STUDI PERBANDINGAN KINERJA ALGORITMA KOMPRESI
SHANNON-FANO DAN HUFFMAN PADA CITRA DIGITAL
SKRIPSI
ADE ADRIANI
051401086
PROGRAM STUDI S1 ILMU KOMPUTER
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
STUDI PERBANDINGAN KINERJA ALGORITMA KOMPRESI SHANNON-FANO DAN HUFFMAN PADA CITRA DIGITAL
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Komputer
ADE ADRIANI 051401086
PROGRAM STUDI S1 ILMU KOMPUTER DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : STUDI PERBANDINGAN KINERJA ALGORITMA
KOMPRESI SHANNON-FANO DAN HUFFMAN PADA CITRA DIGITAL
Kategori : SKRIPSI
Nama : ADE ADRIANI
Nomor Induk Mahasiswa : 051401086
Program Studi : SARJANA (S1) ILMU KOMPUTER
Departemen : ILMU KOMPUTER
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, 28 September 2009 Komisi Pembimbing :
Pembimbing 2, Pembimbing 1,
Drs. James Piter Marbun, M.Kom Syahriol Sitorus, S.Si, MIT
NIP. 195806111986031002 NIP. 197103101997031004
Diketahui/ Disetujui oleh
Program Studi S1 Ilmu Komputer Ketua,
PERNYATAAN
STUDI PERBANDINGAN KINERJA ALGORITMA KOMPRESI SHANNON-FANO DAN HUFFMAN PADA CITRA DIGITAL
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, 28 September 2009
PENGHARGAAN
Alhamdulillah, segala puji syukur penulis panjatkan kehadirat Allah SWT yang telah memberikan rahmat dan hidayah-Nya sehingga penulis dapat meyelesaikan Tugas Akhir ini. Dalam pengerjaan Tugas Akhir ini penulis banyak sekali mendapatkan dukungan, masukan, dan nasehat dari berbagai pihak.
ABSTRAK
STUDY OF COMPARISON OF COMPRESSION ALGORITHM SHANNON-FANNO AND HUFFMAN PERFORMANCE
FOR DIGITAL IMAGE
ABSTRACT
DAFTAR ISI
LEMBAR PERSETUJUAN ... ..i
LEMBAR PERNYATAAN ... .ii
PENGHARGAAN ... iii
DAFTAR ISTILAH ... xii
BAB 1 PENDAHULUAN 1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Batasan Masalah ... 3
1.4 Tujuan Penelitian ... 3
1.5 Manfaat Penelitian ... 4
1.6 Metode Penelitian... 4
1.7 Tinjauan Pustaka ... 5
1.8 Skema Penelitian ... 6
1.9 Sistematika Penulisan ... 9
BAB 2 LANDASAN TEORI 2.1 Pengolahan Citra Digital ... 11
2.2 Format Citra Bitmap (BMP) ... 13
2.3 Model Citra RGB ... 14
2.4 Pohon ... 15
2.5 Pohon Biner (Binary Tree) ... 15
2.6 Teori Informasi dan Entropi ... 16
2.7 Kompresi Citra ... 18
2.8 Algoritma Huffman ... 23
2.10 Kompleksitas Algoritma ... 32
2.10.1 Kompleksitas Waktu ... 32
2.10.2 Kompleksitas Waktu Asimptotik ... 33
BAB 3 ANALISIS KOMPLEKSITAS ALGORITMA 3.1 Kompleksitas Waktu Huffman ... 42
3.2 Kompleksitas Waktu Shannon-Fano ... 50
BAB 4 IMPLEMENTASI SISTEM 4.1 Flowchart Proses Kompresi Citra ... 55
4.1.1 Flowchart Algoritma Kompresi Huffman ... 56
4.1.2 Flowchart Algoritma Dekompresi Huffman... 57
4.1.3 Flowchart Algoritma Kompresi Shannon-Fano ... 59
4.1.4 Flowchart Algoritma Dekompresi Shannon-Fano ... 60
4.2 Perhitungan Performansi ... 61
4.2.1 Rasio Kompresi ... 62
4.2.2 Ukuran File Citra Kompresi ... 62
4.2.3 Kecepatan Kompresi dan Dekompresi Citra ... 62
4.2.4 PSNR (Peak Signal to Noise Ratio) ... 62
4.3 Desain Antarmuka Aplikasi Kompresi... 63
4.4 Alur Kerja Aplikasi Kompresi Citra ... 66
BAB 5 PENGUJIAN DAN ANALISIS SISTEM 5.1 Pengujian Sistem ... 71
5.1.1 Skenario Pengujian ... 71
5.1.2 Analisis Data Hasil Pengujian Sistem ... 74
5.1.2.1 Analisis Rasio Kompresi yang Dihasilkan Oleh Kedua Algoritma...74
5.1.2.2 Analisis Ukuran File Citra Hasil Kompresi...78
5.1.2.3 Analisis Kecepatan Proses Kompresi dan Dekompresi..79
5.1.2.5Analisis Panjang Rata-Rata Kode yang Digunakan setelah Dikompresi... 88
5.1.2.6 Analisis Nilai Entropi Citra... 89
BAB 6 KESIMPULAN DAN SARAN
6.1 Kesimpulan ... 92 6.2 Saran ... 93
DAFTAR GAMBAR
Gambar 1.1 Skema penelitian ... 6
Gambar 1.2 Diagram Algoritma Shannon-Fano ... 7
Gambar 1.3 Diagram Algoritma Huffman ... 8
Gambar 2.1 Matriks citra digital N x M ... 12
Gambar 2.2 Ilustrasi sistem koordinat piksel ... 12
Gambar 2.3 Pohon biner ... 16
Gambar 2.4 Entropy ... 17
Gambar 2.5 Metode kompresi berdasarkan hasilnya... 19
Gambar 2.6 Ilustrasi tipe per piksel ... 20
Gambar 2.7 Metode kompresi berdasarkan hasilnya...23
Gambar 2.8 Potongan Data Citra Digital... 25
Gambar 2.9 Data biner hasil substitusi kode Huffman ... 28
Gambar 2.10 Data biner hasil substitusi kode Shannon-Fano...31
Gambar 3.1 Potongan Data Citra Digital ... 42
Gambar 3.2 Data biner hasil substitusi kode Huffman...46
Gambar 3.3 Heap Graph O(n log n)...50
Gambar 3.4 Data biner hasil substitusi kode Shannon-Fano ... 53
Gambar 3.5 Heap Graph O(n log n) ... 54
Gambar 4.1 Flowchart Sistem Kompresi-Dekompresi Citra...56
Gambar 4.2 Flowchart Algoritma Kompresi Huffman... 56
Gambar 4.3 Flowchart Algoritma Dekompresi Huffman... 58
Gambar 4.4 Flowchart Algoritma Kompresi Shannon-Fano...59
Gambar 4.5 Flowchart Algoritma Dekompresi Shannon-Fano…... 61
Gambar 4.6 Tampilan antarmuka aplikasi kompresi citra... 63
Gambar 4.7 Tampilan open file citra... 66
Gambar 4.8 Tampilan proses kompresi citra... 67
Gambar 4.9 Tampilan pemilihan file citra yang akan di dekompresi... 68
Gambar 4.10 Tampilan open citra terkompresi...68
Gambar 4.11 Tampilan citra hasil rekonstruksi... 69
Gambar 5.1 Grafik perbandingan rasio kompresi Huffman terhadap tipe per plane ... 75 Gambar 5.2 Grafik perbandingan rasio kompresi Shannon-Fano tipe per
plane...76 Gambar 5.3 Perbandingan kecepatan kompresi algoritma Huffman dan
Shannon-Fano tipe per plane ... 81 Gambar 5.4 Perbandingan kecepatan kompresi algoritma Huffman dan
Shannon-Fano tipe per piksel ... 82 Gambar 5.5 Perbandingan kecepatan dekompresi algoritma Huffman dan
Shannon-Fano tipe per plane ... 84 Gambar 5.6 Perbandingan kecepatan dekompresi algoritma Huffman dan
DAFTAR TABEL
Tabel 2.1 Contoh warna 24-bit ... 14
Tabel 2.2 Tabel distribusi frekuensi Huffman ... 25
Tabel 2.3 Codebook Huffman ... 28
Tabel 2.4 Tabel distribusi frekuensi Shannon-Fano ... 29
Tabel 2.5 Codebook Shannon-Fano ... 31
Tabel 2.6 Perbandingan pertumbuhan T(n) dengan n2 Tabel 2.7 Pengelompokan Algoritma Berdasarkan Notasi O-Besar ... 39
... 33
Tabel 2.8 Nilai masing-masing fungsi untuk setiap nilai n ... 37
Tabel 3.1 Tabel distribusi frekuensi Huffman ... 43
Tabel 3.2 Codebook Huffman ... 46
Tabel 3.3 Tabel distribusi frekuensi Shannon-Fano ... 51
Tabel 3.4 Codebook Shannon-Fano ... 52
Tabel 5.1 Citra uji ... 72
Tabel 5.2 Rasio Kompresi algoritma Shannon-Fano dan Huffman tipe per plane...75
Tabel 5.3 Rasio Kompresi algoritma Shannon-Fano dan Huffman tipe per piksel... 77
Tabel 5.4 Kecepatan proses kompresi algoritma Shannon-fano dan Huffman tipe per plane...80
Tabel 5.5 Kecepatan proses kompresi algoritma Shannon-fano dan Huffman tipe per piksel...82
Tabel 5.6 Kecepatan proses dekompresi algoritma Shannon-fano dan Huffman tipe per plane... 83
Tabel 5.7 Kecepatan proses dekompresi algoritma Shannon-fano dan Huffman tipe per piksel...85
Tabel 5.8 Nilai PSNR citra algoritma Shannon-Fano dan Huffman dengan tipe kompresi per plane dan per piksel... ...86
Tabel 5.9 Panjang rata-rata kode kompresi Shannon-fano dan Huffman tipe per plane... 88
Tabel 5.10 Panjang rata-rata kode kompresi Shannon-fano dan Huffman tipe per piksel...89
Tabel 5.11 Nilai entropi citra, tipe kompresi per plane... 90
DAFTAR ISTILAH
Bitmap Reperesentasi dari citra grafis yang terdiri dari susunan titik yang tersimpan di memori komputer.
