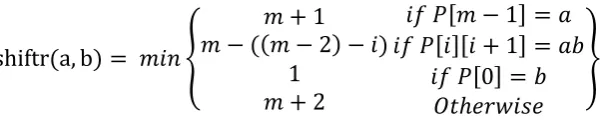DENGAN MENGGUNAKAN ALGORITMA TWO SLIDING WINDOWS
SKRIPSI
FRANS OCTAVIANUS
091402089
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
▸ Baca selengkapnya: kata rasila bersinonim dengan kata…
(2)DENGAN MENGGUNAKAN ALGORITMA TWO SLIDING WINDOWS
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah
Sarjana Teknologi Informasi
FRANS OCTAVIANUS
091402089
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
Judul : PENCARIAN KATA DAN SINONIM KATA
DALAM DOKUMEN DENGAN MENGGUNAKAN
ALGORITMA TWO SLIDING WINDOWS
Kategori : SKRIPSI
Nama : FRANS OCTAVIANUS
Nomor Induk Mahasiswa : 091402089
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI
Diluluskan di
Medan, 22 Oktober 2015
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dedy Arisandi, ST.M.Kom Dr. Erna Budhiarti Nababan, M.IT
NIP. 19790831 200912 1 002 NIP. -
Diketahui/ Disetujui Oleh
Program Studi Teknologi Informasi
Ketua,
Muhammad Anggia Muchtar, ST.,MM.IT
PENCARIAN KATA DAN SINONIM KATA DALAM DOKUMEN DENGAN
MENGGUNAKAN ALGORITMA TWO SLIDING WINDOWS
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, 22 Oktober 2015
FRANS OCTAVIANUS
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa dan Maha Penyayang, dengan segala rahmat dan karuniaNya penulisan tugas akhir ini berhasil diselesaikan dalam waktu yang telah ditetapkan. Selama penyelesaian tugas akhir ini, banyak bantuan dan kerja sama serta doa dan dukungan dari berbagai pihak, oleh karena itu penulis sampaikan ucapan terima kasih sedalam - dalamnya dan penghargaan kepada :
1. Kedua orang tua dan sanak saudara penulis yang telah memberikan dukungan dan motivasi baik materil dan spiritual selama penulis mengikuti pendidikan hingga selesainya tugas akhir ini.
2. Ibu Dr. Erna Budhiarti Nababan, M.IT dan Bapak Dedy Arisandi, S.T., M.Kom selaku pembimbing yang telah banyak meluangkan waktu dan pikiran beliau, memotivasi, memberikan arahan, kritik dan saran kepada penulis.
3. Bapak Romi Fadillah Rahmat, B.Comp.Sc, M.Sc dan Ibu Amalia, ST.,M.T yang telah bersedia menjadi dosen pembanding yang telah memberikan kritik dan saran kepada penulis.
4. Ketua dan Sekretaris Program Studi Teknologi Informasi, Bapak M. Anggia Muchtar, ST.,MM.IT dan Bapak M. Fadly Syahputra, B.Sc.,M.Sc.IT. Dekan dan Pembantu Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara, semua dosen di Fakultas Ilmu Komputer dan Teknologi Informasi.
5. Kepada Bang Manap, Kakak Umi, dan Ibu Mega dan semua staff dan pegawai di Fakultas Ilmu Komputer dan Teknologi Informasi yang tidak dapat saya sebutkan satu-persatu.
6. Kepada sahabat seperjuangan dan rekan – rekan mahasiswa Program Studi Teknologi Informasi USU yang telah memberikan dukungan dan semangat untuk saya.
ABSTRAK
Saat ini informasi mudah didapatkan terutama informasi yang tersimpan di dalam
dokumen. Di dalam dokumen terutama artikel sering dijumpai kata-kata yang masih
jarang digunakan seperti beranda, telaga, bilik, misai, dan jeram. Kata-kata tersebut
mengandung persamaan kata dengan kata-kata umum yang sudah sering digunakan
dalam pembicaraan sehari-hari. Akan tetapi, kata kunci pencarian yang umumnya dicari
oleh user, dominan berupa kata-kata umum yang sering dijumpai. Oleh karena itu,
diperlukan suatu metode untuk mempermudah pengguna dalam mencari informasi yang
berhubungan dengan kata dan sinonim kata pada dokumen. Peneliti menggunakan
metode stemming yaitu Porter Stemming yang digunakan untuk mengolah kata-kata berimbuhan menjadi kata dasar. Selanjutnya diproses lebih lanjut untuk dicari
kecocokan persamaan makna kata yang sesuai. Kata dan sinonim kata yang telah
diproses akan dicari menggunakan algoritma Two Sliding Windows sebagai metode pencarian teks pada dokumen. Pencarian menjadi lebih cepat karena TSW melakukan
pengecekan dengan menggunakan dua sisi (windows) yaitu sisi kiri dan kanan secara paralel. Hasil pengujian menunjukkan metode yang dipakai bisa menyelesaikan
permasalahan mencari sinonim kata baik kata dasar maupun kata majemuk. Tingkat
keakuratan tidak mencapai 100% karena adanya perbedaan kata imbuhan baik serapan
maupun sisipan yang menimbulkan makna berbeda.
Words and Synonym Searching in Documents using Two Sliding Windows Algorithm
ABSTRACT
Nowadays information is obtained easily, especially information stored in the document. In the document, especially the article often found words that are rarely used such as porches, pond, walk, whiskers, and rafting. These words contain a synonym with common words that have been frequently used in everyday conversation. However, the search keywords are generally searched by the user, the form of common words that are often encountered. Therefore, a method is needed in order to facilitate the user while searching the information in the document. the application uses stemming method namely Porter Stemming used to process from much affix words into root words. Then processed further to look for the meaning of the equation match several appropriate word. Word and synonym that has been processed will be searched by Two Sliding Windows algorithm as a method of text searching in the document. Search becomes faster because TSW check by using double-sided (windows) that the left and right being searched in parallel. The test results showed that the method can be used to solve the problems of searching for a synonym both basic words and compound words. The accuracy does not reach 100% because of different affixes; “serapan” as well as
“sisipan” which giving several different meanings.
DAFTAR ISI
1.6 Metodologi Penelitian 3
1.7 Sistematika Penulisan 3
BAB 2 LANDASAN TEORI 6
2.1 Sinonim Kata 6
2.2 Stemming 8
2.3 Stopword 13
2.4 Pattern Matching 14
2.5 Penelitian Terdahulu 16
BAB 3 ANALISIS DAN PERANCANGAN SISTEM 17
3.1 Data Yang Digunakan 17
3.2 Arsitektur Umum 17
3.3 Analisis Data 18
3.4 Rancangan Antar Muka 33
BAB 4 IMPLEMENTASI DAN PENGUJIAN 37
4.1 Implementasi Sistem 37
4.2 Tahapan Operasi Aplikasi 40
BAB 5 KESIMPULAN DAN SARAN 49
5.1 Kesimpulan 49
5.2 Saran 50
DAFTAR TABEL
Hal.
Tabel 2.1Aturan untuk Infection Particle 11
Tabel 2.2 Aturanuntuk Possesive Pronoun 12
Tabel 2.3 Aturan untuk First Order Derivational Prefix 12 Tabel 2.4 Aturan untuk Second Order Derivational Prefix 13
Tabel 2.5 Aturan untuk Derivation Suffix 13
Tabel 2.6 Penelitian Terdahulu 18
Tabel 4.1 Pengujian terhadap variasi jumlah kata pada kalimat baku 44
Tabel 4.2 Hasil pencocokan dengan kata kunci 45
“pelaku,pasar,jibaku,reda,polemic,krisis,ekonomi”
Tabel 4.3 Hasil pencocokan dengan sinonim kata kunci 47
DAFTAR GAMBAR
Hal.
