1
BAB 1
PENDAHULUAN
1.1 Latar Belakang Masalah
SMKN 14 Bandung adalah sekolah menengah kejuruan yang memiliki kelompok bidang keilmuan keahlian seni rupa, kriya, dan teknologi. SMKN 14 Bandung ini memiliki sekitar 800 orang siswa yang terdiri dari kelas X, XI, dan XII dengan bidang keilmuan yang berbeda, yaitu bidang studi keahlian seni rupa dan kriya dan juga bidang studi keahlian teknologi. SMKN 14 Bandung sudah menerapkan teknologi Learning Management System (LMS) dalam proses pembelajarannya.
Berdasarkan wawancara dengan Pak Muziasih selaku pihak Information
and Communications Technology (ICT) dan Pak Subandi selaku bidang
kurikulum SMKN 14 Bandung, Learning Management System (LMS) yang ada saat ini sudah memiliki fitur untuk mengecek tugas siswa tetapi fitur tersebut hanya membantu pengajar untuk mengunduh tugas yang dikumpulkan siswa dengan mengunggah tugas kepada pengajar yang bersangkutan dan pengajar harus memeriksa manual tugas siswa yang sudah di unduh, hal ini menjadi kurang efektif karena membutuhkan waktu yang cukup lama karena pengajar harus memeriksa satu per satu tugas dan membandingkan tugas siswa 1 dengan tugas siswa lainnya dan hampir tidak ada bedanya dengan mengumpulkan tugas secara manual. Siswa pun terkadang melakukan kecurangan dengan menyalin tugas temannya dan hanya mengganti nomor induk siswa dan juga nama lalu dikumpulkan kepada pengajar dengan mengunggah ke akun pengajar bersangkutan melalui LMS yang sudah ada saat ini. Maka dari itu dibutuhkan suatu metode yang dapat membantu mengurangi beban pengajar dalam memeriksa tugas yang di unggah siswa dan juga dapat mendeteksi tindakan plagiat yang dilakukan oleh siswa pada LMS SMKN 14 Bandung.
Solusi yang ditawarkan yaitu dengan mengembangkan fitur pengecekan tugas pada LMS dengan menambahkan kemampuan untuk mendeteksi plagiarisme tugas. Metode yang akan digunakan pada pengecekan plagiarisme tugas adalah dengan menggunakan algoritma Term Frequency-Inverse Document Frequency
(TF-IDF) dan Concept Frequency-Inverse Document Frequency (CF-IDF). Algoritma TF-IDF adalah jenis algoritma pembobotan yang sering digunakan dalam information retrieval dan text mining, pembobotan ini adalah suatu pengukuran statistik untuk mengukur seberapa penting sebuah kata dalam kumpulan dokumen, tingkat kepentingan meningkat ketika sebuah kata muncul beberapa kali dalam sebuah dokumen tetapi diimbangi dengan frekuensi kemunculan kata tersebut dalam kumpulan dokumen. Algoritma CF-IDF ini dilakukan dengan pendekatan representasi isi dokumen dengan menggunakan jaringan semantik yang disebut dokumen inti semantik, dokumen tersebut kemudian dipetakan dalam jaringan semantik yang disebut wordnet dan dikonversikan dari sekumpulan terms menjadi sekumpulan konsep (concept). Algoritma CF-IDF mempunyai tingkat akurasi yang lebih tinggi dibanding algoritma TF-IDF, namun pada algoritma CF-IDF membutuhkan komputasi yang lebih sehingga membutuhkan waktu komputasi yang lebih lama dibandingkan algoritma TF-IDF, sedangkan untuk menentukan persentase kemiripan tiap dokumen digunakan metode Vector Space Model [1].
Pengembangan aplikasi Learning Management System (LMS) SMKN 14 Bandung ini diharapkan dapat menjadi media yang dapat membantu dan mengevaluasi sistem pembelajaran yang saat ini ada di SMKN 14 Bandung. Pengembangan aplikasi LMS ini juga diharapkan dapat membantu pengajar untuk memeriksa tugas siswa dan mengurangi tindakan plagiarisme yang dilakukan oleh siswa.
1.2 Rumusan Masalah
3
CF-IDF untuk pendeteksian plagiarisme pada Learning Management System
(LMS) di SMKN 14 Bandung.
1.3 Maksud dan Tujuan
Berdasarkan permasalahan yang ada, maka maksud dari pengembangan
Learning Management System (LMS) ini adalah untuk mengembangkan fitur
pengecekkan tugas menggunakan kombinasi algoritma TF-IDF dan CF-IDF untuk pendeteksian plagiarisme pada Learning Management System yang sudah ada di SMKN 14 Bandung sehingga dapat digunakan dengan lebih optimal. Sedangkan tujuan yang ingin dicapai adalah:
1. Membantu meringankan tugas pengajar untuk memeriksa tugas siswa 2. Mengurangi aksi plagiarisme tugas yang dilakukan oleh siswa
1.4 Batasan Masalah
Adapun batasan masalah dari pengembangan Learning Managament
System (LMS) ini adalah:
1. Sistem yang dikembangkan adalah LMS yang ada di SMKN 14 Bandung. 2. Dokumen yang dideteksi adalah dokumen yang memiliki format .pdf.
3. Algoritma yang digunakan untuk pendeteksian plagiarisme pada pengembangan LMS di SMKN 14 Bandung adalah Term Frequency-Inverse
Document Frequency (TF-IDF) dan Concept Frequency-Inverse Document
Frequency (CF-IDF).
4. Sistem hanya mendeteksi kesamaan pada dokumen yang berupa teks yang tidak meliputi dokumen yang berisi gambar dan rumus.
5. Metode analisis yang digunakan dalam pembangunan sistem menggunakan ERD (Entity Relationship Diagram), serta untuk menggambarkan pemodelan fungsionalnya menggunakan DFD (Data Flow Diagram).
6. Bahasa pemrograman yang digunakan dalam mengembangkan Learning
Management System (LMS) ini adalah bahasa pemrograman PHP dan
1.5 Metodologi Penelitian
Metodologi penelitian adalah cara yang digunakan dalam proses pengumpulan data pada penelitian yang dilakukan. Berdasarkan pengertian tersebut dapat dikatakan bahwa metode adalah cara yang dipergunakan untuk mengumpulkan data yang diperlukan dalam penelitian. Metode penelitian ini dilakukan dengan pengumpulan data dan pembangunan perangkat lunak dengan model waterfall. Alur metode penelitian yang dilakukan akan ditampilkan pada gambar 1.1 seperti berikut:
Pengumpulan Data
Analisis Data
Perancangan Data
Implementasi
Perancangan Interface Perancangan
Analisis Sistem Yang Berjalan
Analisis Kebutuhan Sistem Tujuan Perumusan Masalah
Analisis Sistem yang di Bangun
Kesimpulan
Gambar 1.1 Alur penelitian pada pengembangan Learning Management System SMKN 14 Bandung
Keterangan :
1. Pengumpulan data yaitu proses pengumpulan data yang diperlukan untuk kepentingan penelitian.
2. Analisis data dilakukan setelah proses pengumpulan data mengenai pengembangan LMS selesai dilakukan.
5
4. Tujuan, tujuan dari pengembangan LMS akan terlihat setelah proses perumusan masalah selesai dilakukan.
5. Analisis sistem yang sedang berjalan yaitu proses analisis kegiatan belajar mengajar yang sedang berjalan di SMKN 14 Bandung baik yang berjalan secara manual atau pun yang sedang berjalan berdasarkan sistem yang sudah ada.
6. Analisis sistem yang akan dibangun yaitu proses pengembangan/penambahan LMS yang sudah ada guna memperoleh sistem yang dapat digunakan dengan lebih optimal.
7. Analisis kebutuhan sistem yaitu menganalisa kebutuhan apa saja yang akan dibutuhkan pada LMS yang akan dikembangkan.
8. Perancangan yaitu proses melakukan rancangan dari LMS yang akan dikembangkan.
9. Perancangan data yaitu melakukan analisis perancangan data yang akan di kembangkan dan atau ditambahkan.
10.Perancangan interface/antarmuka yaitu proses perancangan antarmuka dari LMS yang akan dikembangkan.
11.Implementasi yaitu proses pengetesan aplikasi LMS yang dikembangkan. 12.Kesimpulan yaitu penilaian dari hasil pengembangan yang dilakukan pada
LMS SMKN 14 Bandung.
1.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah sebagai berikut:
1. Studi Literatur
2. Wawancara
Wawancara yaitu melakukan tanya jawab dengan pihak yang ada kaitannya dengan judul penelitian, yaitu Pak Muziasih selaku pihak ICT dan Pak Subandi selaku kesiswaan SMKN 14 Bandung.
3. Observasi
Observasi yaitu mengamati secara langsung prosedur pengumpulan tugas dan pemeriksaan yang sedang berjalan saat ini, baik analisis manual maupun analisis yang sedang berjalan pada Learning Management System (LMS) di SMKN 14 Bandung yang sudah ada saat ini.
