PENGENALAN KARAKTER TULISAN TANGAN DENGAN
MENGGUNAKAN JARINGAN SYARAF TIRUAN
PROPAGASI BALIK
RESILIENT
Oleh :
DONNY WAHYU SAPUTRO
G06499031
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENGENALAN KARAKTER TULISAN TANGAN DENGAN
MENGGUNAKAN JARINGAN SYARAF TIRUAN
PROPAGASI BALIK
RESILIENT
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
DONNY WAHYU SAPUTRO
G06499031
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
DONNY WAHYU SAPUTRO. Pengenalan Karakter Tulisan Tangan dengan Menggunakan Jaringan Syaraf Tiruan Propagasi Balik Resilient. Dibimbing oleh PRAPTO TRI SUPRIYO dan
AZIZ KUSTIYO.
Teknologi komputer telah banyak diterapkan untuk membantu menyelesaikan berbagai masalah. Salah satu permasalahan tersebut adalah pengenalan karakter tulisan tangan, yang telah lama diidentifikasi sebagai salah satu permasalahan yang sulit. Untuk memecahkan masalah tersebut dirancang suatu perangkat lunak yang menerapkan sistem yang menyerupai sistem kerja otak manusia yang dikenal dengan jaringan syaraf tiruan (JST).
Dalam penelitian ini dibangun suatu sistem yang dapat melakukan pengenalan citra-citra karakter tulisan tangan menggunakan JST resilientbackpropagation (RPROP). Data yang diambil berupa karakter numeral (0,1,2,…,9) dari 13 orang dengan menggunakan media kertas. Dari 13 orang tersebut 10 orang menuliskan karakter sebanyak 2 kali, di mana penulisan pertama digunakan untuk data pelatihan dan penulisan kedua digunakan untuk data pengujian. Tiga orang sisanya hanya menuliskan karakter sebanyak 1 kali, karakter tulisan tangan dari 2 orang digunakan untuk menambah data pelatihan sedangkan karakter tulisan tangan dari 1 orang lainnya digunakan untuk menambah data pengujian. Karakter-karakter tulisan tangan tersebut kemudian diubah menjadi citra digital dengan menggunakan scanner dan setiap karakter disimpan sebagai satu file citra, sehingga didapat 230 buah file citra. Dari data tersebut 120 citra digunakan sebagai data pelatihan dan 110 citra lainnya digunakan sebagai data pengujian.
Sistem dibangun dengan graphical user interface (GUI) sehingga sistem mudah digunakan dan user-friendly. Dari hasil percobaan didapatkan parameter-parameter optimal yaitu JST dengan 80 neuron hidden, toleransi galat 10-5, Faktor Naik sebesar 1.2 dan Faktor Turun sebesar 0.7. Dengan penggunaan parameter-parameter tersebut sistem dapat mengenali karakter tulisan tangan dengan tingkat generalisasi tertinggi sebesar 93.64%.
Judul
Skripsi
: Pengenalan Karakter Tulisan Tangan dengan
Menggunakan Jaringan Syaraf Tiruan Propagasi
Balik
Resilient
Nama
: Donny Wahyu Saputro
NIM :
G06499031
Menyetujui,
Pembimbing I
Drs. Prapto Tri Supriyo, M.Kom.
NIP 131878952
Pembimbing II
Aziz Kustiyo, S.Si., M.Kom.
NIP 132206241
Mengetahui,
Dekan Fakultas Matematika Dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, M.S.
NIP 131473999
RIWAYAT HIDUP
Penulis lahir di Bogor pada tanggal 31 Juli 1981 sebagai anak pertama dari tiga bersaudara, anak dari pasangan Budi Iswahyudi dan Betty Subardini.
Tahun 1999 penulis lulus dari SMU Negeri 3 Bogor dan pada tahun yang sama melanjutkan pendidikan ke Institut Pertanian Bogor (IPB) melalui jalur Ujian Seleksi Masuk IPB (USMI) pada Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
KATA PENGANTAR
Alhamdulillah, segala puji dan syukur penulis panjatkan kepada Allah Subhanahu Wa Taala atas segala rahmat dan karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Topik yang dipilih dalam penelitian ini adalah sistem pengenalan karakter tulisan tangan, dengan judul Pengenalan Karakter Tulisan Tangan dengan Menggunakan Jaringan Syaraf Tiruan Propagasi Balik Resilient.
Penulis mengucapkan terima kasih kepada Bapak Drs. Prapto Tri Supriyo, M.Kom., dan Bapak Aziz Kustiyo, S.Si, M.Kom. selaku dosen pembimbing serta Bapak Irman Hermadi, S.Kom, M.S. selaku dosen penguji yang telah memberikan saran, koreksi, dan bimbingan selama pengerjaan tugas akhir ini. Selanjutnya penulis juga mengucapkan terima kasih kepada:
1 Seluruh keluarga besar penulis, khususnya kepada kedua orang tua penulis tercinta, Ibu dan Bapak, serta adik penulis Siwi dan Onggo atas segala cinta kasih, doa, kesabaran, dukungan, dan dorongan semangat kepada penulis selama ini.
2 Ade, Yustin dan Hadi yang bersedia menjadi pembahas. Erwin, Yogi, ilkomerz 39 dan ilkomerz 40 yang datang ke seminar.
3 Rahmat, Arum, Ipink, Dhika, Hanief, Baskoro, Dewis, Pepenk, Farid, Boy, Udho, Henny, Copit, dan rekan-rekan Ilkomerz 36. Terima kasih sebesar-besarnya atas semua dukungan dan doanya. Penelitian ini bisa diselesaikan berkat kalian semua.
4 Seluruh staf pengajar dan pegawai Departemen Ilmu Komputer.
5 Semua rekan, sahabat, dan saudara yang tidak dapat penulis sebutkan satu persatu. Semoga karya ilmiah ini dapat bermanfaat.
Bogor, Desember 2006
Donny Wahyu Saputro
DAFTAR ISI
Halaman
DAFTAR TABEL...ix
DAFTAR GAMBAR ...ix
DAFTAR LAMPIRAN ...ix
PENDAHULUAN...1
Latar Belakang ...1
Tujuan...1
Ruang Lingkup ...1
TINJAUAN PUSTAKA...1
Representasi Citra Digital...1
Normalisasi...2
Jaringan Syaraf Tiruan ...2
Propagasi Balik Resilient (RPROP) ...2
METODE PENELITIAN...4
Akuisisi Data ...4
Tahapan Pengenalan Karakter ...4
Karakteristik JST Yang Digunakan ...5
Parameter Penilaian Sistem ...5
Lingkungan Pengembangan ...5
HASIL DAN PEMBAHASAN ...6
Menentukan Parameter-Parameter JST yang Optimal...6
Menguji Parameter-Parameter JST yang Optimal ...9
Kelebihan dan Keterbatasan Sistem ...9
Perbandingan dengan Penelitian Sebelumnya ...9
KESIMPULAN DAN SARAN ...10
Kesimpulan...10
Saran...10
DAFTAR PUSTAKA ...10
DAFTAR TABEL
Halaman
1 Karakteristik JST yang digunakan ...5
2 Definisi target jaringan...5
3 Perbandingan dengan penelitian sebelumnya...10
DAFTAR GAMBAR
Halaman 1 Representasi citra digital ...12 Model JST sederhana ...2
3 Model JST propagasi balik...3
4 Tahapan Pengenalan...4
5 Grafik perbandingan generalisasi rata-rata terhadap jumlah hidden neuron...6
6 Grafik perbandingan epoch rata-rata terhadap hidden neuron...6
7 Grafik perbandingan generalisasi rata-rata terhadap toleransi galat...7
8 Grafik perbandingan epoch rata-rata terhadap toleransi galat ...7
9 Grafik perbandingan generalisasi rata-rata terhadap FN ...8
10 Grafik perbandingan epoch rata-rata terhadap FN ...8
11 Grafik perbandingan generalisasi rata-rata terhadap FT ...8
12 Grafik perbandingan epoch rata-rata terhadap FT...9
13 Grafik generalisasi pada setiap ulangan ...9
DAFTAR LAMPIRAN
Halaman 1 Algoritme JST RPROP ...122 Tabel percobaan jumlah hidden neuron dengan toleransi galat 10-5, Faktor Naik sebesar 1.2 dan Faktor Turun sebesar 0.5 ...14
3 Tabel percobaan toleransi galat dengan 80 hidden neuron, Faktor Naik sebesar 1.2 dan Faktor Turun sebesar 0.5...16
4 Tabel percobaan Faktor Naik dengan 80 hidden neuron, toleransi galat 10-5 dan Faktor Turun sebesar 0.5 ...17
5 Tabel percobaan Faktor Turun dengan 80 hidden neuron, toleransi galat 10-5 dan Faktor Naik sebesar 1.2 ...18
6 Hasil pengujian menggunakan parameter-parameter JST yang optimal ...19
PENDAHULUAN
Latar Belakang
Saat ini pemanfaatan teknologi komputer telah banyak diterapkan dalam berbagai aspek kehidupan manusia. Tujuan utamanya adalah untuk membantu menyelesaikan masalah-masalah tertentu. Salah satu permasalah-masalahan tersebut adalah pengenalan karakter tulisan tangan. Pengenalan karakter tulisan tangan telah lama diidentifikasikan sebagai permasalahan yang sulit dipecahkan oleh komputer (Tay & Khalid 1997). Untuk memecahkan masalah tersebut dirancang suatu perangkat lunak yang menerapkan sistem yang menyerupai sistem kerja otak manusia yang dikenal dengan jaringan syaraf tiruan (neural network).
