JARINGAN SARAF TIRUAN UNTUK PREDIKSI
TINGKAT KELULUSAN MAHASISWA DIPLOMA
PROGRAM STUDI MANAJEMEN INFORMATIKA
UNIVERSITAS NEGERI GORONTALO
LILLYAN HADJARATIE
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis Jaringan Saraf Tiruan untuk Prediksi Tingkat Kelulusan Mahasiswa Diploma Program Studi Manajemen Informatika Universitas Negeri Gorontalo adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun yang tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam daftar pustaka di bagian akhir tesis ini.
Bogor, Juli 2011
Lillyan Hadjaratie
ABSTRACT
LILLYAN HADJARATIE. Artificial Neural Network on graduation rate prediction for Informatic Management diploma students of Gorontalo State University. Under direction of KUDANG BORO SEMINAR and AZIZ KUSTIYO.
In this research is made a system of student graduation rate prediction using artificial neural network and back propagation method. Predicted graduation rate is length of study and grade point average. The Input variables is the value of 16 subjects in the first year program. Output variables are 2 categories for the length of study and 3 categories for grade point average. The aims of this research are to get the best parameters and architecture of artificial neural network, to predict student graduation rate and to measure the input variable sensitivity. To obtain a convergent learning outcomes, has done some trial and error with several variations the number of hidden node, learning rate and training function, to generate the high level of data. The result shows, graduation rate prediction using artificial naural network with back propagation method has good result, which 100.00% validation data generalization and 93.94% testing data generalization for lenght of study prediction model, and 96.67% validation data generalization and 100% testing data generalization for grade point average prediction model. The best parameters and architecture from the both of prediction models generated by training in second data group and levenbarg-marquardt training functions. Length of study prediction model, optimal on learning rate 0.1 and number of hidden node 10, and grade point average prediction models optimal on learning rate 0.05 and number of hidden node 15. The sensitivity analysis results that subject as input variables, which have the most impact is Aljabar Vector and Matriks.
RINGKASAN
LILLYAN HADARATIE. Tesis Jaringan Saraf Tiruan untuk Prediksi Tingkat Kelulusan Mahasiswa Diploma Program Studi Manajemen Informatika Universitas Negeri Gorontalo. Dibimbing oleh KUDANG BORO SEMINAR dan AZIZ KUSTIYO.
Tingkat kelulusan mahasiswa D3 Manajemen Informatika UNG sejak lulusan angkatan pertama tahun 2000 hingga dengan tahun 2007 menunjukkan persentase rata-rata jumah mahasiswa lulusan yang menyelesaikan studi tepat waktu yakni 3 (tiga) tahun hanya sebesar 14% dan sisanya sebesar 86% menyelesaikan studi dengan melewati batas studi yang ditetapkan. Begitupula dengan pencapaian IPK lulusan dari tahun 2000 hingga tahun 2007, lulusan dengan IPK > 3.00 hanya mencapai 42%, dan berdasarkan status predikat lulusan, persentase IPK lulusan di atas 3.50 (predikat terpuji) hanya sebesar 9%, persentase IPK kisaran 2.75 hingga 3.50 (predikat sangat memuaskan) sebesar 62%, selebihnya IPK di bawah 2.75 (predikat memuaskan) sebesar 29%. Sasaran mutu yang ditetapkan oleh universitas sebagai standar lama studi dan IPK adalah persentase lulusan tepat waktu (3 tahun) minimal 50%, pencapaian IPK lebih dari 3.00 minimal 65% dan lulusan dengan predikat terpuji memiliki persentase lebih besar dari lulusan dengan predikat memuaskan (Universitas Negeri Gorontalo, 2009).
Data faktual yang telihat masih dibawah sasaran mutu yang ditetapkan. Kondisi tersebut mendorong program studi untuk terus melakukan evaluasi dan langkah strategis dalam upaya meningkatkan tingkat kelulusan mahasiswa agar sasaran mutu bisa tercapai. Evaluasi akhir semester dan akhir program yang merupakan evaluasi rutin program studi perlu ditingkatkan dengan dibuatnya sistem prediksi tingkat kelulusan pada tahun pertama penyelenggaraan proses perkuliahan. Dengan diketahuinya hasil prediksi tingkat kelulusan di tahun pertama program, dapat dijadikan informasi dan bahan pertimbangan program studi dalam pengambilan keputusan dan tindak lanjut sekiranya hasil prediksi masih jauh dari sasaran mutu yang telah ditetapkan.
Tujuan penelitian ini untuk mendapatkan parameter dan arsitektur jaringan saraf tiruan yang terbaik, melakukan prediksi tingkat kelulusan mahasiswa dan mengetahui sensitivitas variabel masukan. Untuk mendapatkan hasil pembelajaran yang konvergen, dilakukan trial & error dengan beberapa variasi jumlah hidden-node, laju pembelajaran dan fungsi pelatihan untuk mendapatkan tingkat generalisasi yang tinggi.
menggunakan data mahasiswa angkatan 2008, 2009 dan 2010. Praproses data dilakukan untuk data target yang bersifat kategorikal, dengan menggunakan metode transformasi Unary Encoding, dimana data target dipresentasikan dengan kombinasi angka 0 dan 1 (numerical binary variable). Arsitektur JST yang digunakan adalah jumlah node input 16, jumlah node lapisan tersembunyi (hidden nodei) divariasikan pada nilai 5, 10 dan 15, serta jumlah node output 2 untuk kategori lama studi dan 3 untuk kategori IPK. Parameter yang akan diberikan pada proses pembelajaran antara lain adalah fungsi aktivasi, toleransi galat, jumlah
epoch maksimal, variasi nilai laju pembelajaran (learning rate) dan variasi fungsi pelatihan (training function).
Hasil penelitian menunjukkan bahwa Arsitektur JST dengan generalisasi terbaik dihasilkan oleh jaringan dengan jumlah input node 16, hidden node 10 dan
output node 2 untuk model prediksi lama studi, serta hidden node 15 dan output node 3 untuk model prediksi indeks prestasi kumulatif. Parameter jaringan terbaik diperoleh dari percobaan menggunakan kelompok data kedua, dengan fungsi fungsi pelatihan levenberg-marquardt, dimana untuk model prediksi lama studi, percobaan dengan tingkat generalisasi data pengujian tertinggi, yakni 96.97% untuk data validasi dan 100.00% untuk data testing berada pada laju pembelajaran 0.1. Untuk model model prediksi indeks prestasi kumulatif, percobaan dengan tingkat generalisasi data pengujian tertinggi (100.00% untuk data validasi dan 93.94% untuk data testing) berada pada laju pembelajaran 0.05.
Hasil prediksi tingkat kelulusan mahasiswa angkatan 2008, 2009 dan 2010, baik berdasarkan lama studi maupun IPK, belum mencapai sasaran mutu yang ditetapkan, dimana persentase mahasiswa yang diprediksi lulus tepat waktu (3 tahun) masing-masing hanya sebesar 17.07% untuk angkatan 2008, 17.31% untuk angkatan 2009 dan 13.51% untuk angkatan 2010. Begitupula dengan hasil prediksi tingkat kelulusan mahasiswa angkatan 2008, 2009 dan 2010 berdasarkan predikat IPK diperoleh bahwa persentase mahasiswa yang diprediksi lulus dengan predikat
terpuji (IPK ≥ 3.5) sebesar 17.07% untuk angkatan 2008, 3.85% untuk angkatan
2009 dan 16.22% untuk angkatan 2010, dimana hasil prediksi mahasiwa yang lulus dengan predikat terpuji memiliki persentase yang lebih rendah dibandingkan dengan mahasiwa yang lulus dengan predikat sangat memuaskan, sebagaimana yang menjadi salah satu sasaran mutu Universitas Negeri Gorontalo.
© Hak Cipta milik IPB, tahun 2011
Hak Cipta dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiyah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan yang wajar IPB.
JARINGAN SARAF TIRUAN UNTUK PREDIKSI
TINGKAT KELULUSAN MAHASISWA DIPLOMA
PROGRAM STUDI MANAJEMEN INFORMATIKA
UNIVERSITAS NEGERI GORONTALO
LILLYAN HADJARATIE
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
LEMBAR PENGESAHAN
Judul : Jaringan Saraf Tiruan Untuk Prediksi Tingkat Kelulusan Mahasiswa Diploma Program Studi Manajemen Informatika Universitas Negeri Gorontalo.
Nama : Lillyan Hadjaratie
NRP : G651060024
Program Studi : Ilmu Komputer
Disetujui Komisi Pembimbing
Prof. Dr. Ir. Kudang Boro Seminar, M.Sc Ketua
Aziz Kustiyo, S.Si, M.Kom Anggota
Diketahui Ketua Program Studi
Dr. Ir. Agus Buono, M.Si, M.Kom
Dekan Sekolah Pascasarjana IPB
Dr.Ir. Dahrul Syah, M.Sc. Agr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala karunia-Nya sehingga karya ilmiah dengan judul Jaringan Saraf Tiruan Untuk Prediksi Tingkat Kelulusan Mahasiswa Diploma Program Studi Manajemen Informatika Universitas Negeri Gorontalo, dapat diselesaikan. Oleh karena itu penulis menyampaikan terima kasih yang setinggi-tingginya kepada :
1. Tim komisi pembimbing Bapak Prof.Dr. Ir. Kudang Boro Seminar, M.Sc dan Bapak Aziz Kustiyo, MSi, M.Kom selaku pembimbing yang telah memberikan bimbingan, arahan, saran, dan motivasi.
2. Bapak Dr. Ir. Agus Buono, M.Si, M.Kom atas waktu dan kesediaannya menjadi penguji di luar komisi.
3. Staf dosen di program studi Ilmu Komputer, Institut Pertanian Bogor, atas segala pengetahuan, bimbingan dan motivasinya selama proses perkuliahan, dan terimakasih kepada bapak Ruchiyan atas bantuan dan dukungannya.
4. Rektor Universitas Negeri Gorontalo dan Dekan Fakultas Teknik Universitas Negeri Gorontalo, yang telah memberi kesempatan untuk melanjutkan studi di Institut Pertanian Bogor.
5. Staf pengajar di program studi Manajemen Informatika, Universitas Negeri Gorontalo, M. Rifai Katili, Hidayat Koniyo, Arip Mulyanto, Agus Lahinta, Muhlisulfatih Latief, Dian Novian, Aziz Bouty, Manda Rohandi, Darman, Tajuddin Abdillah, Ningrayati Amali, Roviana Dai, Sitti Suhada, terimakasih atas motivasinya.
