i
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Teknik Program Studi Teknik Informatika
OLEH:
Y. YENI KRISTIAWAN
NIM : 055314039
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
FINAL PROJECT
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Teknik Degree
In Informatics Engineering
By:
Y. YENI KRISTIAWAN
NIM : 055314039
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Penulis
vi
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Y. Yeni Kristiawan
NIM : 055314039
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
MESIN PENCARI DATA TOKOH DAN CERITA WAYANG DALAM KAMUS PEWAYANGAN
Beserta perangkat yang diperlukan ( bila ada ). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini yang saya buat dengan sebenarnya.
Dibuat di Yogyakarta Pada tanggal : 16 Juli 2009
Yang menyatakan
vii
Skripsi ini saya persembahkan untuk:
Ibu, Bapak dan Mas Toro atas dukungan, semangat, kasih sayang dan dukungan kalian semua, tanpa kalian semua ini tidak akan berarti.
Buat pacar dan semua sahabatku atas semua dukungan dan kritik kalian dalam penyusunan skripsi ini.
viii
Nikmati dan syukurilah hari ini, seolah hari ini adalah hari terakhir dalam hidup kita.
Kae manungsa golek upa angkara Sesingidan mawuni ngGawa bandha donya
mBuwang rasa agama Nyingkiri sesanti ati
Tan wedi dosa Tan eling bakal mati
ix
melimpahkan berkat-Nya. Sehingga saya dapat menyelesaikan Laporan Tugas
Akhir ini.
Pada kesempatan ini saya ingin mengucapkan terima kasih kepada pihak –
pihak yang telah membantu saya dalam menyelesaikan skripsi ini, baik dalam hal
bimbingan, perhatian, kasih sayang, semangat, kritik, dan saran yang telah
diberikan. Ucapan terima kasih ini saya sampaikan antara lain kepada :
1. Bapak Yosef Agung Cahyanta, S.T., M.T., selaku Dekan Fakultas Sains dan
Teknologi Universitas Sanata Dharma Yogyakarta.
2. Bapak Puspaningtyas Sanjaya Adi, S.T., M.T., selaku Ketua Jurusan Teknik
Informatika Universitas Sanata Dharma.
3. Bapak JB. Budi Darmawan S.T., M.Sc, selaku Dosen Pembimbing Akademik
Teknik Informatika angkatan 2005.
4. Bapak Alb. Agung Hadhiatma, S.T, M.T, selaku Dosen Pembimbing TA.
Terima kasih atas bimbingan selama saya mengerjakan Laporan Skripsi ini.
5. Kedua orangtua dan kakak, terima kasih atas dukungan, kasih sayang dan
semangat yang tiada henti sehingga saya dapat menyelesaikan Tugas Akhir
ini.
6. Seluruh pihak yang membantu saya baik secara langsung maupun tidak
Saya menyadari masih banyak kekurangan yang terdapat pada laporan ini. Saran dan kritik selalu saya harapkan dari pembaca untuk perbaikan – perbaikan di masa yang akan datang.
Akhir kata, saya berharap tulisan ini dapat bermanfaat bagi kemajuan dan perkembangan ilmu pengetahuan dan berbagai pihak pengguna pada umumnya.
Yogyakarta, Juli 2009
xi
lakon wayang, hal ini menyebabkan banyaknya dokumen dalam pewayangan.
Oleh karena banyaknya dokumen yang ada akan mempersulit proses pencarian
dokumen berdasarkan kriteria tertentu.
Tugas akhir ini bertujuan untuk membangun aplikasi yang dapat
digunakan untuk membantu proses pencarian dokumen wayang dari koleksi
dokumen yang dimiliki dan dapat mengelola jika ada dokumen baru yang
ditambahkan ke dalam koleksi dokumen. Aplikasi ini dikembangkan
menggunakan perangkat lunak Visual Basic Versi 6 dan basis data SQL SERVER
2000.
Hasil yang dapat diperoleh mengunakan aplikasi ini adalah dapat
mempermudah pengguna untuk mencari dokumen wayang berdasarkan kriteria
xii
matter causes document quantity in puppetry. Therefore, document quantity
existence will complicate document livelihood process based on certain criteria.
The aim from this task ends to build application that can be used to help
livelihood process puppet document from document collection that has and can
managed if there new document that is added into document collection. This
application is developed to use Visual Basic Version 6 software and database SQL
SERVER 2000.
The result that obtainable use this application can simplify user to look for
xiii
HALAMAN PENGESAHAN ... iv
PERNYATAAN KEASLIAN KARYA ...v
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vi
HALAMAN PERSEMBAHAN ... vii
HALAMAN MOTO ... viii
KATA PENGANTAR ... ix
ABSTRAKSI ... xi
ABSTRACT... xii
DAFTAR ISI... xiii
DAFTAR TABEL... xvii
DAFTAR GAMBAR ... xviii
BAB I ...1
PENDAHULUAN ...1
1.1 Latar Belakang ...1
1.2 Rumusan Masalah ...2
1.3 Batasan Masalah...2
1.5 Metode Penelitian...3
1.6 Sistematika Penulisan...4
BAB II...6
LANDASAN TEORI...6
2.1 Pengertian Sistem Temu-kembali Informasi...6
2.2 Pengindeksan (Indexing) Dalam Sistem Temu-Kembali Informasi ...11
2.2.1 Stemming...13
2.2.2 Porter Stemmer for Bahasa Indonesia...14
2.3 Teknik-teknik Temu-kembali Informasi ...17
2.4 Algoritma TF/IDF ...20
2.5 Evaluasi Sistem Temu Kembali Informasi...21
BAB III ...23
ANALISIS DAN PERANCANGAN ...23
3.1 Analisa Sistem...23
3.1.1 Analisis Kebutuhan ...23
3.2 Metode Pengumpulan Data ...24
3.3 Perancangan Sistem...24
3.3.1 Model Use Case ...24
3.3.1.1 Actor...24
3.3.1.2 Diagram Use Case ...25
3.3.2 Data Flow Diagram (DFD) ...26
3.3.3 Bagan Alir Program ...29
3.3.3.1 Algoritma proses indexing...30
3.3.3.2 Algoritma proses pencarian dokumen...38
3.3.4 Perancangan Database...46
3.3.4.1 Conceptual Database Design...46
3.3.4.2 Logical Database Design...46
3.3.4.3 Physical Database Design...47
3.4 Perancangan Antarmuka (Interface)...49
1. Desain Menu Utama...50
2. Desain Form Pencarian ...51
3. Desain Form Login...52
4. Desain Form Menu Utama Admin ...52
5. Desain Form Admin Tambah Dokumen ...53
6. Desain Form Admin Manage Stoplist ...54
BAB IV ...55
IMPLEMENTASI...55
4.1 Spesifikasi Software dan Hardware yang digunakan ...55
4.1.1 Spesifikasi Software...55
4.1.2 Spesifikasi Hardware ...55
4.2 Koneksi Basisdata dengan Sistem...55
4.3 Pembuatan Antarmuka (Interface) ...56
4.3.1 Form Menu Utama ...56
4.3.2 Form Cari Dokumen Wayang ...57
4.3.3 Form About ...68
4.3.4 Form Login ...68
4.3.5 Form Menu Admin ...69
4.3.6 Form Tambah Dokumen ...70
4.3.7 Form Manage Stopword ...74
BAB V ...79
ANALISIS HASIL...79
5.1 Analisa Hasil Program ...79
5.2 Kelebihan dan Kekurangan Sistem ...101
5.2.1 Kelebihan Sistem ...101
5.2.2 Kekurangan Sistem ...102
BAB VI ...103
KESIMPULAN DAN SARAN...103
6.1 Kesimpulan...103
6.2 Saran...104
DAFTAR PUSTAKA ...105
xvii
Tabel 2.2 Kelompok rulekedua: inflectional possessive pronouns………… 15
Tabel 2.3 Kelompok ruleketiga: first order of derivational prefixes………. 16
Tabel 2.4 Kelompok rulekempat:second order of derivational prefixes…… 16
Tabel 2.5Kelompok rulekelima: derivatioanal suffixes……… 16
Tabel 2.6 Tabel Extended Boolean……….. 18
Tabel 3.1 Tabel Use Case ……… 26
Tabel 3.2 Tabel Term ……….. 47
Tabel 3.3 Tabel Term List ………... 48
Tabel 3.4 Tabel Dokumen ………... 48
Tabel 3.5 Tabel Stoplist ………... 49
Tabel 3.6 Tabel Admin ……… 49
Tabel 5.1 Perhitungan TF*IDF Untuk Kata Kunci “Semar” ………... 82
Tabel 5.2 Hasil Pengurutan Dokumen Untuk Kata Kunci “Semar” ………… 83
Tabel 5.3 Urutan Dokumen Untuk Kata Kunci “Semar” ……… 83
Tabel 5.4 Nilai Recall-Precision Untuk Kata Kunci “Semar” ………. 84
Tabel 5.5 Nilai Recall-Precision Untuk Kata Kunci “Bima” ……….. 87
Tabel 5.6 Hasil Perhitungan Recall-Precision ………. 92
Tabel 5.7 Hasil Perhitungan Interpolasi Recall-Precision ………... 92
Tabel 5.8 Hasil Perhitungan Interpolasi dan Average ………. 93
