KAJIAN SELF-ORGANIZING MAPS (SOM) DALAM
PENGELOMPOKAN OBJEK
(studi kasus: pengelompokan desa/kelurahan di Kabupaten Wajo
Sulawesi Selatan)
IRWAN THAHA
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Kajian Self-Organizing Maps (SOM) dalam Pengelompokan Objek(studi kasus: pengelompokan desa/kelurahan di Kabupaten Wajo Sulawesi Selatan) adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
RINGKASAN
IRWAN THAHA. Kajian Self-Organizing Maps (SOM) Dalam Pengelompokan Objek (studi kasus: pengelompokan desa/kelurahan di Kabupaten Wajo Sulawesi Selatan). Dibimbing oleh ERFIANI dan I MADE SUMERTAJAYA.
Penggerombolan adalah proses mengelompokkan objek ke dalam kelompok-kelompok yang memiliki kemiripan. Hasil dari penggerombolan akan menunjukkan bahwa objek-objek yang dalam satu gerombol akan lebih homogen dibandingkan antar gerombol. Terdapat dua metode dalam analisis gerombol klasik yaitu metode penggerombolan berhirarki dan tak berhirarki. Penentuan jumlah gerombol yang terbentuk untuk dua metode ini dilakukan secara subjektif. Metode penggerombolan lain juga berkembang dengan menggunakan kecerdasan buatan. Jaringan syaraf tiruan (artificial neural network) adalah suatu paradigma pengolahan informasi yang diilhami oleh sistem biologi yaitu neuron, seperti otak yang memproses informasi.
Self organizing maps (SOM) merupakan salah satu bentuk topologi dari Unsupervised Artificial Neural Network (Unsupervised ANN) yang dalam proses trainingnya tidak memerlukan pengawasan (target output). Penerapan penggerombolan menggunakan algoritme SOM diharapkan dapat dijadikan alat untuk menganalisis data sehingga diperoleh karakteristik dari data yang akan dikelompokkan. Penggerombolan digunakan untuk mengelompokkan data secara alamiah tanpa berdasarkan target kelas tertentu.
Pada penelitian ini, SOM dibandingkan dengan metode penggerombolan dengan ukuran data besar yaitu two step cluster (TSC). Menurut Bacher (2004), metode two step cluster merupakan suatu metode penggerombolan yang dapat mengatasi masalah skala pengukuran, khususnya untuk data berukuran besar dengan peubah yang memiliki tipe data kategorik dan numerik. Kinerja penggerombolan SOM dan metode two step cluster dibandingkan melalui data simulasi, dan selanjutnya menerapkan metode SOM pada penggerombolan desa/kelurahan di Kabupaten Wajo Sulawesi Selatan.
Data dalam penelitian ini terdiri dari dua sumber yaitu data simulasi dan data sekunder. Data simulasi berupa data bangkitan sebaran normal ganda (μ,Ʃ) yang berguna untuk mengukur kinerja metode two step clster dan SOM dalam mengelompokkan objek. Data sekunder yang digunakan dalam penelitian ini berupa data dari Badan Pusat Statistik (BPS) wilayah/desa di kecamatan di Kabupaten Wajo provinsi Sulawesi Selatan adalah data Potensi Desa (PODES) tahun 2011.
Data simulasi merupakan data bangkitan dengan tipe data numerik (M) yang terdiri dari tiga bentuk populasi yaitu satu populasi yang beranggotakan tiga gerombol yang berpisah secara tegas, satu populasi yang beranggotakan tiga gerombol yang saling tumpang tindih (overlap) satu sama lain dalam jumlah kecil, dan satu populasi yang beranggotakan tiga gerombol yang saling tumpang tindih (overlap) satu sama lain dalam jumlah besar.
pengelompokan SOM akan berubah menjadi lebih besar, namun perubahannya relatif kecil. Sebaliknya, semakin besar jumlah data maka kesalahan pengelompokan metode TSC semakin kecil.
Data sekunder yang digunakan dalam penelitian ini berupa dokumentasi tertulis dan identifikasi peubah yang digunakan tentang desa/kelurahan di Kabupaten Wajo Provinsi Sulawesi Selatan adalah data Potensi Desa (PODES) tahun 2011 yaitu: X1 (jumlah penduduk), X2 (keluarga tani), X3 (keluarga buruh tani), X4 (keluarga pengguna listrik), X5 (bahan bakar untuk memasak sehari-hari), X6 (fasilitas pendidikan), X7 (tenaga kesehatan), X8 (kematian penduduk). Objek dalam terapan penelitian ini adalah seluruh desa/kelurahan di Kabupaten Wajo.
Hasil penggerombolan dengan metode SOM desa/kelurahan di Kabupaten Wajo menghasilkan 3 gerombol. Gerombol yang terbentuk memiliki nilai deskriptif yang sama antar gerombol dan setiap gerombol yang terbentuk didominasi oleh beberapa kecamatan di daerah tersebut. Beberapa desa/kelurahan lain yang yang tergabung juga memiliki kemiripan dari peubah pencirinya, misalkan berada di sekitar kecamatan tersebut.
SUMMARY
IRWAN THAHA. Studies of Self-Organizing Maps (SOM) In Grouping Objects (case study: grouping of villages/urbans in Wajo Regency, South Sulawesi). Supervised by ERFIANI and I MADE SUMERTAJAYA.
Clustering is a process of classifying objects into groups which have similarity. The result of clustering will show that objects in one cluster will be more homogeneous than others. There are two methods in classic clustering analysis i.e. hierarchical cluster method and non-hierarchical cluster method. Determination of the number of clusters which formed by them is done subjectively. The cluster other methods also developed by using artificial intelligence. Artificial neural network is an information processing paradigm that inspired by the biology systems, it is neuron. Like brain which process information.
Self-organizing maps (SOM) is one of the topology of Unsupervised Artificial Neural Network (Unsupervised ANN) which process does not require monitoring in his training. Application clustering using SOM algorithm is expected to be used as a tool to analyze the data in order to obtain the characteristics of the data that will be grouped. Clustering is used to group the data naturally without based on the specific class target.
In this study, SOM compared with clustering method with large data sizes, it was two-step cluster. According to Bacher (2004), two-step cluster method (TSC) was a cluster method which can resolve the problem clustering measurement scale, especially for large data with variables which have categorical and numerical data types. Performance clustering SOM and two-step cluster method compared by the simulation data, afterwards, applying the method of SOM on clustering villages/urbans in Wajo regency, South Sulawesi.
The data in this study consisted of two sources i.e. simulated data and secondary data. Simulated data was generated data multivariate distribution (μ,Ʃ) which useful to measure the performance of two-step cluster method and SOM in classifying an object. Secondary data, which used in this study, BPS’s data in Wajo regency, South Sulawesi, was Village Potential Data (VPD) in 2011.
Simulation data was the generated data numeric type (M) which consisted of three forms of the population i.e. a). a population consisted of three clusters were clearly separated, b). a population which consisted of three clusters of overlapping (overlap) each other in small numbers, and c). a population that consisted of three clusters of overlapping (overlap) each other in large numbers.
The results of methods SOM and TSC showed that simulation data has the good ability to classify data, however, TSC provides better clustering results for large data sizes than SOM. In addition, it is also showed that the larger the number of data, the misclassification of SOM would become larger, nevertheless, the changes were relatively smaller. In the other hand, the larger the number of data the misclassification of TSC method was become smaller.
cooking), X6 (educational facilities), X7 (health personnel), X8 (population mortality). Objects in this research were applied around the village/urbans in Wajo district.
The results of clustering with SOM method, village/urbans in the Wajo regency produced 3 clusters. The formed clusters have the same descriptive value between clusters, and each clusters which formed, was dominated by a few districts in that area. Some other villages/urbanss incorporated also have similar caracteristic of variables, e.g. they being around the district.
