CSLU TOOLKIT
Oleh
ELLYSA KURNIASARI
G64101043
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
Oleh
ELLYSA KURNIASARI
G64101043
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ELLYSA KURNIASARI. Hybrid Jaringan Syaraf Tiruan dan Model Markov Tersembunyi untuk Pengenalan Bilangan Berbahasa Indonesia Menggunakan CSLU Toolkit. Dibimbing oleh AGUS BUONO dan YENI HERDIYENI.
Sistem pengenal kata untuk bahasa Indonesia masih sangat minim dalam pengembangannya, khususnya dalam penerapannya sebagai pengenal bilangan (Continuous Digit Recognizer CDR). Penelitian ini membandingkan metode pengenalan kata menggunakan data hand-labeled, force alignment, dan Forward Backward Neural Networks (FBNN) pada pengenalan bilangan berbahasa Indonesia menggunakan CSLU toolkit. Penelitian dilakukan dengan bantuan CSLU toolkit, dengan berfokus pada akurasi pengenalan pada tingkat kata dan kalimat. Kata-kata yang dapat dikenali terbatas pada kata dasar bilangan sesuai dengan ejaan bahasa Indonesia yang disempurnakan.
Melalui penelitian ini telah dibuat basisdata suara kata dasar bilangan bahasa Indonesia berikut dengan transkripsi tingkat kata dan fonemnya. Selain itu didefinisikan pula kamus kata dan grammar yang dapat digunakan untuk pengembangan selanjutnya. Hasil penelitian menunjukkan bahwa pengenalan terbaik diperoleh menggunakan data hand-labeled dengan variasi neuron lapis tersembunyi sebanyak 400 unit yaitu sebesar 98,33% untuk pengenalan tingkat kata dan 92,50% untuk pengenalan tingkat kalimat. Penggunaan force alignment dan FBNN untuk mengoptimalkan akurasi sistem memberikan hasil yang tidak berbeda nyata dengan proses data hand-labeled. Hasil pengenalan menggunakan force alignment mencapai 97,08% pada tingkat kata dan 87,50% pada tingkat kalimat, sedangkan pengenalan menggunakan FBNN memberikan akurasi tingkat kata sebesar 97,92% dan 90,00% untuk tingkat kalimat.
Menyetujui
Pembimbing I
Ir. Agus Buono, M.Si, M.Kom
NIP. 132 045 532
Pembimbing II
Yeni Herdiyeni, S.Si, M.Kom
NIP. 132 282 665
Mengetahui
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Dr. Ir. Yonny Koesmaryono, M.S.
NIP. 131 473 999
Penulis dilahirkan di Jakarta pada tanggal 8 Agustus 1983 dari ayah Agus Hery Soekamto dan ibu Titiek Wuryani. Penulis merupakan putri kedua dari empat bersaudara.
Tahun 2001 penulis lulus dari SMU Negeri 70 Jakarta dan pada tahun yang sama lulus seleksi masuk IPB melalui Ujian Masuk Perguruan Tinggi Negeri (UMPTN). Penulis memilih Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Shalawat serta salam selalu buat Nabi Muhammad Shallalahu ‘alaihi wasallam beserta seluruh sahabat dan umatnya hingga akhir zaman. Tema yang dipilih pada penelitian ini adalah pengenalan suara, dengan judul Hybrid Jaringan Syaraf Tiruan dan Model Markov Tersembunyi untuk Pengenalan Bilangan Berbahasa Indonesia Menggunakan CSLU Toolkit.
Penulis sampaikan terima kasih yang tiada berhingga kepada semua pihak yang telah membantu dan memberikan pengalaman yang menyenangkan selama melakukan penelitian ini. Khususnya kepada Bapak Ir. Agus Buono, M.Si, M.Kom dan Ibu Yeni Herdiyeni, S.Si, M.Kom serta Bapak Aziz Kustiyo, S.Si, M.Kom yang telah memberikan begitu banyak masukan, bimbingan dan pelajaran berharga selama menjadi pembimbing dan penguji. Selanjutnya penulis juga ingin mengucapkan terima kasih kepada:
1. Keluargaku tercinta, khususnya kedua orangtuaku atas rasa cinta, kasih sayang, kesabaran dan dukungannya kepadaku. Kepada kakakku dan kedua adik kecilku yang sangat aku sayangi yang juga tiada hentinya memberikan semangat.
2. Hendra Saputra, yang merelakan hati dan telinganya untuk mendengarkan keluh kesah penulis.
3. Sahabat-sahabat Ilkom angkatan 38, terimakasih atas persahabatan kita selama ini. 4. Sahabat-sahabat ‘serumah’ di Cirahayu6, terimakasih atas keceriaan dan
semangatnya.
5. Departemen Ilmu Komputer, staf dan dosen yang telah begitu banyak membantu baik selama pelaksanaan skripsi ini maupun sebelumnya.
Dan semua pihak lainnya yang telah memberikan kontribusi yang besar selama pengerjaan penelitian ini yang tidak dapat disebutkan satu-persatu, terima kasih.
Semoga penelitian ini dapat memberikan manfaat.
Bogor, 15 Oktober 2005
DAFTAR TABEL ... viii
DAFTAR GAMBAR ... ix
DAFTAR LAMPIRAN ... x
PENDAHULUAN ... 1
TINJAUAN PUSTAKA Gelombang Suara ... 1
Spektral, Spektrogram, dan Formant ... 2
Fonem Bahasa Indonesia dan Karakteristik Formant-nya ... 2
Jaringan Syaraf Tiruan (JST)... 3
Ekstraksi Ciri... 4
Algoritma Viterbi ... 5
Algoritma Forward Backward... 6
METODOLOGI Data... 6
Pendefinisian Kamus Kata dan Grammar... 8
Pelabelan Data ... 8
Penentuan MFCC... 8
Klasifikasi Frame Berdasarkan Kategori... 9
Pencocokan Kategori dengan Target Kata... 9
Rancangan Percobaan ... 9
Parameter Percobaan... 10
Lingkungan Pengembangan... 10
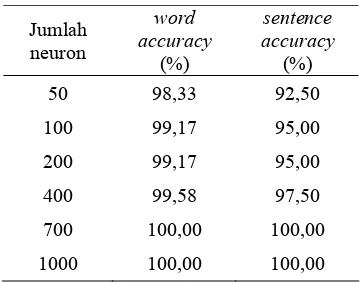
HASIL DAN PEMBAHASAN Pengaruh Jumlah Neuron Hidden dan Iterasi Terhadap Akurasi Sistem ... 10
Perbandingan Akurasi Menggunakan Hand Labeled, Force Alignment, dan FBNN... 12
KESIMPULAN DAN SARAN Kesimpulan ... 13
Saran ... 13
2. Spektrogram skala keabuan dan berwarna dari suatu gelombang suara tertentu ... 2
3. Arsitektur JST dengan sebuah lapisan tersembunyi... 3
4. Blok diagram MFCC... 5
5. Tahapan pengembangan CDR bahasa Indonesia ... 7
6. Skema pembagian data untuk pelatihan dan pengujian... 7
7. Gelombang suara yang sudah di hand label... 9
8. Arsitektur jaringan syaraf tiruan yang digunakan dalam proses pengenalan kata ... 9
9. Perbandingan akurasi tingkat kata dan kalimat pada data tes 1 ... 11
10. Perbandingan akurasi tingkat kata dan kalimat pada data tes 2 ... 12
1. Struktur jaringan syaraf tiruan ... 9
2. Hasil pengenalan terbaik untuk masing-masing variasi neuron hidden pada data tes 1... 11
3. Hasil pengenalan terbaik untuk masing-masing variasi neuron hidden pada data tes 2... 12
2. Definisi kamus kata dan grammar yang digunakan ... 17
3. Hasil pengenalan kata pada data tes 1... 18
4. Hasil pengenalan kata pada data tes 2... 34
Berbicara merupakan metode komunikasi yang paling alamiah. Begitu nyamannya orang menggunakan suara sebagai media komunikasi sampai menginginkan dapat berkomunikasi dengan komputer melalui media ini dibandingkan menggunakan antarmuka primitif seperti keyboard atau alat penunjuk lainnya.
Teknologi Automatic Speech Recognizer
(ASR) merupakan cabang ilmu kecerdasan buatan yang mencakup akuisisi pengetahuan, pemodelan bahasa, pencocokan pola, dan adaptasi. Seperti telah diketahui, Hidden Markov Model telah banyak diaplikasikan untuk masalah pengenalan suara beberapa tahun belakangan ini. Jaringan syaraf tiruan banyak digunakan untuk menyelesaikan masalah pengenalan-pengenalan pola, yang memetakan sejumlah input ke sejumlah output. Salah satunya adalah masalah pengenalan suara.
Teknologi ASR, khususnya dalam penerapannya sebagai Continuous Digit
Recognizer (CDR), berkembang seiring
dengan kebutuhan akan interaksi manusia dengan komputer yang semakin meningkat. CDR banyak diaplikasikan dalam berbagai hal contohnya pemasukan data otomatis, voice dialing telephone, sistem perbankan otomatis, dan sistem telephone-based lainnya.
