SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
Program Strata Satu Jurusan Teknik Informatika
Fakultas Teknik dan Ilmu Komputer
Universitas Komputer Indonesia
TRI MULYANI
10109799
JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
i Oleh Tri Mulyani
10109799
Sepeti penelitian pada umumnya, penelitian CIRAI juga mempunyai kegiatan utama berupa pengumpulan data penelitian. Pengolahan data penelitian yang komplek seperti data kematian membutuhkan sebuah aplikasi yang mampu mengelola data penelitian dari proses input data sampai penyajian informasi yang dibutuhkan. Data kematian yang diolah disini merupakan data otopsi verbal dengan acuan data korespondensi ICD 10. Salah satu teknik yang dapat digunakan untuk melakukan proses penyajian informasi data hasil penelitian adalah data mining. Dimana data mining dapat menggali pengetahuan atau knowledge dalam data. Teknik data mining yang dipakai dalam aplikasi identifikasi penyebab kematian disini adalah classification dengan decision tree. Teknik ini melakukan proses pencarian model atau fungsi yang menjelaskan atau membedakan konsep atau kelas dari suatu objek yang belum diketahui labelnya.
Dengan adanya aplikasi identifikasi penyuebab kematian ini dapat membantu pihak penelitian dalam mengelola data penelitian dan menghasilkan informasi identifikasi penyebab kematian dari hasil data penelitian. Aplikasi ini berguna baik dari pihak entri data untuk mengelola data penelitian (input, edit dan delete) maupun dari pihak manajer data untuk mengidentifikasi penyebab kematian untuk proses penelitian selanjutnya dari data hasil penelitian yang diinputkan oleh pihak entri data.
ii by
Tri Mulyani 10109799
As research in general, CIRAI research also has major activities in the form of gathering research data. Processing of complex research data such as mortality data requires an application that is able to manage research data from the data input process until the presentation of information needed. Mortality data are processed here is a verbal autopsy data with reference data corresponding ICD10 as reference. One technique that can be used to make the process of presenting data information is data mining. Which is data mining can discover knowledge in the data. Data mining techniques used in the identification of the cause of death application here is the classification with decision tree. These techniques make the search process or model that explains the functions or classes or distinguishes the concept of an unknown object label.
With this cause of death identification application can help the research in managing research data and produce information identifying the cause of death from the results of the research data. This application is useful both from the data entry for managing research data (input, edit and delete) as well as from the data manager to identify the cause of death for the further study of the research results of the input data by the data entry.
iii
Puji syukur kehadirat Allah SWT, karena atas berkat rahmat, taufik dan hidayah-Nya penulis dapat menyelesaikan laporan tugas akhir dengan baik. Tugas akhir dengan judul “APLIKASI IDENTIFIKASI PENYEBAB KEMATIAN PADA PENELITIAN CIRAI UPK - FK UNPAD” ini diajukan untuk memenuhi salah satu syarat kelulusan program Sarjana Jurusan Teknik Informatika Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia.
Pada kesempatan ini dengan segala kerendahan hati, penulis ingin menyampaikan ucapan terima kasih yang sebesar-besarnya atas kerja sama, bantuan dan dorongan banyak pihak terutama kepada :
1. Orang tua yang selalu memberi dukungan baik secara moril dan materiil. 2. Mira Kania Sabariah, S.T.,M.T. selaku ketua jurusan Teknik Informatika
Universitas Komputer Indonesia.
3. Andri Heryandi, S.T.,M.T. selaku dosen pembimbing atas bimbingan dan bantuannya dalam penyusunan tugas akhir ini.
4. Galih Hermawan, S.Kom.,M.T. Selaku dosen wali kelas IF-17K Jurusan Teknik Informatika.
6. Prof. Dr. Cissy B. Kartasasmita.dr, SpA(K), MSc selaku pimpinan Penelitian yang memberikan ijin untuk penulis melaksanakan penelitian tugas akhir di CIRAI.
