IMPLEMENTASI ALGORITMA LEVENSHTEIN DISTANCE
DAN BOYER MOORE UNTUK FITUR AUTOCOMPLETE
DAN AUTOCORRECT PADA APLIKASI KATALOG
PERPUSTAKAAN DAERAH ACEH TIMUR
SKRIPSI
TEUKU IGHFAR HAJAR
131421063
PROGRAM STUDI S1 EKSTENSI ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
2015
IMPLEMENTASI ALGORITMA LEVENSHTEIN DISTANCE
DAN BOYER MOORE UNTUK FITUR AUTOCOMPLETE
DAN AUTOCORRECT PADA APLIKASI KATALOG
PERPUSTAKAAN DAERAH ACEH TIMUR
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh
ijazah Sarjana Ilmu Komputer
TEUKU IGHFAR HAJAR
131421063
PROGRAM STUDI S1 EKSTENSI ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
2015
PERSETUJUAN
Judul : IMPLEMENTASI ALGORITMA LEVENSHTEIN
DISTANCE DN BOYER MOORE UNTUK FITUR
AUTOCOMPLETE DAN AUTOCORRECT PADA APLIKASI KATALOG PERPUSTAKAAN
ACEH TIMUR
Kategori : SKRIPSI
Nama : TEUKU IGHFAR HAJAR
Nomor Induk Mahasiswa : 131421063
Program Studi : SARJANA (S1) ILMU KOMPUTER Departemen : ILMU KOMPUTER
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI (FASILKOMTI) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, 2 Agustus 2015
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Maya Silvi Lydia, B.Sc, M.Sc Dr. Poltak Sihombing, M.Kom NIP. 19740127 200212 2 001 NIP. 19620317 199103 1 001
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
Dr. Poltak Sihombing, M.Kom NIP. 19620317 199103 1 001
PERNYATAAN
IMPLEMENTASI ALGORITMA LEVENSHTEIN DISTANCE DAN BOYER
MOORE UNTUK FITUR AUTOCOMPLETE DAN AUTOCORRECT PADA
APLIKASI PERPUSTAKAAN DERAH ACEH TIMUR
SKRIPSI
Saya menyatakan bahwa skripsi ini adalah hasil karya saya sendiri, kecuali
beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Juni 2015
Teuku Ighfar Hajar
131421063
PENGHARGAAN
Puji dan syukur kehadirat Allah SWT yang telah memberikan rahmat dan hidayah-Ny
a, sehingga Penulis dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk
memperoleh gelar Sarjana Komputer pada Program Studi S1 Ilmu Komputer Universit
as Sumatera Utara.
Penulis ingin menyampaikan rasa hormat dan terima kasih yang sebesar–besar
nya kepada :
1. Bapak Prof. Dr. Subhilhar, M.A., Ph.D. selaku Plt Rektor Universitas Sumatera
Utara.
2. Bapak Prof. Dr. Muhammad Zarlis selaku Dekan Fakultas Ilmu Komputer dan
Teknologi Informasi Universitas Sumatera Utara.
3. Bapak Dr. Poltak Sihombing, M.Kom selaku Ketua Program Studi S1 Ilmu
Komputer Universitas Sumatera Utara dan Dosen Pembimbing I yang telah
memberikan kritik dan saran dalam penyempurnaan skripsi ini.
4. Ibu Maya Silvi Lydia, B.Sc, M.Sc selaku Sekretaris Program Studi S1 Ilmu
Komputer Universitas Sumatera Utara dan sebagai Dosen Pembimbing II yang
telah memberikan kritik dan saran dalam penyempurnaan skripsi ini..
6. Bapak M. Andri Budiman, ST, M.Comp, Sc.M.E.M selaku Dosen Pembanding
I yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
7. Bapak Ade Candra ST, M.Kom selaku Dosen Pembanding II yang telah
memberikan kritik dan saran dalam penyempurnaan skripsi ini.
9. Pembantu Dekan Fakultas Ilmu Komputer dan Teknologi Informasi
Universitas Sumatera Utara, seluruh tenaga pengajar serta pegawai di Program
Studi S1 Ilmu Komputer Fasilkom-TI USU.
10.Ayahanda H. Bustami T. Ibrahim, S.Ag dan Ibunda Hj. Farida AR yang selalu
memberikan doa dan dukungan serta kasih sayang kepada penulis, serta
kakanda tersayang Miftahul Wardah, S.Si, Musriyani Safitri, S.Si, Teuku
Muarrif Ikramullah, S.Kom dan adik tersayang Teuku Ichsanul Aulia yang
terus memberikan dukungan dan dorongan bagi penulis untuk menyelesaikan
skripsi ini.
11. Sahabat terbaik saya, terutama Satriyo Wibowo,Ryan Dhika Priyatna, Adli
Abdillah Nababan, Ade Rizka, Nurul Zakya Haque,Fera Ferdian,Wiwin
Agustini Lubis, Tiany Dwi Lestari, Ratno Zulita dan Tika Puspita Sari serta
teman-teman seperjuangan yang sedang menyelesaikan skripsinya terutama
stambuk 2013 terkhusus kom B atas semangat dan dorongannya dan Padlian
Chairi yang membantu dalam menyelesaikan skripsi ini.
12. Buat Silvia Bilqis Magdalena yang selalu memberikan semangat dan
dorongannya sehingga saya bersemangat dalam menyelesaikan skripsi saya
ini.
13. Sahabat kecil saya, Sayed Multazam, Teuku Nazarullah dan Cahya Isna Kirani
Lubis atas semangat dan dorongannya membantu dalam menyelesaikan skripsi
ini.
14.Dan semua pihak yang telah banyak membantu yang tidak bisa disebutkan
satu-persatu.
Semoga semua kebaikan, bantuan, perhatian, serta dukungan yang telah diberikan kep
ada penulis mendapatkan pahala yang melimpah dari Allah SWT.
Medan, Juni 2015
Penulis
ABSTRAK
Katalog perpustakaan adalah suatu media yang dapat menampilkan sejumlah data buku atau koleksi pada suatu perpustakaan. Dengan mencari judul buku pada katalog perpustakaan maka informasi mengenai judul buku yang dicari dapat diperoleh dengan mudah. Namun, terkadang dalam pengetikan judul buku terdapat kendala ketika ingin memperoleh informasi mengenai judul buku yang dicari. Kendala tersebut adalah kesalahan dalam pengetikan judul buku pada kotak pencarian. Kesalahan dalam pengetikan judul buku tersebut akan mengakibatkan informasi dari buku tersebut tidak dapat ditemukan. Oleh karena itu, diperlukan suatu aplikasi yang dapat membantu penguna ketika mengetikkan judul buku yang akan dicari seperti
autocomplete dan autocorrect. Autocomplete merupakan suatu fitur atau layanan yang
dapat menampilkan prediksi kata yang diketikkan belum lengkap, sedangkan
autorrect merupakan suatu fitur/layanan yang dapat menampilkan perbaikan kata.
Algoritma Levenshtein Distance merupakan algoritma pencocokan string berdasarkan pendekatan perkiraan dan digunakan untuk menampilkan autocorrect sedangkan algoritma Boyer Moore adalah algoritma pencocokan string berdasarkan lompatan dari setiap string yang digunakan untuk menghasilkan autocomplete. Keluaran yang dihasilkan dari sistem ini berupa prediksi judul buku yang diketikkan oleh pengguna
Kata kunci : Algoritma Levenshtein Distance, Algoritma Boyer Moore, Autocomplete,
Autocorrect, katalog perpustakaan, Aceh Timur
Implementation Levenshtein Distance Algorithm and Boyer Moore for Autocomplete and Autocorrect Feature in Aceh Timur’s Library Catalog
ABSTRACT
A library catalogue is a medium which can show some data, book, or collection in a
library by searching for a title in the library catalogue. Therefore, the information
connected to the title which the readers are looking for can be found easily. However,
sometimes, there are some difficulties in searching some books by using its title. The
difficulties are the type missing in the searching box. As a result, the book which is
searched for cannot be found. Therefore, it is needed to create an application to help
the users when they type the title of the book,with some essential feature such as auto
complete and autocorrect. Autocomplete is a feature that can show missing word.
Algorithm Levenshtein Distance is an algorithm which can match string based on
hypotheses approach. Boyer Moore is used to make autocomplete. The output create
from this system is a oprediction of the book’s title that is typed by the users.