Hingga saat ini ilmuwan dari berbagai negara telah dan masih mengembangkan CDR untuk bahasanya masing-masing. Penelitian mengenai CDR sudah banyak berkembang untuk bahasa Inggris. Salah satu contohnya adalah penelitian yang dilakukan oleh Cosi et al (1997). Penelitian ini menggunakan basisdata suara yang cukup besar berisi ribuan kalimat. Penelitian ini memberikan akurasi tingkat kata sebesar 96,36% dan 86,82% untuk akurasi tingkat kalimat. Duc et al
(2001) juga telah mengembangkan CDR untuk bahasa Vietnam. CDR berbahasa Vietnam ini memiliki akurasi sebesar 90,48% pada tingkat kata dan 73,97% pada tingkat kalimat. CDR juga telah dibuat untuk bahasa Italia oleh Cosi (2000) dengan akurasi mencapai 98,24% untuk akurasi tingkat kata dan 87,89% untuk tingkat kalimat. Penelitian yang disebut di atas dilakukan menggunakan
Centre for Speech and Language Understanding (CSLU) toolkit dari Oregon Graduate Institute of Science and Technology
mengenai ASR berbahasa Indonesia belum banyak dilakukan dan sejauh pengamatan penulis CDR berbahasa Indonesia belum tersedia sehingga perlu dilakukan penelitian lebih lanjut mengenai hal tersebut.
Tujuan
Penelitian ini bertujuan untuk membandingkan metode pengenalan kata menggunakan data hand-labeled, force alignment, dan Forward Backward Neural Networks (FBNN) pada pengenalan bilangan berbahasa Indonesia menggunakan CSLU
toolkit.
Ruang Lingkup
1 Kata yang dapat dikenali dibatasi pada kata dasar bilangan sesuai dengan ejaan bahasa Indonesia yang disempurnakan.
2 Pengenalan kata dilakukan berdasarkan fonem. Setiap fonem hanya dibagi ke dalam satu bagian saja (independent part).
3 Analisis kinerja sistem dilakukan berfokus pada akurasi pengenalan sistem yang meliputi insertion, deletion, dan
substitution.
TINJAUAN PUSTAKA
Gelombang Suara
Input ke dalam suatu sistem pengenal suara adalah gelombang suara yang merupakan barisan perubahan udara yang cukup kompleks. Perubahan udara ini disebabkan oleh jalur spesifik yang dilewati udara mulai dari celah suara (glottis) sampai ke rongga mulut atau rongga hidung.
Gelombang suara direpresentasikan dengan memetakan perubahan tekanan udara terhadap waktu. Contoh gelombang suara dapat dilihat pada Gambar 1.
gelombang suara adalah frekuensi dan amplitudo. Frekuensi adalah banyaknya gelombang tersebut berulang (cycles) dalam satu detik. Banyaknya cycles per detik disebut Hertz (Hz). Amplitudo suatu gelombang merupakan jumlah variasi tekanan udara pada suatu titik. Amplitudo yang besar menunjukkan tekanan udara yang lebih besar pada waktu tersebut, nilai nol menandakan tekanan udara normal (atmospheric), sedangkan amplitudo dengan nilai negatif menandakan tekanan udara di bawah normal. Dua sifat yang berhubungan dengan frekuensi dan amplitudo adalah pitch dan loudness.
Pitch berkorelasi positif dengan frekuensi, sedangkan loudness berkorelasi positif dengan
power, yang merupakan nilai kuadrat dari amplitudo (Jurafsky & Martin 2000).
Spektral, Spektrogram, dan Formant
Jika hanya melalui gelombang suara saja, klasifikasi fonem tidak dapat dilakukan secara rinci. Untuk menghasilkan klasifikasi fonem yang lebih terperinci dibutuhkan representasi gelombang suara dalam bentuk fitur-fitur spektral. Spektrum adalah representasi komponen-komponen gelombang suara dalam frekuensi yang berbeda-beda (Jurafsky & Martin 2000). Spektrum dihasilkan dari proses transformasi fourier yang dapat memisahkan komponen frekuensi sebuah gelombang. Pada gelombang suara, dengan representasi bentuk spektrum terlihat jelas karakteristik yang berbeda dari setiap fonem.
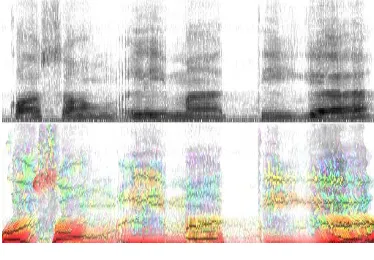
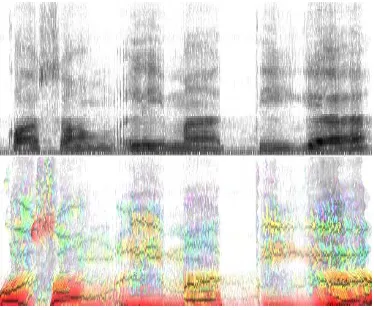
Jika sebuah spektrum menunjukkan komponen frekuensi dari sebuah gelombang pada suatu waktu tertentu, maka spektrogram menggambarkan perubahan frekuensi ini terhadap waktu (Jurafsky & Martin 2000). Sumbu horizontal pada spektrogram menyatakan waktu, sama seperti pada gelombang suara, sedangkan sumbu vertikal menyatakan frekuensi. Contoh spektrogram dapat dilihat pada Gambar 2.
Spektrogram biasanya dihitung dan disimpan di dalam memori komputer dalam bentuk array 2 dimensi. Untuk sebuah spektrogram S, kekuatan energi dari sebuah komponen frekuensi pada waktu t direpresentasikan dengan warna pada titik yang dimaksud S(t, f). Daerah dengan warna yang lebih gelap pada spektrogram menggambarkan amplitudo pada komponen frekuensi tersebut. Bagian berwarna gelap dalam spektrogram merepresentasikan
(Jurafsky & Martin 2000).
Selain ditampilkan dalam bentuk skala keabuan, terdapat pula spektrogram yang digambarkan dengan warna untuk menunjukkan fitur penting dari sebuah spektrogram. Sumbu horizontal dari spektrogram menyatakan waktu sedangkan sumbu horizontal menyatakan frekuensi dalam satuan Hertz. Warna yang berbeda-beda menandakan intensitas energi pada suatu titik tertentu. Warna merah menggambarkan peningkatan energi sepanjang sumbu vertikal, warna biru menggambarkan penurunan energi, warna kuning dan hijau menggambarkan energi maksimum, sedangkan warna putih berarti tidak terdapat energi yang cukup untuk menjadi perhatian.
Gambar 2 Spektrogram skala keabuan dan berwarna dari suatu gelombang suara tertentu.
Representasi spektral dapat memberikan petunjuk yang spesifik pada identifikasi fonem. Hal ini disebabkan karena setiap fonem memiliki formant yang unik.
Fonem Bahasa Indonesia dan Karakteristik
Formant-nya
Para ahli bahasa mengelompokkan bunyi yang digunakan dalam sebuah bahasa ke dalam sejumlah kategori abstrak yang disebut fonem. Fonem juga dapat diartikan sebagai unit bunyi terkecil yang membedakan arti. Di dalam bahasa Indonesia dikenal 31 simbol fonem yaitu [PPPBDEPDIKBUD 1996]: Fonem vokal (6 buah): /a/, /i/, /u/, /e/, /ə/,
dan /o/
Fonem serapan (4 buah): /f/, /z/, /ſ/, /x/ Fonem diftong (3 buah): /aw/, /ay/, /oy/.
Kata-kata yang akan dikenali pada penelitian kali ini hanya terbatas pada kata dasar bilangan saja, maka tidak semua fonem di atas digunakan dalam penelitian ini, beberapa yang digunakan adalah sebagai berikut:
/a/, /i/, /u/, /e/, /o/, /p/, /t/, /k/, /b/, /d/, /j/, /g/, /m/, /n/, /ŋ/, /s/, /h/, dan /l/.
Setiap fonem memiliki karakteristik
formant yang unik yang dapat membedakan satu dengan lainnya. Untuk fonem vokal (/a/, /i/, /u/, /e/, /o/), formant yang dihasilkan relatif stabil, kuat, dan tidak berubah-ubah. Pada spektrogram fonem dari kategori ini mudah diidentifikasi.
Hal ini berbeda pada kategori huruf nasal (/m/, /n/, /ŋ/). Kategori ini memiliki energi yang jauh lebih sedikit dibandingkan dengan kategori fonem vokal. Penyebabnya adalah terhalangnya hampir seluruh rongga sehingga suara keluar melalui rongga hidung.
Kategori berikutnya adalah plosive yang terdiri dari fonem /p/, /t/, /k/, /b/, /d/, /g/.
Formant kategori plosive ditandai dengan ledakan energi akustik yang diikuti oleh jeda yang singkat. Selain itu kategori ini juga ditandai oleh perubahan yang cepat dari energi akustik yang kecil atau sama sekali tidak ada sampai ledakan singkat berenergi tinggi pada pita frekuensi yang luas.
Kategori fonem fricative juga merupakan kategori fonem yang mudah dikenali. Fonem /s/ termasuk dalam kategori ini. Keberadaan fonem ini pada spektrogram ditandai pada daerah dengan frekuensi tinggi dengan distribusi energiyang bersifat random.
Fonem /l/ termasuk ke dalam kategori
approximant. Penanda kategori ini adalah energi yang labih lemah dibandingkan dengan kategori fonem. Hal ini disebabkan adanya sedikit penghalang pada jalur vocal tract.
Kategori fonem lainnya adalah affricate,
contohnya adalah fonem /j/. Kategori ini merupakan gabungan dari plosive dan
fricative (Carmell et al 1997).
Jaringan Syaraf Tiruan (JST)
Studi mengenai JST terinspirasi oleh bidang ilmu neurobiologi. Menurut Fausett (1994), JST adalah suatu pemrosesan
informasi yang memiliki karakteristik sebagai berikut
1 Arsitektur jaringan, yaitu pola hubungan antar neuron.
2 Algoritma pelatihan atau pembelajaran, merupakan metode penentuan bobot pada hubungan antar neuron.
3 Fungsi aktivasi yang dijalankan pada masing-masing neuron pada input untuk menentukan output.
JST mampu belajar membentuk asosiasi antara input dan output, menyimpan data pelatihan serta mempelajari polanya. Hal ini penting pada proses pengenalan suara mengingat pola akustik yang tidak pernah sama. JST juga mampu menghitung fungsi-fungsi non-linear dan non-parametrik dari input sehingga dapat mentransformasi data secara lebih kompleks.
