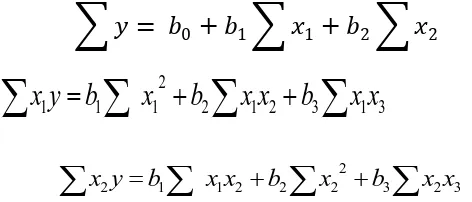LAMPIRAN I
Data yang didapat dari kantor Badan Pusat Statistika (BPS) Kota Medan dan dari website resmi BPS yaitu www.sumut.bps.go.id. Datanya meliputi data jumlah sampah masyarakat Kota Medan dari tahun 1992 sampai dengan tahun 2015 dan data jumlah penduduk Kota Medan serta data pengeluaran masyarakat terhadap makan dan non makan (tingkat konsumsi masyarakat) dari tahun 2005 sampai tahun 2015.
1) Data Jumlah Sampah Masyarakat
Data jumlah sampah masyarakat berasal dari data rata-rata produksi sampah masyarakat per hari Kota Medan setiap tahunnya dikalikan 365, yang diasumsikan sebagai jumlah sampah masyarakat per tahun dari tahun 1992 sampai tahun 2015
Data Sampah Masyarakat
No Tahun Jumlah Sampah
2) Data jumlah penduduk dan tingkat konsumsi masyarakat Kota Medan Data jumlah penduduk berasal dari data jumlah penduduk Kota Medan setiap tahunnya dari tahun 2005 sampai tahun 2015. Serta data pengeluaran masyarakt terhadap makanan dan non makanan perkapital per bulannya yang dikalikan 12 yang diasumsikan sebagai tingkat konsumsi masyarakat setiap tahunnya dari tahun 2005 sampai tahun 2015.
No Tahun
Jumlah Sampah Masyarakat (ton) Tingkat Konsumsi Masyarakat per Kapita (Rp) Jumlah Penduduk (jiwa)
1 2005
406.245 5.717.652
2.036.185 2 2006
445.950 7.087.740
2.067.288 3 2007
452.304 5.857.416
2.083.156 4 2008
400.496 8.457.828
2.102.105 5 2009
406.774 9.030.144
2.121.053 6 2010
482.727 11.058.240
2.097.610 7 2011
478.267 9.480.012
2.117.224 8 2012
573.300 10.332.228
2.122.804 9 2013
616.825 12.112.164
2.135.516 10 2014
629.625 11.487.204
2.191.140 11 2015
634.965 17.204.856
LAMPIRAN II
Data yang akan digunakan sebagai input untuk proses peramalan menggunakan Jaringa Syaraf Tiruan model Backpropagation. Dengan sebagai koefisen input yang didapat berdasarkan plot PACF dengan 1 lag yang signifikan. Dengan inputnya dan Target
sebagai berikut:
� Target
405073,4 414088,9
414088,9 421513,0
421513,0 428517,3
428517,3 435437,7
435437,7 435574,6
435574,6 435711,5
435711,5 447490,0
447490,0 416830,0
416830,0 432890,0
432890,0 438000,0
438000,0 401500,0
401500,0 406245,0
406245,0 445949,7
445949,7 452304,4
452304,4 400496,3
400496,3 406774,3
406774,3 482727,1
482727,1 478266,8
478266,8 573300,0
573300,0 616824,5
616824,5 629625,0
LAMPIRAN III
Proses evaluasi data, dimana data akan dibagi 2 menjadi 75% data untuk proses training dan 25% data untuk proses testing. Karena data yang digunakan sebagai input adalah 22 data maka data untuk proses training sebanyak 17 dan data dan untuk proses testing sebanyak 5 data.
1) Data untuk proses training
No
Training
Target Training 1 405.073,4 414.088,9 2 414.088,9 421.513,0 3 421.513,0 428.517,3 4 428.517,3 435.437,7 5 435.437,7 435.574,6 6 435.574,6 435.711,5 7 435.711,5 447.490,0 8 447.490,0 416.830,0 9 416.830,0 432.890,0 10 432.890,0 438.000,0 11 438.000,0 401.500,0 12 401.500,0 406.245,0 13 406.245,0 445.949,7 14 445.949,7 452.304,4 15 452.304,4 400.496,3 16 400.496,3 406.774,3 17 406.774,3 482.727,1
2) Data untuk proses testing
No
Testing
LAMPIRAN IV
Data input dan target pada proses training akan dinormalisasi menggunakan perintah prestd pada MATLAB, hasil normalisasinya adalah sebagai berikut:
No
�
��
�1 -1,1604 -0,7236
2 -0,6345 -0,3758
3 -0,2014 -0,0476
4 0,2073 0,2767
5 0,6110 0,2831
6 0,6190 0,2895
7 0,6270 0,8415
8 1,31410 -0,5952
9 -0,4746 0,1573
10 0,4624 0,3968
11 0,7605 -1,3135
12 -1,3689 -1,0912
13 -1,0921 0,7693
14 1,2243 1,0670
15 1,5950 -1,3606
16 -1,4275 -1,0664
LAMPIRAN V
Program dengan algoritma Backpropagation menggunakan MATLAB (dengan fungsi aktivasi bipolar pada hidden layer, fungsi linier padalapisan output dan menggunakan proses pembeljaran traingdx
P=[405073.4 414088.9 421513.0 428517.3 435437.7 435574.6
435711.5 447490.0 416830.0 432890.0 438000.0 401500.0 406245.0
445949.7 452304.4 400496.3 406774.3 ];
T=[414088.9 421513.0 428517.3 435437.7 435574.6 435711.5
447490.0 416830.0 432890.0 438000.0 401500.0 406245.0 445949.7
452304.4 400496.3 406774.3 482727.1];
[m, n]=size(P);
[Pn,meanp,stdp]=prestd(P);
[Tn,meant,stdt]=prestd(T);
net=newff(minmax(Pn),[9 1],{'tansig','purelin'},'traingdx');
BobotAwal_Input=net.IW{1,1}
BobotAwal_Bias_Input=net.b{1,1}
BobotAwal_Lapisan=net.LW{2,1}
BobotAwal_Bias_Lapisan=net.b{2,1}
net.trainParam.epochs=100000;
net.trainParam.goal=0.05;
net.trainParam.max_fail=6;
net.trainParam.max_perf_inc=1.04;
net.trainParam.lr=0.01;
net.trainParam.lr_dec=0.7;
net.trainParam.mc=0.9;
net.trainParam.min_grad=1e-5;
net.trainParam.show=25;
net=train(net,Pn,Tn);
BobotAkhir_Input=net.IW{1,1}
BobotAkhir_Bias_Input=net.b{1,1}
BobotAkhir_Lapisan=net.LW{2,1}
BobotAkhir_Bias_Lapisan=net.b{2,1}
ab=sim(net,Pn);
a=poststd(ab,meant,stdt);
[ml,al,rl]=postreg(a,T)
E=T-a;
MSE=mse(E)
mape=[abs(((T-a)./T).*100)];
MAPE=sum(mape)/17
Q=[482727.1 478266.8 573300.0 616824.5 629625.0];
TQ=[478266.8 573300.0 616824.5 629625.0 634965.0];
Qn=trastd(Q,meanp,stdp);
bn=sim(net,Qn);
b=poststd(bn,meant,stdt);
E1=TQ-b
MSE1=mse(E1)
mape1=[abs(((TQ-b)./TQ).*100)];
LAMPIRAN VI
Program dengan algoritma Backpropagation untuk peramalan jumlah sampah masyarakat menggunakan MATLAB (dengan fungsi aktivasi bipolar pada hidden layer, fungsi linier padalapisan output dan menggunakan proses pembeljaran traingdx dengan 10 node tersembunyi dan sebagai input
P=[405073.4 414088.9 421513.0 428517.3 435437.7];
T=[414088.9 421513.0 428517.3 435437.7 435574.6];
[m, n]=size(P);
[Pn,meanp,stdp]=prestd(P);
[Tn,meant,stdt]=prestd(T);
net=newff(minmax(Pn),[9 1],{'tansig','purelin'},'traingdx');
BobotAwal_Input=net.IW{1,1}
BobotAwal_Bias_Input=net.b{1,1}
BobotAwal_Lapisan=net.LW{2,1}
BobotAwal_Bias_Lapisan=net.b{2,1}
net.trainParam.epochs=100000;
net.trainParam.goal=0.05;
net.trainParam.max_fail=6;
net.trainParam.max_perf_inc=1.04;
net.trainParam.lr=0.01;
net.trainParam.lr_inc=1.05;
net.trainParam.lr_dec=0.7;
net.trainParam.mc=0.9;
net.trainParam.min_grad=1e-5;
net=train(net,Pn,Tn);
BobotAkhir_Input=net.IW{1,1}
BobotAkhir_Bias_Input=net.b{1,1}
BobotAkhir_Lapisan=net.LW{2,1}
BobotAkhir_Bias_Lapisan=net.b{2,1}
vji=BobotAkhir_Input
vj0=BobotAkhir_Bias_Input
wkj=BobotAkhir_Lapisan
wk0=BobotAkhir_Bias_Lapisan
xi=4.2375
znet=(vj0)+(xi.*vji)
zj=(1-exp(-znet))./(1+exp(-znet))
ynet=wk0+(wkj*zj)
yk=ynet
LAMPIRAN VII
BobotAwal_Input =
12.0148 12.0148 -12.0148 12.0148 12.0148 -12.0148 -12.0148 12.0148 12.0148
BobotAwal_Bias_Input = -12.2333 -9.0833 5.9333 -2.7833 0.3667 -3.5167 -6.6667 9.8167 12.9667
BobotAwal_Lapisan = 0.9298 -0.6848 0.9412 0.9143 -0.0292 0.6006 -0.7162 -0.1565 0.8315
BobotAwal_Bias_Lapisan = 0.5844
BobotAkhir_Input =
11.6559 11.9095 -12.0148 11.9676 12.0148 -12.0148 -12.0150 12.0059 12.1817
BobotAkhir_Bias_Input = -12.5812 -9.2087 5.9323 -2.9818 0.3667 -3.5167 -6.6666 9.8257 12.8108
BobotAkhir_Lapisan = 0.4252 -0.3163 0.3534 1.2968 0.1591 0.4129 -0.9039 -0.0143 -1.0718
BobotAkhir_Bias_Lapisan = 0.8014
vji =
11.6559 11.9095 -12.0148 11.9676 12.0148 -12.0148 -12.0150 12.0059 12.1817
vj0 =
-6.6666 9.8257 12.8108
wkj =
0.4252 -0.3163 0.3534 1.2968 0.1591 0.4129 -0.9039 -0.0143 -1.0718
wk0 = 0.8014
xi = 4.2375
znet =
36.8105 41.2579 -44.9806 47.7311 51.2796 -54.4296 -57.5800 60.7006 64.4307
zj =
1.0000 1.0000 -1.0000
1.0000 1.0000 -1.0000 -1.0000 1.0000 1.0000
ynet = 1.4176
yk = 1.4176 y =
LAMPIRAN VIII
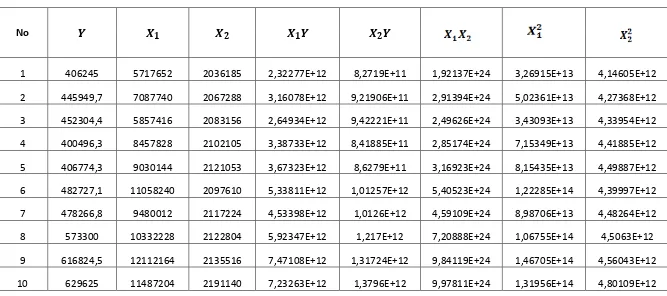
Tabel penolong ini merupakan hasil pengolahan dari data yang akan digunakan untuk mencari persamaan regres berganda. Dengan jumlah sampah masyarakat Kota Medan (Y), tingkat konsumsi masyarakat (X1) dan jumlah
penduduk Kota Medan (X2).
