SKRIPSI
NADIA WIDARI NASUTION
110803016
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PENERAPAN HIDDEN MARKOV MODEL
UNTUK PENGENALAN UCAPAN
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
NADIA WIDARI NASUTION 110803016
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : PENERAPAN HIDDEN MARKOV MODEL
UNTUK PENGENALAN UCAPAN
Kategori : Skripsi
Nama : NADIA WIDARI NASUTION
Nomor Induk Mahasiswa : 110803016
Program Studi : SARJANA (S1) MATEMATIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di Medan, April 2015
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dr. Sawaluddin, M.IT Dra. Normalina Napitupulu, M.Sc NIP.19591231 199802 1 001 NIP.19631106 198902 2 001
Diketahui/Disetujui oleh
Departemen Matematika FMIPA USU Ketua
Prof. Dr. Tulus, M.Si
PERNYATAAN
PENERAPAN HIDDEN MARKOV MODEL UNTUK PENGENALAN UCAPAN
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, April 2015
PENGHARGAAN
Puji syukur kehadirat Allah SWT Yang Maha Pemurah dan Maha Penyayang, dengan limpahan karunia-Nya, skripsi ini berhasil diselesaikan dalam waktu yang telah ditetapkan. Shalawat beriring salam kepada Rasulullah SAW, sebagai rahmatan lil’alamin.
Ucapan terima kasih penulis sampaikan kepada Ibu Dra. Normalina Napitupulu, M.Sc dan Bapak Dr. Sawaluddin, M.IT selaku pembimbing yang telah memberikan panduan dan penuh kepercayaan kepada penulis untuk menyempurnakan skripsi ini. Bapak Drs. Marihat Situmorang, M.Kom dan Bapak Dr. Suyanto, M.Kom selaku penguji yang telah memberikan kritikan dan saran yang membangun dalam penyempurnaan skripsi ini. Dekan dan Pembantu Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara. Ketua dan Sekretaris Departemen Matematika Bapak Prof. Dr. Tulus, M.Si dan Ibu Dr. Mardiningsih, M.Si. Seluruh staf pengajar dan staf administrasi di lingkungan Departemen Matematika, serta seluruh civitas akademika di lingkungan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara.
Ucapan terima kasih juga ditujukan kepada kedua orang tua penulis tercinta, Ayahanda Muhammad Daud Nasution, S.H dan Ibunda Winarti yang telah memberikan banyak bantuan baik materi, moral maupun spiritual. Kepada adik-adik penulis, Iqbal Naufal Khalis Nasution dan Rohid Zaidan Nasution. Penulis juga mengucapkan banyak terima kasih kepada teman-teman yang banyak memberikan masukan kepada penulis dalam menyelesaikan skripsi ini dan menyelesaikan studi di Departemen Matematika Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara.
Tidak terlupakan, ucapan terima kasih kepada teman-teman stambuk 2011, teman-teman di Himpunan Mahasiswa Matematika, teman-teman di Ikatan Mahasiswa Matematika Muslim diFakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara, dan kepada semua pihak yang telah memberikan bantuan dan dorongan yang tidak dapat disebutkan satu per satu.
PENERAPAN HIDDEN MARKOV MODEL
UNTUK PENGENALAN UCAPAN
ABSTRAK
Pengenalan ucapan adalah suatu proses yang dilakukan komputer untuk mengenali kata-kata yang diucapkan oleh seseorang tanpa memperdulikan identitas orang terkait. Kata-kata tersebut akan diubah bentuknya menjadi sinyal digital dengan cara mengubah gelombang suara menjadi sekumpulan angka lalu disesuaikan dengan kode-kode tertentu dan dicocokkan dengan suatu pola yang tersimpan dalam suatu perangkat. Pada tulisan ini dibahas tentang bagaimana pengenalan ucapan menggunakan metode Hidden Markov Model(HMM). HMM adalah suatu model statistik dari sebuah sistem yang diasumsikan sebuah proses Markov dengan parameter-parameter yang tidak diketahui dan memiliki ketepatan dalam identifikasi suara. Hasil dari identifikasi kata yang diucapkan dapat ditampilkan dalam bentuk tulisan atau dapat dibaca oleh perangkat teknologi, yaitu menggunakan software Microsoft Speech Application Programming Interface.
THE APPLICATION OF HIDDEN MARKOV MODEL FOR SPEECH RECOGNITION
ABSTRACT
Speech recognition is a process that is done the computer to recognize words spoken by a person without regard to the identity of persons.The words will be transformed into digital signals by converting sound waves into a set of numbers and then adjusted with certain codes and matched with a pattern stored in a device. In this paper discussed about how speech recognition using hidden Markov Model (HMM). HMM is a statistical model of a system that is assumed to be a Markov process with parameters that are unknown and has accuracy in voice identification. The result of the identification of the spoken word can be displayed in written form or can be read by the device technology, which uses software Microsoft Speech Application Programming Interface.
DAFTAR ISI
Halaman
PERSETUJUAN iii
PERNYATAAN iv
PENGHARGAAN v
ABSTRAK vi
ABSTRACT vii
DAFTAR ISI viii
DAFTAR GAMBAR x
DAFTAR TABEL xi
DAFTAR SINGKATAN xii
BAB 1 PENDAHULUAN
1.1.Latar Belakang 1
1.2.Rumusan Masalah 2
1.3.Batasan Masalah 2
1.4.Tinjauan Pustaka 3
1.5.Tujuan Penelitian 6
1.6.Manfaat Penelitian 6
1.7.Metodologi Penelitian 7
BAB 2 LANDASAN TEORI
2.1.Suara 8
2.2.Proses Sinyal Suara 10
2.2.1. Pulse Code Modulation 10
2.2.2. Delta Modulation 18
2.3.Pengenalan Ucapan 19
2.4.Tahapan-Tahapan dalam Pengenalan Ucapan 21
2.3.1. Ekstraksi Fitur 22
2.3.2. Pemodelan Akustik 26
2.3.3. Pemodelan Ucapan 27
2.3.4. Model Bahasa 29
2.3.5. Decoder 31
2.5.Hidden Markov Model (HMM) 31
2.4.1. Tipe HMM 32
2.4.2. Elemen HMM 33
2.4.3. Fungsi Rekursif HMM 35
2.6.Contoh Penyelesaian Rantai Markov pada Kasus Cuaca 38 2.7.Contoh Penyelesaian Hidden Markov Model pada Kasus Cuaca 40
2.8.Microsoft Speech API 42
BAB 3 PEMBAHASAN
3.1.1 Flowchart Proses Suara 45
3.1.2 Flowchart Pemodelan HMM 46
3.2.Perancangan Perangkat Lunak 47
3.3.SoftwareMicrosoft Speech API 47
3.4.Halaman Perekaman 51
3.5.Halaman Hasil 52
BAB 4 KESIMPULAN DAN SARAN
4.1.Kesimpulan 53
4.2.Saran 53
DAFTAR GAMBAR
Nomor Judul Halaman
Gambar
1.1. Rantai Markov 3
1.2. Blok diagram untuk sistem pengenalan ucapan 5
2.1. Organ Pernapasan Manusia 9
2.2 Pengkodean PCM 11
2.3 Pencacahan dengan berbagai frekuensi pencacah 12
2.4 Pencacahan natural dan sample and hold 14
2.5 Proses kuantisasi 15
2.6 Ilustrasi Delta Modulation (DM) 18
2.7. Blok diagram untuk sistem pengenalan ucapan 22
2.8. Blok diagram LPC 23
2.9. Rantai Markov 27
2.10. HMM model basis phone 28
2.11. HMM model ergodic 32
2.12. HMM model kiri-kanan 33
2.13. Contoh Hidden Markov Model (HMM) 34
2.14. Ilustrasi Alur Algoritma Forward 35
2.15. Ilustrasi Alur Algoritma Backward 36
2.16. Ilustrasi Perhitungan pada Algoritma Baum-Welch 38
2.17. Rantai Markov pada kasus cuaca 39
2.18. Arsitektur Microsoft Speech Application Programming Interface 43
3.1. Flowchart Proses Suara 45
3.2. Flowchart Pemodelan HMM 46
3.3. Tampilan Utama Windows Speech Recognition 48
3.4. Jenis microphone 48
3.5. Set up microphone 49
3.6. Read the following the sentence 49
3.7. Microphone is now set up 50
3.8. Run Speech Recognition 50
3.9. Tampilan Speech Dictionary 51
3.10. Tampilan menambahkan kata yang akan diucapkan 51
DAFTAR TABEL
Nomor Judul Halaman
Tabel
2.1. Pengkodean digital 16
DAFTAR SINGKATAN
HMM = Hidden Markov Model
ASR = Automatic Speech Recognition LPC = Linear Prediction Coding ANN = Artificial Neural Network DBN = Dinamic Bayesian Network SVM = Supported Vectoc Machine
API = Application Programming Interface SDK = System Development Kit
PAM = Pulse Amplitudo Modulation PCM = Pulse Code Modulation DM = Delta Modulation SNR = Signal to Noise Ratio
PENERAPAN HIDDEN MARKOV MODEL
UNTUK PENGENALAN UCAPAN
ABSTRAK
Pengenalan ucapan adalah suatu proses yang dilakukan komputer untuk mengenali kata-kata yang diucapkan oleh seseorang tanpa memperdulikan identitas orang terkait. Kata-kata tersebut akan diubah bentuknya menjadi sinyal digital dengan cara mengubah gelombang suara menjadi sekumpulan angka lalu disesuaikan dengan kode-kode tertentu dan dicocokkan dengan suatu pola yang tersimpan dalam suatu perangkat. Pada tulisan ini dibahas tentang bagaimana pengenalan ucapan menggunakan metode Hidden Markov Model(HMM). HMM adalah suatu model statistik dari sebuah sistem yang diasumsikan sebuah proses Markov dengan parameter-parameter yang tidak diketahui dan memiliki ketepatan dalam identifikasi suara. Hasil dari identifikasi kata yang diucapkan dapat ditampilkan dalam bentuk tulisan atau dapat dibaca oleh perangkat teknologi, yaitu menggunakan software Microsoft Speech Application Programming Interface.
