1 1.1Latar Belakang
Internet telah menjadi sarana berbagi informasi dan mengekspresikan opini dengan respon yang cepat oleh pengguna di jejaring sosial [1]. Layanan jejaring sosial memungkinkan setiap orang saling berinteraksi dan berbagi informasi tanpa batasan ruang dan waktu. Salah satu jejaring sosial yang populer dan banyak digunakan adalah Twitter.
Twitter adalah microblogging service yang telah memperoleh popularitas untuk berbagi informasi dan opini terhadap topik yang bermacam-macam dalam bentuk 140 Karakter pesan yang dinamakan tweet, twitter juga dikenal sebagai sarana penyebaran informasi dan mengekspresikan opini [2]. Contohnya selama peristiwa besar terjadi seperti bencana gempa bumi, gunung meletus, badai ataupun peristiwa seperti pemilihan umum, ataupun pendapat terhadap tokoh. Hal-hal tersebut selalu ditanggapi oleh aktivitas di internet [2].
Pengguna twitter menyebarkan tweet dengan konten yang berbeda-beda sesuai dengan pola kebiasaan dan gaya menulis pengguna. Konten seperti ini dapat mengandung informasi yang bernilai. Konten yang disebarkan pengguna twitter dapat dikategorikan, secara umum kategorinya yaitu informasi/berita, opini/keluhan, promosi, pernyataan, random tweet, pertanyaan, membuktikan eksistensi, obrolan dan tweet mengenai pengguna tersebut [3]. Pada penelitian ini akan dilakukan analisis tweet yang bersifat opini terhadap partai politik peserta PEMILU 2014.
2
analisis terhadap konten tweet yaitu menggunakan pohon keputusan atau decision tree learning yang dibangun dengan algoritma C 4.5. metode ini dipilih karena
proses analisis bersifat klasifikasi. Algoritma C4.5 adalah salah satu sistem untuk membangun model klasifikasi yang umum digunakan [4].
Berdasarkan masalah yang diuraikan diatas dibutuhkan sebuah sistem untuk menganalisis sentimen pengguna twitter terhadap partai politik peserta PEMILU 2014 menggunakan algoritma C4.5 decision tree learning untuk mengklasifikasikan tweet. Hasil dari penelitian tugas akhir ini adalah untuk mengetahui apakah model pohon keputusan yang dihasilkan algoritma C4.5 dalam aplikasi dapat digunakan untuk menganalisa sentimen positif dan negatif pengguna twitter terhadap partai politik. Penelitian sebagai topik untuk tugas akhir ini mengangkat judul “Analisis Sentimen Pengguna Twitter Terhadap Partai Politik Peserta PEMILU 2014 Menggunakan Algoritma C4.5 Decision Tree Learning”.
1.2Rumusan Masalah
Berdasarkan latar belakang masalah yang telah diuraikan di atas, yang menjadi permasalahan dalam penelitian ini adalah bagaimana menerapkan Algoritma C4.5 untuk membangun pohon keputusan dan membangun aplikasi analisis sentimen pengguna twittter terhadap partai politik peserta PEMILU 2014 untuk menjadi informasi tambahan mengenai partai politik bagi masyarakat.
1.3Maksud dan Tujuan
Maksud dari penelitian ini adalah untuk menerapkan algoritma C4.5 untuk membangun pohon keputusan untuk analisis sentimen pengguna twitter terhadap partai politik peserta PEMILU 2014.
Sedangkan tujuan yang dicapai untuk penelitian ini adalah:
1. Dapat mengetahui tingkat akurasi pohon keputusan yang dibentuk algoritma C4.5 dalam mengklasifikasi tweet sentimen.
1.4Batasan Masalah
Mengingat permasalahan yang dikaji sangat luas, agar penyajian lebih terarah dan mencapai sasaran yang ditentukan, maka diperlukan suatu pembatasan masalah atau ruang lingkup kajian yang meliputi hal-hal sebagai berikut:
1. Tweet yang akan dianalisis mengandung kata nama partai politik peserta PEMILU 2014 setelah dilakukan pengambilan data menggunakan Twitter Streaming API.
2. Opini yang dianalisis adalah opini terhadap 12 partai politik yaitu Partai Nasional Demokrat, Partai Kebangkitan Bangsa, Partai Keadilan Sejahtera, Partai Demokrasi Indonesia Perjuangan, Partai Golongan Karya, Partai Gerakan Indonesia Raya, Partai Demokrat, Partai Amanat Nasional, Partai Persatuan Pembangunan, Partai Hati Nurani Rakyat, Partai Bulan Bintang, dan Partai Keadilan dan Persatuan Indonesia. 3. Metode untuk klasifikasi tweet menggunakan pohon keputusan yang
dibentuk algoritma C4.5.
4. Aplikasi ini akan dibangun dengan menggunakan pemodelan terstruktur dengan tools Data Flow Diagram (DFD) sebagai analisis kebutuhan fungsional dan Entitiy Relationship Diagram (ERD) sebagai analisis basis data.
5. Aplikasi ini dibangun dengan menggunakan bahasa pemrograman PHP dan database MySQL.
1.5Metode Penelitian
Metode penelitian dalam penyusunan tugas akhir ini dibagi menjadi dua tahap yaitu, tahap pengumpulan data dan tahap pembangunan perangkat lunak.
1.5.1 Metode Pengumpulan Data a) Studi Literatur
4
b) Observasi
Pengumpulan data dengan cara melakukan pengamatan langsung terhadap tweet yang bermunculan yang membahas tentang pemilihan umum 2014 dan partai politik pesertanya.
1.5.2 Metode Pembangunan Perangkat Lunak
Teknik analisis data dalam pembuatan perangkat lunak menggunakan paradigma perangkat lunak secara waterfall, yang meliputi beberapa proses diantaranya:
a. System/Information Engineering
Merupakan tahap yang terbesar dalam pengerjaan aplikasi, dimulai dengan mengumpulkan tweet menggunakan Twitter Streaming API.
b. Analisis
Merupakan tahap menganalisis hal-hal yang diperlukan dalam pelaksanaan pembuatan perangkat lunak. Pada tahap ini juga dilakukan analisis terhadap pohon keputusan yang dibangun algoritma C4.5.
c. Design
Design adalah tahap menerjemahkan dari keperluan-keperluan yang
dianalisis ke dalam bentuk yang lebih mudah dimengerti oleh pemakai. d. Coding
Coding adalah hasil perancangan sistem diterjemahkan ke dalam kode-kode dengan menggunakan bahasa pemrograman PHP.
e. Testing
Testing adalah tahap pengujian terhadap program yang telah dibuat. Pengujian ini dilakukan untuk memastikan tidak ada kesalahan dalam melakukan klasifikasi terhadap tweet dan memberikan hasil yang sesuai dengan yang diinginkan.
f. Maintenance
permintaan user. Pada program yang dibangun ini tidak dilakukan tahap maintenance.
Gambar 1.1 Skema Model Waterfall [14]
1.6Sistematika Penulisan
Sistematika penulisan penelitian ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi latar belakang masalah, rumusan masalah, maksud dan tujuan, metodologi penelitian, dan sistematikan penulisan.
BAB II LANDASAN TEORI
Bab ini berisi landasan teori yang membahas tentang Text Mining, Text Pre-processing, Klasifikasi, Algoritma C4.5, Basis data, Database Management System(DBMS), Pemodelan Analisis, ERD, DFD, MySQL, PHP, HTML yang digunakan untuk membangun aplikasi ini.
6
Bab ini berisi analisis sistem, analisis masalah, perancangan sistem, pengenalan aplikasi yang dibangun, definisi kebutuhan perangkat lunak, perancangan sistem, perancangan antarmuka.
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi implementasi sistem yang meliputi kebutuhan perangkat keras, kebutuhan perangkat lunak, implementasi basis data, implementasi antarmuka. Pengujian alpha dan pengujian beta.
BAB V KESIMPULAN DAN SARAN
7
BAB 2
LANDASAN TEORI
2.1 Twitter
Twitter adalah jejaring sosial dan microblogging service yang memungkinkan penggunanya untuk mengirim 140 karakter pesan teks yang disebut “tweet”. Pengguna yang terdaftar dapat membaca dan mengirim tweet. Tetapi pengguna yang tidak terdaftar hanya dapat membaca tweet. Pengguna mengakses twitter melalui antarmuka website, SMS, atau aplikasi perangkat mobile. Twitter memiliki popularitas yang mendunia dengan 29,5 juta pengguna yang terdaftar pada tahun 2012 yang mengirim sebanyak 340 juta tweet per hari [5]
2.2 Partai Politik
Pemilihan umum 2014 dibagi menjadi dua putaran yaitu PEMILU legislatif yang dilaksanakan tanggal 9 April 2014 dan PEMILU Presiden yang diadakan tanggal 9 juli 2014. PEMILU 2014 diikuti oleh 12 peserta partai politik yang disaring dari 46 partai politik yang mendaftar. 12 partai politik peserta pemilu yaitu Partai Nasional Demokrat, Partai Kebangkitan Bangsa, Partai Keadilan Sejahtera, Partai Demokrasi Indonesia Perjuangan, Partai Golongan Karya, Partai Gerakan Indonesia Raya, Partai Demokrat, Partai Amanat Nasional, Partai Persatuan Pembangunan, Partai Hati Nurani Rakyat, Partai Bulan Bintang, dan Partai Keadilan dan Persatuan Indonesia.
