LAMPIRAN
UJI VALIDITAS I
Correlations
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 Y
X1 Pearson Correlation 1 .092 .256* .057 .151 -.047 .111 -.018 .211* -.026 .258* .394**
Sig. (2-tailed) .366 .011 .580 .139 .649 .277 .860 .037 .798 .010 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
X2 Pearson Correlation .092 1 .389** -.025 -.025 .176 .297** .106 .206* -.076 .068 .475**
Sig. (2-tailed) .366 .000 .808 .808 .083 .003 .298 .042 .460 .507 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
X3 Pearson Correlation .256* .389** 1 -.053 .065 .059 .127 -.017 .316** -.044 .046 .432**
Sig. (2-tailed) .011 .000 .605 .526 .566 .214 .871 .002 .671 .652 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
X4 Pearson Correlation .057 -.025 -.053 1 .090 .231* .151 .128 .211* -.111 .210* .413**
Sig. (2-tailed) .580 .808 .605 .377 .022 .138 .210 .037 .276 .038 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
X5 Pearson Correlation .151 -.025 .065 .090 1 .205* .225* .266** .270** .083 .280** .532**
Sig. (2-tailed) .139 .808 .526 .377 .043 .026 .008 .007 .415 .005 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
X6 Pearson Correlation -.047 .176 .059 .231* .205* 1 .159 .141 .089 .079 .086 .443**
Sig. (2-tailed) .649 .083 .566 .022 .043 .118 .165 .385 .442 .397 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
X7 Pearson Correlation .111 .297** .127 .151 .225* .159 1 .014 .182 .010 .215* .524**
Sig. (2-tailed) .277 .003 .214 .138 .026 .118 .889 .072 .926 .034 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
X8 Pearson Correlation -.018 .106 -.017 .128 .266** .141 .014 1 -.060 -.169 .098 .347**
Sig. (2-tailed) .860 .298 .871 .210 .008 .165 .889 .560 .096 .335 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
X9 Pearson Correlation .211* .206* .316** .211* .270** .089 .182 -.060 1 .008 .295** .549**
Sig. (2-tailed) .037 .042 .002 .037 .007 .385 .072 .560 .942 .003 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
X10 Pearson Correlation -.026 -.076 -.044 -.111 .083 .079 .010 -.169 .008 1 .127 .149
Sig. (2-tailed) .798 .460 .671 .276 .415 .442 .926 .096 .942 .211 .142
N 98 98 98 98 98 98 98 98 98 98 98 98
X11 Pearson Correlation .258* .068 .046 .210* .280** .086 .215* .098 .295** .127 1 .562**
Sig. (2-tailed) .010 .507 .652 .038 .005 .397 .034 .335 .003 .211 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
Y Pearson Correlation .394** .475** .432** .413** .532** .443** .524** .347** .549** .149 .562** 1
Sig. (2-tailed) .000 .000 .000 .000 .000 .000 .000 .000 .000 .142 .000
N 98 98 98 98 98 98 98 98 98 98 98 98
*. Correlation is significant at the 0.05 level (2-tailed).
UJI VALIDITAS II
Correlations
X1 X2 X3 X4 X5 X6 X7 X8 X9 X11 Y
X1 Pearson Correlation 1 .092 .256* .057 .151 -.047 .111 -.018 .211* .258* .403**
Sig. (2-tailed) .366 .011 .580 .139 .649 .277 .860 .037 .010 .000
N 98 98 98 98 98 98 98 98 98 98 98
X2 Pearson Correlation .092 1 .389** -.025 -.025 .176 .297** .106 .206* .068 .494**
Sig. (2-tailed) .366 .000 .808 .808 .083 .003 .298 .042 .507 .000
N 98 98 98 98 98 98 98 98 98 98 98
X3 Pearson Correlation .256* .389** 1 -.053 .065 .059 .127 -.017 .316** .046 .445**
Sig. (2-tailed) .011 .000 .605 .526 .566 .214 .871 .002 .652 .000
N 98 98 98 98 98 98 98 98 98 98 98
X4 Pearson Correlation .057 -.025 -.053 1 .090 .231* .151 .128 .211* .210* .438**
Sig. (2-tailed) .580 .808 .605 .377 .022 .138 .210 .037 .038 .000
N 98 98 98 98 98 98 98 98 98 98 98
X5 Pearson Correlation .151 -.025 .065 .090 1 .205* .225* .266** .270** .280** .523**
Sig. (2-tailed) .139 .808 .526 .377 .043 .026 .008 .007 .005 .000
N 98 98 98 98 98 98 98 98 98 98 98
X6 Pearson Correlation -.047 .176 .059 .231* .205* 1 .159 .141 .089 .086 .433**
Sig. (2-tailed) .649 .083 .566 .022 .043 .118 .165 .385 .397 .000
N 98 98 98 98 98 98 98 98 98 98 98
X7 Pearson Correlation .111 .297** .127 .151 .225* .159 1 .014 .182 .215* .527**
Sig. (2-tailed) .277 .003 .214 .138 .026 .118 .889 .072 .034 .000
N 98 98 98 98 98 98 98 98 98 98 98
X8 Pearson Correlation -.018 .106 -.017 .128 .266** .141 .014 1 -.060 .098 .382**
Sig. (2-tailed) .860 .298 .871 .210 .008 .165 .889 .560 .335 .000
N 98 98 98 98 98 98 98 98 98 98 98
X9 Pearson Correlation .211* .206* .316** .211* .270** .089 .182 -.060 1 .295** .554**
Sig. (2-tailed) .037 .042 .002 .037 .007 .385 .072 .560 .003 .000
N 98 98 98 98 98 98 98 98 98 98 98
X11 Pearson Correlation .258* .068 .046 .210* .280** .086 .215* .098 .295** 1 .544**
Sig. (2-tailed) .010 .507 .652 .038 .005 .397 .034 .335 .003 .000
N 98 98 98 98 98 98 98 98 98 98 98
Y Pearson Correlation .403** .494** .445** .438** .523** .433** .527** .382** .554** .544** 1
Sig. (2-tailed) .000 .000 .000 .000 .000 .000 .000 .000 .000 .000
N 98 98 98 98 98 98 98 98 98 98 98
*. Correlation is significant at the 0.05 level (2-tailed). **. Correlation is significant at the 0.01 level (2-tailed).
CRONBACH ALPHA
Case Processing Summary
N %
Cases Valid 98 100.0
Excludeda 0 .0
Case Processing Summary
N %
Cases Valid 98 100.0
Excludeda 0 .0
Total 98 100.0
a. Listwise deletion based on all variables in the procedure.
Reliability Statistics
Cronbach's
Alpha N of Items
.702 11
ANALISIS FAKTOR KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .601
Bartlett's Test of Sphericity Approx. Chi-Square 112.628
Df 45
Sig. .000
Communalities
Initial Extraction
X1 1.000 .597
X2 1.000 .723
X3 1.000 .672
X4 1.000 .608
X5 1.000 .618
X6 1.000 .542
X7 1.000 .424
X8 1.000 .739
X9 1.000 .507
X11 1.000 .545
Extraction Method: Principal
Component Analysis.
Total Variance Explained
Compon
ent
Initial Eigenvalues Extraction Sums of Squared Loadings Rotation Sums of Squared Loadings
Total % of Variance Cumulative % Total % of Variance Cumulative % Total % of Variance Cumulative %
2 1.426 14.259 37.928 1.426 14.259 37.928 1.559 15.588 31.825
3 1.182 11.817 49.745 1.182 11.817 49.745 1.484 14.837 46.662
4 1.002 10.018 59.763 1.002 10.018 59.763 1.310 13.102 59.763
5 .872 8.722 68.486
6 .822 8.223 76.708
7 .732 7.318 84.027
8 .672 6.718 90.745
9 .519 5.192 95.936
10 .406 4.064 100.000
Extraction Method: Principal Component Analysis.
Component Matrixa
Component
1 2 3 4
X1 .446 -.290 -.476 .296
X2 .490 -.404 .565 .018
X3 .468 -.608 .188 .220
X4 .427 .377 -.081 -.526
X5 .527 .407 -.117 .401
X6 .405 .352 .475 -.169
X7 .559 -.043 .141 -.301
X8 .192 .557 .312 .543
X9 .649 -.158 -.223 -.106
X11 .561 .201 -.433 -.053
Extraction Method: Principal Component Analysis.
a. 4 components extracted.
Rotated Component Matrixa
Component
1 2 3 4
X1 .737 .170 -.159 -.003
X2 -.053 .826 .184 .067
X3 .290 .757 -.114 -.052
X4 .149 -.156 .749 .003
X5 .432 -.014 .145 .640
X6 -.198 .222 .558 .377
X7 .179 .337 .527 -.014
X8 -.084 -.005 -.013 .856
X11 .623 -.113 .357 .132
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
a. Rotation converged in 6 iterations.
