RANCANG BANGUN PROGRAM APLIKASI KAMUS BAHASA JEPANG BERBASIS POCKET PC
Oleh :
Nama : Hamzah Rizaldy
NIM : 97410105001
Program : S1 (Strata Satu)
Jurusan : Sistem Informasi
SEKOLAH TINGGI
MANAJEMEN INFORMATIKA & TEKNIK KOMPUTER SURABAYA
DAFTAR ISI
Halaman
ABSTRAKSI ... ii
KATA PENGANTAR ... iv
DAFTAR ISI ... v
DAFTAR TABEL ... vii
DAFTAR GAMBAR ... viii
BAB I PENDAHULUAN ... 1
1.1. Latar Belakang Masalah ... 1
1.2. Perumusan Masalah ... 3
1.3. Pembatasan Masalah ... 4
1.4. Tujuan ... 5
1.5. Sistematika Penulisan ... 6
BAB II LANDASAN TEORI ... 8
2.1. Japanese Orthography ... 8
2.2. Unicode Character Encoding System ... 12
2.3. Unistroke Kanji ... 13
2.4. Pocket PC ... 18
2.5. Windows CE API ... 20
2.6. Microsoft eMbedded Visual Basic 3.0 ... 20
2.7. Microsoft SQL Server CE 2.0 ... 23
BAB III PERANCANGAN SISTEM ... 26
3.1. Flowchart Sistem ... 26
Halaman
3.2. Struktur Database ... 52
3.3. Desain User Interface ... 54
3.4. Algoritma ... 72
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM ... 90
4.1. Implementasi Sistem ... 90
4.2. Pengujian Sistem ... 103
BAB V PENUTUP ... 115
5.1. Kesimpulan ... 115
5.2. Saran ... 115
DAFTAR PUSTAKA ... 116
LAMPIRAN ... 117
DAFTAR TABEL
Halaman
Tabel 2.1. Hiragana dan Katakana beserta Romajinya ... 11
Tabel 2.2. Kanji stroke order rules ... 13
Tabel 2.3 Contoh perhitungan pengkodean Unistroke Kanji ... 17
Tabel 2.4. Beberapa perbedaan eVB 3.0 dengan VB 6.0 ... 22
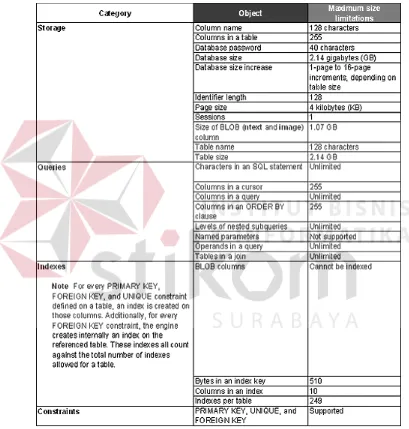
Tabel 2.5. Maximum size limitations of database objects in SQL Server CE 2.0 ... 24
Tabel 2.6. Tipe data yang didukung oleh SQL server CE 2.0 ... 25
Tabel 3.1. Struktur database-database yang digunakan oleh aplikasi ... 52
Tabel 3.2. Pengaruh options use extra filter, majority vote dan ignore single non-mandaroty rule pada proses Unistroke Kanji recognition ... 71
Tabel 4.1. Hardware yang digunakan untuk mengembangkan aplikasi ... 91
Tabel 4.2. Software yang digunakan untuk mengembangkan aplikasi ... 92
Tabel 4.3. Prosedur dan contoh pengujian penggunaan Radical Kanji SIP dan Unicode Charmap SIP ... 107
Tabel 4.4. Prosedur dan contoh pengujian penggunaan Unistroke Kanji SIP ... 108
Tabel 4.5. Prosedur dan contoh pengujian penggunaan Kana-keyboard SIP dan default SIP (Romaji-Hiragana/Romaji-Katakana) ... 109
Tabel 4.6. Prosedur dan contoh pengujian English query dan Japanese query .. 111
Tabel 4.7. Rangkuman hasil dari serangkaian uji coba sesi pertama ………. ... 112
Tabel 4.8. Rangkuman hasil dari serangkaian uji coba sesi kedua ... 113
DAFTAR GAMBAR
Halaman
Gambar 2.1. Contoh Japanese orthografy ... 8
Gambar 2.2. Contoh Kanji yang dibentuk dari beberapa Kanji radikal ... 10
Gambar 2.3. Kanji radikal dan jumlah goresannya ... 10
Gambar 2.4. Unicode coding layout ... 12
Gambar 2.5. Unistroke Kanji signature code beserta filter ekstranya ... 14
Gambar 2.6. Persamaan Translasi dan persamaan Euclidean Inner Product ... 17
Gambar 2.7. Pocket PC Hp Jornada 548 ... 18
Gambar 2.8. Contoh default SIP Pocket PC pada Hp Jornada 548 ... 19
Gambar 2.9. Tampilan eVB 3.0 dan Pocket PC 2000 Emulator ... 21
Gambar 3.1 Flowchart proses input menggunakan default SIP maupun Custom SIP... 27
Gambar 3.2. Flowchart proses input menggunakan Kana-keyboard SIP ... 30
Gambar 3.3. Flowchart proses input menggunakan default SIP ... 32
Gambar 3.4. Flowchart Radical Kanji SIP ... 33
Gambar 3.5. Flowchart proses input menggunakan Unistroke Kanji SIP ... 35
Gambar 3.6. Flowchart Unicode Characters Map SIP ... 36
Gambar 3.7. Flowchart proses query dictionary ... 39
Gambar 3.8. Flowchart pengelolaan word query buffer ... 40
Gambar 3.9. Flowchart proses pemeliharaan database kamus ... 42
Gambar 3.10. Flowchart proses pemeliharaan data Kanji reference ... 44
Gambar 3.11. Flowchart proses pemeliharaan data Unistroke Kanji signature code ... 46
Halaman
Gambar 3.12. Flowchart proses pemeliharaan data Radical Kanji ... 48
Gambar 3.13. Flowchart proses pemeliharaan data Kanji meanings ... 50
Gambar 3.14. Flowchart proses pemeliharaan data Kanji readings ... 51
Gambar 3.15. Relasi tabel KnjInf, KnjMean, KnjRead dan Unistroke ... 53
Gambar 3.16. Rancangan tampilan utama aplikasi (proses query dictionary) ... 54
Gambar 3.17. Susunan custom SIP menu (default SIP tidak aktif) ... 55
Gambar 3.18. Susunan custom SIP menu (default SIP aktif) ... 56
Gambar 3.19. Rancangan interface Kana-Keyboard SIP ... 57
Gambar 3.20. Rancangan interface pada saat default SIP aktif dan active input triggernya Romaji-Hiragana atau Romaji-Katakana ... 58
Gambar 3.21. Rancangan interface Radical Kanji SIP ... 60
Gambar 3.22. Rancangan interface Unistroke Kanji SIP ... 60
Gambar 3.23. Rancangan Unicode characters map SIP ... 61
Gambar 3.24. Rancangan interface pemeliharaan data histories word query buffer ... 62
Gambar 3.25. Rancangan interface pemeliharaan database kamus ... 63
Gambar 3.26. Rancangan interface Kanji information grup Kanji reference ... 65
Gambar 3.27. Rancangan interface Kanji information grup Unistroke Kanji signature code ... 66
Gambar 3.28. Rancangan interface Kanji information grup Radical Kanji ... 67
Gambar 3.29. Rancangan interface Kanji information grup Kanji meanings ... 68
Gambar 3.30. Rancangan interface Kanji information grup Kanji readings ... 69
Gambar 3.31. Rancangan interface Options ... 70
Gambar 4.1. Tampilan splash screen ... 93
Gambar 4.2. Tampilan utama aplikasi ... 94
Halaman
Gambar 4.3. Tampilan SIP pada saat default SIP aktif : (a) custom SIP menu (b) input trigger Romaji-Katakana dan (atas) input trigger
Romaji-Hiragana ... 96
Gambar 4.4. Tampilan SIP pada saat default SIP dalam keadaan tidak aktif : (a) custom SIP menu, (b) Small-Hiragana keyboard,
(c) Okurigana Kanji Candidate List, (d) Katakana keyboard dan (e) Small-Katakana keyboard ... 99
Gambar 4.5. Tampilan SIP pada saat default SIP dalam keadaan tidak aktif (lanjutan) : Unicode characters map SIP, Radical Kanji SIP dan Unistroke Kanji SIP pengenalan non-parsial dan parsial ... 100
Gambar 4.6. Tampilan pemeliharaan data kamus ... 101
Gambar 4.7. Tampilan Kanji Information ... 104
Gambar 4.8. Tampilan options : Konfigurasi path file, (a) Konfigurasi Kana ke Kanji, (b) Konfigurasi pengenalan pola Unistroke Kanji,
(c) Konfigurasi Umum ... 105
BAB I PENDAHULUAN
1.1 Latar Belakang Masalah
Semakin populernya pengembangan program aplikasi komputer
berarsitektur tiga lapis pada awal tahun 1990 dan aplikasi berbasis web pada akhir
tahun 1990, teknik-teknik pemrograman berkembang dari masa ke masa. Internet
memberikan sumbangan besar dalam pengembangan aplikasi yang
memungkinkan penggunanya mempunyai fleksibilitas tinggi dalam menjalankan
bisnisnya tanpa kendala jarak. Saat ini, target pengembangan program aplikasi
diarahkan pada perangkat cerdas dengan mobilitas tinggi (smart-mobile devices). Perangkat ini memiliki kemampuan yang mengesankan meskipun ukurannya kecil
dan memberikan tantangan tersendiri bagi software developer karena harus memperhitungkan kemampuan dan fitur dari perangkat tersebut, misalnya ukuran
layar yang kecil, kecepatan prosesor yang lambat, kapasitas memori yang terbatas
dan lain sebagainya.