Jaringan syaraf tiruan merupakan salah satu teknik untuk pengenalan pola yang memiliki kemampuan yang sangat baik (Tay & Khalid 1997).
Telah banyak penelitian yang dilakukan untuk mengenali karakter tulisan tangan, di antaranya dilakukan oleh Nugroho (2003) yang menggunakan metode-metode jaringan syaraf tiruan propagasi balik standar. Penelitian tersebut masih dapat dikembangkan dengan penggunaan metode praproses dan juga penggunaan jaringan syaraf tiruan yang lain dan juga diperlukan kombinasi percobaan yang lebih banyak.
Beberapa modifikasi dari prosedur propagasi balik telah diajukan untuk menambah kecepatan pembelajaran. Martin Riedmiller dan Heinrich Braun telah mengembangkan suatu metode yang disebut Resilient Backpropagation (RPROP). Menurut Riedmiller & Braun (1993), algoritme RPROP sejauh ini terbukti sebagai metode yang memiliki kecepatan pembelajaran yang baik dan juga andal.
Salah satu kelemahan jaringan propagasi balik adalah pelatihan akan berjalan dengan lambat jika dimensi input terlalu besar. Untuk mengatasi masalah tersebut biasanya dilakukan praproses tertentu untuk mengekstraksi ciri pada data input sehingga dimensi input-nya menjadi lebih kecil. Algoritme RPROP mampu mengatasi masalah lambatnya waktu pelatihan, sehingga praproses untuk mereduksi dimensi input tidak perlu dilakukan.
Dalam penelitian kali ini akan ditelaah pengenalan karakter tulisan tangan dengan jaringan syaraf tiruan RPROP.
Tujuan
Tujuan dari penelitian ini adalah untuk mengimplementasikan jaringan syaraf tiruan propagasi balik resilient dalam mengenali pola citra karakter tulisan tangan.
Ruang Lingkup
Penelitian ini dibatasi pada pemrosesan citra digital dengan komposisi warna grayscale. Karakter tulisan tangan yang digunakan hanya dibatasi pada karakter numeral Arabic (0,1,2,…,9).
TINJAUAN PUSTAKA
Representasi Citra Digital
Citra digital merupakan suatu fungsi intensitas cahaya dua dimensi f(x,y), dimana x dan y menunjukkan koordinat spasial. Nilai f pada setiap titik (x,y) menunjukkan tingkat kecerahan citra pada titik tersebut (Gonzales & Woods 2002). Citra digital dapat berupa citra dalam skala keabuan (grayscale) ataupun citra berwarna (color).
Setiap citra digital direpresentasikan dalam bentuk matriks yang berukuran m × n dimana m dan n menunjukkan jumlah baris dan kolom matriks tersebut. Seperti yang diperlihatkan pada Gambar 1.
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = ) , ( ) 2 , ( ) 1 , ( ) , 2 ( ) 2 , 2 ( ) 1 , 2 ( ) , 1 ( ) 2 , 1 ( ) 1 , 1 ( ) , ( n m f m f m f n f f f n f f f y x f L L L L L L L
Gambar 1 Representasi citra digital
Setiap elemen matriks tersebut menunjukkan nilai pixel. Suatu citra digital dengan format grayscale 8 bit memiliki 256 intensitas warna pada setiap pixel-nya.
Nilai pixel tersebut berkisar antara 0 sampai 255, dimana nilai 0 menunjukkan intensitas paling gelap, sedangkan nilai 255 menunjukkan intensitas paling terang.
Citra karakter tulisan tangan yang direpresentasikan sebagai matriks m × n, dikonversi menjadi sebuah vektor kolom yang disebut vektor citra. Transpose dari vektor citra tersebut adalah sebagai berikut :
Normalisasi
Proses pembelajaran JST dapat dikerjakan lebih efisien jika dilakukan praproses tertentu pada input jaringan. Menurut Mathworks (1999), praproses dapat dilakukan dengan cara menormalisasi data. Tujuan normalisasi ini adalah untuk mendapatkan data dengan mean nol dan standar deviasi sama dengan satu.
Jika kumpulan citra pelatihan terdiri dari p citra dan setiap citra Ii berukuran n×n
direpresentasikan sebagai vektor Gi
berdimensi n2, terbentuk matriks A:
A = [G1 G2 ... Gp]
Normalisasi pada matriks A dilakukan dengan langkah-langkah sebagai berikut: 1 Cari mean dari tiap baris matriks A
∑
= = p j ij i pixel p 1 1 μdengan i = 1, 2, ..., n2
2 Cari standar deviasi dari setiap baris matriks A
∑
= − − = p j i ij i pixelp 1 1( )
1 μ
δ
dengan i = 1, 2, ..., n2.
3 Kurangi setiap pixel dengan mean-nya lalu bagi dengan standar deviasi.
i i ij ij pixel normal pixel δ μ ) ( _ = −
dengan i = 1, 2, ..., n2 dan j = 1, 2, ..., p. Jika kumpulan citra pelatihan dinormalisasi menggunakan langkah-langkah di atas, setiap citra input baru G juga harus dinormalisasi dengan menggunakan mean dan standar deviasi setiap baris matriks A.
Jaringan Syaraf Tiruan
Sebuah jaringan syaraf tiruan (JST) adalah sebuah sistem pemrosesan informasi yang mempunyai karakteristik serupa dengan jaringan syaraf biologis (Fausett 1994). Jaringan syaraf tiruan merupakan generalisasi dari pemodelan matematis syaraf biologis, berdasarkan asumsi bahwa:
1 Pengolahan informasi dilakukan oleh elemen-elemen sederhana yang disebut neuron.
2 Sinyal-sinyal disampaikan antar-neuron melalui suatu hubungan komunikasi. 3 Setiap hubungan komunikasi memiliki
bobot tertentu yang akan dikalikan dengan sinyal yang disampaikan melalui hubungan tersebut.
