Fakultas Ilmu Komputer
2851
Pengenalan Entitas Bernama untuk Identifikasi Transaksi Akuntansi
Menggunakan
Hidden Markov Model
Rika Raudhotul Rizqiyah1, Lailil Muflikhah2, Mochammad Ali Fauzi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Akuntansi merupakan suatu pekerjaan yang memiliki peranan penting dalam mendukung kelancaran ekonomi, karena pencatatan setiap proses bisnis yang terjadi dilakukan dalam akuntansi. Namun, pencatatan transaksi keuangan dalam akuntansi untuk dapat dilakukan identifikasi ke dalam bentuk jurnal masih dilakukan secara manual, sehingga dibutuhkan klasifikasi dan ekstraksi informasi yang terdapat pada teks transaksi akuntansi. Named Entity Recognition (NER) atau pengenalan entitas bernama merupakan langkah awal yang dibutuhkan untuk melakukan proses ekstraksi informasi. Untuk menyelesaikan masalah tersebut, dilakukan pengenalan entitas bernama untuk identifikasi transaksi akuntansi. Pada penelitian ini digunakan metode Hidden Markov Model (HMM), karena HMM dapat menyelesaikan pelabelan serta dikenal handal dalam melakukan pengenalan entitas bernama. Proses utama dalam pengenalan entitas bernama ini dibagi menjadi dua, yaitu proses pemodelan menggunakan Hidden Markov Model dan proses decoding menggunakan Viterbi Algorithm. Pada penelitian ini akan dilakukan pengenalan terhadap 12 entitas, antara lain DATE, TITLE, PER, TRANS, EXP_MON, TYP_COMP, FIRST_ORG, SECOND_ORG, EXP_DATE, NO_DATE, MONTH dan YEAR. Secara keseluruhan pengenalan entitas yang dilakukan pada penelitian ini menghasilkan nilai rata-rata precision, recall dan f-measure berturut-turut yaitu 81.75%, 87.88% dan 82.39%.
Kata kunci: pelabelan transaksi akuntansi, named entity recognition, hidden markov model, information extraction
Abstract
Accounting is a task which has an important role in supporting economic continuity, due to the recording of any business process that occurred was done in accounting. However, the recording of financial transactions in accounting for identification into journal is still done manually, so that required classification and extraction of information contained in the accounting transaction text to make it easier. Named Entity Recognition (NER) is the first step needed to perform information extraction. To solve this problem, named entity recognition done for identification of accounting transaction. In this research used method of Hidden Markov Model (HMM), because HMM can resolve labeling task and and known robustly in performing named entity recognition. The main process in this named entity recognition is divided into modeling process using Hidden Markov Model and decoding process using Viterbi Algorithm. In this research will be recognize 12 entities namely DATE, TITLE, PER, TRANS, EXP_MON, TYP_COMP, FIRST_ORG, SECOND_ORG, EXP_DATE, NO_DATE, MONTH and YEAR. Overall entity recognition with addition Laplace Smoothing and Regular Expression techniques produce a value of average precision, recall and f-measure consecutive 81.75%, 87.88%, and 82.39%.
Keywords: labeling accounting transaction, named entity recognition, hidden markov model, information extraction
1. PENDAHULUAN
Pertumbuhan ekonomi dunia merupakan fenomena penting yang terjadi akhir-akhir ini.
keuangan sehingga dapat digunakan untuk menentukan keputusan. Fungsi utama dari akuntansi yaitu menyajikan informasi keuangan suatu organisasi, yang mana hasil dari laporan akuntansi tersebut dapat dilihat kondisi keuangan serta perubahan yang terjadi di dalamnya. Penyajian informasi yang tepat harus berdasarkan pencatatan transaksi akuntansi yang ada. Transaksi akuntansi merupakan transaksi yang memengaruhi minimal dua atau lebih data akuntansi. Proses pencatatan transaksi akuntansi ini dituliskan dalam sebuah jurnal yang mana dibutuhkan pemahaman mengenai konsep dasar akuntansi (Iswandi et al., 2015).