Component Transformation Matrix
Compo
nent 1 2 3 4
1 .612 .487 .548 .296
2 -.157 -.639 .398 .639
3 -.744 .577 .158 .297
4 .216 .144 -.718 .645
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
Anti-image Matrices
X1 X2 X3 X4 X5 X6 X7 X8 X9 X11
Anti-image Covariance X1 .852 .011 -.175 -.014 -.060 .082 -.025 .028 -.049 -.171
X2 .011 .728 -.245 .073 .136 -.119 -.220 -.132 -.096 -.003
X3 -.175 -.245 .755 .046 -.007 -.010 .012 .047 -.154 .060
X4 -.014 .073 .046 .842 .087 -.155 -.117 -.123 -.166 -.113
X5 -.060 .136 -.007 .087 .745 -.138 -.165 -.236 -.185 -.092
X6 .082 -.119 -.010 -.155 -.138 .871 -.032 -.054 .008 -.013
X7 -.025 -.220 .012 -.117 -.165 -.032 .801 .120 .012 -.091
X8 .028 -.132 .047 -.123 -.236 -.054 .120 .852 .135 -.038
X9 -.049 -.096 -.154 -.166 -.185 .008 .012 .135 .732 -.130
X11 -.171 -.003 .060 -.113 -.092 -.013 -.091 -.038 -.130 .809
Anti-image Correlation X1 .677a .014 -.218 -.017 -.075 .095 -.030 .033 -.062 -.206
X2 .014 .529a -.331 .093 .184 -.149 -.289 -.168 -.132 -.003
X3 -.218 -.331 .610a .058 -.010 -.013 .016 .058 -.206 .077
X4 -.017 .093 .058 .575a .109 -.181 -.142 -.145 -.212 -.136
X5 -.075 .184 -.010 .109 .540a -.172 -.214 -.296 -.251 -.118
X6 .095 -.149 -.013 -.181 -.172 .668a -.038 -.062 .010 -.015
X7 -.030 -.289 .016 -.142 -.214 -.038 .629a .145 .016 -.113
X8 .033 -.168 .058 -.145 -.296 -.062 .145 .696a .171 -.046
X9 -.062 -.132 -.206 -.212 -.251 .010 .016 .171 .660a -.169
X11 -.206 -.003 .077 -.136 -.118 -.015 -.113 -.046 -.169 .729a
DAFTAR JAWABAN RESPONDEN
NO X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11
1 3 2 2 5 4 3 2 2 5 5 4
2 4 5 3 2 3 2 5 4 3 3 4
3 3 3 2 2 2 4 2 2 2 4 2
4 3 3 2 2 3 3 4 4 4 5 2
5 4 4 4 3 3 3 3 3 4 4 1
6 4 3 2 4 5 3 5 4 4 4 3
7 4 3 2 4 3 5 4 5 4 3 5
8 4 3 4 2 4 2 3 4 4 4 4
9 4 4 4 2 4 4 5 5 3 5 3
10 4 5 4 3 2 3 2 3 4 5 4
11 4 2 2 5 4 4 5 3 4 5 3
12 5 3 3 4 4 3 5 4 4 3 5
13 3 3 2 4 3 3 5 5 4 2 2
14 1 1 1 1 3 3 1 5 1 5 1
15 4 2 2 3 5 2 5 1 5 5 5
16 4 4 3 3 5 5 3 5 5 4 2
17 3 4 3 2 3 2 4 3 3 4 3
18 3 4 2 2 3 3 4 3 2 4 3
19 5 4 3 2 4 3 5 4 3 5 4
20 4 4 3 3 4 3 5 4 4 4 4
21 4 5 4 2 5 3 4 3 5 4 3
22 4 5 5 2 3 4 4 5 4 5 3
23 4 2 3 5 4 5 5 2 4 5 4
24 4 4 4 4 4 4 5 4 5 5 3
25 5 4 3 2 4 4 3 2 5 5 4
26 3 5 4 3 5 4 5 4 4 5 4
27 4 4 5 2 4 3 4 5 5 5 5
28 4 3 2 1 5 5 4 4 2 5 3
29 4 2 3 2 4 3 4 4 2 4 3
30 4 1 4 4 4 3 3 2 3 5 4
31 4 3 2 4 3 4 3 4 2 3 4
32 4 3 4 3 4 3 4 4 4 4 4
33 5 4 4 4 5 4 4 4 4 2 2
34 5 4 3 4 4 2 4 2 4 4 4
35 3 2 2 2 4 4 4 3 4 4 5
36 4 5 4 3 5 4 5 3 4 5 5
37 4 4 4 3 4 3 4 3 4 2 3
38 3 3 5 4 2 4 4 2 4 3 4
39 2 5 3 3 4 5 5 2 5 4 3
40 5 5 5 2 2 5 4 4 4 4 5
41 4 3 4 2 5 3 4 4 4 5 3
42 5 5 4 3 5 5 4 4 5 5 4
43 5 4 4 2 4 3 4 2 2 4 2
44 5 4 3 5 5 3 5 4 5 5 3
46 4 5 2 2 2 5 3 1 5 4 1
47 4 4 3 3 4 3 5 5 5 3 4
48 5 5 5 3 2 2 5 3 5 2 1
49 4 4 3 2 4 3 5 3 5 5 4
50 4 4 4 3 3 3 3 2 4 5 2
51 4 5 3 5 5 5 5 5 5 5 5
52 4 4 4 4 4 4 4 5 4 4 4
53 4 2 2 2 5 2 2 4 4 4 4
54 4 2 4 4 3 4 4 4 5 3 3
55 3 3 3 4 5 5 3 5 4 4 2
56 4 4 5 5 5 5 5 4 5 4 4
57 5 5 3 3 5 4 2 5 5 5 5
58 4 2 3 5 5 3 4 5 5 3 5
59 5 2 2 2 5 4 5 5 5 5 5
60 4 4 4 3 4 4 3 5 5 4 4
61 5 3 4 3 5 4 3 5 5 5 4
62 5 4 4 2 3 2 3 4 3 5 3
63 4 3 4 5 4 3 2 5 5 4 3
64 3 2 3 2 3 2 3 2 5 5 3
65 4 4 4 2 2 2 3 4 4 4 3
66 4 5 5 2 4 2 4 2 4 3 3
67 2 5 2 4 2 3 5 2 4 5 3
68 4 5 5 2 4 4 5 2 5 5 2
69 4 4 3 3 4 4 5 2 4 5 5
70 4 3 2 2 5 3 5 4 4 4 4
71 2 2 3 4 3 4 5 4 3 5 1
72 4 5 2 5 5 5 5 5 2 5 4
73 4 5 2 5 4 4 5 5 4 3 4
74 4 5 3 5 1 3 4 4 5 5 5
75 4 2 2 2 2 4 3 2 2 5 2
76 3 5 4 3 5 4 4 4 5 3 4
77 2 5 4 4 4 4 5 4 4 4 4
78 4 3 4 2 5 3 5 4 4 4 4
79 5 3 3 2 4 4 5 2 5 4 4
80 4 5 4 3 5 4 5 4 5 5 4
81 5 4 4 4 3 3 3 2 4 3 4
82 4 4 3 4 5 5 2 4 4 3 4
83 5 3 2 5 4 3 3 5 4 3 5
84 4 3 5 4 5 4 4 4 4 5 3
85 2 5 3 2 4 5 4 4 4 2 3
86 5 2 4 4 4 5 5 4 4 3 4
87 5 5 4 2 5 3 5 5 5 3 4
88 3 2 3 2 4 3 2 4 4 5 4
89 4 3 3 2 3 3 3 4 3 4 3
90 4 2 3 2 3 3 3 2 4 4 4
91 3 4 4 2 4 3 2 4 4 3 4
92 4 4 4 4 4 5 4 4 4 4 4
94 5 4 5 4 4 5 5 1 5 5 5
95 5 5 4 4 3 4 4 4 3 5 5
96 5 4 3 2 3 4 5 3 5 5 5
97 5 3 4 2 5 3 5 1 5 5 5
98 3 2 2 5 4 3 3 2 5 5 5
Correlation Matrixa
x1 x2 x3 x4 x5 x6 x7 x8 x9 x11
Sig. (1-tailed) x1 .180 .005 .253 .076 .374 .114 .407 .016 .005
x2 .180 .000 .403 .495 .038 .001 .193 .018 .236
x3 .005 .000 .477 .281 .275 .101 .312 .002 .326
x4 .253 .403 .477 .187 .017 .038 .100 .009 .011
x5 .076 .495 .281 .187 .017 .011 .005 .003 .006
x6 .374 .038 .275 .017 .017 .064 .067 .138 .156
x7 .114 .001 .101 .038 .011 .064 .415 .032 .016
x8 .407 .193 .312 .100 .005 .067 .415 .294 .206
x9 .016 .018 .002 .009 .003 .138 .032 .294 .002
x11 .005 .236 .326 .011 .006 .156 .016 .206 .002
Correlation Matrixa
x1 x2 x3 x4 x5 x6 x7 x8 x9 x11
Sig. (1-tailed) x1 .180 .005 .253 .076 .374 .114 .407 .016 .005
x2 .180 .000 .403 .495 .038 .001 .193 .018 .236
x3 .005 .000 .477 .281 .275 .101 .312 .002 .326
x4 .253 .403 .477 .187 .017 .038 .100 .009 .011
x5 .076 .495 .281 .187 .017 .011 .005 .003 .006
x6 .374 .038 .275 .017 .017 .064 .067 .138 .156
x7 .114 .001 .101 .038 .011 .064 .415 .032 .016
x8 .407 .193 .312 .100 .005 .067 .415 .294 .206
x9 .016 .018 .002 .009 .003 .138 .032 .294 .002
x11 .005 .236 .326 .011 .006 .156 .016 .206 .002
PERHITUNGAN KMO DAN MSA
Untuk menghitung KMO dan MSA maka diperlukan matriks korelasi sederhana dan matriks korelasi parsial yang semua entrinya telah
dikuadratkan. Berikut ini akan disajikan matriks korelasi sederhana dan matriks korelasi parsial yang semua entrinya telah dikuadratkan.