6. Tim Pengembangan Sumber Daya Manusia (TPSDM) Provinsi Gorontalo, atas dukungan beasiswanya.
7. Rekan Unggul Utan Sufandi, atas kebaikan, motivasi dan bantuannya dalam pelaksanaan dan penyusunan tesis hingga proses penyelesaian studi penulis. 8. Rekan-rekan mahasiswa program magister ilmu komputer IPB, atas motivasi,
kebersamaan dan persahabatannya.
10.Rekan-rekan Asrama Gorontalo di Bogor, Srisukmawati Tuli, Marini Hamidun, Hasim, Irwan Bempah, Samad Hiola, Arifasno Napu, Iswan Dunggio, Alfi Baruadi, Silvana Naiu, Rita Harmain, Nikmawati Yusuf, Misriyani Hidiya, Munirah Tuli, Zahra Khan, Ahmad Fadhli, Muhammad Akili, Lius Ahmad, Zaenal Koemadji, Faisal Kasim, Wawan Pembengo, Febriyanto Kolanus, Vicky Katili, Akbar Arsyad, serta anakda Dhea, Nabhan, Astri dan Rizky, atas kebersamaan dan kekompakkan kita selama ini.
11.Ayahanda Hamid Hadjaratie (alm) dan Ibunda Hj.Nurani Safii, Ayahanda Karim Tolinggi dan Ibunda Nurhayati Akili, Adik M. Ichdar Hajaratie dan Hardiman Tolinggi atas segala doa, dukungan dan motivasinya.
12.Suami tercinta Wawan K. Tolinggi, Anakda Galang Revolusi Tolinggi dan Nadhifah Carissa Tolinggi, terima kasih atas segala doa, motivasi, cinta dan kasih sayangnya.
13.Terima kasih pula kepada rekan-rekan yang tidak disebutkan satu persatu dan kepada semua pihak, atas segala bantuan dan kerjasamanya selama ini, semoga Allah membalasnya lebih baik.
Akhirnya, penulis menyadari bahwa tulisan ini masih belum sempurna, oleh karena itu kritik dan saran yang membangun sangat diperlukan. Semoga karya ilmiah ini bermanfaat dan memberikan tambahan informasi di bidang ilmu komputer.
RIWAYAT HIDUP
Penulis dilahirkan di Gorontalo pada tanggal 17 April 1980 sebagai anak pertama dua bersaudara dari pasangan Hamid Hadjaratie (Alm) dan Nurani Safii. Penulis menikah dengan Wawan K. Tolinggi, SP, M.Si pada tanggal 7 Agustus 2004 dan telah dikaruniai satu putra Galang Revolusi Tolinggi dan satu putri Nadhifah Carissa Tolinggi.
Penulis menamatkan pendidikan menengah pada Sekolah Menengah Umum Negeri 3 Gorontalo tahun 1998. Pendidikan sarjana ditempuh di Program Studi Manajemen Informatika, Sekolah Tinggi Manajemen Informatika dan Komputer (STMIK) Dipanegara Makassar, lulus pada tahun 2002. Penulis mendapat kesempatan untuk melanjutkan studi di program magister pada Program Studi Ilmu Komputer IPB diperoleh tahun 2006, melalui beasiswa Tim Pengembangan Sumber Daya Manusia (TPSDM) Provinsi Gorontalo.
DAFTAR ISI
Halaman
DAFTAR ISI ... xi
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xiv
DAFTAR LAMPIRAN ... xvi
1. PENDAHULUAN ...1
1.1 Latar Belakang ...1
1.2 Perumusan Masalah ...5
1.3 Tujuan Penelitian ...5
1.4 Manfaat Penelitian ...5
1.5 Ruang Lingkup Penelitian...5
2. TINJAUAN PUSTAKA ...7
2.1 Evaluasi Keberhasilan Studi ...7
2.2 Kurikulum Program Studi Manajemen Informatika ...8
2.3 Praproses Data ...9
2.4 Jaringan Saraf Tiruan (JST) ...10
2.5 Review Riset yang Relevan ...16
3. METODOLOGI PENELITIAN...19
3.1 Diagram Alir Penelitian ...19
3.2 Alat Bantu Penelitian ...25
3.3 Waktu dan Tempat Penelitian ...25
4. HASIL DAN PEMBAHASAN ...27
4.1 Praproses Data ...27
4.2 Pembentukan Model JST ...28
4.3 Analisis hasil pembelajaran dan pengujian ...40
4.4 Analisis waktu pembelajaran ...42
4.5 Tingkat generalisasi data validasi dan data testing dengan variasi nilai laju pembelajaran, jumlah hidden-node dan fungsi pelatihan ...59
4.6 Arsitektur jaringan yang terbaik ...63
4.7 Pengujian arsitektur terbaik terhadap data validasi dan data testing ...66
4.8 Hasil Prediksi Tingkat Kelulusan Mahasiswa ...67
4.9 Analisa Sensitivitas ...68
4.10 Manfaat bagi manajemen ...70
5. SIMPULAN DAN SARAN ...73
5.1 Simpulan ...73
5.2 Saran ...74
DAFTAR TABEL
Halaman
1 Penilaian Acuan Patokan (PAP) ... 7
2 Kurikulum D3 Manajemen Informatika ... 8
3 Pengelompokkan dan Komposisi Data Penelitian ... 21
4 Karakteristik dan Struktur JST yang digunakan ... 23
5 Kelompok data pertama MPLS dengan fungsi pelatihan resilent backpropagation ... 28
6 Kelompok data pertama MPLS dengan fungsi pelatihan scaled conjugate gradient ... 29
7 Kelompok data pertama MPLS dengan fungsi pelatihan levenberg-marquardt ... 30
8 Kelompok data kedua MPLS dengan fungsi pelatihan resilent backpropagation ... 31
9 Kelompok data kedua MPLS dengan fungsi pelatihan scaled conjugate gradient ... 32
10 Kelompok data kedua MPLS dengan fungsi pelatihan levenberg- marquardt ... 33
11 Kelompok data pertama MPIPK dengan fungsi pelatihan resilent backpropagation ... 34
12 Kelompok data pertama MPIPK dengan fungsi pelatihan scaled conjugate gradient ... 35
13 Kelompok data pertama MPIPK dengan fungsi pelatihan levenberg- marquardt ... 36
14 Kelompok data kedua MPIPK dengan fungsi pelatihan resilent backpropagation ... 37
15 Kelompok data kedua MPIPK dengan fungsi pelatihan scaled conjugate gradient ... 38
17 Hasil Pembelajaran dan Pengujian dari MPLS ... 40
18 Hasil Pembelajaran dan Pengujian dari MPIPK ... 41
19 Analisis Waktu Pembelajaran dengan variasi jumlah hidden-node pada MPLS ... 49
20 Analisis Waktu Pembelajaran dengan variasi laju pembelajaran pada MPLS ... 50
21 Analisis Waktu Pembelajaran dengan variasi jumlah hidden-node pada MPIPK ... 58
22 Analisis Waktu Pembelajaran dengan variasi laju pembelajaran pada MPIPK ... 58
23 Parameter jaringan terbaik ... 63
24 Pengujian dengan data validasi dan data testing MPLS ... 66
25 Pengujian dengan data validasi dan data testing MPIPK... 67
26 Prediksi tingkat kelulusan mahasiswa angakatn 2008-2010 berdasarkan lama studi ... 68
27 Prediksi tingkat kelulusan mahasiswa angakatn 2008-2010 berdasarkan IPK ... 68
28 Hasil analisa sensitivitas variabel masukan pada MPLS ... 69
29 Hasil analisa sensitivitas variabel masukan pada MPIPK ... 69
DAFTAR GAMBAR
Halaman
1 Tingkat Kelulusan Mahasiswa Berdasarkan Lama Studi ... 2
2 Tingkat Kelulusan Mahasiswa Berdasarkan IPK ... 2
3 Tingkat Kelulusan Mahasiswa Berdasarkan Predikat IPK ... 3
4 Sasaran Mutu dan Data Faktual IPK dan Lama Studi ... 3
5 Saraf Biologis dan Struktur Saraf Tiruan ... 11
6 Arsitektur Jaringan Saraf ... 12
7 Akurasi dan Generalisasi ... 15
8 Diagram Alir Penelitian ... 19
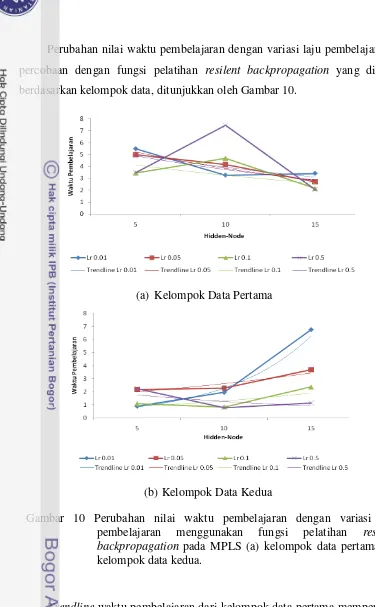
9 Perubahan nilai waktu pembelajaran dengan variasi jumlah hidden-node menggunakan fungsi pelatihan resilent backpropagation pada MPLS ... 43
10 Perubahan nilai waktu pembelajaran dengan variasi laju pembelajaran menggunakan fungsi pelatihan resilent backpropagation pada MPLS ... 44
11 Perubahan nilai waktu pembelajaran dengan variasi jumlah hidden-node menggunakan fungsi pelatihan scaled conjugate gradient pada MPLS ... 45
12 Perubahan nilai waktu pembelajaran dengan variasi laju pembelajaran menggunakan fungsi pelatihan scaled conjugate gradient pada MPLS ... 46
13 Perubahan nilai waktu pembelajaran dengan variasi jumlah hidden-node menggunakan fungsi pelatihan levenberg-marquardt pada MPLS ... 48
14 Perubahan nilai waktu pembelajaran dengan variasi laju pembelajaran menggunakan fungsi pelatihan levenberg-marquardt pada MPLS ... 49
15 Perubahan nilai waktu pembelajaran dengan variasi jumlah hidden-node menggunakan fungsi pelatihan resilent backpropagation pada MPIPK ... 51
16 Perubahan nilai waktu pembelajaran dengan variasi laju pembelajaran menggunakan fungsi pelatihan resilent backpropagation pada MPIPK ... 52
18 Perubahan nilai waktu pembelajaran dengan variasi laju pembelajaran menggunakan fungsi pelatihan scaled conjugate gradient pada MPIPK ... 55 19 Perubahan nilai waktu pembelajaran dengan variasi jumlah hidden-node
menggunakan fungsi pelatihan levenberg-marquardt pada MPIPK ... 56 20 Perubahan nilai waktu pembelajaran dengan variasi laju pembelajaran
menggunakan fungsi pelatihan levenberg-marquardt pada MPIPK ... 57 21 Grafik perbadingan tingkat generalisasi data validasi dan data testing pada
MPLS kelompok data pertama ... 59 22 Grafik perbadingan tingkat generalisasi data validasi dan data testing pada
MPLS kelompok data kedua ... 60 23 Grafik perbadingan tingkat generalisasi data validasi dan data testing pada
MPIPK kelompok data pertama ... 61 24 Grafik perbadingan tingkat generalisasi data validasi dan data testing pada
MPIPK kelompok data kedua ... 62 25 Arsitektur JST terbaik pada Model Prediksi Lama Studi (MPLS) ... 64 26 Arsitektur JST terbaik pada Model Prediksi Indeks Prestasi Kumulatif
