terbaik untuk
Indikator desa tertinggal menurut BPS : A. Desa perkotaan
1. Lapangan usaha mayoritas penduduk. 2. Fasilitas kesehatan.
3. Sarana komunikasi