1.5.2 Metode Pembangunan Perangkat Lunak
Metode yang digunakan untuk pengembangan perangkat lunak ini adalah metode waterfall. Menurut Pressman model waterfall adalah model klasik yang bersifat sistematis, berurutan dalam membangun software. Nama model ini sebenarnya adalah “Linear Sequential Model” [2]. Tahapan yang dilakukan dalam metode waterfall dapat dilihat seperti pada gambar 1.2.
7
Berikut ini deskripsi dari tahapan-tahapan tersebut :
a. Requirements Analysis and Definition
Requirements Analysis and Definition merupakan tahap mengumpulkan data
yang dibutuhkan secara lengkap, kemudian menganalisis dan mendefinisikan kebutuhan yang dibutuhkan untuk mengembangkan LMS.
b. System and Software Design
System and software design merupakan tahap membuat perancangan yang
dibutuhkan untuk mengembangkan LMS sesuai dengan tahapan analisis yang sudah dilakukan sebelumnya, dengan membuat ERD, DFD, database dan tampilan antarmuka dari LMS yang akan dikembangkan.
c. Implementation and Unit Testing
Implementation and Unit Testing merupakan penulisan kode dengan bahasa
pemrograman PHP dan MySQL sebagai database management system
(DBMS) berdasarkan hasil pemodelan pada tahap sebelumnya, kemudian dilakukan pengujian terhadap kode program yang dibuat, yaitu pendeteksian plagiarisme.
d. Integration and System Testing
Integration and System Testing merupakan tahap menggabungkan
modul-modul program kemudian diuji secara keseluruhan.
e. Operation and Maintenance
Operation and maintenance merupakan tahap pengoperasian program
dilingkungannya dan melakukan pemeliharaan, seperti penyesuaian atau perubahan karena adaptasi dengan situasi sebenarnya.
1.6 Sistematika Penulisan
BAB 1 PENDAHULUAN
Bab ini berisi antara lain latar belakang, rumusan masalah, maksud dan tujuan, batasan masalah, metodologi penelitian dan sistematika penulisan. Bab ini juga membahas secara singkat metode yang dipakai dalam penelitian yang dilakukan.
BAB 2 TINJAUAN PUSTAKA
Bab ini berisi profil, visi misi, dan struktur organisasi di SMKN 14 Bandung. Bab ini juga membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan. Pembahasan pada bab ini berfungsi sebagai dasar untuk jawaban sementara terhadap rumusan masalah yang diajukan.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Bab ini akan membahas analisis masalah dari model penelitian. Hal ini untuk memperlihatkan analisis dari perancangan sistem pendeteksian plagiarisme dan juga untuk menunjukkan model matematisnya.
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini membahas tentang implementasi dari hasil tahapan analisis dan perancangan dari LMS yang akan dikembangkan. Serta berisi uji coba dan hasil pengujian sistem pendeteksian plagiarisme yang akan dibangun pada LMS SMKN 14 Bandung.
BAB 5 KESIMPULAN DAN SARAN
9
BAB 2
TINJAUAN PUSTAKA
2.1 Profil Instansi
SMKN 14 Bandung adalah sekolah menengah kejuruan yang memiliki kelompok bidang keahlian seni rupa, kriya dan teknologi. Keberadaannya didukung oleh dunia usaha dan industri, baik dalam pembelajaran maupun penyerapan lulusannya. Pembelajaran teori dan praktek tidak hanya dilakukan didalam kelas tetapi dilakukan di dunia industri melalui praktek kerja industri di perusahaan-perusahaan yang relevan.
Lulusan SMKN 14 Bandung telah tersebar diberbagai perguruan tinggi dan dunia usaha/industri. Kesempatan untuk melanjutkan studi dan bekerja sangat terbuka luas bagi lulusannya. Jalur PMDK tersedia bagi lulusan yang berprestasi baik PTN (Perguruan Tinggi Negeri) maupun swasta. Bagi siswa yang ingin bekerja penempatannya didukung oleh Dinas Tenaga Kerja belalui Bursa Kerja Khusus (BKK) sesuai dengan kualifikasi yang dipersyaratkan poleh perusahaan.
Perkembangan ilmu dan teknologi merupakan hal yang tidak dibantah lagi, sangat berpengaruh pada gaya hidup (life style) manusia. Sekolah seni rupa, kriya dan teknologi merupakan lembaga yang sangat dekat dengan kebutuhan manusia yang semakin berkembang tersebut. Semua hal tersebut sangat erat kaitannya dengan industri kreatif. SMKN 14 Bandung merupakan sekolah yang melaksanakan pendidikan dan pelatihan bagi calon-calon tenaga kerja dan wirausahawan yang sangat cocok dengan dunia industri kreatif.
2.1.1 Sejarah Instansi
Program Keahlian Kerajinan/Kriya. Pada tahun 1994 sesuai dengan pemberlakuan kurikulum baru, terjadi perubahan nama program keahlian terdahulu menjadi Program Keahlian Seni Rupa (DKV) dan Program Keahlian Kriya yang terdiri dari kriya : kulit, logam, kayu, tekstil, keramik. Sesuai dengan perkembangan zaman dan tuntutan dunia usaha/industri SMK Negeri 14 Bandung terus berkembang, maka pada tahun 2004 dibuka jurusan baru yaitu Teknik Perbaikan Bodi Otomotif dan Teknologi Informatika/Multimedia.
2.1.2 Visi dan Misi Instansi
Visi dari SMKN 14 Bandung adalah menjadi menjadi sekolah unggulan. Sedangkan misi dari SMKN 14 Bandung adalah :
1. Menyiapkan tenaga kerja unggulan (tingkat madya) dalam bidang seni rupa, kriya dan teknologi yang berwawasan profesional.
2. Produktif dan memiliki budaya kerja keras, budaya tertib, budaya bersih untuk menjadi manusia unggulan yang jujur dan mandiri dengan branding unggul dalam prestasi.
3. Santun dalam perilaku.
2.1.3 Bidang Studi
Terdapat dua jenis bidang studi keahlian di yang ada di SMKN 14 Bandung yaitu, bidang studi keahlian seni rupa dan kriya dan juga bidang studi keahlian teknologi.
2.1.3.1Bidang Studi Keahlian Seni Rupa dan Kriya
Bidang studi ini mempelajari proses pembuatan produk seni rupa dan kriya dari proses pembuatan desain/perancangan. Proses produksi dan packaging
hingga menjadi sebuah desain/produk yang siap dipasarkan. Bidang studi keahlian ini meliputi program studi :
11
3. Desain & Produksi Kriya Kayu 4. Desain & Produksi Kriya Keramik 5. Desain & Produksi Kriya Logam 6. Desain & Produksi Kriya Tekstil
2.1.3.2Bidang Studi Keahlian Teknologi
Bidang studi ini mempelajari proses pembuatan produk teknologi informatika/multimedia dan proses pembuatan desain/perancangan body repair. Proses produksi hingga menjadi sebuah desain atau produk yang siap dipasarkan/dijual. Bidang keahlian ini meliputi program studi :
1. Teknologi Informatika (Multimedia) 2. Teknologi Animasi
3. Teknik Perbaikan Bodi Otomotif (TPBO)
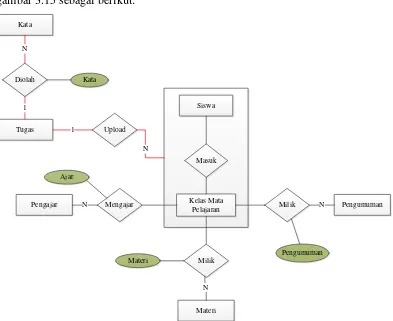
2.1.4 Struktur Organisasi
13
Tugas dan fungsi setiap bagian dari struktur organisasi SMKN 14 Bandung pada gambar 2.1 dapat dideskripsikan sebagai berikut:
1. Kepala Sekolah
a. Bertanggung jawab sepenuhnya terhadap kegiatan sekolah b. Merencanakan pengembangan penyelenggaraan pendidikan c. Mengetahui perkembangan siswa/i SMKN 14 Bandung
d. Mengetahui perkembangan pengajar serta tenaga pendidik lainnya e. Pelaksanaan hubungan sekolah dengan lingkungan atau masyarakat 2. Komite Sekolah
a. Bertanggung jawab terhadap pelaksanaan tugas dan kewajiban komite sekolah
b. Mendorong tumbuhnya perhatian dan komitmen masyarakat terhadap penyelenggaraan pendidikan yang bermutu
c. Melakukan kerjasama dengan masyarakat dalam aspek pendidikan siswa/i
d. Menampung dan menganalisis aspirasi, ide, tuntutan, dan berbagai kebutuhan pendidikan
3. Kepala Tata Usaha
a. Mengelola administrasi sekolah yang mendukung kegiatan sekolah b. Menyiapkan dan mengganti kelas
c. Menyiapkan buku isian mengajar dengan bagian kurikulum d. Mengurus administrasi pelayanan surat dan pengarsipan. 4. Wakasek Bidang Kurikulum
a. Menyusun program pengajaran
b. Menyusun pembagian tugas dan jadwal pengajaran
c. Menyusun jadwal dan pelaksanaan UTS, UAS, dan ujian akhir (UN) d. Menerapkan kriteria persyaratan naik/tidak naik dan kriteria
kelulusan
e. Mengatur jadwal penerimaan buku laporan penilaian hasil belajar dan ijazah siswa/i
g. Menyusun laporan pelaksanaan pelajaran
h. Melaksanakan pemilihan guru teladan dan membina kegiatan lomba akademis
5. Wakasek Bidang Kesiswaan
a. Mengatur penerimaan siswa baru
b. Mengatur pengelompokkan belajar siswa c. Memonitor kehadiran siswa
d. Mengatur kegiatan OSIS
e. Mengatur perpindahan/mutasi siswa/i 6. Wakasek Bidang Sarana dan Prasarana
a. Menyusun rencana kebutuhan sarana/prasarana b. Mengkoordinasikan pendayagunaan sarana/prasarana c. Pengelolaan pembiayaan alat-alat pelajaran
d. Menyusun laporan pelaksanaan urusan sarana/prasarana secara berkala
7. Wakasek Bidang Hubungan Industri
a. Mengatur dan mengadakan hubungan sekolah dengan dunia usaha/industri
b. Mengatur dan mengadakan hubungan sekolah dengan orang tua/wali siswa/i
c. Membina hubungan sekolah dengan komite sekolah
d. Membina pengembangan sekolah dengan lembaga pemerintah dan lembaga sosial lainnya
e. Menyusun dan melaksanakan praktek kerja industri untuk siswa/i SMKN 14 Bandung
f. Melaksanakan dan melakukan penelusuran alumni SMKN 14 Bandung pada dunia kerja
g. Menyusun laporan secara berkala 8. Wakasek Bidang Manajemen Mutu
15
c. Mengkoordinasikan pengembangan kesejahteraan d. Mengkoordinasikan pengembangan akreditasi
2.2 Landasan Teori
Landasan teori membahas beberapa teori dasar yang berhubungan dengan penulisan tugas akhir. Teori yang akan dibahas dalam subbab 2.2 adalah sistem, informasi, sistem informasi, kualitas sistem, kualitas informasi, E-Learning,
Learning Management System (LMS), analisis terstruktur, skala likert,
plagiarisme, Preprocessing, algoritma Terms Frequency-Inversed Document
Frequency (TF-IDF) dan Concept Frequency-Inversed Dokumen Frequency
(CF-IDF), PHP, database mySQL, Data Manipulation Language (DML), Data
Definition Language (DDL), dan Create, Read, Update, Delete (CRUD).