THE APPLICATION OF HIDDEN MARKOV MODEL FOR SPEECH RECOGNITION
ABSTRACT
Speech recognition is a process that is done the computer to recognize words spoken by a person without regard to the identity of persons.The words will be transformed into digital signals by converting sound waves into a set of numbers and then adjusted with certain codes and matched with a pattern stored in a device. In this paper discussed about how speech recognition using hidden Markov Model (HMM). HMM is a statistical model of a system that is assumed to be a Markov process with parameters that are unknown and has accuracy in voice identification. The result of the identification of the spoken word can be displayed in written form or can be read by the device technology, which uses software Microsoft Speech Application Programming Interface.
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Seiring dengan berkembangnya teknologi informasi, aplikasi pengolah kata merupakan sarana kebutuhan sehari-hari bagi kalangan pengguna komputer. Teknologi ini yang memungkinkan suatu perangkat untuk mengenali dan memahami kata-kata yang diucapkan.
Untuk dapat mengenali ucapan dari pembicara, komputer perlu diberi kecerdasan sehingga dari ucapan yang diterima oleh komputer akan direspons atau mendapatkan tanggapan yang sesuai.
Pengenalan ucapan adalah proses yang dilakukan komputer untuk mengenali kata yang diucapkan oleh seseorang tanpa memperdulikan identitas orang terkait. Pengenalan ucapan juga dikenal sebagai Automatic Speech Recognition (ASR). ASR merupakan pengenalan ucapan komputer yang berarti suara pemahaman komputer dan melakukan setiap tugas yang diperlukan atau kemampuan untuk mencocokkan suara terhadap kosakata yang tersedia atau diperoleh (Saini dan Kaur, 2013).
Penelitian pengenalan ucapan ini menggunakan Model Markov Tersembunyi atau biasa disebut Hidden Markov Model (HMM)karena memiliki ketepatan yang tinggi untuk identifikasi suara.
Parameter-parameter yang ditentukan kemudian dapat digunakan untuk analisis yang lebih jauh, misalnya untuk aplikasi pattern recognition(Monika, 2012).
Berdasarkan uraian tersebut, penulis memilih judul “Penerapan
Hidden Markov Model untuk Pengenalan Ucapan.“
1.2. Rumusan Masalah
Masalah dalam penelitian ini adalah sebagai berikut:
1. Bagaimana tahapan-tahapan dalam merancang sistem pengenalan ucapan (speech recognition).
2. Bagaimana mencocokan perintah suara yang dibuat agar komputer dapat mengenali dan memahami kata-kata yang diucapkan.
3. Bagaimana melakukan uji coba dan analisis terhadap parameter-parameter yang berpengaruh terhadap pengenalan ucapan (speech recognition).
1.3. Batasan Masalah
Batasan-batasan masalah dalam penelitian ini adalah sebagai berikut:
1. Perintah suara yang dibuat dalam penelitian ini hanya mampu mengenali kata yang diucapkan melalui hardware yaitu mikrophone dengan bantuan soundcard yang terdapat pada komputer.
2. Pengucapan bunyi (lafal) dilakukan oleh orang yang tidak mengalami cacat artikulasi (orang normal).
3. Kata yang diucapkan dalam penelitian ini adalah “open notepad” untuk
membuka aplikasi komputer
1.4. Tinjauan Pustaka
Hidden Markov Model (HMM) adalah suatu model statistik dari sebuah sistem yang diasumsikan sebuah proses Markov dengan parameter yang tidak diketahui. Kita harus menentukan parameter-parameter tersembunyi
(state) dari parameter-parameter yang dapat diamati. Parameter-parameter yang ditentukan kemudian dapat digunakan untuk analisis yang lebih jauh,
misalnya untuk aplikasi pattern recognition (Monika, 2012).
HMM pada dasarnya perluasan dari rantai Markov yang merupakan model stokastik. Biasanya dalam model Markov setiap keadaan (state) dapat terlihat langsung oleh pengamatan, sehingga kemungkinan transisi antara keadaan menjadi satu-satunya parameter yang teramati.
Rabiner (1989) mengemukakan bahwa transisi pada Rantai Markov yaitu:
a. Transisi dari suatu keadaan tergantung pada keadaan sebelumnya. (1.1) b. Transisi keadaan bebas terhadap waktu.
(1.2)
Berikut ini adalah contoh gambar dari rantai Markov.
Gambar 1.1. Rantai Markov Sumber: (Monika, 2012) 13
a
31 a
12 a
21 a
32 a
23 a
33
a a22
11 a
1
2 3
] |
[ ...] |
|
[qt Sj qt 1 Si qt 2 Sk P qt Sj qt 1 Si
P = − = − = = = − =
] |
[q S q 1 i P
Hidden Markov Model(HMM) terdiri dari keadaan (state), peluang transisi (state probabilities), peluang emisi (emission probabilities), dan peluang awal(initial probabilities).
HMM didefinisikan sebagai berikut:
1. N, jumlah state dalam model yang didefinisikan oleh
{
S SN}
S = 1,...,
2. M, jumlah simbol pengamatan yang berbeda tiap state, misalnya ukuran alfabet diskrit didefinisikan oleh V =
{
v1,...,vM}
. Jika pengamatankontinumaka M adalah tak terbatas.
3. Distribusi peluang keadaan transisi A=
{ }
aij , dimana aij adalahdistribusi yang state pada waktu t+1adalahSj, diberikan ketika keadaan
pada waktut adalah
i
S . Struktur matriks stokastik ini mendefinisikan
hubungan struktur model.
[
t 1 j | t i]
,ij pq S q S
a = + = = 1≤i,
j
≤
N
(1.3)4. Distribusi peluang simbol pengamatan pada masing-masing state j,
{
b (k)}
B= j dimanabj(k)adalah peluang yang simbol Vkdiemisi dalam
keadaan j
S .
[
|]
,)
( t k t j
j k pO V q S
b = = = 1≤ j≤N,1≤k≤M (1.4)
jika pengamatankontinu, maka kita harus menggunakan fungsi kepadatan peluang kontinu.
5. Distribusi keadaan awal π =
{ }
πi dimana πiadalah peluang bahwa modeltersebut berada dalam keadaan Si pada waktu t=0 didefinisikan oleh
{
q1 i}
, pi = =
π 1≤i≤N (1.5)
Hidden Markov Model (HMM) dapat dituliskan sebagai
) , ,
( π
λ= A B . Dengan diketahuinya parameter-parameter N,M,A,B,
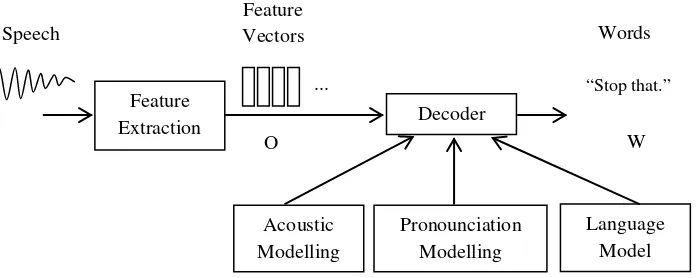
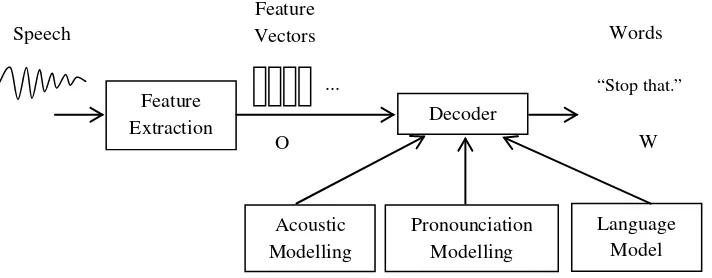
Sistem pengenalan ucapan (speech recognition) terdiri dari 5 blok, yaitu: ekstraksi fitur (feature extraction), pemodelan akustik (acoustic modelling), pemodelan pengucapan (pronounciation modelling), model bahasa (language model), dan decoder.
Blok diagram untuk sistem pengenalan ucapan adalah sebagai berikut:
Gambar 1.2. Blok diagram untuk sistem pengenalan ucapan Sumber : (Gales dan Young, 2007)
Pengenalan ucapan juga dikenal sebagai Automatic Speech Recognition (ASR). ASR merupakan pengenalan ucapan komputer yang berarti suara pemahaman komputer dan melakukan setiap tugas yang diperlukan atau kemampuan untuk mencocokkan suara terhadap kosakata
yang tersedia atau diperoleh.
