KLASIFIKASI DOKUMEN MENGGUNAKAN
ANDY PRAMURJADI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
KLASIFIKASI DOKUMEN MENGGUNAKAN
ANDY PRAMURJADI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
ANDY PRAMURJADI. Document Classification Using Background Smoothing. Supervised by JULIO ADISANTOSO.
Naïve Bayes Classifier (NBC) is one of the methods for text or document classification. A common problem that often occurs on NBC method is data sparsity, especially when the size of training data is too small. One way to handle the sparsity problem is to use background smoothing technique. The aims of this research are to look at the background smoothing effect on short and long query, and to compare it with NBC on small training data.
In this research, we use documents from the Agricultural Research Journal of horticultural domain. The results indicate that the accuracy of document classification on NBC+Background Smoothing is 92.3%, not significantly different from that obtained using only NBC. Improvement of the accuracy is only 1.78% from the results obtained on NBC. However, the results of the classification with NBC+Background Smoothing has been able to properly classify documents of Agriculture Research Journal at horticultural domain, so that it can be used to organize documents much easier for users to find information related to the documents.
Dosen Penguji:
Judul : Klasifikasi Dokumen Menggunakan Background Smoothing Nama : Andy Pramurjadi
NRP : G64076001
Menyetujui,
Pembimbing
Ir. Julio Adisantoso, M.Kom NIP. 19620714 198601 1 002
Mengetahui, Ketua Departemen
Dr. Ir. Sri Nurdiati, M.Sc NIP. 19601126 198601 2 001
PRAKATA
Alhamdulillahi Rabbil’alamin, puji syukur penulis panjatkan ke hadirat Allah SWT atas segala rahmat dan karuniaANya, sehingga tugas akhir ini dengan judul Klasifikasi Dokumen Menggunakan
Background Smoothing dapat diselesaikan. Penelitian ini dilaksanakan mulai November 2009 sampai dengan April 2010, bertempat di Departemen Ilmu Komputer.
Penulis berterima kasih kepada Bapak Ir. Julio Adisantoso, M.Kom selaku pembimbing yang telah banyak memberikan arahan, bimbingan, waktu, serta kesabarannya selama pengerjaan tugas akhir ini. Terima kasih yang setulusAtulusnya juga Penulis tujukan bagi istri dan anak tercinta yaitu Yurida Amdani Putri dan Salma Lathifah Pramdani, serta keluarga besar Penulis atas doa serta dukungan untuk keberhasilan Penulis.
Joko Purwanto, Ahmad Zafaroni, Decky Prayoga, Teguh, Dodot, Wanda, Arifa, Annissa, dan seluruh rekan ektensi S1 Ilkom Angkatan 2 atas dukungan, bantuan, serta kebersamaannya selama ini, semoga sukses selalu dan tetap semangat; juga untuk Pak Henky dan Arlan Hernawan staf Jasa Penelitian di Balai Penelitian Tanaman Hias yang telah membantu Penulis dalam mengumpulkan bahan dan data pendukung untuk tugas akhir ini.
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu selama penyelesaian tugas akhir ini yang tidak dapat disebutkan satuApersatu. Semoga karya ilmiah ini bermanfaat.
Bogor, Mei 2010
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 2 Oktober 1971, dari pasangan Bapak Prabowo dan Ibu Ellin. Penulis merupakan putra ketiga dari empat bersaudara. Pada Tahun 1991 penulis lulus dari SMAN 3 Bogor dan pada tahun yang sama, penulis melanjutkan pendidikan Diploma 3 di Program Studi Manajemen Keuangan dan Perbankan, STIE Perbanas Jakarta dan lulus pada tahun 1996.
Tahun 1997, penulis bekerja di BII Jakarta, setahun kemudian penulis pindah bekerja di Balai Penelitian Tanaman Buah, Solok, Sumatera Barat. Tahun 2000, penulis diangkat sebagai Pegawai Negeri Sipil golongan II/a dan dipindahtugaskan di Balai Penelitan Tanaman Hias, Pacet, Jawa Barat sampai dengan sekarang.
vi
DAFTAR ISI
Halaman
DAFTAR TABEL ……….. vii
DAFTAR GAMBAR ………. vii
DAFTAR LAMPIRAN ……….. vii
PENDAHULUAN ………. 1
Latar Belakang ………. 1
Tujuan ………... 1
Ruang Lingkup ………. 1
Manfaat Penelitian ……… 1
TINJAUAN PUSTAKA ……… 2
Sistem Temu Kembali Informasi ………. 2
Klasifikasi Dokumen ………... 2
Naïve Bayes Classifier (NBC)………... 3
Language Model dalam Temu Kembali Informasi …………...………... 3
Smoothing………. 4
Laplace Smoothing ….…………...………... 4
Background Smoothing …………...………... 4
Confusion Matrix …. ……….………………..……….………. 4
METODE PENELITIAN ………... 5
Gambaran Umum Sistem ………. 5
Koleksi Dokumen ………. 5
Praproses………... 5
Naïve Bayes dengan Background Smoothing ………..……… 6
Evaluasi Hasil Klasifikasi ………... 6
HASIL DAN PEMBAHASAN ……….. 6
Uji Coba Klasisfikasi Dokumen ………... 6
NBC+Background Smoothing………….. 7
NBC dan NBC+Background Smoothing ……..……… 8
KESIMPULAN DAN SARAN ……….. 10
Kesimpulan ……….. 10
Saran ………. 10
DAFTAR PUSTAKA ……… 11
vii
DAFTAR TABEL
Halaman
1 Micro Average untuk Short Query……….. 7
2 Confusion Matrix Short Query ………………..……… 7
3 Micro Average untuk Long Query……….. 8
4 Confusion Matrix Long Query ….………………. 8
5 Micro Average NBC dan NBC+Background Smoothingλ =0.3 ……….……….. 9
6 Confusion Matrix NBC dan NBC+Background Smoothing (Short Query)………. 9
7 Micro Average NBC dan NBC+Background Smoothingλ =0.7 ………... 9
8 Confusion matrix NBC dan NBC+Background Smoothing (Long Query) ………. 10
DAFTAR GAMBAR
Halaman 1 Proses Sistem Temu Kembali Informasi ……….………... 22 Proses Klasifikasi Dokumen ………... 3
3 Format Confusion Matrix ….……….. 4
4 Gambaran Umum Sistem ……… 5
5 Tingkat Akurasi Koefisien λ pada Short Query ……….……… 7
6 Tingkat Akurasi Koefisien λ pada Long Query ………..………... 8
7 Perbandingan Tingkat Akurasi pada Short Query ……….………….. 9
8 Perbandingan Tingkat Akurasi pada Long Query ……….……….……… ………. 10
DAFTAR LAMPIRAN
Halaman 1 Confusion Matrix untuk Semua Koefisien λ pada Short Query………..…………. 132 Hasil Pengukuran NBC+ Backgorund Smoothing pada Short Query……… 14
3 Confusion Matrix Semua Koefisien λ pada Long Query……… 15
4 Hasil Pengukuran NBC+ Backgorund Smoothing pada Long Query………...………… 16
5 Confusion Matrix NBC dan NBC+ Backgorund Smoothing ……… 17
1
PENDAHULUAN
Latar Belakang
Kemudahan dalam mengakses dan menyebarkan informasi saat ini menyebabkan informasi menjadi banyak dan beragam. Sejalan dengan hal tersebut, banyak orang cenderung lebih memilih informasi yang berguna secara selektif. Untuk itu diperlukan suatu metode dalam menyajikan dan mengorganisasikan informasi agar memudahkan pengguna dalam mencari informasi yang dibutuhkan.