Keywords: Algorithm Levenshtein Distance, Algoritm Boyer Moore, Autocomplete,
Autocorrect, Library catalogue, Aceh Timur
DAFTAR ISI
1.3 Ruang Lingkup Penelitian 3
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 4
1.6 Metode Penelitian 4
1.7 Sistematika Penulisan 5
BAB 2 LANDASAN TEORI
2.1 Katalog Perpustakaan 6
2.2 Fitur atau Layanan Autocomplete 7 2.3 Fitur atau Layanan Autocorrect 8
2.4 Approximate String Matching 8
2.4.1 Operasi penghapusan 8
2.4.2 Operasi penyisipan 9
2.4.3 Operasi penukaran 10
2.5 Algoritma Levenshtein Distance 10
2.6 Algoritma Boyer Moore 13
2.6.1 Cara Kerja Algoritma Boyer Moore 16
2.6.2 Prosedur Algoritma Boyer Moore 19
2.7 Penelitian Terdahulu 22
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
3.1 Analisis Masalah 24
3.2 Analisis Kebutuhan Sistem 25
3.2.1 Kebutuhan fungsional sistem 25
3.2.2 Kebutuhan nonfungsional sistem 26
3.3 Pemodelan sistem 27
3.3.1 Use case Diagram 27
3.3.2 Activity Diagram 29
3.3.3 Sequence Diagram 31
3.4 Analisis Data 31
3.5 Perancangan Sistem 34
3.5.1 Flowchart sistem Autocomplete 34
3.5.2 Proses pencarian Boyer Moore untuk autocomplete 35
3.5.3 Flowchart sistem Autocorrect 40
3.5.4 Proses pencarian pada Levenshtein Distance untuk 41
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM 4.1 Perhitungan Nilai Levenshtein Distance dan Boyer Moore pada Fitur Autocomplete dan Autocorrect secara manual 57 4.1.1 Perhitungan Nilai Levenshtein Distance Untuk Fitur Autocorrect 57
4.1.1.1 Potongan Program dari Metode Levenshtein Distance 59
4.1.2 Perhitungan Nilai Boyer Moore untuk Fitur Autocomplete 61 4.1.2.1Potongan Program dari Metode Boyer Moore 65
4.3 Implementasi Perancangan Antarmuka 69
4.3.1 Tampilan halaman awal user 70
4.3.2 Tampilan halaman hasil pencarian judul buku 70 4.3.3 Tampilan halaman informasi data buku 71
4.3.4 Tampilan halaman login admin 71
4.3.5 Tampilan halaman awal admin 72
4.3.6 Tampilan halaman daftar buku 73
4.3.7 Tampilan halaman tambah buku 73
4.3.8 Tampilan halaman edit buku 74
BAB 5 KESIMPULAN DAN SARAN
5.1 Kesimpulan 75
5.2 Saran 76
DAFTAR PUSTAKA 77
LAMPIRAN
DAFTAR TABEL
Halaman
Tabel 2.1 Penelitian sebelumnya 22
Tabel 3.1 Tabel Use Case Proses Pencarian Judul Buku 28 Tabel 3.2 Keterangan Bagian-Bagian Rancangan Halaman Utama 30
Tabel 3.3 Sampel Data Buku 32
Tabel 3.4 Occurence Heuristic 37
Tabel 3.5 Math Heuristic 37
Tabel 3.6 Math Heuristic 39
Tabel 4.1 Occurence Heuristic 63
Tabel 4.2 Math Heuristic 63
Tabel 4.3 Tabel nilai OH dan MH 65
Tabel 4.4 Rencana Pengujian Sistem 67
Tabel 4.5 Hasil Pengujian Fungsi Dasar Sistem 68 Tabel 4.6 Pengujian Hasil pencarian Autocorrect 68 Tabel 4.7 Pengujian Hasil pencarian Autocomplete 69
Gambar 4.9 Tampilan halaman informasi data buku 68
Gambar 4.10 Tampilan halaman login admin 69
Gambar 4.11 Tampilan halaman awal admin 69
Gambar 4.12 Tampilan halaman daftar buku 70
Gambar 4.13 Tampilan halaman tambah buku 70
Gambar 4.14 Tampilan halaman edit buku 71
Gambar 4.15 Autocomplete untuk “panduan” 72
Gambar 4.16 Autocorrect untuk “sehat”
73
ABSTRAK
Katalog perpustakaan adalah suatu media yang dapat menampilkan sejumlah data buku atau koleksi pada suatu perpustakaan. Dengan mencari judul buku pada katalog perpustakaan maka informasi mengenai judul buku yang dicari dapat diperoleh dengan mudah. Namun, terkadang dalam pengetikan judul buku terdapat kendala ketika ingin memperoleh informasi mengenai judul buku yang dicari. Kendala tersebut adalah kesalahan dalam pengetikan judul buku pada kotak pencarian. Kesalahan dalam pengetikan judul buku tersebut akan mengakibatkan informasi dari buku tersebut tidak dapat ditemukan. Oleh karena itu, diperlukan suatu aplikasi yang dapat membantu penguna ketika mengetikkan judul buku yang akan dicari seperti
autocomplete dan autocorrect. Autocomplete merupakan suatu fitur atau layanan yang
dapat menampilkan prediksi kata yang diketikkan belum lengkap, sedangkan
autorrect merupakan suatu fitur/layanan yang dapat menampilkan perbaikan kata.
Algoritma Levenshtein Distance merupakan algoritma pencocokan string berdasarkan pendekatan perkiraan dan digunakan untuk menampilkan autocorrect sedangkan algoritma Boyer Moore adalah algoritma pencocokan string berdasarkan lompatan dari setiap string yang digunakan untuk menghasilkan autocomplete. Keluaran yang dihasilkan dari sistem ini berupa prediksi judul buku yang diketikkan oleh pengguna
Kata kunci : Algoritma Levenshtein Distance, Algoritma Boyer Moore, Autocomplete,
Autocorrect, katalog perpustakaan, Aceh Timur
Implementation Levenshtein Distance Algorithm and Boyer Moore for Autocomplete and Autocorrect Feature in Aceh Timur’s Library Catalog
ABSTRACT
A library catalogue is a medium which can show some data, book, or collection in a
library by searching for a title in the library catalogue. Therefore, the information
connected to the title which the readers are looking for can be found easily. However,
sometimes, there are some difficulties in searching some books by using its title. The
difficulties are the type missing in the searching box. As a result, the book which is
searched for cannot be found. Therefore, it is needed to create an application to help
the users when they type the title of the book,with some essential feature such as auto
complete and autocorrect. Autocomplete is a feature that can show missing word.
Algorithm Levenshtein Distance is an algorithm which can match string based on
hypotheses approach. Boyer Moore is used to make autocomplete. The output create
from this system is a oprediction of the book’s title that is typed by the users.
Keywords: Algorithm Levenshtein Distance, Algoritm Boyer Moore, Autocomplete,
Autocorrect, Library catalogue, Aceh Timur
BAB 1
PENDAHULUAN
1.1.Latar Belakang
Kemajuan teknologi pada masa sekarang sangat membantu serta memberi kemudahan
bagi manusia dalam melakukan berbagai aktivitas, khususnya aktivitas yang berkaitan
dengan informasi seperti mencari informasi buku, mencari bahan kuliah, mencari informasi
seseorang, dan lain-lain. Jika informasi yang dicari memiliki jumlah yang masih sedikit,
pencarian dapat dilakukan secara manual. Namun jika informasi yang dicari sudah memiliki
jumlah yang banyak dan besar maka pengguna akan mengalami kesulitan dalam mencari
informasi yang dicari (Chiquita, 2011). Untuk memperoleh informasi dengan cepat dan
mudah dari banyaknya kumpulan informasi maka dapat menggunakan mesin pencari.
Mesin pencari merupakan program komputer yang dirancang agar mampu
menemukan informasi yang dicari dari banyaknya kumpulan informasi yang tersedia Dengan
adanya mesin pencari setiap orang dapat dengan mudah memperoleh informasi yang
diinginkan. Dengan mengetikkan kata yang ingin dicaripada mesin pencari maka seluruh
informasi yang diinginkan akan ditampilkan. Namun sejumlah penelitian terhadap mesin
pencari menyimpulkan bahwa rata-rata kesalahan dalam pengetikan kata yang dicari yang
dilakukan oleh pengguna cukup tinggi ,kesalahan dalam pengetikan kata yang dicari oleh
pengguna dapat menyebabkan informasi yang dicari tidak dapat ditemukan.Untuk itu
dibutuhkan penambahan fitur yang dapat membantu pengguna ketika mengetik, dimana fitur
tersebut dapat menampilkan prediksi kata seperti autocomplete dan autocorrect yang dapat
membantu pengguna untuk mengetikkan kata pada mesin pencari.
Autocomplete merupakan fitur atau layanan yang dapat menampilkan prediksi kata
jika kata yang diketikkan belum lengkap (Chiquita, 2011). Beberapa penelitian yang
berkaitan dengan masalah ini diantaranya yaitu penelitian yang pernah dilakukan oleh
(Chiquita, 2011), pada penelitiannya Chiquita menerapkan algoritma Boyer-Moore untuk
layanan autocomplete dan menggunakan algoritma Dynamic Programming untuk layanan
autocorrect untuk mencari kata di dalam paragraf. Kemudian selanjutnya penelitian yang
pernah dilakukan oleh Chiquita (2011), pada penelitiannya Kusuma melakukan pencocokan
string untuk fitur autocompletion pada text editor atau integrated development environment
(IDE) menggunakan algoritma Brute Force dan KMP. Selanjutnya penelitian yang pernah
dilakukan oleh Pradhana (2012), pada penelitiannya Pradhana menerapkan algoritma string
matching seperti Brute Force, Knuth-Morris Pratt dan Boyer-Moore untuk fitur autocorrect
dan fitur autotext pada smart phones. Pada penelitian ini, penulis akan mensimulasikan
algoritma Levenshtein Distance dan Boyer Moore untuk menghasilkan fitur autocomplete dan
autocorrect. Pada simulasinya fitur autocomplete digunakan untuk membantu pengetikan
judul buku pada aplikasi katalog perpustakaan, sedangkan autocomplete untuk membenarkan
pencarian judul buku yang dicari. Algoritma Levenshtein Distance dan Boyer Moore
merupakan salah satu algoritma Approximate String Matching yang digunakan dalam
pencarian string berdasarkan pendekatan perkiraan (Adiwidya, 2009). Pada penelitian
sebelumnya algoritma string matching seperti Brute Force,, dan Knuth-Morris Pratt
melakukan pencocokan secara bertahap pada seluruh rangkaian string sehingga memiliki
proses yang cenderung panjang dan rumit.Sedangkan algoritma Levenshtein Distance
melakukan modifikasi dengan mengubah suatu string menjadi string yang lain sehingga
prosesnya lebih sederhana.