2.2.1 Sistem
Sistem terdiri dari sejumlah komponen yang berinteraksi artinya saling bekerja sama membentuk suatu kesatuan. Beberapa para ahli mengemukakan pegertian sistem seperti dibawah ini :
Menurut Zulkifli dalam bukunya yang berjudul “Manajemen Sistem
Informasi”, sistem adalah elemen-elemen yang saling berhubungan membentuk satu kesatuan atau organisasi [3]. Menurut Edhy Sutanto sistem adalah kumpulan elemen-elemen yang berinteraksi untuk mencapai suatu tujuan tertentu [4].
2.2.2 Informasi
Telah diketahui bahwa informasi merupakan hal yang sangat penting dalam pengambilan keputusan. Beberapa ahli mendefinisikan informasi sebagai berikut :
Terstruktur Teori dan Praktek Aplikasi Bisnis” adalah sebagai berikut: yaitu merupakan pengolahan data sehingga menjadi bentuk yang penting bagi penerimanya dan mempunyai kegunaan sebagai dasar dalam pengambilan keputusan yang dapat dirasakan akibatnya secara langsung saat itu juga atau tidak langsung pada saat yang akan datang [5].
2.2.3 Sistem Informasi
Definisi sistem informasi menurut Jogiyanto HM dalam bukunya yang berjudul “Analisis & Disain Sistem Informasi Pendekatan Terstruktur
Teori dan Praktek Aplikasi Bisnis” adalah sebagai berikut: Sistem informasi
adalah suatu sistem di dalam suatu organisasi yang mempertemukan kebutuhan pengolahan transaksi harian, mendukung operasi, bersifat manajerial dan kegiatan strategi dari suatu organisasi dan menyediakan pihak luar tertentu dengan laporan-laporan yang diperlukan [5]. Berdasarkan penjelasan di atas, dapat disimpulkan bahwa system informasi adalah kumpulan dari sub-sub sistem yang saling berhubungan dan bekerjasama untuk mencapai satu tujuan, yaitu menghasilkan informasi yang kemudian dapat diberikan kepada pihak luar.
2.2.4 Kualitas Sistem
Kualitas sistem adalah penilaian yang dilakukan oleh responden dan user dari sistem yang dibangun atau sistem yang sudah ada untuk mengetahui kriteria tentang sistem tersebut. Penilaian tersebut didapat dari penyebaran kuisioner dan wawancara yang dilakukan kepada pihak pengguna di SMKN 14 Bandung tentang
Learning Management System yang akan dibangun.
2.2.5 Kualitas Informasi
17
relevan (relevance). Namun selain tiga hal yang telah disebutkan ada juga yang menambahkan dua elemen lagi yaitu kelengkapan dan kejelasan informasi.
Akurat berarti informasi harus bebas dari kesalahan-kesalahan dan tidak bias atau menyesatkan. Informasi tersebut harus jelas mencerminkan maksudnya karena dari sumber informasi ke penerima informasi kemungkinan banyak terjadi gangguan (noise) yang dapat merubah atau merusak informasi tersebut.
Tepat pada waktunya, berarti informasi yang datang pada penerima tidak boleh terlambat. Informasi yang sudah usang tidak akan mempunyai nilai lagi, karena informasi merupakan landasan didalam pengambilan keputusan, bila pengambilan keputusan terlambat, maka dapat berakibat fatal untuk organisasi.
Relevan, berarti informasi tersebut mempunyai manfaat untuk pemakainya. Relevansi informasi untuk tiap-tiap orang satu dengan yang lainnya berbeda.
2.2.6 E-Learning
E-learning adalah sistem pembelajaran yang memanfaatkan media
elektronik sebagai alat untuk membantu kegiatan pembelajaran. Sebagian besar elektonik yang dimaksud di sini lebih diarahkan pada penggunaan teknologi komputer dan internet. Kegiatan siswa dalam mengakses bahan belajar melalui
e-learning dapat dideteksi apa yang mereka pelajari, bagaimana prosesnya,
bagaimana kemajuan belajarnya, berapa skor hasil belajarnya dan lain-lain [5]. Dalam sebuah E-Learning ada tiga komponen pembentuk E-Learning
yang digunakan untuk menerapkan sebuah E-Learning, diantaranya yaitu sebagai berikut :
1. Infrastruktur e-learning, yaitu dapat berupa Personal Computer (PC), jaringan komputer, internet dan perlengkapan multimedia. Termasuk didalamnya peralatan teleconference apabila menggunakan layanan
synchronous learning melalui teleconference.
penilaian, sistem ujian dan segala fitur yang berhubungan dengan manajemen proses belajar mengajar. Sistem perangkat lunak tersebut sering disebut dengan Learning Management System (LMS). LMS banyak yang bersifat open source sehingga bisa dimanfaatkan dengan mudah dan murah untuk dikembangkan disekolah, universitas, atau lembaga pendidikan lainya.
3. Konten e-learning, yaitu konten dan bahan ajar yang ada pada e-learning
system (Learning Management System). Konten dan bahan ajar ini bisa berbentuk multimedia based content (konten berbentuk multimedia interaktif) atau text-based (konten berbentuk teks seperti pada buku pelajaran biasa).
Sistem penyampaian isi dalam e-learning, dapat digolongkan menjadi dua, yaitu komunikasi satu arah (one way communication) atau komunikasi dua arah
(two way communication). Komunikasi atau interaksi antara instruktur/pengajar
dan siswa dalam proses pembelajaran memang sebaiknya melalui sistem dua arah. Dalam e-learning, sistem komunikasi dua arah dapat diklarifikasikan menjadi dua, yaitu :
1. Secara langsung (synchronous), artinya pada saat instruktur/pengajar memberikan pembelajaran, murid dapat langsung mendengarkan.
2. Secara tidak langsung (asynchronous), misalnya pesan dari instruktur/pengajar direkam dahulu sebelum digunakan.
2.2.7 Learning Management System (LMS)
LMS merupakan sebuah sistem yang digunakan dalam mengelola kegiatan pembelajaran jarak jauh (e-learning) serta hasil-hasilnya. LMS berfungsi untuk menyimpan, mengelola, dan mendistribusikan berbagai materi pelatihan, soal ujian, beserta nilai-nilai yang didapatkan dari ujian tersebut. Sebuah learning management system yang kuat harus dapat melakukan hal-hal berikut :
a. Memusatkan dan mengotomisasi administrasi. b. Menggunakan self service dan self guide services.
19
d. Konsolidasi pelatihan inisiatif pada sebuah scaleable web-based platform. e. Mendukung portabilitas dan standar.
f. Mendukung personalisasi konten dan memungkinkan penggunaan kembali.
