PENGEMBANGAN MODEL MARKOV TERSEMBUNYI
UNTUK IDENTIFIKASI PEMBICARA
Oleh :
WINI PURNAMASARI
G64102051
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENGEMBANGAN MODEL MARKOV TERSEMBUNYI
UNTUK IDENTIFIKASI PEMBICARA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
WINI PURNAMASARI
G64102051
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
WINI PURNAMASARI. Pengembangan Model Markov Tersembunyi untuk Identifikasi Pembicara. Dibimbing oleh AGUS BUONO dan SRI WAHJUNI.
Salah satu cabang dari SpeechProcessing adalah Identifikasi Pembicara yang merupakan suatu proses mengenali seseorang berdasarkan suaranya. Metode yang digunakan untuk Identifikasi Pembicara pada penelitian ini adalah Model Markov Tersembunyi dengan fungsi peluang Gaussian, dan untuk ekstraksi ciri sinyal suara digunakan fitur MFCC. Jenis Identifikasi Pembicara pada penelitian ini adalah Closed-Set Identification yang mana suara masukan yang akan dikenali merupakan bagian dari sekumpulan suara pembicara yang telah terdaftar atau diketahui dan kata yang dilatih maupun diujikan telah ditentukan.
Hasil penelitian ini berupa tingkat akurasi kebenaran dari data yang diujikan. Secara keseluruhan untuk pelatihan dengan 20 data menghasilkan tingkat akurasi 71,25%, untuk pelatihan dengan 30 data menghasilkan tingkat akurasi 77,92%, dan pelatihan dengan 40 data menghasilkan tingkat akurasi tertinggi yaitu sebesar 86,25%.
Judul
: Pengembangan Model Markov Tersembunyi
untuk Identifikasi Pembicara
Nama : Wini Purnamasari
NRP :
G64102051
Menyetujui:
Pembimbing I,
Ir. Agus Buono, M.Si, M.Kom
NIP 132045532
Pembimbing II,
Ir. Sri Wahjuni
NIP 132311920
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS
NIP 131473999
RIWAYAT HIDUP
Penulis dilahirkan di jakarta pada tanggal 8 September 1984 dari ayah Enjang Ali Nurdin dan ibu Yanah Rosbani. Penulis merupakan putri pertama dari empat bersaudara. Tahun 2002 penulis lulus dari SMU Negeri 1 Bogor dan pada tahun yang sama lulus seleksi masuk IPB melalui jalur SPMB. Penulis memilih Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur Penulis panjatkan kepada Allah SWT atas
segala curahan rahmat dan karunia-Nya sehingga skripsi dengan judul Pengembangan Model Markov Tersembunyi untuk Identifikasi Pembicara, dapat diselesaikan.
Penulis juga mengucapkan terima kasih kepada Mamah Yanah Rosbani atas do’a, cinta kasih, dan ajarannya tentang kesabaran dan keikhlasan. Terima kasih juga Penulis ucapkan kepada Bapak Enjang Ali Nurdin yang senantiasa memberi dukungan dan pengabdian yang tulus kepada keluarga. Selanjutnya Penulis juga ingin mengucapkan terima kasih kepada:
1. Bapak Ir. Agus Buono, M.Si., M.Kom. selaku pembimbing I, Ibu Ir. Sri Wahjuni selaku pembimbing II dan Bapak Aziz Kustiyo, S.Si selaku dosen penguji.
2. Adik-adikku Dini Cahya, Widia Adistani, dan Adella Aini, terimakasih untuk keceriaan dan semangat yang membuat hari-hari penulis jauh dari bosan.
3. Mulan, Nana, dan Puspa yang telah bersedia menjadi pembahas.
4. Sahabat-sahabatku Anggy, Dian, Mulan, Puspa untuk kenangan yang indah dan susah senang bersamanya.
5. Ichoy sebagai teman curhat Korea yang baik, terimakasih atas obrolan-obrolan kita yang seringkali sangat “bermutu” tapi menghibur hati dan juga Mutia terimakasih atas kebaikan hati dan perhatiannya selama kita berkuliah di IPB ini.
6. Nafi dan Nana serta Alfath terimakasih karena mau meminjamkan komputernya.
7. Mang Nanang dan Bi Ningsih serta keluarga juga Mas Min dan Mba Ratmi serta keluarga yang telah banyak membantu.
8. Mba Yani, Ka Lisa dan Edu yang telah bersedia membantu dalam penelitian ini.
9. Erna, Tika, Heni, Ratna, Ichoy, Puspa, Sophia, Ratih karena telah bersedia menampung penulis dikostannya.
10. Alfath, Zaki, Mulan, dan Anggy yang telah bersedia menyumbangkan suara.
11. Mas Irfan, Pak Soleh, Pak Fendi, Pak Yadi serta seluruh staf Departemen Ilmu Komputer. 12. Ilkomerz 39, terimakasih atas segala hal yang telah kita lalui bersama, jalan-jalan, beragam
konflik, futsal, makan-makan, gosip-gosip, pokoknya semuanya baik yang senang ataupun mem-BTkan, karena pada akhirnya semua hal itulah yang membuat kehidupan kita lebih berwarna dan bergairah serta akan menjadi kenangan yang semoga membuat kita tersenyum bila mengingatnya dihari tua nanti.Amiin.
Kepada semua pihak lainnya yang telah memberikan kontribusi yang besar selama pengerjaan penelitian ini yang tidak dapat disebutkan satu-persatu, Penulis ucapkan terimakasih banyak.
Semoga penelitian ini dapat memberi manfaat.
Bogor, September 2006
DAFTAR ISI
Halaman
DAFTAR TABEL··· vi
DAFTAR GAMBAR ··· vi
DAFTAR LAMPIRAN··· vi
PENDAHULUAN ··· 1
Latar Belakang ··· 1
Tujuan ··· 1
Ruang Lingkup··· 1
Manfaat ··· 1
TINJAUAN PUSTAKA··· 1
Digitalisasi Gelombang Suara··· 1
Ekstraksi Sinyal Suara ··· 2
MFCC (Mel-Frequency Cepstrum Coefficients) ··· 2
Hidden Markov Model··· 3
Jenis Pengenalan Pembicara ··· 4
METODE PENELITIAN··· 5
Data··· 5
Analisis Fitur Suara ··· 6
Pelatihan HMM ··· 6
Pengujian··· 6
Lingkungan Pengembangan··· 6
HASIL DAN PEMBAHASAN ··· 6
Hasil Identifikasi Pada Pelatihan dengan 20 Data ··· 7
Hasil Identifikasi Pada Pelatihan dengan 30 Data ··· 7
Hasil Identifikasi Pada Pelatihan dengan 40 Data ··· 8
Perbandingan Tingkat Akurasi Setiap Pembicara ··· 9
Perbandingan Kesalahan Identifikasi pada Masing-masing Pembicara ··· 9
Perbandingan Tingkat Akurasi Berdasarkan Tipe Data Uji··· 10
Perbandingan Tingkat Akurasi Berdasarkan Jumlah Data Pelatihan ··· 10
KESIMPULAN DAN SARAN ··· 10
Kesimpulan ··· 10
Saran ··· 11
DAFTAR TABEL
Halaman
Hasil Identifikasi pada Pelatihan dengan 20 Data··· 7
Total Tingkat Akurasi Identifikasi pada Pelatihan Dengan 20 Data··· 7
Hasil Identifikasi pada Pelatihan dengan 30 Data··· 8
Total Tingkat Akurasi Identifikasi pada Pelatihan dengan 30 Data··· 8
Hasil Identifikasi pada Pelatihan dengan 40 Data··· 8
Total Tingkat Akurasi Identifikasi pada Pelatihan dengan 40 Data··· 9
DAFTAR GAMBAR
Halaman Diagram Blok dari Proses MFCC (Do 1994)··· 2Diagram Blok Proses Pelatihan ··· 5
Diagram Blok Proses Pengujian ··· 5
Grafik Tingkat Akurasi Identifikasi dengan 20 Data ··· 7
Grafik Tingkat Akurasi Identifikasi dengan 30 Data ··· 8
Grafik Tingkat Akurasi Identifikasi dengan 40 Data ··· 9
Grafik Perbandingan Tingkat Akurasi Setiap Pembicara ··· 9
Grafik Kesalahan Identifikasi pada Masing-Masing Pembicara··· 9
Grafik Perbandingan Tingkat Akurasi Identifikasi Berdasarkan Tipe Data Uji··· 10
Grafik Perbandingan Tingkat Akurasi Identifikasi Berdasarkan Jumlah Data Pelatihan ··· 10
DAFTAR LAMPIRAN
Halaman Algoritma Forward··· 13Algoritma Viterbi··· 13
Algoritma Segmental K-Means··· 14
Hasil Identifikasi pada Pelatihan dengan 20 Data (Pembicara Perempuan) ··· 15
Hasil Identifikasi pada Pelatihan dengan 20 Data (Pembicara Laki-Laki) ··· 16
Hasil Identifikasi pada Pelatihan dengan 30 Data (Pembicara Perempuan) ··· 17
Hasil Identifikasi pada Pelatihan dengan 30 Data (Pembicara Laki-Laki) ··· 18
Hasil Identifikasi pada Pelatihan dengan 40 Data (Pembicara Perempuan) ··· 19
1
PENDAHULUAN
Latar Belakang
Suara merupakan media yang sering digunakan manusia untuk berinteraksi dengan manusia lainnya. Dari berbagai penelitian yang telah dilakukan diketahui bahwa sinyal suara dapat juga digunakan untuk berinteraksi dengan komputer, sehingga interaksi tersebut dapat berjalan lebih alami.
