SENTIMENT ANALYSIS
PADA TEKS BAHASA INDONESIA
MENGGUNAKAN
SUPPORT VECTOR MACHINE(SVM)
DAN
K-NEAREST NEIGHBOR(K-NN)
TESIS
SYAHFITRI KARTIKA LIDYA
127038007
PROGRAM STUDI MAGISTER (S-2) TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
SENTIMENT ANALYSIS
PADA TEKS BAHASA INDONESIA
MENGGUNAKAN
SUPPORT VECTOR MACHINE(SVM)
DAN
K-NEAREST NEIGHBOR(K-NN)
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh ijazah
Magister (S-2) Teknik Informatika
Syahfitri Kartika Lidya
127038007
PROGRAM STUDI MAGISTER (S-2) TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul Tesis : SENTIMENT ANALYSIS PADA TEKS BAHASA
INDONESIA MENGGUNAKAN SUPPORT
VECTOR MACHINE (SVM) DAN K-NEAREST
NEIGHBOR (K-NN)
Kategori : TESIS
Nama Mahasiswa : SYAHFITRI KARTIKA LIDYA
Nomor Induk Mahasiswa : 127038007
Program Studi : MAGISTER (S-2) TEKNIK INFORMATIKA
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
(FASILKOM-TI) UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2, Pembimbing 1,
Dr. Syahril Efendi, S.Si M.IT Prof. Dr. Opim Salim Sitompul, M.Sc NIP. 19671110 199602 1 001 NIP. 19610817 198701 1 001
Diketahui/Disetujui Oleh,
Program Studi Magister (S-2) Teknik Informatika, Ketua,
PERNYATAAN
SENTIMENT ANALYSIS
PADA TEKS BAHASA INDONESIA
MENGGUNAKAN
SUPPORT VECTOR MACHINE(SVM)
DAN
K-NEAREST NEIGHBOR(K-NN)
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan
ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 21 Agustus 2014
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, Saya yang bertanda tangan di bawah
ini :
Nama : Syahfitri Kartika Lidya
NIM : 127038007
Program Studi : Magister (S-2) Teknik Informatika
Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas
Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty Free Right) atas
Tesis Saya yang berjudul.
SENTIMENT ANALYSIS PADA TEKS BAHASA INDONESIA
MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM)
DAN K-NEAREST NEIGHBOR (K-NN)
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-Eksklusif ini,
Universitas Sumatera Utara berhak menyimpan, mengalih media, menformat, mengelola,
dalam bentuk database, merawat, dan mempublikasikan Tesis Saya tanpa meminta izin dari
Saya selama tetap mencantumkan nama Saya sebagai penulis dan sebagai pemegang dan atau
sebagai pemilik hak cipta.
Demikian Pernyataan ini dibuat dengan sebenarnya.
Medan, 21 Agustus 2014
Telah diuji pada
Tanggal : 21 Agustus 2014
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Opim Salim Sitompul, M.Sc Anggota : 1. Dr. Syahril Efendi, S.Si M.IT
2. Prof. Dr. Muhammad Zarlis
3. Dr. Erna Budhiarti Nababan, M.IT
RIWAYAT HIDUP
DATA PRIBADI
Nama lengkap berikut gelar : Syahfitri Kartika Lidya, S.TI
Tempat dan Tanggal Lahir : Medan, 21 April 1991
Alamat Rumah : Jl. Denai, Jermal IV No. 15
Telepon / HP : 082167512054
Email : [email protected]
DATA PENDIDIKAN
SD : SD Negeri No.091644 Bah Lias Tamat : 2000
SMP : SMP Negeri 1 Bandar Tamat : 2006
SMA : SMA Negeri 3 Medan Tamat : 2008
Strata-1 : Teknologi Informasi USU Tamat : 2012
UCAPAN TERIMA KASIH
Puji syukur saya panjatkan kehadirat Allah SWT, yang telah memberikan rahmat dan hidayah-Nya serta segala sesuatunya dalam hidup, sehingga saya dapat menyelesaikan penyusunan Tesis ini, sebagai syarat untuk memperoleh ijazah Magister Teknik Informatika, Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara. Dalam pengerjaan Tesis ini penulis banyak sekali mendapatkan dukungan, saran, dan nasehat dari berbagai pihak.
Dalam kesempatan ini penulis mengucapkan terima kasih kepada: Bapak Prof. Dr. Opim Salim Sitompul, M.Sc, selaku Dosen Pembimbing I, yang telah bersedia meluangkan waktu dan pikirannya dalam membimbing, memotivasi untuk menyelesaikan Tesis ini. Bapak Dr. Syahril Efendi, S.Si M.IT, selaku Dosen Pembimbing II, yang telah bersedia meluangkan waktu dan pikirannya dalam menyelesaikan Tesis ini, Ucapan terima kasih juga ditujukan kepada Dosen Pembanding Bapak Prof. Dr. Muhammad Zarlis, Ibu Dr. Erna Budhiarti Nababan M.IT, dan Bapak Dr. Benny Benyamin Nasution Dipl. Ing., M. Eng, kemudian ucapan terima kasih untuk Ketua Program Studi Magister Teknik Informatika Bapak Prof. Dr. Muhammad Zarlis dan Sekretaris Program Studi Magister Teknik Informatika Bapak M. Andri Budiman, ST, McompSc, MEM. Serta kepada dosen-dosen Program Studi Magister Teknik Informatika dan pegawai di Program Studi Magister Teknik Informatika, khususnya kak Widya, kak Ines, kak Maya dan bang Ewin yang telah membantu kelancaran proses administrasi.
Segala hormat dan terima kasih secara khusus penulis ucapkan kepada ayahanda Yonnes Hasan dan Ibunda Nova Mustika atas motivasi, kasih sayang, dan dukungan baik
secara materi maupun do‟a yang tak pernah putus yang diberikan kepada penulis, tak lupa
kepada adik-adik tersayang Vayon Rachmat Ramadhan dan Sabilla Afiya, serta tante dan Om tersayang Julia Reveny, Imsyah Satari, Julia Maulina, Imsyahrial yang telah memberi motivasi dan nasehat serta nenek Syahiar tersayang yang selalu mendoakan. Tidak lupa kepada seluruh sahabat penulis Stambuk 2012 Kom A yang selalu berusaha menjadi sahabat terbaik khususnya kak Ananda, bg Johanes, bg bambang, kak Mawadda dan seluruh Stambuk 2012, kemudian orang terdekat yang selalu disayang, yang selalu memberi motivasi dan nasehat khususnya Karina Ayesha, Alfarisi, Karina Andi, Bowo, Ishri, Cahya, Dika, Mauza, Khalil.
Penulis berharap bahwa Tesis ini bermanfaat terutama kepada penulis maupun para pembaca. Saya menyadari bahwa Tesis ini perlu saran dan kritik yang bersifat membangun demi kesempurnaan Tesis ini sehingga dapat bermanfaat bagi kita semua. Sekali lagi saya ucapkan terima kasih atas segalanya. Semoga segala kebaikan diberikan balasan yang setimpal oleh Allah SWT.
Medan, 21 Agustus 2014
ABSTRAK
Analisis Sentimen adalah proses menganalisis, memahami, dan mengklasifikasi pendapat,
evaluasi, penilaian, sikap, dan emosi terhadap suatu entitas seperti produk, jasa, organisasi,
individu, peristiwa, topik, secara otomatis untuk mendapatkan informasi. Penelitian ini
menggunakan teks Bahasa Indonesia yang terdapat di website berupa artikel berita, kemudian
metode K-Nearest Neighbor akan mengklasifikasi secara langsung pada data pembelajaran
agar dapat menentukan model yang akan dibentuk oleh metode Support Vector Machine
untuk menentukan kategori dari data baru yang ingin ditentukan kategori tekstual, yaitu kelas
sentimen positif, negatif dan netral. Berdasarkan seluruh hasil pengujian, bahwa pengaruh
nilai k pada k-fold cross validation yang terlalu kecil menghasilkan akurasi yang rendah,
sedangkan nilai k yang terlalu besar menghasilkan nilai akurasi yang besar, kemudian
Pengaruh nilai k pada K-NN terhadap akurasi, jika n memiliki akurasi rendah pada saat nilai
k kecil. Hal ini dikarenakan, data yang masuk pada k tetangga terdekat terlalu sedikit dan
belum bisa merepresentasikan kelas pada data uji.
SENTIMENT ANALYSIS USING SUPPORT VECTOR MACHINE
(SVM) AND K-NEAREST NEIGHBOR (K-NN) ON INDONESIAN TEXT
ABSTRACT
Sentiment analysis is the process of analyzing, understanding, and classifying opinions, evaluation, assessment, attitudes, and emotions to an entity such as products, services, organizations, individuals, events, topics, automatically to obtain the information. This study uses Indonesian text contained in the website in the form of news articles, then the K-Nearest Neighbor method will classify directly to the learning data in order to determine the model that will be established by the Support Vector Machine method for determining the category of the new data to be determined categories of textual, the class of sentiment is positive, negative and neutral. Based on the test results, that influence the value of k in the k-fold cross validation is too small resulting in low accuracy, while too large values of k produce great accuracy value, then the value of k on the Influence of K-NN to accuracy, if n has an accuracy low when the value of k is small. This is because, the incoming data on the k nearest
neighbor too little and can not represent a class on test data.