Codebook Kumpulan simbol dan kode biner yang dihasilkan setelah pembuatan pohon Huffman atau Shannon-Fano.
Citra terkompresi Citra yang diperoleh dari hasil kompresi. Citra rekonstruksi Citra yang diperoleh dari proses dekompresi.
Decibel Satuan logaritmik yang digunakan untuk menggambarkan perbandingan antara matriks asli dengan matriks rekonstruksi. Decoder Suatu proses yang merupakan kebalikan dari proses encoder
yang melibatkan citra hasil kompresi sebagai masukan dan citra hasil dekompresi sebagai keluaran atau dengan kata lain proses dekompresi pada bagian penerima.
Encoder Proses yang melibatkan citra asli sebagai masukan dan citra hasil kompresi sebagai keluaran atau dengan kata lain proses kompresi pada bagian pengirim.
MSE Sigma dari jumlah error antara citra hasil kompresi dan citra asli.
Pixel Elemen citra digital yang menunjukkan intensitas citra di suatu titik.
PSNR Peak Signal to Noise Ratio yang merupakan nilai logaritma basis 10 dari hasil pembagian nilai piksel tertinggi terhadap MSE dalam satuan dB (decibel).
Rasio kompresi Suatu nilai yang menyatakan suatu nilai perbandingan ukuran file citra asli dibandingkan dengan file citra hasil kompresi. Resolusi Kerapatan titik-titik pada bitmap yang menunjukkan seberapa
ABSTRAK
STUDY OF COMPARISON OF COMPRESSION ALGORITHM SHANNON-FANNO AND HUFFMAN PERFORMANCE
FOR DIGITAL IMAGE
ABSTRACT
BAB 1
PENDAHULUAN
1.1Latar Belakang
Peningkatan teknologi komputer memberikan banyak manfaat bagi manusia di berbagai aspek kehidupan, salah satu manfaatnya yaitu untuk menyimpan data, baik data berupa teks ataupun data digital lain seperti gambar, suara dan video. Kecepatan pengiriman informasi secara real-time akan menjadi bagian utama dalam proses pertukaran informasi di masa yang akan datang. Hingga saat ini pengiriman informasi secara real-time masih mengalami kendala, diantaranya adalah besarnya jumlah data yang harus dikirim melampaui kecepatan transmisi yang dimiliki oleh perangkat keras, sehingga masih terdapat delay time yang relatif besar (Madenda et al, 2004: 1).
Salah satu solusi untuk mengatasi masalah di atas adalah dengan melakukan kompresi citra. Kompresi citra terdiri dari dua proses utama yaitu kompresi dan dekompresi citra. Jika file citra dikompresi, maka file tersebut harus dapat dibaca kembali setelah file tersebut dikompresi. Ide kompresi citra adalah apabila frekuensi kemunculan warna pada tiap piksel diketahui, terdapat suatu cara untuk mengodekan warna tersebut sehingga dibutuhkan ruang yang lebih kecil untuk menyimpan citra. Metode kompresi yang diharapkan dari kompresi citra adalah proses kompresi dan dekompresinya cepat, meminimalkan pemakaian memori, kualitas citra bagus dan proses transfer yang mudah (Hestiningsih, 2008: 33).
Metode yang pertama muncul untuk proses kompresi diperkenalkan oleh Shannon-Fano, yang dikenal dengan Shannon-Fano coding. Shannon dan Fano (1948) mengembangkan algoritma yang didasarkan pada variable-length code yang berarti beberapa karakter pada data yang akan dikodekan direpresentasikan dengan kode yang lebih pendek dari karakter yang ada pada data. Jika frekuensi kemunculan karakter semakin tinggi, maka kode semakin pendek, sebaliknya jika frekuensi kemunculan karakter rendah, maka kode semakin panjang, dengan demikian kode yang dihasilkan tidak sama panjang, sehingga kode tersebut bersifat unik. Pada prinsipnya algoritma ini menggunakan pendekatan top-down dalam penyusunan binary tree. Pada tahun 1952 David Huffman memperkenalkan algoritma kompresi yang dinamakan Huffman coding. Metode ini memakai hampir semua karakteristik dari Shannon-Fano coding. Pada prinsipnya Huffman coding menggunakan pendekatan buttom-up dalam penyusunan binary tree. Thomas H. Cormen et al (dalam Hasibuan, 2008: 5).
1.2Rumusan Masalah
Permasalahan yang akan diteliti dan diuraikan dalam Tugas Akhir ini adalah:
1. Menentukan rasio kompresi yang dihasilkan oleh algoritma Shannon-Fano dan Huffman.
2. Apakah algoritma Shannon-Fano dan Huffman dapat merekonstruksikan kembali (dekompresi) data citra sesuai dengan data aslinya.
3. Algoritma mana yang lebih baik digunakan untuk kompresi citra ditinjau dari rasio kompresi yang dihasilkan, ukuran file hasil kompresi, kecepatan proses kompresi dan dekompresi, dan kualitas citra hasil dekompresi (PSNR).
1.3Batasan Masalah
Ruang lingkup penelitian ini dibatasi pada:
1.File citra yang dikompresi merupakan file citra warna RGB format BMP ukuran 256 x 256 piksel.
2.Studi perbandingan ini akan ditinjau dari rasio kompresi yang dihasilkan kedua algoritma.
3.Studi perbandingan ini akan ditinjau dari ukuran file citra dan kebutuhan memori citra terkompresi yang dihasilkan.
4.Studi perbandingan ini akan ditinjau dari kecepatan proses kompresi dan dekompresi dari masing-masing algoritma yang digunakan.
5.Studi perbandingan ini akan mengukur kualitas citra hasil dekompresi dengan menggunakan metode PSNR (Peak Signal to Noise Ratio).
6.Menggunakan aplikasi kompresi Shannon-Fano dan Huffman yang telah ada untuk proses analisis dan perbandingan kinerja algoritma kompresi.
1.4Tujuan Penelitian
diambil kesimpulan algoritma mana yang tepat digunakan dalam proses kompresi citra digital.
1.5Manfaat Penelitian
Manfaat penelitian ini adalah memutuskan algoritma yang tepat dalam proses kompresi citra digital sehingga dihasilkan citra mampat yang dapat meminimalkan pemakaian memori (storage device) serta dapat meminimalkan waktu pengiriman data pada saluran komunikasi.
1.6Metode Penelitian
Tahapan yang diambil dalam penelitian ini yaitu: 1. Studi literatur
Penulisan ini dimulai dengan studi kepustakaan yaitu mengumpulkan bahan-bahan referensi baik dari buku, artikel, paper, jurnal, makalah, maupun situs internet mengenai proses kompresi data digital terutama kompresi citra, algoritma Shannon-Fano dan Huffman serta beberapa referensi lainnya untuk menunjang pencapaian tujuan Tugas Akhir.
2. Analisis algoritma
Pada tahap ini akan dilakukan proses analisis algoritma kompresi Huffman dan Shannon-Fano meliputi karakteristik masing-masing algoritma.
3. Implementasi sistem
Sistem diimplementasikan dalam bentuk perangkat lunak yang siap pakai menggunakan bahasa pemrograman Borland Delphi 7.0.
4. Pengujian dan analisis sistem
Pada tahap ini akan dilakukan analisis terhadap fokus permasalahan penelitian, yaitu apakah proses kompresi berhasil atau tidak serta perbaikan bila terdapat kesalahan.
5. Dokumentasi sistem
1.7Tinjauan Pustaka
Rinaldi Munir dalam buku yang berjudul Pengolahan Citra Digital dengan Pendekatan Algoritmik, memberikan penjelasan mengenai klasifikasi dan metode kompresi. Kompresi bertujuan untuk meminimalkan kebutuhan memori. Prinsip umum yang digunakan pada proses kompresi, misalnya kompresi citra adalah mengurangi duplikasi data di dalam citra digital sehingga memori yang dibutuhkan untuk merepresentasikan citra menjadi lebih sedikit daripada representasi citra semula.
Ida Mengyi Pu dalam bukunya yang berjudul Fundamental Data Compression, menjelaskan tentang kompresi data. Buku ini mengedepankan materi yang dapat dipelajari dengan mudah, dengan topik-topik yang sangat berguna dalam teknik kompresi teks, suara, gambar, video, dan standar internasional. Buku ini juga dilengkapi dengan berbagai contoh dan ilustrasi yang dapat meningkatkan proses belajar.
