SHARFINA FAZA 101402088
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERGURUAN TINGGI MENGGUNAKAN ALGORITMA FP-GROWTH
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
SHARFINA FAZA 101402088
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
Judul : PENCARIAN ASSOCIATION RULES PADA DATA ._LULUSAN MAHASISWA PERGURUAN TINGGI ._MENGGUNAKAN ALGORITMA FP-GROWTH
Kategori : SKRIPSI
Nama : SHARFINA FAZA
Nomor Induk Mahasiswa : 101402088
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI ..UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dedy Arisandi, ST.,M.Kom Dr. Erna Budhiarti Nababan, M.IT NIP. 19790831200912 1 002 NIP. –
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
PERNYATAAN
PENCARIAN ASSOCIATION RULES PADA DATA LULUSAN MAHASISWA PERGURUAN TINGGI MENGGUNAKAN ALGORITMA FP-GROWTH
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 15 Januari 2015
Puji dan syukur penulis panjatkan kepada Allah SWT yang telah memberikan rahmat, karunia, taufik dan hidayah-Nya, serta segala sesuatu dalam hidup, sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Teknologi Informasi, Program Studi (S1)Teknologi Informasi, Fakultas Ilmu Komputer dan Teknologi Informasi.
Ucapan terima kasih penulis sampaikan kepada semua pihak yang telah membantu penulis dalam menyelesaikan skripsi ini baik secara langsung maupun tidak langsung. Pada kesempatan ini penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Keluarga penulis, Ayahanda Ir. Silmi, MT., Ibunda Ir. Rina Anugrahwaty, MT., Kakak penulis Insidini Fawwaz, S.Kom, dan adik penulis Faizzufar Taqy beserta keluarga besar yang selalu memberikan dukungan, perhatian serta doa kepada penulis sehingga dapat menyelesaikan skripsi ini.
2. Ibu Dr. Erna Budhiarti Nababan, M.IT. selaku Dosen Pembimbing I dan Bapak Dedy Arisandi, ST., M.Kom, selaku Dosen Pembimbing II yang telah banyak meluangkan waktunya serta memberikan bimbingan dan dukungan kepada penulis dalam penyusunan dan penulisan skripsi ini.
3. Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc. selaku Dosen Penguji I dan Bapak Dani Gunawan, ST., MT. selaku Dosen Penguji II yang telah memberikan kritik dan saran yang membangun dalam penyempurnaan skripsi ini.
4. Bapak Muhammad Anggia Muchtar, ST., MM.IT. selaku Ketua Program Studi S1 Teknologi Informasi dan Bapak Mohammad Fadly Syahputra, B.Sc., M.Sc.IT. selaku Sekretaris Program Studi S1 Teknologi Informasi.
5. Seluruh Dosen Program Studi S1 Teknologi Informasi yang telah memberikan ilmu yang bermanfaat bagi penulis dari awal perkuliahan.
6. Teman-teman penulis, Rahma Diana, Dian Puspitasari Sebayang, Nurul Putri Ibrahim, Rini Jannati, Maslimona Harimita Ritonga, Tri Annisa, Novi, Amel, dan Andrew yang telah memberikan semangat dan menjadi teman diskusi penulis dalam menyelesaikan skripsi ini.
7. Seluruh staf TU (Tata Usaha) serta pegawai di Program Studi S1 Teknologi Informasi
8. Semua pihak yang terlibat langsung ataupun tidak langsung yang tidak dapat penulis ucapkan satu per satu yang telah membantu penyelesaian skripsi ini.
ABSTRAK
Beragamnya atribut pada data lulusan mahasiswa membuat pihak perguruan tinggi sulit mencari dan mengetahui kombinasi atribut yang sering muncul dan memiliki keterhubungan tinggi antar atribut. Association rules mining merupakan teknik data mining untuk menentukan hubungan diantara data atau bagaimana suatu kelompok data mempengaruhi suatu kelompok data lain. Dengan kata lain, dapat dicarinya keterhubungan antar data pada data skala besar. Algoritma Frequent Pattren-Growth (FP-Growth) adalah salah satu teknik association rules mining untuk menentukan himpunan item yang paling sering muncul (frequent itemset) dalam sekumpulan data dalam bentuk FP-Tree. Dari hasil pencarian association rules pada data lulusan mahasiswa perguruan tinggi didapat kombinasi atribut yang sering muncul dan memiliki keterhubungan tinggi adalah kombinasi dari jenis sekolah SMA/MA Negeri Luar Medan, jalur masuk SNMPTN, nilai IPK antara 3.00 s/d 3.49, dan lama studi lebih dari 4 tahun.
ABSTRACT
The attribute diversity of data graduate students makes it difficult for the university to find and know combination of attributes that apperar most frequently and have high connectivity between attributes. Association rules mining is a data mining techniques to determine a relationship between data or how a group of data affects another group of data. In other words, it can be find a connectivity between data in large scale of data. Frequent pattren-Growth Algorithm (FP-Growth) is one of the association rules mining techniques to determine a set of items that appear most frequently (frequent itemset) in a set of data in the form FP-Tree. From the results of searching association rules of data graduate students university, combination of attributes that appear most frequently and have high connectivity obtained is a combination of the type of State Senior High School Outside Medan, university entrance test SNMPTN , GPA between 3.00 - 3.49 , and times of study more than 4 years .
DAFTAR ISI
Hal.
PERSETUJUAN ii
PERNYATAAN iii
UCAPAN TERIMA KASIH iv
ABSTRAK v
ABSTRACT vi
DAFTAR ISI vii
DAFTAR TABEL x
DAFTAR GAMBAR xi
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 3
1.3 Batasan Masalah 4
1.4 Tujuan Penelitian 4
1.5 Manfaat Penelitian 4
1.6 Metodologi 5
1.7 Sistematika Penulisan 6
BAB 2 LANDASAN TEORI 7
2.1 Data Mining 7
2.1.1 Knowledge discovery in database (KDD) 7
2.1.2 Teknik data mining 10
2.2 Association Rule Mining 11
2.2.1 Algoritma FP-Growth 13
2.2.2 Pencarian association rules dengan algoritma FP-Growth 13
2.3 Penelitian Terdahulu 17
BAB 3 ANALISIS DAN PERANCANGAN SISTEM 19
3.1 Data yang Digunakan 19
3.3.1 Data mining 24
3.3.2 Analisis frequent itemset 26
3.3.3 Pembentukan association rules 32
3.3.4 Pencocokan saran 33
3.4 Analisis Komponen Sistem 35
3.4.1 Data Flow Diagram (DFD) 35
3.4.1.1 DFD level-0 36
3.4.1.2 DFD level-1 37
3.4.1.3 DFD level-2 38
3.4.2 Flowchart 40
3.4.3 Sitemap aplikasi 41
3.5 Database Relationship 42
3.6 Perancangan Sistem 43
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM 49
4.1 Implementasi Sistem 49
4.1.1 Spesifikasi software dan hardware yang digunakan 49 4.1.2 Implementasi Perancangan Antarmuka 49 4.1.2.1 Halaman home pengguna sebagai user 50 4.1.2.2 Halaman home pengguna sebagai admin 50 4.1.2.3 Halaman input lulusan mahasiswa 51 4.1.2.4 Halaman daftar lulusan mahasiswa 52
4.1.2.5 Halaman parameter 52
4.1.2.6 Halaman jumlah mahasiswa 53
4.2 Pengujian Sistem 54
4.2.1 Rencana pengujian sistem 54
4.2.2 Kasus dan hasil pengujian sistem 54
4.2.3 Pengujian kinerja sistem 56
BAB 5 KESIMPULAN DAN SARAN 73
5.2 Saran 73
DAFTAR PUSTAKA 74
Hal.