Tabel Penolong
No
DAFTAR PUSTAKA
Ade Irma Aprilia. (2014). Analisis Model NEURO-GARCH dan Model Backpropagation Untuk Peramalan Indeks Harga Saham Gabungan. Skripsi. Medan, Indonesia:
Universitas Sumatera Utara.
Erlis Ardila Sari. (2013). Peramalan Tinggi Muka Air Sungai Bengawan Solo Menggunakan Jaringan Syaraf Tiruan Backpropagation dengan Algoritma Levenberg Marquardt dan
Modified Levenberg Marquardt. Jurnal, Teknik Informatika, Universitas Sebelas Maret.
Felasufah Kusumadewi. (2014). Peramalan Harga Emas Menggunakan Feedforward Neural Network Dengan Algoritma Backpropagation. Skripsi. Yogyakarta, Indonesia:
Universitas Negri Yogyakarta.
Hanke, John E and Winchern, Dean W. (2004). Business Forecasting Eight Edition. United States of Amerika: Pearson Edition, Inc.
Hermawan, Arief. (2006). Jaringan Syaraf Tiruan, Teori dan Aplikasi. Yogyakarta: Andi.
I.Kadar Shereef, DR.S.Santhosh Baboo. (2011). A New Weather Forecasting Technique using Back Propagation Neural Network with Modified Levenberg Marquardt
Algorithm for Learing. Research Scholar, Dravidian University.
Jong Jek Siang. (2009). Jaringan Syaraf Tiruan dan Pemogramannya Menggunakan MATLAB. Yogyakarta: Andi.
Sepri Permata Sari, Muthia Ferliani Balqis. (2015). Analisis yang Mempengaruhi Produksi Tembakau Deli pada PT. Pekebunan Nusantara II Helvetia Kebun Klambir Lima. Paper,
Universitas Sumatera Utara
Sumut.bps.go.id
Tim Pengkaji. (2013). Kajian Model Pengolahan Sampah dan SDM Kebersihan di Kota Medan. Pemerintah Kota Medan, Provinsi Sumnatera Utara.
BAB 3
METODE PENELITIAN
3.1 Merumuskan Masalah
Langkah awal pada penelitian ini adalah merumuskan masalah yang aka dipecahkan. Masalah yang dirumuskan berdasarkan pendahuluan yaitu bagaimana menggunakan jaringan syaraf tiruan model backpropagation untuk meramalkan jumlah sampah masyarakat Kota Medan pada tahun 2016 dan mengetahui tingkat akurasi dari peramalan tersebut. Serta mengetahui pengaruh manakah yang paling mempengaruhi jumlah sampah masyarakat di Kota Medan.
Adapun data yang akan dibutuhkan dalam proses penelitian ini adalah data jumlah sampah masyarakat dari tiap kecamatan yang terdapat di Kota Medan dari tahun 1992 sampai tahun 2015. Kemudian data jumlah penduduk Kota Medan dan jumlah pengeluaran masyarakat kota Medan terhadap makanan dan non makanan yang diasumsikan sebagai tingkat kosumsi masyarakat pada tahun 2005 sampai tahun 2015.
3.2 Studi Literatur
Dalam studi literatur ini digunakan sumber pustaka yang relevan yang digunakan untuk mengumpulkan informasi yang diperlukan dalam penelitian. Studi literatur dengan mengumpulkan sumber pustaka yang dapat berupa buku, teks, makalah, jurnal dan sebagainya. Setelah semua sumber pustaka terkumpul dilanjutkan dengan penelaahan dari sumber pustaka tersebut. Pada akhirnya sumber pustaka itu dijadikan landasan dalam menganalisis permasalahan yang akan dipecahkan.
33
membantu menyelesaikan permasalahan yang ada. Pada tahap ini, permasalahan akan diidentifikasi, dikaji dan dianalisis model penelitiannya agar mendapatkan hasil yang akurat dengan merujuk dari sumber yang ada.
3.3 Pemecahan Masalah
3.3.1 Pengamatan dan Pengolahan Data
Pada tahap ini dilakukan pengamatan dan pengumpulan data sekunder yang diperoleh dari Kantor Badan Pusat Statistik (BPS) Kota Medan yang meliputi data jumlah sampah masyarakat dari tiap kecamatan yang terdapat di Kota Medan dari tahun 1992 sampai tahun 2015. Kemudian data jumlah penduduk Kota Medan dan jumlah pengeluaran masyarakat kota Medan terhadap makanan dan non makanan yang diasumsikan sebagai tingkat kosumsi masyarakat yang berasal dari website resmi BPS Sumatera Utara yaitu sumut.bps.go.id.
Data jumlah sampah masyarakat Kota Medan dari tahun 1992 sampai tahun 2015 akan digunakan untuk peramalan jumlah sampah masyarakat Kota Medan pada tahun 2016 menggunakan jaringan syaraf tiruan backpropagation. Sedangkan data jumlah penduduk Kota Medan dan data tingkat konsumsi masyarakat akan digunakan untuk mencari faktor mana yang paling mempengaruhi meningkatnya umlah sampah masyarakat Kota Medan.
3.3.2 Membuat Landasan Teori
Setelah mendapatkan data yang dibutuhkan dalam penelitian, selanjutnya dilakukan pembahasan secara toritis mengenai metode yang digunakan dalam penelitian berdasarkan hasil studi literatur. Hal ini dilakukan untuk mengetahui bagaimana metode yang digunakan dalam kajian teorinya sebelum digunakan dalam penelitian. Pembahasan ini terdapat dalam tinjauan pustaka.
3.3.3 Analisis Jaringan Syaraf Tiruan Model Backpropagation
Error) dan MAPE (Mean Absolute Percentage Error) dari hasil peramalan. Dalam menganalisis data dengan model backpropagation digunakan software MATLAB sebagai alat bantu perhitungan. Untuk melakukan peramalan digunakan algoritma backpropagation yang memerlukan beberapa langkah. Langkah-langkah dalam algoritma backpropagation kemudian dibagi kedalam beberapa tahap, yaitu:
1. Menentukan input
Identifikasi input didasarkan pada lag-lag signifikan pada plot fungsi auto correlation function (ACF) dan partial auto correlation function (PACF) untuk memastikan data yang akan diinput adalah data yang stationer.
2. Pembagian data
Data yang telah diinput dibagi menjadi 2 yaitu data untuk proses training dan data untuk proses testing. Komposisi yang digunakan adalah 75% data untuk proses training dan 25% data untuk proses testing.
3. Normalisasi data
Data yang telah diinput dan dibagi menjadi 2 kemudian dinormalisasi menggunakan perintah prestd dalam MATLAB. Fungsi aktivasi yang digunakan pada hidden layer adalah sigmoid biner (tansig), sedangkan pada output layer adalah fungsi aktivasi linier (purelin). Hal ini dilakukan dengan meletakkan data pada renge tertentu. Proses ini juga dapat dilakukan dengan bantuan mean dan standar deviasi.
4. Penentuan arsitektur jaringan yang optimum.
Dalam menentukan arsitektur jaringan yang optimum dilihat dari nilai MSE dan MAPE yang terkecil setelah melakukan proses pelatihan (training). Proses penentuan arsitektur jaringan yang optimum adalah:
a. Menentukan banyaknya neuron pada hidden layer b. Menentukan input yang optimal
c. Menentukan output yang optimal
35
Beberapa parameter lain: 1. Kinerja tujuan
2. Learning rate
3. Rasio untuk menaikkan leraning rate 4. Rasio untuk menurunkan learning rate 5. Maksimum kegagalan
6. Maksimum kinerja kerja 7. Gradien minimum 8. Momentum
9. Jumlah epoh yang akan ditunjukkan kemajuannya 10.Waktu maksimum untuk pelatihan
6. Uji kesesuaian model
7. Denormalisasi
Setelah proses selesai maka data akan didenormalisasi atau dikembalikan ke proses semula.