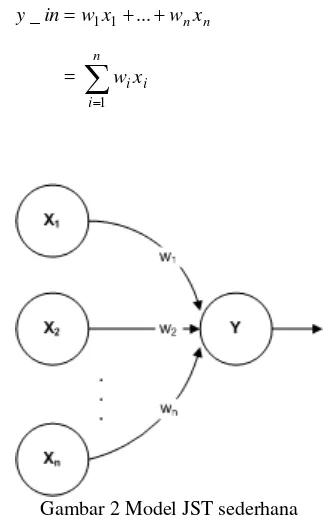
4 Setiap neuron memiliki fungsi aktivasi yang akan menentukan sinyal output terhadap input yang diberikan kepadanya. Sebagai contoh, neuron Y diilustrasikan pada Gambar 2 menerima input dari neuron X1,. .., Xn. Bobot pada hubungan dari X1, …, dan Xn ke neuron Y adalah w1, …, wn. Input untuk neuron ke Y (y_in) adalah jumlah perkalian antara sinyal X1, …, Xn dengan bobotnya sebagai berikut :
n nx w x w in
y_ = 1 1+...+
=
∑
= n i i ix w 1Gambar 2 Model JST sederhana
Nilai aktivasi y dari neuron Y ditentukan oleh fungsi aktivasi terhadap input yang diterimanya, y=f(y_in). Fungsi aktivasi merupakan fungsi yang menentukan level aktivasi, yakni keadaan internal sebuah neuron dalam jaringan. Output aktivasi ini biasanya dikirim sebagai sinyal ke semua neuron pada layer di atasnya.
Propagasi Balik Resilient (RPROP)
Propagasi balik merupakan algoritme pembelajaran yang terawasi (supervised learning) dan biasanya digunakan oleh jaringan multilayer untuk mengubah bobot-bobot yang terhubung dengan semua neuron pada hidden layer (Kusumadewi 2004).
Jaringan propagasi balik memiliki karakteristik sebagai berikut:
• Jaringan multilayer
o Arsitektur yang digunakan adalah
jaringan multilayer, yaitu satu input layer, satu output layer, dan satu atau lebih hidden layer. JST propagasi balik dengan satu hidden layer ditunjukkan oleh Gambar 3. Pada gambar tersebut, input layer ditunjukkan oleh unit-unit Xi, sementara output layer ditunjukkan
oleh unit-unit Yj. Hidden layer
ditunjukkan oleh unit-unit Zk.
o Setiap neuron pada suatu layer dalam
jaringan propagasi balik mendapat sinyal input dari semua neuron pada layer sebelumnya beserta satu sinyal bias.
• Fungsi aktivasi
o Fungsi aktivasi yang umum digunakan
pada JST propagasi balik adalah:
ß Fungsi Sigmoid biner (output-nya memiliki rentang [0,1])
) exp( 1 1 ) ( x x f − + = dengan turunannya )] ( 1 )[ ( ) ( ' x f x f x
f = −
ß Fungsi Sigmoid bipolar (output-nya memiliki rentang [-1,1])
) exp( 1 ) exp( 1 ) ( x x x f − + − − = dengan turunannya )] ( 1 )][ ( 1 [ 2 1 ) ( ' x f x f x
f = + −
Proses pelatihan jaringan propagasi balik melibatkan tiga tahap, yaitu:
• Feedforward
Penghitungan nilai aktivasi. Setiap neuron pada hidden layer dan output layer menghitung masing-masing nilai aktivasinya sesuai dengan fungsi aktivasi yang digunakan.
• Propagasi balik galat
Setiap output neuron menghitung informasi galat antara nilai output yang dihasilkan dan nilai target. Informasi galat ini dikirimkan ke layer di bawahnya (propagasi balik galat).
• Penyesuaian bobot-bobot jaringan
Setiap output neuron dan hidden neuron mengubah bias dan bobot-bobotnya sesuai dengan nilai galat.
Model JST propagasi balik dengan satu hidden layer ditunjukkan pada Gambar 3.
input layer hidden layer output layer X1
Xm
Xi
1 1
v01
v0k
v0p
v11
v1k
v1p
vi1
vik
vip
vm1
vmk
vmp
w01
w0j
w0n
w11
w1j
w1n
wk1
wkj
wkn
wp1
wpj wpn . . . . . . . . . . . . . . . . . . Zp Zk
Z1 Y1
Yj
Yn
Gambar 3 Model JST propagasi balik.
Sebelum proses pelatihan dilakukan, inisialisasi bobot awal merupakan satu hal yang perlu diperhatikan, mengingat nilai bobot awal sangat mempengaruhi kinerja akhir jaringan. Inisialisasi bobot awal dapat dilakukan menggunakan metode Nguyen-Widrow.
Metode Nguyen-Widrow akan menginisialisasi bobot-bobot jaringan dengan nilai antara -0.5 sampai 0.5, sedangkan bobot-bobot dari input layer ke hidden layer dirancang sedemikian rupa sehingga dapat meningkatkan kemampuan hidden layer dalam melakukan proses pelatihan. Metode Nguyen-Widrow dilakukan dengan menentukan terlebih dahulu faktor pengali (β) yang didefinisikan sebagai berikut:
n
p)1 ( 7 . 0 = β
n : jumlah unit input p : jumlah unit tersembunyi
Kemudian inisialisasikan bobot-bobot dari input layer ke hidden layer
) ( ) ( ) ( old V old V new V k ik ik β =
Vik(old)= nilai acak antara -0.5 sampai 0.5
i = 1, 2, ..., m k = 1, 2, ..., p
Di sisi lain, bobot bias (V0k) diinisialisasi
JST yang dibangun dengan struktur multilayer biasanya menggunakan fungsi aktivasi sigmoid. Fungsi aktivasi ini akan membawa input dengan rentang yang tak terbatas ke nilai output dengan rentang terbatas, yaitu antara 0 sampai 1. Salah satu karakteristik dari fungsi sigmoid adalah gradien-nya akan mendekati nol, apabila input yang diberikan sangat banyak. Gradien yang mendekati 0 akan menyebabkan rendahnya perubahan bobot. Apabila bobot-bobot tidak cukup mengalami perubahan, maka algoritme akan sangat lambat untuk mendekati nilai optimumnya (Kusumadewi 2004).
Algoritme RPROP berusaha untuk mengeliminasi besarnya efek dari turunan parsial dengan cara hanya menggunakan tanda turunannya saja dan mengabaikan besarnya nilai turunan. Tanda turunan ini akan menentukan arah perbaikan bobot-bobot. Besarnya perubahan setiap bobot ditentukan oleh suatu faktor yang diatur pada parameter yang disebut Faktor Naik (FN) atau Faktor Turun (FT). Apabila gradien fungsi error berubah tanda dari satu iterasi ke iterasi berikutnya, maka bobot akan berkurang sebesar FT. Sebaliknya, apabila gradienerror tidak berubah tanda dari satu iterasi ke iterasi berikutnya, maka bobot akan bertambah sebesar FN. Apabila gradien error sama dengan 0, maka perubahan bobot sama dengan perubahan bobot sebelumnya.
Pada awal iterasi, besarnya perubahan bobot diinisialisasikan dengan parameter delta0. Besarnya perubahan tidak boleh melebihi batas maksimum yang terdapat pada parameter deltamax, apabila perubahan bobot melebihi maksimum perubahan bobot, maka perubahan bobot akan di set sama dengan maksimum perubahan bobot. Untuk lebih jelasnya algoritme RPROP disajikan pada Lampiran 1.
METODE PENELITIAN
Akuisisi Data
Data awal diambil dari 13 orang dan data yang diambil berupa karakter numeral (0,1,2,…,9) dengan menggunakan media kertas. Dari 13 orang tersebut 10 orang menuliskan karakter sebanyak 2 kali, di mana penulisan pertama digunakan untuk data pelatihan dan penulisan kedua digunakan untuk data pengujian. Tiga orang sisanya hanya menuliskan karakter sebanyak 1 kali, dari 3 orang tersebut karakter tulisan tangan
dari 2 orang digunakan untuk menambah data pelatihan sedangkan karakter tulisan tangan dari 1 orang lainnya digunakan untuk menambah data pengujian. Karakter-karakter tulisan tangan tersebut kemudian diubah menjadi citra digital dengan menggunakan scanner dan setiap karakter disimpan sebagai satu file citra, sehingga didapat 230 buah file citra. Dari data tersebut 120 citra digunakan sebagai data pelatihan dan 110 citra lainnya digunakan sebagai data pengujian. Setiapcitra disimpan dengan komposisi warna grayscale berukuran 50 × 50 pixel.