© Hak Cipta Milik IPB, Tahun 2013
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika
KAJIAN SELF-ORGANIZING MAPS (SOM) DALAM
PENGELOMPOKAN OBJEK
(studi kasus: pengelompokan desa/kelurahan di Kabupaten Wajo Sulawesi Selatan)
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2013
Judul Tesis : Kajian Self-Organizing Maps (SOM) dalam pengelompokan objek (studi kasus: pengelompokan desa/kelurahan di Kabupaten Wajo Sulawesi Selatan)
Nama : Irwan Thaha NRP : G151110091
Disetujui oleh Komisi Pembimbing
Dr Ir Erfiani, MSi Ketua
Dr Ir I Made Sumertajaya, MSi Anggota
Diketahui oleh
Ketua Program Studi Statistika
Dr Ir Erfiani, MSi
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah yang berjudul “Kajian Self-Organizing Maps (SOM) dalam pengelompokan objek (studi kasus: pengelompokan desa/kelurahan di Kabupaten Wajo Sulawesi Selatan)” berhasil diselesaikan.
Terima kasih penulis ucapkan kepada
1. Ibu Dr Ir Erfiani, MSi selaku pembimbing I dan ketua program studi Pascasarjana Statistika dan Bapak Dr Ir I Made Sumertajaya, MSi selaku pembimbing II, yang telah banyak memberikan bimbingan dan saran dalam penyusunan karya ilmiah ini.
2. Penguji luar komisi bapak Farit Mochamad Afendi, Ph D pada ujian tesis, yang telah memberikan kritik dan saran dalam perbaikan penyusunan karya ilmiah ini.
3. Kedua orangtua, papa dan mama, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
4. Sahabat mahasiswa pascasarjana Statistika dan Statistika Terapan IPB 2011 atas kebersamaannya.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 3
Analisis Gerombol 3
Self-Organizing Maps (SOM) 4
Indeks Davies-Bouldin 6
Two Step Cluster (TSC) 6
Penentuan Jumlah Gerombol TSC 8
Ukuran Jarak 9
3 METODE PENELITIAN 11
Data 11
Metode 14
4 HASIL DAN PEMBAHASAN 17
Simulasi 17
Perbandingan Kinerja SOM dan TSC 19
Penerapan Metode SOM 22
5 SIMPULAN DAN SARAN 26
Simpulan 26
Saran 26
DAFTAR PUSTAKA 27
LAMPIRAN 28
DAFTAR TABEL
1 Eksplorasi data simulasi dan persentasi overlap 11 2 Learning Rate dan Penurunan LR setiap scenario dengan IDB terkecil 17
3 Eksplorasi data simulasi 18
4 Hasil penggerombolan dengan metode SOM dan TSC 19
5 Nilai koefisien korerasi antar peubah 23
6 Eksplorasi peubah tiap gerombol 25
DAFTAR GAMBAR
1 Ilustrasi sebaran gerombol yang terpisah secara tegas 11 2 Ilustrasi sebaran gerombol yang overlap dalam jumlah kecil 12 3 Ilustrasi sebaran gerombol yang overlap dalam jumlah besar 13
4 Diagram alir tahapan penelitian 16
5 CP dan U-matriks skenario I 20
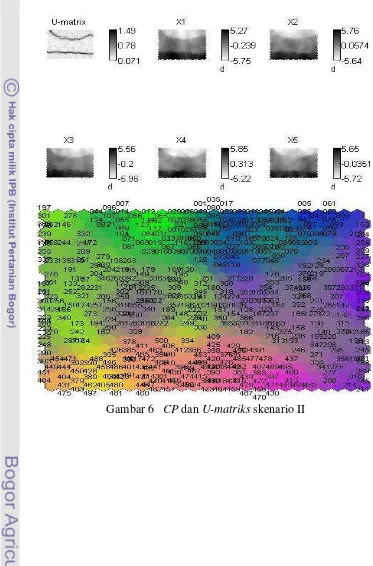
6 CP dan U-matriks skenario II 21
7 CP dan U-matriks skenario III 22
8 Visualisasi U-matriks dan CP desa/kelurahan 23
9 Output dengan jumlah 3 gerombol 24
DAFTAR LAMPIRAN
1 Kombinasi LR dan PLR dengan nilai IDB terkecil untuk masing-masing
skenario 28
1
1 PENDAHULUAN
Latar Belakang
Penggerombolan adalah proses mengelompokkan objek ke dalam kelompok-kelompok yang memiliki kemiripan. Hasil dari penggerombolan akan menunjukkan bahwa objek-objek yang dalam satu gerombol akan lebih homogen dibandingkan antar gerombol. Terdapat dua metode dalam analisis gerombol klasik yaitu metode penggerombolan berhirarki dan tak berhirarki. Penentuan jumlah gerombol yang terbentuk untuk dua metode ini dilakukan secara subjektif. Pada metode penggerombolan berhirarki, penentuan besarnya pemotongan (cut off) pada dendogram masih ditentukan oleh peneliti. Sedangkan pada metode penggerombolan non hirarki, penentuan banyaknya jumlah gerombol akhir ditentukan oleh pengetahuan dan pengalaman peneliti (Hair et al. 1998). Kedua metode ini berbasis pada data yang berskala interval atau rasio.
Metode penggerombolan lain juga berkembang dengan menggunakan kecerdasan buatan. Jaringan syaraf tiruan (artificial neural network) adalah suatu paradigma pengolahan informasi yang diilhami oleh sistem biologi yaitu neuron, seperti otak yang memproses informasi. Kunci jaringan syaraf tiruan (JST) adalah struktur sistem pengolahan informasi, yang terdiri atas sejumlah unsur-unsur (syaraf) yang bekerja saling berhubungan untuk memecahkan permasalahan spesifik. Proses pembelajaran terhadap perubahan bobot dalam jaringan syaraf tiruan ada dua, yaitu pembelajaran terawasi (supervised learning) dan pembelajaran tak terawasi (unsupervised learning) (Klobucar dan Subasic 2012).
Self organizing maps (SOM) merupakan salah satu bentuk topologi dari Unsupervised Artificial Neural Network (Unsupervised ANN) yang dalam proses pembelajarannya tidak memerlukan pengawasan (target output). Penerapan penggerombolan menggunakan algoritme SOM diharapkan dapat dijadikan alat untuk menganalisis data sehingga diperoleh karakteristik dari data yang akan dikelompokkan. Penggerombolan digunakan untuk mengelompokkan data secara alamiah tanpa berdasarkan target kelas tertentu, sedemikian sehingga objek-objek dalam gerombol yang sama lebih mirip dibandingkan dengan objek-objek dalam gerombol yang lain. Metode pembelajarannya dilakukan dengan update weight berdasarkan input sensor yang terdapat pada vektor input. SOM diperuntukkan untuk ukuran data besar dan kecil serta mampu memvisualisasikan hasil penggerombolan tersebut dalam dimensi lebih rendah. Kemampuan dalam visualisasi ini dapat mengatasi masalah dalam metode cluster lain yang sulit jika ukuran data besar, misalnya penggunaan dendogram.
2
berbeda nyata dengan yang dihasilkan dari metode gerombol tak berhirarki misalnya
k-means jika peubahnya kontinu (Lathifaturrahmah 2010).