Pocket PC adalah salah satu jenis mobile device yang secara struktural
hampir sama dengan PC baik perangkat keras, sistem operasi dan perangkat
lunaknya, sehingga teknik pemrogramannya lebih mudah dipelajari dan
dikembangkan. Para praktisi dibidang software berlomba-lomba menciptakan
berbagai macam aplikasi praktis yang dapat membantu pengguna perangkat ini
mengerjakan pekerjaannya ketika sedang berada dalam perjalanan. Salah satu
jenis aplikasi Pocket PC yang sering digunakan dalam perjalanan adalah kamus.
Aplikasi kamus bahasa yang menggunakan dasar tulisan Latin paling banyak
2
beredar, sedangkan kamus bahasa yang menggunakan dasar tulisan yang rumit
dan unik dalam hal cara baca maupun penulisannya (complex glyph) seperti : Jepang, Cina atau Korea sangat jarang dijumpai. Hal ini didasari oleh
permasalahan sistem input pada Pocket PC. Dalam kondisi standar suatu Pocket
PC hanya memiliki sebuah pena (stylus) sebagai media touch-screen. Selain itu, untuk memfasilitasi proses input data Pocket PC dilengkapi Soft Input Panel (SIP) berbentuk on-screen keyboard atau handwriting recognition, tetapi fasilitas ini masih belum cukup ketika akan menginputkan data dalam bahasa yang terdiri dari
complex glyph karena Pocket PC pada umumnya menggunakan SIP berbasis
huruf Latin, kecuali Pocket PC yang diproduksi dan dipasarkan secara khusus dan
terbatas pada wilayah tertentu.
Selain bahasa Inggris sebagai bahasa internasional, salah satu bahasa
yang cukup banyak menarik minat masyarakat adalah bahasa Jepang seiring
dengan peningkatan hubungan bilateral Indonesia-Jepang dalam berbagai sektor,
terutama ekonomi, pendidikan, iptek, sosial budaya dan pariwisata. Tetapi di sisi
lain, terdapat fakta yang menunjukan bahwa tidak sedikit masyarakat yang
mengaku kesulitan mempelajari bahasa Jepang karena kendala tulisan, terutama
huruf Kanji. Kanji sering dituduh sebagai penghambat proses pembelajaran bahasa Jepang karena jumlahnya banyak, betuknya rumit dan memiliki beragam
cara baca. Hal tersebut memang beralasan mengingat sebagian besar kata dalam
bahasa Jepang dibentuk dari satu atau lebih huruf Kanji, sedangkan kamus bahasa
Jepang pada umumnya sangat bergantung kepada pengucapan kata yang biasanya
3
seperti ini harus melalui beberapa tahapan. Tahap pertama adalah mencari
pengucapan setiap huruf Kanji pada kata tersebut dalam indeks yang terdiri dari
ribuan huruf Kanji. Proses ini dilakukan berluang-ulang sampai dipastikan bahwa
tidak terdapat pengucapan lain dari masing-masing huruf Kanji tersebut. Tahap
kedua adalah mencari kata-kata sesuai dengan pengucapan-pengucapan yang telah
ditemukan pada tahap pertama. Tahap ketiga adalah memilih terjemahan yang
paling cocok dari beberapa kata yang telah kita temukan pada tahap kedua.
Kondisi seperti ini menyebabkan proses penerjemahan menggunakan kamus
konvensional bagi non-native merupakan kegiatan yang melelahkan dan cukup banyak menyita waktu.
Oleh karena itu dibutuhkan sebuah kamus bahasa Jepang dalam bentuk
program aplikasi komputer yang dapat memudahkan dan mempercepat proses
penerjemahan dengan menggunakan landasan pencarian kata yang lebih
komprehensif dari pada kamus konvensional. Dengan memanfaatkan mobilitas
Pocket PC, diharapkan akan semakin menambah daya guna program aplikasi ini,
sebab dapat diakses kapan saja dan dimana saja.
1.2 Perumusan Masalah
1. Bagaimana merancang dan membangun sebuah program aplikasi kamus bahasa
Jepang yang memanfaatkan mobilitas Pocket PC sehingga dapat diakses kapan
saja dan dimana saja.
2. Bagaimana merancang dan membangun sebuah program aplikasi kamus bahasa
Jepang yang dapat memudahkan dan mempercepat proses penerjemahan kata
dengan menggunakan landasan pencarian kata yang lebih komprehensif dari
4
1.3 Pembatasan Masalah
1. Program aplikasi ini diimplementasikan ke Pocket PC yang memiliki sistem
operasi Microsoft Windows for Pocket PC 2000 atau 2002, bergantung pada
Software Development Kit (SDK) yang dipergunakan.
2. Program aplikasi ini menggunakan font khusus (MS Gothic) yang di dalamnya
terdapat Japanese characters dengan sistem coding karakter standar Unicode. 3. Data kosa kata yang digunakan adalah data kosa kata bahasa Jepang beserta
terjemahannya dalam bahasa Inggris, sehingga dalam hal ini kamus tidak
bersifat bi-directional (Jepang-Inggris dan Inggris-Jepang). Bahasa Inggris digunakan sebagai terjemahan karena pertimbangan penggunaan aplikasi dan
jangkauan user yang lebih universal.
4. Data Kanji yang digunakan terbatas pada joyoo Kanji, yaitu 1945 buah Kanji standar yang telah dibakukan penggunaannya oleh pemerintah Jepang.
5. Aplikasi ini memiliki SIP tersendiri (custom SIP) yang digunakan sebagai landasan proses pencarian kata dalam bahasa Jepang. Selain masih mengusung
gagasan konvensional tentang landasan proses pencarian kata (Kana-keyboard SIP dan Romaji Input), aplikasi ini juga memperkenalkan landasan-landasan alternatif proses pencarian kata berdasarkan bentuk sederhana Kanji yang
disebut Kanji radikal (Radical Kanji SIP), berdasarkan cara dan urutan penulisan suatu Kanji (Unistoke Kanji SIP) dan berdasarkan Unicode characters coding system (Unicode characters map SIP). Masing-masing custom SIP dapat dikolaborasikan sebagai satu sistem input tulisan Jepang.
6. SIP aplikasi ini berbeda dari default SIP Pocket PC yang bekerja independen
5
dari suatu aplikasi tertentu, sehingga karakter-karakter yang diinputkan dapat
langsung dikirim pada aplikasi lain. Sedangkan SIP aplikasi ini merupakan
dummy SIP dengan cara kerja yang berlawanan dengan default SIP, sehingga hanya dapat berkomunikasi dengan aplikasi lain yang mendukung penggunaan
Unicode melalui clipboard memanfaatkan operasi copy dan paste.
7. Khusus pada Unistoke Kanji SIP, penggambaran Kanji adalah bersifat stroke order rule dependent, sehingga user harus mempelajari terlebih dahulu aturan dan urutan penulisan huruf Kanji yang benar.
8. Custom SIP dalam aplikasi ini tidak memberikan rekomendasi dalam hal
pelengkapan kata (word compeletion).
9. Sedangkan untuk pencarian kata dalam bahasa Jepang berdasarkan kata dalam
bahasa Inggris menggunakan default SIP Pocket PC.
1.4 Tujuan
1. Merancang dan membangun sebuah program aplikasi kamus bahasa Jepang
yang memanfaatkan mobilitas Pocket PC sehingga dapat diakses kapan saja
dan dimana saja.
2. Menerapkan Hiragana-Katakana dan Romaji pronunciation sebagai landasan proses pencarian kata. Dilengkapi dengan Kanji radikal, Unistoke Kanji dan
Unicode characters map sebagai landasan alternatifnya, sehingga proses
penerjemahan kata menggunakan aplikasi ini dapat lebih cepat dan lebih
mudah.
3. Menambah keanekaragaman jenis aplikasi Pocket PC sehingga diharapkan
dapat mengoptimalkan pemakaian Pocket PC dikalangan masyarakat,
6
1.5 Sistematika Penulisan BAB I : PENDAHULUAN
Pendahuluan berisi pembahasan tentang latar belakang masalah,
perumusan masalah, pembatasan masalah, tujuan yang ingin dicapai dari tugas
akhir ini dan sistematika penulisan yang dijelaskan secara singkat.
BAB II : LANDASAN TEORI
Dalam bab ini memuat tentang landasan teori yang menjadi dasar untuk
menyelesaikan masalah sehubungan dengan pembuatan aplikasi kamus bahasa
Jepang berbasis Pocket PC. Pada bab ini akan dibahas mengenai Japanese orthography, Unicode character coding system, Unistroke Kanji, Pocket PC, Windows CE API, Microsoft eMbedded Visual Basic 3.0 dan Microsoft SQL Server CE 2.0.
BAB III : PERANCANGAN SISTEM
Perancangan sistem bertujuan untuk menganalisa dan mendesain sistem
yang akan dibuat. Analisa sistem bertujuan untuk menganalisa sistem kerja
aplikasi kamus bahasa Jepang berbasis Pocket PC dan desain bertujuan untuk
mendesain flowchart sistem, user interface dan algoritma dari hasil analisis yang telah dilakukan.