DAFTAR ISI
Halaman
HALAMAN JUDUL i
PERSETUJUAN ii
PERNYATAAN ORISINALITAS iii
PERSETUJUAN PUBLIKASI iv
PANITIA PENGUJI v
RIWAYAT HIDUP vi
UCAPAN TERIMA KASIH vii
ABSTRAK viii
ABSTRACT ix
DAFTAR ISI x
DAFTAR TABEL xii
DAFTAR GAMBAR xiii
BAB 1 PENDAHULUAN 1
1.1. Latar Belakang 1
1.2. Rumusan Masalah 2
1.3. Batasan Masalah 2
1.4. Tujuan Penelitian 3
1.5. Manfaat Penelitian 3
BAB 2 LANDASAN TEORI 4
2.1. Text Mining 4
2.2. Sentiment Analysis 6
2.3. Support Vector Machine (SVM) 11
2.3.1. Konsep Support Vector Machine (SVM) 11
2.3.2. Klasifikasi Data Linear Separable 13
2.3.3. Klasifikasi Data Linear Non-Separable 14
2.3.4. Klasifikasi Data Non-Linear 14
2.3.5. Metode Kernel 15
2.3.6. Algoritma SVM untuk Menganalisis Dokumen Web 17
2.3.7. Karakterisitik Support Vector Machine (SVM) 18 2.3.8. Kelebihan Support Vector Machine (SVM) 19
2.3.9. Kelemahan Support Vector Machine (SVM) 19
2.4. K-Nearest Neighbor (K-NN) 20
2.4.1. Konsep K-Nearest Neighbor (K-NN) 20 2.4.2. Algoritma K-NN untuk Menganalisis Dokumen Web 23
2.4.3. Kelebihan K-Nea rest Neighbor (K-NN) 23
2.4.4. Kelemahan K-Nearest Neighbor (K-NN) 23
2.5. K-Fold Cross Validation 23
2.6. Riset Terkait 25
2.7. Perbedaan dengan Riset yang lain 26
BAB 3 METODOLOGI PENELITIAN 27
3.1. Identifikasi Masalah 27
3.2. Proses Analisis Sentimen pada Dokumen 27
3.3. Pengumpulan Data 28
3.4. Pre-Processing 29
3.4.1. Cleaning 29
3.4.2. Case Folding 30
3.5. Ekstraksi Fitur 30
3.5.1. Tokenization 30
3.5.2. Stopwords Removing 31
3.5.3. Stemming 32
3.6. Pembobotan Term 33
3.7. Pembelajaran dan Analisis 36
3.7.1. Rancangan Analisis Dokumen dengan K-NN 36 3.7.2. Rancangan Analisis Dokumen dengan SVM 41 3.8. Validasi dengan K-Fold Cross Validation 45
BAB 4 HASIL DAN PEMBAHASAN 47
4.1. Tentang Penelitian 47
4.2. Implementasi Metode K-NN dan Support Vector Machine 48
4.2.1. Persiapan Data 48
4.2.2. Proses Analisis 48
4.2.3. Antar Muka Sistem 49
4.3. Hasil dan Pembahasan Percobaan 52
4.3.1. Hasil dan Pembahasan Percobaan dengan Metode K-NN dan SVM
untuk data Berbahasa Indonesia 52
4.3.2 Pengaruh Pemilihan Nilai K pada K-NN 65
4.3.3 Akurasi K-Fold Cross Validation 66
BAB 5 KESIMPULAN DAN SARAN 69
5.1. Kesimpulan 69
5.2. Saran 70
DAFTAR PUSTAKA 71
LAMPIRAN 74
DAFTAR TABEL
Halaman
Tabel 2.1. Daftar Prefiks yang Meluluh 9
Tabel 2.2. Daftar Kemungkinan Perubahan Prefiks 9
Tabel 2.3. Daftar Kombinasi Prefiks dan Sufiks yang Tidak Diperbolehkan 10 Tabel 2.4. Rangkuman Penelitian Sentiment Analysis Sebelumnya 25
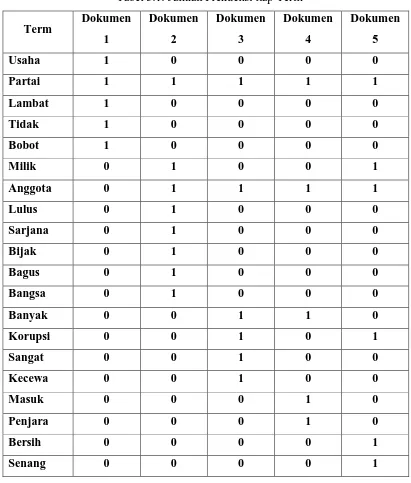
Tabel 3.1. Jumlah Frekuensi tiap Term 35
Tabel 3.2. Bobot Term 35
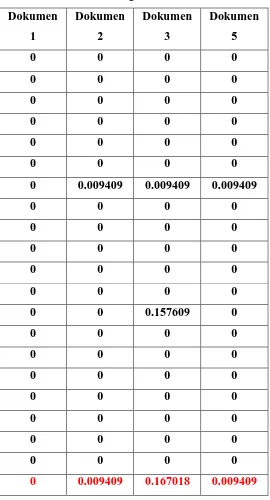
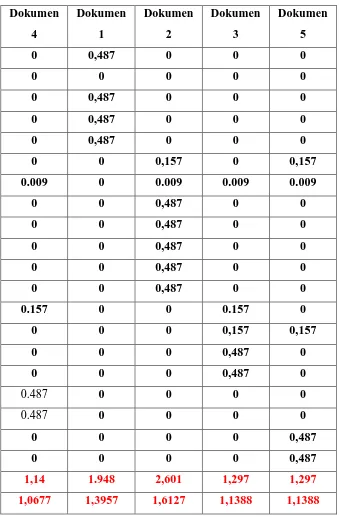
Tabel 3.3. Hitung Perkalian Skalar 39
Tabel 3.3. Hitung Panjang Vektor 40
Tabel 4.1. Spesifikasi Perangkat Keras 47
Tabel 4.2. Kata Positif pada Dokumen Positif 53
Tabel 4.3. Kata Negatif pada Dokumen Positif 54
Tabel 4.4. Kata Positif pada Dokumen Negatif 56
Tabel 4.5. Kata Negatif pada Dokumen Negatif 56
Tabel 4.6. Kata Positif pada Dokumen Netral 59
Tabel 4.7. Kata Negatif pada Dokumen Netral 59
Tabel 4.8. Persentase (%) Analisis Sentimen K-NN 61
Tabel 4.9. Jumlah Dokumen Hasil Analisis Sentimen K-NN 61
Tabel 4.10. Akurasi dan Waktu Proses K-NN dalam Menganalisis Sentimen 61
Tabel 4.11. Persentase (%) Analisis Sentimen SVM 62
Tabel 4.12. Jumlah Dokumen Hasil Analisis Sentimen K-NN 62
Tabel 4.13. Akurasi dan Waktu Proses SVM dalam Menganalisis Sentimen 63 Tabel 4.14. Hasil Rata-rata Semua Fold Cross Validation pada SVM dan K-NN
DAFTAR GAMBAR
Halaman
Gambar 2.1. Hyperplane (Bidang Pemisah) 14
Gambar 2.2. Transformasi dari vektor input ke feature space 15 Gambar 2.3. Suatu Kernel map mengubah problem yang tidak linier menjadi
Linier dalam space baru 16
Gambar 2.4. Ilustrasi Data dipisahkan dalam kasus XOR 18 Gambar 2.5. Delapan titik dalam satu dimensi dan estimasi densitas
K-NN dengan k=3 dan k=5 22 Gambar 2.6. K-NN mengestimasi densitas dua dimensi dengan k=5 22 Gambar 3.1. Proses Analisis Sentimen 27
Gambar 3.2. Pseudocode Cra wling 28
Gambar 3.3. Pseudocode Cleaning 29
Gambar 3.4. Pseudocode Case Folding 30
Gambar 3.5. Pseudocode Tokenization 30
Gambar 3.6. Pseudocode Stopwords Removing 31
Gambar 3.7. Pseudocode Stemming 32
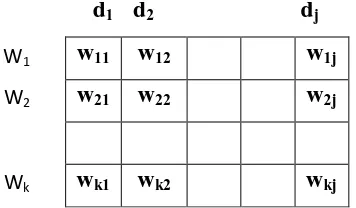
Gambar 3.8. Term Documents Matrix 33
Gambar 3.9. Pseudocode Pembobotan Term 34
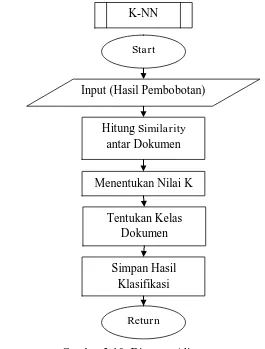
Gambar 3.10. Diagram Alir K-NN 37
Gambar 3.11. Pseudocode Analisis Menggunakan K-NN 38
Gambar 3.12. Diagram Alir SVM 42
Gambar 3.13. Pseudocode Analisis Menggunakan SVM 44
Gambar 3.14. Fungsi Pemisah antara Dokumen Relevan dan Tidak Relevan 45
Gambar 3.15. Pseudocode K-Fold Cross Validation 46
Gambar 4.1. Tampilan Beranda 49
Gambar 4.2. Tampilan Sub Menu “Kelola Data” 50
Gambar 4.3. Tampilan Menu “Tambah” 50
Gambar 4.4. Tampilan Sub Menu “Analisis Sentimen” 51
Gambar 4.5. Dokumen Positif 53
Gambar 4.6. Dokumen Negatif 54
Gambar 4.7. Dokumen Netral 55
Gambar 4.8. Jumlah Dokumen Positif, Negatif dan Netral Hasil Analisis
Sentimen 59
Gambar 4.9. Akurasi Rata-Rata K-NN dan SVM dalam Menganalisis Sentimen 59
Gambar 4.10. Waktu Rata-Rata K-NN dan SVM Menganalisis Sentimen 60
Gambar 4.11. Pengaruh Nilai k pada K-NN terhadap Akurasi 61
Gambar 4.12. Hasil Pengujian Konfigurasi Niilai k pada K-Fold Cross Validation
ABSTRAK
Analisis Sentimen adalah proses menganalisis, memahami, dan mengklasifikasi pendapat,
evaluasi, penilaian, sikap, dan emosi terhadap suatu entitas seperti produk, jasa, organisasi,
individu, peristiwa, topik, secara otomatis untuk mendapatkan informasi. Penelitian ini
menggunakan teks Bahasa Indonesia yang terdapat di website berupa artikel berita, kemudian
metode K-Nearest Neighbor akan mengklasifikasi secara langsung pada data pembelajaran
agar dapat menentukan model yang akan dibentuk oleh metode Support Vector Machine
untuk menentukan kategori dari data baru yang ingin ditentukan kategori tekstual, yaitu kelas
sentimen positif, negatif dan netral. Berdasarkan seluruh hasil pengujian, bahwa pengaruh
nilai k pada k-fold cross validation yang terlalu kecil menghasilkan akurasi yang rendah,
sedangkan nilai k yang terlalu besar menghasilkan nilai akurasi yang besar, kemudian
Pengaruh nilai k pada K-NN terhadap akurasi, jika n memiliki akurasi rendah pada saat nilai
k kecil. Hal ini dikarenakan, data yang masuk pada k tetangga terdekat terlalu sedikit dan
belum bisa merepresentasikan kelas pada data uji.
