PEMODELAN REGRESI LOGISTIK PADA KASUS BERAT
BADAN LAHIR RENDAH (BBLR) DAN PENGARUH
AGREGASI DATA TERHADAP HASIL PENDUGAAN
ANT. BENNY SETYAWAN
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Pemodelan Regresi Logistik pada Kasus Berat Badan Lahir Rendah (BBLR) dan Pengaruh Agregasi Data terhadap Hasil Pendugaan adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Oktober 2015
Ant. Benny Setyawan
RINGKASAN
ANT. BENNY SETYAWAN. Pemodelan Regresi Logistik pada Kasus Berat Badan Lahir Rendah (BBLR) dan Pengaruh Agregasi Data terhadap Hasil Pendugaan. Dibimbing oleh KHAIRIL ANWAR NOTODIPUTRO dan INDAHWATI.
Berat Badan Lahir Rendah (BBLR) didefinisikan sebagai kelahiran hidup dengan berat badan di bawah 2500 gram tanpa memperhatkan usia kehamilan. Kejadian BBLR berkaitan erat dengan kematian bayi, kesakitan bayi, pertumbuhan fisik dan mental yang terhambat serta penyakit menahun ketika dewasa. Berdasarkan hanya pada Survei Demografi dan Kesehatan Indonesia (SDKI) yang dilaksanakan setiap lima tahun sekali, sulit untuk memonitor apakah suatu kebijakan untuk menekan angka BBLR dapat dikatakan efektif. Oleh karena itu, pemodelan statistik, pada kasus ini, Regresi Logistik, diperlukan untuk menduga prevalensi BBLR. Permasalahan dalam pemodelan timbul pada dua sisi, sisi peubah respon dan peubah penjelas. Pada sisi peubah respon, data berat badan lahir memiliki dua dasar respon: data tercatat dan ingatan ibu. Sedangkan pada peubah penjelas, ketersediaan data individu tidak selalu terpenuhi, tetapi yang tersedia adalah data agregat. Permasalahan tersebut berpengaruh dalam akurasi dan presisi model yang dibangun.
Pada tesis ini permasalahan pada sisi peubah respon diatasi dengan menyertakan peubah boneka dan memboboti amatan berdasarkan ragam tiap kelompok ke dalam model. Berdasarkan hasil dari model individu, tidak terdapat perbedaan nyata pada kedua kelompok akan tetapi pembobotan berdasarkan ragam meningkatkan kebaikan model. Pada sisi peubah bebas, untuk membandingkan setiap level aggregat, data diagregasikan pada level ibu, rumah tangga, cluster (blok sensus), dan kabupaten/kota. Peubah respon diagregasikan dari sebaran Bernoulli ke sebaran Binomial. Hasil pemodelan pada level individu, ibu dan rumah tangga cenderung mirip, sedangkan model blok sensus dan kabupaten/kota memiliki lebih sedikit jumlah penduga parameter yang nyata. AIC dan Luas area di bawah kurva
Receiver Operating Characteristics (ROC) menurun drastis pada model level blok sensus dan kabupaten/kota, mengindikasikan penurunan kebaikan model. Agregasi data pada level yang lebih tinggi secara konsisten meningkatkan ragam pendugaan dan memperlebar pendugaan. Akan tetapi dibandingkan dengan selang pendugaan langsung pada prevalensi provinsi, selang pendugaan yang dihasilkan model cenderung lebih sempit.
SUMMARY
ANT. BENNY SETYAWAN. A Study of Low Birth Weight (LBW) Models using Logistic Regression and the Effect of Data Aggregation on Estimation Results. Supervised by KHAIRIL ANWAR NOTODIPUTRO and INDAHWATI.
Low Birth-Weight (LBW) is defined as a birth weight of a live-born infant of less than 2500 grams regardless of gestational age. Case of LBW has been known to be associated with infant mortality, infant morbidity, inhibited growth and slow cognitive development, also chronic diseases in later life. Based only on Indonesia Demographic and Health Survey (IDHS), available every five year, it has been acknowledged to be hard to monitor if a policy is effective to suppress LBW case. Therefore, statistical modelling, in this case Logistic Regression, was needed to estimate LBW rates. The problems on modelling have arisen both for the response variable side and the explanatory variables side. On the response variable side the birth weight data was recorded in two ways: written record and mother’s recall. Moreover, in practice the individual level data is not always available. What we usually have is aggregated data of higher level. These problems theoretically have affected the accuracy and the precision of the model.
In this thesis the problem on the response side was handled by inserting dummy variables for each group of measurements. Moreover the variance of each group was used to weight the model. Based on the result of individual level model, there was no significant difference between these groups. However, by using variances as weights in the model, it is shown that the goodness of fit of the model has improved. On the explanatory side, the effects of aggregation levels were compared. The aggregation levels were mother level, household level, cluster or census block level and district level. The response variable was aggregated accordingly, and hence the response variable has changed from Bernoulli to Binomial distribution. The result showed that the aggregation at individual, mother and household levels produced similar models, while aggregation at cluster and district levels resulted in models with fewer significant parameter estimates. The AIC and Area under Receiver Operating Characteristics (ROC) curves were drastically decreased at the cluster and district levels model, indicating that the goodness of fit has decreased. Data aggregation from lower levels to higher levels was found to consistently increase the variances, and widen the interval estimates. However, in comparison with the direct estimates of provincial rates, the interval estimates of the models have shown narrower intervals.
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika Terapan
PEMODELAN REGRESI LOGISTIK PADA KASUS BERAT
BADAN LAHIR RENDAH (BBLR) DAN PENGARUH
AGREGASI DATA TERHADAP HASIL PENDUGAAN
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2015
Judul Tesis : Pemodelan Regresi Logistik pada Kasus Berat Badan Lahir Rendah (BBLR) dan Pengaruh Agregasi Data terhadap Hasil Pendugaan Nama : Ant. Benny Setyawan
NIM : G 152130394
Disetujui oleh Komisi Pembimbing
Prof Dr Ir Khairil Anwar Notodiputro, MS Ketua
Dr Ir Indahwati, MSi Anggota
Diketahui oleh
Ketua Program Studi Statistika Terapan
Dr Ir Indahwati, MSi
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji Syukur kepada Tuhan Yang Maha Kuasa atas berkat dan penyertaan-Nya yang tak kunjung henti sehingga penulis dapat menyelesaikan tesis yang berjudul “Pemodelan Regresi Logistik pada Kasus Berat Badan Lahir Rendah (BBLR) dan Pengaruh Agregasi Data terhadap Hasil Pendugaan” ini dengan baik.
Penulis mengucapkan terima kasih yang sebesar-besarnya kepada Bapak Prof. Dr. Ir. Khairil Anwar Notodiputro, MS dan Ibu Dr. Ir. Indahwati, M.Si selaku pembimbing dan Bapak Dr. Ir. Budi Susetyo, MS selaku penguji atas arahan dan bimbingannya hingga tesis ini dapat terselesaikan dengan baik. Ucapan terima kasih juga penulis sampaikan kepada seluruh Dosen Departemen Statistika IPB atas seluruh ilmu yang diberikan dan seluruh karyawan Departemen Statistika atas segala bantuan, pelayanan dan kemudahan selama pendidikan yang ditempuh oleh penulis. Terima kasih pula disampaikan kepada seluruh pimpinan Badan Pusat Statistik (BPS) baik di Pusat maupun di Daerah Istimewa Yogyakarta atas pembiayaan dan kesempatan yang diberikan.
Tesis ini penulis persembahkan bagi kedua mendiang orang tua Bapak Henricus Suyamto dan Ibu Maria Immaculata Marilah atas doa dan kasih sayang yang diberikan kepada penulis hingga akhir hayatnya. Bagi istri tercinta Cicilia Widyasari dan buah hatiku Tadeus Dhirajati Bratamandala semoga penyelesaian tesis ini dapat sedikit menebus kegundahan atas kebersamaan yang hilang. Terima kasih kepada kakak dan adik-adikku serta seluruh keluarga atas doa dan dukungannya selama studi yang ditempuh. Terima kasih juga kepada rekan-rekan S2 Statistika Terapan IPB BPS angkatan I atas persahabatan dan kegembiraannya serta seluruh teman-teman mahasiswa Sekolah Pascasarjana Statistika IPB.
Penulis menyadari masih terdapat kekurangan baik dalam isi maupun penulisan tesis ini. Namun demikian besar harapan penulis agar tesis ini dapat menjadi karya ilmiah yang bermanfaat.