Saat ini ada banyak jenis LMS yang ditawarkan, setiap jenis LMS memiliki fiturnya masing-masing, yang dapat berbeda fiturnya. Fitur-fitur yang terdapat dalam LMS pada umumnya antara lain :
a. Administrasi, yaitu informasi tentang unit-unit terkait dalam proses belajar mengajar, seperti :
1. Tujuan dan sasaran 2. Silabus
3. Metode pengajaran 4. Jadwal belajar 5. Tugas
6. Jadwal ujian
7. Daftar referensi atau bahan bacaan 8. Profil dan kontak pengajar
9. Pelacakan/tracking dan monitoring
b. Penyampaian materi dan kemudahan akses ke sumber referensi, diantaranya yaitu :
1. Diktat dan catatan belajar 2. Bahan presentasi
3. Contoh ujian yang lalu
4. FAQ (Frequently Asked Question)
5. Sumber-sumber referensi untuk pengerjaan tugas 6. Situs-situs bermanfaat
7. Artike-artikel dan jurnal-jurnal online
c. Penilaian
d. Ujian online dan pengumpulan feedback
2. Mailing list diskusi 3. Chat
2.2.8 Analisis Terstruktur
Analisis Terstruktur (Structured Analysis), merupakan salah satu teknik analisis yang mengunakan pendekatan berorientasi fungsi. Analisis ini terfokus pada aliran data dan proses bisnis perangkat dan perangkat lunak. Teknik ini mempunyai sekumpulan petunjuk dan perangkat komunikasi grafis yang memungkinkan analis sistem mendefinisikan spesifikasi fungsional perangkat lunak secara terstruktur.
Pada metode ini semua fungsi sistem direpresentasikan sebagai sebuah proses transformasi informasi, dan disusun secara hirarkis sesuai tingkat abstraksinya (sistem maupun perangkat lunak) yang hasilnya ditujukan untuk entitas-entitas eksternal. Prinsip dari teknik ini adalah dekomposisi fungsi dari sistem berdasarkan aliran data dan proses-prosesnya untuk mendapatkan produk analisis yang dapat diubah dan diperbaiki secara mudah (highly maintainable).
2.2.8.1Perangkat Pemodelan Analisis Terstruktur
Perangkat pemodelan analisis terstruktur adalah alat bantu pemodelan yang digunakan untuk menggambarkan hasil pelaksanaan analisis terstruktur.
Perangkat analisis terstruktur antara lain :
1. Entity Relational Diagram (ERD)
ERD merupakan notasi grafis dalam pemodelan data konseptual yang mendeskripsikan hubungan antara penyimpanan. ERD digunangan untuk memodelkan struktur data dan hubungan antar data, karena hal ini relative kompleks. Dengan ERD kita dapat menguji model dengan mengabaikan proses yang dilakukan. ERD menggunakan sejumlah notasi dan simbol untuk menggambarkan struktur dan hubungan antar data.
2. Diagram Konteks
21
tertinggi dari DFD yang menggambarkan seluruh input ke sistem atau output dari sistem. Ia akan memberi gambaran tentang keseluruhan sistem. Sistem dibatasi oleh boundary (dapat digambarkan dengan garis putus). Dalam diagram konteks hanya ada satu proses. Tidak boleh ada store dalam diagram konteks. Diagram konteks berisi gambaran umum (secara garis besar) sistem yang akan dibuat. Secara kalimat, dapat dikatakan bahwa diagram konteks ini berisi siapa saja yang memberi data (dan data apa saja) ke sistem, serta kepada siapa saja informasi (dan informasi apa saja) yang harus dihasilkan sistem.
3. Data Flow Diagram (DFD)
Diagram untuk menggambarkan aliran data dalam sistem, sumber dan tujuan data, proses yang mengolah data tersebut, dan tempat penyimpanan datanya. Keuntungan dari diagram arus data adalah memungkinkan pengembangan sistem dari level yang paling tinggi dan memecah menjadi level yang lebih rendah.
DFD dapat dipartisi ke dalam tingkat-tingkat yang merepresentasikan aliran informasi yang bertambah dan fungsi ideal. Tingkatan-tingkatan yang ada pada DF, yaitu:
a. Diagram Konteks
Diagram konteks menggambarkan ruang lingkup sistem untuk memberikan pandangan umum sistem. Diagram konteks merupakan level tertinggi dari DFD.
b. Diagram level satu
Tingkat yang lebih bawah dari diagram konteks adalah diagram level satu atau DFD level 1. Diagram level satu menggambarkan proses-proses utama dari sistem
c. Diagram level n
4. Kamus Data
Merupakan suatu tempat penyimpanan (gudang) dari data dan informasi yang dibutuhkan oleh suatu sistem informasi. Kamus data digunakan untuk mendeskripsikan rincian dari aliran data atau informasi yang mengalir dalam sistem, elemen-elemen data, file maupun basis data (tempat penyimpanan) dalam DFD.
2.2.9 Pengujian Alpha dan Beta
Pengujian alpha dan beta dilakukan untuk memungkinkan pelanggan untuk melakukan validasi seluruh keperluan. Test ini dilakukan karena memungkinkan pelanggan menemukan kesalahan yang lebih rinci dan membiasakan pelanggan memahami aplikasi yang dibuat.
1. Pengujian Alpha
Pengujian alpha bertujuan untuk identifikasi dan menghilangkan sebanyak mungkin masalah sebelum akhirnya sampai ke user, pengujian dilakukan setelah software selesai oleh orang-orang yang tidak terlibat dalam pengembangan dan memang ahli di bidangnya.
2. Pengujian Beta
Pengujian beta dievaluasi sepenuhnya oleh pengguna. Pengguna dipilih beberapa yang dibagi menjadi potensial, average, slow learner. Mereka diberitahukan prosedur evaluasi, diamati proses penggunaannya, diwawancara lalu dinilai dan dilakukan revisi.
2.2.10 Plagiarisme
23
plagiator, yaitu orang yang mengambil karangan (pendapat dan sebagainya) orang lain dan disiarkan sebagai karangan (pendapat dan sebagainya) sendiri penjiplak.
Plagiarisme berasal dari bahasa latin plagiari(us) yang berarti penculik dan plagium yang berarti plagi(um) yang berarti menculik. Kata tersebut pertama kali diperkenalkan oleh penyair Romawi, Marcus Valerius Martialis, pada abad pertama masehi. Pada saat itu ia mengeluhkan puisi lain yang kata-katanya sama dengan yang telah dibuatnya. Pada tahun 1601, kata Latin itu dimasukkan ke dalam bahasa Inggris oleh Ben Johnson ke dalam plagiarism. Melihat akar katanya, jelas bahwa plagiarisme dalam penulisan laporan akademis mengandung unsur “pencurian” intelektual karena terjadi pengambilan paksa kata-kata/gagasan tanpa seizin pemiliknya.
2.2.11 Text Mining
Text mining adalah salah satu bidang khusus dari data mining. Text
mining dapat didefinisikan sebagai suatu proses menggali informasi dimana
seorang user berinteraksi dengan sekumpulan dokumen menggunakan
tools/perangkat analisis yang merupakan komponen-komponen dalam data mining
yang salah satunya adalah kategorisasi. Secara umum proses-proses pada text
mining adalah mengadopsi dari proses data mining. Proses-proses utama pada text
mining diantaranya pemrosesan awal text (text preprocessing), penemuan pola
(pattern discovery), transformasi teks (text transformation), pemilihan fitur
(feature selection). Proses yang umum dilakukan oleh penambangan teks di
antaranya adalah perangkuman otomatis, kategorisasi dokumen, penggugusan teks.
Teks yang akan dilakukan proses text mining, pada umumnya memiliki beberapa karakteristik diantaranya adalah memiliki dimensi yang tinggi, terdapat
noise pada data, dan terdapat struktur teks yang tidak baik. Cara yang digunakan
dalam mempelajari suatu data teks, adalah dengan terlebih dahulu menentukan fitur-fitur yang mewakili setiap kata untuk setiap fitur yang ada pada dokumen. Sebelum menentukan fitur-fitur yang mewakili, diperlukan tahap preprocessing
yang dilakukan secara umum dalam text mining pada dokumen, yaitu case folding, tokenizing, dan filtering.
2.2.12 Pre-processing
Pre-processing atau pemrosesan teks merupakan proses menggali,
mengolah, mengatur informasi dengan cara menganalisis hubungannya, aturan-aturan yang ada di data tekstual semi terstruktur atau tidak terstruktur. Untuk lebih efektif dalam proses pemrosesan dilakukan langkah transformasi data ke dalam suatu format yang memudahkan untuk kebutuhan pemakai. Proses ini disebut
pre-processing dokumen. Setelah teks sudah dalam bentuk yang lebih terstruktur
dengan adanya proses pre-processing, data dapat dijadikan sumber data yang dapat diolah lebih lanjut. Sama halnya preprocessing pada Information Retrieval
(IR), tahapan preprocessing ang digunakan untuk pengembangan LMS ini terdiri dari case folding, tokenizing, dan filtering.
1. Case Folding
Case folding adalah mengubah semua huruf dalam dokumen menjadi
huruf kecil (lowercase). Hanya huruf „a‟ sampai dengan „z‟ yang diterima,
25
PHP (Pemrograman Hyper Processor) merupakan sebuah bahasa scripting server-side, dimana pemrosesan datanya dilakukan
pada sisi server
php pemrograman hyper processor merupakan sebuah bahasa scripting server
side dimana datanya dilakukan pada sisi server
(Teks input)
(Teks output)
Gambar 2.2 Case Folding
2. Tokenizing
Tokenizing adalah tahap pemotongan string input berdasarkan tiap kata
yang menyusunnya. Tahapan ini tidak harus dilakukan apabila terdapat pengolahan pada bentuk frase yaitu dua kata yang bermakna dalam satu arti. Contoh dari tahap ini seperti adalah pada Gambar 2.5.