BAB IV : IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi tentang implementasi dari hasil desain sistem yang telah
dibuat sehingga menjadi sebuah program aplikasi dan pengujian dari hasil
implementasi yang telah dilakukan. Pengujian sistem dilakukan untuk mengetahui
apakah sistem yang telah dibuat dapat berjalan secara optimal sesuai dengan
7
BAB V : PENUTUP
Merupakan bab terakhir yang berisi kesimpulan yang merupakan
rangkuman singkat dari keseluruhan aplikasi yang dibuat, serta saran-saran yang
diberikan untuk melengkapi aplikasi yang telah dibuat sehingga dapat berguna
BAB II
LANDASAN TEORI
2.1 Japanese Orthography
Japanese orthography adalah sistem bahasa Jepang tertulis yang terdiri
dari 4 elemen, yaitu : Kanji, Hiragana, Katakana dan Romaji. Contoh Japanese
orthography dapat dilihat pada gambar 2.1.
(a) Conventional Japanese orthography:
晴美はあのビツで働いているOLです
1: Kanji 2: Hiragana 3: Katakana 4: Romaji
(b) Hiragana pronounciation:
はるみはあのびるではたらいているおおえるです
晴 美はあのビツで働 いているO L です
Gambar 2.1. Contoh Japanese orthografy.
2.1.1 Kanji
Menurut Adimihardja (2003:1) Kanji adalah ideographic characters yang dipinjam dari bangsa Cina sejak jaman dinasti Han, setelah mengalami berbagai proses perubahan selama rentang waktu hampir 1500 tahun, pada tahun
1981 pemerintah Jepang secara resmi membakukan 1945 Kanji (joyoo Kanji)
yang dipakai untuk bahasa Jepang.
Menurut Adimihardja (2003:1) Kanji selalu dituduh sebagai penghambat
keberhasilan proses pembelajaran bahasa Jepang karena jumlahnya banyak,
bentuk tulisannya rumit dan memiliki berbagai cara baca. Sehingga dinilai
9
menghambat proses visualisasi sebuah kata atau kalimat, sebaliknya sulit
mengungkapkan kata atau kalimat secara tertulis karena hambatan huruf. Hal ini
memang cukup beralasan mengingat setiap Kanji memiliki standar baku cara
penulisannya mulai dari Kanji dengan hanya 1 goresan hingga 23 goresan, selain
itu sebuah Kanji dapat memiliki beragam cara baca mulai dari 1 sampai 12 cara
baca. Disamping itu, ada beberapa Kanji yang mengalami perubahan cara baca
setelah dikombinasikan dengan Kanji lain.
Secara umum Kanji dikelompokkan menjadi 2 cara baca, yaitu cara baca
Cina (On-yumi) dan cara baca Jepang (Kun-yumi). Beberapa Kanji memiliki satu atau lebih cara baca On-yumi saja atau Kun-yumi saja. Disamping itu, Kanji Cina
yang memiliki kesamaan arti dalam bahasa Jepang dikukuhkan cara bacanya
sebagai cara baca Jepang. Hal ini menyebabkan sebuah Kanji dapat memiliki satu
atau lebih cara baca On-yumi sekaligus Kun-yumi. Sehingga sulit menentukan
apakah sebuah Kanji dibaca On-yumi atau Kun-yumi tanpa mempertimbangkan
konteks kalimat dan hubungan kombinasi dengan Kanji lain yang berada di
depannya atau di belakangnya.
Dari segi komponen bentuk, suatu Kanji dapat dibentuk dari gabungan
Kanji-kanji lain yang bentuknya lebih sederhana yang disebut Kanji radikal.Kanji
radikal memiliki peran dalam menentukan arti sebuah huruf Kanji hasil
bentukannya sehingga sering digunakan sebagai kunci untuk mencari Kanji atau
kata dalam kamus. Contoh Kanji yang dibentuk oleh beberapa Kanji radikal dapat
dilihat pada gambar 2.2. Sedangkan Kanji radikal yang dikelompokkan
10
学
study, learning, science.子
child.冖
covering, wa-shaped crown.K
small on top, ray.Gambar 2.2. Contoh Kanji yang dibentuk dari beberapa Kanji radikal.
1 一 | ノ 丶 亅 乙 2 八 亠 十 二 儿 冂
A B
厶 人 冖 勹 匕又 厂
C
冫 卜D
刀 凵 力 卩E
匚 几F
マ 九 入 乃 ユ 3 口土
G H
大I
宀 女 山 夂 寸J
ヨ 广 小 囗 尸K
巾 士 工 彡夕 弓 子 彳 干 廾 已
L
幺 川 弋 廴 屮 亡 彑 也 尢 及 久 4 日木 月
M
王 心 戈 攵 火 止 爪 斤 方 水 欠 比 牛 殳 老 爿 戸 勿N
氏 歹 犬 手 毛 母 父 文 巴 支 爻 斗 牙 井 曰 元 尤 无 屯 五片 气 5 田 立 目 禾 白
O
皿 石P Q
甘 矢 穴 示 疋 用R
癶冊 皮 矛 瓦 生 世 瓜 玄 巨 6 糸 虫 米 竹 衣 耳 羊 臼 艮 西 羽
虍 臣 舟 缶 至 自 聿 而 舌 行 舛 耒 血 色 肉 7 貝 言 車 足 辛
豆 酉 里 豕 見 釆 角 辰 谷 豸 走 身 赤 8 金 隹 門 雨 長 非 隶
斉 青 免 奄 岡 9 頁 食 革 音 品 韭 風 韋 面 首 香 飛 10 馬 鬼
髟 高 骨 鬥 鬲 竜 鬯 11 鳥 魚 鹿 麦 麻 亀
S
鹵 12 黒 黄 無 黍黹 13 鼠 黽 鼓 鼎 14 薺 鼻 15 歯 16
龍 龜
17 龠Gambar 2.3. Kanji radikal dan jumlah goresannya.
2.1.2Hiragana dan Katakana
Hiragana dan Katakana (Kana) merupakan sekumpulan karakter yang dibentuk dari penyederhanaan beberapa huruf Kanji. Fungsi utama dari Hiragana
dan Katakana adalah sebagai representasi pengucapan suku-suku kata dalam
bahasa Jepang.
Secara khusus Hiragana digunakan sebagai partikel pembentuk
gramatika bahasa Jepang. Sedangkan Katakana memiliki fungsi khusus untuk
merepresentasikan pengucapan suku-suku kata bahasa Jepang yang merupakan
11
Perbedaan bentuk antara Hiragana dan Katakana dapat dilihat pada tabel
2.1. Hiragana atau Katakana yang berwarna selain hitam dibaca sesuai dengan
warnanya, contohnya : ち (chi), つ (tsu), しゅ (shu) dan を (o). Hiragana atau
Katakana yang berwarna hitam dibaca sesuai indeks baris warna hitam dan
mengabaikan warna indeks kolomnya, contohnya : ひ (hi), そ (so) dan りょ(ryo),
tetapi jika indeks barisnya kosong maka yang dibaca hanya indeks kolomnya saja
contohnya : い (i), よ (yo) dan ん(n).
Tabel 2.1. Hiragana dan Katakana beserta Romajinya.
2.1.3Romaji
Romaji mengandung alphabet Latin yang digunakan untuk
merepresentasikan tulisan Latin dalam bahasa Jepang. Romaji juga digunakan
untuk mengkonversikan setiap suku kata bahasa Jepang ke dalam huruf Latin,
12
2.2 Unicode Character Coding System
Representasi Japanese characters dalam komputer difasilitasi oleh suatu
sistem pengkodean karakter. Salah satu dari sistem pengkodean karakter Jepang
yang familier di lingkungan sistem operasi Microsoft Windows adalah Unicode.
Selain itu, terdapat sistem pengkodean karakter Jepang lain yang sering
digunakan, yaitu : JIS dan shift-JIS.
Karakter Unicode berbentuk Double Byte Character Set (DBCS) atau 16-bits characters yang artinya satu karakter Unicode diwakili oleh dua karakter
ASCII (1 karakter ASCII = 1 byte dan 1 byte = 8 bits). Sebagai Contoh karakter 字
(u5B57) merupakan gabungan dari karakter ASCII “[“ dengan kode heksadesimal
5B dan “W” dengan kode heksadesimal 57.
Unicode coding layout yang diimplementasikan dalam sistem operasi Microsoft Windows berbentuk True Type Fonts (TTF) ditunjukkan oleh gambar 2.4. Hiragana dan Katakana berada pada posisi Kana (u3041-u30FE). Sedangkan
Kanji ada pada posisi Ideographs (u4E00-uFA2D). Unicode juga digunakan untuk merepresentasikan bahasa-bahasa lain yang menggunakan complex glyph.
13
2.3 Unistroke Kanji
Unistroke adalah suatu teknik sederhana yang digunakan dalam
pengenalan karakter tulisan tangan menggunakan pola-pola tertentu berdasarkan
kepada suatu aturan dan urutan penulisan. Sehingga sukses tidaknya proses
pengenalan karakter menggunakan metode ini sangat bergantung pada
pemahaman user terhadap aturan dan urutan penulisan yang telah ditentukan.
Unistroke Kanji diperkenalkan oleh Tood David Rudick, metode tersebut
menyederhanakan setiap goresan Kanji menjadi sequential signature code yang didasari oleh Kanji stroke order rules seperti yang tertera pada tabel 2.2.
14
Unistoke Kanji mengkodekan setiap goresan Kanji sesuai dengan arah
goresannya. Kode suatu goresan dengan kode goresan yang berikutnya dipisahkan
oleh spasi. Pada beberapa kasus terdapat satu atau lebih kombinasi kode untuk
satu goresan (substroke), kode-kodenya tidak dipisahkan oleh spasi. Khusus untuk kombinasi kode 62, 26, 21 dan 23 diberikan kode khusus karena kombinasi ini
sering sekali dipakai. Contoh sequential signature code yang dibentuk oleh
Unistroke Kanji dapat dilihat pada gambar 2.5.
