SUATU KAJIAN DALAM PENENTUAN FAKTOR DOMINAN
YANG MEMPENGARUHI MENINGKATNYA PENDERITA
KANKER SERVIKS DENGAN ANALISIS FAKTOR
TUGAS AKHIR
NURDIAN SURAIYA 070803011
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
ALAM UNIVERSITAS SUMATERA UTARA
SUATU KAJIAN DALAM PENENTUAN FAKTOR DOMINAN
YANG MEMPENGARUHI MENINGKATNYA PENDERITA
KANKER SERVIKS DENGAN ANALISIS FAKTOR
TUGAS AKHIR
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar sarjana sains
NURDIAN SURAIYA
070803011
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
ALAM UNIVERSITAS SUMATERA UTARA
PENGHARGAAN
Puji dan syukur penulis panjatkan kehadirat Allah SWT Yang Maha Pemurah dan Maha Penyayang, dengan limpahan kurnia-Nya skripsi ini berhasil diselesaikan dalam waktu yang telah ditetapkan. Shalawat beriring salam kepada
Baginda Rasulullah SAW, sebagai rahmatan lil’alamin.
Dalam menyelesaikan skripsi ini penulis mengucapkan banyak terimakasih kepada Bapak Dr. Sutarman, M.Si selaku Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara.Bapak Prof. Dr. Tulus, M.Si selaku ketua Departemen Matematika Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara. Bapak Drs. Pasukat Sembiring, M.Si dan Drs. Rachmad Sitepu, M.Si, selaku dosen pembimbing skripsi penulis yang telah memberi dukungan moral, motivasi dan ilmu pengetahuan bagi penulis dalam menyelesaikan penulisan ini, serta Bapak Drs. Open Darnius,
M.Sc dan Ibu Dra. Elly Rosmaini, M.Si sebagai dosen penguji skripsi ini yang telah memberikan kritik dan saran agar penulisan ini lebih baik. Seluruh Staf
Pengajar Departemen Matematika Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara.
Ucapan terimakasih juga ditujukan kepada kedua Orangtua tercinta Sukisno dan Zainab Lubis yang telah memberikan banyak bantuan materi, moril maupun spiritual. Kepada saudara-saudari saya, M. Iskandar, Yusniar Triya, Kiki Rizky Hidayat dan Susanti Yusuf yang selalu memberi semangat untuk menyelesaikan skripsi ini.
Tak lupa pula ucapan terimakasih ditujukan kepada sahabat-sahabat yaitu: Zulham, Lia, Novi, Mizwar, Warsini, Nelly, Memel, Sheila, Isnaini, Irma yang telah memberikan semangat dan persaudaraan selama mengenyam pendidikan di FMIPA USU, serta rekan-rekan stambuk 2007 Departemen Matematika FMIPA USU dan para sahabat di Ikatan Mahasiswa Matematika Muslim FMIPA USU dan kepada seluruh pihak yang telah memberikan motivasi yang tidak dapat disebutkan satu per satu.
ABSTRAK
ABSTRACT
DAFTAR ISI
Halaman
PERSETUJUAN i
PERNYATAAN ii
PENGHARGAAN iii
ABSTRAK iv
ABSTRACT v
DAFTAR vi
DAFTAR TABEL vii
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 2
1.3 Batasan Masalah 3
1.4 Tinjauan Pustaka 3
1.5 Tujuan Penelitian 5
1.6 Manfaat Penelitian 5
1.7 Metodologi Penelitian 5
BAB 2 LANDASAN TEORI 7
2.1 Variabel 7
2.2 Data 7
2.2.1 Data Menurut Sifatnya 8
2.2.2 Data Menurut sumbernya 8
2.3 Skala Pengukuran 9
2.4 Skala Untuk Instrumen (ModelSkala Sikap) 11
2.5 Faktor-faktor Yang Mempengaruhi Kanker Serviks 12
2.5.1 Pendidikan 12
2.5.2 Pekerjaan 13
2.5.4 Usia Pertama Kali Melakukan Hubungan Seksual 13
2.5.5 Papsmear 14
2.5.6 Ganti Pasangan 14
2.5.7 Infeksi 14
2.5.8 Pemakaian Kontrasepsi 15
2.5.9 Merokok 15
2.6 Uji Vvaliditas 16
2.7 Uji Reliabilitas 16
2.8 Analisis Faktor 16
2.8.1 Model Analisis Faktor 17
2.8.2 Statistik Yang Berkaitan Dengan Analisis Faktor 18
2.8.3 Pelaksanaan Analisis Faktor 21
BAB 3 PEMBAHASAN 26
3.1 Gambaran Umum 26
3.2 Uji Validitas 27
3.3 Uji Reliabilitas 29
3.4 Analisis Faktor Dengan SPSS for Windows 17.0 30
3.4.1 Membuat Matriks Korelasi 30
3.4.2 Penentuan Jumlah Faktor 32
3.4.3 Rotasi Faktor 33
3.4.4 Interpretasi Faktor 33
3.4.5 Ketepatan Model (Model Fit) 35
BAB 4 KESIMPULAN DAN SARAN 37
4.1 Kesimpulan 37
4.2 Saran 38
DAFTAR PUSTAKA 39
LAMPIRAN A: HASIL OUTPUT SPSS FOR WINDOWS 17.0 40
LAMPIRAN B: KUISIONER PENELITIAN 49
DAFTAR TABEL
Halaman Tabel 2.1 Matrik Korelasi Untuk Jumlah Variabel n = 3 19 Tabel 2.2 Matrik Korelasi Untuk Jumlah Variabel n = 4 19
Tabel 3.1 Tabel Deskripsi Faktor Kanker Servik 27
Tabel 3.2 Tabel Hasil Uji Validitas 28
Tabel 3.3 Tabel Hasil Uji Reliabilitas 29
Tabel 3.4 Tabel Matrik Korelasi 31
Tabel 3.5 Tabel Uji KMO dan Uji Barlett 31
Tabel 3.6 Anti-image Matrices 32
Tabel 3.7 Faktor-faktor Yang Mempengaruhi Meningkatnya 33 Penderita Kanker Serviks
Tabel 3.8 Tabel Hasil Rotasi Faktor Varimax 33
Tabel 3.9 Tabel Selisih (Residuals) Antara Observed Correlation 35 Dengan Reproduced Correlation
ABSTRAK
ABSTRACT
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Kanker merupakan penyakit tidak menular. Penyakit ini akan timbul karena pola hidup yang tidak sehat dan mengakibatkan kondisi fisik yang tidak normal. Kanker dapat menyerang berbagai jaringan di dalam organ tubuh, termasuk organ reproduksi pada wanita dari payudara, rahim, induk telur dan vagina. Layaknya semua kanker, kanker serviks terjadi ditandai dengan adanya pertumbuhan sel-sel pada leher rahim yang tidak lazim (abnormal). Tetapi sebelum sel-sel tersebut menjadi sel-sel kanker, terjadi beberapa perubahan yang dialami oleh sel-sel tersebut. Kanker serviks
merupakan salah satu penyakit yang menimbulkan dampak psikologis yang luas bagi pasien dan keluarga pasien (Mangan, 2003).
Kanker serviks merupakan penyebab kematian kedua setelah jantung koroner. Di Negara berkembang, kanker serviks menempati peringkat teratas sebagai penyakit yang diidap oleh wanita. Diperkirakan terdapat 500.000 kasus setiap tahunnya di dunia dan 80% diantaranya terjadi di negara-negara yang sedang berkembang. Indonesia yang merupakan salah satu negara berkembang tercatat lebih dari 100 per 1.000.000 jiwa kasus kanker serviks atau sekitar 180.000 kasus kanker serviks setiap tahunnya ( Sahil, 2003. Mustari, 2006 ).
memeriksakan kesehatan dirinya terutama kesehatan reproduksi dan minimnya pengetahuan kaum wanita terhadap faktor-faktor penyebab kanker serviks.
Lebih dari 90 persen penyebab kanker serviks ditularkan oleh virus HPV (Human Papiloma Virus) yang ditularkan melalui hubungan seksual. Virus ini memiliki lebih dari 100 tipe. Selain HPV, ada beberapa faktor yang diduga mempengaruhi meningkatnya kanker serviks yaitu faktor sesiodemografis yang meliputi usia, status ekonomi sosial, pendidikan dan faktor aktivitas seksual yang meliputi usia pertama kali melakukan hubungan seks, pasangan seks yang berganti-ganti, paritas, intesitas menjaga kebersihan genital, merokok, riwayat penyakit kelamin, trauma kroniks pada seviks, serta penggunaan kontrasepsi oral dalam jangka yang cukup lama yaitu lebih dari 4 tahun (Diananda,2007).
Analisis multivariat merupakan salah satu jenis analisis yang digunakan untuk menganalisis data yang mempunyai banyak peubah bebas ( independent variable ) dan peubah tidak bebas ( dependent variable ).
Analisis faktor merupakan salah satu metode statistik multivariat yang digunakan untuk menganalisis variabel-variabel yang diduga memiliki keterkaitan satu sama lain sehingga keterkaitan tersebut dapat dijelaskan dan dipetakan atau
dikelompokkan pada faktor yang tepat.
Berdasarkan latar belakang tersebut dan tingginya jumlah wanita yang
menderita penyakit kanker seviks, penulis tertarik untuk mngetahui lebih lanjut faktor-faktor yang mempengaruhi meningkatnya penyakit kanker serviks, sehingga dengan hasil yang diperoleh dapat dijadikan acuan dalam penyusunan rencana program penanggulangan kanker serviks.
1.2Perumusan Masalah
1.3Batasan Masalah
1. Penelitian ini dilakukan di RSU dr. Pirngadi Medan
2. Faktor yang dilihat adalah pendidikan, pekerjaan, paritas, usia pertama kali melakukan hubungan seksual, papsmear, ganti pasangan, infeksi, pemakaian kontrasepsi, dan merokok.