Penelitian yang dilakukan dengan menggunakan data sinyal suara ini umumnya disebut dengan pemrosesan sinyal suara
(speech processing). Speech Processing
sendiri memiliki beberapa cabang kajian. Salah satu kajian dalam speech processing
adalah identifikasi pembicara. Identifikasi pembicara (speaker identification) adalah suatu proses mengenali seseorang berdasarkan suaranya (Campbell 1997).
Teknologi identifikasi pembicara telah digunakan untuk berbagai kepentingan, seperti layanan bank melalui telepon, belanja melalui telepon, layanan akses ke basis data, dan akses jarak jauh ke komputer. Berbagai metode yang dapat digunakan dalam penelitian mengenai identifikasi pembicara, antara lain
Dynamic Time Warping (DTW), Model
Markov Tersembunyi, Jaringan Syaraf Buatan, Vector Quantization (VQ).
Pada penelitian ini akan dilakukan identifikasi pembicara menggunakan Model Markov Tersembunyi atau biasa disebut
Hidden Markov Model (HMM). Hal itu
dikarenakan metode HMM telah terbukti memiliki tingkat ketepatan yang tinggi untuk identifikasi kata bahasa Indonesia (Mandasari 2005).
Tujuan
Penelitian ini bertujuan untuk mengembangkan Model Markov Tersembunyi dengan fungsi peluang Gaussian untuk identifikasi pembicara.
Ruang Lingkup
Ruang lingkup penelitian ini dibatasi pada: 1. Pembahasan difokuskan pada tahap
pemodelan pembicara dengan Model Markov Tersembunyi, tidak pada pemrosesan sinyal analog sebagai praproses sistem.
2. Ekstraksi ciri sinyal suara menggunakan
Mel-Frequency Cepstrum Coefficients
(MFCC).
3. Pendugaan terhadap parameter–parameter Model Markov Tersembunyi dibatasi pada
algoritma segmental K-means, sedangkan peluang munculnya barisan observasi dihitung dengan algoritma forward.
4. Uji kinerja model dilakukan dengan menghitung tingkat akurasi identifikasi.
Manfaat
Penelitian ini diharapkan dapat memberikan informasi mengenai tingkat akurasi Model Markov Tersembunyi untuk Identifikasi Pembicara.
TINJAUAN PUSTAKA
Digitalisasi Gelombang Suara
Bunyi atau suara adalah kompresi mekanikal atau gelombang longitudinal yang merambat melalui medium. Medium atau zat perantara ini dapat berupa zat cair, padat, gas. Manusia mendengar bunyi saat gelombang bunyi, yaitu getaran di udara atau medium lain, sampai ke gendang telinga manusia (id.wikipedia.org/wiki/Suara).
Gelombang suara merupakan gelombang analog, sehingga agar dapat diolah dengan peralatan elektronik, gelombang suara harus direpresentasikan dalam bentuk digital. Proses mengubah masukan suara dari gelombang analog menjadi representasi data digital disebut digitalisasi suara.
Proses digitalisasi suara terdiri dari dua tahap yaitu sampling dan kuantisasi (Jurafsky & Martin 2000). Sampling adalah proses pengambilan nilai setiap jangka waktu tertentu. Nilai ini menyatakan amplitudo (besar/kecilnya) volume suara pada saat itu. Hasilnya adalah sebuah vektor yang menyatakan nilai-nilai hasil sampling. Panjang vektor data ini tergantung pada panjang atau lamanya suara yang didigitalisasikan serta sampling rate yang digunakan pada proses digitalisasinya.
Sampling rate itu sendiri adalah banyaknya
nilai yang diambil setiap detik. Sampling rate
yang biasa digunakan adalah 8000 Hz dan 16000 Hz (Jurafsky & Martin 2000). Hubungan antara panjang vektor data yang dihasilkan dengan sampling rate dan panjangnya data suara yang didigitalisasikan dapat dinyatakan secara sederhana sebagai berikut:
S = Fs* T, dengan S = panjang vektor
Fs = sampling rate yang digunakan
(Hertz)
2 Setelah melalui tahap sampling, proses
digitalisasi suara selanjutnya adalah kuantisasi yaitu menyimpan nilai amplitudo ini ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky & Martin 2000).
Ekstraksi Ciri Sinyal Suara
Sinyal suara merupakan sinyal bervariasi yang diwaktukan dengan lambat atau biasa disebut quasi-stationary (Do 1994). Ketika diamati dalam jangka waktu yang sangat pendek (5 - 100 ms), karakteristiknya hampir sama. Namun, dalam jangka waktu yang panjang (0,2 detik atau lebih) karakteristik sinyal berubah dan merefleksikan perbedaan sinyal suara yang diucapkan. Oleh karena itu, digunakan spektrum waktu pendek (short-time
spectral analysis) untuk mengkarakterisasi
sinyal suara.
Beberapa fitur yang biasa digunakan antara lain Linear Predictive Coding,
Perceptual Linear Prediction, dan
Mel-Frequency Cepstrum Coefficients.
MFCC (Mel-Frequency Cepstrum
Coefficients)
MFCC didasarkan pada variasi yang telah diketahui dari jangkauan kritis telinga manusia dengan frekuensi. Filter dipisahkan secara linear pada frekuensi rendah dan logaritmik pada frekuensi tinggi. Hal ini telah dilakukan untuk menangkap karakteristik penting dari sinyal suara.
Tujuan utama MFCC adalah untuk meniru perilaku telinga manusia. Selain itu MFCC telah terbukti lebih bisa menyebutkan variasi dari pada gelombang suara itu sendiri.
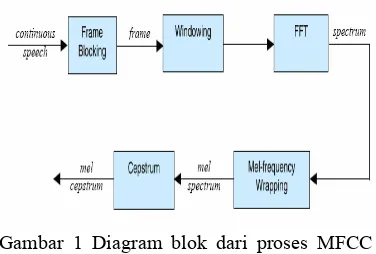
Gambar 1 Diagram blok dari proses MFCC (Do 1994)
Penjelasan tiap tahapan pada proses MFCC sebagai berikut (Do 1994):
1. Frame Blocking. Pada tahap ini sinyal
suara (continous speech) dibagi ke dalam
frame-frame. Tiap frame terdiri dari N
sample.
2. Windowing. Proses selanjutnya adalah
melakukan windowing pada tiap frame
untuk meminimalkan diskontinuitas sinyal pada awal dan akhir tiap frame. Konsepnya adalah meminimisasi distorsi spektral dengan menggunakan window
untuk memperkecil sinyal hingga mendekati nol pada awal dan akhir tiap
frame. Jika window didefinisikan sebagai
w(n), 0 ≤ n ≤ N-1, dengan N adalah
banyaknya sampel tiap frame, maka hasil dari windowing adalah sinyal dengan persamaan:
Yt(n)=x1(n)w(n), 0 ≤ n ≤ N-1
Pada umumnya, window yang digunakan adalah hamming window, dengan persamaan:
w(n)=0.54-0.46cos(2πn/N-1), 0 ≤ n ≤ N-1
3. Fast Fourier Transform (FFT). Tahap ini
mengkonversi tiap frame dengan N sampel dari time domain menjadi frequency
domain. FFT adalah suatu algoritma untuk
mengimplementasikan Discrete Fourier
Transform (DFT) yang didefinisikan pada
himpunan N sampel {xn} sebagai berikut:
∑−
= = −
−
= 1
0 , 0,1,2,..., 1 /
2
N
k n N
N jkn e k x n
X π
j digunakan untuk menotasikan unit imajiner, yaitu j = −1. Secara umum
Xn adalah bilangan kompleks. Barisan {Xn} yang dihasilkan diartikan sebagai berikut: frekuensi nol berkorespondensi dengan n = 0, frekuensi positif 0 < f <
Fs/2berkorespondensi dengan nilai 1 ≤ n ≤ N/2-1, sedangkan frekuensi negatif –Fs/2 <
f < 0 berkorespondensi dengan N/2+1 < n
< N-1. Dalam hal ini Fs adalah sampling
frequency. Hasil yang didapatkan dalam
tahap ini biasa disebut dengan spektrum sinyal atau periodogram.