Beberapa penelitian yang menggunakan SOM dan two step cluster dalam penggerombolan objek, diantaranya: Fujino dan Yoshida (2006), Annas et al. (2007) menggunakan PCA dan SOM dalam bidang kehutanan untuk klasifikasi dan risiko kebakaran wilayah hutan, begitupun dengan Klobucar dan Subasic (2012). Hasil penelitian tersebut memberikan kesimpulan bahwa SOM melakukan pengurangan dimensi nonlinear dan menghasilkan penggerombolan yang baik, dan merupakan dasar yang baik untuk hasil visualisasi data. Namun, SOM akan memberikan kinerja yang buruk jika terdapat hubungan linier antar variabelnya. Edward dkk (2006) menggunakan Indeks Davies-Bouldin (IDB) untuk validasi gerombol. Adapun penelitian yang menggunakan two step cluster untuk penggerombolan diantaranya Lathifaturrahmah (2010) membandingkan hasil penggerombolan metode k-means, fuzzy k-means dan two step cluster untuk menentukan jumlah gerombol yang ideal untuk masing-masing metode. Pada penelitian tersebut, hasil two step cluster relatif jauh berbeda dari metode lainnya diantaranya dipengaruhi oleh kesesuaian metode dengan jumlah data yang digunakan. He et al. (2005) dan Shih et al. (2010) menggunakan metode two step cluster untuk data numerik dan kategorik. Hasil percobaan menunjukkan bahwa pendekatan data yang diusulkan dengan tipe numerik dan kategorik dapat mencapai kualitas tinggi dari hasil penggerombolan.
Pada penelitian ini akan dibandingkan kinerja penggerombolan SOM dan metode two step cluster melalui data simulasi, dan selanjutnya menerapkan metode SOM pada penggerombolan desa/kelurahan di Kabupaten Wajo Sulawesi Selatan.
Tujuan
Tujuan dari penelitian ini adalah:
1. Membandingkan hasil penggerombolan metode SOM dan two step cluster (TSC) 2. Menerapkan metode SOM pada penggerombolan kondisi sosial desa/kelurahan di
3
2 TINJAUAN PUSTAKA
Analisis Gerombol
Analisis gerombol merupakan salah satu dari teknik penggerombolan peubah ganda (multivariate) yang tujuan utamanya adalah mengelompokkan objek berdasarkan atas kriteria yang dimiliki. Analisis gerombol mengelompokkan objek, sehingga antara satu objek dengan objek lainnya yang terletak dalam satu gerombol akan memiliki kesamaan tinggi yang sesuai dengan kriteria pemilihan yang ditentukan. Hasil dari penggerombolan harus memperlihatkan keragaman yang homogen di dalam gerombol dan keragaman yang heterogen antargerombol yang terbentuk (Hair et al. 1998). Ada dua metode dalam analisis gerombol satu tahap, yaitu:
Metode berhirarki
Metode pengelompokan berhirarki ditujukan untuk ukuran contoh kecil. Pengelompokan berhirarki menghasilkan seluruh kemungkinan terbentuknya gerombol. Metode pengelompokan berhirarki digunakan apabila banyak gerombol yang akan dibentuk belum diketahui sebelumnya. Pada dasarnya, terdapat dua prosedur pada pengelompokan berhirarki, yaitu prosedur penggabungan (agglomerative) dan prosedur pembagian (divisive).
Metode agglomerative dimulai dengan n buah gerombol yang masing-masing beranggotakan satu objek. Kemudian dua gerombol yang paling dekat digabung dan ditentukan kembali kedekatan antargerombol yang baru. Proses ini berlanjut sampai didapatkan satu gerombol yang anggotanya adalah seluruh objek. Metode divisive dimulai dengan satu gerombol yang anggotanya adalah seluruh objek, kemudian objek-objek yang paling jauh dipisah dan membentuk gerombol lain. Proses ini berlanjut sampai semua objek masing-masing membentuk satu gerombol.
Dalam metode berhirarki terdapat beberapa ukuran jarak antargerombol, antara lain metode pautan tunggal (single linkage), pautan lengkap (complete linkage), pautan rataan (average linkage), metode Ward, dan metode centroid. Fungsi jarak yang sering digunakan diantaranya adalah jarak Euclidean dan jarak Mahalanobis.
Metode tak berhirarki
4
Self-Organizing Maps (SOM)
Kohonen Self Organizing Feature Maps, disingkat dengan SOFM atau lebih terkenal dengan istilah SOM ditemukan dan dikembangkan oleh Teuvo Kohonen 1982, seorang profesor di Academy of Finland. Metode ini memungkinkan untuk menggambarkan data multidimensi ke dalam dimensi yang lebih kecil, biasanya satu atau dua dimensi. Proses penyederhanaan ini dilakukan dengan mengurangi vektor yang menghubungkan masing-masing node. Cara ini disebut juga dengan Vektor Quantization. Teknik yang dipakai dalam metode SOM dilakukan dengan membuat jaringan yang menyimpan informasi dalam bentuk hubungan node dengan training set yang ditentukan (Annas et al. 2007). SOM merupakan salah satu bentuk topologi dari Unsupervised Artificial Neural Network (Unsupervised ANN) dimana dalam proses pelatihannya tidak memerlukan pengawasan (target output). SOM digunakan untuk mengelompokkan (penggerombolan) data berdasarkan karakteristik/fitur-fitur data.
SOM menggunakan competitive unsupervised learning dengan bobot awal diberikan secara acak dan disesuaikan selama dalam proses pengelompokan. Nodes akan mengelompok ke dalam gerombol berdasarkan kemiripannya. Sampel yang paling umum dari SOM adalah Kohonen Self-organizing Maps dengan 1 lapisan input dan 1 lapisan khusus yang menghasilkan nilai-nilai keluaran yang saling berkompetisi. Nodes pada lapisan khusus ini dipandang sebagai grid 2 dimensi berisi nodes dengan fungsi aktivasinya yang masing-masing terhubung dengan tiap input node oleh satu arc yang memiliki suatu nilai bobot. Data dapat dimasukkan ke dalam banyak competitive nodes secara parallel (Klobucar and Subasic 2012).
Penggunaan SOM dalam memvisualisasikan struktur gerombol data tidak memiliki kelemahan tertentu yang dimiliki oleh teknik gerombol lainnya. Meskipun SOM dapat digunakan untuk memvisualisasikan gerombol, kadang-kadang diperlukan spesifikasi lebih lanjut dari gerombol SOM. Dalam hal lain bahwa semua algoritme penggerombolan termasuk SOM biasanya mempunyai masalah dalam menentukan batas-batas kelompok. Ini adalah masalah yang menyebabkan kesulitan untuk menghasilkan tingkat klasifikasi tinggi output SOM. Metode SOM lebih fleksibel terhadap berbagai asumsi, sehingga dapat digunakan untuk berbagai jenis data (Annas et al. 2007).
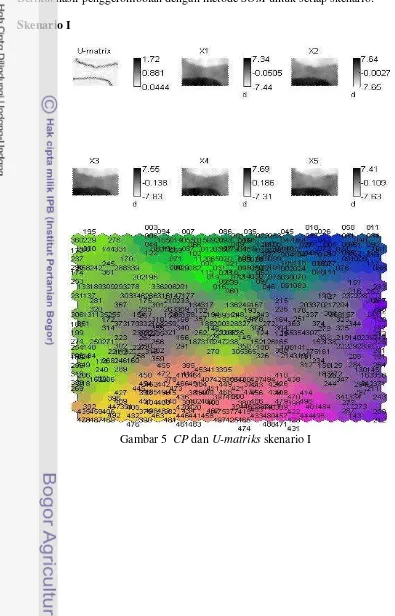
Ada tiga jenis visualisasi dari SOM yang digunakan (Annas et al. 2007) yaitu: Unified distance matrix (U-matrix), Component Planes (CP), dan Color Coding.