Bogor, Oktober 2015
“The fear of the LORD is the beginning of knowledge”
(Proverbs 1:7a)
DAFTAR ISI
Berat Badan Lahir Rendah (BBLR) 3
Survei Demografi dan Kesehatan Indonesia (SDKI) 4
Generalized Linear Model (GLM) 5
Regresi Terboboti (Weighted Regression) 7
Perbandingan Model 7
3 METODE PENELITIAN 10
Data 10
Peubah Penelitian 10
Metode Analisis 13
Pembobotan Model Individu 14
Agregasi Data 14
4 HASIL DAN PEMBAHASAN 15
Eksplorasi Data 15
Perbandingan Model dan Hasil Dugaan 20
Pemilihan Model 21
Perbandingan Hasil Pemodelan dan Publikasi BPS 23
5 SIMPULAN DAN SARAN 25
Simpulan 25
Saran 25
DAFTAR PUSTAKA 26
LAMPIRAN 29
DAFTAR TABEL
2.1. Tabulasi silang dugaan dan kejadian BBLR 8
3.1. Peubah-peubah yang digunakan dalam penelitian 11 4.1. Kelompok dasar respon dan pembobotan yang diberikan 17
4.2. Nilai dugaan odds Ratio dan peluang BBLR 19
4.3. Perbandingan dugaan parameter model per level agregat 20
4.4. Perbandingan statistik kebaikan model 21
4.5. Perbandingan kepekaan dan kekhususan model pada c = 0.09439 23 4.6. Perbandingan dugaan prevalensi model terhadap nilai publikasi 24
DAFTAR GAMBAR
2.1. Ilustrasi kurva Receiver Operating Charasteristics (ROC) 9 3.1. Komposisi data SDKI 2012 yang menjadi cakupan penelitian 10
3.2. Bagan alur penelitian 13
4.1. Persebaran prevalensi BBLR menurut provinsi 15
4.2. Persebaran IPM menurut provinsi 15
4.3. Pola hubungan berat badan lahir bayi dengan urutan kelahiran,
umur ibu saat melahirkan dan jarak dengan kelahiran sebelumnya 16 4.4. Perbandingan ROC pada tiap level agregasi 22
DAFTAR LAMPIRAN
1
PENDAHULUAN
Latar Belakang
Berat Badan Lahir Rendah (BBLR) didefinisikan oleh WHO (2011) sebagai kejadian bayi lahir hidup dengan berat di bawah 2500 gram, tanpa memperhatikan usia kandungan (gestational age). Observasi epidemiologi menunjukkan bahwa bayi dengan berat lahir di bawah 2500 gram memiliki resiko 20 kali lebih besar untuk mengalami kematian (Kramer 1987). Selain itu, kejadian BBLR juga erat kaitannya dengan morbiditas bayi, pertumbuhan yang terhambat, perkembangan kognitif yang lambat, dan penyakit akut ketika dewasa (Barker 1995). Kramer (1987) mengidentifikasi faktor-faktor yang mempengaruhi kejadian BBLR yang secara umum terdiri dari beberapa kelompok: genetis, obstetris, asupan nutrisi, penyakit, paparan zat beracun, pemeliharaan kehamilan dan faktor sosial. Sebagian faktor-faktor yang mempengaruhi kejadian BBLR berasal dari pihak ibu. Oleh karena itu, menekan angka BBLR selain secara tidak langsung menekan angka kematian bayi juga merupakan cerminan dari peningkatan kesehatan ibu yang merupakan 2 dari 8
Millennium Development Goals (MDGs) (UN 2014).
Karena dampaknya yang bersifat jangka panjang, penurunan prevalensi BBLR hingga 30 persen juga dicanangkan oleh WHO sebagai salah satu dari Six Global Nutrition Targets 2025 (WHO 2014). Kondisi ini menjadi krusial di Indonesia yang pada periode 2005-2040 berada pada demographic window (of opportunity) dimana proporsi penduduk usia dibawah 15 tahun berada di bawah 30%, sebagai akibat dari menurunnya angka kelahiran, dan berakibat lebih besarnya proporsi penduduk usia kerja. Pada periode ini, dengan rendahnya angka ketergantungan, potensi SDM yang maksimal secara umum akan mendorong negara berkembang menjadi negara maju (Bloom et al. 2003). Risiko jangka panjang BBLR terhadap pertumbuhan dan kesehatan individu berpengaruh pada kualitas SDM ketika dewasa. Kualitas SDM yang kurang, baik pada individu tersebut maupun ibunya, meskipun merupakan bagian dari proporsi angkatan kerja yang besar akan menjadi kurang produktif dalam memperoleh pertumbuhan ekonomi yang besar (bonus demografi/demographic dividend) (UN 2004).
Angka prevalensi BBLR diperoleh dari Survei Demografi dan Kesehatan Indonesia (SDKI) yang dilakukan setiap 5 tahun oleh BPS bekerjasama dengan BKKBN dan Kemenkes. Berdasarkan SDKI 2012, angka nasional 7,3 persen dengan angka provinsi berkisar antara 4.7-15.7 persen, angka terendah di DKI Jakarta (4.7%) dan tertinggi di NTT (15.7%) (BPS et al. 2013). Sebagai perbandingan WHO (2011) mencatat pada tahun 2000, rata-rata negara maju 7 persen dan negara berkembang 16.9 persen, Asia Tenggara 11.6 persen dan Indonesia 9 persen. Meskipun angka nasional terbilang rendah untuk negara berkembang, tingginya kisaran angka provinsi menunjukkan bahwa permasalahan BBLR cukup serius pada beberapa provinsi. Dengan ketersediaan data secara lima-tahunan, sulit untuk memonitor apakah suatu kebijakan dapat dikatakan efektif. Oleh karena itu pemodelan untuk mengestimasi angka BBLR perlu dikembangkan.
2
Kedua kelompok ini tentu secara logika memiliki akurasi dan presisi yang berbeda. Oleh karena itu pemodelan yang dilakukan secara statistik harus mengakomodasi perbedaan akurasi (rataan) dan presisi (ragam) tersebut ke dalam model. Permasalahan berikutnya adalah model dari data SDKI tersebut dibangun dari data pada level individu, sedangkan secara umum pada tahun-tahun yang tidak dilaksanakan SDKI data individu tersebut juga tidak tersedia. Data yang tersedia umumnya adalah data pada tataran agregat yang lebih tinggi, sehingga model tersebut tidak dapat diaplikasikan. Untuk itu pemodelan dengan tataran agregat antara peubah respon dan peubah bebas yang sama perlu juga dilakukan.
Berdasarkan permasalahan tersebut perlu dikaji bagaimana pemodelan untuk prevalensi BBLR dapat dilakukan dalam keadaan terdapat dugaan perbedaan akurasi (rataan) dan presisi (ragam) dalam cara pengukuran, serta berdasarkan data yang ada sampai sejauh mana agregasi dapat dilakukan dengan tetap menghasilkan model dan nilai dugaan yang baik.
Perumusan Masalah
Berdasarkan latar belakang tersebut maka permasalahan yang dikaji dalam penelitian ini adalah:
1. Faktor-faktor apa saja yang mempengaruhi kejadian BBLR baik pada level individu maupun pada level agregat?
2. Apakah terdapat pengaruh perbedaan dasar respon (ingatan dan catatan) pada akurasi dan presisi dugaan BBLR?
3. Sampai sejauh mana agregasi data masih menghasilkan pemodelan kejadian BBLR yang baik?
4. Bagaimana perbandingan dugaan prevalensi BBLR dari model yang dihasilkan jika dibandingkan dengan nilai prevalensi BBLR yang dipublikasikan?
Tujuan Penelitian
Tujuan yang hendak dicapai dalam penelitian ini adalah sebagai berikut: 1. Mengembangkan model yang dapat menerangkan kejadian BBLR dengan
faktor-faktor yang mempengaruhi dengan mempertimbangkan perbedaan pengaruh dan ragam data berdasarkan dasar respon (ingatan dan catatan).
2. Mengkaji dampak level agregasi dari data kejadian BBLR dan faktor-faktor yang mempengaruhinya terhadap pemodelan BBLR.
3. Mengevaluasi seberapa besar perbedaan hasil dugaan tidak langsung BBLR (yaitu menggunakan model) pada beberapa level agregat dengan nilai yang dipublikasikan.
Manfaat Penelitian
3
2
TINJAUAN PUSTAKA
Berat Badan Lahir Rendah (BBLR)
Kasus Berat Badan Lahir Rendah (BBLR) ditentukan oleh hasil pengukuran berat badan bayi lahir hidup di bawah 2500 gram. Pengukuran ini dilakukan tanpa memperhatikan usia kandungan (gestational age) dan dilakukan pada jam-jam pertama setelah kelahiran (WHO 2011). Hal ini karena pada hari-hari pertama setelah kelahiran, bayi akan mengalami penurunan berat badan yang signifikan. Penentuan batas 2500 gram didasarkan pada kisaran persentil ke-10 dan persentil ke-90 pada usia kandungan 40 minggu yaitu antara 2500 – 4000 gram sebagai berat wajar untuk usia kandungan 40 minggu (appropriate for gestational age). Berat badan lahir dibawah 2500 gram disebut sebagai kategori kecil untuk usia kandungan tersebut (small for gestational age) dan disebut sebagai kasus Berat Badan Lahir Rendah (BBLR), sedangkan diatas 4000 gram disebut sebagai kategori besar untuk usia kandungan tersebut (large for gestational age) (Hutcheon et al. 2010).
Kramer (1987) menyatakan bahwa berdasarkan hasil observasi epidemiologi, bayi dengan berat lahir di bawah 2500 gram memiliki resiko 20 kali lebih besar untuk mengalami kematian. Selain itu, kejadian BBLR juga erat kaitannya dengan morbiditas bayi, pertumbuhan yang terhambat, perkembangan kognitif yang lambat, dan penyakit akut ketika dewasa (Barker 1995).