Tabel 2.1 Penelitian Terdahulu 18
Tabel 3.1 Jumlah lulusan mahasiswa per fakultas 20 Tabel 3.2 Pengelompokan prestasi keberhasilan 22 Tabel 3.3 Jumlah lulusan mahasiswa berdasarkan prestasi 22
Tabel 3.4 Data Lulusan mahasiswa 24
Tabel 3.5 Kode untuk setiap item atribut 25 Tabel 3.6 Data lulusan mahasiswa dengan itemset 25
Tabel 3.7 Nilai support per item 26
Tabel 3.8 Data itemset lulusan mahasiswa 27 Tabel 3.9 Nilai support dari suffix M 31 Tabel 3.10 Nilai support dari suffix N 32 Tabel 3.11 Nilai support dari suffix O 32 Tabel 3.12 Nilai confidence dari frequentitemset 32
Tabel 4.1 Rencana pengujian 54
Tabel 4.2 Hasil pengujian 55
DAFTAR GAMBAR
Hal. Gambar 2.1 Proses KDD (Han & Kamber 2006) 8 Gambar 2.2 Arsitektur sistem data mining (Han & Kamber 2006) 9 Gambar 2.3 Transaction data set (Tan, et al. 2005) 14 Gambar 2.4 Tree setelah membaca TID1 (Tan, et al. 2005) 14 Gambar 2.5 Tree setelah membaca TID2 (Tan, et al. 2005) 15 Gambar 2.6 Tree setelah membaca TID10 (Tan, et al. 2005) 15 Gambar 2.7 Tree yang mengandung suffix e (Tan, et al. 2005) 16 Gambar 2.8 Tree yang mengandung suffix d (Tan, et al. 2005) 16 Gambar 3.1 Proses analisis association rules 19 Gambar 3.2 Tree setelah pembacaan itemset-1 28 Gambar 3.3 Tree setelah pembacaan itemset-2 28 Gambar 3.4 Tree setelah pembacaan itemset-3 29 Gambar 3.5 Tree setelah pembacaan itemset-30 29 Gambar 3.6 Conditional FP-tree dengan suffix M 30 Gambar 3.7 Conditional FP-tree dengan suffix N 30 Gambar 3.8 Conditional FP-tree dengan suffix O 30
Gambar 3.9 DFD level 0 36
Gambar 3.10 DFD level 1 37
Gambar 3.11 DFD level 2 : proses management data mahasiswa 38 Gambar 3.12 DFD level 2 : proses management parameter 38 Gambar 3.13 DFD level 2 : proses management pengguna 39 Gambar 3.14 DFD level 2 : proses pencarian association rules 39 Gambar 3.15 Flowchartassociation rules dengan algoritma FP-growth 40
Gambar 3.16 Sitemap aplikasi 41
Gambar 3.17 Database relationship 42
Gambar 3.23 Rancangan tampilan daftar lulusan mahasiswa 46 Gambar 3.24 Rancangan tampilan parameter data 47 Gambar 3.25 Rancangan tampilan jumlah mahasiswa 47 Gambar 3.26 Rancangan tampilan kelola pengguna 48 Gambar 4.1 Halaman home pengguna sebagai user 50 Gambar 4.2 Halaman home pengguna sebagai admin 51 Gambar 4.3 Halaman input lulusan mahasiswa 51 Gambar 4.4 Halaman daftar lulusan mahasiswa 52
Gambar 4.5 Halaman parameter 53
Gambar 4.6 Halaman jumlah mahasiswa 53
Gambar 4.7 Proses pencarian association rules 57
Gambar 4.8 Hasil uji coba pencarian 57
Gambar 4.9 Hasil proses pencarian 58
ABSTRAK
Beragamnya atribut pada data lulusan mahasiswa membuat pihak perguruan tinggi sulit mencari dan mengetahui kombinasi atribut yang sering muncul dan memiliki keterhubungan tinggi antar atribut. Association rules mining merupakan teknik data mining untuk menentukan hubungan diantara data atau bagaimana suatu kelompok data mempengaruhi suatu kelompok data lain. Dengan kata lain, dapat dicarinya keterhubungan antar data pada data skala besar. Algoritma Frequent Pattren-Growth (FP-Growth) adalah salah satu teknik association rules mining untuk menentukan himpunan item yang paling sering muncul (frequent itemset) dalam sekumpulan data dalam bentuk FP-Tree. Dari hasil pencarian association rules pada data lulusan mahasiswa perguruan tinggi didapat kombinasi atribut yang sering muncul dan memiliki keterhubungan tinggi adalah kombinasi dari jenis sekolah SMA/MA Negeri Luar Medan, jalur masuk SNMPTN, nilai IPK antara 3.00 s/d 3.49, dan lama studi lebih dari 4 tahun.
ABSTRACT
The attribute diversity of data graduate students makes it difficult for the university to find and know combination of attributes that apperar most frequently and have high connectivity between attributes. Association rules mining is a data mining techniques to determine a relationship between data or how a group of data affects another group of data. In other words, it can be find a connectivity between data in large scale of data. Frequent pattren-Growth Algorithm (FP-Growth) is one of the association rules mining techniques to determine a set of items that appear most frequently (frequent itemset) in a set of data in the form FP-Tree. From the results of searching association rules of data graduate students university, combination of attributes that appear most frequently and have high connectivity obtained is a combination of the type of State Senior High School Outside Medan, university entrance test SNMPTN , GPA between 3.00 - 3.49 , and times of study more than 4 years .
PENDAHULUAN
1.1. Latar Belakang
Association rules mining merupakan teknik data mining untuk menentukan hubungan diantara data atau bagaimana suatu kelompok data mempengaruhi suatu kelompok data lain (Ruldeviyani & Fahrian 2008). Dengan kata lain, dapat dicarinya keterhubungan antar data maupun antar kategori pada data skala besar.
Data dengan skala besar biasanya sering terdapat pada perusahaan maupun instansi-instansi pendidikan seperti perguruan tinggi. Dari beberapa data yang ada pada suatu perguruan tinggi salah satunya adalah data lulusan mahasiswa. Pada data lulusan mahasiswa terdapat berbagai macam atribut yang ada pada data diri mahasiswa yang dikumpulkan pada masa registrasi awal masuk perguruan tinggi dan data akademik yang dikumpulkan pada masa perkuliahan hingga akhir perkuliahan. Data diri mahasiswa yang dikumpulkan pada masa registrasi awal meliputi data pribadi, data asal sekolah, data keluarga, dan data masuk program studi. Data akademik yang dikumpulkan adalah data nilai mahasiswa pada setiap semesternya dengan nama lain sebagai indeks prestasi (IP) yang nantinya akan diakumulasi menjadi indeks prestasi kumulatif (IPK).
Setiap tahunnya perguruan tinggi meluluskan mahasiswa dari berbagai fakultas. Mahasiswa yang telah lulus dan mendapat gelar sarjana dari perguruan tinggi berasal dari jalur masuk dan asal pendidikan yang berbeda-beda pada awalnya, serta memiliki IPK dan lama masa studi yang berbeda-beda pula. Pencapaian gelar sarjana membutuhkan waktu normal selama empat tahun, akan tetapi dalam praktiknya banyak mahasiswa yang tidak selalu dapat menuntaskan studinya selama waktu normal yang ditentukan.
Beragamnya atribut seperti jenis sekolah, jalur masuk, IPK, dan masa studi membuat pihak perguruan tinggi sulit mencari dan mengetahui kombinasi atribut mana yang sering muncul dan memiliki keterhubungan tinggi antar atribut pada data lulusan mahasiswa. Maka dari itu, dibutuhkan suatu pendekatan untuk mendapatkan kombinasi atribut yang sering muncul dan memiliki keterhubungan tinggi antar atribut dengan melakukan association rules mining pada data lulusan mahasiswa. Association rules mining dapat menghasilkan kombinasi atribut yang memiliki keterhubungan tinggi antar atribut dalam bentuk rules dengan melakukan pencarian kombinasi atribut yang sering muncul terlebih dahulu.
dengan algoritma regresi linier berganda (Siregar, 2011) yang menghasilkan sebanyak 61% keterhubungan antara data mahasiswa terhadap masa studi, pada penilitian ini memiliki kekurangan pada data yang masih sedikit, berdasarkan kedua penelitian sebelumnya penulis akan menganalisis data lulusan mahasiswa dengan mengambil algoritma lain pada teknik association rules mining yaitu algoritma FP-Growth sebagai algoritma yang akan digunakan pada penelitian penulis, dan menggunakan data yang lebih banyak dari penelitian sebelumnya.
Algoritma Frequent Pattern-Growth (FP-Growth) merupakan salah satu algoritma yang dapat digunakan pada teknik association rules mining untuk menentukan himpunan item yang paling sering muncul (frequent itemset) dalam sekumpulan data (Hutasoit, 2010). Algoritma ini hanya melakukan dua kali proses scanning database untuk menentukan frequent itemset dalam bentuk FP-Tree. Algoritma FP-Growth telah digunakan pada data mining seperti pencarian association rules terhadap barang sebuah butik (Hutasoit, 2010), dan penentuan kelayakan sertifikasi guru berdasarkan keterkaitan NUPTIK (Ramdanie, et al. 2013).
Pada penelitian ini, penulis akan menganalisis data lulusan mahasiswa suatu perguruan tinggi yang didalamnya terdapat atribut jenis sekolah, jalur masuk, fakultas, IPK, dan masa studi menggunakan algoritma FP-Growth. Hasil yang didapat nantinya berupa rules yang sering muncul dan memiliki keterhubungan tinggi antar atribut pada data lulusan mahasiswa perguruan tinggi.
1.2. Rumusan Masalah
1.3. Batasan Masalah
Pada penelitian ini, penulis memberi batasan sebagai berikut.
1. Hanya meneliti lulusan mahasiswa S1 reguler dari suatu perguruan tinggi.
2. Parameter yang digunakan adalah jenis sekolah, jalur masuk, IPK, dan lama studi. 3. Jalur masuk yang digunakan adalah PMP, UMB, SNMPTN, dan SPMPRM 1.4. Tujuan Penelitian
Tujuan dari penelitian ini adalah mendapatkan association rules atau gabungan dari kombinasi atribut yang sering muncul dan memiliki keterhubungan tinggi antar atribut pada data lulusan mahasiswa perguruan tinggi menggunakan algoritma FP-Growth. 1.5. Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut.
1. Mendapatkan informasi tentang bagaimana lulusan mahasiswa yang sering muncul dan memiliki keterhubungan antar atribut yang tinggi berdasarkan rules yang didapat.