1. U-matriks
U-matriks menggambarkan jarak antara node terdekat pada peta SOM. Jika menggunakan algoritme SOM, ukuran jarak dapat dihitung antara vektor dari node dengan yang di sekitarnya. Nilai tertinggi yang berarti jarak antara node yang berdekatan pada U-matriks dan indikasi ini menjadi wilayah pembeda antara kelompok. Nilai terendah menggambarkan persamaan node pada wilayah kelompok tersebut.
2. Component Planes (CP)
U-5
matriks dan CP dapat divisualisasikan secara simultan dengan menggunakan SOM. Visualisasi ini dapat digunakan untuk membuat pengertian dari peubah yang termasuk dalam kelompok.
3. SOM color-coding
SOM color-coding juga ditambahkan untuk pembuatan informasi pada peta. Metode kombinasi seperti ukuran jarak dan kode warna mampu meningkatkan tampilan pengelompokan SOM. Nilai jarak digunakan untuk mendefinisikan node dengan perbedaan warna, yang memberikan kejelasan penggambaran kelompok. Code warna menandai node menurut struktur kelompok. Kelompok yang memiliki kesamaan nilai akan diwarnai seragam, jika wilayah dari peta tidak sesuai dengan kelompok, maka akan mempunyai warna yang berbeda. Sehingga, SOM color-coding menguraikan tanda node, yang menjadi masalah bagaimana membedakan wilayah antara kelompok yang dapat dijelaskan jika pewarnaannya tidak jelas untuk menyatakan batas dari kelompok.
Algoritme SOM
Algoritma SOM terdiri atas (Siang, 2005):
1. Mengisikan bobot antar neuron input dan output wji dengan bilangan random
0 sampai 1.
2. Menetapkan parameter learning rate ( )
3. Memilih salah satu input dari vektor input yang ada.
4. Menghitung jarak (dj) antarvektor input terhadap vektor output dengan
masing-masing neuron output dengan rumus:
= ∑( − )
�
=
5. Mencari nilai terkecil dari seluruh bobot (dj). Index dari bobot (dj) yang
paling mirip disebut winning neuron.
6. Memperbarui setiap bobot μij dengan menggunakan rumus:
= + � −
7. Memperbarui learning rate.
8. Menyimpan bobot yang telah konvergen.
9. Mengulangi langkah 6 sampai dengan langkah 7 hingga tidak ada perubahan pada bobot map atau telah mencapai iterasi atau epoch maksimal.
Perubahan tingkat pembelajaran (LR/α/ ) 0 < < 1, dengan rumus
6
Indeks Davies-Bouldin
Validasi gerombol adalah prosedur evaluasi hasil analisis gerombol secara kuantitatif dan objektif. Indeks validitas digunakan sebagai metode validasi gerombol untuk evaluasi kuantitatif dari hasil penggerombolan. Salah satu indeks validitas ialah Indeks Davies-Bouldin (Salazar et al. 2002). Pengukuran ini memaksimalkan jarak antar-gerombol antara gerombol Ci dan Cj dan pada waktu
yang sama mencoba untuk meminimalkan jarak antartitik dalam sebuah gerombol. Jarak intra-gerombol sc (Qk) dalam gerombol Qk ialah:
= ∑ ‖� − ‖�
dengan Nk adalah banyak titik yang termasuk dalam gerombol Qk dan Ck adalah
centroid dari gerombol Qk. Jarak antar-gerombol didefinisikan:
= ‖ − ‖
dengan Ck dan Cl adalah centroid gerombol k dan l. Di lain pihak, Indeks
Davies-Bouldin didefinisikan:
= ∑�� max≠ { +, }
=
dengan nc adalah banyak gerombol. Skema penggerombolan yang optimal menurut Indeks Davies-Bouldin ialah yang memiliki Indeks Davies-Bouldin minimal (Salazar et al. 2002).
Two step cluster (TSC)
Metode ini dapat mengatasi masalah skala pengukuran yang tidak sama, dalam hal ini bertipe kontinu dan kategorik, serta memiliki jumlah objek amatan relatif besar. Metode ini masih memiliki kelemahan yaitu sensitif terhadap data yang berupa urutan atau tingkatan, sehingga masih tidak mampu dalam menangani data ordinal. Apabila terdapat peubah yang bertipe ordinal, maka sebelum dianalisis peubah tersebut harus ditransformasi terlebih dahulu.
Jarak antara dua gerombol didefinisikan sebagai jarak antar pusat dari masing-masing gerombol tersebut. Pusat dari suatu gerombol adalah vektor dari rataan masing-masing peubahnya. Jarak yang digunakan dalam metode two step cluster adalah jarak Log-Likelihood dan jarak Euclidean.
Prosedur pengelompokan objek dalam metode two step cluster dilakukan melalui dua tahapan (Bacher et al. 2004), yaitu tahap pembentukan gerombol awal dan tahap pembentukan gerombol akhir (optimal).
Pembentukan gerombolawal
7
tersebut harus masuk pada gerombol yang telah terbentuk sebelumnya atau membentuk gerombol yang baru. Prosedur pada tahap ini diimplementasikan dengan membangun modifikasi Clustering Feature (CF) Tree. Misalkan diberikan N titik objek d dimensi pada suatu gerombol dimana i = 1,2,…,N. Vektor penggerombolan feature dari gerombol didefinisikan sebagai quadriple: CF=(N,M,V,K) dimana N adalah banyaknya objek pada gerombol, M menyatakan rata-rata dari peubah kontinu dari N objek, V adalah variansi dari setiap peubah kontinu pada N objek, K adalah banyaknya taraf pada setiap peubah kategorik. CF-tree adalah keseimbangan tinggi pohon dengan dua parameter yaitu branching factor (B) dan threshold (T) (SPSS 2001).
Outlier pada analisis two step cluster adalah data yang tidak dapat dimasukkan pada gerombol manapun. Pada saat CF Tree akan dibangun ulang, maka akan diperiksa daun entri yang berpotensi sebagai outlier. Daun entri yang anggotanya berpotensi sebagai outlier merupakan daun entri yang jumlah anggotanya kurang dari fraksi ukuran gerombol yang memiliki jumlah paling besar yang telah ditetapkan (SPSS Technical Support 2001). Pada saat pembangunan ulang, daun entri yang berpotensi sebagai outlier disimpan. Setelah CF Tree dibangun ulang, maka satu per satu data dalam daun entri yang berpotensi sebagai pencilan dimasukkan ke dalam CF Tree yang baru tanpa mengubah ukuran CF Tree tersebut. Jika masih ada data yang tidak masuk ke dalam daun entri manapun, maka data tersebut dikatakan sebagai outlier. Dan data-data yang dideteksi sebagai outlier dimasukkan ke dalam satu gerombol.
Gerombol yang memiliki jarak terbesar dikatakan memiliki pencilan jika jarak antara gerombol tersebut lebih besar dari titik kritis c, dengan rumusnya
Lm = jumlah kategori untuk peubah kategori ke-m
Pada jarak Euclidean, data yang memuat pencilan memiliki prosedur yang sama dengan jarak Log-Likelihood. Dikatakan pencilan jika jarak Euclidean terbesar antara gerombol tersebut lebih besar dari titik kritis c, dengan rumus c
�̂ = ragam dugaan untuk peubah kontinu ke-l dalam gerombol k
8
begitu seterusnya untuk objek selanjutnya. Dari pencilan tersebut akan dibuat suatu gerombol yang baru. Tahap ini merupakan tahap rebuilding. Batas jarak maksimum harus ditingkatkan sehingga dapat memasukkan lebih banyak objek. Peningkatan jarak ini dapat mengakibatkan objek-objek yang tadinya berasal dari gerombol yang berbeda bergabung menjadi satu gerombol CF Tree, sehingga menghasilkan CF Tree yang berukuran lebih kecil dari semula (Bacher et al. 2004).