Sarifuddin Madenda, Hayet L. dan I. Bayu dalam makalahnya yang berjudul
Kompresi Citra Berwarna Menggunakan Metode Pohon Biner Huffman menjelaskan tentang algoritma kompresi citra dengan menggunakan metode pohon biner Huffman. Metode ini biasanya digunakan untuk mengkompres file teks dikembangkan menjadi algoritma untuk mengkompres citra berwarna. Hasil yang diperoleh menunjukan bahwa algoritma ini memiliki nilai rasio kompresi di atas satu jika jumlah warna yang terdapat dalam citra tidak lebih dari 100 warna. Sedang kualitas citra hasil dekompresinya memiliki kualitas yang sama dengan citra aslinya.
1.8Skema Penelitian
Skema/ alur proses kerja dari studi perbandingan kinerja kedua algoritma kompresi secara umum adalah sebagai berikut:
Gambar 1.1 Skema Penelitian File citra
Pembentukan pohon biner dengan penggabungan frekuensi
Kompresi dan Dekompresi citra dengan kedua algoritma
File hasil kompresi dan dekompresi beserta informasinya
Analisis dan bandingkan informasi hasil kompresi dan dekompresi Pembentukan pohon biner dengan
pembagian frekuensi kemunculan simbol secara rekursif
Hitung frekuensi kemunculan simbol pada tiap-tiap piksel citra
Start
Input file citra
Pembentukan pohon Shannon-Fano dengan membagi dua dengan frekuensi mendekati/sama
secara rekursif
Pembentukan kode Shannon-Fano, sisi pohon biner kiri dilabeli 0 dan sisi kanan =1
Kode Shannon-Fano output
Stop
Urutkan warna secara menurun (descending order) 1.8.1 Diagram Algoritma Shannon-Fano
Alur kerja pada algoritma Shannon-Fano secara umum dapat dilihat pada Gambar 1.2 di bawah ini.
Hitung frekuensi kemunculan simbol pada tiap-tiap piksel citra
Start
Input file citra
Pembentukan pohon Huffman dengan menggabung dua frekuensi terkecil, hingga
tersisa 1 pohon biner
Pembentukan kode Huffman, sisi pohon biner kiri dilabeli 0 dan sisi kanan =1
Kode Huffman output
Stop
Urutkan simbol secara menaik (ascending order) 1.8.2 Diagram Algoritma Huffman
Alur kerja pada algoritma Huffman secara umum dapat dilihat pada Gambar 1.3 di bawah ini.
1.9Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri dari beberapa bagian utama sebagai berikut:
BAB 1: PENDAHULUAN
Bab ini akan menjelaskan mengenai latar belakang pemilihan judul skripsi “Studi Perbandingan Kinerja Algoritma Kompresi Shannon-Fano dan Huffman pada Citra Digital”, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metode penelitian, tinjauan pustaka, sistematika penulisan dan skema penelitian.
BAB 2: LANDASAN TEORI
Bab ini akan membahas teori-teori yang berkaitan dengan kompresi data dalam hal ini citra digital serta beberapa prinsip yang melandasi pembuatan Tugas Akhir ini.
BAB 3: ANALISIS KOMPLEKSITAS ALGORITMA
Bab ini berisi tentang uraian kompleksitas algoritma Huffman dan Shannon-Fano. Nilai kompleksitas dinyatakan dengan notasi Big-O notation.
BAB 4: IMPLEMENTASI SISTEM
Bab ini berisikan penjelasan tentang aplikasi yang digunakan untuk menguji performansi algoritma Shannon-Fano dan Huffman dalam proses kompresi file citra.
BAB 5: PENGUJIAN DAN ANALISIS SISTEM
BAB 6: KESIMPULAN DAN SARAN
BAB 2
LANDASAN TEORI
2.1 Pengolahan Citra Digital
Citra digital dapat didefinisikan sebagai fungsi dua variabel yaitu f(x,y), dimana x dan y adalah koordinat spasial dan nilai f(x,y) adalah intensitas citra pada koordinat tersebut. Teknologi dasar untuk menciptakan dan menampilkan warna pada citra digital berdasarkan pada penelitian bahwa sebuah warna merupakan kombinasi dari tiga warna dasar, yaitu merah, hijau, dan biru atau RGB (Suhendra, 2008: 1).
Pengolahan citra adalah kegiatan untuk memperbaiki kualitas citra agar mudah diinterpretasi oleh manusia/ mesin (komputer). Inputannya adalah citra dan keluarannya juga citra tapi dengan kualitas lebih baik daripada citra masukan sesuai dengan kebutuhan terhadap citra itu sendiri, misalnya citra warnanya kurang tajam, kabur (blurring), mengandung noise (misal bintik-bintik putih) dan lain-lain, sehingga perlu ada pemrosesan untuk memperbaiki citra karena citra tersebut menjadi sulit diinterpretasikan karena informasi yang disampaikan menjadi berkurang.
Tingkat ketajaman/ resolusi warna pada citra digital tergantung pada jumlah bit yang digunakan oleh komputer untuk merepresentasikan setiap piksel tersebut. Tipe yang sering digunakan untuk merepresentasikan citra adalah 8-bit citra yang terdiri dari 256 warna (0 untuk hitam-255 untuk putih), tetapi dengan kemajuan teknologi perangkat keras grafik, kemampuan tampilan citra di komputer meningkat hingga 32 bit (232 warna).
Gambar 2.1 Matriks citra digital N x M
Gambar 2.2 Ilustrasi sistem koordinat piksel
Menurut Wijaya dan Prijono (2007: 30), pengolahan citra digital dapat dilakukan dengan berbagai cara, adapun beberapa operasi dalam pengolahan citra antara lain:
1. Perbaikan citra (image restoration)
2. Peningkatan kualitas citra (image enhancement) 3. Registrasi citra (image registration)
4. Pemampatan data citra (image data compression) 5. Pemilahan citra (image segmentation)
2.2 Format Citra Bitmap (BMP)
Citra disimpan di dalam file dengan format tertentu. Format citra yang baku di lingkungan sistem operasi Microsoft Windows dan IBM OS/2 adalah file bitmap (BMP). Saat ini format BMP memang kalah populer dibandingkan format JPG atau GIF. Hal ini karena file citra BMP pada umumnya tidak dikompresi, sehingga ukuran filenya relatif lebih besar daripada file JPG maupun GIF. Hal ini juga menyebabkan format BMP sudah jarang digunakan.
Meskipun format BMP tidak mangkus dari segi ukuran berkas, namun format BMP memiliki kelebihan dari segi kualitas gambar. Citra dalam format BMP lebih bagus daripada citra dalam format yang lainnya, karena citra dalam format BMP umumnya tidak dimampatkan sehingga tidak ada informasi yang hilang. Terjemahan bebas bitmap adalah pemetaan bit, artinya nilai intensitas piksel di dalam citra dipetakan kesejumlah bit tertentu. Peta bit yang umum adalah 8, artinya setiap piksel panjangnya 8 bit. Delapan bit ini merepresentasikan nilai intensitas piksel. Dengan demikian ada sebanyak 28 = 256 derajat keabuan, mulai dari 0-255.
Citra dalam format BMP ada tiga macam: citra biner, citra berwarna, dan citra hitam-putih (grayscale). Citra biner hanya mempunyai dua nilai keabuan, yaitu nilai 0 dan 1. Oleh karena itu, 1 bit sudah cukup merepresentasikan nilai piksel. Citra berwarna adalah citra yang lebih umum. Warna yang terlihat pada citra bitmap merupakan kombinasi dari tiga warna dasar, yaitu mereh, hijau, dan biru. Setiap piksel disusun oleh tiga komponen warna: R (red), G (green), dan B (blue). Kombinasi dari ketiga warna RGB tersebut menghasilkan warna yang khas untuk piksel yang bersangkutan.
keabuan biru (B) untuk masing-masing piksel yang bersangkutan. Namun pada citra hitam-putih, nilai R = G = B untuk menyatakan bahwa citra hitam putih hanya mempunyai satu kanal warna. Citra hitam putih umumnya adalah citra 8 bit.
Citra yang lebih kaya warna adalah citra 24 bit. Setiap piksel panjangnya 24 bit, karena setiap piksel langsung menyatakan komponen warna merah, komponen warna hijau, dan komponen warna biru. Masing-masing komponen panjangnya 8 bit. Citra 24 bit disebut juga citra 16 juta warna, karena citra ini mampu menghasilkan 224 = 16.777.216 kombinasi warna.
2.3 Model Citra RGB
Pada umumnya, representasi citra digital membutuhkan kapasitas ruang penyimpanan yang besar. Citra RGB merupakan citra true color yang mendefinisikan warna merah, hijau dan biru untuk setiap pikselnya (RGB), walaupun belum ada standar yang ditetapkan secara umum untuk citra RGB, tetapi TV dan industri video memiliki standar data warna RGB yang mengikuti rekomendasi ITU-R BT.709 untuk High Definition TV (HDTV), monitor juga dibangun dengan mengikuti rekomendasi tersebut. Dalam model RGB, warna pada setiap piksel ditentukan dari kombinasi warna merah, hijau dan biru. Format file citra menyimpan citra RGB menggunakan 1 byte (8 bit) untuk menampilkan masing-masing warna primer, yang memiliki rentang [0, 255] atau [1, 256], jadi warna RGB memiliki 3 byte (3 x 8 bit = 24 bit) untuk menggambarkan tiap-tiap piksel, dengan demikian terdapat 2563 = 16.777.216 warna berbeda yang bisa direpresentasikan pada citra RGB.
Tabel 2.1 Contoh warna 24 bit
2.4 Pohon
Pohon (tree) membentuk salah satu subklas dari graf yang paling banyak digunakan. Dalam ilmu komputer, pohon berguna dalam mengatur dan mengaitkan data dalam suatu basis data.
