ABSTRACT
WORO INDRIYANI. Pseudo-Relevance Feedback on Retrieval Using Sentence Segmentation. Supervised by JULIO ADISANTOSO.
A very large amount of information has stimulated the development of search engine to help users in finding information they need. To retrieve information that relevant to the user’s needs, users should be able to formulate queries correctly. Pseudo-relevance feedback is an automatically local analysis technique for improving queries. This technique takes the top n-ranked documents and takes the top x-n-ranked terms from relevant documents. The purpose of this research is to implement query expansion with pseudo-relevance feedback using sentence segmentation. There are two groups of documents, 1.000 agriculture documents and 93 medicine plants documents which are used. The test result shows that the use of medicine plants documents is better than agriculture documents. This is due to agriculture documents have a high enough similarity between documents. The performance of information retrieval with pseudo-relevance feedback using sentence segmentation gave good result with around 89% average precision for medicine plants documents and 56% for agriculture documents.
PENDAHULUAN
Latar Belakang
Sistem temu-kembali informasi merupakan suatu sistem yang dapat membantu seseorang dalam menemukan informasi yang dibutuhkan. Kebutuhan pengguna akan suatu informasi direpresentasikan dalam bentuk kueri yang selanjutnya akan digunakan sebagai acuan dalam proses temu-kembali. Dengan kueri tersebut, sistem akan melakukan proses penelusuran untuk menemukan dokumen yang relevan atau dokumen yang mempunyai topik yang berkaitan dengan kebutuhan informasi pengguna.
Tidak semua pengguna dapat memberikan kueri yang tepat pada saat mencari sebuah informasi yang dibutuhkan atau dapat terjadi kata yang digunakan dalam kueri tidak terdapat di dalam dokumen. Oleh karena itu, digunakanlah teknik untuk merekonstruksi kueri yaitu pseudo-relevance feedback. Kueri yang diberikan pengguna selanjutnya diperluas untuk memperoleh dokumen relevan dalam jumlah yang lebih banyak.
Pseudo-relevance feedback merupakan teknik analisis lokal secara otomatis (teknik relevance feedback tanpa input eksplisit pengguna). Teknik ini mengekstrak terms dari dokumen peringkat teratas (diasumsikan bahwa dokumen peringkat teratas dianggap relevan) untuk memformulasikan sebuah kueri baru pada temu-kembali selanjutnya.
Rusidi (2008) telah melakukan penelitian menggunakan peluang bersyarat dan mengaplikasikan ekspansi kueri dalam sistem temu kembali informasi. Ekspansi kueri yang dilakukan yaitu menggunakan analisis lokal dengan memilih istilah ekspansi berdasarkan keeratan hubungan suatu istilah dengan istilah lainnya.
Penelitian sebelumnya dilakukan oleh Anbiana (2009) dengan menggunakan segmentasi dokumen. Masalah pada penelitian tersebut yaitu ukuran segmen yang relatif besar. Segmen yang digunakan berupa paragraf yang terdiri atas beberapa kalimat yang mengandung banyak kata. Pemilihan term/kata untuk ekspansi kueri menggunakan rasio antara kata terhadap ukuran segmen.
Tujuan Penelitian
Tujuan utama dari penelitian ini adalah mengimplementasikan perluasan kueri dengan teknik pseudo-relevance feedback menggunakan segmentasi kalimat.
Ruang Lingkup Penelitian
Dokumen yang digunakan dalam penelitian adalah dokumen XML berbahasa Indonesia. Dokumen ini merupakan dokumen tentang pertanian yang tersedia di Laboratorium Temu-kembali Informasi yang berjumlah 1000 dokumen dan dokumen tanaman obat yang tersedia di Laboratorium Kecerdasan Komputasional berjumlah 93 dokumen, sedangkan iterasi yang dilakukan dalam proses reformulasi kueri pada penelitian ini yaitu sebanyak satu kali.
TINJAUAN PUSTAKA
Information Retrieval (Temu-Kembali Informasi)
Temu-kembali informasi berkaitan dengan merepresentasikan, menyimpan, mengorganisasikan, dan mengakses informasi. Merepresentasikan dan mengorganisasikan suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Akan tetapi, untuk mengetahui informasi yang diinginkan pengguna bukan merupakan suatu hal yang mudah. Untuk itu pengguna harus menransformasikan informasi yang dibutuhkan ke dalam suatu kueri yang akan diproses mesin pencari (IR system), sehingga kueri tersebut akan merepresentasikan informasi yang dibutuhkan oleh pengguna. Dengan kueri tersebut, IR system akan menemukembalikan informasi yang relevan dengan kueri (Baeza-Yates & Ribeiro-Neto 1999).
Relevance Feedback
PENDAHULUAN
Latar Belakang
Sistem temu-kembali informasi merupakan suatu sistem yang dapat membantu seseorang dalam menemukan informasi yang dibutuhkan. Kebutuhan pengguna akan suatu informasi direpresentasikan dalam bentuk kueri yang selanjutnya akan digunakan sebagai acuan dalam proses temu-kembali. Dengan kueri tersebut, sistem akan melakukan proses penelusuran untuk menemukan dokumen yang relevan atau dokumen yang mempunyai topik yang berkaitan dengan kebutuhan informasi pengguna.
Tidak semua pengguna dapat memberikan kueri yang tepat pada saat mencari sebuah informasi yang dibutuhkan atau dapat terjadi kata yang digunakan dalam kueri tidak terdapat di dalam dokumen. Oleh karena itu, digunakanlah teknik untuk merekonstruksi kueri yaitu pseudo-relevance feedback. Kueri yang diberikan pengguna selanjutnya diperluas untuk memperoleh dokumen relevan dalam jumlah yang lebih banyak.
Pseudo-relevance feedback merupakan teknik analisis lokal secara otomatis (teknik relevance feedback tanpa input eksplisit pengguna). Teknik ini mengekstrak terms dari dokumen peringkat teratas (diasumsikan bahwa dokumen peringkat teratas dianggap relevan) untuk memformulasikan sebuah kueri baru pada temu-kembali selanjutnya.
Rusidi (2008) telah melakukan penelitian menggunakan peluang bersyarat dan mengaplikasikan ekspansi kueri dalam sistem temu kembali informasi. Ekspansi kueri yang dilakukan yaitu menggunakan analisis lokal dengan memilih istilah ekspansi berdasarkan keeratan hubungan suatu istilah dengan istilah lainnya.
Penelitian sebelumnya dilakukan oleh Anbiana (2009) dengan menggunakan segmentasi dokumen. Masalah pada penelitian tersebut yaitu ukuran segmen yang relatif besar. Segmen yang digunakan berupa paragraf yang terdiri atas beberapa kalimat yang mengandung banyak kata. Pemilihan term/kata untuk ekspansi kueri menggunakan rasio antara kata terhadap ukuran segmen.
Tujuan Penelitian
Tujuan utama dari penelitian ini adalah mengimplementasikan perluasan kueri dengan teknik pseudo-relevance feedback menggunakan segmentasi kalimat.
Ruang Lingkup Penelitian
Dokumen yang digunakan dalam penelitian adalah dokumen XML berbahasa Indonesia. Dokumen ini merupakan dokumen tentang pertanian yang tersedia di Laboratorium Temu-kembali Informasi yang berjumlah 1000 dokumen dan dokumen tanaman obat yang tersedia di Laboratorium Kecerdasan Komputasional berjumlah 93 dokumen, sedangkan iterasi yang dilakukan dalam proses reformulasi kueri pada penelitian ini yaitu sebanyak satu kali.
TINJAUAN PUSTAKA
Information Retrieval (Temu-Kembali Informasi)
Temu-kembali informasi berkaitan dengan merepresentasikan, menyimpan, mengorganisasikan, dan mengakses informasi. Merepresentasikan dan mengorganisasikan suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Akan tetapi, untuk mengetahui informasi yang diinginkan pengguna bukan merupakan suatu hal yang mudah. Untuk itu pengguna harus menransformasikan informasi yang dibutuhkan ke dalam suatu kueri yang akan diproses mesin pencari (IR system), sehingga kueri tersebut akan merepresentasikan informasi yang dibutuhkan oleh pengguna. Dengan kueri tersebut, IR system akan menemukembalikan informasi yang relevan dengan kueri (Baeza-Yates & Ribeiro-Neto 1999).
Relevance Feedback
pengguna, expansion terms peringkat x teratas ditambah kueri pengguna digunakan sebagai formulasi kueri baru. Formulasi kueri baru ini diharapkan dapat menggeser dokumen relevan ke atas dan dokumen tidak relevan ke bawah.
Permasalahan teknik relevance feedback seperti yang dijelaskan Risjbergen (1997) adalah cara pengguna dalam menentukan dokumen yang relevan dan tidak relevan dalam hasil temu-kembali. Secara operasional, pengguna perlu menelusuri lebih lanjut isi dokumen hasil temu-kembali, agar diketahui relevansi suatu dokumen, kemudian dilakukan perumusan ulang kueri baru untuk temu-kembali selanjutnya.
Pseudo-Relevance Feedback
Menurut Yu, Cai, Wen dan Ma (2003), pseudo-relevance feedback (PRF), dikenal juga sebagai local feedback atau blind feedback, merupakan sebuah teknik yang biasanya digunakan untuk memperbaiki hasil temu-kembali. Ide dasarnya, yaitu mengekstrak expansion terms dari top-n documents yang dianggap sebagai dokumen relevan untuk merumuskan sebuah kueri baru yang akan digunakan dalam proses temu-kembali selanjutnya. Melalui ekspansi kueri, beberapa dokumen yang hilang pada proses inisialisasi temu-kembali ditemukembalikan dalam proses selanjutnya, sehingga kinerja temu-kembali dapat ditingkatkan secara menyeluruh. Teknik ini sangat bergantung pada kualitas expansion terms yang dipilih dan sangat dipengaruhi oleh dokumen-dokumen peringkat teratas.
Sistem yang mengambil top-n documents sebagai dokumen relevan lebih baik dari pada pengguna mengambil top-k relevant documents. Pada teknik pseudo-relevance feedback, pengguna dapat memperbaiki hasil temu-kembali (Baeza-Yates dan Ribeiro-Neto 1999 dalam Anbiana 2009).