Algoritma Levenshtein Distance terbukti dapat menyelesaikan beberapa permasalahan
dalam penelitian ilmiah, beberapa penelitian yang pernah dilakukan yang berkaitan dengan
algoritma Levenshtein Distance, diantaranya yaitu Adriyani (2012) menggunakan algoritma
Levenstein Distance dan metode empiris untuk menampilkan saran perbaikan kesalahan
pengetikan dokumen berbahasa Indonesia, (2010) di dalam penelitiannya menggunakan
algoritma Levenshtein Distance untuk menampilkan string suggestion pada aplikasi seperti
spell checker dan kamus. Selanjutnya Benisius (2010) menggunakan algoritma Levenshtein
Distance untuk sistem pengoreksian kata kunci, dimana di dalam penelitiannya Benisius
melakukan studi kasus terhadap website Universitas Halmahera. Di dalam penelitiannya juga,
Benisius menggunakan proses crawling dan indexing untuk mengumpulkan informasi dari
website Universitas Halmahera untuk dicocokkan dengan kata kunci sebagai hasil koreksi
kata kunci.
1.2.Rumusan Masalah
1. Bagaimana cara kerja fitur autocomplete dan fitur autocorrect dalam proses pencarian
judul buku pada katalog perpustakaan menggunakan Algoritma Levenshtein Distance
dan Algoritma Boyer Moore?
1.3.Ruang Lingkup Penelitian
Adapun batasan masalah yang diberikan pada penelitian ini adalah sebagai berikut :
1. Peneliti menerapkan algoritma Levenshtein Distance pada fitur autocorrect dan
Algoritma Boyer Moore pada fitur autocomplete.
2. Data koleksi perpustakaan yang akan digunakan di dalam penelitian hanya data buku
saja seperti judul buku, pengarang, penerbit, tahun terbit, edisi, jenis, deskripsi,
subjek, bahasa dan jumlah eksemplar, sedangkan jurnal dan kumpulan dokumen
pendidikan yang lain tidak diikut sertakan.
3. Data judul buku yang diambil berasal dari Dinas Perpustakaan dan Arsip Daerah Aceh
Timur
4. Dalam hal ini peneliti menggunakan PHP (Hypertext Prepocessor) dan MySQL
sebagai DBMS
1.4.Tujuan Penelitian
Mensimulasikan algoritma Levenshtein Distance dan Boyer Moore dalam membuat fitur
autocomplete dan autocorrect pada aplikasi katalog perpustakaan Daerah Aceh Timur agar
dapat membantu pengguna ketika menuliskan judul buku yang ingin dicari.
1.5. Manfaat Penelitian
Manfaat yang diharapkan dari penelitian ini adalah
1. Membantu pengguna dalam mencari buku dengan menggunakan aplikasi
perpustakaan ini.
2. Menerapkan fitur autocomplete dan autocorrect untuk mempermudah dalam
pencarian buku pada aplikasi ini.
3. Mempersingkat waktu serta keefesienan waktu dalam pencarian judul buku pada
aplikasi ini.
1.6. Metode Penelitian
Adapun metode penelitian yang akan digunakan adalah:
1. Studi Literatur
Pada tahap ini dilakukan dengan membaca dan mempelajari lebih dalam buku-buku
referensi, jurnal atau sumber-sumber penelitian lain yang berkaitan dengan autocomplete
serta teori algoritma Levenshtein Distance.
2. Analisis dan Perancangan Desain Sistem
Pada tahap ini akan dilakukan analisis terhadap penerapan algoritma Levenshtein
Distance pada autocomplete, serta perancangan aplikasi, antara lain: menggambar flowchart, use case, DFD dan perancangan antarmuka atau interface.
3. Implementasi Sistem
Pada tahap ini akan dilakukan pengkodean dan menerapkan perancangan aplikasi
tersebut ke dalam bahasa pemrograman PHP dan MYSQL.
4. Pengujian Sistem
Pada tahap ini akan dilakukan pengujian terhadap aplikasi apakah telah memenuhi
kriteria atau tidak.
5. Dokumentasi Sistem
Pada tahap ini akan dilakukan penulisan laporan mengenai aplikasi tersebut yang
bertujuan untuk menunjukkan hasil penelitian ini.
1.7.Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri dari lima bagian utama sebagai berikut:
BAB 1: PENDAHULUAN
Bab ini akan menjelaskan tentang latar belakang, rumusan masalah, batasan masalah, tujuan
penelitian, manfaat penelitian, metode penelitian, dan sistematika penulisan.
BAB 2: LANDASAN TEORI
Bab ini akan menjelaskan tentang segala teori yang berkaitan dengan penelitian seperti
pengertian autocomplete, pembahasan algoritma Levenshtein Distance, penelitian-penelitian
terdahulu dan teori-teori lainnya yang berkaitan dengan penelitian.
BAB 3: ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi analisis terhadap fokus permasalahan penelitian dan perancangan sistem yang
akan dibangun seperti menggambar flowchart atau diagram alur kerja system, analisis
terhadap proses kerja algoritma Levenshtein Distance pada autocomplete dan perancangan
antarmuka atau interface.
BAB 4: IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi pembahasan tentang implementasi algoritma yang disusun pada bab 3 dan
pengujian terhadap sistem yang dibangun.
BAB 5: KESIMPULAN DAN SARAN
Bab ini memuat kesimpulan dari keseluruhan uraian bab-bab sebelumnya dan saran yang
diperoleh yang diharapkan dapat bermanfaat untuk pengembangan program selanjutnya.
BAB 2
LANDASAN TEORI
Pada bab ini akan dibahas tentang teori-teori dan konsep dasar yang mendukung pembahasan
dari sistem yang akan dibuat.
2.1. Katalog Perpustakaan
Katalog perpustakaan adalah suatu media yang dibutuhkan oleh perpustakaan agar dapat
memudahkan pengunjung dalam memperoleh informasi mengenai koleksi apa saja yang
dimiliki oleh perpustakaan.
Ada beberapa pengertian tentang katalog perpustakaan, antara lain yaitu :
a. Gates (1989) menyatakan bahwa katalog perpustakaan adalah suatu daftar yang
sistematis dari buku dan bahan-bahan lain dalam suatu perpustakaan, dengan
informasi deskriptif mengenai pengarang, judul, penerbit, tahun terbit, bentuk fisik,
subjek, dan ciri khas bahan.
b. Sulistyo-Basuki (1991) menyatakan bahwa katalog perpustakaan adalah senarai
dokumen yang dimiliki sebuah perpustakaan atau kelompok perpustakaan
2.2. Fitur atau Layanan Autocomplete
Autocomplete merupakan pola yang pertama kali muncul dalam bantuan fungsi aplikasi
dekstop, dimana pengguna mengentrikan teks ke dalam kotak kemudian saran pengetikan
akan muncul secara otomatis . Autocomplete memecahkan beberapa masalah umum pada
pengetikan (Morville & Callender, 2010) yaitu :
a. Mengetik membutuhkan waktu.
b. Pengguna tidak dapat mengeja kata dengan baik.
c. Pengguna sering salah atau lupa ketika mengetikkan kata-kata, sulit mengingat istilah
yang tepat.
Autocomplete bekerja ketika pengguna menulis huruf pertama atau beberapa huruf/karakter
dari sebuah kata, program yang melakukan prediksi akan mencari satu atau lebih
kemungkinan kata sebagai pilihan. Jika kata yang dimaksud ada dalam pilihan kata prediksi
maka kata yang dipilih tersebut akan disisipkan pada teks (Kusuma, 2012). Saat ini
autocomplete tidak hanya terdapat pada dekstop, tetapi terdapat juga pada web browser, email-programs, search engine interface, source code editors, database query tools, word processor, dan command line interpreters (Kusuma, 2012). Ilustrasi penggunaan layanan autocomplete dapat dilihat pada gambar 2.1.
Gambar 2.1. Ilustrasi Penggunaan Autocomplete
2.3. Fitur atau layanan Autocorrect
Auto Correct adalah fitur yang berguna untuk memberikan sugesti kata (suggestion). Dengan
mengetikkan beberapa huruf atau seluruh huruf maka sistem akan mencari kedalam database
apakah ada kata yang memenuhi kriteria dari huruf-huruf yang dimasukkan untuk mencari
judul buku,penerbit bahkan pengarang dari buku tersebut. Ilustrasi penggunaan fitur
autocorrect dapat dilihat pada gambar 2.2
Gambar 2.2. Ilustrasi Penggunaan Autocorrect
2.4. Approximate String Matching
Approximate string matching merupakan pencocokan string dengan dasar kemiripan dari segi
penulisannya (jumlah karakter dan susunan karakter), tingkat kemiripan ditentukan dengan
jauh tidaknya beda penulisan dua buah string yang dibandingkan tersebut (Haryanto, 2011).