MATRIKS KORELASI SEDERHANA�rij�
X1 X2 X3 X4 X5 X6 X7 X8 X9 X11
X1 1.000 0.180 0.005 0.253 0.076 0.374 0.114 0.407 0.016 0.005
X2 0.180 1.000 0.000 0.403 0.495 0.038 0.001 0.193 0.018 0.236
X3 0.005 0.000 1.000 0.477 0.281 0.275 0.101 0.312 0.002 0.326
X4 0.253 0.403 0.477 1.000 0.187 0.017 0.038 0.100 0.009 0.011 Σ = X5 0.076 0.495 0.281 0.187 1.000 0.017 0.011 0.005 0.003 0.006
X6 0.374 0.038 0.275 0.017 0.017 1.000 0.064 0.067 0.138 0.156
X7 0.114 0.001 0.101 0.038 0.011 0.064 1.000 0.415 0.032 0.016
X8 0.407 0.193 0.312 0.100 0.005 0.067 0.415 1.000 0.294 0.206
X9 0.016 0.018 0.002 0.009 0.003 0.138 0.032 0.294 1.000 0.002
X11 0.005 0.236 0.326 0.011 0.006 0.156 0.016 0.206 0.002 1.000
MATRIKS KORELASI PARSIAL
X1 X2 X3 X4 X5 X6 X7 X8 X9 X11
X1 0.018 -0.272 -0.020 -0.095 0.110 -0.037 0.039 -0.079 -0.248
X2 0.018 -0.446 0.119 0.250 -0.187 -0.378 -0.214 -0.181 -0.004
X3 -0.272 -.446 0.072 -0.013 -0.016 0.020 0.073 -0.278 0.099
X4 -0.020 0.119 0.072 0.138 -0.211 -0.173 -0.171 -0.270 -0.165
X5 -0.095 0.250 -0.013 0.138 -0.213 -0.276 -0.372 -0.339 -0.152
A = (aij) = X6 0.110 -0.187 -0.016 -0.211 -0.213 -0.045 -0.073 0.013 -0.018
X7 -0.037 -0.378 0.020 -0.173 -0.276 -0.045 0.175 0.021 -0.141
X8 0.039 -0.214 0.073 -0.171 -0.372 -0.073 .0175 0.216 -0.056
X9 -0.079 -0.181 -0.278 -0.270 -0.339 0.013 0.021 0.216 -0.220
Kuadrat Matriks Korelasi Sederhana
X1 X2 X3 X4 X5 X6 X7 X8 X9 X11 Jumlah
X1 0.0324 0.000025 0.064009 0.005776 0.139876 0.01300 0.165649 0.000256 0.000025 1.421016
X2 0.03240 0.000000 0.162409 0.245025 0.001444 0.00000 0.037249 0.000324 0.055696 1.534547
X3 0.00003 0.000000 0.227529 0.078961 0.075625 0.01020 0.097344 0.000004 0.106276 1.595969
X4 0.06401 0.162409 0.227529 0.034969 0.000289 0.00144 0.01 0.000081 0.000121 1.500848
Σ = (���2) = X5 0.00578 0.245025 0.078961 0.034969 0.000289 0.00012 0.000025 0.000009 0.000036 1.365214
X6 0.13988 0.001444 0.075625 0.000289 0.000289 0.00410 0.004489 0.019044 0.024336 1.269496
X7 0.01300 0.000001 0.010201 0.001444 0.000121 0.004096 0.172225 0.001024 0.000256 1.202368
X8 0.16565 0.037249 0.097344 0.01 0.000025 0.004489 0.17223 0.086436 0.042436 1.615859
X9 0.00026 0.000324 0.000004 0.000081 0.000009 0.019044 0.00102 0.086436 0.000004 1.107182
X11 0.00003 0.055696 0.106276 0.000121 0.000036 0.024336 0.00026 0.042436 0.000004 1.229195
Jumlah 13.84169
Kuadrat Matriks Korelasi Parsial
X1 X2 X3 X4 X5 X6 X7 X8 X9 X11 Jumlah
X1 0.000324 0.073984 0.0004 0.009025 0.0121 0.00137 0.001521 0.006241 0.061504 0.16647 X2 0.000324 0.198916 0.014161 0.0625 0.034969 0.14288 0.045796 0.032761 0.000016 0.53232 X3 0.073984 0.198916 0.005184 0.000169 0.000256 0.00040 0.005329 0.077284 0.009801 0.37132 X4 0.0004 0.014161 0.005184 0.019044 0.044521 0.02993 0.029241 0.0729 0.027225 0.24261
D = (���2) = X5 0.009025 0.0625 0.000169 0.019044 0.045369 0.07618 0.138384 0.114921 0.023104 0.48870
X6 0.0121 0.034969 0.000256 0.044521 0.045369 0.00203 0.005329 0.000169 0.000324 0.14507 X7 0.001369 0.142884 0.0004 0.029929 0.076176 0.002025 0.030625 0.000441 0.019881 0.30373 X8 0.001521 0.045796 0.005329 0.029241 0.138384 0.005329 0.00031 0.046656 0.003136 0.27570 X9 0.006241 0.032761 0.077284 0.0729 0.114921 0.000169 0.00044 0.046656 0.0484 0.39977 X11 0.061504 0.000016 0.009801 0.027225 0.023104 0.000324 0.01988 0.003136 0.0484 0.19339
1. KMO= ∑ ∑ ��� 2
� � ≠1
� �=1 ∑ ∑� ���2
�≠1
�
�=1 +∑ ∑ ���2
� �≠1
� �=1
KMO = 13.84169
13.84169 +3.11908 = 0,601
2. MSA = ∑ ∑ ��� 2
� �≠1
� �=1 ∑� ���2
�=1 +∑ ���2
� �=1
���1=
1.421016
1.421016 +0.16647 = 0,677
���2 =
1.534547
1.534547 +0.53232 = 0,529
���3 =
1.595969
1.595969+0.37132 = 0,610
���4=
1.500848
1.500848 +0.24261 = 0,575
���5=
1.365214
1.365214 +0.48870 = 0,540
���6=
1.269496
1.269496 +0.14507 = 0,668
���7=
1.202368
1.202368 +0.30373 = 0,629
���8 =
1.615859
1.615859 +0.27570 = 0,696
���9=
1.107182
1.107182 +0.39977 = 0,660
���11=
1.229195
1.229195 +0.19339 = 0,729
UJI BARLETT PENDEKATAN STATISTIK CHI AQUARE
Untuk menguji apakah matriks korelasi sederhana bukan merupakan suatumatriks idensitas, maka digunakan uji Barlett dengan pendekatan statistik chi square. Berikut ini langkah-langkah pengujiannya:
1. Hipotesis
Ho : Matriks korelasi sederhana merupakan matriks idensitas H1 : Matriks korelasi sederhana bukan merupakan matriks idensitas 2. Statistik Uji
�2 = �(� −1)−(2�+ 5) 6 � ��|∑| 3. Taraf nyata α dan nilaiχ2 dari tabel diperoleh:
α = 5% = 0,05
dengan df =p(p−1)
2 =
10(10−1)
2 = 45
χ2
tabel = 61,66 4. Kriteria pengujian:
H0 ditolak apabila χ2hitung ≥χ2tabel
H0 diterima apabila χ2hitung < χ2tabel
5. Perhitungan �2: Det (R) = 0,297
�2 =− �(98−1)−(2(10) + 5)
6 � ��|0,297|
= −[97−4,167](−1,214) = −(92,83)(−1,214) =112,695
6. Kesimpulan:
χ2
hitung = 112,695>χ 2
DAFTAR PUSTAKA
Arikunto. 1998. Prosedur Penelitian Suatu Pendekatan Praktek. Jakarta: PT.
Rineka Cipta
Badan Pusat Statistik 2015. Peta ketenagakerjaan dan pengangguran menurut
kabupaten/kota Sumatera Utara Tahun 2015.Medan: Badan Pusat Statistik
Badan Pusat Statistik 2015. Medan Selayang Dalam Angka Tahun 2015.Medan: Badan Pusat Statistik
Imam Ghozali. 2006. Analisis Multivariat dengan Program SPSS. Semarang:
Badan Penerbit Universitas Diponegoro.
Johnson, R. A and D. W. Wichern. (1982). Applied Multivariate Statistical
Analysis, Prentice-Hall, Inc. New Jersey.
Suparmoko. 1991. Metodologi Penelitian Edisi Ketiga. Yogyakarta: BPPFE
Supranto, J. 2004. Analisis Multivariate Arti dan Interpretasi. Jakarta: PT.
Rineka Cipta Jakarta
Santoso Singgih. Statistik Multivariat konsep dan Aplikasi dengan SPSS.Jakarta: Penerbit PT Elex Media Komputindo
Teken.1965. Analisis Multivariat Arti dan Interpretasi. Jakarta: PT Rineka
Cipta
PEMBAHASAN DAN PENGOLAHAN DATA
3.1 Pengambilan Sampel
Pengambilan jumlah sampel dalam penelitian ini menggunakan teknik
Slovin. Jumlah data pengangguran yang diambil dari Kantor Kecamatan Medan
Selayang adalah 4630 orang.
�
=
�1+��2
�= 4630
1 + 4630(10%)2
�= 4630
1 + 4630(0,01)
�
=
46301+46,3
�
=
4630
47,3
n = 97,885
Sehingga jumlah sampel yang akan diteliti dalam penelitian ini adalah sebanyak
98 orang.
Penelitian ini menggunakan teknik Accidental Sampling yaitu
membagikan kuesioner terhadap responden yang memenuhi kriteria sebagai
berikut:
- Usia 15-65 tahun yang tidak memiliki pekerjaan.
- Orang yang bekerja kurang dari dua hari dalam seminggu.
- Ibu rumah tangga.
3.2 Penskalaan Data Ordinal Menjadi Data Interval
Dari data mentah hasil kuesioner dibuat suatu matriks data Xpxn yang telah
dilakukan penskalaan menjadi skala interval.Teknik penskalaan yang digunakan
dalam penelitian ini adalah Methode Successive Interval dengan bantuan
Microsoft Office Excel 2007.
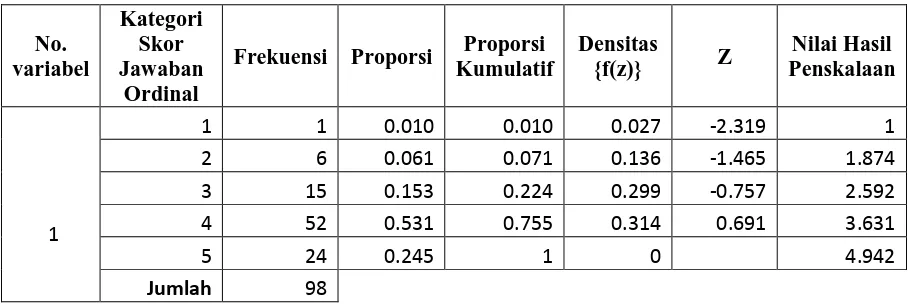
Tabel 3.1 Penskalaan Variabel 1
No. variabel Kategori Skor Jawaban Ordinal
Frekuensi Proporsi Proporsi Kumulatif
Densitas
{f(z)} Z
Nilai Hasil Penskalaan
1
1 1 0.010 0.010 0.027 -2.319 1
2 6 0.061 0.071 0.136 -1.465 1.874 3 15 0.153 0.224 0.299 -0.757 2.592 4 52 0.531 0.755 0.314 0.691 3.631
5 24 0.245 1 0 4.942
Jumlah 98
Langkah-langkah Methode Successive Interval:
1. Menghitung frekuensi skor jawaban dalam skala ordinal
2. Menghitung proporsi dan proporsi kumulatif untuk masing-masing skor
jawaban
3. Menentukan nilai Z untuk setiap kategori, dengan asumsi bahwa proporsi
kumulatif dianggap mengikuti distribusi normal baku. Nilai Z diperoleh dari
Tabel Distribusi Normal Baku.