4. Mel-frequency Wrapping. Studi psikofisik
menunjukkan bahwa persepsi manusia terhadap frekuensi sinyal suara tidak berupa skala linear. Oleh karena itu, untuk setiap nada dengan frekuensi aktual f
(dalam Hertz), tinggi subjektifnya diukur dengan skala ‘mel’. Skala mel-frequency
3 dapat digunakan untuk menghitung
mel-frequency untuk frekuensi f dalam Hz:
Mel(f) = 2595*log10(1+f/700)
5. Cepstrum. Langkah terakhir, konversikan
log mel spectrum ke domain waktu.
Hasilnya disebut mel frequency cepstrum
coefficients. Representasi cepstral
spektrum suara merupakan representasi properti spektral lokal yang baik dari suatu sinyal untuk analisis frame. Mel spectrum
coefficients (dan logaritmanya) berupa
bilangan riil, sehingga dapat dikonversikan ke domain waktu dengan menggunakan
Discrete Cosine Transform (DCT).
Hidden Markov Model
Hidden Markov Model (HMM), atau
Model Markov Tersembunyi, ialah suatu model peluang temporal yang menggambarkan keterkaitan antar peubah
state (state variable) dari waktu ke waktu,
serta antara peubah state dengan peubah teramati (observable variable). Secara visual, model ini dapat digambarkan menggunakan suatu finite state automata dengan banyaknya kemungkinan kombinasi nilai variabel dalam model. Dalam hal ini, setiap state merupakan suatu kombinasi variabel tersebut. Sebagai contoh, jika terdapat suatu model temporal dengan tiga variabel biner maka banyaknya
state adalah 23 = 8 buah. Di dalam HMM,
peubah state adalah peubah yang tak teramati
(hidden variable), dan peubah yang teramati
adalah observable variable.
Berikut adalah notasi yang digunakan dalam HMM (Dugad & Desai 1996):
N : Banyaknya hidden state (state ke 1, 2, 3, …, n), qt menotasikan state ke-q
pada indeks waktu t.
M : Banyaknya kemungkinan kemunculan peubah teramati, vk, untuk
k=1,2,3,…,M, adalah nilai-nilai peubah teramati.
Л : adalah {Лi}, dengan Лi=P(q1=i), yaitu
peluang pada tahap awal berada pada
state i. Dalam hal ini
∑
= = N i 1 1 1 πA : adalah {aij} dengan aij=P(qt+1=j|qt=i),
yaitu peluang berada di state j pada waktu t+1 jika pada waktu t berada di
state i. Dalam hal ini diasumsikan aij
bebas dari waktu.
B : adalah {bj(k)}, dengan bj(k)=P(vk pada
waktu t|qt=j), yaitu peluang peubah
teramatinya yang muncul adalah simbol vk.
Ot : adalah notasi untuk nilai teramati pada waktu t, sehingga barisan nilai teramati (observablesymbol) adalah O=O1, O2,
O3, …, OT. T adalah panjang observasi
yang dilakukan.
Dengan notasi-notasi seperti di atas, maka suatu HMM dilambangkan dengan:
= (A, B, Л)
Secara umum ada tiga masalah dasar yang terdapat dalam HMM (Dugad & Desai 1996), yaitu:
1. Masalah 1 (Evaluation): Untuk suatu = (A, B, Л) tertentu, ingin diketahui P(O| ), yaitu peluang munculnya barisan O=O1,O2,O3,…,OT.
Solusi:
Barisan O=O1,O2,O3,…,OT adalah nilai
teramati yang merupakan refleksi dari barisan hidden state Q = q1,q2,…,qT.
Untuk suatu barisan hidden state tertentu, Q = q1,q2,…,qT, nilai P(O| ) dapat dihitung
dengan rumus berikut:
) , | ( 1 ) , |
( λ P Ot qt λ
T t Q O P = ∏ =
Menggunakan asumsi kebebasan antar observasi, nilai tersebut dapat dirumuskan menjadi: ) ( )... 2 ( 2 ). 1 ( 1 ) , |
( OT
T q b O q b O q b Q O
P λ =
(1) Peluang kemunculan suatu barisan Q = q1,
q2, …, qT tertentu adalah:
T q T q a q q a q q a q q a q Q P 1 ... 4 3 3 2 2 1 1 ) | ( − =π λ (2) Distribusi bersama O dengan Q diperoleh dengan mengalikan (1) dengan (2).
) | ( ). , | ( ) , |
(O Q λ P O Qλ P Q λ
P =
(3) Oleh karena itu nilai P(O| ) diperoleh
4
∑ ∀ =
Q P O Q P Q O
P( | λ) ( | ,λ) ( | λ)
∑
∀ −
=
Qπq1bq1(O1)aq1q2bq2(O2)...aqT 1qTbqT(OT) (4) dengan Q = q1,q2,q3,…,qT
Terlihat orde perkalian tesebut adalah (2TNT). Sebagai contoh untuk N=5 dan T=100 saja, banyaknya operasi adalah sekitar 1072. Oleh karena itu diperlukan suatu metode yang efisien untuk masalah tersebut. Solusi permasalahan ini adalah dengan prosedur forward-backward. Kedua algoritma ini berjalan dengan orde O(N2T), yang jauh lebih cepat dibanding O(2TNT).
2. Masalah 2 (Decoding) : Untuk suatu =(A, B, Л) dan barisan observasi O=O1, O2, O3,
…, OT tertentu, bagaimana kita memilih
barisan dari state Q = q1, q2, …, qT yang
‘optimal’, yaitu yang paling besar kemungkinannya menghasilkan O.
Solusi:
Pada masalah 1, solusi yang diberikan bersifat pasti. Dilain pihak pada masalah 2, solusi tergantung dari kriteria optimum yang dipakai. Ada beberapa kriteria optimum yang dapat dilakukan, yaitu: a. Memaksimumkan banyaknya hidden
state yang sesuai.
Besaran untuk optimisasi ini adalah
γt(i)=P(qt=Si|O,λ) yang dirumuskan
sebagai:
∑ = =
= N
i t i t i i t i t O P i t i t i t
1 ( ) ( ) ) ( ) ( ) | ( ) ( ) ( ) ( β α β α λ β α γ
Oleh karena itu, hidden state yang paling mungkin untuk setiap periode t adalah:
Qt = arg max γt(i) untuk 1 ≤ t ≤ T
1≤i≤N
Kelemahan algoritma ini adalah tidak memperhatikan adanya transisi state
yang tidak mungkin, sehingga tidak menutup kemungkinan munculnya barisan state yang ‘janggal’.
b. Modifikasi kriteria poin a, yaitu dengan memaksimumkan banyaknya segmen
hidden state yang benar, yaitu dengan
dua (qt,qt+1) tiga (qt,qt+1,qt+2) atau lebih
segmen hidden state yang berurutan.
c. Menemukan satu barisan hidden state
(path) yang paling sesuai. Solusi dengan kriteria ini diperoleh dengan memaksimumkan peluang kemunculan barisan state, Q, untuk suatu O dan tertentu, P(Q,|O,λ), yang setara dengan memaksimumkan P(O,Q|λ). Pencarian
path ini dilakukan dengan konsep pemrograman dinamik (dynamic
programming) dan dikenal dengan
algoritma viterbi.
Pada penelitian ini akan digunakan solusi dengan menggunakan algoritma viterbi. 3. Masalah 3 (Learning) : Bagaimana kita
melakukan pendugaan terhadap parameter-parameter model HMM, =(A,B,Л), sehingga P(O|λ), atau P(O,Q|λ)
maksimum. Solusi :
Permasalahan ini berkaitan dengan pelatihan terhadap HMM dengan tujuan model mampu mengenali pola dengan karakteristik yang “mirip” dengan data yang dilatihkan. Secara umum ada dua algoritma pelatihan, yaitu:
a. Algoritma Segmental K-Means: Pada metode ini, parameter dari model HMM =(A,B,Л) disesuaikan untuk memaksimumkan P(O,Q|λ) dengan Q
adalah barisan state yang optimum hasil dari solusi masalah 2.
b. Formula Baum-Welch reestimation: Pada metode ini, parameter dari model HMM =(A,B,Л) disesuaikan untuk meningkatkan P(O|λ) hingga maksimum dicapai. Pada persamaan (1) terlihat bahwa penghitungan P(O|λ)
mencakup penjumlahan nilai peluang
P(O,Q|λ) untuk semua kemungkinan
barisan Q.
Jenis Pengenalan Pembicara
Menurut Campbell (1997), Pengenalan Pembicara berdasarkan jenis aplikasinya dibagi menjadi:
1. Identifikasi pembicara adalah proses mengenali seseorang berdasarkan suaranya. Identifikasi pembicara dibagi dua, yaitu:
• Identifikasi tertutup (closed-set
identification) yang mana suara
masukan yang akan dikenali merupakan bagian dari sekumpulan suara pembicara yang telah terdaftar atau diketahui.
• Identifikasi terbuka (open-set
5 tidak ada pada kumpulan suara
pembicara yang telah terdaftar.