Tabel 5.9 Hasil Perhitungan TF*IDF Untuk Kata Kunci “Subali dan Sugriwa” ……….. 97
xviii
Gambar 2.2 Bagian-bagian Sistem Temu Kembali Informasi …………...…... 9
Gambar 2.3 Algoritma Porter stemming for Bahasa Indonesia……… 15
Gambar 3.1 Diagram Use Case ………... 25
Gambar 3.2 Diagram Konteks ………... 27
Gambar 3.3 Diagram Berjenjang ………... 27
Gambar 3.4 DFD Level 0 Admin ……….. 28
Gambar 3.5 DFD Level 0 User ……….. 28
Gambar 3.6 DFD Level 1 Proses 2 Proses admin manage stoplist …………... 29
Gambar 3.7 Ilustrasi Proses Indexing……… 30
Gambar 3.8 Blok Diagram Proses Indexing……….. 31
Gambar 3.9 Flowchart Proses Parsing ………... 32
Gambar 3.10 Flowchart Proses Romoving Stopword ………... 33
Gambar 3.11 Flowchart Proses Perhitungan Frekuensi Kata ……… 35
Gambar 3.12 Flowchart Proses Filtering ………... 37
Gambar 3.13 Blok Diagram Proses Pencarian Dokumen ………. 38
Gambar 3.14 Flowchart Proses Pembuatan Kondisi Where Statement Untuk Query ………..………... 41
Gambar 3.15 Flowchart Proses Query ke Database ……….. 43
Gambar 3.16 Flowchart Proses Tampil Hasil Query ……….... 45
Gambar 3.17 Diagram E-R ……… 46
Gambar 3.18 Relasi Antar Tabel ………... 46
Gambar 3.19 Desain Menu Utama ……… 50
Gambar 3.20 Desain Form Pencarian ……… 51
Gambar 3.21 Desai Form Login ……… 52
Gambar 3.22 Desain Form Menu Utama Admin ……….. 52
Gambar 3.24 Desain Form Manage Stoplist ………... 54
Gambar 4.1 Form Menu Utama ………... 56
Gambar 4.2 Form Cari Dokumen ……….. 57
Gambar 4.3 Form About ……… 68
Gambar 4.4 Form Login ……… 69
Gambar 4.5 Form Manu Utama Admin ……….... 70
Gambar 4.6 Form Tambah Dokumen ……… 71
Gambar 4.7 Form Mange Stoplist ………... 75
Gambar 5.1 Hasil Pencarian Dokumen Kata Kunci “Semar” ………... 80
Gambar 5.2 Grafik Recall-Precision Untuk Kata Kunci “Semar” …..……... 85
Gambar 5.3 Hasil Pencarian Dokumen Kata Kunci “Bima” ………. 87
Gambar 5.4 Grafik Recall-Precision Untuk Kata Kunci “Bima” …..……... 88
Gambar 5.5 Hasil Pencarian Dokumen Dengan Kata kunci “Shinta” ………... 90
Gambar 5.6 Hasil Pencarian Dokumen Dengan Kata kunci “Sita” …………... 91
Gambar 5.7 Grafik Interpolasi Recall-Precision ………... 94
Gambar 5.8 Hasil Pencarian dengan Kata Kunci “Subali dan Sugriwa” …….. 99
Gambar 5.9 Hasil Pencarian dengan Kata Kunci “bagong+gareng&petruk,semar(Ismaya)”……….. 100
1 1.1 Latar Belakang
Dalam pewayangan terdapat begitu banyak tokoh dan judul kriteria atau lakon wayang, hal ini menyebabkan banyaknya dokumen dalam pewayangan. Oleh karena banyaknya dokumen yang ada akan mempersulit proses pencarian dokumen berdasarkan kriteria tertentu. Contohnya ketika kita ingin mencari dokumen yang membahas tentang tokoh Arjuna dari 100 dokumen yang dimiliki, kita harus membaca isi dari setiap dokumen satu persatu sebanyak 100 kali. Atau kita ingin mencari dokumen yang berhubungan dengan judul kriteria atau lakon Mahabarata, kita juga harus membaca semua koleksi dokumen yang dimiliki satu persatu. Masalahnya adalah bagaimana memilih dokumen dari keseluruhan koleksi dokumen yang dimiliki dengan kriteria pencarian tertentu tapi dengan tingkat kesesuaian yang paling maksimal, kemudian menyajikan isi dari dokumen yang berhasil dicari kepada user.
Sistem temu-kembali informasi (information retrieval system) adalah solusi yang tepat untuk menangani banyaknya dokumen dalam pewayangan. Sistem temu-kembali informasi terbagi dalam beberapa proses, yakni proses
indexing, pencarian dokumen yang relevan dengan querydari user.
proses indexing ini teknik yang dapat digunakan untuk mencari dokumen yang relevan dengan query dari user adalah berdasarkan jumlah frekuensi kemunculan kata yang paling banyak, dengan teknik ini akan ditemukan urutan dokumen yang berhasil ditemukan berdasarkan jumlah frekuensi kemunculan kata.
1.2 Rumusan Masalah
Dari latar belakang masalah di atas dapat dirumuskan menjadi beberapa masalah sebagai berikut:
1. Bagaimana mengimplementasikan program bantu pencarian atau mesin pencari untuk mempermudah pencarian dokumen dari koleksi dokumen wayang berdasarkan kriteria tertentu dengan tingkat kesesuaian yang tertinggi?
1.3 Batasan Masalah
Dalam aplikasi mesin pencari data tokoh dan kriteria wayang dilakukan beberapa batasan sebagai berikut:
1. Dokumen yang dapat diproses adalah dokumen teks (*.txt).
2. Teknik temu-kembali informasi yang dipakai adalah teknik Boolean biasa dengan operator “OR”.
1.4 Tujuan Penelitian
Adapun tujuan penulisan skripsi adalah sebagai berikut:
1. Membuat program bantu pencarian atau mesin pencari untuk mempermudah pencarian dokumen dari koleksi dokumen wayang berdasarkan kriteria tertentu dengan tingkat kesesuaian yang tinggi.
1.5 Metode Penelitian
Dalam penyusunan skripsi dan pembuatan program bantu pencarian data tokoh dan kriteria wayang, dipakai beberapa metode untuk mencari informasi yang diperlukan, yaitu:
1. Metode studi literatur
Mencari dan mengumpulkan literatur-litaratur yang berkaitan dengan permasalahan yang dikerjakan, yaitu mengenai Sistem temu-kembali informasi (information retrieval system), data tokoh dan kriteria wayang melalui internet, buku-buku dan media informasi lainnya, selain itu juga menegenai Visual Basic dan SQL Server .
2. Metode pengembangan sistem
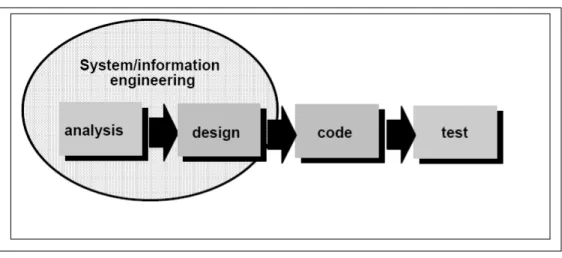
Metode pengembangan system yang dipakai dalam pembuatan program bantu pencarian data tokoh dan kriteria wayang menggunakan metode Linear
Fase-fase dalam Waterfall Modelmenurut referensi Pressman:
1. Analisa: Membuat bagan alir program, diagram arus data (DFD) dan ER-Diagram.
2. Desain: Membuat desain databasedan desain antarmuka (interfaces).. 3. Implementasi: Menerapkan hasil analisa dan desain pada tahap
sebelumnya.
4. Testing: Menguji dan menganalisa hasil program.
Gambar 1.1 Fase-fase dalam Waterfall Model menurut referensi Pressman
1.6 Sistematika Penulisan BAB I PENDAHULUAN
BAB II LANDASAN TEORI
Berisi konsep dasar sistem temu-kembali informasi (information retrieval system), bagian-bagian dari sistem temu kembali informasi, teknik-teknik temu-kembali informasi, dan evaluasi sistem temu kembali informasi. BAB III ANALISIS dan PERANCANGAN SISTEM
Berisi analisis kebutuhan, metode pengumpulan data, diagram arus data, kamus data, E-R diagram sistem, perancangan proses, perancangan basis data, perancangan modul, perancangan tampilan masukan dan keluaran untuk pengguna, dan perancangan teknologi.
BAB IV IMPLEMENTASI
Berisi penjelasan dan fungsi program bantu pencarian sebagai alat bantu pencarian data tokoh dan kriteria wayang.
BAB V ANALISIS HASIL
Berisi evaluasi program sistem temu kembali informasi, kelebihan dan kekurangan program.
BAB VI KESIMPULAN dan SARAN
Berisi kesimpulan dan saran dari pembuatan program bantu pencarian data tokoh dan kriteria wayang.
6
2.1 Pengertian Sistem Temu-kembali Informasi
Pada dasarnya sistem temu-kembali informasi adalah suatu proses untuk mengidentifikasi, kemudian memanggil (retrieve) suatu dokumen dari suatu simpanan (file), sebagai jawaban atas pemintaan informasi. Menurut Lancaster (1968) dalam Rijsbergen (1979): “Sebuah information retrieval system (Sistem Temu-kembali Informasi) tidak memberitahu (yakni tidak mengubah pengetahuan) pengguna mengenai masalah yang ditanyakannya. Sistem tersebut hanya memberi-tahukan keberadaan (atau ketidakberadaan) dan keterangan dokumen-dokumen yang berhubungan dengan permintaannya”.