Kejadian BBLR memiliki dua penyebab: kelahiran prematur (usia kandungan di bawah 37 minggu) dan pertumbuhan janin yang terhambat (intra uterine growth restriction) selama kehamilan, serta kombinasi dari keduanya. Faktor-faktor yang mempengaruhi kejadian BBLR secara umum bersifat tidak langsung yang meningkatkan resiko (faktor resiko) kelahiran prematur dan pertumbuhan janin yang terhambat yang lebih lanjut oleh Kramer (1987) dikelompokkan menjadi:
1. Faktor dasar dan genetis: jenis kelamin bayi, kembar, ras, tinggi ibu, berat ibu sebelum hamil, tekanan darah selama kehamilan, berat dan tinggi ayah, serta faktor genetis lain.
2. Faktor demografis dan psikososial: umur ibu saat hamil, pendidikan, pekerjaan dan kesejahteraan, status perkawinan dan faktor psikologi ibu lainnya.
3. Faktor obstetrik: paritas, jarak kehamilan, aktivitas seksual, riwayat BBLR, riwayat prematur, riwayat aborsi/keguguran/lahir mati/kematian neonatal, masalah kesuburan, dan paparan diethylstilbestrol dalam rahim.
4. Faktor nutrisi: penambahan berat selama kehamilan, asupan kalori, aktivitas fisik, asupan protein, zat besi dan anemia, vit. B9 (asam folat), B6 dan B12, asupan seng, tembaga, kalsium, fosfor dan vit. D dan nutrisi lainnya.
5. Penyakit selama kehamilan: malaria, infeksi saluran kencing dan kelamin, diare, ISPA, TBC, anoreksia dan penyakit-penyakit lainnya.
6. Paparan zat beracun: rokok (pasif maupun aktif), alkohol, kafein, marijuana, narkotika dan paparan racun lainnya.
7. Pemeriksaan kehamilan: pemeriksaan kehamilan pertama, jumlah pemeriksaan selama kehamilan dan kualitas perawatan kehamilan.
4
(2007) dengan Regresi Berganda dan Puspitasari (2011) dengan Regresi Logistik yang dilakukan pada satu atau beberapa fasilitas kesehatan. Nilai-nilai amatan yang digunakan dalam penelitian cenderung lebih akurat karena berasal dari record
(catatan) fasilitas kesehatan tersebut. Akan tetapi kesimpulan yang diambil bersifat lokal dan hanya berlaku terhadap individu-individu yang memiliki akses terhadap fasilitas kesehatan tersebut.
Penelitian dengan lingkup area yang lebih luas dengan menggunakan data survei rumah tangga antara lain oleh Arpansah (2010) dengan Regresi Berganda di Sumatera dari data Riskesdas 2007 dan Setyowati et al. (1996) dengan Regresi Logistik di Indonesia dengan data SDKI 1994. Kesimpulan dari penelitian tersebut sebaliknya dapat digeneralisasikan ke populasi secara umum, namun karena berasal dari data dengan amatan yang bersumber dari dua kelompok respon (ingatan atau catatan), terdapat potensi bias dari kesimpulan yang diambil karena perbedaan akurasi dan presisi dari dua kelompok respon tersebut diabaikan.
Selain itu sebagian besar penelitian tersebut memandang kejadian BBLR sebagai bagian dari nilai amatan berat badan lahir bayi (kontinu), sedangkan faktor risiko yang menyebabkan dan dampak yang diakibatkan oleh kejadian BBLR tidak bergerak secara linier terhadap berat badan lahir bayi. Dengan demikian kejadian BBLR lebih tepat dipandang sebagai kasus khusus dan dipandang sebagai peubah acak biner, sehingga pendekatan regresi logistik seperti yang dilakukan Puspitasari (2011) dan Setyowati et al. (1996) akan lebih tepat.
Survei Demografi dan Kesehatan Indonesia (SDKI)
Survei Demografi dan Kesehatan Indonesia (SDKI) merupakan satu-satunya sumber data BBLR pada skala nasional. SDKI dilaksanakan setiap lima tahun sekali oleh Badan Pusat Statistik (BPS) bekerjasama dengan Badan Kependudukan dan Keluarga Berencana Nasional (BKKBN) dan Kementerian Kesehatan. ICF International memberikan bantuan teknis karena SDKI adalah bagian dari program MEASURE Demographic and Health Surveys (DHS) dari United States Agency for International Development (USAID) yang dilaksanakan secara internasional di 91 negara.
SDKI 2012 merupakan SDKI ketujuh yang dilaksanakan oleh BPS. SDKI 2012 memiliki rancangan berlapis (stratified) dan bertahap (multistage). Pada rancangan acak berlapis populasi yang heterogen dibagi ke dalam subpopulasi yang lebih homogen sehingga diperoleh ragam pendugaan yang lebih kecil. Sedangkan rancangan acak bertingkat digunakan untuk mengatasi kondisi: (1) kerangka contoh pada tingkat terkecil tidak tersedia secara keseluruhan dan (2) kondisi geografis yang sangat luas menyebabkan penyebaran unit contoh menjadikan rancangan tidak ekonomis (Scheaffer et al. 2006). Penarikan contoh pada setiap tahap (stage) dilakukan secara
systematic untuk menjamin cakupan wilayah.
5 Untuk setiap rumah tangga terpilih terdapat 4 jenis kuesioner yang digunakan: 1. Kuesioner Rumah Tangga
2. Kuesioner Wanita umur 15-49 tahun 3. Kuesioner Pria Kawin umur 15-54 tahun
4. Kuesioner Pria Belum Pernah Kawin umur 15-24 tahun
Data BBLR berasal dari kuesioner wanita umur 15-49 tahun, sedangkan peubah-peubah bebas individu yang digunakan berasal dari kuesioner rumah tangga dan kuesioner wanita umur 15-49 tahun.
Generalized Linear Model (GLM)
Kelahiran dengan BBLR dapat dinyatakan dalam peubah acak biner Yi, dimana kejadian BBLR dinyatakan dengan nilai Yi = 1 dan kejadian kelahiran bukan BBLR dengan nilai Yi = 0. Apabila peluang kejadian BBLR sebesar πi maka sebarannya akan mengikuti sebaran Bernoulli (πi), dimana nilai peluang πi untuk setiap bayi berbeda-beda tergantung pada karakteristik bayi yang lahir tersebut.
Pada kasus aggreggasi data, secara lebih umum peubah acak Yi menyatakan jumlah kejadian BBLR dari keseluruhan ni kejadian kelahiran pada agregat ke-i. Dengan asumsi bahwa setiap kejadian kelahiran bersifat saling bebas dan peluang dari setiap kejadian BBLR pada agregat ke-i adalah identik sebesar πi maka peubah acak
Yi akan mengikuti sebaran Binomial (ni, πi).
Oleh karena itu pemodelan kejadian BBLR dengan model linier klasik akan melanggar asumsi normalitas dan homoskedastisitas. Sebaran data bagi Yi ~ Binomial (ni, πi) berimplikasi juga kepada ragam yang tidak homogen yang merupakan fungsi dari nilai harapannya Var (Yi) = niπi (1 –πi). Untuk mengatasi permasalahan tersebut Nelder dan Wedderburn (1972) memperkenalkan Generalized Linear Model (GLM) untuk mengakomodasi peubah yang tidak menyebar Normal namun masih termasuk dalam sebaran eksponensial sehingga dapat dimodelkan dalam model linier (2.1).
= �� + �
(2.1) GLM terdiri dari tiga komponen utama (Azen dan Walker 2011):
1. Komponen Acak (random component) Y yang merupakan peubah respon acak yang memiliki sebaran yang termasuk dalam keluarga sebaran eksponensial. Keluarga sebaran eksponensial memiliki bentuk umum fungsi persamaan 2.2.
, , � = { −� + , � }�
(2.2) 2. Penduga Linier (linear predictor) Xβ dengan X adalah matriks peubah bebas dan
β adalah vektor parameter model yang hendak diduga.
3. Fungsi Hubung (link function) g(.) yang menghubungkan komponen acak dan penduga linier.
= � =
(2.3) Sebaran Binomial dapat dinyatakan seperti dalam bentuk umum (2.2) sehingga sebaran Binomial merupakan salah satu anggota keluarga sebaran eksponensial (2.4).
= ��� − � �−�� = exp [ ln ( �
− � ) + ln − � + ln ]
6
sehingga diperoleh fungsi hubung (2.5) yang disebut sebagai fungsi logit
= � = ln ( − � )�
(2.5) dan pemodelan BBLR dengan GLM akan mengikuti model 2.6 yang disebut sebagai model regresi logistik.
� digunakan dalam pendugaan. Pada pemodelan terhadap data agregat dengan
kondisi 0 < yi < ni nilai logit dari masing-masing amatan dapat dihitung sehingga pendugaan secara Ordinary Least Square (OLS) dapat dilakukan dengan transformasi ∗= ln �̂�
−�̂� . Permasalahan pada pemodelan regresi logistik dengan
data individu atau data agregat terjadi ketika nilai yi = 0 atau yi = ni.