Gambar 2.5. Unistroke Kanji signature code beserta filter ekstranya.
Proses Unistroke Kanji recognition dilakukan setiap kali user selesai
menggambarkan satu goresan, sehingga terbuka kemungkinan bahwa user akan
mendapatkan Kanji yang diinginkan sebelum seluruh goresan Kanji tersebut
15
mengkodekan setiap sudut goresan Kanji dalam bentuk Unistroke Kanji signature
code dengan memberikan toleransi simpangan maksimum ± 22° dari sudut asli
untuk suatu kode (50 % dari range sudut antar kode), misalnya : untuk kode 9
sudut aslinya adalah 45°, maka range toleransinya adalah 23° sampai 67°. Khusus
untuk kode 8, terdapat 2 range toleransi, yaitu : 338° sampai 0° dan 0° sampai 22°.
Dengan Unistroke Kanji diharapkan bahwa setiap Kanji memiliki
signature code yang unik, namun kenyataanya terdapat beberapa Kanji yang
memiliki signature code yang sama, seperti pada gambar 2.5. Untuk mengatasi
masalah ini perlu adanya suatu filter ekstra. Bentuk umum dari filter ekstra
tersebut memiliki arti bahwa suatu input cenderung mirip dengan suatu Kanji jika
nilai sebelum “-“ lebih besar dari nilai sesudahnya. Besarnya nilai-nilai input
tersebut disesuaikan dengan Code dan Stroke ID. Sedangkan “!” menandakan
bahwa filter ekstra tersebut merupakan mandatory rules yang bersifat mutlak harus terpenuhi. Nilai koordinat mengikuti koordinat layar komputer dengan titik
(0,0) berada pada pojok kiri atas layar. Dengan kata lain, semakin ke kanan maka
nilai x semakin tinggi dan semakin ke bawah nilai y semakin tinggi. Pada gambar
2.5, Kanji pertama memiliki filter ekstra x5-i4 yang berarti bahwa nilai koordinat
x pada titik awal goresan ke 5 seharusnya lebih besar dari nilai koordinat x pada
titik akhir goresan ke 4. Sedangkan pada Kanji kedua memiliki filter ekstra x4-x5
y5-y3 yang berarti bahwa nilai koordinat x pada titik awal goresan ke 4
seharusnya lebih besar dari nilai koordinat x pada titik awal goresan ke 5 dan nilai
koordinat y pada titik awal goresan ke 5 seharusnya lebih besar dari nilai
16
Ditinjau dari koridor aljabar linier, Unistroke Kanji menganggap bahwa
setiap goresan Kanji sebagai serangkaian vektor berarah di R2. Setiap vektor
memiliki sudut tertentu yang relatif terhadap vektor satuan [0,1] atau sumbu-y,
seperti yang pada gambar 2.6. Sudut-sudut inilah yang diterjemahkan dalam
sequential signature code. Hal ini berlaku pada signature code Kanji yang
disimpan dalam database dan Kanji yang digambarkan oleh user. Sehingga derajat kemiripan antara Kanji yang digambarkan oleh user dengan Kanji-kanji
yang tersimpan dalam database ditentukan oleh jumlah dari seluruh perbedaan
sudut (relatif terhadap sumbu-y) setiap pasang goresannya, jika semakin kecil
jumlah perbedaan sudutnya maka tingkat kemiripannya semakin tinggi. Sistem
koordinat yang dipakai oleh input adalah sistem koordinat layar komputer bukan
sistem koordinat cartesius yang digunakan oleh Unistoke Kanji, sehingga untuk mendapatkan sudut relatif yang sesuai, dibutuhkan persamaan translasi yang dapat
merubah masing-masing vektor input ke dalam bentuk sistem koordinat cartesius.
Menurut Howard (1997:98) untuk mentranslasikan sumbu koordinat xy
menjadi sistem koordinat x’y’ yang titik asal 0’ berada dititik (x,y)=(k,l)
dibutuhkan persamaan translasi (persamaan 1). Menurut Howard (1997:100)
panjang vektor v = (x,y) atau ||v|| (norma v) di R2 didapatkan dengan persamaan 2.
Menurut Howard (1997:103) jika u dan v adalah vektor tak nol di R2 maka sudut
(θ) antara u dan v didapatkan dengan persamaan Euclidean Inner Product (persamaan 3). Misalkan vektor u = (0,y’) atau sumbu-y’ dan vektor v = (x’,y’)
didapatkan persamaan 4 yang digunakan untuk menghitung sudut vektor v yang
relatif terhadap sumbu-y’ dengan mensubstitusikan persamaan 1, 2 dan 3 secara
17
Gambar 2.6. Persamaan Translasi dan persamaan Euclidean Inner Product.
Contoh proses perhitungan untuk mengkodekan setiap goresan dari suatu
Kanji dalam kode-kode Unistroke Kanji dapat dilihat pada tabel 2.3.
Tabel 2.3. Contoh perhitungan pengkodean Unistroke Kanji
Algoritma Unistroke Kanji menawarkan sebuah solusi yang sederhana
terhadap pengenalan Kanji, dengan performa dan tingkat akurasi yang relatif
tinggi, meskipun keterikatannya kepada aturan dan urutan penulisan Kanji
18
2.4 Pocket PC
Pocket PC adalah perangkat cerdas dengan mobilitas tinggi yang mampu
menyimpan dan mengelola informasi layaknya komputer. Pocket PC juga
merupakan salah satu jenis Personal Digital Assistan (PDA) yang menggunakan
sistem operasi Microsoft Windows CE (WinCE). PC dan Pocket PC saling
berkomunikasi dan bertukar data melalui suatu sistem sinkronisasi menggunakan
koneksi kabel atau tanpa kabel. Contoh Pocket PC dapat dilihat pada gambar 2.7.
Gambar 2.7. Poket PC Hp Jornada 548.
Pocket PC menggunakan prosesor seperti : Multiprocessor without Interlocked Pipeline Stages (MIPS), Intel Strong Arm atau Hitachi SHx. Walaupun kecepatannya lebih lambat dari PC, namun sudah mencukupi untuk
19
Pocket PC tidak memiliki hard drive. Pada Pocket PC hanya terdapat tiga jenis memori yang digunakan sebagai storage yaitu Random Access Memory (RAM), Read-Only Memory (ROM) dan external memory. Seluruh data dan program dipertahankan dalam RAM dengan menggunakan daya dari re-chargeable baterai. ROM berfungsi menyimpan sistem operasi dan program-program aplikasi standar dari pabriknya. External memory adalah memori
tambahan yang sengaja dipasang untuk memperbesar kapasitas penyimpanan data.
Layar Pocket PC merupakan Liquid Crystal Display (LCD) dengan resolusi 240x320 pixel dan colour depth mencapai 16-bits. Layar Pocket PC berfungsi ganda sebagai media output dan media input touch-screen.
Pocket PC hanya dilengkapi stylus sebagai media touch-screen.
Meskipun secara fisik Pocket PC tidak dilengkapi dengan alat input yang
memadai, tetapi secara software Pocket PC dilengkapi dengan fasilitas input data
yang disebut Soft Input Panel (SIP). Contoh default SIP terdapat pada gambar 2.8.
20
2.5 Windows CE API
Microsoft Windows CE Aplication Program Interface (WinCE API) adalah kumpulan beragam fungsi dan prosedur bawaan yang digunakan pada
lingkungan sistem operasi windows CE. WinCE API ditulis dalam bentuk
dynamic link library (DLL). Dengan memanfaatkan WinCE API, seorang programer diberikan keleluasaan untuk menggali lebih dalam kekuatan dan
keampuhan sistem operasi windows CE, misalnya : pengelolaan Windows
registry, Windows clipboard, Windows massage, Windows handle dan memori serta penggunaan fungsi-fungsi grafis yang lebih cepat, manipulasi terhadap
control standar, pembuatan menu pop-up dan hal-hal lain yang tidak akan didapat memalui teknik pemrograman biasa pada suatu software pemrograman. Tetapi
dibalik semua manfaat tersebut, programer dituntut untuk berhati-hati dalam
menggunakan WinCE API, sebab probabilitas error-nya sangat tinggi bahkan dapat menyebabkan program crash.
Arsitektur Pocket PC lebih sederhana dibandingkan dengan PC. Oleh
karena itu, WinCE API strukturnya sedikit berbeda dengan WIN32 API, tetapi cara pendeklarasian dan pemanggilan fungsi-fungsi WinCE API masih sama
dengan WIN32 API.
2.6 Microsoft eMbedded Visual Basic 3.0
Microsoft eMbedded Visual Basic 3.0 adalah sebuah software yang
digunakan untuk membuat aplikasi berbasis Windows CE menggunakan
21
setiap instruksi secara berurutan menggunakan intermediate program (disebut command interpreter) sehingga eVB tidak menghasilkan file executable (.exe) mandiri tetapi menghasilkan file .vb yang nantinya akan diterjemahkan oleh target device pada saat program dijalankan. Tampilan eVB 3.0 dan Pocket PC 2000 Emulator pada dapat dilihat gambar 2.9.
Gambar 2.9. Tampilan eVB 3.0 dan Pocket PC 2000 Emulator.
Microsoft eVB berbasis dekstop PC, sehingga semua proses pembuatan aplikasi mulai dari coding, debugging, sampai dengan compiling dilakukan pada PC. Aplikasi yang dibuat menggunakan eVB dapat dijalankan pada platform
Handheld PC Pro (H/PC Pro), Palm-size PC 1.2 dan Pocket PC. Keragaman jenis
22
(SDK) khusus yang berisikan berbagai macam control dan run-time file berbentuk file .DLL sesuai dengan target device yang diinginkan. Hal ini menyebabkan
distribusi program aplikasi yang telah dibuat dalam bentuk installer bersifat spesifik, satu installer untuk suatu jenis perangkat.