3.3.4 Analisis Korelasi Berganda
Pada tahap ini akan diketahui faktor manakah yang paling mempengaruhi meningkatnya jumlah sampah masyarakat. Antara jumlah penduduk yang terus meningkat dan tingkat konsumsi masyarakat yang terus meningkat. untuk mengetahuinya dilakukan analis korelasi berganda dengan perhitungan koefisien korelasi antara variabel Y dengan variabel X. Dengan jumlah sampah masyarakat (Y), tingkat konsumsi masyarakat (X1) dan jumlah penduduk
(X2). Dengan langkah sebagai berikut:
1. Menentukan persamaan regresi
2. Mengetahui hubungan antar variabel
Untuk mengetahui hubungan antar variabel maka dilakukan analisis korelasi antar variabel dengan rumus yang sudah dijelaskan pada tinjauan pustaka.
3.4 Mengambil Kesimpulan
BAB 4
HASIL DAN PEMBAHASAN
4.1 Peramalan menggunakan Jaringan Syaraf Tiruan model Backpropagation
4.1.1 Identifikasi Kestationeran Data
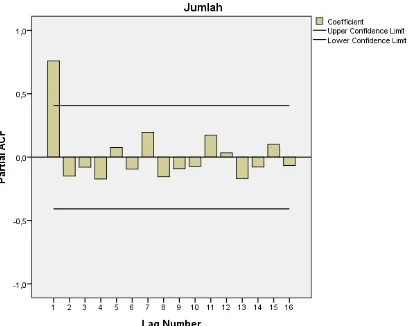
Langkah awal yang dilakukan sebelum menginput data untuk peramalan menggunakan jaringan syaraf tiruan adalah dengan melihat kestationeritasan data. Hal ini diperlukan karena untuk meramalkan data menggunakan jaringan syaraf tiruan model backpropagation dianjurkan menggunakan data yang stationer. Kestationeran data dapat dilihat berdasarkan plot auto correlation function (ACF) dan partial auto correlation function (PACF). Jika ada garis yang melewati selang kepercayaan berarti selang tersebut telah signifikan.
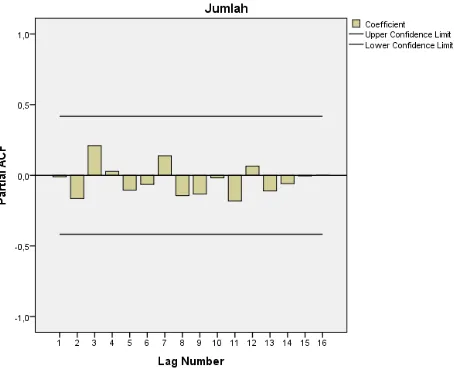
Berdasarkan data jumlah sampah masyarakat Kota Medan (Lampiran 1), dengan menggunakan software SPSS maka didapatkan plot ACF dan PACF sebagai berikut:
Gambar 4.2 Plot PACF jumlah sampah masyarakat Kota Medan tahun 1992-2015
Pada data jumlah sampah masyarakat Kota Medan tahun 1992 sampai tahun 2015 seperti yang terlihat pada Gambar 4.1, plot ACF yang signifikan adalah lag 1, dan lag 2. Sedangkan pada Gambar 4.2, plot PACF yang signifikan adalah lag 1. Ini berarti data yang ada tidak stationer.
4.1.2 Penerapan Jaringan Syaraf Tiruan Model Backpropagation Untuk Meramalkan
Jumlah Sampah Masyarakat
Penerapan jaringan syaraf tiruan model backpropagation untuk meramalkan jumlah sampah masyarakat dengan variabel input yaitu jumlah sampah masyarakat Kota Medan. Data yang digunakan periode tahunan dari tahun 1992 sampai tahun 2015.
4.1.2.1 Penentuan Input Jaringan
Input jaringan dilakukan berdasarkan lag-lag yang signifikan pada plot ACF dan PACF yang
sudah dibahas sebelumnya. Berdasarkan hasil plot ACF dan PACF sebelum dilakukan pembedaan, input yang akan digunakan pada penelitian ini didasarkan pada plot PACF yaitu pada lag 1. Maka input jaringan terdiri atas sebagai jumlah sampah masyarakat sehingga banyaknya data menjadi 22 data (Lampiran II).
39
Data untuk peramalan menggunakan algoritma backpropagation dibagi menjadi dua bagian, yaitu data training dan data testing. Pada peramalan jumlah sampah masyarakat ini, menggunakan 75% data untuk proses training dan 25% data untuk proses testing. Maka dari itu data untuk proses training pada peramalan ini sebanyak 17 data dan data untuk proses testing pada peramalan ini sebanyak 5 data (Lampiran III).
4.1.2.3 Normalisasi Data
Di dalam algoritma jaringan syaraf tiruan model backpropagation digunakan fungsi aktivasi sigmoid bipolar di mana fungsi ini bernilai antara 1 s.d -1. Namun fungsi tersebut tidak pernah mencapai angka 1 maupun -1. Oleh sebab itu, data yang akan digunakan untuk peramalan perlu dinormalisasi terlebih dahulu ke dalam range tertentu. Oleh karena itu, data yang akan digunakan pada proses training dan proses testing yang terdapat pada lampiran III akan dinormalisasikan terlebih dahulu. Untuk menormalisasi data tersebut menggunakan perintah prestd pada MATLAB sebagai berikut:
[Pn,meanp,stdp]=prestd(P); [Tn,meant,stdt]=prestd(T);
Hasil proses normalisasi yang telah dilakukan dapat dilihat pada Lampiran IV.
4.1.2.4 Menentukan Arsitektur Jaringan yang Optimal pada Proses Training
Arsitektur jaringan syaraf tiruan model backpropagation secara umum dapat dilihat pada Gambar 2.4 yang terdiri dari input layer, hidden layer dan output layer. Pada tahap ini akan ditentukan arsitektur jaringan yang optimal yang sesuai dengan data dan proses peramalan yang akan dilakukan. Untuk menentukan arsitektur jaringan yang optimal yang akan digunakan pada peramalan jumlah sampah masyarakat Kota Medan, maka perlu diketahui parameter-parameter yang mempengaruhi arsitektur jaringan tersebut.
1) Menentukan banyaknya node yang tersembunyi
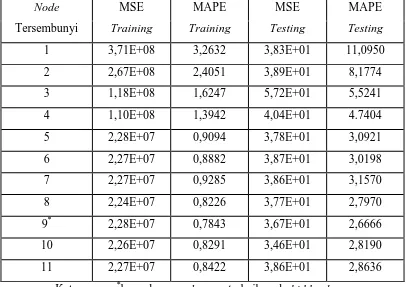
Pada proses training algoritma backpropagation yang dilakukan akan ditentukan banyaknya node pada hidden layer. Untuk menentukan banyaknya node yang akan digunakan, maka akan dilakukan percobaan dengan menginput mulai dari satu node sampai 11 node menggunakan perintah pembelajaran traingdx pada MATLAB. Banyaknya node yang dipilih adalah banyaknya node yang terbaik berdasarkan nilai MAPE yang terkecil. Hasil yang diperoleh dapat dilihat dari tabel berikut:
Tabel 4.1 Nilai MSE dan MAPE hasil pembelajaran traingdx dengan algoritma Backpropagation
Node Tersembunyi MSE Training MAPE Training MSE Testing MAPE Testing
1 3,71E+08 3,2632 3,83E+01 11,0950
2 2,67E+08 2,4051 3,89E+01 8,1774
3 1,18E+08 1,6247 5,72E+01 5,5241
4 1,10E+08 1,3942 4,04E+01 4.7404
5 2,28E+07 0,9094 3,78E+01 3,0921
6 2,27E+07 0,8882 3,87E+01 3,0198
7 2,27E+07 0,9285 3,86E+01 3,1570
8 2,24E+07 0,8226 3,77E+01 2,7970
9* 2,28E+07 0,7843 3,67E+01 2,6666
10 2,26E+07 0,8291 3,46E+01 2,8190
11 2,27E+07 0,8422 3,86E+01 2,8636
Keterangan: *banyaknya node yang terbaik pada hidden layer 2) Menentukan input yang optimal
Arsitektur jaringan yang akan dibangun haruslah berdasarkan input yang sederhana namun optimal, untuk itu perlu dilakukan pengecekan terhadap input jaringan. Karena penelitian ini mengambil input data berdasarkan plot PACF dan hanya ada satu lag yang signifikan, maka lag 1 ( ) sudah dianggap sebagai jaringan yang paling optimal untuk digunakan.
41
Pada proses peramalan ini, output yang dibutuhkan hanyalah 1 output yaitu hasil dari peramalan jumlah sampah masyarakat Kota Medan pada tahun 2016
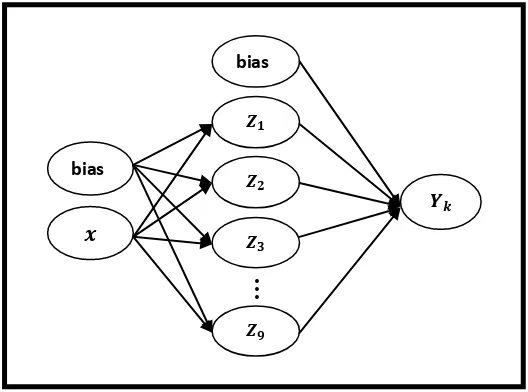
Arsitektur model jaringan syaraf tiruan dengan algoritma backpropagation yang dibangun dari 9 node pada hidden layer dengan input dan output untuk peramalan jumlah sampah masyarakat Kota Medan adalah sebagai berikut:
Gambar 4.3 Arsitektur model jaringan syaraf tiruan dengan Algoritma backpropagation pada peramalan jumlah sampah.