Pembobotan BM25
Pembobotan BM25, disebut juga sebagai pembobotan Okapi, merupakan pembobotan yang digunakan sejak TREC ketiga. Pembobotan BM25 menggabungkan idf dengan koleksi pengskalaan khusus untuk dokumen dan kueri (Kontostathis 2008 dalam Herdi 2010). Bobot suatu kata t dalam dokumen i didefinisikan sebagai:
[ ]
dengan, ⁄ ,
merupakan frekuensi term t pada dokumen i, dan merupakan panjang dokumen Di dan rata-rata panjang dokumen
dalam koleksi, dan merupakan parameter-parameter pengskalaan terhadap tf dokumen dan panjang dokumen, umumnya menggunakan nilai = 1,2 dan = 0,75 (Jones 1999 dalam Herdi 2010).
Dengan demikian ukuran kemiripan dokumen i dengan kueri q adalah:
∑ [ ] Peluang Bersyarat
Dalam penelitian Le, Chenmin, dan Jamie (2008), digunakan metode temu-kembali yang sama dengan dua penelitian sebelumnya TREC 2006 dan TREC 2007, yaitu teknik pseudo-relevance feedback yang menggunakan peluang bersyarat (peluang bayes) untuk perluasan kueri.
Peluang bersyarat dapat digunakan untuk menghitung peluang kejadian apabila suatu kejadian diketahui. Berikut ini adalah rumusan dari formula peluang bersyarat:
| | ∑ | |
̅
dimana, | adalah peluang A terjadi jika B terjadi, | adalah peluang B terjadi jika A terjadi, adalah peluang kejadian A, dan adalah peluang kejadian B dan P(B) ≠ 0.
Evaluasi
Manning (2008) menyatakan, terdapat dua hal mendasar yang paling sering digunakan untuk mengukur kinerja temu-kembali secara efektif adalah recall dan precision (R-P). Perhitungan recall-precision diformulasikan sebagai berikut:
Relevant Not Relevant
Retrieved tp fp
Not
Retrieved fn tn
Recall = R = tp/(tp+fn)
Menurut Baeza-Yates dan Ribeiro-Neto (1999), algoritma temu-kembali yang dievaluasi menggunakan beberapa kueri berbeda akan menghasilkan nilai R-P yang berbeda untuk masing-masing kueri. Average Precision (AVP) diperlukan untuk menghitung rata-rata tingkat precision pada berbagai tingkat recall, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Perhitungan AVP dapat diformulasikan sebagai berikut:
̅( ) ∑
dimana, ̅( )adalah AVP pada level recall r, Nq adalah jumlah kueri yang digunakan, dan Pi(r) adalah precision pada level recall r untuk kueri ke-i.
METODE PENELITIAN
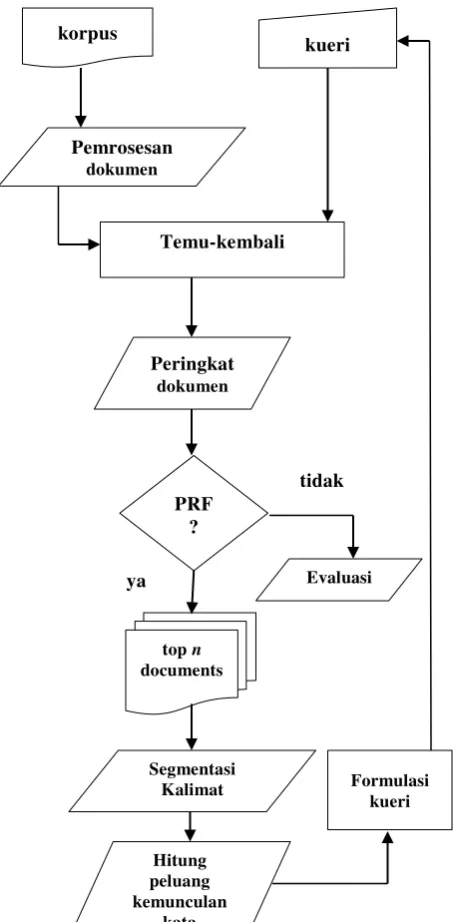
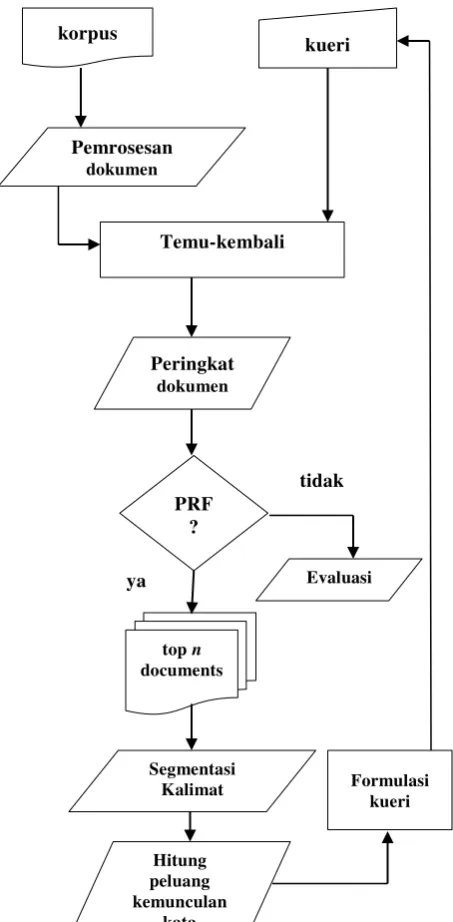
Penelitian ini dilaksanakan dalam beberapa tahap seperti yang diilustrasikan pada Gambar 1.
Pemrosesan Dokumen
Sebelum dilakukan proses temu-kembali, terlebih dahulu dilakukan pemrosesan dokumen yang meliputi stemming, eliminasi kata buangan dan pengindeksan menggunakan Sphinx search. Pada tahap ini koleksi dokumen yang berformat XML diindeks dengan file konfigurasi yang sesuai. Dalam penelitian ini digunakan dua koleksi dokumen yang memiliki struktur yang berbeda maka pengindeksan dilakukan terpisah. Pada koleksi dokumen (korpus) sebelumnya dilakukan tahap pembersihan data, yaitu memperbaiki penulisan kata dan tag.
Hasil pengindeksan inilah yang digunakan pada tahap selanjutnya, yaitu tahap temu-kembali.
Temu-kembali
Pada tahap ini diterapkan proses temu-kembali informasi yang diimplementasikan menggunakan platform Sphinx Search. Hasil dari temu-kembali klasik yaitu berupa dokumen-dokumen yang sesuai dengan kueri yang diberikan. Pada tahap ini diambil top n
dokumen untuk selanjutnya digunakan dalam tahap ekspansi kueri. Penelitian ini menggunakan satu, dua dan tiga dokumen teratas untuk ekspansi kueri.
Gambar 1 Metodologi Penelitian Segmentasi Kalimat
Pada tahap pemrosesan, dokumen dipilih menjadi unit-unit yang lebih kecil berupa kata, frasa atau kalimat. Unit terkecil hasil pemrosesan disebut token (Ridha, 2002). Pada penelitian ini dokumen dipisah menjadi unit-unit kecil yaitu kalimat yang terdiri atas
tidak ya korpus kueri Temu-kembali Peringkat dokumen PRF ?
top n
Recall = R = tp/(tp+fn)
Menurut Baeza-Yates dan Ribeiro-Neto (1999), algoritma temu-kembali yang dievaluasi menggunakan beberapa kueri berbeda akan menghasilkan nilai R-P yang berbeda untuk masing-masing kueri. Average Precision (AVP) diperlukan untuk menghitung rata-rata tingkat precision pada berbagai tingkat recall, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Perhitungan AVP dapat diformulasikan sebagai berikut:
̅( ) ∑
dimana, ̅( )adalah AVP pada level recall r, Nq adalah jumlah kueri yang digunakan, dan Pi(r) adalah precision pada level recall r untuk kueri ke-i.
METODE PENELITIAN
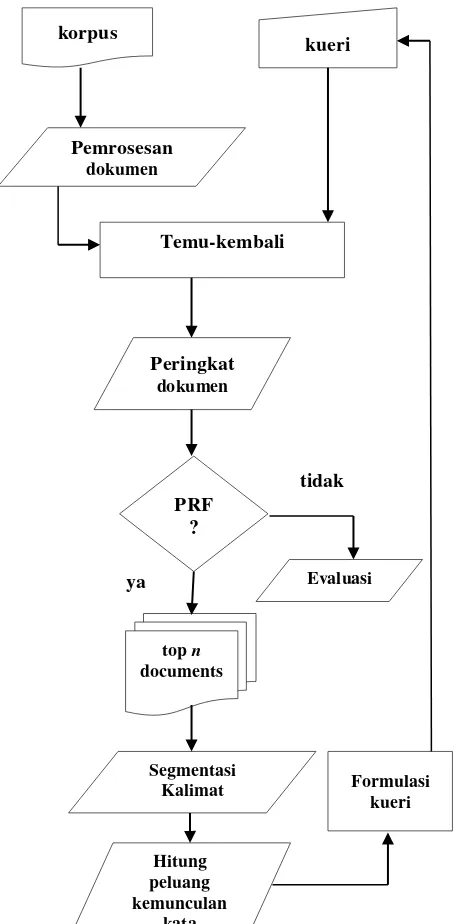
Penelitian ini dilaksanakan dalam beberapa tahap seperti yang diilustrasikan pada Gambar 1.
Pemrosesan Dokumen
Sebelum dilakukan proses temu-kembali, terlebih dahulu dilakukan pemrosesan dokumen yang meliputi stemming, eliminasi kata buangan dan pengindeksan menggunakan Sphinx search. Pada tahap ini koleksi dokumen yang berformat XML diindeks dengan file konfigurasi yang sesuai. Dalam penelitian ini digunakan dua koleksi dokumen yang memiliki struktur yang berbeda maka pengindeksan dilakukan terpisah. Pada koleksi dokumen (korpus) sebelumnya dilakukan tahap pembersihan data, yaitu memperbaiki penulisan kata dan tag.
Hasil pengindeksan inilah yang digunakan pada tahap selanjutnya, yaitu tahap temu-kembali.