1.4Tinjauan Pustaka
Analisis faktor merupakan salah satu metode multivariat yang digunakan untuk menganalisis variabel-variabel yang diduga memiliki keterkaitan satu sama lain sehingga keterkaitan tersebut dapat dijelaskan dan dipetakan atau dikelompokkan pada faktor yang tepat. Dalam menganalisis faktor yang mempengaruhi meningkatnya penderita kanker serviks, metode analisis faktor dianggap sangat cocok untuk penelitian ini, disebabkan penelitian ini mencoba menemukan hubungan (interrelationship) beberapa variabel yang saling independen satu dengan yang lainnya, sehingga bisa dibuat kumpulan variabel yang lebih sedikit dari jumlah variabel awal sehingga akan lebih mudah dikontrol (Kerlinger, 1993).
Tujuan dari analisis faktor adalah untuk menggambarkan hubungan-hubungan kovarian antara beberapa variabel yang mendasari tetapi tidak teramati, kuantitas
random yang disebut faktor, (Johnson &Wichern, 2002).
Tujuan analisis faktor adalah menggunakan matriks korelasi hitungan untuk 1.) Mengidentifikasi jumlah terkecil dari faktor umum (yaitu model faktor yang paling parsimoni) yang mempunyai penjelasan terbaik atau menghubungkan korelasi diantara variabel indikator. 2.) Mengidentifikasi, melalui faktor rotasi, solusi faktor yang paling masuk akal. 3.) Estimasi bentuk dan struktur loading, komunality dan varian unik dari indikator. 4.) Intrepretasi dari faktor umum. 5.) Jika perlu, dilakukan estimasi faktor skor (Subash Sharma, 1996).
varian yang disumbangkan oleh suatu variabel dengan variabel lainnya tercakup dalam analisis disebut communality. Kovarians antar variabel yang diuraikan, dinyatakan dalam suatu common factors yang sedikit jumlahnya ditambah dengan faktor yang unik untuk setiap variabel. Dari variabel-variabel yang dibakukan
(standardized), model faktor dapat ditulis sebagai berikut:
X1 - µ1 = L11F1 + L12F2 + ... + L1m+ ε1
X2 - µ2 = L21F2 + L22F2 + ... + L2m +ε2
: :
: :
Xp - µp = Lp1F1 + Lp2F2 + ... + Lpm + εp
Dimana
µi = rata-rata dari peubah ke-i Fj = faktor umum ke-j
εj = faktor unik ke-j
Lij = loading dari peubah ke-i pada faktor ke-j
Atau dalam notasi matriks:
Xpx1 -µpx1 = LpxmFmx1+ εpx1
Faktor unik tidak berkorelasi dengan sesama faktor unik dan juga tidak berkorelasi dengan common faktor. Common factor dapat dinyatakan sebagai kombinasi linier dari variabel-variabel yang terobservasi, yaitu:
Fi = Wi1X1 + Wi2X2 + Wi3X3 + ...
+ WikXk
Keterangan:
Fi = Estimasi faktor ke i
Wi = Bobot atau koefisien nilai faktor ke i k = Jumlah variabel
Variasi observasi yang muncul tentu saja disebabkan adanya konsep variansi. Inilah asumsi pertama dalam anlisis faktor. Jenis varians yaitu: common varians,
bawah standar, kondisi psikologi dan perubahan tertentu pada diri individu dan pengaruh lain yang menimbulkan unreliabilitas. Varians ini di asumsikan tidak berkolerasi dengan varians yang reliabel (Fructer, 1954).
1.5Tujuan Penelitian
Berdasarkan permasalahan, maka penulisan ini bertujuan untuk mengetahui faktor-faktor yang paling berpengaruh penyebab meningkatnya penderita kanker serviks yang dirawat di RSU dr. Pirngadi Medan.
1.6Manfaat Penelitian
Penulisan ini diharapkan dapat menjadi acuan bagi RSU dr. Pirngadi Medan dalam penanganan penderita kanker serviks dan bagi seluruh lapisan masyarakat khususnya perempuan sebagai gambaran tentang faktor yang mempengaruhi meningkatnya penderita kanker serviks sehingga penderita kanker serviks dapat diminimalisir.
1.7Metodologi Penelitian
Cara mengumpulkan data adalah dengan membuat quisioner, yaitu dengan membuat daftar pertanyaan untuk diisi oleh responden, disini diminta agar responden memberikan jawaban sejujur mungkin.
Selanjutnya dilakukan langkah-langkah sebagai berikut: 1. Uji Validitas (kesahihan)
Validitas mempunyai arti sejauh mana ketepatan dan kecermatan suatu alat ukur dalam melakukan fungsinya. Suatu angket dikatakan valid (sah) jika pertanyaan pada suatu angket mampu mengungkapkan sesuatu yang diukur oleh angket tersebut (Azwar, 2003).
2. Uji Reliabilitas (keandalan)
Menurut Azwar (2003), reliabilitas alat ukur menunjukkan sejauh mana hasil usaha pengukuran dapat dipercaya.
3. Analisis Faktor
Secara garis besar tahapan dalam melakukan analisis faktor adalah:
a. Merumuskan masalah, dangan mengidentifikasi variabel-variabel, yaitu:
X1 = Pendidikan X2 = Pekerjaan
X3 = Usia pertama kali kawin/melakukan hubungan seks X4 = Papsmear
X5 = Paritas
X6 = Ganti pasangan X7 = Infeksi
X8 = Pemakaian kontrasepsi X9 = Merokok
b. Membuat matriks korelasi c. Penentuan jumlah faktor d. Rotasi faktor
BAB 2
LANDASAN TEORI
2.1 Variabel
Variabel di dalam suatu penelitian merupakan atribut dari sekelompok objek yang diteliti, mempunyai variasi antara satu dengan yang lainnya dalam kelompok tersebut, misalnya: tinggi badan dan berat badan yang merupakan atribut dari seseorang yang dalam hal ini objek penelitiannya (Ridwan, 2002).
Variabel memiliki bermacam-macam bentuk menurut hubungan antara satu variabel dan variabel lainnya. Yaitu:
a. Variabel independent, yaitu: variabel yang menjadi sebab terjadinya atau
terpengaruhnya variabel dependen.
b. Variabel dependen, yaitu: variabel yang nilainya dipengaruhi variabel independen.
c. Variabel moderator, yaitu: variabel yang memperkuatdan memperlemah hubungan antaravariabel dependen dan independen.
d. Variabel intervining, yaitu: variabel moderator, tetepi nilainya tidak dapat diukur, seperti: kecewa, gembira, sakit hati.
e. Variabel kontrol, yaitu: variabel yang dikendalikan peneliti.
2.2 Data
Data adalah suatu bahan mentah yang jika diolah denga baik melalui berbagai analisis dapat melahirkan berbagai informasi, dimana dengan informasi tersebut kita dapat mengambil kesimpulan.
2.2.1 Data menurut sifatnya
Menurut sifatnya data dibagi menjadi 2 bagian, yaitu: a. Data kuantitatif
Data kuantitatif adalah serangkaian observasi atau pengukuran yang dapat dinyatakan dalam angka-angka. Contoh: data hasil pengukuran kemampuan Matematika siswa yang berwujud skor hasil tes kemampuan. Data itu akan berupa angka seperti: 80, 75, 60, 70 dan sebagainya.
b. Data kualitatif
Data kualitatif adalah serangkaian observasi dimana tiap observasi ysng
terdapat dalam sampel (atau populasi) tergolong dalam salah satu kelas-kelas yang saling lepas dan tidak dinyatakan dalam angka-angka. Contoh: hasil
penelitian tentang pendapat mahasiswa terhadap cara mengajar dosen Matematika di Universitas mereka.
2.2.2 Data menurut sumbernya
Menurut sumbernya data dibagi atas 2 bagian, yaitu: a. Data Intern
Data intern adalah data yang dibutuhkan oleh seseorang pemimpin perusahaan guna dipakai sebagai landasan pengambilan keputusan yang diperoleh dari catatan-catatan intern perusahaan itu sendiri.
b. Data Ekstern
Data ekstern adalah data yang hanya diperolehri sumber-sumber dari luar perusahaan atau instansi. Data ekstern dibagi menjadi 2, yaitu:
1. Data Primer
Data primer adalah data yang langsung dikumpulkan oleh orang yang berkepentingan atau yang memakai data tersebut.data yang diperoleh,seperti hasil wawancara atau hasil penelitian kuisioner. Dalam metode pengumpulan data primer, peneliti atau observer melakukan sendiri observasi di lapangan atau di laboratorium. Pelaksanaanya dapat berupa survei atau percobaan (eksperimen).
2. Data Sekunder
Data sekunder adalah data yang diterbitkan oleh organisasi yang bukan merupakan pengolahannya atau data yang tidak secara langsung dikumpulkan oleh orang yang berkepentingan dengan data tersebut. Data sekunder umumnya disajikan dalam bentuk tabel atau diagram.
2.3 Skala Pengukuran Data
Skala merupakan suatu prosedur pemberian angka atau simbol lain dari suatu objek agar dapat menyatakan karakteristik angka pada ciri tersebut. Skala pengukuran oleh S.S Steven (1976) dibagi atas 4 bagian:
a. Skala nominal (klasifikasi)
angka-angka tersebut hanya menunjukkan keberadaan atau ketidakadanya karaktersitik tertentu.
b. Skala ordinal.
Skala pengukuran ordinal memberikan informasi tentang jumlah relatif karakteristik berbeda yang dimiliki oleh obyek atau individu tertentu. Tingkat pengukuran ini mempunyai informasi skala nominal ditambah dengan sarana peringkat relatif tertentu yang memberikan informasi apakah suatu obyek memiliki karakteristik yang lebih atau kurang tetapi bukan berapa banyak kekurangan dan kelebihannya.