4. Menghitung nilai densitas dari nilai Z yang diperoleh dengan cara
memasukkan nilai Z tersebut kedalam fungsi densitas normal baku sebagai
berikut:
f(z) = 1
√2��
−12�2
f(-2.31876) = 1
√2��
−12(−2.31876)2 = 0,027
SV = ������������������� −�������������������
������������������� −�������������������
SV1 =
0,000− 0,027
0,010−0,000 = -2,658
SV2 =
0,027−0.136
0.071−0.010 = - 1,784
SV3 =
0.136−0.299
0.224−0,071= - 1,066
SV4 =
0.299−0.314
0.755−0.224= - 0,028
SV5 =
0.314−0.000
1,000−0.755= 1,283
6. Menentukan Scale Value min sehingga SVterkecil + |SVmin| = 1
Scale Value Terkecil = -2,658
Nilai 1 diperoleh dari:
-2,658 + X = 1
X = 1 + 2,658
X = 3,658
7. Mentransformasikan nilai skala dengan menggunakan rumus:
Y = SV + |SVmin|
Y1 = -2,658 + 3,658 = 1
Y2 = -1,784 + 3,658 = 1,874
Y3 = -1,066 + 3,658 = 2,592
Y4 = -0,028 + 3,658 = 3,631
Y5 = 1,283 + 3,658 = 4,942
Dengan perhitungan manual yang dilakukan terbukti sama dengan perhitungan
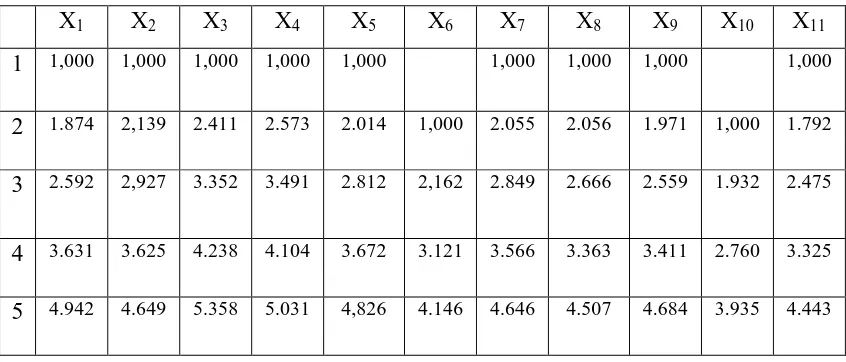
yang dilakukan pada Microsoft excel. Selanjutnya dengan melakukan cara
yang sama, maka semua variabel akan ditransformasikan ke dalam data
Tabel 3.2 Hasil Penskalaan Variabel
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11
1 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000 1,000
2 1.874 2,139 2.411 2.573 2.014 1,000 2.055 2.056 1.971 1,000 1.792
3 2.592 2,927 3.352 3.491 2.812 2,162 2.849 2.666 2.559 1.932 2.475
4 3.631 3.625 4.238 4.104 3.672 3.121 3.566 3.363 3.411 2.760 3.325
5 4.942 4.649 5.358 5.031 4,826 4.146 4.646 4.507 4.684 3.935 4.443
3.3Uji Validitas
Hasil uji validitas data kuesioner dari 11 variabel yang diukur kemudian
dihitung dengan menggunakan software SPSS yang ditunjukkan pada tabel
Tabel 3.3 Uji Validitas 1
No Variabel r-tabel r-hitung Keterangan
1 Variabel 1 0,199 0,394 Valid
2 Variabel 2 0,199 0,475 Valid
3 Variabel 3 0,199 0,432 Valid
4 Variabel 4 0,199 0,413 Valid
5 Variabel 5 0,199 0,532 Valid
6 Variabel 6 0,199 0,443 Valid
7 Variabel 7 0,199 0,524 Valid
8 Variabel 8 0,199 0,347 Valid
9 Variabel 9 0,199 0,549 Valid
10 Variabel 10 0,199 0,149 Tidak Valid
11 Variabel 11 0,199 0,562 Valid
Dalam penelitian ini, peneliti menggunakan teknik analisis butir dengan
uji coba semua responden sebanyak 98 orang, kemudian mengkorelasi skor butir
dengan skor total. Kaidah pengambilan kesimpulan apabila butir/item pertanyaan
adalah valid. Jika suatu butir pertanyaan tidak valid maka butir pertanyaan
tersebut harus dibuang kemudian lakukan uji sesuai prosedur sebelumnya dengan
mengurangi butir pertanyaan yang tidak valid.
Karena terdapat 1 variabel yang tidak valid, yaitu variabel ke 10, maka uji
validitas harus dilakukan kembali dengan mengurangi 1 variabel yang tidak valid
[image:30.595.110.517.269.507.2]tersebut. Tabel menunjukkan uji validitas 2 (kedua).
Tabel 3.4 Uji Validitas 2
No Variabel r-tabel r-hitung Keterangan
1 Variabel 1 0,199 0,403 Valid
2 Variabel 2 0,199 0,494 Valid
3 Variabel 3 0,199 0,445 Valid
4 Variabel 4 0,199 0,438 Valid
5 Variabel 5 0,199 0,523 Valid
6 Variabel 6 0,199 0,433 Valid
7 Variabel 7 0,199 0,527 Valid
8 Variabel 8 0,199 0,382 Valid
9 Variabel 9 0,199 0,554 Valid
10 Variabel 11 0,199 0,544 Valid
Dari perhitungan pada tabel 3.4 dimana nilai r-hitung dibandingkan
dengan niali r-tabel dimana jumlah N sebanyak 98 responden dengan taraf
signifikan 5% (0,199) dimana nilai r-hitung lebih besar dari r-tabel sehingga dapat
disimpulkan bahwa 10 variabel pada tabel diatas dinyatakan valid.
Secara manual perhitungan korelasi product moment antara variabel
X1dengan skor total variabel lainnya (Y) dapat dilihat pada tabel berikut:
Tabel 3.5 Contoh Perhitungan Korelasi Product Moment No
Reponden
X Y XY X2 Y2
[image:30.595.107.519.685.756.2]2 4 35 140 16 1225
3 3 24 72 9 576
4 3 30 90 9 900
5 4 32 128 16 1024
. . . .
. . . .
98 3 34 102 9 1156
JUMLAH 386 3581 14268 1592 133141
r
xy=
�(∑��)− (∑�.∑�)
�{�∑�2− ( ∑�)2}{�∑�2− (∑�)2}
r
xy=
98(14268 )− (386�3581 )
�{98(1592)− (386)2}{98(133141 )−(3581 )2}
r
xy=
1398264−1382266
�(156016−148996 )(13047818−12823561 )
r
xy=
15998 �(7020)(224257 )
r
xy=
15998
√1574284140
r
xy=
15998 39677 ,24965
rxy = 0,40320335
Diperoleh nilai validitas untuk variabel X1 dengan perhitungan manual
adalah 0,403 sama dengan output SPSS yakni 0,403. Selanjutnya untuk
perhitungan variabel lainnya akan dilakukan dengan software SPSS.
3.4Uji Reliabilitas
Berikut adalah hasil perolehan data dari uji reliabilitas dengan SPSS:
Reliability Statistics
Cronbach’s Alpha Cronbach’s Alpha Based on Standardized Items
No of Items
,702 ,702 10
Berdasarkan hasil perhitungan diatas, nilai Cronbach Coefficien Alpha
adalah 0,702 untuk uji reliabilitas atas daftar pilihan responden. Nilai tersebut
menyatakan bahwa 10 variabel yang valid tersebut memenuhi persyaratan uji
reliabilitas, dimana nilai yang diperoleh sudah lebih dari minimum untuk sebuah
penelitian yaitu 0,6.
3.5Prosedur Pengolahan Data Dengan Analisis Faktor
Terdapat beberapa prosedur pengolahan data analisis faktor yang umum
dilakukan dalam sebuah penelitian. Prosedur analisis ini dilakukan dengan
langkah-langkah sebagai berikut:
1. Melakukan input data hasil tabulasi pada SPSS 20 di lembar data view
2. Mengisi desain variabel dengan mengatur nama tabel pada variabel view
3. Melakukan prosedur analisis data dengan SPSS 20
Langkah-langkahnya adalah sebagai berikut: • Klik analyze
• Pilih sub menu Dimension Reduction, kemudian pilih Faktor
• Pindahkan semua variabel di kolom kiri ke kolom variabel sebelah kanan • Pada pilihan Correlation Matrix, aktifkan pilihan KMO and Bartlett’s Test
of Sphericity dan anti-image, kemudian klik continue
• Pilih Extraction
• Pada pilihan Method, pilih Principal Component dan pada pilihan analyze, pilihan Correlation Matrix
[image:32.595.107.519.111.224.2]• Pada pilihan Mtehod, pilih metode Varimax dan pada pilihan display, aktifkan Rotate Solution, kemudian klik continue
• Klik Ok untuk diproses 4. Penyusunan Matrik Interkorelasi
Data disusun dalam matriks korelasi, proses analitik dilakukan pada korelasi
matrik dari variabel-variabel yang diuji. Beberapa pengujian nilai dilakukan
yaitu KMO and Bartlett’s Test yang berguna untuk menguji kelayakan sampel.
Jika nilai KMO MSA lebih dari 0,5 dan nilai signifikansi lebih kecil dai 0,05
maka analisis data bisa dilanjutkan.
5. Ekstraksi Faktor
Terdapat 5 jenis pendekatan metode ekstraksi faktor, yaitu:
a. Principal Component Analysis (PCA)
b. Common Factor Analysis/Principals Axis Factoring
c. Maximum Likehood
d. Unweighted Least Square
e. Generalized Least Square
Pada penelitian ini digunakan pendekatan PCA karena sesuai dengan
fungsinya umtuk mengetahui jumlah faktor minimal yang dapat diekstrasi dengan
mengahsilkan faktor yang memiliki specific variance dan error variance yang
paling kecil. Dan untuk menentukan banyaknya faktor, terdapat beberapa hal
sebagai acuan, yaitu:
a. Berdasarkan penelitan sebelumnya
b. Pendekatan dengan eigenvalue lebih dari 1
c. Menentukan banyaknya faktor dengan plot eigenvalue
d. Sampel dipisah menjadi dua analisis
6. Rotasi Faktor
Rotasi faktor adalah hasil penting dalam analisis faktor. Didalamnya
terdapat koefisien yang digunakan untuk menunjukkan variabel-variabel yang
distandarisasi dalam batasan sebagai faktor. Faktor diharapkan tidak bernilai 0.
Dan untuk menilai representasi variabel yang mempresentasikan faktor,
dikategorikan dengan korelasi kuat dan korelasi lemah. Variabel yang lemah
adalah variabel yang cukup kuat diwakili oleh faktor.