2. Rules yang dihasilkan dapat digunakan sebagai bahan dasar untuk memprediksi masa studi mahasiswa, sehingga dapat membantu pihak perguruan tinggi maupun fakultas untuk dapat memberikan arahan kepada mahasiswa yang memiliki kemiripan atribut terhadap salah satu rules untuk meningkatkan pembelajaran sehingga dapat meningkatkan tingkat kelulusan.
1.6. Metodologi
Terdapat beberapa tahapan dalam penelitian ini untuk menghasilkan suatu sistem yang sesuai dengan yang diharapkan.
1. Studi Literatur
Kegiatan mempelajari dokumentasi literatur dan teori yang berkaitan dengan penelitian. Dalam tahap ini merupakan proses pengumpulan referensi, baik buku, jurnal, tesis, makalah dan sumber-sumber lain termasuk yang diperoleh dari internet sebagai sumber data dan informasi yang berkaitan dengan data mining, association rules mining, algoritma FP-Growth, dan data lulusan mahasiswa perguruan tinggi di Sumatera Utara
2. Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap data yang telah dikumpulkan sebelumnya untuk mendapatkan pemahaman mengenai teknik association rules mining dan algoritma FP-Growth yang akan digunakan dalam membangun sistem data mining.
3. Perancangan
Pada tahap ini dilakukan perancangan perangkat lunak yang dibangun, seperti perancangan proses dan antarmuka.
4. Implementasi
Pada tahap ini dilakukannya pembangunan program dengan pengkodean perangkat lunak sesuai dengan alur yang ditentukan.
5. Pengujian
Pada tahap ini dilakukannya pengujian terhadap perangkat lunak yang dibangun, dan bagaimana keakuratan dari sistem yang dibuat.
6. Penyusunan Laporan
1.7. Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri dari lima bagian utama sebagai berikut. BAB 1 : PENDAHULUAN
Bab ini berisi latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian, dan sistematika penulisan.
BAB 2 : LANDASAN TEORI
Bab ini berisi teori-teori yang digunakan untuk memahami permasalahan yang dibahas pada penelitian ini. Pada bab ini dijelaskan data mining secara umum, association rules mining, dan algoritma FP-Growth.
BAB 3 : ANALISIS DAN PERANCANGAN
Bab ini membahas tentang perancangan sistem seperti data flow, dan perancangan sistem untuk melakukan pencarian association rules.
BAB 4 : IMPLEMENTASI DAN PENGUJIAN
Bab ini berisi pembahasan tentang implementasi dari analisis dan perancangan perangkat lunak yang disusun pada Bab 3 dan pengujian terhadap sistem yang dibangun.
BAB 5 : KESIMPULAN DAN SARAN
LANDASAN TEORI
Pada bab ini akan dibahas tentang konsep dasar dan teori-teori pendukung yang berhubungan dengan sistem yang akan dibangun.
2.1. Data Mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan didalam database. Data mining merupakan suatu proses kegiatan yang meliputi pengumpulan dan pemakaian data historis untuk menemukan keteraturan pola maupun hubungan dalam suatu set data berukuran besar (Santosa, 2007). Data mining adalah tentang memecahkan suatu masalah dengan menganalisis data yang sudah ada. Data mining juga didefinisikan sebagai proses menemukan pola dalam data, dimana pola yang didapat harus memiliki beberapa keuntungan (Witten & Frank 2005).
Data mining sering disebut knowledge discovery in database (KDD), yaitu kegiatan yang meliputi kumpulan pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan. Sehingga istilah pattern recognition sekarang jarang digunakan karena ia termasuk bagian dari datamining (Santosa, 2007).
2.1.1. Knowledge discovery in database (KDD)
Menurut Han & Kamber (2006) proses KDD secara garis besar terdiri dari urutan yang berulang dari langkah-langkah berikut.
1. Data Cleaning (untuk menghilangkan noise dan data yang tidak konsisten) 2. Data Integration (mengkombinasikan beberapa dari sumber data)
4. Data Transformation (pengubahan data atau mengkonsolidasikan data kedalam bentuk yang sesuai untuk dilakukannya proses mining, seperti ringkasan atau agregasi operasi)
5. Data Mining (proses penting dimana metode cerdas diterapkan untuk mengekstrak pola)
6. Pattern Evaluation (mengidentifikasi pola-pola menarik yang mewakili pengetahuan berdasarkan proses data mining sebelumnya)
7. Knowledge presentation (menggunakan pengetahuan teknik representasi dan visualisasi untuk menyajikan pengetahuan kepada pengguna)
Gambar 2.1 Proses KDD (Han & Kamber 2006)
Gambar 2.2 Arsitektur sistem data mining (Han & Kamber 2006)
Database, Data Warehouse, World Wide Web, dan Other Info Repositories merupakan satu atau kumpulan dari database, gudang data, spreadsheet atau jenis lain dari informasi repository. Cleaning data, integrasi data dan pemilihan data dapat dilakukan pada data.
Database atau Data Warehouse Server: bertanggung jawab untuk mengambil data yang relevan berdasarkan permintaan data mining pengguna.
Data Mining Engine : penting untuk sistem data mining seperti untuk tugas-tugas karakteristik, asosiasi dan analisis korelasi, klasifikasi, prediksi, analisis cluster, analisis outlier, dan analisis evolusi.
Pattern Evaluation : melakukan pemfokusan pencarian terhadap pola yang menarik dengan berinteraksi dengan modul data mining, atau dapat diintegrasikan dengan modul pertambangan, tergantung pada pelaksanaan metode data mining yang digunakan.
User Interface : diperlukan sebagai perantara pengguna dengan sistem untuk berkomunikasi yang memungkinkan pengguna untuk berinteraksi dengan sistem dengan menentukan pemberian tugas, memberi informasi untuk membantu memfokuskan pencarian. Selain itu juga memungkinkan pengguna untuk menelursuri database dan skema data warehouse atau struktur data, mengevaluasi pola, dan memvisualisasikan pola dalam bentuk yang berbeda.
2.1.2. Teknik data mining
Terdapat beberapa teknik dan sifat data mining sebagai berikut (Hermawati, 2009) : 1. Klasifikasi (clasification)
Klasifikasi adalah menentukan sebuah record data baru ke salah satu dari beberapa kategori (atau klas) yang telah didefinisikan sebelumnya. Contoh aplikasinya adalah pada penjualan langsung, yaitu untuk mengurangi cost surat menyurat dengan menentukan satu set konsumen yang mempunyai kesamaandalam membeli produk telepon selular baru.
2. Regresi (regression)
3. Klasterisasi (clustering)
Mempartisi data-set menjadi beberapa sub-set atau kelompok sedemikian rupa sehingga elemen-elemen dari suatu kelompok tertentu memiliki set property yang dishare bersama dengan tingkat similaritas yang tinggi dalam satu kelompok dan tingkat similaritas kelompok yang rendah. Contoh aplikasinya adalah : document clustering, dengan tujuan untuk mendapatkan kelompok dokumen yang mempunyai kesamaan berdasarkan kata-kata penting yang muncul dalam dokumen.
4. Kaidah Asosiasi (association rules)
Mendeteksi kumpulan atribut-atribut yang muncul bersamaan (co-occur) dalam frekuensi yang sering, dan membentuk sejumlah kaidah dari kumpulan-kumpulan tersebut. Contoh aplikasinya adalah pada supermarket shelf management, dengan tujuan untuk mengenali item-item yang dibeli bersama-sama oleh cukup banyak pelanggan.
5. Pencarian Pola sekuensial (sequence mining)
Mencari sejumlah event yang secara umum terjadi bersama-sama. Sebagai contoh dalam suatu set urutan DNA, ACGTC diikuti oleh GTCA setelah suatu celah selebar 9 dengan probabilitas sebesar 30 %.
2.2 Association Rule Mining
Assotiation rule mining atau aturan asosiasi sering dinamakan market basket analysis, karena awalnya berasal dari studi tentang database transaksi pelanggan uantuk menentukan kebiasaan suatu produk dibeli bersama produk apa (Santosa,2007). Sebagai contoh studi transaksi di supermarket, seseorang yang membeli susu bayi juga membeli sabun mandi. Disini berarti susu bayi bersama dengan sabun mandi.
1. Support (nilai penunjang/pendukung): suatu ukuran yang menunjukkan seberapa besar tingkat kemunculan suatu item/itemset dari keseluruhan transaksi. Ukuran ini menentukan apakah suatu itemset layak untuk dicari confidence pada tahapan selanjutnya.
2. Confidence (nilai kepastian/keyakinan): suatu ukuran yang menunjukkan hubungan antara 2 item secara conditional.
Keduan ukuran tersebut akan digunakan dalam menentukan interesting association rules, yaitu untuk dibandingkan dengan batasan (threshold) yang ditentukan oleh user. Batasan tersebut umumnya terdiri dari minimum support dan minimum confidence, yang digunakan pada proses pencarian association rules. Menurut Hermawati (2009), tujuan dari association rules mining adalah untuk menentukan semua aturan yang mempunyai support >= min_support dan confidence >= min_confidence. Sebuah association rule dengan confidence sama atau lebih besar dari minimum confidence dapat dikatakan sebagai valid association rule (Agrawal & Srikant, 1994).