Temu-kembali
Pada tahap ini diterapkan proses temu-kembali informasi yang diimplementasikan menggunakan platform Sphinx Search. Hasil dari temu-kembali klasik yaitu berupa dokumen-dokumen yang sesuai dengan kueri yang diberikan. Pada tahap ini diambil top n
dokumen untuk selanjutnya digunakan dalam tahap ekspansi kueri. Penelitian ini menggunakan satu, dua dan tiga dokumen teratas untuk ekspansi kueri.
Gambar 1 Metodologi Penelitian Segmentasi Kalimat
Pada tahap pemrosesan, dokumen dipilih menjadi unit-unit yang lebih kecil berupa kata, frasa atau kalimat. Unit terkecil hasil pemrosesan disebut token (Ridha, 2002). Pada penelitian ini dokumen dipisah menjadi unit-unit kecil yaitu kalimat yang terdiri atas
tidak ya korpus kueri Temu-kembali Peringkat dokumen PRF ?
top n
beberapa kata. Menurut Baeza-Yates dan Ribeiro-Neto (1999), tidak semua kata dapat digunakan untuk merepresentasikan sebuah dokumen secara signifikan
Pemrosesan teks yang dilakukan dalam penelitian ini dibagi dalam tiga tahap, yaitu: ● Lexical analysis of the text atau tokenisasi,
bertujuan untuk identifikasi kata dalam teks. Tokenisasi adalah proses yang mengubah sekumpulan karakter (teks dari dokumen) ke dalam sekumpulan kata (kandidat kata yang digunakan sebagai indeks istilah).
● Eliminasi kata buangan, hal tersebut bertujuan untuk meminimumkan kata yang digunakan sebagai istilah yang diindeks dalam proses temu-kembali. ● Pengindeksan teks dalam dokumen,
bertujuan untuk menghitung frekuensi kata yang berada dalam sebuah dokumen. Pembobotan dalam tahap ini menggunakan pembobotan bolean. Peluang Kemunculan Kata
Pada setiap kata dalam segmen kalimat yang sebelumnya telah diberi bobot, maka tahap selanjutnya yaitu dilakukan perhitungan peluang kemunculan kata menggunakan peluang bersyarat seperti berikut:
| | ∑ | |
̅
Perhitungan peluang bersyarat ini menggunakan vektor kata terhadap kalimat untuk melihat peluang kemunculan suatu kata ketika diberikan suatu kueri. Kata diurutkan berdasarkan nilai peluang yang diperoleh. Proses pengurutan dilakukan dari nilai peluang terbesar sampai nilai peluang terkecil.
Formulasi Kueri
Formulasi kueri baru bertujuan untuk memperbaiki hasil temu-kembali, yaitu dapat menggeser dokumen relevan ke atas dan dokumen yang tidak relevan ke bawah. Kata dengan peluang tertinggi yang merupakan term dari n dokumen teratas, digunakan untuk merumuskan kueri baru yang diformulasikan sebagai berikut:
dimana, adalah formulasi kueri baru, adalah formulasi kueri awal, dan adalah kueri dari perhitungan peluang kemunculan term pada kalimat. Kueri baru yang telah
diformulasikan digunakan dalam proses temu
kembali selanjutnya.
Evaluasi Hasil Temu-Kembali
Pada proses evaluasi hasil temu-kembali dilakukan penilaian kinerja sistem dengan melakukan pengukuran recall-precision untuk menentukan tingkat keefektifan proses temu-kembali. Recall adalah rasio dokumen relevan yang ditemukembalikan dan precision adalah dokumen relevan yang ditemukembalikan. Average precision (AVP) dihitung berdasarkan 11 standard recall levels, yaitu 0%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% dengan menggunakan interpolasi maksimum (Baeza-Yates & Ribeiro-Neto 1999).
Lingkungan Implementasi
Lingkungan implementasi yang digunakan adalah sebagai berikut :
Perangkat lunak :
Sistem operasi Windows 7 Ultimate sebagai sistem operasi.
PHP sebagai bahasa pemrograman. SPHINX Search sebagai platform untuk
pencarian berbasis teks.
Wamp Server Apache version 2.2.11 sebagai web server.
Notepad++, dan
Microsoft Office 2010 sebagai aplikasi yang digunakan untuk melakukan perhitungan dalam evaluasi sistem. Perangkat keras
Processor Intel Core 2 Duo 1,66GHz RAM 2 GB
Harddisk dengan kapasitas 120 GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen Pengujian
beberapa kata. Menurut Baeza-Yates dan Ribeiro-Neto (1999), tidak semua kata dapat digunakan untuk merepresentasikan sebuah dokumen secara signifikan
Pemrosesan teks yang dilakukan dalam penelitian ini dibagi dalam tiga tahap, yaitu: ● Lexical analysis of the text atau tokenisasi,
bertujuan untuk identifikasi kata dalam teks. Tokenisasi adalah proses yang mengubah sekumpulan karakter (teks dari dokumen) ke dalam sekumpulan kata (kandidat kata yang digunakan sebagai indeks istilah).
● Eliminasi kata buangan, hal tersebut bertujuan untuk meminimumkan kata yang digunakan sebagai istilah yang diindeks dalam proses temu-kembali. ● Pengindeksan teks dalam dokumen,
bertujuan untuk menghitung frekuensi kata yang berada dalam sebuah dokumen. Pembobotan dalam tahap ini menggunakan pembobotan bolean. Peluang Kemunculan Kata
Pada setiap kata dalam segmen kalimat yang sebelumnya telah diberi bobot, maka tahap selanjutnya yaitu dilakukan perhitungan peluang kemunculan kata menggunakan peluang bersyarat seperti berikut:
| | ∑ | |
̅
Perhitungan peluang bersyarat ini menggunakan vektor kata terhadap kalimat untuk melihat peluang kemunculan suatu kata ketika diberikan suatu kueri. Kata diurutkan berdasarkan nilai peluang yang diperoleh. Proses pengurutan dilakukan dari nilai peluang terbesar sampai nilai peluang terkecil.
Formulasi Kueri
Formulasi kueri baru bertujuan untuk memperbaiki hasil temu-kembali, yaitu dapat menggeser dokumen relevan ke atas dan dokumen yang tidak relevan ke bawah. Kata dengan peluang tertinggi yang merupakan term dari n dokumen teratas, digunakan untuk merumuskan kueri baru yang diformulasikan sebagai berikut:
dimana, adalah formulasi kueri baru, adalah formulasi kueri awal, dan adalah kueri dari perhitungan peluang kemunculan term pada kalimat. Kueri baru yang telah
diformulasikan digunakan dalam proses temu
kembali selanjutnya.
Evaluasi Hasil Temu-Kembali
Pada proses evaluasi hasil temu-kembali dilakukan penilaian kinerja sistem dengan melakukan pengukuran recall-precision untuk menentukan tingkat keefektifan proses temu-kembali. Recall adalah rasio dokumen relevan yang ditemukembalikan dan precision adalah dokumen relevan yang ditemukembalikan. Average precision (AVP) dihitung berdasarkan 11 standard recall levels, yaitu 0%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% dengan menggunakan interpolasi maksimum (Baeza-Yates & Ribeiro-Neto 1999).
Lingkungan Implementasi
Lingkungan implementasi yang digunakan adalah sebagai berikut :
Perangkat lunak :
Sistem operasi Windows 7 Ultimate sebagai sistem operasi.
PHP sebagai bahasa pemrograman. SPHINX Search sebagai platform untuk
pencarian berbasis teks.
Wamp Server Apache version 2.2.11 sebagai web server.
Notepad++, dan
Microsoft Office 2010 sebagai aplikasi yang digunakan untuk melakukan perhitungan dalam evaluasi sistem. Perangkat keras
Processor Intel Core 2 Duo 1,66GHz RAM 2 GB
Harddisk dengan kapasitas 120 GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen Pengujian
Tabel 1 Deskripsi dokumen pengujian Uraian Dokumen Pertanian Nilai (byte) Ukuran keseluruhan dokumen 4.139.332 Ukuran rata-rata dokumen 4139 Ukuran dokumen terbesar 54.082 Ukuran dokumen terkecil 451 Uraian Dokumen Tanaman
Obat
Nilai (byte)
Ukuran keseluruhan dokumen 297.796 Ukuran rata-rata dokumen 3202 Ukuran dokumen terbesar 13.628 Ukuran dokumen terkecil 928
Contoh salah satu dokumen pertanian yang digunakan dalam penelitian ini seperti yang tercantum pada Gambar 2, sedangkan contoh dokumen tanaman obat tercantum pada Gambar 3.
<DOC> <DOCNO>jurnal000000-001</DOCNO> <TITLE> PEMBANGUNAN PERTANIAN BERWAWASAN LINGKUNGAN YANG BERKELANJUTAN</TITLE> <AUTHOR>Triharso, Universitas Gadjah Mada </AUTHOR>
<TEXT>
……
<P>Konsep Dasar Pengendalian Hama dan Penyakit Hutan</P>
……
</TEXT> </DOC>
Gambar 2 Contoh dokumen pertanian <DOCNO>017</DOCNO>
<nama>Sosor Bebek</nama> <namal>Kalanchoe pinnata Lamk.</namal>
<content>Famili :
Crassulaceae. Nama Lokal : Cakar itek
……
</content>
<fam>Crassulaceae</fam> <penyakit>Kulit</penyakit>
Gambar 3 Contoh dokumen tanaman obat
Dokumen dikelompokkan ke dalam tag-tag sebagai berikut:
<DOC></DOC>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag lain yang lebih spesifik.
<DOCNO></DOCNO>, tag ini menunjukkan ID dari dokumen.
<DATE></DATE>, menunjukkan tanggal dari berita.
<AUTHOR></AUTHOR>, menunjukkan penulis dari berita tersebut.
<TEXT></TEXT>, tag ini menunjukkan isi dari dokumen.
<nama></nama>, tag ini menunjukkan nama dari tanaman obat.
<namal></namal>, tag ini menunjukkan nama latin dari tanaman obat.
<content></content>, tag ini mewakili isi dari dokumen meliputi deskripsi tanaman dan kegunaannya. <fam></fam>, tag ini menunjukkan
nama family dari tanaman obat.