Tahapan Pengenalan Karakter
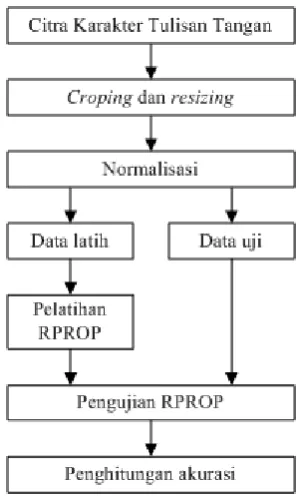
Tahapan proses pengenalan karakter tulisan tangan dapat dilihat pada Gambar 4.
Gambar 4 Tahapan Pengenalan
Pada setiap citra akan dilakukan proses cropping (pemotongan) untuk menghilangkan bagian-bagian dari citra yang kurang penting. Bagian-bagian tersebut adalah sisi-sisi di bagian luar pola yang bukan merupakan pola karakter tulisan tangan.
Dari proses cropping akan dihasilkan ukuran citra yang beragam. Kalau ukuran citra terlalu besar akan memperlambat kinerja sistem. Oleh karena itu, akan dilakukan proses resizing untuk mereduksi dan menyeragamkan ukuran citra input. Citra input akan diseragamkan ukurannya menjadi citra grayscale berukuran 20 × 15. Citra karakter tulisan tangan berukuran 20 × 15 akan direpresentasikan menjadi vektor kolom
berdimensi 300. Dengan demikian seluruh data latih akan direpresentasikan berupa matriks berukuran 300 × 120.
Kemudian dilakukan proses normalisasi data input dengan mengurangi intensitas setiap pixel dengan rataan nilai pixel dimensinya dan dibagi dengan standar deviasinya.
Tahap berikutnya adalah tahap pelatihan JST RPROP dengan menggunakan data pelatihan. Kemudian dilakukan proses pengujian dengan menggunakan parameter-parameter JST yang didapat dari proses pelatihan dan pengujian dilakukan dengan menggunakan data pengujian. Hasil dari proses pengujian berupa tingkat akurasi dan waktu yang dibutuhkan untuk melakukan pengenalan.
Karakteristik JST Yang Digunakan
Pada penelitian ini akan digunakan model JST dengan struktur yang ditunjukkan pada Tabel 1.
Tabel 1 Karakteristik JST yang digunakan
Karakteristik Spesifikasi
Arsitektur 1 hiddenlayer
Neuroninput 300
Hidden neuron 10 sampai 100
Neuronoutput 10
Inisialisasi bobot Nguyen-Widrow Fungsi aktivasi Sigmoid biner delta0 0.07 deltamax 50 Toleransi galat 10-3, 10-4, 10-5, 10-6,
10-7, dan 10-8
FN 1.1, 1.2, 1.3, 1.4, 1.5, dan 1.6
FT 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, dan 0.9 Maksimum epoch 500
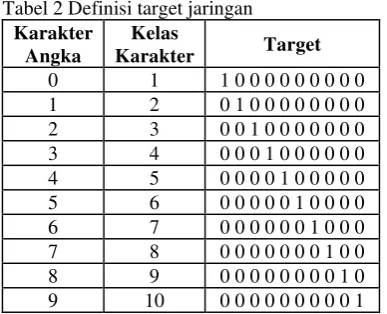
Jumlah output neuron disesuaikan dengan banyaknya kelas target (pada penelitian ini terdapat 10 kelas target). Setiap target akan merepresentasikan satu karakter tulisan tangan. Elemen target ke-i yang bernilai 1 merepresentasikan kelas target ke-i. Definisi target secara lengkap dapat dilihat pada Tabel 2. Misalnya target dengan nilai elemen pertamanya satu dan yang lain nol maka target tersebut merepresentasikan kelas karakter pertama.
Tabel 2 Definisi target jaringan
Karakter Angka
Kelas
Karakter Target
0 1 1 0 0 0 0 0 0 0 0 0 1 2 0 1 0 0 0 0 0 0 0 0 2 3 0 0 1 0 0 0 0 0 0 0 3 4 0 0 0 1 0 0 0 0 0 0 4 5 0 0 0 0 1 0 0 0 0 0 5 6 0 0 0 0 0 1 0 0 0 0 6 7 0 0 0 0 0 0 1 0 0 0 7 8 0 0 0 0 0 0 0 1 0 0 8 9 0 0 0 0 0 0 0 0 1 0 9 10 0 0 0 0 0 0 0 0 0 1
Parameter Penilaian Sistem a Proses Pelatihan Sistem
Parameter-parameter yang dinilai pada proses pelatihan sistem adalah parameter konvergensi JST untuk mengetahui kecepatan sistem dalam mempelajari pola-pola pada data pelatihan baik dalam satuan detik (waktu latih) maupun dalam satuan epoch. Satu epoch adalah satu iterasi pembelajaran semua pola pada data pelatihan.
b Proses Pengenalan Karakter Tulisan Tangan
Pada proses pengenalan karakter tulisan tangan yang akan dinilai adalah waktu yang dibutuhkan untuk melakukan pengenalan.
JST propagasi balik dikenal sebagai JST yang dapat memberikan respon yang cukup baik untuk pola-pola yang serupa tetapi tidak identik dengan pola pembelajaran (Fausett 1994). Pengujian JST untuk pengenalan pola dapat dilakukan dengan generalisasi, yaitu jumlah (dalam %) pola yang berhasil dikenali dengan benar oleh JST. Generalisasi diberikan oleh persamaan berikut (Nugroho 2003):
Jumlah pola yang dikenali
Lingkungan Pengembangan
Sistem dikembangkan dengan menggunakan kompiler Matlab versi 6.5 yang dilengkapi dengan image processing toolbox dan neural network toolbox. Untuk pengolahan citra digunakan perangkat lunak Adobe Photoshop 8.0. Sistem operasi yang digunakan adalah Microsoft Windows XP.
Spesifikasi hardware komputer yang digunakan adalah PC dengan prosesor AMD Athlon 650 MHz, RAM sebesar 256 MB, dan kapasitas harddisk 40 GB.
Jumlah seluruh pola
HASIL DAN PEMBAHASAN
Menentukan Parameter-Parameter JST yang Optimal
Pada penelitian ini dilakukan empat jenis percobaan untuk mengetahui dampak pengubahan karakteristik JST terhadap nilai-nilai parameter konvergensi dan generalisasi. Keempat percobaan ini bertujuan untuk menemukan kombinasi optimal antara hidden neuron , toleransi galat, Faktor Naik (FN) dan Faktor Turun (FT).
1 Percobaan 1: Pengaruh Jumlah Hidden Neuron
Pada percobaan ini jumlah hiddenneuron diubah-ubah dengan tujuan untuk mendapatkan jumlah hidden neuron yang optimal sehingga menghasilkan generalisasi yang baik. Jumlah hidden neuron yang digunakan JST dalam percobaan ini adalah 10, 20, 30, 40, 50, 60, 70, 80, 90, dan 100 neuron. Di sisi lain, toleransi galat ditentukan sebesar 10-5, FN sebesar 1.2, FT sebesar 0.5, sehingga seluruhnya terdapat 10 perlakuan. Proses pelatihan diulang sebanyak 5 kali untuk setiap perlakuan.
Generalisasi maksimum yang dihasilkan JST adalah sebesar 95.45% (105 citra uji dikenal dengan benar). Generalisasi maksimum didapat pada saat jumlah hidden neuron berjumlah 80 (data selengkapnya disajikan pada Lampiran 2). Dari 5 kali pengulangan, generalisasi rata-rata terbesar juga dicapai pada jumlah hidden neuron sebanyak 80. Grafik hubungan antara jumlah hidden neuron terhadap rata-rata generalisasi dapat dilihat pada Gambar 5.