3.6Pengolahan Data Hasil Kuesioner
Dalam bagian ini menjelaskan pengolahan analisis komponen utama
variabel data tingkat kepentingan yang didapatkan dari hasil pengisian kuesioner
oleh responden menggunakan SPSS. Berdasarkan hasil uji validitas diatas,
terdapat 10 variabel valid yang akan dilakukan analisis faktor.
Pengolahan data untuk komponen utama dari analisis faktor adalah dengan
melakukan perhitungan nilai KMO and Bartlett’s Test untuk10 variabel yang
[image:34.595.105.515.351.440.2]valid.
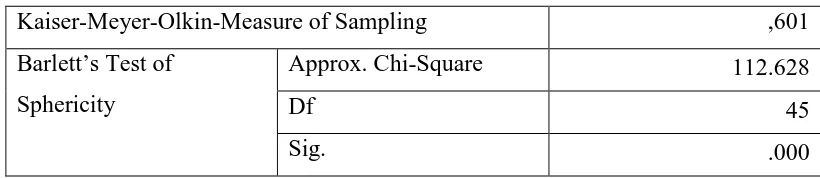
Tabel 3.7 KMO and Barlett’s Test
Kaiser-Meyer-Olkin-Measure of Sampling ,601
Barlett’s Test of
Sphericity
Approx. Chi-Square 112.628
Df 45
Sig. .000
Hasil output SPSS seperti tabel diatas menunjukkan angka KMO and
Bartlett’s Test adalah 0,601 lebih besar dari 0,5 dengan signifikansi 0,000 lebih
kecil dari 0,05 maka variabel dan sampel sudah layak untuk dianalisis lebih lanjut.
Perhitungan manualnya sebagai berikut:
KMO= ∑ ∑ ���
2
� � ≠1
� �=1 ∑ ∑� ���2
�≠1
�
�=1 +∑ ∑ ���2
� �≠1
� �=1
KMO = 13.84169
13.84169 +3.11908 = 0,601
Proses pengolahan selanjutnya adalah dengan melihat nilai MSA. Hasil
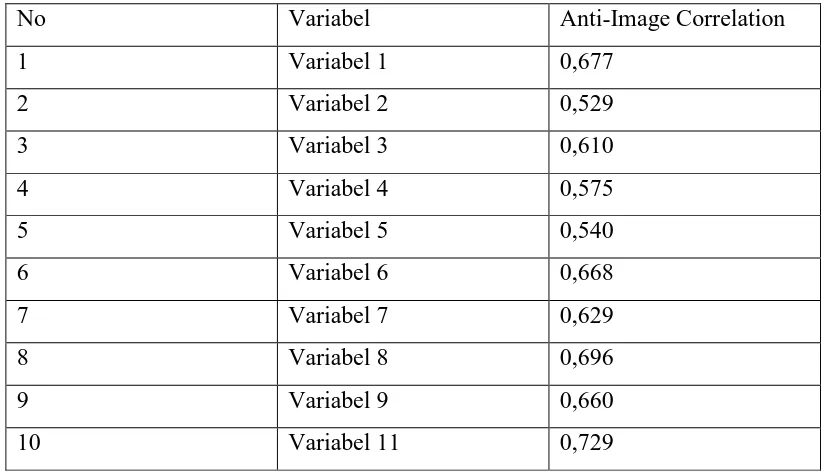
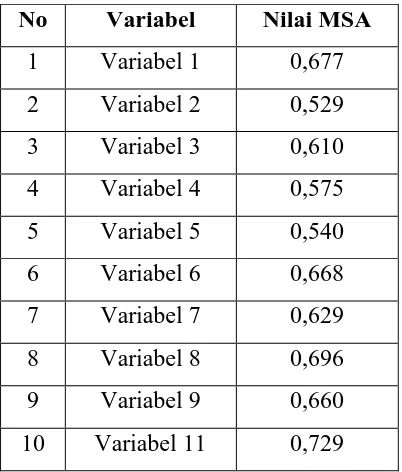
Tabel 3.8 Measure of Sampling Adequacy
No Variabel Anti-Image Correlation
1 Variabel 1 0,677
2 Variabel 2 0,529
3 Variabel 3 0,610
4 Variabel 4 0,575
5 Variabel 5 0,540
6 Variabel 6 0,668
7 Variabel 7 0,629
8 Variabel 8 0,696
9 Variabel 9 0,660
10 Variabel 11 0,729
Dengan melihat anti image correlation diketahui ke 10 variabel
menunjukkan kriteria angka MSA lebih besar dari 0,5 yang berarti semua variabel
masih bisa diprediksi untuk dianalisa lebih lanjut. Dari kedua hasil pengujian
diatas, semua variabel mempunyai korelasi yang cukup tinggi dengan variabel
lain, sehingga analisis layak untuk dilanjutkan dengan mengikutkan 10 variabel.
Perhitungan manualnya sebagai berikut:
MSA = ∑ ∑ ��� 2
� �≠1
� �=1 ∑� ���2
�=1 +∑ ���2
� �=1
���1=
1.421016
1.421016 +0.16647 = 0,677
Perhitungan nilai MSA2 – MSA11 dilanjutkan di dalamlampiran.
3.7 Hasil Analisis Faktor
Pada proses analisis faktor, dilakukan beberapa tahap sampai dengan
perolehan faktor-faktor baru sebagai faktor dominan yang ingin diperoleh. Proses
pertama yaitu tabulasi pada data serta melakukan pengolahan dengan software
yang telah direfrensikanyaitu program SPSS dengan mengambil versi SPSS 20.
Untuk data 10 variabel penelitian pada kuesioner yang dijawab oleh 98 responden.
Ada beberapa variabel yang mempengaruhi tingkat pengangguran
khususnya di Kota Medan Kecamatan Medan Selayang, faktor-faktor tersebut
berjumlah 10 variabel yang valid.
Berdasarkan hasil perhitungan tabel 3.7 diperoleh KMO and Barlett’s
Test sebesar 0,601 dengan signifikansi sebesar 0,000. Berdasarkan teori nilai
KMO memang harus di atas 0,5 dan signifikansi atau probabilitas dibawah 0,05
maka variabel layak dapat dianalisa lebih lanjut (Santoso, 2002).
Perhitungan selanjutnya adalah dengan melihat nilai MSA.Hasil nilai
MSA dapat dilihat pada tabel. Hasil pada tabel menunjukkan bahwa 10 variabel
yang tersisa mempunyai nilai lebih dari 0,5. Berdasarkan 10 variabel yang dinilai
dalam kuesioner yang merupakan jawaban 98 responden, diperoleh bahwa nilai
MSA yang diperoleh diatas 0,5. Ini menandakan bahwa semua variabel memiliki
korelasi cukup tinggi dengan variabel lainnya, sehingga selanjutnya dapat
[image:36.595.212.413.464.700.2]dilakukan analisis pada seluruh variabel yang diteliti.
Tabel 3.9 MSA
No Variabel Nilai MSA
1 Variabel 1 0,677
2 Variabel 2 0,529
3 Variabel 3 0,610
4 Variabel 4 0,575
5 Variabel 5 0,540
6 Variabel 6 0,668
7 Variabel 7 0,629
8 Variabel 8 0,696
9 Variabel 9 0,660
3.7.2 Hasil Ekstraksi Faktor
Dalam penelitian ini metode ekstraksi yang digunakan adalah Principal
Component Analysis (Analisis Komponen Utama). Di dalam Principal
Component Analysis jumlah varians data dipertimbangkan yaitu diagonal matriks
korelasi, setiap elemennya sebesar satu daan full variance dipergunakan untuk
dasar pembentukan faktor, yaitu variabel-variabel lama yang jumlahnya lebih
sedikit dan tidak berkorelasi lagi satu sama lain, seperti variabel-variabel asli yang
[image:37.595.110.471.300.539.2]memang saling berkorelasi.
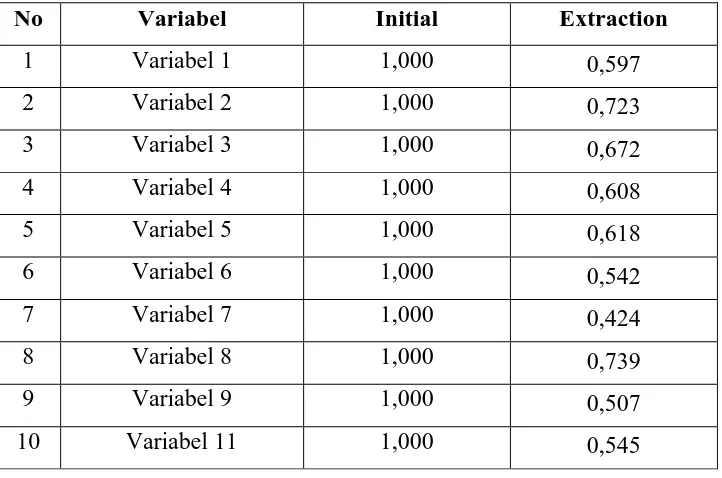
Tabel 3.10 Communalities
No Variabel Initial Extraction
1 Variabel 1 1,000 0,597
2 Variabel 2 1,000 0,723
3 Variabel 3 1,000 0,672
4 Variabel 4 1,000 0,608
5 Variabel 5 1,000 0,618
6 Variabel 6 1,000 0,542
7 Variabel 7 1,000 0,424
8 Variabel 8 1,000 0,739
9 Variabel 9 1,000 0,507
10 Variabel 11 1,000 0,545
Dalam proses pengolahan ekstraksi, rotasi serta nilai terhadap variabel
sampai menghasilkan faktor dengan metode Principals Component Analysis dan
metode Explained dari 10 variabel yang dianalisis dengan nilai eigenvalue ≥ 1,
diperoleh 4 faktor yang terbentuk.
Tabel 3.11 Total Variance Explained Faktor atau
Komponen
Initial Eigenvalues
Total % of Variance Cumulative %
1 2.367 23.669 23.669
[image:37.595.107.519.690.754.2]3 1.182 11.817 49.745
4 1.002 10.018 59.763
5 .872 8.722 68.486
6 .822 8.223 76.708
7 .732 7.318 84.027
8 .672 6.718 90.745
9 .519 5.192 95.936
10 .406 4.064 100.000
Ada 10 variabel yang dimasukkan dalam analisis faktor. Dengan total
variansi masing-masing, maka total variansinya adalah 10 x 1 = 10. Variansi
faktor 1 tersebut adalah 2,367/10 x 100% = 23,67%, faktor 2 adalah 1,426/10 x
100% = 14,26% dan selanjutnya sebagaimana bisa dilihat pada tabel diatas pada
kolom % of Variance. Total jumlah keseluruhan variansi dari 4 faktor tersebesar
[image:38.595.106.523.84.278.2]adalah 59,763.