Operasi mengubah string ini bisa berupa mengubah satu huruf ke huruf yang lain, menghapus
satu huruf dari string, atau memasukkan satu huruf ke dalam string. Operasi-operasi ini
digunakan untuk menghitung jumlah perbedaan yang diperlukan untuk pertimbangan
kecocokan suatu string dengan string sumber, jumlah perbedaan tersebut diperoleh dari
penjumlahan semua pengubahan yang terjadi dari masing-masing operasi. Penggunaan
perbedaan tersebut diaplikasikan dalam berbagai macam algoritma, seperti Hamming,
Levenshtein, Damerau-Levenshtein, Jaro-Winkler, Wagner-Fischer, dan lain-lain (Husain,
2013). Operasi penghitungan tersebut meliputi tiga operasi string seperti di bawah ini
(Adiwidya, 2009).
2.4.1. Operasi penghapusan
Operasi penghapusan dilakukan dengan menghapus karakter pada indeks tertentu untuk
menyamakan string sumber (S) dengan string target (T), misalnya S= matching dan T=
match. Penghapusan dilakukan untuk karakter i pada lokasi ke-6, penghapusan karakter n
pada lokasi ke-7, penghapusan karakter g pada lokasi ke-8. Operasi penghapusan tersebut
menunjukkan tranformasi S ke T, ilustrasinya adalah sebagai berikut :
1 2 3 4 5 6 7 8
T = m a t c h - - -
S = m a t c h i n g
2.4.2. Operasi penyisipan
Operasi penyisipan dilakukan dengan menyisipkan karakter pada indeks tertentu untuk
menyamakan string sumber (S) dengan string target (T), misalnya S= cerdas dan T=
kecerdasan. Operasi penyisipan dapat dilakukan dengan menyisipkan e pada posisi 2,
menyisipkan c pada posisi 3, menyisipkan a pada posisi 8 dan menyisipkan n pada posisi 9.
Yang dapat diilustrasikan sebagai berikut:
K e c e r d a s a n
K - - e r d a s - -
1 2 3 4 5 6 7 8 9
T = K e c e r d a s a n
S = K - - e r d a s - -
e c a n
2.4.3. Operasi penukaran
Operasi penukaran dilakukan dengan menukar karakter pada indeks tertentu untuk
menyamakan string sumber (S) dengan string target (T), misalnya S= computer dan T=
komputer. String S ditranformasikan menjadi T dengan melakukan penggantian (substitusi)
pada posisi ke-1. Huruf C ditukar menjadi K. Prosesnya dapat diilustrasikan sebagai berikut:
1 2 3 4 5 6 7 8
T = k o m p u t e r
S = c o m p u t e r
k
2.5. Algoritma Levenshtein Distance
Algoritma Levenshtein Distance ditemukan oleh Vladimir Levenshtein, seorang
ilmuan asal Rusia pada tahun 1965 (Janowski, 2010), algoritma ini sering juga disebut
dengan Edit Distance (Husain,2013). Yang dimaksud dengan distance adalah jumlah
modifikasi yang dibutuhkan untuk mengubah suatu bentuk string ke bentuk string yang lain,
sebagai contoh hasil penggunaan algoritma ini, string “komputer” dan “computer” memiliki
distance 1 karena hanya perlu dilakukan satu operasi saja untuk mengubah satu string ke
string yang lain. Dalam kasus dua string di atas, string “computer” dapat menjadi
“komputer” hanya dengan melakukan satu penukaran karakter „c‟ menjadi „k‟ (Andhika,
2010). Algoritma Levenshtein Distance digunakan secara luas dalam berbagai bidang,
misalnya mesin pencari, pengecek ejaan (spell checking), pengenal pembicaraan (speech
recognition), pengucapan dialek, analisis DNA, pendeteksi pemalsuan, dan lain-lain.
Algoritma ini menghitung jumlah operasi string paling sedikit yang diperlukan untuk
mentransformasikan suatu string menjadi string yang lain (Adiwidya, 2009). Algoritma
Levenshtein Distance bekerja dengan menghitung jumlah minimum pentranformasian suatu
string menjadi string lain yang meliputi penghapusan, penyisipan, dan penukaran (Husain,
2013). Selisih perbedaan antar string dapat diperoleh dengan memeriksa apakah suatu string
sumber sesuai dengan string target. Nilai selisih perbedaan ini disebut juga Edit distance/
jarak Levenhstein. Jarak Levenshtein antar string s dan string t tersebut adalah fungsi D
yang memetakan (s,t) ke suatu bilangan real nonnegatif, sebagai contoh diberikan dua buah
string s = s(1)s(2)s(3)...s(m) dan t = t(1)t(2)t(3)...t(n) dengan | s | = m dan | t | = n sepanjang
alfabet V berukuran r sehingga s dan t anggota dari V*. S(j) adalah karakter pada posisi ke-j
pada string s dan t(i) adalah karakter pada posisi ke-i pada string t. Sehingga jarak
Levenshtein dapat didefinisikan sebagai (Harahap, 2013).
D ( s, t) adalah banyaknya operasi minimum dari operasi penghapusan, penyisipan dan
penukaran untuk menyamakan string s dan t. Pada implementasi pencocokan antar string,
ketiga operasi tersebut dapat dilakukan sekaligus untuk menyamakan string sumber dengan
string target seperti pada contoh berikut ini. Jika diberikan string sumber (S) =
“pemrograman” dan T = “ algoritma” merupakan string target, dengan | s | = 11, | t | = 9,
maka proses pencocokan string dapat diilustrasikan sebagai berikut :
1 2 3 4 5 6 7 8 9 10 11
T = a l g o r i t m a - -
S = p e m p r o s e s a n
a l g o i t m a
Pada contoh di atas terlihat bahwa proses penukaran karakter „p‟ pada indeks ke-1, „e‟ pada indeks ke-2,”m” pada indeks ke-3, ‟p‟ pada indeks ke-4, ‟o‟ pada indeks ke-6, ‟s‟ pada indeks ke-7, ‟e‟ pada indeks ke-8, penyisipan karakter „g‟ pada indeks ke-3 dan proses penghapusan karakter „a‟ pada indeks ke-9, dan „n‟ pada indeks ke-11. Maka jarak Levenshtein antara S dan T adalah sebagai berikut ini.
= d( s1, t1 ) + d( s2, t2 ) + d( s3, t3 ) + d( s4, t4 ) + d( s5, t5 ) +
d( s6, t6 ) + d( s7, t7 ) + d( s8, t8 ) + d( s9, t9 ) + d( s10, t10 ) +
d( s11, t11 ) + d( s12, t12 )
= d( a, p ) + d( l, e ) + d( g, - ) + d( o, m ) + d( r, r ) + d( i, o) +
d( t, g ) + d( m, r) + d( a, a ) + d( -, m )+ d( -, a) + d(-, n)
= 1 + 1 + 1 + 1 + 0 + 1 + 1 + 1 + 1 + 1 + 1
= 10
Sehingga jarak Levenshtein antara string T = “pemprosesan” dan T = “algoritma”
adalah D(s, t) = 10.
2.6. Algoritma Boyer Moore
Algoritma Boyer Moore termasuk algoritma string matching yang paling efisien
dibandingkan algoritma-algoritma string matching lainnya. Karena sifatnya yang efisien,
banyak dikembangkan algoritma string matching dengan bertumpu pada konsep algoritma
Boyer Moore, beberapa di antaranya adalah algoritma Turbo BM dan algoritma Quick
Search.( Chiquita. 2012).
Algoritma Boyer Moore menggunakan metode pencocokan string dari kanan ke kiri
yaitu men-scan karakter pattern dari kanan ke kiri dimulai dari karakter paling kanan.
Algoritma Boyer Moore menggunakan dua fungsi shift yaitu good-suffix shift dan
character shift untuk mengambil langkah berikutnya setelah terjadi ketidakcocokan antara
karakter pattern dan karakter teks yang dicocokkan ( Sagita Vina, 2012).
1. Deskripsi kerja algoritma Boyer Moore
Untuk menjelaskan konsep dari good-suffix shift dan bad-character shift diperlukan
contoh kasus, seperti kasus ketidakcocokan ditengah pencocokan karakter pada teks dan
pattern. Karakter pattern x[i]=a tidak cocok dengan karakter teks y[i+j]=b saat pencocokan
pada posisi j. Maka x[i+l .. m-1]= y[i+j+1 .. j+m-1]=u dan x[i] ≠ y[i+j].
2. Good-suffix shift
Konsep dari fungsi good-suffix shift adalah sebagai berikut:
1. Good-suffix shift adalah pergeseran yang dibutuhkan dari x[i]=a ke karakter lain yang
letaknya lebih kiri dari x[i] dan terletak di sebelah kiri segmen u. Kasus ini ditunjukkan
pada Gambar 2.3.
y
x shift
x
Gambar 2.3 Good-suffix shift, uterjadi lagi didahului karakter c berbeda dari a
2. Jika tidak ada segmen yang sama dengan u, maka dicari u yang merupakan suffiks
terpanjang u. Kasus ini ditunjukkan pada Gambar 2.4
y
x shift
x
Gambar 2.4 Good-suffix shift, hanya suffix dari u yang terjadi lagi di pattern x
3. Bad-character shift
Berdasarkan contoh kasus di atas, bad-character adalah karakter pada teks yaitu y
[i+j] yang tidak cocok dengan karakter pada pattern.