4.1.2.5 Proses Training Jaringan Syaraf Tiruan Model Backpropagation
Pada proses training ini akan digunakan metode pembelajaran traingdx pada software MATLAB. Ada beberapa parameter yang dimasukkan dalam metode pembelaran ini. Adapun parameternya adalah sebagai berikut:
1) Menentukan bobot model
Inisialisasi bobot dilakukan secara acak, dalam penelitian ini untuk menentukan bobot masukan menggunakan software MATLAB yaitu sebagi berikut:
Bobot awal input layer ke hidden layer pertama:
bias
�
bias
�
BobotAwal_Input=net.IW{1,1}
Bobot bias awal input layer ke hidden layer pertama:
BobotAwal_Bias_Input=net.b{1,1}
Bobot awal hidden layer pertama ke hidden layer kedua:
BobotAwal_Lapisan=net.LW{2,1}
Bobot bias awal hidden layer pertama ke hidden layer kedua:
BobotAwal_Bias_Lapisan=net.b{2,1}
2) Menentukan nilai maksimum epoch
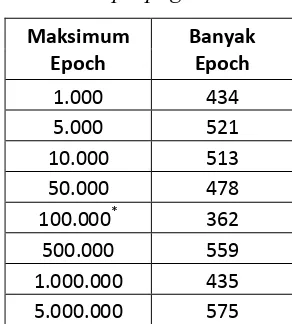
untuk menentukan nilai dari maksimum epoch dari peramalan jumlah sampah maka dilakukan percobaan dari maksimum jumlah epoch 1.000 sampai maksimum jumlah epoch 5.000.000. Hasil dari percobaan tersebut adalah sebagai berikut:
Tabel 4.2 Maksimum Jumlah epoch Pada proses pembelajaran traingdx dengan algoritma Backpropagation
Maksimum Epoch
Banyak Epoch
1.000 434
5.000 521
10.000 513
50.000 478
100.000* 362
500.000 559
1.000.000 435
5.000.000 575
Keterangan: * maksimum jumlah epoch yang akan digunakan
43
Pada metode pembelajaran traingdx pada proses training dengan menginput maksimum epoch dan beberapa parameter lainnya di MATLAB dapat dituliskan sebagai berikut:
net.trainParam.epochs= 100000; net.trainParam.goal=0.05; net.trainParam.max_fail=6;
net.trainParam.max_perf_inc=1.04; net.trainParam.lr=0.01;
net.trainParam.lr_inc=1.05; net.trainParam.lr_dec=0.7; net.trainParam.mc=0.9;
net.trainParam.min_grad=1e-5; net.trainParam.show=25;
net=train(net,Pn,Tn);
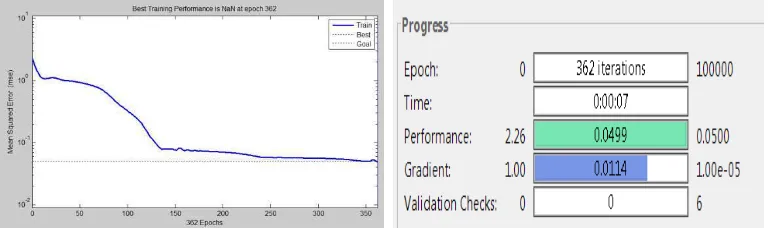
Dari proses training yang dilakukan berdasarkan parameter-parameternya, sehingga didapatlah hasil proses training pada MATLAB seperti gambar berikut:
Gambar 4.4 Hasil proses training sampai 100.000 epoch(iterasi)
Pada Gambar 4.3 terlihat bahwa performance jaringan telah goal (berhenti saat nilai MSE (berhenti saat nilai MSE terkecil jaringan lebih kecil dari batas nilai goalnya) dimana 0,0499 < 0,05 dan berhenti pada epoch ke 362.
BobotAkhir_Input=net.IW{1,1} BobotAkhir_Bias_Input=net.b{1,1} BobotAkhir_Lapisan=net.LW{2,1} BobotAkhir_Bias_Lapisan=net.b{2,1}
Kemudian dilakukan evaluasi output jaringan data (data training) untuk mengetahui gradient garis terbaik dan koefisen korelasi pada peramalan dengan perintah postreg pada MATLAB yang ditulis sebagai berikut:
[ml,al,rl]=postreg(a,T)
Menghasilkan:
Gradient garis terbaik (ml):
ml = 0,9137
Konstanta:
al = 3,70E+004
koefisien korelasi:
rl = 0,9738
45
Gambar 4.5 Koefisien korelasi output dan target
4.1.2.6 Uji Kesesuaian Model
[image:30.595.211.386.264.406.2]Model backpropagation yang telah terbentuk dari 9 node pada hidden layer dengan input diuji kesesuaian modelnya. Pengujiannya dilihat dari plot ACF dan PACF dari data training, dengan hasil plot seperti gambar berikut:
[image:30.595.185.412.482.667.2]Gambar 4.6 Plot ACF arsitektur jaringan algoritma Backpropagation dengan 9 node pada hidden layer dan sebagai input
Dalam Gambar 4.5 dan Gambar 4.6 , ACF dan PACF terlihat bahwa semua lag berada dalam selang kepercayaan, berarti error bersifat acak/random. Sehingga model jaringannya dapat digunakan sebagai model peramalan jumlah sampah masyarakat Kota Medan.
4.1.3 Peramalan Jumlah Sampah Masyarakat
4.1.3.1 Hasil Peramalan Menggunakan Algoritma Backpropagation
Proses peramalan ini menggunakan arsitektur jaringan terbaik yang telah terbangun dari 9 node pada hidden layer dengan input . Nilai input untuk peramalan untuk jumlah sampah
masyarakaat Kota Medan pada tahun 2016 adalah data jumlah sampah masyarakat Kota Medan dari tahun 1992 sampai tahun 2015. Pada tahun 2015 jumlah sampah masyarakat Kota Medan adalah 634.965 ton. Setelah dinormalisasi data input menjadi 4,2375. Output layer merupakan hasil peramalan algoritma backpropagation dengan rumus yang merujuk pada persamaan (14) yaitu sebagai berikut:
=
1−− 0+ 1=1
1+ − 0+
1 =1
9
=1 (26)
Operasi output pada input layer ke-j ke hidden layer dengan rumus yang merujuk dari persamaan (11) yang digunakan sebagai berikut:
_
=
0+
1=1 (27)_ =
−12,5812
12,8108
+ (4,2375)
11,6559
12,1817
1
47
_ =
36,8105
64,4307
Dengan menggunakan fungsi aktivasi sigmoid bipolar menggunakan rumus yang merujuk pada persamaan (12), sehingga diperoleh:
=
_
=
1−− _
1+ − _ (28)
= −12,5812 12,8108 + (4,2375) 11,6559 12,1817 1 =1
=1−
− −12,5812 12,8108
+ (4,2375 )
11,6559
12,1817 1
=1
1 + −
−12,5812
12,8108
+ (4,2375 )
11,6559 12,1817 1 =1 = 1,000 1,000
Operasi output pada hidden layer dengan node tambahan menuju output layer dengan rumus sebagai berikut:
= _
=
0+
9=1.
(29)= 0,8014 + 0,4252 −1,0718
1,000
1,000
9
=1
4.1.3.2 Denormalisasi Data
Hasil dari peramalan sebelumnya merupakan data yang dinormalisasi, maka hasil tersebut akan dikembalikan seperti semula yang disebut denormalisasi data. Data akan didenormalisasi dengan fungsi poststd pada MATLAB, dengan perintah sebagai berikut:
[P]=poststd(pn,meanp,stdp) [T]=poststd(tn,meant,stdt)
Hasil peramalan yang diperoleh adalah nilai = 1,4176 yang kemudian didenormalisasikan menggunakan perintah poststd pada MATLAB sehinggan menjadi 6,7906e+005 yaitu sekitar 679.060 ton. Hasil tersebut merupakan hasil peramalan jumlah sampah masyarakat Kota Medan pada tahun 2016.
4.2 Analisis Korelasi antar Variabel
Pada analisis ini akan meentukan faktor manakah yang paling mempengaruhi jumlah sampah masyarakat Kota Medan yang terus meningkat. metode yang digunakan adalah analisis regresi dan korelasi.
4.2.1 Analisis Regresi Berganda
Untuk mengetahui pengaruh manakah yang paling mempengaruhi meningkatnya jumlah sampah masyarakat maka akan digunakan analisis korelasi. Sebelum menghituang analisis korelasi antar variabel, maka akan dilakukan terlebih dahulu analisis regresi berganda untuk melihat apakah kedua variabel yang dianggap paling berpengaruh terhadap meningkatnya jumlah sampah masyarakat berpengaruh positif.