Sifat pencarian sistem temu-kembali informasi berbeda dengan sistem temu-kembali data (misalnya dalam sistem manajemen basis data) dalam beberapa segi, antara lain spesifikasi kueri yang tidak lengkap, dan tingkat ketanggapan kesalahan yang tidak peka (Rijsbergen, 1979). Alasan utamanya adalah Sistem Temu-kembali Informasi menangani teks bahasa alami yang tidak selalu terstruktur dengan baik dan bersifat ambigu (Baeza-Yates & Ribeiro-Neto, 1999).
Sistem Temu-kembali Informasi bekerja berdasarkan kueri yang diberikan pengguna yang menghasilkan daftar dokumen yang dianggap relevan. Selanjutnya pengguna dapat menggunakan hasil tersebut untuk mengakses informasi lebih lanjut. Sistem Temu-kembali Informasi mungkin saja tidak menghasilkan apa-apa jika memang tidak ditemukan dokumen yang relevan. Juga perlu diingat bahwa tidak ada jaminan bahwa seluruh materi yang ditemukembalikan tersebut relevan dengan yang diinginkan pengguna dan belum tentu seluruh materi yang relevan dengan permintaan pengguna berhasil ditemukembalikan.
Sistem temu-kembali informasi pada prinsipnya adalah suatu sistem yang sederhana. Misalkan ada sebuah kumpulan dokumen dan seorang user yang memformulasikan sebuah pertanyaan (request atau query). Jawaban dari pertanyaan tersebut adalah sekumpulan dokumen yang relevan dan membuang dokumen yang tidak relevan. Secara matematis hal tersebut dapat dituliskan sebagai berikut :
Q = pertanyaan (queri)
D = dokumen
n = jumlah dokumen
2n = jumlah kemungkinan himpunan bagian dari dokumen yang ditemukan.
Sistem temu-kembali akan mengambil salah satu dari kemungkinan tersebut. Sistem temu-kembali informasi pada dasarnya dibagi dalam dua komponen utama yaitu sistem pengindeksan (indexing) yang menghasilkan basis data sistem dan temu-kembali yang merupakan gabungan dari user interfacedan
look-up-table.
Sistem temu kembali informasi (information retrieval system) digunakan untuk menemukan kembali (retrieve) informasi-informasi yang relevan terhadap kebutuhan pengguna dari suatu kumpulan informasi secara otomatis.
Sistem
Gambar 2.1 Ilustrasi Sistem Temu Kembali Informasi
Salah satu aplikasi umum dari sistem temu kembali informasi adalah
Pengguna dapat mencari halaman-halaman web yang dibutuhkannya melalui
search engine.
Sistem temu kembali informasi terutama berhubungan dengan pencarian informasi yang isinya tidak memiliki struktur. Demikian pula ekspresi kebutuhan pengguna yang disebut query, juga tidak memiliki struktur. Hal ini yang membedakan sistem temu kembali informasi dengan sistem basis data. Dokumen adalah contoh informasi yang tidak terstruktur. Isi dari suatu dokumen sangat tergantung pada pembuat dokumen tersebut.
Sebagai suatu sistem, sistem temu kembali informasi memiliki beberapa bagian yang membangun sistem secara keseluruhan. Gambaran bagian-bagian yang terdapat pada suatu sistem temu kembali informasi digambarkan pada Gambar 2.2.
Gambar 2.2 memperlihatkan bahwa terdapat dua buah alur operasi pada sistem temu kembali informasi. Alur pertama dimulai dari koleksi dokumen dan alur kedua dimulai dari query pengguna. Alur pertama yaitu pemrosesan terhadap koleksi dokumen menjadi basis data indeks tidak tergantung pada alur kedua. Sedangkan alur kedua tergantung dari keberadaan basis data indeks yang dihasilkan pada alur pertama.
Bagian-bagian dari sistem temu kembali informasi menurut gambar 2.2 meliputi :
1. Text Operations (operasi terhadap teks) yang meliputi pemilihan kata-kata dalam query maupun dokumen (term selection) dalam pentransformasian dokumen atau query menjadi terms index (indeks dari kata-kata).
2. Query formulation (formulasi terhadap query) yaitu memberi bobot pada indeks kata-kata query.
3. Ranking (perangkingan), mencari dokumen-dokumen yang relevan terhadap query dan mengurutkan dokumen tersebut berdasarkan kesesuaiannya dengan query.
4. Indexing (pengindeksan), membangun basis data indeks dari koleksi dokumen. Dilakukan terlebih dahulu sebelum pencarian dokumen dilakukan.
Namun relevansi dokumen terhadap suatu query merupakan penilaian pengguna yang subjektif dan dipengaruhi banyak faktor seperti topik, pewaktuan, sumber informasi maupun tujuan pengguna.
Model sistem temu kembali informasi menentukan detail sistem temu kembali informasi yaitu meliputi representasi dokumen maupun query, fungsi pencarian (retrieval function) dan notasi kesesuaian (relevance notation) dokumen terhadap query.
2.2 Pengindeksan (Indexing) Dalam Sistem Temu-Kembali Informasi
Indexing merupakan sebuah proses untuk melakukan pengindeksan terhadap kumpulan dokumen yang akan disediakan sebagai informasi kepada pemakai. Proses pengindeksan bisa secara manual ataupun secara otomatis. Dewasa ini, sistem pengindeksan secara manual mulai digantikan oleh sistem pengindeksan otomatis. Adapun tahapan dari pengindeksan adalah sebagai berikut:
Parsing Dokumen yaitu proses pengambilan kata-kata dari kumpulan dokumen.
Stoplist yaitu proses pembuangan kata buang seperti: tetapi, yaitu, sedangkan, dan sebagainya.
Term Weighting dan Inverted File yaitu proses pemberian bobot pada istilah.
Didalam memberikan bobot pada sebuah istilah, terdapat berbagai macam teknik antara lain yaitu :
1. Teknik pembobotan berdasarkan frekuensi kemunculan istilah pada satu dokumen. Teknik pembobotan ini cukup sederhana dimana bobot suatu istilah pada sebuah dokumen berdasarkan jumlah kemunculannya pada dokumen tersebut.
2. Teknik pembobotan berdasarkan rumus Savoy(1993) yaitu: Wik= ntfik* nidfk,
Wikadalah bobot istilah k pada dokumen i.
tfikmerupakan frekuensi dari istilah k dalam dokumen i.
n adalah jumlah dokumen dalam kumpulan dokumen.
dfkadalah jumlah dokumen yang mengandung istilah k.
Maxjtfijadalah frekuensi istilah terbesar pada satu dokumen.
yang sama. Selain itu teknik ini juga memperhitungkan jumlah dokumen yang mengandung istilah yang bersangkutan dan jumlah keseluruhan dokumen. Hal ini berguna untuk mengetahui posisi relatif bobot istilah bersangkutan pada suatu dokumen dibandingkan dengan dokumen-dokumen lain yang memiliki istilah yang sama. Sehingga jika sebuah istilah mempunyai frekuensi kemunculan yang sama pada dua dokumen belum tentu mempunyai bobot yang sama.
2.2.1 Stemming
Stemming adalah proses penghilangan prefiks dan sufiks dari kueri dan istilah-istilah dokumen. Stemming dilakukan atas dasar asumsi bahwa kata-kata yang memiliki stem yang sama memiliki makna yang serupa sehingga pengguna tidak keberatan untuk memperoleh dokumen-dokumen yang di dalamnya terdapat kata-kata dengan stem yang sama dengan kuerinya. Teknik-teknik stemming dapat dikategorikan menjadi:
Berdasarkan aturan sesuai bahasa tertentu
Berdasarkan kamus
suatu kata disimpan secara terpisah dalam indeks. Akan tetapi, stemming dapat menurunkan tingkat precision jika setiap bentuk suatu stem diperoleh, sedangkan yang relevan hanyalah bentuk yang sama dengan yang digunakan dalam kueri.
Parsing dan stemming dalam suatu IRS tergantung pada bahasa yang digunakan dalam dokumen yang akan dicari. IRS untuk Bahasa Inggris kurang optimal untuk menangani dokumen dalam Bahasa Indonesia. Bahasa Indonesia memiliki daftar kata buang (stoplist) serta sistem pembentukan kata yang sangat berbeda dengan bahasa Inggris, sehingga diperlukan IRS yang khusus untuk Bahasa Indonesia.
2.2.2 Porter Stemmer for Bahasa Indonesia
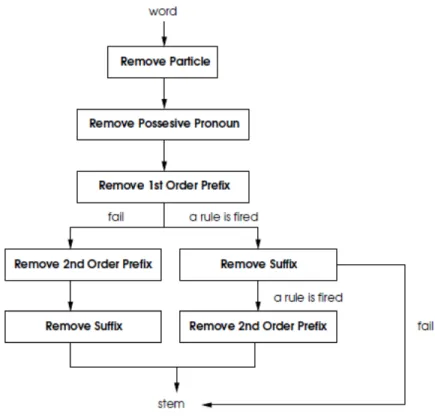
Porter Stemmer for Bahasa Indonesiadikembangkan oleh Fadillah Z. Tala pada tahun 2003. Implementasi Porter Stemmer for Bahasa Indonesia
Gambar 2.3 Algoritma Porter Stemmer for Bahasa Indonesia
Pada gambar 2.3 terlihat beberapa langkah 'removal' menurut aturan yang ada pada tabel 2.1 sampai dengan tabel 2.5.