Contoh:
Jawaban pertanyaan berupa peringkat misalnya: sangat tidak setuju, tidak setuju, netral, setuju dan sangat setuju dapat diberi symbol angka 1, 2,3,4 dan 5. Angka-angka ini hanya merupakan simbol peringkat, tidak mengekspresikan jumlah.
c. Skala interval
Skala interval mempunyai karakteristik seperti yang dimiliki oleh skala nominal dan ordinal dengan ditambah karakteristik lain, yaitu berupa adanya
interval yang tetap. Dengan demikian peneliti dapat melihat besarnya perbedaan karaktersitik antara satu individu atau obyek dengan lainnya. Skala
pengukuran interval benar-benar merupakan angka. Angka-angka yang digunakan dapat dipergunakan dapat dilakukan operasi aritmatika, misalnya dijumlahkan atau dikalikan. Untuk melakukan analisa, skala pengukuran ini menggunakan statistik parametric.
Contoh:
Jawaban pertanyaan menyangkut frekuensi dalam pertanyaan, misalnya: Berapa kali Anda melakukan kunjungan ke Jakarta dalam satu bulan? Jawaban: 1 kali, 3 kali, dan 5 kali. Maka angka-angka 1, 3, dan 5 merupakan angka sebenarnya dengan menggunakan interval 2.
d. Skala rasio
nilai 0 (nol) empiris absolut. Nilai absoult nol tersebut terjadi pada saat ketidakhadirannya suatu karakteristik yang sedang diukur. Pengukuran ratio biasanya dalam bentuk perbandingan antara satu individu atau obyek tertentu dengan lainnya.
Contoh:
Berat Sari 35 Kg sedang berat Maya 70 Kg. Maka berat Sari dibanding dengan berat Maya sama dengan 1 dibanding 2.
2.4 Skala Untuk Instrumen (Model Skala Sikap)
Bentuk-bentuk model skala sikap yang sering digunakan dalam penelitian ada 5 macam yaitu:
a. Skala Likert b. Skala Guttman
c. Skala Diferensial Semantik d. Skala Rating (Rating Sca le) e. Skala Thurstone
a. Skala Likert
Skala likert digunakan untuk mengatur sikap, pendapatan, dan persepsi seseorang
atau sekelompok tentang kejadian atau gejala sosial. Dengan menggunaka skala likert, maka variabel yang akan diukur dijabarkan menjadi subvariabel. Kemudian subvariabel dijabarkan lagi menjadi beberappa indikator dan indikator-indikator yang terukur ini dijadikan titik tolak untuk membuat item instrumen yang berupa pertanyaan-pertanyaan atau pernyataan yang perlu dijawab responden. Setiap jawaban diungkapkan dengan kata-kata.
Misalnya:
SS (Sangat Setuju) = 5
S (Setuju) = 4
N (Netral) = 3
b. Skala Guttman
Skala Guttman mengukur suatu dimensi saja dari suatu variabel multidimensi. Skala Guttman adalah skala yang digunakan untuk jawaban yang bersifat jelas (tegas) dan konsisten.
Misalnya:
Yakin-Tidak yakin, benar-salah, setuju-tidak setuju, dan sebagainya.
c. Skala Diferensial Semantik
Skala diferensial smantik atau skala perbedaan semantik berisikan serangkaian bipolar (dua kutub). Responden diminta untuk menilai suatu objek atau konsep pada suatu skala yang mempunyai 2 ejektif yang bertentangan.
Misalnya:
Panas-dingin. Populer-tidak populer, bagus-beruk, dan sebagainya.
d. Skala Rating (Rating Scale)
Rating scale yaitu data mentah yang dapat berupa angka kemudian ditafsirkan dalam pengertian kualitatif.
Misalnya:
Ketat-longgar, lemah-kuat, positif-negatif, Responden tidak akan menjawab salah satu dari jawaban kuantitatif yang telah disediakan.
e. Skala Thurstone
Skala Thurtone meminta responden untuk memilih pertanyaan yang ia setujui dari beberapa pertanyaan yang menyajikan pandangan yang berbeda-beda. Pada umumnya setiap item mempunyai asosiasi nilai antara 1 sampai 10 tetapi nilai-nilainya tidak diketahui responden.
2.5Faktor-faktor yang mempengaruhi kanker seviks
2.5.1 Pendidikan
yan berpendidikan tinggi (88,9 persen). Tinggi rendahnya pendidikan berkaitan dengan tingkat sosial ekonomi, kehidupan seks, dan kebersihan. Sedangkan penelitian yang dilakukan oleh surbakti E (2004) pendidikan mempunyai hubungan yang bermakna dengan kanker serviks OR= 2,012 dengan kata lain penderita kanker serviks yang berpendidikan rendah merupakan faktor resiko yang mempengaruhi terjadinya kanker serviks.
2.5.2 Pekerjaan
Menurut Teheru (1998) dan Hidayat (1999) terdapat hubungan antara kanker serviks dengan pekerjaan, dimana wanita pekerja kasar, seperti buruh, petani memperlihatkan 4 kali lebih mungkin terkena kanker serviks dibandingkan wanita pekerja ringan atau bekerja dikantor. Dua kejadian yang terpisah memperlihatkan adanya hubungan antara kanker serviks dengan pekerjaan. para istri pekerja kasar 4 kali lebih mungkin terkena kanker serviks dibandingkan para istri pekerja kantor atau pekerja ringan, kebanyakan dari kekin standart ekonomi yang tidak baik pada umumnya kelompok pertama ini dapat diklasifikasikan kedalam kelompok sosial ekonomi rendah, mungkin standart kebersihan yang tidak baik pada umumnya faktor sosial rendah
memulai aktifitas seksual pada usia lebih muda.
2.5.3 Paritas
Kanker serviks dijumpai pada wanita yang sering partus atau melahirkan. Kategori partus sering belum ada keseragaman akan tetapi menurut beberapa pakar berkisar 3 – 5 kali melahirkan (Tambunan, 1996). Bila persalinan banyak maka kanker serviks cenderung akan timbul.
2.5.4 Usia pertama kali kawin/melakukan hubungan seks
Kawin di usia muda berpengaruh terhadap terjadinya kanker serviks. Penelitian Sandra Van Loon (1996), wanita penderita kanker serviks kawin pertama kali usia 15 – 19 tahun. Usia pertama kali melakukan hubungan seks merupakan salah satu faktor yang cukup penting. Dimana makin muda seorang perempuan melakukan hubungan seksual semakin besar resiko harus ditanggungnya, karena terjadinya kanker serviks dengan masa laten kanker serviks memerlukan waktu 30 tahun sejak melakukan hubungan seksual pertama, sehingga hubungan seksual pertama awal dari mula proses munculnya kanker serviks pada wanita (Yakub, 1993).
Menurut Riono (1999), Edward (2001), Aziz (2002) wanita yang
menikah dibawah 16 tahun biasanya 10 – 12 kali lebih besar kemungkinan terjadinya kanker serviks daripada mereka yang menikah setelah usia 20 tahun.
Pada usia tersebut kondisi rahim seorang remaja putri sangat sensitif. Serviks remaja lebih rentan terhadap stimulus karsinogenik karena terdapat proses metaplasia skuamosa yang aktif, yang terjadi didalam zona transformasi selama periode perkembangan.
2.5.5 Papsmear
2.5.6 Ganti Pasangan
Berbagai penelitian epidemiologi kanker serviks berhubungan kuat dengan perilaku seksual seperti multiple mitra seks, dan usia saat melakuka hubungan seks yang pertama. Resiko meningkat lebih dari 10 kali bila bermitra seks 3 atau lebih. Juga resiko meningkat bila berhubungan dengan pria yang melakukan hubungan seks dengan multiple mitra seks atau yang mengidap kodiloma akuminatum (Aziz, 2001).
2.5.7 Infeksi
Penyebab utama kanker serviks adalah infeksi virus Human Papiloma Virus (HPV) lebih dari 90 kanker serviks jenis skuamosa mengandung DNA virus HPV dan 50 persen kanker serviks berhubungan dengan HPV tipe 16. Infeksi virus HPV lebih terbukti menjadi penyebab sesi pra kanker, kondiloma akuminatum, dan kanker. Terdapat lebih dari 200 tipe virus HPV dari tipe tersebut tipe 16 dan 18 mempunyai peranan penting melalui sekuensi gen E6 dan E7 dengan mengkode pembentukan protein-protein yang penting dengan replikasi virus. Tipe virus resiko tinggi menghasilkan protein yang dikenal dengan protein E6 dan E7yang mampu berikatan dan menonaktifkan protein
p53 dan p Rb sel yang bermutasi akibat infeksi HPV dapat meneruskan siklus tanpa harus memperbaiki kelainan DNA nya, ikatan E6 dan E7 serta adnya
mutasi DNA merupakan dasar utama terjadinya kanker, dengan mengkode pembentukan protein-protein yang penting dalam replikasi virus, virus Hpv ini menginfeksi membran basalis pada daerah metaplasia dan zona transformasi serviks, setelah menginfeksi sel epitel sebagai upaya untuk berkembang biak, virus ini akan meninggalkan sekuensi genonnya pada sel inang. Genon HPV dijumpai pada CIN dan berintegrasi dengan DNA inang pada kanker infasif dimana infeksi terjadi melalui kontak lansung (Edianto, 2006).
2.5.8 Pemakaian alat kontrasepsi
sehingga beresiko untuk terjadinya kanker serviks (Hidayati, 2001). Pil kontrasepsi oral akan menyebabkan defisiasi asam folat yang mengurangi metabolisme nitrogen sedangkan estrogen kemungkinan menjadi salah satu kofaktor yang membuat replikasi DNA HPV.