Gambar 2.1 Desain Porter Stemmer 10
Gambar 2.2 Bad character shift a dan b (nextl) 15 Gambar 2.3 Bad character shift a dan b (nextr) 15
Gambar 3.1 Arsitektur Umum Sistem 18
Gambar 3.2 Proses Stopwords 19
Gambar 3.3 Algoritma Porter dalam proses stemming 21
Gambar 3.4 Proses Pencarian Teks 24
Gambar 3.5 Ilustrasi posisi penentuan letak pada bagian kiri teks 25
Gambar 3.6 Aturan Operasi Hitung Nilai shift kiri 26
Gambar 3.7 Ilustrasi posisi penentuan letak pada bagian kanan teks 27
Gambar 3.8 Aturan Operasi Hitung Nilai shift kanan 28
Gambar 3.9 Pre-processing bad character shift algoritma Berry-Ravindran 29
Gambar 3.10 Algoritma Two Sliding Windows (TSW) 33
Gambar 3.11 Perancangan Sistem 34
Gambar 4.1 Tampilan halaman input 38
Gambar 4.2 Tampilan database file 39
Gambar 4.3 Tampilan halaman kamus kata 39
Gambar 4.4 Tampilan saat menuliskan kata-kata pada textbox 40 Gambar 4.5 Tampilan hasil pencarian sinonim kata pada dokumen 41
Gambar 4.6 Tampilan saat memilih berkas 42
Gambar 4.7 Tampilan hasil penyimpanan berkas 43
Gambar 4.8 Tampilan saat menambah kata dan sinonim kata 43
Gambar 4.9 Hasil pengujian dengan kata kunci “para pelaku pasar berjibaku 45
ABSTRAK
Saat ini informasi mudah didapatkan terutama informasi yang tersimpan di dalam
dokumen. Di dalam dokumen terutama artikel sering dijumpai kata-kata yang masih
jarang digunakan seperti beranda, telaga, bilik, misai, dan jeram. Kata-kata tersebut
mengandung persamaan kata dengan kata-kata umum yang sudah sering digunakan
dalam pembicaraan sehari-hari. Akan tetapi, kata kunci pencarian yang umumnya dicari
oleh user, dominan berupa kata-kata umum yang sering dijumpai. Oleh karena itu,
diperlukan suatu metode untuk mempermudah pengguna dalam mencari informasi yang
berhubungan dengan kata dan sinonim kata pada dokumen. Peneliti menggunakan
metode stemming yaitu Porter Stemming yang digunakan untuk mengolah kata-kata berimbuhan menjadi kata dasar. Selanjutnya diproses lebih lanjut untuk dicari
kecocokan persamaan makna kata yang sesuai. Kata dan sinonim kata yang telah
diproses akan dicari menggunakan algoritma Two Sliding Windows sebagai metode pencarian teks pada dokumen. Pencarian menjadi lebih cepat karena TSW melakukan
pengecekan dengan menggunakan dua sisi (windows) yaitu sisi kiri dan kanan secara paralel. Hasil pengujian menunjukkan metode yang dipakai bisa menyelesaikan
permasalahan mencari sinonim kata baik kata dasar maupun kata majemuk. Tingkat
keakuratan tidak mencapai 100% karena adanya perbedaan kata imbuhan baik serapan
maupun sisipan yang menimbulkan makna berbeda.
Words and Synonym Searching in Documents using Two Sliding Windows Algorithm
ABSTRACT
Nowadays information is obtained easily, especially information stored in the document. In the document, especially the article often found words that are rarely used such as porches, pond, walk, whiskers, and rafting. These words contain a synonym with common words that have been frequently used in everyday conversation. However, the search keywords are generally searched by the user, the form of common words that are often encountered. Therefore, a method is needed in order to facilitate the user while searching the information in the document. the application uses stemming method namely Porter Stemming used to process from much affix words into root words. Then processed further to look for the meaning of the equation match several appropriate word. Word and synonym that has been processed will be searched by Two Sliding Windows algorithm as a method of text searching in the document. Search becomes faster because TSW check by using double-sided (windows) that the left and right being searched in parallel. The test results showed that the method can be used to solve the problems of searching for a synonym both basic words and compound words. The accuracy does not reach 100% because of different affixes; “serapan” as well as
“sisipan” which giving several different meanings.
BAB 1
PENDAHULUAN
1.1.Latar Belakang
Saat ini informasi sangat mudah didapatkan terutama melalui media internet. Dengan
banyaknya informasi yang terkumpul atau tersimpan dalam jumlah yang banyak, user
akan kesulitan mendapatkan informasi berbentuk dokumen yang diinginkan.
Semakin bertambahnya dokumen, penggunaan sistem pencarian pola teks ataupun
informasi yang terdapat di dalamnya menjadi penting. Dengan adanya sistem pencarian
teks banyak menghemat waktu pengerjaan untuk menemukan informasi yang terdapat
dalam dokumen.
Sistem tersebut menerima kata kunci (keyword) yang ditulis oleh user dan melakukan pencocokan dengan database. Selama ada penyimpanan dan pencarian
kembali dokumen, sistem dapat bekerja dengan baik.
Tiap dokumen teks bisa diolah untuk menemukan informasi baru. Di dalam
dokumen tersebut terkadang terdapat kata penghubung yang saling berhubungan dan
menimbulkan makna yang berbeda, sedangkan dalam bahasa seringkali terdapat
sinonim kata yang sama maknanya dengan kata kunci pencarian.
Dalam beberapa dokumen seperti artikel bahasa terkadang memiliki kata-kata yang
masi jarang digunakan atau dijumpai seperti beranda, telaga, bilik, misai, dan jeram.
Kata-kata tersebut mengandung persamaan kata dengan kata-kata umum yang sudah
sering digunakan dalam pembicaraan sehari-hari.Akan tetapi, kata kunci pencarian
yang umumnya dicari oleh user, dominan berupa kata-kata umum yang sering dijumpai.
Beberapa penelitian telah dilakukan berhubung dengan sistem pencarian kata antara
(term) dan menghitung cosine similaritas untuk menghitung kesamaan kata dalam dokumen. (Februariyanti, et al. 2010). Hasil uji menunjukan bahwa algoritma dapat
digunakan untuk menghitung tingkat similaritas (kesamaan) dokumen berdasarkan kata
kunci yang diinputkan oleh pengguna tetapi tidak berdasarkan persamaan makna kata
yang sering muncul di dalam dokumen .
Bari, et al (2010) menerapkan pencarian kata dengan vector space model untuk melakukan perhitungan kemiripan data berdasarkan kata yang diinput. Kemiripan data
dipertimbangkan berdasarkan tingkat kemunculan data tersebut.
Oleh karena itu, apabila dihadapkan dengan jumlah dokumen yang banyak dan
kemunculan kata baku yang masih jarang dijumpai, diperlukan adanya suatu metode
untuk menyelesaikan permasalahan tersebut. Metode yang diajukan didalam penelitian
ini adalah metode stemming yang merupakan salah satu teknik text mining untuk mendapatkan kata dasar dan diakhiri dengan eliminasi kata-kata umun yang muncul
dalam jumlah besar dan dianggap tidak memiliki makna (stopword).
Dalam implementasinya, metode ini akan menggunakan algoritma pattern matching sebagai algoritma pencarian kata dalam dokumen. Salah satu metode yang digunakan
dalam pencocokan pola (pattern matching) yaitu algoritma two sliding windows (TSW) yang mempunyai keunggulan dalam fase pencarian (searching phase).
Berdasarkan penelitian yang dilakukan oleh Hudaib et al, algoritma TSW mempunyai performasi yang lebih unggul khususnya jika pola tersebut berada diakhir
teks. Hasil pengujian menunjukkan percobaan dan perbandingan dengan algoritma
lainnya seperti algoritma Knuth-Morris-Pratt dan Boyer-Moore lebih cepat dan membutuhkan usaha yang lebih sedikit. Pada mulanya, algoritma ini memulai pre-processing phase untuk membagi string menjadi dua bagian (two windows) sebanyak n/2 ukuran string. Kemudian, dilakukan scanning pada fase pencarian dari kiri dan kanan secara paralel dan bersamaan( Hudaib et al, 2008 ).
1.2.Rumusan Masalah
Terdapat kesulitan dalam memahami kata dalam bahasa Indonesia yang jarang
digunakan dalam pembicaraan sehari-hari misalnya kata baku yang terdapat di dalam
artikel atau jurnal. Oleh karena itu, dibutuhkan suatu pendekatan untuk mengatasi
permasalahan persamaan kata dalam dokumen.
1.3.Tujuan Penelitian
Penelitian ini bertujuan untuk mencari makna kata dan sinonim kata dalam dokumen
dengan menggunakan algoritma two sliding windows.
1.4.Batasan Masalah
Agar penelitian dapat berjalan dengan baik dan terarah, maka penelitian ini akan
menggunakan batasan sebagai berikut:
1. Dokumen yang diproses berupa artikel atau jurnal ilmiah.
2. Pencarian kata menggunakan bahasa Indonesia.
3. Sinonim kata yang dipakai hanya dibatasi pada kata benda dan kata kerja.
4. Referensi kata dasar dari KBBI ( Kamus Besar Bahasa Indonesia ).
5. Referensi sinonim kata dari thesaurus Indonesia.
1.5.Manfaat Penelitian
Hasil dari penelitian ini diharapkan dapat memberikan manfaat, yaitu :
1. Menambah referensi penelitian mengenai berbagai sistem yang menyangkut
pencarian kata atau informasi.
2. Memberikan pendekatan hasil yang lebih optimal dengan penerapan
algoritma two sliding windows.
3. Menambah pengetahuan mengenai penggunaan algoritma TSW yang lebih
cepat dalam menghadapi jumlah data yang kompleks.
4. Menjadi salah satu alternatif algoritma pencarian bagi sistem temu daya
1.6.Metodologi Penelitian
Penelitian akan dilakukan dengan tahapan-tahapan metodologi penelitian sebagai
berikut :
1. Studi Literatur
Pada tahap ini dilakukan studi kepustakaan dengan melakukan pengumpulan
referensi melalui berbagai macam buku, jurnal, artikel, dan sumber referensi
lainnya yang berkaitan dengan penelitian ini.
2. Pengumpulan Data
Pada tahap ini dilakukan pengumpulan data dan informasi berupa kamus data
dan sejumlah jurnal ilmiah yang akan diperlukan dalam penelitian ini.
3. Analisis dan Perancangan
Pada tahap ini dilakukan analisis terhadap studi literatur untuk mendapatkan
pendekatan kata dalam dokumen. Setelah itu, dilakukan perancangan arsitektur
sistem yang akan dibangun berdasarkan analisis yang telah dibuat sebelumnya.