2.3 Text Mining
Text data mining fokus terhadap metode data mining yang diaplikasikan pada tekstual data. Beberapa bagian dari text mining adalah term, corpus, lexicon, dan dokumen. Term adalah kata atau kombinasi kata atau prasa. Dokumen adalah sekumpulan kata dan tanda baca, dokumen dapat terdiri dari beberapa segmen teks dan memiliki panjang yang tidak ditentukan. Contoh dari dokumen adalah kalimat, paragraf, bagian sebuah buku atau bab, buku, halaman web, email dan lain-lain. Corpus adalah koleksi dokumen. Lexicon adalah sekumpulan kata yang bersifat unik yang terdapat pada corpus[6].
2.4 Text Pre-Processing
Text Pre-Processing adalah serangkaian proses yang dilakukan untuk mempersiapkan data sebelum proses lebih lanjut. Tahapan ini memiliki tujuan untuk mengubah data agar dapat dilanjukan ke proses klasifikasi.
Terdapat beberapa proses yang harus dilakukan dalam tahap text pre-processing atau persiapan dokumen teks, yaitu tokenization, casefolding, stemming.
2.4.1Tokenization
Tokenization merupakan proses memecah suatu kalimat dalam seluruh isi
dokumen menjadi sekumpulan kata atau token yang dipisahkan oleh spasi. Hasil dari proses tokenization selanjutnya digunakakan pada proses selanjutnya seperti casefolding dan stemming.
9
2.4.2Casefolding
Case Folding, merupakan proses mengubah semua huruf yang ada pada seluruh dokumen menjadi huruf kecil. Huruf “a” sampai dengan “z”yang akan diproses, karakter selain huruf akan dianggap delimiter.
Gambar 2.2 Casefolding
2.4.3Stemming
Stemming adalah salah satu cara untuk meningkatkan performa dalam text processing dengan cara mentransformasi kata-kata dalam sebuah dokumen teks ke kata dasarnya. Algoritma stemming untuk masing-masing bahasa berbeda-beda, sebagai contoh bahasa Inggris memiliki morfologi yang berbeda dengan bahasa Indonesia sehingga algoritma stemming untuk kedua bahasa tersebut juga berbeda [7].
Stemming menggunakan aturan-aturan tertentu sebagai contoh kata bersama, kebersamaan dan menyamai mempunyai root word yang sama yaitu “sama”. Pada teks berbahasa Inggris, proses yang perlu dilakukan hanya proses menghilangkan suffiks, sedangkan pada teks berbahasa Indonesia, selain suffiks, prefiks dan konfiks juga dihilangkan. Salah satu algoritma untuk stemming pada teks berbahasa Indonesia adalah algoritma nazief & adriani yang dibuat oleh Bobby Nazief dan Mirna Adriani. Algoritma tersebut memiliki tahap-tahap sebagai berikut:
2. Penghapusan Inflexion Suffix, (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”). Cek kata dalam kamus, jika kata ditemukan maka diasumsikan bahwa kata tersebut adalah root word.
3. Penghapusan derivation suffiks (“-i”, “-an”, “kan”). Jika kata ditemukan di kamus, maka algoritma berhenti, jika tidak maka lanjutkan ke langkah 3a. a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k” ,
maka “-k” juga dihapus. Jika kata ditemukan dalam kamus maka algoritma berhenti. Jika tidak maka lanjutkan ke langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an”, atau “-kan”). Dikembalikan, lanjut ke langkah 4.
4. Hapus derivation prefix. Jika pada langkah 3 ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak maka lanjut ke langkah 4b.
a. Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan. Jika ditemukan maka algoritma berhenti, jika tidak lanjutkan ke langkah 4b. b. Tentukan tipe awalan kemudian hapus awalan. Jika root word belum juga
ditemukan lakukan langkah 5.
5. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagai root word. Proses selesai.
Pada tahap ke empat langkah-langkah yang dilakukan proses stemming, terdapat pemeriksaan kombinasi awalan dan akhiran yang tidak dizinkan. Tabel II.1 menunjukan kombinasi awalan akhiran yang tidak diizinkan.
Tabel 2.1 Kombinasi Awalan Akhiran
11
Salah satu aplikasi dari data mining adalah klasifikasi. Menggunakan sampel data sebelumnya yang telah memiliki kategori untuk dijadikan data training, tujuannya adalah untuk memberikan kategori pada data baru yang belum dikategorikan. Klasifikasi pada teks melibatkan banyak teknik termasuk indexing pada information retieval dan teknik dari machine learning untuk menentukan kategori secara otomatis dari data training yang sudah diberi label. Pada proses klasifikasi sebuah dokumen, tidak digunakan informasi lain selain konten dari dokumen tersebut.
2.6 Decision Tree
Decision Tree atau pohon keputusan adalah model yang dikembangkan untuk
membantu mencari dan membuat keputusan untuk masalah yang akan dipecahkan dengan memperhitungkan berbagai macam faktor yang ada di dalam lingkup masalah tersebut. Mekanisme dari pohon keputusan seperti struktur pohon, dimana tiap internal node menunjukan sebuah test pada sebuah attribut, setiap cabang menunjukan hasil dari test, dan leaf node menunjukan kelas atau kategori. Pada decision tree terapat terdapat tiga jenis node, yaitu:
a) Root Node, merupakan node teratas atau akar, pada node ini tidak memiliki parent dan mempunyai child lebih dari satu.
b) Internal Node, merupakan node percabangan, memiliki parent dan minimal dua child.
c) Leaf Node, merupakan node akhir, pada node ini memiliki parent dan tidak memiliki child.
Gambar 2.3 Model Pohon Keputusan
Setiap percabangan atau internal node menyatakan kondisi yang harus dipenuhi dan tiap ujung pohon atau leaf node menyatakan kelas atau kategori dari setiap sampel pada training set.
2.7 Algoritma C4.5
13
pohon keputusan. Mempunyai masukan berupa data training. Data training berupa data contoh yang telah mempunyai label kelas positif atau negatif, akan digunakan untuk membangun sebuah tree. Sedangkan atribut-atribut data digunakan sebagai parameter dalam proses klasifikasi data.
2.7.1Perhitungan Information Gain
Perhitungan information gain dilakukan untuk attribute selection measure yang digunakan untuk memilih atribut pada setiap simpul pada pohon keputusan. Atribut dengan information gain tertinggi atau nilai pengurangan entropy yang terbesar dipilih sebagai tes atribut pada simpul. Untuk menghitung gain digunakan rumus seperti tertera dalam persamaan (1)
(1)
Perhitungan nilai entropy dapat dilihat pada persamaan (2).
(2) Keterangan :
S : Jumlah seluruh kasus
Neg(S) : Jumlah kasus dengan kelas negatif Pos(S) : Jumlah kasus dengan kelas positif
2.7.2Pembentukan Pohon Keputusan
1. Terdapat masukan berupa training set yang setiap sampelnya telah diberi kelas atau kategori.
2. Jika seluruh sampel pada training set memiliki kelas yang sama maka pohon keputusan akan memiliki satu node berupa leaf node yang diberi label kelas yang terdapat pada semua sampel dalam training set.
3. Jika seluruh sampel tidak dalam satu kelas yang sama maka akan dicari gain tertinggi dari seluruh atribut untuk memilih atribut yang paling berpengaruh pada training set, dan akan dijadikan atribut penguji pada node tersebut. 4. Jumlah cabang setiap node dibangun berdasarkan partisi nilai dari atribut
pengujian. Jika ada partisi nilai yang memiliki nilai entropy nol, maka cabang dari partisi nilai tersebut menjadi leaf node yang diisi kelas yang memiliki jumlah kemunculan tertinggi pada training data.
5. Jika ada cabang dari node yang dibentuk pada langkah sebelumnya belum mencapai leaf node, maka akan dicari nilai gain seperti pada langkah nomor 3 dimulai dari cabang paling kiri yang belum mencapai leaf node.
6. Jika seluruh cabang dari node yang dibentuk pada langkah sebelumnya sebelumnya telah mencapai leaf node, maka akan dicek cabang dari node diatas dari node yang dibentuk pada langkah sebelumnya, jika cabang tersebut belum mencapai leaf node maka akan dicari nilai gain seperti pada langkah nomor 3.
7. Proses yang sama akan dilakukan secara rekursif untuk membentuk pohon keputusan dari setiap sampel.
8. Proses rekursif akan berhenti jika semua sampel pada node memiliki kelas yang sama, semua simpul sudah mencapai leaf node atau semua atribut telah digunakan untuk mempartisi sampel.
15
Gambar 2.4 Algoritma Pembentukan Pohon
Berikut ini adalah contoh proses pembentukan pohon keputusan menggunakan algoritma C4.5 menggunakan empat kalimat opini yang diberi kelas negatif dan positif mengenai PEMILU.