Pada kondisi demikian pendugaan dilakukan dengan pendekatan metode
Maximum Likelihood Estimation (MLE). Fungsi likelihood diperoleh dari sebaran bersama seluruh data amatan sejumlah m dengan mensubstitusikan parameter model pada persamaan 2.6 ke parameter sebaran binomial (2.4). Pendugaan dengan metode MLE dilakukan dengan memaksimumkan nilai fungsi log-likelihood lnL(�) terhadap parameter � yang diduga. diselesaikan melalui metode numerik dengan algoritma Newton-Raphson hingga diperoleh iterasi ke-r yang konvergen dari persamaan 2.9 (Dobson 2002).
�� = ��− − (��− ) dimana W adalah matriks diagonal pembobot yang memiliki elemen-elemen = � − � . Vektor U(β) disebut sebagai vektor score yang memiliki karakteristik :
= ; � � = = − ′ = �
7
��− �� = � �− ��− + � (��− )
(2.12) Pendekatan numerik ini disebut sebagai metode scoring dan proses penghitungannya serupa dengan metode Iterative Weighted Least Squares (IWLS).
Regresi Terboboti (Weighted Regression)
Informasi tentang sebaran data sangat penting dalam melakukan suatu pemodelan. Pengabaian terhadap sebuah informasi dapat berujung pada pemodelan yang tidak valid dan kesimpulan yang diambil dapat menjadi bias. Pada kondisi terdapat indikasi ketidakhomogenan ragam (heteroskedastisitas) ataupun antar amatan tidak saling bebas (autokorelasi) pada sebaran data, pemodelan yang dilakukan perlu disesuaikan. Pemodelan pada kondisi heteroskedastisitas maupun autokorelasi, meskipun tetap tak bias, berdampak pada pendugaan yang menjadi tidak efisien (ragam tidak minimum) dan hasil uji statistik menjadi tidak valid.
Aitken (1935) memperkenalkan Generalized Least Squares (GLS) untuk regresi dengan sebaran yang memiliki ragam yang tidak homogen ataupun amatan yang tidak saling bebas.
= �� + � ; ��~ , �
(2.13) dimana V adalah matriks simetrik non singular dan W = V-1 dan matriks H adalah
matriks sedemikian hingga HTH = W dan HTVH = I maka menyertakan matriks H
dalam model akan menghasilkan:
= � + � ; ��E = � ; ��Var = =
(2.14) Sehingga penduga yang dihasilkan:
�̂GL = − � = −
(2.15) adalah penduga yang bersifat Best Linear Unbiased Estimator (BLUE) dengan W = V-1 disebut sebagai matriks pembobot dan model regresi yang digunakan disebut
sebagai model regresi terboboti.
Dalam kasus terdapat indikasi perbedaan ragam (heteroskedastisitas) dalam pemodelan dengan GLM prinsip yang sama dapat digunakan dengan menyertakan matriks diagonal H seperti pada persamaan 2.14 ke dalam persamaan 2.1.
= � + �
(2.16) Sehingga penduga dari parameter �diperoleh dari solusi persamaan 2.17,
� �× = � ln � ��� = − ̅∗ = ;� ̅∗ = �∗ =
ℎ�� ���
+ ℎ�� ��� (2.17) Perbandingan Model
8
maksimum log-likelihood (2.7) dari model dengan dikoreksi oleh jumlah parameter model yang diduga (p) menjadi formula 2.18.
= − ln � � +
(2.18) Meskipun setiap model yang diperbandingkan dalam penelitian ini memiliki jumlah amatan yang sama akan tetapi jumlah kejadian kelahiran (n), kejadian BBLR (y) yang diamati dan jumlah parameter yang diduga (p) untuk setiap model tetap sama. Sehingga perbandingan AIC yang dihasilkan merupakan perbandingan kesesuaian (fit) karena perbedaan AIC yang dihasilkan hanya berdasarkan perbedaan nilai dugaan peluang kejadian (π). Nilai dugaan peluang kejadian (π) itu sendiri tergantung pada hasil agregasi peubah bebas (X) dan dugaan parameter model (β).
Kurva ROC disusun dari plot antara kepekaan (Se) terhadap 1 – kekhususan (1 – Sp) pendugaan pada setiap nilai cut-off (c) yang ketiga-tiganya memiliki nilai berada pada interval 0 dan 1. Nilai cut-off (c) adalah batas nilai dugaan peluang yang ditentukan untuk mengklasifikasikan dugaan kejadian. Sehingga dugaan kejadian BBLR dapat dinyatakan sebagai fungsi dari nilai cut-off (c).
̂ = { � ; �̂
� � ; �̂ <
Sehingga penghitungan kepekaan (Se) dan kekhususan (Sp) pada kejadian BBLR dapat digambarkan pada Tabel 2.1 dan persamaan 2.19.
Tabel 2.1. Tabulasi silang dugaan dan kejadian BBLR
Kenyataan Jumlah
Dugaan
BBLR Non BBLR
Dugaan(c) BBLR(c) True Positive(c) False Positive(c) Positive(c) Non BBLR(c) False Negative(c) True Negative(c) Negative(c)
Jumlah Kelahiran Event Non Event Total
= + ; = +
; ��� � ; ���
(2.19) Kepekaan menunjukkan proporsi kejadian BBLR yang diduga dengan benar dan kekhususan menunjukkan proporsi kejadian Non BBLR yang diduga dengan benar. Karena penghitungan kepekaan dilakukan pada kelompok data event (BBLR) dan kekhususan pada kelompok data non event (Non BBLR) maka kedua ukuran tersebut tidak tergantung terhadap prevalensi data (prevalence-independent), sehingga ketika dugaan model sudah diperoleh, besarnya nilai kepekaan dan kekhususan hanya tergantung pada nilai c. Karena hanya berdasarkan nilai c, konsekuensi dari formula 2.19 semakin tinggi kepekaan, maka kekhususannya akan semakin rendah, demikian juga sebaliknya.
9 nilai 1 – kekhususannya, semakin besar kecenderungan perbedaannya semakin baik model tersebut sebagai penduga (classifier). Contoh ilustrasi dari kurva ROC dapat dilihat pada Gambar 2.1. Model penduga yang baik akan menghasilkan kurva ROC yang cekung ke bawah dan mendekati kondisi sempurna.
Gambar 2.1. Ilustrasi kurva Receiver Operating Charasteristics (ROC) Agar kebaikan model dapat diukur, kurva ROC dapat dipandang sebagai fungsi dari nilai cut-off point (c) terhadap nilai ROC dan luas area dibawah kurva (area under curve/AUC) sebagai ukuran kebaikan model (2.20).
= − −
= ∫ ;
10
3
METODE PENELITIAN
Data
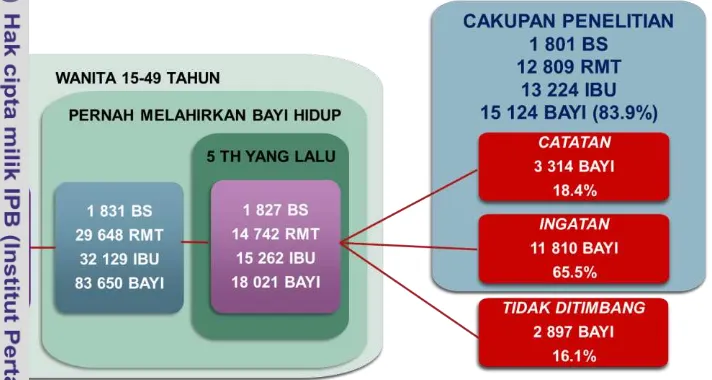
Data yang digunakan dalam penelitian ini terdiri dari data primer dan data sekunder. Data primer berasal dari data mentah SDKI 2012 sedangkan data sekunder berupa data komponen-komponen Indeks Pembangunan Manusia (IPM) kabupaten/kota se-Indonesia tahun 2011. Amatan yang digunakan adalah bayi lahir hidup dalam periode 5 tahun yang lalu yang berat badannya ditimbang. Komposisi data primer yang digunakan adalah seperti pada Gambar 3.1.