Definisi 2.1 Sebuah pohon T (tree T) adalah sebuah graf sederhana yang memenuhi:
jika v dan w adalah verteks atau node di T, maka terdapat sebuah lintasan sederhana tunggal dari v ke w (Johnsonbaught, Richard, 1998: 75).
Definisi 2.2 Sebuah pohon berakar adalah pohon dimana sebuah node tertentu
dirancang seperti akar (Johnsonbaught, Richard, 1998: 75).
2.5 Pohon Biner (Binary Tree)
Definisi 2.3 Pohon biner (binary tree) adalah pohon berakar yang setiap nodenya
mempunyai paling banyak dua anak dan masing-masing anak dari sebuah node disebut sebagai anak kiri (left child) dan anak kanan (right child) (Jong, Jek Siang, 2002: 283).
Definisi 2.4 Pohon biner penuh (full binary tree) adalah pohon biner yang setiap
nodenya (kecuali daun) mempunyai tepat dua anak (Jong, Jek Siang, 2002: 283).
Pohon biner dapat digunakan untuk menyatakan ekspresi aljabar maupun pencarian dan pengurutan data.
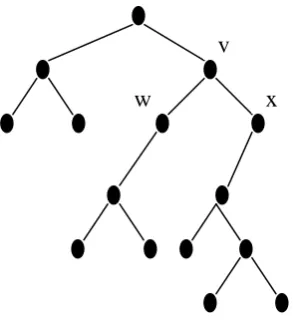
Definisi 2.5 Misalkan T adalah pohon biner dan v є V(T) adalah suatu titik cabang dalam T. Sub pohon kiri (left sub tree) v adalah pohon biner yang:
1. Titik-titiknya adalah anak kiri v dan semua turunannya.
2. Garis-garisnya adalah garis-garis dalam E(T) yang menghubungkan titik-titik subpohon kiri v.
Gambar 2.3 Pohon Biner
Gambar diatas merupakan pohon biner dengan dua subpohon, yaitu subpohon kiri v dengan w sebagai akar dan subpohon kanan v dengan x sebagai akar.
2.6 Teori Informasi dan Entropi
Kompresi data citra memanfaatkan teori informasi karena kompresi menitikberatkan pada masalah redudansi. informasi yang redundan pada kumpulan data citra menimbulkan bit-bit tambahan pada pengkodean, jika informasi tambahan itu bisa diambil maka data yang diperlukan tersebut bisa direduksi.
Teori informasi memanfaatkan terminologi entropi sebagai tolak ukur seberapa besar informasi yang dikodekan pada sebuah citra. Entropi merupakan suatu ukuran informasi yang dikandung oleh suatu citra dan digunakan sebagai ukuran untuk mengukur kemampuan kompresi dari citra. Entropi memiliki persamaan matematis sebagai berikut:
m
H (X) = - ∑ pi log2 pi i=1
m = jumlah simbol
pi = probabilitas simbol ke-i
w
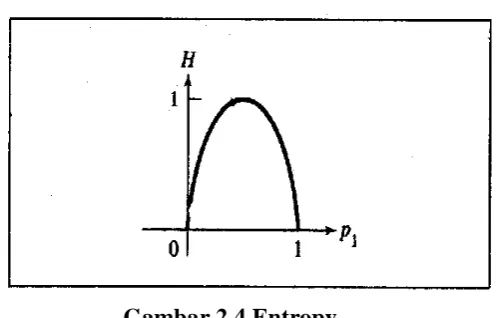
Contoh:
Untuk sumber biner, set probabilitasnya adalah: P = {p1, p2} = {p1, 1-p1}
H(p1,p2) = -p1lgp1 – p2lgp2
= -p1lgp1 – (1 – p1)lg(1 – p1) = H(p1)
Gambar 2.4 Entropy
Contoh konsep entropy pada Shannon-Fano Coding: S = {A, B, C, D, E}
P = {0.35, 0.17, 0.17, 0.16, 0.15}
Pengkodean Shannon-Fano:
1. Bagi S kedalam s1 dan s2 (pilih yang memberikan perbedaan p(s1) dan p(s2
2. s
)
terkecil
1 = (A,B) p(s1
3. s
) = p(A) + p(B) = 0,52
2 = (C,D,E) p(s2
4. Panggil ShannonFano()
) = p(C) + p(D) + p(E) = 0,48
Panjang code rata-rata:
Semakin kecil nilai entropi yang dihasilkan maka kemampuan kompresi lebih baik. entropi juga didefinisikan sebagai limit kemampuan kompresi citra yang tidak dapat dilampau oleh algoritma manapun. jika nilai entropi dan jumlah simbol diketahui maka sebuah citra dapat diprediksi berapa besar ukuran terkompresinya, sehingga dapat diprediksi pula rasio kompresinya dengan menggunakan persamaan matematis berikut ini:
ukuran terkompresi = w x h x t x m x entropi : 8 + (m x j)
w: lebar citra digital h: tinggi citra digital
t: menyatakan jumlah plane yang digunakan pada saat kompresi, bernilai 3 jika menggunakan tipe per plane, karena plane R, G, B digunakan secara terpisah dan bernilai 1 jika menggunakan tipe kompresi per piksel karena plane R, G, B digunakan secara satu kesatuan menjadi sebuah plane.
m: jumlah simbol
j: menyatakan ukuran codebook setiap barisnya, jumlah baris sama dengan jumlah simbol.
2.7 Kompresi Citra
Semakin besar ukuran citra, semakin besar memori yang dibutuhkan, namun kebanyakan citra mengandung duplikasi data, yaitu:
1. Suatu piksel memiliki intensitas yang sama dengan piksel tetangganya, sehingga penyimpanan piksel membutuhkan memori (space) yang lebih besar sehingga sangat memboroskan tempat.
2. Citra banyak mengandung bagian (region) yang sama sehingga bagian yang sama ini tidak perlu dikodekan berulang kali karena mubazir atau redudan.
Contohnya: citra langit biru dengan beberapa awan putih yang memiliki banyak intensitas dan region yang sama.
sehingga memori yang dibutuhkan menjadi lebih sedikit daripada representasi citra semula (Munir, 2004: 160).
Tipe kompresi citra, yaitu bagaimana data digital di proses sebelum digunakan untuk proses kompresi, tipe kompresi yang digunakan untuk proses kompresi ini adalah:
1. Tipe per plane
Tipe per plane memperlakukan data citra digital yang terdiri dari tiga plane yaitu Red, Green dan Blue dijadikan sebuah matrik satu dimensi dengan panjang matrik sepanjang hasil perkalian dari panjang dan lebar citra digital. Sehingga masing-masing data digital di setiap plane nya akan dipetakan satu per satu ke dalam matriks tersebut. Setiap matriks diisi nilai antara 0-255, diilustrasikan sbb:
Gambar 2.5 Ilustrasi tipe per plane
2. Tipe per piksel
Tipe per piksel memperlakukan data citra digital yang terdiri atas tiga buah plane, yaitu red, green dan blue dijadikan sebuah matriks satu dimensi dengan panjang matriks sepanjang hasil perkalian dari tinggi dan lebar citra. Sehingga masing-masing data citra digital di setiap plane nya akan dijadikan sebuah nilai dengan persamaan matematis sebagai berikut:
RGB = (B x 65536) + (G x 256) + R
B
G
R
w
h R G B … R
w x h
Kemudian nilai RGB yang dihasilkan dimasukkan kedalam matriks tersebut. Setiap matriks diisi nilai antara 0-16777215, ilustrasinya sebagai berikut:
Gambar 2.6 Ilustrasi tipe per piksel
Manfaat kompresi citra adalah:
1. Waktu pengiriman data pada saluran komunikasi data lebih singkat.
Contoh: pengiriman gambar dari fax, videoconferencing, handphone, download dari internet, pengiriman data medis, pengiriman dari satelit, dan sebagainya. 2. Membutuhkan ruang memori dalam storage lebih sedikit daripada representasi
citra yang tidak dikompresi.
Metode kompresi yang diharapkan dari sebuah kompresi citra adalah: 1. Proses kompresi dan dekompresinya cepat.
Proses kompresi adalah citra dalam representasi tidak mampat dikodekan dengan representsi yang meminimumkan kebutuhan memori. Citra terkompresi disimpan dalam file dengan format tertentu misalnya JPEG (Joint Photographic Expert Group). Proses dekompresi adalah citra yang sudah dikompresi dikembalikan lagi (decoding) menjadi representasi yang tidak mampat. Diperlukan jika citra tersebut dikembalikan ke layar/ disimpan dalam format tidak mampat yaitu format bitmap (BMP).
2. Memori yang dibutuhkan seminimal mungkin
Ada metode yang berhasil melakukan kompresi dengan persentase besar, ada yang kecil. Ukuran memori hasil kompresi juga bergantung pada citra itu sendiri, yaitu citra yang mengandung banyak elemen duplikasi biasanya berhasil dikompresi
B
G
R
w
h
RGB RGB … RGB RGB
dengan memori yang lebih sedikit. Contoh: citra langit biru tanpa awan dibandingkan dengan citra pemandangan alam (mengandung banyak objek).
3. Kualitas citra hasil kompresi harus bagus (fidelity)
Informasi yang hilang akibat kompresi seharusnya seminimal mungkin sehingga kualitas hasil kompresi bagus. Tetapi biasanya kualitas kompresi bagus bila proses kompresi menghasilkan pengurangan memori yang tidak begitu besar, demikian sebaliknya.