Agar informasi lebih mudah untuk diorganisasikan dan dikelompokkan, dalam temu kembali informasi dapat dilakukan dengan klasifikasi dokumen berdasarkan kategori atau kelas yang telah ditentukan. Salah satu tujuan dari klasifikasi teks atau dokumen adalah proses menggolongkan atau mengelompokkan suatu dokumen ke dalam suatu kategori tertentu (Christopher et al. 2009).
Ada banyak algoritme yang digunakan untuk klasifikasi dokumen, di antaranya adalah
Naïve Bayes, k)Nearest Neighbor, Support Vector Machines, Decision Trees, dan Neural Network. Diantara algoritme klasifikasi tersebut, Naïve Bayes Classifier (NBC) atau sering juga disebut sebagai simple bayesian classification merupakan algoritme klasifikasi yang paling mudah untuk diimplementasikan. Masalah umum yang sering terjadi pada metode tersebut, yaitu adanya sparsity data terutama bila ukuran data latih (training) yang digunakan terlalu kecil. Hal ini biasanya terjadi ketika ada kataAkata atau terms yang ada pada dokumen uji tidak muncul pada dokumen latih, sehingga menggunakan metode smoothing untuk menghindarinya. Tujuan utama dari metode
smoothing adalah memberikan suatu nilai pada kata atau term yang tersembunyi (unseen) dan untuk menambah keakurasian dari penduga peluang kata yang ada pada dokumen latih.
Saat ini telah banyak metode smoothing
yang dihasilkan, di antaranya adalah Kneiser) Ney, Katz, Good)turing Estimation, Dirichlet Prior, Witten)Bell, Jelinek)Mercer (Chen & Goodman 1998) , dan Semantic Smoothing yang menggunakan pendekatan melalui language modeling (Zhou et al. 2008). Studi tentang
language model saat ini menjadi topik yang banyak dibicarakan dalam komunitas temu kembali informasi seiring dengan meningkatnya popularitas penggunaan dari languange modeling dalam sistem temu kembali informasi (Zhou et al. 2007). Jelinek)Mercer Smoothing
merupakan teknik smoothing yang menggunakan metode interpolasi linier antara
maximum likelihood model dengan collection background model, dan sebagai parameter pengontrolnya adalah koefisien λ. Teknik ini biasa disebut dengan simple languange model
atau dalam semantic smoothing teknik ini digunakan sebagai background smoothing.
Pada penelitian ini metode smoothing yang digunakan adalah background smoothing. Selanjutnya proses pengklasifikasian dokumen menggunakan algoritme klasifikasi NBC untuk melihat pengaruh parameter koefisien λ pada
query yang pendek (short query) dan panjang (long query) serta membandingkan tingkat keakurasian klasifikasi NBC dan NBC+
background smoothing. Tujuan
Penelitian ini bertujuan untuk 1) melihat pengaruh metode background smoothing
dengan parameter kontrol (koefisien λ) yang berbeda pada short query dan long query, dan 2) membandingkan tingkat akurasi klasifikasi NBC dan NBC+Background Smoothing dengan nilai koefisien λ terbaik.
Ruang Lingkup
Adapun ruang lingkup penelitian ini dibatasi pada:
1. Evaluasi keakurasian klasifikasi dokumen menggunakan background smoothing
dengan nilai parameter pengontrol yang berbedapada short dan long query.
2. Membandingkan nilai parameter koefisien λ terbaik pada background smoothing dengan NBC.
3. Dokumen yang digunakan adalah artikel dari jurnal penelitian terbatas pada bidang pertanian dengan domain tanaman hortikultura.
4. Proses yang terlibat dalam pembentukan
collection background model tidak memperhatikan semantic language model.
Manfaat Penelitian
2
TINJAUAN PUSTAKA
Sistem Temu Kembali Informasi
Sistem temu kembali informasi adalah suatu bentuk sistem yang melakukan proses penemuan kembali informasi yang relevan terhadap kebutuhan pengguna dari kumpulan informasi secara otomatis. Sistem temu kembali informasi berhubungan dengan pencarian informasi yang isinya tidak memiliki struktur. Demikian pula ekspresi kebutuhan pengguna yang disebut query, juga tidak memiliki struktur. Hal ini yang membedakan sistem temu kembali informasi dengan sistem basis data. Ada tiga komponen yang mendasari proses dari sistem temu kembali informasi, yaitu representasi dokumen, representasi informasi yang dibutuhkan dari pengguna, dan perbandingan dari kedua representasi tersebut. Proses tersebut di atas diilustrasikan seperti Gambar 1.
Representasi dari dokumen adalah pengindeksan yang dilakukan menggunakan teknik pengindeksan tertentu seperti tokenisasi kata, membuang stopword, dan stemming
sehingga menghasilkan himpunan kosa kata sebagai dokumen indeks. Proses pengindeksan tersebut melibatkan isi dari seluruh kumpulan dokumen atau biasanya hanya terdiri atas judul atau kata kunci dan abstrak dari kumpulan dokumen.
Proses informasi yang dibutuhkan (information need) oleh pengguna berupa suatu
query dari pengguna yang merepresentasikan permintaan informasi. Query umumnya tidak memiliki struktur, untuk itu query perlu diformulasikan (formulasi query) sehingga terjadi dialog interaktif antara pengguna dan sistem agar pengguna memahami betul akan permintaan informasi yang dibutuhkannya (feedback).
Gambar 1 Proses Sistem Temu Kembali Informasi (Hiemstra, 2001)
Perbandingan query terhadap permintaan informasi disebut proses penyesuaian (matching process). Pada proses inilah diharapkan dapat dihasilkan suatu keluaran yang relevan dengan permintaan pengguna.