Dalam sistem pengenalan ucapan automatis (automatic speech recognition)berbasis statistik, ucapan diwakili oleh beberapa urutan
pengamatan fitur akustik O, berasal dari urutan kata-kata W. Gelombang
input audio dari sebuah mikrophone dikonversikan menjadi sebuah urutan
vektor akustik O1:T =O1,...,OT dalam proses yang disebut ekstraksi fitur
(fitur extraction). Decoder kemudian berusaha untuk menemukan urutan
kata-kata W1:L =W1,...,WL.
Sinyal akustik dirumuskan oleh:
(1.6)
)} | ( { max
arg PW O
W
w
=
Language Model Feature
Extraction Decoder
Acoustic Modelling
Pronounciation Modelling Speech
Feature Vectors
...
O W
“Stop that.”
Akan tetapi, karena P(W|O) sulit untuk dimodelkan secara
langsung, maka dapat menggunakan aturan Baye (Baye’s Rule) dapat ditulis sebagai berikut:
(1.7)
Dalam persamaan (1.7), P(O|W)adalah probabilitas pengamatan
dan dievaluasi berdasarkan pemodelan akustik (acoustic
modelling)sedangkan P(W)ditentukan oleh model bahasa (languange
model) dan diperoleh dari Hidden Markov Model(HMM). Di antara berbagai model, HMM sejauh ini merupakan teknik yang paling banyak digunakan karena yang algoritma yang efisien untuk pengenalan ucapan (speech recognition)(Saini dan Kaur, 2013).
1.5. Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk mempermudah pengguna (user) dalam membuka aplikasi komputer secara cepat dengan tanpa mengklik icon.
1.6. Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut:
1. Dapat menambah pengetahuan dan wawasan bagi masyarakat terutama
mahasiswa tentang pengenalan ucapan (speech recognition).
2. Dapat berguna bagi orang-orang yang mengalami kesulitan menggunakan tangan dalam mengetik.
) ( . ) | ( max
arg P O W PW
W
1.7. Metodologi Penelitian
Metode penelitian yang digunakan antara lain: 1. Studi Literatur
Penulis menggunakan metode ini untuk memperoleh informasi yang berkaitan dengan penelitian yang penulis buat, mengacu pada buku-buku pegangan, informasi yang didapat dari internet, jurnal-jurnal dan makalah-makalah yang membahas tentang pengenalan ucapan (speech recognition).
2. Perancangan dan Pembuatan Sistem
Proses perancangan merupakan suatu proses perencanaan bagaimana
sistem akan bekerja. Sistem akan dibuat dengan menggunakan perangkat lunak/ softwareMicrosoft Speech Application Programming Interface.
3. Pengujian dan Analisis Kerja Sistem
Pengujian dan anilisis kerja sistem dilakukan berdasarkan parameter-parameter yang dapat yang berpengaruh terhadap pengenalan ucapan (speech recognition), yaitu parameter jumlah pelatihan, jumlah parameter yang diekstrak, dialek pembicara, model HMM, dan jumlah state yang digunakan dalam sistem tersebut.
4. Penulisan Hasil Penelitian
BAB 2
LANDASAN TEORI
2.1. Suara
Suara adalah fenomena fisik yang dihasilkan oleh getaran suatu benda yang berupa sinyal analog dengan amplitudo yang berubah secara kontinu terhadap waktu. Suara merupakan gelombang yang mengandung sejumlah parameter (amplitudo, simpangan, frekuensi, spectrum), yang dapat menyebabkan suara yang satu berbeda dari suara lain. Suara beramplitudo lebih besar akan terdengar lebih keras. Suara dengan frekuensi lebih besar akan terdengar lebih tinggi. Sementara itu bisa juga ditemukan dua suara
yang beramplitudo dan berfrekuensi sama, misalnya biola dan piano dibunyikan secara bersamaan dengan tingkat kekerasaan dan nada yang
sama, namun telinga masih dapat membedakan mana yang suara piano dan mana yang suara biola. Ini terjadi karena suara memiliki warna suara. Warna suatu suara ditentukan oleh pola dasar dari gelombang suara (Nurlaily, 2009).
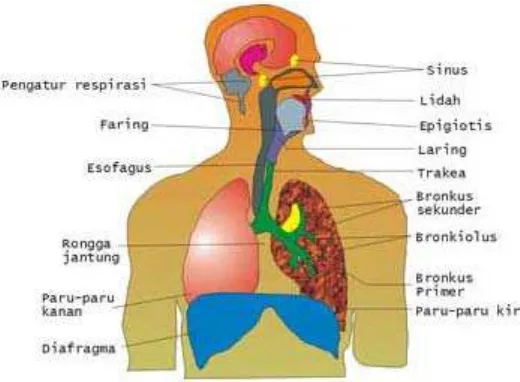
Perbedaan pola dasar gelombang bunyi biola dan piano antara lain disebabkan oleh perbedaan faktor resonansi yang timbul pada masing-masing instrumen. Demikian juga pada manusia, resonansi yang terjadi pada rongga mulut akan menimbulkan pola dasar gelombang bunyi yang berbeda-beda.
tertentu.Gerakan membuka dan menutup pita suara itu akan mengakibatkan arus udara dan udara yang berada di sekitar pita suara akan turun berubah tekanan dan ikut bergetar.
Adanya perubahan bentuk saluran suara yang terdiri dari rongga faring, rongga mulut dan rongga hidung akan menghasilkan bunyi bahasa yang berbeda-beda. Pada saat udara dari paru-paru dihembuskan, kedua pita suara dapat merapat atau merenggang. Jika kedua pita itu bergantian merapat atau merenggang dalam pembentukan suatu bunyi bahasa, maka bunyi bahasa yang dihasilkan terasa berat. Bunyi bahasa ini dinamakan bunyi bersuara (voiced). Jika kedua pita merenggang sehingga arus udara dapat lewat dengan mudah (ringan), maka bunyi bahasa ini umumnya dinamakan bunyi tak bersuara (unvoiced).
Gambar 2.1. Organ Pernapasan Manusia
2.2. Proses Sinyal Suara
Di sekitar kita, dalam kehidupan sehari-hari, sebenarnya lebih banyak sinyal yang direpresentasikan dalam bentuk analog daripada sinyal dalam bentuk digital. Misalnya, suara, cahaya, suhu, bau dan sebagainya. Namun sinyal-sinyal analog semacam itu akan lebih mudah disimpan, diolah, direproduksi kembali apabila disimpan dalam bentuk data digital. Sebagai contoh, Compact Disc yang dijual di pasaran dapat menampung sejumlah besar lagu adalah hasil konversi sinyal suara analog ke dalam bentuk digital. Film-film yang dapat dinikmati melalui DVD juga merupakan hasil dari rekayasa digital. Dan masih banyak lagi manfaat yang dapat kita rasakan saat ini dengan adanya teknologi digital (Mafisamin, 2014).
Untuk memperoleh data digital dibutuhkan suatu proses untuk mengubah sinyal analog menjadi data digital. Ada beberapa metode yang dapat digunakan, yaitu Pulse Code Modulation (PCM) dan Delta Modulation (DM).
2.2.1. Pulse Code Modulation (PCM)
Gambar 2.2. memberikan ilustrasi seluruh proses mengubah sinyal analog menjadi data digital dengan menggunakan PCM.
Gambar 2.2. Pengkodean PCM Sumber: (Mafisamin, 2014)
1. Proses pencacahan (sampling)
Proses pencacahan dilakukan dengan mencacah sinyal analog dalam periode waktu tertentu dirumuskan sebagai berikut:
(2.1) Keterangan :
= s
f frekuensi pencacahan
= s
T periode pencacahan
Semakin tinggi frekuensi pencacahan, atau semakin kecil periode pencacahan maka sinyal hasil cacahan akan semakin menyerupai sinyal analog asli. Sinyal hasil cacahan seringkali disebut juga istilah sinyal Pulse Amplitudo Modulation (PAM). Namun semakin tinggi frekuensi pencacahan membawa konsekuensi pada harga keseluruhan dalam proses pencacahan semakin mahal.
Sebaliknya menggunakan frekuensi pencacahan rendah akan menurunkan harga proses pencacahan tetapi mengandung konsekuensi pada represensitasi sinyal PAM yang kurang dapat mewakili sinyal analog asli.
Sinyal
Analog Pengkodean PCM
Data Digital
Pencacahan Kuantisasi Pengkodean 1101...001
s
s T
Proses pencacah dilakukan dengan didasarkan asumsi bahwa sinyal percakapan berada pada daerah frekuensi 300-3400 Hz.
Teori Nyquist menyebutkan bahwa frekuensi pencacah harus minimal dua kali frekuensi tertinggi (bukan bandwidth) yang dikandung oleh sinyal asli.
Dengan menggunakan representasi domain frekuensi tersebut kita dapat melihat frekuensi tertinggi yang dikandung oleh suatu sinyal. Karena itu dapat menarik acuan umum bahwa proses pencacahan hanya dapat dilakukan apabila sinyal memiliki bandwidth terbatas (band-limited). Apabila bandwidth dari suatu sinyal tak terbatas, maka pencacahan tidak dapat dilakukan. Dengan kata lain, akan dibutuhkan frekuensi tak terhingga untuk mencacah sinyal dengan bandwidth tak terbatas.