2. Verifikasi pembicara adalah proses menerima atau menolak permintaan identitas dari seseorang berdasarkan suaranya.
Berdasarkan teks yang digunakan pengenalan pembicara dibagi menjadi dua (Campbell 1997):
1. Pengenalan pembicara bergantung teks yang mengharuskan pembicara untuk mengucapkan kata atau kalimat yang sama baik pada pelatihan maupun pengenalan. 2. Pengenalan pembicara bebas teks yang
tidak mengharuskan pembicara untuk mengucapkan kata atau kalimat yang sama baik pada pelatihan maupun pengenalan. Pada penelitian kali ini akan dilakukan penelitian identifikasi pembicara dengan jenis identifikasi tertutup dengan bergantung pada teks.
METODE PENELITIAN
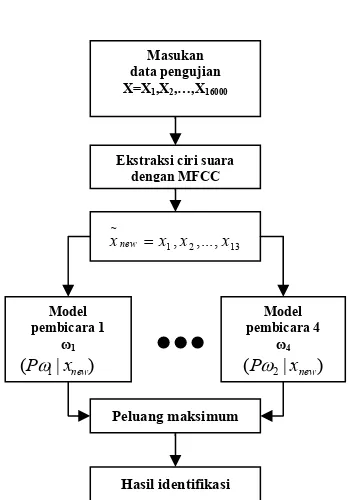
Proses identifikasi pembicara dengan menggunakan Model Markov Tersembunyi menggunakan fungsi Gaussian dalam penelitian ini dilakukan dalam 2 tahap, yaitu tahap pelatihan dan tahap pengujian. Langkah kedua tahap tersebut dapat dilihat pada Gambar 2 dan 3.
Gambar 2 Diagram blok proses pelatihan
Masukan data pengujian X=X1,X2,…,X16000
Ekstraksi ciri suara dengan MFCC
13 2 1 ~
,...,
,x x
x xnew=
Model pembicara 1
ω1
) | (Pω1 xnew
Model pembicara 4
ω4
) | (Pω2 xnew
Peluang maksimum
Hasil identifikasi
Gambar 3 Diagram blok proses pengujian
Data
Data yang digunakan pada penelitian ini adalah gelombang suara yang telah didijitasi dan direkam dari 4 pembicara, yaitu 2 pembicara laki-laki dan 2 pembicara perempuan dengan rentang usia 22-50 tahun dan masing-masing pembicara diambil suaranya dalam jangka waktu yang sama. Pembicara 1 dan 2 merupakan pembicara perempuan, sedangkan pembicara 3 dan 4 merupakan pembicara laki-laki. Data tersebut diambil menggunakan fungsi wavrecord pada Matlab, dan disimpan menjadi file berekstensi WAV. Setiap suara diambil dengan sampling
rate 16000 Hz dan direkam selama 1 detik,
sehingga masing-masing menghasilkan ukuran file 31,2 KB. Pemilihan sampling rate
16000 Hz didasarkan pada pengetahuan bahwa sampling rate di atas 10000 Hz dapat meminimalkan efek aliasing pada konversi dari analog menjadi dijital.
Masukan data pelatihan X=X1,X2,…,X16000
Ekstraksi ciri suara dengan MFCC
Pelatihan HMM dengan algoritma Segmental K-Means
13 2 1 ~
,...,
,x x
x x=
Model pembicara
ω
Jenis identifikasi pembicara yang dilakukan bersifat bergantung pada teks, maka kata yang diucapkan baik untuk pelatihan maupun pengujian telah ditentukan yaitu “komputer” dan diucapkan sebanyak 60 kali, sehingga terdapat 240 file data.
Penelitian ini akan menggunakan 6 kombinasi proporsi pembagian data pelatihan dan data yang diujikan. Kombinasi tersebut antara lain:
1. 20 data pelatihan dengan pengujian dilakukan pada:
• 20 data pelatihan.
6 2. 30 data pelatihan dengan pengujian
dilakukan pada:
• 30 data pelatihan.
• 30 data pengujian.
3. 40 data pelatihan dengan pengujian dilakukan pada:
• 40 data pelatihan.
• 20 data pengujian.
Analisis Fitur Suara
Analisis fitur suara pada penelitian ini menggunakan MFCC. Pada implementasi MFCC ini, kecuali tahap frame blocking, digunakan fungsi dari Auditory Toolbox yang dikembangkan oleh Slanley pada tahun 1998. Setiap data suara akan dibagi menjadi frame
berukuran masing-masing 30 ms. Dengan overlap 50% dan tanpa noise. Sehingga menghasilkan 66 frame.
Hasil dari analisis fitur suara MFCC ini adalah 13 koefisien mel cepstrum untuk masing-masing frame. Dengan demikian setiap data menjadi matriks 13 x 66. Hasil ini merupakan masukan untuk pelatihan HMM, yaitu berupa O=O1,O2,…,O66.
Pelatihan HMM
Pelatihan bertujuan untuk membangun HMM, = (A,B,Л) untuk setiap model pembicara. Faktor-faktor yang diperhatikan antara lain adalah pemilihan jenis HMM dan pendugaan parameter untuk tiap model (Rabiner 1989). Pada penelitian ini, jenis HMM yang digunakan adalah HMM
left-right. Hal itu dikarenakan jenis ini cocok
untuk memodelkan sinyal suara yang propertinya berubah terhadap waktu. Untuk menduga parameter-parameter HMM digunakan algoritma Segmental K-means
dengan jumlah state 6. Karena menurut Rabiner (1989), error minimum berada pada
state yang berjumlah6.
Input untuk membangun HMM adalah sinyal suara yang telah ditransformasi menjadi barisan vektor ciri, O, ke nilai peluang kemunculannya pada suatu barisan hidden
state tertentu, W, dan dinotasikan dengan
P(O|W). Peluang kemuculan setiap vektor ciri,
Ot, yang berkaitan dengan hidden state
tertentu, wt, adalah bwt(Ot).
Oleh karena itu yang akan dilakukan adalah menduga nilai bwt(Ot), yaitu peluang suatu vektor ciri pada waktu t sebagai representasi suara dari hidden state ke-j, dalam hal ini wt = j, yang dinotasikan sebagai
bj(Ot).
Dalam penelitian ini, bj(Ot) diduga dengan menggunakan asumsi kenormalan yang menggunakan fungsi peluang Gaussian untuk memetakan setiap vektor ciri ke hidden state
yang ada dengan peluang tertentu.
Melalui asumsi kenormalan, vektor ciri pada indeks t sebagai representasi hidden state j berdistribusi normal dengan vektor rataan j
dan matriks kovarian ∑j. Dengan asumsi ini,
maka nilai peluang tersebut dirumuskan sebagai: ∑ = − − − −
∑
) ( ) ( 2 1 2 / 1 2 / 1 )) (det( ) 2 ( 1 )( ot j jot j
j d
t
j o e
b μ μ
π
Nilai-nilai parameter dari distribusi normal untuk setiap hidden state diduga dengan menggunakan algoritma Segmental K-means.
Pengujian
Pengujian bertujuan untuk mengukur akurasi model dalam mengenali pembicara. Pengujian dilakukan secara manual dengan menghitung berapa banyak data yang diujikan dapat memberikan hasil yang tepat yaitu data yang diujikan berhasil dikenali dengan benar, misalnya data yang diujikan adalah data Pembicara 1 maka hasil yang tepat adalah dikenali sebagai Pembicara 1.
Masukan untuk menguji model adalah barisan vektor ciri sinyal suara dari seorang pembicara. Setiap model akan memberikan nilai peluang atas masukan yang diberikan. Pembicara diidentifikasi berdasarkan model yang memberikan nilai peluang tertinggi.
Hasil kinerja pengujian ini kemudian dihitung sebagai rasio antara jumlah data pembicara yang diidentifikasi secara benar dengan jumlah seluruh data pembicara yang diujikan.
Lingkungan Pengembangan
Perangkat keras yang digunakan adalah komputer personal dengan prosesor Pentium IV 2,4 GHz, RAM sebesar 128 Mb, serta kapasitas harddisk sebesar 40 Gb.
Sistem operasi yang digunakan adalah Windows XP Profesional. Perangkat lunak yang digunakan adalah Matlab 6.5 dan untuk MFCC digunakan beberapa fungsi dari Auditory Toolbox.
HASIL DAN PEMBAHASAN
Pada penelitian ini, matriks koragam yang digunakan pada algoritma Segmental
7 ini dilakukan dengan asumsi bahwa tidak ada
korelasi antar state.
Tingkat keberhasilan pada penelitian ini dilihat dari persentase keakuratan identifikasi pembicara, yang didapatkan dari rasio jumlah pembicara yang diidentifikasi benar dengan jumlah pembicara yang diujikan .