Gambar 3.1. Komposisi data SDKI 2012 yang menjadi cakupan penelitian Peubah Penelitian
Peubah-peubah penelitian yang digunakan terdiri dari peubah respon dan peubah-peubah penjelas. Peubah-peubah penjelas terdiri dari tiga kelompok: proxy
11 Tabel 3.1. Peubah-peubah yang digunakan dalam penelitian
No. Nama Peubah Definisi Operasional Skala Kategori/Satuan Peubah Respon
Kategorik Sangat Kecil (D2) Kecil (D3)
Kategorik Anak Pertama (D7) < 2 th dan ke 2-3 (D8)
Kategorik Ada riwayat (D14) Tidak ada riwayat (–)
8. Umur Ibu Pengelompokan menurut umur kelahiran beresiko
Kategorik < 20 tahun (D15) 20-34 tahun (–) 35-49 tahun (D16) 9. Jenis Kelamin
Bayi
Jenis kelamin bayi Kategorik Laki-laki (D17) Perempuan (–) 10. Pendidikan Ibu Pendidikan yang
ditamatkan oleh ibu
12
Tabel 3.1. (lanjutan)
No. Nama Peubah Definisi Operasional Skala Kategori/Satuan 13. Suplemen 16. Pekerjaan Ibu Kategori pekerjaan
sehari-hari ibu
Kategorik Pekerjaan fisik (D27) Pekerj. non fisik (D28)
Tidak bekerja (–) Pengaruh Area
17. Desa/Kota Kategori Desa/Kota Kategorik Desa (D29) Kota (–)
Numerik dalam ribu rupiah (000 Rp) (Dj) peubah boneka untuk kategori bukan referensi (–) kategori referensi ** data kosong karena desain kuesioner, hanya ditanyakan pada anak terakhir
Pengkategorian peubah-peubah bebas secara umum merujuk pada pengkategorian yang dilakukan Kramer (1987). Berdasarkan hasil eksplorasi data pengkategorian beberapa peubah yang terlalu banyak menghasilkan kategori-kategori yang tidak signifikan. Oleh karena itu beberapa peubah pengkategoriannya disederhanakan sehingga diperoleh kategori-kategori yang pengaruhnya lebih signifikan. Peubah-peubah yang disederhanakan pengkategoriannya antara lain: Pendidikan Ibu (5 kategori), Kesejahteraan Rumah Tangga (5 kategori), Sumber Air Minum (12 kategori), dan Pekerjaan Ibu (8 kategori).
13 Metode Analisis
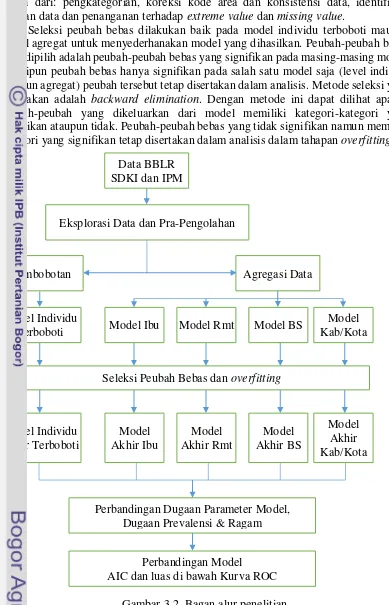
Secara umum tahapan-tahapan analisis dalam penelitian ini dapat diringkas dalam bagan alur penelitian berikut seperti pada Gambar 3.2. Tahapan pra-pengolahan terdiri dari: pengkategorian, koreksi kode area dan konsistensi data, identifikasi sebaran data dan penanganan terhadap extreme value dan missing value.
Seleksi peubah bebas dilakukan baik pada model individu terboboti maupun model agregat untuk menyederhanakan model yang dihasilkan. Peubah-peubah bebas yang dipilih adalah peubah-peubah bebas yang signifikan pada masing-masing model. Meskipun peubah bebas hanya signifikan pada salah satu model saja (level individu maupun agregat) peubah tersebut tetap disertakan dalam analisis. Metode seleksi yang digunakan adalah backward elimination. Dengan metode ini dapat dilihat apakah peubah-peubah yang dikeluarkan dari model memiliki kategori-kategori yang signifikan ataupun tidak. Peubah-peubah bebas yang tidak signifikan namun memiliki kategori yang signifikan tetap disertakan dalam analisis dalam tahapan overfitting.
Gambar 3.2. Bagan alur penelitian Pembobotan
Model Individu Terboboti
Perbandingan Dugaan Parameter Model, Dugaan Prevalensi & Ragam
Seleksi Peubah Bebas dan overfitting
14
Pembobotan Model Individu
Pemodelan kejadian BBLR pada level individu menggunakan Model Regresi Logistik Terboboti. Pembobotan dilakukan untuk mengatasi indikasi perbedaan presisi (ragam) dari kejadian BBLR pada kelompok data berat badan lahir yang berdasarkan ingatan ibu dan berdasarkan data catatan. Pembobotan dilakukan dengan menghitung ragam dari masing-masing kelompok ke-j. Bobot yang diperoleh (hj) kemudian distandarisasi (hj*) sehingga total amatan tidak berubah.
Var( ̂ ) = Var = −
ℎ = ⁄√Var( ) ; ℎ∗ = ℎ
∑ = ℎ
(3.1) Masing-masing bobot tersebut diterapkan pada setiap amatan ke-i (hi*) sesuai dengan kelompok datanya sehingga diperoleh model regresi logistik individu terboboti 1seperti pada persamaan (3.2):
Untuk dapat mengetahui sejauh mana pemodelan dari data agregasi menghasilkan model yang baik, pemodelan pada beberapa level agregasi perlu dilakukan. Agregasi data individu dilakukan pada level Ibu, Rumah Tangga, Blok Sensus, dan Kabupaten/Kota. Agregasi pada level Desa dan Kecamatan tidak dilakukan karena ukuran sampel SDKI yang kecil sehingga rancangan yang diperoleh, pada level desa dan kecamatan hampir semuanya hanya memperoleh 1 (satu) BS sampel. Agregasi dilakukan pada peubah respons maupun peubah penjelas pada level individu/level agregat terendah (misalnya: pendidikan ibu mulai diagregasi pada level rumah tangga, sumber air minum mulai diagregasi pada level BS, dst.).
Pada level agregat pemodelan dilakukan dengan mengasumsikan bahwa peluang kejadian BBLR (πi) dalam suatu agregat identik. Sehingga dari ni kelahiran dalam suatu agregat jumlah kejadian BBLR yi akan mengikuti sebaran Binomial (ni, πi). Karena dalam pemodelan yang digunakan adalah nilai �̂ = ��
� maka agregat
15
4
HASIL DAN PEMBAHASAN
Eksplorasi Data
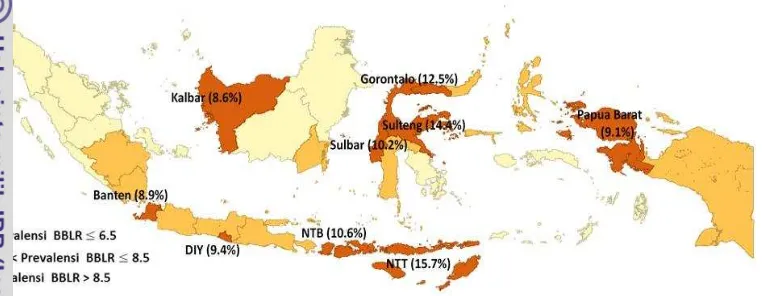
Dari hasil publikasi SDKI 2012 yang diterbitkan BPS, prevalensi BBLR nasional 7.3 persen dengan prevalensi BBLR provinsi berkisar antara 4.7-15.7 persen, angka terendah di DKI Jakarta (4.7%) dan tertinggi di NTT (15.7%). Provinsi-provinsi dengan prevalensi BBLR yang cukup tinggi (> 8.5%) adalah Banten, D.I. Yogyakarta, Kalimantan Barat, Sulawesi Barat, Sulawesi Tengah, Gorontalo, NTB, NTT dan Papua Barat (Gambar 4.1).
Gambar 4.1. Persebaran prevalensi BBLR menurut provinsi
Persebaran ini cukup berbeda dengan persebaran data Indeks Pembangunan Manusia (IPM) yang mencerminkan kesejahteraan suatu daerah (Gambar 4.2). Beberapa daerah dengan nilai IPM tinggi namun memiliki prevalensi BBLR yang tinggi pula adalah Banten, D.I. Yogyakarta, Sulawesi Barat, Sulawesi Tengah, dan Gorontalo. Sedangkan Maluku Utara dan Papua memiliki prevalensi BBLR pada kategori sedang meskipun nilai IPM nya terbilang rendah. Karena IPM sendiri terdiri dari beberapa komponen (pendidikan, kesehatan dan kemiskinan) maka perlu dikaji komponen-komponen mana yang berpengaruh terhadap prevalensi BBLR.
Gambar 4.2. Persebaran IPM menurut provinsi
16
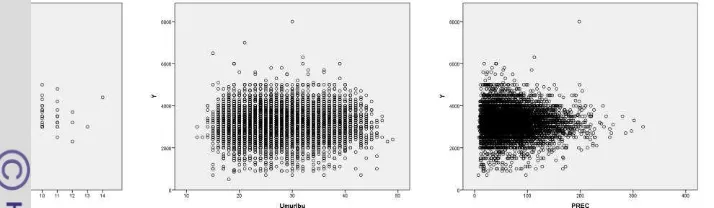
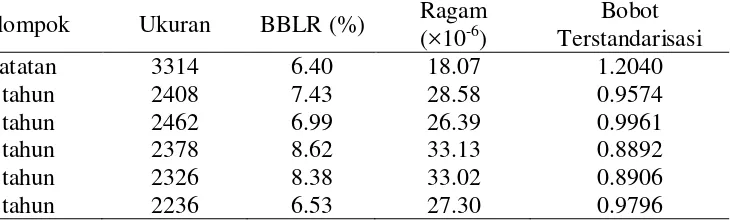
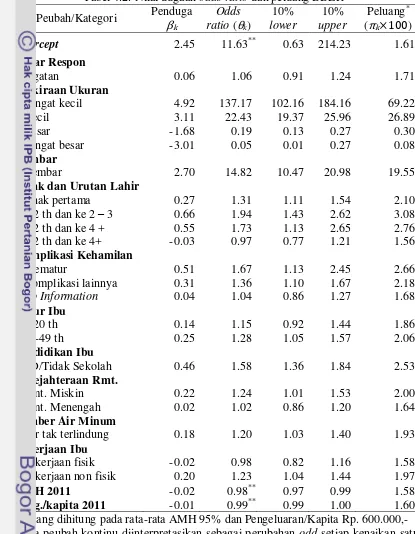
adanya outlier serta karakteristik data yang cenderung digit preference, karena sebagian besar data berdasarkan ingatan (78.1 %). Peubah penjelas yang bersifat numerik seperti: umur ibu, jarak kelahiran dan urutan kelahiran juga tidak menunjukkan pola hubungan terhadap berat badan bayi (Gambar 4.3).