Tabel 2.2 Contoh Training Data
No. Kalimat Opini Kelas
1 Pemilu gagal Negatif
2 Pemilu gagal dicurangi Positif
3 Pemilu sukses Positif
4 Pemilu dicurangi Negatif
dari training data dan proses perhitungan information gain terhadap semua atribut penguji.
Tabel 2.3 Nilai Training Data
No curang pemilu gagal sukses kelas
1 0 1 1 0 Negatif
2 1 1 1 0 Negatif
3 0 1 0 1 Positif
4 1 1 0 0 Negatif
Perhitungan entropy untuk seluruh training data : = 1
Perhitungan information gain pada setiap atribut penguji untuk menentukan simpul akar :
1. curang
Perhitungan entropy atribut “curang” dengan nilai 0 dan 1:
= 1 = 1
(2/4) + (2/4) )
= 0 2. pemilu
Perhitungan entropy atribut “pemilu” dengan nilai 0 dan 1: = 0
= 1
(0/4) + (4/4) )
= 0 3. gagal
Perhitungan entropy atribut “gagal” dengan nilai 0 dan 1:
17
= 1
(2/4) + (2/4) )
= 0 4. sukses
Perhitungan entropy atribut “sukses” dengan nilai 0 dan 1:
= 0.918 = 0
(3/4) + (1/4) )
= 0.312
Proses perhitungan dilakukan sampai ditentukan simpul daun. Seluruh hasil perhitungan nilai gain untuk membentuk simpul akar pohon keputusan terdapat pada Tabel 2.4,
Tabel 2.4 Perhitungan Information Gain Untuk Simpul Akar Perhitungan Node Akar
Hasil perhitungan nilai gain untuk menentukan simpul akar akan membentuk rule tree seperti pada Gambar II.4.
Karena nilai entropy untuk cabang simpul “sukses” dengan nilai 0 masih tidak sama dengan 0, maka dilakukan perhitungan kembali untuk menentukan simpul berikutnya.
Tabel 2.5 Perhitungan Information Gain Untuk Cabang Simpul Sukses Nilai 0
Perhitungan Cabang Node 'sukses' Value '0' Total Entropy : 0.918
Attribut Neg(0) Pos(0) Entropy(0) Neg(1) Pos(1) Entropy(1) Gain
Hasil perhitungan nilai gain untuk menentukan cabang simpul sukses dengan nilai 0 akan membentuk rule tree seperti pada Gambar II.5.
Gambar 2.6 Hasil Perhitungan Nilai Gain Cabang Simpul Sukses Nilai 0 Karena nilai entropy untuk cabang simpul “curang” dengan nilai 1 masih tidak sama dengan 0, maka dilakukan perhitungan kembali untuk menentukan simpul berikutnya.
Tabel 2.6 Perhitungan Information Gain Untuk Cabang Simpul Curang Nilai 1
Perhitungan Cabang Node 'curang' Value '1' Total Entropy : 1
Attribut Neg(0) Pos(0) Entropy(0) Neg(1) Pos(1) Entropy(1) Gain
pemilu 0 0 0 1 1 1 0
19
Max Gain : 1 Node : gagal
Hasil perhitungan nilai gain untuk menentukan cabang simpul ‘curang’ dengan nilai 1 akan membentuk rule tree seperti pada Gambar II.6.
Gambar 2.7 Hasil Perhitungan Nilai Gain Cabang Simpul Curang Nilai 1 Kedua nilai entropy untuk cabang simpul “gagal” bernilai 0, maka kedua cabang atribut “gagal” berupa leaf node dan tidak dilakukan perhitungan nilai gain untuk menentukan simpul berikutnya.
Pohon keputusan yang dibangun oleh algoritma C4.5 ini bergantung pada training data yang disiapkan. Tweet yang akan diklasifikasikan akan diuji dimulai dari simpul teratas atau simpul akar. Jika sebuah tweet mengandung kata yang menjadi atribut penguji pada simpul akar yaitu ‘sukses’ maka kata atau simpul selanjutnya yang akan diuji adalah simpul ruas kanan, jika tweet tidak mengandung kata ‘sukses’ maka simpul yang diuji selanjutnya adalah simpul ruas kiri, proses ini akan terus dilakukan sampai ditemukan simpul daun yang berisi kelas sentimen negatif, positif dan netral. Jika sebuah tweet mengandung kata yang tidak diuji pada jalur yang sedang ditelusuri, maka kata tersebut tidak akan diuji.
2.7.3. Klasifikasi Menggunakan Pohon Keputusan
yang akan diuji adalah kata-kata yang menjadi atribut penguji pada pohon keputusan, jika pada kalimat opini terdapat kata yang tidak menjadi atribut penguji pada pohon keputusan maka kata tersebut tidak akan diuji. Jika pada kalimat terdapat kata yang menjadi atribut penguji simpul yang sedang diuji maka simpul berikutnya yang diuji adalah simpul ruas kanan dan seluruh simpul ruas kiri tidak akan diuji begitu juga sebaliknya. Berikut adalah langkah-langkah klasifikasi menggunakan pohon keputusan :
1. Simpul akar akan menjadi simpul pertama yang akan diuji,
2. jika pada kalimat terdapat kata yang menjadi atribut penguji pada simpul maka selanjutnya akan diuji simpul pada ruas kanan yang merupakan cabang dari simpul yang diuji sebelumnya. Jika pada kalimat tidak terdapat kata yang menjadi atribut penguji pada simpul tersebut maka selanjutnya akan diuji simpul pada ruas kiri yang merupakan cabang dari simpul yang diuji sebelumnya.
3. Jika pada simpul yang diuji bukan merupakan leaf node maka akan dilakukan langkah sebelumnya yaitu langkah 2 pada simpul yang sedang diuji.
4. Proses akan berhenti jika simpul yang diuji merupakan leaf node.
Selanjutnya adalah contoh klasifikasi sebuah kalimat menggunakan pohon keputusan yang telah dibentuk.
Kalimat Opini : “Pemilu gagal dicurangi”
21
Gambar 2.8 Proses Pengecekan Kalimat Opini 2.8 Cross Validation
K-fold cross-validation adalah sebuah pengujian dimana dataset X dibagi secara acak kedalam K bagian dengan ukuran yang sama, Xi, i=1,...,K. Untuk memproses tiap pasangnya, diambil terlebih dahulu salah satu bagian dari K bagian sebagai data tes, dan mengkombinasikan sisanya sebanyak K-1 bagian sebagai data latih. Proses pengujian dilakukan sebanyak K kali [13].
Dari pengujian yang dilakukan, dievaluasi dengan menggunakan confusion matrix untuk mengetahui tingkat kebenaran dari penelitian.
Tabel 2.7 Confusion Matrix
Tested Class
Predicted Class Positive Negative Total
Positive
True Positive : Hasil diprediksi bernilai True, dan pengujian menghasilkan True
False Negative : Hasil diprediksi bernilai True, dan pengujian menghasilkan False
True Negative : Hasil diprediksi bernilai False, dan pengujian menghasilkan False.
Setelah hasil pengujian menggunakan k-fold cross validation dievaluasi menggunakan confusion matrix, selanjutnya dapat dihitung nilai error dari keseluruhan iterasi dengan persamaan berikut.
Keterangan
: Nilai error pada pengujian K : jumlah fold
: Jumlah error pada masing-masing iterasi 2.9 Basis Data
Basis data adalah kumpulan data yang saling berkaitan, berhubungan yang disimpan secara bersama-sama sedemikian rupa tanpa pengulangan yang tidak perlu, untuk memenuhi berbagai kebutuhan. Data ini mengandung semua informasi untuk mendukung semua kebutuhan sistem.
Basis data merupakan salah satu komponen yang penting dalam sebuah sistem, karena merupakan basis dalam menyediakan informasi. Basis data menjadi penting karena munculnya beberapa masalah bila tidak menggunakan data terpusat, seperti adanya duplikasi data, hubungan antar data tidak jelas, organisasi data dan perbaharuan data menjadi rumit. Bahasa yang digunakan dalam basis data yaitu [9] :
1. DDL (Data Definition Language)
Merupakan bahasa definisi data yang digunakan untuk membuat dan mengelola objek database seperti database, tabel, view. Adapun perintah yang dimiliki adalah :
23
c. ALTER : Perintah untuk pengubahan struktur tabel yang telah dibuat, seperti menambahkan atribut, mengganti nama atribut ataupun merubah nama tabel.
2. DML (Data Manipulation Language)
Merupakan bahasa manipulasi data yang dilakukan setelah DDL, digunakan untuk memanipulasi data pada objek database seperti tabel yang telah dibuat sebelumnya, adapun perintah yang dimiliki DDL adalah :
a. INSERT : untuk melakukan penginputan atau pemasukan data pada tabel database.
b. UPDATE : : Untuk melakukan perubahan/peremajaan terhadap data yang ada pada tabel.
c. DELETE : Untuk melakukan penghapusan data pada tabel. Penghapusan ini dapat dilakukan secara sekaligus (seluruh isi tabel) maupun hanya beberapa recordset.