Hasil Identifikasi Pada Pelatihan dengan 20 Data
Tabel 1 Hasil identifikasi pada pelatihan dengan 20 data
Teridentifikasi Sebagai Pembicara
Pembi-cara ke- 1 (%) 2 (%) 3 (%) 4 (%)
1 100
2 20 80
3 5 40 55
Data Pe-
latih-an 4 5 5 90
1 100
2 60 40
3 5 37,5 57,5
Data Peng-uji-
an 4 5 95
Dari Tabel 1 dapat dilihat bahwa pembicara 1 pada data pelatihan mendapatkan tingkat akurasi yang baik yaitu 100%. Pembicara 2 mendapatkan tingkat akurasi yang lebih rendah yaitu sebesar 80%, dengan 20% sisa data yang diujikan teridentifikasi sebagai pembicara 1. Pembicara 3 mendapatkan tingkat akurasi yang cukup kecil, hanya sekitar 40% dengan 55% teridentifikasi sebagai pembicara 4 dan hanya sekitar 5% saja yang teridentifikasi sebagai pembicara 1. Di lain pihak pembicara 4 mendapatkan tingkat akurasi yang cukup baik yaitu sebesar 90% dengan masing-masing 5% teridentifikasi sebagai pembicara 1 dan pembicara 2.
Pada data pengujian, pembicara 1 masih menghasilkan tingkat akurasi yang terbaik yaitu 100%. Dengan demikian pembicara 2 mengalami penurunan tingkat akurasi yang cukup besar yaitu menjadi 40 % dengan 60 % sisanya teridentifikasi sebagai pembicara 1. Pembicara 3 juga mengalami penurunan tingkat akurasi namun tidak besar yaitu menjadi 37,5%, dengan 57,5% teridentifikasi sebagai pembicara 4 dan 5 % lainnya teridentifikasi sebagai pembicara 1. Sementara itu pembicara 4 mengalami peningkatan tingkat akurasi pada pengujian dengan data pengujian ini, walaupun tidak banyak yaitu menjadi 95% dengan 5% teridentifikasi sebagai pembicara 1.
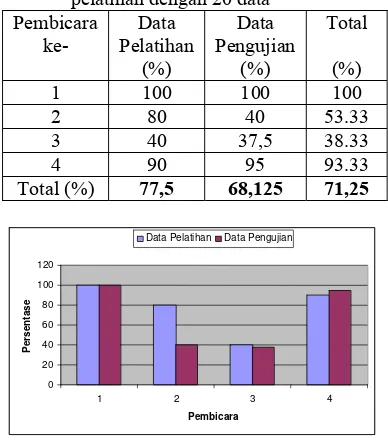
Tabel 2 Total tingkat akurasi identifikasi pada pelatihan dengan 20 data
Pembicara ke- Data Pelatihan (%) Data Pengujian (%) Total (%)
1 100 100 100
2 80 40 53.33
3 40 37,5 38.33
4 90 95 93.33
Total (%) 77,5 68,125 71,25
0 20 40 60 80 100 120
1 2 3 4
Pembicara
Per
sen
tas
e
Data Pelatihan Data Pengujian
Gambar 4 Grafik tingkat akurasi identifikasi dengan 20 data
Secara keseluruhan seperti terlihat pada Tabel 2 dan Gambar 4, pembicara 1 menghasilkan tingkat akurasi yang paling baik yaitu sebesar 100% dan pembicara 3 menghasilkan tingkat akurasi yang paling buruk yaitu 38,33%. Pembicara 2 menghasilkan tingkat akurasi 53,33% dan pembicara 4 menghasilkan tingkat akurasi yang cukup besar yaitu 93,33%. Hasil akurasi kecil yang didapatkan pembicara 2 dan pembicara 3 dikarenakan tingkat variasi berbicara pada kedua pembicara tersebut cukup besar.
Total tingkat akurasi identifikasi pembicara pada data pelatihan adalah 77,5% dan untuk total tingkat akurasi identifikasi pembicara pada data pengujian didapatkan lebih rendah yaitu sebesar 68,125%. Namun demikian untuk total tingkat akurasi identifikasi pembicara secara keseluruhan dengan data pelatihan sebanyak 20 adalah 71,25%
Hasil Identifikasi Pada Pelatihan dengan 30 Data
8 0 20 40 60 80 100 120
1 2 3 4
Pembicara
Per
sen
tas
e
Data Pelatihan Data Pengujian
Tabel 3 Hasil identifikasi pada pelatihan dengan 30 data
Teridentifikasi Sebagai Pembicara
Pembi-cara ke- 1 (%) 2 (%) 3 (%) 4 (%)
1 100
2 30 70
3 16,67 66,67 16,67
Data Pe-
latih-an 4 13,33 86,67
1 100
2 50 50
3 16,67 70 13,33
Data Peng-uji-
an 4 20 80
Seperti terlihat pada Tabel 3, pembicara 1 pada data pelatihan masih mendapatkan tingkat akurasi yang baik yaitu 100%. Pembicara 2 mendapatkan tingkat akurasi sebesar 70%, dengan 30% sisa data yang diujikan teridentifikasi sebagai pembicara 1. Pembicara 3 mendapatkan tingkat akurasi 66,67% dengan 16,67% teridentifikasi sebagai pembicara 4 dan hanya sekitar 16,7% lainnya teridentifikasi sebagai pembicara 1. Di lain pihak pembicara 4 mendapatkan tingkat akurasi sebesar 86,67% dengan 13,33% teridentifikasi sebagai pembicara 1.
Pada data pengujian, pembicara 1 tetap menghasilkan tingkat akurasi yang sangat baik yaitu 100%. Pembicara 2 juga mengalami penurunan tingkat akurasi menjadi 50% dengan 50% sisanya teridentifikasi sebagai pembicara 1. Di sisi lain pembicara 3 mengalami peningkatan tingkat akurasi menjadi sekitar 70%, dengan 16,67% teridentifikasi sebagai pembicara 1 dan 13,33% lainnya teridentifikasi sebagai pembicara 4. Pembicara 4 tingkat akurasinya turun menjadi 80% dengan 20% teridentifikasi sebagai pembicara 1.
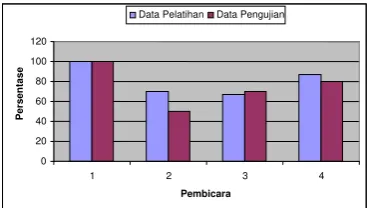
Tabel 4 Total tingkat akurasi identifikasi pada pelatihan dengan 30 data
Pembicara ke- Data Pelatihan (%) Data Pengujian (%) Total (%)
1 100 100 100
2 70 50 60
3 66,67 70 68,33
4 86,67 80 83,33
Total (%) 80,83 75 77,92
Gambar 5 Grafik tingkat akurasi identifikasi dengan 30 data
Secara keseluruhan pembicara 1 masih menghasilkan tingkat akurasi yang paling baik yaitu sebesar 100% dan pembicara 2 menghasilkan tingkat akurasi yang paling buruk yaitu 60%. Pembicara 3 menghasilkan tingkat akurasi 68,33% dan pembicara 4 menghasilkan tingkat akurasi sebesar 83,33%.
Total tingkat akurasi identifikasi pembicara pada data pelatihan adalah 80,83% dan untuk total tingkat akurasi identifikasi pembicara pada data pengujian adalah 75%. Di lain pihak untuk total tingkat akurasi identifikasi pembicara secara keseluruhan dengan data pelatihan sebanyak 30 adalah 77,92%.
Hasil Identifikasi Pada Pelatihan dengan 40 Data
Dari hasil percobaan dengan data pelatihan sebanyak 40 untuk masing-masing pembicara didapatkan hasil sebagaimana terlihat pada Tabel 5.
Tabel 5 Hasil identifikasi pada pelatihan dengan 40 data
Teridentifikasi Sebagai Pembicara
Pembi-cara ke- 1 (%) 2 (%) 3 (%) 4 (%) 1 100
2 20 80
3 5 80 15
Data Pe-
latih-an 4 15 85
1 100
2 35 65
3 10 90
Data Peng-uji-
an 4 10 90
9 tingkat akurasi 80% dengan 15%
teridentifikasi sebagai pembicara 4. Di sisi lain pembicara 4 mendapatkan tingkat akurasi sebesar 85% dengan 15% teridentifikasi sebagai pembicara 1.
Pada data pengujian, pembicara 1 tetap menghasilkan tingkat akurasi yang sangat baik yaitu 100%. Pembicara 2 mengalami penurunan tingkat akurasi menjadi 65% dengan 35% sisanya teridentifikasi sebagai pembicara 1. Namun demikian pembicara 3 kembali mengalami peningkatan tingkat akurasi menjadi sekitar 90%, dengan 10% teridentifikasi sebagai pembicara 1. Pembicara 4 tingkat akurasinya pun naik menjadi 90% dengan 10% teridentifikasi sebagai pembicara 1.