Sinonim adalah suatu kata yang memiliki bentuk yang berbeda namun memiliki arti atau pengertian yang sama atau mirip
sinonim
Gambar 2.3 Proses Tokenizing
3. Filtering
Tahap filtering adalah tahap mengambil kata-kata penting dari hasil token dapat menggunakan algoritma stoplist (membuang kata yang kurang penting) atau wordlist (menyimpan kata penting). Stoplist / stopword
sinonim
Gambar 2.4 Proses Filtering
2.2.13 Algoritma TF-IDF (Terms Frequency – Inverse Document Frequency)
Pembobotan TF - IDF adalah jenis pembobotan yang sering digunakan dalam information retrieval dan text mining [8]. Pembobotan ini adalah suatu pengukuran statistik untuk mengukur seberapa penting sebuah kata dalam kumpulan dokumen. Tingkat kepentingan meningkat ketika sebuah kata muncul beberapa kali dalam sebuah dokumen tetapi diimbangi dengan frekuensi kemunculan kata tersebut dalam kumpulan dokumen.
Pembobotan dalam TF-IDF dilakukan dengan menghitung TF (Terms
Frequency):
(2.1)
Keterangan:
= rasio frekuensi terms pada dokumen
Setelah itu, lakukan perhitungan nilai IDF dengan membagi jumlah total dokumen dengan jumlah dokumen yang terdapat kemunculan terms (Ti)
|{ | | }| (2.2) Keterangan:
= rasio frekuensi dokumen
27
{ } = jumlah dokumen yang terdapat kemunculan terms Terakhir, nilai tf dikalikan dengan nilai IDF.
(2.3)
Keterangan:
= bobot TF-IDF
= rasio frekuensi terms pada dokumen = rasio frekuensi dokumen.
2.2.14 Algoritma CF-IDF (Concept Frequency–Inversed Document Frequency)
Menentukan nilai kecocokan antara dokumen dan keyword diperlukan pembobotan. Pembobotan atau disebut juga weighting merupakan pemberian bobot terhadap kata/frase yang telah dihasilkan dari tahap sebelumnya. Model pembobotan tersebut dapat dengan pembobotan global, lokal atau pun kombinasi dari keduanya. Terdapat beberapa macam pembobotan teks yaitu TF-IDF (Term
Frequency-Inverse Document Frequency) dan CF-IDF (Concept
Frequency-Inverse Document Frequency).
Salah satu pembobotan kombinasi tersebut adalah CF-IDF (Concept
Frequency-Inverse Document Frequency). Algoritma ini merupakan
pengembangan dari algoritma TF-IDF (Term Frequency-Inverse Document
Frequency). Pada algoritma ini, tidak melakukan perhitungan terhadap term
(seperti pada TF-IDF) namun dengan menghitung key concept yang ditemukan dalam teks [8]. Pada CF-IDF, dilakukan pendekatan representasi isi dokumen dengan menggunakan jaringan semantik yang disebut dokumen inti semantik. Dokumen tersebut kemudian dipetakan dalam jaringan semantik yang disebut
wordnet dan dikonversikan dari sekumpulan terms menjadi sekumpulan konsep
(concept). Pendekatan ini membuat konsep CF-IDF terlihat lebih cerdas
katanya dapat memiliki banyak arti dan menimbulkan ambiguitas dalam pembacaannya.
Dalam mendeteksi concept dari dokumen dapat dilakukan dengan dua cara yaitu dengan memproyeksikan ontologi ke dalam dokumen dengan mengekstrak semua frase (istilah majemuk) dari ontologi kemudian mengidentifikasikan kemunculannya dalam dokumen. Cara yang kedua adalah dengan memproyeksikan dokumen ke dalam ontology, untuk setiap calon frase yang terbentuk (yang dideteksi dari kedekatan kata atau adjacent).
Tabel 2.1 Pemetaan Concept
Token / Frasa Concept Keterangan
Kitab Buku dengan level kata yang berbeda
Tidak baik Buruk Frasa yang bersinonim
Setelah itu, dilakukan pembobotan seperti yang dilakukan pada TF-IDF. Pembobotan dalam CF-IDF dilakukan dengan menghitung CF (Concept
Frequency):
Setelah itu, lakukan perhitungan nilai IDF dengan membagi jumlah total dokumen dengan jumlah dokumen yang terdapat kemunculan konsep (Ci)
|{ | | }| (2.5) Keterangan:
= rasio frekuensi dokumen
29
{ } = jumlah dokumen yang terdapat kemunculan concept
Terakhir, nilai Cf dikalikan dengan nilai IDF.
(2.6)
Keterangan:
= bobot CF-IDF
= rasio frekuensi concept pada dokumen = rasio frekuensi dokumen.
2.2.15 Vector Space Model (VSM)
Vector space model (VSM) adalah gambaran dokumen dalam bentuk
vektor kata. Penentuan relevansi dokumen dengan query dipandang sebagai pengukuran kesamaan antara vektor dokumen dengan vektor query. Semakin sama suatu vektor dokumen dengan vektor query maka dokumen dapat dipandang semakin relevan dengan query [10]. Perhitungan kesamaan antara vektor query dan vektor dokumen dilihat dari sudut paling kecil. Sudut yang dibentuk oleh dua buah vektor dapat dihitung dengan melakukan perkalian dalam (inner product), sehingga rumus relevansinya adalah:
| || | (2.7)
Keterangan: Q = bobot query D = bobot dokumen |Q| = panjang query |D| = panjang dok
2.2.16 PHP
PHP (Pemrograman Hyper Preprocessor) merupakan sebuah bahasa
scripting server-side, dimana pemrosesan datanya dilakukan pada sisi server.
Contoh sintak dari pemrograman PHP adalah sebagai berikut : 1. <?php
2. echo “Halo Dunia”;
3. //ini akan menampilkan tampilan Halo Dunia 4. $sebuah_bilangan = 4;
5. $bilangan yang lain = 8; 6. ?>
2.2.16.1Sejarah singkat PHP
PHP dibuat oleh Resmus Lerdorf pada tahun 1994, pada awalnya tidak untuk didistribusikan dan hanya digunakan pada homepage pribadinya. Pada tahun 1995 dikeluarkan versi pertama yang dapat digunakan oleh umum dengan nama Personal Home Page Tools. Ditulis kembali pada pertengahan 1995 dan diberi nama sebagai PHP/FI Version 2. FI berasal dari paket resmus yang mana merupakan HTML interpreter untuk data form. Pada hasil kombinasi tersebut juga ditambah dukungan terhadap SQL. PHP/FI terus berkembang dan banyak orang mulai memberikan kontribusi dalam pengembangannya.
Pada tahun 1996 PHP/FI diperkirakan telah digunakan 15.000 situs web
didunia, dan pada pertengahan 1997 jumlah ini berkembang melebihi 50.000. Pada pertengahan 1997 juga terjadi perubahan pada PHP dimana berubah menjadi proyek yang didukung oleh tim yang lebih terorganisasi. Persyaratan ditulis ulang oleh Zeev Suraski dan Andi Gutmans dan parser baru inilah yang membentuk basis untuk PHP versi 3.Banyak kode utility dari PHP/FI yang dimasukan ke PHP dan banyak diantaranya telah selesai ditulis kembali. Sekarang baik PHP /FI telah diikutsertakan dalam sejumlah produk komersial seperti C2‟s Strong web server
31
2.2.17 Database dan MySQL
Pembahasan mengenai perintah-perintah SQL yang berhubungan dengan
database dan tabel yang berguna untuk pengembangan aplikasi Learning
Management System (LMS) yang akan dibahas adalah:
1. Membuat Database
Database dapat dibuat dengan dua cara yang dapat anda lakukan, cara yang pertama dari shell dan cara yang kedua dapat anda lakukan dari MySQL.
2. Membuat Database Dari MySQL
Untuk membuat database dari MySQL digunakan perintah CREATE
DATABASE.
3. Melihat Database
Untuk melihat semua database yang berada dalam server anda dapat menggunakan perintah mysql show dari shell atau anda dapat menggunakan perintah show database dari MySQL anda dapat memberikan perintah dibawah ini : Mysql> SHOW DATABASE. 4. Menghapus Database
Untuk menghapus database ini dapat digunakan perintah DROP. 5. Mengaktifkan Database
Untuk mengaktifkan database dapat anda berikan perintah USE nama_database contoh: Use database.
6. Melihat Database Aktif
Untuk melihat database yang aktif dapat digunakan fungsi SELECT DATABASE.
7. Tipe Data
Tipe data dalam MYSQL terbagi menjadi 3 bagian: a. Tipe Data Numerik
Untuk melakukan operasi matematika dalam php dapat dilakukan dengan menggunakan beberapa jenis tipe data numerik.