3. DCL (Data Control Language)
Merupakan bahasa yang digunakan untuk mengendalikan pengaksesan data pada database, adapun perintah yang dimiliki DCL adalah:
a. GRANT : Untuk memberikan hak akses atau izin oleh administrator server kepada pengguna.
b. REVOKE : Untuk menghilangkan atau mencabut hak akses yang telah diberikan kepada user oleh administrator.
Pengolahan basis data meliputi proses ketiga bahasa yang digunakan diatur dengan menggunakan perangkat sistem manajemen basis data (Database Management Sistem / DBMS).
2.10 Pemodelan Analisis
Model analisis merupakan representasi teknis yang pertama dari sistem. Pertama analisis terstruktur adalah metode pemodelan klasik, dan analisis berorientasi objek.
yang memungkinkan analisis sistem mendefinisikan spesifikasi fungsional perangkat lunak secara terstruktur, yang dimaksud dengan perangkat analisis terstruktur adalah alat bantu pemodelan yang digunakan untuk menggambarkan hasil pelaksanaan analisis.
Entity-relational diagram (ERD) adalah notasi yang digunakan untuk melakukan aktivitas pemodelan data, sedangkan data flow diagram (DFD) memberikan informasi sebagai dasar bagi pemodelan fungsi
2.11 ERD
Entity-relational diagram (ERD) adalah model konseptual untuk mendeskripsikan data dari sebuah sebuah domain. Komponen utama dari ERD adalah entitas dan relasi yang menghubungkan entitas. ERD digunakan untuk memodelkan struktur data dan hubungan antar data. Dengan ERD, model dapat diuji dengan mengabaikan proses yang dilakukan. Entity-relational diagram pertama kali dikembangkan oleh Peter Chen dalam sebuah penelitiannya pada tahun 1976. Untuk menggambarkan ERD digunakan beberapa notasi dan simbol. Pada dasarnya ada tiga simbol yang digunakan , yaitu [10] :
a. Entity
Entiti merupakan objek yang mewakili sesuatu yang nyata dan dapat dibedakan dengan objek yang lain. Simbol dari entiti ini biasanya digambarkan dengan persegi panjang.
b. Atribut
Setiap entitas pasti mempunyai elemen yang disebut atribut yang berfungsi untuk mendeskripsikan karakteristik dari entitas tersebut. Isi dari atribut mempunyai sesuatu yang dapat mengidentifikasikan isi elemen satu dengan yang lain. Gambar atribut diwakili oleh simbol elips.
c. Hubugan / Relasi
Hubungan antara sejumlah entitas yang berasal dari himpunan entitas yang berbeda. Relasi dapat digambarkan sebagai berikut :
25
Hubungan relasi satu ke satu yaitu setiap entitas pada himpunan entitas A berhubungan paling banyak dengan satu entitas pada himpunan entitas B. 2. Satu ke banyak (One to many)
Setiap entitas pada himpunan entitas A dapat berhubungan dengan banyak entitas pada himpunan entitas B, tetapi setiap entitas pada entitas B dapat berhubungan dengan satu entitas pada himpunan entitas A. 3. Banyak ke banyak (Many to many)
Setiap entitas pada himpunan entitas A dapat berhubungan dengan banyak entitas pada himpunan entitas B.
2.12 DFD mempertimbangkan lingkungan fisik dimana data tersebut mengalir atau dimana data tersebut akan disimpan. Diagram aliran data disefinisikan sebagai berikut [10] :
“Model dari sistem untuk menggambarkan pembagian sistem ke modul
yang lebih kecil“.
DFD merupakan alat yang digunakan pada metodologi pengembangan sistem yang terstruktur. Kelebihan utama pendekatan alir data, yaitu :
1. Kejelasan dari menjalankan implementasi teknis sistem.
2. Pemahaman lebih jauh mengenai keterkaitan satu sama lain dalam sistem dan subsistem.
3. Menghubungkan sistem dengan pengguna melalui diagram alir data.
DFD terdiri dari context diagram dan diagram rinci (DFD leveled), context diagram berfungsi memetakan model lingkungan (menggambarkan hubungan
antara entitas luar, masukan dan keluaran sistem), yang direpresentasikan dengan lingkaran tunggal yang mewakili keseluruhan sistem. DFD leveled menggambarkan sistem jaringan kerja antara fungsi yang berhubungan satu sama lain dengan aliran data penyimpanan data, model ini hanya memodelkan sistem dari sudut pandang fungsi.
a. Penggambaran
Secara garis besar penggambaran DFD adalah sebagai berikut : 1. Buat Diagram Konteks
Diagram ini adalah diagram level tertinggi dari DFD yang menggambarkan hubungan sistem dengan lingkungan luarnya. Cara penggambarannya adalah :
a. Tentukan nama sistemnya. b. Tentukan batasan sistemnya.
c. Tentukan terminator apa saja yang ada dalam sistem.
d. Tentukan apa yang diterima/diberikan terminator dari/pada sistem.
e. Gambarkan diagram konteks.
Gambar 2.9 Contoh Diagram Konteks 2. Buat diagram level satu
Diagram ini adalah dekomposisi dari diagram konteks. Cara penggambarannya adalah :
27
b. Tentukan apa yang diberikan/diterima masing-masing proses pada/dari sistem sambil memperhatikan konsep keseimbangan (alur data yang keluar/masuk dari suatu level harus sama dengan alur data yang masuk/keluar pada level berikutnya).
c. Apabila diperlukan, munculkan data store (master) sebagai sumber maupun tujuan alur data.
d. Gambarkan diagram level satu. e. Hindari perpotongan arus data.
f. Beri nomor pada proses utama (nomor tidak menunjukkan urutan proses).
Gambar 2.10 Contoh DFD Level 1
3. Buat diagram level dua
Diagram ini merupakan dekomposisi dari diagram level satu. Cara penggambarannya adalah :
a. Tentukan proses yang lebih kecil (sub-proses) dari proses utama yang ada di level satu.
b. Tentukan apa yang diberikan/diterima masing-masing sub-proses pada/dari sistem dan perhatikan konsep keseimbangan.
c. Apabila diperlukan, munculkan data store (transaksi) sebagai sumber maupun tujuan alur data.
Gambar 2.11 Penomoran DFD Level Berikutnya
4. DFD level tiga, empat, ..
Diagram ini merupakan dekomposisi dari level sebelumnya. Proses dekomposisi dilakukan sampai dengan proses siap dituangkan ke dalam program. Aturan yang digunakan sama dengan level satu.
b. Elemen Dasar
1. Entitas Luar (External Entity)
Sesuatu yang berada diluar sistem, tetapi memberikan data kedalam sistem atau memberikan data dari sistem, disimbolkan dengan suatu kotak notasi. External Entity tidak termasuk bagian dari sistem. Bila sistem informasi dirancang untuk satu bagian maka bagian lain yang masih terkait menjadi external entity.
2. Arus Data (Data Flow)
Arus data merupakan tempat mengalirnya informasi dan digambarkan dengan garis yang menghubungkan komponen dari sistem. Arus data ditunjukan dengan arah panah dan garis diberi nama atas arus data yang mengalir.
3. Proses (Process)
29
proses memiliki satu atau beberapa masukan serta menghasilkan satu atau beberapa data keluar.
4. Simpanan Data (Data Store)
Simpanan data merupakan tempat penyimpanan data yang ada dalam sistem. Data store dapat disimbolkan dengan dua garis sejajar atau dua garis dengan salah satu sisi samping terbuka. Proses dapat mengambil data dari atau memberikan data ke simpanan data (database).
2.13MySQL
MySQL adalah sebuah perangkat lunak sistem manajemen basis data SQL (database management system) atau DBMS yang multithread, multi-user, dengan sekitar 6 juta instalasi di seluruh dunia. MySQL AB membuat MySQL tersedia sebagai perangkat lunak gratis dibawah lisensi GNU General Public License (GPL), tetapi mereka juga menjual dibawah lisensi komersial untuk kasus-kasus dimana penggunaannya tidak cocok dengan penggunaan GPL.
Berbeda dengan proyek-proyek seperti Apache, dimana perangkat lunak dikembangkan oleh komunitas umum, dan hak cipta untuk kode sumber dimiliki oleh penulisnya masing-masing, MySQL dimiliki dan disponsori oleh sebuah perusahaan komersial Swedia MySQL AB, dimana memegang hak cipta hampir atas semua kode sumbernya. Kedua orang Swedia dan satu orang Finlandia yang mendirikan MySQL AB adalah: David Axmark, Allan Larsson, dan Michael "Monty" Widenius. Perintah-perintah yang ada di SQL antara lain [11] :
a. Menambah data (Insert)
Perintah SQL yang digunakan untuk menambah data ke database adalah perintah INSERT. Perintah ini mempunyai bentuk umum sebagai berikut: INSERT [INTO] nama_tabel [(daftar field/kolom)] VALUES (daftar_data). b. Mengakses data (Select)
Perintah SQL yang digunakan untuk memilih data adalah perintah SELECT. Bentuk umum perintah ini adalah sebagai berikut:
[GROUP BY daftar_group_by] [HAVING kondisi_pencarian]
[ORDER BY daftar_order[ASC│DESC ]] c. Mengedit/Mengubah data (Update)
Perintah SQL yang digunakan untuk mengubah data adalah perintah UPDATE SET. Perintah ini mempunyai bentuk umum sebagai berikut:
UPDATE nama_table SET field1=databaru1 [,data2=databaru2] [WHERE kondisi_update].
d. Menghapus data (Delete)
Perintah SQL yang digunakan untuk menghapus data adalah perintah DELETE FROM. Perintah ini mempunyai bentuk umum sebagai berikut: DELETE FROM tabel_hapus WHERE kondisi_hapus.