Pembentukan gerombol akhir (optimal)
Pembentukan gerombol akhir ditandai dengan terbentuknya gerombol yang optimal. Suatu gerombol dikatakan optimal apabila memiliki jarak antar gerombol paling jauh dan jarak antarobjek dalam gerombol tersebut paling dekat. Semakin dekat jarak antarobjek maka semakin besar kemiripan antarobjek dalam satu gerombol. Pada tahapan ini, hasil dari tahap pertama yaitu daun entri (anak gerombol) dari Clustering Feature (CF) Tree dikelompokkan menggunakan metode gerombol berhirarki dengan prosedur penggabungan (agglomerative). Tiap-tiap daun entri akhir yang terbentuk pada tahap pertama akan digabungkan satu per satu sesuai dengan ukuran jarak yang telah ditetapkan. Prosedur ini berakhir sampai seluruh daun entri menjadi satu gerombol. Apabila pada tahap pertama terdeteksi daun entri yang beranggotakan outlier, maka daun entri tersebut tidak diikutsertakan pada tahap kedua.
Penentuan jumlah gerombol TSC
Dalam penentuan jumlah gerombol optimal, ada dua langkah yang harus dilakukan. Langkah yang pertama yaitu menghitung BIC (Bayesian Information Criterion) atau AIC (Akaike’s Information Criterion) untuk tiap–tiap gerombol. Kemudian hasil perhitungan tersebut digunakan untuk menduga jumlah gerombol. Langkah yang kedua yaitu mencari peningkatan jarak terbesar antara dua gerombol terdekat pada masing-masing tahapan pengelompokan.
Rumus BIC dan AIC untuk gerombol J adalah sebagai berikut: = − ∑ � + log � KB = jumlah total peubah kategorik
Lk = jumlah kategori untuk peubah kategorik ke-k
N = jumlah total data
9
dua gerombol terdekat pada masing-masing tahapan pengelompokan. Solusi gerombol yang terbaik memiliki BIC terkecil, tetapi ada beberapa kasus dalam pengelompokan dimana BIC akan terus menurun nilainya bila jumlah gerombol semakin meningkat. Maka dalam situasi tersebut, ratio BIC Changes (rasio perubahan BIC) dan ratio of Distance Measure Changes (rasio perubahan jarak) mengidentifikasi solusi gerombol terbaik.
Menurut Bacher (2004) BICk atau AICk menghasilkan penduga awal yang
baik bagi jumlah gerombol maksimum. Jumlah gerombol maksimum adalah banyaknya gerombol yang memiliki rasio BICk/BIC1 yang pertama kali lebih kecil
dari c1 (SPSS menetapkan c1 = 0.04 yang didasarkan atas studi simulasi). Jumlah
gerombol yang terbentuk dapat diketahui dengan menggunakan perbandingan antar jarak untuk k gerombol, dengan rumus perbandingannya sebagai berikut:
= −
Jumlah gerombol diperoleh berdasarkan ketentuan ditemukannya perbedaan yang nyata pada rasio perubahan gerombol. Rasio perubahan gerombol dihitung sebagai berikut:
Ukuran kemiripan dan ketakmiripan yang digunakan dalam analisis gerombol adalah jarak antarobjek dan jarak antargerombol. Fungsi jarak yang digunakan pada analisis Two step cluster adalah:
Jarak Euclidean
10
yang digunakan bertipe kontinu (numerik). Jarak Euclidean antara gerombol ke-i dan gerombol ke-j dari p peubah didefinisikan:
, = [∑(�̅ − �̅ )
�̅ = nilai tengah pada gerombol ke-i untuk peubah ke-k �̅ = nilai tengah pada gerombol ke-j untuk peubah ke-k p = banyaknya peubah yang diamati
Jarak Log-Likelihood
Jarak Log-Likelihood dapat digunakan untuk peubah kontinu maupun kategorik. Jarak antara gerombol j dan s didefinisikan sebagai berikut:
, = � +��− � ,�
Njkl = jumlah data digerombol j untuk peubah kontinu ke-k dengan kategorik
ke-l
�̂ = ragam dugaan untuk peubah kontinu ke-k untuk keseluruhan observasi dalam gerombol ke-j
�̂ = ragam dugaan untuk peubah kontinu ke-k untuk keseluruhan observasi �̂� = ragam dugaan untuk peubah kontinu ke-k untuk keseluruhan observasi
dalam gerombol ke-s dan ke-j KA = jumlah total peubah kontinu KB = jumlah total peubah kategorik
Lk = jumlah kategorik untuk kategori ke-k
11
3 METODE PENELITIAN
Data
Data dalam penelitian ini terdiri dari dua sumber yaitu data sekunder dan data simulasi. Data sekunder digunakan untuk menggerombolkan desa/kelurahan di Kabupaten Wajo dan data simulasi berguna untuk mengukur kinerja metode TSC dan SOM dalam mengelompokkan objek.
Data simulasi
Data simulasi merupakan data bangkitan dengan tipe data numerik (M) yang terdiri dari tiga bentuk populasi yaitu satu populasi yang beranggotakan tiga gerombol yang berpisah secara tegas, satu populasi yang beranggotakan tiga gerombol yang saling tumpang tindih (overlap) satu sama lain dalam jumlah kecil, dan satu populasi yang beranggotakan tiga gerombol yang saling tumpang tindih (overlap) satu sama lain dalam jumlah besar.
Tabel 1 Kombinasi data simulasi dan persentasi overlap Model populasi Model komposisi
peubah
Skenario III Numerik 500
1000
80 85 Skenario 1: satu populasi yang beranggotakan tiga gerombol yang berpisah secara tegas (jarak antar gerombol relative besar). Gambar 1 menunjukkan ilustrasi gerombol pada sebaran populasi model univariat.
12
Gerombol 1: μ(X1i) = -6.00; i=1,2,3,..., n1, (note: n1 = n/4)
Gerombol 2: μ(X2i) = 0.00; i=1,2,3,..., n2, (note: n2 = n/2)
Gerombol 3: μ(X3i) = +6.00; i=1,2,3,..., n3, (note: n3 = n/4)
Pembangkitan data simulasi sesuai dengan kombinasi yang terlihat pada Tabel 1. Setiap gugus data terdiri atas 5 peubah yaitu X1, X2,…, X5. Gugus data
yang dibangkitkan n = 500, n = 1000 masing-masing diulang 100 kali dengan
sebaran normal ganda Ng (μ,Ʃ), dengan μ(X1i) = [-6,-6,-6,-6,-6], μ(X2i) = [0,0,0,0,0], μ(X3i) = [6,6,6,6,6], dan matriks peragamnya
Ʃ =
[ ]
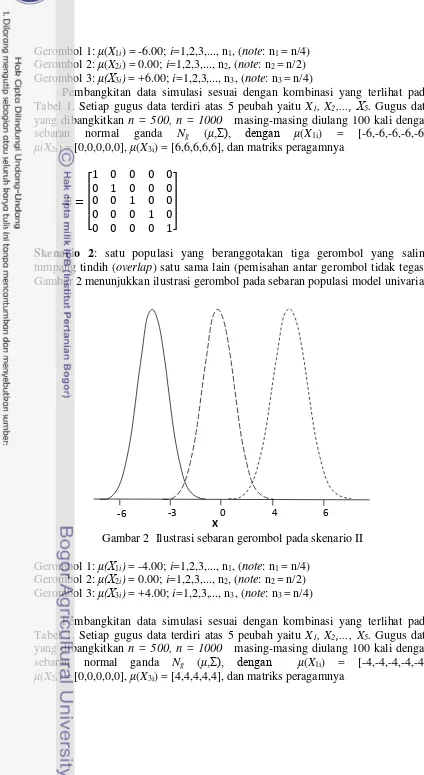
Skenario 2: satu populasi yang beranggotakan tiga gerombol yang saling tumpang tindih (overlap) satu sama lain (pemisahan antar gerombol tidak tegas). Gambar 2 menunjukkan ilustrasi gerombol pada sebaran populasi model univariat.