Konsep dari fungsi bad-character shift adalah sebagai berikut:
1. Jika bad-character y[i+j] terdapat pada pattern di posisi terkanan k yang lebih kiri dari
x[i] maka pattern digeser ke kanan sejauh i-k. Kasus ini ditunjukkan pada Gambar 2.5.
y
x shift x
Gambar 2.5 Bad-character shift, b terdapat di pattern x
2. Jika bad-character y[i+j] tidak ada pada pattern sama sekali, maka pattern digeser ke
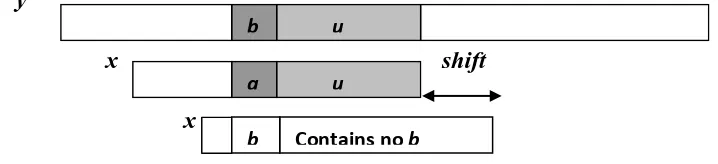
kanan sejauh i. Kasus ini dit tunjukkan pada Gambar 2.6.
y
u b
u a
Contains no b b
u b
u a
Contains no b
x shift
x
Gambar 2.6 Bad-character shift, b tidak ada di pattern x
3. Jika bad-character y[i+j] terdapat pada pattern di posisi terkanan k yang lebih kanan
dari x[i] maka pattern seharusnya digeser sejauh i-k yang hasilnya negatif (pattern
digeser kembali ke kiri). Maka bila kasus ini terjadi. akan diabaikan.
Pada kasus ketidakcocokan di atas, algoritma akan membandingkan langkah yang
diambil oleh fungsi good-suffix shift dan bad-character shift di mana langkah yang paling
besar yang akan digunakan.
2.6.1 Cara kerja algoritma Boyer Moore
Cara kerja dari algoritma Boyer Moore adalah sebagai berikut:
1. Menjalankan prosedur preBmBc dan preBmGs untuk mendapatkan inisialisasi.
a.Menjalankan prosedur preBmBc. Fungsi dari prosedur ini adalah untuk
menentukan berapa besar pergeseran yang dibutuhkan untuk mencapai karakter
tertentu pada pattern dari karakter pattern terakhir/terkanan. Hasil dari prosedur
preBmBc disimpan pada tabel BmBc.
b.Menjalankan prosedur preBmGs. Sebelum menjalankan isi prosedur ini,
prosedur suffix dijalankan terlebih dulu pada pattern. Fungsi dari prosedur suffix
adalah memeriksa kecocokan sejumlah karakter yang dimulai dari karakter
terakhir/terkanan dengan sejumlah karakter yang dimulai dari setiap karakter
yang lebih kiri dari karakter terkanan tadi. Hasil dari prosedur suffix disimpan
pada tabel suff. Jadi suff[i] mencatat panjang dari suffix yang cocok dengan
segmen dari pattern yang diakhiri karakter ke-i.
c.Dengan prosedur preBmGs, dapat diketahui berapa banyak langkah pada pattern
dari sebeuah segmen ke segmen lain yang sama yang letaknya lebih kiri dengan
karakter di sebelah kiri segmen yang berbeda. Prosedur preBmGs menggunakan
tabel suff untuk mengetahui semua pasangan segmen yang sama. Contoh pada
Gambar 2.1, yaitu berapa langkah yang dibutuhkan dari au(u = segmen, a =
karakter di sebelah kiri u) ke cu yang mempunyai segmen u pada pattern dengan
karakter di sebelah kiri segmen yaitu c berbeda dari a dan terletak lebih kiri dari
au. Hasil dari prosedur preBmGs disimpan pada tabel BmGs.
2. Dilakukan proses pencarian string dengan menggunakan hasil dari prosedur preBmBc
dan preBmGs yaitu tabel BmBc dan BmGs.
Berikut ini diberikan contoh untuk menjelaskan proses inisialisasi dari algoritma Boyer
Moore dengan pattern gcagagag yang akan dicari pada string gcatcgcagagagtatacagtacg.
1. Dengan prosedur preBmBc, didapatkan jumlah pergeseran pada pattern yang
dibutuhkan untuk mencapai karakter a,c,g,t dari posisi terkanan. Berdasarkan contoh
diketahui untuk mencapai masing-masing karakter tadi dibutuhkan pergeseran
sebanyak 1, 6, 2 dan 8.
2. Dengan prosedur preBmGs, dijalankan prosedur suffix terlebih dulu. Dengan prosedur
suffix akan diketahui:
suff[0] = 1, 1 karakter g posisi 7 cocok dengan 1 karakter g posisi 0.
suff[1] = 0, karakter g posisi 7 tidak cocok dengan karakter c posisi 1.
suff[2] = 0, karakter g posisi 7 tidak cocok dengan karakter a posisi 2.
suff[3] = 2, 2 karakter dimulai dari karakter g posisi 7 cocok dengan 2 karakter
dimulai dari karakter g posisi 3, yang artinya karakter a,g posisi 6,7 cocok dengan
karakter a,g posisi 2,3.
suff[4] = 0, karakter g posisi 7 tidak cocok dengan karakter a posisi 4.
suff[5] = 4, 4 karakter dimulai dari karakter g posisi 7 cocok dengan 4 karakter
dimulai dari karakter 5,artinya karakter a,g,a,g posisi 4,5,6,7 cocok dengan karakter
a,g,a,g posisi 2,3,4,5.
suff[6] = 0,karakter g posisi 7 tidak cocok dengan karakter a posisi 6.
suff[7] = 8, 8 karakter g,c,a,g,a,g,a,g posisi 0,1,2,3,4,5,6,7 cocok dengan 8 karakter
g,c,a,g,a,g,a,g posisi 0,1,2,3,4,5,6,7.
3. Dengan prosedur BmGs akan didapatkan:
0 1 2 3 4 5 6 7
g c a g a g a g
bmGs[0]= 7, karakter ke-0 g adalah karakter sebelah kiri segmen cagagag.Tidak ada
segmen cagagag lain dengan karakter sebelah kiri bukan g maka digeser 7 langkah.
bmGs[1]= 7, karakter ke-1 c adalah karakter sebelah kiri segmen agagag. Tidak ada
segmen agagag lain dengan karakter sebelah kiri bukan c maka digeser 7 langkah.
bmGs[2]= 7, karakter ke-2 a adalah karakter sebelah kiri segmen gagag. Tidak ada
segmen gagag lain dengan karakter sebelah kiri bukan a maka digeser 7 langkah.
bmGs[3]= 2. karakter ke-3 g adalah karakter sebelah kiri segmen agag. Karena ada
segmen agag posisi 2,3,4,5 dengan karakter sebelah kiri bukan g yaitu c posisi 1 maka
digeser 2 langkah.
bmGs[4]= 7, karakter ke-4 a adalah karakter sebelah kiri segmen gag. Karena tidak ada
seamen gag lain dengan karakter sebelah kiri bukan a maka digeser 7 langkah.
bmGs[5]= 4. karakter ke-5 g adalah karakter sebelah kiri seamen ag. Karena ada
segmen ag posisi 2,3 dengan karakter sebelah kiri bukan g yaitu c posisi 1 maka
digeser 4 langkah.
bmGs[6]= 7, karakter ke-6 a adalah karakter sebelah kiri segmen yaitu a posisi 7.
Karena tidak ada segmen g dengan karakter sebelah kirinya bukan a maka digeser 7
langkah.
bmGs[7]= 1, karakter ke-7 g adalah karakter sebelah kiri segmen dan karena segmen
tidak ada maka digeser 1 langkah
2.6.2 Prosedur Algoritma Boyer Moore
procedure preBmBc(in/out x: string, m: integer, output BmBc: array of integer)
{ ASIZE = ukuran ∑ }
i traversal [0..ASIZE - 1]
BmBc[i] ← m
i traversal [0..m - 2]
BmBc[x[i] ] ← m - i - 1
Gambar 2.7 Prosedur preBmBc algoritma Boyer Moore
procedure suffix (in/out x: string, m: integer, output suff: array of integer)
suff [m – 1] ← m
g ← m – 1
i traversal [m – 2..0]
if ( i > g and suff [i + m -1 – f] < i – g) then
suff [i] ← suff [ i + m – 1 – f]
else
if (i < g) then
g ← i
f ← i
while (g ≥ 0 and x[g] ← x [ g + m - 1 - f ] ) do
g ← g - 1
f ← i
while ( g ≥ 0 and x [g] ← x [g] + m - 1 - f ] ) do
g ← g - 1
suff [ i ] ← f - g
Gambar 2.7 Prosedur suffix algoritma Boyer Moore
procedure preBmGs(in/out x: string, m: integer, output BmGs: array of integer)
suffix (x, m, suff)
i traversal [0..m - 1]
BmGs[i] ← m
i traversal [m – 1 .. -1]
if (I = - 1 or suff [i] = i + 1 ) then
j traversal [ 0 .. m - 2 - i ) do
if (BmGs [j] = m) then BmGs [j] ← m - 1 - i
i traversal [0..m - 2]
BmGs [m - 1 - suff [i] ] ← m - 1 - i
Gambar 2.7 prosedur preBmGs algoritma Boyer Moore
procedure BM(in/out x,y: string, m,n: integer)
{ Preprocessing }
preBmGs(x, m, BmGs)
preBmBc(x, m, BmBc)
{ Searching }
j ← 0
while ( j ≤ n – m )do
i traversal [m - 1..0]
if (x[i] = y [ i + j ] ) then
if ( i < 0 )
OUTPUT ( j )
j ← j + BmGs [ 0 ]
else
j ← j + MAX( BmGs [i] , BmBc [ y [ i + j ] ] - m + 1 + i )
2.7 Penelitian Terdahulu
Pada bagian ini akan dijelaskan beberapa penelitian terdahulu, layanan autocorrect dan
autocomplete telah banyak digunakan pada penelitian terdahulu. Seperti layanan autocomplete dan autocorrect pada teks editor (Chiquita, 2011), dengan menggunakan
algoritma Boyer-Moore dan Dynamic Programming. Kemudian layanan autocorrect juga
pernah diterapkan pada Smart Phones (Pradhana, 2012), dengan menggunakan kombinasi
algoritma Brute Force, Boyer-Moore dan Knuth-Morris Pratt. Untuk lebih jelasnya, pada
tabel 2.1 berikut akan dijelaskan penelitian-penelitian yang telah dibuat sebelumnya.