Tabel 2.1: Kelompok rulepertama : inflectional particles
Suffix Replacement Measure Condition
Additional Condition
Example
kah NULL 2 NULL bukukah → buku
lah NULL 2 NULL adalah → ada
pun NUUL 2 NULL bukupun → buku
Tabel 2.2: Kelompok rulekedua :inflectional possesive pronouns
Suffix Replacement Measure Condition
Additional Condition
Example
ku NULL 2 NULL bukuku → buku
mu NULL 2 NULL Bukumu → buku
Tabel 2.3: Kelompok ruleketiga: first order of derivational prefixes
Tabel 2.4: Kelompok rulekeempat: second order of derivational prefixes
Prefix Replacement Measure
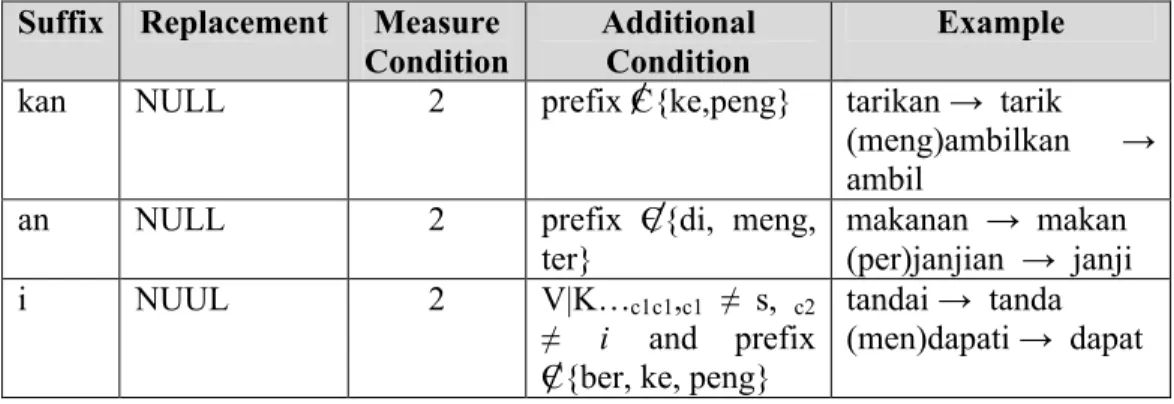
Tabel 2.5: Kelompok rulekelima: derivational suffixes
2.3 Teknik-teknik Temu-kembali Informasi
Ada beberapa teknik temu-kembali informasi yang telah dikembangkan yaitu teknik Boolean sederhana dan teknik Boolean, serta teknik Extended Boolean. Untuk lebih jelasnya mengenai perbedaan dan keunggulan masing-masing teknik ini dapat dilihat pada penjelasan berikut.
1. Teknik Boolean
Teknik Boolean merupakan suatu cara dalam mengekspresikan keinginan pemakai ke sebuah kueri dengan mamakai operator-operator Boolean
(Salton,1989) yaitu : “and”, “or”, dan “not”. Adapun maksud dari operator “and” adalah untuk menggabungkan istilah-istilah kedalam sebuah ungkapan, dan operator “or” adalah untuk memperlakukan istilah-istilah sebagai sinonim, sedangkan operator “not” merupakan sebuah pembatasan. Pada teknik
Booleansederhana, kueri diproses sesuai dengan operator yang digunakan dan menampilkan dokumen berdasarkan urutan dokumen ditemukan. Sedangkan pada teknik Boolean berperingkat, dokumen diperingkat berdasarkan bobot dari dokumen. Adapun pembobotan dari masing-masing dokumen berdasarkan aturan sebagai berikut :
A and B D1AB, D2AB, ...d1AB> d2AB >
... dengan dAB = min(dA,dB)
A or B D1AB, D2AB, ...d1AB > d2AB >
... dengan dAB = max(dA,dB)
Dimana dA menyatakan bobot istilah A pada dokumen D. Bobot
istilah ini didapat dari hasil proses Indexing. Min(dA,dB) berarti bahwa sebuah
dokumen di retrieve dengan bobot sebesar nilai terkecil dari bobot-bobot istilah yang dipunyainya. Max(dA,dB) berarti bahwa sebuah dokumen di
retrieve dengan bobot sebesar nilai terbesar dari bobot-bobot istilah yang dipunyainya.
Kekurangan dari model boolean ini antara lain :
Hasil pencarian dokumen berupa himpunan, sehingga tidak dapat dikenali dokumen-dokumen yang paling relevan atau agak relevan (partial match).
Query dalam ekspresi boolean dapat menyulitkan pengguna yang tidak mengerti tentang ekpresi boolean.
2. Teknik Extended Boolean
Teknik Extended Boolean berdasarkan p-norm model merupakan pengembangan lebih lanjut dari model Boolean. Teknik ini memakai operator yang dikomputasi berdasarkan rumus Savoy(1993), sebagai berikut :
Tabel 2.6 TabelExtended Boolean
Query Retrieval Status Value
p adalah nilai p-norm yang dimasukkan pada kueri.
Wiaadalah bobot istilah A dalam indeks pada dokumen Di.
Wibadalah bobot istilah B dalam indeks pada dokumen Di.
Pemeringkatan yang dipakai bisa dua cara :
Langsung mengurutkan dokumen (dari besar ke kecil) berdasarkan bobot dokumen yang didapat dengan rumus RSV (retrieval status value) di atas.
Memakai rumus Learning Scheme.
RSV(Di) = RSVinit (Di) +
r
k 1
ik norm * RSVinit (Dk)
untuk i= 1, 2,...., n, Dimana :
RSVinit(Di) merupakan retrieval status value dari dokumen i yang
dikomputasi berdasarkan rumus teknik retrieval P-norm model.
ik merupakan bobot keterhubungan antara dokumen i dan k. Bobot
2.4 Algoritma TF/IDF
Algoritma TF/IDF dalam sistem temu-kembali informasi dapat diilustrasikan seperti pada gambar berikut.
Gambar 2.4 Ilustrasi Algoritma TF/IDF Keterangan:
D1,D2,D3,D4,D5 = dokumen
tf = banyaknya kata yang dicari pada sebuah dokumen D = total dokumen
df = banyaknya dokumen yang megandung kata yang dicari. t1 = “Wayang”
t2 = “Kulit”
Formula yang digunakan untuk menghitung bobot (w) masing-masing dokumen terhadap kata kunci adalah:
Wd,t = tfd,t * IDFt
Dimana:
d = dokumen ke-d
t = kata ke-t dari kata kunci
Wd,t = bobot dokumen ke-d terhadap kata ke-t
Setelah bobot (w) masing-masing dokumen diketahui, maka dilakukan proses sorting/pengurutan dimana semakin besar nilai w, semakin besar tingkat similaritas dokumen tersebut terhadap kata yang dicari, demikian sebaliknya.
2.5 Evaluasi Sistem Temu Kembali Informasi
Dalam bidang temu kembali informasi (information retrieval) terdapat berbagai metode yang digunakan dalam pembobotan kata, pengukuran kesesuaian, perangkingan, umpan balik relevansi, model sistem temu kembali informasi dan lain-lain. Sehingga diperlukan suatu ukuran sebagai perbandingan keefektifan metode-metode tersebut.
Tujuan dari sistem temu kembali informasi yang ideal adalah : 1. Menemukan seluruh dokumen yang relevan terhadap suatu query.
2. Hanya menemukan dokumen relevan saja, artinya tidak terdapat dokumen yang tidak relevan pada dokumen hasil pencarian.
Recall dinyatakan sebagai bagian dari dokumen relevan dalam dokumen yang ditemukan:
Sedangkanprecisiondinyatakan sebagai bagian dokumen relevan yang ditemukan:
23 3.1 Analisa Sistem
Pada bagian ini akan dijelaskan mengenai analisis sistem, metode pengumpulan data dan perancangan sistem mesin pencari data tokoh dan kriteria wayang dalam kamus pewayangan.
3.1.1 Analisis Kebutuhan
Kebutuhan yang dibutuhkan oleh pengguna/user dari mesin pencari data tokoh dan kriteria wayang dalam kamus pewayangan adalah:
1. User membutuhkan program untuk membantu dalam mencari dokumen dari koleksi dokumen wayang yang sesuai dengan kriteria yang diinginkan.
2. User membutuhkan program yang dapat secara otomatis melakukan proses
indexing ketika user menambahkan dokumen baru ke dalam koleksi dokumen wayang.
3. User membutuhkan program yang dapat mengelola atau memanage daftar
3.2 Metode Pengumpulan Data
Metode pengumpulan data yang dimaksud adalah metode yang dilakukan untuk mengumpulkan data-data mengenai tokoh dan kriteria wayang. Data-data wayang didapatkan dari media internet, data diambil dari http://id.wikipedia.org/wiki/. Karena data yang didapatkan berupa file html, maka
dilakukan proses pemindahan isi dari html ke file teks (.txt) secara manual. Penamaan dokumen berdasarkan judul dokumen yang didapatkan dari sumber (sesuai http://id.wikipedia.org/wiki/), pada proses pengumpulan data tidak dilakukan pemeriksaan mengenai kebenaran data, baik data tokoh maupun kriteria wayang karena penulis hanya mengacu pada data yang disediakan oleh sumber.