Pada lingkup dunia pendidikan, biasanya dipelajari transaksi akuntansi berupa teks yang tidak terstruktur untuk kemudian diubah menjadi bentuk terstruktur ke dalam tabel jurnal. Studi kasus transaksi akuntansi sering digunakan untuk melatih kemampuan pelajar dalam mendalami ilmu akuntansi. Dibutuhkan suatu analisis terhadap transaksi akuntansi yang ada untuk dapat dikenali apa saja akun yang terdapat pada transaksi tersebut. Untuk itu diperlukan suatu teknik yang dapat membantu pekerjaan ini dalam memilah informasi dari teks transaksi akuntansi yang tidak terstruktur. Selanjutnya, dari hasil pemilahan informasi didapatkan informasi penting yang dibutuhkan yaitu informasi akun yang terdapat dalam transaksi tersebut. Teknik ini dikenal sebagai ekstraksi informasi, yang mana dari data yang berbentuk tekstual dapat diambil informasinya. Ekstraksi informasi memiliki tujuan utama yaitu mengambil informasi spesifik yang diinginkan dari dokumen teks bahasa alami, yang mana proses ekstraksi ini dilakukan secara otomatis menggunakan metode komputer (Abdelmagid et al., 2015).
Named Entity Recognition (NER) atau dikenal juga dengan pengenalan entitas bernama merupakan subpekerjaan dari ektraksi informasi. NER bertugas mengenali entitas nama (bisa nama orang, perusahaan, organisasi, lokasi), ekspresi bilangan (seperti kardinal, persen, uang, numerik) dan ekspresi waktu (misal durasi, tanggal, waktu) pada kumpulan dokumen teks (Chinchor et al., 1999). NER dapat diselesaikan dengan pelabelan urutan kata statistik (statistical sequence labelling). Salah satu metode yang dapat menyelesaikan pelabelan ialah Hidden Markov Model (HMM) yang merupakan pengembangan model statistik dari model Markov. HMM dikenal mempunyai beberapa kelebihan, diantaranya memiliki fondasi statistik
yang kuat, sangat cocok untuk domain bahasa alami, dan penanganan data baru dilakukan dengan baik atau robustly pengembangan komputasional yang efisien (Seymore et al., 1999). Untuk model seperti HMM, yang berisi hidden state, tugas untuk menentukan urutan variabel merupakan hal yang mendasari beberapa urutan pengamatan yang disebut sebagai tugas decoding. Algoritme decoding yang paling umum digunakan adalah Algoritme Viterbi yang merupakan sejenis pemrograman dinamis (Jurafsky & Martin, 2016).
Penelitian mengenai pengenalan entitas bernama pada teks berbahasa India, Bengali dan Telugu pernah dilakukan oleh Sudha Morwal dan Deepti Chopra menggunakan metode Hidden Markov Model (HMM) pada tahun 2013. Terdapat tiga fase dalam sistem berbasis NER ini, diantaranya yaitu fase anotasi, fase pelatihan HMM dan fase pengujian HMM. Algoritme Viterbi diterapkan pada penelitian ini untuk menghitung urutan optimal untuk kalimat yang telah dimasukkan ke dalam sistem. Dari hasil pengujian pada penelitian ini didapatkan nilai F-Measure sebesar 96% untuk bahasa India, 98% untuk bahasa Bengali dan 98.5% untuk bahasa Telugu.
2. STUDI PUSTAKA
2.1. Transaksi Akuntansi
Transaksi akuntansi ialah transaksi yang memengaruhi minimal dua data akuntansi. Transaksi akuntansi dapat dibedakan menjadi transaksi penjualan, transaksi pembelian, transaksi penerimaan uang serta transaksi pengeluaran uang. Sebuah transaksi akuntansi harus terdiri dari tanggal terjadinya transaksi, nama perusahaan, nilai uang dan jenis transaksi (Iswandi et al., 2015). Berikut merupakan label entitas yang biasa terdapat dalam transaksi akuntansi:
1. Tanggal. Bentuk penulisan tanggal terjadinya akuntansi biasa ditulis dengan Sd = {dd, MM, yy}
Sd = Sample of Date dd = date
MM = month yy = year
3. Nilai uang. Untuk melakukan identifikasi nilai uang pada teks transaksi akuntansi dapat berupa angka maupun kata-kata. 4. Kuantitas. Untuk melakukan identifikasi
nilai dari kuantitas dalam teks transaksi akuntansi.