<penyakit></penyakit>, tag ini menunjukkan penyakit yang berkaitan dengan tanaman obat.
Pemrosesan Dokumen
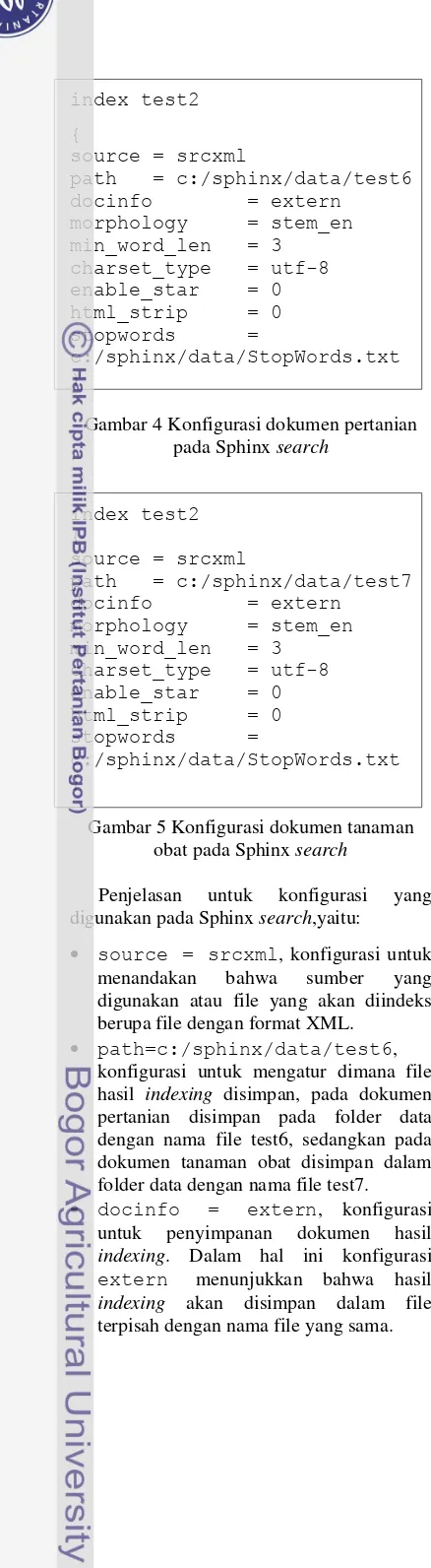
Sebelum dilakukan tahap temu-kembali terlebih dahulu dilakukan tahap pemrosesan dokumen dengan Sphinx Search. Karena pada penelitian ini digunakan dua koleksi dokumen yang berbeda, maka terdapat dua file konfigurasi yang berbeda pula. Cuplikan konfigurasi untuk dokumen pertanian tercantum pada Gambar 4, sedangkan cuplikan konfigurasi untuk dokumen tanaman obat tercantum pada Gambar 5.
index test2
{
source = srcxml
path = c:/sphinx/data/test6 docinfo = extern
morphology = stem_en min_word_len = 3
charset_type = utf-8 enable_star = 0 html_strip = 0 stopwords =
c:/sphinx/data/StopWords.txt }
Gambar 4 Konfigurasi dokumen pertanian pada Sphinx search
index test2 {
source = srcxml
path = c:/sphinx/data/test7 docinfo = extern
morphology = stem_en min_word_len = 3
charset_type = utf-8 enable_star = 0 html_strip = 0 stopwords =
c:/sphinx/data/StopWords.txt }
Gambar 5 Konfigurasi dokumen tanaman obat pada Sphinx search
Penjelasan untuk konfigurasi yang digunakan pada Sphinx search,yaitu:
source = srcxml, konfigurasi untuk menandakan bahwa sumber yang digunakan atau file yang akan diindeks berupa file dengan format XML.
path=c:/sphinx/data/test6, konfigurasi untuk mengatur dimana file hasil indexing disimpan, pada dokumen pertanian disimpan pada folder data dengan nama file test6, sedangkan pada dokumen tanaman obat disimpan dalam folder data dengan nama file test7. docinfo = extern, konfigurasi
untuk penyimpanan dokumen hasil indexing. Dalam hal ini konfigurasi extern menunjukkan bahwa hasil indexing akan disimpan dalam file terpisah dengan nama file yang sama.
morphology = stem_en,
konfigurasi untuk stemmer, stem_en menunjukkan bahwa stemmer yang digunakan yaitu english stemmer. min_word_len = 3, konfigurasi ini
menjelaskan panjang minimal kata yang diindeks yaitu minimal 3 karakter.
charset_type = utf-8,
konfigurasi ini menunjukkan tipe karakter yang digunakan yaitu utf-8.
enable_star = 0, konfigurasi untuk pengindeksan prefiks. Digunakan nilai 0 yang menunjukkan bahwa tidak dilakukan pengindeksan untuk prefiks.
html_strip = 0, konfigurasi untuk menghilangkan tag. Digunakan nilai 0 yang berarti tidak menghilangkan tag. Stopwords=c:/sphinx/data/Sto
pWords.txt, konfigurasi untuk eliminasi kata buangan.
Temu-Kembali
Pada tahap temu-kembali klasik kueri dimasukkan oleh pengguna. Pembobotan yang digunakan yaitu pembobotan BM25, sedangkan perangkingan yang digunakan yaitu SPH_RANK_PROXIMITY_BM25 pada Sphinx search. Pembobotan BM25 mirip seperti pembobotan tf.idf, tapi dalam pembobotan BM25 diperhatikan juga panjang dokumen sehingga hasil temu-kembali semakin bagus. Urutan dokumen yang ditampilkan sesuai dengan kemiripan antara suatu dokumen dan kueri yang diberikan
menggunakan mode
SPH_SORT_RELEVANCE pada Sphinx search.
Pada tahap ini diperoleh n dokumen teratas dari hasil pencarian dan diambil konten/isi dari dokumen format XML yang merupakan dokumen dengan kemiripan tertinggi dengan kueri. Informasi lain dalam dokumen tersebut seperti judul, nama pengarang, id dokumen dan lain lain tidak disertakan.
Segmentasi Kalimat
berisi informasi kalimat, kata dan frekuensi untuk setiap kata.
Pengujian Kinerja Sistem
Proses evaluasi dalam penelitian ini dilakukan pada dua koleksi yang berbeda. a. Pengujian pada Dokumen Pertanian
Proses evaluasi pada dokumen pertanian menggunakan 30 kueri uji yang telah ada sebelumnya berikut dokumen-dokumen yang relevan (Lampiran 2). Pencarian dengan kueri uji ini dilakukan dengan tujuan mendapatkan nilai recall dan precision dari sistem. 1. Dokumen Relevan
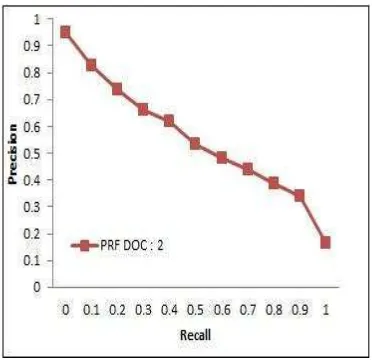
Dalam pseudo-relevance feedback, n dokumen teratas dianggap sebagai dokumen relevan. Untuk mengetahui pengaruh pengambilan dokumen peringkat n teratas, dilakukan evaluasi PRF dengan mengambil dokumen peringkat 1, 2, dan 3 teratas. Gambar 6 mengilustrasikan pengambilan satu dokumen teratas (Lampiran 4). Pada kondisi pengambilan satu dokumen teratas menghasilkan nilai recall rata-rata sebesar 0,9370 sedangkan nilai average precision (AVP) yang dihasilkan sebesar 0.5599. Hal ini menunjukkan bahwa kondisi pencarian dengan satu dokumen teratas dapat menemukembalikan 94% dari total dokumen dengan tingkat relevansi sebesar 56%.
Gambar 6 Grafik R-P untuk pengambilan satu dokumen teratas pada dokumen
pertanian
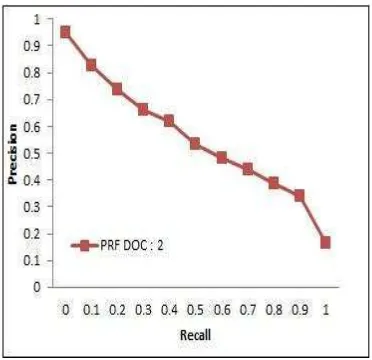
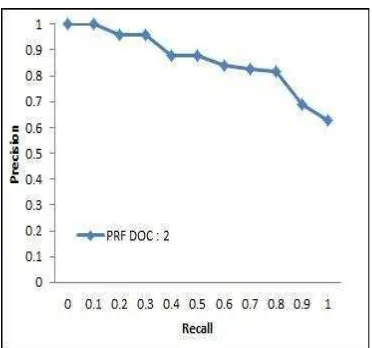
Kinerja sistem pada pengambilan dua dokumen teratas diilustrasikan pada Gambar 7 (Lampiran 5).
Gambar 7 Grafik R-P untuk pengambilan dua dokumen teratas pada dokumen pertanian
Pada kondisi pencarian ini didapatkan nilai recall rata-rata sebesar 0.9413 yang menunjukkan bahwa pencarian ini dapat menemukembalikan 94% dari total dokumen dengan tingkat relevansi sebesar 56%. Nilai AVP yang didapat relatif sama, yaitu sebesar 0,5582.
Gambar 8 menunjukkan kinerja pencarian dengan pengambilan tiga dokumen teratas (Lampiran 6).
Gambar 8 Grafik R-P untuk pengambilan tiga dokumen teratas pada dokumen pertanian
Pada kondisi pencarian dengan pengambilan tiga dokumen teratas didapatkan nilai recall rata-rata yang sama dengan kondisi pencarian sebelumnya yaitu sebesar 0.9413 dan juga tidak banyak mengubah nilai AVP, yaitu 0,5574 atau sebesar 56%.
pengambilan dokumen satu teratas. Hal ini karena semakin banyak dokumen yang diambil maka semakin banyak pula peluang terambil dokumen yang tidak relevan. Terambilnya dokumen yang tidak relevan menyebabkan perluasan kueri yang tidak relevan juga.