DAFTAR LAMPIRAN
Halaman
1 Daftar Nilai Mahasiswa Angkatan 2005 sampai dengan 2007 ... 79 2 Daftar Nilai Mahasiswa Angkatan 2008 sampai dengan 2010 ... 89 3 Detail Proses Pembelajaran pada Model Prediksi Lama Studi (MPLS) ... 96 4 Detail Proses Pembelajaran pada Model Prediksi Indeks Prestasi
1. PENDAHULUAN
1.1 Latar Belakang
Program studi merupakan garda terdepan dalam penyelenggaraan pendidikan dari sebuah perguruan tinggi, karena program studi merupakan satuan rencana belajar terkecil yang diselenggarakan atas dasar suatu kurikulum dan ditunjukkan agar mahasiswa dapat menguasai pengetahuan dan sikap yang sesuai dengan sasaran kurikulum, sehingga setiap program studi harus dapat mengetahui kondisi aktual salah satunya dengan melakukan evaluasi guna meningatkan mutu dan efisiensi perguruan tinggi termasuk peningkatan kualitas lulusan untuk mengantisipasi peluang kerja bagi para lulusan yang dihasilkan. Proses evaluasi program studi dapat ditempuh dengan berbagai macam cara, bahkan Direktorat Jendral Perguruan Tinggi (DIKTI) sendiri telah menyelenggarakan beberapa program evaluasi bagi program studi, seperti Evaluasi Program Studi Berbasis Evaluasi Diri (EPSBED), Akreditasi Program Studi, dan program evaluasi lainnya yang mensyaratkan setiap program studi untuk dapat menyediakan data dan informasi secara periodik terkait dengan semua unsur penyelenggaraan program studi berdasarkan standar evaluasi dari borang akreditasi. Data hasil evaluasi dapat mempengaruhi akreditasi dari sebuah program studi, sehingga setiap program studi tentunya mengharapkan tercapainya standar evaluasi yang sudah ditetapkan, salah satunya terkait dengan tingkat kelulusan mahasiswa berdasarkan sasaran mutu lulusan yang diatur oleh perguruan tinggi yang digunakan sebagai tolok ukur di dalam menentukan keberhasilan, yang beberapa diantaranya mempertimbangkan faktor lama studi dan pencapaian IPK mahasiswa.
Begitupula dengan pencapaian IPK lulusan dari tahun 2000 hingga tahun 2007, lulusan dengan IPK > 3.00 hanya mencapai 42% (Gambar 2) dan berdasarkan status predikat lulusan, persentase IPK lulusan di atas 3.50 (predikat terpuji) hanya sebesar 9%, persentase IPK kisaran 2.75 hingga 3.50 (predikat sangat memuaskan) sebesar 62%, dan sisanya persentase IPK di bawah 2.75 (predikat memuaskan) sebesar 29% (Gambar 3).
Gambar 1 Tingkat Kelulusan Mahasiswa Berdasarkan Lama Studi
Data dan informasi di atas cukup mempengaruhi penilaian keberhasilan program studi D3-MI UNG, karena berdasarkan aturan yang dituangkan dalam Pedoman Akademik Universitas Negeri Gorontalo, sasaran mutu yang ditetapkan sebagai standar lama studi dan IPK dalam kondisi ideal adalah persentase lulusan tepat waktu (3 tahun) minimal 50%, pencapaian IPK lebih dari 3.00 minimal 65% atau lulusan dengan predikat terpuji haruslah memiliki persentase lebih besar dari lulusan dengan predikat memuaskan (Universitas Negeri Gorontalo, 2009). Data faktual yang terlihat masih di bawah sasaran mutu yang ditetapkan (Gambar 4).
Gambar 3 Tingkat Kelulusan Mahasiswa Berdasarkan Predikat IPK
Untuk dapat menjaga besarnya persentase lama studi dan IPK agar dapat memenuhi sasaran mutu yang ditetapkan, maka perlu dilakukan evaluasi tingkat kelulusan secara dini untuk mendapatkan informasi yang cepat dan akurat dalam memprediksi besaran persentase lama studi dan IPK yang akan diperoleh mahasiswa di akhir program nanti. Salah satu teknik evaluasi tingkat kelulusan secara dini adalah sistem prediksi tingkat kelulusan mahasiswa, dimana informasi yang dihasilkan oleh hasil prediksi ini dapat dijadikan sebagai bahan pertimbangan bagi pihak manajemen program studi untuk melakukan langkah-langkah persuasif dalam rangka meningkatkan persentase tingkat kelulusan mahasiswa yang memenuhi standar mutu yang ditetapkan oleh universitas.
nantinya akan digunakan untuk melakukan prediksi tingkat kelulusan mahasiswa mahasiswa D3-MI Universitas Negeri Gorontalo.
1.2 Perumusan Masalah
Berdasarkan latar belakang masalah di atas, maka permasalahan yang bisa dirumuskan dalam penelitian ini adalah bagaimana pembentukan model JST untuk mendapatkan parameter dari arsitektur jaringan JST terbaik yang dapat digunakan untuk prediksi tingkat kelulusan mahasiswa mahasiswa D3-MI Universitas Negeri Gorontalo berdasarkan nilai mata kuliah dari 2 (dua) semester pada tahun pertama program perkuliahan.
1.3 Tujuan Penelitian
Penelitian ini bertujuan untuk :
1. Mendapatkan parameter dan arsitektur jaringan JST terbaik untuk prediksi tingkat kelulusan mahasiswa program studi D3 (Diploma Tiga) Manajemen Informatika Universitas Negeri Gorontalo.
2. Melakukan prediksi tingkat kelulusan mahasiswa program studi D3 (Diploma Tiga) Manajemen Informatika Universitas Negeri Gorontalo pada 2 (dua) bentuk pemodelan dengan target yang berbeda, yaitu Lama Studi dan IPK. 3. Melihat pengaruh atau tingkat sensitivitas variabel input untuk mencapai
output akurat dari model yang dikembangkan.
1.4 Manfaat Penelitian
Informasi dan pengetahuan yang dihasilkan dari penelitian ini dapat digunakan sebagai dasar pertimbangan dalam pengambilan keputusan bagi pihak manajemen program studi dalam melakukan evaluasi tingkat kelulusan mahasiswa program studi D3 (Diploma Tiga) Manajemen Informatika, Universitas Negeri Gorontalo.
1.5 Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah :
Universitas Negeri Gorontalo angkatan 2005 hingga 2007, dengan pertimbangan bahwa kurikulum yang dipergunakan hingga saat ini adalah kurikulum tahun 2005. Untuk memperoleh data lama studi dan IPK sebagai output dari model yang akan dibentuk, maka data mahasiswa yang dipilih untuk digunakan sebagai data penelitian adalah mahasiswa yang telah menyelesaikan studi sejak angkatan 2005 sampai dengan angkatan 2007.
2. Data mahasiswa yang digunakan untuk memprediksi tingkat kelulusan adalah data mahasiswa program studi D3 (Diploma Tiga) Manajemen Informatika, Universitas Negeri Gorontalo angkatan 2008, 2009 dan 2010. Data mahasiswa pada ketiga angkatan tersebut belum memiliki informasi tingkat kelulusan, baik lama studi yang ditempuh maupun IPK yang diperoleh.
2. TINJAUAN PUSTAKA
2.1 Evaluasi Keberhasilan Studi
Evaluasi keberhasilan studi mahasiswa dapat ditempuh dengan beberapa tahapan, yaitu evaluasi keberhasilan belajar matakuliah, evaluasi keberhasilan studi di setiap semester dan evaluasi studi di akhir tahun ajaran (Universitas Negeri Gorontalo 2009). Evaluasi keberhasilan belajar matakuliah adalah penilaian terhadap hasil belajar mahasiswa dalam suatu matakuliah, yang dilakukan secara menyeluruh dan berkesinambungan dalam satu semester dengan cara yang sesuai dengan karakteristik matakuliah yang bersangkutan. Evaluasi keberhasilan belajar matakuliah ini dinyatakan dalam bentuk Nilai Akhir (NA) yang dikonversi menjadi Huruf Mutu (HM) dan Angka Mutu (AM) dan dilakukan dengan Penilaian Acuan Patokan (PAP), dengan kriteria seperti pada Tabel 1. Tabel 1 Penilaian Acuan Patokan (PAP)
Nilai Akhir (NA) Huruf Mutu (HM) Angka Mutu (AM)
80 – 100 A 4
70 – 79 B 3
60 – 69 C 2
50 – 59 D 1
< 49 E 0
Evaluasi keberhasilan studi dimaksudkan untuk menilai keberhasilan studi seorang mahasiswa yang dapat digambarkan dengan koefisien Indeks Prestasi (IP). Evaluasi ini dilakukan setiap semester yang ditunjukkan dengan Indeks Prestasi Semester (IPS) dan akhir studi yang ditunjukkan dengan Indeks Prestasi Kumulatif (IPK). IPK merupakan angka yang menujukkan keberhasilan mahasiswa secara kumulatif mulai dari semester pertama sampai dengan semester yang paling akhir ditempuh, yang juga dapat digunakan untuk menentukan beban studi semester berikutnya, dihitung dengan rumus sebagai berikut :
IPK =
dengan AM adalah Angka Mutu
SKS adalah Satuan Kredit Semester Jumlah (AM x bobot SKS)
Jumlah SKS
2.2 Kurikulum Program Studi Manajemen Informatika
Kurikulum Pendidikan Tinggi adalah seperangkat rencana dan pengaturan mengenai isi maupun bahan kajian dan pelajaran serta penyampaian dan penilaiannya yang digunakan sebagai pedoman penyelenggaraan kegiatan belajar-mengajar di Perguruan Tinggi (Universitas Negeri Gorontalo 2009). Berikut adalah Kurikulum Program Studi D3 Manajemen Informatika Universitas Negeri Gorontalo.