5. Jenis transaksi. Untuk melakukan identifikasi jenis transaksi pada teks transaksi akuntansi yang dapat berupa transaksi pembelian, transaksi penjualan, transaksi penerimaan uang dan transaksi pengeluaran uang.
Hasil identifikasi terhadap transaksi akuntansi berupa pengenalan entitas-entitas akuntansi yang dibutuhkan untuk membuat pencatatan akuntansi atau biasanya lebih dikenal dengan istilah jurnal akuntansi.
2.1. Text Mining
Proses text mining dimulai dengan pengumpulan atau koleksi dokumen dari berbagai sumber, kemudian diambil sebuah dokumen tertentu untuk dilakukan preprocessing dengan memeriksa format dan set karakter. Setelah itu dilakukan analisa teks yang merupakan analisis semantik guna memperoleh informasi yang berkualitas tinggi dari teks. Informasi yang didapatkan ini dapat disimpan dalam sistem informasi (Gaikwad et al., 2014). Pre-processing yang biasa dilakukan antara lain tokenisasi, filtering dan case folding.
2.2. Named Entity Recognition (NER)
NER merupakan komponen utama dari ekstraksi informasi memiliki berbagai fungsi seperti mengenali entitas nama (bisa nama orang, perusahaan, organisasi, lokasi), ekspresi bilangan (seperti kardinal, persen, uang, numerik) dan ekspresi waktu (misal durasi, tanggal, waktu) pada kumpulan dokumen teks (Chinchor et al., 1999). Pada intinya named entity recognition ini mengidentifikasi kata-kata yang ditujukan sebagai sesuatu yang bersifat menarik dalam aplikasi tertentu. NER bukanlah hal yang sulit dilakukan oleh manusia, karena bahasa alami dalam bentuk teks ini sering digunakan manusia dalam kehidupan sehari-hari. Manusia dapat dengan mudahnya mengenali mana kata yang merupakan nama orang, organisasi, lokasi dan lain sebagainya. Hal ini dikarenakan entitas nama tersebut memiliki ciri unik, misal nama orang atau nama kota yang diawali dengan huruf kapital.
Risa Amalia mendatangi acara ulang tahun [PERSON]
perusahaan Medika Indonesia di Bandung
mendatang[ORGANIZATION] [LOC] pada bulan Februari
pada tahun [DATE]
Gambar 1. Contoh pengenalan entitas
2.3. Hidden Markov Model (HMM)
HMM dapat dikatakan sebagai model urutan atau klasifikasi terurut merupakan model yang memiliki fungsi untuk menetapkan label atau kelas untuk setiap unit secara berurutan. HMM adalah model urutan probabilistik urutan dari unit-unit (kata, huruf, morfem, kalimat dan lain sebagainya) yang kemudian dihitung nilai distribusi probabilitas untuk didapatkan urutan label yang memungkinkan dan memilih urutan label yang terbaik. HMM ditentukan oleh komponen-komponen berikut, yaitu (Jurafsky & Martin, 2016):
1. 𝑄 = 𝑞1𝑞2… 𝑞𝑁, sebagai kumpulan N kondisi 2. 𝐴 = 𝑎01𝑎02… 𝑎𝑛1𝑎𝑛𝑛, merupakan matriks transition probability A, setiap 𝑎𝑖𝑗 mewakili probabilitas perpindahan dari kondisi 𝑖 ke kondisi 𝑗. Transition probability dapat dihitung dengan menggunakan rumus pada persamaan 1.