3.3 Perancangan Sistem 3.3.1 Model Use Case 3.3.1.1 Actor
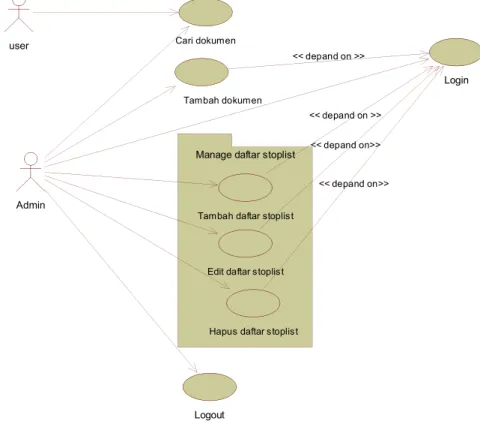
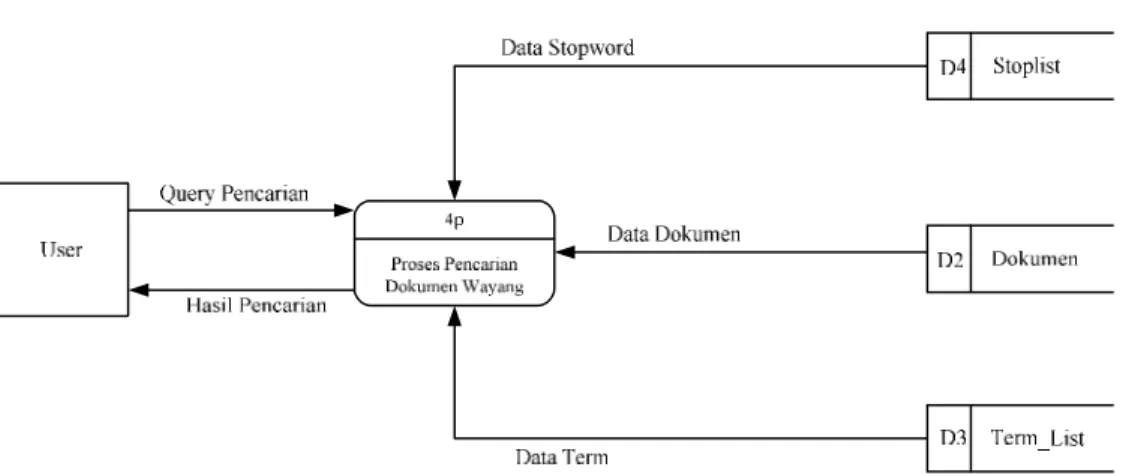
3.3.1.2 Diagram Use Case
Terdapat lima use case dalam mesin pencari data tokoh dan kriteria wayang dalam kamus pewayangan yaitu: 1) Tambah dokumen, 2) Tambah daftar stoplist, 3) Rubah daftar stoplist, 4) Hapus daftar stoplist, dan 5) Cari dokumen. Untuk use case tambah daftar stoplist, rubah daftar stoplist, dan hapus daftar
stoplistdijadikan dalam satu package yakni manage stoplist. Untuk lebih jelasnya dapat dilihat dalam gambar 3.1 di bawah ini:
Manage daftar stoplist user
Logout Admin
Cari dokumen
Tambah dokumen
Tambah daftar stoplis t
Edit daftar stoplis t
Hapus daftar stoplis t
Login << depand on >>
<< depand on >>
<< depand on>>
<< depand on>>
3.3.1.3 Tabel Use Case
Tabel 3.1 Tabel Use Case
Nama Use Case Keterangan Aktor
Login Verifikasi untuk mengakses menu
utama dengan cara memasukkan
usernamedan password
Admin
Logout Keluar dari Program Admin
Tambah Dokumen Menambah koleksi dokumen wayang yang ada
Admin
Manage daftar stoplist Menambah, merubah, dan menghapus data dalam daftar stoplist
Admin
Cari dokumen Mencari dokumen dalam koleksi dokumen yang sesuai dengan kriteria yang diinginkan
Admin, User
3.3.2 Data Flow Diagram (DFD)
DFD merupakan alat yang digunakan pada metodologi pengembangan sistem yang terstruktur. DFD menggambarkan arus data di dalam sistem dengan terstruktur dan jelas.
Adapun rancangan DFD dari mesin pencari data tokoh dan kriteria wayang dalam kamus pewayangan adalah sebagai berikut :
1. Diagram Konteks
data tokoh dan kriteria wayang dalam kamus pewayangan disajikan pada gambar 3.2 berikut ini :
Gambar 3.2 Diagram Konteks
2. Diagram Berjenjang
Diagram berjenjang (hirarchy chart) digunakan untuk mempersiapkan penggambaran DFD ke level-level lebih bawah lagi. Diagram berjenjang dapat digambar dengan menggunakan notasi proses yang digunakan di DFD. Diagram berjenjang dari mesin pencari data tokoh dan kriteria wayang dalam kamus pewayangan dapat dilihat dalam gambar 3.3 dibawah ini:
3. Data Flow Diagram Level 0 Admin
Gambar 3.4 DFD Level 0 Admin
4. Data Flow Diagram Level 0 User
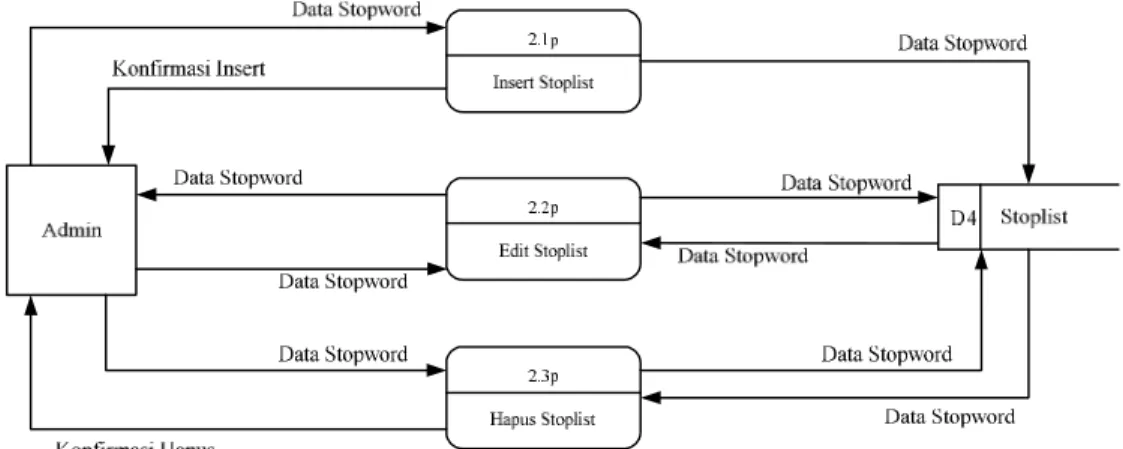
5. Data Flow Diagram Level 1 Proses 2 Admin Manage Stoplist
Gambar 3.6 DFD Level 1 Proses 2 Proses admin manage Stoplist
3.3.3 Bagan Alir Program
3.3.3.1 Algoritma proses indexing
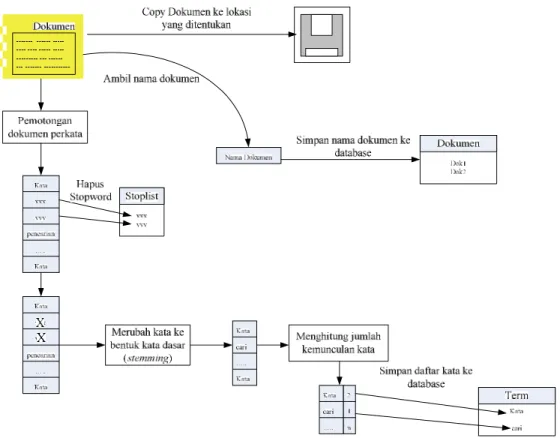
Proses indexing berfungsi untuk mengolah dokumen teks baru untuk disimpan ke database sehingga dapat mendukung proses pencarian dokumen. Proses indexing dokumen dalam mesin pencari data tokoh dan kriteria wayang dalam kamus pewayangan digambarkan dalam ilustrasi gambar 3.7 dibawah ini:
Gambar 3.7 Ilustrasi Proses Indexing
Gambar 3.8 Blok Diagram Proses Indexing
Berikut ini adalah penjelasan untuk setiap proses dalam proses indexing
dokumen:
1. Parsing ke dalam array
Proses ini berfungsi untuk memotong-motong dokumen kata per kata dan menyimpannya ke dalam array. Untuk langkah program jelasnya digambarkan dalam gambar 3.9 dibawah ini:
Dokumen Parsing ke dalam array
Stemming
Penghapusan
Stopword
Penghitungan Term
Frekuensi
Filtering
Stoplist
2. Proses penghapusan stopworddari array
Proses ini digunakan untuk menghapus kata-kata yang ‘tidak relevan’ dari array. Kata dalam array dibandingkan dengan table Stopwordyang ada dalam
database, jika ditemukan kata dalam array yang ada dalam table Stopword
kata tersebut akan dihapus dari array. Proses pencocokan dan penghapusan dilakukan dari data pertama sampai terakhir dalam array. Untuk langkah program jelasnya digambarkan dalam gambar 3.10 dibawah ini:
3. Proses Stemming
Proses ini digunakan untuk mencari kata dasar dari kata yang ada dalam array, proses stemming menggunakan algoritma Porter Stemmer for Bahasa Indonesia yang telah dijelaskan pada bab 2, sub bab 2.1.3, untuk algoritma proses stemming sesuai dengan Gambar 2.3 Algoritma Porter Stemmer for Bahasa Indonesia.