MySQL memiliki beberapa kelebihan diantaranya [11] :
1. MySQL sebagai Data Management System (DBMS) dan Relation Databese Management System (RDBMS).
2. MySQL adalah software database yang OpenSource, artinya program ini bersifat free atau bebas digunakan oleh siapa saja tanpa harus membeli dan membayar lisensi kepada pembuatnya.
3. MySQL merupakan database server, jadi dengan menggunakan database ini dapat menghubungkan ke media internet sehingga dapat diakses jarak jauh.
4. MySQL merupakan sebuah database client. Selain menjadi server yang melayani permintaan, MySQL juga dapat melakukan query yang mengakses database pada server, jadi MySQL dapat juga berperan sebagai Client.
5. MySQL mampu menerima query yang bertumpuk dalam satu permintaan atau yang disebut Multi-Threading.
6. MySQL merupakan sebuah database yang mampu menyimpan data berkapasitas sangat besar hingga berukuran Gigabyte sekalipun.
31
8. MySQL adalah database menggunakan enkripsi password. Jadi database ini cukup aman karena memiliki password untuk mengaksesnya.
9. MySQL dapat menciptakan lebih dari 16 kunci per tabel dan dalam satu kunci memungkinkan berisi belasan field. Serta MySQL mendukung field yang dijadikan sebagai kunci primer dan kunci unik atau (Unique).
10. MySQL memiliki kecepatan dalam pembuatan tabel maupun peng-update-an tabel.
2.14 PHP
PHP (Hypertext Processor) adalah bahasa pemrograman scripting sisi server (server-side), bahasa pemrograman yang digunakan oleh server web untuk menghasilkan dokumen HTML secara on-the-fly. PHP merupakan interpreter yang dapat dieksekusi sebagai program CGI untuk server web. PHP merupakan bahasa script, selain paling popular di lingkungan programer, pengembang web, di lingkungan server web apache [12].
Kelebihan script program menggunakan PHP antara lain :
a. Web server pendukung PHP banyak ditemukan di mana-mana, mulai dari IIS sampai dengan apache, dan konfigurasinya pun relatif mudah.
b. Pengembangannya mudah karena banyaknya milis-milis dan developer pengembang.
c. Referensi yang merujuk PHP banyak ditemukan, sehingga mudah untuk dipahami.
d. Merupakan bahasa open source yang dapat dioperasikan di berbagai sistem operasi, juga dapat dijalankan secara run time melalui console dan dapat menjalankan perintah-perintah sistem.
Selanjutnya akan dijelaskan mengenai dasar-dasar PHP yaitu sintak-sintak sederhana pada PHP. Sintaksis standar PHP ini diawali dengan <?php , dan diakhiri dengan ?>, setiap akhir baris kode PHP harus diakhiri dengan titik koma. Titik koma adalah pemisah dan digunakan untuk membedakan satu set instruksi dari yang lain.
Pernyataan print() hanya akan membalikan satu nilai keluaran saja. Printf memiliki aturan seperti dibawah ini.
2. pernyataan echo()
echo memiliki tujuan yang sama dengan print() meskipun ada perbedaan teknis antara echo() dan print(). Echo memiliki struktur dibawah ini.
3. Variabel
Variabel adalah sebuah simbol yang dapat menyimpan nilai yang berbeda pada waktu yang berbeda. Dalam mendeklarasikan sebuah variabel, dimulai dengan menulis tanda dolar $, yang kemudian diikuti oleh nama variabel. Nama variabel dapat dimulai dengan huruf atau garis bawah, karakter ASCII 127 sampai 255 karakter. Contoh penulisan variabel yang valid adalah $color, $model_, $operating_system, atau $_schema.
4. Ekspresi
Ekspresi merupakan sebuah frasa yang mengekspresikan keterangan aksi dalam suatu program. Ekspresi terdiri dari operand dan operator. Operand merupakan masukan dari sebuah ekspresi.
5. Struktur Kontrol <?php
print(“<p>Baju saya berwarna kuning.</p>”);
?> $a++; //$a adalah operand
Gambar 2.12 Pernyataan print
Gambar 2.13 Pernyataan echo
33
Struktur kontrol menerangkan alur kode yang terdapat dalam sebuah aplikasi. Mendefinisikan pengeksekusian karakteristik seperti bagaimana dan berapa kali kode tersebut di eksekusi.
a. Pernyataan Kondisi
Pernyataan kondisi memungkinkan sebuah program untuk melakukan berbagai macam input, menggunakan bermacam kondisi yang didasari dengan sebuah nilai masukan.
a) Pernyataan if
b) Pernyataan else
c) Pernyataan else-if b. Pernyataan Perulangan
Pernyataan perulangan memungkinkan sebuah program untuk melakukan sebuah instruksi yang berulang sampai kondisi yang diinginkan tercapai.
a) Pernyataan while
b) Pernyataan do-while
c) Pernyataan for
35
BAB 3
ANALISIS DAN PERANCANGAN
3.1 Analisis Sistem
Dalam proses pembuatan suatu sistem dilakukan analisis terhadap sistem yang akan dibangun. Analisis yang dilakukan untuk membangun aplikasi analisis sentimen pengguna twitter terhadap partai politik peserta PEMILU 2014 menggunakan pohon keputusan yang dibangun oleh algoritma C4.5.
3.1.1 Analisis Masalah
Masalah yang timbul dalam sistem analisis sentimen pengguna twitter terhadap partai politik peserta PEMILU 2014 adalah mengklasifikasikan tweet ke dalam opini positif dan negatif menggunakan algoritma C4.5.
3.1.2 Analisis Proses
Analisis proses ini akan menjelaskan mengenai proses yang digunakan aplikasi analisis sentimen pengguna twitter terhadap partai politik peserta PEMILU 2014 menggunakan pohon keputusan yang dibangun oleh algoritma C4.5.
3.1.2.1 Proses Text Pre-processing
3.1.2.1.1 Tokenization
Tokenization dilakukan untuk memecah suatu kalimat dalam seluruh isi
dokumen menjadi sekumpulan kata. Setiap kata yang telah dipecah dari kalimat/tweet akan disimpan ke basis data dengan atributnya yaitu id tweet.
Gambar 3.1 Tokenization
3.1.2.1.2 Casefolding
Case folding adalah proses mengubah semua huruf yang ada pada seluruh dokumen menjadi huruf kecil. Huruf “a” sampai dengan “z”yang akan diproses, karakter selain huruf akan dianggap delimiter. Proses ini dilakukan untuk menghindari duplikasi data sehingga kata yang memiliki perbedaan huruf kecil dan besar tetapi sama maka kata tersebut tidak akan disimpan.
37
3.1.2.1.3 Stemming
Algoritma stemming yang digunakan pada penelitian ini adalah algoritma nazief dan adriani yang dibuat oleh Bobby Nazief dan Mirna Adriani
Gambar 3.3 Stemming
3.1.2.2 Proses Pembentukan Pohon Keputusan
Data hasi text preprocessing selanjutnya diklasifikasikan menggunakan pohon keputusan yang dibangun algoritma C4.5. Sebelum pohon keputusan digunakan untuk mengklasifikasikan ke data sebenarnya, model pohon keputusan belajar dari data training yang telah mempunyai kelas, yaitu negatif dan positif.
Pada seluruh dokumen tweet yang ada, setiap kata yang muncul dijadikan atribut untuk perhitungan entropi dan gain. nilai dari atribut tersebut adalah biner (0 dan 1)., dimana nilai 0 mengartikan tidak munculnya kata tersebut pada tweet, dan nilai 1 mengartikan bahwa kata tersebut muncul pada tweet.
Pada tabel III.1 adalah data latih yang digunakan dan tabel III.2 adalah implementasi perhitungan kasus algoritma C4.5 untuk membangun model pohon keputusan dengan atribut semua kata yang muncul dengan nilai 1 atau 0, dan atribut tujuan opini dengan nilai positif dan negatif.
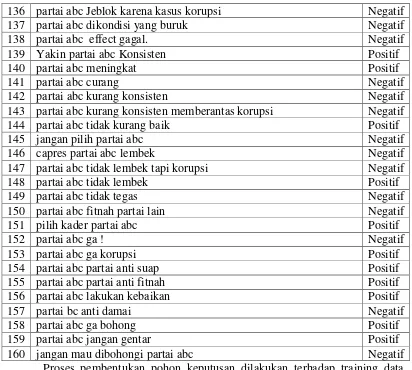
Tabel 3.1 Training Data
No. Training Data Kelas
1 dukung caleg pejuang partai abc Positif
2 masih muda sudah dibohongi partai abc Negatif
3 tidak jadi Dukung partai abc Negatif
4 Wiranto memiliki pergaulan internasional yang cukup baik. Positif
5 gua bilang partai abc partai korupsi Negatif
7 yg siap dukung partai abc. Alhamdulillah dan smoga barokah. Amin.