4. Implementasi
Pata tahap ini, perancangan sistem yang telah dibuat akan diimplementasikan ke
dalam suatu aplikasi yang dibuat dengan menggunakan bahasa pemrograman
PHP dan database MySQL. 5. Pengujian
Pada tahap ini dilakukan pengujian aplikasi yang telah dibuat untuk mengetahui
apakah aplikasi tersebut sudah berjalan dengan benar dan sesuai dengan
perancangan yang telah dilakukan sebelumnya.
6. Penyusunan Laporan
Pada tahap ini diakukan penyusunan dokumentasi dari hasil analisis dan
implementasi dari aplikasi yang telah dibuat.
1.7.Sistematika Penulisan
Bab 1: Pendahuluan
Bab ini akan menjelaskan tentang latar belakang penelitian, rumusan masalah, batasan
masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian, dan sistematika
penulisan.
Bab 2: Landasan Teori
Bab ini berisi tentang teori dan penelitian terdahulu yang digunakan untuk
menyelesaikan permasalahan yang akan dibahas dalam penelitian ini.
Bab 3: Analisa dan Perancangan Sistem
Pada bab ini penulis menjelaskan arsitektur sistem yang akan dibangun dan pemrosesan
stemming dengan menggunakan algoritma Porter serta pencarian teks dibantu dengan
algoritma two sliding windows.
Bab 4: Implementasi dan Pengujian Sistem
Pada bab ini dibahas implementasi dari metode yang digunakan serta pengujian hasil
penelitian dengan kriteria yang telah ditentukan.
Bab 5: Kesimpulan dan Saran
Bab ini memuat kesimpulan dari penelitian yang dilakukan serta saran yang diharapkan
BAB 2
LANDASAN TEORI
2.1 Sinonim kata
2.1.1. Definisi Sinonim
Menurut Chaer (2009), “Relasi makna adalah hubungan kemaknaan atau relasi semantik antara sebuah kata atau satuan bahasa lainnya dengan akta atau satuan bahasa
lainnya lagi”. Hubungan relasi kemaknaan ini menyangkut hal misalnya sinonim.
Secara etimologi, kata sinonimi atau disingkat sinonim berasal dari bahasa Yunani kuno, yaitu onoma yang berarti ‘nama’, dan syn yang berarti ‘dengan’. Untuk mendefinisikan sinonim, ada tiga batasan yang dapat dikemukakan. Batasan atau
definisi itu ialah: (i) kata-kata dengan acuan ekstra linguistik yang sama, misalnya kata
mati dan mampus; (ii) kata-kata yang mengandung makna yang sama, misalnya kata memberitahukan dan kata menyampaikan; dan (iii) kata-kata yang dapat disubtitusikan
dalam konteks yang sama misalnya “ kami berusaha agar pembangunan berjalan terus.
“, “ kami berupaya agar pembangunan berjalan terus.” Kata berupaya bersinonim dengan kata berusaha (Pateda, 2010).
2.1.2. Kemunculan Sinonim
Menurut Aminuddin (2008), ada lima cara yang dapat digunakan dalam
menentukan kemungkinan adanya sinonim. Kelima cara yang dimaksud adalah:
1. Seperangkat sinonim itu mungkin saja merupakan kata-kata yang
digunakan dalam dialek yang berbeda-beda. Kata pena dan rika dalam bahasa Jawa dialek Surabaya memiliki terjemahan kedalam bahasa
2. kata tersebut memiliki makna dasar berbeda-beda, kata-kata tersebut tidak
dapat ditentukan sebagai sinonim.
3. Suatu kata yang semula dianggap memiliki kemiripan atau kesamaan
makna, setelah berada dalam berbagai pemakaian ada kemungkinan
membuahkan makna yang berbeda-beda. Kata bisa dan dapat, misalnya, meskipun secara leksikal merupakan sinonim, dalam konteks pemakaian
“Saya nanti bisa datang” dan “Saya nanti dapat datang” tetap pula dapat dianggap sinonim. Sewaktu berada dalam konteks pemakaian “Bisa ular itu berbahaya”, kedua kata tersebut tidak dapat lagi disebut sinonim.
4. Suatu kata, apabila ditinjau berdasarkan makna kognitif, makna emotif,
maupun makna evaluatif, mungkin aja akhirnya menunjukkan adaya
karakteristik tersendiri meskipun dalam pemakaian sehari-hari semula
dianggap memiliki kesinoniman dengan kata lainnya. Bentuk demikian
misalnya dapat ditemukan dalam pasangan kata ilmu dan pengetahuan, mengamati dan meneliti serta antara mengusap dengan membelai. Apabila hal itu terjadi, maka kata-kata yang semula dianggap sinonim itu harus
dianggap sebagai kata yang berdiri sendiri-sendiri.
5. Suatu kata yang semula memiliki kolokasi sangat ketat, misalnya antara
kopi dengan minuman maupun pohon dengan batang, seringkali dipakai secara tumpang tindih karena masing-masing dianggap memiliki
kesinoniman. Hal itu tentu saja tidak benar karena masing-masing kata
tersebut jelas masih memiliki makna sendiri-sendiri. Sebab itu, pemakaian
yang tumpang tindih dapat mengakibatkan adanya salah pengertian.
6. Kekurangtahuan terhadap nilai makna suatu kata maupun kelompok kata,
seringkali bentuk kebahasaan yang berbeda-beda begitu saja dianggap
sinonim, misalnya antara bentuk kembali ke pangkuan ilahi dengan meninggalkan dunia kehidupan, antara merencanakan dengan menginginkan, serta antara gambaran dengan bayangan.
2.1.3. Jenis - jenis Sinonim
1. Kata dasar bersinonim dengan kata dasar.
cantik : anggun, ayu, elok
hidup : jiwa, nyawa, tumbuh
2. Kata dasar tunggal bersinonim dengan kata majemuk
Gelandangan : tunawisma
Pembantu : pramuwisma
3. Kata tunggal bersinonim dengan frasa
asmara : cinta berahi, cinta kasih
muhibah : cinta kasih, rasa sahabat
4. Kata majemuk bersinonim dengan kata tunggal
awan hitam : mendung
sakit hati : kecewa
5. Frase bersinonim dengan frase
tinggi hati : besar kepala
merah jambu : merah muda
2.2. Stemming
2.2.1. Definisi Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem IR yang mentransformasi
kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan
menggunakan aturan-aturan tertentu. Sebagai contoh, kata bersama, kebersamaan, menyamai,
akan distem ke root word-nya yaitu “sama”. Proses stemming pada teks berbahasa Indonesia
berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris, proses yang
diperlukan hanya proses menghilangkan sufiks. Sedangkan pada teks berbahasa Indonesia,
2.2.2. Metode Stemming
Metode stemming memerlukan input berupa term yang terdapat dalam dokumen. Sedangkan outputnya berupa stem. Ada tiga jenis metode stemming, antara lain : 1. Successor Variety (SV) : lebih mengutamakan penyusunan huruf dalam kata
dibandingkan dengan pertimbangan atas fonem. Contoh untuk kata-kata : corpus, able, axle, accident, ape, about menghasilkan SV untuk kata apple:
a. Karena huruf pertama dari kata “ apple” adalah “a”, maka kumpulan kata yang ada substring“a” diikuti “b”, “x”, “c”, “p” disebut SV dari “a” sehingga “a” memiliki 4 SV.
b. Karena dua huruf pertama dari kata “apple” adalah “ap”, maka kumpulan kata yang ada substring “ap” hanya diikuti “e” disebut SV dari “ap” sehingga “ap” memiliki 1 SV.
2. N-Gram Conflation : ide dasarnya adalah pengelompokan kata-kata secara bersama berdasarkan karakter-karakter (substring) yang teridentifikasi sepanjang N karakter.
3. Affix Removal (penghilangan imbuhan) : membuang prefix (awalan) dan suffix (akhiran) dari term menjadi suatu stem. Yang paling sering digunakan adalah algoritma Porter Stemmer karena modelnya sederhana dan efisien.
a. Jika suatu kata diakhiri dengan “ies” tetapi bukan “eies” atau “aies”, maka “ies”
di-replace dengan “y”
b. Jika suatu kata diakhiri dengan “es” tetapi bukan “aes” atau “ees” atau “oes”, maka “es” di-replace dengan “e”
c. Jika suatu kata diakhiri dengan “s” tetapi bukan “us” atau “ss”, maka “s” di -replace dengan “NULL”
2.2.3. Porter Stemming
Porter Stemming merupakan salah satu teknik stemming yang umum digunakan. Algoritma Porter adalah cara pencarian root word (kata dasar) yang dilakukan secara stripping imbuhan dan akhiran tanpa memperhatikan sisipin dan tanpa pengecekan kamus kata dasar. Porter Stemmer for Bahasa Indonesia dikembangkan oleh Fadillah Z. Tala pada tahun 2003.