49
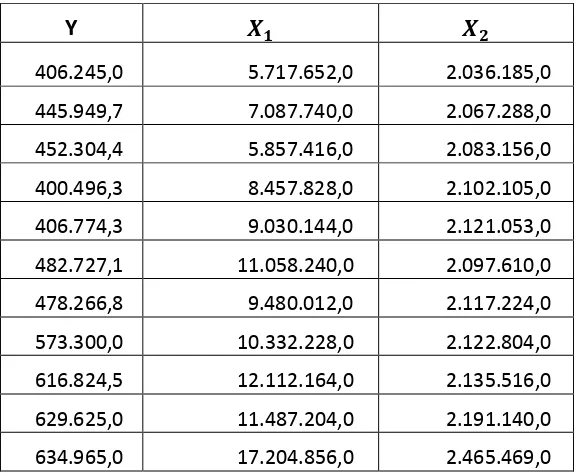
[image:34.595.154.443.169.407.2]Dengan data yang akan digunakan untuk menghitung analisis regresi berganda dalam penelitian ini terlihat pada tabel berikut:
Tabel 4.3 Data untuk menghitung analisis regresi berganda
Y
406.245,0 5.717.652,0 2.036.185,0 445.949,7 7.087.740,0 2.067.288,0 452.304,4 5.857.416,0 2.083.156,0 400.496,3 8.457.828,0 2.102.105,0 406.774,3 9.030.144,0 2.121.053,0 482.727,1 11.058.240,0 2.097.610,0 478.266,8 9.480.012,0 2.117.224,0 573.300,0 10.332.228,0 2.122.804,0 616.824,5 12.112.164,0 2.135.516,0 629.625,0 11.487.204,0 2.191.140,0 634.965,0 17.204.856,0 2.465.469,0
Dimana:
Y = Jumlah sampah masyarakat Kota Medan (ton) X1= Tingkat konsumsi masyarakat (Rp)
X2= Jumlah penduduk (jiwa)
Untuk mengetahui pengaruh mana yang paling mempengaruhi jumlah sampah masyarakat, maka harus dicari persamaan regresi terlebih dahulu. Untuk itu, maka data yang akan digunakan untuk analisis regresi berganda pada Tabel 4.3 perlu disusun kedalam Tabel penolong yang ada pada Lampiran VIII untuk membantu menyelesaikan persamaan regresi.
Bedasarkan Tabel penolong pada Lampiran VIII diperoleh:
= 5527478,1 2 = 1,19005E+14
1 = 107825484 1 2= 6,74792E+25
1 = 5,66172E+13 22 = 5,05059E+13
Selanjutnya data akan digunakan untuk mencari persamaan regresi berganda, yaitu:
Ŷ
= b
0+ b
1X
1+ b
2X
2 (30)Untuk menghitung nilai dari b0, b1, dan b2 dapat menggunakan rumus berikut:
= 0 + 1 1 + 2 2
(31)
Jika rumus tersebut dimasukkan dalam persamaan tersebut, maka:
5527478,1 = 11 b0 + 107825484 b1 + 23539550 b2
5,66172E+13 = 107825484 b0 + 1,16389E+15 b1 + 6,74792E+25 b2
1,19005E+14 = 23539550 b0 + 6,74792E+25 b1 + 5,05059E+13 b2
[image:35.595.169.405.233.334.2]Untuk menemkan hasilnya maka digunakan bantuan dari software SPSS agar ditemukan persamaan. Dengan hasilnya adalah sebagai berikut:
Tabel 4.4 Hasil Koefisien menggunakan SPSS Coefficientsa
Model Unstandardized Coefficients Standardized Coefficients
T Sig.
B Std. Error Beta
1
(Constant) 91,044 21220,499 ,004 ,997
X1 ,018 ,007 ,362 2,685 ,025 X2 ,150 ,032 ,638 4,729 ,001 a. Dependent Variable: Y
3 1 3 2 1 2 2 1 1
1
y
b
x
b
x
x
b
x
x
x
2 3 2 32 2 2 1 1
2y b xx b x b x x
51
Berdasarkan hasil dari software SPSS maka didapatlah persamaan regresinya sebagai berikut:
Ŷ = 91,004 + 0,018X1 + 0,150X2 (32)
Persamaan ini menunjukkan bahwa tingkat konsumsi masyarakat (+0,018) dan jumlah penduduk (+0,150) memiliki pengaruh positif terhadap jumlah sampah masyarakat. Yaitu jika tingkat konsumsi masyarakat meningkat maka jumlah sampah juga akan meningkat. begitu pula dengan jumlah penduduk, jika jumlah penduduk meningkat maka jumlah sampah juga akan meningkat.
4.2.2 Korelasi Antar Variabel
Setelah mendapatkan hasil persamaan regresi berganda dan membuktikan bahwa jumlah penduduk dan tingkat konsumsi masyarakat Kota Medan memiliki pengaruh positif terhadap jumlah sampah masyarakat Kota Medan. Selanjutnya akan dilakukan perhitungan korelasi antar variabel Y dengan X1 dan X2 untuk mengetahui pengaruh manakah yang paling
mempengaruhi jumlah sampah masyarakat kota medan.
1) Korelasi antara variabel Y dengan X1
Untuk mengetahui hubungan antara jumlah sampah masyarakat Kota Medan dengan tingkat konsumsi masyarakat Kota Medan digunakan rumus yang merujuk pada persamaan (25), sehingga didapatlah hasil:
ryx1 = 1 − 1
12− 1 2 2− 2
(33)
ryx1=
12 56617182571047,6 − (107825484,0)(5527478,1)
12 1163892957379060,0 − 107825484,0 2 12 2864866153375,5 − 5527478,1 2
ryx1 =
83403189420671 94619469449975
Berdasarkan hasil korelasi yang bernilai positif menandakan hubungan yang searah antara jumlah sampah masyarakat dan tingkat konsumsi masyarakat dengan hasil korelasi sebesar 0,88146.
2) Korelasi antara variabel Y dengan X2
Untuk mengetahui hubungan antara jumlah sampah masyarakat Kota Medan dengan pertumbuhan jumlah penduduk Kota Medan digunakan rumus yang merujuk pada persamaan (25), sehingga didapatlah hasil:
ryx2 =
2 − 2
22− 2 2 2− 2
(34)
ryx2=
12 11900488495295,6 − (23539550,0)(5527478,1)
12 50505941685848,0 − 23539550,0 2 12 2864866153375,5 − 5527478,1 2
ryx2 =
12691514834692 14098585685092
ryx2 =0,90019
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan penelitian yang telah dilakukan dapat diambil beberapa kesimpulan yaitu
1. Hasil peramalan jumlah sampah masyarakat Kota Medan pada tahun 2016 adalah
= 1,4176 yang kemudian didenormalisasikan menggunakan perintah poststd pada MATLAB sehinggan menjadi 6,7906e+005 yaitu sekitar 679.060 ton. Yang berarti meningkat dari tahun sebelumnya (2015) yaitu sebesar 634.965 ton.
2. MSE dan MAPE terbaik yang didapatkan pada proses training yaitu sebesar 2,28E+07 dan 0,7843, yang berarti tingkat akurasi peramalan semakin tinggi dengan 9 node pada hidden layer. Dengan iterasi maksimum pada proses training dan proses
testing yaitu 100.000 iterasi.
5.2Saran
1. Dilakukan peramalan jumlah sampah masyarakat dengan mempertimbangkan parameter lain yang menjadi penyebab adanya perubahan pada jumlah sampah masyarakat. Sehingga hasil yang didapat akan lebih akurat.
2. Dengan adanya hasil peramalan jumlah sampah masyarakat dan membuktikan bahwa jumlah sampah masyarakat mengalami peningkatan diharapkan pada instanti yang bersangkutan untuk menyiapkan sistem pengolahan sampah, menyediakan tenaga kerja dan armada yang sesuai dengan jumlah sampah yang diperkirakan.
BAB 2
TINJAUAN PUSTAKA
2.1 Konsep Dasar Deret Waktu (Time Series)
Dalam statistika, deret wktu atau time series merupakan rangkaian data yang berupa nilai pengamatan yang diukur selama kurun waktu tertentu, berdasarkan waktu dengan interval yang sama. Sebagai contohnya adalah produksi total tahunan produk pertanian Indonesia, suhu udara per jam, penjualan total bulanan dan lain-lain. Sedangkan analisis deret waktu atau time series analysis merupakan metode yang mempelajari deret waktu , baik dari segi teori yang menaunginya maupun untuk membuat peramalan atau prediksi (Wikipedia).
Pada analisis deret waktu digunakan suatu metode kuantitatif untuk menentukan pola data yang dapat digunakan untuk prediksi maupun peramalan. Pada umumnya pola data yang terbentuk adalah dalam periode tertentu, misalnya harian, bulanan, tahunan dan sebagainya. Untuk memastikan data tidak mengalami perubahan drastis maka data yang akan digunakan harus stationer.
2.2 Stationeritas
Stationeritas dalam data deret waktu atau time series adalah tidak adanya pertumbuhan atau penurunan data, dengan kata lain data tetap konstan sepanjang waktu pengamatan dimana keadaan rata-ratanya tidak berubah seiring dengan berubahnya waktu dan data tersebut berada disekitar nilai rata-rata dan variansi yang konstan (Santoso: 2009).
Untuk melihat data stationer atau tidak stationer dapat dilihat pada plot data deret waktu, demikian pula plot autokorelasi dapat dengan mudah memperlihatkan stationeritas dari data. Karena kebanyakan dari data deret waktu atau time series tidak stationer maka perlu dilakukan pengujian mengenai stationaritas pada data time series tersebut.