Pada setiap pencarian satu dokumen teratas yang didapatkan, dapat dipastikan bahwa dokumen tersebut merupakan dokumen yang relevan dengan kueri, sedangkan untuk dua dan tiga dokumen teratas yang didapatkan relatif tidak relevan sehingga pada kondisi pencarian dengan satu dokumen teratas mendapatkan hasil yang paling baik.
2. Panjang Kueri
Panjang kueri diduga akan mempengaruhi kinerja perluasan kueri. Dalam penelitian ini digunakan tiga kelompok kueri, yaitu kueri dengan panjang 2, 3, dan 4 kata. Kueri uji yang berjumlah 30 dipisahkan menjadi tiga kelompok sesuai dengan panjang kata. Kelompok pertama untuk kueri dengan panjang dua kata sebanyak 16 kueri, kelompok kedua untuk kueri dengan panjang tiga kata sebanyak 9 kueri, dan kelompok ketiga untuk kueri dengan panjang empat kata sebanyak 5 kueri. Ketiga kelompok kueri tersebut selanjutnya diekspansi atau diperluas dengan menambahkan satu kata ekspansi dan dua kata ekspansi.
Tabel 2 mengilustrasikan perbandingan nilai AVP untuk setiap kelompok kueri yang diperluas dengan satu kata (Lampiran 7) dan dua kata (Lampiran 8). Ekspansi kueri untuk setiap kelompok kueri diambil dari satu dokumen teratas.
Tabel 2 Perbandingan nilai AVP untuk setiap panjang kueri Panjang Kueri Ekspansi Satu Kata Ekspansi Dua Kata
2 Kata 0,6313 0,5857
3 Kata 0,5144 0,5027
4 Kata 0,3191 0,2943
Pada Tabel 2 dapat dilihat untuk hasil ekspansi kueri, nilai AVP tertinggi pada saat kueri dengan panjang dua kata dan ditambah satu istilah ekspansi. Kueri dengan panjang tiga dan empat kata memiliki nilai AVP yang
lebih kecil dibanding kueri dengan panjang dua kata. Hal tersebut dikarenakan penggunaan operator OR pada formulasi kueri baru menyebabkan semakin panjang kueri yang digunakan, maka dokumen hasil temu-kembali akan semakin banyak. Dokumen yang terambil ini banyak yang tidak relevan dengan kueri dan menempati peringkat yang lebih tinggi dari dokumen yang relevan, sehingga kinerja sistem semakin buruk. Hasil uji menunjukkan bahwa kinerja perluasan kueri untuk panjang kueri asli dua kata cukup baik, yaitu sebesar 0,6313.
3. Kinerja PRF
Tabel 3 mengilustrasikan perbandingan kinerja sistem, yaitu sistem dengan PRF segmentasi dokumen dan sistem dengan PRF segmentasi kalimat. Kueri yang digunakan pada pengujian ini berjumlah 30 kueri. Tabel 3 Perbandingan nilai average precision
Perlakukan Sistem AVP
PRF Segmentasi Dokumen 0.5214 PRF Segmentasi Kalimat 0.5599
Pada Tabel 3 dapat dilihat pencarian dengan PRF menggunakan segmentasi dokumen didapatkan nilai AVP sebesar 0,5214 dan pencarian dengan PRF menggunakan segmentasi kalimat menghasilkan nilai AVP sebesar 0,5599.
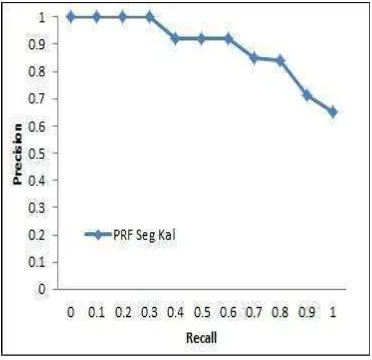
Gambar 9 menunjukkan perbandingan kinerja sistem PRF segmentasi dokumen dan sistem dengan PRF segmentasi kalimat. Hasil uji menunjukkan kinerja sistem dengan PRF segmentasi kalimat lebih bagus dibanding sistem dengan PRF segmentasi dokumen. Hal tersebut disebabkan pemilihan segmen pada sistem PRF dengan segmentasi dokumen terlalu luas yaitu untuk setiap paragraf, sedangkan sistem PRF dengan segmentasi kalimat mengambil segmen yang lebih kecil yaitu berdasarkan segmen kalimat.
Tahap awal dilakukan pengujian kinerja PRF pada pengambilan 1, 2, dan 3 dokumen teratas. Seperti halnya dengan pengujian dokumen pertanian, pada pengujian dokumen tanaman obat dilakukan pengujian untuk melihat pengaruh pengambilan satu dokumen teratas. Gambar 10 mengilustrasikan perbandingan kinerja PRF pada pengambilan satu dokumen teratas (Lampiran 9).
Gambar 10 Grafik R-P untuk pengambilan satu dokumen teratas pada dokumen tanaman
obat
Pada pengambilan satu dokumen teratas didapatkan nilai recall rata-rata sebesar 0,9895 dan nilai AVP yang lebih tinggi yaitu sebesar 0,8921.
Pengujian selanjutnya yaitu pengambilan dua dokumen teratas pada dokumen tanaman obat. Gambar 11 menunjukkan kinerja
sistem PRF pengambilan dua dokumen teratas (Lampiran 10).
Gambar 11 Grafik R-P untuk pengambilan dua dokumen teratas pada dokumen tanaman
obat
Pengambilan dua dokumen teratas untuk dokumen tanaman obat menghasilkan nilai recall rata-rata sebesar 0,9895 dengan nilai AVP yang lebih rendah dari kondisi pencarian sebelumnya yaitu sebesar 0,8618. Kondisi ini bisa menemukembalikan dokumen sebesar 99% dari total seluruh dokumen.
dokumen teratas menghasilkan nilai recall rata-rata sebesar 0,9895. Namun demikian pengambilan dokumen tiga teratas terjadi penurunan nilai AVP sebesar 0,8545 atau lebih rendah 0,0377 dari pengambilan satu dokumen teratas.
Gambar 12 Grafik R-P untuk pengambilan tiga dokumen teratas pada dokumen tanaman
obat
Dari ketiga kondisi pengujian untuk pengambilan n dokumen teratas pada dokumen tanaman obat didapatkan hasil nilai AVP tertinggi yaitu pada pengambilan satu dokumen teratas. Hal ini disebabkan pada setiap pencarian yang dilakukan rata-rata dokumen pertama yang ditemukembalikan merupakan dokumen yang relevan, sehingga ekspansi yang didapatkan juga relevan. Pada pengambilan dua dan tiga dokumen teratas, dokumen yang didapatkan tidak semuanya merupakan dokumen yang relevan. Semakin banyak dokumen yang terambil, maka semakin banyak peluang terambilnya dokumen yang tidak relevan. Terambilnya dokumen yang tidak relevan ini menyebabkan perluasan kueri yang tidak relevan juga.
Gambar 13 mengilustrasikan kinerja sistem dengan PRF segmentasi kalimat pada dokumen tanaman obat. Hasil uji menunjukkan bahwa kinerja sistem PRF dengan segmentasi kalimat yang didapat cukup baik yaitu 0,8921. Nilai rata-rata recall yang didapat juga lebih tinggi dari sistem tanpa PRF yaitu sebesar 0.9895.
Pengujian pada dokumen tanaman obat mendapatkan hasil yang lebih baik dari pengujian dokumen pertanian. Hal ini karena dokumen pertanian memiliki kemiripan yang tinggi antara satu dokumen dengan dokumen lainnya. Ketika sistem melakukan perluasan
kueri maka yang terambil adalah kata-kata pada bidang pertanian yang tidak bisa digunakan sebagai penciri sebuah dokumen. Dokumen yang terambil banyak yang tidak relevan dan menempati peringkat yang lebih tinggi dari pada dokumen yang relevan. Meskipun demikian sistem dapat menemukembalikan dokumen sampai 94%.
Hasil pengujian pada dokumen tanaman obat memberikan hasil yang lebih baik karena dokumen tanaman obat lebih beragam isinya. Setiap dokumen memiliki penciri yang berbeda dari dokumen lainnya yang membuat hasil temu-kembali semakin baik. Ketika dilakukan ekspansi kueri, maka sistem bisa menemukembalikan dokumen relevan dalam jumlah yang lebih besar.
Gambar 13 Grafik R-P untuk sistem dengan PRF pada dokumen tanaman obat
KESIMPULAN DAN SARAN
Kesimpulan
Hasil penelitian ini menunjukkan bahwa: 1. Ekspansi kueri akan optimal pada
dokumen yang kurang homogen.
2. Ekspansi kueri menemukembalikan dokumen relevan dalam jumlah yang lebih banyak.
3. Kinerja perluasan kueri optimal pada kondisi pengambilan satu dokumen teratas.
4. Kinerja sistem dengan PRF segmentasi kalimat lebih baik dari pada sistem dengan PRF segmentasi dokumen. 5. Kinerja sistem yang didapat sudah cukup
dokumen teratas menghasilkan nilai recall rata-rata sebesar 0,9895. Namun demikian pengambilan dokumen tiga teratas terjadi penurunan nilai AVP sebesar 0,8545 atau lebih rendah 0,0377 dari pengambilan satu dokumen teratas.
Gambar 12 Grafik R-P untuk pengambilan tiga dokumen teratas pada dokumen tanaman
obat
Dari ketiga kondisi pengujian untuk pengambilan n dokumen teratas pada dokumen tanaman obat didapatkan hasil nilai AVP tertinggi yaitu pada pengambilan satu dokumen teratas. Hal ini disebabkan pada setiap pencarian yang dilakukan rata-rata dokumen pertama yang ditemukembalikan merupakan dokumen yang relevan, sehingga ekspansi yang didapatkan juga relevan. Pada pengambilan dua dan tiga dokumen teratas, dokumen yang didapatkan tidak semuanya merupakan dokumen yang relevan. Semakin banyak dokumen yang terambil, maka semakin banyak peluang terambilnya dokumen yang tidak relevan. Terambilnya dokumen yang tidak relevan ini menyebabkan perluasan kueri yang tidak relevan juga.