Positif 8 dukung partai abc. tidak melakukan politk uang Positif 9 partai abc Dukung Pemiskinan dan Hukum Mati Koruptor Positif 10 tolak partai terkorupsi di Indonesia yaitu partai abc Negatif 11 Mengajak saudaraku partai abc kembali baik. Amin ya Rob Positif
12 oke cocok sama partai abc Positif
13 Justru dg dukung Jokowi presiden diharapkan bs dorong kader2 muda partai abc yg bersih
Positif
14 partai abc itu bersih peduli tegas Positif
15 Pemilih yg baik memilih politisi yg sdh teruji... Positif 16 sikap partai abc menjadi hal yang tidak baik Negatif 17 Ingin Indonesia lebih baik pilih partai abc Positif
18 Koalisi ideal partai abc Positif
19 saya anti partai partai abc Negatif
20 disini banyak sekali yg tidak pilih partai abc Negatif
21 jangan lupa pilih partai abc Positif
22 kader partai abc yang anti korupsi Positif
23 capres partai abc memliki elektabilitas tinggi Positif 24 Pemimpin partai abc yang memeberikan harapan Positif
25 capres pencitraan partai partai abc Negatif
26 tanpa prabowo Indonesia damai partai abc Negatif
27 yes mantap capres partai abc satu ini Positif
28 partai abc mengutamakan intelektualitas tinggi calegnya Positif 29 banyak caleg dengan intelektualitas jelek di partai partai abc Negatif 30 prestasi ditonjolkan di partai partai abc Positif
31 yakin dan percaya partai abc juaranya Positif
32 Hasil survey menyebutkan partai abc tidak dipercaya Positif 33 partai abc saya yakin prabowo bisa membuat indonesia semakin
maju dan berkembang
Positif 34 partai abc yakin peroleh 10 persen kursi DPR Positif 35 BAPAK jujur peduli tegas partai abc itu mah! Positif
36 kader partai abc melakukan politik uang Negatif
37 Cuma partai abc yg kadernya bisa membela tanpa masalah. Positif 38 Saya tidak yakin partai abc akan selesaikan masalah RI Negatif
39 Pendidikan Politik partai abc Berhasil Positif
39
demokrasi
49 visi misi partai partai abc kurang berpihak kepada rakyat Negatif 50 ada yang tidak mendukung pencapresan dari partai partai abc Negatif
51 partai abc punya gagasan sangat baik Positif
52 kesalahan utama partai abc adalah sistem kampanye Negatif 53 partai abc yang tidak terlibat kasus korupsi Positif 54 kader partai abc berkomunikasi politik dengan baik Positif 55 kita tidak mau dipimpin partai korupsi partai abc Negatif 56 kader partai abc banyak yang tidak sopan berkampanye Negatif
57 elektabilitas partai abc menurun Negatif
58 strategi kampanye partai abc tidak berhasil Negatif
59 partai abc anti pencitraan Positif
60 partai abc sangat pro rakyat Positif
61 visi partai abc tidak pro rakyat Negatif
62 percaya partai abc mampu selesaikan masalah Positif
63 siap menangkan partai abc Positif
64 kita mantap pilih partai abc Positif
65 elektabilitas partai abc tidak turun Positif
66 banyak yang tak percaya kader capres partai abc bersih Negatif
67 saya bukan pemilih partai abc Negatif
68 partai abc bukan sarang koruptor Positif
69 kader partai abc menolak politik uang Positif
70 damai dengan pilih partai abc Positif
71 partai abc kurang konsisten Negatif
72 partai abc partai korupsi Negatif
73 banyak yang menolak dukung partai abc Negatif
74 partai abc gagal Negatif
75 payah politik uang partai abc Negatif
76 partai abc partai tak korupsi Positif
77 partai abc bertahan tanpa korupsi Positif
78 banyak kader partai abc terlibat korupsi Negatif 79 partai abc kurang baik dalam berkampanye Negatif
80 partai abc ga buruk lah Positif
81 partai abc memiliki sistem yang baik Positif
82 partai abc partai yang ga konsisten Negatif
83 partai abc partai tidak korupsi Positif
84 banyak kader yang ga baik di partai abc Negatif
85 ga yakin deh sama partai abc Negatif
86 kader partai abc tak pernah bohong Positif
87 partai abc jujur ! Positif
88 saya mantap dukung partai abc Positif
89 partai abc untuk perubahan Positif
90 parlemen partai abc payah Negatif
92 partai abc tanpa pencitraan Positif
93 yakin partai abc akan menang Positif
94 partai abc tak kurang apapun Positif
95 partai abc yang tidak berbohong Positif
96 partai abc dipimpin pemimpin salah Negatif
97 partai abc cermin politik tanpa pencitraan Positif
98 politik jujur partai abc Positif
99 sip semangat untuk partai abc Positif
100 capres partai abc pemimpin yang dipercaya Positif
101 partai abc ga baik untuk rakyat Negatif
102 partai abc korupsi tertinggi Negatif
103 partai abc adalah partai yang konsisten memberantas korupsi Positif
104 Tapi Hanya partai abc yang konsisten Positif
105 partai abc mengambil tindakan yang benar Positif
106 partai abc tidak seburuk itu Positif
107 tidak salah pilih partai abc Positif
108 Komunikasi Politik partai abc Payah Negatif
109 partai abc ga payah sebagai parpol Positif
110 partai abc sarang koruptor Negatif
111 partai abc kurangi korupsi Positif
112 partai abc tolak korupsi Positif
113 partai abc banyak yang ga jujur Negatif
114 kader tidak jujur di partai abc Negatif
115 partai abc , Ayo kita dukung ! Positif
116 partai abc partai yang ga salah Positif
117 partai ga curang, partai abc lah! Positif
118 partai abc tak pernah berbohong Positif
119 partai abc tak pernah curang Positif
120 partai abc penuh janji palsu Negatif
121 kader partai abc anti korupsi Positif
122 partai abc anti curang Positif
123 kader partai abc anti politik uang Positif
124 partai abc ? 1. Konsisten bela rakyat Positif
125 partai abc ? 3. Anti Korupsi Positif
126 partai abc ? 2. Berprestasi Positif
127 partai abc tidak akan gagal Positif
128 partai abc erat dengan politik uang Negatif
129 partai abc tolak korupsi Positif
130 tidak tolak dukung partai abc Positif
131 tak tolak dukung partai abc Positif
132 partai abc tak menolak kader korupsi Negatif
133 partai abc tidak menolak kader korupsi Negatif
134 partai abc menolak kader korupsi Positif
41
136 partai abc Jeblok karena kasus korupsi Negatif
137 partai abc dikondisi yang buruk Negatif
138 partai abc effect gagal. Negatif
139 Yakin partai abc Konsisten Positif
140 partai abc meningkat Positif
141 partai abc curang Negatif
142 partai abc kurang konsisten Negatif
143 partai abc kurang konsisten memberantas korupsi Negatif
144 partai abc tidak kurang baik Positif
145 jangan pilih partai abc Negatif
146 capres partai abc lembek Negatif
147 partai abc tidak lembek tapi korupsi Negatif
148 partai abc tidak lembek Positif
149 partai abc tidak tegas Negatif
150 partai abc fitnah partai lain Negatif
151 pilih kader partai abc Positif
152 partai abc ga ! Negatif
153 partai abc ga korupsi Positif
154 partai abc partai anti suap Positif
155 partai abc partai anti fitnah Positif
156 partai abc lakukan kebaikan Positif
157 partai bc anti damai Negatif
158 partai abc ga bohong Positif
159 partai abc jangan gentar Positif
160 jangan mau dibohongi partai abc Negatif
Proses pembentukan pohon keputusan dilakukan terhadap training data yang terdapat pada tabel training data. setiap atribut yang merupakan kata yang muncul pada seluruh training data akan memiliki nilai information gain dari hasil perhitungan tersebut. Atribut dengan nilai information gain tertinggi akan ditentukan sebuah simpul yang berisi kata pada atribut tersebut. Berikut tabel perhitungan simpul menggunakan algoritma C4.5.
Tabel 3.2 Perhitungan Information Gain Simpul Akar Perhitungan Node Akar
Total Entropy : 0.971
sarang 63 95 0.97 1 1 1 0.001
Setelah perhitungan untuk menentukan simpul berakhir maka selanjutnya ditentukan atribut dengan nilai gain tertinggi. Nilai gain tertinggi pada perhitungan simpuln adalah atribut tes dengan kata tidak dengan nilai 0.018.
45
Nilai entropy untuk atribut tes dengan kata tidak memiliki nilai tidak sama dengan nol. Maka simpul tersebut masih memiliki cabang. Selanjutnya akan dilakukan perhitungan nilai gain untuk menentukan simpul cabang.