Tabel 6 Total tingkat akurasi identifikasi pada pelatihan dengan 40 data
Pembicara ke- Data Pelatihan (%) Data Pengujian (%) Total (%)
1 100 100 100
2 80 65 75
3 80 90 83,33
4 85 90 86,67
Total (%) 86,25 86,25 86,25
Gambar 6 Grafik tingkat akurasi identifikasi dengan 40 data
Secara keseluruhan pembicara 1 menghasilkan tingkat akurasi yang paling baik yaitu sebesar 100% dan pembicara 2 kembali menghasilkan tingkat akurasi yang paling buruk yaitu 75%. Pembicara 3 memiliki tingkat akurasi sebesar 83,33% dan pembicara 4 memiliki tingkat akurasi sebesar 86,67%.
Total tingkat akurasi identifikasi pembicara pada data pelatihan adalah 86,25 % dan untuk total tingkat akurasi identifikasi pembicara pada data pengujian adalah 86,25%. Di lain pihak untuk total tingkat akurasi identifikasi pembicara secara keseluruhan dengan data pelatihan sebanyak 40 adalah 86,25%.
Perbandingan Tingkat Akurasi Setiap Pembicara
Perbandingan tingkat akurasi setiap pembicara pada masing-masing jumlah data pelatihan dapat dilihat pada Gambar 7.
0 20 40 60 80 100 120
20 30 40
Jumlah data pelatihan
P er s en ta se
Pembicara 1 Pembicara 2 Pembicara 3 Pembicara 4
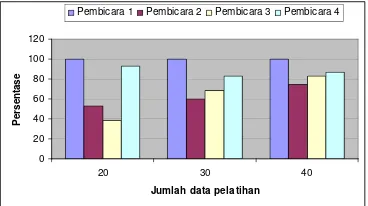
Gambar 7 Grafik perbandingan tingkat akurasi setiap pembicara
Seperti terlihat pada Gambar 7, pembicara 1 selalu menempati tingkat akurasi identifikasi yang tertinggi baik pada pelatihan dengan 20 data, 30 data maupun 40 data dengan nilai 100%. Pembicara 3 memiliki tingkat akurasi terkecil pada pelatihan dengan 20 data, nilai yang dihasilkan hanya sekitar 38,33%. Namun demikian pada pelatihan dengan 30 data dan 40 data, pembicara 2 memiliki tingkat akurasi yang terkecil masing-masing dengan nilai 60% dan 75%.
Terlihat juga pada Gambar 7 bahwa pembicara 2 dan 3 selalu mendapat tingkat akurasi yang lebih rendah dari pembicara 1 dan 4. Seperti telah disebutkan sebelumnya, hal ini dikarenakan tingkat variasi berbicara kedua pembicara tersebut lebih besar dari pada pembicara 1 dan 4.
Perbandingan Kesalahan Identifikasi pada Masing-masing Pembicara
Perbandingan kesalahan identifikasi yang terjadi pada penelitian ini untuk masing-masing pembicara dapat dilihat pada Gambar 8. 0 2 4 6 8 10
1 2 3 4
Salah Teridentifikasi Sebagai Pembicara
P er s en ta se
Pembicara 1 Pembicara 2 Pembicara 3 Pembicara 4
Gambar 8 Grafik kesalahan identifikasi pada masing-masing pembicara
Terlihat pada Gambar 8, untuk pembicara 2 seluruh kesalahan merupakan salah
0 20 40 60 80 100 120
1 2 3 4
Pembicara
Per
sen
tas
e
10
0 20 40 60 80 100
Data Pengujian
Diujikan Pada
Per
sen
tas
e
Pelatihan 20 Data Pelatihan 30 Data Pelatihan 40 Data
Data Pelatihan
identifikasi sebagai pembicara 1, dimana pembicara 1 dan 2 merupakan perempuan. Di lain pihak kesalahan identifikasi pembicara 3 yang merupakan laki-laki sebagian besar merupakan kesalahan identifikasi sebagai pembicara 4 yang juga laki-laki.
Secara keseluruhan, kesalahan identifikasi sebagian besar memang merupakan salah identifikasi sebagai pembicara 1 dan 4 dan seperti telah diketahui dari pembahasan sebelumnya, pembicara 1 dan 4 memiliki tingkat akurasi yang tinggi.
Tingkat akurasi yang tinggi dari pembicara 1 dan 4 dikarenakan variasi gaya berbicara kedua pembicara tersebut yang tidak terlalu besar pada saat perekaman data.
Perbandingan Tingkat Akurasi Berdasarkan Tipe Data Uji
Perbandingan tingkat akurasi berdasarkan tipe data yang diujikan dapat dilihat pada Gambar 9.
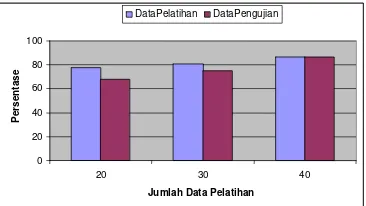
Gambar 9 Grafik perbandingan tingkat akurasi identifikasi berdasarkan tipe data uji
Dari Gambar 9 terlihat bahwa tingkat akurasi yang lebih tinggi didapatkan pada pelatihan dengan 20 data dan 30 data dengan data pelatihan. Di sisi lain pada pelatihan dengan 40 data, tingkat akurasi yang didapatkan sama baik pada data pelatihan maupun data pengujian.
Perbandingan Tingkat Akurasi Berdasarkan Jumlah Data Pelatihan
Perbandingan tingkat akurasi berdasarkan jumlah data pelatihan dapat dilihat pada Gambar 10.
Gambar 10 Grafik perbandingan tingkat
akurasi identifikasi berdasarkan jumlah data
pelatihan
Dari Gambar 9 dapat diketahui bahwa tingkat akurasi identifikasi dengan 20 data pelatihan memiliki nilai yang paling kecil baik pada data pelatihan maupun data pengujian. Tingkat akurasi yang terbesar baik yang di ujikan pada data pelatihan maupun data pengujian adalah pada pelatihan dengan 40 data. Terlihat pula bahwa tingkat akurasi bertambah seiring dengan bertambahnya jumlah data pelatihan.
0 20 40 60 80 100
20 30 40
Jumlah Data Pelatihan
Per
sen
tas
e
DataPelatihan DataPengujian
KESIMPULAN DAN SARAN
Kesimpulan
Dari penelitian yang telah dilakukan, maka dapat disimpulkan bahwa Model Markov Tersembunyi dapat digunakan untuk identifikasi pembicara.
Tingkat akurasi tertinggi yaitu 100% didapatkan pembicara 1 pada semua tipe data uji pada jumlah data pelatihan 20, 30, dan 40. Sementara itu tingkat akurasi terendah sebesar 37,5% didapatkan pembicara 3 di data pengujian pada jumlah data pelatihan 20.
Nilai tinggi yang didapatkan pembicara 1 dikarenakan pembicara 1 menghasilkan data dengan sedikit variasi gaya berbicara, sedangkan pembicara 3 menghasilkan data dengan variasi gaya berbicara yang banyak sehingga tingkat akurasi yang didapatkan rendah.
Dengan demikian variasi gaya berbicara berpengaruh pada hasil akurasi identifikasi dalam penelitian ini. Hal ini dapat dilihat pula pada pembicara 1 dan 4 yang selalu menghasilkan tingkat akurasi yang lebih tinggi dibandingkan pembicara 2 dan 3.
11 Slanley M. 1998. Auditory Toolbox. Interval
Research Corporation, Palo Alto. http://rv14.ecn.purdue.edu/~malcolm/inter val/1998-010/). [4 Juni 2006]
Pelatihan dengan jumlah data 20, total persentase tingkat akurasi yang dihasilkan adalah 71,25%. Pelatihan dengan jumlah data 30, total persentase yang dihasilkan meningkat menjadi 77.92%, dan pelatihan dengan jumlah data 40 menghasilkan total persentase tingkat akurasi dengan nilai tertinggi yaitu 86,25%.
Saran
Untuk penelitian selanjutnya, disarankan untuk meningkatkan tingkat akurasi dengan berbagai cara misalnya:
1. Pada tahap praproses, dilakukan segmentasi dan penggunaan variasi besar
frame dan overlap yang digunakan.
2. Pada tahap pelatihan digunakan jumlah
state yang beragam.
3. Perlu dikembangkan model classifier
yang mengakomodasi variability data.
DAFTAR PUSTAKA
Campbell,Jr JP. 1997. Speaker Recognition: A
Tutorial. Proceeding IEEE, Vol 85 No.9,
hal 1437-1461, September 1997.
Do MN. 1994. Digital Signal Processing Mini-Project: An Automatic Speaker
Recognition System. Audio Visual
Communications Laboratory, Swiss Federal Institute of Technology,
Laussanne, Switzerland. http://lcavwww.epfl.ch/~minhdo/asr_proje
ct.pdf [12 Juli 2006].
Dugad R, Desai UB. 1996. A Tutorial on
Hidden Markov Models. Technical Report,
Department of Electrical Engineering, Indian Institute of Technology-Bombay, India.