𝑃(𝑡𝑖|𝑡𝑖−1) =𝐶(𝑡𝐶(𝑡𝑖−1𝑖−1,𝑡)𝑖) (1)
3. 𝑂 = 𝑜1𝑜2… 𝑜𝑟, merupakan urutan dari 𝑇 pengamatan masing-masing diambil dari kosakata
4. 𝐵 = 𝑏1(𝑜𝑡), merupakan urutan pengamatan likelihood, disebut juga emission probabilities yang mana masing-masing mewakili probabilitas dari pengamatan 𝑜𝑡 yang dihasilkan dari kondisi 𝑖. Emission probabilities dapat dihitung dengan menggunakan rumus pada persamaan 2.
𝑃(𝑤𝑖|𝑡𝑖) =𝐶(𝑡𝐶(𝑡𝑖,𝑤𝑖)𝑖) (2)
5. 𝑞0, 𝑞𝐹, sebagai kondisi awal dan kondisi akhir (final) yang tidak berhubungan dengan pengamatan
2.4. Algoritme Viterbi
probability dan emission probability yang telah didapatkan pada pemodelan Hidden Markov Model. Algoritme Viterbi ini dilakukan secara rekursif sebanyak kata yang akan dikenali pada data uji. A Persamaan 3 digunakan untuk menghitung nilai setiap sel pada Viterbi pada waktu 𝑡 (Jurafsky & Martin, 2016)
𝑣𝑡(𝑗) =
𝑁 𝑚𝑎𝑥
𝑖 = 1𝑣𝑡−1(𝑖)𝑎𝑖𝑗𝑏𝑗(𝑜𝑡) (3) Keterangan:
𝑣𝑡−1(𝑖) : probabilitas jalur Viterbi sebelumnya
dari langkah waktu sebelumnya 𝑎𝑖𝑗 : probabilitas transisi dari kondisi
sebelumnya 𝑞𝑖 ke kondisi sekarang 𝑞𝑗 𝑏𝑗𝑜𝑡 : kemungkinan kondisi pengamatan
dari 𝑜𝑡 berdasarkan kondisi 𝑗 sekarang
2.5. Laplace Smoothing
Martin Haulrich pada tahun 2009 melakukan penelitian mengenai implementasi Hidden Markov Model untuk part-of-speech tagger dan melakukan beberapa pendekatan yang berbeda untuk menangani kata yang tidak diketahui atau unknown word. Martin melakukan Laplace Smoothing untuk menghindari kalimat tanpa urutan tag dengan menambahkan nilai satu ketika melakukan estimasi transition probability. Penerapan Laplace Smoothing pada transiton probability dapat dilakukan dengan menggunakan rumus pada Persamaan 4.
𝑎𝑘𝑚=𝑞𝑞𝑘𝑘𝑞+𝑄𝐴𝑚+1 (4)
𝑎𝑘𝑚 merupakan nilai transition probability dari kondisi 𝑞𝑘 ke kondisi 𝑞𝑚, yaitu probabilitas dari kata dengan POS-tag 𝑞𝑚 yang diikuti dengan kata dengan POS_tag 𝑞𝑘. 𝑄𝐴 adalah jumlah dari kemungkinan POS-tag. Penerapan Laplace Smoothing pada emission probabilities dapat dilakukan menggunakan rumus pada Persamaan 5.
𝑏𝑖(𝑜𝑡) =𝑜𝑞𝑡𝑞𝑖+1
𝑖+𝑉 (5)
𝑏𝑖(𝑜𝑡) adalah nilai emission probability, dengan 𝑜𝑡 adalah kata ke 𝑡 dan 𝑞𝑖 adalah kondisi ke 𝑖. Nilai 𝑉 adalah jumlah dari keseluruhan kata yang berbeda pada data latih.