Awal mula Porter Stemmer for Bahasa Indonesia berdasarkan English Porter Stemmer yang dikembangkan oleh W.B. Frakes pada tahun 1992. Karena bahasa Inggris datang dari kelas yang berbeda, beberapa modifikasi telah dilakukan untuk membuat
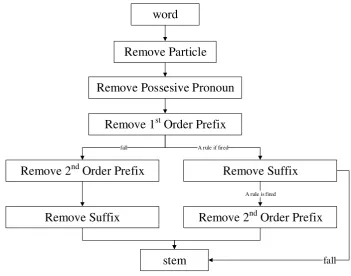
algoritma Porter dapat digunakan sesuai dengan bahasa Indonesia seperti pada gambar 2.1.
word
Remove Particle
Remove Possesive Pronoun
Remove 1st Order Prefix
Remove 2nd Order Prefix Remove Suffix
fall A rule if fired
Remove Suffix Remove 2nd Order Prefix
A rule is fired
stem fall
Gambar 2.1. Desain Porter Stemmer (Tala, 2003)
Adapun tahap-tahap algoritma ini adalah :
1. Hapus partikel.
2. Hapus kata ganti kepunyaan. (-ku, -mu, -nya)
3. Hapus awalan pertama. Jika tidak ada, lanjutkan ke langkah 4a, jika ada hapus
awalan dan lanjutkan ke langkah 4b.
b. Hapus akhiran, jika tidak ditemukan maka kata tersebut diasumsikan sebagai
root word. Jika ditemukan maka lanjutkan ke langkah 5b.
5. a. Hapus akhiran. Kemudian kata akhir diasumsikan sebagai root word. b. Hapus awalan kedua. Kemudian kata akhir diasumsikan sebagai root word.
Ada lima kumpulan aturan pada algoritma Porter Bahasa Indonesia. Aturan tersebut
dapat dilihat pada table 2.1 sampai table 2.5. Acuan pemotongan partikel pada infleksi
kata bahasa Indonesia dapat dilihat pada tabel 2.1, acuan kata ganti milik orang pertama
pada tabel 2.2, kumpulan imbuhan awalan bahasa Indoensia pada tabel 2.3 dan tabel
2.4, serta kumpulan akhiran bahasa Indoneisa dapat dilihat pada tabel 2.5.
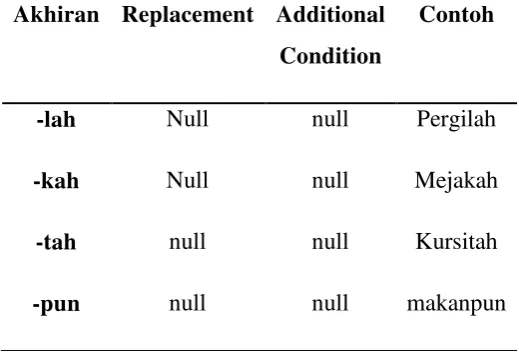
Tabel 2.1 Aturan untuk InfectionParticle (Tala, 2003)
Akhiran Replacement Additional
Condition
Contoh
-lah Null null Pergilah
-kah Null null Mejakah
-tah null null Kursitah
-pun null null makanpun
Tabel 2.2 Aturan untuk InfectionPossesive Pronoun(Tala, 2003)
Akhiran Replacement Additional Condition Contoh
-ku null null Pensilku
-mu null null Punyamu
-nya null null miliknya
Tabel 2.3 Aturan untuk First Order Derivational Prefix(Tala, 2003)
Awalan Replacement Addtional Condition Contoh
meng- null null Mengambil
meny- S V...* Menyelesaikan
men- null null Mendaki
mem- P V...* Mempunyai
me- null null Melarang
peng- null null Penghijauan
peny- null null Penyiksaan
pen- null null pendaki
pem- P V.... Pemahat
pem- null null Pembantu
di- null null Diberi
ter- null null terlepas
ke- null null kelaparan
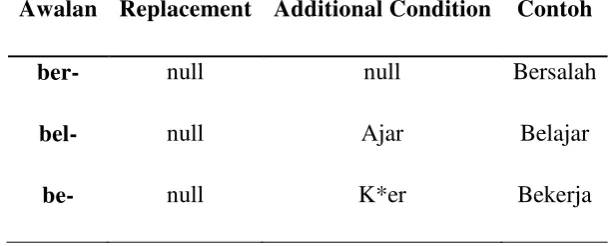
Tabel 2.4 Aturan untuk Second Order Derivational Prefix(Tala, 2003)
Awalan Replacement Additional Condition Contoh
ber- null null Bersalah
bel- null Ajar Belajar
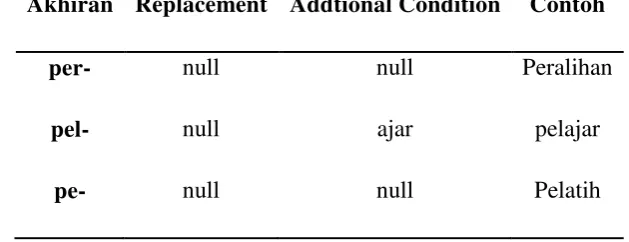
Tabel 2.4 Aturan untuk Second Order Derivational Prefix (lanjutan , Tala, 2003)
Akhiran Replacement Addtional Condition Contoh
per- null null Peralihan
pel- null ajar pelajar
pe- null null Pelatih
Tabel 2.5 Aturan untuk Derivation Suffix(Tala, 2003)
Akhiran Replacement Addtional Condition Contoh
-kan null Prefix bukan anggota ( ke, peng ) Salahkan
-an null Prefix bukan anggota ( di, meng, ter ) Makanan
-i null Prefix bukan anggota ( ber, ke, peng ) tandai
2.3. Stopword
2.3.1. Definisi Stopword
Penghilangan kata-kata yang frekuensinya terlalu banyak terdapat dalam dokumen.
Frekuensi kata-kata yang terlalu banyak bukan merupakan kata kunci yang tepat.
Faktanya sebuah kata yang frekuensi kemunculannya lebih banyak dari dokumen tidak
berguna untuk tujuan retrieval. Kata-kata seperti itu dinamakan stopwords dan biasanya tidak dimasukkan ke dalam index terms. Kata depan dan kata penghubung biasanya menjadi kandidat sebagai stopwords.
Berikut ini adalah contoh stopwords dalam bahasa Indonesia : yang, juga, dari, dia, kami, kamu, aku, saya, ini, itu, atau, dan, tersebut, pada, dengan, adalah, yaitu, ke, tak,
2.4. Pattern matching
2.4.1. Definisi Pattern Matching
Pattern Matching adalah suatu teknik pencarian string yang berisi teks atau data biner dari sekumpulan karakter berdasarkan pola yang ingin dicari. Berhubung pengenalan
pola (pattern recognition), pencocokan biasanya harus mempunyai nilai yang tepat atau sama.
Beberapa algoritma pencocokan pola yang sering digunakan antara lain Knuth-Moris-Pratt algorithm, Boyer-Moore, Rabin-Karp, Two Sliding Windows dan lain sebagainya.
2.4.2. Algoritma Two Sliding Windows (TSW)
Pada umumnya, algoritma TSW mendeteksi teks dari dua sisi secara bersamaan.
Algoritma ini membagi teks menjadi dua bagian (windows) dan tiap bagian memiliki panjang sebesar n/2 . Bagian kiri (left window) akan melakukan pemindaian dari kiri ke kanan dan bagian kanan (right window) melakukan pemindaiandari kanan ke kiri. Kemudian kedua windows tersebut bekerja bersamaaan secara paralel. Algoritma ini akan berhenti jika salah satu dari windows telah menemukan pola atau pola tersebut tidak ditemukan di dalam keseluruhan teks. Algoritma TSW mengimplementasikan ide
dari algoritma Berry-Ravindran mengenai fungsi bad character shift untuk mendapatkan nilai shift pada saat fase pencarian. Disamping itu, algoritma BR juga digunakan oleh Hussain, et al (2010) untuk menentukan nilai pergeseran dan diterapkan pada algoritma pencarian Bidirectional. Perbedaan utama dari algoritma TSW dan algoritma BR antara lain :
1. TSW menggunakan dua slide sementara algoritma BR hanya menggunakan satu slide untuk melakukan pencarian teks.
2. TSW menggunakan dua array , tiap array merupakan array satu dimensi yang memiliki ukuran sebesar m – 1. Array tersebut digunakan untuk menyimpan nilai shift yang sudah terkalkulasi pada proses algoritma. Disamping itu, algoritma BR menggunakan array dua dimensi untuk menyimpan nilai shift pada pemrosesannya. Menggunakan array satu dimensi mempersingkat waktu pemrosesan dan mengurangi pemakaian memori yang diperlukan untuk
2.4.2.1. Pre-processing Phase
Fase pre-processing menghasilkan dua array berupa nextl dan nextr. Nilai dari nextl dihitung berdasarkan algoritma bad character Berry-Ravindran (BR). Nextl berisi nilai shift yang diperlukan untuk mencari teks pada sisi kiri. Untuk menghitungnya, algoritma ini mempertimbangkan dua karakter a dan b berturut-turut yang didapat sesaat
setelah pergeseran window selesai. Nilai indeks dari dua karakter tersebut dari dihitung dari sebelah kiri (m+1) dan (m+2) .