7. dr. Kuswandewi Mutyara, MSc sebagai project manager pada penelitian CIRAI.
8. dr. Putri Teesa M.Kes., sebagai data manager CIRAI atas bantuan dan penjelasannya tentang sistem yang sedang berjalan.
9. Seluruh Staff CIRAI dan UPK yang telah membantu semua kegiatan dalam melaksanakan tugas akhir sehingga berjalan dengan lancar dan baik sesuai rencana.
10.Kakak-kakak dan ponakan, kalianlah salah satu alasan untuk semua ini, serta seluruh kelurga di Yogya untuk doa yang selalu diberikan.
11.Semua teman-teman skripsi 2011 khususnya anak bimbingan pak Andri Heryandi, atas kerjasamanya.
12.Semua teman-teman IF-17K, Alif, Om Hari, Dani, Opik, Panji, Epul ,Ade, Icha, Ugan Widhie, Rizal dan semuanya yang tidak bisa penulis sebut satu persatu, atas dukungannya satu sama lain.
13.Teman – teman PT eBdesk Indonesia, mas Josef, Reni, Nunu untuk solusi validasi yang sudah diberikan.
14.Maurice van Leeuwen, untuk ide, saran dan motivasinya.
Akhirnya atas segala bantuan, dukungan dan kebaikan yang telah diberikan dalam penyusunan Tugas Akhir ini, penulis mengucapkan terima kasih, semoga Tugas Akhir ini bermanfaat bagi penulis khususnya dan bagi pembaca pada umumnya.
Bandung, Juli 2011
1 1.1 Latar Belakang Masalah
Penelitian CIRAI yang merupakan kependekan dari Community-based and
Integrated Research of Influenza adalah salah satu kelompok kerja yang dilakukan
oleh Unit Penelitian Kesehatan (UPK) Fakultas Kedokteran Universitas
Padjajaran - Rumah Sakit Hasan Sadikin (UPK FK – Unpad) tentang penyakit
influenza. Seperti penelitian kesehatan pada umumnya CIRAI mempunyai
kegiatan utama mengumpulkan data objek penelitian, dimana data tersebut
dikelola dalam beberapa modul aplikasi yang terintregasi satu sama lain dalam
sebuah sistem berbasis web.
Dengan berkembangnya data penelitian, saat ini CIRAI melakukan
pengambilan data kematian didaerah penelitian dengan metode otopsi verbal,
tujuannya untuk mengidentifikasi penyebab kematian. Dari kegiatan ini akan
dihasilkan data otopsi verbal yang harus dikelola ke dalam sistem yang sudah
terintegrasi untuk menghasilkan sebuah informasi berupa pendukung diagnosa
tentang identifikasi penyebab kematian berdasarkan symptoms atau gejala yang
berhubungan dengan penyakit influenza yang dimiliki almarhum sebelum
meninggal. Dimana pada modul aplikasi yang sudah ada, untuk mendapatkan
informasi setiap modulnya, masih dilakukan secara manual.
Karena form manual otopsi verbal standar WHO yang digunakan cukup
meminimalisasi kesalahan input data. Sedangkan sumber data kematian yang
didapat dari form otopsi verbal tersebut harus bisa digali keterkaitan dan
informasinya berdasarkan data korespondensi penyebab kematian untuk otopsi
verbal dengan kode ICD-10. ICD-10 merupakan standarisasi penyebab kematian
berdasarkan data otopsi verbal yang juga sudah disediakan oleh WHO melalui
penelitian selama 3 tahun. Hal ini untuk menghindari kerancuan atau pendapat
subjective mengenai hasil data otopsi verbal.