Gambar 2 Ilustrasi sebaran gerombol pada skenario II Gerombol 1: μ(X1i) = -4.00; i=1,2,3,..., n1, (note: n1 = n/4)
Gerombol 2: μ(X2i) = 0.00; i=1,2,3,..., n2, (note: n2 = n/2)
Gerombol 3: μ(X3i) = +4.00; i=1,2,3,..., n3, (note: n3 = n/4)
Pembangkitan data simulasi sesuai dengan kombinasi yang terlihat pada Tabel 1. Setiap gugus data terdiri atas 5 peubah yaitu X1, X2,…, X5. Gugus data
yang dibangkitkan n = 500, n = 1000 masing-masing diulang 100 kali dengan
sebaran normal ganda Ng (μ,Ʃ), dengan μ(X1i) = [-4,-4,-4,-4,-4], μ(X2i) = [0,0,0,0,0], μ(X3i) = [4,4,4,4,4], dan matriks peragamnya
-6 -3 0 4 6
13
Ʃ =
[ ]
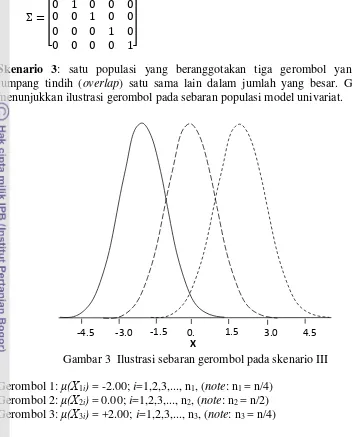
Skenario 3: satu populasi yang beranggotakan tiga gerombol yang saling tumpang tindih (overlap) satu sama lain dalam jumlah yang besar. Gambar 3 menunjukkan ilustrasi gerombol pada sebaran populasi model univariat.
Gambar 3 Ilustrasi sebaran gerombol pada skenario III Gerombol 1: μ(X1i) = -2.00; i=1,2,3,..., n1, (note: n1 = n/4)
Gerombol 2: μ(X2i) = 0.00; i=1,2,3,..., n2, (note: n2 = n/2)
Gerombol 3: μ(X3i) = +2.00; i=1,2,3,..., n3, (note: n3 = n/4)
Pembangkitan data simulasi sesuai dengan kombinasi yang terlihat pada Tabel 1. Setiap gugus data terdiri atas 5 peubah yaitu X1, X2,…, X5. Gugus data
yang dibangkitkan n = 500, n = 1000 masing-masing diulang 100 kali dengan
sebaran normal ganda Ng (μ,Ʃ), dengan μ(X1i) = [-2,-2,-2,-2,-2], μ(X2i) = [0,0,0,0,0], μ(X3i) = [2,2,2,2,2], dan matriks peragamnya
Ʃ =
[ ]
Data sekunder
Data sekunder yang digunakan dalam penelitian ini data data Potensi Desa (PODES) tahun 2011 Kabupaten Wajo provinsi Sulawesi Selatan dengan peubah
-4.5 -3.0 -1.5 0. 1.5 4.5
0
14
X3 (jumlah keluarga buruh tani), X4 (jumlah keluarga pengguna listrik), X5 (jumlah fasilitas pendidikan), X6 (jumlah tenaga kesehatan), X7 (jumlah kematian penduduk). Objek dalam terapan penelitian ini adalah seluruh desa/kelurahan di Kabupaten Wajo.
Metode
Langkah-langkah analisis data yang dilakukan berkaitan dengan tujuan penelitian dilakukan melalui tahapan sebagai berikut:
1. Eksplorasi dan deskriptif data bangkitan
Tahapan ini dilakukan untuk melihat sebaran data bangkitan pada masing-masing skenario. Selain itu, juga untuk menunjukkan tingkat kekonsistenan rataan, korelasi, dan ragam-peragam data bangkitan.
2. Penggerombolan dengan metode SOM
Penggerombolan dilakukan dengan membuat map pada masing-masing skenario, selanjutnya menetapkan jumlah gerombol untuk menguhitung nilai IDB gerombol tersebut. Jumlah iterasi yang digunakan adalah jumlah iterasi yang telah konsisten dengan nilai IDB terkecil.
3. Penggerombolan dengan metode two step cluster Tahapan dalam metode ini adalah sebagai berikut: a. Penggerombolan awal (prepenggerombolan).
Algoritma pertama pada CF Tree adalah memasukkan data satu per satu. Data yang masuk dihitung jaraknya pada daun entri yang telah ada dengan menggunakan ukuran jarak yang telah ditentukan. Apabila jarak tersebut kurang dari kriteria ukuran penerimaan (threshold distance) maka data tersebut masuk ke dalam daun entri yang telah ada, tetapi jika sebaliknya maka data membentuk daun entri baru.
Proses ini berlanjut sampai semua data selesai dimasukkan. Jika CF Tree berkembang melewati batas ukuran maksimum yang telah ditetapkan, maka CF Tree yang telah ada akan dibangun ulang dengan cara meningkatkan kriteria ukuran penerimaan.
b. Penggerombolan akhir.
Dalam penentuan jumlah gerombol optimal, ada dua langkah yang harus dilakukan. Langkah yang pertama yaitu menghitung BIC (Bayesian Information Criterion) atau AIC (Akaike’s Information Criterion) untuk tiap–tiap gerombol. Kemudian hasil perhitungan tersebut digunakan untuk menduga jumlah gerombol.
Metode ini menggunakan software SPSS dalam analisis gerombolnya. 4. Mengevaluasi kinerja metode SOM dan two step cluster
15
5. Penerapan metode SOM
Tahapan yang dilakukan dalam analisis ini:
a. Menstandarisasikan gugus peubah data di Kabupaten Wajo Sulawesi Selatan b. Menggerombolkan gugus data dengan metode SOM
Pada tahap ini, hasil penggerombolan dicobakan pada berbagai jumlah gerombol yang terbentuk. Kemudian, mancari nilai IDB terkecil untuk masing-masing jumlah gerombol tersebut.
16
k
Data
Metode SOM
Perbandingan kebaikan gerombol
Pembahasan
Simpulan
Data sekunder Data simulasi
Penggerombolan
SOM TSC
k
Standarisasi
17
4 HASIL DAN PEMBAHASAN
Simulasi
Perbandingan kinerja metode SOM dan two step cluster (TSC) melalui data simulasi dimaksudkan untuk mencari metode yang memberikan hasil pengelompokan yang maksimal yaitu tingkat kesalahan pengelompokan paling minimum. Kinerja kedua metode diukur dengan berbagai kondisi populasi data yaitu, populasi dengan tiga gerombol yang terpisah, bercampur dalam jumlah yang sedikit, dan bercampur dalam jumlah yang besar.
Pada metode SOM, pembelajaran diawali dengan memilih secara acak suatu vektor input kemudian menghitung jarak vektor input yang terpilih dengan satiap bobot input (centroid). Selanjutnya nilai bobot input pemenang akan diperbaharui berdasarkan nilai Learning Rate (LR) yang telah ditentukan. Untuk setiap iterasi, terjadi penurunan Learning Rate (PLR). Nilai dari LR dan PLR dipilih secara acak dari 0 < / < 1. Parameter awal dari algoritme SOM yang digunakan yaitu: i. Learning rate (LR), = 0.1, 0.5, 0.9
ii. Penurunan learning rate (PLR), = 0.1, 0.5, 0.9 iii. Jumlah iterasi/epoch: 50 iterasi
Pada data simulasi, diperoleh kombinasi LR dan PLR dengan nilai IDB terkecil (lampiran 1) untuk masing-masing skenario sebagai berikut:
Tabel 2 Learning Rate dan Penurunan LR setiap skenario dengan IDB terkecil Model populasi Ukuran data
18
Nilai matriks peragam setiap skenario sama untuk masing-masing jumlah sampel.