Salah satu pendekatan dalam merepresenA tasikan informasi yang terorganisasi adalah dengan mengelompokkan dokumen ke dalam beberapa kategori atau klasifikasi. Dengan klasifikasi dokumen diharapkan informasi yang diambil dari kumpulan dokumen dapat lebih relevan.
Klasifikasi Dokumen
Klasifikasi dokumen adalah proses pengelompokan dokumen sesuai dengan kategori yang dimilikinya. Sebuah dokumen dapat dikelompokkan ke dalam kategori tertentu berdasarkan kataAkata dan kalimatAkalimat yang ada di dalam dokumen tersebut.
Metode klasifikasi dokumen secara otomatis pun memiliki tingkat keakuratan yang tinggi jika aturan (rule) dibuat dengan baik. Metode klasifkasi dibagi menjadi dua, yaitu klasifikasi secara manual dan klasifikasi dokumen secara otomatis. Klasifikasi manual umumnya akurat karena dilakukan oleh tenaga ahli dan konsisten, namun cenderung sulit dilakukan dan butuh waktu yang lama.
Klasifikasi dokumen secara otomatis terdiri atas dua kategori, yaitu hand‐coded rule‐based systems dan supervised learning
(Christopher et al. 2009). Hand‐coded rule‐
based systems tingkat akurasinya tinggi jika
rule dibuat dengan sangat baik oleh ahlinya dan sangat kompleks serta dibutuhkan biaya yang mahal.
Pada supervised learning menggunakan data latih (learning) untuk memberikan label kategori yang telah terdefinisi sebelumnya. Dengan semakin meningkatnya kebutuhan untuk klasifikasi dokumen, algoritme untuk membantu melakukan aktivitas tersebut juga semakin dikembangkan.
Ada banyak model yang digunakan dalam
supervised learning, di antaranya adalah Vector Space Model (VSM), Naïve Bayes, Bernoulli,
k‐Nearest Neighbors (KNN), dan maximum a posteriori. Klasifikasi dokumen dilakukan dalam dua tahap. Tahap pertama adalah pelatihan (training) terhadap kumpulan dokumen. Sedangkan tahap kedua adalah proses klasifikasi dokumen yang belum diketahui kategorinya (testing). Proses pengklasifikasian terhadap dokumen dapat dilihat pada Gambar 2.
Kebutuhan
feedback Dokumen retrieved
3 Gambar 2 Proses Klasifikasi Dokumen
(NBC)
Metode klasifikasi Bayesian adalah bagian dari teknik klasifikasi berbasis statistik. Metode ini dapat memprediksi kemungkinan anggota sebuah kelompok atau kategori, berdasarkan sampel yang berasal dari anggota kelompok tersebut. Klasifikasi NBC termasuk dalam model multinomial yang mengambil jumlah kata yang muncul pada sebuah dokumen. Pada model ini, sebuah dokumen terdiri atas beberapa kejadian kata dan diasumsikan panjang dokumen tidak bergantung pada kelasnya. Dengan menggunakan asumsi Bayes
bahwa kemungkinan tiap kejadian kata dalam sebuah dokumen adalah bebas tidak terpengaruh dengan konteks kata dan posisi kata dalam dokumen.
NBCadalah penyederhanaan dari Bayesian Classification, metode ini sering juga disebut sebagai Simple Bayesian Classification. NBC merupakan klasifikasi peluang sederhana yang didasarkan asumsi yang kuat (naïve) dan bebas (independence), serta dapat dilatih dengan sangat efisien pada kondisi supervised learning.
Penggunaan NBC dalam klasifikasi teks pada sistem temu kembali informasi sebagai penduga peluang suatu dokumen dalam kelas atau kategori tertentu (Christopher et al. 2009). Peluang dari suatu dokumen d ada pada kelas c
dapat diformulasikan sebagai berikut:
| ∞ ∏ k| (1)
Dengan P(tk|c) adalah peluang kata atau
termtk muncul pada dokumen kelas c, dan
P(c) merupakan prior probability peluang dokumen ada pada kelas .
Pendekatan yang digunakan untuk menduga parameter P(c) dan P(tk|c) adalah dengan
Penggunaan Language Modeling (LM) atau
statistical language modeling muncul sebagai
probabilistic framework yang baru untuk menangkap ketidakteraturan statistik yang menjadi ciri dari ketidakteraturan penggunaan bahasa. Sebuah LM adalah suatu model tentang distribusi kondisional dari identitas kataAkata dalam sebuah rangkaian, yang ditentukan oleh identitas dari semua kataAkata sebelumnya.
Dalam bidang penelitian Information Retrieval (IR), LM yang digunakan adalah
unigram model karena urutAurutan kata tidak terlalu dipermasalahkan, tidak seperti dalam pengenalan suara (speech recognition) otomatis yang sangat bergantung pada kemampuan mesin memahami urutan kataAkata.
Salah satu model IR yang menggunakan LM adalah Query)Likelihood Model yang pertama diusulkan oleh Ponte dan Croft (dalam Liu & Croft 2004) yang menganggap sebuah query
sebagai sebuah vektor dari atribut biner, masingAmasing atribut untuk sebuah istilah yang unik di dalam kosa kata indeks, dan menandakan ada atau tidaknya istilah tersebut di dalam query.
Jumlah kemunculan istilah tersebut di dalam
query sendiri tidak diperhitungkan. Ada dua asumsi yang mendasari model ini, pertama adalah semua atribut bernilai biner. Jika sebuah istilah ada di query, maka atribut yang mewakili istilah tersebut bernilai 1 dan jika tidak bernilai 0. Kedua, istilah dianggap tidak berkaitan di dalam sebuah dokumen. Asumsi ini mirip dengan dugaan yang digunakan dalam teoriAteori peluang pada IR.
Berdasarkan dua asumsi di atas, maka query likelihood P(Q|D) dapat dirumuskan sebagai hasil dari dua peluang, yaitu peluang kemunculan istilah pada query dan peluang ketidakAmunculan istilah itu.
| ! | !"1.0 & | '
()* ( *
P(t|D) dihitung dengan metode nonA parametrik yang memanfaatkan peluang rataA rata dari t (term) di dalam dokumen yang mengandung term tersebut. Untuk istilahAistilah yang tidak muncul, maka peluang global dari t
dalam koleksi dokumen yang digunakan.