70 72 74 76 78 80 82 84 86 88 90 92 94
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G e n e ra li s a s i R a ta -r a ta (% )
Gambar 5 Grafik perbandingan generalisasi rata-rata terhadap jumlah hidden neuron
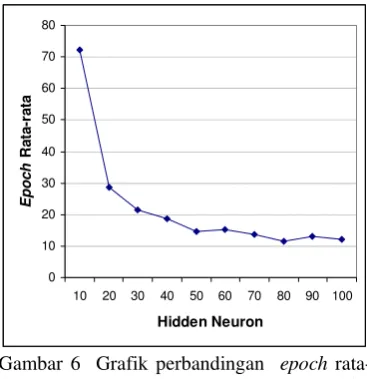
Dari Gambar 6 dapat diketahui jumlah epoch cenderung mengecil seiring dengan penambahan jumlah hidden neuron. Semakin banyak jumlah hidden neuron maka akan semakin banyak pula hubungan antar neuron-neuron sehingga akan semakin banyak pula proses perhitungan yang harus dilakukan. Dari percobaan yang dilakukan, epoch yang diperlukan untuk mencapai toleransi galat cenderung untuk mengecil jika jumlah hidden neuron diperbesar.
0 10 20 30 40 50 60 70 80
10 20 30 40 50 60 70 80 90 100
Hidden Neuron E poc h R a ta -r a ta
Gambar 6 Grafik perbandingan epoch rata-rata terhadap jumlah hidden neuron
Jumlah epoch minimum sebesar 10 epoch dicapai pada hidden neuron sebanyak 80, 90, dan 100. Dari 5 kali pengulangan diperoleh rata-rata epoch 80 hidden neuron sebesar 11.6, rata-rata epoch untuk 90 dan 100 hidden neuron adalah sebesar 13.2 dan 12.2. Hal ini menunjukkan bahwa JST dengan 80 hidden neuron menghasilkan menghasilkan epoch yang lebih kecil dibandingkan JST dengan 90 atau 100 hidden neuron.
Dari uraian di atas diketahui bahwa arsitektur JST dengan 80 hidden neuron dapat menghasilkan tingkat generalisasi tertinggi dengan epoch terkecil sehingga merupakan pilihan terbaik.
2 Percobaan 2: Pengaruh Toleransi Galat Percobaan selanjutnya bertujuan untuk menentukan toleransi galat yang optimal, sehingga didapatkan sistem dengan generalisasi yang baik.
Sistem akan diuji menggunakan JST dengan 80 hiddenneuron, FN sebesar 1.2, FT sebesar 0.5, dan 6 nilai toleransi galat yang berbeda yaitu 10-3, 10-4, 10-5, 10-6, 10-7, dan 10-8, yang masing-masing akan diulang sebanyak 5 kali.
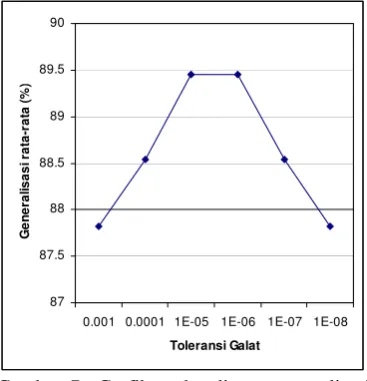
Dari Gambar 7 dapat dilihat bahwa generalisasi rata-rata meningkat seiring dengan penurunan toleransi galat. Ini menunjukkan bahwa dengan menurunkan toleransi galat maka tingkat akurasi JST akan semakin tinggi, walaupun peningkatan generalisasinya tidak terlalu besar. Hanya saja pada saat toleransi galat 10-6 mulai terlihat gejala sistem yang overfit. Hal ini tampak pada penggunaan toleransi galat sebesar 10-6 tidak terjadi peningkatan generalisasi rata-rata, bahkan pada pemilihan nilai toleransi galat yang lebih kecil dari 10-6 terjadi penurunan generalisasi rata-rata pada toleransi galat sebesar 10-7 dan 10-8. Gejala sistem overfit timbul disebabkan sistem mulai terlalu spesifik mempelajari pola pada data pelatihan (seen data), sehingga sulit untuk mempelajari pola-pola baru pada data pengujian (unseen data).
Generalisasi tertinggi didapat pada toleransi galat sebesar 10-5 yaitu sebesar 91.82% (hasil selengkapnya disajikan pada Lampiran 3).
87 87.5 88 88.5 89 89.5 90
0.001 0.0001 1E-05 1E-06 1E-07 1E-08
Toleransi Galat
G
en
eral
isas
i rat
a-rat
a (
%
)
Gambar 7 Grafik perbandingan generalisasi rata-rata terhadap toleransi galat
Jumlah epoch rata-rata meningkat seiring dengan penurunan toleransi galat (Gambar 8). Hal ini disebabkan karena semakin kecil toleransi galat maka proses penghitungan untuk mencapai toleransi galat akan semakin banyak. Karena perbedaan jumlah epoch rata-rata antara keenam nilai toleransi galat yang dicobakan tidak besar dan keenamnya menghasilkan rata-rata epoch yang cukup kecil, maka parameter toleransi galat optimal dapat dipilih dari nilai toleransi galat yang mencapai generalisasi rata-rata tertinggi.
0 2 4 6 8 10 12 14 16
0.001 0.0001 0.00001 1E-06 1E-07 1E-08
Toleransi Galat
Ep
o
c
h
r
a
ta
-r
a
ta
Gambar 8 Grafik perbandingan epoch rata-rata terhadap toleransi galat
Dari hasil ini diketahui bahwa dengan menggunakan toleransi galat sebesar 10-5 cukup untuk menghasilkan sistem dengan generalisasi yang tinggi.
Dari hasil dari percobaan 1 dan 2 dapat diambil kesimpulan bahwa JST dengan 80 hidden neuron dan toleransi galat 10-5 merupakan parameter-parameter yang optimal bagi sistem.
3 Percobaan 3 : Pengaruh Faktor Naik (FN) Percobaan selanjutnya bertujuan untuk menentukan parameter FN yang optimal, sehingga dapat menghasilkan sistem yang stabil dan memiliki tingkat generalisasi yang tinggi.
Sesuai dengan hasil dari percobaan sebelumnya, pada percobaan ini akan digunakan JST dengan 80 hidden neuron, toleransi galat 10-5, dan FT sebesar 0.5 yang masing-masing akan diulang sebanyak 5 kali. Sedangkan nilai FN yang akan diuji adalah 1.1, 1.2, 1.3, 1.4, 1.5, dan 1.6. Data selengkapnya dapat dilihat pada Lampiran 4.
0 10 20 30 40 50 60 70 80 90 100
1.1 1.2 1.3 1.4 1.5 1.6
Faktor Naik Ge n e ra li sa si r a ta -r at a ( % )
Gambar 9 Grafik perbandingan generalisasi rata-rata terhadap FN
Epoch minimum dicapai oleh FN sebesar 1.1 dan 1.2, yaitu 9 epoch, sedangkan rata-rata epoch minimum dicapai pada nilai FN sebesar 1.1 yaitu 10 epoch.Jika dilihat pada Gambar 10, dengan memperbesar nilai FN jumlah epoch juga akan semakin besar. Perbedaan jumlah epoch rata-rata dari nilai FN sebesar 1.1 sampai dengan 1.4 tidak begitu signifikan. Tetapi dengan memperbesar nilai FN dari 1.5 ke 1.6 terjadi peningkatan jumlah epoch yang cukup besar, rata-rata epoch naik sampai 39 epoch. Pemilihan nilai FN sebesar 1.2 dapat menghasilkan generalisasi yang tinggi dengan epoch yang cukup kecil.
0 10 20 30 40 50 60 70
1.1 1.2 1.3 1.4 1.5 1.6
Faktor Naik Ep o c h r a ta-r ata
Gambar 10 Grafik perbandingan epoch rata-rata terhadap FN
Dari uraian di atas, pemilihan nilai FN 1.2 mampu menghasilkan sistem yang stabil dengan generalisasi yang tinggi. Dari hasil dari percobaan 1, 2 dan 3 dapat diambil kesimpulan bahwa JST dengan 80 hidden
neuron, toleransi galat sebesar 10-5 dan FN sebesar 1.2 merupakan parameter-parameter yang optimal bagi sistem.
.
4 Percobaan 4 : Pengaruh Faktor Turun (FT)
Percobaan selanjutnya bertujuan untuk menentukan nilai parameter FT yang optimal. Pada percobaan ini, akan diuji 9 nilai parameter FT yaitu 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, dan 0.9 yang masing-masing akan diulang sebanyak 5 kali. Di lain pihak, berdasarkan hasil dari percobaan sebelumnya akan digunakan parameter JST dengan 80 hidden neuron, toleransi galat 10-5, dan FN sebesar 1.2.