Tabel 3.11 Extraction Sums of Squared Loadings Extraction Sums of Squared Loadings
Total % of Variance Cumulative %
2.367 23.669 23.669
1.426 14.259 37.928
1.182 11.817 49.745
1.002 10.018 59.763
Nilai eigenvalues menunjukkan kepentingan relatif masing-masing faktor
dalam menghitung varians dari 10 variabel yang di analisis.Susunan eigenvalues
selalu diurutkan dari yang terbesar sampai yang terkecil, dengan kriteria bahwa
angka eigenvalues dibawah angka 1 tidak digunakan untuk menghitung faktor
yang terbentuk. Selanjutnya, dari tabel diatas terlihat bahwa 4 faktor yang akan
terbentuk yang mempunyai nilai eigenvalues diatas angka 1. Gambar merupakan
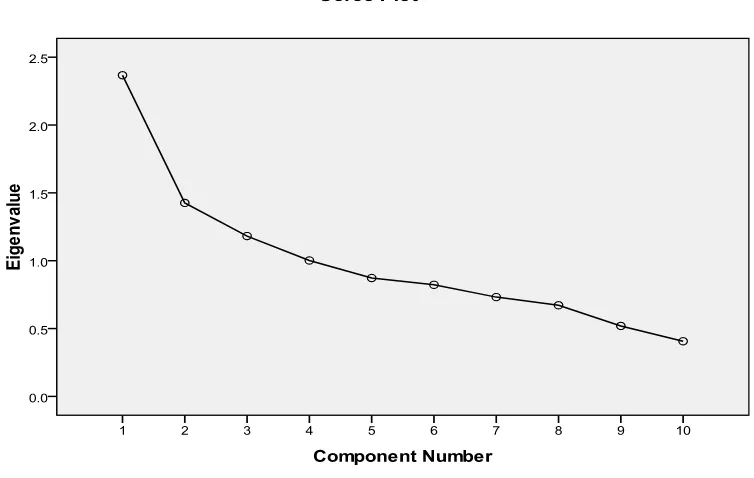
Gambar 3.1 Scree Plot
Suatu Scree Plot adalah plot dari eigenvalue melawan banyaknya faktor
yang bertujuan untuk melakukan ekstraksi agar diperoleh jumlah faktor. Scree
Plot berupa suatu kurva yang diperoleh dengan memplot eigenvalue sebagai
sumbu vertikal dan banyaknya faktor sebagai sumbu horizontal. Bentuk kurva
atau plotnya dipergunakan untuk menentukan banyaknya faktor.
Jika tabel total varians menjelaskan dasar jumlah faktor yang didapat
dengan perhitungan angka, maka Scree Plot memperlihatkan hal tersebut dengan
grafik. Terlihat bahwa dari situ kedua faktor (garis dari sumbu Component 1 ke 2),
arah garis cukup menurun tajam.Kemudian dari 2 ke 3 garis juga menurun
begitupun 3 ke 4.Pada faktor 5 sudah dibawah angka 1 dari sumbu eigenvalue.Hal
ini menunjukkan bahwa ada 4 faktor yang mempengaruhi tingkat pegangguran
yang dapat diekstraksi berdasarkan scree plot.
3.7.3 Hasil Rotasi Faktor
Hasil rotasi faktor awal memberikan informasi bahwa terdapat 4 faktor
dari 10 variabel yang dapat diolah dengan variansi kumulatif sebesar 59,763%.
tersebut dapat dilihat pada tabel berikut.
Tabel 3.12 Factor Loading Variabel
Penelitian
Faktor
1 2 3 4
X1 0,446 -0,290 -0,476 0,296
X2 0,490 -0,404 0,565 0,018
X3 0,468 -0,608 0,188 0,220
X4 0,427 0,377 -0,081 -0,526
X5 0,527 0,407 -0,117 0,401
X6 0,405 0,352 0,475 -0,169
X7 0,559 -0,043 0,141 -0,301
X8 0,192 0,557 0,312 0,543
X9 0,649 -0,158 -0,223 -0,106
X11 0,561 0,201 -0,433 -0,053
Dari tabel 3.12 dapat dilihat bahwa variabel-variabel berkorelasi kuat
dengan lebih dari satu faktor, sehingga sulit untuk menginterpretasikan
faktor-faktor tersebut. Dalam hal ini, factor loading perlu dirotasi agar masing-masing
variabel berkorelasi kuat hanya pada satu faktor. Berikut ini adalah factor loading
setelah dirotasi (rotated factor loading).
Tabel 3.13 Rotated Factor Loading Variabel
Penelitian
Faktor
1 2 3 4
X1 0,737 0,170 -0,159 -0,003
X2 -0,053 0,826 0,184 0,067
X3 0,290 0,757 -0,114 -0,052
X4 0,149 -0,156 0,749 0,003
[image:40.595.108.515.587.739.2]X6 -0,198 0,222 0,558 0,377
X7 0,179 0,337 0,527 -0,014
X8 -0,084 -0,005 -0,013 0,856
X9 0,565 0,273 0,334 -0,043
X11 0,623 -0,113 0,357 0,132
Factor Loading hasil rotasi menunjukkan bahwa variabel-variabel
berkorelasi kuat hanya pada satu faktor tertentu, misalnya korelasi antara variabel
X1 dan faktor 1 sebesar 0,737 (korelasi kuat), sedangkan korelasi dengan faktor 2,
3 dan 4 masing-masing sebesar 0,170, -0,159 dan -0,003 (korelasi lemah).
Nilai Eigen Value dari faktor yang diekstraksi mencerminkan jumlah
variansi yang dapat dijelaskan oleh suatu faktor.Pada tabel 3.13 berikut ini adalah
hasil rekapitulasi faktor yang dihasilkan dengan metode analisis faktor yaitu
terbagi menjadi 4 faktor.
3.7.4 Interpretasi Faktor
Faktor pertama hasil rotasi faktor didukung oleh 3 variabel.
Variabel-variabel tersebut yang secara berurutan nilai bobotnya adalah X1, X9 dan X11.
Bobot masing-masing variabel pendukung faktor pertama tersebut sesuai tabel
berikut ini:
[image:41.595.107.519.84.194.2]Faktor Pertama
Tabel 3.14 Bobot Variabel Pendukung Faktor Pertama Variabel
Pendukung
Nama Variabel Bobot
Variabel
X1 Banyaknya pengangguran karena disebabkan besarnya
persaingan untuk melamar pekerjaan
0,737
X9 Kepadatan penduduk mempengaruhi tingkat
pengangguran
0,565
X11 Banyaknya jumlah pengangguran disebabkan karena
susahnya menerapkan kecerdasan yang dimiliki
0,623
Dari tabel diatas, variabel X1 mempunyai bobot terbesar, yaitu 0,737.
Berdasarkan uraian tersebut dapat disimpulkan bahwa faktor pertama cukup layak
diberi nama faktor persaingan.
Faktor pertama ini adalah faktor yang paling kuat yang mempengaruhi
tingkat pengangguran di Kota Medan Kecamatan Medan Selayang dengan
variansi sebesar 23.669%.
Faktor Kedua
Faktor kedua hasil rotasi faktor didukung oleh 2 variabel. Bobot masing-masing
[image:42.595.107.521.358.527.2]variabel pendukung faktor kedua tersebut sesuai tabel berikut ini:
Tabel 3.15 Bobot Variabel Pendukung Faktor Kedua Variabel
Pendukung
Nama Variabel Bobot
Variabel
X2 Banyaknya pengangguran karena lowongan pekerjaan
sangat sedikit
0,826
X3 Melonjaknya tingkat pengangguran karena banyaknya
PHK (pemutusan hubungan kerja) di
perusahaan-perusahaan ataupun instansi
0,757
Dari tabel di atas, variabel X2 mempunyai bobot terbesar, yaitu sebesar
0,826. Berdasarkan uraian tersebut dapat disimpulkan bahwa untuk faktor kedua
diberi nama faktor lowongan pekerjaan.
Faktor ini adalah faktor terkuat kedua yang mendasari penilaian terhadap
tingkat pengangguran di Kota Medan Kecamatan Medan Selayang dengan
variansi sebesar 14,259%.
Faktor Ketiga
Faktor ketiga yang rotasi faktornya didukung oleh 3 variabel. Bobot
Tabel 3.16 Bobot Variabel Pendukung Faktor Ketiga Variabel
Pendukung
Nama Variabel Bobot
Variabel
X4 Susahnya mendapatkan pekerjaan karena kurangnya
informasi tentang lowongan pekerjaan
0,749
X6 Susahnya mendapatkan pekerjaan karena tingginya
tuntutan perusahaan terhadap keahlian seorang
pelamar pekerja
0,558
X7 Banyaknya jumlah pengangguran karena kurangnya
perhatian pemerintah terhadap tingkat pengangguran
0,527
Dari hasil di atas, variabel X4 mempunyai bobot terbesar, yaitu sebesar
0,749. Berdasarkan uraian tersebut dapat disimpulkan bahwa untuk faktor ketiga
diberi nama sebagai faktor informasi.
Faktor ini adalah faktor terkuat ketiga yang mendasari penilaian terhadap
tingkat pengangguran di Kota Medan Kecamatan Medan Selayang dengan
variansi sebesar 11,817%.
Faktor Keempat
Faktor keempat yang rotasi faktornya didukung oleh 2 variabel. Bobot
masing-maing variabel pendukung faktor keempat tersebut sesuai tabel berikut
ini:
Tabel 3.16 Bobot Variabel Pendukung Faktor Keempat Variabel
Pendukung
Nama Variabel Bobot
Variabel
X5 Susahnya mendapatkan pekerjaan karena kurangnya
informasi tentang lowongan pekerjaan
0,640
X8 Susahnya mendapatkan pekerjaan karena tingginya
tuntutan perusahaan terhadap keahlian seorang
pelamar pekerja
0,856
0,856. Berdasarkan uraian tersebut dapat disimpulkan bahwa untuk faktor
keempat diberi nama sebagai faktor tuntutan perusahaan.