" #$
Smoothing adalah bagian pen yang berfungsi untuk membandin kata yang muncul dan yang tidak suatu dokumen. Smoothing aka keakurasian perkiraan peluang pada dokumen latih. Denga
smoothing juga memberikan nil peluang pada kata yang tidak mun Pada konteks LM, smo
dikatakan sebagai pengontrol d
likelihood estimator agar hasilny (Zhai dan Lafferty 2001). Menu Goodman (1998) telah ban
smoothing yang dihasilkan, anta
Laplace smoothing, Katz smoo turing Estimation, Dirichlet Prio Jelinek)Mercer Smoothing,
Smoothing (Zhou et al. 2008)
% " #$
Laplace smoothing merup
smoothing yang biasa digu
penghitungan Maximum Likeliho
(MLE). Kegunaannya untuk m dugaan parameter yang bernilai n
Laplace smoothing disebut
add)one karena pada notasi penghitungan kata dalam kelas dengan satu. Formula laplace sm
MLE sebagai berikut: | ∑ +,-./01 .
collection model. Dalam seman
teknik ini digunakan sebagai
smoothing (Zhou et al.
komunitas Temu Kembali Inform dikenal dengan Jelinek)Mercer S Smoothing) yang mengguna interpolasi linier untuk memo
unigram dari maximum likel
dengan collection backgroun
parameter pengontrol yang mem adalah koefisien λ. Tujuannya menduga peluang dari kata yang (unseen) berdasarkan backgroun
seluruh koleksi dokumen latih.
an penting dari LM bandingkan peluang tidak muncul dalam akan menambah
asilnya lebih akurat Menurut Chen dan Informasi, teknik ini
er Smoothing (JM
Model background smoothing
dinyatakan dalam bentuk:
b | j 1 & < ml | ? @ <
Dengan ml | ? adalah model kel dengan pendugaan parameter
likelihood, b | j adalah model kel dengan background smoothing.
simple language model yang meng kan frekuensi kata (t) query di dal koleksi dokumen D dengan jumlah s dalam koleksi dokumen.
Sedangkan koefisien λ gunany parameter pengontrol dari
background model, dalam semantic
digunakan sebagai komponen pengo pemetaan topic signature sebag campuran atau mixture model (Z 2007).
# '
Confusion matrix atau disebut ju klasifikasi adalah suatu alat vi biasanya digunakan dalam supervise
Matriks klasifikasi berisi jumlah k yang diklasifikasikan dengan benar kasus yang salah diklasifikasikan. yang diklasifikasikan dengan ben pada diagonal, karena kelompok p kelompok aktual adalah sama. Elem selain diagonal menunjukkan kasus diklasifikasikan. Jumlah elemen diag total jumlah kasus adalah rasio ting dari klasifikasi. Format dari confus
dapat dilihat pada Gambar 3.
Gambar 3 Format Confusion Ma
2008)
Evaluasi kesamaan dokumen da menggunakan recall, precision dan Hasil klasifikasi (predicted class
kemungkinan yaitu benar dalam ke dan TN) atau salah, masuk kelas l dan FN).
Hasil pengukuran (performace m
diperoleh dengan melihat pada forma
4
thing tersebut
< | (3)
el kelas unigram
eter maximum
del kelas unigram
5
matrix di atas. Akurasi dari pengklasifikasian diperoleh dari formula:
ABCDEFG 7 @ 7H @ I @ IH 7 @ 7H (4)
Pengukuran lain yaitu recall, precision, F)measure (F1) dapat dinotasikan sebagai berikut:
JK ELL 7 @ IH 7 (5555)
DK GFGNO 7 @ I 7
I1 2 Q JK ELL Q DK GFGNOJK ELL @ DK GFGNO
Recall adalah tingkat keberhasilan pengenalan suatu kelas yang harus dikenali.
Recall dinyatakan dalam jumlah pengenalan entitas bernilai benar, dibagi dengan jumlah entitas yang seharusnya dapat dikenali oleh sistem. Sedangkan Precision adalah tingkat ketepatan hasil klasifikasi dari seluruh dokumen. Precision dihitung dari jumlah pengenalan yang bernilai benar oleh sistem, dibagi dengan jumlah keseluruhan pengenalan yang dilakukan oleh sistem. F)measure adalah nilai yang mewakili keseluruhan kinerja sistem dan merupakan gabungan nilai recall dan
precision.
METODE PENELITIAN
Gambaran Umum Sistem
Secara garis besar pengerjaan sistem dilakukan dalam beberapa tahap, seperti yang terlihat pada Gambar 4.
Koleksi Dokumen
Koleksi dokumen yang digunakan sebagai dokumen latih dan dokumen uji adalah hasil penelitian dari Jurnal Penelitian Hortikultura tahun 2002 sampai dengan tahun 2009. Namun tidak semua edisi jurnal tersebut digunakan karena tidak semua jurnal tersebut disimpan dalam format file yang sama, sehingga butuh waktu lama untuk dilakukan kompilasi data.
Adapun pembagian jenis tanaman hortikultura adalah komoditas tanaman hias, buah tropik, buah sub tropik, dan sayuran. Dokumen tersebut terdiri atas berbagai bidang penelitian pertanian yaitu ekofisiologiA
agronomi, pemuliaanAteknologi benih, dan proteksi.
Proporsi dokumen yang digunakan adalah dengan 70 % untuk data latih dan 30 % untuk data uji. Dokumen uji untuk setiap dokumen dibagi menjadi dua, yaitu untuk short dan long query.
Gambar 4 Gambaran Umum Sistem
Praproses
Praproses merupakan tahapan awal dalam proses klasifikasi dokumen setelah koleksi dokumen terkumpul. Praproses dalam penelitian ini dilakukan dalam beberapa tahapan, yaitu: 1. Pengelompokan dan kompilasi dokumen.
Pada tahap ini koleksi dokumen diseleksi berdasarkan kategori atau kelas yang telah ditentukan sebelumnya.
2. Indexing. Proses indexing melibatkan konsep linguistic processing dengan tujuan untuk mengekstrak kataAkata dari dokumen yang merupakan representasi dari
bag)of)words. Ekstraksi kata yang pada penelitian ini melibatkan tiga operasi utama, yaitu:
a. Proses parsing yaitu dilakukan dengan memilah dokumen menjadi unitAunit yang lebih kecil berupa kata.
b. Proses stopwords yaitu dihilangkannya kata yang tidak berhubungan dengan subyek utama dari dokumen. Kata yang dihilangkan adalah kata yang sering muncul dalam koleksi dokumen dan tidak memunyai arti seperti: dan, yang, ini, itu serta string yang berupa angka, dilanjutkan dengan kataAkata
6 yang tidak berarti sebagai pembeda
antar dokumen.
c. Pembobotan indeks yaitu pembobotan secara lokal dan global. Pembobotan lokal dilakukan dengan cara menghitung frekuensi kemunculan kata dan total seluruh kata pada kelas dari dokumen. Pembobotan global akan menghasilkan total kata dan jumlah total kata unik yang ada pada dokumen latih.