Tabel 2 Kurikulum D3 Manajemen Informatika
NO KODE MATA KULIAH SKS
SEMESTER I
1 5313-1-011-3 Pendidikan Agama 3
2 5313-1-021-2 Bahasa Indonesia 2
3 5313-3-061-2 Pemrograman 1 (Pascal Dasar) 2
4 5313-2-071-3 Sistem Operasi 3
5 5313-2-081-3 Matematika 3
6 5313-2-091-2 Pengantar Sistem Komputer 3 7 5313-3-021-3 Paket Program Aplikasi 3 8 5313-3-041-3 Algoritma dan Struktur Data 3
Jumlah SKS 22
SEMESTER II
1 5313-1-042-2 Bahasa Inggris 2
2 5313-2-062-2 Konsep Sistem Informasi 2 3 5313-2-012-2 Dasar Manajemen dan Bisnis 2 4 5313-2-022-2 Aljabar Vektor & Matriks 2 5 5313-3-162-3 Pengantar Instalasi Komputer 3 6 5313-3-072-3 Pemrograman 2 (Pascal Lanjutan) 3 7 5313-3-012-2 Pengantar Teknologi Informasi 2
8 5313-3-112-3 Desain Grafis 3
Jumlah SKS 19
SEMESTER III
1 5313-4-013-2 Etika Profesi 2
2 5313-2-033-2 Statistika 2
3 5313-2-044-3 Analisis & Desain Sistem Informasi 3 4 5313-2-113-4 Sistem Basis Data (MS Access) 4 5 5313-3-173-2 Instalasi Jaringan Komputer 2 6 5313-3-033-2 Pengantar Jaringan Komputer 2 7 5313-3-083-3 Pemrograman 3 (Delphi) 3 8 5313-4-043-2 Organisasi dan Perilaku 2
Jumlah SKS 20
SEMESTER IV
1 5313-3-104-2 Pengolahan Data Statistik 2
2 5313-3-143-3 Pemrograman Web 1 3
3 5313-5-014-2 Kewirausahaan 2
4 5313-3-094-3 Perancangan Basis Data (MySQL) 3 5 5313-3-194-3 Aplikasi Desain Grafis (Macromedia) 3 6 5313-3-124-3 Pemrograman Visual 1 (VB) 3 7 5313-1-032-3 Pancasila & Kewarganegaraan 2 8 5313-4-034-2 Pengetahuan Lingkungan 3
Tabel 2 Kurikulum D3 Manajemen Informatika (Lanjutan)
NO KODE MATA KULIAH SKS
SEMESTER V
1 5313-2-045-3 Sistem Informasi Manajemen 3
2 5313-2-135-2 Metodologi Riset 2
3 5313-3-135-3 Proyek Sistem Informasi 3 4 5313-3-185-4 Pemrograman Web 2 (PHP/MySQL) 4 5 5313-3-155-3 Analisis dan Desain Berorientasi Objek 3 6 5313-4-025-2 Komputer dan Masyarakat 2 7 5313-3-205-3 Pemrograman Visual 2 (VFP) 3 8 5313-2-145-2 Kapita Selekta Komputer 2
Jumlah SKS 22
SEMESTER VI
1 5313-5-026-3 Magang 3
2 5313-5-036-4 Tugas Akhir 4
Jumlah SKS 7
Total SKS 110
2.3 Praproses Data
Sebelum menggunakan data dengan teknik JST perlu dilakukan praproses terhadap data. Hal ini dilakukan untuk mendapatkan hasil analisis yang lebih akurat dalam pemakaian teknik JST. Dalam beberapa hal, praproses bisa membuat nilai data menjadi kecil tanpa merubah informasi yang dikandungnya. Beberapa cara antara lain adalah transformasi/normalisasi data, yaitu prosedur mengubah data sehingga berada dalam skala tertentu. Skala ini bisa antara (0,1), (-1,1) atau skala lain yang dikehendaki. Beberapa metode yang umum dipakai untuk transformasi data, yaitu :
a) Min-Max
Min-max merupakan metode normalisai dengan melakukan transformasi linier terhadap data asli. Metode ini akan menormalisasi input dan target sedemikian rupa sehingga hasil normalisasi akan berada pada interval -1 dan 1.
Pn=2*(p-minp)/(maxp-minp)-1 (2)
dengan p adalah nilai dari sebelum transformasi, pn adalah nilai hasil transormasi, minp dan maxp adalah nilai minimum dan maksimum dari p.
b) Unary Encoding
suatu bilangan numerik mewakili nilai suatu kategori. Atribut kategori yang
demikian disebut dengan “dummy variable” (Kantardzic 2003). Misalnya „10‟
untuk kategori „melebih masa studi‟ dan „01‟ untuk kategori „tepat waktu‟ dan
untuk data tingkat kelulusan mahasiswa dengan target lama studi.
2.4 Jaringan Saraf Tiruan (JST)
dengannya. Neuron-neuron akan dikumpulkan dalam lapisan-lapisan (layer) yang disebut dengan lapisan neuron (nuron layer) yang saling berhubungan. Infomasi akan dirambatkan mulai dari lapisan input sampai ke lapisan output melalui lapisan lainnya yang sering dikenal dengan lapisan tersembunyi (hidden layer), dan perambatannya tergantung algoritma pembelajarannya (Kusumadewi 2010).
Arsitektur Jaringan Saraf
Hubungan antar neuron dalam jaringan saraf mengikuti pola tertentu tergantung pada arsitektur jariangan sarafnya (Kusumadewi 2010).
a. Jaringan dengan lapisan tunggal (single layer net)
Jaringan dengan lapisan tunggal hanya memiliki satu lapisan dengan bobot-bobot terhubung. Jaringan ini hanya menerima input kemudian secara langsung akan mengolahnya menjadi output tanpa harus melalui lapisan tersembunyi. b. Jaringan dengan banyak lapisan (multilayer net)
Jaringan dengan banyak lapisan memiliki satu atau lebih lapisan yang terletak diantara lapisan input dan lapisan output (memiliki satu atau lebih lapisan tersembunyi). Jaringan dengan banyak lapisan ini dapat menyelesaikan permasalahan yang lebih sulit daripada lapisan tunggal.
c. Jaringan dengan lapisan kompetitif (competitive layer net)
Saraf Biologis Saraf Tiruan
Pada jaringan ini sekumpulan neuron bersaing untuk mendapatkan hak menjadi aktif.
Algoritma Pembelajaran
Salah satu bagian terpenting dari konsep JST adalah terjadinya proses pembelajaran. Tujuan utama dari proses pembelajaran adalah melakukan pengaturan terhadap bobot-bobot yang ada pada jaringan saraf, sehingga diperoleh bobot akhir yang tepat yang sesuai dengan pola data yang dilatih. Cara berlangsungnya pembelajaran atau pelatihan JST dikelompokkan menjadi 3 (tiga), yaitu (Puspitaningrum 2006) :
1. Pembelajaran terawasi (supervised learning)
Pada metode ini setiap pola yang diberikan ke dalam JST telah diketahui outputnya. Selisih antara pola output yang dihasilkan dengan ouput yang dikehendaki (output target) yang disebut error digunakan untuk mengoreksi bobot JST sehingga JST mampu menghasilkan output sedekat mungkin dengan pola target yang telah diketahui oleh JST.
2. Pembelajaran yang tak terawasi (unsupervised learning)
Pada metode pembelajaran yang tak terawasi tidak memerlukan target ouput. Pada metode ini tidak ditentukan hasil yang seperti apakah yang diharapkan selama proses pembelajaran. Selama proses pembelajaran, nilai bobot
disusun dalam suatu range tertentu tergantung pada nilai input yang diberikan. Tujuan pembelajran ini adalah mengelompokkan unit-unit yang hampir sama dalam suatu area tertentu. Pembelajaran ini biasanya sangat cocok untuk pengeleompokkan (klasifikasi) pola.
3. Pembelajaran Hibrida (Hybrid Learning)
Merupakan kombinasi dari metode pembelajaran supervised learning dan
unsupervised learning. Sebagian dari bobot-bobotnya ditentukan melalui pembelajaran terawasi dan sebagian lainnya melalui pembelajaran tak terawasi.
Propagasi Balik (Backpropagation)
Propagasi balik (backpropagation) adalah salah satu algoritma pembelajaran dalam teknik JST yang sering digunakan untuk pencocokan pola. Propagasi balik merupakan algoritma pembelajaran yang terawasi dan biasanya digunakan oleh perceptron dengan banyak lapisan (multilayer perceptron) untuk mengubah bobot-bobot yang terhubung dengan neuron-neuron yang ada pada lapisan tersembunyinya. Algoritma propagasi balik menggunakan error output untuk mengubah nilai-nilai bobotnya dalam perambatan error output untuk mengubah nilai bobot-bobotnya dalam perambatan mundur (backward). Untuk mendapatkan error ini, tahap perambatan maju (forward propagation) harus dikerjakan terlebih dahulu (Puspitaningrum 2006).
Algoritma Pelatihan pada Propagasi Balik
1. Perbaikan dengan Teknik Heuristik
Teknik ini merupakan pengembangan dari suatu analisis kinerja pada algoritma steepest (gradient) descent standard. Ada 3 (tiga) algoritma dengan teknik ini, yakni :
a. Gradient descent dengan Adaptive Learning Rate
Pada fungsi ini, selama proses pembelajaran, learning rate akan terus bernilai konstan karena apabila learning rate terlalu tinggi maka algoritma menjadi tidak stabil dan jika terlalu rendah algritma akan sangat lama dalam mencapai kekonvergenan.
b. Gradient descent dengan Momentun dan Adaptive Learning Rate
Fungsi ini akan memperbaiki bobot-bobot berdasarkan gradient descent dengan learning rate yang bersifat adaptive seperti traingda tapi juga dengan menggunakan momentum
c. Resilent Backpropagation
Algoritma pelatihan ini menggunakan fungsi aktivasi sigmoid yang membawa input dengan range yang tak terbatas ke nilai output dengan range yang terbatas, yaitu antara 0 sampai 1. Algoritma ini berusaha mengeliminasi besarnya efek dari turunan parsial dengan cara hanya menggunakan turunannya saja dan mengabaikan besarnya nilai turunan.