SENTIMENT ANALYSIS USING SUPPORT VECTOR MACHINE
(SVM) AND K-NEAREST NEIGHBOR (K-NN) ON INDONESIAN TEXT
ABSTRACT
Sentiment analysis is the process of analyzing, understanding, and classifying opinions, evaluation, assessment, attitudes, and emotions to an entity such as products, services, organizations, individuals, events, topics, automatically to obtain the information. This study uses Indonesian text contained in the website in the form of news articles, then the K-Nearest Neighbor method will classify directly to the learning data in order to determine the model that will be established by the Support Vector Machine method for determining the category of the new data to be determined categories of textual, the class of sentiment is positive, negative and neutral. Based on the test results, that influence the value of k in the k-fold cross validation is too small resulting in low accuracy, while too large values of k produce great accuracy value, then the value of k on the Influence of K-NN to accuracy, if n has an accuracy low when the value of k is small. This is because, the incoming data on the k nearest
neighbor too little and can not represent a class on test data.
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Analisis Sentimen adalah proses menganalisis, memahami pendapat, evaluasi, penilaian,
sikap, dan emosi terhadap suatu entitas seperti produk, jasa, organisasi, individu, peristiwa,
topik, secara otomatis untuk mendapatkan informasi (Liu, 2010). Besarnya pengaruh dan
manfaat dari Sentiment Analysis, menyebabkan penelitian ataupun aplikasi mengenai
Sentiment Analysis berkembang pesat, bahkan di Amerika ada kurang lebih 20-30 perusahaan
menggunakan Sentiment Analysis untuk mendapatkan informasi tentang sentimen masyarakat
terhadap pelayanan perusahaan (Sumartini, 2011). Pada dasarnya Sentiment Analysis
merupakan klasifikasi, tetapi kenyataannya tidak semudah proses klasifikasi biasa karena
terkait penggunaan bahasa. Terdapat ambigu dalam penggunaan kata, tidak adanya intonasi
dalam sebuah teks, dan perkembangan dari bahasa itu sendiri (Bo & Lilian, 2008).
Adapun penelitian-penelitian terdahulu yang terkait dengan Sentiment Analysis, antara
lain adalah penelitian (Abbasi et al, 2008) mendeteksi situs website palsu atau asli dengan
klasifikasi artikel berita pada website. Penelitian (Han et al, 2013) menganalisis sentimen
pada teks twitter, dengan menggunakan karakter bahasa n-gram model dan SVM untuk
mengatasi variasi leksikal tinggi dalam teks Twitter. Penelitian (Vinodhini &
Chandrasekaran, 2012) mengembangkan sistem yang dapat mengidentifikasi dan
mengklasifikasikan sentimen masyarakat untuk memprediksi produk yang menarik dalam
pemasaran.
Penelitian ini menggunakan teks Bahasa Indonesia yang terdapat di website berupa
artikel berita, kemudian akan dibagi ke dalam tiga kelas, yaitu kelas sentimen positif, negatif
dan netral. Pada sentiment analysis, metode K-Nearest Neighbor akan menganalisis secara
langsung pada data pembelajaran agar dapat menentukan model yang akan dibentuk. Metode
Support Vector Machine kemudian digunakan untuk menentukan kategori dari data baru yang
ingin ditentukan secara tekstual, yaitu kelas sentimen positif, negatif dan netral. Support
Vector Machine digunakan pada penelitian ini karena memiliki teknik yang berakar pada
teori pembelajaran statistik dan telah menunjukkan hasil yang baik dalam berbagai aplikasi
baik pada data dengan banyak dimensi dan menghindari kesulitan dari permasalahan
dimensionalitas (Tan & Kumar, 2006). Dipilih k-nearest neighbor karena implementasi yang
sangat sederhana, baik untuk ruang pencarian karena kelas tidak harus dipisahkan linear (Li,
2006). K-NN tangguh terhadap training data yang noise dan efektif apabila training data-nya
besar (Darujati, 2010).
Support Vector Machine (SVM) dan K-Nea rest Neighbor (K-NN) dapat melakukan
menganalisis dengan cara belajar dari sekumpulan contoh dokumen yang telah diklasifikasi
sebelumnya. Keuntungan dari metode ini adalah dapat menghemat waktu kerja dan
memperoleh hasil yang lebih baik, tetapi pada Support Vector Machine untuk ekstraksi
informasi dari dokumen teks tidak terstruktur karena jumlah fitur jauh lebih besar daripada
jumlah sampel, metode ini memiliki performansi yang kurang baik, terhadap domain tertentu,
oleh karena itu perlunya K-Nea rest Neighbor untuk meminimalkan jumlah fitur yang akan
digunakan untuk analisis sehingga lebih akurat. Kemudian SVM tidak memperhatikan
distribusi data, karena hanya berdasarkan kelas yang memiliki pola berbeda dan dipisahkan
oleh fungsi pemisah, sehingga analisis yang dihasilkan kemungkinan salah, sehingga K-NN
akan mendistribusikan data tersebut dengan berdasarkan jarak data ke beberapa data terdekat,
sehingga analisis yang dihasilkan lebih akurat. Penelitian ini diharapkan dapat mempercepat
upaya mendapatkan informasi yang akurat tentang sentimen pemberitaan media massa pada
suatu hal.
1.2. Rumusan Masalah
Informasi terus bertambah setiap waktu dengan adanya arus informasi yang cepat, yang
dibutuhkan oleh masyarakat. Diantaranya kebutuhan untuk mendapatkan informasi yang
tersedia di Internet berupa informasi dalam bentuk teks. Semakin banyak informasi yang
ingin diketahui, maka dibutuhkan waktu yang cukup lama untuk mendapatkan informasi
tersebut, sehingga analisis sentimen sangat diperlukan, untuk mempercepat proses untuk
mendapatkan informasi.
1.3. Batasan Masalah
Dalam menganalisis sentimen menggunakan algoritma Support Vector Machine (SVM) dan
1. Dataset yang digunakan adalah artikel berita berbahasa Indonesia yang didapatkan
dari web menggunakan cra wler
2. Fitur yang digunakan berupa Unigram yaitu token yang terdiri dari satu kata. 3. Dataset hanya berupa teks, tidak menggunakan simbol, angka, tanda baca dan icon
emoticon, untuk menganalisis sentimen.
1.4. Tujuan Penelitian
Tujuan penelitian ini adalah untuk menganalisis sentimen pada artikel berita berbahasa
Indonesia, sehingga mempercepat proses mendapatkan informasi yang diinginkan.
1.5. Manfaat Penelitian
Manfaat dari penelitian ini adalah diharapkan dengan adanya aplikasi dari metode Support
Vector Machine (SVM) dan K-Nea rest Neighbor (K-NN) dapat berguna untuk menganalisis
sentimen pada artikel berita berupa teks berbahasa Indonesia, sehingga mempercepat proses
BAB 2
LANDASAN TEORI
2.1. Text Mining
Text mining, pada proses mengambil informasi dari teks. Informasi biasanya diperoleh
melalui peramalan pola dan kecenderungan pembelajaran pola statistik. Text mining yaitu
parsing, bersama dengan penambahan beberapa fitur linguistik turunan dan penghilangan
beberapa diantaranya, dan penyisipan subsequent ke dalam database, menentukan poladalam
data terstruktur, dan akhirnya mengevaluasi dan menginterpretasi output, text mining
biasanya mengacu ke beberapa kombinasi relevansi, kebaruan, dan interestingness. Proses
text mining yang khas meliputi kategorisasi teks, text clustering, ekstraksi konsep/entitas,
produksi taksonomi granular, sentiment analysis, penyimpulan dokumen, dan pemodelan
relasi entitas yaitu, pembelajaran hubungan antara entitas (Bridge, 2011).