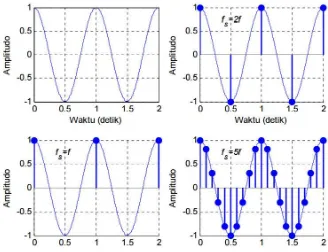
Efek dari variasi frekuensi pencacah ditunjukkan dalam Gambar 2.3. Gambar sebelah kanan atas adalah contoh pencacahan sinyal dengan menggunakan frekuensi pencacah sama dengan
frekuensi yang diisyaratkan oleh Nyquist, yaitu fs =2fmax.
Gambar bawah sebelah kiri adalah pencacahan dengan frekuensi pencacah kurang dari syarat Nyquist. Karena jumlah sinyal pencacah kurang dari syarat minimal, maka sinyal pencacah tidak akan dapat merepresentasikan sinyal analog asli. Sedangkan pada gambar terakhir terlihat bahwa frekuensi pencacah jauh di atas syarat Nyquist, karena itu sinyal pencacah dapat merepresentasikan sinyal analog asli dengan sangat baik.
Contoh 1:
Dalam Gambar 2.3., sinyal memiliki frekuensi 1 Hz. Tentukan frekuensi pencacah yang dibutuhkan untuk mencacah sinyal tersebut.
Sesuai dengan kriteria Nyquist, maka frekuensi pencacah minimal
adalah fs =2fmax, maka nilai fs =2Hz. Frekuensi pencacah
tersebut adalah pencacah minimal. Apabila frekuensi pencacah
ditingkatkan menjadi 5 kali frekuensi maksimal, maka fs =5Hz.
Seperti terlihat dalam Gambar 2.3, dengan menggunakan frekuensi pencacah 5 Hz, sinyal hasil sampling lebih menyerupai sinyal asli.
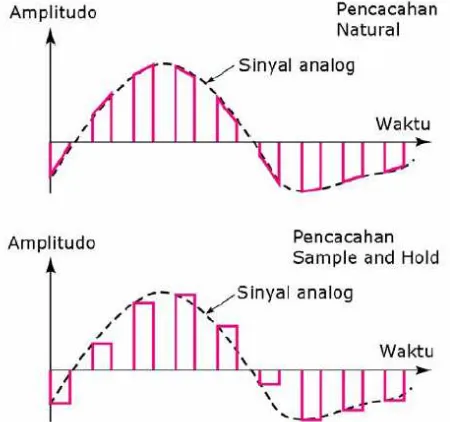
2. Proses kuantisasi
Pencacahan menghasilkan deretan pulsa PAM dengan amplitudo bervariasi dari nilai minimum tegangan sampai nilai maksimum tegangan sinyal analog asli. Jumlah variasi amplitudo tak terhingga. Karena itu langkah selanjutnya adalah melakukan proses kuantisasi amplitudo.
Gambar 2.4. Pencacahan natural dan sample and hold Sumber: (Mafisamin, 2014)
Lebar kuantisasi (∆) ditentukan dengan rumusan berikut:
L V Vmax − min =
∆ (2.2)
Keterangan:
max
V = tegangan maksimal dari sinyal analog asli
min
V = tegangan minimum yang dapat dicapai oleh
sinyal analog asli
L = jumlah level kuantisasi yang diinginkan
Ilustrasi proses kuantisasi dapat dilihat dalam gambar 2.4.
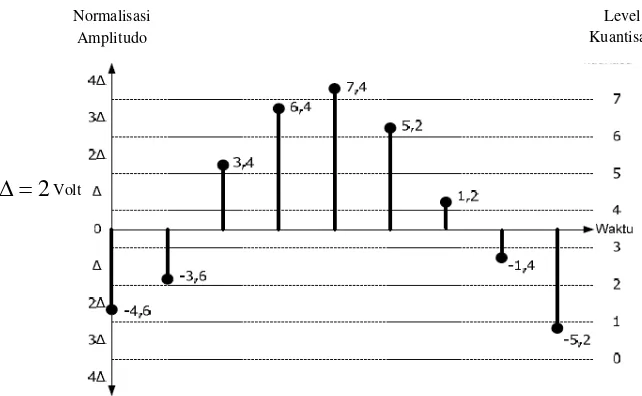
Apabila diinginkan level kuantisasi sebanyak 8 level, maka dengan menggunakan persamaan 2.2 didapatkan lebar kuantisasi
2
=
∆ volt. Normalisasi PAM dalam Gambar 2.4 adalah nilai
tegangan PAM hasil dari pencacahan dibagi dengan delta (∆).
Sedangkan normalisasi kuantisasi adalah hasil pembulatan normalisasi PAM ke level kuantisasi terdekat, dalam gambar level kuantisasi ditandai dengan garis terputus-putus yaitu pada:
. 5 , 3 ; 5 , 2 ; 5 , 1 ; 5 , 0 ; 5 , 0 ; 5 , 1 ; 5 , 2 ; 5 ,
3 ∆− ∆− ∆− ∆ ∆ ∆ ∆ ∆
−
PCM dengan lebar kuantisasi (∆) yang memiliki nilai tetap
seperti terlihat dalam gambar disebut dengan kuantisasi seragam
(uniform quantization). Dalam kasus yang lain, misalnya perubahan amplitudo sinyal analog lebih sering terjadi pada tegangan rendah, tidak digunakan kuantisasi seragam tetapi digunakan kuantisasi tidak seragam. Kuantisasi tidak seragam akan menghasilkan lebar kuantisasi berbeda-beda untuk setiap level kuantisasi. Berikut adalah gambar dari proses kuantisasi dan tabel pengkodean digital.
Gambar 2.5. Proses kuantisasi Sumber: (Mafisamin, 2014)
Normalisasi Amplitudo
Level Kuantisasi
Tabel 2.1. Pengkodean digital
Sumber: (Mafisamin, 2014)
Hal lain yang perlu mendapatkan perhatian khusus adalah adanya kesalahan kuantisasi akibat adanya pembulatan level tegangan PAM ke level kuantisasi terdekat. Nilai kesalahan dari setiap cacahan tidak akan melebihi ∆/2, karena itu kesalahan
kuantisasi akan berada pada nilai −∆/2≤kesalahan kuantisasi
2 /
∆
≤ . Kesalahan kuantisasi berkontribusi pada peningkatan Signal
to Noise Ratio (SNR) dari sinyal yang tentu saja akan berakibat langsung pada penurunan kapasitas kanal. SNR akibat adanya kesalahan kuantisasi dirumuskan oleh persamaan berikut:
76 . 1 log 02 , 6 )
(dB = x 2L+
SNR (2.3)
Keterangan:
SNR = perbandingan sinyal asli dengan sinyal gangguan (noise)
L = jumlah level kuantisasi
Rata-rata kesalahan kuantisasi dapat dikurangi dengan memberikan penambahan derau dalam jumlah kecil. Proses penambahan derau seperti ini disebut dengan dithering. Perlu diketahui bahwa tidak semua derau bersifat mengganggu, justru sebaliknya derau yang terkendali akan sangat bermanfaat sebagaimana halnya implementasi dithering dalam proses kuantisasi.
Normalisasi PAM -2,3 -1,8 1,7 3,2 3,7 2,6 0,6 -0,7 -2,6
Normalisasi kuantisasi -2,5 -1,5 1,5 3,5 3,5 2,5 0,5 -0,5 -2,5
Kesalahan kuantisasi 0,2 0,3 0,2 0,3 0,2 0,1 0,1 0,2 0,1
Level kuantisasi 1 2 5 7 7 6 4 3 1
Contoh 2:
Berapakah SNR akibat adanya kesalahan kuantisasi dari proses kuantisasi dalam Gambar 2.5. dan Tabel 2.1.
Dalam Gambar 2.5. dan Tabel 2.1 terlihat bahwa proses kuantisasi menggunakan 8 level kuantisasi, berarti untuk setiap cacahan dibutuhkan representasi kode digital sebanyak 3 bit.
dB x
dB
SNR( )=6,02 log2(8)+1,76=19,82 .
Sesuai dengan persamaan 2.3, apabila level kuantisasi dinaikkan, maka nilai SNR juga akan meningkat.
3. Proses Pengkodean Digital
Langkah terakhir dalam metode PCM adalah pengkodean data digital. Seperti terlihat dalam Gambar 2.5., pengkodean digital terletak pada baris terakhir dalam gambar. Pengkodean ini mengubah level kuantisasi seperti dalam Gambar 2.5. ke dalam bentuk digital. Misalnya level kuantisasi 7 memiliki bentuk digital 111, level kuantisasi 3 memiliki bentuk digital 011, dan seterusnya. Dengan cara demikian, sinyal analog sekarang telah berubah menjadi bentuk digital.
Kecepatan data dapat dihitung dengan rumusan dalam persamaan
berikut:
L x f
R= s log2 (2.4)
Keterangan:
R = kecepatan data (dalam satuan bps)
s
Dalam persamaan 2.4, log2L pada dasarnya adalah jumlah bit yang
digunakan untuk merepresentasikan Llevel, sebagai contoh untuk
8
=
L , maka dibutuhkan jumlah bit 3 seperti dapat dilihat dalam Gambar 2.5.