Untuk jumlah sampel 1000
Ʃ =
Adapun nilai rataan sampel masing-masing skenario adalah sebagai berikut: Tabel 3 Eksplorasi data simulasi
19
Perbandingan kinerja metode SOM dan TSC
Perbandingan hasil penggerombolan metode SOM dan TSC terlihat pada tabel berikut:
Tabel 4 Hasil penggerombolan dengan metode SOM dan TSC Model populasi Ukuran data
(n) mengelompokkan objek dengan tingkat kesalahan 0% untuk kondisi populasi terpisah secara tegas. Metode SOM maupun TSC dapat mengelompokkan data dengan tingkat kebaikan gerombol 100% jika populasi datanya terpisah secara tegas (tidak ada overlap).
Pada kondisi populasi data yang overlap dalam jumlah kecil (skenario II), terdapat perbedaan hasil pengelompokan. Kedua metode tersebut memberikan hasil yang cukup baik dalam mengelompokkan objek. Metode SOM dapat mengelompokkan dengan benar data sekitar 99.6% dan 99.2% untuk masing-masing jumlah data 500 dan 1000. Tabel 4 juga terlihat hasil pengelompokan metode TSC, bahwa metode ini mampu mengelompokkan data sekitar 99.99% untuk masing-masing jumlah data. Skenario III juga memberikan hasil yang serupa bahwa kedua metode ini mampu melakukan pengelompokan dengan baik. Metode SOM dapat mengelompokkan dengan benar data sekitar 92.5% dan 90.0% untuk masing-masing jumlah data 500 dan 1000. Tabel 4 juga terlihat hasil pengelompokan metode TSC, bahwa metode ini mampu mengelompokkan data sekitar 99.3% untuk masing-masing jumlah data.
Dengan demikian, hasil dari kedua metode ini memiliki kemampuan untuk mengelompokkan data dengan baik, namun TSC memberikan hasil pengelompokan yang lebih baik untuk ukuran data yang besar dibandingkan dengan SOM. Selain itu, juga terlihat bahwa semakin besar jumlah data maka kesalahan pengelompokan SOM akan berubah menjadi lebih besar, namun perubahannya relatif kecil. Sebaliknya, semakin besar jumlah data maka kesalahan pengelompokan metode TSC semakin kecil.
20
Berikut hasil penggerombolan dengan metode SOM untuk setiap skenario: Skenario I
21
Skenario II
22
Skenario III
Gambar 7 CP dan U-matriks skenario III
Penerapan metode SOM
Pada bagian ini akan dibahas penerapan SOM untuk menggerombolkan dan mengidentifikasi desa/kelurahan di Kabupaten Wajo Sulawesi Selatan dengan mengunakan metode SOM. Untuk memperoleh hasil yang lebih maksimal dan mempermudah pendeskripsian hasil pengelompokan, maka setiap desa/kelurahan dilakukan pengkodean.
23
Gambar 8 Visualisasi U-matriks dan CP desa/kelurahan
Gambar 8 menunjukkan visualisasi U-matriks dan CP dalam bentuk 2-D dengan ukuran map 20 x 25, tidak ada aturan dalam memilih ukuran map, tetapi satu keuntungan bahwa ukuran map dapat memudahkan dalam mendeteksi struktur dari SOM. CP dapat digunakan untuk visualisasi perbedaan antar peubah dan masing-masing CP mewakili peubah yang diukur. Gerombol yang terbentuk dapat dideteksi dengan melihat perbedaan warna untuk masing-masing CP, semakin gelap maka pengaruhnya akan semakin besar.
Table 5 Nilai koefisien korerasi antar peubah
X1 X2 X3 X4 X5 X6 X7
X1 1.000
X2 0.355 1.000
X3 0.034 0.325 1.000
X4 0.919 0.204 0.023 1.000
X5 -0.248 0.159 -0.001 -0.342 1.000
X6 0.664 0.096 -0.045 0.658 -0.192 1.000
X7 0.510 0.119 0.031 0.558 -0.158 0.306 1.000
24
Hasil gerombol desa/kelurahan dengan metode SOM
Pengerombolan data dengan SOM digambarkan oleh U-matriks yaitu dengan ukuran jarak dan SOM color-coding. Pada map SOM, kode dari desa dengan nilai yang sama, secara otomatis memiliki warna yang sama pada grid dan jarak yang dekat dengan yang lain. Ukuran jarak yang besar pada map, akan memiliki warna yang berbeda dan gerombol yang berbeda. Pembentukan gerombol berdasarkan warna pada node, sehingga jika terdapat kondisi bahwa daerah yang memiliki warna abu-abu (pertengahan) dapat diidetifikasi dari ukuran jaraknya untuk memperjelas kelompok. Selanjutnya ditentukan beberapa jumlah gerombol yang teridentifikasi yaitu 3 gerombol, 4 gerombol dan 5 gerombol. Gerombol yang memiliki nilai IDB terkecil merupakan gerombol yang terpilih (lampiran 2).
Gambar 9 Output dengan jumlah 3 gerombol
Hasil penggorombolan SOM dengan data dari 176 desa/kelurahan tersebut menghasilkan 3 gerombol dengan LR 0.9, PLR 0.5, dan nilai IDB terkecil yaitu 1.33487.
Gerombol 1 adalah gerombol yang paling banyak anggotanya, terdiri dari 88 objek (desa/kelurahan) yang ada di Kabupaten ini. Gerombol 1 dipengaruhi oleh peubah X2 (keluarga tani) dan X5 (fasilitas pendidikan) yang terlihat pada gambar 8. Bagian gelap yang terlihat (gambar 8) menunjukkan pengaruh yang lebih besar. Gerombol ini pada umumnya terdiri dari desa/kelurahan dari kecamatan Bola, kecamatan Sabbangparu, kecamatan Majauleng, kecamatan Tanasitolo, kecamatan Gilireng, dan kecamatan Takkalalla. Hal ini menunjukkan bahwa kecamatan tersebut berada pada wilayah yang berdekatan dan memiliki tingkat kemiripan yang tinggi, sehingga memiliki hubungan persamaan ciri dari segi perekonomian. Adapun desa/kelurahan dari kecamatan lain yang menjadi anggota dari gerombol
Gerombol I
25
ini memiliki kemiripan peubah penciri, diantaranya Pammana, Sajoanging, Keera dan Penrang.
Gerombol 2 terdiri 26 objek (desa/kelurahan). Beberapa peubah yang mempengaruhi gerombol ini (gambar 8) diantaranya X1 (jumlah penduduk), X4 (keluarga pengguna listrik), X6 (tenaga kesehatan), dan X7 (kematian penduduk). Pada kelompok ini hanya didominasi oleh desa/kelurahan dari kecamatan Tempe dengan 16 desa/kelurahan. Desa/kelurahan dari kecamatan Tempe yang keseluruhan masuk dalam kelompok ini memiliki kesamaan ditinjau dari peubah gerombol ini. Dari segi geografis, letak desa/kelurahan tersebut sebagai ibu kota Kabupaten Wajo, sehingga memiliki tingkat pertumbuhan diberbagai bidang lebih besar dari pada gerombol yang lain. Adapun desa/kelurahan yang bergabung dalam gerombol ini berada di sekitar kota, misalnya desa/kelurahan dari Pammana dan desa/kelurahan lain yang memiliki kemiripan peubah penciri gerombol ini.