2. Perbaikan dengan Teknik Optimasi Numeris Teknik ini terbagi menjadi 2 macam, yaitu : a. Algoritma Conjugate Gradient
Pada algrotma ini pengaturan bobot tidak selalu dilakukan dalam arah turun seperti pada metode gradient descent, tapi menggunakan conjugate gradient
dimana pengaturan bobot tidak selalu dengan arah menurun tapi disesuaikan dengan arah konjugasinya. Algoritma ini memanfaatkan fungsi line search untuk menempatkan sebuah titik minimum. Dari 4 (empat) algoritma Conjugate Gradient, tiga diantaranya melakukan proses line search secara terus menerus selama iterasi, yaitu : Fletcher-Reeves Update, Polak-Ribiere, dan Powell-Beale Restarts. Proses ini mamakan waktu yang cukup lama untuk jumlah data yang besar dan iterasi yang besar pula, sehingga algoritma keempat, yaitu algoritma
b. Algortima Quasi Newton
Metode Newton merupakan salah satu alternatif conjugate gradient yang bisa mendapatkan nilai optimum lebih cepat. Metode Newton ini memang berjalan lebih cepat, namun metode ini sangat kompleks, memerlukan waktu dan memori yang cukup besar karena pada setiap iterasinya harus menghitung turunan kedua, perbaikan dari metode ini dikenal dengan nama metode Quasi-Newton atau metode Secant. Terdapat 2 (dua) alternatif algoritma dalam metode ini, yaitu : (1) Algortima one step secant yang menjembatani antara metode Quasi-Newton
dengan Gradient Conjugate, dimana algoritma ini tidak menyimpan matriks Hessian secara lengkap dengan asumsi bahwa pada setiap iterasi matriks Hessian sebelumnya merupakan matriks identitas sehingga pencarian arah baru dapat dihitung tanpa harus menghitung invers matriks.
(2) Algoritma Levenbarg-Marquardt
Metode ini dirancang dengan menggunakan turunan kedua tanpa harus menghitung matriks Hessian, melainkan matriks Jacobian yang dapat dihitung dengan teknik propagasi balik standar yang tentu saja lebih sederhana dibanding dengan menghitung matriks Hessian.
Akurasi dan Generalisasi
Gambar 7 menunjukkan akurasi dan generalisasi berkaitan dengan tingkat kompleksitas dari suatu jaringan saraf tiruan (JST). Peningkatan kompleksitas dari JST meningkatkan akurasi dari JST terhadap data pelatihan, tetapi peningkatan akurasi dan kompleksitas ini dapat menurunkan tingkat generalisasi JST pada data validasi dan data pengujian (Larose 2005).
J j ji j kj k p
ki o w y v
S 1 ' ' P p p ki ki S S ,..., 1 max max{ }
K k ki i S ,..., 1 } max{ Analisa Sensitivitas
Analisa sensitivitas bertujuan untuk melihat perubahan output dari model yang didapatkan jika dilakukan perubahan terhadap input dari model. Selain itu analisa ini berguna untuk mengetahui variabel mana yang lebih berpengaruh atau sensitif untuk mencapai output akurat dari model yang dikembangkan (Engelbrecht 2001). Untuk mengetahui sensitivitas dari Skip dimana JST yang
digunakan memiliki 1 layer input Z = (z1,…,zi,….,zI), 1 layer tersembunyi Y =
(y1,…,yj,…,yJ), dan 1 layer output O = (o1,…,ok,…,oK) dan data training adalah P=(p1,…,pp,…,pP) digunakan :
Untuk mendapatkan matrik sensitivitas dari semua data training terhadap output dapat digunakan :
Kemudian dilanjutkan dengan memghitung matrik sensitivitas dari input secara menyeluruh dapat digunakan :
2.5 Review Riset yang Relevan
Poh et al (1998) melakukan penelitian dengan menerapkan jaringan saraf tiruan untuk analisa dan prediksi terhadap akibat dari iklan dan promosi. Penelitian ini juga menerapkan analisa sensitivitas. Salah satu kesimpulan dari penelitian ini yaitu JST dengan pembelajaran propagasi balik merupakan metode yang efisien untuk mempelajari hubungan antara input varibel dan output variabel. Sufandi (2007) melakukan penelitian untuk melakukan prediksi kemajuan belajar mahasiswa berbasis jaringan saraf tiruan ke dalam dua kelas yaitu selesai dan tidak selesai dengan melibatkan varibel input dengan tiga buah parameter, yaitu parameter individual (umur, jenis kelamin), parameter lingkungan (status pernikahan, status pekerjaan, beasiswa), dan parameter akademik (semester masuk, IP semester 1, sks semester 1, IP semester 2, IPS semester 2, IPK, SKS Kumulatif, semester tempuh, program studi dan jurusan asal). Salah satu (3)
(4)
kesimpulan dari penelitian ini adalah JST propagasi balik baik digunakan untuk tujuan prediksi, dan analisa sensitivitas merupakan metode yang potensial untuk mereduksi kompleksitas JST dan meningkatkan tingkat generalisasi.
Agung (2007) melakukan penelitian untuk mengklasifikasi mahasiswa STEKPI menggunakan Jaringan Saraf Tiruan dengan aloritma pembelajaran propagasi balik. Data input yang digunakan adalah Nilai Psikotest, sedangkan data target adalah Indeks Prestasi Kumulatif (IPK) yang dipresentasikan dalam bentuk data kategori, dimana kategori “mahasiwa yang berhasil” adalah mahasiswa yang di tahun pertamanya mempunyai IPK daru 2.75 sampai dengan 4, sedangkan
3.
METODE PENELITIAN
3.1 Diagram Alir Penelitian
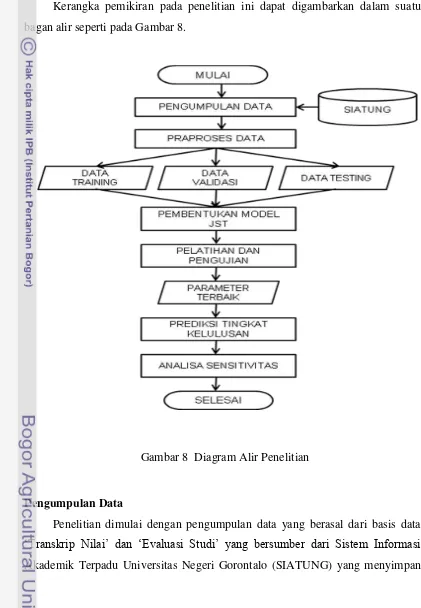
Kerangka pemikiran pada penelitian ini dapat digambarkan dalam suatu bagan alir seperti pada Gambar 8.
Pengumpulan Data
Penelitian dimulai dengan pengumpulan data yang berasal dari basis data
„Transkrip Nilai‟ dan „Evaluasi Studi‟ yang bersumber dari Sistem Informasi
[image:37.595.89.510.166.774.2]informasi mahasiswa berupa nilai mutu mata kuliah, lama studi dan IPK. Mata kuliah yang dipilih sebagai data input dalam penelitian ini berjumlah 16 (enam belas) buah mata kuliah dasar yang wajib diprogramkan pada 2 (dua) semester tahun pertama program perkuliahan sebelum mengambil program peminatan. Pada penelitian ini, data mata kuliah digunakan sebagai data input. Sedangkan data lama studi dan IPK digunakan sebagai data target. Data nilai mata kuliah yang diperoleh berupa Huruf Mutu (HM) dan dikonversi ke Angka Mutu (AM) dengan kisaran nilai 0 hingga 4. Data target lama studi dikategorikan menjadi 2 (dua), yaitu kategori mahasiwa yang lulus dengan melewati masa studi program diploma (> 3 tahun) dan kategori mahasiswa yang lulus tepat waktu (3 tahun). Data target IPK dikategorikan menjadi 3 (tiga), yaitu kategori mahasiswa yang lulus dengan predikat terpuji (IPK >3.5), kategori predikat sangat memuaskan
(IPK ≥ 2.75 hingga IPK ≤3.5) dan kategori predikat memuaskan (IPK<2.75). Data mahasiswa yang digunakan dalam penelitian ini adalah data mahasiswa D3 (Diploma Tiga) Manajemen Informatika UNG angkatan 2005 hingga 2010. Pembelajaran dan pengujian JST menggunakan data mahasiwa angkatan 2005, 2006 dan 2007 (Lampiran 1), yang dibagi ke dalam 3 (tiga) komposisi data dan dibedakan ke dalam 2 (dua) kelompok data. Total jumlah data pada kelompok data pertama dan kelompok data kedua adalah sama, yakni 216 data. Pengelompokkan data dibedakan berdasarkan cara pembagian komposisi data dimana pada kelompok data pertama, setelah data mahasiswa angkatan 2005, 2006 dan 2007 diurutkan, kemudian dibagi ke dalam 3 (tiga) komposisi data. Sedangkan pada kelompok data kedua, komposisi data dibagi berdasarkan angkatan, sehingga data mahasiswa pada masing-masing angkatan dibagi ke dalam 3 (tiga) komposisi data.
komposisi data adalah 70% data pelatihan, 15% data validasi dan 15% data pengujian. Prediksi tingkat kelulusan menggunakan data mahasiswa angkatan 2008, 2009 dan 2010 9 (Lampiran 2). Pembagian data mahasiswa untuk pembelajaran JST dan prediksi ditunjukkan oleh Tabel 3.
Tabel 3 Pengelompokkan dan Komposisi Data Penelitian
DATA PEMBELAJARAN & PENGUJIAN
Komposisi Data Data Pelatihan
(70%)
Data Validasi (15%)
Data Testing
(15%) Total
Kelompok Data Pertama 150 33 33 216
Kelompok Data Kedua
2005 60 13
12 8
13 12 8
86 79 51
2006 55
2007 35
Total 150 33 33 216
DATA PREDIKSI
Angkatan 2008 2009 2010 Total
Jumlah 41 52 37 130
Praproses Data
Sebelum data digunakan dilakukan praproses untuk meningkatkan efisiensi dan skalabilitas dari sebuah sistem prediksi. Pada penelitian ini, dilakukan beberapa praproses data, yakni pembersihan data, analisa relevansi dan tranformasi data (Han & Kember 2001). Proses transformasi data dilakukan untuk data target yang bersifat kategorikal, dengan menggunakan metode Unary Encoding, dimana data target dipresentasikan dengan kombinasi angka 0 dan 1 (numerical binary variable). Berdasarkan data kategori targetnya maka dalam penelitian ini, seluruh proses pembelajaran, pengujian hingga prediksi akan dibedakan ke dalam 2 (dua) model, yaitu Model Prediksi Lama Studi (MPLS) dan Model Prediksi Indeks Prestasi Kumulatif (MPIPK).