Proses pencarian association rules terbagi menjadi dua tahap yaitu analisis frequent itemset dan pembentukan association rules (Han & Kamber 2006).
1. Analisis Frequent Item
Tahapan ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus 2.1 atau 2.2, yaitu:
� � =Jumlah Transaksi yang Mengandung A
Total Transaksi � 100
% (2.1)
Sedangkan nilai support dari 2 item diperoleh dengan rumus sebagai berikut:
� � , =Jumlah Transaksi yang Mengandung A dan B
2. Pembentukan Asosiation Rules
Setelah semua pola frekuensi tinggi ditemukan, kemudian dicari aturan asosiasi yang memenuhi syarat minimum untuk confidence dengan menghitung confidence
aturan asositif A→B. Nilai confidencedari aturan A→B diperoleh dari rumus 2.3,
� → = Jumlah Transaksi yang Mengandung A dan B
Jumlah Transaksi yang Mengandung A � 100%
(2.3)
2.2.1. Algoritma FP-growth
Algoritma FP-Growth mempresentasikan transaksi dengan menggunakan struktur data FP-Tree (Han, et al. 2000). FP-growth adalah salah satu alternatif algoritma yang dapat digunakan untuk menentukan himpunan data yang sering muncul (frequent itemset) dalam sebuah kumpulan data (Samuel, 2008).
FP-Tree merupakan struktur penyimpanan data yang dibentuk oleh sebuah akar yang diberi label null (Han & Kamber 2006). Pada FP-Tree, item dipetakan ke item lainnya pada setiap lintasan. Pada setiap itemset yang dipetakan mungkin saja terdapat item yang sama, sehingga pada FP-Tree ini memungkinkan untuk saling menimpa. FP-Tree akan semakin efektif apabila semakin banyak pula item yang sama pada setiap itemset (Samuel, 2008).
2.2.2. Pencarian association rules dengan algoritma FP-growth
Proses pencarian association rules terbagi menjadi dua tahap yaitu analisis pola frekuensi tinggi dan pembentukan aturan assosiasi (Han & Kamber 2006).
1. Analisis frequent itemset, atau analisis pola frekuensi tinggi untuk mencari kombinasi item yang memenuhi syarat minimum dari nilai support itemset, dimana nilai support menunjukkan perhitungan frekuensi kemunculan pada suatu data. Proses pencarian frequent itemset pada sistem ini menggunakan algoritma FP-Growth yang melalui tiga tahapan.
a. Pencarian frequent item
frequent atau kemunculan sedikit maka item akan dibuang. Nilai support dapat diperoleh dengan rumus (2.1)
b. Pembangunan FP-Tree
Pembangunan FP-tree diawali dengan pembangunan tree pada setiap itemset. Pembangunan tree diawali dengan prefix atau awalan yang sama dari setiap itemset. Apabila terdapat itemset yang memiliki prefix berbeda, maka itemset berikutnya dibangun pada lintasan berbeda (Tan, et al. 2005).
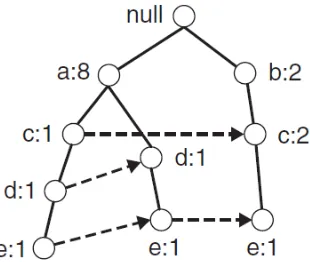
Sebagai contoh dapat dilihat pada Gambar 2.3, Gambar 2.4 dan Gambar 2.5.
Gambar 2.3 Transaction data set (Tan, et al. 2005) FP-tree yang dapat dibangun dari itemset yang ada adalah sebagai berikut :
Gambar 2.5 Setelah membaca TID 2 (Tan, et al. 2005)
Setiap item pada setiap lintasan diberi nilai awal 1 sebagai support count, apabila itemset berikutnya memiliki prefix yang sama maka akan ditambahkan nilai support count pada item yang sama. Walaupun b ada pada lintasan pertama, namun karena berbeda prefix, maka penambahan support count tidak bisa dilakukan. Proses terus dilanjutkan sampai semua itemset selesai dibaca seperti pada Gambar 2.5.
Gambar 2.6 Setelah membaca TID 10 (Tan, et al. 2005) c. Pencarian frequent itemset
Frequent itemset didapat melalui tiga tahapan (Tan, et al. 2005).
Gambar 2.7 Tree yang mengandung suffix e (Tan, et al. 2005)
Gambar 2.8 Tree yang mengandung suffix d (Tan, et al. 2005) 2. Mengecek kembali nilai support dari suffix item lebih besar atau tidak dari
minimum support yang telah diinput oleh pengguna sebelumnya. Apabila memenuhi, maka item tersebut termasuk frequent itemset. Nilai support setiap itemnya pada tahap ini dihitung dengan rumus (2.1).
3. Apabila terdapat item yang frequent, maka akan dilanjutkan dengan metode divide and conquer untuk memecahkan subproblem yang lebih kecil, yaitu untuk menemukan frequent itemset yang berakhir dengan dua item dari frequent item yang didapat sebelumnya. Kemudian membangun kembali tree yang diakhiri dengan dua item kombinasinya, dimana nilai support pada itemset hanya mengandung nilai yang diakhiri dari frequent item. Begitu pula selanjutnya sampai prefix dari kombinasi.
2. Pembentukan association rules atau aturan assosiasi untuk mencari aturan assositif
A→B yang memenuhi syarat minimum nilai confidence. Pencarian nilai
confidence dapat dihitung dengan rumus (2.3)
Dimana A adalah antecendent (item setelah jika) dan B adalah consequent (item setelah maka). Untuk antecendent dapat terdiri lebih dari satu unsur, akan tetapi consequent hanya terdiri dari satu unsur. Ini digunakan untuk mengetahui keterhubungan anatr item dalam suatu itemset. Sebagai contoh, pada penelitian ini akan mencari seberapa keterhubungannya jalur masuk, asal pendidikan, fakultas, dan IPK terhadap masa studi seorang mahasiswa.
Rules yang telah didapat dilakukan pencocokan untuk memberikan saran kepada pengguna, dengan kata lain rules yang didapat akan diterjemahkan kedalam informasi yang dapat dimengerti oleh pengguna, yaitu berupa informasi kategori apa saja yang paling banyak muncul dan memiliki keterhubungan pada data lulusan mahasiswa perguruan tinggi serta saran/arahan yang dapat dilakukan oleh perguruan tinggi maupun fakultas.
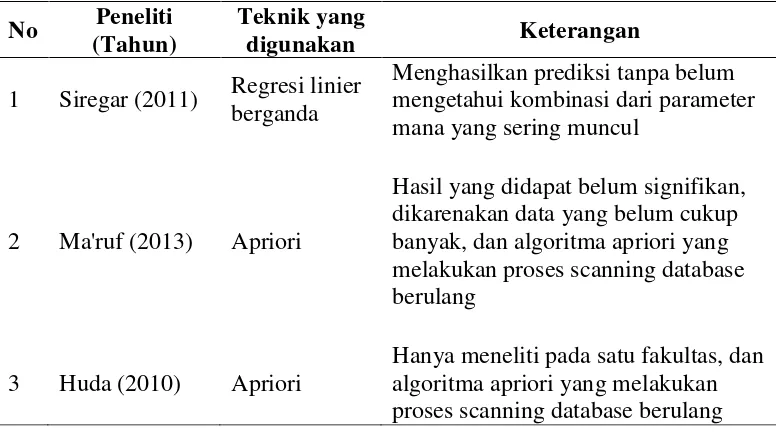
2.3 Penelitian Terdahulu
Terdapat beberapa penelitian pada data mahasiswa yang telah dilakukan, yaitu penentu keterhubungan antara data mahasiswa dan masa studi dengan algoritma regresi linier berganda (Siregar, 2011). Pada penelitian ini menghasilkan sebanyak 61% keterhubungan antara data mahasiswa terhadap masa studi, Parameter yang digunakan dalam penentu keterhubungan adalah IPK, rata-rata UN, jumlah SKS, dan pendidikan orang tua. Data yang digunakan sebanyak 500 data mahasiswa, dan mengahasilkan sebuah prediksi tanpa belum mengetahui kombinasi dari parameter mana yang sering muncul.
Penelitian selanjutya oleh Ma’ruf (2013) yaitu aplikasi data mining untuk
keberhasilan proses masuk mahasiswa itu berasal dari mana untuk menjadi acuan dalam memaksimalkan iklan pada daerah tertentu, pada penelitian ini algoritma yang digunakan adalah algoritma apriori yang melakukan candidate generate dari setiap item sehingga memerlukan banyak perulangan pencarian ke database, juga data yang digunakan pada penilitian ini belum menggunakan data yang cukup banyak, sehingga hasil yang diperoleh masih belum signifikan.
Selanjutnya Huda (2010) membangun aplikasi data mining untuk menampilkan informasi tingkat kelulusan mahasiswa. Pada penelitian ini juga menggunakan algoritma apriori, hasil dari proses data mining pada penelitian ini dapat digunakan sebagai pertimbangan dalam mengambil keputusan lebih lanjut tentang faktor yang mempengaruhi tingkat kelulusan khususnya faktor dalam data induk mahasiswa pada satu fakultas. Data induk mahasiswa yang diproses mining meliputi data proses masuk, data asal sekolah, data kota mahasiswa, dan data program studi. Pada penelitian ini menganjurkan peneliti selanjutnya untuk menggunakan algoritma FP-Growth, dikarenakan algoritma apriori memerlukan banyak perulangan pencarian ke database. Ringkasan penelitian terdahulu dapat dilihat pada Tabel 2.1.