2.5.9 Merokok
Tembakau mengandung bahan-bahan karsinogen baik yang dihisap sebagai rokok atau yang dikunyah. Wanita perokok konsentrasi nikotin pada getah serviks 56 persen lebih tinggi dibandingkan didalam serum. Efek langsung bahan tersebut pada leher rahim akan menurunkan status immin lokal sehingga dapat menjadi kokarsinogen. Hasil penelitian bila merokok 40 batang setiap hari, resiko untuk terkena kanker serviks adalah 14 kali dibanding yang tidak perokok. Hasil penelitian menyimpulkan bahwa semakin banyak dan lama wanita mrokok maka semakin tinggi resiko untuk terkena kanker serviks (Hidayati, 2001. Evemett, 2003)
2.6Uji Validitas
Suharsimi Arikunto (1996) memberikan pengertian validitas adalah suatu ukuran yang menunjukkan tingkat kevalidan atau kesahihan sesuatu instrumen.
Untuk menguji tingkat validitas data, dalam penelitian ini menggunakan uji validitas konstruk (construct validity) dengan teknik korelasi “product
moment” yang rumusnya adalah :
r =
Y = skor total (Singarimbun dan Effendi, 1989)
Bila probabilitas hasil korelasi lebih kecil dari 0.05 (5%) maka dinyatakan valid dan jika sebaliknya dinyatakan tidak valid.
Singarimbun dan Effendi (1989) memberikan pengertian reliabilitas adalah indeks yang menunjukkan sejauh mana suatu alat pengukur dapat dipercaya atau dapat diandalkan. Dalam penelitian ini uji reliabilitas data menggunakan pendekatan alpha cronbach dengan rumus :
r11 =
r11 = reliabilitas instrumen
k = banyaknya butir pertanyaan atau banyaknya soal b2 = jumlah varians butir
t2 = varians total (Arikunto 1996)
2.8Analisis Faktor
Analisis faktor adalah alat statistik yang digunakan untuk mereduksi faktor-faktor yang mempengaruhi suatu varibel menjadi beberapa set indikator saja, tanpa kehilangan informasi yang berarti. Analisis faktor digunakan untuk penelitian awal dimana faktor-faktor yang mempengaruhi suatu variabel belum diidentifikasi secara baik. Analisis faktor sedikit berbeda dengan analisis regresi, yaitu lebih memfokuskan analisisnya kepada teknik interdependensi (Supranto, 2004).
Menurut Jhonson dan Wicher (1992), analisis faktor pada dasarnya bertujuan untuk mendapatkan sejumlah kecil faktor atau komponen utama yang memiliki sifat:
- Mampu menerangkan semaksimal mungkin keragaman data - Terdapat kebebasan antar faktor
- Setiap faktor dapat diinterpretasikan sejelas-jelasnya Analisis faktor digunakan dalam hal-hal berikut:
a. Untuk mengidentifikasi dimensi atau faktor yang dapat menjelaskan korelasi diantara sekelompok variabel.
c. Untuk mengidentifikasi sekelompok variabel relevan dari sekelompok variabel yang lebih besar yang akan digunakan untuk analisis multivariat lanjutannya.
2.8.1 Model Analisis Faktor
Secara matematis analisis faktor agak mirip dengan analisis regresi, yaitu dalam bentuk fungsi linier artinya setiap variabel dinyatakan sebagai suatu kombinasi linier dari faktor yang mendasari. Jumlah varians yang dikontribusi dari sebuah variabel dengan seluruh variabel lainnya lebih dikelompokkan sebagai komunalitas (communality). Kovarians diantara variabel dijelaskan terbatas dalam sejumlah kecil faktor umum (common factor) ditambah sebuah faktor unik (unique fa ctor) untuk setiap variabel. Faktor-faktor tersebut tidak secara eksplisit diamati. Jika variabel distandarisasi, model analisis faktor dapat di tulis sebagai berikut:
X1 - µ1 = L11F1 + L12F2 + ... + L1m+ ε1
X2 - µ2 = L21F2 + L22F2 + ... + L2m +ε2
: :
: :
Xp - µp = Lp1F1 + Lp2F2 + ... + Lpm + εp
Dimana
µi = rata-rata dari peubah ke-i
Fj = faktor umum ke-j
εj = faktor unik ke-j
Lij = loading dari peubah ke-i pada faktor ke-j
Atau dalam notasi matriks:
Xpx1 -µpx1 = LpxmFmx1+ εpx1
Dengan asumsi:
E(F) = 0 E(ε) = 0
Cov(F) = E(F’F) = 1 cov(ε) = E(εε’) = Y
F dan ε saling bebas, sehingga cov(ε, F) = E(εF’) = 0 Model X-µ = LF + ε adalah linier dalam faktor bersama.
Bagian dari var (Xi) yang dapat diterangkan oleh m faktor bersama disebut
2 2 2 2
Dimungkinkan untuk memilih bobot atau skor koefisien faktor sehingga faktor pertama menjelaskan porsi terbesar dari total varians. Kemudian, kelompok kedua dari bobot dapat dipilih, sehingga faktor kedua tersebut merupakan varians sisa yang terbesar dengan tetap mempertimbangkan bahwa faktor kedua ini tidak berkolerasi dengan faktor pertama. Prinsip yang sama dapat diaplikasikan untuk penambahan bobot skor faktornya yang tidak berkolerasi (tidak seperti nilai dari variabel aslinya). Lebih jauh lagi, faktor pertama diperhitungkan sebagai varians tertinggi dari data, faktor kedua sebagai varians tertinggi berikutnya, dan seterusnya.
2.8.2 Statistik yang Berkaitan dengan Analisis Faktor
Statistik penting yang berkaitan dengan analisis faktor adalah:
a. Barlett’s test of spericity, adalah uji statistik yang digunakan untuk menguji hipotesis yang menyatakan bahwa variabel-variabel tersebut tidak berkolerasi dalam populasinya. Denaga kata lain, matrik korelasi populasi adalah sebuah matrik identitas (identity matrik), setiap variabel berkolerasi sempurna dengan variabel itu sendiri (r = 1), tetapi tidak berkolerasi dengan variabel lainnya (r = 0).
b. Correlation Matrix, adalah matrik segitiga (triangel matrix) yang lebih rendah yang menunjukkan korelasi sederhana r, antara seluruh kemungkinan pasangan variabel yang dilibatkan dalam analisis. Jumlah kuadrat dari loading untuk variabel ke-j disebut communality ke-i dan varians dari specific factor
disebut specific variance Ψ. Jika communality ditandai dengan hi 2 matriks korelasi misalnya untuk jumlah variabel n = 3.
X1 X2 X3
X1
X2 r21
X3 r31 r32
Tabel 2.2 Matrik Korelasi Untuk Jumlah variabel n = 4
X1 X2 X3 X4
X1
X2 r21
X3 r31 r32
X4 r41 r42 r43
c. Communality, adalah jumlah varians yang dikotribusi dari sebuah variabel dengan seluruh variabel lainnya yang dipertimbangkan. Ini juga merupakan proporsi dari varians yang diterangkan oleh common factor. Nilai communality
(h2) diperoleh dengan menghitung jumlah kuadrat loading faktor setiap
h = komunalitas variabel ke-j
2
ij
W = loading faktor di faktor ke-i untuk variabel ke-j
d. Eigen Value, merepresentasikan total varians yang dijelaskan oleh setiap faktor dari matriks identitas. Persamaan nilai eigen dan vektor eigen sebagaimana kita ketahui adalah :
A x = λ x
x = vektor eigen dalam bentuk matriks
λ = nilai eigen dalam bentuk skalar
Untuk mencari nilai eigen (nilai λ) dari sebuah matriks A yang berukuran n x n
maka kita lakukan langkah berikut :A x = λ x Agar kedua sisi berbentuk vektor, maka sisi kanan dikali dengan matriks identitas I, sehingga A x = λ I
x
λ I x - A x = 0
x . ( λ I - A ) = 0 sehingga det ( λ I - A ) = 0
e. F actor Loadings, adalah korelsi sederhana antara variabel dengan faktor.
1 1... p p pada faktor yang diderivasi. Factor score merupakan taksiran dari nilai vector
F1, F2, ..., Fm. fˆjadalah taksiran fj yang dicapai oleh Fj, untuk j = 1, 2, 3, ..., m. Selanjutnya untuk mencari factor score adalah
' 1 '
j j
f LL L X X
i. Keiser Meyer-Oikin (KMO) Measure of Sampling Adequacy (MSA), adalah indeks yang digunakan untuk menguji kesesuaian analisis faktor. Nilai yang tinggi (antara 0.50 sampai 1.00) mengindikasikan analisis faktor yang sesuai. Nilai dibawah 0,50 menunjukkan bahwa analisis faktor tidak sesuai untuk diapliksikan.
j. Percentage of Variance, adalah persentase total varians yang menjadi tribut kepada setiap faktor.
l. Scree Plot, adalah sebuah plot dari eigenvalue dan banyaknya faktor yang dapat dikembangkan.
2.8.3 Pelaksanaan Analisis Faktor
a. Merumuskan masalah dan identifikasi variabel.