Arsitektur JST meliputi pengaturan neuron dalam suatu lapisan dan pola hubungan dalam lapisan dan di antara lapisan. Dalam JST, neuron diatur dalam sebuah lapisan (layer). Ada 3 tipe lapisan, yaitu lapisan input, lapisan tersembunyi, dan lapisan output. Berdasarkan lapisannya JST dikelompokkan sebagai jaringan lapis tunggal (single layer), jaringan lapis banyak (multi
layer), dan jaringan lapis kompetitif
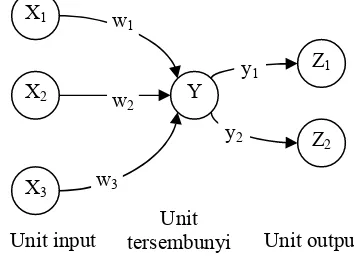
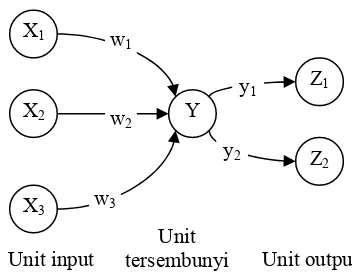
(competitive layer). Jaringan lapis tunggal memiliki satu lapis hubungan bobot. Jaringan lapis banyak memiliki satu atau lebih lapisan tersembunyi antara lapisan input dan output. Sedangkan jaringan dengan lapis kompetitif membentuk suatu bagian dari sejumlah besar jaringan-jaringan syaraf. Gambar 3 merupakan contoh sederhana dari sebuah JST.
Gambar 3 Arsitektur JST dengan sebuah lapisan tersembunyi.
Berdasarkan skema interkoneksinya, jaringan dapat dibagi menjadi jaringan feed
X1
X2
X3
Y
Z2
Z1
w1
w2
w3
y1
y2
Unit input Unit output
dibagi ke dalam koneksi simetrik dan asimetrik. Pada jaringan feed forward semua koneksinya satu arah berasal dari lapisan input menuju lapisan output. Sedangkan pada jaringan recurrent terdapat loop atau koneksi
feedback. Sebuah jaringan dikatakan memiliki koneksi yang simetrik apabila terdapat koneksi dari node i ke node j, begitu juga sebaliknya. Kedua koneksi itu memiliki bobot yang sama. Jika koneksi antar node tidak simetrik seperti disebutkan di atas, maka koneksinya disebut koneksi asimetrik (Fu 1994).
Sebelum JST digunakan untuk mengklasifikasikan pola, terlebih dahulu dilakukan proses pembelajaran untuk menentukan struktur jaringan, terutama dalam penentuan nilai bobot. Ada dua tipe pembelajaran, yaitu pembelajaran dengan pengarahan (supervised learning) dan tanpa pengarahan (unsupervised learning). Beberapa metode pembelajaran yang digunakan antara lain metode Hebb, Perceptron, Adaline, Madaline, Backpropagation, Self Organizing
Map (SOM), dan Learning Vector
Quantization (LVQ). Arsitektur jaringan yang digunakan pada penelitian ini adalah multi layer perceptron (MLP) karena MLP dapat digunakan untuk menyelesaikan masalah klasifikasi nonlinear karena dapat membentuk daerah keputusan yang lebih kompleks (Fu 1994). MLP merupakan jaringan syaraf tiruan
feed forward dengan paling tidak satu lapis tersembunyi layer. MLP biasa dilatih menggunakan algoritma pembelajaran
backpropagation. Pelatihan menggunakan
algoritma backpropagation terdiri dari tiga fase yaitu fase feed forward pola input pembelajaran, fase kalkulasi dan propagasi balik error yang didapat dan fase penyesuaian bobot.
Fungsi aktivasi merupakan fungsi yang menentukan level aktivasi, yaitu keadaan internal sebuah neuron dalam JST. Keluaran aktivasi ini biasanya dikirim sebagai sinyal ke neuron lainnya. Fungsi aktivasi yang umum digunakan adalah (Fausett 1994):
Fungsi identitas
( )
x xf = untuk setiap x
Fungsi tangga biner
( )
⎩
⎨
⎧
< ≥ = θ θ x jika x jika x f 0 1 ) exp( 1 1 ) ( x x f − + = Fungsi sigmoid bipolar
) exp( 1 ) exp( 1 ) ( x x x f − + − − = Ekstraksi Ciri
Ekstraksi ciri mempunyai input sinyal suara analog dan sebagai outputnya adalah
feature vector untuk setiap frame (time slice). Untuk dapat menghasilkan feature vector
terdapat beberapa langkah yang dilalui. Tahap pertama adalah melakukan digitasi terhadap sinyal suara analog. Proses ini terdiri dari
sampling dan kuantisasi (Jurafsky & Martin 2000).
Sampling artinya mengukur amplitudo
sinyal pada suatu indeks waktu tertentu. Dalam hal ini dikenal istilah sampling rate, yaitu banyaknya sampling yang dilakukan setiap detik. Sampling rate yang umum digunakan adalah 8000 Hz dan 16000 Hz. Jumlah sample minimum untuk sebuah cycle
adalah sebanyak dua sample, satu sample
untuk mengukur bagian positif dan sisanya mengukur bagian negatif gelombang. Jumlah
sample yang melebihi ketentuan di atas dapat meningkatkan akurasi penghitungan amplitudo, sedangkan sebaliknya, jika jumlah
sample tidak memenuhi akan mengakibatkan hilangnya frekuensi gelombang suara. Sehingga frekuensi maksimum yang dapat diukur adalah setengah dari sampling rate.
Berikutnya adalah kuantisasi, yaitu menyimpan nilai amplitudo ini ke dalam nilai integer, yang dalam hal ini memakai representasi 8 bit atau 16 bit.
Setelah sinyal didigitisasi, berikutnya adalah menyekatnya dalam bagian-bagian kecil penyusun sinyal suara dengan ukuran waktu yang tetap, misalnya 10 ms. Bagian-bagian kecil ini disebut frame. Langkah berikutnya adalah merepresentasikannya dalam domain spektral menjadi feature vector
yang merupakan input bagi tahap berikutnya. Beberapa fitur yang sering digunakan adalah
linear predictive coding (LPC), koefisien
cepstral, atau perceptual linear prediction
(PLP).
Penelitian ini menggunakan fitur yang berasal dari Mel Frequency Cepstral Coefficient
(MFCC) beserta turunannya yaitu MFCC delta. MFCC ditambah fitur energinya menghasilkan 13 koefisien demikian pula MFCC delta dengan fitur energinya juga menghasilkan 13 koefisien. Secara keseluruhan dihasilkan 26 koefisien untuk sebuah frame.
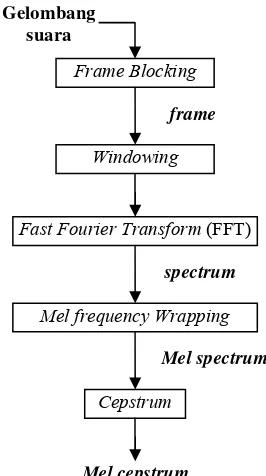
MFCC didasarkan pada variasi dari frekuensi kritis telinga manusia. Filter diletakkan secara linear pada frekuensi rendah dan logaritmik pada frekuensi tinggi untuk mendapatkan karakteristik suara yang penting dari fonem. Gambar 4 merupakan blok diagram yang menjelaskan secara umum proses untuk mendapatkan mel cepstrum.
Gambar 4 Blok diagram MFCC.
Berikut adalah penjelasan dari blok diagram di atas (Do 1994)
1 Frame Blocking. Pada tahap ini
gelombang suara dipecah ke dalam frame
yang terdiri dari N sampel. Penelitian ini membagi gelombang suara menjadi
frame-frame berukuran 10 msec dengan 80 sampel.
2 Windowing. Proses windowing ini
dilakukan untuk setiap frame, dengan tujuan untuk meminimalisasi diskontinuitas sinyal pada awal dan akhir
frame. Konsepnya adalah memperhalus
distorsi spektral hingga mendekati nol pada awal dan akhir setiap frame.
Beberapa window yang biasa digunakan
antara lain adalah rectangle, gaussian, hamming, atau hanning window. Jika didefinisikan window sebagai w(n) dengan 0≤n≤ N−1, dimana N adalah banyaknya sampel dalam tiap frame,
maka sinyal hasil proses windowing dapat dinyatakan sebagai berikut:
yl(n)=xl(n)w(n) 0≤n≤ N−1
3 Fast Fourier Transform (FFT). Tahap ini mengkonversi tiap frame dengan N sampel dari domain waktu ke domain frekuensi. FFT, algoritma implementasi
Discrete Fourier Transform (DFT),
didefinisikan pada himpunan N sampel
{xn} sebagai berikut
N jkn e N
k xk n
X 1 2 /
0 π − ∑−
=
= n=0, 1, 2,…, N-1.
Nilai j pada persamaan di atas merupakan
unit imajiner yaitu j= −1. Secara umum Xn merupakan bilangan kompleks.
Hasil dari langkah ini disebut spektrum sinyal atau periodogram.