2.2.2. Delta Modulation (DM)
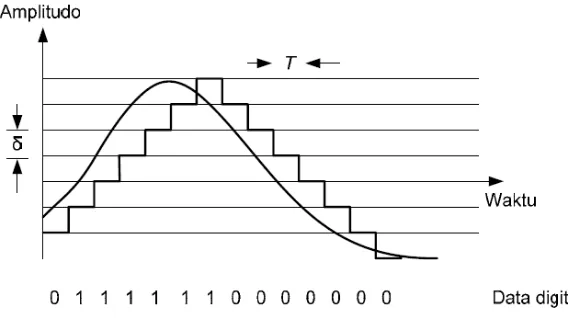
Teknik konversi dari sinyal analog menjadi data digital akan menjadi lebih sederhana apabila diimplementasikan dengan menggunakan Delta Modulation (DM) daripada menggunakan Pulse Code Modulation (PCM). DM tidak mendeteksi amplitudo sebagaimana
halnya pada PCM, melainkan mendeteksi perubahan amplitudo antara cacahan seperti ini dengan cacahan sebelumnya. Perbedaan antara amplitudo saat ini dengan amplitudo sebelumnya disebut dengan δ (Mafisamin, 2014).
[image:32.595.198.482.465.624.2]Ilustrasi Delta Modulation (DM) digambarkan sebagai berikut.
Gambar 2.6. Ilustrasi Delta Modulation (DM) Sumber: (Mafisamin, 2014)
Apabila δ bernilai positif, maka DM akan membangkitkan
merupakan deretan bit yang menggambarkan perubahan amplitudo dari sinyal analog. Untuk dapat menghasilkan unjuk kerja DM yang lebih baik, δ dapat dibuat menjadi adaptif. Dengan menggunakan
DM adaftif nilai δ akan berubah-ubah mengikuti amplitudo dari sinyal analog.
2.3. Pengenalan ucapan
Pengenalan ucapan dalam perkembangan teknologinya merupakan bagian dari pengenalan suara (voice recognition), yaitu proses identifikasi seseorang berdasarkan suaranya.
Pengenalan ucapan adalah proses yang dilakukan komputer untuk mengenali kata yang diucapkan oleh sesorang tanpa memperdulikan
identitas orang terkait. Pengenalan ucapan merupakan suatu teknik yang memungkinkan sistem komputer untuk menerima input berupa kata yang
diucapkan. Kata-kata tersebut diubah bentuknya menjadi sinyal digital dengan cara mengubah gelombang suara menjadi sekumpulan angka lalu disesuaikan dengan kode-kode tertentu dan dicocokkan dengan suatu pola yang tersimpan dalam suatu perangkat. Hasil dari identifikasi kata yang diucapkan dapat ditampilkan dalam bentuk tulisan atau dapat dibaca oleh perangkat teknologi.
Pengenalan ucapan juga dikenal sebagai Automatic Speech Recognition (ASR). ASR merupakan pengenalan ucapan komputer yang berarti suara pemahaman komputer dan melakukan setiap tugas yang diperlukan atau kemampuan untuk mencocokkan suara terhadap kosakata yang tersedia atau diperoleh (Saini dan Kaur, 2013).
melalui mikrophone dan mengubahnya menjadi sinyal digital. Kemudian program menganalisa sinyal digital tersebut dengan membandingkannya dengan digital pattern yang ada dalam databasenya. Setelah itu akan diambil digital pattern yang paling besar prosentase kemiripannya, kemudian dari digital pattern tersebut diubah menjadi teks. Karena setiap manusia memiliki karakteristik suara yang berbeda-beda, maka diberikan suatu metode untuk melatih program dan kemudian data-data spesifik tentang karakter suara tersebut disimpan dalam database dengan tujuan supaya proses pengenalan suara berikutnya memiliki prosentase keberhasilan yang lebih besar.
Ada 2 tipe pengenalan ucapan (speech recognition), dilihat dari ketergantungan pembicara yaitu:
a. Independent Speech Recognition(ISR), yaitu sistem pengenalan ucapan tanpa terpengaruh dengan siapa yang berbicara, tetapi mempunyai keterbatasan dalam jumlah kosakata. Model ini akan mencocokkan setiap ucapan dengan kata yang dikenali dan memilih yang “sepertinya” cocok. Untuk mendapatkan kecocokan kata yang diucapkan maka digunakan model statistik yang dikenal dengan nama Hidden Markov Model (HMM).
Berdasarkan kemampuan dalam mengenal kata yang diucapkan, terdapat 4 jenis kata yaitu:
1. Kata-kata yang terisolasi : proses pengidentifikasi kata yang hanya terdapat mengenali kata yang diucapkan jika kata tersebut memiliki jeda waktu pengucapan antar kata.
2. Kata-kata yang berhubungan : proses pengidentifikasian kata yang mirip dengan kata yang terisolasi, namun membutuhkan jeda waktu yang sangat sedikit.
3. Kata-kata yang berkelanjutan : proses pengidentifikasian kata yang sudah lebih maju karena dapat mengenali kata-kata yang diucapkan secara berkesinambungan dengan jeda waktu yang sangat sedikit atau tanpa jeda waktu. Proses pengenalan suara ini sangat rumit karena membutuhkan metode khusus untuk membedakan kata-kata yang diucapkan tanpa jeda waktu. Pengguna perangkat ini dapat mengucapkan kata-kata secara normal.
4. Kata-kata spontan : proses pengidentifikasian kata yang dapat mengenal kata-kata yang diucapkan secara spontan tanpa jeda waktu antar kata.
Proses pengenalan suara ini sangat bergantung pada bahasa yang digunakan, karena setiap bahasa memiliki cara pengucapan yang berbeda. Sehingga teknologi ASR ini bersifat language dependent.
2.4. Tahapan-tahapan dalam pengenalan ucapan (speech recognition)
modelling), pemodelan pengucapan (pronounciation modelling), model bahasa (language model), dan decoder.
[image:36.595.149.505.181.320.2]Blok diagram untuk sistem pengenalan ucapan adalah sebagai berikut:
Gambar 2.7. Blok diagram untuk sistem pengenalan ucapan Sumber : (Gales dan Young, 2007)
2.4.1. Ekstraksi Fitur
Gelombang input audio dari sebuah microphone dikonversikan
menjadi sebuah urutan vektor akustik O1:T =O1,...,OT dalam proses
yang disebut ekstraksi fitur (fitur extraction)(Gales dan Young, 2007).
Tahap ekstraksi fitur bertujuan untuk memberikan sebuah gambaran dari gelombang ucapan. Tahap ekstraksi fitur ini dapat meminimalkan hilangnya informasi yang membedakan antara kata-kata, dan memberikan kecocokan dengan asumsi distribusi yang dibuat oleh model akustik. Metode yang digunakan adalah Linear Predictive Coding(LPC).
Language Model Feature
Extraction Decoder
Acoustic Modelling
Pronounciation Modelling Speech
Feature Vectors
...
O W
“Stop that.”
Pre-emphasis Frame
Blocking Windowing
Auto Correlation
Analisa LPC LPC
Parameter
LPCmerupakan salah satu teknik analisis sinyal percakapan yang paling powerful dan menyediakan ekstraksi fitur yang berkualitas baik dan efisien untuk digunakan dalam perhitungan .
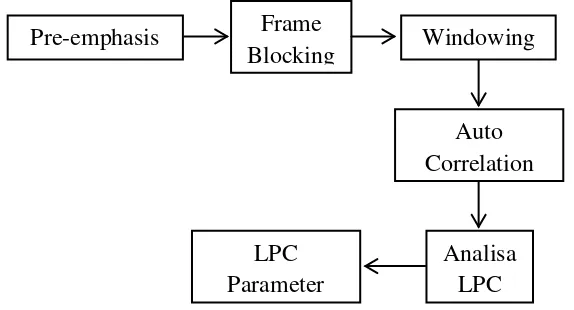
[image:37.595.192.479.221.376.2]Prosedur untuk mendapatkan koefisien LPC diperlihatkan pada blok diagram berikut:
Gambar 2.8. Blok Diagram LPC
Langkah-langkah dasar yang harus dilakukan mengenai blok diagram tersebut adalah sebagai berikut:
1. Pre-emphasis : Proses dimana sinyal/ speech ucapan dirubah menjadi sinyal.
2. Frame Blocking : pada tahap ini, sinyal yang telah di pre-emphasis, diblok menjadi beberapa bagian dengan jumlah sampel N, dan tiap bagian dipisahkan dengan sejumlah M sampel.
3. Windowing : Tahap berikutnya adalah melakukan proses window pada setiap bagian sinyal yang telah dibuat sebelumnya. Hal ini dilakukan untuk meminimalkan pada bagian awal dan akhir sinyal. Jika didefinisikan sebuah windoww(n) dan sinyal tiap
4. Auto Correlation Analysis : Tiap bagian yang telah diberi window kemudian akan dibentuk autokorelasinya.
5. Analisa LPC : Langkah berikutnya adalah analisa LPC dimana semua nilai autokorelasinya yang telah dihitung pada tahap sebelumnya akan diubah menjadi parameter LPC.