Merumuskan masalah akan melibatkan banyak kegiatan. Pertama, tujuan dari analisis faktor harus diidentifikasi. Variabel yang dilibatkan harus dispesifikasi berdasarkan kepada penelitian terdahulu, teori dan keinginan peneliti. Ukuran variabel yang sesuai adalah interval atau rasio. Menentukan banyaknya sampel, sedikitnya empat kali atau lima kali dari banyaknya variabel. Proses analisis berbasis pada matrik korelasi antar variabel. Agar analisis faktor sesuai, variabel-variabel harus berkolerasi. Dalam praktek, persoalan yang sering timbul adalah jika korelasi antar variabel itu kecil, maka analisis faktor tidak sesuai untuk diaplikasi. Harapannya, selain antar variabel itu berkolerasi, juga berkolerasi tinggi dengan sebuah faktor yang sama atau faktor-faktor lain.
b. Statistik untuk menguji kesesuaian model adalah Barlett’s test of spericity
Yaitu menguji Ho yang menyatakan bahwa variabel-variabel tersebut tidak berkolerasi, atau dengan kata lain bahwa matrik korelasinya adalah matrik
identitas. Test of spericity berbasis transformasi χ2, nilai determinan dari matrik korelasi. Nilai statistik tinggi diharapkan untuk menolak Ho, jika tidak maka kesesuaian penggunaaan analisis faktor patut dipertanyakan.
Untuk hasil uji Barlett’s test of spericity nilai signifikan harus < 0,05 untuk menunjukkan bahwa antar variabel terjadi korelasi. Sedangkan untuk
Tes of spericity berbasis transformasi χ2, nilai determinan harus mendekati nol (0) untuk menunjukkan antar variabel mempunyai korelasi.
dijelaskan oleh variabellain dan analisis faktor bisa menjadi tidak tepat. Nilai
rij = koefisien korelasi sederhana antara peubah i dan j
aij = koefisien korelasi parsial antara peubah i dan j
d. Menentukan jumlah faktor adalah hal yang tidak mungkin menghitung faktor sebanyak jumlah variabel. Dalam rangka meringkas informasi yang dikandung dalam variabel asli, sejumlah faktor yang lebih sedikit akan diekstraksi. Beberapa jenis prosedur untuk menentukan banyaknya faktor yang harus diekstraksi antara lain;penentuan apriori, dan pendekatan berdasarkan
eigenvalue, scree plot, percentage of variance accounted for, split-and-half dan significance test.
1. Penentuan Apriori.
Kadang-kadang karena adnya dasar teori, maka peneliti dapat menentukan banyaknya faktor yang akan diekstraksi. Hampir sebagian besar program memberikan peluang untuk pendekatan ini.
2. Penentuan Berbasis Eigenvalue.
Pada pendekatan ini, hanya faktor dengan eigenvalue lebih besar
daripada 1,00 yang akan dipertahankan. Eigenvalue merepresentasikan total varians yang berkaitan dengan faktor. Faktor dengan eigenvalue lebih kecil daripada 1,00 tidak lebih baik daripada sebuah variabel tunggal, karena untuk keperluan standarisasi setiap variabel memiliki varians = 1,00.
3. Penentuan Berdasarkan Scree Plot.
menentukan banyaknya faktor. Biasanya, plot akan berbeda antara slop
tegak faktor, dengan eigenvalue yang besar dan makin kecil pada sisa faktor yang tidak perlu diekstrasi. Pengecilan slop ini yang disebut
scree.
4. Penentuan Berbasis Percentage of Variace.
Dalam pendekatan ini banyaknya faktor yang diekstraksi ditentukan sampai persentase kumulatif varians mencapai tingkat yang memuaskan peneliti. Tingkat persen kumulatif yang memuaskan tersebut tergantung kepada persoalannya. Bagaimanapun sangat direkomendasikan bahwa faktor-faktor yang diekstraksi sampai mencapai persen kumulatif paling sedikit = 60,00 persen.
5. Penentuan Berdasarkan Split and Half.
Sampel dibagi menjadi data, dan analisis faktor diaplikasikan kepada masing-masing bagian. Hanya faktor yang memilih factor loadings
tinggi antar data bagian itu yang akan dipertahankan.
6. Penentuan Berbasis Significance Test.
Pendekatan ini adlah untuk memperthankan faktor yang memiliki
saparate eigenvalue signifikan. Dengan sampel besar (> 200), banyak faktor yang cenderung signifikan, walaupun dari pandangan praktis, banyak dari faktor tersebut yang memiliki proporsi varians yang kecil terhadap total varians.
variabel berkorelasi kuat. Koefisien tersebut dapat digunakan untuk menginterpretasikan faktor. Untuk batasan factor loadings nilainya sebesar ≥
0,3, ≥ 0,4 atau ≥ 0,5.
Walaupun initial atau unrotated factor matrix mengindikasikan hubungan antara faktor dengan dengan variabel individual tertentu, kadang-kadang dapat diperoleh di dalam faktor yang bisa diinterpretasikan, karena faktor tersebut berkolerasi dengan banyak variabel. Pada banyak persoalan yang kompleks, maka sulit melakukan interpretasi. Untuk itu diperlukan suatu langkah merotasi factor matrik agar lebih mudah menginterpretasikan faktor.
Dalam merotasi faktor, dilanjutkan setiap faktor memiliki loadings factor atau koefisien non zero, atau signifikan hanya untuk beberapa variabel. Atau diharapkan setiap varibel memiliki factor loadings signifikan hanya dengan sedikit faktor. Rotasi tidak berpengaruh terhadap komunalitas dan persentase total varians yang dijelaskan. Namun demikian, rotasi berpengaruh terhadap persentase varians dari setiap faktor.
Beberapa metode rotasi yang bisa digunakan adalah : orthogonal
rotation, varimax rotation, dan oblique rotation. Orthogonal Rotation adlah jika sumbu-sumbu tetap dijaga pada sudut yang benar. Varimax Rotation adalah
rotasi ortogonal dengan meminimumkan banyaknya variabel yang memiliki loadings faktor, sehingga lebih bisa menginterpretasi faktor. Rotasi ortogonal menghasilkan faktor-faktor yang tidak berkolerasi. Oblique rotation adalah jika sumbu-sumbu tidak dijaga pada sudut yang benar dan faktor-faktor berkolerasi. Kadang-kamg, mentoleransi korelasi antar faktor-faktor bisa menyederhanakan matrik pola faktor. Oblique rotation akan digunakan jika faktor-faktor pada populasi diperkirakan berkolerasi kuat.
Rotasi faktor dilakukan dengan cara merotasikan loading factor L, dengan menggunakan metode rotasi sehingga menghasilkan loading faktor
baru L.
(pxm) (pxm) (pxm)
L L T
f. Interpretasi Faktor adalah interpretasi difasilitasi melalui identifikasi variabel yang memiliki loadings besar pada faktor yang sama. Faktor tersebut kemudian dapat diinterpretasi dalam batas variabel yang memiliki loadings tinggi dalam faktor tersebut.
Cara lain yang bisa digunakan adalah melalui plot variabel dengan factor loadings sebagai koordinat. Variabel yang berada pada akhir sebuah sumbu adalah adalah variabel yang memiliki loadings tinggi hanya pad faktor yang bersangkutan, didekat titik origin memiliki loadings yang rendah terhadap kedua faktor. Variabel tersebut berkolerasi dengan kedua faktor. Jika sebuah faktor tidak bisa secara jelas didefinisikan dalam batas variabel awalnya, maka disebut sebgai faktor umum saja (tidak perlu diberi lebel khusus).
g. Mengukur Ketepatan Model (Model Fit) adalah asumsi dasar yang digunakan dalam analisis faktor adalah korelasi dari data awal dapat menjadi atribut dari faktor. Untuk itu, korelasi data awal dapat direproduksi melalui estimasi korelasi reproduksi dapat digunakan untuk mengukur kesesuaian model.
Selisih tersebut disebut sebagai residuals. Untuk menentukan sebuah model sesuai atau tidak, maka nilai absolut residuals harus kurang dari 50 persen
BAB 3
PEMBAHASAN
3.1 Gambaran Umum
Kanker merupakan penyakit tidak menular. Penyakit ini akan timbul karena pola hidup yang tidak sehat dan mengakibatkan kondisi fisik yang tidak normal. Kanker dapat menyerang berbagai jaringan di dalam organ tubuh, termasuk organ reproduksi pada wanita dari payudara, rahim, induk telur dan vagina (Mangan, 2003). Adapun deskripsi dari variabel-variabel yang mempengaruhi kanker serviks tersebut antara lain:
a. X1 = Pendidikan.
Jenjang pendidikan terakhir yang ditempuh oleh penderita kanker serviks. b. X2 = Pekerjaan.
Pekerjaan merupakan kegiatan rutin yang dilakukan oleh penderita kanker serviks yang menghasilkan penghasilan atau tidak.
c. X3 = Usia pertama kali kawin/hubungan seks.
Hal ini merupakan usia penderita kanker serviks pertama kali melakukan hubungan seksual baik sebelum atau sesudah pernikahan.
d. X4 = Papsmear
Pemeriksaan lendir serviks yang pernah dilakukan oleh penderita kanker serviks.
e. X5 = Paritas
Paritas merupakan jumlah persalinan yang dialami oleh penderita kanker serviks baik dengan bayi hidup atau meninggal.
Hal ini merupakan aktivitas seksual penderita kanker serviks dengan mitra seksual yang berganti-ganti.
g. X7 = Infeksi kelamin.
Apakah penderita mempunyai riwayat menderita infeksi kelamin selama masa hidup.
h. X8 = Pemakaian kontrasepsi
Jangka waktu dalam penggunaan alat kontrasepsi yang pernah digunakan oleh penderita kanker serviks.
i. X9 = Merokok
Konsumsi rokok sehari-hari yang dilakukan penderita kanker serviks.
Dari hasil pembagian dan pengisian kuisioner tentang faktor yang mempengaruhi kanker serviks kepada 45 orang penderita diperoleh deskripsi sebagai berikut:
Tabel 3.1 Tabel Diskripsi Faktor Kanker Serviks
Variabel Skor Frekuensi Persentase
3.2 Uji Validitas.
Uji validitas yang dilakukan pada penelitian ini adalah uji validitas eksternal, yaitu dengan membandingkan nilai r hitung dengan nilai r tabel (r poduct moment). uji validitas dapat dihitung dengan menggunakan rumus teknik korelasi product moment
(Husein Umar, 2003 : 84).