4 Mel frequency (MF) wrapping. Studi
psikofisik menunjukkan bahwa persepsi manusia mengenai frekuensi sebuah sinyal suara tidak berupa skala linear sehingga untuk tiap suara dengan frekuensi f, pitch subjektifnya diukur dengan skala “mel”. Skala MF merupakan selang frekuensi linear untuk frekuensi dibawah 1000 Hz, dan selang frekuensi logaritmik untuk frekuensi di atas 1000 Hz. Persamaan berikut digunakan untuk menghitung MF jika diberikan suatu frekuensi f
) 700 1 ( 10 log * 2595 )
(f = +
mel
5 Cepstrum. Pada langkah terakhir ini
dikonversikan kembali log mel spectrum
ke domain waktu, hasilnya disebut MFCC. Representesi cepstral dari spektrum suara memberikan representasi yang baik tentang local spectral properties dari sinyal yang diberikan. Karena hasil dari mel spectrum coeffients
dan logaritmanya (dari hasil 4) adalah bilangan real, maka dapat dikonversikan ke domain waktu menggunakan Discrete Cosine Transform (DCT).
Algoritma Viterbi
Algoritma ini ingin menemukan barisan state yang optimum, Q={ q1, q2, q3, …, qT},
jika diberikan barisan observasi O={O1, O2,
O3, …, OT}. Pada algoritma ini didefinisikan Frame Blocking
Windowing
Fast Fourier Transform (FFT)
Mel frequency Wrapping
Cepstrum frame
Gelombang suara
spectrum
Mel spectrum
(peluang tertinggi) yang dihitung pada path dari state periode pertama hingga state Si pada
periode t. ) | ,..., 2 , 1 , ,..., 2 , 1 ( 1 ,..., 2 , 1 )
( max λ
δ Pq q qt iO O Ot
t q q q i t = − =
Prosedur lengkap algoritma Viterbi adalah :
1. Inisialisasi, untuk 1≤i≤N :
0 ) ( 1 ) 1 ( ) ( 1 = = i O i b i i ψ π δ
2. Proses rekursi :
[
1()]
( )1max )
( t iaij bj Ot
N i j
t = ≤≤ δ− ⋅
δ
untuk 2≤t≤T dan 1≤j≤N
]
)
(
[
max
arg
)
(
11i N t ij
t
j
−i
a
≤ ≤
=
δ
ψ
untuk 2≤t≤T dan 1≤j≤N 3. Terminasi :
)
(
max
1 *i
P
T N i≤δ
≤=
dan)
(
max
arg
1 *i
q
T N i Tδ
≤ ≤=
4. Backtracking :
)
(
* 1 1 * + +=
t tt
q
q
ψ
untuk t=T-1, T-2, …, 1.
Algoritma Forward Backward
Pada sebuah model Markov tersembunyi peluang observasi barisan O didefinisikan sebagai
P
T(
O
|
S
,
π
)
:)
(
)
(
)
(
)
,
|
(
s1 1 s2 2 sT TT
O
S
b
O
b
O
b
O
P
π
=
K
Peluang dari barisan state didefinisikan sebagai sT sT s s s s
T
S
a
a
a
P
(
|
π
)
=
1 2 2 3K
−1Sedangkan peluang
P
T(
O
|
π
)
adalah∑
=
S semua T TT
O
P
O
S
P
S
P
(
|
π
)
(
|
,
π
)
(
|
π
)
∑ ∏
= −=
S semua T t t s ss
b
O
a
t t t 1)
(
1Peluang forward didefinisikan sebagai berikut
∑
−=
i t j ij t 1(
i
)
a
b
(
O
)
α
Peluang backward adalah
)
,
|
,
,
,
(
)
(
1 2π
β
ti
=
P
TO
t+O
t+K
O
TS
t=
i
∑
+ +=
i t t iji
b
(
O
1)
β
1(
i
)
α
Jadi peluang posterior dari suatu transisi dari
state i ke state j, λij , diberikan peluang
observasi dan model Markov tersembunyinya adalah sebagai berikut
)
,
|
,
(
)
(
1π
λ
ijt
=
P
Ts
t=
i
s
t+=
j
O
)
|
(
)
(
)
(
)
(
1 1π
β
α
O
P
j
O
b
a
i
T t t j ijt + +
=
∑
∈ + +=
S k T t t j ij tk
j
O
b
a
i
)
(
)
(
)
(
)
(
1 1α
β
α
Peluang posterior berada pada state i pada waktu t dapat dihitung dari persamaan berikut
)
,
|
(
)
(
π
λ
it
=
P
Ts
t=
i
O
∑
∈=
S k T t tk
i
i
)
(
)
(
)
(
α
β
α
Dan transisi antara state pada sebuah model Markov tersembunyi dapat diestimasi menggunakan persamaan berikut (Yan et al 1997).
∑ ∑
∑
− = − ==
1 1 1 1)
(
)
(
)
(
Tt k ik
T t ij ij
t
t
t
a
λ
λ
∑
∑
− = − ==
1 1 1 1)
(
)
(
T t i T t ijt
t
λ
λ
METODOLOGI
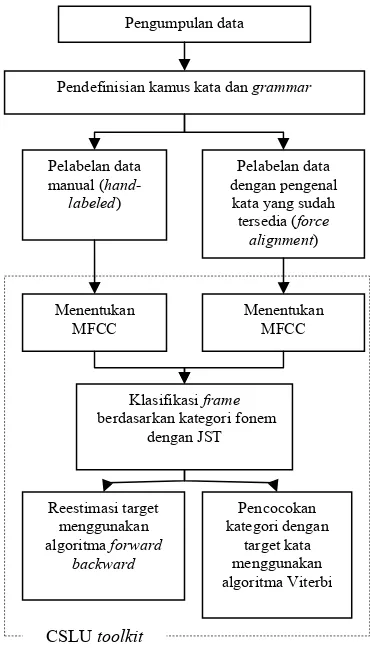
Sistem CDR berbahasa Indonesia dalam penelitian ini dikembangkan dengan langkah-langkah pada Gambar 5.
Data
pengujian yang suaranya juga dilatihkan ke sistem (data tes 1), serta data pengujian lain yang berasal dari sampel suara yang tidak dilatihkan kesistem (data tes 2). Untuk lebih jelasnya pembagian data dapat dilihat pada Gambar 6.
Data yang digunakan untuk pelatihan berasal dari sampel suara 4 orang, 2 orang pria dan 2 orang wanita. Sisa suara yang berasal dari 4 orang lain tidak diikutsertakan dalam pelatihan tetapi digunakan untuk pengujian.
Gambar 5 Tahapan pengembangan aplikasi CDR bahasa Indonesia.
Setiap speaker diminta untuk
menyebutkan deretan 6 angka acak untuk setiap filenya. Deretan angka acak ini didapatkan dari basis data telepon. Speaker
yang suaranya akan digunakan untuk pelatihan diminta untuk menyebutkan sebanyak 20 kalimat, setengahnya akan digunakan untuk pelatihan dan setengahnya lagi untuk pengujian. Empat speaker lainnya, yang datanya hanya digunakan pada tahap pengujian saja, diminta untuk menyebutkan
10 kalimat. Keseluruhan file yang diperoleh berjumlah 120 file, secara lebih rincinya dapat dilihat pada Lampiran 1.
Jumlah file gelombang suara yang diperoleh untuk masing-masing bagian data adalah sebagai berikut; 40 buah data pengujian, 40 buah data tes 1, dan 40 buah data tes 2.
Gambar 6 Skema pembagian data untuk pelatihan dan pengujian.
Ketiga jenis file tadi disimpan terpisah dan proses penamaannya mengikuti aturan yang sudah diberikan CSLU. Ketiga file ini diberi nama yang sama hanya ekstensinya saja yang berbeda. Agar lebih mudah, penamaan file dilakukan sesuai dengan format berikut
Format : {TLP-([0-9]+)-([0-9]+)}
Format di atas terdiri dari tiga bagian. Bagian pertama adalah TLP, yang menunjukkan bahwa kalimat yang disebutkan speaker
berasal dari basis data nomor telepon. Bagian yang kedua, ([0-9]+), menunjukkan urutan
file. Bagian ini juga sangat berhubungan dengan partisi file. Jika angka pada bagian ini menghasilkan bilangan 0, 1, 2, 3, atau 4 setelah dimodulokan dengan 10 maka file tersebut akan digunakan sebagai data pelatihan. Sisanya, jika hasilnya adalah 5, 6, 7, atau 8, merupakan data tes 1. File pada data tes 2 menghasilkan nilai 9 setelah dimodulokan dengan 10. Bagian angka yang
Data suara
Speaker 1, 10 file pelatihan 10 file pengujian Speaker 2, 10 file pelatihan
10 file pengujian Speaker 3, 10 file pelatihan
10 file pengujian Speaker 4, 10 file pelatihan
10 file pengujian Speaker 5, 10 file pengujian
Speaker 6, 10 file pengujian
Speaker 7, 10 file pengujian
Speaker 8, 10 file pengujian
Pengumpulan data
Pendefinisian kamus kata dan grammar
Pelabelan data manual (
hand-labeled)
Pelabelan data dengan pengenal
kata yang sudah tersedia (force
alignment)
Menentukan MFCC Menentukan
MFCC
Klasifikasi frame
berdasarkan kategori fonem dengan JST
Pencocokan kategori dengan
target kata menggunakan algoritma Viterbi Reestimasi target
menggunakan algoritma forward
backward
yang diucapkan speaker.
Pendefinisian kamus kata dan grammar
Pendefinisian kamus kata merupakan hal yang penting dalam membuat sistem pengenal kata. CDR berbahasa Indonesia ini dibatasi hanya mengenali 10 kata dasar bilangan. Bahasa Indonesia memiliki banyak sekali variasi penyebutan sebuah kata. Dari sekian banyak variasi yang ada, kamus kata CDR hanya mendefinisikan variasi penyebutan bilangan 0 menjadi dua yaitu nol dan kosong.
Selain mendefinisikan kata-kata yang dapat dikenali sistem, dilakukan juga pendefinisian kategori yang menyusun sebuah kata beserta separator yang menjadi pemisah antar kata. Penentuan kategori yang dapat dikenali bergantung pada jumlah fonem pembentuk semua kata pada kamus kata.