Pendekatan manual text mining secara intensif dalam laboratorium pertama muncul
pada pertengahan 1980-an, namun kemajuan teknologi telah memungkinkan ranah tersebut
untuk berkembang selama dekade terakhir. Text mining adalah bidang interdisipliner yang
mengacu pada pencarian informasi, pertambangan data, pembelajaran mesin, statistik, dan
komputasi linguistik. Dikarenakan kebanyakan informasi (perkiraan umum mengatakan lebih
dari 80%) saat ini disimpan sebagai teks, text mining diyakini memiliki potensi nilai
komersial tinggi (Bridge, 2011).
Saat ini, text mining telah mendapat perhatian dalam berbagai bidang (Sumartini,
2011):
1. Aplikasi keamanan.
Banyak paket perangkat lunak text mining dipasarkan terhadap aplikasi keamanan,
khususnya analisis plaintext seperti berita Internet. Hal ini juga mencakup studi enkripsi
2. Aplikasi biomedis.
Berbagai aplikasi text mining dalam literatur biomedis telah disusun. Salah satu
contohnya adalah PubGene
3. Perangkat Lunak dan Aplikasi
Departemen riset dan pengembangan perusahaan besar, termasuk IBM dan Microsoft,
sedang meneliti teknik text mining dan mengembangkan program untuk lebih
mengotomatisasi proses pertambangan dan analisis. Perangkat lunak text mining juga
sedang diteliti oleh perusahaan yang berbeda yang bekerja di bidang pencarian dan
pengindeksan secara umum sebagai cara untuk meningkatkan performansinya
4. Aplikasi Media Online
Text mining sedang digunakan oleh perusahaan media besar, seperti perusahaan Tribune,
untuk menghilangkan ambigu informasi dan untuk memberikan pembaca dengan
pengalaman pencarian yang lebih baik, yang meningkatkan loyalitas pada site dan
pendapatan. Selain itu, editor diuntungkan dengan mampu berbagi, mengasosiasi dan
properti paket berita, secara signifikan meningkatkan peluang untuk menguangkan
konten.
5. Aplikasi Pemasaran
Text mining juga mulai digunakan dalam pemasaran, lebih spesifik dalam analisis
manajemen hubungan pelanggan yang menerapkan model analisis prediksi untuk churn
pelanggan (pengurangan pelanggan).
6. Sentiment Analysis
Sentiment Analysis mungkin melibatkan analisis dari review film untuk memperkirakan
berapa baik review untuk sebuah film. Analisis semacam ini mungkin memerlukan
kumpulan data berlabel atau label dari efektifitas kata-kata. Sebuah sumber daya untuk
efektivitas kata-kata telah dibuat untuk WordNet.
7. Aplikasi Akademik
Masalah text mining penting bagi penerbit yang memiliki database besar untuk
mendapatkan informasi yang memerlukan pengindeksan untuk pencarian. Hal ini
terutama berlaku dalam ilmu sains, di mana informasi yang sangat spesifik sering
terkandung dalam teks tertulis. Oleh karena itu, inisiatif telah diambil seperti Nature’s
proposal untuk Open Text Mining Interface (OTMI) dan Health’s common Journal
Publishing untuk Document Type Definition (DTD) yang akan memberikan isyarat
semantik pada mesin untuk menjawab pertanyaan spesifik yang terkandung dalam teks
Sebelumnya, website paling sering menggunakan pencarian berbasis teks, yang hanya
menemukan dokumen yang berisi kata-kata atau frase spesifik yang ditentukan oleh
pengguna. Sekarang, melalui penggunaan web semantik, text mining dapat menemukan
konten berdasarkan makna dan konteks (Sumartini, 2011).
2.2. Sentiment Analysis
Sentiment analysis atau opinion mining mengacu pada bidang yang luas dari pengolahan
bahasa alami, komputasi linguistik dan text mining. Secara umum, bertujuan untuk
menentukan attitude pembicara atau penulis berkenaan dengan topik tertentu. Attitude
mungkin penilaian atau evaluasi mereka, pernyataan afektif mereka (pernyataan emosional
penulis saat menulis) atau komunikasi emosional dimaksud (efek emosional penulis inginkan
terhadap pembaca) (Ian et al, 2011).
Tugas dasar dalam analisis sentimen adalah mengelompokkan polaritas dari teks yang
ada dalam dokumen, kalimat, atau fitur/tingkat aspek – apakah pendapat yang dikemukakan dalam dokumen, kalimat atau fitur entitas/aspek Ekspresi atau sentiment mengacu pada fokus
topik tertentu, pernyataan pada satu topik mungkin akan berbeda makna dengan pernyataan
yang sama pada subject yang berbeda. Sebagai contoh, adalah hal yang baik untuk
mengatakan alur film tidak terprediksi, tapi adalah hal yang tidak baik jika „tidak terprediksi‟
dinyatakan pada kemudi dari kendaraan. Bahkan pada produk tertentu, kata-kata yang sama
dapat menggambarkan makna kebalikan, contoh adalah hal yang buruk untuk waktu start-up
pada kamera digital jika dinyatakan “lama”, namun jika ”lama” dinyatakan pada usia baterai
maka akan menjadi hal positif. Oleh karena itu pada beberapa penelitian, terutama pada
review produk, pekerjaan didahului dengan menentukan elemen dari sebuah produk yang
sedang dibicarakan sebelum memulai proses opinion mining (Ian et al, 2011).
Hal pertama dalam pemrosesan dokumen adalah memecah kumpulan karakter ke
dalam kata atau token, sering disebut sebagai tokenisasi. Tokenisasi adalah hal yang
kompleks untuk program komputer karena beberapa karakter dapat dapat ditemukan sebagai
token delimiters. Delimiter adalah karakter spasi, tab dan baris baru “newline”, sedangkan
karakter ( ) <> ! ? “ kadangkala dijadikan delimiter namun kadang kala bukan tergantung pada lingkungannya (Wulandini & Nugroho, 2009).
1. Proses training
Pada proses training digunakan training set yang telah diketahui label-labelnya untuk
membangun model atau fungsi. 2. Proses testing
Untuk mengetahui keakuratan model atau fungsi yang akan dibangun pada proses training, maka digunakan data yang disebut dengan testing set untuk memprediksi label-labelnya.
Mengklasifikasi dokumen merupakan salah satu cara untuk mengorganisasikan dokumen. Dokumen yang memiliki isi yang sama akan dikelompokkan ke dalam kategori yang sama. Dengan demikian, orang-orang yang melakukan pencarian informasi dapat dengan mudah melewatkan kategori yang tidak relevan dengan informasi yang dicari atau yang tidak menarik perhatian (Feldman, 2004).
Berikut ini adalah langkah-langkah analisis sentimen pada dokumen :
1. Crawling dan Input Data
Pada tahap ini dilakukan pembacaan terhadap korpus, korpus adalah database besar
yang menyimpan text yang akan dianalisis. Korpus didapat dengan cara
mengumpulkan data dengan meng-cra wling.
2. Pre-processing
Pada tahapan ini akan dilakukan, yaitu:
a. Cleaning, yaitu membersihkan dokumen dari kata yang tidak diperlukan
sesuai kamus data yang telah ditentukan.Kata yang dihilangkan adalah HTML,
simbol, ikon emosi, email, URL. Agar mengurangi noise saat menganalisis
sentimen.
b. Case Folding, yaitu pengubahan bentuk huruf menjadi huruf kecil dan
penghapusan tanda baca serta angka, sesuai dengan kamus data yang telah
ditentukan.
3. Ekstraksi Fitur
Proses ekstraksi fitur bertujuan untuk meng-ekstrak kata-kata kunci dari korpus yang
telah dibaca. Kata-kata kunci tersebut disebut dengan fitur atau term. Fitur inilah yang
nantinya akan di proses dalam tahap analisis. Dalam proses ekstraksi fitur terdapat
a. Tokenization adalah proses memecah text menjadi kata tunggal. Pada
penelitian ini fitur yang digunakan dalam memecah text adalah unigram yaitu
token yang terdiri hanya satu kata.
b. Stopwords Removing adalah proses menghilangkan kata tidak penting dalam
text. Hal ini dilakukan untuk memperbesar akurasi dari pembobotan term.
Untuk proses ini, diperlukan suatu kamus kata-kata yang bisa dihilangkan.
Dalam Bahasa Indonesia, misalnya kata: dan, atau, mungkin, ini, itu, dll
adalah kata-kata yang dapat dihilangkan.
c. Stemming adalah proses pemetaan variansi morfologikal kata dalam kata dasar
atau kata umumnya (stem). Misalnya kata "perancangan" dan "merancang"
akan diubah menjadi sebuah kata yang sama, yaitu "rancang".
Proses stemming sangat tergantung kepada bahasa dari kata yang akan di-stem.
Hal ini dikarenakan, dalam melakukan proses stemming harus
mengaplikasikan aturan morfologikal dari suatu bahasa. Algoritma Nazief &
Adriani yang menyimpulkan sebuah kata dasar dapat ditambahkan imbuhan
berupa derivation prefix (DP) di awal dan/atau diakhiri secara berurutan
oleh derivation suffix (DS), possesive pronoun (PP), dan particle (P).