Gambar 13 mengilustrasikan kinerja sistem dengan PRF segmentasi kalimat pada dokumen tanaman obat. Hasil uji menunjukkan bahwa kinerja sistem PRF dengan segmentasi kalimat yang didapat cukup baik yaitu 0,8921. Nilai rata-rata recall yang didapat juga lebih tinggi dari sistem tanpa PRF yaitu sebesar 0.9895.
Pengujian pada dokumen tanaman obat mendapatkan hasil yang lebih baik dari pengujian dokumen pertanian. Hal ini karena dokumen pertanian memiliki kemiripan yang tinggi antara satu dokumen dengan dokumen lainnya. Ketika sistem melakukan perluasan
kueri maka yang terambil adalah kata-kata pada bidang pertanian yang tidak bisa digunakan sebagai penciri sebuah dokumen. Dokumen yang terambil banyak yang tidak relevan dan menempati peringkat yang lebih tinggi dari pada dokumen yang relevan. Meskipun demikian sistem dapat menemukembalikan dokumen sampai 94%.
Hasil pengujian pada dokumen tanaman obat memberikan hasil yang lebih baik karena dokumen tanaman obat lebih beragam isinya. Setiap dokumen memiliki penciri yang berbeda dari dokumen lainnya yang membuat hasil temu-kembali semakin baik. Ketika dilakukan ekspansi kueri, maka sistem bisa menemukembalikan dokumen relevan dalam jumlah yang lebih besar.
Gambar 13 Grafik R-P untuk sistem dengan PRF pada dokumen tanaman obat
KESIMPULAN DAN SARAN
Kesimpulan
Hasil penelitian ini menunjukkan bahwa: 1. Ekspansi kueri akan optimal pada
dokumen yang kurang homogen.
2. Ekspansi kueri menemukembalikan dokumen relevan dalam jumlah yang lebih banyak.
3. Kinerja perluasan kueri optimal pada kondisi pengambilan satu dokumen teratas.
4. Kinerja sistem dengan PRF segmentasi kalimat lebih baik dari pada sistem dengan PRF segmentasi dokumen. 5. Kinerja sistem yang didapat sudah cukup
Saran
Hasil temu-kembali awal diperbaiki terlebih dahulu dengan cara menghilangkan kesalahan penulisan pada koleksi dokumen. Penggunakan koleksi dokumen yang lebih banyak dan topiknya bervariasi akan memberikan perbedaan pada saat pengambilan istilah ekspansi, sehingga sistem dapat diperbaiki kinerjanya.
DAFTAR PUSTAKA
Anbiana ED. 2009. Pseudo-relevance Feedback pada Temu-Kembali Menggunakan Segmentasi Dokumen [skripsi]. Bogor : Departemen Ilmu Komputer, Institut Pertanian Bogor. Baeza-Yates R, Ribeiro-Neto B. 1999.
Modern Information Retrieval. England: Addison Wesley.
Herdi, Hendrex. 2010. Pembobotan dalam Proses Pengindeksan Dokumen Bahasa Indonesia menggunakan Framework Indri [skripsi]. Bogor : Departemen Ilmu Komputer, Institut Pertanian Bogor. Jones K S. 1999. A Probabilistic Model of
Information Retrieval: Development Experiments Part 2. Cambrige: Cambrige University.
Kontosthatis, April. 2008. Distributed EDLSI, BM25, and Power Norm at TREC 2008. USA, Department of Mathematic and Computer Science, Ursinus College.
Le Z, Chenmin L, Jamie C. 2008. Extending Relevance Model for Relevance Feedback.
Manning C D, Raghavan P, Schutze H. 2008. Introduction to Information Retrieval. Cambridge: Cambridge University Press. Ridha A. 2002. Pengindeksan Otomatis
dengan Istilah Tunggal untuk Dokumen Berbahasa Indonesia. [Skripsi]. Bogor : Departemen Ilmu Komputer, Institut Pertanian Bogor.
Rusidi. 2008. Ekspansi Kueri dalam Sistem Temu Kembali Informasi Berbahasa Indonesia Menggunakan Peluang Bersyarat. [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
PSEUDO-RELEVANCE FEEDBACK
PADA TEMU-KEMBALI
MENGGUNAKAN SEGMENTASI KALIMAT
WORO INDRIYANI
G64070018
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Saran
Hasil temu-kembali awal diperbaiki terlebih dahulu dengan cara menghilangkan kesalahan penulisan pada koleksi dokumen. Penggunakan koleksi dokumen yang lebih banyak dan topiknya bervariasi akan memberikan perbedaan pada saat pengambilan istilah ekspansi, sehingga sistem dapat diperbaiki kinerjanya.
DAFTAR PUSTAKA
Anbiana ED. 2009. Pseudo-relevance Feedback pada Temu-Kembali Menggunakan Segmentasi Dokumen [skripsi]. Bogor : Departemen Ilmu Komputer, Institut Pertanian Bogor. Baeza-Yates R, Ribeiro-Neto B. 1999.
Modern Information Retrieval. England: Addison Wesley.
Herdi, Hendrex. 2010. Pembobotan dalam Proses Pengindeksan Dokumen Bahasa Indonesia menggunakan Framework Indri [skripsi]. Bogor : Departemen Ilmu Komputer, Institut Pertanian Bogor. Jones K S. 1999. A Probabilistic Model of
Information Retrieval: Development Experiments Part 2. Cambrige: Cambrige University.
Kontosthatis, April. 2008. Distributed EDLSI, BM25, and Power Norm at TREC 2008. USA, Department of Mathematic and Computer Science, Ursinus College.
Le Z, Chenmin L, Jamie C. 2008. Extending Relevance Model for Relevance Feedback.
Manning C D, Raghavan P, Schutze H. 2008. Introduction to Information Retrieval. Cambridge: Cambridge University Press. Ridha A. 2002. Pengindeksan Otomatis
dengan Istilah Tunggal untuk Dokumen Berbahasa Indonesia. [Skripsi]. Bogor : Departemen Ilmu Komputer, Institut Pertanian Bogor.
Rusidi. 2008. Ekspansi Kueri dalam Sistem Temu Kembali Informasi Berbahasa Indonesia Menggunakan Peluang Bersyarat. [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
PSEUDO-RELEVANCE FEEDBACK
PADA TEMU-KEMBALI
MENGGUNAKAN SEGMENTASI KALIMAT
WORO INDRIYANI
G64070018
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
WORO INDRIYANI. Pseudo-Relevance Feedback on Retrieval Using Sentence Segmentation. Supervised by JULIO ADISANTOSO.
A very large amount of information has stimulated the development of search engine to help users in finding information they need. To retrieve information that relevant to the user’s needs, users should be able to formulate queries correctly. Pseudo-relevance feedback is an automatically local analysis technique for improving queries. This technique takes the top n-ranked documents and takes the top x-n-ranked terms from relevant documents. The purpose of this research is to implement query expansion with pseudo-relevance feedback using sentence segmentation. There are two groups of documents, 1.000 agriculture documents and 93 medicine plants documents which are used. The test result shows that the use of medicine plants documents is better than agriculture documents. This is due to agriculture documents have a high enough similarity between documents. The performance of information retrieval with pseudo-relevance feedback using sentence segmentation gave good result with around 89% average precision for medicine plants documents and 56% for agriculture documents.
PSEUDO-RELEVANCE FEEDBACK
PADA TEMU-KEMBALI
MENGGUNAKAN SEGMENTASI KALIMAT
WORO INDRIYANI
Skripsi
Sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
Judul : Pseudo-Relevance Feedback pada Temu-Kembali Menggunakan Segmentasi Kalimat Nama : Woro Indriyani
NRP : G64070018
Menyetujui: Pembimbing
Ir. Julio Adisantoso, M.Kom NIP 19620714 198601 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP 19601126 198601 2 001
PRAKATA
Alhamdulilahirobbil’alamin, segala puji syukur penulis panjatkan kehadirat Allah SWT atas segala karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul Pseudo-relevance Feedback pada Temu-Kembali Menggunakan Segmentasi Kalimat.
Penulis menyadari bahwa tugas akhir ini tidak akan terselesaikan tanpan bentuan dari berbagai pihak. Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada:
1. Orang tua tercinta, bapak Munadi dan ibu Retno Wijayanti, kedua adik yang saya sayangi Jendro Adi Prabowo dan Sofiana Haryani, yang selalu memberikan doa, nasihat, semangat, dukungan dan kasih sayang yang luar biasa kepada penulis sehingga dapat menyelesaikan tugas akhir ini.
2. Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing tugas akhir. Terima kasih atas kesabaran, bimbingan serta dukungan dalam penyelesaian tugas akhir ini.
3. Ibu Dr. Yeni Herdiyeni, S.Si, M.Kom dan Bapak Sony Hartono Wijaya, S.Kom, M.Kom selaku dosen penguji pada ujian skripsi.
4. Teman-teman satu bimbingan Aprilia Ramadhina, Devi Dian P, Fandi Rahmawan, Agus Umriadi, Isna Mariam, Nova Maulizar, Nutri Rahayuni dan Ilkomerz 44 terima kasih atas kebersamaan dan semangatnya dalam menyelesaikan tugas akhir ini.
5. Sahabat-sahabat dan senior, Arisa Widiastuti, Risa Pragari, Annisa Khairani Aras, Furgon Avero, Dika Agus Satria dan Elenur Dwi Anbiana, terima kasih untuk dukungan dan bantuannya selama penyelesaikan tugas akhir ini.
6. Muhammad Abi Rafdi yang senantiasa memberikan semangat dan doa kepada penulis.
7. Seluruh staf Departemen Ilmu Komputer IPB yang telah banyak membantu baik selama penelitian maupun selama perkuliahan.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis berharap adanya masukan berupa saran atau kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini. Semoga tugas akhir ini bermanfaat.
Bogor, Juli 2011
RIWAYAT HIDUP
Woro Indriyani dilahirkan di Rembang, Jawa Tengah, pada tanggal 23 Oktober 1989 dan merupakan anak pertama dari pasangan bapak Munadi dan ibu Retno Wijayanti. Pada tahun 2007 penulis lulus dari Sekolah Menengah Atas (SMA) 2 Rembang.