(NBC) dengan
& ! " #$
Proses pengklasifikasian dokumen pada penelitian ini menggunakan algoritme klasifikasi NBC yang merupakan multinomial model. Agar mudah dalam implementasinya maka digunakan teknik background smoothing
sebagai pengontrol dari penghitungan maximum likelihood estimator melalui pendekatan simple language model agar hasil klasifikasinya lebih akurat.
Pada tahap ini diawali dengan penghitungan peluang setiap kata dalam dokumen latih menggunakan Maximum Likelihood Estimation
(MLE) berdasarkan kata pada dokumen uji. Proses penghitungan tersebut dimulai dengan pendugaan parameter peluang kata pada dokumen kelas ci sesuai dengan formula (2). Selanjutnya melakukan kombinasi linier pada
unigram class model menggunakan collection background model dengan parameter pengontrol λ sesuai dengan formula (3) pada dokumen latih. Setelah didapatkan peluang tiap kata dari dokumen uji berdasarkan dokumen latih, proses akhir adalah penghitungan peluang dari masingAmasing kelas terhadap dokumen uji dengan formula (1).
Evaluasi Hasil Klasifikasi
Evaluasi hasil klasifikasi dokumen dilakukan untuk menganalisis tingkat keakurasian klasifikasi dokumen dengan metode background smoothing pada parameter pengontrol λ yang berbeda. Hal ini dimaksudkan untuk menentukan nilai ideal dari parameter pengontrol λ yang sesuai dengan data
training.
Setelah diperoleh nilai koefisien λ yang terbaik untuk short dan long query, evaluasi dilanjutkan pada perbandingan klasifikasi dokumen antara NBC dengan NBC+
Background Smoothing. Pengukuran kesamaan dokumen yang digunakan adalah tingkat akurasi, recall, precision, dan F)1
menggunakan formula (4) dan (5) untuk setiap kelasnya berdasarkan tabel confusion matrix.
HASIL DAN PEMBAHASAN
Dokumen yang digunakan sebagai dokumen latih dan uji perlu dikompilasi karena hasil klasifikasi bergantung pada koleksi dokumen yang akan dijadikan dokumen latih. Hasil kompilasi menghasilkan 249 dokumen. Isi dari koleksi dokumen tersebut merupakan judul penelitian, kata kunci dan abstrak dari 3 (tiga) kelas, yaitu:
a) Kelas Ekofisiologi dan Agronomi b) Kelas Pemuliaan dan Teknologi Benih c) Kelas Proteksi (Hama dan Penyakit)
MasingAmasing kelas terdiri atas 83 dokumen. Dokumen tersebut dibagi lagi untuk dijadikan sebagai data latih dan data uji. Data latih untuk setiap kelas terdiri atas 58 dokumen, sedangkan untuk data uji terdiri atas 25 dokumen. Pembagian tersebut sesuai dengan proporsi dokumen pada Bab Metodologi Penelitian, yaitu 70 % untuk data latih dan 30 % untuk data uji.
Setelah melalui proses indexing, diperoleh pembobotan indeks yang diperlukan dalam proses klasifikasi dokumen. Bagian penting dari tahap ini adalah penentuan stoplist atau kata yang akan dibuang sebagai stopword. Penghilangan stopword disesuaikan dengan kebutuhan penelitian, yaitu kata yang sering muncul dalam koleksi dokumen dan tidak memunyai arti dan dilanjutkan dengan menghilangkan kataAkata yang tidak berarti dalam membedakan dokumen. Hasil dari penghilangan stopword dan pembobotan indeks kata, diperoleh total jumlah kata sebanyak 20605 dan jumlah kata unik sebanyak 2949 untuk pembobotan global.
Uji Coba Klasifikasi Dokumen
Uji coba dilakukan dengan dua kombinasi perlakuan, yaitu:
1. NBC+Background Smoothing dengan parameter pengontrol λ= 0.1 sampai dengan 0.9, agar diperoleh nilai koefisien λ terbaik pada short dan long query.
7
Background Smoothing lebih baik daripada NBC.
NBC+ & ! " #$
Tingkat keakurasian yang paling baik untuk
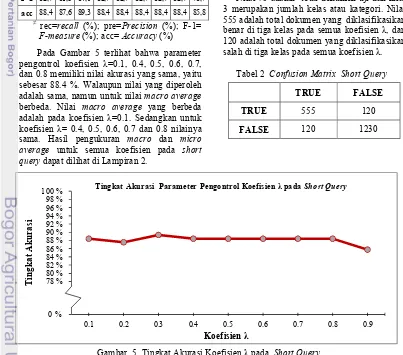
short query diperoleh pada parameter pengontrol koefisien λ=0.3, seperti yang terlihat pada Gambar 5. RataArata nilai recall, precision
dan F)measure untuk semua kelas atau micro average pada koefisien λ=0.3 adalah 84 % dan akurasi yang didapat adalah 89.3 %. Hasil penghitungan pada micro average untuk semua nilai koefisien λ dapat dilihat pada Tabel 1. Hasil klasifikasi dokumen untuk semua koefisien λ pada short query dalam bentuk
confusion matrix ada pada Lampiran 1. Tabel 1 Micro Average untuk Short Query dan 0.8 memiliki nilai akurasi yang sama, yaitu sebesar 88.4 %. Walaupun nilai yang diperoleh adalah sama, namun untuk nilai macro average
berbeda. Nilai macro average yang berbeda adalah pada koefisien λ=0.1. Sedangkan untuk koefisien λ= 0.4, 0.5, 0.6, 0.7 dan 0.8 nilainya sama. Hasil pengukuran macro dan micro average untuk semua koefisien pada short query dapat dilihat di Lampiran 2.
Perbedaan tersebut nampak pada kelas b
(Pemuliaan dan Teknologi Benih) dan kelas c
(Proteksi). Sedangkan untuk kelas a (Fisiologi dan Agronomi) nilai yang diperoleh adalah benar lebih rendah dibandingkan dengan λ= 0.1.
Pada Tabel 2 terlihat bahwa total pengujian untuk tiga kelas a, b, dan c yang diklasifikasiA kan benar adalah 555, dan yang diklasifikasi salah adalah sebanyak 120. Sedangkan untuk dokumen yang diklasifikasikan dari total tiga kelas dengan banyaknya koefisien λ yang diujikan, diperoleh nilai sebanyak 1230. Nilai tersebut diperoleh dengan penghitungan sebagai berikut:
((75 x 3)*9) A (555+120+120) = 2025 A 796 = 1230
Nilai 75 adalah total dokumen uji dan nilai 3 merupakan jumlah kelas atau kategori. Nilai 555 adalah total dokumen yang diklasifikasikan benar di tiga kelas pada semua koefisien λ, dan 120 adalah total dokumen yang diklasifikasikan salah di tiga kelas pada semua koefisien λ.