Gambar 2.2. Bad charactershift a dan b pada nextl (Ravindran et al, 1999)
Sedangkan nilai nextr berisi nilai shift yang diperlukan untuk mencari teks pada sisi kanan dan menyimpan nilai indeks dua karakter tersebut dari teks sebelah kanan (
n-m-1) dan (n-m-2).
Gambar 2.3. Bad character shift a dan b pada nextr (Ravindran et al, 1999)
2.4.2.2. Searching Phase
Dalam fase ini, teks akan dideteksi dari dua arah, kiri ke kanan dan kanan ke kiri. Ketika
2.5 Penelitian terdahulu
Berbagai penelitian telah dilakukan untuk menyelesaikan pencarian kata maupun
persamaannya dengan algoritma pencarian antara lain :
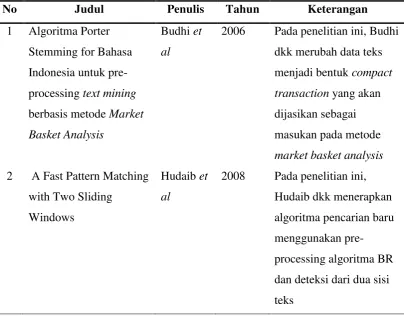
1. Budhi et al. (2006) menggunakan algoritma Porter Stemmer for Bahasa Indonesia, untuk proses Stemmer pada langkah pre-processing yang merubah sebuah teks dalam bahasa Indonesia menjadi bentuk Compact Transaction. Compact Transaction digunakan sebagai masukan untuk proses Keyword-Based Association Analysis, sebuah metode Text Mining yang dikembangkan dari metode Market Basket Analysis, digunakan untuk membentuk rule-rule asosiasi dari data teks. Hasil pengujian terhadap kesalahan proses 'Stem' kata secara
otomatis cukup kecil, yaitu 2% sehingga dapat diatasi dengan cepat
menggunakan pemeriksaan kembali secara manual terhadap hasil Stemmer.
2. Hudaib et al. (2008) melakukan penelitian untuk menerapkan dan membuat sebuah algoritma pattern matching yang cepat.Algoritma tersebut dinamakan algoritma two sliding windows. Penelitian dilakukan dengan menerapkan ide
dari algoritma Berry-Ravindran untuk menentukan nilai pergeseran dan menggunakan dua sisi (window) untuk melakukan scanning karakter. Hasil pengujian menunjukkan bahwa performansi terbaik algoritma TSW apabila
kata-kata tersebut berada di akhir sebuah dokumen.
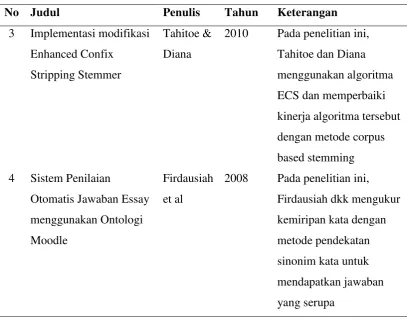
3. Tahitoe & Diana (2010) melakukan penelitian terhadap algoritma Enhanced Confix Stripping Stemmer dan mendapati adanya kesalahan yang dilakukan oleh algoritma tersebut karena ECS Stemmer tidak mengajukan perbaikan terhadap
4. Firdausiah et al. (2008) mencari sinonim kata berdasarkan pengukuran similaritas semantic berbasis WordNet pada sistem penilaian otomatis jawaban
essay menggunakan ontologi moodle. Proses pencarian sinonim menghasilkan
beberapa output sinonim berbeda pada level yang berbeda.
5. Putra, Hedryan K.(2013) menerepkan algoritma Karp Rabin dan metode
pendekatan sinonim kata untuk mendapatkan tingkat duplikasi dengan tingkat
ketelitian tinggi. Akurasi yang dihasilkan cukup tinggi karena pendeteksian
dokumen diproses dengan membandingkan kata perkata yang terdapat di dalam
dokumen dan membandingkan kata yang memiliki sinonim kata. Penjelasan
penelitian sebelumnya dapat dilihat pada tabel 2.6.
Tabel 2.6 Penelitian terdahulu yang berkaitan dengan pencarian sinonim kata
No Judul Penulis Tahun Keterangan
2006 Pada penelitian ini, Budhi
dkk merubah data teks
2008 Pada penelitian ini,
Hudaib dkk menerapkan
algoritma pencarian baru
menggunakan
pre-processing algoritma BR
dan deteksi dari dua sisi
Tabel 2.6 Penelitian terdahulu yang berkaitan dengan pencarian sinonim kata
2010 Pada penelitian ini,
Tahitoe dan Diana
2008 Pada penelitian ini,
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Bab ini membahas data yang digunakan dan mengimplementasikan algortima pattern matching pada pencarian sinonim kata dalam dokumen.
3.1 Data yang digunakan
Data yang digunakan merujuk Kamus Besar Bahasa Indonesia (KBBI) yang berisi
kumpulan kata-kata lengkap bahasa Indonesia dan makna persamaan kata merujuk
kepada Thesaurus bahasa Indonesia.
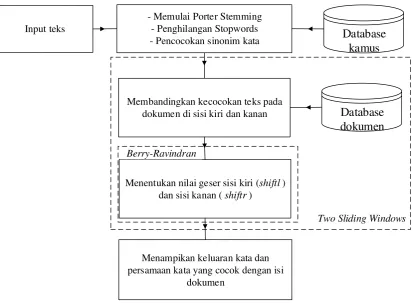
3.2 Arsitektur Umum
Tahapan awal sistem dimulai dengan proses input yang berisi kata-kata yang ingin
dicari oleh user. Sistem melakukan pengecekan tiap kata dan melakukan penghapusan
kata yang tidak penting atau tepat untuk pencarian kata selanjutnya. Kemudian sistem
akan memulai tahapan parsing yang diawali dengan stemming kata, pemisahan struktur kata antara imbuhan dengan kata dasarnya. Pada saat proses stemming berlangsung, sistem mencocokkan inputan user terhadap kata dasar yang sudah disimpan di database;
penambahan persamaan kata yang relevan dengan makna kata tersebut baik kata tunggal
maupun frasa untuk pencarian selanjutnya; pencarian kata atau sinonim kata yang sesuai
dengan dokumen yang ada di database. Hasil berupa nama dan isi dari dokumen yang
sesuai dengan sinonim kata yang ingin dicari oleh pengguna.
Adapun arsitektur umum yang menggambarkan tahapan yang digunakan dalam
dokumen di sisi kiri dan kanan
Menampikan keluaran kata dan persamaan kata yang cocok dengan isi
dokumen
Database kamus
Database dokumen
Menentukan nilai geser sisi kiri (shiftl ) dan sisi kanan ( shiftr )
Two Sliding Windows Berry-Ravindran
Gambar 3.1 Arsitektur Umum Sistem
3.3 Analisis Data
Perincian proses pada gambar 3.1 dijelaskan dengan tahapan sebagai berikut :
1. User mengetikan input kalimat : Perangainya yang degil membuat orang segan
untuk berteman dengannya.
Kalimat tersebut di-parsing menjadi [Perangainya] [yang] [degil] [membuat] [orang] [segan] [untuk] [berteman] [dengannya].
2. Proses Stopwords
Kata-kata yang telah dibagi menjadi kumpulan array, yakni arr_kata(), program akan memulai proses penghilangan kata-kata yang tidak relevan atau tidak tepat
terutama tanda baca dan kata penghubung (stopwords). Program melakukan pendeteksian kata per kata berdasarkan stopword yang ada di database. Kemudian kata-kata tersebut dihapus berdasarkan kamus kata yang berisi kata-kata “tidak
[Perangainya][degil][orang][segan][berteman]
Kata yang dihapus antara lain, :
[yang][membuat][untuk] [dengannya]
Proses penghapusan stopwords dapat dilihat pada Gambar 3.2.
Gambar 3.2 Proses stopwords
3. Proses Stemming
Setelah selesai proses stopword, maka dilanjutkan proses stemming menggunakan algoritma Porter. Pada penelitian ini, algoritma Porter dimodifikasi agar sesuai dengan imbuhan Bahasa Indonesia (Tala, 2003). Aturan ditambahkan untuk
memberikan hasil yang maksimal dan mempermudah proses stemming. Berikut adalah aturan yang ditambahkan dalam algoritma Porter.
1. Kata dasar yang dilekati partikel infleksional yang tidak mempunyai imbuhan
apapun. Contoh : masalah.
2. Kata dasar yang dilekati partikel berprefiks yang tidak mempunyai imbuhan
apapun. Contoh : menikah.
3. Kata dasar yang dilekati kata ganti milik yang tidak mempunyai imbuhan apapun.
Contoh : bangku.
4. Kata dasar yang dilekati kata ganti milik berprefiks yang tidak mempunyai imbuhan
apapun. Contoh : bersuku.
5. Kata dasar yang dilekati prefix pertama yang tidak mempunyai imbuhan apapun.
6. Kata dasar yang dilekati prefix pertama bersufiks yang berarti kata dasar yang
memiliki suku kata pertama awalan dan mempunyai akhiran. Contoh : terapan.
7. Kata dasar yang dilekati prefiks kedua yang tidak mempunyai imbuhan apapun .
Contoh : percaya.