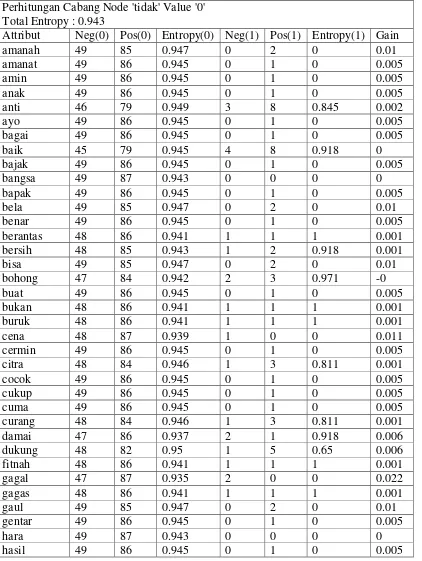
Tabel 3.3 Perhitungan Information Gain Simpul Cabang Tidak Perhitungan Cabang Node 'tidak' Value '0'
Total Entropy : 0.943
uji 49 86 0.945 0 1 0 0.005
Setelah perhitungan untuk menentukan simpul berakhir maka selanjutnya ditentukan atribut dengan nilai gain tertinggi. Nilai gain tertinggi pada perhitungan simpul adalah atribut tes dengan kata kurang dengan nilai 0.028.
Gambar 3.5 Pembentukan Pohon Keputusan Cabang Tidak
Nilai entropy untuk atribut tes dengan kata kurang memiliki nilai tidak sama dengan nol. Maka simpul tersebut masih memiliki cabang. Selanjutnya akan dilakukan perhitungan nilai gain untuk menentukan simpul cabang.
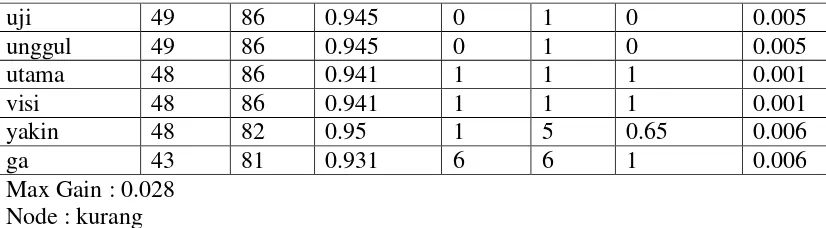
Tabel 3.4 Perhitungan Information Gain Simpul Cabang Kurang Perhitungan Cabang Node 'kurang' Value '0'
Total Entropy : 0.921
51
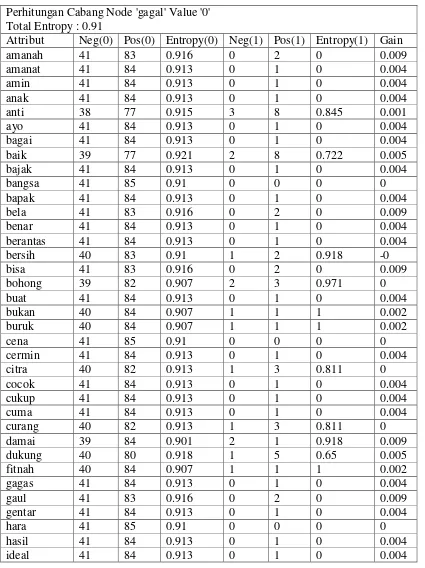
Setelah perhitungan untuk menentukan simpul berakhir maka selanjutnya ditentukan atribut dengan nilai gain tertinggi. Nilai gain tertinggi pada perhitungan simpul adalah atribut tes dengan kata gagal dengan nilai 0.025.
Nilai entropy untuk atribut tes dengan kata gagal memiliki nilai tidak sama dengan nol. Maka simpul tersebut masih memiliki cabang. Selanjutnya akan dilakukan perhitungan nilai gain untuk menentukan simpul cabang.
Tabel 3.5 Perhitungan Information Gain Simpul Cabang Gagal Perhitungan Cabang Node 'gagal' Value '0'
Total Entropy : 0.91
55
Setelah perhitungan untuk menentukan simpul berakhir maka selanjutnya ditentukan atribut dengan nilai gain tertinggi. Nilai gain tertinggi pada perhitungan simpul adalah atribut tes dengan kata payah dengan nilai 0.018.
Gambar 3.7 Perhitungan Pohon Keputusan Cabang Gagal
Nilai entropy untuk atribut tes dengan kata payah memiliki nilai tidak sama dengan nol. Maka simpul tersebut masih memiliki cabang. Selanjutnya akan dilakukan perhitungan nilai gain untuk menentukan simpul cabang.
Tabel 3.6 Perhitungan Information Gain Simpul Cabang Payah Perhitungan Cabang Node 'payah' Value '0'
Total Entropy : 0.895
satu 38 83 0.898 0 1 0 0.004
59
Gambar 3.8 Perhitungan Pohon Keputusan Cabang Payah
Nilai entropy untuk atribut tes dengan kata ga memiliki nilai tidak sama dengan nol. Maka simpul tersebut masih memiliki cabang. Selanjutnya akan dilakukan perhitungan nilai gain untuk menentukan simpul cabang.
Penentuan simpul akan selalu dilakukan untuk cabang kiri terlebih dahulu, jika simpul simpul sudah mencapai leaf node dengan syarat nilai entropy untuk kedua cabang sama dengan nol, maka penentuan simpul akan bergesar pada cabang kanan simpul parent dari simpul ditentukan sebelumnya.
Selanjutnya akan dilakukan perhitungan nilai gain untuk cabang kanan dari simpul ga. Dimisalkan cabang kiri dari simpul ga dan seterusnya sudah mencapai leaf node.
Tabel 3.7 Perhitungan Information Gain Simpul Cabang Ga Perhitungan Cabang Node 'ga' Value '1'
Total Entropy : 0.994
Attribut Neg(0) Pos(0) Entropy(0) Neg(1) Pos(1) Entropy(1) Gain
amanah 6 5 0.994 0 0 0 0
amanat 6 5 0.994 0 0 0 0
amin 6 5 0.994 0 0 0 0
anak 6 5 0.994 0 0 0 0
sangat 6 5 0.994 0 0 0 0
63
Gambar 3.9 Perhitungan Pohon Keputusan Cabang Ga
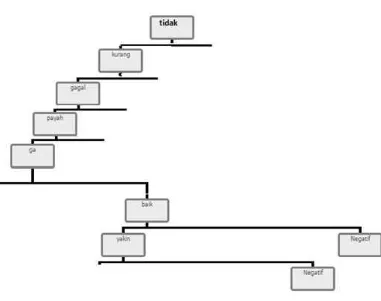
Nilai entropy untuk atribut tes dengan kata ga memiliki nilai tidak sama dengan nol untuk cabang simpul kiri sedangkan nilai entropy cabang simpul kanan adalah sama dengan nol. Maka cabang simpul kanan sudah mencapai leaf node sedangkan cabang simpul kiri masih memiliki cabang. Selanjutnya akan dilakukan perhitungan nilai gain untuk menentukan simpul cabang.
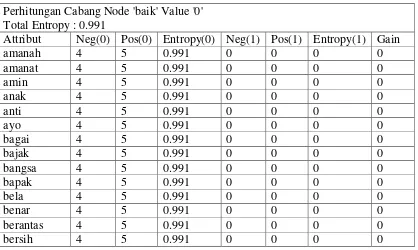
Tabel 3.8 Perhitungan Information Gain Simpu Cabang Baik Perhitungan Cabang Node 'baik' Value '0'
Total Entropy : 0.991
siap 4 5 0.991 0 0 0 0
67
Gambar 3.10 Perhitungan Pohon Keputusan Cabang Baik
Nilai entropy untuk atribut tes dengan kata yakin memiliki nilai tidak sama dengan nol untuk cabang simpul kiri sedangkan nilai entropy cabang simpul kanan adalah sama dengan nol. Maka cabang simpul kanan sudah mencapai leaf node sedangkan cabang simpul kiri masih memiliki cabang.
Setelah perhitungan berakhir dengan memenuhi kondisi untuk mengakhiri proses rekursif, selanjutnya simpil-simpul yang telah ditentukan akan membentuk sebuah pohon keputusan.
3.1.3 Analisis Kebutuhan Perangkat Lunak
3.1.3.1 Analisis Basis Data
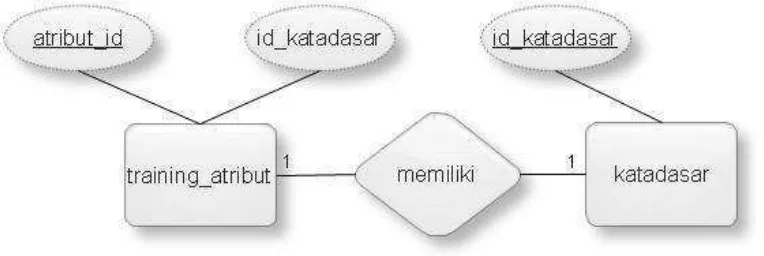
Gambar 3.11 ERD yang digunakan pada Sistem Analisis Sentimen Pengguna Twitter Terhadap Partai Politik
3.1.3.2 Analisis Kebutuhan Non Fungsional
Analisis kebutuhan non fungsional adalah suatu analisis untuk mengetahui elemen-elemen yang berhubungan dengan sistem yang sedang berjalan.