Tabel 2.1. Penelitian Terdahulu
No Peneliti (Tahun)
Teknik yang
digunakan Keterangan
1 Siregar (2011) Regresi linier berganda
Menghasilkan prediksi tanpa belum mengetahui kombinasi dari parameter mana yang sering muncul
2 Ma'ruf (2013) Apriori
Hasil yang didapat belum signifikan, dikarenakan data yang belum cukup banyak, dan algoritma apriori yang melakukan proses scanning database berulang
3 Huda (2010) Apriori
ANALISIS DAN PERANCANGAN SISTEM
Analisis sistem yang akan dibangun meliputi data yang digunakan, praproses data, pemrosesan data, dan analisis komponen sistem. Penyelesaian berupa pencarian association rules berdasarkan association rules mining menggunakan algoritma FP-Growth. Pada tahap perancangan sistem dibahas perancangan Data Flow Diagram (DFD), perancangan alur kerja sistem (flowchart), dan perancangan antarmuka pemakai (userinterface). Proses analisis dapat dilihat pada Gambar 3.1.
Praproses Data
Penentuan Atribut
Pemrosesan Data
Pencocokan Saran Data Mining
Pengelompokan Atribut
Analisis Frequent Itemset (menggunakan algoritma FP-Growth)
Pembentukan Association Rules
Gambar 3.1. Proses analisis association rules 3.1 Data yang Digunakan
muncul, maka dari itu dibutuhkan beberapa atribut dari data diri mahasiswa dan data akademik dari data lulusan mahasiswa.
Pada awal masuk perkuliahan, mahasiswa mengisi data diri seperti nama, tempat dan tanggal lahir, asal sekolah, fakultas maupun program studi yang dimasukinya, dan lainnya. Pada masa perkuliahan mahasiswa mendapatkan nilai pada setiap semester dan akan diakumulasi menjadi IPK (Indeks Prestasi Akademik) yang disimpan kedalam data akademik. Mahasiswa yang telah lulus akan tersimpan pada data lulusan mahasiswa dengan menginformasikan berapa lama masa studi mahasiswa tersebut. Dari data lulusan mahasiswa, terdapat beberapa atribut yang merupakan faktor lama masa studi seorang mahasiswa, sehingga akhir pada sistem ini juga dapat memberikan bahan prediksi masa studi bagi mahasiswa.
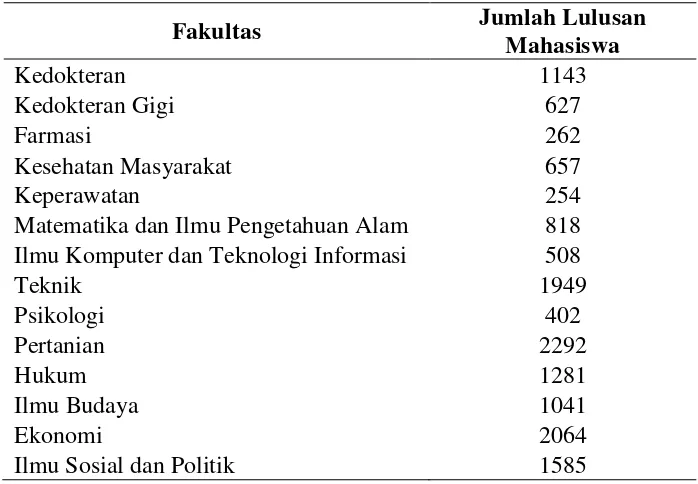
Jumlah data Lulusan Mahasiswa Universitas Sumatera Utara sebanyak 14.884 data yang terdiri dari beberapa fakultas dan jumlah yang berbeda pada setiap fakultasnya. Jumlah mahasiswa per fakultas dapat dilihat pada Tabel 3.1.
Tabel 3.1. Jumlah lulusan mahasiswa per fakultas
Fakultas Jumlah Lulusan
Matematika dan Ilmu Pengetahuan Alam 818 Ilmu Komputer dan Teknologi Informasi 508
Teknik 1949
3.2. Praproses Data
Tahap praproses data merupakan tahap seleksi data yang bertujuan untuk mendapatkan data yang hanya digunakan dalam penelitian dengan membuang beberapa record yang tidak akan dianalisis dikarenakan tidak dapat menjadi faktor dari lama studi seorang mahasiswa. Pada data lulusan mahasiswa, terdapat beberapa record seperti nim, no alumni, nama, jenis kelamin, tempat-tanggal-lahir, agama, kota, kode pos, asal sekolah, jenis sekolah, fakultas, program studi, jalur masuk, ipk, lama studi, dan periode wisuda. Record yang tidak dianalisis adalah nim, no alumni, nama, jenis kelamin, tempat-tanggal lahir, agama, kota, kode pos, asal sekolah, program studi, dan periode wisuda. Sedangkan record yang akan dianalisis adalah jenis sekolah, fakultas, jalur masuk, ipk, dan lama studi.
Tahapan selanjutnya yang dikerjakan adalah melakukan perubahan terhadap beberapa tipe data pada atribut dataset dengan tujuan untuk mempermudah pemahaman terhadap isi record.
3.2.1 Penentuan atribut
Beberapa atribut yang digunakan untuk pembentukan rules adalah sebagai berikut: 1. Jenis Sekolah
Sebagai tempat mendapatkan pengajaran sebelumnya sebelum masuk perguruan tinggi bagi setiap mahasiswa. Terdapat beragamnya jenis sekolah dari mahasiswa yang masuk perguruan tinggi seperti sekolah negeri maupun swasta, dan sekolah dalam maupun luar kota.
2. Jalur Masuk
Sebagai jalur penyeleksian masuk perguruan tinggi yang memiliki beberapa tahapan, dimana calon mahasiswa yang berhak masuk pada tahap pertama adalah calon mahasiswa yang memiliki nilai tinggi.
3. IPK
berdasarkan buku panduan mahasiswa Universitas Sumatera Utara yang dapat dilihat pada Tabel 3.2.
Tabel 3.2. Pengelompokan prestasi keberhasilan Nilai Prestasi Bobot Prestasi Golongan Prestasi
A 4.00 Sangat Baik
Beragam prestasi yang dicapai setiap mahasiswa yaitu pada setiap mata kuliah yang diambil maupun setelah prestasi diakumulasi, berikut jumlah mahasiswa yang diambil secara acak ±20% dari jumlah keseluruhan data lulusan mahasiswa berdasarkan pengelompokan prestasi pada Tabel 3.3.
Tabel 3.3. Jumlah lulusan mahasiswa berdasarkan prestasi Nilai
Berdasarkan data pada Tabel 3.3. dapat dilihat kelompok prestasi dengan jumlah mahasiswa yang tinggi yaitu B+, B, dan C+ dengan nilai 3.50, 3.00, dan 2.50.
4. Lama Studi
empat tahun, dan tidak sedikit pula mahasiswa yang menyelesaikan studinya kurang dari empat tahun.
3.2.2. Pengelompokan atribut
Terdapat beberapa kelompok item pada setiap atribut seperti berikut: 1. Jenis Sekolah
a. SMA/MA Negeri Dalam Medan b. SMA/MA Negeri Luar Medan c. SMA/MA Swasta Dalam Medan d. SMA/MA Swasta Luar Medan
e. SMTA Lain-lain (semua sekolah selain empat diatas) 2. Jalur Masuk
a. PMP b. SNMPTN c. SPMPRM d. UMB 3. IPK
a. IPK < 3.00 b. IPK = 3.00-3.49 c. IPK > 3.49 4. Lama Studi
a. < 4 Tahun b. 4 Tahun c. > 4 Tahun 3.3. Pemrosesan Data
3.3.1. Data mining
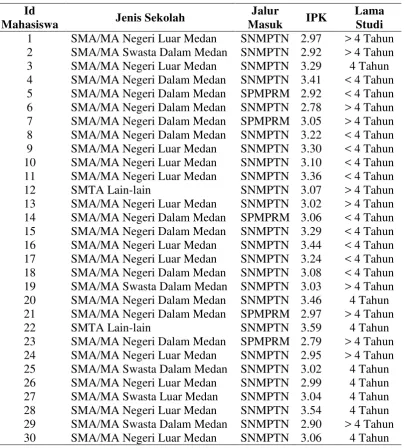
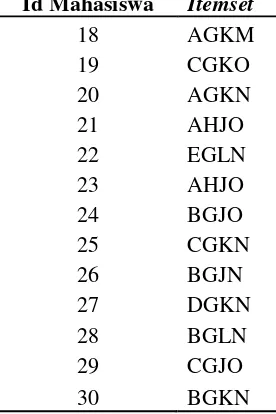
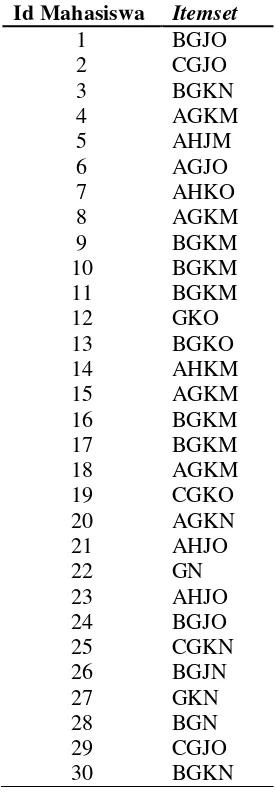
Tahapan ini adalah proses untuk menghasilkan association rules. Berikut merupakan data lulusan mahasiswa sebanyak 30 mahasiswa yang mewakili keseluruhan data dari salah satu fakultas yang akan dilakukan proses pencarian association rules yang dapat dilihat pada Tabel 3.4.