4. Proses Perhitungan TermFrekuensi
Proses ini digunakan untuk menghitung jumlah kemunculan kata (Term
5. Proses filter Term
Pada proses ini daftar kata dalam array yang telah melalui proses perhitungan
termfrekuensi akan disimpan ke dalam database. Tiap kata dalam array akan dicocokkan dengan daftar Term dalam tabel Term, jika kata sudah terdapat dalam dalam tabel Term, kata, frekuensi kemunculan, dan nama dokumen akan disimpan dalam tabel List_Term dengan ID sesuai dengan ID dalam tabel Term dan meng-update jumlah dokumen frekuensi dalam tabel Term
yang sesuai dangan kata dalam array. Sementara jika kata dalam array tidak ditemukan maka kata akan disimpan kedalam tabel Term sebagai record baru dengan ID baru, dan nilai dokumen frekuensi 1. Kemudian kata, frekuensi kemunculan, dan nama dokumen akan disimpan dalam tabel List_Term
Filtering kata dari arrayTF
i ← to jumlah arrayTF
Simpan kata ke tabel Term dalam database
dalam database where
term kata dengan
3.3.3.2 Algoritma proses pencarian dokumen
Proses pencarian dokumen terbagi dalam 5 proses yang digambarkan dalam gambar blok dagram 3.13 dibawah ini:
Gambar 3.13 Blok Diagram Proses Pencarian Dokumen
Berikut ini adalah penjelasan untuk setiap proses dalam proses pencarian dokumen:
1. Parsing ke dalam array
Proses parsing dari query ke dalam array sama dengan proses parsing dokumen ke dalam array yang telah dijelaskan pada Gambar 3.9 Flowchart Proses Parsing.
Query Input Parsing ke dalam
2. Proses penghapusan stopworddari array
Proses penghapusan stopword dari array sama dengan proses penghapusan
stopword dari array dokumen yang telah dijelaskan pada Gambar 3.10 Flowchart Proses Removing Stopword.
3. Proses Stemming
Proses ini digunakan untuk mencari kata dasar dari kata yang ada dalam array, proses stemming menggunakan algoritma Porter Stemmer for Bahasa Indonesia yang telah dijelaskan pada bab 2, sub bab 2.1.3, untuk algoritma proses stemming sesuai dengan Gambar 2.3 Algoritma Porter Stemmer for Bahasa Indonesia.
4. Proses pembuatan kondisi where statementuntuk query
Proses pembuatan kondisi where untuk query digunakan untuk membentuk kondisi kata yang ingin dicari dalam database, kata yang dibentuk berdasarkan isi dari variable array yang telah melewati proses penghapusan
5. Proses queryke database
Proses query ke database dilakukan untuk mencari daftar term beserta bobotnya, dan daftar dokumen. Bobot kata berdasarkan bobot TF-IDF, proses perhitungan bobot kata dilakukan pada sisi database yakni dengan menambahkan formula pada query. Dari query akan menghasilkan ResultSet berupa daftar bobot tiap termserta dokumen yang berhubungan dan nilai IDF untuk tiap term. Daftar kata atau term yang dicari tergantung dari kondisi yang dihasilkan dari proses pembentukan kondisi where pada proses sebelumnya, jika kondisi = null, maka program tidak akan melakukan queryke database, namun jika tidak maka akan melakukan query ke database dengan query
sebagai berikut:
Queryuntuk mengambil nilai IDF:
"select term.id_term, log10((count(dokumen.dokumen)/term.df)) as idf From term, dokumen where " & kondisi & " group by term.id_term, term.df" Query untuk mengambil Dokumen dan nilai TF:
"select dokumen.dokumen,term_list.tf,term_list.id_term From term join term_list on term.id_term = term_list.id_term join dokumen on
term_list.id_dokumen = dokumen.id_dokumen where(" & kondisi & ") order by dokumen.dokumen"
ResultSet1 null
ResultSet2 null
arrayTFIDF[][] Query ke database
Query1 (Ambil nilai IDF)
Query2 (Ambil Dokumen dan nilai TF)
kondisi not null?
true
Return arrayTFIDF[][] Seleksi hasil Query1 dan Query2 ke
dalam arrayTFIDF[][]
Gambar 3.15 Flowchart Proses Query ke Database
6. Proses Tampil Hasil query
dari arrayTFIDF[][] yang dihasilkan dari proses sebelumnya yakni proses
3.3.4 Perancangan Database
Berikut ini langkah-langkah yang akan dilakukan dalam perancangan
database, yaitu :
a) Conceptual Database Design
b) Logical Database Design
c) Physical Database Design
3.3.4.1Conceptual Database Design
Gambar 3.17 Diagram E-R 3.3.4.2Logical Database Design
3.3.4.3Physical Database Design
Desain dari basis data yang akan digunakan dalam program mesin pencari data tokoh dan kriteria wayang dalam kamus pewayangan dapat dijabarkan sebagai berikut
1. Tabel Term
Tabel term berisikan data daftar term atau kata dan df (dokumen frekuensi) dalam database.
Nama Tabel : Term
Nama Field Kunci : id_term
Tabel ini berisi sejumlah field yang dijabarkan sebagai berikut Tabel 3.2 Tabel Term
Nama Field Tipe Data Ukuran Keterangan
Id_term Integer 255 Sebagai field kunci tabel term
Term Varchar 100 Isi term atau kata
Df Integer 255 Jumlah Dokumen
2. Tabel Term_List
Tabel term_list berisikan data daftar list term, id_dokumen, id_term dan tf (term frekuensi) dalam database.
Nama Tabel : Term_List
Nama Field Kunci : id_term_list
Tabel 3.3 Tabel Term_List
Nama Field Tipe Data Ukuran Keterangan
Id_term_list Integer 255 Sebagai field kunci tabel term_list
Id_term Integer 255 Sebagai Foreign key dari tabel term
Id_dokumen Integer 255 Sebagai Foreign key dari tabel dokumen
Tf Integer 255 Jumlah term frekuensi atau
jumlah kemunculan kata
3. Tabel Dokumen
Tabel term berisikan data daftar dokumen, df (dokumen frekuensi) dalam
database.
Nama Tabel : Dokumen
Nama Field Kunci : id_dokumen
Tabel ini berisi sejumlah field yang dijabarkan dalam tabel 3.4 Tabel 3.4 Tabel Dokumen
Nama Field Tipe Data Ukuran Keterangan
Id_dokumen Integer 255 Sebagai field kunci tabel dokumen
dokumen Varchar 100 Nama dokumen
4. Tabel Stoplist
Tabel term berisikan data daftar stopword dalam database.
Nama Field Kunci : id_stopword
Tabel ini berisi sejumlah field yang dijabarkan dalam tabel 3.4 Tabel 3.5 Tabel Stoplist
Nama Field Tipe Data Ukuran Keterangan
Id_stopword Integer 255 Sebagai field kunci tabel stoplist stopword Varchar 100 Isi stopword daftar kata buang
5. Tabel Admin
Tabel admin berisikan data daftar admin dalam database.
Nama Tabel : Admin
Nama Field Kunci : id_admin
Tabel ini berisi sejumlah field yang dijabarkan dalam tabel 3.6 Tabel 3.6 Tabel Admin
Nama Field Tipe Data Ukuran Keterangan
Id_admin Integer 255 Sebagai field kunci tabel admin User_name Varchar 100 Isi user name daftar admin Password Varchar 100 Isi password daftar admin
3.4 Perancangan Antarmuka (Interface)
informasi. Jadi rancangan antarmuka merupakan bagian yang tidak dapat diabaikan dalam membuat suatu program yang interakatif. Karena antarmuka merupakan jembatan antara pengguna dengan program yang digunakan.
1. Desain Menu Utama
Gambar 3.19 Desain Menu Utama
2. Desain Form Pencarian
Gambar 3.20 Desain Form Pencarian
3. Desain Form Login
Gambar 3.21 Desain Form Login
Form ini digunakan utnuk login admin. Admin yang hendak login memasukkan username dan password pada tempat yang telah disediakan. Tombol login digunakan untuk melakukan pengecekan username dan password, jika username dan password terdapat dalam database maka akan masuk ke menu utama admin, sementara jika salah maka akan masuk kembali ke menu utama user. Tombol cancel digunakan untuk membatalkan proses login dan kembali ke menu utama user.
4. Desain Form Menu Utama Admin
Form ini adalah form utama untuk admin, dari form ini admin dapat memilih menu yang diinginkan dengan menekan tombol yang disediakan yakni tombol Tambah Dokumen, Manage Stoplist, Logout, About dan Help.