8. Kata dasar yang dilekati prefiks kedua bersufiks yang berarti kata dasar yang
memiliki suku pertama awalan kedua dan mempunyai akhiran. Contoh: perasaan.
9. Kata dasar yang dilekati sufiks yang tidak mempunyai imbuhan apapun. Contoh:
pantai.
Keseluruhan proses stemming menggunakan algoritma Porter dapat dilihat pada gambar 3.3.
Gambar 3.3 Algoritma Porter dalam proses stemming
Algoritma Porter dimulai dengan langkah-langkah antara lain :
1. Kata yang distemming mula-mula dicari di kamus data, jika ada kata dasar yang sesuai, maka algoritma berhenti, jika tidak ada, maka lanjutkan ke langkah 2.
2. Cek aturan tambahan yang bukan merupakan imbuhan Bahasa Indonesia, jika ada
yang sesuai, maka algoritma berhenti. Jika tidak ada, maka lanjutkan ke langkah 3.
3. Hilangkan partikel (“-lah”, “-kah”,” –tah”,” –pun”).
4. Hilangkan kata ganti kepemilikan (“-ku”, “-mu”, “-nya” ).
5. Hilangkan awalan pertama (“meng-“, “meny-“, “men-“, “mem-“, “me-“, “peng-“,
“peny-“, “pen-“, “pem-“, “di-“, “ter-“, “ke-“ ). Jika tidak terdapat awalan pertama pada kata, maka lanjutkan ke langkah 7. Jika ada, maka lanjutkan ke langkah 6.
6. Hilangkan awalan kedua ( “ber-“, “bel-“, “be-“, “per-“, “pel-“, “pe-“ ). Algoritma akan berhenti jika sebelumnya sudah melalui langkah 7 dan masih tidak menemukan
adanya awalan kedua pada kata. Algoritma akan menggangap kata yang
dimasukkan sebagai kata dasar.
7. Hilangkan akhiran ( “-kan”, “-an”, “-i” ). Jika tidak terdapat akhiran pada kata, maka lanjutkan ke langkah 6.
Berdasarkan kata yang telah dihapus melalui proses stopwords, maka sistem memulai stemming menggunakan algoritma Porter untuk bahasa Indonesia. Proses yang terjadi sebagai berikut :
[perangainya] di-stemming, kamus kata tidak mendapati adanya kata dasar yang cocok dengan kata [perangainya] ,maka akan melalui tahapan berikut :
1. Hapus partikel ( -lah, -kah, -tah, -pun ), tidak ada kecocokan partikel dengan
kata [perangainya], maka dilanjutkan ke langkah 2.
2. Hapus kata ganti kepunyaan(-ku, -mu, -nya), ada kecocokan kata ganti
kepunyaan dengan kata [perangainya], maka dihapus menjadi [perangai].
3. Hapus awalan pertama (First Order Derivational Prefix ) (meng-, meny-, men-, me-, peng- ,dll ), tidak ada kecocokan awalan pertama dengan kata
[perangai], maka dilanjutkan ke langkah 4.
4. Hapus akhiran (Derivation Suffix) ( -kan, -an, -i ), tidak ada kecocokan akhiran dengan kata [perangai], maka [perangai] sudah menjadi kata dasar.
[degil] di-stemming, maka kata [degil] akan dikembalikan menjadi kata dasar.
[orang] di-stemming, maka kata [orang] akan dikembalikan menjadi kata
dasar.
[segan] di-stemming, maka kata [segan] akan dikembalikan menjadi kata
[berteman] di-stemming, kamus kata tidak mendapati adanya kata dasar yang
cocok dengan kata [berteman] ,maka akan melalui tahapan berikut :
1. Hapus partikel ( -lah, -kah, -tah, -pun ), tidak ada kecocokan partikel
dengan kata [berteman], maka dilanjutkan ke langkah 2.
2. Hapus kata ganti kepunyaan(-ku, -mu, -nya), tidak ada kecocokan kata
ganti kepunyaan dengan kata [berteman], maka dilanjutkan ke langkah
3.
3. Hapus awalan pertama (First Order Derivational Prefix ) (meng-, meny-, men-, me-, peng- ,dll ), tidak ada kecocokan awalan pertama
dengan kata [berteman], maka dilanjutkan ke langkah 4.
4. Hapus awalan kedua (Second Order Derivational Prefix ) (ber-, bel-, be-, per-, pel-, pe- ), pemenggalan awalan “ber-“ sesuai dengan
[berteman], maka dihapus menjadi [teman].
5. Hapus akhiran (Derivation Suffix) ( -kan, -an, -i ), ), tidak ada kecocokan akhiran dengan kata [teman], maka [teman] sudah menjadi kata dasar.
4. Pencocokan Kata dan Sinonim Kata
Menurut Murad,et al(2007), pencarian relevansi kata yang satu dengan kata yang lain tidak memerlukan pencarian sinonim kata karena pencarian dilakukan dengan
kemiripan kata yang diubah ke dalam fuzzy set. Pada penelitian ini, pencocokan langsung ditentukan berdasarkan makna kata nya itu sendiri. Kata yang telah di-stem dilanjutkan dengan mencari persamaan kata ( sinonim ) yang ada di dalam kamus
sinonim kata. Tiap arr_kata[] (kata hasil stemming) dilakukan scanning dan hasil pencocokan persamaan kata akan dimuat ke dalam array baru,yaitu arr_Snmkata[]. Apabila hasil pencocokan terdapat lebih dari satu makna kata, maka program tetap akan
memuat sinonim kata tersebut ke dalam arr_Snmkata[].
Kumpulan kata dasar [perangai][degil][orang][segan][teman] akan dicari persamaan
kata pada kamus data yang memiliki makna serupa.
[perangai] memiliki persamaan makna kata dengan [perilaku], maka dibentuk
Fase Pre-processing
Fase Pencarian
Algoritma Two Sliding Windows Algoritma Berry-Ravindran
[degil] memiliki persamaan makna kata dengan [keras kepala], maka dibentuk
arr_Snmkata[i+1] = [keras kepala].
[orang] memiliki persamaan makna kata dengan [manusia], maka dibentuk arr_Snmkata[i+2] = [manusia].
[segan] memiliki persamaan makna kata dengan [sungkan] dan [malu], maka
dibentuk arr_Snmkata[i+3] = [sungkan] dan arr_Snmkata[i+4] = [malu].
[teman] memiliki persamaan makna kata dengan [sahabat] dan [rekan], maka
dibentuk arr_Snmkata[i+5] = [sahabat] dan arr_Snmkata[i+6] = [rekan].
5. Pencarian teks
Pada tahapan pencarian teks digunakan Algoritma Two Sliding Windows (TSW) yang mencakupi dua proses utama yaitu fase pre-processing dan fase pencarian. Pada dasarnya, algoritma TSW melakukan pencarian dari dua sisi ( windows ) yaitu sisi kiri ( left window ) dan sisi kanan( right window ) secara parallel( Hudaib et al, 2008 ). Fase pre-processing menggunakan algoritma Berry-Ravindran untuk menentukan nilai shift yang akan digunakan pada saat fase pencarian. Proses keseluruhan pencarian teks dapat dilihat pada gambar 3.4.
a b
Fase Pre-Processing
Fase pre-processing menggunakan dua array yaitu nextl dan nextr. Nilai dari kedua array tersebut ditentukan oleh algoritma bad character Berry Ravindran (BR). Nilai dari kedua array tersebut akan dimasukkan ke dalam masing-masing variable shiftl dan shiftr. Kata-kata dasar [perangai] [degil] [orang] [segan] [teman] dan
persamaan kata [perilaku] [keras kepala] [manusia] [sungkan] [malu]
[sahabat][rekan] melalui proses penentuan nilai kedua shiftsebagai berikut :
Variabel shiftl
Langkah – langkah pencarian nilai shiftl dijelaskan sebagai berikut :
1. Apabila pencarian dimulai pertama kalinya, maka nilai variabel shiftl adalah 0.
Jika tidak, maka nilai awal shiftl = m+2 dimana m merupakan jumlah pola (
pattern ) yang ingin dicari.
2. Penetapan nilai a dan b yang merupakan dua karakter berurutan di hitung setelah
posisi pola, antara lain :
Dimana, P = Pattern ; m = banyak pola yang dicari ; n = nilai tengah dari banyak
Proses penetapan nilai a dan b dapat dilihat pada gambar 3.5.
shiftl a, b = � { − �+
Gambar 3.5 Ilustrasi posisi penentuan letak pada bagian kiri teks
3. Lakukan loop yang dimulai dari awal sampai akhir karakter yang sebanyak m-2.
4. Pada saat terjadi looping, algoritma menghitung nilai array nextl yang akan dimasukkan kedalam variabel shiftl. Apabila hasil array nextl lebih dari satu
nilai, maka algoritma memilih nilai terkecil dari hasil tersebut. Proses
perhitungan nilai shiftl dapat dilihat pada gambar 3.5.