Dari Tabel 3.4. terdapat 30 lulusan mahasiswa yang masing-masing memiliki kelompok atribut yang berbeda-beda. Maka dari itu, diberikan kode setiap item atribut agar mempermudah proses pencarin rules seperti pada Tabel 3.5.
Tabel 3.5. Kode untuk setiap item atribut
Atribut Item Kode
Jenis Sekolah SMA/MA Negeri Dalam Medan A
SMA/MA Negeri Luar Medan B
SMA/MA Swasta Dalam Medan C
SMA/MA Swasta Luar Medan D
SMTA Lain-lain E
Berdasarkan Tabel 3.5, dapat dilihat itemset dari data lulusan mahasiswa ataupun kumpulan item berdasarkan kode pada Tabel 3.6.
Tabel 3.6. Data lulusan mahasiswa dengan itemset (lanjutan) diberi nilai minimum support = 10% dan kemudian dilakukan pencarian nilai support pada masing-masing item dengan rumus (2.1).
Langkah 1 : Mencari frequent item
Tabel 3.7. Nilai support per item
Berdasarkan data pada Tabel 3.7, frequent item yang memenuhi nilai minimum support yaitu sebanyak 10% adalah jenis sekolah A, B, dan C, jalur masuk G dan H, IPK J dan K, dan lama studi M, N dan O.
Langkah 2 : Pembangunan FP-Tree
FP-tree merupakan struktur penyimpanan data yang dibentuk oleh sebuah akar yang diberi label null (Han &Kamber 2006). Fp-tree yang dibangun terdiri dari frequent item pada setiap mahasiswa, maka item yang tidak frequent atau tidak sering muncul dihilangkan. Berikut data mahasiswa dengan itemset dapat dilihat pada Tabel 3.8.
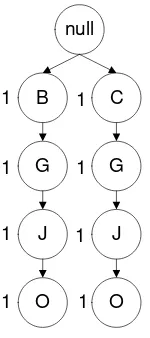
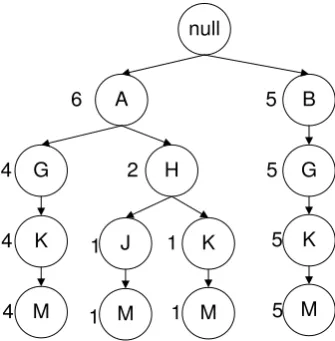
Fp-tree yang dapat dibangun dari itemset yang ada dapat dilihat pada Gambar 3.2, Gambar 3.3, Gambar 3.4, dan Gambar 3.5.
G
Gambar 3.2. Tree setelah pembacaan itemset-1 (BGJO)
Pada Gambar 3.2 pembacaan itemset pertama yaitu BGJO, dimana masing-masing item memiliki nilai awal 1.
G
Gambar 3.3 Tree Setelah pembacaan itemset-2 (CGJO)
G
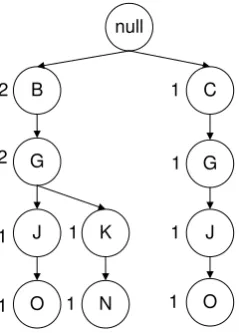
Gambar 3.4 Tree setelah pembacaan itemset-3 (BGKN)
Pada Gambar 3.4 itemset ketiga memiliki prefix yang sama dengan prefix itemset pertama, sehingga B dan G berada dalam lintasan yang sama dengan itemset pertama, akan tetapi K dan N membuat lintasan baru. Proses terus dilakukan sampai pembacaan itemset ke 30 seperti pada Gambar 3.5.
G
Gambar 3.5 Tree setelah pembacaan itemset-30 (BGKN) Langkah 3 : Pencarian frequent itemset
Pencarian frequent itemset dilakukan melalui beberapa tahapan.
G
Gambar 3.6 Conditional FP-tree dengan suffix M
G
Gambar 3.7 Conditional FP-tree dengan suffix N
G
2. Mengecek kembali nilai support dari suffix itemset lebih besar atau tidak dari minimum support yaitu 10% dengan rumus (2.1), apabila memenuhi dilakukan kembali pengecekan terhadap suffix kedua selanjutnya hingga prefix dengan rumus (2.2). Pengecekan nilai support pada suffix M hingga prefix dapat dilihat pada Tabel 3.9.
Tabel 3.9. Nilai support dari suffix M
No Suffix Jumlah Support
1 M 11 11/30 * 100% = 36%
2 KM 10 10/30 *100% = 33%
3 JM 1 1/30 * 100% = 3%
4 GKM 9 9/30 * 100% = 30% 5 HKM 1 1/30 * 100% = 3% 6 AGKM 4 4/30 * 100% = 13% 7 BGKM 5 5/30 * 100% = 16%
Dari Tabel 3.9 dilakukan pengecekan awal terhadap M (suffix), nilai support M memenuhi minimum support, sehingga dilakukan pengecekan kembali terhadap dua suffix terakhir yaitu KM dan JM. Nilai support dari KM memenuhi minimum support, sehingga dilakukan pengecekan terhadap tiga suffix terakhir yang mengandung KM yaitu GKM dan HKM. Nilai support GKM memenuhi minimum support, selanjutnya dilakukan kembali pengecekan nilai support yang mengandung GKM yaitu AGKM dan BGKM. Nilai support AGKM dan BGKM memenuhi minimum support, maka AGKM dan BGKM merupakan frequentitemset.
Tabel 3.10. Nilai support dari suffix N karena nilai support dari itemset tidak memenuhi minimum support.
Tabel 3.11 Nilai support dari suffix O No Suffix Jumlah Support karena nilai support dari itemset tidak memenuhi minimum support. Sehingga itemset dengan kemunculan tinggi hanya AGKM dan BGKM.
3.3.3. Pembentukan association rules
Tabel 3.12. Nilai confidence dari frequent itemset
No Itemset A → B Confidence
1 AGKM AGK → M 5/8 * 100% = 62% 2 BGKM BGK → M 4/5 * 100% = 80%
Berdasarkan Tabel 3.12, itemset AGKM dan BGKM memiliki nilai confidence yang memenuhi nilai minimum confidence. Maka AGKM dan BGKM dapat dijadikan rules dari suatu data lulusan mahasiswa tersebut, dimana memiliki tingkat kemunculan tinggi dan keterhubungan yang tinggi pada suatu data lulusan mahasiswa. Association rules yang didapat :
1. Mahasiswa yang berasal dari SMA/MA Negeri Dalam Medan dengan jalur masuk SNMPTN yang memiliki IPK antara 3.00 s/d 3.50, memiliki lama studi < 4 tahun. 2. Mahasiswa yang berasal dari SMA/MA Negeri Luar Medan dengan jalur masuk SNMPTN yang memiliki IPK antara 3.00 s/d 3.50, memiliki lama studi < 4 tahun. 3.3.4. Pencocokan saran
Dari hasil association rules yang didapat, dapat dilakukan pencocokan saran untuk perguruan tinggi maupun fakultas dengan melihat suffix (akhiran) pada rules yaitu berdasarkan lama studi. Saran yang diberikan dapat berguna untuk perguruan tinggi dalam meningkatkan kelulusan pada setiap waktu kelulusan, ataupun dapat mengurangi tingkat mahasiswa dengan lama studi > 4 tahun.
Apabila lama studi > 4 tahun, maka saran untuk jenis sekolah dari rules yang didapat adalah fakultas dapat memberikan informasi atau melakukan promosi kepada calon mahasiswa dari jenis sekolah selain yang didapat agar memilih fakultas tersebut, dan saran untuk jalur masuk dari rules yang didapat agar perguruan tinggi sedikit membuka kesempatan bagi calon mahasiswa pada jalur masuk yang didapat untuk masuk ke fakultas tersebut.
Pencocokan saran juga melihat IPK dari rules yang didapat, tetapi tanpa berdasarkan lama studi. Apabila IPK pada rules yang didapat dibawah 3.00 maka fakultas diberi saran untuk dapat memberikan pengajaran lebih kepada mahasiswa dan arahan untuk mulai memikirkan serta mendalami materi yang akan diambil pada tugas akhir nantinya. Apabila nilai IPK antara 3.00 s/d 3.49, fakultas diberi saran untuk dapat memberikan arahan kepada mahasiswa untuk meningkatkan IPK dan mulai memikirkan serta mendalami materi yang akan diambil pada tugas akhir. Apabila nilai IPK diatas 3.50, fakultas diberi saran untuk dapat memberikan arahan kepada mahasiswa untuk mempertahankan IPK dan mulai memikirkan serta mendalami materi yang akan diambil pada tugas akhir. Mahasiswa yang ditujukan saran adalah mahasiswa yang telah menjalani perkuliahan lebih dari setahun dan belum mengambil tugas akhir.