Dengan memanfaatkan data otopsi verbal dan data korespondensi
penyebab kematian dengan kode ICD-10, dapat diketahui informasi identifikasi
penyebab kematian oleh symptoms influenza melalui teknik data mining. Kenapa
data mining, karena data mining dapat menggali informasi yang tersimpan dalam
data, dalam hal ini informasi mengenai symptoms influenza dari data otopsi
verbal.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah dipaparkan sebelumnya, maka
rumusan masalah yang mendasari pembuatan tugas akhir ini adalah bagaimana
membangun sebuah aplikasi identifikasi penyebab kematian yang dapat
mengelola data otopsi verbal dan menggunakannya untuk menghasilkan informasi
identifikasi penyebab kematian oleh symptoms influenza berdasarkan data
korespondensi penyebab kematian ICD-10 dengan implementasi data mining.
Informasi identifikasi penyebab kematian yang ditampilkan berupa prosentase
kemungkinan almarhum meninggal karena verbal autopsy themes berdasarkan
1.3 Maksud dan Tujuan
Berdasarkan permasalahan-permasalahan yang ditemukan, maka maksud
dari pembuatan tugas akhir ini adalah membuat aplikasi identifikasi penyebab
kematian dengan otopsi verbal dan implementasi data mining untuk menghasilkan
informasi identifikasi penyebab kematian oleh symptoms influenza berdasarkan
data korespondensi penyebab kematian dengan ICD-10 pada penelitian CIRAI.
Adapun tujuan yang ingin dicapai dari perancangan tugas akhir ini adalah:
1. Menyediakan sebuah aplikasi identifikasi penyebab kematian dengan
pengelolaan data otopsi verbal.
2. Memudahkan staf entri data penelitian untuk mengelola data otopsi verbal
ke dalam sistem.
3. Menyediakan fasilitas penyajian informasi identifikasi penyebab kematian
dengan otopsi verbal yang diperlukan untuk digunakan pada kepentingan
penelitian selanjutnya.
1.4 Batasan Masalah/Ruang Lingkup kajian
Agar dalam perancangan ini dapat mencapai sasaran dan tujuan yang
diharapakan, maka permasalahan yang ada dibatasi sebagai berikut :
1. Implementasi di fokuskan pada data otopsi verbal dengan acuan data
korespondensi daftar penyebab kematian untuk otopsi verbal ICD-10.
2. Aplikasi menghasilkan informasi identifikasi penyebab kematian yang
korespondensi daftar penyebab kematian untuk otopsi verbal ICD-10 oleh
pakar, dalam hal ini dokter penelitian untuk memperoleh data relasi antara
symptoms dengan jenis verbal autopsy themes yang diakibatkannya
sebagai basis pengetahuan (knowledge base).
3. Pengolahan data diawali dengan input data bersih dari lapangan dalam
bentuk form manual (hardcopy) ke dalam sistem, dilengkapi dengan
proses edit dan delete jika diperlukan.
4. Menu aplikasi dibedakan menjadi dua bahasa dari dua modul yang ada,
untuk modul data entri menggunakan bahasa Indonesia dan untuk modul
admin (data manager) menggunakan bahasa Inggris. Pertimbangan untuk
data entry karena form manual dalam bahasa Indonesia. Sedangkan
pertimbangan untuk data manager dikarenakan ada dokter penelitian yang
merupakan warga Asing, yang sesekali membutuhkan melihat aplikasi,
maka akan lebih mudah jika menu nya menggunakan bahasa Inggris.
Kebijakan penggunaan bahasa ini diluar sistem yang dibangun, penulis
hanya mengimplementasikankan modul yang penulis buat sesuai
kebijakan yang berlaku pada sistem yang berjalan.
5. Pemodelan sistem aplikasi otopsi verbal ini menggunakan Use Case
Diagram dan UML.
6. Bahasa pemrograman yang digunakan dalam aplikasi ini adalah PHP
Dengan pembatasan masalah tersebut diharapkan agar jangan sampai
menyimpang dari topik yang terdapat dalam skripsi ini. Sedangkan hal lain yang
ada hubungannya dengan masalah ini adalah sebagai pendukung saja, sehingga
pembahasan yang ada semakin jelas.
1.5 Metodologi Penelitian
Metode penelitian dalam skripsi ini dibagi dalam dua tahap yaitu tahap
pengumpulan data dan tahap implementasi sistem.