Faktor ini adalah faktor terkuat keempat yang mendasari penilaian
terhadap tingkat pengangguran di Kota Medan Kecamatan Medan Selayang
BAB 4
KESIMPULAN DAN SARAN
4.1 KESIMPULAN
Dari hasil pengolahan data dan penelitian dengan 98 responden dan 11
variabel pertanyaan penelitian mengambil kesimpulan:
1. Terdapat 4 faktor dominan hasil ekstraksi yang berpengaruh terhadap
pengangguran di Kota Medan Kecamatan Medan Selayang, yaitu:
a. Faktor persaingan dengan variansi sebesar 23.669%.
b. Faktor lowongan pekerjaan dengan variansi sebesar 14,259%.
c. Faktor informasi dengan variansi sebesar 11,817%.
d. Faktor tuntutan perusahaan dengan variansi sebesar 10,018%.
2. Faktor terbesar dalam pengaruh pengangguran di Kota Medan Kecamatan
Medan Selayang adalah faktor persaingan kerja dengan variansi sebesar
23,669%.
3. Faktor terendah dalam pengaruh pengangguran di Kota Medan Kecamatan
Medan Selayang adalah faktor perhatian pemerintah dengan variansi
sebesar 4,064%.
4.2 SARAN
Berdasarkan kesimpulan yang di ambil, maka saran yang dapat diberikan
dalam penelitian ini adalah:
1. Dari hasil penelitian disimpulkan bahwa faktor persaingan menjadi faktor
terkuat di dalam pengangguran di Kecamatan Medan Selayang, maka dari
itu Pemerintah perlu meningkatkan sumber daya manusia yang lebih
kompeten khususnya di Kecamatan Medan Selayang.
2. Persaingan dan lowongan pekerjaan sangat berkaitan erat dalam
menimlbulkan pengagguran, karena apabila lowongan pekerjaan sangat
itu pemeritah perlu membuka lowonganpekerjaan yang lebih luas
khususnya di Kecamatan Medan Selayang. Seperti yang dilakukan
Pemprov DKI Jakarta membuka lowongan pekerjaan dalam pembersihan
sungai ataupun aliran air yang lain dengan gaji yang lumayan tinggi (lebih
dari Rp. 3.000.000). Mungkin itu bisa diterapkan di Kota Medan yang
BAB 2
LANDASAN TEORI
2.1PERTUMBUHAN EKONOMI
Pertumbuhan ekonomi adalah proses perubahan kondisi perekonomian suatu
negara secara berkesinambungan menuju keadaan yang lebih baik selama periode
tertentu. Pertumbuhan ekonomi dapat diartikan juga sebagai proses kenaikan
kapasitas produksi suatu perekonomian yang diwujudkan dalam bentuk kenaikan
pendapatan nasional. Adanya pertumbuhan ekonomi merupakan indikasi
keberhasilan pembangunan ekonomi.
Faktor-faktor yang mempengaruhi pertumbuhan ekonomi adalah:
• Faktor Sumber Daya Manusia
Sama halnya dengan proses pembangunan, pertumbuhan ekonomi juga
dipengaruhi oleh SDM. Sumber daya manusia merupakan faktor terpenting dalam
proses pembangunan, cepat lambatnya proses pembangunan tergantung kepada
sejauh mana sumber daya manusianya selaku subjek pembangunan memiliki
kompetensi yang memadai untuk melaksanakan proses pembangunan dengan
membangun infrastruktur di daerah-daerah.
• Faktor Sumber Daya Alam
Sebagian besar negara berkembang bertumpu kepada sumber daya alam dalam
melaksanakan proses pembangunannya. Namun, sumber daya alam saja tidak
menjamin keberhasilan proses pembanguan ekonomi, apabila tidak didukung oleh
kemampaun sumber daya manusianya dalam mengelola sumber daya alam yang
tersedia. Sumber daya alam yang dimaksud diantaranya kesuburan tanah,
kekayaan mineral, tambang, kekayaan hasil hutan dan kekayaan laut.
Perkembangan ilmu pengetahuan dan teknologi yang semakin pesat mendorong
adanya percepatan proses pembangunan, pergantian pola kerja yang semula
menggunakan tangan manusia digantikan oleh mesin-mesin canggih berdampak
kepada aspek efisiensi, kualitas dan kuantitas serangkaian aktifitas pembangunan
ekonomi yang dilakukan dan pada akhirnya berakibat pada percepatan laju
pertumbuhan perekonomian.
• Faktor Budaya
Faktor budaya memberikan dampak tersendiri terhadap pembangunan ekonomi
yang dilakukan, faktor ini dapat berfungsi sebagai pembangkit atau pendorong
proses pembangunan tetapi dapat juga menjadi penghambat pembangunan.
Budaya yang dapat mendorong pembangunan diantaranya sikap kerja keras dan
kerja cerdas, jujur, ulet dan sebagainya. Adapun budaya yang dapat menghambat
proses pembangunan diantaranya sikap anarkis, egois, boros, KKN, dan
sebagainya.
• Sumber Daya Modal
Sumber daya modal dibutuhkan manusia untuk mengolah SDA dan meningkatkan
kualitas IPTEK.Sumber daya modal berupa barang-barang modal sangat penting
bagi perkembangan dan kelancaran pembangunan ekonomi karena barang-barang
modal juga dapat meningkatkan produktifitas.
Salah satu masalah ekonomi terbesar di Indonesia adalah bayaknya jumlah
pengangguran, dan pengangguran tersebut tidak lepas dari peran sumber daya
manusia yang ada di suatu negara atau daerah.
2.2PENGANGGURAN
Permasalahan di bidang ketenagakerjaan Indonesia yang paling dirasakan
hingga kini adalah pengangguran. Berdasarkan data Badan Pusat Statistik pada
Agustus 2015, jumlah penganggur terbuka mencapai 7,56 juta orang atau 6,18
Dalam pengamatannya, pengangguran disebabkan oleh dua hal yaitu jumlah
angkatan kerja yang setiap tahun meningkat dan terbatasnya kesempatan kerja.
Peningkatan jumlah angkatan kerja diakibatkan karena adanya lulusan dari
lembaga pendidikan maupun mereka yang belum diserap oleh pasar kerja pada
tahun sebelumnya.
Sedangkan terbatasnya kesempatan kerja antara lain diakibatkan oleh kondisi
pertumbuhan perekonomian nasional dan adanya ketidaksesuaian antara
kebutuhan dengan ketersediaan tenaga kerja.
Tetapi juga pada penciptaan sumber daya manusia (SDM) yang mampu
mengelola sumber daya alam yang tersedia sehingga membawa bangsa ini keluar
menjadi bangsa yang hebat.
Lemahnya SDM Indonesia dalam berkompetisi di dunia kerja salah satunya
disebabkan sistem pendidikan dan penyiapan SDM yang salah. Untuk itu,
lembaga pendidikan di semua level diminta merancang ulang program dan
orientasi dengan memasukkan unsur pendidikan kewirausahaan.
Lembaga pendidikan formal harus mampu menyiapkan calon tenaga kerja
handal dan kompeten selain menyiapkan kader bangsa terdidik dan
nasionalis.Untuk itu kurikulum dan silabinya harus didesain dengan
mempertimbangkan perkembangan zaman dan kebutuhannya selain perubahan
pola pikir bagi peserta didik yang dalam bahasa pemerintahan Jokowi-JK disebut
revolusi mental.
Dalam penelitian ini penulis akan meneliti faktor-faktor penyebab
pengangguran yang dibatasi pada 11 faktor yang telah ditetapkan, yaitu:
persaingan melamar kerja, lowongan pekerjaan, PHK, kurangnya informasi,
karyawan perusahaan tidak sesuai jurusan, tuntutan perusahaan, perhatian
pemerintah, umur, kepadatan penduduk, kemalasan dan penerapan kecerdasan.
Penelitian merupakan suatu proses penyelidikan secara sistematis yang
ditujukan pada penyediaan informasi untuk menyelesaikan masalah-masalah
(Zikmund, et.al, 2009). Penelitian juga didefenisikan sebagai usaha yang secara
sadar diarahkan untuk mengetahui atau mempelajari fakta-fakta baru dan juga
sebagai penyaluran hasrat ingin tahu manusia (Suparmoko, 1991).
Dalam setiap penyusunannya, penelitian dilakukan menggunakan
metode-metode yang telah disesuaikan dengan tujuan dari penelitian yang ingin diperoleh.
Semua bergantung pada bidang penelitian, masalah yang diangkat, tujuan serta
apa yang menjadi parameter ukur dalam penelitian sosial yang menjadi konsep
utama dalam penelitian ini.
2.4KONSEP PENELITIAN
Pada bagian ini dirancanglah kerangka untuk melaksanakan penelitian. Di
dalamnya memuat secara rinci prosedur untuk pengumpulan data, instrumen
penelitian, cara pengujian, kemungkinan jawaban terhadap research questions
sampai dengan model analisis yang dipergunakan.
Berdasarkan klarifikasi atau tujuannya terdapat dua jenis penelitian atau
analisis yang ingin diperoleh (Jollife, 2002), yaitu:
a. Exploratory Analysis, atau disebut juga Turkey Analysis dilakukan dengan
cara melakukan analisis yang memungkinkan untuk
mamahami/menemukan suatu sifat tertentu pada data. Exploratory
Analysis cocok digunakan untuk penelitian yang tidak menguji hipotesis
seperti Data Driven Research.
b. Confirmatory Analysis, adalah analisis yang dilakukan untuk menguji
hipotesis yang telah dibuat berdasarkan teori tertentu (mengkonfirmasi
teori) seperti pada Theory Driven Research.
Pada penelitian ini, peneliti menggunakan konsep Exploratory Analysis,
sehigga teori-teori yang ada hanya akan menjadi pertimbangan, namun tidak
menjadi tolak ukur dari keseluruhan mekanisme penelitian.
Karena tujuan yang ingin diperoleh adalah untuk memperoleh faktor-faktor
dominan yang menyebabkan pengangguran. Dan dari sini, akan teridentifikasi
banyak variabel yang akan diolah sedemikian rupa menjadi faktor-faktor dominan
yang dicari dan teknik multivariat dengan analisis faktor akan dipakai menjadi
acuan bagi peneliti untuk mengidentifikasi data penelitian selanjutnya.
2.5SUMBER DAN DATA SAMPEL
Dalam penelitian, selalu dilakukan pengumpulan data yang merupakan alat
bantu utama dalam penelitian. Berdasarkan cara memperolehnya, terdapat dua
jenis data, yaitu:
1. Data primer
Data primer adalah data yang secara langsung diambil dari objek-objek
penelitian oleh peneliti perorangan maupun organisasi. Dalam penelitian
ini, data primer akan diperoleh dari pengujian kuesioner.