2.3 Uji kestationeran data
Uji yang sangat sederhana untuk melihat kestationeran data adalah dengan analisis grafik, yang dilakukan dengan menggunakana log korelogram. Korelogram memberikan nilai auto correlation (AC) dan Partial Auto Correlation (PAC) (Ade Irma Suryani: 2014). Auto korelasi merupakan suatu korelasi pada data deret waktu atau time series antara Xt dengan Xt+k. Untuk menentukan auto korelasi diperlukan auto kovarian. Auto korelasi dan auto kovarian dapat dirumuskan pada persamaan (1) auto kovarian sebagai berikut (Wei: 2006):
=� , + =� − � + − � (1)
Serta persamaan (2) auto korelasi sebagai berikut:
�
=
�
=
� , +� � � � +
=
0
(2)
dengan:
= Pengamatan pada waktu ke-t
+ = Pengamatan pada waktu ke-t+k
Dimana Var( ) = Var( + ) = 0 dan �0=1. Sebagai fungsi dari k, disebut fungsi auto kovariansi dan � disebut sebagai fungsi auto korelasi (autocorrelation function) atau ACF, yang mewakili kovarians dan korelasi antara dan + dari proses yang sama, hanya dipisahkan oleh time lag-k. Jika dan + independen maka = � , + = 0
11
Hipotesis untuk menguji signifikansi auto korelasi dirumuskan sebagai berikut:
H0: � = 0 (auto korelasi pada lag ke-k tidak signifikan)
H1: � ≠ 0 (auto korelasi pada lag ke-k signifikan)
Uji signifikansi menggunakan distribusi t, dengan statistik uji pada persamaan (3) sebagai berikut:
=
�� (3)
Standar error dan koefisien auto korelasi menggunakan rumus pada persamaan (4) sebagai berikut (Hanke&Winchern: 2004):
��
=
1+2 − 121
−1
(4)
dengan:
�� = standar error koefisien korelasi pada lag ke-k = koefisien pada lag ke-k
N = banyaknya pengamatan
Koefisien korelasi pada lag ke-k dikatakan signifikan jika > −
1 � 2
atau
< - −
1 � 2
. Signifikansi koefisien auto korelasi juga dapat dilihat dari selang
kepercayaan dengan pusat = 0 yang apabila dilihat dari tampilan plot fungsi berupa garis putus-putus.
2.4 Jaringan Syaraf Tiruan
manusia (Hermawan: 2006). Jaringan syaraf tiruan merupakan sistem adaptif yang dapat merubah strukturnya untuk memecahkan masalah berdasarkan informasi eksternal maupun internal yang mengalir melalui jaringan. Secara sederhana, JST adalah sebuah alat
pemodelan data statistik non-linier. JST dapat digunakan untuk memodelkan hubungan yang kompleks antara input dan output untuk menemukan pola-pola data.
2.4.1 Konsep Dasar Jaringan Syaraf Tiruan
Jaringan sayaraf tiruan menerima input atau masukan (baik dari data yang dimasukkan atau dari output sel syaraf pada jaringan syaraf). Setiap input berasal dari suatu koneksi atau hubunga yang mempunyai sebuah bobot (weight). Setiap sel syaraf mempunyai sebuah nilai ambang. Jumlah bobot dari input dan dikurangi dengan nilai ambang kemudian akan mendapatkan suatu aktivasi dari sel syaraf (Post Synaptic Potential dari sel syaraf). Signal aktivasi kemudian menjadi fungsi aktivasi atau fungsi transfer untuk menghasilkan output dari sel syaraf.
Beberapa istilah yang sering ditemui pada JST adalah sebagai berikut:
a) Neuron atau node atau unit, yaitu sel syaraf tiruan yang merupakan elemen pengolahan jaringan syaraf tiruan. Setiap neuron menerima data input, memproses input tersebut kemudian mengirimkan hasilnya berupa sebuah output.
b) Jaringan, yaitu kumpulan neuron yang saling terhubung dan membentuk lapisan. c) Lapisan tersembunyi (hidden layer), yaitu lapisan yang tidak secara langsung
berinteraksi dengan dunia luar. Lapisan ini memperluas kemampuan jaringan syaraf tiruan dalam menghadapi masalah-masalah yang kompleks.
d) Input, yaitu sebuah nilai input yang akan diproses menjadi nilai output. e) Output, yaitu solusi dari nilai input.
f) Bobot, yaitu nilai matematis dari sebuah koneksi antar-neuron.
g) Fungsi aktivasi, yaitu fungsi yang digunakan untuk meng-update nilai-nilai bobot per-iterasi dari semua nilai input.
13
a. Himpunan node-node yang dihubungkan dengan jalur koneki.
b. Suatu node penjumlah yang akan menjumlahkan masukan-masukan sinyal yang sudah dikalikan dengan bobotnya.
c. Fungsi aktivasi yang menentukan apakah sinyal dari input neuron akan diteruskan ke neuron lan ataukah tidak.
Neuron dalam jaringan syaraf tiruan sering diganti dengan istilah simpul. Setiap
simpul tersebut berfungsi untuk menerima atau mengirim sinyal dari atau ke simpul-simpul lainnya. Pengiriman sinyal disampaikan melalui penghubung. Kekuatan hubungan yang terjadi antara setiap simpul yang saling terhubung dikenal dengan nama bobot.
2.4.2 Komponen Jaringan Syaraf Tiruan
Pada umumnya JST memiliki komponen dua lapisan, yaitu input layer dan output layer. Tetapi pada perkembangannya, JST memiliki satu lapisan lagi yang terletak diantara input layer dan output layer. Lapisan ini disebut dengan hidden layer. Berikut penjelasan mengenai
komponen JST:
1) Input layer
Input layer berisi node-node yang masing-masing menyimpan sebuah nilai masukan
yang tidak berubah pada fase pelatihan (training) dan hanya bisa berubah jika diberikan nilai input baru. Node-node input tersebut menerima pola inputan dari luar yang menggambarkan suatu permasalahan. Banyak node atau neuron dalam input layer tergantung pada banyaknya input dalam model dan setiap input menentukan satu
node.
2) Hidden layer
Node-node pada hidden layer disebut node-node tersembunyi, dimana outputnya tidak
dapat diamati secara langsung. Akan tetapi semua proses dam fase training dan fase testing dijalankan di lapisan ini. Jumlah lapisan ini tergatung dari arsitektur yang
dirancang., tetapi pada umumnya terdiri atas satu lapisan hidden layer.
Output layer merupakan solusi dari jaringan syaraf tiruan terhadap suatu
permasalahan yang menampilkan hasil perhitungan sistem oleh fungsi aktivasi pada lapisan hidden layer berdasarkan input yang diterima.
2.4.3 Arsitektur Jaringan Syaraf Tiruan
Arsitektur jaringan syaraf tiruan digolongkan menjadi tiga model yaitu:
1. Jaringan layar tunggal (Single layer)
[image:45.595.220.380.328.461.2]Pada lapisan layar tunggal (single layer) node input yang menerima sinyal dari luar terhubung ke node output tetapi tidak terhubung ke node input lainya, dan node-node output yang terhubung ke node output lainnya. Seperti terlihat pada gambar brikut ini:
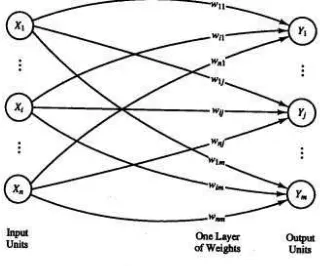
Gambar 2.1 Arsitektur jaringan layar tunggal (single layer)
Keterangan:
x1, xi, xn :Nilai input ke 1 sampai ke n
y1, yj, ym : Nilai output hasil pembangkitan nilai output oleh suatu fungsi aktivasi wi : Bobot atau nilai
Pada Gambar 2.1 diperlihatkan bahwa arsitektur jaringan layar tunggal (single layer) dengan n buah input ( x1, xi, xn ) dan m buah output ( y1, yj, ym ). Dalam jaringan ini semua node input dihubungkan dengan semua node output.
15
Jaringan layar jamak (multi layer) memecahkan masalah yang lebih rumit dari single layer. Pada jaringan tidak hanya terdiri dari ini terdiri dari input layer, hidden layer
[image:46.595.209.382.160.313.2]dan output layer. Sebagi contoh terlihat pada gambarberikut:
Gambar 2.2 Arsitektur jaringan layar jamak (multilayer)
Pada Gambar 2.2 memperlihatkan jaringan layar jamak (multilayer) dengan n buah input ( x1, xi, xn ), hidden layer yang terdiri dari p buah node ( z1, zj, zp ) dan m buah output ( y1, yj, ym ). Pada jaringan layar jamak (multilayer) kadangkala proses trainingnya lebih rumit.
3. Jaringan reccurent
Model jaringan reccurent mirip dengan jaringan layar tunggal (single layer) ataupun jaringan layar jamak (multilayer). Hanya saja, ada node output yang memberikan sinyal node input (feedback loop). Dengan kata lain sinyalnya mengalir dua arah yaitu maju dan mundur. Seperti terlihat pada gambar berikut:
Gambar 2.3 Arsitektur jaringan reccurent
[image:46.595.198.402.550.669.2]Jaringan syaraf tiruan backpropagation adalah salah satu metode yang dapat diaplikasikan dengan baik dalam bidang peramalan (forecasting). Backpropagation melatih jaringan untuk mendapatkan keseimbangan antara kemampuan jaringan mengenali pola yang digunakan selama fase training serta kemampuan jaringan untuk memberikan respon yang benar terhadap pola input yang serupa (tetapi tidak sama) dengan pola yang dipakai selama fase training (J.J Siang: 2009).
Backprogation memiliki node yang ada dalam satu atau lebih hidden layer seperti
[image:47.595.175.425.298.473.2]yang terlihat pada gambar berikut:
Gambar 2.4 Jaringan syaraf tiruan backpropagation
Pada Gambar 2.4 merupakan arsitektur backpropagation dengan n buah input (ditambah sebuah bias), sebuah hidden layer yang terdiri dari p node (ditambah sebuah bias) serta m buah output. Arsitektur ini disebut juga jaringan layar jamak (multilayer). Dengan keterangan gambar vji merupakan bobot garis dari node input xi ke node hidden layer zj (vj0
merupakan bobot garis yang menghubungkan bias di node input ke node hidden layer vj). wkj merupakan bobot dari hidden layer zj ke node output yk (wk0 merupakan bobot dari bias di hidden layer ke node output zk).