Untuk melakukan operasi yang berhubungan dengan tanggal dan waktu, maka dapat digunakan tipe data berikut:
c. Tipe Data String
Untuk melakukan operasi yang berhubungan dengan string, maka dapat digunakan tipe data berikut:
d. Membuat Tabel
Untuk membuat tabel menggunakan perintah Create <namatabel>. e. Perintah Dasar SQL
Yang akan dibahas mengenai perintah-perintah dasar dalam MySQL yang berhubungan dengan manipulasi data. Antara lain:
1. Insert
Perintah Insert digunakan untuk menyisipkan data atau untuk menambah data.
b. Select
Perintah Select berfungsi untuk menampilkan data.
c. Update
Perintah Update berguna untuk merubah data.
d. Delete
Perintah ini digunakan untuk menghapus data dari tabel yang sedang aktif saat ini.
e. Where
Untuk menampilkan data dengan kriteria tertentu dalam suatu tabel.
33
Digunakan untuk menampilkan data dengan urutan tertentu seperti yang tercantum dalam group by.
2.2.18 Data Manipulation Language (DML)
Data Manipulation Language (DML) digunakan untuk memanipulasi
data yang ada dalam suatu tabel. Perintah yang umum dilakukan yaitu :
a. Select untuk menampilkan data
b. Insert untuk menambahkan data baru
c. Update untuk mengubah data yang sudah ada
d. Delete untuk menghapus data
Berikut akan diberikan contoh mengenai syntax dari DML:
1. Select
SELECT*FROM Tb_siswa
2. Insert
INSERT into Tb_siswa (nama, alamat, password) values („test‟, „alamat‟, „pass‟)
3. Update
UPDATE Msuser set password=”123abc” where username =”abc”
4. Delete
DELETE FROM Test where nama=”Test”
2.2.19 Data Definition Language (DDL)
Data Definition Language (DDL) digunakan untuk mendefinisikan,
mengubah, serta menghapus basis data dan objek-objek yang diperlukan dalam basis data, misalnya tabel, view, user dan sebagainya. Fungsi yang biasa digunakan dalam DDL yaitu :
a. Create digunakan untuk membuat basis data maupun objek-objek
basis data.
b. Use untuk menggunakan objek
d. Drop untuk menghapus objek
Berikut contoh syntax dari Data Definition Language :
1. Create
Create Table pelajaran ( Kode_pelajaran CHAR (4).
Nama_pelajaran VARCHAR (100), Jurusan VARCHAR (100),
Primary Key (Kode_pelajaran) );
2. Use
Use_dbelsmkn14;
3. Alter
Alter Table siswa
ADD alamat Varchar (100) After nama; 4. Drop
Drop table dbelsmkn14;
2.2.20 Create, Read, Update, Delete (CRUD)
Menurut Andrew Novick dalam jurnalnya yang berjudul “Implementing
CRUD Operation Using Stored Procedures”, CRUD adalah kependekan dari
empat operasi penting dalam database, yaitu Create (membuat), Read (membaca),
Update (mengolah), Delete (menghapus) [12]. Sistem CRUD banyak digunakan
pada aplikasi perangkat lunak berbasis web yang terintegrasi dengan database. Sistem CRUD yang baik juga mengharuskan penggunanya untuk dapat melakukan 4 operasi dasar, yaitu:
1. CREATE, membuat dan menambahkan data baru
2. READ, membaca, menerima, mencari, dan melihat data masukkan 3. UPDATE, memperbarui atau mengubah data yang ada
35
Berikut akan diberikan contoh sintaks sederhana dari operasi CRUD dengan menggunakan bahasa pemrograman PHP:
1. CREATE 6. $jurusan = $_POST[„jurusan‟];
7. $input = mysql_query(“INSERT INTO siswa VALUES(NULL, „$nis‟, „$nama‟, „$kelas‟, „$jurusan‟)”) or die(mysql_error());
2. READ 1. <td>
2. <select name=”jurusan” required>
3. <option value=””>Pilih Jurusan</option>
4. <option value=”Teknik Komputer dan Jaringan”>Teknik komputer dan Jaringan</option>
5. <option value=”Multimedia”>Multimedia</option> 6. <option value=”Akuntansi”> Akuntansi </option> 7. <option value=”Perbankan”> Perbankan</option> 8. <option value=”Pemasaran”> Pemasaran</option> 9. </select>
10. </td>
3. UPDATE 1. <td>
2. <select name="kelas" required>
3. <option value="">Pilih Kelas</option>
5. <option value="XI" <?php if($data['siswa_kelas'] == 'XI'){ echo 'selected'; } ?>>XI</option>
6. <option value="XII" <?php if($data['siswa_kelas'] == 'XII'){ echo 'selected'; } ?>>XII</option>
7. </select> 8. </td>
4. DELETE
1. $del = mysql_query("DELETE FROM siswa WHERE siswa_id='$id'"); 2. if($del){
3. echo 'Data siswa berhasil di hapus! '; 4. echo '<a href="index.php">Kembali</a>'; 5. }else{
6. echo 'Gagal menghapus data! ';
37
BAB 3
ANALISIS DAN PERANCANGAN
Tahap analisis dan perancangan merupakan tahap sistematis untuk menyesuaikan kegunaan dan tujuan pada aplikasi.Tahap awal pada tahap analisis dimulai dari analisis masalah, menganalisis sistem dengan menganalisis aplikasi sejenis, analisis fungsional dan non-fungsional. Sedangkan untuk tahap perancangan dimulai dengan melakukan perancangan sistem yang mencakup perancangan antar muka dan perancangan struktur menu yang nantinya akan digunakan untuk diterapkan pada aplikasi.
Tahap analisis dan perancangan merupakan tahap sistematis untuk menyesuaikan kegunaan dan tujuan pada aplikasi. Tahap awal pada tahap analisis dimulai dari analisis masalah, analisis fungsional dan non-fungsional. Sedangkan untuk tahap perancangan dimulai dengan melakukan perancangan sistem yang mencakup perancangan antar muka dan perancangan struktur menu yang nantinya akan digunakan untuk diterapkan pada aplikasi.
3.1 Analisis Sistem
Analisis sistem merupakan tahap untuk mempelajari interaksi sistem yang terdiri dari pelaku sistem, prosedur, data serta informasi yang terkait. Analisis dilakukan terhadap sistem yang sedang berjalan sebagai dasar perancangan atau perbaikan sistem lama.
3.1.1 Analisis Masalah
dapat membantu melakukan pengecekan tugas siswa dan mengurangi tindakan plagiarisme yang dilakukan oleh siswa pada saat mengumpulkan tugas secara
online di LMS SMKN 14 Bandung yang sedang berjalan saat ini.
3.1.2 Analisis Sistem yang Berjalan
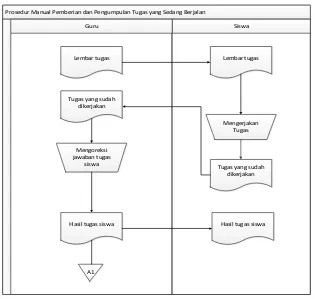
Analisis sistem yang sedang berjalan merupakan kegiatan menganalisis prosedur-prosedur kerja yang terjadi yang ada saat ini. Hasil dari kegiatan analisis ini berupa gambaran nyata dari urutan proses pengumpulan tugas dari siswa ke pengajar di SMKN 14 Bandung. Prosedur manual pemberian dan pengumpulan tugas yang berjalan digambarkan dalam flowmap pada gambar 3.1. Adapun alur prosedur manual pemberian dan pengumpulan tugas di SMKN 14 Bandung adalah sebagai berikut:
Prosedur Manual Pemberian dan Pengumpulan Tugas yang Sedang Berjalan
Siswa
Gambar 3.1 Analisis Sistem yang Sedang Berjalan
Keterangan A1 = arsip hasil tugas siswa 1. Pengajar memberikan tugas pada siswa
39
3. Siswa mengumpulkan tugas kepada pengajar sesuai waktu yang ditentukan 4. Pengajar memeriksa tugas siswa satu per satu
5. Apabila terindikasi ada yang melakukan plagiat maka tugasnya dipisahkan 6. Pengajar memanggil siswa yang tugasnya terindikasi plagiat
Apabila ada siswa yang terbukti melakukan plagiat maka diberi nasihat
3.1.3 Analisis Data Masukkan
Proses pada text mining merupakan proses untuk mendapatkan pengetahuan dari data, dalam text mining pengetahuan tersebut berarti diambil dari dokumen (artikel, tulisan dan sebagainya) dengan mencari keterkaitan kata-kata yang terdapat pada setiap dokumen, dalam kasus ini dokumen tugas siswa. Tujuannya adalah untuk menganalisis informasi setiap kata yang saling berhubungan pada sebuah dokumen atau lebih.
Analisis data masukkan dalam pendeteksian plagiarisme tugas disini menjelaskan tentang data masukkan yang digunakan guna pemrosesan selanjutnya, yaitu adalah dokumen masukan dari siswa yang merupakan tugas berisi judul, abstrak dan isi yang berbahasa Indonesia yang menjadi dokumen banding.