Gerombol 3 terdiri dari 62 objek (desa/kelurahan). Gerombol 3 dipengaruhi hampir semua peubah yang ada sebagaimana yang terlihat pada gambar 8. Gerombol ini percampuran desa/kelurahan dari kecamatan yang mempunyai kemiripan peubah penciri yang tinggi, terutama dari segi perekonomian dengan mayoritas penduduk bergerak disektor pertanian. Wilayah gerombol ini meliputi kecamatan Pitumpanua, Keera, Belawa dan desa/kelurahan dari kecamatan lainnya.
Pengaruh peubah-peubah terhadap gerombol yang terbentuk dapat dilihat pada Gambar 8, jika CP menunjukkan bagian yang gelap maka peubah tersebut
memiliki pengaruh yang besar terhadap daerah yang bersesuaian dengan U-matriksnya. Adapun ekplorasi peubah-peubah tiap gerombol sebagai berikut:
Tabel 6 Eksplorasi peubah tiap gerombol
Kelompok X1 X2 X3 X4 X5 X6 X7
1
rataan 1416 297 107 226 30 3 8
ragam 1226625 8447.678 5323.028 6613.475 197.212 2.356 20.169 simp baku 355.844 91.911 72.959 81.323 14.043 1.535 4.491
2
rataan 4365 513 151 841 19 13 24
ragam 1709131 140630 54220.4 87509.94 182.269 47.938 200.622 simp baku 1307.337 375.008 232.853 295.821 13.501 6.924 14.164
3
rataan 2387 440 115 403 22 6 12
ragam 227251.1 31570.34 9243.302 15033.66 137.704 12.937 38.483 simp baku 476.709 117.681 96.142 122.612 11.735 3.597 6.203
26
Hal ini menunjukkan bahwa daerah di gerombol 2 secara geografis berada di ibukota kabupaten lebih beragam dari daerah yang berada pada gerombol lain.
5 SIMPULAN DAN SARAN
Simpulan
Hasil gerombol dari data simulasi, diperoleh bahwa metode SOM dan TSC memilik kemampuan menggerombolan data dengan tingkat kelasahan penggerombolan relative kecil. Metode TSC memiliki kinerja lebih baik jika dibandingkan dengan SOM untuk ukuran data besar, namun SOM mampu memvisualisaikan hasil penggerombolan ke dalam 2-dimensi.
Hasil penggerombolan dengan metode SOM desa/kelurahan di Kabupaten Wajo menghasilkan 3 gerombol. Gerombol 1 yang anggotanya berasal dari enam (Bola, Sabbangparu, Majauleng, Tanasitolo, Gilireng, dan Takkalalla) yang memiliki rata-rata jumlah fasilitas pendidikan yang terbesar daripada gerombol yang lain. Gerombol 2 dari segi geografis adalah desa/kelurahan yang terletak di ibu kota Kabupaten Wajo. Hal ini terlihat bahwa rata-rata jumlah penduduk paling besar pada gerombol ini, demikian juga untuk penggunaan listrik, tenaga kesehatan dan kematian penduduk. Gerombol 3 terdiri dari tiga kecamatan (Pitumpanua, Keera, dan Belawa) dan dari kecamatan lain yang tergabung dalam gerombol ini. Gerombol ini termasuk dalam kondisi rata-rata dari semua peubah yang digunakan. Secara umum, gerombol yang terbentuk memiliki nilai deskriptif yang sama dalam gerombol dan setiap gerombol yang terbentuk didominasi oleh beberapa kecamatan, sedangkan beberapa desa/kelurahan lain yang yang tergabung juga memiliki kemiripan dari peubah pencirinya, misalkan berada disekitar kecamatan tersebut.
Saran
27
DAFTAR PUSTAKA
Annas S, Kanai T, Koyoma S. 2007. Principal component analysis (PCA) and self-organizing map (SOM) for visualizing and classifying fire risks in forest regions. Osaka Prefecture University, Japan. Agricultural Information Research 16 (2): 44-51.
Bacher J, Wenzig K, Vogler M. 2004. SPSS two step cluster - a first evaluation. [terhubung berkala]. http://www.statisticalinnovations.com/products/Two Step.pdf. [1 Februari 2013].
Edward, Hermadi I, Sitanggang IS. 2006. Penggerombolan menggunakan self organizing maps (studi kasus: data PPMB IPB) [terhubung berkala]. Bogor: Ilmu Komputer FMIPA IPB [7 Februari 2013].
Fujino M, Yoshida M. 2006.Development and validation of a method of forestry region classification using PCA and cluster analysis together with SOM algorithm. Journal of the Japanese Forest Society 88 (4): 221-230.
Hair JF Jr, Anderson RE, Tatham RL, Black WC. 1998. Applied Multivariate Statistical Analysis. Ed ke-5. New Jersey: Prentice-Hall.
He Z, Xu XI, Deng S. 2005. Clustering mixed numeric dan categorical data: A cluster ensemble approach. [terhubung berkala]. http://arxiv.org/ftp/cs/papers/0509/0509011.pdf [7 Februari 2013].
Klobucar D, Subasic M. 2012. Using self-organizing maps in the visualization and analysis of forest inventory. Italian Society of Silviculture and Forest Ecology. October 2012: 216-223.
Lathifaturrahmah, 2010. Perbandingan hasil penggerombolan metode k-means, fuzzy k-means, dan two step cluster [tesis]. Bogor: Matematika terapan. FMIPA IPB.
Salazar GEJ, Veles AC, Parra MCM, Ortega LO. 2002. A cluster validity index for comparing non-hierarchical clustering methods. [terhubung berkala]. http://citeseer.ist.psu.edu/rd/salazar02gerombol.pdf [7 Februari 2013].
Shih YS, Jheng JW, Lai LF. 2010. A two-step method for clustering mixed categorical and numeric data. Department of Computer Science and Information Engineering, National Changhua University of Education, Changhua, Taiwan. Tamkang Journal of Science and Engineering, Vol. 13, No. 1, pp. 11-19.
Siang JJ. 2005. Jaringan saraf tiruan dan pemrogramannya menggunakan matlab. Yogyakarta: Andi.
30
75 5 1.35486 1.17932
76 6 1.2711 1.15867
77 7 1.08043 1.03759
78 8 1.12261 1.12403
79 9 1.26407 1.38649
80 10 1.11509 1.22563
81
0.9
1 1.19194 1.12576
82 2 1.34128 1.14091
83 3 1.31244 1.22719
84 4 1.34612 1.17763
85 5 1.01517 1.12963
86 6 1.12164 1.25959
87 7 1.14248 1.19527
88 8 1.332 1.01147
89 9 1.50306 1.15375
31
Lampiran 2 Nilai IDB terkecil masing-masing jumlah gerombol yang terpilih
No LR PLR Ulangan Epoch IDB
1.79265 1.93859 2.06342
32
38
0.5
8
50
1.89185 1.94248 1.99693
39 9 1.82720 1.97436 1.99496
1.85808 2.10235 2.07093
33
79 9 1.79141 2.13638 1.94063
80 10 1.99577 1.87337 2.09629
81
0.9
1 1.63081 2.21250 1.97722
82 2 1.71910 1.81491 2.09956
83 3 1.95208 1.76037 1.92302
84 4 2.12647 2.00955 2.02975
85 5 1.62184 1.94341 2.08860
86 6 1.80065 1.81939 1.91477
87 7 1.75691 2.06954 2.21335
88 8 2.06399 1.81566 1.72405
89 9 1.79971 2.24928 1.84311
34