2. Data sekunder
Data sekunder adalah data yang didapat tidak secara langsung dari objek
penelitian. Di penelitian ini data sekunder diambil dari fasilitas website
secara rangkuman artikel yang ada di internet dari produsen produk dan
pihak yang berkaitan
Dalam suatu penelitian diperlukan berbagai metode yang menunjang
terlaksananya penelitian secara baik sehingga hasil yang didapatkan benar-benar
akurat.Langkah awal dalam suatu penelitian adalah penetapan populasi sampel
untuk mendapatkan bahan penelitian.
Populasi adalah sekelompok orang, benda, atau hal yang menjadi sumber
pengambian sampel atau sekumpulan yang memenuhi syarat-syarat tertentu yang
berkaitan dengan masalah penelitian.Sampel adalah bagian dari populasi statistik
yang cirinya dipelajari untuk memperoleh informasi tentang seluruhnya atau dapat
juga dikatakan sebagai suatu bagian dari populasi atau semesta sebaga wakil
(representasi) populasi atau semesta itu.
dan jenis penelitian (Ary, Jacobs & Sorensen. 2010) antara lain:
1. Random sampling atau sampel acak adalah sampel yang terdiri dari
unsur yang dipilih dari populasi dianggap random/acak bila tiap
unsur-unsur yang dipilih dari populasi tersebut memiliki probabilitas atau
kemungkinan yang sama untuk dipilih.
2. Sampel representative ialah sampel yang kira-kira memiliki
karakterisrik-karakteristik populasi yang relevan dengan penelitian yang bersangkutan.
3. Sampel sistematis adalah sebuah sampel yang proses pemilihannya
dilakukan secara sistematis dari populasinya. Sampel jenis ini banyak
digunakan dalam penelitian statistika.
4. Sampel luas atau sampel kelompok adalah sampel yang prosedur
pengambilan sampelnya menggunakan lokasi geografis sebagai dasarnya.
5. Sampel bertingkat. Bila populasinya ternyata terdiri dari
bermacam-macam jenis, maka populasi dapat dibagi kedalam beberapa stratum dan
sampelnya dapat dipilih secara random dari tiap stratum.
6. Sampel kuota adalah sampel yang dipilih dari stratum-stratum tertentu
yang dianggap cukup representative bagi populasinya.
Sampel yang digunakan dalam penelitian ini adalah sampel representative.
Sesuai dengan teori multivariat yang dikemukakan Hair bahwa standar ukuran
sampel yang diperlukan untuk analisis faktor ini minimal 5 variabel yang diteliti
(Sheskin, 2000). Jika terdapat 20 variabel, maka sampel haruslah minmal 100
responden.
Daerah penelitian yang akan diteliti adalah Kecamatan Medan Selayang Kota
Medan yang berpopulasi 104.454 orang dan yang pengangguran 4.630 orang
(Badan Pusat Statistik Kota Medan 2015) dan kategori responden yang akan
dijadikan sampel adalah:
- Usia 15-65 tahun yang tidak memiliki pekerjaan.
- Orang yang bekerja kurang dari dua hari dalam seminggu.
2.6 METODE SURVEI
Dalam pengumpulan data ini dilakuan survei.Survei adalah penelitian yang
diadakan untuk memperoleh fakta dari gejala-gejala yang ada dan mencari
keterangan secara faktual.
Jenis-jenis survei:
1. Book Survey
Pada survei ini kita memepelajari buku-buku atau bahan-bahan bacaan
yang berhubungan dengan masalah atau topik permasalahan yang akan
diteliti. Dimana didalamnya meneliti dokumen-dokumen, membaca
buku-buku, karya ilmiah, majalah dan buku lainnya yang berhubungan dengan
literatur ini.
2. Explanatory Survey
Survey bersifat menjelaskan suatu fenomena yang digambarkan. Teori
yang ada memerlukan pengujian dan perencanaan survei, sehingga data
yang dikumpulkan diperlukan penelitian mendapatkan penjelasan.
a. Content Survey
Di dalam survei terlebih dahulu kita harus mengumpulkan informasi
tentang suatu peristiwa kemudian menguraikannya. Sebagai contoh,
jika kita menguraikan pengangguran maka yang dilihat adalah hal apa
digunakan untuk mengukur tingkat pengangguran.
b. Survei Normatif
Survei ini bertujuan untuk mencari kesimpulan-kesimpulan mengenai
keadaan masyarakat tertentu. Norma-norma atau kriteria-kriteria
tertentu yang berlaku pada masyarakat.
c. Survei Status
Survei yang bertujuan untuk mengetahui posisi atau status seseorang
dalam masyarakat.
2.7INSTRUMEN PENELITIAN
Instrumen yang digunakan dalam penelitian ini adalah kuesioner.Kusioner
adalah sejumlah pertanyaan tertulis yang digunakan untuk memperoleh jawaban
yang diketahuinya (Arikunto, 1998). Dengan kata lain kuesioner adalah salah satu
alat yang dipergunakan untuk mengumpulkan data. Kuesioner biasanya berupa
pertanyaan tertulis yang diberikan kepada responden untuk dijawab. Metode
kuesioner ini digunakan apabila:
1. Tanggapan dari pertanyaan diketahui dan dapat dikuantifikasi
2. Mengumpulkan data dari grup besar
3. Data tidak dibutuhkan cepat
4. Ketika kesalahan tanggapan dapat ditoleransi
5. Ketika sumber daya untuk mengumpulkan data terbatas.
Beberapa jenis kuesioner berdasarkan cara pengumpulan data adalah:
1. Mail questionnaire (melalui surat)
2. Self administered (responden mengisi sendiri kuesioner tersebut)
3. Interview
4. Group administered questionnaire
2.8SKALA PENGUKURAN
Teknik pengukuran data yang digunakan adalah attitude scales, yaitu suatu
kumpulan alat pengukuran yang mengukur tanggapan individu terhadap suatu
objek atau fenomena.
Skala pengukuran dari data yang diperoleh adalah berupa skala ordinal dengan
menggunakan skala likert, dengan bobot nilai 5,4,3,2,1.
Berdasarkan skala pengukurannya data dibedakan menjadi 4 macam, yaitu:
1. Skala Nominal
Misalnya: jenis kelamin, agama dan sebagainya. Sering juga data nominal
diberi simbol bilangan saja. Misalnya: laki-laki diberi nilai 1 dan
perempuan diberi nilai 2.
Data yang diukur menggunakan ordinal selain mempunyai ciri nominal,
juga mempunyai ciri berbentuk peringkat atau jenjang. Misalnya tingkat
pendidikan nilai ujian (dalam huruf).
3. Skala Interval
Data yang diukur menggunakan skala interval selain mempunyai ciri
nominal dan ordinal, juga mempunyai ciri interval yang sama.
4. Skala Rasio
Skala rasio ini selain mempunyai ketiga ciri dan skala pengukuran diatas,
juga mempunyai nilai nol yang bersifat mutlak. Misalnya: umur, berat
sesuatu, pendapatan dan sebagainya
2.9TEKNIK SAMPLING
Teknik sampling adalah suatu cara untuk menentukan banyaknya sampel dan
pemilihan calon anggota sampel, sehingga setiap sampel yang terpilih dalam
penelitian dapat mewakili populasinya (representatif) baik dari aspek jumlah
maupun dari aspek karakteristik yang dimiliki populasi. Sampling adalah proses
pemilihan sejumlah elemen dari populasi sehingga dengan meneliti dan
memahami karakteristik sampel dapat digeneralisir untuk karakteristik populasi.
Jarang sekali suatu penelitian dilakukan dengan cara memeriksa semua objek
yang diteliti, tetapi sering digunakan sampling. Alasannya adalah:
1. Biaya, waktu dan tenaga untuk menyelidiki sensus.
2. Populasi yang berukuran besar selain sulit untuk dikumpulkan, dicatat dan
dianalisis juga biasanya akan menghasilkan informasi yang kurang teliti.
Dengan cara sampling jumlah objek yang harus diteliti menjadi lebih
kecil, sehingga lebih terpusat perhatiannya.
3. Percobaan-percobaan yang berbahaya atau bersifat merusak hanya cocok
dilakukan dengan sampling.
Keuntungan dengan menggunakan teknik sampling antara lain adalah
mengurangi ongkos, mempercepat waktu penelitian dan dapat memperbesar ruang
lingkup penelitian (Teken, 1965). Metode pengambilan sampel yang ideal
memiliki sifat-sifat sebagai berikut:
yang diteliti.
2. Dapat menentukan ketepatan hasil penelitian dengan menentukan
penyimpangan baku dari taksiran yang diperoleh.
3. Sederhana dan mudah diperoleh.
4. Dapat memberikan keterangan sebanyak mungkin dengan biaya serendah
mungkin.
Dalam menentukan besarnya sampel dalam suatu penelitian, ada empat
faktor yang harus dipertimbangkan yaitu :
1. Derajat keseragaman populasi.
2. Ketetapan yang dikehendaki dari penelitian.
3. Rencana analisis.
4. Tenaga, biaya dan waktu.
Teknik sampling dapat dikelompokkan jadi dua yaitu:
1. Probability sampling, meliputi :
a. Simple random sampling (populasi homogen) yaitu pengambilan
sampel dilakukan secara acak tanpa memperhatikan strata yang
ada. Teknik ini hanya dilakukan jika populasinya homogen.
b. Proportionale stratifiled random sampling (populasi tidak
homogen) yaitu pengambilan sampel dilakukan secara acak dengan
memperhatikan stara yang ada. Artinya setiap strata terwakili
sesuai proporsinya.
c. Disproportionate stratifiled random sampling yaitu teknik ini
digunakan untuk menentukan jumlah sampel dengan populasi
berstrata tetapi kurang proporsional, artinya ada beberapa
kelompok strata yang ukurannya kecil sekali.
d. Cluster sampling (sampling daerah) yaitu teknik ini digunakan
untuk menentukan jumlah sampel jika sumber data sangat luas.
Pengambilan sampel didasarkan di daerah populasi yang
2. Non Probability Sampling, meliputi: sampling sistematis, sampling kuota,
sampling accidental, purposive sampling, sampling jenuh dan snowball
sampling.
2.10UJI VALIDITAS DAN RELIABILITAS
1. Uji validitas
Validitas merupakan alat ukur untuk melihat atau mengetahui apak