Dalam kompresi citra terdapat standar pengukuran error (galat) kompresi yaitu: 1. MSE (Mean Square Error), yaitu sigma dari jumlah error antara citra hasil
kompresi dan citra asli.
M N
MSE = 1 ∑ ∑ [I(x, y) – I’(x, y)]2
MN y=1 x=1
Dimana: I(x,y) adalah nilai pixel di citra asli.
I’(x,y) adalah nilai pixel pada citra hasil kompresi. M, N adalah dimensi citra.
2. PSNR (Peak Signal to Noise Ratio), yaitu untuk mengukur kualitas hasil kompresi.
PSNR = 20 * log10 (b/sqrt (MSE))
Nilai b merupakan nilai maksimum dari piksel citra yang digunakan, karena Tugas Akhir ini menggunakan citra bitmap 24 bit maka nilai b adalah 224-1 atau 16777215. Nilai MSE yang semakin rendah akan semakin baik, sedangkan semakin besar nilai PSNR, semakin bagus kualitas kompresi. PSNR memiliki satuan decibel (dB).
M N
4. Proses transfer dan penyimpanannya mudah.
Kompresi citra sebaiknya dapat meminimalkan waktu pengiriman citra pada saluran komunikasi.
Metode kompresi diklasifikasikan ke dalam dua metode, yaitu (Munir, 2004: 169): 1. Metode Lossless
Metode lossless merupakan teknik kompresi yang menghasilkan hasil dekompresi tepat sama seperti data semula. Tidak ada informasi yang hilang akibat kompresi. Tetapi rasio kompresinya sangat rendah, misalnya pada data teks, gambar seperti GIF dan PNG. Contoh metode ini adalah Shannon-Fano coding, Huffman coding, Arithmetic coding dan lain sebagainya.
Rasio kompresi = ( ukuran citra asli – ukuran citra terkompresi ukuran citra asli
x 100 % )
2. Metode Lossy
Metode lossy merupakan teknik kompresi yang menghasilkan hasil dekompresi yang hampir sama dengan data semula. Ada informasi yang hilang akibat kompresi,
2 8
tetapi dapat ditolerir oleh persepsi mata. Misalnya pada gambar dan MP3. Kelebihan teknik ini adalah rasio kompresi yang tinggi dibanding metode lossless.
Ada beberapa pendekatan yang digunakan untuk kompresi citra: 1. Pendekatan statistik (statistical compression)
2. Pendekatan ruang (spatial compression)
3. Pendekatan kuantisasi (quantizing compression) 4. Pendekatan fraktal (fractal compression)
5. Pendekatan transformasi wavelet (wavelet compression)
Gambar 2.7 Metode kompresi berdasarkan hasilnya
Pada Tugas Akhir ini kompresi citra akan menggunakan pendekatan statistik dengan membandingkan kinerja dua algoritma kompresi yaitu algoritma kompresi Shannon-Fano dan algoritma Huffman.
2.8 Algoritma Huffman
ini adalah yang paling efisien. Apa yang dilakukan Huffman melampaui profesornya sendiri, yang bekerja sama dengan pencipta bidang teori informasi Claude Shannon mengembangkan kode yang mirip. Huffman menghindari kesalahan besar dari kode Shannon-Fano yang kurang optimal dengan membangun pohon binernya dari bawah ke atas dan bukan dari atas ke bawah. Makalah berjudul “A Method for the Construction of Minimum Redundancy Codes” tersebut lalu dipublikasikan oleh Huffman pada tahun 1952 dalam sebuah jurnal profesional untuk Institute of Radio Engineers.
Algoritma Huffman adalah salah satu algoritma kompresi teks tertua yang disusun oleh David Huffman pada tahun 1952. Algoritma tersebut digunakan untuk membuat kompresi jenis lossless compression, yaitu kompresi data dimana tidak satu byte pun hilang sehingga data tersebut utuh dan disimpan sesuai dengan aslinya. Prinsip kerja algoritma Huffman adalah mengkodekan setiap karakter kedalam representasi bit. Representasi bit untuk setiap karakter berbeda satu sama lain berdasarkan frekuensi kemunculan karakter. Semakin sering karakter tersebut muncul, maka semakin pendek panjang representasi bitnya. Sebaliknya bila semakin jarang frekuensi suatu karakter untuk muncul, maka semakin panjang representasi bit untuk karakter tersebut.
Algoritma Huffman pada citra adalah sebagai berikut:
1. Hitung frekuensi kemunculan masing-masing simbol pada citra.
2. Urutkan frekuensi kemunculan simbol citra dari yang terkecil ke yang terbesar, masing-masing simbol dapat direpresentasikan sebagai sebuah node.
3. Gabungkan dua node yang mempunyai frekuensi kemunculan simbol terkecil, kemudian jumlahkan kedua frekuensi kemunculan sehingga membentuk parent node.
4. Masukkan node parent ke dalam kumpulan node dan urutkan berdasarkan frekuensi kemunculan simbol, dari yang terkecil ke yang terbesar.
5. Hapus node dengan frekuensi kemunculan terkecil yang telah digabungkan dari kumpulan node.
7. Beri label pada setiap sisi pohon biner, sisi kiri dilabeli dengan 0 dan sisi kanan dilabeli dengan 1.
8. Telusuri pohon biner dari akar ke daun. Barisan label-label pada sisi pohon dari akar ke daun menyatakan kode Huffman untuk simbol yang bersesuaian.
Misalnya terdapat data citra digital dalam bentuk matriks seperti gambar dibawah ini:
255 0 50 255 25 25 25 50 50 180 180 180 50 50 120 255 255 25 120 120 50 255 255 50 255 255 180 25 255 255 255 255 180 25 255 255
Gambar 2.8 Potongan data citra digital
Langkah-langkah pembentukan pohon Huffman:
1. Hitung frekuensi kemunculan masing-masing simbol pada citra.
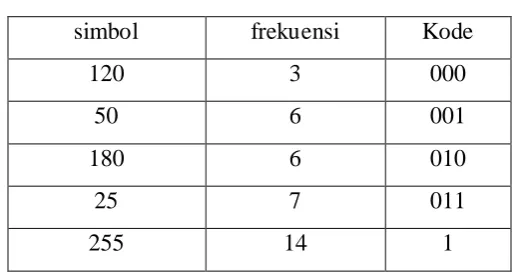
Dari potongan data citra tersebut diperoleh tabel distribusi frekuensi sebagai berikut:
Tabel 2.2 Tabel distribusi frekuensi Huffman
Simbol Frekuensi Total bit
120 3 3 x 1 byte = 3
50 6 6 x 1 byte = 6
180 6 6 x 1 byte = 6
25 7 7 x 1 byte = 7
255 14 14 x 1 byte = 14
Total 36 byte
2. Urutkan frekuensi kemunculan simbol dari yang terkecil ke yang terbesar, masing-masing simbol dapat direpresentasikan sebagai sebuah node.
3. Gabungkan dua node yang mempunyai frekuensi kemunculan simbol terkecil, kemudian jumlahkan kedua frekuensi kemunculan sehingga membentuk parent node.
4. Masukkan node parent ke dalam kumpulan node dan urutkan berdasarkan frekuensi kemunculan simbol, dari yang terkecil ke yang terbesar.
5. Hapus node dengan frekuensi kemunculan terkecil yang telah digabungkan dari kumpulan node.
Langkah 4 dan 5 adalah sebagai berikut:
6. Ulangi lagkah 1-5 sampai semua simbol habis dibangkitkan.
13 9
3
14
6 6 7
7 14
9
3 6
6
7 9
3
14
7. Beri label pada setiap sisi pohon biner, sisi kiri dilabeli dengan 0 dan sisi kanan dilabeli dengan 1.
8. Telusuri pohon biner dari akar ke daun. Barisan label-label pada sisi pohon dari akar ke daun menyatakan kode Huffman untuk simbol yang bersesuaian
14
13 9
3 6 6 7
22
36
255
25 180
50 120
0 1
0
1
0 1 0 1
13 9
3
14
6 6 7
Maka dari pohon Huffman di atas diperoleh kode Huffman sebagai berikut:
Tabel 2.3 Codebook Huffman
simbol frekuensi Kode
120 3 000
50 6 001
180 6 010
25 7 011
255 14 1
Dari tabel di atas dapat dilihat bahwa simbol yang sering muncul dikodekan dengan kode yang lebih pendek, demikian juga sebaliknya. Setelah itu dilakukan substitusi dari simbol-simbol potongan citra digital pada Gambar 2.5 dengan kode Huffman yang terdapat pada Tabel 2.3, sehingga diperoleh data biner sebagai berikut:
101000110110110110010010100100100010010001
1011000000001110111101001111110111101001111
Gambar 2.9 Data biner hasil substitusi kode Huffman
Data biner hasil substitusi kode Huffman memiliki ukuran 85 bit setara 10,625 byte, sedangkan tanpa kompresi dibutuhkan 36 bytes, diperoleh dari total frekuensi kemunculan simbol dikalikan dengan 1 byte. Sehingga Algoritma Huffman dapat mereduksi penggunaan memori sebanyak 25,375 bytes. Dengan rasio kompresinya yaitu (100 – 10,625/36 x 100%) = 70,486 %.
2.9 Algoritma Shannon-Fano
Algoritma Shannon-Fano didasarkan pada variable-length code yang berarti beberapa karakter pada data yang akan dikodekan direpresentasikan dengan kode (codeword) yang lebih pendek dari karakter yang ada pada data. Jika frekuensi kemunculan karakter semakin tinggi, maka kode semakin pendek, dengan demikian kode yang dihasilkan tidak sama panjang, sehingga kode tersebut bersifat unik.