3.1.3.2.1. Analisis Pengguna
Aplikasi ini digunakan oleh dua jenis user yaitu user dan user umum, user berperan menjalankan proses mengolah training data dan membentuk pohon keputusan yang dibentuk dari training data, sedangkan user umum atau masyarakat berperan mengakses data sentimen mengenai partai politik yang telah diklasifikasikan ke dalam kelas positif dan negatif dalam bentuk grafik.
Tabel 3.9 Analisis Pengguna
Pengguna Tanggung Jawab
User Mengelola training data, membentuk pohon keputusan yang akan digunakan untuk klasifikasi dan menjalankan streaming twitter.
69
3.1.3.2.2. Analisis Kebutuhan Perangkat Keras
Adapun spesifikasi perangkat keras minimum yang dibutuhkan untuk membangun aplikasi ini adalah sebagai berikut :
1. Processor 1.6 Ghz.
2. Media Penyimpanan (Hardisk) 40 GB. 3. Memori RAM 256 Mb.
4. Monitor 16 inchi.
3.1.3.2.3. Analisis Perangkat Lunak
Berikut ini adalah spesifikasi perangkat lunak minimum yang dibutuhkan dalam membangun aplikasi:
1. Sistem operasi Windows XP. 2. Wamp Server 2.4.
3. Notepad++.
3.1.3.3 Analisis Kebutuhan Fungsional
Analisis kebutuhan fungsional ini meliputi diagram konteks dan Data Flow Diagram (DFD).
3.1.3.3.1 Diagram Konteks
Diagram konteks adalah diagram yang menunjukkan keterhubungan antara perangkat lunak dengan konteks eksternal di luar program. Gambar berikut adalah diagram konteks yang dibangun dalam sistem.
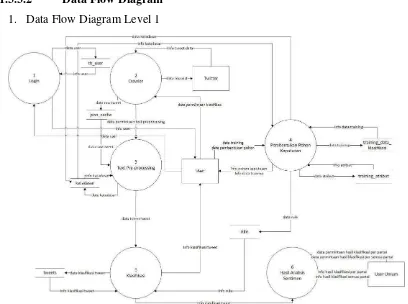
3.1.3.3.2 Data Flow Diagram 1. Data Flow Diagram Level 1
71
2. Data Flow Diagram Level 2 Proses 3
Gambar 3.14 DFD Level 2 Proses Text Pre-processing
3. Data Flow Diagram Level 2 Proses 4
4. Data Flow Diagram Level 2 Proses 6
73
Gambar 3.17 DFD Level 3 Proses Pengolahan Data Training
3.1.3.3.3 Spesifikasi Proses
Spesifikasi proses merupakan deskripsi dari setiap elemen proses yang terdapat dalam program yang meliputi nama proses, input, output, dan keterangan dari proses. Berikut ini spesifikasi proses dari sistem Analisis Sentimen Pengguna Twitter Terhadap Partai Politik.
Tabel 3.10 Spesifikasi Proses Analisis Sentimen Pengguna Twitter Terhadap Partai Politik
No. Proses Keterangan
1. No. Proses 1
Nama Proses Login
Input info user
Output data user
Logika Proses 1. Jika ada masukan data login.
2. Sistem akan mengecek apakah data login masih kosong.
mengisi username / password
4. Jika tidak kosong maka sistem akan memverifikasi data login
5. Jika data login valid maka pengguna akan masuk ke halaman kelola pohon keputusan.
Keterangan Proses Proses ini digunakan untuk verifikasi data login sebelum masuk ke halaman kelola pohon keputusan.
2. No. Proses 2
Nama Proses Crawler
Input info tweet data
Output data request
Logika Proses 1. Jika raw tweet diterima
2. Simpan raw tweet di tabel json_cache Keterangan Proses Proses ini digunakan untuk streaming tweet
dalam bentuk raw tweet.
3. No. Proses 3
Nama Proses Text Pre-Processing
Input data permintaan text preproccesing
Output data_token_tweet
Logika Proses 1. Tokenization (Proses 3.1) 2. Casefolding (Proses 3.2) 3. Stemming (Proses 3.3)
Keterangan Proses Proses tokenisasi, casefolding, dan stemming terhadap tweet yang akan diklasifikasi.
4. No Proses 4
75
Logika Proses 1. Pengolahan Data Training (Proses 4.1) 2. Pembentukan Pohon Keputusan
Menggunakan Training Data (Proses 4.2) Keterangan Proses digunakan untuk Pembentukan Pohon Keputusan Menggunakan Algoritma C4.5.
5. No. Proses 5
Nama Proses Klasifikasi
Input data token tweet
Output Info klasifikasi tweet
Logika Proses 1. Pengecekan data token tweet terhadap simpul akar, jika kata penguji pada simpul ada pada data token tweet maka cek simpul berikutnya pada ruas kanan, jika tidak ada cek simpul pada ruas kiri. 2. Jika simpul yang di cek merupakan
simpul daun maka pengecekan simpul pada pohon keputusan berakhir dan menghasilkan kelas sesuai yang terdapat pada simpul daun.
3. Jika simpul yang di cek bukan simpul daun maka dilakukan pengecekan data token tweet terhadap simpul tersebut seperti pengecekan terhadap simpul akar. 4. Pengecekan simpul berhenti jika simpul
yang dicek adalah simpul daun.
Keterangan Proses Proses ini digunakan untuk klasifikasi tweet yang belum diberi kelas.
6. No. Proses 6
Input data permintaan hasil klasifikasi
Output info hasil klasifikasi
Logika Proses 1. Jika user umum melakukan permintaan untuk melihat hasil klasifikasi, tampilkan hasil klasifikasi.
2. Hitung persentase sentimen positif dan negatif dari masing-masing partai pada tweet yang telah terklasifikasi.
3. Jika tweet kosong, maka tampilkan pesan data tidak tersedia.
Keterangan Proses ini digunakan user umum untuk melihat hasil analisis sentimen
7. No. Proses 3.1
Nama Proses Tokenization
Input data text preprocessing
Output token tweet
Logika Proses 1. Uraikan data raw tweet menjadi tweet beserta atributnya.
2. Cek tweet apakah tidak kosong. 3. Jika tweet tidak kosong, maka tweet
diurai kata per kata.
Keterangan Proses Proses ini digunakan untuk memecah tweet
8. No. Proses 3.2
Nama Proses Case Folding
Input token tweet
Output token tweet huruf kecil
Logika Proses 1. Cek tweet apakah tidak kosong.
2. Jika terdapat huruf besar, maka huruf diubah menjadi kecil.
77
karakter huruf A-Z menjadi a-z.
9. No. Proses 3.3
Nama Proses Stemming
Input token tweet huruf kecil
Output data token tweet
Logika Proses 1. Jika kata yang akan di-stem ditemukan dalam kamus katadasar, maka kata tersebut adalah root word.
2. Jika tidak ditemukan, maka dilakukan penghapusan inflexion suffix
3. Jika hasil sebelumnya bukan root word, maka dilakukan penghapusan derivation suffix,
4. jika pada langkah sebelumnya ada suffix yang dihapus maka dilakukan pemeriksaan kombinasi awalan akhiran yang tidak diijinkan. Jika ditemukan tentukan sebagai root word.
5. jika tidak, maka dilakukan penghapusan derivation prefix
6. jika semua langkah telah dilakukan dan tidak menemukan root word. Maka kata awal ditentukan sebagai root word. Keterangan Proses Proses ini digunakan untuk mencari kata
dasar dari kata berimbuhan.
10. No Proses 4.1
Nama Proses Pengolahan Data Training
Input data training
Output Info data training
2. Hapus Data Training (Proses 4.1.2) Keterangan Proses Proses ini terdiri dari menambah atau
menghapus data training.
11. No Proses 4.2
Nama Proses Pembentukan Pohon Keputusan
menggunakan Training Data
Input data training, data pembentukan pohon,
Output Info pohon keputusan
Logika Proses 1. Terdapat masukan berupa training set yang setiap sampelnya telah diberi kelas tertinggi dari seluruh atribut untuk memilih atribut yang paling berpengaruh pada training set, dan akan dijadikan atribut penguji pada node tersebut.
79
pada training data.
5. Jika ada cabang dari node yang dibentuk pada langkah sebelumnya belum mencapai leaf node, maka akan dicari nilai gain seperti pada langkah nomor 3 dimulai dari cabang paling kiri yang belum mencapai leaf node.
6. Jika seluruh cabang dari node yang dibentuk pada langkah sebelumnya sebelumnya telah mencapai leaf node, maka akan dicek cabang dari node diatas dari node yang dibentuk pada langkah sebelumnya, jika cabang tersebut belum mencapai leaf node maka akan dicari nilai gain seperti pada langkah nomor 3. 7. Proses yang sama akan dilakukan secara
rekursif untuk membentuk pohon keputusan dari setiap sampel.
8. Proses rekursif akan berhenti jika semua sampel pada node memiliki kelas yang sama, semua simpul sudah mencapai leaf node atau semua atribut telah digunakan untuk mempartisi sampel,
Keterangan Proses Proses ini digunakan untuk membentuk pohon keputusan menggunakan algoritma C4.5.
12. No Proses 4.1.1