1.5.1 Tahap Pengumpulan Data
Pada tahap pengumpulan data penulis menggunakan metodologi penelitian
kualitatif yang terdiri dari kombinasi metode-metode berikut ini:
a. Metode Pengamatan/Observasi
Pengumpulan data dengan cara mengamati secara langsung di lapangan
yaitu form manual sebagai sarana pengumpulan data serta konsep atau
alur data yang terjadi.
b. Metode Wawancara
Pengumpulan data dengan cara mengadakan wawancara secara langsung
dengan responden yaitu dokter lapangan yang berkaitan dan terlibat
langsung dengan data yang akan dianalisis guna memperoleh data yang
tepat dan akurat.
Dengan membaca dan meneliti dokumen-dokumen, buku-buku, referensi
yang berkaitan dengan masalah yang diteliti guna mengumpulkan data dan
informasi yang diperlukan
d. Studi Literatur
Studi literatur yaitu pengumpulan data dengan cara mengumpulkan
literatur, jurnal, paper dan bacaan-bacaan yang ada kaitanya dengan judul
penelitian.
1.5.2 Tahap Implementasi Sistem
Teknik analisis data dalam implementasi sistem menggunakan paradigma
perangkat lunak secara Prototyping, yang meliputi beberapa proses diantaranya :
Gambar 1.1 Prototyping Method
a. Pengumpulan Kebutuhan dan perbaikan
Menetapkan segala kebutuhan untuk pembangunan perangkat lunak.
Tahap penerjemahan dari keperluan atau data yang telah dianalisis ke
dalam bentuk yang mudah dimengerti oleh user.
c. Bentuk Prototipe
Menerjemahkan data yang telah dirancang ke dalam bahasa pemrograman
(Program contoh atau setengah jadi )..
d. Evaluasi Pelanggan Terhadap Prototipe
Program yang sudah jadi diuji oleh pelanggan, dan bila ada kekurangan
pada program bisa ditambahkan. Pelanggan yang dimaksud disini adalah
komponen penelitian (dokter ahli) dengan pengujian apakah sesuai dengan
kebutuhan analisa data penelitian.
e. Perbaikan Prototipe
Perbaikan program yang sudah jadi, sesuai dengan kebutuhan konsumen.
Kemudian dibuat program kembali dan di evaluasi oleh konsumen sampai
semua kebutuhan user terpenuhi.
f. Produk Rekayasa
Program yang sudah jadi dan seluruh kebutuhan user sudah terpenuhi
1.6 Sistematika Penulisan
Sistematika penulisan skripsi disini terbagi menjadi beberapa sub bab dari
pokok bahasan, secara umum dapat dijabarkan sebagai berikut :
Pada bab ini penulis membahas tentang latar belakang tugas akhir, perumusan
masalah, maksud dan tujuan tugas akhir, batasan masalah, metode penelitian dan
sistematika pelaporan tugas akhir.
BAB II TINJAUAN PUSTAKA
Pada bab ini penulis menguraikan secara singkat mengenai sejarah institusi
tempat penelitian dilakukan, landasan teori, model proses perangkat lunak, basis
data, metode perancangan dan implementasi sistem, PHP, Apache dan MySQL.
BAB III ANALISIS DAN PERANCANGAN
Pada bab ini membahas tentang analisis sistem, analisis masalah, Analisis
Kebutuhan Fungsional Analisis Non Fungsional, Perancangan Sistem,
Perancangan Database, Perancangan Antarmuka
BAB IV IMPLEMENTASI DAN PENGUJIAN
Pada bab ini membahas tentang Implementasi,Pengujian Sistem, Pengujian
Alpha.