Tabel 2 Confusion Matrix Short Query
TRUE FALSE
TRUE 555 120
FALSE 120 1230
parameter pengontrol koefisien λ
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Tingkat Akurasi Parameter Pengontrol Koefisien λ pada $ # (
0 %
8
Tingkat Akurasi Parameter Pengontrol Koefisien λ pada (
0 %
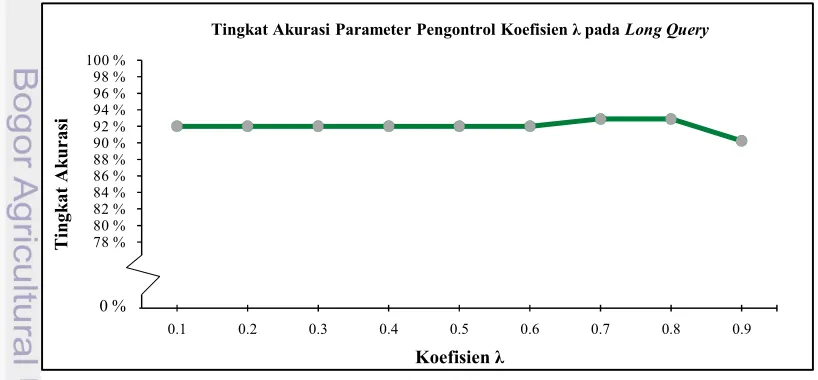
Pada long query, tingkat keakurasian terbaik diperoleh pada parameter pengontrol koefisien λ=0.7 dan λ=0.8. Nilai micro average untuk
recall, precision dan F)measure adalah 89.3 %. Sedangkan akurasi yang didapat adalah 92.8 %. Hasil penghitungan micro average tersebut dapat pada tabel dibawah ini.
Tabel 3 Micro Average untuk Long Query
≠
rec = recall (%); pre=Precision (%); FA1=
F1 (%); acc= Accuracy (%)
Hasil klasifikasi dokumen untuk semua koefisien λ pada long query dalam bentuk
confusion matrix dapat dilihat pada Lampiran 3 dan hasil pengukuran untuk semua koefisien λ pada long query ada di Lampiran 4. Dari Gambar 6 terlihat bahwa parameter pengontrol koefisien λ=0.1 sampai dengan 0.6 memiliki nilai akurasi yang sama, sebesar 92 %. Demikian juga untuk recall, precision dan F) measure pada micro average adalah sama, yaitu 88 %. Perbedaan yang tampak pada koefisien λ=0.1 sampai dengan 0.3, dan koefisien λ=0.4 sampai 0.6.
Perbedaan tersebut tidak terlalu berarti, hanya pada koefisien λ=0.1 sampai 0.3, kelas a
dikenali salah ke dalam kelas b sebanyak satu dokumen uji dan kelas c sebanyak dua dokumen uji. Sebaliknya pada koefisien λ=0.4 sampai
0.6, kelas a salah dikenali ke dalam kelas b
sebanyak 2 (dua) dokumen uji dan kelas c
sebanyak satu dokumen uji. Nilai Micro Average untuk total seluruh nilai parameter pengontrol koefisien λ mulai dari 0.1 sampai dengan 0.9, dapat dilihat pada tabel 4.
Tabel 4 Confusion Matrix Long Query
TRUE FALSE
TRUE 594 81
FALSE 81 1269
Pada Tabel 4 terlihat bahwa total pengujian untuk kelas a, b, dan c yang diklasifikasikan benar adalah 594, dan yang diklasifikasikan salah adalah sebanyak 81. Dari total kelas dengan banyaknya koefisien λ yang diujikan sebanyak 1269.
NBC dan NBC+ & ! " #$
Perbedaan antara klasifikasi dokumen NBC dengan NBC+Background Smoothing adalah
Maximum Likelihood Estimation (MLE). Penghitungan MLE pada NBC seperti pada formula (2), menggunakan jumlah seluruh kata unik dokumen latih di semua kelas, sedangkan pada Background Smoothing tidak menambahkan jumlah seluruh kata unik dalam dokumen uji untuk penghitungannya.
Hasil pengukuran ini dilakukan pada nilai parameter pengontrol koefisien λ yang terbaik untuk background smoothing. Dari hasil pengukuran sebelumnya telah diperoleh nilai koefisien terbaik untuk short query adalah λ=0.3 dan long query pada λ=0.7.
parameter pengontrol koefisien λ
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
rec 88,0 88,0 88,0 88,0 88,0 88,0 89,3 89,3 85,3
pre 88,0 88,0 88,0 88,0 88,0 88,0 89,3 89,3 85,3
F=1 88,0 88,0 88,0 88,0 88,0 88,0 89,3 89,3 85,3
acc 92,0 92,0 92,0 92,0 92,0 92,0 92,9 92,9 90,2
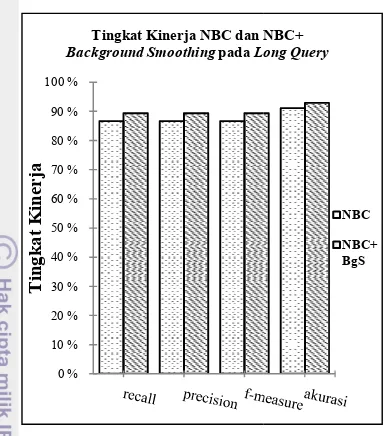
Hasil klasifikasi dokumen untu terlihat pada Tabel 5 dan Gam tingkat akurasi NBC+Backgrou
dengan koefisien λ=0.3 lebih baik dengan NBC. Hasil pengukuran dapat dilihat pada Lampiran 6
measure pada tabel macro averag a dan kelas b, lebih tinggi dibandi
F)measure pada NBC. Hanya kel uji diklasifikasikan dengan baik
a dan b oleh NBC.
Tabel 5 Micro Average NBC
Background Smoothin
Gambar 7 Perbandingan Ting pada Short Query
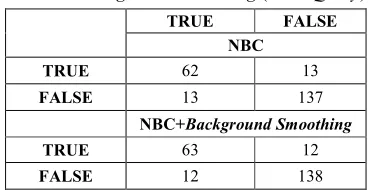
Berdasarkan Tabel 6 penguj untuk tiga kelas a, b, dan c pad diklasifikasikan dengan benar ad yang diklasifikasikan salah yaitu uji dari total 75 dokumen y inilah yang membuat ting NBC+Background Smoothing
Tingkat Kinerja NBC dan N & ! " #$ pada $
Pengukuran Micro
recall precision
NBC 82,67 82,67
NBC+BgS 84,00 84,00
en untuk short query
Gambar 7 bahwa
daripada NBC, walaupun tidak terla Hasil klasifikasi dokumen pada selengkapnya dapat dilihat pada Lam
Tabel 6 Confusion Matrix NBC da
Background Smoothing (Sh
TRUE bahwa tingkat akurasi klasifikasi NBC+Background Smoothing denga λ=0.7 lebih baik dibandingkan den Dimana nilai micro average un
precision, dan F)measure pad
Background Smoothing dengan koef adalah sebesar 89.3 %, sedangkan diperoleh sebesar 86.6 %. Tingkat ak +Background Smoothing mencapa sedangkan NBC menghasilkan ting sebesar 91.1 %.