6. Pengubahan parameter LPC menjadi koefisien cepstral : Parameter LPC yang sangat penting yang bisa diturunkan dari koefisien LPC adalah koefisien cepstral LPC, c(m)
Adapun langkah-langkah analisa LPC untuk pengenalan ucapan (speech recognition) adalah sebagai berikut:
1. Pre-emphasis terhadap cuplikan sinyal dengan persamaan Pre-emphasizer
(2.5)
dengan s(n) adalah sampel ke-n dan harga a yang paling sering
digunakan adalah 0.95
2. Membagi hasil pre-emphasiss(n) ke dalam frame-frame yang
masing-masing memuat N buah sampel yang dipisahkan sejauh M
buah sample. Semakin M <N semakin baik perkiraan spektral LPC dari frame ke frame.
3. Melakukan windowing terhadap setiap frame yang telah dibentuk untuk meminimalkan diskontinuitas pada ujung awal dan ujung akhir setiap frame dengan persamaan Hamming Window untuk sampel ke-n adalah :
) 1 / 2 cos( 46 . 0 54 . 0 )
(n = − n N−
W π , 0≤n≤ N−1 (2.6)
4. Analisis autokorelasi terhadap setiap frame hasil windowingx1(n)
dengan persamaan :
) 1 ( ) ( )
(n =s n −as n−
s
∑
−−= +
= 1 1
0 1 1
1( ) ( ) ( )
n
n x n x n m
(2.7)
dengan mdimulai dari 0 dan nilai tertinggi dari m= p adalah orde
LPC yang biasa bernilai 8-16.
5. Mengubah p+1 buah hasil autokorelasi pada masing-masing
frame menjadi koefisien LPC am =am(p) untuk m=1,2,...,p
dengan persamaan dibawah ini :
) 0 ( ) 0 ( r
E = (2.8)
, / |) (| ) (
{ −
∑
−1 − ( −1)= m m
m r m r m j E
k 1≤m≤ p (2.9)
m m
m =k
) ( α (2.10) , ) 1 ( ) 1 ( ) ( − − − − = m j m m m j m
j α k α
α 1≤ j≤m−1 (2.11)
) 1 ( 2 ) ( ) 1 ( − − = m m m E k E (2.12)
dengan r(0) adalah hasil autokorelasi, E(m) adalah error, km
adalah koefisien pantulan, aj(m) adalah koefisien prediksi untuk
m j≤
≤
1 .
6. Mengubah parameter LPC am ke koefisien cepstralcm untuk
mendapatkan kinerja yang lebih baik dan tahan terhadap noise, yaitu dengan persamaan”
∑
−= −
+
= 1
1( / ) ,
m
k k m k
m
m a k m c a
c 1≤m≤ p (2.13)
∑
−= −
= 1
1( / ) ,
m
k k m k
m k m c a
c m> p (2.14)
2.4.2. Pemodelan Akustik
Dalam sistem pengenalan ucapan automatis (automatic speech recognition)berbasis statistik, ucapan diwakili oleh beberapa urutan
pengamatan fitur akustik O, berasal dari urutan kata-kata W.
Sinyal akustik dirumuskan oleh:
(2.15)
Akan tetapi, karena P(W|O) sulit untuk dimodelkan secara
langsung, maka dapat menggunakan aturan Baye (Baye’s Rule) dapat ditulis sebagai berikut:
(2.16)
Keterangan:
) |
(O W
P = probabilitas bahwa ketika string kata W
diucapkan
) (W
P = probabilitas bahwa string kata W akan
diucapkan
Dalam persamaan (2.13), P(O|W)adalah probabilitas
pengamatan dan dievaluasi berdasarkan pemodelan akustik (acoustic modelling), sedangkan P(W) adalah probabilitas sebagai
model bahasa (language model).
Model akustik diimplementasikan dengan menggunakan pendekatan model seperti Hidden Markov Model (HMM), Artificial Neural Network (ANN), jaringan Bayesian dinamis (DBN), mendukung mesin vektor (SVM).
HMM digunakan dalam beberapa bentuk atau yang lain di setiap keadaan (state) dari sistem pengenalan ucapan.
)} | ( { max
arg PW O
W
w
=
) ( . ) | ( max
arg P O W PW
W
HMM pada dasarnya perluasan dari rantai Markov yang merupakan model stokastik. Biasanya dalam model Markov setiap keadaan (state) dapat terlihat langsung oleh pengamat, sehingga kemungkinan transisi antara keadaan menjadi satu-satunya parameter yang teramati.
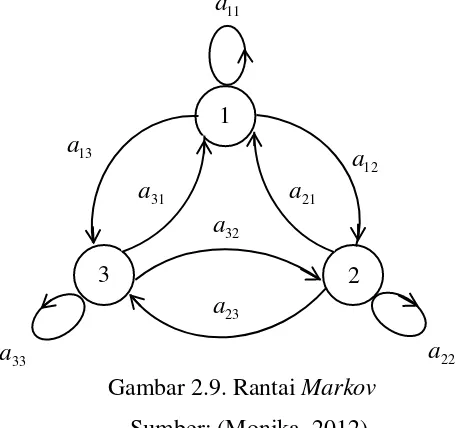
Rabiner (1989) mengemukakan bahwa transisi pada Rantai Markov yaitu:
a. Transisi dari suatu keadaan tergantung pada keadaan sebelumnya.
(2.17) b. Transisi keadaan bebas terhadap waktu.
(2.18)
[image:41.595.219.452.395.609.2]Berikut ini adalah contoh gambar dari rantai Markov.
Gambar 2.9. Rantai Markov Sumber: (Monika, 2012)
2.4.3. Pemodelan ucapan
Dalam pemodelan pengucapan (pronounciation modelling), selama pengenalan, urutan simbol-simbol yang dihasilkan oleh model
12 a 13
a
31
a a21
32 a
23 a
33
a a22
11 a
1
2
3
] |
[ ...] |
|
[qt Sj qt 1 Si qt 2 Sk P qt Sj qt 1 Si
P = − = − = = = − =
] |
[q S q 1 i P
akustik HMM dibandingkan dengan serangkaian kata yang ada dalam kamus untuk menghasilkan urutan kata-kata yang hasil akhir sistem berisi informasi tentang kata-kata yang dikenal ke sistem dan bagaimana kata-kata yang diucapkan yaitu apa yang representasi fonetik mereka.
Gales dan Young (2007) mengemukakan bahwa setiap kata yang diucapkan didekomposisi menjadi urutan suara dasar yang disebut basis phones. Urutan ini disebut pengucapannya. Untuk memungkinkan kemungkinan beberapa pengucapan-pengucapan dapat dihitung:
∑
= Q
W Q P Q O p W
O
p( | ) ( | ) ( | ) (2.19)
di mana penjumlahan selesai semua urutan pengucapan berlaku
untuk w, Qadalah urutan pengucapan partikular,
), | ( )
|
( ( )
1
Wl q P W
Q
P wl
L
l
∏
=
= (2.20)
dan di mana masing-masing pengucapan berlaku untuk kataWl.
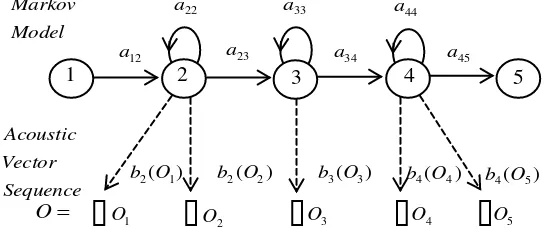
[image:42.595.193.467.542.660.2]Setiap base phone diwakili oleh kepadatan kontinu HMM dengan parameter probabilitas transisi dan distribusi observasi output digambarkan sebagai berikut:
Gambar 2.10. HMM model basis phone Model
Markov
Sequence Vector
Acoustic
1 2 3 4 5
=
O
12
a a23 a34 a45
22
a a33 a44
1
O O2 O3 O4 O5
) ( 1 2 O
Dalam operasi, HMM membuat transisi dari kondisi saat ini ke salah satu keadaan (state) yang terhubung setiap langkah waktu. Kemungkinan membuat transisi stertentu dari state ke state
diberikan oleh probabilitas transisi
{ }
aij . Masuk ke state, fitur vectoryang dihasilkan dengan menggunakan distribusi terkait dengan
keadaan (state) yang masuk,
{ }
bj() .Bentuk proses menghasilkan asumsi bebas bersyarat standar untuk HMM:
• keadaan (state) yang bersyarat independen dari semua state-state lain mengingat keadaan sebelumnya
• pengamatan bersyarat independen dari semua pengamatan lainnya mengingat keadaan yang dihasilkan itu.
2.4.4. Model Bahasa
Model bahasa (Language Model) digunakan untuk membatasi proses pencarian pada pengenalan ucapan (speech recognition), yaitu menuntun pencarian urutan kata yang benar dengan memprediksi kemungkinan kata n menggunakan (n-1) kata-kata sebelumnya.
Model bahasa dapat diklasifikasikan menjadi:
1. Model seragam: setiap kata memiliki probabilitas yang sama terhadap kejadian.
2. Model stokastik: probabilitas terhadap kejadian dari sebuah kata tergantung pada kata yang mendahuluinya.
3. Bahasa state yang terbatas: bahasa menggunakan jaringan anegara yang terbatas untuk menentukan urutan kata yang
diperbolehkan.