3. PERANCANGAN SISTEM
Pada pengenalan entitas bernama untuk identifikasi transaksi akuntansi menggunakan
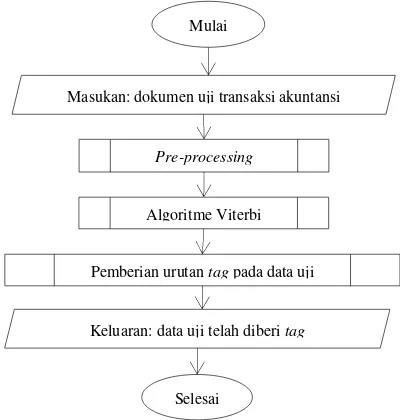
Hidden Markov Model dibagi menjadi dua rancangan sistem. Rancangan pertama ialah perancangan sistem untuk pemodelan yang mana pada rancangan sistem ini menerapkan Hidden Markov Model (HMM) seperti yang ditunjukkan pada Gambar 2 dan rancangan kedua ialah perancangan sistem decoding HMM dan pemberian tag pada data uji seperti yang ditunjukkan pada Gmbar 3.
Gambar 2. Diagram alir pemodelan Hidden Markov Model
Berdasarkan Gambar 2 di atas, dokumen yang digunakan sebagai data latih akan dilakukan pre-processing. Keluaran dari proses ini merupakan pemodelan yang nantinya akan digunakan pada pengujian atau digunakan untuk memproses data uji.
Gambar 3. Diagram alir decoding HMM dan pemberian tag pada data uji
Masukan: dokumen uji transaksi akuntansi
Pre-processing
Algoritme Viterbi
Keluaran: data uji telah diberi tag
Pemberian urutan tag pada data uji Mulai
Selesai
Masukan: kumpulan dokumen transaksi akuntansi sejumlah m data latih
Pre-processing
Proses training dengan Hidden Markov Model
Keluaran: Hidden Markov Model
Berdasarkan Gambar 3 di atas, dokumen yang digunakan sebagai data uji akan dilakukan pre-processing, kemudian dijalankan proses algoritme Viterbi dan pemberian urutan tag yang optimum. Hasil akhir dari proses ini akan memberikan keluaran data yang berupa data uji yang telah dilabeli atau diberi tag.
4. PENGUJIAN DAN ANALISIS
4.1. Pengujian Hidden Markov Model
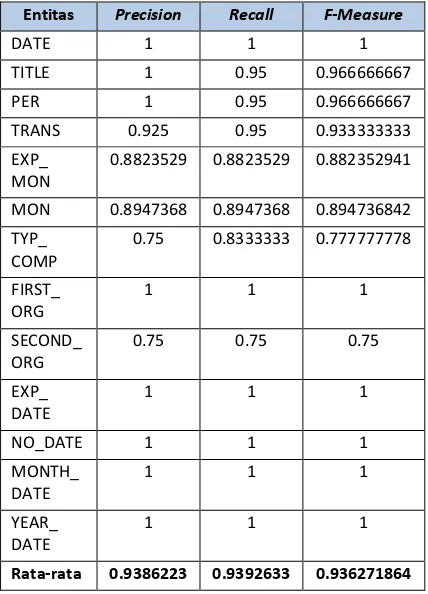
Tabel 1. Pengujian fitting pada model yang telah dibuat
Entitas Precision Recall F-Measure
DATE 1 1 1
0.8823529 0.8823529 0.882352941
MON 0.8947368 0.8947368 0.894736842
TYP_ COMP
0.75 0.8333333 0.777777778
FIRST_
Rata-rata 0.9386223 0.9392633 0.936271864
Pada pengujian ini total data uji yang digunakan adalah sebanyak 20 data yang dipilih secara random dari data latih, sedangkan jumlah data latih yang digunakan adalah 50. Berdasarkan hasil dari pengujian ini didapatkan nilai rata-rata dari precision, recall dan f-measure adalah sebesar 93.86%. Hal ini menunjukkan bahwa pengenalan entitas bernama menggunakan Hidden Markov Model sudah bagus karena mampu mengenali modelnya sendiri dengan baik.