Separator didefinisikan menjadi dua, separator sil dan gar. Separator sil digunakan untuk menandai bagian dari gelombang suara yang tidak terdapat energi yang menjadi perhatian sehingga tidak mencerminkan kategori apapun, sedangkan separator gar
digunakan untuk menandai bunyi-bunyi di luar bunyi kategori fonem yang telah ditetapkan. Contoh penggunaan separator gar
antara lain untuk menandai bunyi yang disebabkan oleh pergerakan microphone. Bunyi ini tentunya tidak termasuk dalam kategori fonem tertentu. Selain dua separator tersebut terdapat separator lain yang hanya digunakan pada kata ”satu”, ”empat”, dan ”delapan”. Hal ini disebabkan adanya jeda waktu yang dihasilkan antar suku kata. Separator ini disebut separator pau. Kamus kata beserta grammar yang digunakan dapat dilihat pada Lampiran 2. Berdasarkan
grammar yang didefinisikan, setiap kata dapat dikuti dengan kata lain dengan nilai peluang yang sama besarnya. Kategori dan separator yang dapat dikenali berjumlah 24 kategori yaitu sebagai berikut
s a t u d i g em
p tcl l m en j h e
n b o k ng sil gar pau
Meskipun setiap huruf memiliki variasi bunyi yang beragam bergantung pada huruf disekitarnya, akan tetapi penelitian ini tidak membagi kategori fonem ini menjadi beberapa bagian (dependent part). Setiap kategori hanya terdiri dari satu bagian saja (independent part).
Setelah mendapatkan data berupa gelombang suara dalam ekstensi .wav diperlukan juga data lain dalam bentuk file teks dan file kategori fonem. File kategori fonem hanya diperlukan untuk data pelatihan saja, sedangkan file teks dibuat untuk setiap file gelombang suara input.
File teks berisi representasi bilangan yang disebutkan speaker bentuk kalimat. Misalnya barisan angka yang disebutkan speaker adalah ”05331”, maka file teks yang harus dibuat berisi ”kosong lima tiga tiga satu satu”.
File kategori fonem didapatkan dengan cara melakukan pelabelan secara manual (hand-labeled). Proses ini dilakukan untuk mendapatkan fonem yang terdapat di dalam sebuah file gelombang suara. Contoh proses pelabelan dapat dilihat pada Gambar 7. File kategori fonem yang memiliki ekstensi .phn ini terdiri dari tiga buah kolom. Kolom yang pertama mendefinisikan waktu dimulainya sebuah kategori fonem, kolom kedua mendefinisikan waktu berakhirnya sebuah kategori fonem, dan kolom terakhir adalah kategori fonem yang terdapat dalam rentang waktu yang disebutkan. Dapat dilihat pada contoh file .phn di bawah ini bahwa waktu berakhirnya sebuah kategori fonem merupakan waktu dimulainya kategori fonem berikutnya.
0.000000 243.012375 sil 243.012375 390.264038 en 390.264038 537.515747 a 537.515747 725.583435 m 725.583435 844.083557 sil 844.083557 898.216553 d 898.216553 995.236450 u 995.236450 1153.056274 a Penentuan MFCC
Sampel suara didigitasi dengan sampling rate sebesar 8000 Hz dengan alasan bahwa informasi yang terkandung dalam suara manusia berada dibawah frekuensi 10000 Hz. Langkah berikutnya adalah membagi gelombang suara ini menjadi frame berukuran 10 msec. Melalui proses MFCC ini didapatkan 13 koefisien mel cepstrum. Selain itu untuk ciri lain juga dihitung menggunakan delta MFCC. Koefisien delta MFCC ini mengindikasikan tingkat perubahan spektral, dapat dihitung dengan persamaan berikut
] [ ] 1 [ ]
[n cn cn
c = + −
Gambar 7 Gelombang suara yang sudah di
hand-label.
Klasifikasi frame berdasarkan kategori JST digunakan untuk mengklasifikasikan fitur-fitur untuk setiap frame ke dalam kategori tertentu. Penentuan jumlah kategori yang dapat diklasifikasikan oleh JST sesuai dengan pendefinisian kategori sebelumnya yaitu sebanyak 24 kategori.
JST yang digunakan dalam percobaan ini merupakan jaringan feed-forward lapis banyak yang terdiri dari satu lapisan lapis tersembunyi dengan propagasi balik sebagai algoritma pelatihannya. Input untuk jaringan ini adalah 5 buah frame dengan frame yang berada di tengah sebagai frame of interest
yang akan dihitung peluangnya untuk setiap kategori. Ketika suatu frame dipetakan kedalam suatu kategori tertentu maka informasi yang diperlukan tidak hanya berasal dari frame yang bersangkutan, akan tetapi juga berasal dari frame-frame sesudah dan sebelumnya. Frame-frame tersebut adalah
frame yang terletak -60, -30, 30, dan 60 msec jauhnya dari frame yang menjadi perhatian. Hal ini dilakukan dengan mempertimbangkan sifat alamiah suara dimana identitas sebuah fonem tidak hanya ditentukan oleh fitur-fitur spektral pada saat itu saja tetapi juga bergantung pada perubahannya terhadap waktu. Arsitektur jaringan yang digunakan dapat dilihat pada Gambar 8, sedangkan ringkasan mengenai struktur jaringan yang digunakan dapat dilihat pada Tabel 1.
Setelah jaringan terbentuk, jaringan akan dilatih menggunakan data pelatihan yang telah disebutkan di atas. Jaringan juga akan diujikan menggunakan dua tipe data tes yaitu file data tes yang suaranya sudah digunakan dalam pelatihan (data tes 1) dan suara yang tidak pernah dilatihkan sebelumnya (data tes 2).
Tabel 1 Struktur jaringan syaraf tiruan
Karakteristik Spesifikasi
Arsitektur feed forward network, 1 layer hidden
Neuron input 130 (26 fitur x 5 frame)
Neuron lapis tersembunyi
50, 100, 200, 400, 700, 1000
Neuron output 24 (jumlah kategori)
Gambar 8 Arsitektur Jaringan Syaraf Tiruan yang digunakan dalam proses pengenalan kata.
Pencocokan kategori dengan target kata Output jaringan syaraf tiruan adalah matriks peluang suatu frame f berada dalam suatu kategori c. Hasil pembelajaran semua data pelatihan berupa matriks berukuran CxF, dengan C adalah banyaknya kategori yang dikenali dan F adalah banyaknya frame.
Matriks ini digunakan sebagai input untuk algoritma Viterbi bersama dengan grammar
yang telah didefinisikan dalam kamus kata. Algoritma ini dilakukan untuk menentukan kata yang paling sesuai dari peluang-peluang fonem yang ada.
Rancangan Percobaan
Penelitian ini dilakukan dengan memperhatikan faktor akurasi tingkat kata dan kalimat. Akurasi ini akan diamati pada beberapa variasi neuron lapis tersembunyi mulai dari 50, 100, 200, 400, 700, sampai 1000 unit. Pelatihan akan dilakukan menggunakan 50 iterasi (epoh).
(hand-labeled) dengan hasil pengenalan menggunakan force alignment. Force alignment adalah proses pengenalan kata menggunakan pengenal kata yang tersedia. Pengenal kata ini didapat dari proses pengenalan sebelumnya yaitu proses pengenalan menggunakan data hand-labeled
dengan bobot terbaik. Jaringan dengan bobot terbaik akan memberikan hasil pengenalan yang baik pula. Hasil dari proses force alignment ini adalah label fonem dengan rentang waktu tertentu untuk suatu gelombang suara tertentu. Pengenalan dengan force
alignment tidak lagi membutuhkan file
kategori fonem untuk data pelatihannya (Hosom et al 1999).
Setelah dibandingkan dengan proses force alignment, dilakukan juga pelatihan jaringan menggunakan algoritma forward backward.
Algoritma forward backward ini biasa digunakan untuk melatih sebuah Hidden Markov Model (HMM). Untuk memulai suatu pelatihan menggunakan Forward Backward Neural Networks (FBNN) dibutuhkan jaringan syaraf tiruan yang didapatkan dari proses pelatihan menggunakan data hand-labeled.
Algoritma forward backward umumnya digunakan untuk melatih sebuah HMM yang menggunakan fungsi Gaussian sebagai penentu peluang observasi. Pada pengenal suara yang menggunakan JST untuk menghitung peluang observasi, algoritma
forward backward digunakan untuk
mengestimasi ulang nilai peluang observasi dan peluang transisi yang didapatkan sebelumnya. Target jaringan syaraf tiruan yang dihasilkan adalah nilai peluang posterior suatu frame merupakan kategori tertentu, tidak seperti pada jaringan syaraf sebelumnya yang targetnya berupa bilangan biner (Yan et al 1997).
Parameter Percobaan
Analisis kinerja pada percobaan kali ini hanya berfokus pada akurasi pengenalan kata. Kesalahan-kesalahan dasar yang sering terjadi adalah deletion, insertion, dan substitution.
Akurasi sistem dihitung pada dua tingkat pengamatan, tingkat kata (word accuracy) dan tingkat kalimat (sentence accuracy). Ketepatan sistem secara keseluruhan pada tingkat kata dapat dirumuskan sebagai berikut
Word Accuracy=100% - (Sub+Ins+Del)
dengan Sub, Ins, dan, Del masing-masing adalah persentase substitution, insertion, dan
juga dihitung untuk tingkat kalimat. Ketepatan pada level kalimat didapatkan dengan menghitung banyaknya gelombang suara yang dikenali dibagi dengan banyaknya gelombang suara yang terdapat pada tahap pengujian.