Model bahasa N-gram merupakan sebuah metode yang diaplikasikan untuk pembangkitan kata atau karakter. Probabilitas
sebelumnya dari urutan kata W =W1,...,Wk diperoleh dari persamaan
berikut:
(2.21)
Untuk pengenalan kosakata yang besar, sejarah pendingin kata dalam biasanya dipotong ke N-1 kata-kata untuk membentuk model bahasa N-gram
) ,..., , | ( )
( 1 2 1
1 + − − − =
∏
= i i i i N
K i W W W W P W P (2.22)
dimana N biasanya diantara 2-4. Model bahasa sering dinilai dari segi kebingungan (perplexity) mereka, H, yang didefinisikan sebagai )) ,..., ( ( log 1 1 2
lim
K K W W P K H ∞ → − =dimana perkiraan tersebut digunakan untuk model bahasa N-gram dengan urutan kata dengan panjang terbatas.
Probabilitas N-gram diperkirakan dari training teks dengan menghitung kejadian N-gram untuk membentuk maximum likelihood
(ML) estimasi parameter.
Sebuah pendekatan alternatif untuk estimasi model bahasa yang kuat adalah dengan menggunakan model berbasis kelas di
mana untuk setiap kata Wkada kelas yang sesuai Ck. Maka,
) ,..., | ( ) | ( )
( 1 1
1 + − − =
∏
= k k k k k N
K k C C C p C W P W P (2.23)
(Gales dan Young, 2007)
) ) ,..., , | ( ( log 1 1 1 2 1 2
∑
= − − − + − ≈ K i N i i ii W W W
W P K ) ,..., | ( )
( 1 1
1 W W W P W
P k k
2.4.5. Decoder
Decoder adalah peralatan yang digunakan untuk mendapatkan kembali sinyal analog yang telah dikodekan menjadi data digital. Perlu diingat bahwa untuk dapat melakukan pembalikkan kode, persyaratan Nyquist harus dipenuhi pada saat melakukan pencacahan (sampling) (Mafisamin, 2014).
Decoder merupakan suatu tahapan yang paling penting dalam proses pengenalan ucapan (speech recognition). Sebuah decoder berfungsi untukmelakukan keputusan yang sebenarnya dengan menggabungkan pemodelan akustik (acoustic modelling), pemodelan pengucapan (pronounciation modelling)dan model bahasa (language model) untuk mencari semua urutan kata yang mungkin dan akan menghasilkan output.
2.5. Hidden Markov Model (HMM)
Hidden Markov Model (HMM) adalah suatu model statistik dari sebuah sistem yang diasumsikan sebuah proses Markov dengan parameter yang tidak diketahui. Kita harus menentukan parameter-parameter tersembunyi (state) dari parameter-parameter yang dapat diamati. Parameter-parameter yang ditentukan kemudian dapat digunakan untuk analisis yang lebih jauh, misalnya untuk aplikasi pattern recognition(Monika, 2012).
HMM pada dasarnya perluasan dari rantai Markov yang merupakan model stokastik. Biasanya dalam model Markov setiap keadaan (state) dapat terlihat langsung oleh pengamat, sehingga kemungkinan transisi antara keadaan menjadi satu-satunya parameter yang teramati. Dalam HMM,
keadaan tidak dapat terlihat langsung meskipun parameter model diketahui, model tersebut tetap tersembunyi, tetapi hasil keluaran (output) yang
HMM terdiri dari dua proses stokastik. Proses stokastik pertama adalah rantai Markov yang ditandai oleh state-state dan probabilitas transisi. State pada bagian rantai Markov secara eksternal tidak terlihat, karena itu “tersembunyi”. Sedangkan proses stokastik kedua menghasilkan emisi diamati pada setiap saat, tergantung pada distribusi probabilitas tergantung pada state. Hal ini penting untuk melihat bahwa dominasi “tersembunyi” serta menciptakan Hidden Markov Model dirujuk ke state bagian Rantai Markov, bukan dengan parameter pada model tersebut.
2.5.1 Tipe HMM
Ada dua tipe HMM, yaitu HMM ergodic dan HMM kiri-kanan. a. HMM ergodic
[image:46.595.265.456.432.605.2]Pada HMM ergodic perpindahan keadaan satu ke keadaan yang lain semuanya memungkinkan, hal ini ditunjukkan pada gambar berikut:
Gambar 2.11. HMM model ergodic Sumber: (Paul, 1990)
b. HMM kiri-kanan
Pada HMM kiri-kanan perpindahan keadaan hanya dapat berpindah dari kiri ke kanan, perpindahan keadaan tidak dapat mundur ke belakang, hal ini ditunjukkan pada gambar berikut:
3
S
1
S
2
Gambar 2.12. HMM model kiri-kanan Sumber: (Paul, 1990)
Hidden Markov Model(HMM) terdiri dari keadaan (state), peluang transisi (state probabilities), peluang emisi (emission probabilities), dan peluang awal(initial probabilities).
2.5.2 Elemen HMM
HMM didefinisikan sebagai berikut:
1. N, jumlah state dalam model yang didefinisikan oleh
{
S SN}
S = 1,...,
2. M, jumlah simbol pengamatan yang berbeda tiap state, misalnya ukuran alfabet diskrit didefinisikan oleh V =
{
v1,...,vM}
. Jikapengamatankontinu maka M adalah tak terbatas.
3. Distribusi peluang keadaan transisi A=
{ }
aij , dimana ija adalah
distribusi yang state pada waktu t+1adalah , diberikan ketika
keadaan pada waktu adalah Si. Struktur matriks stokastik ini
mendefinisikan hubungan struktur model.
(2.24) 1
S S2 S3 S4 S5
t
j
S
, 1≤i
[
t 1 j | t i]
,ij pq S q S
4. Distribusi peluang simbol pengamatan pada masing-masing
state j, B=
{
bj(k)}
dimana adalah peluang yang simbol vkdiemisi dalam keadaan Sj.
(2.25) jika pengamatankontinu, maka kita harus menggunakan fungsi kepadatan peluang kontinu.
5. Distribusi keadaan awal π =
{ }
πi dimana πiadalah peluangbahwa model tersebut berada dalam keadaan Si pada waktu
0 =
t didefinisikan oleh
(2.26)
[image:48.595.167.495.408.555.2]
Adapun contoh Hidden Markov Model (HMM) digambarkan sebagai berikut:
Gambar 2.13. Contoh Hidden Markov Model (HMM) Sumber : (Dymarski, 2011)
Hidden Markov Model (HMM) dapat dituliskan sebagai model
) , ,
( π
λ = A B . Dengan diketahuinya parameter-parameter N,M,A,B,
dan π(Dymarski, 2011).
) (k bj
M k≤
≤ 1
, 1≤ j≤N
[
|]
,)
( t k t j
j k po v q S
b = = =
N i≤
≤ 1
{
q1 i}
,p
i = =
2.5.3 Fungsi Rekursif HMM
Ada tiga fungsi rekursif HMM, yaitu: 1. Algoritma Forward
Variabel algoritma forward : αi =P(O1,O2,...,OT,qT =Si |λ).
Berikut ini langkah-langkah dalam algoritma Forward: Inisialisasi
), ( )
( 1
1 i b O
a =πi i 1≤i≤ N (2.27)
Induksi ), ( ) ( ) ( 1 1 1 + = +
=
∑
N j ti
ij t
t j α i α b O
α (2.28)
dengan 1≤t≤T−1 dan 1≤ j≤N
Terminasi
∑
= = N i T i O P 1 ), ( ) |( λ α 1≤i≤N (2.29)
Ilustrasi algoritma forward dapat dilihat pada gambar berikut:
[image:49.595.231.438.497.710.2]. . .
Gambar 2.14. Ilustrasi Alur Algoritma Forward Sumber: (Rabiner, 1989)
2. Algoritma Backward
Variabel algoritma Backward: βt =P(O1,O2,...,OT,qT =Si|λ).
Berikut ini langkah-langkah dalam algoritma Backward: Inisialisasi
, 1 ) (i = T
β
1≤i≤N (2.30) Induksi , ) ( ) ( 1 1 1 , ⋅ ⋅ =
∑
= + + N i t t j j it α b O β j
β (2.31)
dengan t=T −1,T−2,...,1 dan 1≤i,j≤N.
Ilustrasi untuk algoritma backward dapat dilihat pada gambar berikut:
[image:50.595.239.450.385.598.2]. . .
Gambar 2.15. Ilustrasi Alur Algoritma Backward Sumber: (Rabiner, 1989)
3. Algoritma Baum Welch
Algoritms Baum Welch melibatkan algoritma forward dan algoritma backward.
Untuk menggambarkan prosedur update parameter
HMM, diperlukan variabel ξt(i, j) yang merupakan peluang
gabungan state i dan state j terhadap peluang pengamatan
pada model yang diberikan, dan γt(i) state pada waktu dan
merepresentasikan peluang berada di state i pada waktu t.