Untuk mempermudah mendapatkan nilai r hitung, dapat dilakukan dengan mengolah data hasil pengisian kuisioner menggunakan program SPSS for windows 17.0 adalah sebagai berikut:
a. Klik analyze, pilih scale dan reability analysis.
b. Setelah mencul kotak dialog reliability analysis, pindahkan data (X1 sampai X10)
kedalam item statistik.
c. Klik kotak dialog statistic pilih descriptive for (item, scale dan scale if item deleted).
d. Klik continue dan OK
Pada output kolom corrected item-Total Correlation adalah hasil uji validitas. Untuk jumlah sampel sebesar 45 (n = 45), maka nilai r tabel dengan taraf signifikan α = 5 %
adalah 0,294. Suatu kuisioner dinyatakan valid jika r hitung setiap variabel ≥ r tabel.
Hasil perhitungannya adalah sebagai berikut:
Tabel 3.2. Tabel Uji Validitas
X5 = papsmear 0,327 0,294 Valid
Uji reliabilitas yang dilakukan pada penelitian ini adalah internal consistency reliability, yaitu dengan membandingakan nilai cronbach’s alpha yang telah ditetapkan yaitu sebesar 0,345. Uji reliabilitas dapat dilakukan dengan menggunakan
koefisien alpha (α) dari cronbach (Umar, 2003 : 96):
r11 =
Untuk mempermudah perhitungan, nilai cronbach alpha hitung didapatkan dengan mengolah data hasil pengisian kuisioner dan rekam medik menggunakan program SPSS for windows 17.0 adalah sebagai berikut:
a. Klik analyze, pilih scale dan reability analysis
b. Setelah muncul kotak dialog reliability analysis, pindahkan data (X1 sampai X9)
ke dalam item statistik
c. Klik kotak dialog statistic pilih descriptive for (item, scale dan scale if item
deleted)
d. Klik continue dan OK
e. Pada output kolom cronbach’s Alpha if item deleted adalah hasul uji reliabilitas.
Suatu kuisioner dikatakan relabel jika cronbach’s Alpha hitung setiap variabel ≥
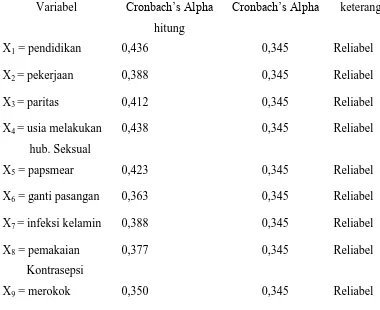
Tabel 3.3 Hasil Uji Realibilitas
Variabel Cronbach’s Alphahitung
Cronbach’s Alpha keterangan
X1 = pendidikan 0,436 0,345 Reliabel
X2 = pekerjaan 0,388 0,345 Reliabel
X3 = paritas 0,412 0,345 Reliabel
X4 = usia melakukan
hub. Seksual
0,438 0,345 Reliabel
X5 = papsmear 0,423 0,345 Reliabel
X6 = ganti pasangan 0,363 0,345 Reliabel
X7 = infeksi kelamin 0,388 0,345 Reliabel
X8 = pemakaian
Kontrasepsi
0,377 0,345 Reliabel
X9 = merokok 0,350 0,345 Reliabel
Dari semua variabel yang diuji terlihat bahwa semua variabel tersebut reliabel.
3.3 Analisis Faktor dengan SPSS for Window’s 17.0
Analisis faktor dengan SPSS for window’s 17.0 dilakukan dengan cara sebagai berikut:
a. Masukkan data pada data editor b. Klik analyze
c. Klik factor
d. Masukkan varabel-variabel yang akan dianalisis dengan analisis faktor (X1
sampai X9) ke kolom varabel
e. Pada menu descriptive, klik initialsolution, coefitions, significance levels,
determinant, KMO and Barlet’s test of spericity, reproduced, dan anti image
lalu klik continue.
g. Pada menu rotation, klik varimax, rotated solution, loading plots, lalu klik continue.
h. Pada menu scores, klik display faktor score coefficient matrix, lalu klik continue.
i. Pada menu missing value, klik exclude cases listwise, lalu klik continue j. Klik OK
3.3.1 Membuat Matrik Korelasi
Variabel-variabel yang tidak saling berhubungan dengan variabel lain dikeluarkan dari analisis. Untuk menguji bahwa 9 variabel saling berhubungan diperlihatkan oleh nilai determinasi matrik korelasi yang mendekati nol (0), nilai KMO (Keiser Meyer Olkin) harus lebih besar dari 0,5, uji Barlett dan uji MSA (Measure of sampling Adequacy).
a. Nilai determinasi matrik korelasi
Hasil determinasi korelasi adalah sebagai berikut:
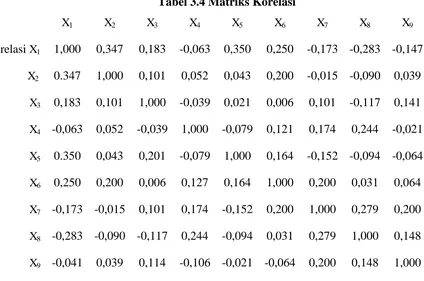
Tabel 3.4 Matriks Korelasi
X1 X2 X3 X4 X5 X6 X7 X8 X9
Korelasi X1 1,000 0,347 0,183 -0,063 0,350 0,250 -0,173 -0,283 -0,147
X2 0.347 1,000 0,101 0,052 0,043 0,200 -0,015 -0,090 0,039
X3 0,183 0,101 1,000 -0,039 0,021 0,006 0,101 -0,117 0,141
X4 -0,063 0,052 -0,039 1,000 -0,079 0,121 0,174 0,244 -0,021
X5 0.350 0,043 0,201 -0,079 1,000 0,164 -0,152 -0,094 -0,064
X6 0,250 0,200 0,006 0,127 0,164 1,000 0,200 0,031 0,064
X7 -0,173 -0,015 0,101 0,174 -0,152 0,200 1,000 0,279 0,200
X8 -0,283 -0,090 -0,117 0,244 -0,094 0,031 0,279 1,000 0,148
X9 -0,041 0,039 0,114 -0,106 -0,021 -0,064 0,200 0,148 1,000
Determinan = 0,0403
Keiser Meyer Olkin (KMO) Measure of sampling Adequacy = 0,567 menunjukkan bahwa pengambilan sampel cukup memadai dengan menggunakan analisis faktor dalam matrik korelasi, karena nilai KMO diatas 0,5.
c. Uji Barlett
Uji barlett yaitu untuk menguji keindependenan dari variabel yang ada. Hasil
Barlett’s test of soericity = 36,51, signifikance = 0,000. Hasil ini menunjukkan
bahwa antar variabel terjadi korelasi (signifikan < 0,05) sehingga model faktor dapat digunakan.
Tabel 3.5 Uji KMO dan Uji Barlette
Kaiser-Meyer-Olkin Measure of Sampling
d. Uji MSA (Measure of Sampling Adequecy)
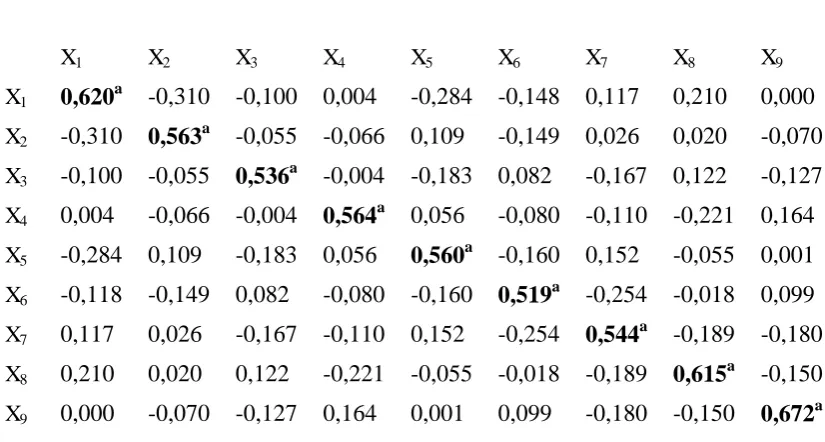
Dari hasil MSA (Measure of Sampling Adequacy) semua variabel telah memenuhi kriteria MSA > 0,5 yang menunjukkan bahwa antar variabel sangat erat. Nilai MSA dapat diperoleh dengan menggunakan rumus:
2
Tabel 3.6 Anti – Image Matrics
X1 X2 X3 X4 X5 X6 X7 X8 X9
X1 0,620a -0,310 -0,100 0,004 -0,284 -0,148 0,117 0,210 0,000 X2 -0,310 0,563a -0,055 -0,066 0,109 -0,149 0,026 0,020 -0,070 X3 -0,100 -0,055 0,536a -0,004 -0,183 0,082 -0,167 0,122 -0,127 X4 0,004 -0,066 -0,004 0,564a 0,056 -0,080 -0,110 -0,221 0,164 X5 -0,284 0,109 -0,183 0,056 0,560a -0,160 0,152 -0,055 0,001 X6 -0,118 -0,149 0,082 -0,080 -0,160 0,519a -0,254 -0,018 0,099 X7 0,117 0,026 -0,167 -0,110 0,152 -0,254 0,544a -0,189 -0,180 X8 0,210 0,020 0,122 -0,221 -0,055 -0,018 -0,189 0,615a -0,150 X9 0,000 -0,070 -0,127 0,164 0,001 0,099 -0,180 -0,150 0,672a
a = nilai Measure of Sampling Adequacy (MSA).