Tabel 2.1 Penelitian sebelumnya
No. Judul Pengarang Tahun Kelebihan Kekurangan
4
Simulasi Algoritma Levenshtein
Distance untuk fitur Autocomplete pada aplikasi katalog
perpustakaan
Yuli Primadani 2014
Algoritma Levenshtein Distance dapat bekerja
maksimal pada fitur autocomplete
Tidak dilengkapi dengan fitur autocorrect
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
3.1. Analisis Masalah
Pada bab ini akan membahas tentang analisis dan perancangan sistem untuk fitur
autocomplete dan autocorrect dengan menggunakan algoritma Levenshtein Distance dan
Boyer Moore, membuat pemodelan sistem seperti merancang alur kerja sistem (flowchart).
Mempelajari dan menganalisis konsep kerja dan proses kerja algoritma Levenstein Disance
dan Boyer Moore dan merancang antar muka.
Untuk mendapatkan informasi buku secara cepat pada katalog perpustakaan, pada
umumnya orang mengetikkan judul buku pada mesin pencari. Dengan adanya mesin pencari,
informasi mengenai buku yang akan dicari akan ditampilkan akan lebih mudah untuk
ditampilkan. Namun ketika mengetikkan judul buku tersebut, biasanya pengguna salah
mengetikkan atau bahkan lupa akan judul buku yang akan dicari.
Kesalahan dalam pengetikan judul buku menyebabkan judul buku yang akan dicari
tidak akan ditemukan, posisi huruf yang salah atau bahkan lupa judul buku keselurahan
sehingga membuat data yang dicari tidak dapat disesuaikan dengan data yang ada di
database, sehingga menyebabkan mesin pencari tidak menemukan informasi yang dicari.
Untuk itu pada mesin pencarian perlu dibutuhkan fitur autocomplete dan autocorrect.
Layanan ini berguna untuk membantu pengguna ketika mengetikkan judul buku yang akan
dicari.
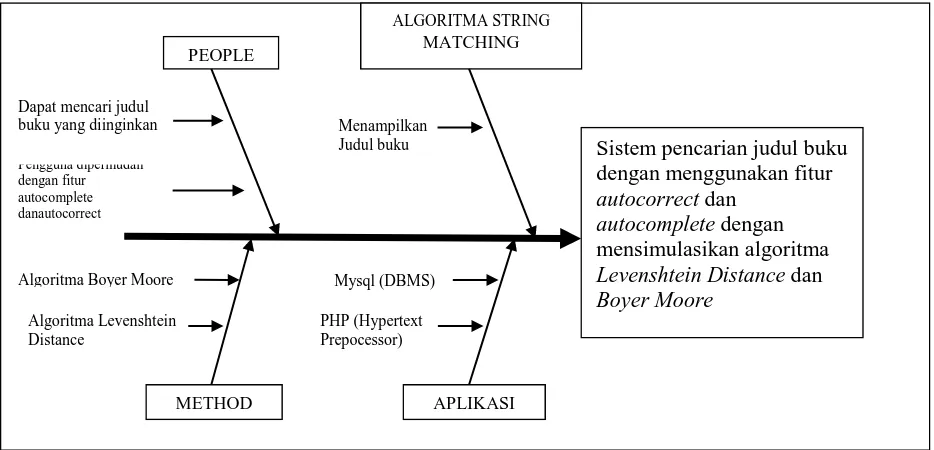
Gambar 3.1. merupakan diagram Ishikawa yang dapat digunakan untuk menganalisis
masalah. Bagian kepala atau segi empat yang berada di sebelah kanan merupakan masalah.
Sementara di pada bagian tulang merupakan penyebab.
Gambar 3.1 Diagram Ishikawa Untuk Ruang Lingkup Penelitian
3.2. Analisis Kebutuhan Sistem
Analisis kebutuhan sistem dapat dibagi pada dua kelompok, yaitu kebutuhan fungsional
sistem dan kebutuhan non fungsional sistem
3.2.1 Kebutuhan Fungsional
Fungsional sistem adalah aktifitas atau pelayanan yang harus dimiliki oleh sebuah sistem
berupa input, proses, output, maupun penyimpanan data ( Harahap, 2013). Adapun kebutuhan
fungsional yang dibutuhkan yaitu :
1. Pengguna memasukkan input berupa judul buku.
2. Sistem melakukan pencocokan string melalui judul buku yang diketikkan oleh
pengguna.
3. Sistem harus mampu menampilkan autocomplete dan autocorret yang mendekati
seperti input yang dimasukkan oleh pengguna.
3.2.2 Kebutuhan Non fungsional
Kebutuhan non fungsional sistem merupakan karakteristik atau batasan yang menentukan
kepuasan pada sebuah sistem seperti kinerja, kemudahan pengguna, biaya, dan kemampuan
sistem bekerja tanpa mengganggu fungsionalitas sistem lainnya (Whitten, 2007).
1. Sisi performa, sistem yang dirancang harus memiliki :
- Antarmuka (interface) yang sederhana dan menarik.
- Autocomplete yang mampu menampilkan judul buku yang diketikkan oleh
pengguna
- Autocorrect yang mampu memperbaiki judul buku yang diketikkan oleh pengguna
2. Sisi kemudahan penggunaan, sistem yang dirancang harus memiliki :
- Tampilan antarmuka (interface) menu bar, serta tombol botton akan dibuat
sederhana sehingga dapat emmudakan bagi para pengguna.
- Halaman form dirancang dengan mempertimbangkan jenis huruf, warna dan
layout dari antar muka.
- Bahasa yang digunakan dapat mudah dimengerti.
3. Sisi Ekonomi, sistem yang dirancang memiliki :
- Instalasi perangkat lunak dan keras yang tidak memerlukan biaya yang besar.
4. Sisi dokumentasi, sistem memiliki kemapuan sebagai berikut :
- Sistem dapat menyimpan data yang diinputkan pada database
5. Sisi kontrol, sistem yang dirancang harus memiliki :
- Sistem mengizinkan pembatalan terhadap suatu tindakan
- Sistem mampu menampilkan pesan kesalahan jika input yang dimasuukan oleh
pengguna tidak tepat.
6. Sisi kualitas, sistem yang akan dirancang memiliki :
- Kemampuan membandingkan input lebih dari satu kata
- Sistem mampu menampilkan hasil yang lebih baik
<<extends>>
Pemodelan sistem dilakukan untuk memperoleh gambaran yang lebih jelas tentang objek apa
saja yang akan berinteraksi dengan sistem, serta hal-hal apa saja yang harus dilakukan oleh
sebuah sistem sehingga sistem dapat berfungsi dengan baik sesuai dengan kegunaannya.
Pada penelitian ini digunakan UML (Unified Modeling Language) sebagai bahasa pemodelan
untuk mendesain dan merancang Sistem Pendukung Keputusan Pemilihan Gitar dengan
Metode Weighted Sum Model. Model UML yang digunakan antara lain use case diagram,
activity diagram, dan sequence diagram.
3.3.1. Use-Case Diagram
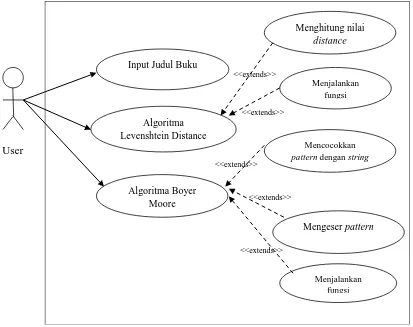
Use case merupakan fungsionalitas dari suatu sistem, sehingga customer atau pengguna
sistem paham dan mengerti mengenai kegunaan sistem yang akan dibangun. Use case berperan menggambarkan interaksi antar komponen-komponen yang berperan dalam sistem yang akan dirancang.
Gambar 3.2 Use Case Diagram Sistem
di dalam use case diagram dapat digambarkan bahwa terdapat 2 orang aktor yang akan
berperan, yaitu user dan admin. Untuk memperoleh informasi mengenai buku yang dicari
maka aktor user harus memasukkan input berupa judul buku ke dalam search box.
Selanjutnya jika pencarian yang dilakukan berhasil maka sistem akan menampilkan sebuah
halaman yang berisi kumpulan dari buku-buku yang berkaitan dengan judul buku yang
diinputkan, kemudian user harus mengklik salah satu dari judul buku yang ditampilkan untuk
dapat melihat informasi buku secara lengkap.