Lingkungan Pengembangan
Semua percobaan yang disebutkan pada rancangan percobaan sebelumnya dilakukan dengan bantuan perangkat lunak pengenal kata CSLU toolkit. Perangkat lunak ini dipilih dengan mempertimbangkan kemudahan baik pada praproses data maupun proses pengolahan data selanjutnya. Proses pengenalan kata dilakukan dengan mengeksekusi barisan script CSLUsh dengan menggunakan file lainnya yang telah dideskripsikan sebelumnya seperti corpora,
kondisi pelatihan, dan arsitektur jaringan.
Script CSLUsh ini digunakan untuk proses-proses mulai dari pengumpulan data, pemetaan kategori, pemilihan data, pelatihan JST, sampai pengujian.
Sistem operasi yang dilakukan adalah Windows XP Professional. Perangkat lunak lain yang digunakan adalah Audacity sebagai editor audio. Perangkat keras yang digunakan ialah komputer dengan processor Pentium IV 1,8 GHz, RAM sebesar 256 Mb, serta kapasitas harddisk sebesar 40 Gb.
HASIL DAN PEMBAHASAN
Pengaruh Jumlah Neuron pada Lapisan
Tersembunyi dan Iterasi Terhadap
Akurasi Sistem
Percobaan pertama bertujuan untuk membandingkan kinerja sistem berdasarkan jumlah neuron yang digunakan pada lapisan tersembunyi. Percobaan ini juga akan melihat seberapa besar pengaruh banyaknya unit pada lapisan tersembunyi terhadap akurasi sistem.
Arsitektur JST yang digunakan pada sistem pengenal kata ini adalah jaringan
perceptron lapis banyak (multi layer
perceptron). MLP dipilih karena dapat
membentuk daerah keputusan yang nonlinear, tidak seperti jaringan lapis tunggal (single
layer perceptron) yang hanya dapat
dihitung dengan MLP dengan lapisan tersembunyi lebih dari satu juga dapat diselesaikan oleh MLP dengan hanya satu lapisan tersembunyi jika jumlah unit pada lapisan tersembunyi telah mencukupi. Selain itu waktu pelatihan untuk MLP dengan jumlah lapisan tersembunyi yang banyak akan meningkat secara signifikan.
Jumlah neuron lapis tersembunyi dalam MLP sangat menentukan kinerja MLP dalam proses pengenalan pola. Banyaknya neuron lapis tersembunyiyang digunakan juga sangat berpengaruh terhadap waktu pelatihan. Apabila suatu jaringan terlalu lama dilatihkan akan timbul keanehan yang akan mengurangi kinerja pada data pelatihan (Tebelskies 1995).
Fungsi aktivasi yang digunakan pada penelitian ini adalah fungsi linear dan fungsi sigmoid biner. Fungsi sigmoid biner dipilih karena daerah hasil yang diinginkan terletak pada interval 0 dan 1.
JST yang dibuat adalah jaringan lapis banyak dengan variasi neuron lapis tersembunyi sebanyak 50, 100, 200, 400, 700, dan 1000 unit. Proses pelatihan dilakukan dengan iterasi sebanyak 50 kali. Setiap iterasi akan menghasilkan bobot jaringan yang berbeda-beda. Setelah pelatihan selesai, semua file pengujian yang ada pada data tes diujikan ke dalam 50 bobot jaringan yang berbeda-beda tadi. Bobot jaringan yang paling baik akan memberikan akurasi pengenalan yang baik pula. Persentase word accuracy
dan sentence accuracy terbaik dari masing-masing variasi neuron dari hasil pengujian menggunakan data tes 1 dapat dilihat pada Tabel 2. Sedangkan untuk hasil akurasi dengan menggunakan data tes 2 tertera pada Tabel 3.
Tabel 2 menunjukkan bahwa akurasi pengenalan kata telah mencapai hasil yang maksimal yaitu 100% menggunakan neuron lapis tersembunyi sebanyak 700 unit.
Meskipun jumlah iterasi yang digunakan adalah 50 iterasi akan tetapi hasil pengenalan terbaik pada masing-masing variasi neuron belum tentu berasal dari iterasi terakhir. Hasil terbaik ini biasanya terjadi lebih awal. Pada variasi jumlah neuron 50 unit hasil terbaik terjadi pada iterasi ke-5 yaitu 98,33% untuk tingkat kata dan 92,50% untuk tingkat kalimat. Iterasi ke-9 pada variasi neuron lapis tersembunyi sebanyak 100 unit memberikan hasil yang paling maksimum yaitu 99,17% untuk akurasi tingkat kata dan 95,00% untuk
tingkat kalimat. Demikian pula untuk variasi neuron 200 unit, hasil terbaik terjadi pada iterasi ke-3. Variasi neuron sebanyak 400 unit memberikan hasil terbaik setelah melalui 9 kali iterasi. Pengenalan terbaik untuk data tes 1, yang didapatkan dari variasi neuron 700 unit, berasal dari iterasi ke-7 sama seperti yang terjadi pada variasi neuron lapis tersembunyi 1000 unit. Gambar 9 menunjukkan perbandingan akurasi pengenalan tingkat kata dan kalimat pada data tes 1.
Tabel 2 Hasil pengenalan terbaik untuk masing-masing variasi neuron tersembunyi pada data tes 1
Jumlah neuron
word accuracy
(%)
sentence accuracy
(%)
50 98,33 92,50
100 99,17 95,00
200 99,17 95,00
400 99,58 97,50
700 100,00 100,00
1000 100,00 100,00
80 85 90 95 100
50 100 200 400 700 1000
jumlah neuron (unit)
aku
rasi
(
%
)
word accuracy (%) sentence accuracy (%)
Gambar 9 Perbandingan akurasi tingkat kata dan kalimat pada data tes 1.
Akan tetapi jika dibandingkan dengan hasil pengenalan kata pada data data yang belum pernah dilatihkan sebelumnya (data tes 2), ketepatan pengenalan sistem menurun untuk semua variasi neuron lapis tersembunyi.
Besar kemungkinan penyebabnya adalah pola suara yang berbeda dengan data sebelumnya yang digunakan dalam pelatihan. Seperti dijelaskan sebelumnya, semua data yang terdapat pada data tes 2 belum pernah dilatihkan ke sistem.
tes 1, akurasi terbaik yang dihasilkan pada data tes 2 juga belum tentu berasal dari iterasi terakhir (iterasi ke-50). Variasi neuron lapis tersembunyi 50 unit memberikan hasil terbaik pada iterasi ke-3, demikian pula yang terjadi pada variasi neuron lapis tersembunyi 100 dan 200 unit. Iterasi ke-29 pada penggunaan neuron lapis tersembunyi sebanyak 400 unit memberikan hasil yang paling baik untuk data tes ini, yaitu 98,33% untuk tingkat kata dan 92,50% untuk tingkat kalimat. Hasil pengenalan menggunakan JST dengan variasi neuron tersembunyi sebanyak 700 dan 1000 unit menghasilkan akurasi terbaik pada iterasi ke-11 dan 25. Gambar 10 menunjukkan perbandingan akurasi tingkat kata dan kalimat pada data tes 2.
Tabel 3 Hasil pengenalan terbaik untuk masing-masing variasi neuron tersembunyipada data tes 2
Jumlah neuron
word accuracy
(%)
sentence accuracy
(%)
50 97,50 87,50
100 97,50 87,50
200 97,50 90,00
400 98,33 92,50
700 97,08 85,00
1000 97,00 90,00
75 80 85 90 95 100
50 100 200 400 700 1000
jumlah neuron (unit)
aku
rasi
(
%
)
word accuracy (%) sentence accuracy (%)
Gambar 10 Perbandingan akurasi tingkat kata dan kalimat pada data tes 2.
Penggunaan neuron lapis tersembunyi yang lebih banyak tidak menjamin akurasi yang baik. Pada data tes 2, akurasi pengenalan kata sudah mencapai puncaknya dengan neuron lapis tersembunyi sebesar400 unit.
banyaknya neuron yang digunakan adalah waktu pelatihan yang dibutuhkan. Penggandaan jumlah neuron lapis tersembunyi juga akan menggandakan waktu pelatihan yang digunakan.
Keseluruhan hasil yang ada menunjukkan bahwa neuron lapis tersembunyi sebanyak400 unit memberikan hasil terbaik. Pemakaian neuron lapis tersembunyi di atas 400 buah memberikan hasil yang relatif konstan, sedangkan jumlah neuron lapis tersembunyi dibawah 400 kurang memberikan hasil yang optimal. Hal ini mengindikasikan banyaknya variasi dalam suara. Meskipun suara berasal dari speaker yang sama dan mengucapkan angka yang sama pula tetap saja terdapat perbedaan. Keragaman ini mengakibatkan jaringan tidak dapat ”mengingat” data pelatihan yang diberikan.
Perbandingan Akurasi Menggunakan
Hand Labeled, Force Alignment, dan FBNN
Percobaan kedua akan membandingkan hasil pengenalan kata menggunakan data yang dilabel secara manual (hand-labeled data)
dengan pengenalan kata menggunakan force alignment.
Pengenal kata yang digunakan pada proses force alignment berasal dari bobot jaringan ke-29 dengan jumlah neuron lapis tersembunyi sebanyak 400 unit. Bobot jaringan ini memberikan hasil pengenalan terbaik berdasarkan percobaan sebelumnya.
Pada dasarnya pelatihan jaringan dengan proses force alignment memiliki tahapan yang sama dengan pelatihan menggunakan data
hand-labeled. Arsitektur JST yang digunakan pun sama dengan yang digunakan pada tahap sebelumnya. Pengenalan menggunakan metode ini tidak lagi memerlukan file transkripsi fonetik yang pada percobaan sebelumnya dihasilkan secara manual. Transkripsi fonetik akan dihasilkan secara otomatis oleh pengenal kata yang telah tersedia. Dalam hal ini pengenal kata yang tersedia berasal dari bobot JST ke-29 dengan neuron lapis tersembunyi sebanyak 400 unit.