DAFTAR ISI
Halaman
DAFTAR GAMBAR
Halaman
1 Metodologi Penelitian ... 3 2 Contoh dokumen pertanian ... 5 3 Contoh dokumen tanaman obat ... 5 4 Konfigurasi dokumen pertanian pada Sphinx search ... 6 5 Konfigurasi dokumen tanaman obat pada Sphinx search ... 6 6 Grafik R-P untuk pengambilan satu dokumen teratas pada dokumen pertanian ... 7 7 Grafik R-P untuk pengambilan dua dokumen teratas pada dokumen pertanian... 7 8 Grafik R-P untuk pengambilan tiga dokumen teratas pada dokumen pertanian ... 7 9 Grafik R-P untuk sistem PRF segmentasi dokumen dan PRF segmentasi kalimat ... 9 10 Grafik R-P untuk pengambilan satu dokumen teratas pada dokumen tanaman obat ... 9 11 Grafik R-P untuk pengambilan dua dokumen teratas pada dokumen tanaman obat ... 9 12 Grafik R-P untuk pengambilan tiga dokumen teratas pada dokumen tanaman obat ... 10 13 Grafik R-P untuk sistem dengan PRF pada dokumen tanaman obat ... 10
DAFTAR TABEL
Halaman
1 Deskripsi dokumen pengujian ... 5 2 Perbandingan nilai AVP untuk setiap panjang kueri ... 8 3 Perbandingan nilai average precision ... 8
DAFTAR LAMPIRAN
Halaman
PENDAHULUAN
Latar Belakang
Sistem temu-kembali informasi merupakan suatu sistem yang dapat membantu seseorang dalam menemukan informasi yang dibutuhkan. Kebutuhan pengguna akan suatu informasi direpresentasikan dalam bentuk kueri yang selanjutnya akan digunakan sebagai acuan dalam proses temu-kembali. Dengan kueri tersebut, sistem akan melakukan proses penelusuran untuk menemukan dokumen yang relevan atau dokumen yang mempunyai topik yang berkaitan dengan kebutuhan informasi pengguna.
Tidak semua pengguna dapat memberikan kueri yang tepat pada saat mencari sebuah informasi yang dibutuhkan atau dapat terjadi kata yang digunakan dalam kueri tidak terdapat di dalam dokumen. Oleh karena itu, digunakanlah teknik untuk merekonstruksi kueri yaitu pseudo-relevance feedback. Kueri yang diberikan pengguna selanjutnya diperluas untuk memperoleh dokumen relevan dalam jumlah yang lebih banyak.
Pseudo-relevance feedback merupakan teknik analisis lokal secara otomatis (teknik relevance feedback tanpa input eksplisit pengguna). Teknik ini mengekstrak terms dari dokumen peringkat teratas (diasumsikan bahwa dokumen peringkat teratas dianggap relevan) untuk memformulasikan sebuah kueri baru pada temu-kembali selanjutnya.
Rusidi (2008) telah melakukan penelitian menggunakan peluang bersyarat dan mengaplikasikan ekspansi kueri dalam sistem temu kembali informasi. Ekspansi kueri yang dilakukan yaitu menggunakan analisis lokal dengan memilih istilah ekspansi berdasarkan keeratan hubungan suatu istilah dengan istilah lainnya.
Penelitian sebelumnya dilakukan oleh Anbiana (2009) dengan menggunakan segmentasi dokumen. Masalah pada penelitian tersebut yaitu ukuran segmen yang relatif besar. Segmen yang digunakan berupa paragraf yang terdiri atas beberapa kalimat yang mengandung banyak kata. Pemilihan term/kata untuk ekspansi kueri menggunakan rasio antara kata terhadap ukuran segmen.
Tujuan Penelitian
Tujuan utama dari penelitian ini adalah mengimplementasikan perluasan kueri dengan teknik pseudo-relevance feedback menggunakan segmentasi kalimat.
Ruang Lingkup Penelitian
Dokumen yang digunakan dalam penelitian adalah dokumen XML berbahasa Indonesia. Dokumen ini merupakan dokumen tentang pertanian yang tersedia di Laboratorium Temu-kembali Informasi yang berjumlah 1000 dokumen dan dokumen tanaman obat yang tersedia di Laboratorium Kecerdasan Komputasional berjumlah 93 dokumen, sedangkan iterasi yang dilakukan dalam proses reformulasi kueri pada penelitian ini yaitu sebanyak satu kali.
TINJAUAN PUSTAKA
Information Retrieval (Temu-Kembali Informasi)
Temu-kembali informasi berkaitan dengan merepresentasikan, menyimpan, mengorganisasikan, dan mengakses informasi. Merepresentasikan dan mengorganisasikan suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Akan tetapi, untuk mengetahui informasi yang diinginkan pengguna bukan merupakan suatu hal yang mudah. Untuk itu pengguna harus menransformasikan informasi yang dibutuhkan ke dalam suatu kueri yang akan diproses mesin pencari (IR system), sehingga kueri tersebut akan merepresentasikan informasi yang dibutuhkan oleh pengguna. Dengan kueri tersebut, IR system akan menemukembalikan informasi yang relevan dengan kueri (Baeza-Yates & Ribeiro-Neto 1999).
Relevance Feedback
pengguna, expansion terms peringkat x teratas ditambah kueri pengguna digunakan sebagai formulasi kueri baru. Formulasi kueri baru ini diharapkan dapat menggeser dokumen relevan ke atas dan dokumen tidak relevan ke bawah.
Permasalahan teknik relevance feedback seperti yang dijelaskan Risjbergen (1997) adalah cara pengguna dalam menentukan dokumen yang relevan dan tidak relevan dalam hasil temu-kembali. Secara operasional, pengguna perlu menelusuri lebih lanjut isi dokumen hasil temu-kembali, agar diketahui relevansi suatu dokumen, kemudian dilakukan perumusan ulang kueri baru untuk temu-kembali selanjutnya.
Pseudo-Relevance Feedback
Menurut Yu, Cai, Wen dan Ma (2003), pseudo-relevance feedback (PRF), dikenal juga sebagai local feedback atau blind feedback, merupakan sebuah teknik yang biasanya digunakan untuk memperbaiki hasil temu-kembali. Ide dasarnya, yaitu mengekstrak expansion terms dari top-n documents yang dianggap sebagai dokumen relevan untuk merumuskan sebuah kueri baru yang akan digunakan dalam proses temu-kembali selanjutnya. Melalui ekspansi kueri, beberapa dokumen yang hilang pada proses inisialisasi temu-kembali ditemukembalikan dalam proses selanjutnya, sehingga kinerja temu-kembali dapat ditingkatkan secara menyeluruh. Teknik ini sangat bergantung pada kualitas expansion terms yang dipilih dan sangat dipengaruhi oleh dokumen-dokumen peringkat teratas.
Sistem yang mengambil top-n documents sebagai dokumen relevan lebih baik dari pada pengguna mengambil top-k relevant documents. Pada teknik pseudo-relevance feedback, pengguna dapat memperbaiki hasil temu-kembali (Baeza-Yates dan Ribeiro-Neto 1999 dalam Anbiana 2009).
Pembobotan BM25
Pembobotan BM25, disebut juga sebagai pembobotan Okapi, merupakan pembobotan yang digunakan sejak TREC ketiga. Pembobotan BM25 menggabungkan idf dengan koleksi pengskalaan khusus untuk dokumen dan kueri (Kontostathis 2008 dalam Herdi 2010). Bobot suatu kata t dalam dokumen i didefinisikan sebagai:
[ ]
dengan, ⁄ ,
merupakan frekuensi term t pada dokumen i, dan merupakan panjang dokumen Di dan rata-rata panjang dokumen
dalam koleksi, dan merupakan parameter-parameter pengskalaan terhadap tf dokumen dan panjang dokumen, umumnya menggunakan nilai = 1,2 dan = 0,75 (Jones 1999 dalam Herdi 2010).
Dengan demikian ukuran kemiripan dokumen i dengan kueri q adalah:
∑ [ ] Peluang Bersyarat
Dalam penelitian Le, Chenmin, dan Jamie (2008), digunakan metode temu-kembali yang sama dengan dua penelitian sebelumnya TREC 2006 dan TREC 2007, yaitu teknik pseudo-relevance feedback yang menggunakan peluang bersyarat (peluang bayes) untuk perluasan kueri.
Peluang bersyarat dapat digunakan untuk menghitung peluang kejadian apabila suatu kejadian diketahui. Berikut ini adalah rumusan dari formula peluang bersyarat:
| | ∑ | |
̅
dimana, | adalah peluang A terjadi jika B terjadi, | adalah peluang B terjadi jika A terjadi, adalah peluang kejadian A, dan adalah peluang kejadian B dan P(B) ≠ 0.
Evaluasi
Manning (2008) menyatakan, terdapat dua hal mendasar yang paling sering digunakan untuk mengukur kinerja temu-kembali secara efektif adalah recall dan precision (R-P). Perhitungan recall-precision diformulasikan sebagai berikut:
Relevant Not Relevant
Retrieved tp fp
Not
Retrieved fn tn
Recall = R = tp/(tp+fn)
Menurut Baeza-Yates dan Ribeiro-Neto (1999), algoritma temu-kembali yang dievaluasi menggunakan beberapa kueri berbeda akan menghasilkan nilai R-P yang berbeda untuk masing-masing kueri. Average Precision (AVP) diperlukan untuk menghitung rata-rata tingkat precision pada berbagai tingkat recall, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Perhitungan AVP dapat diformulasikan sebagai berikut:
̅( ) ∑
dimana, ̅( )adalah AVP pada level recall r, Nq adalah jumlah kueri yang digunakan, dan Pi(r) adalah precision pada level recall r untuk kueri ke-i.
METODE PENELITIAN
Penelitian ini dilaksanakan dalam beberapa tahap seperti yang diilustrasikan pada Gambar 1.
Pemrosesan Dokumen
Sebelum dilakukan proses temu-kembali, terlebih dahulu dilakukan pemrosesan dokumen yang meliputi stemming, eliminasi kata buangan dan pengindeksan menggunakan Sphinx search. Pada tahap ini koleksi dokumen yang berformat XML diindeks dengan file konfigurasi yang sesuai. Dalam penelitian ini digunakan dua koleksi dokumen yang memiliki struktur yang berbeda maka pengindeksan dilakukan terpisah. Pada koleksi dokumen (korpus) sebelumnya dilakukan tahap pembersihan data, yaitu memperbaiki penulisan kata dan tag.