Pembentukan Model JST
Pembentukan model prekdiksi dimaksudkan untuk menentukan parameter dari arsitektur jaringan yang akan digunakan untuk pembelajaran. Pembentukan model prediksi dilakukan dengan menggunakan JST Propagasi Balik (Backpropagation) dengan 1 (satu) lapisan tersembunyi. Jumlah variabel input yang digunakan dalam penelitian ini sebanyak 16 buah variabel. Jumlah node
untuk lapisan input sama dengan jumlah variabel input, karena data input sudah berbentuk data numerik sehingga tidak mengalami praproses data. Jumlah node
pada lapisan output sama dengan jumlah kategori yang akan diklasifikasi dan hal ini berbeda untuk setiap model prediksi. Model prediksi lama studi (MPLS) memiliki 2 (dua) kategori output, sehingga jumlah node pada model prediksi ini sebanyak 2 (dua) node dan Model prediksi IPK (MPIPK) memiliki 3 (tiga) kategori output, sehingga jumlah node pada model prediksi ini menjadi 3 (tiga)
node. Adapun untuk jumlah node pada lapisan tersembunyi (hidden-node), pada penelitian ini akan divariasikan untuk mendapatkan hasil yang lebih optimal. Karena diduga jumlah node pada lapisan tersembunyi berpengaruh terhadap tingkat generalisasi atau pengenalan pola. Variasi jumlah hidden-node yang digunakan adalah 5, 10 dan 15.
Selain jumlah node pada tiap lapisan arsitektur JST, ditetapkan beberapa parameter yang akan diberikan pada proses pembelajaran dan diuji untuk membentuk model prediksi, antara lain adalah fungsi aktivasi, toleransi galat, jumlah epoch maksimal, laju pembelajaran (learning rate) dan fungsi pelatihan (training function). Untuk inisialisasi bobot awal digunakan inisialisasi secara random. Fungsi aktivasi yang digunakan pada lapisan tersembunyi adalah
tansigmoid, sedangkan pada lapisan output menggunakan fungsi aktivasi pure linear. Toleransi kesalahan minimum (galat) ditentukan pada 0.001. Toleransi galat yang cukup kecil diharapkan akan memberikan hasil yang cukup baik. Jumlah epoch maksimal yang ditetapkan dalam penelitian ini adalah 1000. Hal ini diperlukan sebagai kriteria henti jaringan disamping tolerasin galat untuk membatasi waktu yang disediakan bagi jaringan dalam melakukan pembelajaran.
laju pembelajaran yang digunakan adalah 0.01, 0.05, 0.1 dan 0.5. Laju pembelajaran dapat mempengaruhi konvergensi kecepatan pada proses pembelajaran, sehingga perlu dilakukan percobaan pada laju pembelajaran yang berbeda untuk mendapatkan nilai rentang data yang sesuai. Hasil penelitian Purnomo (2001) menyatakan bahwa semakin kecil nilai laju pembelajarannya maka semakin kecil pula nilai dan rentang data matriks vektor hasil pelatihan, dan sebaliknya. Fungsi pelatihan yang divariasikan adalah algoritma pelatihan dengan perbaikan teknik heuristik resilent backpropagation dan perbaikan dengan teknik optimasi scaled conjugate gradient dan levenberg-marquardt.
Tabel 4 Karakteristik dan Struktur JST yang digunakan
KARAKTERISTIK SPESIFIKASI
Arsitektur jaringan Algoritma Pembelajaran
Multi-layer dengan 1 lapisan tersembunyi
Propagasi balik
Jumlah node input 16
Jumlah node lapisan tersembunyi 5, 10, 15
Fungsi aktivasi lapisan tersembunyi Sigmoid bipolar Jumlah node lapisan ouput :
Model Prediksi Lama Studi (MPLS) 2 Model Prediksi IPK (MPIPK) 3
Fungsi aktivasi lapisan output Fungsi linier
Toleransi galat 0.001
Laju Pembelajaran 0.01, 0.05, 0.1, 0.5
Maksimum epoch 1000
Pembelajaran Model
Algoritma pembelajaran propagasi balik meliputi 3 (tiga) tahap, yaitu : prosedur umpan maju (feedforward), perhitungan serta perambatan balik kesalahan (backpropagation) dan penyesuaian bobot. Sebelum proses pelatihan terlebih dahulu ditentukan bobot-bobot awal secara random dan toleransi kesalahan minimum. Bobot-bobot awal ini nantinya akan diinisialisasi dan digunakan pada proses umpan maju awal, sedangkan proses umpan maju selanjutnya menggunakan bobot-bobot yang telah mengalami perbaikan. Toleransi kesalahan minimum berfungsi sebagai pembatas berulangnya proses iterasi dalam suatu pelatihan. Proses pelatihan akan terus berulang hingga diperoleh koreksi kesalahan yang sama atau lebih kecil dari tolerasi kesalahan minimum.
Pengujian dan Generalisasi
Pengujian jaringan bertujuan untuk mengetahui apakah jaringan dapat melakukan generalisasi terhadap data baru yang dimasukkan ke dalamnya yaitu ditunjukkan dengan persentase akurasi jaringan dalam mengenali data pengujian, sehingga arsitektur jaringan yang digunakan untuk pengujian adalah arsitektur terbaik yang diperoleh dari hasil pelatihan jaringan. Dalam penelitian ini digunakan parameter yang disebut generalisasi untuk mengukur tingkat pengenalan jaringan pada pola yang diberikan. Dimana pola yang diberikan adalah data validasi maupun data testing. Generalisasi yang digunakan dalam Agustini (2006) adalah sebagai berikut :
100 _
_
_ x
pola jum
test numkenal test
si
Generalisa (6)
dengan numkel_test adalah jumlah pola yang dikenal dan jum_pola adalah jumlah pola keseluruhan. Jumlah numkel_test dan jum_pola yang ditunjukkan akan berbeda pada setiap model prediksi.
Analisis Sensitivitas
(2001). Analisis sensitivitas ini dilakukan pada percobaan dengan arsitektur dan parameter terbaik yang diperoleh setelah proses pelatihan dan pengujian. Hasil analisis sensitivitas dibedakan berdasarkan model prediksi.
3.2 Alat Bantu Penelitian
Alat-alat Bantu yang digunakan dalam penelitian ini adalah sebagai berikut :
1) Notebook
Notebook dengan spesifikasi prosesor Intel® Pentium (TM)2 Duo CPU T5070, 2.00 GHz, Memory (RAM) 1.87 GB.
2) Sistem Operasi Windows XP Home Edition, Version 2002, Service Pack 2. 3) Aplikasi Microsoft Excel 2007 untuk melakukan praproses terhadap data
sebelum digunakan sebagai input model yang dikembangkan karena tampilan data dalam bentuk data sheet unuk mempermudah dalam pengolahan data. 4) Aplikasi Matlab versi 6.5 digunakan dalam penelitian ini untuk transformasi
data numerik, pengolahan data dan visualisasi hasil.
3.3 Waktu dan Tempat Penelitian
4.
HASIL DAN PEMBAHASAN
4.1 Praproses Data
Praproses data yang dilakukan pada penelitian ini adalah pembersihan data, analisa relevansi dan tranformasi data (Han & Kember 2001). Pembersihan data dilakukan untuk menghilangkan noise akibat data yang hilang atau tidak lengkap, dengan menggantinya dengan nilai yang paling umum muncul untuk data tersebut atau dengan nilai yang paling mungkin muncul secara statistik. Analisa relevansi dilakukan untuk menghilangkan atribut yang redundant dan tidak relevan dengan penelitian. Transformasi data yang dilakukan pada penelitian ini adalah untuk data target yang bersifat kategorikal, dengan menggunakan metode Unary Encoding, dimana data target dipresentasikan dengan kombinasi angka 0 dan 1 (numerical binary variable). Berdasarkan data kategori targetnya maka dalam penelitian ini, seluruh proses pembelajaran, pengujian hingga prediksi akan dibedakan ke dalam 2 (dua) model, yaitu Model Prediksi Lama Studi (MPLS) dan Model Prediksi Indeks Prestasi Kumulatif (MPIPK). Berikut adalah praproses transformasi unary encoding yang dibedakan ke dalam 2 (dua) model prediksi :
1. Model Prediksi Lama Studi (MPLS), variabel target memiliki 2 (dua) kategori
yaitu kategori „Melebihi Batas Studi‟ dan „Tepat Waktu‟. Praproses unary encoding atau numerical binary variable dikenakan pada variabel ini dengan
kategori „10‟ untuk „Melebihi Batas Studi‟ dan kategori „01‟ untuk „Tepat
Waktu‟.
2. Model Prediksi IPK (MPIPK), variabel output memiliki 3 (tiga) kategori yaitu
kategori „Terpuji‟, „Sangat Memuaskan dan „Memuaskan. Praproses unary encoding atau numerical binary variable dikenakan pada variabel ini dengan kategori „100‟ untuk „Terpuji‟, kategori „010‟ untuk „Sangat Memuaskan‟ dan kategori „001‟untuk „Memuaskan‟.
4.2 Pembentukan Model JST
Jaringan Saraf Tiruan dibangun berdasarkan struktur JST pada Tabel 8. Proses pembelajaran dan pengujian menghasilkan informasi waktu pembelajaran dan MSE dengan variasi laju pembelajaran dan jumlah hidden-node, dimana proses pembelajaran maupun pengujian dibedakan berdasarkan model prediksi kelompok data dan fungsi pelatihan. Hal ini dimaksudkan untuk membandingkan kinerja dari ketiga fungsi pelatihan yang digunakan, untuk menguji apakah tingkat generalisasi pada data pengujian benar dapat ditingkatkan dengan adanya teknik perbaikan algoritma pelatihan yang lebih cepat. Fungsi pelatihan yang digunakan adalah algoritma pelatihan dengan perbaikan teknik heuristik resilent backpropagation dan perbaikan dengan teknik optimasi, yakni fungsi pelatihan
scaled conjugate gradient dan levenberg-marquardt. a. Model Prediksi Lama Studi (MPLS)
Percobaan pada kelompok data pertama dengan menggunakan fungsi pelatihan resilent backpropagation disajikan oleh Tabel 5.