Selain terhadap force alignment,
dahulu sebagai permulaannya. Peluang observasi yang dihasilkan oleh JST ini akan dihitung kembali menggunakan persamaan yang diturunkan dari koefisien forward dan
backward. Nilai peluang transisi juga turut dihitung kembali dengan nilai awal yang ditetapkan sebesar 0,4 sebagai peluang untuk berpindah dari suatu state ke state berikutnya dan 0,6 sebagai peluang untuk tetap berada pada state yang sama. Ketepatan pengenalan kata untuk masing-masing proses dapat dilihat pada Tabel 4.
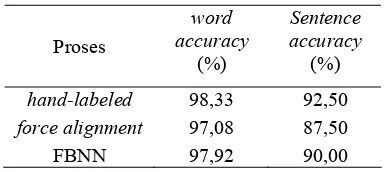
Tabel 4 Hasil pengenalan kata menggunakan proses hand-labeled, force alignment
dan FBNN
Proses
word accuracy
(%)
Sentence accuracy
(%)
hand-labeled 98,33 92,50
force alignment 97,08 87,50
FBNN 97,92 90,00
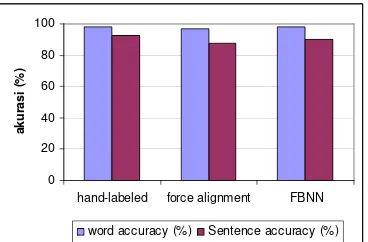
Pengenalan menggunakan data yang dilabel secara manual menghasilkan akurasi yang lebih tinggi dibandingkan dua metode lain. Akurasi tingkat kata menggunakan force alignment lebih rendah 1,25% dibandingkan dengan data hand-labeled yaitu sebesar 97,08%. Sedangkan untuk tingkat kalimat, pengenalan menurun sebesar 5,00% menjadi sebesar 87,50%. Pengenalan menggunakan FBNN menghasilkan akurasi tingkat kata dan kalimat yang tidak jauh berbeda dari sebelumnya yaitu 97,92% dan 90,00%.
Gambar 11 menunjukkan perbandingan akurasi ketiga proses tersebut. Melalui percobaan di atas dapat disimpulkan bahwa untuk kasus kali ini proses pengenalan menggunakan data suara yang dilabel secara manual memberikan hasil terbaik dibandingkan dua metode lainnya. Secara lengkap hasil pengenalan kata menggunakan
force alignment dan FBNN dapat dilihat pada Lampiran 5.
0 20 40 60 80 100
hand-labeled force alignment FBNN
ak
u
ra
si
(
%
)
word accuracy (%) Sentence accuracy (%)
Gambar 11 Perbandingan akurasi dari proses hand-labeled, force alignment,
dan FBNN.
KESIMPULAN DAN SARAN
Kesimpulan
Beberapa kesimpulan yang dihasilkan melalui penelitian ini adalah:
1 Untuk sistem CDR berbahasa Indonesia ini telah didefinisikan kamus kata dasar bilangan dan grammar yang dapat digunakan untuk pengembangan selanjutnya.
2 Hasil pengenalan kata terbaik dicapai dengan variasi neuron pada lapisan tersembunyi sebanyak 400 unit dengan iterasi sebanyak 29 kali yaitu sebesar 98,33% untuk word accuracy dan 92,50% untuk sentence accuracy.
3 Pada kasus ini pengenalan menggunakan data hand-label memberikan hasil yang lebih baik dibandingkan dengan force
alignment dan pelatihan menggunakan
algoritma forward backward. Akurasi tingkat kata berturut-turut untuk ketiga proses tersebut adalah 98,33%, 97,08%, dan 97,92%. Akurasi tingkat kalimat untuk proses hand-label, force alignment,
dan FBNN masing-masing adalah sebesar 92,50%, 87,50%, dan 90,00%.
4 Optimasi pengenalan kata menggunakan
force alignment dan FBNN memberikan asil yang tidak berbeda nyata dengan proses pelabelan manual berdasarkan uji statistik yang dilakukan.
Saran
Untuk pengembangan penelitian selanjutnya disarankan hal-hal sebagai berikut:
berimbuhan perlu dilakukan.
2 Pengembangan lain yang dapat dilakukan adalah optimasi ekstraksi ciri untuk dapat meningkatkan akurasi sistem.
3 Penelitian ini hanya membagi fonem menjadi satu bagian saja (independent part). Perlu dikembangkan juga penelitian yang membagi fonem menjadi dua atau tiga bagian bergantung pada fonem disekitarnya (dependent part) dan mengelompokkan fonem-fonem tersebut ke dalam sebuah kelas berdasarkan posisi artikulasinya. Dengan pengklasifikasian ini diharapkan akurasi sistem akan meningkat.
DAFTAR PUSTAKA
Carmell T et al. 1997. Spectrogram reading. http://cslu.cse.ogi.edu/tutordemos/Sp ectrogramReading/spectrogram.html. [27 Juli 2005].
Cosi P. 2000. Hybrid HMM-ANN architectures for connected digit recognition. IEEE-INS-ENNS 5: 5085.
Cosi P, Hosom JP, Shalkwyk J, Sutton S, Cole RA. 1998. Connected digit recognition experiments with the OGI toolkit’s neural network and HMM-based recognizers. IEEE Workshop on Interactive Voice Technology for Telecommunication Applications
(IVTTA-ETWR98);Turin, September 1998.
hlm135-140.
Do MN. 1994. An automatic speaker recognition system. http:// lcavwww.epfl.ch/~minhdo/asr_proje ct/asr_project.pdf. [18 September 2005].
Duc DN, Hosom JP, Mai LC. 2001. HMM/ANN system for Vietnamese continous digit recognition. http://www.speech.bme.ogi.edu/publi cations/ps/duc03.pdf. [4 Juli 2005].
Fausett L. 1994. Fundamentals of Neural Networks. New Jersey: Prentice Hall.
Fu L. 1994. Neural Networks in Computer Intelligence. Singapura: McGraw-Hill.
networks for speech recognition. http://cslu.cse.ogi.edu/training neural networks for speech recognition.html. [5 Desember 2004]
Jurafsky D, Martin JH. 2000. Speech and Language Processing An Introduction to Natural Language
Processing, Computational Linguistic, and Speech Recognition.
New Jersey: Prentice Hall.
Markowitz JA. 1996. Using Speech Recognition. New Jersey: Prentice Hall.
[PPPBDEPDIKBUD] Pusat Pembinaan dan Pengembangan Bahasa Departemen Pendidikan dan Kebudayaan Repulik Indonesia. 1996. Pedoman Umum Ejaan Bahasa Indonesia yang Disempurnakan dan Pedoman Umum Pembentukan Istilah. Bandung: CV Pustaka Setia.
Rabiner J. 1989. A tutorial on hidden markov model and selected applications in speech recognition. Proc IEEE Vol 22 No.2. Februari 1989.
Tebelskis J. 1995. Speech recognition using neural networks. [disertasi]. Pennsylvania: Carnegie Mellon University.