2.4.5 Fungsi Aktivasi
17
aktivasi digunakan untuk menentukan output suatu node. Fungsi aktivasi adalah net input (kombinasi linier input dan bobotnya). Jika net maka fungsi aktivasinya adalah f (net) = f ( ) (J.J Siang: 2009).
Beberapa fungsi aktivasi yang dipakai adalah sebagai berikut:
a) Fungsi batas ambang (Threshold)
[image:48.595.215.383.286.447.2]Fungsi batas ambang sering juga disebut fungsi under biner atau fungsi Heaviside yang terlihat pada gambar berikut:
Gambar 2.5 Fungsi batas ambang (Threshold)
Fungsi batas ambang (dengan nilai ambang 0) dirumuskan sebagai:
= , <�
1, ≥ �
b) Fungsi linier (Identitas)
Gambar 2.6 Fungsi linier (identitas) c) Fungsi sigmoid biner
Fungsi ini merupakan fungsi yang umum digunakan. Range-nya adalah 0 samapi dengan 1dan dirumuskan pada persamaan (5) sebagi berikut:
1
=
11+ − (5)
Dengan turunan persamaan (5) terdapat pada persamaan (6) sebagai berikut:
1′
=
11
−
1(6)
Fungsi sigmoid biner digambarkan sebagai berikut:
Gambar 2.7 Fungsi sigmoid biner
[image:49.595.208.389.518.665.2]19
Fungsi sigmoid bipolar hampir mirip dengan fungsi sigmoid biner, hanya saja output dari fungsi ini memiliki range antara 1 sampai dengan -1. Fungsi sigmoid bipolar dirumuskan pada persamaan (7) sebagai berikut:
=
1−−
1+ − (7)
Dengan turunan persamaan (7) terdapat pada persamaan (8) sebagai berikut:
′
=
12
1 +
1
−
(8) [image:50.595.218.375.338.478.2]Fungsi sigmoid bipolar digambarkan sebagai berikut:
Gambar 2.8 Fungsi sigmoid bipolar
Fungsi ini sangat dekat dengan fungsi hyperbolic tangent. Keduanya memiliki range antara -1 dan 1. Untuk fungsi hyperbolic tangent, digunakan rumus pada persamaan (9) sebagai berikut:
=
−−
+ − (9)
Dengan turunan persamaan (9) terdapat pada persamaan (10) sebagai berikut:
2.4.6 Algoritma Pelatihan (Training Algorithm)
Algoritma pelatihan untuk jaringan dengan satu hidden layer (dengan fungsi aktivasi sigmoid biner) adalah sebagai berikut (J.J Siang: 2009):
Langkah 0 : Inisialisasi semua bobot dengan bilangan acal kecil.
Langkah 1 : Jika kondisi penghentian belum terpenuhi, lakukan lahngkah 2-9.
Langkah 2 : Untuk setiap pasang data pelatihan, lakukan langkah 3-8.
Fase I: Propagasi Maju
Langkah 3 : Tiap node input menerima sinyal dan meneruskan node tersembunyi
diatasnya
Langkah 4 : Hitung semua output di node tersembunyi zj ( j = 1,2,…,p ).
_
=
0+
=1 (11)=
_
=
11+ − _ (12)
Langkah 5 : Hitung semua output jaringan di node yk (k = 1,2,…,m).
_
=
0+
=1 (13)=
_
=
11+ − _ (14)
Fase II: Propagasi Mundur
Langkah 6 : Hitung faktor node output berdasarkan kesalahan disetiap node output yk (k
= 1,2,…,m)
=
−
′_
=
−
1
−
(15)21
Hitung suku perubahan bobot wkj (yang akan dipakai nanti untuk merubah bobot wkj) dengan laju percepatan α.
∆ = �
Langkah 7 : Hitung faktor node tersembunyi berdasarkan kesalahan disetiap node
tersembunyi zj (j = 1,2,…,p)
_
=
=1 (16)Faktor node tersembunyi:
= _
′_
= _
1
−
(17)Hitung suku perubahan bobot vji (yang dipakai nanti untuk merubah bobot vij)
∆ = �
Fase III: Perubahan bobot
Langkah 8 : Hitung semua perubahan bobot
Perubahan bobot garis yang menuju ke node output
� = +∆ (18)
Perubahan bobot garis yang menuju ke node tersembunyi
� = +∆ (19)
Langkah 9 : Setelah dperoleh bobot yang baru dari hasil perubahan bobot, fase pertama dilakukan kembali kemudian dibandingkan hasil output dengan target apabila hasil output telah sama dengan target dan toleransi error maka proses dihentikan.
Setelah proses pelatihan selesai dilakukan, jaringan dapat dipakai untuk pengenalan pola. Dalam hal ini, hanya propagasi maju (langkah 4 dan 5) saja yang dipakai untuk menentukan output jaringan.
Peramalan adalah salah satu bidang yang paling baik dalam mengaplikasikan metode Backpropagation. Secara umum, masalah peramalan dapat dinyatakan dengan sejumlah data
runtun waktu (time series) x1, x2,..., xn. Masalahnya adalah memperkirakan berapa harga xn+1 berdasarkan x1, x2,..., xn. Jumlah data dalam satu periode (misalnya satu tahun) pada suatu kasus dipakai sebagai jumlah masukan dalam Backpropagation. Sebagai targetnya diambil data bulanan pertama setelah periode berakhir.
Langkah-langkah membangun struktur jaringan untuk peramalan sebagai berikut:
1. Penentuan input jaringan
Identifikasi input didasarkan pada lag-lag signifikan pada plot fungsi auto correlation function (ACF) dan partial auto correlation function (PACF) untuk memastikan data yang akan diinput adalah data yang stationer.
2. Pembagian data
Data yang telah diinput dibagi menjadi 2 yaitu data untuk proses training dan data untuk proses testing. Komposisi yang digunakan adalah 75% data untuk proses training dan 25% data untuk proses testing.
3. Normalisasi data
Sebelum melakukan pembelajaran maka data perlu dinormalisasikan. Hal ini dapat dilakukan dengan meletakkan data-data input dan target pada range tertentu. Proses normalisasi dapat dilakukan dengan bantuan mean dan standar deviasi.
Proses normalisasi data dengan bantuan mean dan standar deviasi menggunakan perintah prestd pada MATLAB yang akan membawa data ke dalam bentuk normal. Berikut
perintahnya:
[Pn,meanp,stdp]=prestd(P);
23
T : matriks target
Fungsi pada matlab akan menghasilkan:
Pn : matriks input yang ternormalisasi (mean = 0, deviasi standar = 1)
Tn : matriks target yang ternormalisasi (mean = 0, deviasi standar = 1)
meanp : mean pada matriks input asli (p)
stdp : deviasi standar pada matriks input asli (p)
meant : mean pada matriks target asli (t)
stdt : deviasi standar pada matriks target asli (t)
4. Menentukan arsitektur jaringan yang optimal
Sebuah jaringan harus dibentuk dengan menentukan input dari jaringan tersebut. Input diketahui dari plot ACF dan PACF yang telah dijelaskan sebelumnya. Jika input sudah diketahui, maka node pada hidden layer harus ditentukan. Penentuan node pada hidden layer dengan cara mengestimasi. Arsitektur jaringan yang sering
digunakan oleh algoritma backpropagation adalah jaringan feedforward dengan banyak lapisan. Untuk membangun suatu jaringan feedforward digunakan perintah newff pada MATLAB, yaitu
net = newff(PR,[S1 S2 ... SN1],{TF1 TF2
... TFN1},BTF,BLF,PF)
dengan:
PR : matriks berukuran Rx2 yang berisi nilai minimum dan maksimum, dengan R adalah jumlah variabel input
Si : jumlah neuron pada lapisan ke-i, dengan i = 1,2,…,N1
TFi : fungsi aktivasi pada lapisan ke i, dengan i = 1,2,…,N1
BLF : fungsi pelatihan untuk bobot (default : learngdm)
PF : fungsi kinerja (default: mse)
Fungsi aktivasi TFi harus merupakan fungsi yang dapat dideferensialkan, seperti tansig, logsig atau purelin. Fungsi pelatihan BTF dapat digunakan fungsi- fungsi
pelatihan untuk backpropagation, seperti trainlm, trainbfg, trainrp atau traind.
Proses untuk Menentukan arsitektur jaringan yang optimal dengan algoritma backpropagation adalah:
a. Menentukan banyaknya node pada hidden layer b. Menentukan input yang optimal
c. Menentukan bobot model
Penentuan bobot model bergantung pada pemilihan parameter pembelajaran.Pemilihan parameter pembelajaran adalah proses yang penting ketika melakukan pembelajaran. Dalam membentuk suatu jaringan, model yang kurang baik dapat diperbaiki dengan paramerer-parameter secara trial and error untuk mendapatkan nilai bobot optimum supaya MAPE jaringan dapat diperbarui. Adapun untuk parameter-parameter yang perlu diatur ketika melakukan pembelajaran traingdx adalah (Sri Kusumadewi: 2004) :
a) Maksimum epoh
Maksimum epoh adalah jumlah epoh maksimum yang boleh dilakukan selama proses pelatihan. Iterasi akan terhenti apabila nilai epoh melebihi maksimum epoh.
Perintah di MATLAB : net.trainParam.epochs = MaxEpoh
b) Kinerja tujuan
25
Perintah di MATLAB : net.trainParam.goal = TargetError
c) Learning rate
Learning rate adalah laju pembelajaran. Semakin besar learning rate akan
berimplikasi pada semakin besar langkah pembelajaran.
Perintah di MATLAB : net.trainParam.Ir = LearningRate.
d) Rasio untuk menaikkan learning rate
Rasio yang berguna sebagai faktor pengali untuk menaikkan learning rate apabila learning rate yang ada terlalu rendah atau mencapai kekonvergenan.