BAB IV KESIMPULAN
Pada bab ini merupakan penutup yaitu berupa kesimpulan yang berisi kesimpulan
dari pembahasan pada bab sebelumnya serta saran yang mungkin berguna bagi
9 2.1Tinjauan Tempat Penelitian
2.1.1 Profil Instansi
CIRAI – Community-based and Integrated Research of Avian Influenza
adalah salah satu kelompok kerja yang dilakukan oleh Unit Penelitian
Kesehatan (UPK) Fakultas Kedokteran Universitas Padjajaran – Rumah
Sakit Hasan Sadikin tentang penyakit flu burung (sekarang meng-generalize
pada penyakit influenza), bekerja sama dengan Colorado University dan Dinas
kesehatan serta Dinas Peternakan provinsi Jawa Barat.
Seluruh jajaran sivitas akademika FK Unpad - RSHS, memberikan
perhatian sangat besar terhadap penelitian. Institusi ini memberikan penambahan
sumber daya untuk penelitian, pengembangan laboratorium, dan
mengakomodasikan pertemuan-pertemuan khusus untuk membahas penelitian.
Momentum ini sebaiknya di manfaatkan oleh kita semua untuk meningkatan
kredibilitas institusi dan karir kita khususnya dalam penelitian. Dalam hal ini,
Unit Penelitian Kesehatan saat ini masih berusaha mengembangkan working
group, kapasitas laboratorium sambil memperbaiki sistem administrasi dan
pendataan penelitian. Disamping upaya ini, minat dari institusi luar yang ingin
bekerja sama sangat besar. Dewasa ini ini sudah terbentuk 6 working group.
Disease (Influenza dan Dengue) dimana CIRAI ada didalamnya. Di bidang
Onkologi, kelompok kerja yang sudah mulai bergerak aktif adalah kelompok Ca
Cervix dan Human Papiloma Virus. Masing-masing kelompok kerja diharapkan
akan dapat menggarap aspek yang luas mulai dari topic ilmiah dasar sampai
penelitian aplikatif, agar sumbangan di berbagai lini bisa tampak. Dalam
pelaksanaannya sinergi kegiatan tetap sangat diharapkan karena secara praktis
kegiatan pengembangan dan penelitian bidang kesehatan menggunakan
metodologi dan instrumen yang sama.
2.1.2 Sejarah Instansi
Unit Penelitian Kesehatan Fakultas Kedokteran Universitas
Padjadjaran/Rumah Sakit Hasan Sadikin (selanjutnya disebut UPK-FKUP/RSHS)
didirikan pada tahun 1991 berdasarkan Surat Keputusan Bersama (SKB) Dekan
FK UNPAD No.14/PT06.H4.FK/Kep/N/91 dan Direktur RS Hasan Sadikin
Bandung No. 801A/D/IV/Kepeg/III/1991. Berdirinya UPK-FKUP/RSHS tersebut
antara lain dilatarbelakangi oleh
1. Program Fakultas Kedokteran UNPAD untuk membina dan
mengembangkan kegiatan-kegiatan penelitian di kalangan staf akademik
sebagai bagian bagian perwujudan Tri Dharma Perguruan Tinggi.
2. Piagam kerja sama antara Universitas Padjadjaran dengan Vlaamse
Interuniversitaire Raad (VLIR) Belgia yang ditandatangani pada tahun 1986
klinik dan biostatistik dalam rangka turut serta meningkatkan status
kesehatan di Jawa Barat.
3. Keterlibatan peneliti yang berasal dari lembaga berbeda yang tidak dapat
dipisahkan, yaitu Fakultas Kedokteran UNPAD sebagai lembaga pendidikan
dan Rumah Sakit Umum Pusat dr. Hasan Sadikin sebagai lembaga
pelayanan kesehatan.
4. Pemikiran bahwa penelitian kesehatan merupakan kegiatan yang tidak dapat
dipisahkan dalam mengembangkan dan mengantisipasi kemajuan ilmu
pengetahuan dan teknologi.
Bertitik tolak pada SKB tersebut, pada awalnya kegiatan UPK-FKUP/RSHS
dititikberatkan pada bidang kajian epidemiologi klinik yang ditopang oleh adanya
8 kelompok studi yang terlibat dalam program kerja sama UNPAD – VLIR
Belgia.