Gambar 3.6 Aturan Operasi Hitung Nilai shift kiri
Berdasarkan contoh sebelumnya, maka :
nilai shiftl(a,b) pada kata “perangai” = (“k”,”a”) = m + 2 = 8 + 2 = 10. nilai shiftl(a,b) pada kata “degil” = (“s”,”a”) = m + 2 = 5 + 2 = 7.
nilai shiftl(a,b) pada kata “orang” = (“s”,”a”) = m + 2 = 5 + 2 = 7.
nilai shiftl(a,b) pada kata “segan” = (“s”,”a”) = m + 2 = 5 + 2 = 7. nilai shiftl(a,b) pada kata “teman“ = (“s”,”a”) = m + 2 = 5 + 2 = 7.
Hal ini berarti bahwa algoritma melakukan penggeseran pada kata “perangai”
sebanyak 7 langkah ke kanan dan kata “degil”, “orang”, “segan”, “teman” sebanyak
7 langkah ke kanan. Penentuan nilai shiftl selanjutnya ditentukan oleh dua karakter
a b
Variabel shiftr
Langkah – langkah penentuan nilai shiftr dijelaskan sebagai berikut :
1. Apabila pencarian dimulai pertama kalinya, maka nilai variabel shiftl adalah 0.
Jika tidak, maka nilai awal shiftl = m+2 dimana m merupakan jumlah pola (
pattern ) yang ingin dicari.
2. Penetapan nilai a dan b seperti pada gambar 3.6 yang merupakan dua karakter
berurutan di hitung setelah pola tersebut, antara lain :
Dimana, P = Pattern ; m = banyak pola yang dicari ; n = nilai tengah dari banyak pola yang dicari.
Pada contoh diatas, berarti :
Kata “perangai” memiliki nilai a = “a” ; b = “a” Kata “degil” memiliki nilai a = “g” ; b = “o” Kata “orang” memiliki nilai a = “g” ; b = “o” Kata “segan” memiliki nilai a = “g” ; b = “o” Kata “teman” memiliki nilai a = “g” ; b= “o”
Proses penetapan nilai a dan b dapat dilihat pada gambar 3.7.
shiftr a, b = � {
Gambar 3.7 Ilustrasi posisi penentuan letak pada bagian kanan teks
3. Lakukan loop yang dimulai dari awal sampai akhir karakter sebanyak m-2. 4. Pada saat terjadi looping, algoritma menghitung nilai array nextl yang akan
dimasukkan kedalam variabel shiftl. Apabila hasil array nextl lebih dari satu
nilai, maka algoritma memilih nilai terkecil dari hasil tersebut. Proses
perhitungan nilai shiftl pada gambar 3.8 sebagai berikut.
Gambar 3.8 Aturan Operasi Hitung Nilai shift kanan
Berdasarkan contoh sebelumnya, maka
Hal ini berarti bahwa algoritma akan melakukan penggeseran kata “orang”
sebanyak 9 karakter ke kiri dan kata”segan” “perangai”, “degil”, “teman”
Gambar 3.9 Pseudocode Pre-processing bad character shift Algoritma
Berry-Ravindran. Sumber : (Hudaib et al, 2008)
Fase Pencarian
Apabila nilai shiftl dan shiftr sudah didapatkan dari fase pre-processing, maka program akan memulai fase pencarian menggunakan algoritma Two Sliding Windows. Proses pencarian kata yang sesuai dengan dokumen adalah sebagai berikut :
1. Pencocokan string dari sebelah kiri teks dimulai dari posisi akhir string sampai posisi awal string. Jika terjadi kecocokan, maka algoritma akan berhenti. Jika tidak, maka lanjutkan ke langkah 3.
2. Pencocokan string dari sebelah kanan teks dimulai dari posisi awal string sampai posisi akhir string. Jika terjadi kecocokan, maka algoritma akan berhenti. Jika tidak, maka lanjutkan ke langkah 3.
3. Penentuan nilai shift kiri dan kanan dari algoritma BR.
4. Menggeser pattern sesuai nilai shift yang didapat dari langkah 3. Pada bagian
kiri akan menggeser ke sebelah kanan dan bagian kanan menggeser ke sebelah
kiri.
Seperti contoh sebelumnya,
Kata “perangai” dengan nilai shiftl = 10 ; shiftr = 10.
1 2 3 4 5 6 7 8 9 10
Kata “degil” dengan nilai shiftl = 7 ; shiftr = 7.
1 2 3 4 5 6 7
1 2 3 4 5 6
1 2 3 4 5 6 7
1 2 3 4 5 6 7 Kata “orang” dengan nilai shiftl = 7 ; shiftr = 6.
Bagian kiri teks
Bagian kanan teks
Kata “segan” dengan nilai shiftl = 7 ; shiftr = 7.
1 2 3 4 5 6 7
1 2 3 4 5 6 7 Kata “teman” dengan nilai shiftl = 7 ; shiftr = 7.
Bagian kiri teks pencarian yang baru ditentukan dari nilai shift pada proses pre-processing algoritma BR. Pencocokan terusdilakukan hingga pattern berada ditengah teks ( n / 2 ). Apabila masih tidak terdapat kecocokan dengan pattern sampai di tengah teks, maka algoritma memberikan hasil kosong. Proses pencocokan
string menggunakan algoritma TSW dapat dilihat pada gambar 3.9 sebagai berikut.
Gambar 3.10 Pseudocode Algoritma Two Sliding Windows (TSW)
Sumber : Hudaib et al (2008)
L=m-1 // text index used from left
R=n-(m-1)-1 // text index used from right
Tindex=0; // text index used to control the scanning process
Gambar 3.10 Pseudocode Algoritma Two Sliding Windows ( lanjutan )
Sumber : Hudaib et al (2008)
3.3 Rancangan Antar Muka
3.3.1 Kebutuhan Perangkat Lunak
Adapun progam ini dibangun dengan bahasa pemrograman HTML pada sisi pengguna
dan menggunakan bahasa pemrograman PHP pada sisi server, serta menggunakan MySQL sebagai kamus kata.
3.3.2 Perancangan Sistem
Langkah awal yang dilakukan adalah pemisahan kalimat menjadi kata per kata dan
dimasukkan ke dalam masing-masing array. Kemudian sistem menghapus kata-kata yang tidak relevan atau tepat, tanda baca, dan karakter whitespace yang terdapat di dalam array tersebut. Pada saat proses stemming, sistem akan melakukan pengecekan
kata, maka kata tersebut telah menjadi kata dasar dan dilanjuti pada tahap pencocokan
persamaan kata. Jika tidak, maka sistem melakukan penghilangan imbuhan awalan dan
akhiran hingga didapatkan kata dasar.
Kemudian, sistem mencocokan kata dan persamaan kata yang ada pada kamus
sinonim kata. Bila kata tersebut mempunyai persamaan kata, maka persamaan kata
ditambahkan dalam query pencarian dokumen. Pencarian dokumen dibagi menjadi dua tahap yaitu fase pre-processing dan fase pencarian. Fase pre-processing menentukan nilai pergeseran (shift) berdasarkan perhitungan nilai bad-character shift algoritma Berry-Ravindran yang akan digunakan oleh algoritma TSW dan fase pencarian menggunakan nilai shift sebelumnya untuk menggeser pencarian teks apabila tidak ditemukan kecocokan kata maupun sinonim kata.
3.3.3 Perancangan Antar Muka Sistem
Perancangan tampilan digunakan untuk memudahkan pengguna dalam pemakaian
sistem. Berikut rancangan yang digunakan dalam skripsi ini.
1. Halaman Utama
Pada tampilan halaman utama menunjukkan sisi kiri yang berisi menu utama dan
textbox sebagai tempat masukan user. Rancangan halaman utama dapat dilihat pada gambar 3.11.
Gambar 3.11 Rancangan halaman utama
a. Pada bagian A merupakan bagian menu utama yang berisi “HOME” untuk
menunjukkan halaman utama; “UPLOAD” untuk menunjukkan halaman penyimpanan dokumen baru; “KAMUS” untuk menunjukkan halaman
penambahan kata pada database.
b. Bagian B terdapat textbox yang digunakan untuk memasukkan kata-kata yang
ingin dicari dan tombol “PROSES” untuk melakukan eksekusi program.
c. Bagian C terdapat tiga checkbox yang dapat dipilih sebelum menekan tombol
“PROSES”.
d. Bagian D untuk menampilkan hasil pencarian kata dan sinonim kata pada
dokumen.
2. Halaman Upload dokumen
Halaman upload berfungsi untuk menambahkan dokumen baru ke dalam database. Rancangan halaman upload dapat dilihat pada gambar 3.12.
Keterangan :
a. Pada bagian A terdapat tombol “Browse” untuk memilih dokumen baru yang
akan disimpan. Tombol “Upload” untuk melakukan penyimpanan dokumen.
b. Bagian B sebagai area tampilan isi dokumen setelah disimpan ke dalam
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Bab ini membahas pengimplementasian dan pengujian pencarian kata dan persamaan
kata terhadap dokumen.
4.1 Implementasi Sistem
Implementasi perancangan sistem menggunakan bahasa pemrograman PHP dan
database MySQL. Dalam tahap ini juga dibahas hasil perancangan dan pengujian pada
sistem.