Perintah di MATLAB: net.trainParam.Ir_inc =IncLearningRate
e) Rasio untuk menurunkan learning rate
Rasio yang berguna sebagai faktor pengali untuk menurunkan learning rate apabila learning rate yang ada terlalu tinggi atau menuju ke
ketidakstabilan.
Perintah MATLAB:net.trainParam.Ir_decc =DecLearningRate
f) Maksimum kegagalan
iterasi ke-(k-1), maka kegagalannya akan bertambah 1. Iterasi akan dihentikan apabila jumlah kegagalan lebih dari maksimum kegagalan.
Perintah di MATLAB :net.trainParam.max_fail =MaxFaile
g) Maksimum kenaikan kerja
Maksimum kenaikan kerja adalah nilai maksimum kenaikan error yang diijinkan, antara error saat ini dan error sebelumnya.
MATLAB : net.trainParam.max_perf_inc =MaxPerfInc
h) Gradien minimum
Gradien minumum adalah akar dari jumlah kuadrat semua gradien (bobot input, bobot lapisan, bobot bias) terkecil yang diperbolehkan. Iterasi akan dihentikan apabila nilai akar kuadrat semua gradien ini kurang dari gradien minimum.
Perintah di MATLAB :net.trainParam.min_grad =MinGradien
i) Momentum
Momentum adalah perubahan bobot yang baru dengan dasar bobot sebelumnya. Besarnya momentum antara 0 sampai 1. Apabila besarnya momentum = 0 maka perubahan bobot hanya akan dipengaruhi oleh gradiennya. Sedangkan, apabila besarnya momentum = 1 maka perubahan bobot akan sama dengan perubahan bobot sebelumnya.
Perintah di MATLAB :net.trainParam.mc =Momentum
27
Parameter ini menunjukkan berapa jumlah epoh yang berselang yang akan ditunjukkan kemajuannya.
Perintah di MATLAB :net.trainParam.show =EpohShow
k) Waktu maksimum untuk pelatihan
Parameter ini menunjukkan waktu maksimum yang diijinkanuntuk melakukan pelatihan. Iterasi akan dihentikan apabila waktu pelatihan melebihi waktu maksimum.
Perintah di MATLAB :net.trainParam.time =MaxTime
5. Denormalisasi
etelah proses pelatihan selesai, maka data yang telah dinormalisasi dikembalikan seperti semula yang disebut denormalisasi data. Data akan di denormalisasi dengan fungsi poststd pada matlab, dengan perintah sebagai berikut:
[P,T]= poststd (pn, meanp, stdp, tn, meant, stdt)
6. Uji Keesuaian Model
Untuk mengecek error pada arsitektur jaringan yang telah dibentuk. Pengujiannya dapat dilihat dari plot ACF dan PACF.
2.5 Analisis Regresi dan Korelasi
kesulitan dalam menunjukkan slop (tingkat perubahan suatu variabel terhadap variabel lainnya dapat ditentukan). Dengan demikian maka melalui analisis regresi, peramalan nilai variabel terikat pada nilai variabel bebas lebih akurat pula.
Korelasi merupakan teknik analisis yang termasuk dalam salah satu teknik pengukuran asosiasi / hubungan (measures of association). Pengukuran asosiasi merupakan istilah umum yang mengacu pada sekelompok teknik dalam statistik bivariat yang digunakan untuk mengukur kekuatan hubungan antara dua variabel. Diantara sekian banyak teknik-teknik pengukuran asosiasi, terdapat dua teknik-teknik korelasi yang sangat populer sampai sekarang, yaitu Korelasi Pearson Product Moment dan Korelasi Rank Spearman. Selain kedua teknik tersebut, terdapat pula teknik-teknik korelasi lain, seperti Kendal, Chi-Square, Phi Coefficient, Goodman-Kruskal, Somer, dan Wilson. Korelasi bermanfaat untuk mengukur
kekuatan hubungan antara dua variabel (kadang lebih dari dua variabel) dengan skala-skala tertentu, misalnya Pearson data harus berskala interval atau rasio; Spearman dan Kendal menggunakan skala ordinal, Chi Square menggunakan data nominal. Dalam korelasi sempurna tidak diperlukan lagi pengujian hipotesis, karena kedua variabel mempunyai hubungan linear yang sempurna. Artinya variabel X mempengaruhi variabel Y secara sempurna. Jika korelasi sama dengan nol (0), maka tidak terdapat hubungan antara kedua variabel tersebut. Dalam korelasi sebenarnya tidak dikenal istilah variabel bebas dan variabel tergantung. Biasanya dalam penghitungan digunakan simbol X untuk variabel pertama dan Y untuk variabel kedua.
29
2.5.1 Regresi Linear Sederhana
Regresi Linear Sederhana adalah Metode Statistik yang berfungsi untuk menguji sejauh mana hubungan sebab akibat antara Variabel Faktor Penyebab (X) terhadap Variabel Akibatnya. Faktor Penyebab pada umumnya dilambangkan dengan X atau disebut juga dengan Predictor sedangkan Variabel Akibat dilambangkan dengan Y atau disebut juga dengan Response. Regresi Linear Sederhana atau sering disingkat dengan SLR (Simple Linear Regression) juga merupakan salah satu Metode Statistik yang dipergunakan dalam produksi untuk melakukan peramalan ataupun prediksi tentang karakteristik kualitas maupun Kuantitas. Analisis regresi linear sederhana dipergunakan untuk mengetahui pengaruh antara satu buah variabel bebas terhadap satu buah variabel terikat. Persamaan umumnya terdapat pada persamaan (20) adalah sebagai berikut :
Y = a + b X (20)
Dengan Y adalah variabel terikat dan X adalah variabel bebas. Koefisien a adalah konstanta (intercept) yang merupakan titik potong antara garis regresi dengan sumbu Y pada koordinat kartesius.
2.5.2 Regresi Linear Berganda
Analisis regresi linear berganda sebenarnya sama dengan analisis regresi linear sederhana, hanya variabel bebasnya lebih dari satu buah. Persamaan umumnya terdapat pada persamaan (21) adalah sebagai berikut:
Y = b0 + b1 X1 + b2 X2 + .... + bn Xn. (21)
Dengan Y adalah variabel bebas, dan X adalah variabel-variabel bebas, a adalah konstanta (intercept) dan b adalah koefisien regresi pada masing-masing variabel bebas.
Analisis regresi linier berganda adalah hubungan secara linear antara dua atau lebih variabel independent (X1, X2,….Xn) dengan variabel dependent (Y). Analisis ini untuk
masing-masing variabel independen berhubungan positif atau negatif dan untuk memprediksi nilai dari variabel dependent apabila nilai variabel independent mengalami kenaikan atau penurunan. Data yang digunakan biasanya berskala interval atau rasio.
Untuk menyelesaikan koefisien taksiran dalam hal ini tidak dapat lagi menggunakan metode kuadrat terkecil terdapat pada persamaan (22) yaitu sebagai berikut :
=
− 2− 2
(22)
Untuk menyelesaikan digunakan sistem persamaan Linier untuk setiap taksiran koefisien sebagai berikut :
(23)
Taksiran persamaan regresi yang kita miliki perlu diuji apakah persamaan regresi tersebut bersifat nyata atau tidak. Dalam mengujinya maka kita dapat menggunakan uji distribusi F.
Perumusan hipotesisnya : H0 : b1 = b2 = ... = bk = 0
H1 : Minimal ada satu taksiran koefisien regresi yang tidak sama dengan nol.
Pengujiannya :
Tolak H0 jika FHitung > FTabel (dengan dk = k; n-k-1)
Terima H0 jika FHitung < FTabel (dengan dk = k; n-k-1)
2.5.3 Uji Koefisien Korelasi Berganda
Uji koefisien korelasi berganda digunakan untuk melihat apakah variabel independent berpengaruh terhadap variabel dependent.
Uji ini disimbolkan dengan R.
ƩYi = b0n + b1ƩX1i + b2ƩX2i + b3ƩX3i
ƩYiX1i = b0ƩX1i + b1ƩX21i + b2ƩX1iƩX2i + b3 ƩX1iƩX3i
ƩYiX2i = b0ƩX2i + b1ƩX1iƩX2i + b2ƩX22i + b3ƩX2iƩX3i
ƩYiX3i = b0ƩX3i + b1ƩX1iƩX3i + b2ƩX2iƩX3i + b3 ƩX
31
R =
1 1 + 2 22 + 3 3(24)
Perhitungan Korelasi Antara Variabel Y dengan Xn, dilakukan dengan rumus:
�
=
−2− 2 2− 2
BAB 1
PENDAHULUAN
1.1Latar Belakang
Menurut Slamet (2002), sampah adalah segala sesuatu yang tidak lagi dikehendaki oleh yang punya
dan bersifat padat. Sementara didalam Naskah Akademis Rancangan Undang-undang Persampahan,
sampah merupakan sisa suatu usaha atau kegiatan yang yang berwujud padat atau semi padat
berupa zat organik atau an organik bersifat dapat terurai maupun tidak dapat terurai yang dianggap
sudah tidak berguna lagi dan dibuang ke lingkungan.
Sampah merupakan masalah krusial yang dihadapi beberapa Kota di Indonesia. Di Kota
Medan permasalahannya lebih kompleks, hal ini disebabkan karena tidak ada intervensi dari
pengambilan kebijakan saat ini. Jika dbiarkan terus menerus maka tidak mustahil terdapat gunungan
sampah diberbagai sudut-sudut Kota. Hal ini tentunya dapat memperburuk kondisi lingkungan
terutama estetika di Kota Medan (Tim pengkaji model pengolahan sampah Kota medan: 2013).
Pertumbuhan penduduk di Kota Medan yang terus meningkat tanpa disertai dengan
pertumbuhan wilayah, akan menyebabkan kepadatan penduduk yang berarti jumlah sampah