Meskipun antara eVB dan VB memiliki banyak kemiripan, tetapi ada
beberapa perbedaan yang cukup mendasar seperti yang tertera pada tabel 2.4.
Tabel 2.4. Beberapa perbedaan eVB 3.0 dengan VB 6.0.
Microsoft eVB memiliki keterbatasan-keterbatasan, seperti bahasa
pemrograman tingkat tinggi lainnya. Hal ini sangat dirasakan oleh para programer
23
menawarkan solusi final untuk mengatasi permasalahan ini dengan memberikan
dukungan terhadap akses WinCE API.
Microsoft eVB 3.0 menawarkan kemudahan dalam membuat sebuah
aplikasi berbasis Pocket PC bagi programer yang telah menguasai Microsoft
Visual Basic. Keistimewaan lain yang dimiliki oleh eVB adalah memakai control
standar Microsoft Form 2.0 yang memberikan dukungan terhadap pemakaian
karakter Unicode hanya dengan merubah setting property font-nya.
2.7 Microsoft SQL Server CE 2.0
Microsoft SQL Server CE 2.0 adalah aplikasi database yang ditujukan
untuk perangkat portable berbasis Windows CE. SQL Server CE memiliki cukup banyak kemiripan dengan Microsoft SQL Server 2000 untuk PC, seperti : format
metadata (struktur database), cara akses, teknik pemrograman, perintah dan dialek Structured Query Language (SQL).
SQL Server CE 2.0 merupakan aplikasi database yang handal dikelasnya
karena meskipun ukurannya cukup kecil tetapi menunjukkan performa yang lebih
baik dalam menggelola database berukuran besar, mampu mengoptimasi query, reliable dan scalabe. SQL Server CE 2.0 mendukung pengelolaan data yang terdiri dari karakter Unicode.
SQL Server CE 2.0 mendukung teknologi pengaksesan data
menggunakan Microsoft Windows CE Data Access 3.1 (ADOCE 3.1). ADOCE
adalah API yang digunakan oleh bahasa pemrograman tingkat tinggi seperti eVB
24
Batas maksimum ukuran dan jumlah untuk beberapa obyek database
yang didefinisikan dalam SQL Server CE 2.0 terdapat pada tabel 2.5.
Tabel 2.5. Maximum size limitations of database objects in SQL Server CE 2.0.
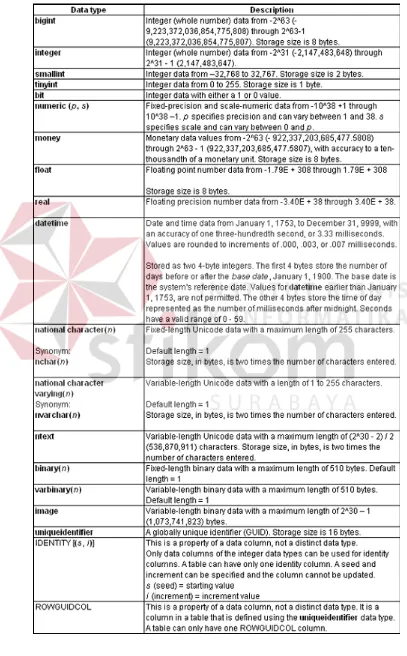
SQL Server CE 2.0 mendukung beberapa tipe data yang hampir sama
25
BAB III
PERANCANGAN SISTEM
3.1 Flowchart Sistem
Sistem yang dirancang untuk aplikasi kamus bahasa Jepang berbasis
Pocket PC, secara umum terbagi menjadi tiga blok proses, yaitu : input data
menggunakan SIP, pencarian kata dalam data kamus dan pemeliharaan
database-database yang digunakan oleh aplikasi.
3.1.1 Flowchart proses input
Aplikasi ini menggunakan dua jenis SIP, yaitu custom SIP dan default
SIP. Keduanya digunakan bersama-sama untuk menginputkan data pada proses
pencarian kata dan proses pemeliharaan database yang digunakan oleh aplikasi.
Fungsi utama custom SIP adalah memfasilitasi proses input tulisan
Jepang yang terdiri dari Kanji atau Kana. Terdapat empat macam custom SIP,
yaitu : Kana-keyboard SIP, Radical Kanji SIP, Unistroke Kanji SIP dan Unicode
characters map SIP.
Default SIP berfungsi untuk memfasilitasi proses input tulisan Latin.
Selain itu, default SIP juga berperan dalam proses input tulisan Jepang dalam
bentuk Romaji. Romaji tersebut akan dikonversi menjadi Kana dan Kana tersebut
dapat dikonversi menjadi Kanji. Selain itu, default SIP juga digunakan untuk
melakukan beberapa fungsi text editing, seperti : copy [Ctrl + C], paste [Ctrl + V], cut [Crtl + X] dan undo [Ctrl + Z]. Flowchart proses input menggunakan default SIP maupun custom SIP dapat dilihat pada gambar 3.1.
28
Temporary input buffer digunakan sebagai penampung sementara input Kana dan Kanji yang berasal dari kombinasi custom SIP dan default SIP
(Romaji). Temporary input buffer juga menampung Japanese word dari word query buffer yang merupakan feedback proses querydictionary.
Input berupa Kanji disajikan dalam bentuk daftar kandidat, sehingga user
diminta memilih salah satu Kanji dalam daftar tersebut untuk dikirimkan ke
temporary input buffer. Daftar kandidat yang dihasilkan dari proses konversi Kana
ke Kanji secara khusus terbagi menjadi daftar kandidat Kanji Okurigana dan non-Okurigana. Tombol [Okurigana] digunakan jika user hanya ingin menampilkan Kanji Okurigana pada daftar kandidat Kanji. Khusus untuk Unicode characters
map SIP, daftar kandidatnya terdiri dari seluruh karakter Unicode yang memiliki
kode heksadesimal berawalan dengan kode yang dinputkan user.
Input berupa Kana tidak langsung masuk dalam temporary input buffer
tetapi ditahan lebih dulu oleh Kana input buffer dengan tujuan memberikan
kesempatan kepada user untuk mengkonversikannya menjadi Kanji. Jika user
tidak ingin melakukan konversi maka user diminta memilih Kana input buffer
untuk mentransferkan isinya ke temporary input buffer.
Tombol [Enter] digunakan untuk mengirimkan temporary input buffer
ke word query buffer sesaat sebelum dimulainya proses dictionary query atau
dikirimkan ke Japanese data fields pada saat proses pemeliharaan database. Sedangkan untuk input berupa tulisan Latin (English word) langsung diinputkan ke word query buffer atau English data fields tanpa melalui temporary input
29
A Kana-keyboard SIP
User menginputkan Kana dengan cara menekan tombol-tombol yang
mewakili setiap karakter Kana dan akan dikirimkan ke Kana input buffer terlebih
dahulu. Jika user menekan tombol [semi-voiced mark] setelah menekan suatu
tombol Kana tertentu, maka karakter Kana tersebut diubah bentuknya dalam semi-voiced Kana. Hal ini juga belaku pada penekanan tombol [voiced mark].
Tombol [Hira/Kata] digunakan untuk merubah susunan tombol-tombol
keyboard dari Hiragana ke Katakana atau sebaliknya. sekaligus merubah isi dari
Kana input buffer dari Hiragana menjadi Katakana atau sebaliknya. Tombol
[Big/Small] digunakan untuk mengubah format beberapa Kana tertentu dari Big-Kana ke Small-Kana atau sebaliknya.
Tombol [Kana2Kanji] digunakan untuk proses konversi Kana ke Kanji.
Algoritma konversi Kana ke Kanji berusaha mencari seluruh Kanji dalam Kanji
reading data yang memiliki cara baca seperti yang tertera pada Kana input buffer,
kemudian memasukkanya dalam Kanji candidate list.
User diminta memilih salah satu Kanji dalam daftar tersebut atau
memilih Kana yang terdapat pada Kana input buffer untuk dikirimkan ke
temporary input buffer. Flowchart proses input menggunakan Kana-keyboard SIP
dapat dilihat pada gambar 3.2.
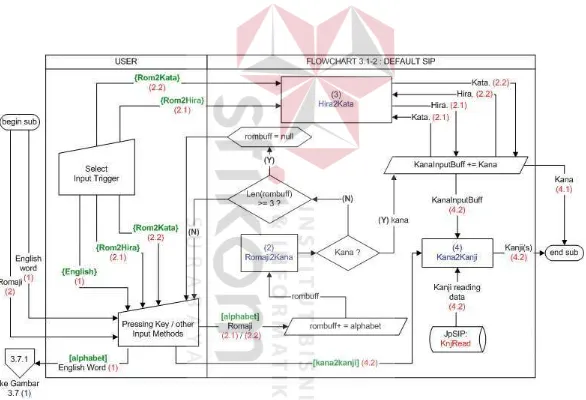
B Default SIP
Pada default SIP terdapat input trigger yang digunakan untuk membedakan antara input Romaji yang akan dikonversi ke Hiragana, Romaji yang
30
31
Jika input trigger yang dipilih user adalah Romaji-Hiragana/Katakana
maka serangkaian karakter alphabet yang dihasilkan dari proses penekanan
tombol-tombol default SIP dianggap oleh aplikasi sebagai Romaji yang akan
dikonversikan ke Hiragana atau Katakana. Sedangkan jika input trigger-nya
adalah English maka serangkaian karakter alphabet yang dihasilkan dari proses
penekanan tombol-tombol pada default SIP dianggap oleh aplikasi sebagai
English word.