Dengan memperbesar nilai FT dari 0.1 sampai dengan 0.7 memang menaikkan generalisasi rata-rata, akan tetapi dengan nilai FT yang lebih besar dari 0.7 terjadi penurunan generalisasi rata-rata. Dari percobaan ini generalisasi tertinggi didapat pada FT sebesar 0.7 yaitu sebesar 94.55% (hasil selengkapnya disajikan pada Lampiran 5). Pada Gambar 11 dapat dilihat grafik perbandingan generalisasi rata-rata terhadap FT.
0 10 20 30 40 50 60 70 80 90 100
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Faktor Turun Ge n e ra li sa si r a ta -r at a ( % )
Gambar 11 Grafik perbandingan generalisasi rata-rata terhadap FT
Epoch minimum dicapai pada FT sebesar 0.5, 0.6, dan 0.7 yaitu 10 epoch, sedangkan jika dilihat dari epoch rata-rata, FT sebesar 0.5 menghasilkan epoch rata-rata 13.8, FT sebesar 0.6 dan 0.7 menghasilkan epoch rata-rata masing-masing sebesar 11 dan 11.8. Dapat dilihat pada Gambar 12, dengan menaikkan nilai FT dari 0.1 sampai dengan 0.7 jumlah epoch rata-rata cenderung untuk turun walaupun perbedaannya tidak besar. Penggunaan nilai FT sebesar 0.8 dan 0.9 terjadi penaikkan jumlah epoch rata-rata,
bahkan dengan menggunakan FN sebesar 0.9 epoch rata-rata naik hingga 113.2 epoch.
0 20 40 60 80 100 120 140
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Faktor Turun Ep o c h r a ta -r a ta (% )
Gambar 12 Grafik perbandingan epoch rata-rata terhadap FT
Dari uraian di atas, pemilihan nilai FT sebesar 0.7 merupakan pilihan yang tepat karena menghasilkan generalisasi yang tinggi dengan epoch yang cukup kecil, sehingga dapat dipilih nilai FT yang optimal yaitu sebesar 0.7.
Menguji Parameter-Parameter JST yang Optimal
Parameter-parameter optimal yang didapat dari percobaan-percobaan sebelumnya digunakan untuk menguji sistem. Parameter-parameter tersebut yaitu, JST dengan 80 hidden neuron, toleransi galat sebesar 10-5, FN sebesar 1.2 dan FT sebesar 0.7. Pengujian diulang sebanyak 5 kali, grafik generalisasi pada setiap ulangan dapat dilihat pada Gambar 13. 85 86 87 88 89 90 91 92 93 94 95
1 2 3 4 5
Ulangan ke-G e n e ra lis a s i ( % )
Gambar 13 Grafik generalisasi pada setiap ulangan
Pada pengujian ini, generalisasi tertinggi didapat pada ulangan pertama yaitu sebesar 93.64% (103 dari 110 citra dikenali dengan benar). Dari 5 kali pengulangan diperoleh rata-rata generalisasi 91.64%, rata-rata epoch 12.6, rata-rata waktu pelatihan 1.8726 detik dan rata-rata waktu uji 0.052 detik. Hasil selengkapnya disajikan pada Lampiran 6.
Kelebihan dan Keterbatasan Sistem
Kelebihan sistem. Dengan pemilihan parameter-parameter JST yang baik (dalam penelitian ini digunakan 80 hidden neuron, toleransi galat sebesar 10-5, FN sebesar 1.2 dan FT sebesar 0.7) sistem dapat mengenali citra-citra uji dengan tingkat akurasi sebesar 93.64%, rata-rata waktu pelatihan 1.8726 detik dan rata-rata waktu uji 0.052 detik.
Pemilihan parameter-parameter JST tersebut dapat dilakukan dengan lebih mudah karena sistem dibangun dengan menggunakan graphical user interface (GUI), sehingga mudah digunakan dan user friendly.
Keterbatasan sistem. Sistem masih mempunyai keterbatasan yaitu belum tersedianya fasilitas untuk menambah data baru secara otomatis.
Perbandingan dengan Penelitian Sebelumnya
Pada penelitian yang dilakukan Nugroho (2003), dilakukan perbandingan metode-metode praproses untuk mereduksi dimensi, mengekstraksi ciri dan mengukur jarak antara 2 vektor citra atau lebih. Penelitian tersebut membandingkan metode tanpa ekstraksi, metode Euclidean, dan metode Principal Component Analysis (PCA), sedangkan model JST yang digunakan adalah JST propagasi balik standar. Data untuk pelatihan dan pengujian digunakan data yang sama, sehingga tingkat akurasi yang didapat cukup tinggi.
Dari hasil yang didapat dari penelitian tersebut, generalisasi tertinggi dicapai oleh metode tanpa ekstraksi dan metode Euclidean yaitu sebesar 98.5% dan 98.8%. Untuk semua metode yang dicobakan, pada epoch ke-1000 belum bisa mencapai target. Bisa dikatakan JST propagasi balik standar yang dipakai dalam penelitian tersebut memerlukan lebih dari 1000 epoch untuk melakukan pelatihan citra-citra karakter tulisan tangan.
didapat pada penelitian ini, menunjukkan bahwa generalisasi tertinggi sebesar 93.64%. Generalisasi yang didapat memang lebih kecil dari penelitian sebelumnya, karena pada penelitian ini data untuk pelatihan berbeda dengan data untuk pengujian. Di lain pihak, epoch rata-rata yang diperlukan untuk melakukan pelatihan citra-citra karakter tulisan tangan hanya 12.6 epoch.
Semakin besar epoch maka semakin besar pula waktu yang dibutuhkan dalam pelatihan JST. Jika dibandingkan dengan penelitian sebelumnya yang menggunakan JST propagasi balik standar, JST RPROP yang digunakan dalam penelitian ini menghasilkan epoch yang sangat kecil, sehingga JST RPROP dapat melakukan pelatihan citra-citra karakter tulisan tangan jauh lebih cepat dibanding JST propagasi balik standar, dengan tingkat generalisasi yang cukup tinggi.
Perbandingan hasil yang diperoleh dalam penelitian ini dengan penelitian sebelumnya dapat dilihat pada Tabel 3.
Tabel 3 Perbandingan dengan penelitian sebelumnya
Model Generalisasi (%) Epoch
RPROP
• Tanpa ekstraksi
Propagasi balik standar
• Tanpa ekstraksi
• PCA 70%
• PCA 85%
• Euclidean
93.64
98.5 91 95.4 98.8
12.6
1000+ 1000+ 1000+ 1000+
KESIMPULAN DAN SARAN
Kesimpulan
Jaringan syaraf tiruan propagasi balik resilient dapat melakukan pembelajaran dengan jumlah epoch yang sedikit dan melakukan pengenalan terhadap suatu pola dengan tingkat generalisasi yang tinggi.
Jaringan syaraf tiruan dikembangkan dengan nilai-nilai parameter sebagai berikut: 80 hidden neuron, toleransi galat sebesar 10-5, Faktor Naik sebesar 1.2 dan Faktor Turun sebesar 0.7 memberikan hasil yang baik.
Sistem mampu melakukan pengenalan dengan tingkat generalisasi tertinggi sebesar 93.64% dicapai dengan waktu rata-rata 0.052 detik. Rata-rata waktu yang diperlukan untuk
melatih seluruh citra pelatihan sebesar 1.8726 detik dan rata-rata epoch sebesar 12.6.
Saran
Penelitian ini masih dapat dikembangkan untuk menciptakan sistem baru yang lebih baik. Saran-saran bagi penelitian lebih lanjut antara lain:
• Pengujian dilakukan secara real time.
• Melakukan penambahan pola citra untuk melihat kinerja sistem dengan jumlah data yang besar.
DAFTAR PUSTAKA
Fauset, L. 1994. Fundamentals of Neural Networks. Prentice-Hall, New Jersey. Gonzales, R. C. & Woods, R. E. 2002. Digital
Image Processing. Addison Wasley, Massachussets.