3.3.2 Penentuan Jumlah Faktor
Hasil perhitungan dengan principal component pada inisial statistik, menunjukkan jumlah faktor yang mempunyai nilai eigenva lue ≥ 1, terdapat 3 faktor yang
mempunyai pengarh meningkatnya penderita kanker serviks. Ketiga faktor tersebut mampu menjelaskan semua varian yang ada dalam data sebesar 50,38 % seperti yang ditunjukkan secara rinci dalam tabel 3.7.
Tabel 3.7 Faktor-faktor yang Mempengaruhi Meningkatnya Penderita Kanker Serviks
Faktor Eigenvalue Variance Cumulative
1 1,937 21,552 % 21,522 %
2 1,528 16,974 % 38,496 %
3.3.3 Rotasi Faktor
Ada 9 variabel yang tersebar kedalam 3 faktor yang merupakan faktor-faktor yang mempengaruhi meningkatnya penderita kanker serviks yang rawat inap di RSU dr. Pirngadi Medan. Ketiga faktor tersebut diberi nama baru sesuai dengan variabel terukur yang berkelompok pada faktor tersebut. Pemberian nama dan konsep pada tiap faktor ditentukan makna umum yang tercakup di dalamnya.
Tabel 3.8 Hasil Rotasi Faktor Varimax.
No. Variabel Faktor Eigenvalue Factor loading Variance (%) yang mempengaruhi meningkatnya penderita kanker serviks yang di rawat inap di
Interpretasi hasil berdasarkan eigenvalue dari setiap faktor dapat dijelaskan sebagai berikut:
a. Faktor 1 : Faktor Sosial Ekonomi
Faktor ini merupakan faktor yang paling dominan yang mempengaruhi meningkatnya penderita kanker serviks di RSU dr. Pirngadi Medan. Faktor ini mempunyai eigenvalue sebesar 1,937 dan mampu menjelaskan keragaman total sebesar 21,522 %. Variabel-variabel yang termasuk kedalam faktor ini adalah pendidikan (factor loading = 0,761), pekerjaan (factor loading = 0,608), papsmear (factor loading = 0,534), dan ganti pasangan (factor loading = 0,591).
b. Faktor 2 : Faktor Aktivitas Seksual
Faktor ini merupakan faktor pendukung yang mempengaruhi meningkatnya penderita kanker serviks di RSU dr. Pirngadi Medan. Faktor ini mempunyai eigenvalue sebesar 1,528 dan mampu menjelaskan keragaman total sebesar 16,974 %. Variabel-variabel yang termasuk kedalam faktor ini adalah usia pertama kali melakukan hubungan seksual (factor loading = 0,624), infeksi (factor loading = 0,694), dan pemakaian kontrasepsi (faktor loading = 0,651).
c. Faktor 3 : Faktor Pola hidup
Faktor ini merupakan faktor pendukung yang mempengaruhi meningkatnya
penderita kanker serviks di RSU dr. Pirngadi Medan. Faktor ini mempunyai eigenvalue sebesar 1,250 dan mampu menjelaskan keragaman total sebesar 13,884 %. Variabel-variabel yang termasuk kedalam faktor ini adalah paritas (factor loading = 0,614), dan merokok (factor loading = 0,781).
3.3.5 Ketepatan Model (Model Fit).
Hal ini menunjukkan bahwa model faktor-faktor yang mempengaruhi meningkatnya penderita kanker serviks yang berobat di RSU dr. Pirngadi Medan memiliki ketepatan sebesar 56 % pada tingkat penyimpangan 5 %.
Ini berarti model faktor- faktor yang mempengaruhi meningkatnya penderita kanker serviks Di RSU dr. Pirngadi Medan dapat diterima.
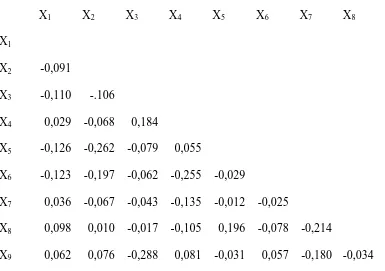
Tabel 3.9 Selisih (Residuals) antara Observed Correlation dengan Repruduced Correlation
X1 X2 X3 X4 X5 X6 X7 X8 X9
X1
X2 -0,091
X3 -0,110 -.106
X4 0,029 -0,068 0,184
X5 -0,126 -0,262 -0,079 0,055
X6 -0,123 -0,197 -0,062 -0,255 -0,029
X7 0,036 -0,067 -0,043 -0,135 -0,012 -0,025
X8 0,098 0,010 -0,017 -0,105 0,196 -0,078 -0,214
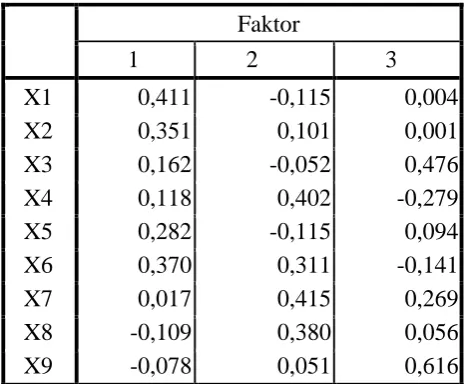
Tabel 3.10 Skor faktor Matrik Koefisien
Faktor
1 2 3
X1 0,411 -0,115 0,004
X2 0,351 0,101 0,001
X3 0,162 -0,052 0,476
X4 0,118 0,402 -0,279
X5 0,282 -0,115 0,094
X6 0,370 0,311 -0,141
X7 0,017 0,415 0,269
X8 -0,109 0,380 0,056
X9 -0,078 0,051 0,616
Adapun model faktor-faktor yang mempengaruhi meningkatnya penderita kanker serviks yang rawat inap di RSU dr. Pirngadi Medan adalah sebagai berikut:
F1 = 0,411X1 + 0,351X2 + 0,162X3 + 0,118X4 + 0,282X5 + 0,370X6 + 0,017X7 –
0,109X8– 0,078X9
F2 = -0,115X1 + 0,101X2 – 0,052X3 + 0,402X4 – 0,115X5 + 0,311X6 + 0,415X7 +
0,380X8 + 0,051X9
F3 = 0,004X1 + 0,001X2 + 0,476X3 – 0,279X4 + 0,094X5 – 0,141X6 + 0,269X7 +
0,056X8 + 0,616X9
Dari model tersebut dapat dengan mudah kita mengartikan variabel-variabel yang ada di setiap faktor. F1 terdiri dari X1 (pendidikan), X2 (pekerjaan), X5 (papsmear), dan X6
(ganti pasangan). F2 terdiri dari X4 (usia melakukan hubungan seksual), X6 (ganti
pasangan), X7 (infeksi), dan X8 (pemakaian kontrasepsi). F3 terdiri dari X3 (paritas), X7
(infeksi), dan X9 (merokok). Pada F1 dan F2 memiliki variabel yang sama yaitu X6
(ganti pasangan), karena nilai skor X6 di F1 lebih besar dari F2 maka X6 dapat
dimasukkan sebagai variabel di F1. Sama juga halnya berlaku pada X7 yang terletak
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Berdasarkan hasil penelitian yang dilakukan di RSU dr. Pirngadi Medan dapat diambil kesimpulan, yaitu:
1. Dari kesembilan variabel yang diteliti, setelah dilakukan analisis faktor, maka terdapat 3 faktor yang merupakan faktor-faktor yang mempengaruhi meningkatnya penderita kanker serviks di RSU dr. Pirngadi Medan, yaitu:
a. Faktor sosial ekonomi. Faktor ini mempunyai eigenvalue sebesar 1,937 dan mampu menjelaskan keragaman total sebesar 21,522%.
Variabel-variabel yang termasuk dalam faktor ini adalah pendidikan (factor loading = 0,761), pekerjaan (factor loading = 0,608), papsmear (factor loading = 0,534), dan ganti pasangan (factor loading = 0,591).
b. Faktor aktivitas seksual. Faktor ini mempunyai eigenvalue sebesar 1,528 dan mampu menjelaskan keragaman total sebesar 16,974%. Variabe-variabel yang termasuk kedalam faktor ini adalah usia pertama kali melakukan hubungan seksual (factor loading = 0,624), infeksi (factor loading = 0,694), dan pemakaian kontrasepsi (factor loading = 0,651).
Variabel-variabel yang termasuk kedalam faktor ini adalah paritas (factor loading = 0,614) dan merokok (factor loading = 0,781).
2. Berdasarkan hasil perhitungan atas dasar nilai absolut > 0,05 diperoleh nilai residual dari analisis ini lebih kecil dari 50 %, yaitu 44 % atau sebanyak 20 residuals. Hal ini menunjukkan bahwa model-model faktor yang mempengaruhi meningkatnya penderita kanker serviks di RSU dr. Pirngadi Medan memiliki ketepatan sebesar 56 % pada tingkat penyimpangan 5 % dan dapat diterima .
4.2 Saran
1. Faktor yang mempengaruhi meningkatnya penderita kanker seviks yang berobat di RSU dr. Pirngadi Medan, pendidikan, pekerjaan, paritas, usia pertamakali mlakukan hubungan seksual, papsmear, ganti pasangan, infeksi kelamin, pemakaian kontrasepsi, dan merokok mengindikasikan masih kurangnya informasi tentang kanker serviks kepada masyarakat. Oleh karena itu rumah sakit dan unit pelayanan kesehatan lainnya perlu melakukan sosialisasi kaknker serviks dan pemberian informasi melalui media cetak dan
media elektronik yang dapat menambah pengetahuan dan merubah perilaku masyarakat.