Proses konversi Romaji ke Kana dilakukan per satu suku kata Romaji.
Pola pemenggalan suku kata Romaji, antara lain : vokal (v), konsonan (k), kv, kk
dan kkv. Ukuran Romaji buffer maksimal adalah 3 karakter. Proses konversi
dikatakan gagal apabila ukuran buffer sudah mencapai 3 huruf tetapi proses
konversinya tidak menghasilkan Kana. Jika konversi gagal maka buffer akan
dikosongkan. Buffer juga akan dikosongkan setelah konversi mencapai
kesuksesan, untuk bersiap-siap menerima input suku kata berikutnya. Di luar
kedua kondisi tersebut, buffer tidak dihapus. Hasil konversi Romaji ke Kana
dikirimkan terlebih dahulu ke Kana input buffer. Flowchart proses input
menggunakan default SIP dapat dilihat pada gambar 3.3.
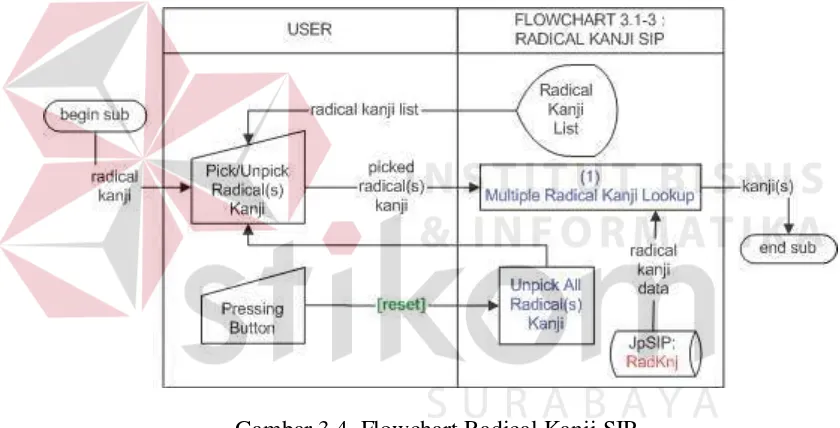
C Radical Kanji SIP
Pada awal proses disajikan daftar Kanji radikal yang dikelompokkan
berdasarkan jumlah goresannya. User diminta memilih satu atau lebih Kanji
radikal tersebut. Dilanjutkan dengan proses pencarian seluruh Kanji yang
32
33
User dapat membatalkan seluruh pilihan Kanji radikalnya dengan
menekan tombol [Reset] atau membatalkan satu demi satu pilihan Kanji
radikalnya. Proses multiple Radical Kanji lookup dilakukan setiap kali user
memilih satu Kanji radikal baru atau membatalkan pilihan terhadap suatu Kanji
radikal yang telah dipilih sebelumnya.
Hasil dari proses ini berupa daftar kandidat Kanji yang memiliki
Kanji-kanji radikal yang bersesuaian dengan pilihan user. Flowchart proses input
menggunakan Radical Kanji SIP dapat dilihat pada gambar 3.4.
Gambar 3.4. Flowchart Radical Kanji SIP.
D Unistroke Kanji SIP
Unistroke Kanji SIP digunakan untuk menginputkan Kanji dengan cara
menggambarkan setiap goresan Kanji pada panel yang disediakan sesuai dengan
Kanji stroke order rules. Pada proses penggambaran Kanji, jika user tidak segera
mengangkat stylus setelah menggambar satu goresan sampai suatu jeda waktu
tertentu habis, maka goresan berikutnya merupakan sub-stroke dari goresan
34
Query dilakukan pada Unistroke Kanji data untuk mendapatkan
Kanji-kanji yang memiliki elemen-elemen signature code yang sama dengan Kanji input
signature code. Meskipun proses pengenalan dengan cara seperti ini dapat
menyebabkan Kanji yang diinginkan tidak selalu berada pada urutan teratas, tetapi
prosesnya lebih cepat dan pemrogramannya lebih mudah jika dibandingkan
dengan cara menghitung satu per satu perbedaan sudut antara Kanji input dengan
seluruh signature code yang tersimpan dalam database kemudian menyortirnya
secara ascending. Terdapat dua Proses signature code matching, yaitu full signature code matchingdan partial signature code matching. Full signature code matching dilakukan dengan mempertimbangkan urutan signature code dari awal
hingga akhir. Sebaliknya, partial signature code matching dilakukan tanpa
mempertimbangkan urutan signature code tersebut. Hal ini bertujuan untuk
memperbesar kemungkinan keberhasilan proses pengenalan Kanji, meskipun user
tidak menggambarkan seluruh goresannya. Proses pengenalan Kanji dilanjutkan
dengan menerapkan filter ekstra untuk mencegah sebagian Kanji yang tidak sesuai
dengan stroke order rules masuk ke dalam Kanji candidate list.
User dapat menghapus seluruh goresan yang telah digambarkan dengan
menekan tombol [Reset]. Selain itu, user dapat membatalkan penggambaran satu
goresan terakhir dengan menekan tombol [Undo]. Sedangkan tombol [Partial]
digunakan untuk merubah status proses full signature code matching ke partial
signature code matching atau sebaliknya. Flowchart proses input menggunakan
35
36
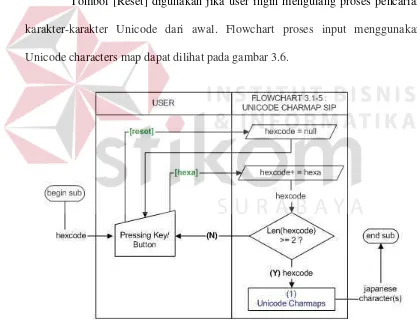
E Unicode characters map SIP
Unicode characters map SIP mengakomodasi seluruh karakter Unicode
dalam Japanese font yang digunakan (MS Gothic), melalui 4 digit kode angka berordo heksadesimal. User diminta untuk memasukkan kode minimal 2 digit
pertama dengan menekan tombol-tombol hexadecimal numpad, sehingga user akan mendapatkan maksimal 256 karakter yang berawalan dengan 2 digit kode
tersebut. Jika user memasukkan 3 digit akan mendapatkan maksimal 16 karakter.
Jika user memasukan 4 digit maka user akan mendapatkan tepat 1 karakter.
Tombol [Reset] digunakan jika user ingin mengulang proses pencarian
karakter-karakter Unicode dari awal. Flowchart proses input menggunakan
Unicode characters map dapat dilihat pada gambar 3.6.
Gambar 3.6. Flowchart Unicode Charaters Map SIP.
37
pertimbangan efisiensi konsumsi memori atau sengaja mengosongkan beberapa
bagian untuk mengklasifikasikan karakter-karakter dalam kategori tertentu.
3.1.2 Flowchart proses dictionary query
Proses dictionary query digunakan untuk mencari kata dalam data kamus
yang sesuai dengan isi word query buffer. Proses query dictionary terdiri dari dua
jenis query, yaitu proses Japanese query dan proses English query. Proses Japanese query digunakan untuk mencari terjemahan dalam bahasa Inggris dari
suatu kata dalam bahasa Jepang. Sebaliknya, proses English query digunakan
untuk mencari suatu kata dalam bahasa Jepang berdasarkan terjemahannya dalam
bahasa Inggris.
Kanji information digunakan untuk menampilkan informasi-informasi penting tentang sebuah Kanji yang dipilih user dari word query buffer, seperti :
hexadecimal Unicode, jumlah goresan, joyoo grade, frekuensi penggunaan, On-yumi readings, Kun-On-yumi readings, Kanji meanings, Unistoke Kanji signature code dan Kanji-kanji radikalnya.
Proses query dictionary menghasilkan daftar sejumlah kata berdasarkan
kata yang terdapat pada word query buffer yang berasal dari : proses input
menggunakan SIP, proses paste Windows CE clipboard, kata yang dipilih oleh
user dari data historis word query buffer atau feedback berupa kata yang dipilih
user dari word found list hasil proses query dictionary sebelumnya. Feedback memberikan konstribusi berupa kemudahan dan kecepatan untuk proses pencarian
kata baru dengan hanya sedikit melakukan modifikasi. Kontribusi yang sama juga
38
Untuk setiap kata yang dipilih user dari word found list akan dicarikan
pasangan terjemahannya pada data kamus. Flowchart proses query dictionary
dapat dilihat pada gambar 3.7.
3.1.3 Flowchart proses pengelolaan word query buffer
Word query buffer merupakan the heart of application, sebab berperan yang dinamis sebagai jembatan penghubung antar proses dalam aplikasi, seperti :
menghubungkan proses input dengan proses dictionary query, menghubungkan
proses input dengan proses Kanji information dan menjadi fasilitator proses copy
dan paste dari dan ke Windows CE clipboard.
Proses pengelolaan word query buffer digunakan untuk mengelola data
historis pencarian kata yang telah dilakukan sebelumnya. Aplikasi akan
menampilkan data historis pencarian yang berawalan dengan kata yang telah
diinputkan user.
User dapat menyimpan kata sebagai data historis pencarian kata dengan
menekan tombol [Save]. Sedangkan, tombol [Remove] digunakan untuk
menghapus data historis tertentu yang telah dipilih oleh user. Flowchart proses
pengelolaan word query buffer dapat dilihat pada gambar 3.8.