Sebagai contoh dimisalkan dalam sebuah dokumen terdapat satu buah masukkan beberapa teks pada judul dokumen uji (Q) dan tiga buah data pada judul dokumen pembanding (A1, A2, A3). Judul dokumen uji (Q) yang merupakan teks yang dideteksi berisi “SISTEM PENDUKUNG KEPUTUSAN PEMILIHAN MOBIL DENGAN MENGGUNAKAN METODE AHP”, dan ketiga judul dokumen banding yang berisi teks sebagai berikut:
1. Judul dokumen banding pertama (A1) berisi “SISTEM VERIFIKASI BIOMETRIKA TELAPAK TANGAN DENGAN METODE DIMENSI FRAKTAL LACUNARITY”.
3. Judul dokumen ketiga (A3) berisi “SISTEM PENDUKUNG KEPUTUSAN PEMBELIAN MOBIL UNTUK PENYEWAAN MOBIL DENGAN METODE AHP”.
3.1.4 Pre-processing
Tahapan awal dari data masukkan yaitu dilakukan pre-processing yang berfungsi untuk melakukan pengolahan dokumen menjadi kata-kata inti, terdapat tiga tahapan yaitu case folding, tokenizing, dan filtering.
3.1.4.1Proses Case Folding
Proses case folding berfungsi untuk mengubah seluruh teks menjadi huruf kecil dan membuang karakter lain selain huruf mulai dari „a’ hingga „z’. berikut contoh proses case folding:
1. Tahap case folding pada judul dokumen uji
Tahap case folding pada judul dokumen uji (Q) ini mengubah huruf kapital menjadi huruf kecil.
Gambar 3.2 Proses case folding pada judul dokumen uji
2. Tahap case folding pada judul dokumen pembanding
41
Gambar 3.3 Proses case folding pada judul dokumen A1
b. Tahap case folding pada judul dokumen kedua (A2)
Gambar 3.4 Proses case folding pada judul dokumen A2
c. Tahap Case folding pada judul dokumen ketiga (A3)
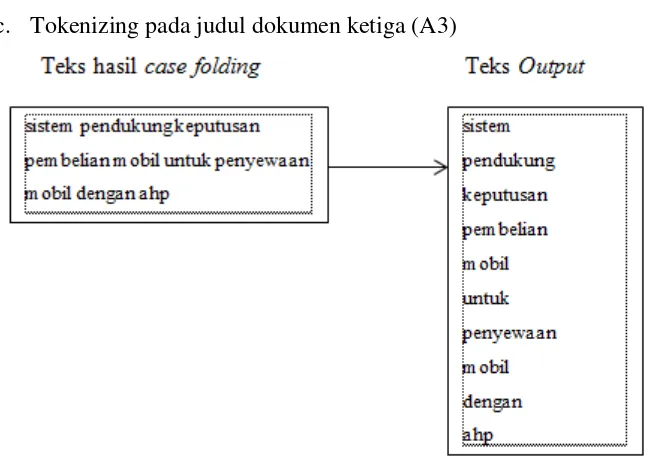
Gambar 3.5 Proses case folding pada judul dokumen A3
3.1.4.2Proses Tokenizing
Proses tokenizing berfungsi untuk melakukan pemotongan string input berdasarkan tiap kata yang menyusunnya. Dari teks akan adanya pemotongan kata dari horizontal menjadi vertikal yang merupakan hasil token. Proses tokenizing
1. Tahap tokenizing pada judul dokumen uji (Q)
Pada tahap ini dilakukan pemotongan string input berdasarkan tiap kata yang menyusunnya, yaitu kalimat pada judul dokumen uji (Q).
Gambar 3.6 Proses tokenizing pada judul dokumen uji (Q)
2. Tahap tokenizing pada judul dokumen pembanding
Pada tahap ini dilakukan pemotongan string input berdasarkan tiap kata yang menyusunnya.
a. Tokenizing pada judul dokumen pertama (A1)
43
b. Tokenizing pada judul dokumen kedua (A2)
Gambar 3.8 Proses tokenizing pada judul dokumen A2
c. Tokenizing pada judul dokumen ketiga (A3)
3.1.4.3Filtering
Proses filtering atau penyaringan ini berfungsi untuk melakukan proses pengambilan kata-kata dari hasil token. Pengambilan kata dapat menggunakan algoritma pembuangan kata yang kurang penting atau menyimpan kata penting. Algoritma pada proses penyaringan ini berupa isi teks berisi kata sambung, depan, nama hari, nama bulan, nama tempat, dan lainnya sehingga proses penyaringan ini mendapatkan kata-kata yang penting saja. Berikut merupakan proses filtering yang dilakukan:
1. Tahap filtering pada judul dokumen uji (Q)
Tahap mengambil kata-kata penting dari hasil token
Gambar 3.10 Proses filtering pada judul dokumen uji (Q)
2. Tahap filtering pada dokumen pertama (A1)
Tahapan dalam mengambil kata-kata penting dari hasil token.
45
Gambar 3.11 Proses filtering pada judul dokumen A1
b. Filtering pada judul dokumen kedua (A2)
Gambar 3.12 Proses filtering pada judul dokumen A2
Gambar 3.13 Proses filtering pada judul dokumen A3
3.1.5 Wordnet
Setelah melalui ketiga tahap pre-processing, maka kemudian akan melalui tahap ekstraksi terhadap wordnet. Tahap ini dilakukan untuk mencari konsep dari setiap kata atau frase yang terdapat pada kalimat. Konsep tersebut dapat berupa kata atau frase yang bersinonim ataupun memiliki makna yang sama. Dari ekstraksi tersebut didapatkan hasil kata yang mengandung makna yang bersinonim, hasil yang didapatkan sebagai berikut:
1. Teks pada judul dokumen pertama (A1) : sistem verifikasi biometrika telapak tangan metode dimensi fraktal lacunarity
2. Teks pada judul dokumen kedua (A2) : sistem pendukung keputusan metode ahp seleksi siswa mengikuti olimpiade sains sekolah menengah atas
3. Teks pada judul dokumen ketiga (A3) : sistem pendukung keputusan pembelian kendaraan penyewaan kendaraan metode ahp
3.1.6 Analisis Algoritma
Dalam penelitian ini untuk memecahkan masalah pendeteksian plagiarisme tugas pada LMS SMKN 14 Bandung digunakan algoritma TF-IDF
47
CF-IDF (Concept Frequency – Inverse Document Frequency). Pembobotan TF-IDF adalah jenis pembobotan yang sering digunakan dalam information retrieval
dan text mining. Pembobotan ini adalah suatu pengukuran statistik untuk
mengukur seberapa penting sebuah kata dalam kumpulan dokumen. Tingkat kepentingan meningkat saat sebuah kata muncul beberapa kali dalam sebuah dokumen tetapi diimbangi dengan frekuensi kemunculan kata tersebut dalam kumpulan dokumen/tugas. Sedangkan pada algoritma CF-IDF (Concept
Frequency – Inverse Document Frequency) tidak melakukan perhitungan terhadap
term (seperti pada TF-IDF) namun dengan menghitung key concept yang ditemukkan dalam teks.
Proses-proses yang dilakukan dalam mencapai output yang diharapkan yaitu pertama-tama merupakan tahapan pre-processing. Dokumen tugas diambil bagian teks dari judul dan abstrak sebagai masukkan, kemudian dilakukan case
folding yaitu mengecilkan huruf seluruh teks dan membuang karakter lain selain
huruf mulai „a’ hingga „z’, kemudian dilakukan tokenizing yaitu memecahkan teks ke dalam kumpulan kata-kata, setelah hasil tokenizing diperoleh kemudian dilakukan proses filtering dimana itu adalah proses menghilangkan kata-kata yang dianggap tidak penting. Setelah pre-processing dilakukan, masuklah pada tahapan
processing algoritma TF-IDF (Term Frequency – Inverse Document Frequency)
untuk menghitung kemunculan kata yang mirip dari judul dan isi abstrak dari dokumen tugas. Setelah hasil dari perhitungan TF-IDF (Term Frequency – Inverse
Document Frequency) didapat, langkah berikutnya yaitu mengukur kesamaan teks
dengan fungsi similaritas yaitu dengan menghitung cosine similarity. Setelah mendapatkan dokumen dengan persentase kemiripan tinggi lalu dilakukan
pre-processing untuk isi dari dokumen tugas hasil output sebelumnya. Setelah
pre-processing dilakukan masuklah pada tahapan processing algoritma CF-IDF
(Concept Frequency – Inverse Document Frequency) untuk menghitung
menghitung cosine similarity sehingga menghasilkan output persentase dokumen tugas dengan isi yang mirip secara kemunculan kata.
Terdapat 3 proses dalam perhitungan pendeteksian plagiarisme tugas siswa. Dokumen tugas terlebih dahulu dilakukan pre-processing, kemudian hasil
pre-processing disimpan pada database. Setelah dokumen tugas hasil pemrosesan
pre-processing dilakukan, langkah berikutnya kemudian akan dilakukan tahapan perhitungan pembobotan dengan TF-IDF (Term Frequency – Inverse Document
Frequency) dan CF-IDF (Concept Frequency – Inverse Document Frequency)
dengan perhitungan VSM (Vector Space Model). Tahapan-tahapan perhitungannya tersebut adalah sebagai berikut:
1. Hitung frekuensi kemunculan setiap terms pada setiap judul dan abstrak dokumen tugas
2. Hitung jumlah dokumen yang mengandung kemunculan terms (DF). 3. Hitung nilai TF dari setiap dokumen menggunakan rumus TF. 4. Hitung nilai IDF
5. Perhitungan bobot dimana TF dikalikan IDF unutk masing-masing dokumen.
6. Hasil dari perhitungan bobot total TF-IDF kemudian dimasukkan pada rumus VSM.
7. Hasil dari perhitungan VSM akan memberikan ranking dokumen yang memiliki persentase kemiripan tertinggi dari kemunculan terms pada dokumen uji dengan dokumen yang ada pada database.