Gambar 4.3. Pola hubungan berat badan lahir bayi dengan urutan kelahiran, umur ibu saat melahirkan dan jarak dengan kelahiran sebelumnya
Oleh karena itu pendekatan regresi logistik dirasa lebih tepat mengingat sebagian besar peubah penjelas bersifat kategorik. Hal ini sesuai dengan kenyataan bahwa kejadian BBLR sebagai kejadian yang bersifat khusus dengan dampak-dampak yang khusus pula. Dari hasil eksplorasi peubah-peubah penjelas individu numerik tersebut lebih berpengaruh nyata ketika dikonversi menjadi peubah kategorik dengan pengkategorian merujuk pada Kramer (1987).
Sedangkan dari sisi faktor-faktor risiko individu, komposisi data SDKI 2012 adalah: 1.44 persen bayi adalah bayi kembar, 2.12 persen bayi lahir prematur dan 9.34 mengalami komplikasi lainnya, 6.81 bayi lahir berjarak < 2 tahun, 38.05 persen adalah anak pertama dan 14.96 persen adalah anak dengan urutan kelahiran 4 (empat) ke atas, 2.43 persen bayi saat kehamilannya tidak diperiksakan pada tenaga medis dan 23.5 persen tidak mengkonsumsi suplemen zat besi saat hamil.
Dari sisi ibu, 14.52 persen ibu punya riwayat keguguran/aborsi/lahir mati, 2.23 merupakan perokok aktif dan 68.12 persen di dalam rumah tangganya ada yg perokok aktif, 28.05 persen ibu berpendidikan SD ke bawah, 8.89 persen melahirkan pada usia < 20 tahun dan 15.21 melahirkan pada usia > 35 tahun, 20.98 persen ibu bekerja pada pekerjaan yg bersifat fisik dan 32.23 persen pada pekerjaan non fisik. Sedangkan pada tingkat rumah tangga, 22.53 persen rumah tangga merupakan rumah tangga yang terindikasi miskin dan 27.25 persen rumah tangga mengkonsumsi air dari sumber air tidak terlindung.
Model Individu Pembobotan
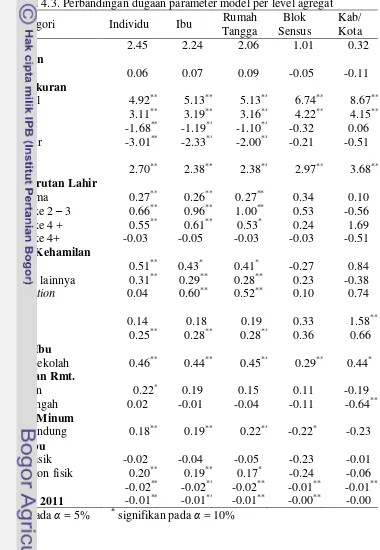
17 Tabel 4.1. Kelompok dasar respon dan pembobotan yang diberikan
Kelompok Ukuran BBLR (%) Ragam
Untuk menyederhanakan pemodelan peubah-peubah bebas diseleksi dengan metode backward elimination dengan dilakukan overfitting pada peubah-peubah bebas yang tidak signifikan tetapi memiliki kategori yang signifikan. Seleksi juga dilakukan pada tiap level agregasi untuk mengakomodasi adanya peubah yang tidak signifikan pada level individu tetapi signifikan pada level agregat maupun sebaliknya. Dari proses seleksi diperoleh peubah-peubah bebas yang disertakan dalam analisis adalah: Dasar Respon (D1), Perkiraan Ukuran (D2 – D5), Kembar (D6), Jarak dan Urutan Kelahiran (D7 – D10), Komplikasi Kehamilan (D11 – D13), Umur Ibu (D15 – D16), Pendidikan Ibu (D18), Kesejahteraan Rumah Tangga (D19 – D20), Sumber Air Minum (D26), Pekerjaan Ibu (D27 – D28), Angka Melek Huruf Kab/Kota 2011 (X31) dan Pengeluaran per Kapita Kab/Kota 2011 (X32).
Persamaan Regresi
Hasil pemodelan data individu menunjukkan model terboboti lebih baik (AIC = 4519.63) daripada model individu yang tidak terboboti (AIC = 4565.19) meskipun luas di bawah kurva ROC untuk kedua model sama (AUC = 0.9142).
ln ( πî-π i
̂) = + . � + . � + . � – .. �+� . + . � �+� . � �–� . � �–� . � �+� . ��+ . � + . � + .
+ . 5+ . � + . � + . � + . + . �
+ . 7+ . � − . � − . � (4.1)
Keterangan: kategori tebal adalah kategori yang signifikan pada α = 5%
Dari model terboboti 4.1 terlihat bahwa, tidak ada pengaruh nyata perbedaan kelompok dasar respon data (D1) baik berdasarkan catatan dan ingatan ibu terhadap dugaan BBLR. Artinya peubah-peubah (kategori-kategori) lain dalam model mampu menjelaskan pengaruh perbedaan kelompok respon terhadap kejadian BBLR sehingga tidak ada perbedaan akurasi yang signifikan pada kedua kelompok. Hal ini terlihat pula dari koefisien-koefisien kategori perkiraan ukuran (D2 – D5) yang konsisten. Semakin kecil perkiraan ukuran yang diberikan oleh ibu semakin besar nilai koefisien (kecenderungan BBLR). Ini menunjukkan bahwa perkiraan ibu akan berat badan bayi secara statisik bisa diandalkan (akurat). Nilai AIC yang menunjukkan bahwa model terboboti lebih baik menunjukkan bahwa terdapat perbedaan ragam dari kelompok dasar respon data. Nilai bobot pada data catatan yang lebih tinggi menunjukkan bahwa data catatan memiliki presisi yang lebih tinggi (karena ragamnya lebih kecil)
18
komplikasi selama kehamilan, bayi dari ibu di atas 35 tahun, bayi dari ibu yang berpendidikan dasar/tidak sekolah, bayi dari rumah tangga miskin, bayi dari ibu yang pekerjaan sehari-harinya bersifat non fisik, dan bayi dari rumah tangga yang mengkonsumsi air dari sumber air tak terlindung.
Sedangkan pengaruh area yang berpengaruh terhadap kejadian BBLR adalah Angka Melek Huruf yang mewakili tingkat pendidikan pada suatu daerah, dan Pengeluaran per Kapita yang mewakili tingkat kesejahteraan suatu daerah. Koefisien yang negatif menunjukkan bahwa daerah dengan AMH dan pengeluaran per kapita yang tinggi cenderung memiliki prevalensi BBLR yang rendah. Kategori daerah Desa/Kota dan Angka Harapan Hidup yang mewakili tingkat kesehatan tidak berpengaruh nyata terhadap kejadian BBLR. Hal ini mungkin dikarenakan kedua indikator tersebut sudah dapat dijelaskan oleh kategori-kategori individu.
Dugaan Odds Ratio dan Peluang
Interpretasi umum dari model regresi logistik adalah dengan menggunakan odds ratio (θk). Odds ratio menyatakan kecenderungan suatu kejadian (BBLR) pada suatu kategori terhadap kategori referensi yg dinyatakan dalam perbandingan odd (peluang sukses dibagi peluang gagal). Nilai odds ratio diduga dengan nilai eksponensial dari penduga parameter regresi (βk) pada peubah kategorik. Pada peubah kontinu nilai ini merupakan nilai perubahan odd secara multiplikatif setiap penambahan satu satuan (dapat juga berarti odds ratio terhadap nilai 0). Eksponensial dari intercept adalah nilai
odd dari kategori referensi.
̂ = �̂� = Selain itu karena regresi logistik memodelkan peluang suatu kejadian, peluang kejadian BBLR pada kategori tertentu (πk), dengan asumsi kategori lain ada pada kondisi referensi, dapat juga diduga dengan mengasumsikan peubah numerik pada suatu nilai tertentu. Formula penghitungan dugaan odds ratio dan peluang kejadian BBLR dapat dilihat pada persamaan 4.2. Dugaan nilai odds ratio dan peluang untuk masing-masing kategori diasjikan pada Tabel 4.2.