Kusumadewi, S. 2004. Membangun Jaringan Syaraf Tiruan Menggunakan MATLAB & Excel Link. Yogyakarta: Graha Ilmu. Mathworks Inc. 1999. Neural Network for
Use With Matlab. Natick: The Mathworks Inc.
Nugroho, M. A. 2003. Perbandingan Beberapa Metode Praproses Pada Pengenalan Karakter Tulisan Tangan Menggunakan Jaringan Syaraf Tiruan Propagasi Balik. Skripsi. Jurusan Ilmu Komputer Fakultas Matematika Dan Ilmu Pengetahuan Alam Institut Pertanian Bogor, Bogor.
Riedmiller, M & Braun, H. 1993. A Direct Adaptive Method For Faster Backpropagation Learning : The RPROP Algorithm.
http://citeseer.ifi.unizh.ch/riedmiller93dire ct.html. [22 Mei 2006]
Tay, Y.H & Marzuki K. 1997. Comparison of Fuzzy ARTMAP and MLP Neural Network for Hand-written Character Recognition. http://citeseer.ifi.unizh.ch/tay97compariso n.html. [22 Mei 2006]
Lampiran 1 Algoritme JST RPROP
Langkah 0. Inisialisasi bobot
Langkah 1. Selama syarat henti salah, lakukan langkah 2-9
Langkah 2. Untuk setiap pasangan pelatihan (masukan dan target), lakukan langkah 3-8
Langkah 3. Setiap unit masukan (Xi, i=1, …,n) menerima sinyal masukan xi dan meneruskannya ke seluruh unit pada lapisan diatasnya (hidden unit).
Langkah 4. Setiap unit tersembunyi (Zj, j=1, …,p) menghitung total sinyal masukan terbobot,
∑
= + = n i ij i jj v xv
in z
1 0
_ ,
lalu menghitung sinyal keluarannya dengan fungsi aktivasi,
(
j)
j f z in
z = _ ,
dan mengirimkan sinyal ini ke seluruh unit pada lapisan atasnya (lapisan output). Langkah 5. Setiap unit output (Yk, k=1, …,m) menghitung total sinyal masukan terbobot,
∑
= + = p j jk j kk w x w
in y
1 0
_ ,
lalu menghitung sinyal keluaran dengan fungsi aktivasi,
(
k)
k f y in
y = _
Langkah 6. Setiap unit output (Yk, k=1, …, m) menerima sebuah pola target yang sesuai dengan pola masukan pelatihannya. Unit tersebut menghitung informasi kesalahan,
(
k k) (
k)
k t y f y_in
' − = δ j k
jk δ z
ϕ2 =
k
k δ
β2 =
) ( 2 2
2jk ϕ jk ϕ jk old
ϕϕ = ∗
) ( 2 2
2k β k β k old
ββ = ∗
kemudian menghitung koreksi bobot (digunakan untuk mengubah wjk nanti),
⎪ ⎩ ⎪ ⎨ ⎧ Δ = Δ ); ( ; ; old w FT FN w jk jk 0 2 0 2 0 2 = < > jk jk jk ϕϕ ϕϕ ϕϕ
(
, max)
min w delta wjk = Δ jk
Δ ⎪ ⎩ ⎪ ⎨ ⎧ Δ Δ − = Δ ; 0 ; ; jk jk jk w w w 0 2 0 2 0 2 = < > jk jk jk ϕ ϕ ϕ
hitung juga koreksi bias (yang nantinya akan digunakan untuk memperbaiki nilai b2k) ⎪ ⎩ ⎪ ⎨ ⎧ Δ = Δ ); ( 2 ; ; 2 old b FT FN b k k 0 2 0 2 0 2 = < > k k k ββ ββ ββ
(
2 , max)
min
2 b delta
b k = Δ k
Lampiran 1 Lanjutan
Langkah 7. Setiap unit tersembunyi (Zj, j=1, …, p) menghitung selisih input (dari unit-unit pada layer atasnya)
∑
= = m k jk k j w in 1 _ δ δlalu mengalikannya dengan turunan fungsi aktivasi untuk menghitung informasi errornya
(
j)
jj _in f' z_in
1 δ
δ =
j j
ij 1 x
1 δ ϕ = j j 1 1 δ β = ) ( 1 1
1ij ϕ ij ϕ ij old
ϕϕ = ∗
) ( 1 1
1j β j β j old
ββ = ∗
kemudian hitung koreksi bobot (yang nantinya akan digunakan untuk memperbaiki nilai vij) ⎪ ⎩ ⎪ ⎨ ⎧ Δ = Δ ); ( ; ; old v FT FN v ij ij 0 1 0 1 0 1 = < > ij ij ij ϕϕ ϕϕ ϕϕ
(
, max)
min v delta vij = Δ ij
Δ ⎪ ⎩ ⎪ ⎨ ⎧ Δ Δ − = Δ ; 0 ; ; jk ij ij w v v 0 1 0 1 0 1 = < > ij ij ij ϕ ϕ ϕ
hitung juga koreksi bias (yang nantinya akan digunakan untuk memperbaiki nilai b1j)
⎪ ⎩ ⎪ ⎨ ⎧ Δ = Δ ); ( 1 ; ; 1 old b FN FT b j j 0 1 0 1 0 1 = < > j j j ββ ββ ββ
(
1 , max)
min1 b delta
b j = Δ j
Δ ⎪ ⎩ ⎪ ⎨ ⎧ Δ Δ = Δ ; 0 ; 1 ; 1 1 j j j b b b 0 1 0 1 0 1 = < > j j j β β β
Langkah 8. Setiap unit output (Yk, k=1, …, m) mengubah bias dan bobot-bobotnya (j=0, …, p) jk
jk
jk new w old w
w ( )= ( )+Δ
k k
k new b old b
b2 ( )= 2 ( )+Δ 2
Setiap unit tersembunyi (Zj, j=1, …, p) mengubah bias dan bobot-bobotnya (i=1, …, n)
ij ij
ij new v old v
v ( )= ( )+Δ
j j
j new b old b
b1 ( )= 1 ( )+Δ 1
Langkah 9. Uji syarat henti:
Jika besar mean square error
∑
(
= − n k k k y t n 1 2 1
)
lebih kecil dari toleransi yang telah
Lampiran 2 Tabel percobaan jumlah hidden neuron dengan toleransi galat 10-5, Faktor Naik sebesar 1.2 dan Faktor Turun sebesar 0.5
Pelatihan Pengujian Hidden
Neuron
Ulangan
ke- Waktu
Latih Epoch
Waktu
Uji Dikenal
Tidak Dikenal
Generalisasi (%)
1 2.143 51 0.04 82 28 74.55
2 2.834 70 0.03 67 43 60.91
3 2.654 65 0.04 84 26 76.36
4 3.445 87 0.04 80 30 72.73
10
5 3.495 88 0.03 76 34 69.09
1 1.763 32 0.03 87 23 79.09
2 1.412 25 0.04 89 21 80.91
3 1.583 27 0.03 88 22 80.00
4 1.512 26 0.04 87 23 79.09
20
5 1.833 33 0.04 86 24 78.18
1 1.442 19 0.04 90 20 81.82
2 1.282 17 0.03 92 18 83.64
3 1.923 27 0.04 97 13 88.18
4 1.652 23 0.04 90 20 81.82
30
5 2.434 21 0.04 94 16 85.45
1 1.372 15 0.04 101 9 91.82
2 1.842 22 0.04 96 14 87.27
3 1.842 22 0.03 98 12 89.09
4 1.582 18 0.04 102 8 92.73 40
5 1.543 17 0.04 92 18 83.64
1 1.352 12 0.05 100 10 90.91
2 1.382 12 0.04 97 13 88.18
3 1.562 14 0.04 97 13 88.18
4 1.603 15 0.04 100 10 90.91 50
5 1.983 20 0.05 95 15 86.36
1 2.243 20 0.05 99 11 90.00