8. Hasil kemiripan tertinggi berdasarkan pencarian kemiripan judul dan abstrak kemudian, dihitung frekuensi kemunculan setiap concept pada setiap dokumen.
9. Hitung jumlah dokumen yang mengandung kemunculan concept (DF). 10.Hitung nilai CF dari setiap dokumen dengan menggunakan rumus CF. 11.Hitung nilai IDF.
49
13.Hasil dari perhitungan bobot total CF-IDF kemudian dimasukkan pada rumus VSM.
14.Hasil dari perhitungan VSM akan memberikan ranking dokumen yang memiliki persentase kemiripan tertinggi dari kemunculan concept pada dokumen tugas uji dengan dokumen tugas pada database.
3.1.7 Pembobotan TF-IDF
Pada tahapan ini akan dilakukan perhitungan frekuensi kemunculan setiap
terms pada dokumen (TF), jumlah dokumen mengandung kemunculan terms (DF)
dan perhitungan bobot menggunakan TF-IDF (Term Frequency – Inverse
Document Frequency). Pembobotan ini dilakukan setelah dokumen yang paling
relevan didapatkan pada tahap pencarian untuk selanjutnya dihitung persentase kemiripannya antara judul dokumen yang diuji. Data masukkan pada perhitungan ini merupakan isi dari judul dokumen yang diuji dan judul dokumen yang akan dibandingkan seperti dapat dilihat pada tabel 3.1 dengan menggunakan rumus yang ada pada persamaan (2.1), (2,2) dan (2.3).
Tabel 3.1 Perhitungan nilai TF-IDF
16 mengikuti 0 0 1 0 1 0.69 0 0 0.69 0 17 olimpiade 0 0 1 0 1 0.69 0 0 0.69 0 18 sains 0 0 1 0 1 0.69 0 0 0.69 0
19 sekolah 0 0 1 0 1 0.69 0 0 0.69 0 20 menengah 0 0 1 0 1 0.69 0 0 0.69 0 21 atas 0 0 1 0 1 0.69 0 0 0.69 0 22 pembelian 0 0 0 1 1 0.69 0 0 0 0.69
23 Penyewaan 0 0 0 1 1 0.69 0 0 0 0.69
TOTAL 7 9 13 9 38 1.36 0.09 1.14 1.19
Nilai 1 yang didapat pada kolom frekuensi Q didapat karena judul dokumen uji (q) dijadikan sebagai acuan dari tiga judul dokumen lainnya yaitu A1, A2, dan A3 sehingga masing-masing kata mendapat nilai 1.
3.1.8 Perhitungan Vector Space Model (VSM) dari Hasil Pembobotan TF-IDF
Setelah mendapatkan nilai TF-IDF (Term Frequency –Inverse Document
Frequency) proses selanjutnya melakukan pendeteksian antar judul dokumen
menggunakan metode VSM dengan menghitung sudut antara koordinat judul dokumen. Semakin besar nilai yang didapat maka judul dokumen tersebut semakin mirip dengan judul dokumen yang diuji. Kebutuhan akan nilai kesamaan
(similarity) judul dokumen sehingga hanya perlu dilakukan perkalian hasil
TF-IDF dari kemunculan kata yang dicari dengan kemunculan pada judul dokumen uji dimana dari hasil perkaliannya akan dihitung menggunakan rumus VSMuntuk setiap kolom matriksnya. Untuk mendapatkan nilai matriks Weighted Document
51
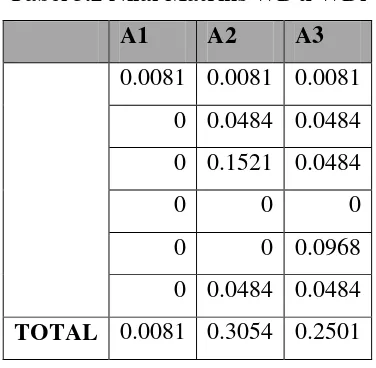
Tabel 3.2 Nilai Matriks WD x WDi
A1 A2 A3
0.0081 0.0081 0.0081 0 0.0484 0.0484 0 0.1521 0.0484
0 0 0
0 0 0.0968 0 0.0484 0.0484
TOTAL 0.0081 0.3054 0.2501
Setiap kolom dari judul dokumen akan dihitung nilai kesamaan
(similarity). Dari tabel 3.3 nilai matriks WD × WDi di atas, kemudian hitung
panjang setiap judul dokumen termasuk Q (judul dokumen uji). caranya kuadratkan bobot setiap term dalam setiap judul dokumen, jumlahkan nilai kuadrat dan terakhir akarkan. Contohnya akan ditunjukkan seperti pada tabel 3.3 berikut:
Tabel 3.3 Nilai panjang judul dokumen
Q A1 A2 A3
0.0081 0.0081 0.0081 0.0081 0.0484 0 0.0484 0.0484 0.0484 0 0.0484 0.0484
0.1521 0 0.1521 0
0.0484 0 0 0.1936
0 0 0 0
0.0484 0 0.0484 0.0484
TOTAL 0.3538 0.0081 0.3054 0.3469
Setelah mendapatkan nilai hasil perkalian Q dengan 3 judul dokumen lainnya dan mendapat nilai panjang judul dokumen, diberikan perhitungan nilai
seterusnya terhadap seluruh judul dokumen yang akan dibandingkan dengan nilai Q sehingga akan didapat nilai kemiripan terdekat dengan Q menggunakan rumus persamaan VSM.
1. ( √ √ )
Hasil 100% 15,13 %
2. ( √ √ )
Hasil 100% 92,90%
3. ( √ √ )
Hasil =
Dari hasil perhitungan VSM tersebut maka dapat diperoleh hasil berupa ranking judul dokumen yang memiliki kemiripan dengan dokumen uji, yaitu A2, A3, dan A1, dimana A2 mendapatkan nilai tertinggi dengan 92,90% dalam kemiripan sedangkan A3 sedikit berada dibawah A2 dengan 71,38% dalam kemiripan. Dari tiga judul dokumen maka terdapat dua judul dokumen yang relevan dengan judul dokumen uji (q).
3.1.9 Pembobotan CF-IDF
53
Tabel 3.4 Perhitungan nilai CF-IDF
No Terms frekuensi df cf q cf a1 Cf a2 Cf a3 idf cf-idf
3.1.10 Perhitungan Vector Space Model (VSM) dari Hasil Pembobotan CF-IDF
CF-IDF dari setiap term uji akan dikalikan dengan nilai CF-CF-IDF judul dokumen yang dibandingkan seperti pada tabel 3.5 berikut ini.
Tabel 3.5 Nilai Matriks WD x WDi
A1 A2 A3
0.00012474 0.00007938 0.00012474 0 0.00047432 0.00074536 0 0.00047432 0.00074536
0 0.00007938 0
0 0 0.00149072
0 0 0
0 0.00047432 0.00074536
TOTAL 0.00012474 0.00299292 0.00385154
Setiap kolom dari judul dokumen akan dihitung nilai kesamaan
(similarity). Dari tabel 3.5 nilai matriks WD WDi di atas, kemudian hitung
panjang setiap judul dokumen termasuk Q (judul dokumen uji). caranya, kuadratkan bobot setiap term dalam setiap judul dokumen, jumlahkan nilai kuadrat dan terakhir akarkan.
Tabel 3.6 Nilai panjang judul dokumen
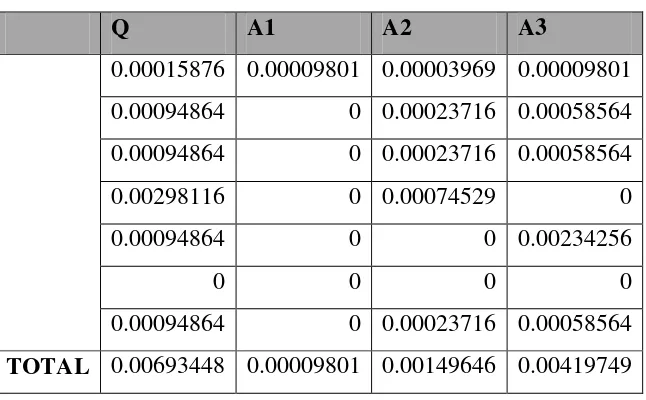
Q A1 A2 A3
0.00015876 0.00009801 0.00003969 0.00009801 0.00094864 0 0.00023716 0.00058564 0.00094864 0 0.00023716 0.00058564
0.00298116 0 0.00074529 0
0.00094864 0 0 0.00234256
0 0 0 0
0.00094864 0 0.00023716 0.00058564