2. Diharapkan kepada para peneliti-peneliti selanjutnya dapat mencari variabel-variabel lain yang berhubungan dengan faktor-faktor yang mempengaruhi meningkatnya penderita kanker serviks sehingga masyarakat dapat mengantisipasi dirinya untuk tidak terjangkit penyakit kanker serviks.
DAFTAR PUSTAKA
Azwar, Sifudin. 2003. Metode Penelitian. Yogyakarta: Pustaka Pelajar.
Dillon, W., and Goldstein, M., 1981, Multivariate Analysis Methods and Application, John Wiley and sons, Inc. Canada.
Johnson, R. And Wichern, D. 2007. Applied Multivariate Statistical Analysis, six edition, Prentice-Hall, Pearson Education,Inc.
Hair, J.F., Anderson, R.E., Tatham, R.L. and Black, W.C. 2006. Multivariate Data Analysis, Sixth Edition, Prentice Hall International: UK.
http://kanker-serviks-leher-rahim-pembunuh-wanita/html. Diakses 22 Mei, 2011.
http://www.Kesproinfo/Kanker/Bambang. Diakses 22 Mei, 2011.
Melva. Faktor-fa ktor Yang Mempengaruhi kejadian Kanker Leher Rahim pada
Penderita Yang Datang Berobat Di RSUP H. Adam Malik Medan, 2008. Tesis.
Nazir, Mohammad. 1999. Metode Penelitian. Jakarta: Ghalia Indonesia.
Santoso, Singgih. 2005. Menggunakan SPSS untuk Statistik Multivariat. Jakarta: PT. Alex Media Komputindo.
Supranto, J. M.A, APU, Prof. 2004. Analisis Multivariat: Arti dan Interpretasi,
cetakan pertama, Jakarta. PT. Asdi Mahasatya.
FACTOR /VARIABLES X1 X2 X3 X4 X5 X6 X7 X8 X9
/MISSING LISTWISE
/ANALYSIS X1 X2 X3 X4 X5 X6 X7 X8 X9
/PRINT INITIAL CORRELATION SIG DET KMO INV AIC EXTRACTION ROTATION FSCORE
/PLOT EIGEN ROTATION /CRITERIA MINEIGEN(1) ITERATE(25)
Inverse of Correlation Matrix
X1 X2 X3 X4 X5 X6 X7 X8 X9
X1 1.445 -.405 -.128 .005 -.379 -.194 .159 .283 .000
X2 -.405 1.187 -.064 -.077 .132 -.177 .032 .024 -.081
X3 -.128 -.064 1.130 -.005 -.215 .095 -.201 .146 -.143
X4 .005 -.077 -.005 1.127 .066 -.093 -.132 -.262 .184
X5 -.379 .132 -.215 .066 1.230 -.193 .190 -.068 .001
X6 -.194 -.177 .095 -.093 -.193 1.189 -.313 -.022 .114
X7 .159 .032 -.201 -.132 .190 -.313 1.272 -.238 -.215
X8 .283 .024 .146 -.262 -.068 -.022 -.238 1.250 -.177
X9 .000 -.081 -.143 .184 .001 .114 -.215 -.177 1.119
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .567
Bartlett's Test of
Sphericity
Approx. Chi-Square 36.51
7
Df 36
Anti-image Matrices
X1 X2 X3 X4 X5 X6 X7 X8 X9
Anti-image Covariance X1 .692 -.236 -.079 .003 -.213 -.113 .087 .156 .000
X2 -.236 .843 -.048 -.057 .090 -.126 .021 .016 -.061
X3 -.079 -.048 .885 -.004 -.155 .070 -.140 .103 -.113
X4 .003 -.057 -.004 .887 .047 -.069 -.092 -.186 .146
X5 -.213 .090 -.155 .047 .813 -.132 .122 -.044 .001
X6 -.113 -.126 .070 -.069 -.132 .841 -.207 -.015 .086
X7 .087 .021 -.140 -.092 .122 -.207 .786 -.150 -.151
X8 .156 .016 .103 -.186 -.044 -.015 -.150 .800 -.127
X9 .000 -.061 -.113 .146 .001 .086 -.151 -.127 .893
Anti-image Correlation X1 .620a -.310 -.100 .004 -.284 -.148 .117 .210 .000
X2 -.310 .563a -.055 -.066 .109 -.149 .026 .020 -.070
X3 -.100 -.055 .536a -.004 -.183 .082 -.167 .122 -.127
X4 .004 -.066 -.004 .564a .056 -.080 -.110 -.221 .164
X5 -.284 .109 -.183 .056 .560a -.160 .152 -.055 .001
X6 -.148 -.149 .082 -.080 -.160 .519a -.254 -.018 .099
X7 .117 .026 -.167 -.110 .152 -.254 .544a -.189 -.180
X8 .210 .020 .122 -.221 -.055 -.018 -.189 .615a -.150
X9 .000 -.070 -.127 .164 .001 .099 -.180 -.150 .672a
a. Measures of Sampling Adequacy(MSA
Communalities
Initial Extraction
X1 1.000 .654
X2 1.000 .380
X3 1.000 .495
X4 1.000 .510
X5 1.000 .361
X6 1.000 .555
X7 1.000 .615
X8 1.000 .504
Communalities
Extraction Method: Principal Component
Analysis.
Variance Cumulative % Total
% of
Variance Cumulative % Total
% of
Component Matrixa
Component
1 2 3
X1 .781 .201 -.061
X2 .446 .411 -.110
X3 .346 .277 .546
X4 -.274 .462 -.470
X5 .581 .134 .077
X6 .235 .620 -.340
X7 -.415 .633 .206
X8 -.590 .394 -.010
X9 -.143 .265 .742
Extraction Method: Principal
Component Analysis.
a. 3 components extracted.
Reproduced Correlations
X1 X2 X3 X4 X5 X6 X7 X8 X9
Reproduced Correlation
X1 .654a .437 .293 -.092 .476 .329 -.210 -.381 -.103
X2 .437 .380a .208 .120 .305 .397 .052 -.100 -.037
X3 .293 .208 .495a -.223 .280 .068 .145 -.100 .430
X4 -.092 .120 -.223 .510a -.133 .382 .309 .348 -.187
X5 .476 .305 .280 -.133 .361a .193 -.140 -.291 .010
X6 .329 .397 .068 .382 .193 .555a .224 .109 -.121
X7 -.210 .052 .145 .309 -.140 .224 .615a .492 .380
X8 -.381 -.100 -.100 .348 -.291 .109 .492 .504a .182
Residualb X1 -.091 -.110 .029 -.126 -.123 .036 .098 .062
X2 -.091 -.106 -.068 -.262 -.197 -.067 .010 .076
X3 -.110 -.106 .184 -.079 -.062 -.043 -.017 -.288
X4 .029 -.068 .184 .055 -.255 -.135 -.105 .081
X5 -.126 -.262 -.079 .055 -.029 -.012 .196 -.031
X6 -.123 -.197 -.062 -.255 -.029 -.025 -.078 .057
X7 .036 -.067 -.043 -.135 -.012 -.025 -.214 -.180
X8 .098 .010 -.017 -.105 .196 -.078 -.214 -.034
X9 .062 .076 -.288 .081 -.031 .057 -.180 -.034
Extraction Method: Principal Component Analysis.
a. Reproduced communalities
b. Residuals are computed between observed and reproduced correlations. There are 20 (44%) nonredundant residuals with absolute values greater than 0.05.
Rotated Component Matrixa
Component
1 2 3
X1 .761 -.273 .024
X2 .608 .095 .025
X3 .331 -.096 .614
X4 .113 .624 -.328
X5 .534 -.242 .131
X6 .591 .430 -.141
X7 -.038 .694 .364
X8 -.270 .651 .084
X9 -.113 .131 .781
Extraction Method: Principal
Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
Component Transformation Matrix
Component 1 2 3
1 .820 -.571 .032
2 .540 .792 .285
3 -.188 -.216 .958
Extraction Method: Principal
Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
Component Score Coefficient Matrix
Component
1 2 3
X1 .411 -.115 .004
X2 .351 .101 .001
X3 .162 -.052 .476
X4 .118 .402 -.279
X5 .282 -.115 .094
X6 .370 .311 -.141
X7 .017 .415 .269
X8 -.109 .380 .056
X9 -.078 .051 .616
Extraction Method: Principal
Component Analysis.
Component Score Covariance Matrix
Component 1 2 3
1 1.000 .000 .000
2 .000 1.000 .000
3 .000 .000 1.000
Extraction Method: Principal
Component Analysis.
LAMPIRAN B : KUISIONER PENELITIAN
Kepada Yth: Bapak/ Ibu/ Saudara/i Responden
Untuk keperluan penelitian dalam menyusun Tugas Akhir, Saya dengan biodata sebagai berikut:
Nama : Nurdian Suraiya NIM : 070803011
Alamat : jl. Jamin Ginting N0. 34 P.Bulan Medan No. Telepon : 085296485728
Universitas : Universitas Sumatera Utara (USU) Program Studi S-1 Matematika
Pada saat ini saya sedang menyusun Tugas Akhir dengan judul:
“ Suatu Kajian Dalam Penentuan Faktor Dominan Yang Mempengaruhi
Meningkatnya Penderita Kanker Serviks Dengan Analisis Faktor”.
Sangat mengharapkan partisipasi anda untuk dapat meluangkan waktu dan dapt membantu saya dalam menjawab beberapa pertanyaan yang akan digunakan sebagai
pengolahan data.
Keterangan:
a. Kuisioner ini tidak dimaksudkan untuk mengetahui apa yang benar dan apa yang salah atau sebaliknya maka diharapkan pengisiannya menurut kenya taan sebenarnya.
b. Kuisioner ini bertujuan untuk kepentingan ilmiah (penelitian).
c. Saya menyampaikan terimakasih atas partisipasi anda dalam mensukseskan