Nilai odds ratio dapat diinterpretasikan sebagai kecenderungan suatu kejadian (BBLR) pada suatu kelompok dibandingkan kelompok lain (kategori referensi). Nilai
odds ratio yang tinggi (θ >1) menunjukkan bahwa pada kategori tersebut kejadian BBLR memiliki kecenderungan terjadi yang lebih tinggi (dibandingkan pada kategori referensi) sedangkan nilai odds ratio yang rendah (θ <1) menunjukkan kecenderungan kejadian BBLR pada kategori tersebut lebih rendah (dibandingkan kategori referensi).
Faktor-faktor sosial yang tidak berpengaruh secara langsung pada kejadian BBLR menarik untuk diperhatikan nilai odds ratio-nya, antara lain: pendidikan ibu, kesejahteraan rumah tangga dan pekerjaan ibu. Ibu dengan pendidikan rendah (SD/tidak sekolah) memiliki kecenderungan BBLR yang tinggi (θ = 1.58, θlower = 1.36,
θupper = 1.84). Hal ini karena ibu dengan pendidikan rendah pada umumnya memiliki
pengetahuan yang rendah pula tentang kesehatan kehamilan. Demikian juga kelahiran pada rumah tangga miskin memiliki kecenderungan BBLR (θ= 1.24, θlower = 1.01,
θupper = 1.53), karena keterbatasan ekonomi berdampak pada keterbatasan akses
19 menarik untuk diamati bahwa kecenderungan BBLR justru lebih banyak terjadi pada ibu yang bekerja pada pekerjaan yang bersifat non fisik (θ = 1.23, θlower = 1.04, θupper
= 1.44) dan bukan pada pekerjaan yang bersifat fisik (θ = 0.98, θlower = 0.82, θupper =
1.16). Kebiasaan aktivitas fisik yang tinggi pada ibu (baik pada kategori ibu rumah tangga maupun ibu dengan pekerjaan fisik) berdampak pada kesehatan dan kebugaran ibu sehingga resiko BBLR cenderung lebih rendah dibandingkan ibu yang memiliki pekerjaan yang minim aktivitas fisik (kantoran).
Tabel 4.2. Nilai dugaan odds ratio dan peluang BBLR Peubah/Kategori Penduga * Peluang dihitung pada rata-rata AMH 95% dan Pengeluaran/Kapita Rp. 600.000,- **Pada peubah kontinu diinterpretasikan sebagai perubahan odd setiap kenaikan satu
20
Model Agregat Perbandingan Model dan Hasil Dugaan
Perbandingan model pada level agregat menunjukkan bahwa pada level ibu dan rumah tangga model hanya sedikit mengalami perubahan pada kategori-kategori yang signifikan (Tabel 4.3). Hal ini disebabkan pada kedua level ini masih didominasi agregat dengan jumlah amatan 1 (sama dengan level individu). Sedangkan pada level agregasi blok sensus dan kabupaten/kota, jumlah kategori yang berpengaruh signifikan berkurang banyak.
Tabel 4.3. Perbandingan dugaan parameter model per level agregat
Kategori Individu Ibu Rumah
21 Peubah-peubah bebas yang hanya terdiri dari dua kategori (kembar, pendidikan, sumber air minum) cenderung mengalami penurunan signifikansi yang lambat. Hal ini dikarenakan penurunan signifikansi hanya dipengaruhi oleh penurunan jumlah amatan. Sedangkan pada peubah-peubah bebas dengan kategori lebih dari dua, penurunan signifikansi terjadi lebih cepat karena selain berkurangnya jumlah amatan terdapat distorsi antar kategori ketika dilakukan proses aggregasi. Sebagai contoh pada peubah umur ibu, ketika diaggregasi proporsi kejadian BBLR pada ibu < 20 tahun dan ibu 35-49 tahun tidak bisa teridentifikasi lagi. Hal ini menyebabkan pada level Blok Sensus dan Kab/Kota peubah-peubah tersebut cenderung tidak signifikan lagi.
Faktor risiko yang berpengaruh (dengan α = 10%) pada level BS, hanya proporsi anak kembar, proporsi ibu yang berpendidikan rendah dan proporsi rumah tangga yang menggunakan sumber air tak terlindung serta nilai AMH dan pengeluaran per kapita. Sedangkan pada level kabupaten/kota proporsi rumah tangga yang menggunakan sumber air tak terlindung dan pengeluaran per kapita menjadi tidak signifikan, sedangkan proporsi rumah tangga dengan kesejahteraan sedang dan proporsi ibu yang melahirkan pada usia di bawah 20 tahun menjadi signifikan berpengaruh terhadap kejadian BBLR. Hal ini dikarenakan aggregasi dari peubah-peubah bebas individu tersebut merupakan indikator yang berbeda. Sebagai contoh, kategori rumah tangga miskin adalah indikator kemiskinan individu, sedangkan proporsi rumah tangga miskin merupakan indikator kemiskinan suatu daerah, yang keduanya merupakan ukuran yang berbeda. Hal ini pula yang dapat menyebabkan agregat peubah individu yang signifikan menjadi tidak signifikan dan juga sebaliknya.
Pemilihan Model
Model terbaik dapat dilihat dari nilai AIC nya yang paling rendah adalah model individu. Uji Hosmer-Lemeshow (Hosmer & Lemeshow 2000) pada model ini juga menunjukkan tidak ada perbedaan signifikan antara nilai dugaan dengan nilai yang teramati. Sedangkan model-model agregasi menunjukkan nilai Hosmer-Lemeshow Chi-Square yang signifikan yang menunjukkan bahwa model-model tersebut tidak terlalu baik secara statistik dalam menduga kejadian BBLR. Hal ini juga terlihat dari penurunan nilai R2yang dihasilkan. Pengecekan asumsi overdispersi hanya relevan pada level BS dan Kab/Kota karena pada level individu, ibu dan rumahtangga datanya didominasi oleh amatan tunggal (Bernoulli). Nilai yang mendekati 1 menunjukkan bahwa tidak ada kondisi overdispersi pada model agregat level BS dan kabupaten/kota. Perbandingan statistik kebaikan model dapat dilihat pada Tabel 4.4.
Tabel 4.4. Perbandingan statistik kebaikan model
22
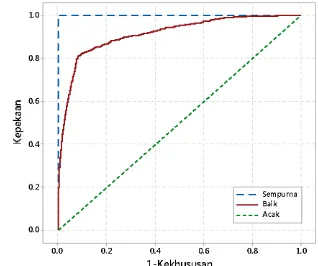
Untuk membandingkan kebaikan model dari tiap-tiap agregasi ukuran yang digunakan adalah luas di bawah kurva (area under curve/AUC) dari ROC. ROC adalah kurva yang menggambarkan hubungan antara kepekaan (proporsi true positive) dan 1 – kekhususan (proporsi false negative) pada setiap nilai dugaan peluang yang dihasilkan dari data sebagai cut-off point. Model yang baik akan menghasilkan ROC dengan luas area dibawah kurva mendekati 1. Dari ROC yang dihasilkan (Gambar 4.4), model individu (AUC = 0.9142), model ibu (AUC = 0.9087) dan model rumahtangga (AUC = 0.9055) memiliki luas area di bawah kurva yang hampir sama dengan akurasi yang tinggi. Hal ini bersesuaian dengan model yang dihasilkan bahwa dugaan parameter model dengan nilai signifikansi yang serupa. Sedangkan pada agregasi level blok sensus (AUC = 0.7505) dan kabupaten/kota (AUC = 0.6525) luas area di bawah kurva yang dihasilkan menurun drastis yang menunjukkan bahwa pendugaan dengan model agregasi blok sensus dan kabupaten/kota sudah tidak akurat lagi.
Gambar 4.4. Perbandingan ROC pada tiap level agregasi
Untuk dapati membandingkan kepekaan dan spesifitas dari masing-masing model maka perlu dipilih nilai cut-off dimana model akan menghasilkan dugaan terbaik. Penentuan nilai cut-off (c) optimal yang paling umum digunakan adalah statistik J(c) yang diperkenalkan oleh Youden (1950) pada persamaan 4.3.
= max�{ + − } ;
(4.3) Dengan menggunakan model individu sebagai patokan, hasil penghitungan diperoleh nilai J(c) = 0.7259 dan c = 0.09439. Pada nilai cut off yang sama maka nilai kepekaan dan kekhususan pada tiap-tiap model dapat dibandingkan pada Tabel 4.5.
23 Tabel 4.5. Perbandingan kepekaan dan kekhususan model pada c = 0.09439
Indikator Model
Individu Ibu Rumah Tangga Blok Sensus Kab/Kota
Kepekaan(c) 0.81 0.80 0.78 0.50 0.36
Kekhususan(c) 0.92 0.91 0.90 0.82 0.82
Hasil perbandingan menunjukkan bahwa kepekaan dan kekhususan cenderung mengalami penurunan seiring proses aggregasi. Proporsi kejadian BBLR yang kecil mengakibatkan penurunan kepekaan model yang lebih drastis dibandingkan penurunan kekhususan yang lebih lambat. Nilai kepekaan yang rendah pada level blok sensus dan kabupaten/kota menunjukkan bahwa model tidak lagi dapat menduga kejadian BBLR dengan baik.