2 1.843 16 0.04 96 14 87.27
3 1.492 12 0.04 94 16 85.45
4 1.933 16 0.05 89 21 80.91
60
5 1.542 12 0.05 100 10 90.91
1 1.903 14 0.05 95 15 86.36
2 1.572 11 0.05 101 9 91.82
3 2.444 19 0.05 94 16 85.45
4 1.762 13 0.05 100 10 90.91 70
5 1.652 12 0.05 98 12 89.09
Lampiran 2 Lanjutan
Pelatihan Pengujian Hidden
Neuron
Ulangan
ke- Waktu
Latih Epoch
Waktu
Uji Dikenal
Tidak Dikenal
Generalisasi (%)
1 1.973 13 0.04 98 12 89.09
2 1.573 10 0.05 97 13 88.18
3 2.073 14 0.05 101 9 91.82 4 1.682 11 0.05 105 5 95.45 80
5 1.572 10 0.05 103 7 93.64 1 2.203 12 0.05 102 8 92.73 2 2.274 17 0.05 102 8 92.73
3 2.654 16 0.06 97 13 88.18
4 1.873 10 0.05 98 12 89.09
90
5 1.993 11 0.05 99 11 90.00
1 2.283 12 0.06 97 13 88.18
2 2.934 16 0.05 98 12 89.09
3 1.943 10 0.05 99 11 90.00
4 2.484 13 0.06 100 10 90.91 100
Lampiran 3 Tabel percobaan toleransi galat dengan 80 hidden neuron, Faktor Naik sebesar 1.2 dan Faktor Turun sebesar 0.5
Pelatihan Pengujian Toleransi
Galat
Ulangan
ke- Waktu
Latih Epoch Waktu Uji Dikenal
Tidak Dikenal
Generalisasi (%)
1 2.293 15 0.04 96 14 87.27
2 1.642 10 0.04 99 11 90.00
3 1.282 7 0.05 92 18 83.64
4 1.372 8 0.05 98 12 89.09
10-3
5 1.252 7 0.05 95 15 86.36
1 2.113 14 0.04 99 11 90.00
2 1.872 12 0.05 96 14 87.27
3 1.943 12 0.05 99 11 90.00
4 1.372 8 0.05 96 14 87.27
10-4
5 1.462 8 0.05 97 13 88.18
1 1.953 13 0.05 99 11 90.00
2 1.833 12 0.04 97 13 88.18
3 2.073 13 0.04 99 11 90.00
4 1.773 11 0.05 101 9 91.82
10-5
5 2.013 13 0.04 96 14 87.27
1 2.163 14 0.04 97 13 88.18
2 1.913 12 0.04 99 11 90.00
3 1.953 13 0.05 99 11 90.00
4 2.233 15 0.05 97 13 88.18
10-6
5 2.053 13 0.05 100 10 90.91
1 2.154 14 0.05 96 14 87.27
2 2.253 15 0.05 97 13 88.18
3 2.123 14 0.05 96 14 87.27
4 2.504 17 0.04 98 12 89.09
10-7
5 2.293 15 0.05 100 10 90.91
1 2.203 13 0.04 96 14 87.27
2 2.033 13 0.05 98 12 89.09
3 2.284 15 0.05 99 11 90.00
4 2.033 13 0.05 94 16 85.45
10-8
5 2.404 16 0.04 96 14 87.27
Lampiran 4 Tabel percobaan Faktor Naik dengan 80 hidden neuron, toleransi galat 10-5 dan Faktor Turun sebesar 0.5
Pengujiam Pengujian Faktor
Naik
Ulangan
ke- Waktu
Latih Epoch
Waktu
Uji Dikenal
Tidak Dikenal
Generalisasi (%)
1 1.582 10 0.05 99 11 90.00
2 1.522 9 0.05 101 9 91.82
3 1.622 10 0.05 98 12 89.09 4 1.733 11 0.05 99 11 90.00 1.1
5 1.672 10 0.04 98 12 89.09 1 2.173 14 0.05 98 12 89.09
2 1.552 9 0.05 102 8 92.73
3 2.263 15 0.05 97 13 88.18 4 1.922 12 0.05 99 11 90.00 1.2
5 1.752 11 0.05 101 9 91.82
1 1.773 11 0.05 98 12 89.09 2 2.133 14 0.05 99 11 90.00 3 1.983 13 0.05 95 15 86.36
4 1.743 11 0.04 101 9 91.82
1.3
5 1.983 13 0.05 102 8 92.73
1 2.534 17 0.05 92 18 83.64 2 2.053 13 0.05 94 16 85.45 3 2.704 19 0.05 95 15 86.36 4 1.912 12 0.05 99 11 90.00 1.4
5 1.762 11 0.05 89 21 80.91 1 2.163 15 0.05 94 16 85.45 2 2.524 17 0.05 95 15 86.36 3 3.155 23 0.05 92 18 83.64 4 2.593 18 0.05 84 26 76.36 1.5
5 4.297 38 0.05 85 25 77.27 1 6.689 53 0.05 62 48 56.36 2 8.933 73 0.04 76 34 69.09 3 7.050 58 0.05 62 48 56.36 4 6.399 52 0.05 73 37 66.36 1.6
Lampiran 5 Tabel percobaan Faktor Turun dengan 80 hidden neuron, toleransi galat 10-5 dan Faktor Naiksebesar 1.2
Pelatihan Pengujian Faktor
Turun
Ulangan
ke- Waktu
Latih Epoch
Waktu
Uji Dikenal
Tidak Dikenal
Generalisasi (%)
1 3.545 28 0.04 91 19 82.73
2 3.746 30 0.04 90 20 81.82
3 2.954 22 0.05 95 15 86.36
4 3.535 28 0.04 91 19 82.73
0.1
5 3.926 31 0.04 94 16 85.45
1 2.223 16 0.04 94 16 85.45
2 2.033 15 0.04 94 16 85.45
3 3.735 28 0.05 94 16 85.45
4 2.534 18 0.05 96 14 87.27
0.2
5 3.405 27 0.05 99 11 90.00
1 2.283 15 0.04 94 16 85.45
2 2.694 20 0.04 102 8 92.73
3 3.425 27 0.04 98 12 89.09
4 1.753 11 0.05 98 12 89.09
0.3
5 1.742 12 0.05 94 16 85.45
1 2.163 16 0.05 98 12 89.09
2 1.732 12 0.05 96 14 87.27
3 2.374 17 0.05 97 13 88.18
4 1.652 11 0.04 95 15 86.36
0.4
5 1.602 11 0.05 102 8 92.73
1 2.253 16 0.05 100 10 90.91
2 1.762 12 0.05 97 13 88.18
3 1.592 10 0.05 101 9 91.82
4 2.193 15 0.04 99 11 90.00
0.5
5 2.143 16 0.05 99 11 90.00
1 1.782 11 0.05 102 8 92.73
2 1.482 10 0.05 99 11 90.00
3 1.822 13 0.04 97 13 88.18
4 1.573 11 0.05 99 11 90.00
0.6
5 1.543 10 0.04 101 9 91.82
1 1.943 13 0.04 102 8 92.73
2 1.672 11 0.05 96 14 87.27
3 1.573 10 0.05 103 7 93.64
4 2.012 13 0.05 104 6 94.55
0.7
5 1.723 12 0.05 101 9 91.82
1 2.283 16 0.05 94 16 85.45
2 2.113 16 0.04 98 12 89.09
3 2.984 21 0.05 100 10 90.91
4 2.503 18 0.05 99 11 90.00
0.8
5 2.193 16 0.05 98 12 89.09
1 3.895 30 0.04 97 13 88.18
2 16.104 141 0.05 81 29 73.64
3 16.884 151 0.05 74 36 67.27
4 16.714 148 0.05 71 39 64.55
0.9
5 15.372 133 0.04 51 59 46.36
Lampiran 6 Hasil pengujian menggunakan parameter-parameter JST yang optimal
Pelatihan Pengujian Ulangan
Pembelajaran
ke- Waktu Latih Epoch Waktu Uji Dikenal Dikenal Tidak Generalisasi (%)
1 1.973 11 0.10 103 7 93.64
2 1.752 12 0.04 100 10 90.91
3 1.993 15 0.04 101 9 91.82
4 1.893 13 0.04 100 10 90.91