Dari hasil association rules yang didapat, sistem dapat memberikan saran kepada perguruan tinggi maupun fakultas sebagai berikut.
1. AGKM
( Jenis Sekolah : SMA/MA Negeri Dalam Medan, Jalur Masuk : SNMPTN,
IPK : IPK = 3.00-3.49 Lama Studi : < 4 Tahun) Saran :
2. Fakultas lebih membuka lebar kesempatan bagi calon mahasiswa baru yang berasal dari jalur masuk SNMPTN untuk masuk fakultas tersebut.
3. Fakultas dapat memberikan arahan terhadap mahasiswa yang memiliki nilai IPK antara 3.00 s/d 3.49 untuk meningkatkan IPK, dan arahan untuk mulai memikirkan serta mendalami materi yang akan diambil pada tugas akhir.
2. BGKM
( Jenis Sekolah : SMA/MA Negeri Luar Medan, Jalur Masuk : SNMPTN,
IPK : IPK = 3.00-3.49 Lama Studi : < 4 Tahun)
Saran :
1. Fakultas dapat memberikan informasi atau menawarkan kepada calon mahasiswa yang berasal dari SMA/MA Negeri Luar Medan untuk memilih fakultas tersebut.
2. Fakultas lebih membuka lebar kesempatan bagi calon mahasiswa baru yang berasal dari jalur masuk SNMPTN untuk masuk fakultas tersebut.
3. Fakultas dapat memberikan arahan terhadap mahasiswa yang memiliki nilai IPK antara 3.00 s/d 3.49 untuk meningkatkan IPK, dan arahan untuk mulai memikirkan serta mendalami materi yang akan diambil pada tugas akhir.
3.4. Analisis Komponen Sistem 3.4.1 Data flow diagram (DFD)
Diagram Alir Data (DAD) atau Data Flow Diagram adalah representasi grafik yang menggambarkan informasi dan transformasi informasi yang diaplikasikan sebagai data yang mengalir dari masukan (input) dan keluaran (output).
yang lebih detail untuk mrepresentasikan aliran informasi atau fungsi yang lebih detail. DFD menyediakan mekanisme untuk pemodelan fungsional ataupun pemodelan aliran informasi. Oleh karena itu, DFD lebih sesuai digunakan untuk memodelkan fungsi perangkat lunak yang akan diimplementasikan menggunakan pemrograman terstruktur karena pemrograman terstruktur membagi-bagi bagiannya dengan fungsi fungsi dan prosedur-prosedur.
3.4.1.1. DFD level-0
DFD Level 0 biasanya disebut dengan diagram sistem inti (fundamental system model) atau biasa disebut juga diagram konteks (contex diagram), berikut adalah dfd level 0 dari sistem pencarian association rules pada Gambar 3.9.
3.4.1.2. DFD Level-1
3.4.1.3. DFD level-2
Berikut adalah gambar DFD Level 2 dari proses management data mahasiswa, management parameter, management pengguna, dan pencarian association rules yang dapat dilihat pada Gambar 3.11, Gambar 3.12, Gambar 3.13, dan Gambar 3.14.
2.1
Gambar 3.11. DFD level 2 : proses management data mahasiswa
3.1
4.1
Gambar 3.13. DFD level 2 : proses management pengguna
5.2
3.4.2. Flowchart
Perancangan sistem dibangun menggunakan bahasa pemrograman PHP dengan database menggunakan mysql dan akan dianalisis dengan algoritma FP-Growth. Flowchart algoritma FP-Growth dapat dilihat pada Gambar 3.15.
Mulai
Frequent itemset
Pembangunan FP-tree
Pengecekan nilai support
pada setiap item
Pembentukan
association rules
Pencarian frequent itemset
Selesai Pembangkitan
conditional FP-tree
Minimum support & minimum confidence
Association rules
3.4.3. Sitemap aplikasi
Sitemap aplikasi merupakan gambaran nyata bagaimana user dapat menjalankan aplikasi, menu-menu apa saja yang dapat diakses dan bagaimana caranya. Sitemap dari sistem pencarian association rules dapat dilihat pada Gambar 3.16.
Jumlah Mahasiswa
Hasil Rule Pencarian
Association Rules
Parameter Data
Daftar Lulusan Mahasiswa Edit Lulusan Mahasiswa Input Lulusan Mahasiswa
Detail
Edit Jenis Sekolah
Jumlah per Fakultas
Login Home
admin
Edit Lama Studi Edit IPK Edit Jalur Masuk
Hasil Rule Pencarian
Association Rules
Info Association Rules
Detail Home user
3.5. Database Relationship
Database atau basis data adalah kumpulan data yang disimpan secara sistematis didalam komputer dan dapat diolah atau dimanipulasi menggunakan perangkat lunak untuk menghasilkan informasi. Tabel-tabel yang ada pada database dapat dihubungkan satu dengan lainnya (database relationship). Database relationship dari sistem pencarian association rules yang dapat dilihat pada Gambar 3.17.
3.6. Perancangan Sistem
Pada tampilan awal pengguna sebagai user, terdapat dua menu yaitu menu home dan menu info. Rancangan tampilan awal sebagai user dapat dilihat pada Gambar 3.18.
HEADER
FOOTER PROSES
Fakultas
Minimum support
v
Minimum confidence Logout
Pencarian Association Rules
Menu 1 Menu 2
B A
Gambar 3.18. Racangan tampilan home pengguna sebagai user Keterangan :
A. Menu home dan menu info. Menu home untuk balik kehalaman utama, dan menu info sebagi informasi untuk pengguna tentang pencarian associationrules.
B. Form pencarian association rules, dimana pengguna dapat memilih fakultas yang akan diproses, serta memasukkan nilai minimum support dan minimum confidence sebagai patokan nilai untuk rules yang nantinya dihasilkan.
Rancangan tampilan dari hasil proses pencarian dapat dilihat pada Gambar 3.19.
HEADER
FOOTER
Pencarian Association Rules
Menu 1
B A
Keterangan :
A. Menu home dan menu info. Menu home untuk balik kehalaman utama, dan menu info sebagai informasi untuk pengguna tentang pencarian association rules.
B. Berupa hasil pencarian association rules, yaitu tabel rules dengan nilai support dan confidence. Serta saran yang diberikan oleh sistem untuk perguruan tinggi maupun fakultas, dan informasi lainnya.
Rancangan tampilan menu info dapat dilihat pada Gambar 3.20.
HEADER
FOOTER
Association Rules
Menu 2
B A
Gambar 3.20. Rancangan tampilan halaman info Keterangan :
A. Menu info
B. Berupa text dan tabel sebagi informasi untuk pengguna tentang sistem pencarian association rules, parameter yang digunakan dan lainnya yang menyangkut pencarian association rules pada data lulusan mahasiswa
HEADER
Gambar 3.21. Rancangan tampilan home pengguna sebagai admin Keterangan :
A. Menu home, menu file dengan sub-menu input lulusan mahasiswa, daftar lulusan mahasiswa, dan parameter data, menu jumlah mahasiswa, dan menu kelola dengan sub-menu kelola pengguna.
B. Form pencarian association rules, dimana pengguna dapat memilih fakultas yang akan diproses, serta memasukkan nilai minimum support dan minimum confidence sebagai patokan nilai untuk rules yang nantinya dihasilkan.
Rancangan tampilan halaman input lulusan mahasiswa dari sub-menu file dapat dilihat pada Gambar 3.22.
Keterangan :
A. Menu file dengan sub-menu input lulusan mahasiswa, daftar lulusan mahasiswa, dan parameter data.
B. Form input data lulusan mahasiswa, dimana pengguna harus menginput data seperti NIM, No.Alumni, Nama dan lainnya.
Rancangan tampilan halaman daftar lulusan mahasiswa dari sub-menu file dapat dilihat pada Gambar 3.23.
HEADER
FOOTER Menu 2
Lulusan Mahasiswa
B A
Gambar 3.23. Rancangan tampilan daftar lulusan mahasiswa Keterangan :
A. Menu file dengan sub-menu input lulusan mahasiswa, daftar lulusan mahasiswa, dan parameter data.
B. Tabel yang berisikan seluruh data lulusan mahasiswa
HEADER
FOOTER
Jenis Sekolah
Menu 2
Jalur Masuk
C B A
Gambar 3.24. Rancangan tampilan parameter data Keterangan :
A. Menu file dengan sub-menu input lulusan mahasiswa, daftar lulusan mahasiswa, dan parameter data.
B. Tabel yang berisikan parameter yang digunakan pada sistem pencarian association rules.
Rancangan tampilan halaman jumlah mahasiswa dapat dilihat pada Gambar 3.25.