Mengingat perkembangan ilmu pengetahuan dan teknologi, semakin
beragamnya tantangan dan peluang yang dihadapi, serta diperlukan pendekatan
multidisiplin dalam mengatasi permasalahan kesehatan yang berkembang, maka
UPK-FKUP/RSHS telah pula mengembangkan kegiatannya yang meliputi bidang
kajian ilmu kedokteran dasar, ilmu kedokteran klinik hingga bidang kesehatan
masyarakat termasuk epidemiologi klinik dan biostatistik yang sebelumnya telah
dikembangkan serta bidang manajemen pelayanan kesehatan. Wujud pelaksanaan
2.1.3 Logo Instansi
Logo CIRAI sendiri se
sementara yang dimiliki oleh C
Gambar 2.1 Logo CIRA
Logo CIRAI mence
pengertian komunitas itu send
organisme yang berbagi lingk
yang sama. Dalam komunita
sebenarnya belum memiliki bentuk baku, berikut
h CIRAI:
AI (Community-based And Integrated Research o
Avian Influenza)
cerminkan lambang sebuah komunitas, dim
ndiri adalah “Sebuah kelompok sosial dari beber
gkungan, umumnya memiliki ketertarikan dan ha
itas manusia, individu-individu di dalamnya d ut logo
h of
dimana
berapa
habitat
memiliki maksud, kepercayaan, sumber daya, preferensi, kebutuhan, risiko dan
sejumlah kondisi lain yang serupa”. Organisasi disini karena CIRAI melibatkan
beberapa pihak luar seperti Colorado University, Dinas Peternakan dan lain – lain.
Sedangkan gambar virus didalamnya adalah virus avian influenza dimana
komunitas ini menitik beratkan pada penelitian virus tersebut.
2.1.4 Struktur Organisasi
Berikut ini adalah struktur organisasi dari working group atau kelompok
kerja Community and Integrated Research of Avian Influenza (CIRAI):
2.1.1.1. Research Leader
Pimpinan penelitian atau Research Leader merupakan pimpinan
tertinggi penelitian. Bertugas mengendalikan kegiatan manajerial serta berperan
dalam pengendalian kerjasama antara satu bagian dengan bagian yang lainnya,
tugas utamanya adalah memimpin penelitian dan bertanggung jawab terhadap
seluruh kelangsungan hidup penelitian.
2.1.1.2. Project Manager
Bertanggung jawab dalam mengawasi dan koordinasi pembangunan
sebuah proyek penelitian, melakukan evaluasi, estimasi waktu dan mengambil
keputusan menyangkut pembangunan suatu proyek penelitian.
2.1.1.3. Laboratory Manager
Bertanggung jawab dalam mengawasi dan koordinasi tentang kegiatan
laboratorium untuk penelitian, termasuk didalamnya pengadaan alat dan hasil
penelitian dari specimen yang didapat di lapangan oleh dokter lapangan.
2.1.1.4. Fields Manager
Bertanggung jawab dalam mengawasi dan koordinasi tentang kegiatan
penelitian dilapangan baik itu dokter lapangan di setiap puskesmas yang
2.1.1.5. Data Manager
Bertanggung jawab dalam mengawasi dan koordinasi tentang semua
aliran data penelitian yang masuk, pengolahannya sampai reporting data yang
dihasilkan. Membawahi bidang IT dan data entry yang bertugas untuk
memasukkan data penelitian ke dalam system yang dibuat oleh team IT.
2.2 Landasan Teori
2.2.1 Sistem Informasi
Pengertian Sistem Informasi sendiri mempunyai banyak versi, diantaranya
adalah sebagai berikut:
1. Sistem informasi adalah aplikasi komputer untuk mendukung operasi dari
suatu organisasi: operasi, instalasi, dan perawatan komputer, perangkat lunak,
dan data.