3.1.4 Flowchart proses pemeliharaan database kamus
Proses pemeliharaan database kamus meliputi proses penambahan,
perubahan dan penghapusan data kosa kata bahasa Jepang. Database kamus
menyimpan tiga field data, yaitu : kata dalam bahasa Jepang (Japanese word
field), penulisan kata tersebut dalam bentuk Kana (Kana field) dan terjemahan
40
41
Japanese word field diinput menggunakan default SIP atau custom SIP
yang menghasilkan Kanji dan Kana. Proses ini akan diulang apabila Japanese
word yang diinputkan sudah ada dalam database. Kana field diinput menggunakan
default SIP (Romaji) atau Kana-keyboard. English meanings field diinputkan oleh
user menggunakan default SIP (English).
Proses perubahan data mengharuskan user melakukan proses dictionary
query terlebih dahulu untuk mencari data yang akan diubah, sedangkan untuk
penambahan data, user tidak boleh menyertakan kata apapun sesaat sebelum
masuk dalam proses pemeliharaan data kamus. Pada setiap penambahan atau
perubahan data, user diminta menekan tombol [Save] untuk menyimpannya.
Tombol [Delete] digunakan untuk menghapus data. Tombol [Ok] digunakan
untuk mengakhiri proses pemeliharaan data kamus dan kembali ke proses
dictionary query. Flowchart proses pemeliharaan database kamus dapat dilihat
pada gambar 3.9.
3.1.5 Flowchart prosespemeliharaan database Kanji information.
Proses pemeliharaan database Kanji information meliputi proses
penambahan, perubahan dan penghapusan data yang memuat informasi-informasi
penting tentang Kanji.
Informasi tersebut terdiri dari empat grup, antara lain : Kanji reference, Unistroke Kanji signature code, Radical Kanji, Kanji meanings dan Kanji readings. Proses pemeliharaan data Kanji reference merupakan induk dari proses pemeliharaan database Kanji information sehingga proses penambahan data Kanji
information baru harus melalui proses pemeliharaan data kelompok ini terlebih
43
A Flowchart grup Kanji reference
Proses pemeliharaan data Kanji reference meliputi data Kanji beserta
jumlah goresannya, joyoo grade-nya dan frekuensi penggunaannya dalam bahasa
Jepang. Kanji field diinputkan oleh user menggunakan default SIP atau Custom
SIP yang dapat menghasilkan Kanji. Proses ini akan diulang apabila Kanji yang
diinput oleh user sudah ada dalam database Kanji Information. Stroke count field, joyoo grade field dan frequence of use field diinputkan oleh user menggunakan default SIP (English) dalam bentuk numerik. Flowchart proses pemeliharaan data
Kanji reference dapat dilihat pada gambar 3.10.
Jika user ingin melakukan perubahan atau penghapusan data maka user
harus memilih sebuah Kanji yang akan diubah atau dihapus datanya pada word
query buffer terlebih dahulu, sedangkan untuk proses penambahan data user tidak
boleh menyertakan Kanji apapun sesaat sebelum masuk dalam masuk dalam
proses pemeliharaan data Kanji information. Untuk setiap proses penambahan
atau perubahan terhadap suatu data, user diminta menekan tombol [Save] untuk
menyimpannya.
Tombol [Detele] digunakan untuk menghapus data informasi Kanji yang
meliputi seluruh kelompok data informasi Kanji. Tombol [Ok] digunakan untuk
mengakhiri proses pemeliharaan data kamus dan kembali ke proses dictionary
query.
B Flowchart grup Unistroke Kanji signature code
Proses pemeliharaan data Unistroke Kanji signature code meliputi data
Kanji beserta Unistroke Kanji signature code dan filter ekstranya. Kanji field
45
Sedangkan Unistroke Kanji signature code field diinputkan oleh user
menggunakan default SIP dengan menginputkan kode-kode Unistroke Kanji dari
setiap goresan Kanji tersebut.
Aplikasi ini akan mencari beberapa Kanji lain yang memiliki kesamaaan
signature code dengan Kanji inputan untuk membuat daftar filter ekstranya. Hal
ini bertujuan agar user dapat menyesuaikan filter ekstra Kanji baru dengan filter
ekstra Kanji yang sudah ada sehingga keunikan signature code setiap Kanji tetap
terjaga. Extra filter field diedit oleh user menggunakan default SIP (English). Untuk setiap proses perubahan terhadap suatu data unistroke signature
code dan filter ekstra suatu Kanji, user diminta menekan tombol [Save]. Daftar
filter ekstra akan diupdate setelah proses penyimpanan selesai dilakukan.
Flowchart proses pemeliharaan data Unistroke Kanji signature code dapat dilihat
pada gambar 3.11.
C Flowchart grup Radical Kanji
Proses pemeliharaan data grup Radical Kanji sebenarnya hanya
mengupdate Radical-based Kanji list field, walaupun dalam struktur databasenya masih terdapat beberapa field lain (Radical Kanji, Radical stroke, Radical meanings dan Radical image code). Field-field tersebut bersifat statis dan telah diinput terlebih dahulu.
Aplikasi akan menampilkan daftar Kanji radikal yang dimiliki oleh
sebuah Kanji sekaligus arti masing-masing Kanji radikal tersebut. Setiap Kanji
radikal yang terdapat dalam daftar tersebut dipetakan pada Radical Kanji SIP
46
47
Radical Kanji SIP digunakan oleh user untuk merubah susunan picked
Radical sekaligus mengupdate daftar Kanji radikal. Setelah itu user dapat
menyimpannya dengan menekan tombol [Save]. Flowchart proses pemeliharaan
data grup Radical Kanji dapat dilihat pada gambar 3.12.
D Flowchart grup Kanji meanings
Proses pemeliharaan data Kanji meanings meliputi data beberapa arti
dari suatu Kanji. Kanji field diambil dari Kanji field kelompok Kanji reference.
Sedangkan Kanji meaning field diinputkan oleh user menggunakan default SIP
(English). Proses ini akan diulang apabila Kanji dan artinya yang diinput oleh user
sudah ada dalam database. User diminta memilih salah satu item pada daftar arti
Kanji terlebih dahulu sebelum merubah atau menghapus item tersebut. Tombol
[Delete] digunakan untuk menghapus item yang dipilih. Tombol [Save] digunakan
untuk menyimpan perubahan data. Flowchart proses pemeliharaan data Kanji
meanings dilihat pada gambar 3.13.
E Flowchart grup Kanji readings
Proses pemeliharaan data Kanji readings meliputi data cara-cara baca
sebuah Kanji. Flowchart proses pemeliharaan data Kanji readings dilihat pada
gambar 3.14. Kanji field diambil dari Kanji field kelompok Kanji reference. Kanji reading class field adalah jenis dari cara baca sebuah Kanji. Terdapat tiga jenis cara baca, yaitu : cara baca biasa, cara baca Kanji sebagai Nanori dan cara baca Kanji sebagai Kanji radikal. Kanji readings field diinputkan oleh user
49
Default SIP digunakan untuk menginputkan Dot (.)atau Dash (-)sebagai bagian dari format data Kanji reading. Formatnya adalah sebagai berikut.
(Dash1)Kana1(Dot)Kana2(Dash2)
Dash1 dan Dash2 digunakan sebagai pertanda bahwa sebuah Kanji
merupakan prefix (Dash1) atau suffix (Dash2) apabila dibaca dengan cara baca tersebut. Dot digunakan sebagai pertanda bahwa Kana1 merupakan cara baca
sebuah Kanji yang dipandang dari sisi Okurigana-nya. Okurigana adalah bagian
dari kata (seharusnya berupa Kanji) yang ditulis dalam bentuk Kana. Dalam hal
ini kata tersebut adalah gabungan antara Kana1 dan Kana2, sedangkan Okurigana
adalah Kana1.
Aplikasi akan menampilkan daftar seluruh cara baca yang dimiliki oleh
sebuah Kanji yang dibagi dalam dua kelompok, yaitu : On-yumi dan Kun-yumi.
User diminta memilih salah satu item daftar On-yumi atau Kun-yumi terlebih
dahulu sebelum merubah atau menghapus item tersebut.
Tombol [Delete] digunakan untuk menghapus item yang dipilih,
sedangkan tombol [Save] digunakan untuk menyimpan perubahan data. Apabila
tidak ada item yang dipilih oleh user maka cara baca Kanji yang diinputkan oleh
user dianggap oleh aplikasi sebagai cara baca baru ketika user menekan tombol
[Save]. Proses penyimpanan data sekaligus akan mengupdate daftar On-yumi
readings (Katakana) atau daftar Kun-yumi readings (Hiragana).
Pada saat disimpan, Kanji reading field akan diperiksa ulang oleh
aplikasi untuk menentukan nilai dari field oku (posisi karakter dot), sp (posisi
51
52
Sedangkan nilai yang disimpan dalam Kanji reading field adalah Kanji
reading polos tanpa dot dan dash. Proses ini sengaja dilakukan untuk keperluan
indexing database agar proses konversi Kana ke Kanji lebih optimal.
3.2 Struktur Database
53
Terdapat 3 jenis database yang berbeda peran dalam aplikasi ini, yaitu :
TEMP, JPSIP dan EDICT. Struktur dari ketiga jenis database tersebut terdapat
pada table 3.1. Database TEMP menyimpan data historis setiap goresan pada
proses penggambaran Kanji menggunakan Unistoke Kanji SIP. Database TEMP
juga menyimpan data historis word query buffer. Database JPSIP menyimpan
data-data yang digunakan oleh custom SIP pada proses input karakter Jepang.
Database JPSIP juga menyimpan data-data digunakan oleh default SIP untuk
proses konversi Romaji ke Kana. Database EDICT menyimpan data-data kosa
kata bahasa Jepang beserta pengucapannya yang ditulis dalam Kana dan
terjemahannya dalam bahasa Inggris.