Tabel 5 Kelompok data pertama MPLS dengan fungsi pelatihan resilent backpropagation
Pembelajaran Pengujian
Laju Pembelajaran
Hidden Node
Waktu
(detik) MSE
Data Validasi (%)
Data Testing (%)
0.01
5 5.5 0.000981795 75.76 60.61
10 3.27 0.0084304 45.45 51.51 15 3.42 0.00528705 51.51 54.54
0.05
5 5 0.00201312 69.70 66.67
10 4.17 0.0050627 51.51 60.61 15 2.7 0.0224537 33.33 39.39
0.1
5 3.44 0.00467662 60.61 60.61 10 4.69 0.000995264 51.51 51.51
15 2.14 0.0170291 45.45 51.51
0.5
5 3.47 0.00233313 54.54 54.54 10 7.47 0.00157674 30.30 51.51
15 2.03 0.0266991 36.36 36.36
diperoleh bahwa waktu pembelajaran tercepat dan terlama berada pada laju pembelajaran 0.5. Waktu pembelajaran tercepat mencapai 2.03 detik dengan jumlah hidden-node 15 dan waktu pembelajaran terlama 7.47 detik dengan jumlah
hidden-node 10. Nilai MSE terkecil adalah 0.000981795, berada pada laju pembelajaraan 0.01 dengan jumlah hidden-node 5. Hasil pengujian menghasilkan tingkat generalisasi untuk data validasi sebesar 75.76% pada laju pembelajaran 0.01 dan jumlah hidden-node 5. Generalisasi tertinggi dari data validasi menunjukkan nilai MSE yang terkecil. Pengujian terhadap data testing menghasilkan tingkat generalisasi tertinggi sebesar 66.67%.
[image:47.595.112.511.374.614.2]Percobaan pada kelompok data pertama dengan menggunakan fungsi pelatihan dengan perbaikan teknik optimasi scaled conjugate gradient disajikan oleh Tabel 6.
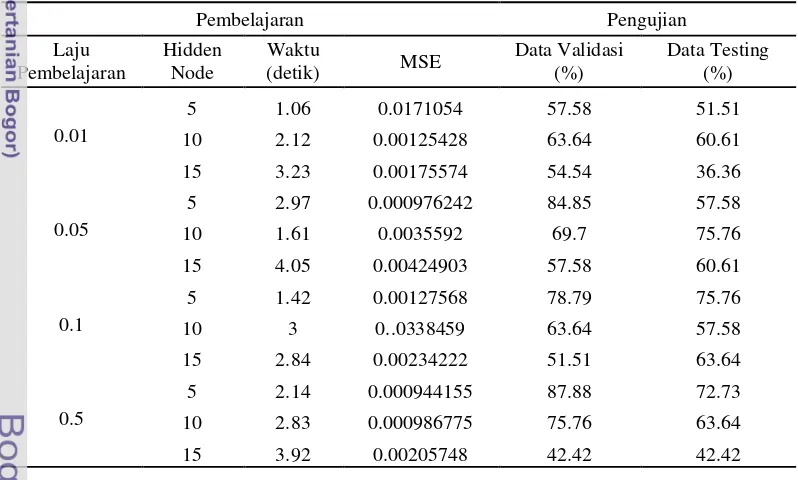
Tabel 6 Kelompok data pertama MPLS dengan fungsi pelatihan scaled conjugate gradient
Pembelajaran Pengujian
Laju Pembelajaran
Hidden Node
Waktu
(detik) MSE
Data Validasi (%)
Data Testing (%)
0.01
5 1.06 0.0171054 57.58 51.51
10 2.12 0.00125428 63.64 60.61 15 3.23 0.00175574 54.54 36.36
0.05
5 2.97 0.000976242 84.85 57.58
10 1.61 0.0035592 69.7 75.76 15 4.05 0.00424903 57.58 60.61
0.1
5 1.42 0.00127568 78.79 75.76
10 3 0..0338459 63.64 57.58
15 2.84 0.00234222 51.51 63.64
0.5
5 2.14 0.000944155 87.88 72.73 10 2.83 0.000986775 75.76 63.64
15 3.92 0.00205748 42.42 42.42
diperoleh dari hasil percobaan ini mengalami perbaikan dengan diperolehnya nilai MSE yang lebih kecil dari percobaan dengan menggunakan variasi fungsi pelatihan resilent backpropagation yang memiliki nilai MSE terkecil 0.000981795 menjadi 0,000944155. Hal yang sama dengan tingkat generalisasi pada data validasi dan data testing, mengalami peningkatan menjadi 87.88% untuk data validasi dan 75.76% untuk data testing. Nilai MSE terkecil dan tingkat generalisasi tertinggi dari data validasi pada percobaan ini berada pada laju pembelajaran 0.5 dan jumlah hidden-node 5.
Tabel 7 merupakan hasil percobaan pada kelompok data pertama dengan menggunakan fungsi pelatihan levenberg-marquardt.
Tabel 7 Kelompok data pertama MPLS dengan fungsi pelatihan levenberg-marquardt
Pembelajaran Pengujian
Laju Pembelajaran
Hidden Node
Waktu
(detik) MSE
Data Validasi (%)
Data Testing (%)
0.01
5 0.97 0.000216378 96.97 81.82
10 1.31 0.000819831 96.97 78.79 15 2.51 0.000246061 93.94 78.79
0.05
5 0.58 0.00076569 51.51 60.61
10 1.08 0.000706945 96.97 81.82 15 1.58 0.000443307 81.82 69.70
0.1
5 0.83 0.000166963 96.97 87.88 10 0.75 0.000300433 63.64 45.45
15 1.14 0.000562517 96.97 75.76
0.5
5 1.06 0.00023595 96.97 84.85 10 1.05 0.000501864 96.97 84.85
15 2.42 0.000269378 51.51 51.51
Percobaan dengan menggunakan fungsi pelatihan levenberg-marquardt
meningkat menjadi 97.97% dan 87.88%. MSE terkecil dan tingkat generalisasi tertinggi dari data validasi dan data testing pada percobaan ini berada pada laju pembelajaran 0.1 dan jumlah hidden-node 5. Dari ketiga hasil percobaan kelompok data pertama pada model prediksi lama studi (MPLS) dengan menggunakan variasi fungsi pelatihan dapat diketahui bahwa proses percobaan dengan menggunakan fungsi pelatihan levenberg-marquardt terbukti dapat memperbaiki bobot sehingga bisa menghasilkan waktu pembelajaran yang lebih cepat pada proses pembelajarannya, nilai MSE yang semakin kecil dan tingkat generalisasi data valiadasi dan data testing yang lebih tinggi.
Tabel 8 menyajikan hasil percobaan pada kelompok data kedua dengan menggunakan fungsi pelatihan dengan perbaikan teknik heuristik resilent backpropagation.
Tabel 8 Kelompok data kedua MPLS dengan fungsi pelatihan resilent backpropagation
Pembelajaran Pengujian
Laju Pembelajaran
Hidden Node
Waktu
(detik) MSE
Data Validasi (%)
Data Testing (%)
0.01
5 0.89 0.0151417 72.73 63.64
10 1.95 0.0217372 36.36 39.39 15 6.76 0.003475 51.51 51.51
0.05
5 2.16 0.016927 72.73 51.51
10 2.28 0.0221829 42.42 30.30 15 3.7 0.0126983 54.54 54.54
0.1
5 1.09 0.0127768 66.67 63.64
10 0.83 0.0293735 42.42 42.42 15 2.37 0.0193201 30.30 39.39
0.5
5 2.23 0.0138682 63.64 72.73 10 0.78 0.0218776 42.42 36.36
15 1.14 0.0218282 30.30 33.33
Hasil percobaan pada kelompok data kedua dengan menggunakan fungsi pelatihan dengan perbaikan teknik optimasi scaled conjugate gradient disajikan oleh Tabel 9
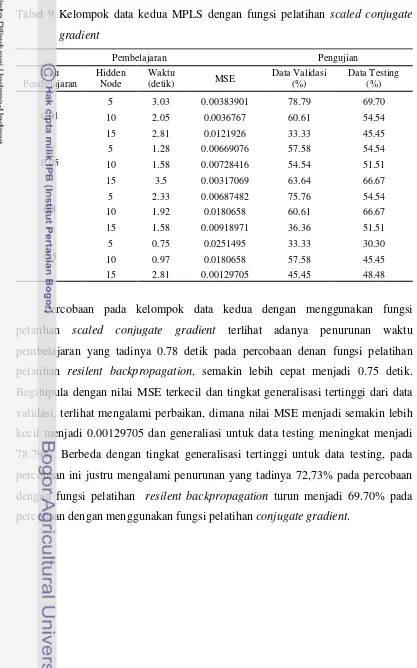
Tabel 9 Kelompok data kedua MPLS dengan fungsi pelatihan scaled conjugate gradient
Pembelajaran Pengujian
Laju Pembelajaran
Hidden Node
Waktu
(detik) MSE
Data Validasi (%)
Data Testing (%)
0.01
5 3.03 0.00383901 78.79 69.70 10 2.05 0.0036767 60.61 54.54
15 2.81 0.0121926 33.33 45.45
0.05
5 1.28 0.00669076 57.58 54.54 10 1.58 0.00728416 54.54 51.51
15 3.5 0.00317069 63.64 66.67
0.1
5 2.33 0.00687482 75.76 54.54 10 1.92 0.0180658 60.61 66.67
15 1.58 0.00918971 36.36 51.51
0.5
5 0.75 0.0251495 33.33 30.30
10 0.97 0.0180658 57.58 45.45
15 2.81 0.00129705 45.45 48.48
[image:50.595.69.486.140.808.2]Tabel 10 merupakan hasil percobaan pada kelompok data kedua dengan menggunakan fungsi pelatihan levenberg-marquardt.