Tabel 2. Pengujian 20 data uji
Entitas Precision Recall F-Measure
DATE 0.3333333 0.3333333 0.333333333
TITLE 0.4285714 0.4285714 0.428571429
PER 0.4285714 0.4285714 0.428571429
TRANS 0.5 0.5 0.5
EXP_ MON
0.5882353 0.5882353 0.588235294
MON 0.3157895 0.3157895 0.315789474
TYP_ COMP
0.3333333 0.3333333 0.333333333
FIRST_ ORG
0.1666667 0.1666667 0.166666667
SECOND_
0.2941176 0.2941176 0.294117647
MONTH_ DATE
0.7058824 0.7058824 0.705882353
YEAR_ DATE
0 0 0
Rata-rata 0.3918847 0.3918847 0.391884689
Pada pengujian ini total data uji yang digunakan adalah sebanyak 20 data yang mana data ini tidak terdapat pada data latih, dan jumlah data latih yang digunakan adalah 50. Nilai precision, recall dan f-measure terendah didapatkan pada entitas SECOND_ORG dan YEAR_DATE yaitu sebesar 0%. Hal ini disebabkan sistem yang diimplementasikan berpacu pada nilai state sebelumnya atau dikenal dengan nilai transition probability dan dipengaruhi dengan nilai emission probability. Apabila suatu kata ditemukan pada data latih dan memiliki entitas, maka kata pada data uji yang seharusnya tidak memiliki entitas akan diberi entitas oleh sistem. Hal ini menyebabkan sistem akan menghasilkan pemberian entitas bernama yang kurang tepat pada kata-kata selanjutnya pada data uji.
4.2. Pengujian Hidden Markov Model dengan
Menambahan Teknik Laplace Smoothing
Penambahan teknik Laplace Smoothing, hal ini ditujukan agar data uji yang tidak ditemukan pada latih tidak bernilai nol atau memiliki nilai transition probability dan emission probability.
Tabel 3. Hasil pengujian 2
Entitas Precision Recall
F-Measure
DATE 0 0 0
TITLE 0.7142857 0.7142857 0.7142857
TRANS 0.6666667 0.7777778 0.7037037
EXP_MON 0.6568627 1 0.7647059
MON 0.8947368 0.8947368 0.7368421
TYP_COMP 0.6666667 0.6666667 0.6666667
FIRST_ORG 0.8333333 0.8333333 0.8333333
SECOND_OR G
1 1 1
EXP_DATE 1 1 1
NO_DATE 0.7156863 0.8235294 0.745098
MONTH_
Pengujian ini dilakukan dengan menambahkan teknik Laplace Smoothing, hal ini ditujukan agar data uji yang tidak ditemukan pada latih tidak bernilai nol atau memiliki nilai transition probability dan emission probability. Pengujian dengan menggunakan 20 data uji dan 50 data latih dengan menambahkan teknik Laplace Smoothing menghasilkan nilai precision, recall dan f-measure tertinggi sebesar 100%. Sedangkan nilai precision, recall dan f-measure terendah ialah 0% yang terdapat pada entitas DATE. Hal ini disebabkan sistem yang diimplementasikan berpacu pada nilai state sebelumnya atau dikenal dengan nilai transition probability dan dipengaruhi dengan nilai emission probability. Mengingat bahwa teknik Laplace Smoothing ini mencegah munculnya nilai 0 pada transition probability dan emission probability, maka kata yang seharusnya diberi entitas DATE jutru diberi entitas MONTH_DATE karena nilai transition probability dari perubahan state START ke MONTH_DATE lebih besar daripada probability dari START ke DATE. Sehingga rata-rata nilai precision, recall dan f-measure yang didapatkan setelah menambahkan teknik Laplace Smoothing ini berturut-turut 74.06%, 80.19% dan 74.69%. Hal ini menunjukkan bahwa dengan menambahkan Laplace Smoothing dapat meningatkan nilai precision, recall dan f-measure namun masih perlu ditambahkan suatu teknik agar dapat meningkatkan nilai precision, recall dan f-measure pada entitas DATE.