Hasil pengindeksan inilah yang digunakan pada tahap selanjutnya, yaitu tahap temu-kembali.
Temu-kembali
Pada tahap ini diterapkan proses temu-kembali informasi yang diimplementasikan menggunakan platform Sphinx Search. Hasil dari temu-kembali klasik yaitu berupa dokumen-dokumen yang sesuai dengan kueri yang diberikan. Pada tahap ini diambil top n
dokumen untuk selanjutnya digunakan dalam tahap ekspansi kueri. Penelitian ini menggunakan satu, dua dan tiga dokumen teratas untuk ekspansi kueri.
Gambar 1 Metodologi Penelitian Segmentasi Kalimat
Pada tahap pemrosesan, dokumen dipilih menjadi unit-unit yang lebih kecil berupa kata, frasa atau kalimat. Unit terkecil hasil pemrosesan disebut token (Ridha, 2002). Pada penelitian ini dokumen dipisah menjadi unit-unit kecil yaitu kalimat yang terdiri atas
tidak ya korpus kueri Temu-kembali Peringkat dokumen PRF ?
top n
beberapa kata. Menurut Baeza-Yates dan Ribeiro-Neto (1999), tidak semua kata dapat digunakan untuk merepresentasikan sebuah dokumen secara signifikan
Pemrosesan teks yang dilakukan dalam penelitian ini dibagi dalam tiga tahap, yaitu: ● Lexical analysis of the text atau tokenisasi,
bertujuan untuk identifikasi kata dalam teks. Tokenisasi adalah proses yang mengubah sekumpulan karakter (teks dari dokumen) ke dalam sekumpulan kata (kandidat kata yang digunakan sebagai indeks istilah).
● Eliminasi kata buangan, hal tersebut bertujuan untuk meminimumkan kata yang digunakan sebagai istilah yang diindeks dalam proses temu-kembali. ● Pengindeksan teks dalam dokumen,
bertujuan untuk menghitung frekuensi kata yang berada dalam sebuah dokumen. Pembobotan dalam tahap ini menggunakan pembobotan bolean. Peluang Kemunculan Kata
Pada setiap kata dalam segmen kalimat yang sebelumnya telah diberi bobot, maka tahap selanjutnya yaitu dilakukan perhitungan peluang kemunculan kata menggunakan peluang bersyarat seperti berikut:
| | ∑ | |
̅
Perhitungan peluang bersyarat ini menggunakan vektor kata terhadap kalimat untuk melihat peluang kemunculan suatu kata ketika diberikan suatu kueri. Kata diurutkan berdasarkan nilai peluang yang diperoleh. Proses pengurutan dilakukan dari nilai peluang terbesar sampai nilai peluang terkecil.
Formulasi Kueri
Formulasi kueri baru bertujuan untuk memperbaiki hasil temu-kembali, yaitu dapat menggeser dokumen relevan ke atas dan dokumen yang tidak relevan ke bawah. Kata dengan peluang tertinggi yang merupakan term dari n dokumen teratas, digunakan untuk merumuskan kueri baru yang diformulasikan sebagai berikut:
dimana, adalah formulasi kueri baru, adalah formulasi kueri awal, dan adalah kueri dari perhitungan peluang kemunculan term pada kalimat. Kueri baru yang telah
diformulasikan digunakan dalam proses temu
kembali selanjutnya.
Evaluasi Hasil Temu-Kembali
Pada proses evaluasi hasil temu-kembali dilakukan penilaian kinerja sistem dengan melakukan pengukuran recall-precision untuk menentukan tingkat keefektifan proses temu-kembali. Recall adalah rasio dokumen relevan yang ditemukembalikan dan precision adalah dokumen relevan yang ditemukembalikan. Average precision (AVP) dihitung berdasarkan 11 standard recall levels, yaitu 0%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% dengan menggunakan interpolasi maksimum (Baeza-Yates & Ribeiro-Neto 1999).
Lingkungan Implementasi
Lingkungan implementasi yang digunakan adalah sebagai berikut :
Perangkat lunak :
Sistem operasi Windows 7 Ultimate sebagai sistem operasi.
PHP sebagai bahasa pemrograman. SPHINX Search sebagai platform untuk
pencarian berbasis teks.
Wamp Server Apache version 2.2.11 sebagai web server.
Notepad++, dan
Microsoft Office 2010 sebagai aplikasi yang digunakan untuk melakukan perhitungan dalam evaluasi sistem. Perangkat keras
Processor Intel Core 2 Duo 1,66GHz RAM 2 GB
Harddisk dengan kapasitas 120 GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen Pengujian
Tabel 1 Deskripsi dokumen pengujian Uraian Dokumen Pertanian Nilai (byte) Ukuran keseluruhan dokumen 4.139.332 Ukuran rata-rata dokumen 4139 Ukuran dokumen terbesar 54.082 Ukuran dokumen terkecil 451 Uraian Dokumen Tanaman
Obat
Nilai (byte)
Ukuran keseluruhan dokumen 297.796 Ukuran rata-rata dokumen 3202 Ukuran dokumen terbesar 13.628 Ukuran dokumen terkecil 928
Contoh salah satu dokumen pertanian yang digunakan dalam penelitian ini seperti yang tercantum pada Gambar 2, sedangkan contoh dokumen tanaman obat tercantum pada Gambar 3.
<DOC> <DOCNO>jurnal000000-001</DOCNO> <TITLE> PEMBANGUNAN PERTANIAN BERWAWASAN LINGKUNGAN YANG BERKELANJUTAN</TITLE> <AUTHOR>Triharso, Universitas Gadjah Mada </AUTHOR>
<TEXT>
……
<P>Konsep Dasar Pengendalian Hama dan Penyakit Hutan</P>
……
</TEXT> </DOC>
Gambar 2 Contoh dokumen pertanian <DOCNO>017</DOCNO>
<nama>Sosor Bebek</nama> <namal>Kalanchoe pinnata Lamk.</namal>
<content>Famili :
Crassulaceae. Nama Lokal : Cakar itek
……
</content>
<fam>Crassulaceae</fam> <penyakit>Kulit</penyakit>
Gambar 3 Contoh dokumen tanaman obat
Dokumen dikelompokkan ke dalam tag-tag sebagai berikut:
<DOC></DOC>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag lain yang lebih spesifik.
<DOCNO></DOCNO>, tag ini menunjukkan ID dari dokumen.
<DATE></DATE>, menunjukkan tanggal dari berita.
<AUTHOR></AUTHOR>, menunjukkan penulis dari berita tersebut.
<TEXT></TEXT>, tag ini menunjukkan isi dari dokumen.
<nama></nama>, tag ini menunjukkan nama dari tanaman obat.
<namal></namal>, tag ini menunjukkan nama latin dari tanaman obat.
<content></content>, tag ini mewakili isi dari dokumen meliputi deskripsi tanaman dan kegunaannya. <fam></fam>, tag ini menunjukkan
nama family dari tanaman obat.
<penyakit></penyakit>, tag ini menunjukkan penyakit yang berkaitan dengan tanaman obat.
Pemrosesan Dokumen
Sebelum dilakukan tahap temu-kembali terlebih dahulu dilakukan tahap pemrosesan dokumen dengan Sphinx Search. Karena pada penelitian ini digunakan dua koleksi dokumen yang berbeda, maka terdapat dua file konfigurasi yang berbeda pula. Cuplikan konfigurasi untuk dokumen pertanian tercantum pada Gambar 4, sedangkan cuplikan konfigurasi untuk dokumen tanaman obat tercantum pada Gambar 5.
index test2
{
source = srcxml
path = c:/sphinx/data/test6 docinfo = extern
morphology = stem_en min_word_len = 3
charset_type = utf-8 enable_star = 0 html_strip = 0 stopwords =
[image:32.595.78.297.40.836.2]c:/sphinx/data/StopWords.txt }
Gambar 4 Konfigurasi dokumen pertanian pada Sphinx search
index test2 {
source = srcxml
path = c:/sphinx/data/test7 docinfo = extern
morphology = stem_en min_word_len = 3
charset_type = utf-8 enable_star = 0 html_strip = 0 stopwords =
c:/sphinx/data/StopWords.txt }
Gambar 5 Konfigurasi dokumen tanaman obat pada Sphinx search
Penjelasan untuk konfigurasi yang digunakan pada Sphinx search,yaitu:
source = srcxml, konfigurasi untuk menandakan bahwa sumber yang digunakan atau file yang akan diindeks berupa file dengan format XML.
path=c:/sphinx/data/test6, konfigurasi untuk mengatur dimana file hasil indexing disimpan, pada dokumen pertanian disimpan pada folder data dengan nama file test6, sedangkan pada dokumen tanaman obat disimpan dalam folder data dengan nama file test7. docinfo = extern, konfigurasi
untuk penyimpanan dokumen hasil indexing. Dalam hal ini konfigurasi extern menunjukkan bahwa hasil indexing akan disimpan dalam file terpisah dengan nama file yang sama.
morphology = stem_en,
konfigurasi untuk stemmer, stem_en menunjukkan bahwa stemmer yang digunakan yaitu english stemmer. min_word_len = 3, konfigurasi ini
menjelaskan panjang minimal kata yang diindeks yaitu minimal 3 karakter.
charset_type = utf-8,
konfigurasi ini menunjukkan tipe karakter yang digunakan yaitu utf-8.
enable_star = 0, konfigurasi untuk pengindeksan prefiks. Digunakan nilai 0 yang menunjukkan bahwa tidak dilakukan pengindeksan untuk prefiks.
html_strip = 0, konfigurasi untuk menghilangkan tag. Digunakan nilai 0 yang berarti tidak menghilangkan tag. Stopwords=c:/sphinx/data/Sto
pWords.txt, konfigurasi untuk eliminasi kata buangan.
Temu-Kembali
Pada tahap temu-kembali klasik kueri dimasukkan oleh pengguna. Pembobotan yang digunakan yaitu pembobotan BM25, sedangkan perangkingan yang digunakan yaitu SPH_RANK_PROXIMITY_BM25 pada Sphinx search. Pembobotan BM25