Perbandingan Hasil Pemodelan dan Publikasi BPS
Pemanfaatan data SDKI yang dilakukan oleh BPS hannya sebatas pendugaan langsung terhadap prevalensi BBLR pada tingkat provinsi (BPS et al. 2013). Dugaan langsung dihitung sesuai desain sampling yang digunakan dan berdasarkan data BBLR saja, sedangkan dugaan tidak langsung dilakukan dengan memperhitungkan faktor-faktor yang mempengaruhi kejadian BBLR melalui pemodelan. Untuk memperbandingkan hasil dugaan tidak langsung dari setiap model dengan dugaan langsung yang dilakukan oleh BPS maka perlu disusun selang kepercayaan untuk masing-masing dugaan. Karena desain survei SDKI yang kompleks, selang pendugaan langsung didekati dengan ragam pendugaan dari rancangan penarikan contoh acak sederhana (simple random sampling/SRS), sedangkan selang pendugaan hasil pemodelan karena tidak dapat diturunkan sebarannya maka didekati dengan diturunkan dari selang pendugaan koefisien parameter (Hosmer & Lemeshow 2000). Secara umum pendugaan tidak langsung (dengan menggunakan model) lebih baik dibandingkan dengan pendugaan langsung. Hal ini dikarenakan dugaan tidak langsung memperhitungkan faktor-faktor lain yang berpengaruh sehingga ragam dari dugaan tidak langsung cenderung lebih kecil (Rao 2003). Secara visual meskipun bervariasi pada tiap provinsi terlihat kecenderungan selang pendugaan tidak langsung yang dihasilkan semakin melebar sejalan dengan agregasi data, tetapi lebarnya tetap cenderung lebih sempit dibandingkan selang pendugaan langsung (Lampiran 1). Pada kasus dimana selang kepercayaan dugaan tidak langsung lebih lebar dibandingkan dengan dugaan langsungnya, hal itu dapat menjadi indikasi adanya permasalahan pada data (sebaran data yang tidak sesuai, pencilan, dll.) maupun dalam pemodelan (link function yang tidak tepat, adanya peubah-peubah bebas yang tidak disertakan, dll.) yang perlu ditindak lanjuti.
24
Tabel 4.6. Perbandingan dugaan prevalensi model terhadap nilai publikasi
Provinsi Dugaan Prevalensi BBLR
Publikasi Individu Ibu Rmt. BS Kab/Kota
25
5
SIMPULAN DAN SARAN
Simpulan
Faktor-faktor risiko yang mempengaruhi kejadian BBLR adalah bayi kembar, anak pertama, kelahiran dengan jarak kurang dari 2 tahun, kelahiran prematur dan komplikasi kehamilan, umur ibu di atas 35 tahun, pendidikan ibu yang rendah, kesejahteraan rumah tangga yang rendah, pekerjaan ibu yang bersifat non fisik dan sumber air minum yang tidak terlindung, sedangkan peubah area yang berpengaruh adalah tingkat pendidikan (AMH) dan kesejahteraan (pengeluaran per kapita) suatu daerah. Perbedaan akurasi (rataan) pada kelompok data berdasarkan catatan dan ingatan ibu dapat dijelaskan oleh peubah-peubah bebas yang disertakan di dalam model, sedangkan perbedaan ragamnya cukup nyata, sehingga penyertaan informasi perbedaan ragam dalam model mampu meningkatkan kebaikan model.
Dalam proses agregasi, pengaruh suatu kategori terhadap kejadian BBLR mengalami distorsi karena pengaruhnya tercampur dengan kategori-kategori lainnya dalam peubah yang sama. Distorsi pengaruh dan menurunnya jumlah amatan mengakibatkan kebaikan model pada level blok sensus dan kabupaten/kota menurun drastis. Berdasarkan model yang dihasilkan pemodelan kejadian BBLR yang baik dapat dilakukan hingga level rumah tangga saja. Selang kepercayaan dari dugaan prevalensi BBLR semakin melebar sejalan dengan proses agregasi akan tetapi cenderung lebih sempit jika dibandingkan selang pendugaan dari dugaan langsung. Namun dugaan yang dihasilkan oleh masing-masing model cukup konsisten (cenderung tidak berbeda) dengan hasil dugaan langsung. Hanya dugaan prevalensi BBLR Sulawesi Tengah (underestimated) dan Sulawesi Tenggara (overestimated) yang berbeda secara nyata.
Saran
26
DAFTAR PUSTAKA
Aitken AC. 1935. On Least Squares and the Linear Combination of Observations.
Proceedings of the Royal Society of Edinburgh, 55: 42-48.
Arpansah. 2010. Analisis Faktor yang Berhubungan dengan Berat Bayi Lahir dan Pengaruhnya terhadap Status Gizi Anak Usia 6-11 Bulan di Sumatera [tesis]. Bogor (ID). IPB.
Akaike H. 1973. Information Theory and an Extension of the Maximum Likelihood Principle. Proceedings of 2nd International Symposium on Information Theory.
267-281.
Azen R, Walker CM. 2011. Categorical Data Analysis for the Behavioral and Social Sciences. New York (US). Routledge
Bloom D, Canning D, Sevilla J. 2003. The Demographic Dividend: A New Perspective on the Economic Consequences of Population Change. Santa Monica, CA (US): RAND Corporation.
Barker DJP. 1995. The Fetal and Infant Origins of Disease. European Journal of Clinical Investigation. 25: 457-463.
[BPS] Badan Pusat Statistik, [BKKBN] Badan Kependudukan dan Keluarga Berencana Nasional, Kementerian Kesehatan, ICF International. 2013.
Indonesia Demographic and Health Survey 2012. Jakarta (ID). BPS.
Dobson AJ. 2002. An Introduction to Generalized Linear Models. Ed ke-2. New York (US). Chapman & Hall/CRC.
Gonçalves L, Subtil A, Oliviera MR, Bermudez PdZ. 2014. ROC Curve Estimation: An Overview. REVSTAT–Statistical Journal 12(1): 1-20.
Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression. Ed ke-2. New York (US). John Wiley & Sons, Inc.
Hutcheon JA, Walker M, Platt RW. 2010. Assessing the Value of Customized Birth Weight Percentiles. American Journal of Epidemiology. 173(4): 459-467. Kawengian SES. 2004. Pola Pertambahan Berat Badan Ibu selama Kehamilan dan
Kaitannya dengan Berat Badan Bayi Lahir di Kota Manado [tesis]. Bogor (ID). IPB.
Kramer MS. 1987. Determinants of Low Birth Weight: Methodological Assessment and Meta-Analysis. Bulletin of World Health Organization. 65(5): 663–737. Nelder JA, Wedderburn RWM. 1972. Generalized Linear Models. Journal of the
Royal Statistical Society, A, 135, 370-384.
Puspitasari ZD. 2011. Identifikasi Faktor-Faktor yang Mempengaruhi Berat Bayi Lahir Rendah (BBLR) Menggunakan Pendekatan Regresi Logistik Biner: Studi Kasus Puskesmas Kecamatan Klakah - Lumajang, Jawa Timur [skripsi]. Bogor (ID). IPB.
Rao JNK. 2003. Small Area Estimation. New Jersey (US): John Wiley and Sons, Inc. Scheaffer RL, Mendenhall W, Ott RL, Gerow KG. 2006. Elementary Survey Sampling.
Ed. ke-6. Belmont, CA (US). Duxbury Press
27 Sianturi AHD 2005. Kajian Status Gizi Ibu Hamil dan Faktor-faktor yang Mempengaruhinya serta Hubungannya dengan Berat Badan Bayi Lahir di Kecamatan Warungkondang, Cianjur, Jawa Barat [tesis]. Bogor (ID). IPB. [UN] United Nations. 2004. World Population to 2300. New York (US). United
Nations.
_________________. 2014. The Millennium Development Goals Report 2014. New York (US). United Nations.
[UNICEF] United Nations Children’s Fund, [WHO] World Health Organization. 2004.
Low Birth Weight: Country, Regional and Global Estimates. New York (US). UNICEF.
[WHO] World Health Organization. 2011. International Statistical Classification of Diseases and Health Related Problems. Ed ke-10. Geneva (CH). WHO.
___________________________. 2014. Global Nutrition Targets 2025: Low Birth Weight Policy Brief. Geneva (CH). WHO.
Yongky. 2007. Analisis Pertambahan Berat Badan Ibu Hamil Berdasarkan Status Sosial Ekonomi dan Status Gizi serta Hubungannya dengan Berat Bayi Baru Lahir [disertasi]. Bogor (ID). IPB.
29 Lampiran 1. Perbandingan dugaan prevalensi BBLR provinsi dan selang
30
32
RIWAYAT HIDUP
Penulis dilahirkan di Klaten, Jawa Tengah pada tanggal 11 April 1982 sebagai putra kedua dari lima bersaudara dari pasangan Henricus Suyamto dan Maria Immaculatta Marilah. Pada tahun 2014 penulis menikah dengan Cicilia Widyasari dan saat ini sudah dikaruniai seorang putra Tadeus Dhirajati Bratamandala.