Selanjutnya untuk bagian admin yaitu terlebih dahulu melakukan login, dengan menginputkan
username dan password, jika username dan password berhasil divalidasi, maka selanjutnya
admin akan masuk ke halaman beranda. Untuk melakukan pengelolahan admin dapat
melakukan penambahan, pengeditan dan penghapusan buku.
Tabel 3.1. Tabel Use Case Proses Pencarian Judul buku
Name Proses Pencarian Judul Buku pada katalog perpustakaan Daerah Aceh Timur
Actors User yang telah ditentukan.
Description Use Case ini mendeskripsikan Pencarian Judul buku
dengan menggunakan fitur autocomplete dan
autocorrect dengan menggunakan algortima
Levenshtein Distance dan algoritma Boyer Moore
Basic Flow User memasukkan inputan karakter berupa judul Buku
yang ingin dicari pada katalog perpustakaan.
Alternate Flow
User dipermudah dengan fitur autocomplete dan autocorrect.
User mendapatkan pencarian judul buku yang ingin
dicari jika tersedia di dalam database.
3.3.2. Activity Diagram
Activity diagram menggambarkan berbagai alir aktivitas dalam sistem yang sedang dirancang
atau menggambarkan proses parallel yang mungkin terjadi dalam beberapa eksekusi. Gambar
3.3 merupakan activity diagram dari sistem yang dibangun.
Pencarian Judul buku Input judul
buku
Info buku
Menampilkan halaman awal
Menampilkan judul buku Mulai
Judul buku tidak ditemukan
User
=Autocomplete
=Autocorrect =Boyer Moore
=Levenshtein Distance
Menampilkan info buku
Sistem
Gambar 3.3 Activity Diagram Sistem
Tabel 3.2 Keterangan Bagian-Bagian Rancangan Halaman Utama
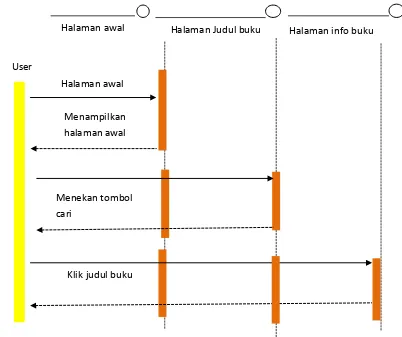
3.3.3. Sequence Diagram
Sequence diagram merupakan diagram yang menggambarkan interaksi antar objek dan
menjelaskan bagaimana suatu operasi dilakukan.Diagram ini juga menunjukkan serangkaian
pesan yang dipertukarkan oleh objek. Dalam sistem yang akan dibangun, interaksi dilakukan
antara pengguna dan sistem. Sequence diagram sistem dapat dilihat pada Gambar 3.4. Name Activity Diagram Activity diagram Sistem
Actors User
Deskripsi Activity ini mendeskripsikan proses Sistem pada Aplikasi
Pencarian Judul buku pada fitur autocomplete dan
autocorrect
Prakondisi Sudah Masuk ke tampilan utama
Bidang Khas Suatu
Kejadian
Kegiatan User Respon system
1. Menginputkan judul buku
yang ingin dicari
2. Menekan tombol cari
3. Memilih judul buku yang
ditampilkan
Pasca kondisi Menampilkan Judul buku
Gambar 3.4 Sequence Diagram Sistem
Dari keterangan diatas dapat digambarkan dengan sequence diagram mengenai informasi
sistem yang berjalan saat ini, sehingga dengan diagram ini dapat menggambarkan pergerakan
sebuah objek dan pesan yang terjadi di dalam sistem penyampaian informasi.
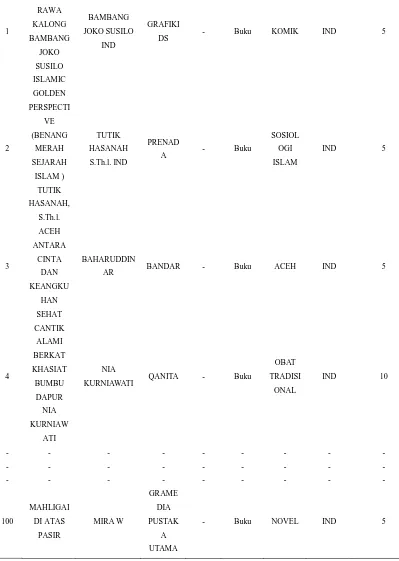
3.4 Analisis Data
Data yang digunakan pada sistem ini adalah data buku yang didapatkan dari Dinas
Perpustakaan dan Arsip Daerah Aceh Timur. Pada tabel 3.1 akan diberikan beberapa data
buku yang diperoleh dari Dinas Peepustakaan dan Arsip Daerah Kabupaten Aceh Timur
No. Judul Pengarang Penerbit Edisi Jenis Subjek Bahasa Jumlah Eksemplar
Halaman awal Halaman Judul buku
User
Halaman info buku
Menekan tombol cari
Halaman awal
Menampilkan halaman awal
Klik judul buku
1
Tabel 3.3 Sampel Data Buku
Dapat dilihat pada tabel 3.1 bahwa data buku yang berhasil dikumpulkan dari katalog Dinas
Perpustakaan dan Arsip Daerah Kabupaten Aceh Timur adalah sebanyak 100 data, data ini
diambil dan dikumpulkan pada tanggal 30 Maret 2015 sampai 03 April 2015
3.5 Perancangan sistem
3.5.1 Flowchart Sistem autocomplete
Adapun alur kerja yang terdapat pada autocomplete dapat dilihat pada gambar 3.5
tidak
ya
Gambar.3.5 Flowchart autocomplete dengan algoritma Boyer Moore Mengambil semua judul buku
pada database
Memodifikasi kata pada judul buku dengan operasi tambah/tukar/hapus
Hitung nilai jarak pada Boyer Moore
Mulai
Ketika ditemukan kata yang pas Input Judul buku
Membandingkan judul buku pada database dengan judul buku yang diinput pengguna
selesai
Menampilkan Autocomplete
3.5.2 Proses pencarian pada Boyer Moore untuk autocomplete
Algoritma Boyer Moore adalah salah satu algoritma pencarian string yang
dipublikasikan oleh Rober S. Boyer an J. Stroher Moore pada tahun 1977. Algoritma Boyer
Moore tidak seperti algoritma pencarian string lainnya, algoritma Boyer Moore mulai
mencocokkan karakter dari sebelah kanan pattern sehingga pencariannya lebih cepat.
Algoritma Boyer Moore dianggap sebagai pencocokan string yang paling efisien
dalam berbagai aplikasi. Algoritma ini sering diimplementasi dalam teks editor seperti
Microsoft Word untuk fungsi Font dan Replace. (Minandar 2009).
1. Sistematika Algoritma Boyer Moore
a. Algoritma Boyer Moore mulai mencocokkan pattern pada awal teks.
b. Dari kanan ke kiri, algoritma ini akan mencocokkan karakter per karakter
pattern dengan karakter di teks yang bersesuain sampai salah satu kondisi
berikut :
- Karakter di pattren dan di teks yang dibandingkan tidak cocok (missmatch)
- Semua karakter dipattern cocok, kemudian algoritma ini akan
memberitahukan penemuan di posisi ini.
c. Algoritma menggeser pattern dengan memaksimalkan nilai pergeseran
Occurrence Heuristic dan pergeseran Math Heuristic untuk melakukan
pergeseran seingga menemukan teks yang sama dengan pattern. R Wald,2012
Cara kerja Algoritma Boyer Moore :
e l e k T r o n I k
Gambar 5.2. Pencocokan 1
Gambar 3.6. Pencocokan 1 R o n I
Langkah ke -1
e l e k T r o n I k
Gambar 3.7. Pencocokan 2
Langkah ke 2
e l e k t r o n I k
Gambar 5.2.
Gambar 3.8. Pencocokan 3
Langkah ke-3
Dari gambar 5.2, dapat dilihat bahwa karakter terakhir dari kata kunci adalah huruf “i” yang
terakhir dari kata kunci adalah huruf “i” yang dicocokkan dengan huruf “k” pada kata
“elektronik”. Karena huruf “i” dan huruf “k” berbeda, maka akan dilakukan pencocokan
huruf “k” dengan seluruh karakter pada kata kunci. Karena huruf “k” tidak terdapat pada
seluruh karakter pada kata kunci, maka kata kunci bergeser ke kanan sebanyak empat
karakter sesuai dengan panjang karakter kata kunci seperti yang tampak pada gambar 5.3.
setelah dilakukan pergeseran maka dicocokkan kembali karakter terakhir pada kata kunci
yaitu huruf “i” dengan huruf “n” dicocokkan dengan keseluruhan karakter pada kata kunci.
Karena pada kata kunci. Karena pada kata kunci terdapat huruf “n”, maka kata kunci akan
bergeser sedemikian rupa sehingga huruf “n” pada kata kunci memiliki posisi yang sejajar
dengan posisi huruf “n” pada kata yang dicocokkan seperti yang ditujukan pada gambar 5.4.
Setelah itu dilakukan kembali pencocokan karakter terkhir kata kunci, yaitu huruf “i” yang
terletak sejajar dengan huruf “i” tersebut, karena karakter tersebut sama maka dicocokkan
kembali karakter yang berbeda dsebelah kiri huruf “i” sehingga kesluruhan karakter pada
kata kunci selesai diperiksa.