Hasil pengukuran macro dan mic
untuk long query dapat dilihat pada Pada tabel macro average terlihat b
F)measure pada kelas a dan kelas b
dibandingkan dengan F)measure
Namun sebaliknya pada kelas c terl nilai F)measure yang diperoleh N tinggi dibandingkan dengan NBC+
Smoothing. Hal inilah yang menyeb klasifikasi dokumen menggunak
Background Smoothing tidak terla dengan NBC karena pada tabel mac
recall precision F
Gambar 8 Perbandingan Ting pada Long Query
Selain dari hasil pengukuran
average, terlihat juga pada Tabe
matrix, bahwa tingkat akura
Background Smoothing lebih b NBC, walaupun hasil yang di terlalu berbeda seperti halnya pad Dimana total pengujian dokume kelas a, b, dan c pada diklasifikasikan dengan benar seb yang diklasifikasikan salah yaitu dari total 75 dokumen ya Sedangkan NBC+Background
mengklasifikasikan dokumen d sebanyak 67 dokumen.
Tabel 8 Confusion Matrix NBC
Background Smoothing
Dari hasil penelitian ini menun hasil klasifikasi menggunakan
smoothing tidak bergantung pad pendeknya query karena hasil sama dicapai pula oleh NBC, ba maupun long query. Hal yang m hasil klasifikasi dengan backgrou
adalah adanya nilai parameter
Tingkat Kinerja NBC dan N & ! " #$ pada ar sebanyak 65, dan yaitu 10 dokumen
yang disesuaikan dengan data sehingga hasilnya lebih baik di dengan NBC kendati tidak terlal Sedangkan nilai λ terbaik pada sho query, terkait dengan domain dokumen yang digunakan sebagai
background model. Pada pene menggunakan domain tanaman h pada penelitian tentang pertanian. Bi koefisien λ untuk domain selain h misalnya untuk domain tanaman p koefisien λ pada short query buka dan sebaliknya untuk long query
λ=0.7.
KESIMPULAN DAN SA
Kesimpulan
Background smoothing merupa
smoothing dengan pendekatan
model. Pada penelitian ini,
smoothing memodelkan seluruh dok sebagai collection background mode
klasifikasi terlihat bahwa tingkat aku
Background Smoothing tidak pengaruhnya dibandingkan deng Peningkatan akurasi tersebut han 1.78% dari hasil yang diperoleh p Untuk dapat menambah tingkat k perlu melibatkan keterkaitan antar
semantic.
Hasil klasifikasi dengan
smoothing dipengaruhi oleh nilai pengontrol λ yang disesuaikan de
training. Nilai λ terbaik yang dipe
short dan long query bergantung pa klasifikasi dokumen yang digunak
collection background model. Hasil p klasifikasi pada dokumen bida pertanian untuk domain h menunjukkan bahwa nilai paramete λ yang terbaik pada short query
λ=0.3 dengan akurasi sebesar 89.3 %
long query diperoleh pada λ=0.7 den 92.8 %. Oleh karena itu, nilai λ sebaiknya digunakan pada data tra
kecil untuk klasifikasi short query
untuk long query dibutuhkan nilai besar.
Saran
Pada penelitian selanjutnya
11 hortikultura agar dapat dilihat hasil klasifikasi
dan pengaruh nilai λ terbaik untuk short dan
long query sama atau berbeda.
Selain dipadankan dengan NBC, metode
Background Smoothing dapat juga dipadankan dengan teknik smoothing yang lain seperti pada
Semantic Smoothing.
DAFTAR PUSTAKA
Christopher D Manning, Raghavan P, Hinrich Schütze.2009. An Introduction to Informa) tion Retrieval. http://nlp.stanford. edu/ IRbook/pdf/irbookprint. Pdf. [12 Jun 2009]. Djoerd Hiemstra. 2001.UsingLanguage Models
for Information Retrieval.[tesis]. Centre for Telematics and Information Technology,
University of Twente. ISSN 1381A3617 no. 01A32; ISBN 90A75296A05A3. http://www home.cs.utwente.nl/~hiemstra/ publications. [7 Feb 2010].
Chen, SF, Goodman J. 1998. An Empirical Study of Smoothing Techniques for Language Modeling. TRA10A98, Harvard University. http://research.Microsoft.com/ enAus/um/people/joshuago/publications. [12 jun 2009].
Kartika I.2005. Evaluasi Penambahan Dokumen Dalam Sistem Temu Kembali Informasi. [skripsi].Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Liu X, Croft WB. 2004. Statistical Language Modeling For Information Retrieval. Annual Review of Information Science and Technology, vol. 39, pp. 3A31. http://ciir. cs.umass.edu/pubfiles. [7 Feb 2010].
Lutz Hamel. Model Assessment with ROC Curves.2008. The Encyclopedia of Data Warehousing and Mining.2nd Edition.Idea Group Publishers. http://homepage.cs.uri. edu/faculty/hamel/pubs. [15 Mar 2010]. Zhai C, Lafferty J. 2001.A study of Smoothing
Methods for Language Models Applied to Ad Hoc Information Retrieval, Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval
(SIGIR'01), hlm 334A342. http://sifaka. cs.uiuc.edu/czhai/ selected.html. [7 Feb 2010]
Zhou X, Zhang X, Hu X. 2008. Semantic Smoothing for Bayesian Text Classification with Small Training Data. Dalam: SIAM SDM 08. Proc of the 2008, SIAM International Conference on Data Mining; Georgia, Atlanta, 24A26 Apr 2008. http:// www.siam.org/proceedings/datamining/ 2008/dm08_26_Zhou.pdf. [7 Jul 2009].