Keterangan diatas dirumuskan sebagai berikut :
DP + DP + DP + root word + DS + PP + P
Adapun langkah-langkah yang digunakan oleh algoritma Nazief dan Adriani
yaitu sebagai berikut: (Nazief & Adriani, 1996)
a. Kata dicari di dalam daftar kamus. Bila kata tersebut ditemukan di dalam
kamus, maka dapat diasumsikan kata tersebut adalah kata dasar sehingga
algoritma dihentikan.
b. Bila kata di dalam langkah pertama tidak ditemukan di dalam kamus, maka
diperiksa apakah sufiks tersebut yaitu sebuah partikel (“-lah” atau “-kah”). Bila ditemukan, maka partikel tersebut dihilangkan.
c. Pemeriksaan dilanjutkan pada kata ganti milik (“-ku”, “-mu”, “-nya”). Bila ditemukan, maka kata ganti tersebut dihilangkan.
d. Memeriksa akhiran (“-i”, “-an”). Bila ditemukan, maka akhiran tersebut dihilangkan. Hingga langkah ke-4 dibutuhkan ketelitian untuk memeriksa
apakah akhiran “-an” merupakan hanya bagian dari akhiran “-kan”, dan
“-mu”, “-nya”) yang telah dihilangkan pada langkah 2 dan 3 bukan merupakan bagian dari kata dasar.
e. Memeriksa awalan (“se-“, ”ke-“, “di-“, “te-“, “be-“, “pe-“, “me-“). Bila ditemukan, maka awalan tersebut dihilangkan. Pemeriksaan dilakukan
dengan berulang mengingat adanya kemungkinan multi-prefix.Langkah ke-5
ini juga membutuhkan ketelitian untuk memeriksa kemungkinan peluluhan
awalan (Tabel 2.1), perubahan prefix yang disesuaikan dengan huruf-awal
kata (Tabel 2.2) dan aturan kombinasi prefix-suffix yang diperbolehkan
(Tabel 2.3).
f. Setelah menyelesaikan semua langkah dengan sukses, maka algoritma akan
mengembalikan kata dasar yang ditemukan.
Tabel 2.1. Daftar Prefiks yang Meluluh (Nazief & Adriani, 1996)
Jenis Prefiks Huruf Hasil Peluluhan
pe-/me- K -ng-
pe-/me- P -m-
pe-/me- S -ny-
pe-/me- T -n-
Tabel 2.2. Daftar Kemungkinan Perubahan Prefiks (Nazief & Adriani, 1996)
Prefiks Perubahan
se- tidak berubah
ke- tidak berubah
di- tidak berubah
be- ber-
te- ter-
pe- per-, pen-, pem-, peng-
Tabel 2.3. Daftar Kombinasi Prefiks dan Sufiks yang Tidak Diperbolehkan (Nazief & Adriani, 1996)
Prefix Sufiks yang tidak diperbolehkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
te- -an
pe- -kan
4. Pembobotan Term
Pembobotan term memberikan sebuah nilai untuk sebuah term berdasarkan tingkat
kepentingan tersebut di dalam sekumpulan dokumen masukan. Pada penelitian ini akan
digunakan metode TF-IDF sebagai proses pembobotan, yaitu dengan cara mencari
representasi nilai dari tiap-tiap dokumen dari sekumpulan data training, dan akan dibentuk
menjadi sebuah vektor. Dapat dirumuskan sebagai berikut : (D Manning et al, 2009)
w(t,d) = tf (t,d)*idf (1)
idf = log (2)
Keterangan :
tf (t,d) = kemunculan kata t pada dokumen d,
N = jumlah dokumen pada kumpulan dokumen,
df = jumlah dokumen yang mengandung term t.
5. Proses Analisis & Validasi
Pada proses ini akan dilakukan analisis dan validasi menggunakan K-NN dan SVM. Setelah
dokumen dalam bentuk matriks kata-dokumen dan telah diberi pembobotan TF-IDF, maka
proses selanjutnya K-NN menganalisis, yaitu setiap dokumen akan diberi tanda positif atau
negatif, jika jumlah positif < jumlah negatif maka skor sentimen:
Jika, jumlah positif > jumlah negatif maka skor sentimen :
(4)
Jika selain kriteria diatas, maka sentimen adalah 0 atau disebut netral. (Khushboo et al, 2012)
Hasil dokumen diatas kemudian, akan ditentukan koordinat data uji, setelah itu cari
tetangga terdekat menggunakan k dan jarak Euclidean atau Cosine Similarity, kemudian
urutkan tetangga berdasarkan paling dekat, dan dilakukan voting yaitu tetangga yang
memiliki data yang terbanyak, apakah termasuk kelas positif, negatif, dan netral.
Kemudian pada hasil dari tahap diatas, yaitu setiap dokumen yang telah diproses tadi
direpresentasikan sebagai vektor dalam ruang term, dimana k adalah ukuran dari kumpulan
term. Nilai dari antara (0,1) direpresentasikan seberapa banyak termtk berkontribusi untuk
semantik dokumen dj. Selanjutnya akan mengolah ruang term tersebut dengan menggunakan
Support Vector Machine bertujuan untuk menganalisis dokumen bagaimana tingkat akurasi
apa sesuai dengan label yang telah diberi, setelah itu melakukan analisis proses K-NN
tetangga berdasarkan paling dekat, dan dilakukan voting yaitu tetangga yang memiliki data
yang terbanyak adalah data yang menang, apakah termasuk kelas positif, negatif, dan netral.
Setelah itu, masuk pada tahap validasi dengan melihat akurasi (ketepatan), suatu
dokumen yang telah direpresentasikan sebagai vektor dalam ruang term, dimana k adalah
ukuran dari kumpulan term. Nilai dari antara (0,1) direpresentasikan seberapa banyak termtk
berkontribusi untuk semantik dokumen dj, memvalidasi ruang term tersebut dengan
menggunakan K-Fold Cross Validation.
2.3. Support Vector Machine (SVM)
2.3.1. Konsep Support Vector Machine (SVM)
Support Vector Machines (SVM) adalah seperangkat metode pembelajaran terbimbing yang
menganalisis data dan mengenali pola, digunakan untuk klasifikasi dan analisis regresi.
Algoritma SVM asli diciptakan oleh Vladimir Vapnik dan turunan standar saat ini Soft
Margin (Cortes & Vapnik, 1995). SVM standar mengambil himpunan data input, dan
memprediksi, untuk setiap masukan yang diberikan, kemungkinan masukan adalah anggota
dari salah satu kelas dari dua kelas yang ada, yang membuat sebuah SVM sebagai
penggolong nonprobabilistik linier biner. Karena SVM adalah sebuah pengklasifikasi,
dari dua kategori, suatu algoritma pelatihan SVM membangun sebuah model yang
memprediksi apakah data yang baru jatuh ke dalam suatu kategori atau yang lain.
Konsep SVM mencari hyperplane terbaik yang berfungsi sebagai pemisah dua buah
kelas pada input space. Pattern yang merupakan anggota dari dua buah kelas : +1 dan -1 dan
berbagi alternative garis pemisah (discrimination boundaries). Margin adalah jarak antara
hyperplane tersebut dengan pattern terdekat dari masing-masing kelas. Pattern yang paling
dekat ini disebut sebagai support vector. Usaha untuk mencari lokasi hyperplane ini
merupakan inti dari proses pembelajaran pada SVM. Secara intuitif, model SVM merupakan
representasi dari data sebagai titik dalam ruang, dipetakan sehingga kategori contoh terpisah
dibagi oleh celah jelas yang selebar mungkin. Data baru kemudian dipetakan ke dalam ruang
yang sama dan diperkirakan termasuk kategori berdasarkan sisi mana dari celah data tersebut
berada.
SVM bekerja atas prinsip Structural Risk Minimization (SRM) dengan tujuan
menemukan hyperlane terbaik yang memisahkan dua buah kelas pada input space. Prinsip
dasar SVM adalah klasifikasikan linear. Pada SVM pemisahan yang baik dicapai oleh
hyperplane yang memiliki jarak terbesar ke titik data training terdekat dari setiap kelas
(margin fungsional disebut), karena pada umumnya semakin besar margin semakin rendah
error generalisasi dari pemilah. Misalkan terdapat m data training
adalah sampel data dan adalah target atau kelas
dari sampel data. Misalkan juga bahwa data untuk kedua kelas terpisah maka ingin dicari
fungsi pemisah (hyperplane). (Kumar & Gopal, 2009)
f x x w b (5)
dimana parameter bobot dan b adalah parameter bias
Pattern yang termasuk kelas +1 (sampel positif) dapat dirumuskan sebagai pattern
yang memenuhi pertidaksamaan
0
i
x w b untuk yi 1 (6)
Pattern yang termasuk kelas -1 (sampel negatif) dapat dirumuskan sebagai pattern
yang memenuhi pertidaksamaan
0
i
x w b untuk yi 1 (7)
Masalah mencari parameter w dan b yang optimal agar diperoleh hyperplane yang optimal
merupakan quadratic programming.
, 1 1 min 2 m T i w b i
Problem ini dapat dipecahkan dengan berbagi teknik komputasi, diantaranya dengan
Lagrange Multiplier.
(9)
adalah Lagrange multipliers, yang bernilai nol atau positif ( ) Dari hasil perhitungan
ini diperoleh yang kebanyakan bernilai positif. Data yang berkorelasi dengan yang positif
inilah yang disebut sebagai Support Vector Machine.
SVM pada prinsipnya adalah klasifikasi linear. Tetapi SVM memiliki keunggulan
dalam klasifikasi untuk problem non-linier. Pada prosesnya data diproyeksikan ke ruang
vektor baru, sering disebut feature space, berdimensi lebih tinggi sedemikian hingga data itu
dapat terpisah secara linier. Selanjutnya, di ruang baru, SVM mencari hyperplane optimal
yaitu bekerja sebagai klasifier linear.