Algoritma Shannon-Fano merupakan salah satu algoritma kompresi yang sangat baik dalam pengkompresian teks. Pada prinsipnya algoritma ini menggunakan pendekatan top down dalam penyusunan binary tree. Metode ini sangat efisien untuk mengkompresi file text yang berukuran besar.
Algoritma Kompresi Shannon-Fano pada citra adalah sebagai berikut: 1. Hitung frekuensi kemunculan masing-masing simbol pada citra.
2. Urutkan frekuensi kemunculan simbol dari simbol yang terbesar ke yang terkecil, masing-masing simbol dapat direpresentasikan sebagai sebuah node.
3. Bagi menjadi dua buah node dengan jumlah frekuensi kemunculan simbol yang sama atau hampir sama. Beri label pada setiap sisi pohon biner, sisi kiri dilabeli dengan 0 dan sisi kanan dilabeli dengan 1.
4. Lakukan langkah 3 sampai node tidak dapat dibagi lagi.
5. Telusuri pohon biner dari akar ke daun. Barisan label-label pada sisi pohon dari akar ke daun menyatakan kode Shannon-Fano untuk simbol yang bersesuaian.
Langkah-langkah pembentukan pohon Shannon-Fano:
1. Hitung frekuensi kemunculan masing-masing simbol pada citra.
Tabel 2.4 Tabel distribusi frekuensi Shannon-Fano
Simbol Frekuensi Total bit
255 14 14 x 1 byte = 14
25 7 7 x 1 byte = 7
180 6 6 x 1 byte = 6
50 6 6 x 1 byte = 6
120 3 3x 1 byte = 3
2. Urutkan frekuensi kemunculan simbol dari simbol yang terbesar ke yang terkecil.
3. Jumlahkan seluruh frekuensi kemunculan simbol dan masukkan dalam sebuah node.
4. Bagi menjadi dua buah node dengan jumlah frekuensi kemunculan simbol yang sama besar atau hampir sama. Beri label pada setiap sisi pohon biner, sisi kiri dilabeli dengan 0 dan sisi kanan dilabeli dengan 1.
5. Lakukan langkah 3 sampai node tidak dapat dibagi lagi.
21 15
36
0
1
14 7 6 6 3
6. Telusuri pohon biner dari akar ke daun. Barisan label-label pada sisi pohon dari akar ke daun menyatakan kode Shannon-Fano untuk simbol yang bersesuaian
Dari pohon Shannon-Fano di atas diperoleh kode Shannon-Fano sebagai berikut:
Tabel 2.5 Codebook Shannon-Fano
simbol frekuensi kode
255 14 00
25 7 01
180 6 10
50 6 110
120 3 111
Dari tabel di atas dapat dilihat bahwa simbol yang sering muncul dikodekan dengan kode yang lebih pendek, demikian juga sebaliknya. Setelah itu dilakukan substitusi dari simbol-simbol potongan citra digital pada Gambar 2.5 dengan kode Shannon-Fano yang terdapat pada Tabel 2.5, sehingga diperoleh data biner sebagai berikut:
0010110000101011101101010110110111000001
111111110000001000010010000000010010000
Gambar 2.10 Data biner hasil substitusi kode Shannon-Fano
Data biner hasil substitusi kode Shannon-Fano memiliki ukuran 79 bit setara 9,875 byte, sedangkan tanpa kompresi dibutuhkan 36 bytes, sehingga Algoritma Shannon-Fano dapat mereduksi penggunaan memori sebanyak 26,125 byte. Sehingga rasio kompresinya adalah (100 – 9,875/36 x 100 % ) = 72,569 %.
2.10 Kompleksitas Algoritma
Sebuah algoritma tidak saja harus benar, tetapi juga harus mangkus (efisien). Algoritma yang bagus adalah algoritma yang mangkus. Kemangkusan algoritma diukur dari berapa jumlah waktu dan ruang (space) memori yang dibutuhkan untuk menjalankannya. Algoritma yang mangkus ialah algoritma yang meminimumkan kebutuhan waktu dan ruang. Kebutuhan waktu dan ruang suatu algoritma bergantung pada ukuran masukan (n), yang menyatakan jumlah data yang diproses. Kemangkusan algoritma dapat digunakan untuk menilai algoritma yang terbaik.
Ada dua macam kompleksitas algoritma, yaitu kompleksitas waktu dan kompleksitas ruang. Kompleksitas waktu, T(n), diukur dari jumlah tahapan komputasi yang dibutuhkan untuk menjalankan algoritma sebagai fungsi dari ukuran masukan n. Kompleksitas ruang, S(n), diukur dari memori yang digunakan oleh struktur data yang terdapat di dalam algoritma sebagai fungsi dari ukuran masukan n. Dengan menggunakan besaran kompleksitas waktu/ ruang algoritma, kita dapat menentukan laju peningkatan waktu (ruang) yang diperlukan algoritma dengan meningkatnya ukuran masukan n.
2.10.1 Kompleksitas Waktu
Dalam praktek, kompleksitas waktu dihitung berdasarkan jumlah operasi abstrak yang mendasari suatu algoritma, dan memisahkan analisanya dari implementasi.
Kompleksitas waktu dibedakan atas tiga macam:
1. Tmax(n) : kompleksitas waktu untuk kasus terburuk (worst case),yaitu berdasarkan
2. Tmin
3. T
(n) : kompleksitas waktu untuk kasus terbaik (best case), yaitu berdasarkan kebutuhan waktu minimum.
avg(n): kompleksitas waktu untuk kasus rata-rata (average case), yaitu
berdasarkan kebutuhan waktu secara rata-rata
2.10.2 Kompleksitas Waktu Asimptotik
Tinjau T(n) = 2n2 + 6n + 1
Tabel 2.6 Perbandingan pertumbuhan T(n) dengan n2
N T(n) = 2n2 + 6n + 1 n2
1. Untuk n yang besar, pertumbuhan T(n) sebanding dengan n2. Pada kasus ini, T(n) tumbuh seperti n2 tumbuh.
2. T(n) tumbuh seperti n2 tumbuh saat n bertambah. Kita katakan bahwa T(n) berorde n2 dan kita tuliskan
T(n) = O(n2)
3. Notasi “O” disebut notasi “O-Besar” (Big-O) yang merupakan notasi kompleksitas waktu asimptotik.
DEFINISI. T(n) = O(f(n)) (dibaca “T(n) adalah O(f(n)” yang artinya T(n) berorde
paling besar f(n) ) bila terdapat konstanta C dan n0 sedemikian sehingga
f(n) adalah batas atas (upper bound) dari T(n) untuk n yang besar.
Aturan Untuk Menentukan Kompleksitas Waktu Asimptotik
d. pada algoritma selection_sort
Penjelasannya adalah sebagai berikut: T(n) = (n + 2) log(n2 + 1) + 5n
= f(n)g(n) + h(n),
2
Kita rinci satu per satu: ⇒ f(n) = (n + 2) = O(n)
2. Menghitung O-Besar untuk setiap instruksi di dalam algoritma dengan panduan di bawah ini, kemudian menerapkan teorema O-Besar.
a. Pengisian nilai (assignment), perbandingan, operasi aritmetik, read, write membutuhkan waktu O(1).
b. Pengaksesan elemen larik atau memilih field tertentu dari sebuah record membutuhkan waktu O(1).
Contoh:
read(x); O(1)
Kompleksitas waktu asimptotik = O(1) + O(1) + O(1) = O(1)
Penjelasan: O(1) + O(1) + O(1) = O(max(1,1)) + O(1)
= O(1) + O(1) = O(max(1,1)) = O(1)
c. if C then S1 else S2; membutuhkan waktu
TC + max(TS1,TS2) Contoh:
read(x); O(1)
if x mod 2 = 0 then O(1) begin
x:=x+1; O(1)
writeln(x); O(1) end
else
writeln(x); O(1)
Kompleksitas waktu asimptotik:
= O(1) + O(1) + max(O(1)+O(1), O(1)) = O(1) + max(O(1),O(1))
= O(1) + O(1) = O(1)
d. Kalang for. Kompleksitas waktu kalang for adalah jumlah pengulangan dikali dengan kompleksitas waktu badan (body) kalang.
Contoh:
for i:=1 to n do
jumlah:=jumlah + a[i]; O(1)
Contoh: kalang bersarang
for i:=1 to n do for j:=1 to n do
a[i,j]:=0; O(1) Kompleksitas waktu asimptotik:
nO(n) = O(n.n) = O(n2)
Contoh: kalang bersarang dengan dua buah instruksi
for i:=1 to n do for j:=1 to i do
begin
a:=a+1; O(1)
b:=b-2 O(1) end;
waktu untuk a:=a+1 : O(1) waktu untuk b:=b-2 : O(1)
total waktu untuk badan kalang = O(1) + O(1) = O(1) kalang terluar dieksekusi sebanyak n kali
kalang terdalam dieksekusi sebanyak i kali, i = 1, 2, …, n jumlah pengulangan seluruhnya = 1 + 2 + … + n = n(n + 1)/2
kompleksitas waktu asimptotik = n(n + 1)/2 .O(1)
= O(n(n + 1)/2) = O(n2)
Contoh: kalang tunggal sebanyak n-1 putaran
i:=2; O(1)
while i <= n do O(1)
begin
jumlah:=jumlah + a[i]; O(1)
i:=i+1; O(1)
end;
Kompleksitas waktu asimptotiknya adalah = O(1) + (n-1) { O(1) + O(1) + O(1) } = O(1) + (n-1) O(1)
= O(1) + O(n-1) = O(1) + O(n) = O(n)
Contoh: kalang yang tidak dapat ditentukan panjangnya:
ketemu:=false;
while (p <> Nil) and (not ketemu) do if p^.kunci = x then
ketemu:=true else
p:=p^.lalu { p = Nil or ketemu }
Di sini, pengulangan akan berhenti bila x yang dicari ditemukan di dalam senarai. Jika jumlah elemen senarai adalah n, maka kompleksitas waktu terburuknya adalah O(n) -yaitu kasus x tidak ditemukan.