5. Desain Form Admin Tambah Dokumen
Gambar 3.23 Desain Form Tambah Dokumen
6. Desain Form Admin Manage Stoplist
Gambar 3.24 Desain Form Manage Stoplist
55
4.1 Spesifikasi Software dan Hardware yang digunakan 4.1.1 Spesifikasi Software
Sistem Operasi Microsoft Windows XP Profesional S.P 2
Basisdata SQL SERVER 2000
Bahasa Pemrograman Visual Basic versi 6.0 4.1.2 Spesifikasi Hardware
Prosesor Intel Core 2 Duo 2.0 GHz
Memory 2GB DDR2
HardDisk 160GB
4.2 Koneksi Basisdata dengan Sistem
4.2.1 Koneksi basisdata SQL SERVER 2000 dengan sistem
Koneksi ini dibuat untuk menghubungkan sistem dengan basisdata SQL SERVER 2000 sebagai basisdata yang berfungsi untuk menyimpan data dokumen, hasil indexingdokumen, dan daftar stopword.
Adapun scriptnya sebagai berikut:
Public Const con = "Driver={SQL Server};SERVER=.; DATABASE=dbWayang; UID=sa; PWD="
Public db As ADODB.Connection
Dari script koneksi di atas menggunakan provider SQLOLEDB yaitu provider untuk basisdata SQLSERVER yang disediakan oleh Microsoft OLE DB. DATABASE adalah nama basisdata yang digunakan yakni dbWayang, UID adalah nama user, dan PWD adalah password yang digunakan untuk login ke basisdata.
4.3 Pembuatan Antarmuka (Interface)
Antarmuka merupakan tampilan yang nantinya akan berinteraksi langsung dengan pengguna. Antarmuka untuk aplikasi program ini adalah sebagai berikut: 4.3.1 Form Menu Utama
Form menu utama ini akan muncul pada saat system pertama kali dijalankan. Form menu utama ini berupa frmMenuUser yang berisikan 4 tombol yaitu tombol cari dokumen yang digunakan untuk melakukan proses pencarian dokumen, tombol help yang digunakan untuk membuka help atau bantuan, tombol about yang digunakan untuk menampolkan informasi tentang program dan tombol login yang dugunakan untuk login sebagai administrator program.
4.3.2 Form Cari Dokumen Wayang
Form cari dokumen wayang digunakan untuk melakukan proses pencarian data pada basisdata sesuai dengan kata kunci yang dimasukkan pengguna. Pada pencarian dokumen dilakukan proses pemotongan kata (parsing), penghapusan
stopword, stemming, dan pembuatan kondisi untuk proses query ke basisdata. Untuk melakukan proses pencarian pengguna tinggal memasukkan kata kunci pada text field kata kunci kemudian tekan tombol cari dokumen, daftar dokumen yang ditemukan akan ditampilkan pada bagian hasil pencarian diurutkan berdasarkan nilai bobot dokumen dari yang paling besar. Sedangkan bagian isi dokumen untuk menampilkan isi dokumen dari daftar dokumen yang dipilih oleh pengguna.
Script yang ada pada form cari dokumen yang digunakan untuk melakukan proses pencarian:
Method untuk pemotongan kata (parsing)
'*******************************'
' Method Untuk Parsing '
'*******************************'
Private Function parsingArray(ByVal text As String, ByRef output() As String) As String
'Inisialisasi Counter Untuk Proses Loop
Dim i As Integer
Dim pemenggal_kata() As String, tmp() As String
ReDim pemenggal_kata(0 To 27)
pemenggal_kata(0) = Chr(34)
pemenggal_kata(1) = "<"
pemenggal_kata(2) = ">"
pemenggal_kata(3) = "+"
pemenggal_kata(18) = "("
pemenggal_kata(19) = ")"
pemenggal_kata(20) = "-"
pemenggal_kata(21) = "/"
pemenggal_kata(22) = "\"
pemenggal_kata(23) = "&"
pemenggal_kata(24) = "?"
pemenggal_kata(25) = "!"
pemenggal_kata(26) = ";"
pemenggal_kata(26) = " "
For i = LBound(pemenggal_kata) To UBound(pemenggal_kata)
text = Replace(text, pemenggal_kata(i), ".")
Method untuk penghapusan stopword
'*********************************************'
' Method Remove Stopword Dari Array '
'*********************************************'
Private Function removeStopword()
'Deklarasi semua variabel yang dibutuhkan
Dim dataRS As ADODB.Recordset
Dim dtStopword() As String, i As Integer, j As Integer
Dim k As Integer, kode As Boolean
Set dataRS = CreateObject("ADODB.Recordset")
dataRS.CursorLocation = adUseClient
dataRS.CursorType = adOpenStatic
'Ambil Isi Tabel stopword
dataRS.Open "select stopword from stoplist", db, adOpenStatic, adLockOptimistic
ReDim arrayRemove(10000)
ReDim dtStopword(10000)
i = 0
For i = LBound(arrayText) To UBound(arrayText)
End If
Next
End Function
Method untuk stemming
Public Function steaming(ByVal word As String) As String
Dim panjag As Integer, kode As Boolean
panjang = Len(word)
'Inisialisasi isi array Particle
Particle(0) = "kah"
Particle(1) = "lah"
Particle(2) = "pun"
'Inisialisasi isi array Pronoun
Pronoun(0) = "ku"
Pronoun(1) = "mu"
Pronoun(2) = "nya"
'Inisialisasi isi array Prefix1
Prefix1(6, 1) = "peny"
For i = LBound(Particle) To UBound(Particle)
pjg = Len(Particle(i))
For i = LBound(Pronoun) To UBound(Pronoun)
pjg = Len(Pronoun(i))
word = Left$(word, panjang - pjg)
For i = LBound(Prefix1) To UBound(Prefix1)
pjg = Len(Prefix1(i, 1))
Method untuk pencarian dokumen
'*********************************************'
' Method Cari Dokumen '
'*********************************************'
Private Function cariDokumen(ByVal kondisi As String)
Dim dataIDF As ADODB.Recordset, dataTF As ADODB.Recordset
Dim arrayIDF() As String, arrayTF() As String, i As Integer
Dim arrayTFIDF() As String, bobot As Double, jum As Integer, kode As Boolean
jum = 0
'Buat object
Set dataIDF = CreateObject("ADODB.Recordset")
dataIDF.CursorLocation = adUseClient
dataIDF.CursorType = adOpenStatic
'Buat object
Set dataTF = CreateObject("ADODB.Recordset")
dataTF.CursorLocation = adUseClient
dataTF.CursorType = adOpenStatic
'Ambil nilai idf untuk keyword yang dimasukkan
dataIDF.Open "select term.id_term,
log10((count(dokumen.dokumen)/term.df)) as idf From term, dokumen where " & kondisi & " group by term.id_term, term.df", _
db, adOpenStatic, adLockOptimistic
'Ambil nilai tf untuk keyword yang dimasukkan
dataTF.Open "select dokumen.dokumen,term_list.tf,term_list.id_term From term join term_list on term.id_term = term_list.id_term join dokumen on term_list.id_dokumen = dokumen.id_dokumen where(" & kondisi & ") order by dokumen.dokumen", _
db, adOpenStatic, adLockOptimistic
ReDim arrayIDF(10000, 2)
ReDim arrayTF(10000, 3)
ReDim arrayTFIDF(10000, 2)
For o = 0 To jum
MsgBox "Tidak Ada Dokumen Yang Ditemukan", vbInformation, "Pesan Konfirmasi"
Else
If Len(hasil(r, 1)) > 1 And hasil(r, 2) > 0 Then
Script untuk menampilkan isi dokumen
Private Sub lstHasil_Click()
Dim file() As String
file() = Split(lstHasil.text, "#")
txtIsi.text = ""
F = FreeFile
If FileExists(App.Path & "\Dokumen\" & file(1)) Then
Open App.Path & "\Dokumen\" & file(1) For Input As #F
MsgBox "Maaf File Tidak Ditemukan", vbInformation, "Pesan Konfirmasi"
End If
4.3.3 Form About
Form ini berisi tentang informasi program, yakni data diri pembuat program
Gambar 4.3 Form About 4.3.4 Form Login
Gambar 4.4 Form Login 4.3.5 Form Menu Admin
Gambar 4.5 Form Menu Utama Admin
4.3.6 Form Tambah Dokumen
Gambar 4.6 Form Tambah Dokumen Wayang
Script yang ada pada form tambah dokumen wayang yang digunakan untuk melakukan proses indexing:
Method perhitungan term frekuensi
Private Function HitungTFArray()
'Inisialisasi Counter Untuk Proses Loop
Dim i As Integer, j As Integer, kode As Boolean, X As Integer
ReDim arrayTF(10000, 2)
arrayTF(1, 1) = arrayRemove(0)
arrayTF(1, 2) = 1
jum = 1
For i = (LBound(arrayRemove) + 1) To UBound(arrayRemove)
kode = True
For j = 1 To jum
If LCase$(arrayRemove(i)) = LCase$(arrayTF(j, 1)) Then
arrayTF(j, 2) = arrayTF(j, 2) + 1
kode = False
End If
Next
jum = jum + 1
If kondisi = True And kodeIndexing = 0 Then
'Copy Dokumen like '" & nmDokumen & "'")
idDokumen = dataDokumen("id_dokumen")
jumTerm = jumTerm + 1 '" & LCase$(arrayTF(i, 1)) & "'")
dataTermList.AddNew
dataTermList("tf") = arrayTF(i, 2) LCase$(arrayTF(i, 1)) & "'", db, adOpenDynamic, adLockPessimistic
dataTerm("df") = df
lblKonfirmasi.Caption = "Proses indexing dokumen '" & nmDokumen & "' berhasil dikerjakan" & vbNewLine & _
"Silahkan restart ulang program jika anda ingin menambah dokumen baru lagi"
Else
lblKonfirmasi.Caption = "Anda Belum Merestart Ulang Program" & vbNewLine & "Silahkan Restart Ulang Program Agar Bisa Menambah Dokumen Baru"
MsgBox "Anda Belum Merestart Ulang Program" & vbNewLine & "Silahkan Restart Ulang Program Agar Bisa Menambah Dokumen Baru", _
vbInformation, "Peringatan"
End If
kodeIndexing = 1
4.3.7 Form Manage Stopword
belum ada dalam basisdata. Sedangkan untuk melakukan proses perubahan atau penghapusan data dengan memilih dahulu data stopword yang ingin dirubah atau dihapus dari table daftar stoplist, kemudian rubah data pada text field data stopword dan tekan tombol edit untuk menyimpan perubahan data, atau tekan tombol hapus untuk menghapus data stopword.