Relasi antara tabel KnjInf dengan tabel KnjMean, KnjRead dan
Unistroke dapat dilihat pada gambar 3.15.
Gambar 3.15. Relasi tabel KnjInf, KnjMean, KnjRead dan Unistroke.
Tabel RadKnj bersifat semi-statis karena jumlah datanya tidak
berkembang, hanya field knjlst saja berubah. Tabel Romanji bersifat read-only karena tabel ini sengaja dibuat sebagai bagian proses konversi Romaji ke Kana
54
3.3 Desain User Interface
Secara umum interface aplikasi ini terdiri dari, SIP panel, word query
buffer, statusbar, word found list, translation box dan toolbar. Gambar 3.16 merupakan rancangan tampilan utama dari aplikasi.
Secara umum toolbar terdiri dari custom SIP menu, selected custom SIP button, tools buttons, selected default SIP button dan default SIP menu. Tools buttons merupakan susunan serangkaian tombol yang mewakili fungsi-fungsi
tertentu dan secara dinamis akan berubah susunannya disesuai dengan
proses-proses tertentu. Sebagai contoh pada proses-proses query dictionary dimana custom SIP
maupun default SIP tidak dalam keadaan aktif dan word query buffer tidak dalam
keadaan terfokus, maka susunan dari tools button seperti yang terlihat pada
gambar 3.16.
55
Statusbar digunakan untuk menampilkan berbagai informasi, seperti :
waktu yang diperlukan untuk melakukan proses tertentu. Word found list
digunakan untuk menampilkan daftar kata hasil dari proses query data. Sedangkan
translation box digunakan untuk menampilkan translasi dari kata yang dipilih dari
word found list.
Interface custom SIP menu pada saat default SIP tidak aktif dapat dilihat
pada gambar 3.17. Kelompok menu custom SIP digunakan untuk memilih jenis
custom SIP. Jenis custom SIP yang sedang aktif pada menu ditandai dengan bullet mark, selain itu ditunjukkan juga dengan icon yang tertera pada selected custom SIP button. selected custom SIP button merupakan switch button yang digunakan untuk menampilkan active custom SIP.
Gambar 3.17. Susunan custom SIP menu (default SIP tidak aktif)
Menu Exit digunakan untuk menutup program. Menu View Statusbar
digunakan untuk menampilkan atau menyembunyikan statusbar. Menu Options
digunakan untuk menampilkan berbagai setting yang berkaitan dengan aplikasi.
Menu Kanji Info digunakan untuk menampilkan Kanji information berdasarkan
56
proses pemeliharaan database Kanji information. Menu Dictionary data digunakan
untuk proses pemeliharaan database kamus. Untuk menampilkan petunjuk
penggunaan aplikasi pilih menu Help pada Start menu Pocket PC.
Sedangkan apabila default SIP aktif, kelompok menu custom SIP
berubah menjadi default SIP input trigger seperti pada gambar 3.18. Jenis input
trigger yang sedang aktif pada menu ditandai dengan bullet mark, selain itu
ditunjukkan juga dengan icon yang tertera pada selected custom SIP button.
Romaji-Hiragana atau Romaji-Katakana input trigger digunakan sebagai pertanda
bahwa data yang diinputkan menggunakan default SIP merupakan Romaji yang
akan diubah menjadi Hiragana atau Katakana. Sedangkan English input trigger
digunakan sebagai pertanda bahwa data yang diinputkan menggunakan default
SIP merupakan English word (karakter Latin).
Gambar 3.18. Susunan custom SIP menu (default SIP aktif)
3.3.1 Interface SIP
Pada aplikasi ini terdapat lima jenis SIP yang digunakan untuk
menginputkan data, yaitu : Kana-keyboard SIP, default SIP, Radical Kanji SIP,
57
A Kana-Keyboard SIP
Kana-keyboard SIP terdiri dari SIP panel, Kana input buffer, Kanji
candidate list dan temporary input buffer. SIP panel berbentuk sebuah keyboard
dengan beberapa tombol yang mewakili karakter Kana yang disusun sesuai
dengan Kana-syllabary layout. Gambar 3.19 merupakan rancangan interface Kana-keyboard SIP.
Terdapat beberapa tombol khusus, antara lain : ideograph comma, ideograph full-stop, voiced mark, semi-voiced mark, Katakana prolong dan space. Ideograph comma adalah karakter koma dalam tulisan Jepang. Ideograph
full-stop adalah karakter titik dalam tulisan Jepang. Tombol [voiced mark]
digunakan untuk merubah Kana yang dinputkan paling akhir dalam bentuk voiced Kana. Hal ini berlaku pada tombol [semi-voiced mark].
Gambar 3.19. Rancangan interface Kana-keyboard SIP
Tombol [Backspace] digunakan untuk menghapus suatu karakter pada
temporary input buffer. Tombol [Esc] digunakan untuk membatalkan inputan
58
memindahkan cursor pada temporary input buffer satu karakter ke kiri atau ke
kanan. Tombol [Smal/Big] Kana digunakan untuk merubah beberapa tombol
Kana tertentu dalam format Small-Kana atau Big-Kana. Tombol
[Hiragana/Katakana] digunakan untuk mengubah layout Kana-keyboard dari
Hiragana menjadi Katakana atau sebaliknya. Tombol [Kana2Kanji] digunakan
untuk mengkonversi Kana yang terdapat pada Kana input buffer menjadi Kanji.
Tombol [Okurigana] digunakan untuk menampilkan Kanji Okurigana pada daftar
kandidat Kanji.
B Default Pocket PC SIP
Default Pocket PC SIP dapat digunakan untuk menginputkan English
word (karakter Latin) maupun Japanese word (Kana dan Kanji) bergantung pada
input trigger yang dipilih oleh user. Gambar 3.20 merupakan rancangan interface
pada saat default SIP aktif dan active input triggernya Romaji-Hiragana atau
Romaji-Katakana.
59
Jika active input trigger yang dipilih adalah English maka Kana input
buffer, Kanji candidate list dan temporary input buffer tidak dipakai karena setiap
karakter Latin langsung diinputkan ke word query buffer sebagai English word.
Jika active input trigger yang dipilih adalah Romaji-Hiragana atau
Romaji-Katakana maka Kana input buffer, Kanji candidate list dan temporary
input buffer difungsikan kembali seperti pada Kana-keyboard SIP tetapi setiap
Kana pada Kana input buffer tidak didapatkan dari penekanan satu tombol
melainkan serangkaian tombol yang membentuk satu suku kata Romaji. Setiap
satu suku kata Romaji dikonversikan menjadi Hiragana atau Katakana.
Tombol [Esc] digunakan untuk membatalkan inputan pada Kana input
buffer. [Kana2Kanji] digunakan untuk mengkonversi Kana pada Kana input
buffer menjadi Kanji. Tombol [Okurigana] digunakan untuk menampilkan
Kanji-kanji Okurigana pada daftar kandidat Kanji.
C Radical Kanji SIP
Radical Kanji SIP terdiri dari SIP panel dan temporary input buffer.
Pada SIP panel terdapat Radical Kanji grid dan Kanji candidate list. Radical Kanji grid berisi Kanji radikal yang dikelompokkan berdasarkan jumlah goresannya.
User diharuskan memilih minimal satu Kanji radikal dalam grid tersebut untuk
mendapatkan Kanji yang diinginkannya. User dapat membatalkan suatu pilihan
Kanji radikal dengan memilih ulang Kanji radikal tersebut. Kanji candidate list
digunakan untuk menampung hasil proses multiple Radical Kanji Lookup.
Tombol [Reset] digunakan untuk membatalkan semua pilihan Kanji
radikal yang telah dipilih sebelumnya. Tombol [Backspace] digunakan untuk
60
digunakan untuk mengirim temporay input buffer ke word query buffer. Gambar
3.21 merupakan rancangan interface Radical Kanji SIP.
Gambar 3.21. Rancangan interface Radical Kanji SIP.
D Unistroke Kanji SIP
Unistroke Kanji SIP terdiri dari SIP panel dan temporary input buffer.
Pada SIP panel terdapat Kanji drawing panel dan Kanji candidate list. User diharuskan menggambarkan setiap goresan Kanji yang diinginkannya sesuai
dengan Unistroke Kanji stroke order rules. Kanji candidate list digunakan untuk
menampung sejumlah Kanji hasil proses Unistroke Kanji recognition. Gambar
3.22 merupakan rancangan interface Unistroke Kanji SIP.
61
Tombol [Backspace] digunakan untuk menghapus karakter yang terdapat
pada temporary input buffer. Tombol [Enter] digunakan untuk mengirim
temporay input buffer ke word query buffer. Tombol [Reset] digunakan untuk
mengulang proses penggambaran Kanji dari awal. Tombol [Undo] digunakan
untuk mengulang proses penggambaran satu goresan terakhir. Tombol switch
[Partial] digunakan sebagai pertanda bahwa proses Unistroke Kanji signature code
matching bersifat normal atau parsial.
E Unicode characters map SIP
Unicode characters map SIP terdiri dari SIP panel dan temporary input
buffer. Pada SIP panel terdapat hexadecimal numpad dan Kanji candidate list.
User diharuskan memasukkan minimal 2 digit pertama hexadecimal Unicode
untuk mendapatkan karakter-karakter Unicode yang terdapat pada font Ms Gothic.
Rancangan Unicode characters map SIP dapat dilihat pada gambar 3.23.
Gambar 3.23. Rancangan Unicode characters map SIP.
Susunan tools button pada toolbar terdiri dari Backspace, Enter dan