13 Lampiran 1 Confusion Matrix untuk Semua Koefisien λ pada Short Query
Koefisien λ
Kelas A Kelas B Kelas C
AA AB AC BA BB BC CA CB CC
0.1 17 3 5 3 22 0 1 1 23
0.2 17 3 5 3 22 0 2 1 22
0.3 18 2 5 2 23 0 2 1 22
0.4 17 2 6 2 23 0 2 1 22
0.5 17 2 6 2 23 0 2 1 22
0.6 17 2 6 2 23 0 2 1 22
0.7 17 2 6 2 23 0 2 1 22
0.8 17 2 6 2 23 0 2 1 22
0.9 14 5 6 3 22 0 0 2 23
14 Lampiran 2 Hasil Pengukuran Macro dan Micro Average pada Short Query
Koefisien λ
MACRO AVERAGE (%) MICRO AVERAGE (%)
) *+"
) *+"
A B C A B C A B C A B C
0.1 80.95 84.62 82.14 68.00 88.00 92.00 73.91 86.27 86.79 84.00 90.67 90.67 82.67 82.67 82.67 88.44
0.2 77.27 84.62 81.48 68.00 88.00 88.00 72.34 86.27 84.62 82.67 90.67 89.33 81.33 81.33 81.33 87.56
0.3 81.82 88.46 81.48 72.00 92.00 88.00 76.60 90.20 84.62 85.33 93.33 89.33 84.00 84.00 84.00 89.33
0.4 80.95 88.46 78.57 68.00 92.00 88.00 73.91 90.20 83.02 84.00 93.33 88.00 82.67 82.67 82.67 88.44
0.5 80.95 88.46 78.57 68.00 92.00 88.00 73.91 90.20 83.02 84.00 93.33 88.00 82.67 82.67 82.67 88.44
0.6 80.95 88.46 78.57 68.00 92.00 88.00 73.91 90.20 83.02 84.00 93.33 88.00 82.67 82.67 82.67 88.44
0.7 80.95 88.46 78.57 68.00 92.00 88.00 73.91 90.20 83.02 84.00 93.33 88.00 82.67 82.67 82.67 88.44
0.8 80.95 88.46 78.57 68.00 92.00 88.00 73.91 90.20 83.02 84.00 93.33 88.00 82.67 82.67 82.67 88.44
0.9 82.35 75.86 79.31 56.00 88.00 92.00 66.67 81.48 85.19 81.33 86.67 89.33 78.67 78.67 78.67 85.78
≠ A = Kelas Fisiologi dan Agronomi B = Kelas Pemuliaan dan Teknologi Benih C = Kelas Proteksi
1
15 Lampiran 3 Confusion Matrix Semua Koefisien λ pada Long Query
Koefisien
λ
Kelas A Kelas B Kelas C
AA AB AC BA BB BC CA CB CC
0.1 22 1 2 3 22 0 2 1 22
0.2 22 1 2 3 22 0 2 1 22
0.3 22 1 2 3 22 0 2 1 22
0.4 22 2 1 3 22 0 2 1 22
0.5 22 2 1 3 22 0 2 1 22
0.6 22 2 1 3 22 0 2 1 22
0.7 22 2 1 2 23 0 2 1 22
0.8 22 2 1 2 23 0 2 1 22
0.9 19 4 2 2 23 0 2 1 22
16 Lampiran 4 Hasil Pengukuran Macro dan Micro Average pada Long Query
Koefisien λ
MACRO AVERAGE (%) MICRO AVERAGE (%)
) *+"
) *+"
A B C A B C A B C A B C
0.1 81.48 91.67 91.67 88.00 88.00 88.00 84.62 89.80 89.80 89.33 93.33 93.33 88.00 88.00 88.00 92.00
0.2 81.48 91.67 91.67 88.00 88.00 88.00 84.62 89.80 89.80 89.33 93.33 93.33 88.00 88.00 88.00 92.00
0.3 81.48 91.67 91.67 88.00 88.00 88.00 84.62 89.80 89.80 89.33 93.33 93.33 88.00 88.00 88.00 92.00
0.4 81.48 88.00 95.65 88.00 88.00 88.00 84.62 88.00 91.67 89.33 92.00 94.67 88.00 88.00 88.00 92.00
0.5 81.48 88.00 95.65 88.00 88.00 88.00 84.62 88.00 91.67 89.33 92.00 94.67 88.00 88.00 88.00 92.00
0.6 81.48 88.00 95.65 88.00 88.00 88.00 84.62 88.00 91.67 89.33 92.00 94.67 88.00 88.00 88.00 92.00
0.7 84.62 88.46 95.65 88.00 92.00 88.00 86.27 90.20 91.67 90.67 93.33 94.67 89.33 89.33 89.33 92.89
0.8 84.62 88.46 95.65 88.00 92.00 88.00 86.27 90.20 91.67 90.67 93.33 94.67 89.33 89.33 89.33 92.89
0.9 82.61 82.14 91.67 76.00 92.00 88.00 79.17 86.79 89.80 86.67 90.67 93.33 85.33 85.33 85.33 90.22
≠ A = Kelas Fisiologi dan Agronomi B = Kelas Pemuliaan dan Teknologi Benih C = Kelas Proteksi
1
17 Lampiran 5 Confusion Matrix NBC dan NBC+ Background Smoothing
$ # ( Kelas A Kelas B Kelas C
AA AB AC BA BB BC CA CB CC
NBC+BgS
(λ = 0.3) 18 3 4 4 21 0 1 1 23
NBC 18 2 5 2 23 0 2 1 22
≠ Kelas A = Fisiologi dan Agronomi Kelas B = Pemuliaan dan Teknologi Benih Kelas C = Proteksi
NBC = Naïve Bayes Classifier
NBC+BgS = Naïve Bayes Classifier+Background Smoothing
( Kelas A Kelas B Kelas C
AA AB AC BA BB BC CA CB CC
NBC+BgS
(λ = 0.7) 22 1 2 2 23 0 2 1 22
18 Lampiran 6 Hasil Pengukuran NBC dan NBC+ Backgorund Smoothing
$ # (
MACRO AVERAGE (%) MICRO AVERAGE (%)
) *+"
) *+"
A B C A B C A B C A B C
NBC+BgS
(λ = 0.3) 81.82 88.46 81.48 72.00 92.00 88.00 76.60 90.20 84.62 85.33 93.33 89.33 84.00 84.00 84.00 89.33
NBC 78.26 84.00 85.19 72.00 84.00 92.00 75.00 84.00 88.46 84.00 89.33 92.00 82.67 82.67 82.67 88.44
(
MACRO AVERAGE (%) MICRO AVERAGE (%)
) *+" ) *+"
A B C A B C A B C A B C
NBC+BgS
(λ = 0.7) 84,62 92,00 91,67 88,00 92,00 88,00 86,27 92,00 89,80 90,67 94,67 93,33 89.33 89.33 89.33 92.89
NBC 78,57 87,50 95,65 88,00 84,00 88,00 83,02 85,71 91,67 88,00 90,67 94,67 86.67 86.67 86.67 91.11
≠ A = Kelas Fisiologi dan Agronomi B = Kelas Pemuliaan dan Teknologi Benih C = Kelas Proteksi
NBC = Naïve Bayes Classifier
NBC+BgS = Naïve Bayes Classifier+Background Smoothing
1