Gambar 4.7 Form Manage Stoplist
Script yang ada pada form tambah dokumen wayang yang digunakan untuk melakukan proses indexing:
Script untuk menambah data baru
'Deklarasi semua variabel yang dibutuhkan
Dim dataRS As ADODB.Recordset, objRS As ADODB.Recordset
'Buat object
Set dataRS = CreateObject("ADODB.Recordset")
dataRS.CursorLocation = adUseClient
dataRS.CursorType = adOpenStatic
'Buat object
Set objRS = CreateObject("ADODB.Recordset")
objRS.CursorLocation = adUseClient
'Ambil data dari Text Field
stopword = LCase$(txtStopword.text)
'Cek apakah data stopword baru sudah ada atau belum
dataRS.Open "select stopword from stoplist where stopword like '" & stopword & "'", db, adOpenStatic, adLockOptimistic
If dataRS.BOF = False Then
'Jika sudah ada
MsgBox "Data Stopword Tidak Boleh Kosong", vbInformation,
txtStopword.SetFocus
Method untuk merubah dan menghapus data
Private Function editStopword(ByVal dataLama As String, ByVal dataBaru As String, ByVal kode As String) As Boolean
Dim dataRS As ADODB.Recordset
'Buat object
Set dataRS = CreateObject("ADODB.Recordset")
dataRS.CursorLocation = adUseClient
dataRS.CursorType = adOpenStatic
dataRS.Open "select stopword from stoplist where stopword like '" & dataLama & "'", db, adOpenDynamic, adLockPessimistic
End If
End Function
Method untuk menampilkan seluruh data
Private Function setDataGrid()
Adodc1.CommandType = adCmdText
Adodc1.ConnectionString = con
Adodc1.CursorLocation = adUseClient
Adodc1.CursorType = adOpenStatic
Adodc1.RecordSource = "select stopword from stoplist order by id_stopword"
Adodc1.Refresh
79 5.1 Analisa Hasil Program
Pada sub bab ini akan dibahas mengenai evaluasi hasil dari pengimplementasian mesin pencari data tokoh dan kriteria wayang dalam kamus pewayangan dengan media kuisioner yang dibagikan kepada 30 orang responden dari berbagai tingkat umur dan pekerjaan yang dilakukan dalam 2 tahap, rangkuman hasil kuesioner dapat dilihat pada lampiran. Selain melalui media kuisioner juga dilakukan percobaan langsung oleh penulis.
Pada media kuesioner tahap pertama responden diminta untuk mendeskripsikan apa yang responden inginkan tentang wayang kulit, kemudian responden menuliskan kata kunci untuk membantu mencari dan terakhir responden memasukan kata kunci kedalam aplikasi dan menentukan relevansi dari dokumen yang ditemukan sistem, apakah sesuai dengan yang diingnkan atau tidak. Hasil yang diperoleh dari responden kemudian ditentukan nilai recall-precision.
Hasil yang diperoleh dari beberapa kuisioner tahap pertama yang dibagikan kepada 20 orang responden berdasarkan kata kunci yang paling banyak dipakai oleh responden adalah:
1. Kata kunci : “Semar”
berhasil di-retrive dengan nilai bobot paling besar, dan ditemukan 3 dokumen yang menurut responden adalah relevant atau sesuai dengan deskripsi. Gambar hasil pencarian dokumen dengan kata kunci “Semar” ditampilkan pada gambar 5.1.
Gambar 5.1 Hasil Pencarian Dokumen Kata Kunci “Semar”
1. Proses perhitungan nilai IDF.
Proses perhitungan nilai IDF dilakukan di sisi database, nilai IDF didapatkan dari rumus IDF = log(D/df), log yang digunakan adalah log base-10, D adalah total seluruh dokumen dan df adalah jumlah dokumen yang memuat kata kunci (Semar). Queryyang digunakan adalah:
select term.term, log10((count(dokumen.dokumen)/term.df)) as idf From term, dokumen semar 0.90308998699194354
Output yang dihasilkan menunjukkan nilai IDF untuk kata kunci “Semar”. 2. Proses pengambilan daftar dokumen beserta nilai TF.
Proses ini digunakan untuk mengambil daftar dokumen yang memuat kata kunci yang ingin dicari. Queryyang digunakan adalah:
select t.term, tl.tf, d.dokumen from term t, term_list tl, dokumen d
semar 2 Punakawan.txt
3. Proses penghitungan total TF*IDF.
Setelah didapatkan nilai IDF untuk kata kunci yang dicari, dan daftar dokumen beserta nilai tf-nya selanjutnya dilakukan proses perhitungan nilai TF*IDF untuk masing-masing dokumen. Hasil perhitungan ditampilkan dalam table dibawah ini:
Tabel 5.1 Perhitungan TF*IDF Untuk Kata Kunci Semar
No Nama Dokumen TF IDF TF*IDF
1 Bagong.txt 1 0.903089986991943 0.903089986991943
2 Batara Guru.txt 1 0.903089986991943 0.903089986991943 3 Batara Kamajaya.txt 1 0.903089986991943 0.903089986991943 4 Batara Semar.txt 17 0.903089986991943 15.352529778863000
5 Gareng.txt 2 0.903089986991943 1.806179973983890
6 Kangsa Adu Jago.txt 1 0.903089986991943 0.903089986991943 7 Petruk Kantong Bolong.txt 2 0.903089986991943 1.806179973983890
8 Punakawan.txt 2 0.903089986991943 1.806179973983890
9 Pusaka Hyang Kalimusada.txt 1 0.903089986991943 0.903089986991943
10 Salya.txt 1 0.903089986991943 0.903089986991943
11 Sang Hyang Tunggal.txt 1 0.903089986991943 0.903089986991943 12 Semar dan Wahyu.txt 30 0.903089986991943 27.092699609758300
13 Semar.txt 21 0.903089986991943 18.964889726830800
Tabel 5.2 Hasil Pengurutan Dokumen Untuk Kata Kunci Semar
No Nama Dokumen TF IDF TF*IDF
1 Semar dan Wahyu.txt 30 0.903089986991943 27.0926996097583
2 Semar.txt 21 0.903089986991943 18.9648897268308
3 Batara Semar.txt 17 0.903089986991943 15.352529778863
4 Gareng.txt 2 0.903089986991943 1.80617997398389
5 Petruk Kantong Bolong.txt 2 0.903089986991943 1.80617997398389
6 Punakawan.txt 2 0.903089986991943 1.80617997398389
7 Bagong.txt 1 0.903089986991943 0.903089986991943
8 Batara Guru.txt 1 0.903089986991943 0.903089986991943 9 Batara Kamajaya.txt 1 0.903089986991943 0.903089986991943 10 Kangsa Adu Jago.txt 1 0.903089986991943 0.903089986991943 11 Pusaka Hyang Kalimusada.txt 1 0.903089986991943 0.903089986991943
12 Salya.txt 1 0.903089986991943 0.903089986991943
13 Sang Hyang Tunggal.txt 1 0.903089986991943 0.903089986991943 Sedangkan urutan dokumen berdasarkan bobot dokumen (nilai TF*IDF) yang didapatkan dari hasil perhitungan program ditampilkan dalam table 5.3.
Tabel 5.3 Urutan Dokumen Untuk Kata Kunci “Semar”
No Nama Dokumen Bobot Dokumen
1 Semar dan Wahyu.txt 27.0926996097583
2 Semar.txt 18.9648897268308
3 Batara Semar.txt 15
4 Gareng.txt 2
5 Petruk Kantong Bolong.txt 2
6 Punakawan.txt 2
7 Bagong.txt 1
8 Batara Guru.txt 1
(Lanjutan Tabel 5.3)
Berdasarkan hasil perhitungan yang dilakukan secara manual terlihat perbedaan hasil yang didapatkan mulai dari urutan dokumen ke-3 s/d ke-13. Perbedaan ini dikarenakan program secara otomatis melakukan pembulatan ke atas. Walaupun terjadi proses pembulatan nilai untuk beberapa data, tidak mempengaruhi urutan dokumen berdasarkan bobot dokumen.
Dari hasil kuesioner yang didapatkan untuk kata kunci “Semar” hubungan nilai recall-precision ditampilkan dalam table 5.4 di bawah ini:
Tabel 5.4 Nilai Recall-Precision Untuk Kata Kunci “Semar” No Dokumen Recall Precision
No Nama Dokumen Bobot Dokumen
10 Kangsa Adu Jago.txt 1
11 Pusaka Hyang Kalimusada.txt 1
12 Salya.txt 1