Tabel 2.7 Pengelompokan Algoritma Berdasarkan Notasi O-Besar
Kelompok Algoritma Nama O(1)
Urutan spektrum kompleksitas waktu algoritma adalah :
algoritma polinomial algoritma eksponensial
Penjelasan masing-masing kelompok algoritma adalah sebagai berikut : 1. O(1)
Kompleksitas O(1) berarti waktu pelaksanaan algoritma adalah tetap, tidak bergantung pada ukuran masukan. Contohnya prosedur tukar di bawah ini:
procedure tukar(var a:integer; var b:integer); var
2. O(log n)
Kompleksitas waktu logaritmik berarti laju pertumbuhan waktunya berjalan lebih lambat daripada pertumbuhan n. Algoritma yang termasuk kelompok ini adalah algoritma yang memecahkan persoalan besar dengan mentransformasikannya menjadi beberapa persoalan yang lebih kecil yang berukuran sama (misalnya algoritma pencarian_biner). Di sini basis algoritma tidak terlalu penting sebab bila n dinaikkan dua kali semula, misalnya, log n meningkat sebesar sejumlah tetapan.
3. O(n)
Algoritma yang waktu pelaksanaannya lanjar umumnya terdapat pada kasus yang setiap elemen masukannya dikenai proses yang sama, misalnya algoritma pencarian_beruntun. Bila n dijadikan dua kali semula, maka waktu pelaksanaan algoritma juga dua kali semula.
4. O(n log n)
Waktu pelaksanaan yang n log n terdapat pada algoritma yang memecahkan persoalan menjadi beberapa persoalan yang lebih kecil, menyelesaikan tiap persoalan secara independen, dan menggabung solusi masing-masing persoalan. Algoritma yang diselesaikan dengan teknik bagi dan gabung mempunyai kompleksitas asimptotik jenis ini. Bila n = 1000, maka n log n mungkin 20.000. Bila n dijadikan dua kali semual, maka n log n menjadi dua kali semula (tetapi tidak terlalu banyak).
5. O(n2
Algoritma yang waktu pelaksanaannya kuadratik hanya praktis digunakan untuk persoalana yang berukuran kecil. Umumnya algoritma yang termasuk kelompok ini memproses setiap masukan dalam dua buah kalang bersarang, misalnya pada algoritma urut_maks. Bila n = 1000, maka waktu pelaksanaan algoritma adalah 1.000.000. Bila n dinaikkan menjadi dua kali semula, maka waktu pelaksanaan algoritma meningkat menjadi empat kali semula.
6. O(n3
Seperti halnya algoritma kuadratik, algoritma kubik memproses setiap masukan dalam tiga buah kalang bersarang, misalnya algoritma perkalian matriks. Bila n = 100, maka waktu pelaksanaan algoritma adalah 1.000.000. Bila n dinaikkan menjadi dua kali semula, waktu pelaksanan algoritma meningkat menjadi delapan kali semula.
)
7. O(2n
Algoritma yang tergolong kelompok ini mencari solusi persoalan secara "brute force". Bila n = 20, waktu pelaksanaan algoritma adalah 1.000.000. Bila n dijadikan dua kali semula, waktu pelaksanaan menjadi kuadrat kali semula.
)
8. O(n!)
BAB III
ANALISIS KOMPLEKSITAS ALGORITMA
3.1Kompleksitas Waktu Huffman
Algoritma Huffman adalah sebagai berikut:
9. Hitung frekuensi kemunculan masing-masing simbol pada citra.
10.Urutkan frekuensi kemunculan simbol citra dari yang terkecil ke yang terbesar, masing-masing simbol dapat direpresentasikan sebagai sebuah node.
11.Gabungkan dua node yang mempunyai frekuensi kemunculan simbol, kemudian jumlahkan kedua frekuensi kemunculan sehingga membentuk parent node.
12.Masukkan node parent ke dalam kumpulan node dan urutkan berdasarkan frekuensi kemunculan simbol, dari yang terkecil ke yang terbesar.
13.Hapus node dengan frekuensi kemunculan terkecil yang telah digabungkan dari kumpulan node.
14.Ulangi lagkah 1-5 sampai semua simbol habis dibangkitkan.
15.Beri label pada setiap sisi pohon biner, sisi kiri dilabeli dengan 0 dan sisi kanan dilabeli dengan 1.
16.Telusuri pohon biner dari akar ke daun. Barisan label-label pada sisi pohon dari akar ke daun menyatakan kode Huffman untuk simbol yang bersesuaian.
Misalnya terdapat data citra digital dalam bentuk matriks seperti gambar dibawah ini:
256 0 50 255 25 25 26 50 50 180 180 180 51 50 120 255 255 25 121 120 50 255 255 50 255 255 180 25 255 255 255 255 180 25 255 255
Gambar 3.1 Potongan data citra digital
Langkah-langkah pembentukan pohon Huffman:
Dari potongan data citra tersebut diperoleh tabel distribusi frekuensi sebagai berikut:
Tabel 3.1 Tabel distribusi frekuensi Huffman
Simbol Frekuensi Total bit
120 3 3 x 1 byte = 3
50 6 6 x 1 byte = 6
180 6 6 x 1 byte = 6
25 7 7 x 1 byte = 7
255 14 14 x 1 byte = 14
Total 36 byte
10.Urutkan frekuensi kemunculan simbol dari yang terkecil ke yang terbesar, masing-masing simbol dapat direpresentasikan sebagai sebuah node.
11.Gabungkan dua node yang mempunyai frekuensi kemunculan simbol terkecil, kemudian jumlahkan kedua frekuensi kemunculan sehingga membentuk parent node.
12.Masukkan node parent ke dalam kumpulan node dan urutkan berdasarkan frekuensi kemunculan simbol, dari yang terkecil ke yang terbesar.
13.Hapus node dengan frekuensi kemunculan terkecil yang telah digabungkan dari kumpulan node.
3 6 6 7 14
7 14
9
3 6
Langkah 4 dan 5 adalah sebagai berikut:
14.Ulangi lagkah 1-5 sampai semua simbol habis dibangkitkan.
15.Beri label pada setiap sisi pohon biner, sisi kiri dilabeli dengan 0 dan sisi kanan dilabeli dengan 1.
7 9
3
14
6 6
13 9
3
14
6 6 7
22
13 9
3
14
16.Telusuri pohon biner dari akar ke daun. Barisan label-label pada sisi pohon dari akar ke daun menyatakan kode Huffman untuk simbol yang bersesuaian
Maka dari pohon Huffman di atas diperoleh kode Huffman sebagai berikut:
Tabel 3.2 Codebook Huffman
Simbol frekuensi Kode
120 3 000
50 6 001
180 6 010
25 7 011
255 14 1
Dari tabel di atas dapat dilihat bahwa simbol yang sering muncul dikodekan dengan kode yang lebih pendek, demikian juga sebaliknya. Setelah itu dilakukan
14
13 9
3 6 6 7
22
36
255
25 180
50 120
0 1
0
1
substitusi dari simbol-simbol potongan citra digital pada Gambar 3.1 dengan kode Huffman yang terdapat pada Tabel 3.2, sehingga diperoleh data biner sebagai berikut:
101000110110110110010010100100100010010001
1011000000001110111101001111110111101001111
Gambar 3.2 Data biner hasil substitusi kode Huffman
Kompleksitas waktu Huffman tergantung pada dua bagian utama, yaitu proses sorting dan proses pembentukan pohon Huffman. Proses sorting data dapat mempengaruhi kompleksitas algoritma total, apabila kita mengambil pengurutan data dengan kompleksitas algoritma O(n2) atau mengambil pengurutan data dengan kompleksitas algoritma O(log n) tentu akan menghasilkan kompleksitas algoritma yang berbeda. Untuk algoritma pengurutan data, kompleksitas waktu yang paling ideal adalah O(n), yaitu algoritma pengurutan hanya dengan 1 kali pass saja. Namun sampai saat ini belum ada algoritma yang mampu untuk mencapai keadaan ini. Algoritma sorting yang dipilih adalah algoritma Heap Sort dimana proses pengurutan didasarkan pada prioritas.
Algoritma utamanya:
Procedure Huffman (L: list of tree)
{membangun pohon Huffman code dari list of
tree yang berisikan karakter-karakter yang
ada pada data}
Deklarasi
A, B, T : tree
Algoritma
Sort(L) {mengurutkan elemen list of tree
L}
While member (L) ≠ 1 do
Deletefirst(L, A) { mendelete elemen
pertama dari
list of tree L,dan menyimpan nilai dari
yang di
delete di variable A}
DeleteFirst(L, B) { mendelete elemen
pertama dari
heapify();
for (i = 0; i < n; i++) { remove();
reheapify();
Algoritma Metoda Heapify()
Ide secara intuitif mungkin adalah melakukan operasi heapify ini dari root ke arah leaf. Namun ide ini tidak efisien dalam kenyataannya karena akan terjadi operasi rutun-naik mirip algoritma bubble-sort. Ide yang efisien adalah membentuk heaptree-heaptree mulai dari subtree-subtree yang paling bawah. Jika subtree-subtree suatu node sudah membentuk heap maka tree dari node tersebut mudah dijadikan heaptree dengan mengalirkannya ke bawah.