Secara matematis nilai ξt(i,j) danγt(i) dapat
diformulasikan dengan persamaan berikut:
) , | , ( ) ,
( 1 λ
ξt i j =P qt =Si qt+ =Sj O
(2.32) Variabel state: ) , | ( ) ( λ
γt i =P qt =Si O (2.33)
Dengan menggunakan persamaan (2.32) dan (2.33), maka persamaan untuk mengupdate parameter-parameter
) , ,
(A B
π
pada HMM dapat dirumuskan sebagai berikut: Probabilitas state transisi:, ) ( ) , ( 1 1 1 1
∑
∑
− = − = = T t t T t t ij i j i a γ ξ ,1≤i≤N 1≤ j≤M (2.34)
Simbol probabilitas emisi
, ) ( ) ( ) ( 1 , 1
∑
∑
= = = = T t t T V O t j j j kb T k γ
γ
,
1≤i≤N 1≤ j≤M (2.35) ) | ( ) ( ) ( )
( , 1 1
λ β α α O P j O b
i i j j t t
t + +
Probabilitas state awal
), 1 (
t
i γ
π = 1≤i≤N (2.36)
Ilustrasi mengenai algoritma Baum-Welch dapat dilihat sebagai berikut:
. .
. .
[image:52.595.191.511.199.370.2]. .
Gambar 2.16. Ilustrasi Perhitungan pada Algoritma Baum-Welch Sumber: (Rabiner, 1989)
2.6. Contoh Penyelesaian Rantai Markov pada Kasus Cuaca
Cuaca dalam tiga hari yang lalu dimodelkan dalam tiga state: cerah(1), berawan(2), dan hujan(3). Misalkan, kita asumsikan bahwa probabilitas cuaca esok hari berdasarkan cuaca hari ini dalam tabel berikut:
Tabel 2.2. Probabilitas cuaca hari ini berdasarkan cuaca esok hari
Cuaca Esok Hari
Cuaca Hari Ini
Cerah Hujan Berawan
Cerah 0,8 0,05 0,15
Hujan 0,2 0,6 0,2
Berawan 0,2 0,3 0,5
Sumber: (Lussier, 1998)
) ( t+1 j ijb O a
t t+1
) (i t
α βt+1(j)
1 −
t t+1
i
[image:52.595.150.512.616.728.2]Penyelesaian:
[image:53.595.180.477.112.303.2]Diketahui rantai Markov sebagai berikut:
Gambar 2.17. Rantai Markov pada kasus cuaca
Contoh 3:
Jika hari ini cuaca cerah, berapakah probabilitas bahwa esok hari cuaca cerah dan lusa adalah hujan?
Jika hari ini cuaca cerah, maka probabilitas bahwa esok hari cuaca cerah dan lusa adalah hujan, yaitu:
Contoh 4:
Jika hari ini cuaca berawan, berapakah probabilitas bahwa lusa akan hujan?
Jika hari ini cuaca berawan, maka probabilitas bahwa lusa akan hujan, yaitu: hujan berawan cerah 6 , 0 2 , 0 05 ,
0 0,3
2 , 0
8 ,
0 0,5
Dari penjelasan diatas, dapat disimpulkan bahwa Markov Chain bermanfaat untuk menghitung probabilitas urutan state yang dapat diamati. Masalahnya terkadang ada urutan state yang ingin diketahui tetapi tidak dapat diamati. Untuk menyelesaikan kasus tersebut, dikembangkan oleh model baru yang memodelkan kejadian yang tersembunyi, disebut Hidden Markov Model (HMM).
2.7. Contoh Penyelesaian Hidden Markov Model pada Kasus Cuaca
Anggaplah bahwa Anda sedang terkunci di sebuah ruangan untuk beberapa hari, dan Anda ditanya tentang cuaca diluar. Satu-satunya bukti yang Anda miliki adalah apakah orang yang datang ke ruangan sedang membawa makanan sehari-hari Anda membawa sebuah payung atau tidak. Probabilitas melihat ada sebuah payung berdasarkan cuaca tersebut dapat dilihat pada tabel berikut:
Tabel 2.3. Probabilitas melihat sebuah payung berdasarkan cuaca
Probabilitas Payung
Cerah 0.1
Hujan 0.8
Berawan 0.3
Sumber: (Lussier, 1998)
Contoh 5:
Anggaplah hari dimana Anda terkunci adalah cuaca cerah. Hari berikutnya, penjaga rumah membawa sebuah payung ke ruangan. Asumsikan bahwa probabilitas utama dari penjaga rumah yang membawa sebuah payung pada hari itu adalah 0.5. Berapakah probabilitas bahwa hari kedua adalah hujan?
Anggaplah hari dimana Anda terkunci adalah cuaca cerah. Hari berikutnya, penjaga rumah membawa sebuah payung ke ruangan. Asumsikan bahwa probabilitas utama dari penjaga rumah yang membawa sebuah payung pada hari itu adalah 0.5
Maka, probabilitas bahwa hari kedua adalah hujan, yaitu:
2
(W dan O1 tidak bergantung)
) ( ) | , ( 1 2 1 2 cerah O P T W cerah O hujan O P = = = = = ) ( ) ( ) , ( ) , | ( ) ' ( 1 1 2 2 1 2 T W P cerah O P cerah O hujan O P hujan O cerah O T W P Rule s Baye = = = = = = = = ) ( ) ( ) , ( ) | ( ) ( 2 1 1 2 2 2 T W P cerah O P cerah O hujan O P hujan O T W P assumption Markov = = = = = = = ) ( ) | ( ) | ( )) ( : ( 2 1 2 2 2 T W P cerah O hujan O P hujan O T W P cerah P Cancel = = = = = = Contoh 6:
Anggaplah hari dimana Anda terkunci di ruangan adalah cerah. Penjaga rumah membawa sebuah payung di hari kedua, tetapi tidak di hari ketiga. Asumsikan bahwa probabilitas utama dari penjaga rumah membawa sebuah payung adalah 0.5. Berapakah probabilitas bahwa hari tersebut berawan di hari ketiga?
Anggaplah hari dimana Anda terkunci di ruangan adalah cerah. Penjaga rumah membawa sebuah payung di hari kedua, tetapi tidak di hari ketiga.
Asumsikan bahwa probabilitas utama dari penjaga rumah membawa sebuah payung adalah 0.5
Maka, probabilitas bahwa hari tersebut berawan di hari ketiga, yaitu:
3.1. Microsoft Speech API
Speech Application Programming Interface adalah sebuah API yang dikembangkan oleh Microsoft yang digunakan sebagai pengenal suara di
dalam lingkungan pemrograman aplikasi Windows. Sampai saat ini Speech APIdikemas baik berupa SDK (Sistem Development Kit) maupun disertakan dalam sistem operasi Windows itu sendiri.
Salah satu aplikasi yang telah menggunakan Speech Application Programming interface antara lain Microsoft Office. Secara arsitektur
pemrograman SAPI dapat dilihat sebagai sebuah middleware yang terletak antara aplikasi dan speech engine.
[image:57.595.158.493.238.446.2]Di dalam SAPI versi 1 sampai 5, aplikasi dapat berkomunikasi langsung dengan speech engine seperti tampak pada gambar berikut:
Gambar 2.18. Arsitektur Microsoft Speech Application Programming Interface
Komponen-komponen utama di dalam Microsoft Speech API adalah sebagai berikut:
a. Voice Command, sebuah objek level tinggi untuk perintah dan kontrol menggunakan pengenalan suara.
b. Voice Dictation, sebuah obyek level tinggi continuous dictationspeech recognition.
d. Direct Speech Recognition, sebuah obyek sebagai mesin untuk mengontrol pengenalan suara (direct control of recognition engine).
e. Direct Text to Speech, sebuah mesin yang mengontrol synthesis.
BAB 3
PEMBAHASAN
3.1. Flowchart
Flowchart adalah bagan (chart) yang menunjukkan aliran (flow) di dalam program atau prosedur sistem secara logis. Bagan alir (program flowchart) merupakan bagan yang menjelaskan secara rinci langkah-langkah dari proses program.
a. Flowchart Proses Suara
Gambar 3.1. Flowchart ProsesSuara
Tampilan Aplikasi Komputer
Ya Testing Mulai
Selesai Input Suara
Pemodelan HMM Proses Sinyal
Suara
Bandingkan data digital baru dengan data digital template
Data Digital Baru
[image:59.595.166.503.328.723.2]b. Flowchart Pemodelan HMM
Gambar 3.2. Flowchart Pemodelan HMM
Mulai
Masukan Runtun Pengamatan
Pilih State dan Bentuk Model HMM
Inisialisasi Parameter HMM
Pelatihan Parameter HMM
Penyimpanan Parameter HMM
Masukan Urutan (Sequence) Data
Pencocokan ke Model HMM
[image:60.595.223.413.125.589.2]3.2. Perancangan Perangkat Lunak
Perancangan sistem pengenalan ucapan (speech recognition) ini menggunakan Microsoft Speech Application Programming (SAPI) dengan spesifikasi perangkat keras (hardware) dan perangkat lunak (software) sebagai berikut:
1. Perangkat keras(hardware)
a. Notebook Toshiba Satellite L735
- Processor Dual Core B960 2.20 GHz - Memory 2GB
- Harddisk 320GB - Soundcard terintegrasi
b. Microphone Sony PC Headseat MDR-788
2. Perangkat lunak (software) a. Sistem Operasi Windows 7
b. Software Microsoft Speech Application Programming Interface
3.3. Software Microsoft Speech API
Pengenalan ucapan (speech recognition)dapatditampilkan dengan menggunakan Microsoft Speech APIdengan speech engine Windows Speech Recognition.
Berikut adalah langkah-langkah praktis setup atau setting memulai Speech
Recognition:
1. Nyalakan dan pastikan semua hardware termasuk microp