Dapat diasumsikan bahwa kedua belah kelas dapat terpisah secara sempurna oleh
hyperplane (linear sepa rable). Akan tetapi, pada umumnya dua belah kelas pada input space
tidak dapat terpisah secara sempurna (non linear separable). Untuk mengatasi masalah ini,
SVM dirumuskan ulang dengan memperkenalkan metode Margin Soft. (Cortes & Vapnik,
1995) menyarankan ide margin maksimal dimodifikasi yang memungkinkan untuk contoh
mislabeled. Jika terdapat hyperplane yang dapat memecah contoh "ya" dan "tidak", metode
Margin Soft akan memilih hyperplane yang membagi contoh-contoh sebersih mungkin.
Metode ini memperkenalkan variabel slack ξi (ξi ≥ 0), yang mengukur tingkat kesalahan klasifikasi.
. ≥ 1- ξi (i = 1,2,,….,l) (10)
Sedangkan objective function (8) yang dioptimasikan menjadi.
minimize 2 + C
C merupakan parameter yang mengkontrol trade-off antara margin dan error klasifikasi ξ. Semakin besar nilai C, berarti nilai akhir terhadap kesalahan menjadi semakin besar, sehingga
proses training menjadi lebih ketat. Parameter C ditentukan dengan mencoba beberapa nilai
dan dievaluasi efeknya terhadap akurasi yang dicapai oleh SVM.
2.3.2. Klasifikasi Data Linear Separable
Data Linear Separable merupakan data yang dapat dipisahkan secara linier. Misalkan
{X1,…Xn} adalah dataset dan {+1,-1} adalah label kelas dari data Xi. Pada gambar 2.1 dapat
dengan kelasnya. Namun, bidang pemisah terbaik tidak hanya dapat memisahkan data tetapi
juga memiliki margin paling besar. (Kumar & Gopal, 2009)
Gambar 2.1 Hyperlane (Kumar & Gopal, 2009)
2.3.3. Klasifikasi Data Linear Non-Separable
Pada umumnya dua buah kelas pada input space tidak dapat terpisahkan secara sempurna.
Untuk mengatasi kondisi ini, SVM menggunakan teknik soft margin, dengan
mengikutsertakan slack variable ξ > 0. Misalkan ξ adalah jarak antara garis pemisah
(decision boundary) dengan data, maka persamaan dirumuskan menjadi:
. ≤ -1+ ξ, jika (11)
. ≥ 1- ξ, jika
2.3.4. Klasifikasi Data Non-Linear
Untuk menyelesaikan problem non-linear, SVM dimodifikasi dengan memasukkan fungsi
kernel. Dalam non-linear SVM, pertama-tama data dipetakan oleh fungsi Ф ( ) ke ruang vektor yang berdimensi lebih tinggi. Hyperplane yang memisahkan kedua kelas tersebut
dapat dikontruksikan. Selanjutnya bahwa fungsi Ф memetakan tiap data pada input space
tersebut ke ruang vektor baru yang berdimensi lebih tinggi (dimensi 3), sehingga kedua kelas
dapat dipisahkan secara linear oleh sebuah hyperplane. Notasi matematika dari mapping ini
adalah sebagai berikut :
: Ŕd → Ŕd
d < q (12)
y
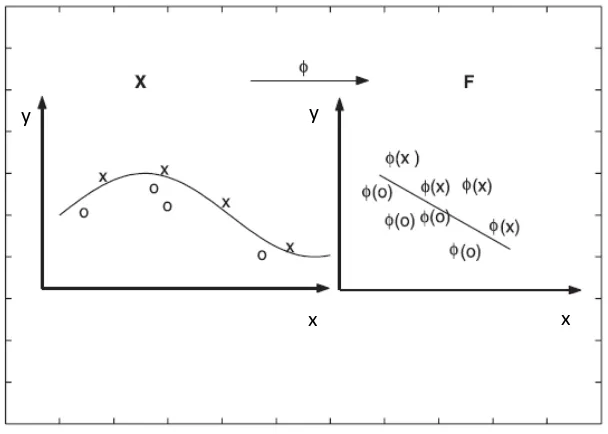
Gambar 2.2. Transformasi dari vektor input ke feature space (Tan et al, 2006)
Selanjutnya proses pembelajaran pada SVM dalam menemukan titik-titik support
vector, hanya bergantung pada dot product (perkalian titik) dari data yang sudah
ditransformasikan pada ruang baru yang berdimensi lebih tinggi, yaitu Ф( ).Ф( ).
Karena umumnya transformasi Φ ini tidak diketahui, dan sangat sulit untuk difahami secara mudah, maka perhitungan dot product (perkalian titik) dapat digantikan dengan fungsi
kernel K ( ) yang mendefinisikan secara implisit transformasi Φ. Hal ini disebut sebagai Kernel Trick, yang dirumuskan :
K( ) = Ф( ).Ф( )
f(Ф( )) = . Ф( )+b
= i yi K(x,xi) +b (13)
SV pada persamaan di atas dimaksudkan dengan subset dari training set yang terpilih sebagai
support vector, dengan kata lain data yang berkorespondensi pada αi ≥ 0
2.3.5. Metode Kernel
Kasus klasifikasi memperlihatkan ketidaklinieran, algoritma seperti perceptron tidak bisa
mengatasinya. Metoda kernel adalah salah satu untuk mengatasinya, dengan metoda kernel
suatu data x di input space dimapping ke feature space F dengan dimensi yang lebih tinggi
melalui map sebagai berikut : x→ (x). Karena itu data x di input space menjadi (x) di feature space. (Sumartini, 2011)
Sering kali fungsi (x) tidak tersedia atau tidak bisa dihitung. tetapi dot product
(perkalian titik) dari dua vektor dapat dihitung baik di dalam input space maupundi feature
y
x
y
space. Dengan kata lain, sementara (x) mungkin tidak diketahui, dot product (perkalian
titik) < (x1), (x2)> masih bisa dihitung di feature space. Untuk bisa memakai metoda
kernel, pembatas (constraint) perlu diekspresikan dalam bentuk dot product (perkalian titik)
dari vektor data xi. Sebagai konsekuensi, pembatas yang menjelaskan permasalahan dalam
klasifikasi harus diformulasikan kembali sehingga menjadi bentuk dot product (perkalian
titik). Dalam feature space ini dot product (perkalian titik) < .> menjadi < (x), (x)‟>. Suatu fungsi kernel, k (x, x‟), bisa untuk menggantikan dot product (perkalian titik) < (x), (x)‟>. Kemudian di feature space, dapat membuat suatu fungsi pemisah yang linier yang mewakili fungsi nonlinear di input space. Gambar 2.3 mendeskripsikan suatu contoh
feature mapping dari ruang dua dimensi ke feature space dua dimensi. Dalam input space,
data tidak bisa dipisahkan secara linier, tetapi memisahkan di feature space. Karena itu
[image:34.595.171.475.327.544.2]dengan memetakan data ke feature space menjadikan tugas klasifikasi menjadi lebih mudah.
Gambar 2.3. Suatu kernel map mengubah problem yang tidak linier menjadi linier dalam
space baru. (Karatzouglou et al, 2004)
Menurut (Karatzouglou et al, 2004) ada beberapa fungsi kernel yang sering digunakan
dalam literatur SVM anatara lain sebagai berikut:
1. Kernel linear adalah kernel yang paling sederhana dari semua fungsi kernel. Kernel
ini biasa digunakan dalam kasus klasifikasi teks.
xT x (14)
2. Kernel Radial Basis Gaussian adalah kernel yang umum digunakan untuk data yang
sudah valid (available) dan merupakan default dalam tools SVM.
y y
y
exp(− σ2||x – xi||2) (15)
3. Kernel Polynominal adalah kernel yang sering digunakan untuk klasifikasi gambar.
(xT xi + 1)p (16)
4. Kernel Tangent Hyperbolic (sigmoid) adalah kernel yang sering digunakan untuk
neural networks.
tan h(βxT xi + β1), dimana β, β1∈Ŕ (17)
Fungsi kernel mana yang harus digunakan untuk subtitusi dot product (perkalian titik) di
feature space sangat bergantung pada data. Biasanya metode cross-validation digunakan
untuk pemilihan fungsi kernel ini. Pemilihan fungsi kernel yang tepat adalah hal yang sangat
penting. Karena fungsi kernel ini akan menentukan feature space di mana fungsi klasifier
akan dicari. Sepanjang fungsi kernelnya legitimate, SVM akan beroperasi secara benar
meskipun tidak tahu seperti apa map yang digunakan, sehingga lebih mudah menemukan
fungsi kernel daripada mencari map seperti apa yang tepat untuk melakukan mapping dari
input space ke feature space. Pada penerapan metoda kernel, tidak perlu tahu map apa yang
digunakan untuk satu per satu data, tetapi lebih penting mengetahui bahwa dot product
(perkalian titik) dua titik di feaure space bisa digantikan oleh fungsi kernel.
2.3.6. Algoritma SVM untuk Menganalisis Dokumen Web
Proses ekstraksi informasi (Information Extraction atau IE) adalah proses pengubahan
dokumen teks tidak terstruktur dengan domain tertentu ke dalam sebuah struktur informasi yang relevan. Domain penelitian ini berbahasa Indonesia, dengan menerapkan teknik pembelajaran mesin. Pendekatan pembelajaran mesin yang digunakan adalah pendekatan
statistik, dengan metode klasifikasi token. Algoritma yang digunakan adalah Support Vector
Machine (SVM) dengan uneven margin, yang didesain khusus untuk imbalanced dataset.