R o n i
r o n I
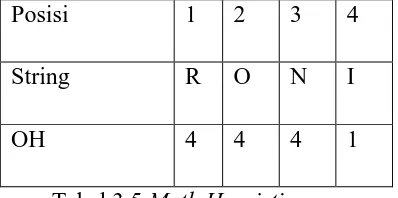
2. Cara menghitung Tabel Occurrence Heuristic
Posisi 1 2 3 4
String R O N I
OH 3 2 1 0
Tabel 3.4. Occurence Heuristic
1. Lakukan pencacahan mulai dari posisi terakhir string sampai ke posisi awal,
dimulai dengan nilai 0, catat karakter yang sudah ditemukan (dalam contoh ini
karakter “I”)
2. Mundur ke posisi sebelumnya, nilai pencacah ditambah 1, jika karakter pada
posisi ini belum pernah ditemukan, maka nilai pergeserannya adala sama dengan
nilai pencacah.(dalam contoh ini, karakter “N” belum pernah ditemukan sehingga
nilai pergeserannya adalah sebesar nilai pencacah yaitu 1).
3. Mundur ke posisi sebelumnya, karakter”O” nilai pergeserannya 2
4. Mundur lagi, karakter “R” nilai pergeserannya yaitu 3.
5. Begitu seterusnya sampai posisi awal string.
3. Cara menghitung tabel Math Heuristic
Posisi 1 2 3 4
String R O N I
OH 4 4 4 1
Tabel 3.5 Math Heuristic
Nilai MH didapat dari langkah-langkah sebagai berikut :
String R O N X A B C D
Pattern R O N I
R O N I
Gambar 3.9. Proses pencarian Math Heuristic 1
Untuk ketidakcocokan karakter pada posisi terakhir (posisi 4), karakter “I” maka nilai
pergesernnya selalu I
String R O X I A B C D
Pattern R O N I
R O N I
Gambar 3.10. Proses pencarian Math Heuristic 2
Jika karakter “I” sudah cocok, tetapi karakter pada posisi 3 (sebelum “I”) bukan “N” maka
geser sebanyak 4 posisi, sehingga posisi string melawati teks. Karena sudah pasti “ ROXI”
bukan “RONI”
String R X N I A B C D
Pattern R O N I
R O N I
Gambar 3.11. Proses pencarian Math Heuristic 3
Jika karakter “N” sudah cocok, tetapi karakter pada posisi 2 (sebelum “N”) bukan “O” maka
geser sebanyak 4 posisi, sehingga posisi string melewati teks. Karena sudah past “RXNI”
bukan “RONI”
String X O N I A B C D
Pattern R O N I
R O N I
Gambar 3.12. Proses pencarian Math Heuristic 4
Jika karakter “O” sudah cocok, tetapi karakter posisi 1 (sebelum”O”) bukan “R” maka geser
sebanyak 4 posisi, sehingga posisi string melewati teks. Karena sudah pasti “XONI” bukan
“RONI”. Dari proses diatas maka pergeseran Math Heuristic nya ditemukan R=4, O=4, I=1.
Hasil pencocokan :
String 1 2 3 4
Pattern R O N I
OH 3 2 1 0
MH 4 4 4 1
Tabel 3.6. Tabel nilai OH dan MH
3.5.3 Flowchart Sistem autocorrect
Adapun alur kerja yang terdapat pada autocorrect dapat dilihat pada gambar 3.13
tidak
ya
ya
Gambar 3.13 Flowchart autocorrect dengan menggunakan algoritma Levenshtein Distance Mengambil semua judul buku
pada database
Memodifikasi kata pada judul buku dengan operasi tambah/tukar/hapus
Hitung nilai jarak Levenstein Distance
Jika nilai Levenshein Distance = 0
Input Judul buku
Membandingkan judul buku pada database dengan judul buku yang diinput pengguna
selesai
Menampilkan Autocorrect Start
3.5.4 Proses pencarian jarak Levenshtein untuk autocorrect
Langkah-langkah yang terdapat pada flowchart sistem dapat menjelaskan bagaimana
alur kerja yang terdapat di dalam sistem , proses kerja algoritma Levenshtein Distance untuk
mendapatkan nilai jarak Levenshtein yang akan menghasilkan autocorrect, yaitu :
1. Memberikan input berupa judul buku pada kotak pencarian.
2. Selanjutnya judul buku yang akan diinputkan akan dibandungkan dengan semua
judu buku yang terdapat di database
3. Kemudian akan dilakukan modifikasi kata pada judul buku dengan menggunakan
operasi sisip, tukar dan hapus, hal ini dilakukan jika kata yang dicocokkan berbeda
4. Setelah modifikasi dilakukan selanjutnya yaitu menghitung nilai Levenshtein
Distance, nilai Levenshtein Distance di peroleh dari hasil modifikasi.
5. Jika nilai jarak Levenshtein Distance sama dengan 0 maka judul buku yang
diinputkan dengan judul buku yang terdapat pada database dianggap sama persis
sehingga proses perulangan itu dihentikan karena dianggap sudah cocok, dan jika
tidak maka perulangan akan terus berlanjut.
6. Kemudian judul buku yang dianggap sudah cocok atau mendekati maka akan
ditampilkan sebagai autocorrect.
Algoritma Levenshtein Distance akan menampilkan layanan autocorrect dengan
melakukan perbandingan berdasarkan judul buku yang diinputkan dengan judul buku yang
terdapat di dalam database. Ketika judul buku diketikkan, sistem akan melakukan modifikasi
terhadap judul buku yang terdapat di dalam database. Modifikasi tersebut meliputi proses
penyisipan, penukaran dan penghapusan, jika proses modifikasi telah dilakukan selanjutnya
akan dilakukan perhitungan nilai jarak Levenshtein.
Penentuan jarak Levenshtein didasarkan kepada nilai yang paling terkecil atau paling
sedikit jumlah modifikasinya, sehingga string atau kata yang memiliki nilai modifikasi yang
paling sedikit saat dibandingkan dengan string atau kata lain dianggap sebagai kata yang
cocok atau paling mendekati.
Berikut adalah langkah-langkah proses pencarian jarak Levenshtein dengan kata depan
dari judul buku yaitu:
1. Membandingkan string
String yang akan dibandingkan yaitu judul buku yang diinput sebagai string target dan
judul buku yang terdapat di dalam database sebagai string sumber.
Misalkan :
String Target : algoritma
String Sumber : algoritma pencarian, pemrograman basic, kecerdasan buatan.
Misalkan string target atau judul buku yang diinputkan adalah “algoritma” sedangkan
string sumber atau judul buku yang terdapat di dalam database misalnya adalah “algoritma
pencarian”,”pemrograman c++”,“kecerdasan buatan”. Judul buku yang terdapat di dalam
database akan diubah menjadi string target atau judul buku yang diinputkan.
2. Melakukan modifikasi dan perhitungan jarak Levenshtein
Operasi Levenshtein Distance terdiri dari 3 yaitu, operasi penyisipan, operasi penukaran
dan operasi penghapusan. Sehingga proses modifikasi yang dapat dilakukan yaitu :
a. Target = algoritma
Sumber = Algoritma pencarian
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Target = A l g o r i t m a - - - - - - - - - -
Sumber = A l g o r i t m a - P e n c a r i a n
a
Pada proses modifikasi dapat dilihat terdapat 10 operasi penghapusan, yang dimulai dengan
menghapus spasi pada indeks ke-10, kemudian menghapus karakter ‘p’ pada indeks ke-11, ‘e’
pada indeks ke-12,’n’ pada indeks 13, ‘c’ pada indeks ke-14, ‘a’ pada indeks ke-15, ‘r’ pada
indeks ke-16, ‘i’ ke-17 ,‘a’ pada indeks ke-18, dan ‘n’ pada indeks ke 19. Kemudian
melakukan di dalam 1 operasi penukaran yaitu menukar karakter ‘A’ menjadi ‘a’ pada posisi
indeks ke-1, sedangkan operasi penyisipan tidak perlu dilakukan. Selanjutnya melakukan
perhitungan jarak levenshtein dengan rumus yaitu:
= d( s1, t1 ) + d( s2, t2 ) + d( s3, t3 ) + d( s4, t4 ) + d( s5, t5 ) +
d( s6, t6 ) + d( s7, t7 ) + d( s8, t8 ) + d( s9, t9 ) + d( s10, t10 ) +
d( s11, t11 )+ d( s12, t12 )+ d( s13, t13 )+ d( s14, t14 )+
d( s15, t15 )+ d( s16, t16 )+ d( s17, t17 ) + d( s18, t18 )+( s19, t19)
= d( A, a ) + d( l, l) + d( g, g ) + d( o, o ) + d( r, r ) +
d( i, i) + d( t, t) + d( m, m) + d( a, a ) + d( -, - ) +
d( p, - )+ d (e,-) +d (n,-) + d (c,-) + d (a,-) + d(r,-) +
d (i,-) + d (a,-)+ d (n,-)
= 1 + 0 + 0 + 0 + 0 + 0 + 0 + 0 + 0 + 1 + 1 + 1 + 1 + 1 + 1 +
1 + 1 + 1+1
= 11
Dari perhitungan yang dilakukan diperoleh nilai modifikasi atau jarak Levenshtein yang
diperoleh adalah 11.
b. Target = algoritma
Sumber = Pemrograman basic
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Target = a l g o r i t m a - - - - - - - -
Sumber = P e m r o g r a m a n - B a s i c
a l g o r i t m a