No Speaker 1 Speaker 2 Speaker 3 Speaker 4
1 05331.wav 014686.wav 078421.wav 059065.wav
2 059607.wav 106544.wav 119180.wav 157758.wav
3 062150.wav 170269.wav 123520.wav 199311.wav
4 100500.wav 210881.wav 127975.wav 306818.wav
5 109611.wav 313157.wav 189054.wav 321032.wav
6 129725.wav 422430.wav 400585.wav 459349.wav
7 157397.wav 450073.wav 500641.wav 533595.wav
8 356737.wav 483279.wav 518319.wav 534586.wav
9 375710.wav 562152.wav 556018.wav 559144.wav
10 444161.wav 585875.wav 596255.wav 608197.wav
11 482703.wav 630085.wav 622904.wav 611731.wav
12 489753.wav 631833.wav 653313.wav 618212.wav
13 573086.wav 705962.wav 672490.wav 634168.wav
14 601281.wav 729948.wav 709530.wav 638252.wav
15 610159.wav 846884.wav 728943.wav 704837.wav
16 874818.wav 854842.wav 731632.wav 724660.wav
17 912372.wav 920035.wav 787330.wav 809098.wav
18 914498.wav 932220.wav 819774.wav 818125.wav
19 916728.wav 945472.wav 874311.wav 849089.wav
20 946508.wav 957556.wav 938589.wav 920177.wav
No Speaker 5 Speaker 6 Speaker 7 Speaker 8
1 118000.wav 081689.wav 374713.wav 561664.wav 2 163534.wav 314568.wav 316763.wav 566900.wav 3 253527.wav 898093.wav 425209.wav 119964.wav 4 309884.wav 806574.wav 168440.wav 956663.wav 5 492512.wav 317595.wav 087082.wav 126662.wav 6 617919.wav 800464.wav 401132.wav 231370.wav 7 834625.wav 641999.wav 145039.wav 202809.wav 8 880911.wav 987625.wav 290617.wav 990049.wav 9 943614.wav 951655.wav 232828.wav 215214.wav
10 957530.wav 669549.wav 688052.wav 447667.wav
Lampiran 2 Definisi kamus kata dan grammar yang digunakan
nol {n o l} kosong {k o s o ng} satu {s a pau t u}
dua {d u a}
tiga {t i g a} empat {em pau p a tcl} lima {l i m a} enam {en a m} tujuh {t u j u h} delapan {d e l a pau p a n} sembilan {s em b i l a n}
separator {[gar] sil [gar]}
Hasil pengenalan kata bilangan menggunakan 50 neuron lapis tersembunyi dengan 50 iterasi. (Kalimat dicetak tebal adalah hasil sebenarnya, sedangkan yang tidak dicetak tebal adalah hasil keluaran sistem)
nol tujuh delapan empat dua satu nol tujuh delapan empat dua satu
kosong lima sembilan kosong enam lima kosong lima sembilan kosong enam lima
satu satu sembilan satu delapan nol satu satu sembilan satu delapan nol
satu dua tiga lima dua nol satu dua tiga lima dua nol
satu dua tujuh sembilan tujuh lima satu dua tujuh sembilan tujuh lima
satu delapan sembilan nol lima empat satu delapan sembilan nol lima empat
satu lima tujuh tujuh lima delapan satu lima tujuh tujuh lima delapan
satu sembilan sembilan tiga satu satu satu sembilan sembilan tiga satu satu
tiga kosong enam delapan satu delapan tiga kosong enam delapan satu delapan
tiga dua satu kosong tiga dua tiga dua satu kosong tiga dua
empat delapan dua tujuh nol tiga empat delapan dua tujuh nol tiga
empat delapan sembilan tujuh lima tiga empat delapan sembilan tujuh lima tiga
empat nol nol lima delapan lima empat nol nol lima delapan lima
empat lima sembilan tiga empat sembilan empat lima sembilan tiga empat sembilan
lima tujuh tiga kosong delapan enam lima tujuh tiga kosong delapan enam
lima kosong kosong enam empat satu lima kosong kosong enam empat satu
lima satu delapan tiga satu sembilan lima satu delapan tiga satu sembilan
lima lima sembilan satu empat empat lima lima sembilan satu empat empat
enam kosong satu dua delapan satu enam kosong satu dua delapan satu
enam satu kosong satu lima sembilan enam satu kosong satu lima sembilan
enam tiga kosong kosong delapan lima enam tiga kosong kosong delapan lima
enam tiga satu delapan tiga tiga enam tiga satu delapan tiga tiga
enam kosong delapan satu sembilan tujuh enam kosong delapan satu sembilan tujuh
tujuh kosong lima sembilan enam dua tujuh kosong lima sembilan enam dua
tujuh dua sembilan sembilan empat delapan tujuh dua sembilan sembilan empat delapan
delapan tujuh empat delapan satu delapan delapan tujuh empat delapan satu delapan
delapan empat enam delapan delapan empat delapan empat enam delapan delapan empat
delapan lima empat delapan empat dua delapan lima empat delapan empat dua
delapan satu sembilan tujuh tujuh empat delapan satu sembilan tujuh tujuh empat
sembilan satu dua tiga tujuh dua sembilan satu dua tiga tujuh dua
sembilan satu empat empat sembilan delapan sembilan satu empat empat sembilan delapan
sembilan satu enam tujuh dua delapan sembilan satu enam tujuh dua delapan
sembilan empat ENAM lima kosong delapan sembilan empat TIGA lima kosong delapan
Lanjutan
lima sembilan enam dua lima lima lima sembilan enam dua lima lima
lima tiga tiga lima sembilan lima lima tiga tiga lima sembilan lima
lima tiga empat lima delapan enam lima tiga empat lima delapan enam
SEMBILAN empat lima empat tujuh dua TIGA empat lima empat tujuh dua
sembilan lima tujuh lima lima enam sembilan lima tujuh lima lima enam
SEMBILAN dua nol nol tiga LIMA TIGA dua nol nol tiga DUA
Hasil pengenalan kata bilangan menggunakan 50 neuron lapis tersembunyidengan 100 iterasi.
nol tujuh delapan empat dua satu nol tujuh delapan empat dua satu
kosong lima sembilan kosong enam lima kosong lima sembilan kosong enam lima
satu satu sembilan satu delapan nol satu satu sembilan satu delapan nol
satu dua tiga lima dua nol satu dua tiga lima dua nol
satu dua tujuh sembilan tujuh lima satu dua tujuh sembilan tujuh lima
satu delapan sembilan nol lima empat satu delapan sembilan nol lima empat
satu lima tujuh tujuh lima delapan satu lima tujuh tujuh lima delapan
satu sembilan sembilan tiga satu satu satu sembilan sembilan tiga satu satu
tiga kosong enam delapan satu delapan tiga kosong enam delapan satu delapan
tiga dua satu kosong tiga dua tiga dua satu kosong tiga dua
empat delapan dua tujuh nol tiga empat delapan dua tujuh nol tiga
empat delapan sembilan tujuh lima tiga empat delapan sembilan tujuh lima tiga
empat nol nol lima delapan lima empat nol nol lima delapan lima
empat lima sembilan tiga empat sembilan empat lima sembilan tiga empat sembilan
lima tujuh tiga kosong delapan enam lima tujuh tiga kosong delapan enam
lima lima sembilan satu empat empat lima lima sembilan satu empat empat
enam kosong satu dua delapan satu enam kosong satu dua delapan satu
enam satu kosong satu lima sembilan enam satu kosong satu lima sembilan
enam tiga kosong kosong delapan lima enam tiga kosong kosong delapan lima
enam tiga satu delapan tiga tiga enam tiga satu delapan tiga tiga
enam kosong delapan satu sembilan tujuh enam kosong delapan satu sembilan tujuh
tujuh kosong lima sembilan enam dua tujuh kosong lima sembilan enam dua
tujuh dua sembilan sembilan empat delapan tujuh dua sembilan sembilan empat delapan
delapan tujuh empat delapan satu delapan delapan tujuh empat delapan satu delapan
delapan empat enam delapan delapan empat delapan empat enam delapan delapan empat
delapan lima empat delapan empat dua delapan lima empat delapan empat dua
delapan satu sembilan tujuh tujuh empat delapan satu sembilan tujuh tujuh empat
sembilan satu dua tiga tujuh dua sembilan satu dua tiga tujuh dua
sembilan satu empat empat sembilan delapan sembilan satu empat empat sembilan delapan
lima kosong kosong enam empat satu lima kosong kosong enam empat satu
lima satu delapan tiga satu sembilan lima satu delapan tiga satu sembilan
lima sembilan enam dua lima lima lima sembilan enam dua lima lima
lima tiga tiga lima sembilan lima lima tiga tiga lima sembilan lima
lima tiga empat lima delapan enam lima tiga empat lima delapan enam
sembilan empat ENAM lima kosong delapan sembilan empat TIGA lima kosong delapan
sembilan tiga dua dua dua kosong sembilan tiga dua dua dua kosong
sembilan empat lima empat tujuh dua sembilan empat lima empat tujuh dua
sembilan lima tujuh lima lima enam sembilan lima tujuh lima lima enam
sembilan dua nol nol tiga lima sembilan dua nol nol tiga lima
Hasil pengenalan kata bilangan menggunakan 100 neuron lapis tersembunyidengan 50 iterasi.
nol tujuh delapan empat dua satu nol tujuh delapan empat dua satu
kosong lima sembilan kosong enam lima kosong lima sembilan kosong enam lima
satu satu sembilan satu delapan nol satu satu sembilan satu delapan nol
satu dua tiga lima dua nol satu dua tiga lima dua nol
satu dua tujuh sembilan tujuh lima satu dua tujuh sembilan tujuh lima
satu delapan sembilan nol lima empat satu delapan sembilan nol lima empat
satu lima tujuh tujuh lima delapan satu lima tujuh tujuh lima delapan
satu sembilan sembilan tiga satu satu satu sembilan sembilan tiga satu satu
tiga kosong enam delapan satu delapan tiga kosong enam delapan satu delapan
tiga dua satu kosong tiga dua tiga dua satu kosong tiga dua
empat delapan dua tujuh nol tiga empat delapan dua tujuh nol tiga
empat delapan sembilan tujuh lima tiga empat delapan sembilan tujuh lima tiga
empat nol nol lima delapan lima empat nol nol lima delapan lima
lima lima sembilan satu empat empat lima lima sembilan satu empat empat
enam kosong satu dua delapan satu enam kosong satu dua delapan satu
enam satu kosong satu lima sembilan enam satu kosong satu lima sembilan
enam tiga kosong kosong delapan lima enam tiga kosong kosong delapan lima
enam tiga satu delapan tiga tiga enam tiga satu delapan tiga tiga
enam kosong delapan satu sembilan tujuh enam kosong delapan satu sembilan tujuh
tujuh kosong lima sembilan enam dua tujuh kosong lima sembilan enam dua
tujuh dua sembilan sembilan empat delapan tujuh dua sembilan sembilan empat delapan
delapan tujuh empat delapan satu delapan delapan tujuh empat delapan satu delapan
delapan empat enam delapan delapan empat delapan empat enam delapan delapan empat
delapan lima empat delapan empat dua delapan lima empat delapan empat dua
delapan satu sembilan tujuh tujuh empat delapan satu sembilan tujuh tujuh empat
Lanjutan
empat lima sembilan tiga empat sembilan empat lima sembilan tiga empat sembilan
lima tujuh tiga kosong delapan enam lima tujuh tiga kosong delapan enam
lima kosong kosong enam empat satu lima kosong kosong enam empat satu
lima satu delapan tiga satu sembilan lima satu delapan tiga satu sembilan
lima sembilan enam dua lima lima lima sembilan enam dua lima lima
lima tiga tiga lima sembilan lima lima tiga tiga lima sembilan lima
lima tiga empat lima delapan enam lima tiga empat lima delapan enam
sembilan satu empat empat sembilan delapan sembilan satu empat empat sembilan delapan
sembilan satu enam tujuh dua delapan sembilan satu enam tujuh dua delapan
sembilan empat enam lima kosong delapan sembilan empat enam lima kosong delapan
sembilan tiga dua dua dua kosong sembilan tiga dua dua dua