HEADER
FOOTER
Jumlah Mahasiswa
Menu 3
B A
Keterangan :
A. Menu jumlah mahasiswa
B. Tabel yang berisikan jumlah mahasiswa per fakultasnya, dan juga per parameter yang digunakan.
Rancangan tampilan halaman kelola pengguna dari sub-menu kelola dapat dilihat pada Gambar 3.26.
HEADER
FOOTER Simpan
Status Username Password Input Pengguna Menu 4
Admin User B
A
Gambar 3.26. Rancangan tampilan kelola pengguna Keterangan :
A. Menu kelola dengan sub-menu kelola pengguna
IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab ini akan dijelaskan tentang proses pengimplementasian association rules mining dengan algoritma FP-Growth pada sistem, sesuai dengan perancangan sistem yang telah dilakukan di Bab 3 serta melakukan pengujian sistem yang telah dibangun. 4.1. Implementasi Sistem
Tahap implementasi sistem merupakan proses pengubahan spesifikasi sistem menjadi sistem yang dapat dijalankan. Implementasi dan analisis dan perancangan sistem ini berbasis web dengan menggunakan bahasa pemrograman PHP.
4.1.1. Spesifikasi hardware dan software yang digunakan
Spesifikasi perangkat keras (hardware) dan perangkat lunak (software) yang digunakan dalam membangun sistem pencaian association rules ini adalah sebagai berikut.
1. Sistem operasi Windows 7 Home Premium 64-bit (6. 1, Build 7601).
2. Processor Intel(R) Core(TM) i7-3612QM CPU @ 2.10GHz (8 CPUs), ~2.1GHz. 3. Memory 4096MB RAM
4. Kapasitas hardisk 120 GB. 5. XAMPP versi 1.8.3-1 6. MySQL versi 5.6.16 7. Notepad ++
4.1.2. Implementasi Perancangan Antarmuka
kemudian copy folder program kedalam folder htdocs serta import database-nya (.sql), kemudian buka aplikasi pada browser.
4.1.2.1. Halaman home pengguna sebagai user
Halaman ini merupakan halaman home apabila pengguna telah masuk sebagai user. Halaman home ini juga merupakan halaman untuk memulai pencarian association rules. Halaman home pengguna sebagai user dapat dilihat pada Gambar 4.1.
Gambar 4.1. Halaman home pengguna sebagai user
Untuk memulai pencarian association rules, user dapat memilih data dari fakultas mana yang akan diproses, lalu menginput nilai minimum support dan minimum confidence sebagai nilai patokan dari rules yang dihasilkan nantinya kemudian klik button PROSES.
4.1.2.2. Halaman home pengguna sebagai admin
Gambar 4.2. Halaman home pengguna sebagai admin
Gambar 4.2 dan Gambar 4.1 merupakan halaman yang sama yaitu untuk melakukan pencarian association rules.
4.1.2.3. Halaman input lulusan mahasiswa
Halaman input lulusan mahasiswa digunakan admin untuk menginput data lulusan yang baru atau mahasiswa yang baru lulus melalui form yang telah disediakan. Halaman ini merupakan sub-menu dari menu file. Halaman input lulusan mahasiswa dapat dilihat pada Gambar 4.3.
Data yang akan diinput untuk melengkapi data lulusan mahasiswa adalah nim, no.alumni, nama, jenis kelamin, tempat-tanggal lahir, agama, kota, kode pos, asal sekolah, jenis sekolah, fakultas, program studi, jalur masuk, ipk, lama studi, dan wisuda periode.
4.1.2.4. Halaman daftar lulusan mahasiswa
Halaman daftar lulusan mahasiswa berguna untuk melihat data mahasiswa yang telah lulus secara lengkap. Halaman daftar lulusan mahasiswa dapat dilihat pada Gambar 4.4.
Gambar 4.4. Halaman daftar lulusan mahasiswa 4.1.2.5. Halaman parameter
Gambar 4.5. Halaman parameter
Dari Gambar 4.5, parameter yang digunakan adalah jenis sekolah, jalur masuk, IPK, dan lama studi dengan kelompok yang berbeda-beda.
4.1.2.6. Halaman jumlah mahasiswa
Halaman jumlah mahasiswa menginformasikan jumlah seluruh mahasiswa yang ada pada database perfakultas. Halaman jumlah mahasiswa dapat dilihat pada Gambar 4.6.
4.2. Pengujian Sistem
Tahap pengujian sistem ini dilakukan untuk memeriksa kinerja antar komponen pada sistem pencarian association rules. Pengujian sistem bertujuan untuk memastikan bahwa komponen-komponen pada sistem telah berfungsi sesuai dengan yang diharapkan. Metode pengujian yang digunakan adalah metode pengujian black box. Pengujian black box merupakan pengujian yang dilakukan pada interface sistem yang digunakan untuk mendemonstrasikan fungsi sistem yang dioperasikan (Gea, 2011). 4.2.1. Rencana pengujian sistem
Adapun rancangan pengujian sistem yang akan diuji dapat dilihat pada Tabel 4.1. Tabel 4.1. Rencana pengujian
No Komponen sistem yang diuji Butir Uji
1 Login Tombol Login
Informasi kegagalan login
2 Halaman awal mencoba semua menu halaman pada menu
3 Halaman input lulusan
mahasiswa Form input data lulusan mahasiswa Tombol Simpan
4 Halaman daftar lulusan
mahasiswa Link 'Edit'
link 'Hapus' 5 Halaman parameter Link 'Edit'
link 'Hapus'
6 Halaman kelola pengguna Form input pengguna Tombol Simpan Link 'Edit' link 'Hapus'
7 Logout link 'logout'
4.2.2. Kasus dan hasil pengujian sistem
Tabel 4.2. Hasil pengujian
No
Komponen sistem yang diuji
Skenario Uji Hasil yang diharapkan Hasil Pengujian tombol Login diklik, maka akan dilakukan proses pengecekan
Ketika menu ditekan, maka akan berpindah ke halaman yang
Pada saat merubah data lulusan mahasiswa dan tombol Simpan diklik, maka sistem akan memberi pemberitahuan data berhasil tersimpan atau data belum lengkap, dan pada saat link 'Hapus' di klik, maka data berhasil dihapus berhasil dirubah, dan pada saat link 'Hapus' di klik, maka parameter berhasil dihapus
Tabel 4.2. Hasil pengujian (lanjutan)
No
Komponen sistem yang diuji
Skenario Uji Hasil yang diharapkan Hasil Pengujian
Ketika link 'Logout' diklik, maka pengguna sebagai admin maupun user keluar dari halaman
pengguna dan kembali masuk ke halaman login
Berhasil
4.2.3. Pengujian kinerja sistem
Gambar 4.7. Proses pencarian association rules
Pada Gambar 4.7, pengguna memilih data fakultas ekonomi untuk dilakukan proses mining dengan minimum support 70% dan minimum confidence 70%. Hasil proses pencarian dapat dilihat pada Gambar 4.8.
Gambar 4.8. Hasil uji coba pencarian
Gambar 4.9. Hasil proses pencarian
Dari hasil proses pencarian data fakultas ekonomi pada Gambar 4.9, dengan nilai minimum support = 6 dan minimum confidence = 50, maka didapat dua rules yaitu kombinasi atribut dari jenis sekolah SMA/MA Negeri Dalam Medan, jalur masuk SNMPTN, nilai IPK antara 3.00 s/d 3.49, Lama Studi < 4 Tahun, dan kombinasi atribut dari jenis sekolah SMA/MA Negeri Luar Medan, jalur masuk SNMPTN, nilai IPK antara 3.00 s/d 3.49, Lama Studi < 4 Tahun.
Kedua rules yang didapat merupakan rules yang nilai support (nilai penunjang/pendukung) dan nilai confidence-nya (nilai kepastian/keyakinan) memenuhi nilai minimum support dan minimum confidence yang telah diinput sebelumnya pada saat memulai melakukan proses pencarian.
1. Rules 1 (SMA/MA Negeri Dalam Medan, SNMPTN, IPK = 3.00-3.49, Lama Studi < 4 Tahun) :
a. Fakultas dapat memberikan informasi atau melakukan promosi kepada calon mahasiswa yang berasal dari SMA/MA Negeri Dalam Medan untuk memilih fakultas Ekonomi.
b. Perguruan tinggi lebih membuka lebar kesempatan bagai mahasiswa yang berasal dari jalur masuk SNMPTN untuk masuk kedalam fakultas Ekonomi. c. Fakultas Ekonomi dapat memberikan arahan kepada mahasiswa yang memiliki
nilai IPK antara 3.00 s/d 3.49 untuk meningkatkan IPK dan arahan untuk mulai memikirkan serta mendalami materi yang akan di ambil pada tugas akhir. 2. Rules 2 (SMA/MA Negeri Luar Medan, SNMPTN, IPK = 3.00-3.49, Lama Studi
< 4 Tahun) :
a. Fakultas dapat memberikan informasi atau melakukan promosi kepada calon mahasiswa yang berasal dari SMA/MA Negeri Dalam Medan untuk masuk fakultas Ekonomi.
b. Perguruan tinggi lebih membuka lebar kesempatan bagai mahasiswa yang berasal dari jalur masuk SNMPTN untuk masuk kedalam fakultas Ekonomi. c. Fakultas Ekonomi dapat memberikan arahan kepada mahasiswa yang memiliki