Jadi algoritma utamanya beriterasi mulai dari internal node paling kanan-bawah (atau berindeks array paling besar) hingga root lalu ke kiri dan naik ke level di atasnya, dan seterusnya hingga root (sebagai array [0..N-1] maka iterasi dilakukan mulai j = N/2, berkurang satu-satu hingga j = 0.
1. Pada internal node itu pemeriksaan hanya dilakukan pada node anaknya langsung. 2. Pada saat berada di level yang lebih tinggi, subtree-subtreenya selalu sudah
membentuk heap. Jadi paling buruk restrukturisasi hanya mengalirkan node tersebut ke arah bawah.
3. Algoritma ini melakukan sebanyak N/2 kali iterasi, dan pada setiap interasi paling buruk akan melakukan pertukaran sebanyak log2(N) kali.
Algoritma hanya menukarkan elemen array[0] dengan elemen array terakhir dalam heaptree. Secara logik node paling bawah-kanan dipindahkan ke root menggantikan node root yang akan diambil. Setelah reheapify panjang array yang menjadi bagian heaptree berkurang satu node dan elemen array tersebut digunakan untuk menyimpan hasil pengurutan hingga saat itu.
Algoritma Metoda reheapify()
Melakukan restrukturisasi dari atas ke bawah seperti halnya iterasi terakhir dari
heapify() (karena baik subtree kiri maupun kanannya merupakan heap, jadi tidak perlu dilakukan seperti heapify).
Kompleksitas waktu dari algoritma ini adalah O(n log n) yang diperoleh dari n-1 kali iterasi dikalikan dengan proses reheapify yang merupakan proses logaritmis. Inisialisasi dengan heapify hanya memerlukan O(n), worse case adalah O(n log n), sehingga kompleksitas waktu total masih merupakan O(n log n). Algoritma ini termasuk stabil dimana perbedaan antara worse case dengan best case tidak besar. Kompleksitas waktu Huffman adalah sebagai berikut:
1. Heap Sort : O(n log n) 2. Repeat n times
a. Form new sub-tree : O(1) b. Move sub-tree : O(log n)
(binary search)
Total : O(1) + O( log n) = O(max(1, log n)) : O(log n).
3. Total keseluruhan waktu yang dibutuhkan untuk mengerjakan algoritma Huffman ini adalah = O(n log n) + O(log n) = O(max(n log n, log n)) = O(n log n).
independen, dan menggabung solusi masing-masing persoalan. Algoritma yang diselesaikan dengan teknik bagi dan gabung mempunyai kompleksitas asimptotik jenis ini.
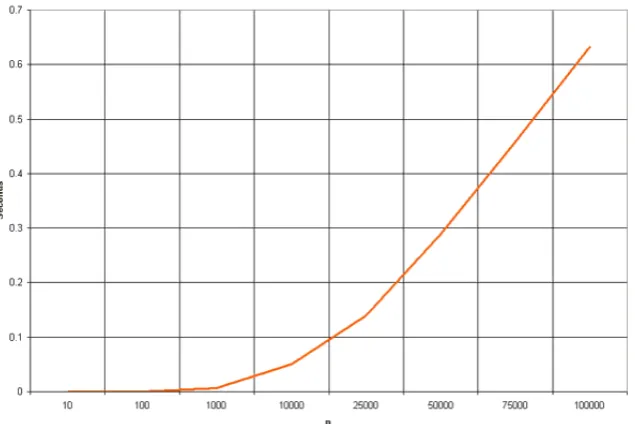
Gambar 3.3 Heap Graph O(n log n)
3.2Kompleksitas Waktu Shannon-Fano
Keterangan Analisa Kompleksitas Algoritma Shannon-Fano: 6. Hitung frekuensi kemunculan masing-masing simbol pada citra.
7. Urutkan frekuensi kemunculan simbol dari simbol yang terbesar ke yang terkecil, masing-masing simbol dapat direpresentasikan sebagai sebuah node.
8. Bagi menjadi dua buah node dengan jumlah frekuensi kemunculan simbol yang sama atau hampir sama. Beri label pada setiap sisi pohon biner, sisi kiri dilabeli dengan 0 dan sisi kanan dilabeli dengan 1.
9. Lakukan langkah 3 sampai node tidak dapat dibagi lagi.
10.Telusuri pohon biner dari akar ke daun. Barisan label-label pada sisi pohon dari akar ke daun menyatakan kode Shannon-Fano untuk simbol yang bersesuaian.
Langkah-langkah pembentukan pohon Shannon-Fano:
Tabel 3.3 Tabel distribusi frekuensi Shannon-Fano
Simbol frekuensi Total bit
255 14 14 x 1 byte = 14
25 7 7 x 1 byte = 7
180 6 6 x 1 byte = 6
50 6 6 x 1 byte = 6
120 3 3x 1 byte = 3
Total 36 byte
8. Urutkan frekuensi kemunculan simbol dari simbol yang terbesar ke yang terkecil.
9. Jumlahkan seluruh frekuensi kemunculan simbol dan masukkan dalam sebuah node.
10. Bagi menjadi dua buah node dengan jumlah frekuensi kemunculan simbol yang sama besar atau hampir sama. Beri label pada setiap sisi pohon biner, sisi kiri dilabeli dengan 0 dan sisi kanan dilabeli dengan 1.
11. Lakukan langkah 3 sampai node tidak dapat dibagi lagi. 36
14 7 6 6 3
21 15
36
0
12.Telusuri pohon biner dari akar ke daun. Barisan label-label pada sisi pohon dari akar ke daun menyatakan kode Shannon-Fano untuk simbol yang bersesuaian
Dari pohon Shannon-Fano di atas diperoleh kode Shannon-Fano sebagai berikut:
Tabel 3.4 Codebook Shannon-Fano
Simbol frekuensi kode
255 14 00
25 7 01
180 6 10
50 6 110
120 3 111
Dari tabel di atas dapat dilihat bahwa simbol yang sering muncul dikodekan dengan kode yang lebih pendek, demikian juga sebaliknya. Setelah itu dilakukan substitusi dari simbol-simbol potongan citra digital pada Gambar 3.1 dengan kode Shannon-Fano yang terdapat pada Tabel 3.4, sehingga diperoleh data biner sebagai berikut:
0010110000101011101101010110110111000001
111111110000001000010010000000010010000
Gambar 3.4 Data biner hasil substitusi kode Shannon-Fano
Data biner hasil substitusi kode Shannon-Fano memiliki ukuran 79 bit setara 9,875 byte, sedangkan tanpa kompresi dibutuhkan 36 bytes, sehingga Algoritma
Shannon-Fano dapat mereduksi penggunaan memori sebanyak 26 bytes. Sehingga rasio kompresinya adalah (100 – 9,875/36 x 100%) = 72,569 %.
Kompleksitas Waktu Shannon-Fano:
Kompleksitas waktu Shannon-Fano adalah sebagai berikut: 1. Heap Sort : O(n log n)
2. Repeat n times
a. Form new sub-tree : O(1) b. Devide and conquer : O(log n)
Total : O(1) + O(n log n) = O(max(1, log n)) : O( log n).
3. Total keseluruhan waktu yang dibutuhkan untuk mengerjakan Algoritma kompresi Shannon-Fano ini adalah = O(n log n) + O(log n)
=O(max(n log n, log n)) = O(n log n).
make_codes(S)
if |S| = 1 then S[0] else
sort S by probabilities split S into S1 and S2 such that W(S1) approx. W(S2) return node(make_code(S1), make_code(S2))
BAB 4
IMPLEMENTASI SISTEM
Sistem kompresi citra yang disimulasikan dalam Tugas Akhir ini adalah kompresi citra yang bersifat lossless compression dimana tidak ada informasi yang hilang saat citra direkonstruksikan/ didekompresikan kembali. Algoritma yang digunakan pada kompresi citra jenis lossless ini yaitu algoritma kompresi Huffman dan algoritma Shannon-Fano.
4.1 Flowchart Proses Kompresi Citra
Dua proses utama dalam proses kompresi citra adalah proses kompresi dan dekompresi. Pada proses kompresi citra, file citra yang tidak dikompresi dikodekan dengan representasi yang meminimumkan kebutuhan memori. Dan pada proses dekompresi, file citra yang sudah mengalami kompresi harus bisa dikembalikan lagi menjadi representasi semula/ tidak terkompresi.
Hitung frekuensi kemunculan simbol pada citra, urutkan secara menaik
Pembentukan pohon Huffman dengan menggabung dua frekuensi terkecil
Pembentukan kode Huffman, sisi kiri =0 dan sisi kanan =1
Start
Input file citra
Kode Huffman output file
Stop
Gambar 4.1 Flowchart Sistem Kompresi-Dekompresi Citra
4.1.1 Flowchart Algoritma Kompresi Huffman
Flowchart yang menggambarkan proses algoritma kompresi Huffman dapat dilihat dalam Gambar 4.2 berikut ini.
Gambar 4.2 Flowchart Algoritma Kompresi Huffman
Start
Kompresi
Dekompresi
Hitung performansi