(Cawley, 2006)
Variabel dan parameter
x = {x0, x1, x2, .., xm}: sampel training
y = {y1, .., ym}⊂{±1}: label data training
kernel : jenis fungsi kernel
par : parameter kernel
α = [α1, .., αm]: Lagrange multiplier dan bias b
1. Hitung matriks kernel H
[image:36.595.130.473.171.448.2]2. Tentukan pembatas untuk programa kuadratik, termasuk Aeq, beq, A dan b
Gambar 2.4. Ilustrasi data dipisahkan dalam kasus XOR. (Cawley, 2006)
3. Tentukan fungsi tujuan quadratic programming x Hx + f’x
4. Selesaikan masalah QP.
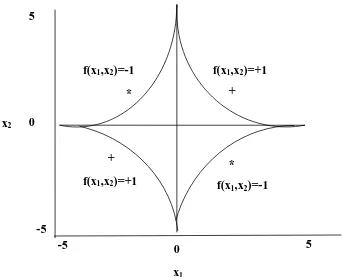
2.3.7. Karakteristik Support Vector Machine (SVM)
Karakteristik SVM sebagaimana telah dijelaskan pada bagian sebelumnya, dirangkumkan
sebagai berikut (Cawley, 2006):
1. Secara prinsip SVM adalah linear classifier
2. Pattern recognition dilakukan dengan mentransformasikan data pada input space ke
ruang yang berdimensi lebih tinggi, dan optimisasi dilakukan pada ruang vector yang
baru tersebut.
3. Menerapkan strategi Structural Risk Minimization (SRM). SVM bekerja berdasarkan
prinsip SRM, Untuk menjamin generalisasi.
+
-5
f(x1,x2)=-1 f(x1,x2)=+1
f(x1,x2)=+1 f(x
1,x2)=-1
x2
5
0
-5
x1
0 5
*
4. Prinsip kerja SVM pada dasarnya hanya mampu menangani klasifikasi dua class.
2.3.8. Kelebihan Support Vector Machine (SVM)
Kelebihan dari metode Support Vector Machine ini adalah sebagai berikut (Cawley, 2006):
1. Generalisasi
Generalisasi didefinisikan sebagai kemampuan suatu metode untuk mengklasifikasikan
suatu pattern, yang tidak termasuk data yang dipakai dalam fase pembelajaran metode
itu.
2. Curse of dimensionality
Curse of dimensionality didefinisikan sebagai masalah yang dihadapi suatu
metode pattern recognition dalam mengestimasikan parameter (misalnya jumlah
hidden neuron pada neural network, stopping criteria dalam proses pembelajaran dsb.)
dikarenakan jumlah sampel data yang relatif sedikit dibandingkan dimensional ruang
vektor data tersebut. Semakin tinggi dimensi dari ruang vektor informasi yang diolah,
membawa konsekuensi dibutuhkannya jumlah data dalam proses pembelajaran (Cortes
& Vapnik, 1995) membuktikan bahwa tingkat generalisasi yang diperoleh oleh SVM
tidak dipengaruhi oleh dimensi dari input vector. Hal ini merupakan alasan mengapa
SVM merupakan salah satu metode yang tepat dipakai untuk memecahkan masalah
berdimensi tinggi, dalam keterbatasan sampel data yang ada.
3. Feasibility
SVM dapat diimplementasikan relative mudah, karena proses penentuan support
vector dapat dirumuskan dalam QP problem. Dengan demikian jika memiliki libra ry
untuk menyelesaikan QP problem, dengan sendirinya SVM dapat diimplementasikan
dengan mudah.
2.3.9. Kelemahan Support Vector Machine (SVM)
Kekurangan dari metode Support Vector Machine ini adalah sebagai berikut (Cawley, 2006):
1. Sulit dipakai dalam problem berskala besar. Skala besar dalam hal ini dimaksudkan
dengan jumlah sample yang diolah.
2. SVM secara teoritik dikembangkan untuk problem klasifikasi dengan dua class.
Dewasa ini SVM telah dimodifikasi agar dapat menyelesaikan masalah dengan class
lebih dari dua, antara lain strategi One versus rest dan strategi Tree Structure. Namun
penelitian dan pengembangan SVM pada multiclass-problem masih merupakan tema
penelitian yang masih terbuka.
2.4. K-Nearest Neighbor (K-NN)
2.4.1. Konsep K-Nearest Neighbor (K-NN)
Algoritma K-Nea rest Neighbor (K-NN) adalah sebuah metode melakukan klasifikasi
terhadap objek berdasarkan data pembelajaran jaraknya paling dekat dengan objek tersebut.
K-NN termasuk algoritma supervised learning dimana hasil dari query instance yang baru
diklasifikasikan berdasarkan mayoritas dari kategori pada K-NN, kemudian kelas yang paling
banyak muncul yang akan menjadi kelas hasil klasifikasi.
Tujuan dari algoritma ini adalah mengklasifikasikan obyek berdasarkan atribut dan
training sample. Clasifier tidak menggunakan apapun untuk dicocokkan dan hanya
berdasarkan pada memori. Diberikan titik query, akan ditemukan sejumlah k obyek atau (titik
training) yang paling dekat dengan titik query. Klasifikasi menggunakan voting terbanyak
diantara klasifikasi dari k obyek. Algoritma K-Nearest Neighbor (K-NN) menggunakan
klasifikasi ketetanggaan sebagai nilai prediksi dari query instance yang baru.
Algoritma metode K-Nearest Neighbor (K-NN) sangat sederhana,
bekerja berdasarkan jarak terpendek dari query insta nce ke tr a i ning sa mple
untuk menentukan K-NN. Tr a ining sa mple diproyeksikan ke ruang berdimensi banyak,
dimana masing-masing dimensi merepresentasikan fitur dari data. Ruang ini dibagi menjadi
bagian-bagian berdasarkan klasifikasi tra ining sa mple. Sebuah titik pada ruang ini ditandai
jika merupakan klasifikasi yang paling banyak ditemukan pada k buah tetangga terdekat
dari titik tersebut. Metode pencarian jarak, ada dua jenis yaitu metode Cosine Similarity atau
Euclidean Distance yaitu perhitungan jarak terdekat. Perhitungan jarak terdekat dibutuhkan
untuk menentukan jumlah kemiripan yang dihitung dari kemiripan kemunculan teks yang
dimiliki suatu paragraf. Setelah itu kemunculan teks yang sedang diujikan dibandingkan
terhadap masing-masing sample data asli. Ada dua metode untuk menghitung jarak antar
tetangga yaitu metode Euclidean Distance dan Cosine Similarity yang direpresentasikan
sebagai berikut : (Guo et al, 2001)
dimana matriks D(a,b) adalah jarak skalar dari kedua vektor a dan b dari matriks dengan
ukuran d dimensi.
Satuan jarak yang digunakan Euclidian, jenis dari metode ini, jika dilihat dari nilai
N-nya ada dua macam yaitu (Darujati, 2010):
1. 1-NN
Pengklasifikasian dilakukan pada 1 label data terdekat, algoritmanya sebagai berikut :
- Menghitung jarak antara data baru ke setiap pelabelan data
- Menentukan 1 pelabelan data yang mempunyai jarak paling minimal
- Klasifikasi data baru ke dalam pelabelan data tersebut
. 2. k-NN
Pengklasifikasian dilakukan dengan menentukan nilai pada k label data terdekat,
dengan syarat nilai k >1, algoritmanya sebagai berikut :
- Menghitung jarak antara data baru ke setiap pelabelan data
- Menentukan k pelabelan data yang mempunyai jarak paling minimal
- Klasifikasi data baru ke dalam pelabelan data yang mayoritas.
Cosine simila rity adalah penentuan kesesuaian dokumen dengan query untuk
pegukuran antara vektor dokumen (D) dengan vektor query (Q). Persamaan yang digunakan
(Darujati, 2010):
sim(Q,D)=cos(Q, D) = ………...(19)
|D| =
|Q| =
Dimana Q adalah dokumen uji, D dokumen training, dan adalah nilai bobot yang telah
diberikan pada setiap term pada dokumen.
Pada fase training, algoritma ini hanya melakukan penyimpanan vektor-vektor fitur
dan klasifikasi data training sample. Pada fase klasifikasi, fitur-fitur yang sama dihitung
untuk testing data (yang klasifikasinya tidak diketahui). Jarak dari vektor baru yang ini
terhadap seluruh vektor training sample dihitung dan sejumlah k buah yang paling dekat
diambil. Titik yang baru klasifikasinya diprediksikan termasuk pada klasifikasi terbanyak
dari titik-titik tersebut. Sebagai contoh, untuk mengestimasi p(x) dari ntraining sample dapat
memusatkan pada sebuah sel disekitar x dan membiarkannya tumbuh hingga meliputi k
akan berukuran relatif kecil yang berarti memiliki resolusi yang baik. Jika densitas rendah,
sel akan tumbuh lebih besar, tetapi akan berhenti setelah memasuki wilayah yang memiliki
densitas tinggi. Pada Gambar 2.5 dan 2.6 ditampilkan estimasi densitas satu dimensi dan dua
[image:40.595.238.396.383.528.2]dimensi dengan K-NN
Gambar 2.5. Delapan titik dalam satu dimensi dan estimasi densitas K-NN
dengan k= 3 dan k= 5 (Darujati, 2010)
Gambar 2.6. K-NN mengestimasi densitas dua dimensi dengan k= 5 (Darujati, 2010)
Nilai k yang terbaik untuk algoritma ini tergantung pada data. Secara umum, nilai k
yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara
setiap klasifikasi menjadi semakin kabur. Nilai k yang bagus dapat dipilih dengan optimasi
parameter, misalnya dengan menggunakan cross-validation. Kasus khusus dimana klasifikasi
diprediksikan berdasarkan training data yang paling dekat (dengan kata lain, k = 1) disebut
algoritma nea rest neighbor. Ketepatan algoritma K-NN sangat dipengaruhi oleh ada atau
tidaknya fitur-fitur yang tidak relevan atau jika bobot fitur tersebut tidak setara dengan
2.4.2. Algoritma K-NN untuk Menganalisis Dokumen Web
Berikut ini adalah langkah-langkah menghitung K-Nearest Neighbors pada dokumen :
1. Tentukan paremeter k sebagai jumlah tetangga terdekat, dalam sistem ini digunakan k=1,
sehingga jika ada tetangga terdekat, itu yang akan digunakan sebagai nilai prediksi.