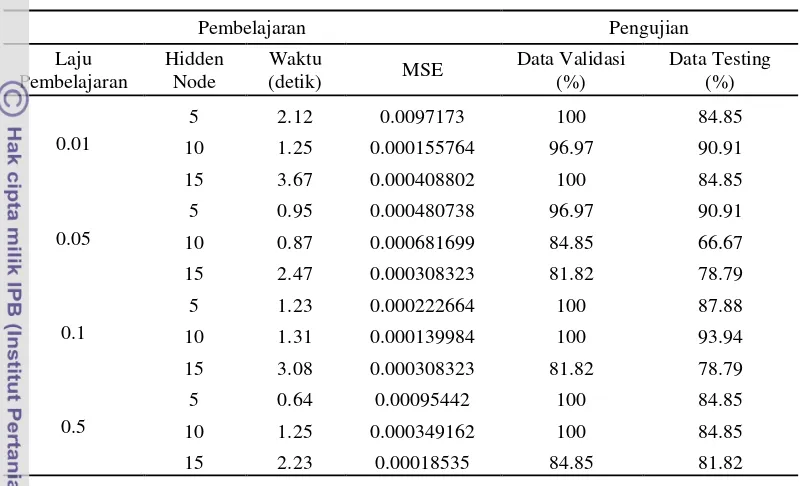
Tabel 10 Kelompok data kedua MPLS dengan fungsi pelatihan levenberg-marquardt
Pembelajaran Pengujian
Laju Pembelajaran
Hidden Node
Waktu
(detik) MSE
Data Validasi (%)
Data Testing (%)
0.01
5 2.12 0.0097173 100 84.85
10 1.25 0.000155764 96.97 90.91
15 3.67 0.000408802 100 84.85
0.05
5 0.95 0.000480738 96.97 90.91
10 0.87 0.000681699 84.85 66.67
15 2.47 0.000308323 81.82 78.79
0.1
5 1.23 0.000222664 100 87.88
10 1.31 0.000139984 100 93.94
15 3.08 0.000308323 81.82 78.79
0.5
5 0.64 0.00095442 100 84.85
10 1.25 0.000349162 100 84.85 15 2.23 0.00018535 84.85 81.82
Percobaan terakhir untuk model prediksi lama studi (MPLS) pada kelompok data kedua dengan menggunakan fungsi pelatihan levenberg-marquardt memperlihatkan bahwa nilai waktu pembelajaran tercepat, nilai MSE terkecil dan tingkat generalisasi untuk data validasi dan data testing mengalami perbaikan nilai jika dibandingkan dengan hasil percobaan dengan menggunakan fungsi pelatihan
[image:51.595.111.512.163.406.2]minimum dan tingkat generalisasi tertinggi dari data validasi dan data testing berada pada laju pembelajaran 0.5 dan jumlah hidden-node 5.
b. Model Prediksi IPK (MPIPK)
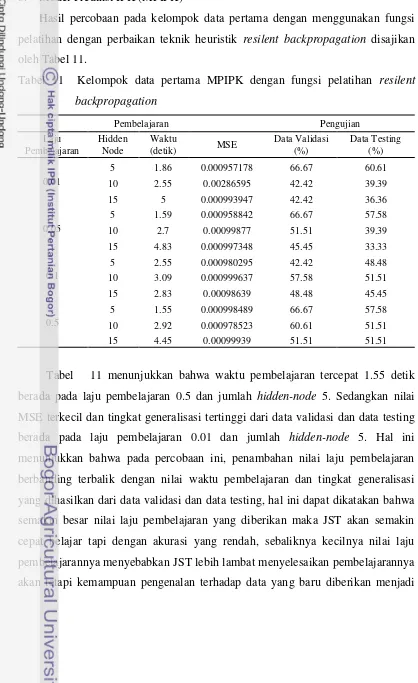
Hasil percobaan pada kelompok data pertama dengan menggunakan fungsi pelatihan dengan perbaikan teknik heuristik resilent backpropagation disajikan oleh Tabel 11.
Tabel 11 Kelompok data pertama MPIPK dengan fungsi pelatihan resilent backpropagation
Pembelajaran Pengujian
Laju Pembelajaran
Hidden Node
Waktu
(detik) MSE
Data Validasi (%)
Data Testing (%)
0.01
5 1.86 0.000957178 66.67 60.61
10 2.55 0.00286595 42.42 39.39 15 5 0.000993947 42.42 36.36
0.05
5 1.59 0.000958842 66.67 57.58 10 2.7 0.00099877 51.51 39.39
15 4.83 0.000997348 45.45 33.33
0.1
5 2.55 0.000980295 42.42 48.48 10 3.09 0.000999637 57.58 51.51
15 2.83 0.00098639 48.48 45.45
0.5
5 1.55 0.000998489 66.67 57.58 10 2.92 0.000978523 60.61 51.51
15 4.45 0.00099939 51.51 51.51
[image:52.595.67.485.136.819.2]semakin baik, ditunjukkan dengan nilai MSE yang lebih kecil dan tingkat generalisasi data pengujian yang lebih tinggi.
Hasil percobaan pada kelompok data pertama dengan menggunakan fungsi pelatihan dengan perbaikan teknik optimasi scaled conjugate gradient
ditunjukkan oleh Tabel 12.
Tabel 12 Kelompok data pertama MPIPK dengan fungsi pelatihan scaled conjugate gradient
Pembelajaran Pengujian
Laju Pembelajaran
Hidden Node
Waktu
(detik) MSE
Data Validasi (%)
Data Testing (%)
0.01
5 1.45 0.000955635 69.70 48.48 10 1.48 0.000981308 78.79 69.70
15 2.95 0.000971796 54.54 48.48
0.05
5 1.36 0.000769821 75.76 45.45 10 2.08 0.000965313 60.61 48.48
15 1.09 0.000972445 54.54 45.45
0.1
5 0.98 0.000868043 51.51 42.42 10 0.86 0.000949777 54.54 45.45
15 1.17 0.000974621 57.58 45.45
0.5
5 1.53 0.000959069 69.70 60.61
10 0.92 0.000970857 57.58 36.36
15 1.98 0.000989036 54.54 51.51
Percobaan dengan menggunakan fungsi pelatihan scaled conjugate gradient
Tabel 13 merupakan hasil percobaan pada kelompok data pertama dengan menggunakan fungsi pelatihan levenberg-marquardt.
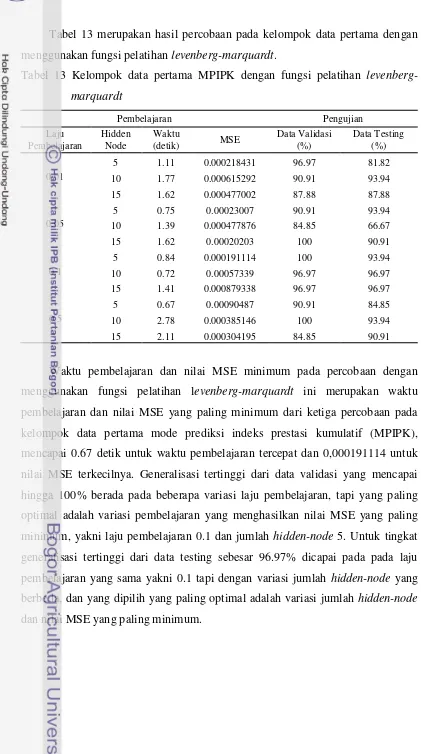
Tabel 13 Kelompok data pertama MPIPK dengan fungsi pelatihan levenberg-marquardt
Pembelajaran Pengujian
Laju Pembelajaran
Hidden Node
Waktu
(detik) MSE
Data Validasi (%)
Data Testing (%)
0.01
5 1.11 0.000218431 96.97 81.82 10 1.77 0.000615292 90.91 93.94
15 1.62 0.000477002 87.88 87.88
0.05
5 0.75 0.00023007 90.91 93.94
10 1.39 0.000477876 84.85 66.67
15 1.62 0.00020203 100 90.91
0.1
5 0.84 0.000191114 100 93.94
10 0.72 0.00057339 96.97 96.97
15 1.41 0.000879338 96.97 96.97
0.5
5 0.67 0.00090487 90.91 84.85
10 2.78 0.000385146 100 93.94 15 2.11 0.000304195 84.85 90.91
Waktu pembelajaran dan nilai MSE minimum pada percobaan dengan menggunakan fungsi pelatihan levenberg-marquardt ini merupakan waktu pembelajaran dan nilai MSE yang paling minimum dari ketiga percobaan pada kelompok data pertama mode prediksi indeks prestasi kumulatif (MPIPK), mencapai 0.67 detik untuk waktu pembelajaran tercepat dan 0,000191114 untuk nilai MSE terkecilnya. Generalisasi tertinggi dari data validasi yang mencapai hingga 100% berada pada beberapa variasi laju pembelajaran, tapi yang paling optimal adalah variasi pembelajaran yang menghasilkan nilai MSE yang paling minimum, yakni laju pembelajaran 0.1 dan jumlah hidden-node 5. Untuk tingkat generalisasi tertinggi dari data testing sebesar 96.97% dicapai pada pada laju pembelajaran yang sama yakni 0.1 tapi dengan variasi jumlah hidden-node yang berbeda, dan yang dipilih yang paling optimal adalah variasi jumlah hidden-node
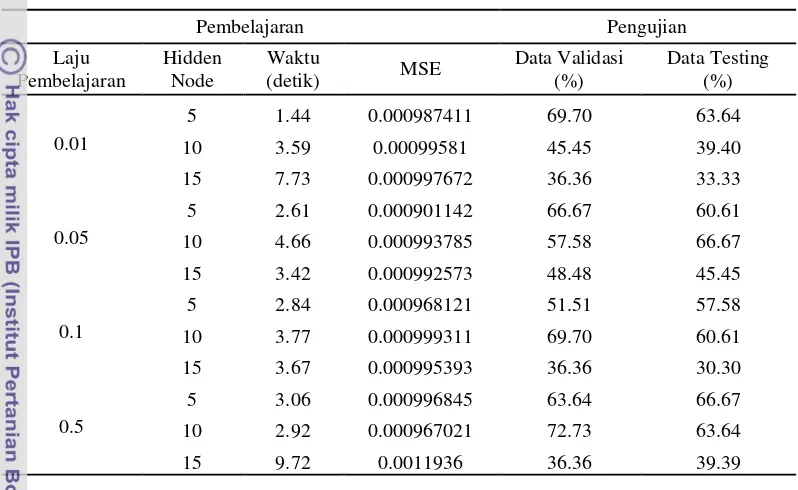
[image:54.595.64.485.58.812.2]Percobaan pada kelompok data kedua dengan menggunakan fungsi pelatihan dengan perbaikan teknik heuristik resilent backpropagation disajikan oleh Tabel 14.
Tabel 14 Kelompok data kedua MPIPK dengan fungsi pelatihan resilent backpropagation
Pembelajaran Pengujian
Laju Pembelajaran
Hidden Node
Waktu
(detik) MSE
Data Validasi (%)
Data Testing (%)
0.01
5 1.44 0.000987411 69.70 63.64 10 3.59 0.00099581 45.45 39.40