Jurafsky D, Martin JH. 2000. Speech and Language Processing An Introduction to Natural Language Processing, Computational Linguistic, and Speech
Recognition. New Jersey: Prentice Hall.
Mandasari Y. 2005. Pengembangan Model Markov Tersembunyi untuk Pengenalan
kata Berbahasa Indonesia [Skripsi].
Bogor: Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Rabiner LR. 1989. A Tutorial on Hidden Markov Models and Selected Applications
in Speech Recognition . Proceeding IEEE,
12
13 Lampiran 1 Algoritma Forward (Rabiner 1989)
Terdapat variabel αt(i) yang merupakan peluang barisan observasi O1, O2, O3, …, Ot dan state
Si pada waktu t, yang dikenal sebagai variabel forward , dan dirumuskan: ) | , ,..., , ( )
( 1 2 λ
αt i =PO O Ot qt =Si
1. Inisialisasi
), ( )
( 1
1 i πibi O
α = 1 ≤ i ≤ N
2. Induksi ), ( ) ( ) ( 1 1 1 + = + ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡
=
∑
N j ti
ij t
t j α i a b O
α 1 ≤ t ≤ T-1dan 1 ≤ i ≤ N
3. Terminasi
∑
= = N i T i O P 1 ) ( ) | ( λ αLampiran 2 Algoritma Viterbi (Rabiner 1989)
Terdapat variabel δT(i) yang merupakan skor terbaik (peluang tertinggi) yang dihitung pada
path dari state periode pertama hingga state Si pada periode t.
1. Inisialisasi
), ( )
( 1
1 i πibi O
δ = 1 ≤ i ≤ N 0
) (
1 i =
ψ 2. Rekursi
[
()]
( ), max ) ( 11 i N t ij j t
t j = ≤≤ δ − i a b O
δ 2 ≤ t ≤ T dan 1 ≤ i ≤ N
[
()]
, max arg ) ( 1 1 ij t N it j − i a
≤ ≤
= δ
ψ 2 ≤ t ≤ T dan 1 ≤ i ≤ N
3. Terminasi
[
()]
max 1 * i P T N i δ = = ≤ ≤[
()]
max arg 1 * i q T N i T δ ≤ ≤ = 4. Backtracking ), ( *! 1 * + += t t
T q
14 Lampiran 3 Algoritma Segmental K-Means (Dugad & Desai 1996)
Metode ini digunakan pada pelatihan dengan data pelatihan yang berupa barisan O sebanyak ω dengan masing-masing mempunyai panjang T, O=O1, O2, O3, …, OT.
1. Pilih N observasi secara acak dan kelompokkan semua observasi data pelatihan (ada ωT observasi) ke salah satu dari N observasi yang dipilih secara acak tersebut, dengan kriteria jarak euklid minimum. Dari sini terbentuk N klaster, yang masing-masing sebagai sebuah state. 2. Hitung nlai peluang awal dan peluang transisi:
untuk 1 ≤ i ≤ N :
) ( 1 kejadian total } 1 { kejadian banyaknya ˆ ω π O i O i ∈ =
untuk 1 ≤ i ≤ N dan 1 ≤ j ≤ N :
t i t O t j t O i t O ij a semua untuk } { kejadian banyaknya semua untuk } 1 , { kejadian banyaknya ˆ ∈ ∈ + ∈ =
3. Hitung vektor rataan dan matriks koragam untuk setiap 1 ≤ i ≤ N:
∑
∈ = i O t i i t O N 1 ˆ μ∑
∈ − − = i O i t T i t i i t O O NVˆ 1 ( μˆ) ( μˆ)
4. Hitung distribusi peluang observasi dari setiap data pelatihan untuk setiap state (dalam hal ini diasumsikan berdistribusi Normal), 1 ≤ i ≤ N:
[
T]
i t i i t i d t
i O V O
V O
b exp 1/2( ˆ )ˆ ( ˆ )
| ˆ | ) 2 ( 1 ) ( ˆ 1 2 / 1 2 / μ μ π − − − = −
5. Temukan barisan state (path) optimal, Q*, (dengan algoritma pada Lampiran 2), untuk setiap data pelatihan dari HMM yang dihitung dari tahap 2 sampai 4 di atas. Jika suatu observasi ke r, O
) ˆ , ˆ , ˆ ( ˆ i i B i A i π λ =
r, pada pelatihan ke k, diklasterkan ke state j, sedangkan hidden state ke
r pada barisan state optimal yang diperoleh dari pelatihan ke-k adalah state p (p≠j), maka Or
di-reassign ke state p dari state j.
15 Lampiran 4 Hasil Identifikasi Pada Pelatihan dengan 20 Data (Pembicara Perempuan)
Pembicara 1 Pembicara 2
Data Pelatihan Data Pengujian Data Pelatihan Data Pengujian Data
Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai 1 Pembicara 1 1 Pembicara 1 1 Pembicara 2 1 Pembicara 2 2 Pembicara 1 2 Pembicara 1 2 Pembicara 2 2 Pembicara 2 3 Pembicara 1 3 Pembicara 1 3 Pembicara 2 3 Pembicara 2 4 Pembicara 1 4 Pembicara 1 4 Pembicara 2 4 Pembicara 1 5 Pembicara 1 5 Pembicara 1 5 Pembicara 2 5 Pembicara 2 6 Pembicara 1 6 Pembicara 1 6 Pembicara 2 6 Pembicara 1 7 Pembicara 1 7 Pembicara 1 7 Pembicara 2 7 Pembicara 2 8 Pembicara 1 8 Pembicara 1 8 Pembicara 2 8 Pembicara 1 9 Pembicara 1 9 Pembicara 1 9 Pembicara 1 9 Pembicara 2 10 Pembicara 1 10 Pembicara 1 10 Pembicara 1 10 Pembicara 1 11 Pembicara 1 11 Pembicara 1 11 Pembicara 1 11 Pembicara 1 12 Pembicara 1 12 Pembicara 1 12 Pembicara 2 12 Pembicara 2 13 Pembicara 1 13 Pembicara 1 13 Pembicara 2 13 Pembicara 1 14 Pembicara 1 14 Pembicara 1 14 Pembicara 2 14 Pembicara 1 15 Pembicara 1 15 Pembicara 1 15 Pembicara 2 15 Pembicara 2 16 Pembicara 1 16 Pembicara 1 16 Pembicara 2 16 Pembicara 2 17 Pembicara 1 17 Pembicara 1 17 Pembicara 1 17 Pembicara 2 18 Pembicara 1 18 Pembicara 1 18 Pembicara 2 18 Pembicara 1 19 Pembicara 1 19 Pembicara 1 19 Pembicara 2 19 Pembicara 1 20 Pembicara 1 20 Pembicara 1 20 Pembicara 2 20 Pembicara 2
21 Pembicara 1 21 Pembicara 1
22 Pembicara 1 22 Pembicara 1
23 Pembicara 1 23 Pembicara 1
24 Pembicara 1 24 Pembicara 1
25 Pembicara 1 25 Pembicara 2
26 Pembicara 1 26 Pembicara 2
27 Pembicara 1 27 Pembicara 1
28 Pembicara 1 28 Pembicara 2
29 Pembicara 1 29 Pembicara 1
30 Pembicara 1 30 Pembicara 1
31 Pembicara 1 31 Pembicara 1
32 Pembicara 1 32 Pembicara 1
33 Pembicara 1 33 Pembicara 1
34 Pembicara 1 34 Pembicara 2
35 Pembicara 1 35 Pembicara 2
36 Pembicara 1 36 Pembicara 1
37 Pembicara 1 37 Pembicara 1
38 Pembicara 1 38 Pembicara 1
39 Pembicara 1 39 Pembicara 1
16 Lampiran 5 Hasil Identifikasi Pada Pelatihan dengan 20 Data (Pembicara Laki-Laki)
Pembicara 3 Pembicara 4
Data Pelatihan Data Pengujian Data Pelatihan Data Pengujian Data
Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai 1 Pembicara 4 1 Pembicara 4 1 Pembicara 1 1 Pembicara 4 2 Pembicara 1 2 Pembicara 4 2 Pembicara 4 2 Pembicara 4 3 Pembicara 4 3 Pembicara 4 3 Pembicara 4 3 Pembicara 4 4 Pembicara 4 4 Pembicara 4 4 Pembicara 4 4 Pembicara 4 5 Pembicara 3 5 Pembicara 3 5 Pembicara 4 5 Pembicara 4 6 Pembicara 3 6 Pembicara 4 6 Pembicara 4 6 Pembicara 4 7 Pembicara 3 7 Pembicara 4 7 Pembicara 4 7 Pembicara 4 8 Pembicara 4 8 Pembicara 3 8 Pembicara 4 8 Pembicara 4 9 Pembicara 4 9 Pembicara 3 9 Pembicara 4 9 Pembicara 4 10 Pembicara 4 10 Pembicara 3 10 Pembicara 4 10 Pembicara 1 11 Pembicara 4 11 Pembicara 4 11 Pembicara 4 11 Pembicara 4 12 Pembicara 4 12 Pembicara 4 12 Pembicara 4 12 Pembicara 4 13 Pembicara 4 13 Pembicara 4 13 Pembicara 4 13 Pembicara 1 14 Pembicara 4 14 Pembicara 4 14 Pembicara 2 14 Pembicara 4 15 Pembicara 4 15 Pembicara 4 15 Pembicara 4 15 Pembicara 4 16 Pembicara 3 16 Pembicara 4 16 Pembicara 4 16 Pembicara 4 17 Pembicara 3 17 Pembicara 4 17 Pembicara 4 17 Pembicara 4 18 Pembicara 3 18 Pembicara 4 18 Pembicara 4 18 Pembicara 4 19 Pembicara 3 19 Pembicara 4 19 Pembicara 4 19 Pembicara 4 20 Pembicara 3 20 Pembicara 4 20 Pembicara 4 20 Pembicara 4
21 Pembicara 1 21 Pembicara 4
22 Pembicara 4 22 Pembicara 4
23 Pembicara 3 23 Pembicara 4
24 Pembicara 1 24 Pembicara 4
25 Pembicara 3 25 Pembicara 4
26 Pembicara 4 26 Pembicara 4
27 Pembicara 4 27 Pembicara 4
28 Pembicara 4 28 Pembicara 4
29 Pembicara 3 29 Pembicara 4
30 Pembicara 4 30 Pembicara 4
31 Pembicara 4 31 Pembicara 4
32 Pembicara 4 32 Pembicara 4
33 Pembicara 3 33 Pembicara 4
34 Pembicara 3 34 Pembicara 4
35 Pembicara 3 35 Pembicara 4
36 Pembicara 3 36 Pembicara 4
37 Pembicara 3 37 Pembicara 4
38 Pembicara 3 38 Pembicara 4
39 Pembicara 3 39 Pembicara 4
17 Lampiran 6 Hasil Identifikasi Pada Pelatihan dengan 30 Data (Pembicara Perempuan)
Pembicara 1 Pembicara 2
Data Pelatihan Data Pengujian Data Pelatihan Data Pengujian Data
Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai
Data Ke-
18 Lampiran 7 Hasil Identifikasi Pada Pelatihan dengan 30 Data (Pembicara Laki-Laki)
Pembicara 3 Pembicara 4
Data Pelatihan Data Pengujian Data Pelatihan Data Pengujian Data
Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai
Data Ke-
19 Lampiran 8 Hasil Identifikasi Pada Pelatihan dengan 40 Data (Pembicara Perempuan)
Pembicara 1 Pembicara 2
Data Pelatihan Data Pengujian Data Pelatihan Data Pengujian Data
Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai
Data Ke-
Diidentifikasi Sebagai 1 Pembicara 1 1 Pembicara 1 1 Pembicara 2 1 Pembicara 2 2 Pembicara 1 2 Pembicara 1 2 Pembicara 2 2 Pembicara 1 3 Pembicara 1 3 Pembicara 1 3 Pembicara 1 3 Pembicara 2 4 Pembicara 1 4 Pembicara 1 4 Pembicara 2 4 Pembicara 1 5 Pembicara 1 5 Pembicara 1 5 Pembicara 1 5 Pembicara 2 6 Pembicara 1 6 Pembicara 1 6 Pembicara 2 6 Pembicara 1 7 Pembicara 1 7 Pembicara 1 7 Pembicara 2 7 Pembicara 2 8 Pembicara 1 8 Pembicara 1 8 Pembicara 2 8 Pembicara 2 9 Pembicara 1 9 Pembicara 1 9 Pembicara 1 9 Pembicara 1 10 Pembicara 1 10 Pembicara 1 10 Pembicara 1 10 Pembicara 2 11 Pembicara 1 11 Pembicara 1 11 Pembicara 1 11 Pembicara 1 12 Pembicara 1 12 Pembicara 1 12 Pembicara 2 12 Pembicara 2 13 Pembicara 1 13 Pembicara 1 13 Pembicara 2 13 Pembicara 2 14 Pembicara 1 14 Pembicara 1 14 Pembicara 2 14 Pembicara 2 15 Pembicara 1 15 Pembicara 1 15 Pembicara 2 15 Pembicara 2 16 Pembicara 1 16 Pembicara 1 16 Pembicara 2 16 Pembicara 2 17 Pembicara 1 17 Pembicara 1 17 Pembicara 1 17 Pembicara 2 18 Pembicara 1 18 Pembicara 1 18 Pembicara 2 18 Pembicara 2 19 Pembicara 1 19 Pembicara 1 19 Pembicara 2 19 Pembicara 1 20 Pembicara 1 20 Pembicara 1 20 Pembicara 2 20 Pembicara 1
21 Pembicara 1 21 Pembicara 2
22 Pembicara 1 22 Pembicara 1
23 Pembicara 1 23 Pembicara 2
24 Pembicara 1 24 Pembicara 2
25 Pembicara 1 25 Pembicara 2
26 Pembicara 1 26 Pembicara 2
27 Pembicara 1 27 Pembicara 2
28 Pembicara 1 28 Pembicara 2
29 Pembicara 1 29 Pembicara 2
30 Pembicara 1 30 Pembicara 2
31 Pembicara 1 31 Pembicara 2
32 Pembicara 1 32 Pembicara 2
33 Pembicara 1 33 Pembicara 1
34 Pembicara 1 34 Pembicara 2
35 Pembicara 1 35 Pembicara 2
36 Pembicara 1 36 Pembicara 2
37 Pembicara 1 37 Pembicara 2
38 Pembicara 1 38 Pembicara 2
39 Pembicara 1 39 Pembicara 2
20 Lampiran 9 Hasil Identifikasi Pada Pelatihan dengan 40 Data (Pembicara Laki-Laki)
Pembicara 3 Pembicara 4
Data Pelatihan Data Pengujian Data Pelatihan Data Pengujian 1 Pembicara 3 1 Pembicara 1 1 Pembicara 1 1 Pembicara 4 2 Pembicara 1 2 Pembicara 3 2 Pembicara 4 2 Pembicara 4 3 Pembicara 3 3 Pembicara 3 3 Pembicara 4 3 Pembicara 1 4 Pembicara 1 4 Pembicara 1 4 Pembicara 4 4 Pembicara 4 5 Pembicara 3 5 Pembicara 3 5 Pembicara 4 5 Pembicara 4 6 Pembicara 3 6 Pembicara 3 6 Pembicara 4 6 Pembicara 4 7 Pembicara 3 7 Pembicara 3 7 Pembicara 4 7 Pembicara 4 8 Pembicara 4 8 Pembicara 3 8 Pembicara 4 8 Pembicara 4 9 Pembicara 4 9 Pembicara 3 9 Pembicara 4 9 Pembicara 4 10 Pembicara 3 10 Pembicara 3 10 Pembicara 4 10 Pembicara 1 11 Pembicara 3 11 Pembicara 3 11 Pembicara 4 11 Pembicara 4 12 Pembicara 3 12 Pembicara 3 12 Pembicara 1 12 Pembicara 4 13 Pembicara 3 13 Pembicara 3 13 Pembicara 4 13 Pembicara 4 14 Pembicara 4 14 Pembicara 3 14 Pembicara 4 14 Pembicara 4 15 Pembicara 3 15 Pembicara 3 15 Pembicara 4 15 Pembicara 4 16 Pembicara 3 16 Pembicara 3 16 Pembicara 4 16 Pembicara 4 17 Pembicara 3 17 Pembicara 3 17 Pembicara 1 17 Pembicara 4 18 Pembicara 3 18 Pembicara 3 18 Pembicara 4 18 Pembicara 4 19 Pembicara 3 19 Pembicara 3 19 Pembicara 4 19 Pembicara 4 20 Pembicara 4 20 Pembicara 3 20 Pembicara 4 20 Pembicara 4
21 Pembicara 3 21 Pembicara 4
22 Pembicara 3 22 Pembicara 4
23 Pembicara 3 23 Pembicara 4
24 Pembicara 3 24 Pembicara 4
25 Pembicara 3 25 Pembicara 1
26 Pembicara 3 26 Pembicara 4
27 Pembicara 3 27 Pembicara 4
28 Pembicara 3 28 Pembicara 4
29 Pembicara 3 29 Pembicara 4
30 Pembicara 3 30 Pembicara 1
31 Pembicara 3 31 Pembicara 4
32 Pembicara 4 32 Pembicara 4
33 Pembicara 3 33 Pembicara 4
34 Pembicara 3 34 Pembicara 4
35 Pembicara 3 35 Pembicara 4
36 Pembicara 3 36 Pembicara 4
37 Pembicara 4 37 Pembicara 1
38 Pembicara 3 38 Pembicara 4
39 Pembicara 3 39 Pembicara 4