2. Hitung jarak antara data yang masuk dan semua sampel latih yang sudah ada. Pada
penelitian ini jenis jarak terdekat yang digunakan yaitu cosine similarity pada persamaan
(19).
3. Mengurutkan objek-objek tersebut ke dalam kelompok yang mempunyai jarak terkecil.
4. Mengumpulkan kategori Y (klasifikasi nearest neighbor).
5. Dengan menggunakan kategori mayoritas, maka dapat diprediksikan nilai query instance
yang telah dihitung, kemudian tentukan jarak tetangga terdekat yang akan digunakan
sebagai nilai prediksi dari data berikutnya. (Zee-Jing & Hsien-Wu, 2004)
2.4.3. Kelebihan K-Nearest Neighbor (K-NN)
Kelebihan dari metode K-Nearest Neighbor ini adalah sebagai berikut (Gorunescu, 2011):
1. Lebih efektif di data training yang besar
2. Dapat menghasilkan data yang lebih akurat
3. Metode yang baik dalam hal ruang pencarian, misalnya, kelas tidak harus linear
dipisahkan.
4. Sangat cocok terhadap training data yang noise.
2.4.4. Kelemahan K-Nearest Neighbor (K-NN)
Kekurangan dari metode K-Nearest Neighbor ini adalah perlu ditentukan nilai k yang paling
optimal yang menyatakan jumlah tetangga terdekat. (Gorunescu, 2011)
2.5. K-Fold Cross Validation
Pada ukuran kinerja dari model pada test set sering kali berguna karena ukuran tersebut
memberikan estimasi yang tidak bias dari error generalisasinya. Akurasi dari tingkat error
yang dihitung dari test set dapat juga digunakan untuk membandingkan kinerja relatif dari
classifier-classifier pada domain yang sama. Berikut adalah metode yang digunakan untuk
Dalam pendekatan cross-validation, setiap record digunakan beberapa kali dalam
jumlah yang sama untuk training dan tepat sekali untuk testing. Untuk mengilustrasikan
metode ini, anggaplah mempartisi data ke dalam dua subset yang berukuran sama. Pertama,
dipilih satu dari kedua subset tersebut untuk training dan satu lagi untuk testing. Kemudian
dilakukan pertukaran fungsi dari subset sedemikian sehingga subset yang sebelumnya sebagai
training set menjadi test set demikian sebaliknya. Pendekatan ini dinamakan two-fold cross
validation. Total error diperoleh dengan menjumlahkan error untuk kedua proses tersebut.
Dalam contoh ini, setiap record digunakan tepat satu kali untuk training dan satu kali untuk
testing. Metode k-fold cross validation mengeneralisasi pendekatan ini dengan
mensegmentasi data ke dalam k partisi berukuran sama. Selama proses, salah satu dari partisi
dipilih untuk testing, sedangkan sisanya digunakan untuk training. Prosedur ini diulangi k
kali sedemikian sehingga setiap partisi digunakan untuk testing tepat satu kali. Total error
ditentukan dengan menjumlahkan error untuk semua k proses tersebut. Kasus khusus untuk
metode k-fold cross validation menetapkan k = N, ukuran dari data set. (Auria & Moro,
2008)
Dalam k-fold cross validation, yang disebut juga dengan rotation estimation, dataset
yang utuh di pecah secara random menjadi „k‟ subset dengan size yang hampir sama dan
saling eksklusif satu sama lain. Model dalam classification‟ di-latih dan di-test sebanyak „k‟ kali. Setiap kali pelatihan semua dilatih pada semua fold kecuali hanya satu fold saja yang
disisakan untuk pengujian. Penilaian cross-validation terhadap akurasi model secara
keseluruhan dihitung dengan mengambil rata-rata dari semua hasil akurasi individu „k‟, seperti yang ditunjukkan dengan persaman berikut:
CVA = I (20)
Dimana CVA adalah akurasi cross-validation, k adalah jumlah fold yang digunakan, dan A
adalah ukuran akurasi (misalnya, hit-rate, sensitivitas, specifity) dari masing-masing fold.
Metode ini merupakan evaluasi standard yaitu stratified 10-fold cross-validation
karena menunjukkan bahwa 10-fold cross-validation adalah pilihan terbaik untuk
mendapatkan hasil validasi yang akurat, 10-fold cross-validation akan mengulang pengujian
sebanyak 10 kali dan hasil pengukuran adalah nilai rata-rata dari 10 kali pengujian.
Keuntungan metode ini, menghindari overlapping pada data testing. Test set bersifat mutually
exclusive dan secara efektif mencakup keseluruhan data set. Kekurangan dari pendekatan ini
2.6. Riset Terkait
Beberapa riset terkait dengan penelitian ini mengenai analysis sentiment maka dapat
dibuatkan rangkuman seperti ditunjukkan oleh tabel 2.4.
Tabel 2.4. Rangkuman Penelitian Sentiment Analysis Sebelumnya
No Peneliti Judul Penelitian Hasil dan Kesimpulan
1 Barber (2009)
Bayesian Opinion Mining
Dilakukan pada data review film berbahasa Inggris dan diujikan untuk 5000 record opini negatif dan 5000 record opini positif sebagai data latih dan 333 record opini negatif sebagai data uji serta menghasilkan akurasi sebesar 80%
2 Wulandini & Nugroho (2009)
Text Classification Using Support Vector Machine for
Webmining Based Spation Temporal Analysis of the Spread of Tropical Diseases
Dilakukan pada 3713 feature dan 360 instance. 360 instance sebagai data latih dan 120 instance sebagai data uji. SVM dan NBC menunjukkan hasil yang jauh lebih baik 92,5% dan 90%.
3 Jason & Ryan (2010)
Improving Multiclass Text Classification with the Support Vector Machine,
SVM menghasilkan performansi yang lebih baik dibandingkan NBC
4 Colas & Brazdil (2011)
Comparison of SVM and Some Older Classification Algorithms in Text Classification Tasks
2.7. Perbedaan dengan Riset yang lain
Berdasarkan riset yang telah dilakukan, peneliti membuat beberapa perbedaan dalam
penelitian ini, yaitu;
1. Pada umumnya analisis sentimen berdasarkan dokumen yang berisi kata-kata atau
frase spesifik yang ditentukan oleh pengguna. Tetapi pada penelitian ini, dapat
menemukan konten berdasarkan konteks yang telah ditentukan.
2. Sebuah metode yang berbeda untuk menentukan sentimen adalah penggunaan sistem
skala terhadap kata-kata terkait memiliki sentimen negatif, netral atau positif dengan
diberi nomor pada skala -1 sampai +1 (paling negatif hingga yang paling positif) dan
ketika sepotong teks terstruktur dianalisis dengan pemrosesan bahasa alami, konsep
selanjutnya dianalisis untuk memahami kata-kata ini dan bagaimana berhubungan
dengan konsep. Setiap konsep kemudian diberi skor berdasarkan bagaimana kata-kata
sentimen berhubungan dengan konsep, dan skor yang terkait.
2.8. Kontribusi Riset
Dalam penelitian ini, diharapkan algoritma K-NN dan SVM dapat mampu menganalisis
sentimen dalam dokumen dengan jumlah yang besar dapat dilakukan secara terkomputerisasi
sebagai ganti dari proses manual. Hal ini terutama akan dirasakan manfaatnya untuk analisis
BAB 3
METODOLOGI PENELITIAN
3.1. Identifikasi Masalah
Support Vector Machine (SVM) dan K-Nearest Neighbor (K-NN) dapat melakukan
klasifikasi dengan cara belajar dari sekumpulan contoh dokumen yang telah diklasifikasi
sebelumnya. Namun, Pada Support Vector Machine untuk ekstraksi informasi dari dokumen
teks tidak terstruktur karena jumlah fitur jauh lebih besar daripada jumlah sampel, metode ini
memiliki performansi yang kurang baik, terhadap domain tertentu, oleh karena itu perlunya
K-Nearest Neighbor untuk meminimalkan jumlah fitur yang akan digunakan untuk
pengklasifikasian sehingga lebih akurat, karena K-NN metode yang baik dalam hal ruang
pencarian, kelas tidak harus dipisahkan secara linear.
3.2. Proses Analisis Sentimen pada Dokumen
Berikut ini adalah metode yang digunakan untuk proses analisis sentimen yang digunakan
dalam penelitian ini.
Gambar 3.1. Proses Analisis Sentimen Pengumpulan Data
Cra wling
Pre-processing Cleaning Case Folding
Ekstraksi Fitur
Tokenization