4.3. Pengujian Hidden Markov Model dengan
Menambahan Teknik Laplace Smoothing
dan Regular Expression
Pengujian ini dilakukan dengan menambahkan teknik Laplace Smoothing dan
Regular Expression agar data uji yang tidak ditemukan pada latih tidak bernilai nol atau memiliki nilai transition probability dan emission probability serta apabila data uji yang ditemukan memiliki pola seperti pada entitas DATE maka sistem akan memberi entitas DATE. Penambahan Regular Expression ini dikarenakan melihat dari pola kata pada entitas DATE memiliki pola yang sama yaitu angka-angka yang dipisahkan oleh 2 garis miring.
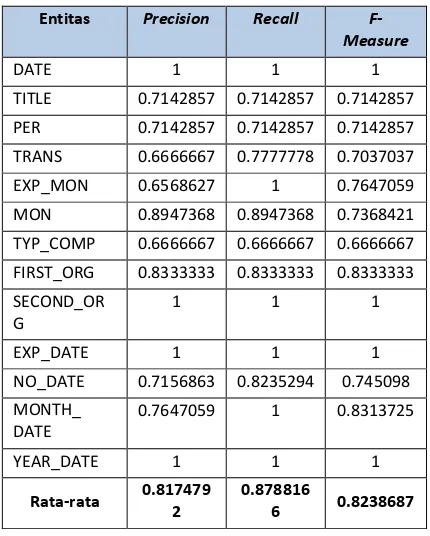
Tabel 4. Hasil pengujian 3
Entitas Precision Recall
F-Measure
DATE 1 1 1
TITLE 0.7142857 0.7142857 0.7142857
PER 0.7142857 0.7142857 0.7142857
TRANS 0.6666667 0.7777778 0.7037037
EXP_MON 0.6568627 1 0.7647059
MON 0.8947368 0.8947368 0.7368421
TYP_COMP 0.6666667 0.6666667 0.6666667
FIRST_ORG 0.8333333 0.8333333 0.8333333
SECOND_OR G
1 1 1
EXP_DATE 1 1 1
NO_DATE 0.7156863 0.8235294 0.745098
MONTH_
Nilai precision terendah terdapat pada entitas EXP_MON sebesar 65.69% serta nilai recall dan f-measure terdapat pada entitas TYPE_COMP sebesar 66.67%. Penambahan Regular Expression pada sistem dapat menangani kesalahan pemberian entitas DATE pada pengujian sebelumnya. Sehingga rata-rata nilai precision, recall dan f-measure yang didapatkan setelah menambahkan teknik Laplace Smoothing dan Regular Expression ini berturut-turut 81.75%, 87.88% dan 82.39%. Hal ini menunjukkan bahwa dengan menambahkan teknik Laplace Smoothing dan Regular Expression dapat meningatkan nilai precision, recall dan f-measure pada sistem pengenalan bernama untuk identifikasi transaksi akuntansi.
5. ANALISIS
menambahkan teknik Laplace Smoothing dan Regular Expression dengan rata-rata nilai precision, recall dan f-measure berturut-turut sebesar 81.75%, 87.88% dan 82.39%. Variasi terbaik kedua terdapat pada pengujian Hidden Markov Model dengan menambahkan teknik Laplace Smoothing dengan rata-rata nilai precision, recall dan f-measure berturut-turut sebesar 74.06%, 80.19%, dan 74.69%. Variasi terbaik ketiga terdapat pada pengujian Hidden Markov Model dengan rata-rata nilai precision, recall dan f-measure sebesar 39.19%.
Berdasarkan pengujian yang telah dilakukan, terlihat bahwa pemodelan asli Hidden Markov Model memiliki kinerja yang cukup baik dalam mengenali entitas kata. Namun, pemodelan asli Hidden Markov Model akan memiliki hasil yang buruk apabila kata-kata pada data uji belum pernah dikenali sebelumnya atau tidak ada dalam data latih. Penambahan teknik Laplace Smoothing pada pemodelan Hidden Markov Model mampu menangani kata-kata yang belum pernah dikenali sebelumnya, sehingga penambahan teknik Laplace Smoothing ini dapat meningkatkan nilai precision, recall dan f-measure menjadi 74.06%, 80.19%, dan 74.69%.. Meskipun dengan penambahan teknik ini juga terdapat kelemahan, seperti kata yang seharusnya tidak memiliki entitas namun diberi entitas oleh sistem. Misalnya kata yang seharusnya diberi entitas DATE tetapi sistem memberikan entitas MONTH_DATE. Penambahan teknik Laplace Smoothing ini belum bisa menangani kata yang berentitas DATE, hal ini disebabkan transition probability dari tag START ke MONTH_DATE lebih besar daripada transition probability dari tag START ke DATE berdasarkan data latih.