4.1.1 Spesifikasi perangkat lunak dan perangkat keras yang digunakan
Spesifikasi perangkat lunak yang digunakan dalam skripsi sebagai berikut :
1. Processor Intel® Core™ i3 CPU M370 @ 1.40GHz 2. RAM 2048 MB
3. Kapasitas Hardisk 480 GB
Spesifikasi perangkat lunak yang digunakan dalam skripsi sebagai berikut :
1. Windows 7 Ultimate 32 bit
2. XAMPP
3. Notepad++
4.1.2 Implementasi Perancangan Antar Muka
Implementasi perancangan antarmuka untuk pencarian informasi berdasarkan kata dan
a. Tampilan halaman pencarian dokumen
Pada halaman utama terdapat textbox dimana user dapat memasukan input yang
ingin dicari dan tombol “Proses” untuk melanjutkan proses pencarian. Sebelum melakukan “Proses”, ada tiga parameter yaitu “stopword”, “stemming”, dan “sinonim” untuk melakukan hasil pengujian dengan parameter yang berbeda. Tampilan halaman pencarian dokumen dapat dilihat pada gambar 4.1.
Gambar 4.1 Tampilan halaman input
b. Tampilan halaman upload
Gambar 4.2 Tampilan halaman database file
c. Tampilan halaman kamus kata
Halaman ini bertujuan untuk menambahkan kata dan sinonim kata yang tidak
terdapat pada kamus kata. Tampilan halaman kamus kata dapat dilihat pada gambar
4.3.
4.2 Tahapan Operasi Aplikasi
4.2.1 Pencarian dokumen
Pada halaman utama ada tiga buah checkboxyaitu “stemming”, “stopword”, “sinonim”. Masing-masing mempunyai fungsi tersendiri dalam melakukan proses pengolahan kata
yang akan dijadikan sebagai keyword pada pencarian dokumen. Sebagai contoh, apabila user memilih “stemming” dan “stopword”, maka sistem hanya menjalankan dua
tahapan proses pengolahan kata dan tidak melaksanakan proses “sinonim”. Dengan kata
lain, hasil pencarian hanya memunculkan dokumen terkait tanpa menelusuri persamaan
kata dari input-an kata.
Langkah awal dalam mencari persamaan kata dalam dokumen adalah
menuliskan kata-kata yang dicari ke dalam textbox dan mencentang semua checkbox agar hasil pencarian lebih akurat. Tampilan pada saat menuliskan kata-kata pada textbox dapat dilihat pada gambar 4.4.
Gambar 4.4 Tampilan saat menuliskan kata-kata pada textbox
Setelah memasukan input kedalam textbox, program akan menampilkan hasil yang terkait dengan pilihan parameter yang disediakan. Output ditampilkan di bagian
bawah input dan program menampilkan hasil setiap langkah pengolahan kata yang telah
diinput oleh user serta hasil pencarian berupa judul dokumen dan beberapa baris di
dalam isi dokumen yang serupa dengan kata yang diinput oleh user. Hasil pencarian
Gambar 4.5 Tampilan hasil pencarian sinonim kata pada dokumen
4.2.2 Pengolahan database
Bagian ini digunakan untuk menambahkan berkas-berkas yang berupa artikel dan
dokumen. Dokumen-dokumen yang dipilih berasal dari Google dan menggunakan
ekstensi doc, docx, dan pdf. Pengguna bisa menambahkan berkas dengan memilih menu
Gambar 4.6 Tampilan saat memilih berkas
Setelah berkas dipilih, maka pengguna menekan tombol “Upload” untuk memroses
Gambar 4.7 Tampilan hasil penyimpanan berkas
Pengguna juga dapat menyimpan kata dan sinonim kata apabila pada saat pengolahan
kata tidak terdapat sinonim kata. Pengguna bisa mengakses menu “Kamus” untuk
menambahkan pasangan kata dan sinonim kata yang tidak terdapat dalam database.
Pengguna mengisi textbox yang disediakan pada halaman upload kata seperti pada gambar 4.8.
4.2 Pengujian Sistem
Pada bagian akan ditunjukan hasil pengujian berdasarkan tiga parameter yang
disediakan oleh program. Tahapan proses pengujian dimulai dengan memasukkan
berbagai jumlah kata sebagai keyword pada hasil pencarian. Jumlah variasi kata dimulai dari 1 kata sampai dengan 5 kata yang berupa kalimat baku yang jarang diucapkan pada
bahasa Indonesia. Hasil pengujian dengan kata kunci “algoritma pencocokan pola kalimat baku” ditampilkan pada tabel 4.1.
Tabel 4.1 Pengujian terhadap variasi jumlah kata pada kalimat baku.
No Jumlah kata Jumlah dokumen
hasil pencarian
oleh pengguna semakin banyak dokumen yang cocok dengan kata kunci tersebut. Hal
ini dipengaruhi oleh pilihan pencarian yang lebih banyak sehingga jumlah dokumen
yang terdeteksi juga lebih banyak. Tingkat keakuratan diukur dari rumus umum
matematika antara lain :
% � = � ℎ � − ℎ � � � × %
Hasil pengujian menunjukkan isi dokumen yang sesuai dengan kata kunci tidak
mencapai 100% karena adanya perbedaan kata imbuhan baik serapan maupun sisipan
“redam”. Pengujian selanjutnya menggunakan kata kunci “Para pelaku pasar berjibaku
redakan polemik krisis ekonomi” sehingga didapat hasil yang terlihat pada gambar 4.9.
Gambar 4.9. Hasil pengujian dengan kata kunci “para pelaku pasar berjibaku redakan polemik krisis ekonomi”
Hasil pengujian dengan menggunakan algoritma TSW dapat dilihat pada tabel 4.2. dan
table 4.3.
Tabel 4.2. Hasil pencocokan dengan kata kunci “pelaku,pasar,jibaku,reda,polemic,krisis,ekonomi”
Keyword Judul dokumen yang sesuai Letak kata
(kiri)
Letak kata
(kanan)
Tabel 4.2. Hasil pencocokan dengan kata kunci
“pelaku,pasar,jibaku,reda,polemic,krisis,ekonomi” (lanjutan)
Keyword Judul dokumen yang sesuai Letak kata
(kiri)
reda Kebijakan Pemidanaan dalam
Tindak Pidana Psikotropika
polemik Etika Penulisan Ilmiah - 37754
Proud to be Confucian 45822 -
krisis Perjuangan Memperbaiki Citra Guru Indonesia
Tabel 4.3. Hasil pencocokan dengan sinonim kata kunci “aktor,nekat,surut,reda,perdebatan,berhenti,darurat,krisis”
Keyword Judul dokumen yang sesuai Letak kata
(kiri)
Pilihan Kata (Diksi) template 10860 -
Analisis Mendelian 1 - 45600
Etika Penulisan Ilmiah 7129 -
Kebijakan Pemidanaan dalam
Tindak Pidana Psikotropika
- 119064
Landasan Teori Pengajaran Bahasa
Indonesia sebagai bahasa asing
- 222270
nekat - - -
surut Ekosistem Sawah 1003 -
perdebatan Proud to be Confusian 36258 -
Pendekatan Simantik menurut
Toshiko Izutsu
- 88023
berhenti Analisis Mendelian 1 - 45523
Landasan Teori Pengajaran Bahasa
darurat Peraturan Komisi Informasi - 16025
Anatomi dan Fisiologi Sistem
Endokrin
Pada hasil pengujian diatas dapat disimpulkan bahwa proses pengujian sistem
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Pencarian kata dan sinonim kata pada dokumen dengan menggunakan algoritma Two Sliding Windows menghasilkan kesimpulan sebagai berikut :
1. Pencarian sinonim kata dengan menggunakan algoritma Two Sliding Windows dapat diimplementasikan ke dalam dokumen.
2. Kata-kata yang jarang digunakan dalam bahasa Indonesia dapat dipahami dengan
menemukan sinonim kata sehingga memudahkan pemahaman informasi dalam
dokumen.
3. Semakin banyak kata dan sinonim kata kunci yang ingin dicari oleh user, maka semakin banyak dokumen yang terdeteksi pada hasil pencarian.
4. Pada saat proses pencarian menggunakan algoritma Two Sliding Windows, kata pertama yang ditemukan sesuai dengan kata kunci akan dianggap sebagai hasil
pencarian dan proses algoritma berhenti.
5. Hasil pencocokan terhadap isi dokumen terdapat beberapa kata yang tidak sesuai
dengan makna kata dari kata kunci. Hal ini disebabkan adanya imbuhan terutama
kata serapan dan sisipan yang menimbulkan makna berbeda dari kata dasar itu
5.2 Saran
Adapun saran yang diusulkan, oleh peneliti sebagai bahan pertimbangan pada penelitian
selanjutnya yang berhubungan dengan pencarian sinonim kata, diantaranya:
1. Ada beberapa penulisan kata-kata yang sama tetapi memiliki makna yang berbeda,
sehingga penulis menyarankan metode lain yang dapat membedakan makna dari
dua kata yang berbeda.
2. Hasil pencarian menjadi kurang tepat jika kata dasar pada proses stemming didapat dari kata berimbuhan terutama serapan dan sisipan yang menimbulkan makna
berbeda pada dokumen, sehingga pada penelitian selanjutnya disarankan bisa