Penggunaan teknik Regular Expression dapat menangani masalah ini, yaitu kata yang terdapat di data uji pada pengujian sebelumnya yang diberi tag MONTH_DATE berhasil diperbaiki menjadi tag DATE. Contohnya kata 23/1/2010 dikenali sebagai entitas MONTH_DATE pada pengujian sebelumnya, berhasil diperbaiki oleh sistem dengan mengenali ata 23/1/2010 sebagai entitas DATE. Hal ini dikarenakan apabila kata yang diujikan memiliki pola yang sama dengan entitas DATE akan dikenali oleh Regex, kemudian sistem secara otomatis akan memberikan tag DATE pada kata tersebut.
6. KESIMPULAN
Untuk mengimplementasikan Hidden Markov Model dan algoritme Viterbi yang harus dilakukan terlebih dahulu yaitu pre-processing terhadap data latih maupun data uji dengan menghilangkan stopword, melakukan tokenisasi serta case folding. Selanjutnya menghitung frekuensi tag yang muncul pada data latih serta frekuensi suatu kata dengan entitas tertentu pada data latih dan menghitung frekuensi perpindahan state pada data latih. Frekuensi yang telah disimpan akan dipanggil pada proses perhitungan transition probability dan emission probability. Setelah data latih telah dilakukan proses pemodelan menggunakan Hidden Markov Model, data uji akan diproses berdasarkan pemodelan yang telah dibuat menggunakan algoritme Viterbi.
Berdasarkan hasil pengujian, nilai precision, recall dan f-measure yang didapatkan dari implementasi Hidden Markov Model ialah sebesar 93.86%, 93.93% dan 93.63% yang mana pengujian ini menggunakan data uji yang terdapat pada data latih. Namun, apabila data uji yang digunakan tidak terdapat pada data latih nilai precision, recall dan f-measure yang didapatkan cenderung menurun.
Laplace Smoothing terbukti mampu menangani kata yang belum pernah muncul sebelumnya pada data latih. Serta penambahan Regular Expression mampu menangani kata-kata dengan pola seperti pada entitas DATE. Sehingga dapat disimpulkan pengenalan entitas bernama untuk identifikasi transaksi akuntansi menggunakan Hidden Markov Model dengan penambahan teknik Laplace Smoothing dan Regular Expression akan menjadikan sistem handal atau robustly.
REFERENSI
Abdelmagid, M., Ahmed, A. & Himmat, M., 2015. Information Extraction Methods and Etraction Techniques in the Chemical Document's Contents: Survey. ARPN Journal of Engineering and Applied Sciences, X, pp.1068-73.
Chinchor, N., Brown, E., Ferro, L. & Robinson, P., 1999. Named Entity Recognition Task Definition. The MITRE Corporation and SAIC.
Haulrich, M., 2009. Different Approaches to Unknown Words in a Hidden Markov Model Part-of-Speech Tagger. pp.1-8.
Iswandi, I., Suwardi, I.S. & Maulidevi, N.U., 2015. Perancangan Named Entity Recognition dalam Akuntansi untuk Identifikasi Transaksi berdasarkan Teks Indonesia. In Seminar Nasional Pengembangan Aktual Teknologi Informasi (SENA BAKTI). Surabaya, 2015.
Jurafsky, D. & Martin, J.H., 2016. Speech and Language Processing.
Morwal, S. & Chopra, D., 2013. Identification and Classification of Named Entities in Indian Languages. International Journal on Natural Language Computing (IJNLC), II, pp.37-43.