2. Sistem Informasi adalah sekumpulan komponen dari informasi yang saling
terintegrasi untuk mencapai tujuan yang spesifik. Komponen yang dimaksud
adalah komponen input, model, output, teknologi, basis data (data base),
kontrol atau komponen pengendali.
3. Sistem Informasi adalah Proses yang menjalankan fungsi mengumpulkan,
memproses, menyimpan, menganalisis, dan menyebarkan informasi untuk
kepentingan tertentu; kebanyakan SI dikomputerisasi.
4. Sistem informasi adalah sekumpulan komponen pembentuk sistem yang
bertujuan menghasilkan suatu informasi dalam suatu bidang tertentu. Dalam
sistem informasi diperlukannya klasifikasi alur informasi, hal ini disebabkan
keanekaragaman kebutuhan akan suatu informasi oleh pengguna informasi.
Kriteria dari sistem informasi antara lain, fleksibel, efektif dan efisien.
5. Sistem informasi adalah kumpulan antara sub-sub sistem yang saling
berhubungan yang membentuk suatu komponen yang didalamnya mencakup
input-proses-output yang berhubungan dengan pengolaan informasi (data yang
telah dioleh sehingga lebih berguna bagi user)
6. Suatu sistem informasi (SI) atau information system (IS) merupakan
aransemen dari orang, data, proses-proses, dan antar-muka yang berinteraksi
mendukung dan memperbaiki beberapa operasi sehari-hari dalam suatu bisnis
termasuk mendukung memecahkan soal dan kebutuhan pembuat-keputusan
manejemen dan para pengguna yang berpengalaman di bidangnya.
2.2.2 Data
Data adalah fakta atau apapun yang dapat digunakan sebagai input dan
menghasilkan informasi. Data adalah kenyataan yang menggambarkan suatu
kejadian dan kesatuan kenyataan. Data merupakan suatu istilah yang berbentuk
jamak dari kata “datum” yang berarti fakta atau bagian dari fakta yang
mengandung arti yang menghubungkan dengan kenyataan, simbol-simbol,
gambar-gambar, kata-kata, angka-angka, hurufhuruf yang menunjukan suatu ide,
objek, kondisi dan situasi. Menurut the Liang Gie: ”Data atau bahan keterangan
pengetahuan untuk dijadikan dasar guna penyusunan keterangan pembuatan
kesimpulan atau penetapan keputusan, atau data ibarat bahan mentah yang melalui
pengolahannya tertentu lalu menjadi keterangan (informasi)”. Kumpulan data
yang saling berkaitan, berhubungan yang disimpan secara bersama-sama
sedemikian rupa tanpa pengulangan yang tidak perlu, untuk memenuhi berbagai
kebutuhan disebut basis data (database). Data-data ini harus mengandung semua
informasi untuk mendukung semua kebutuhan sistem. Proses dasar yang dimiliki
oleh database ada empat, yaitu:
1. Pembuatan data-data baru (create database)
2. Penambahan data (insert)
3. Mengubah data (update)
4. Menghapus data (delete)
Database merupakan salah satu komponen yang penting dalam sistem informasi,
karena merupakan basis dalam menyediakan informasi pada para pengguna.
Database menjadi penting karena munculnya beberapa masalah bila tidak
menggunakan data yang terpusat, seperti adanya duplikasi data, hubungan antar
data tidak jelas, organisasi data dan update menjadi rumit. Jadi tujuan dari
pengaturan data dengan menggunakan database adalah :
a. Menyediakan penyimpanan data untuk dapat digunakan oleh organisasi saat
b. Cara pemasukan data sehingga memudahkan tugas operator dan menyangkut
pula waktu yang diperlukan oleh pemakai untuk mendapatkan data serta
hak-hak yang dimiliki terhadap data yang ditangani.
c. Pengendalian data untuk setiap siklus agar data selalu up-todate dan dapat
mencerminakan perubahan spesifik yang terjadi di setiap sistem.
d. Pengamanan data terhadap kemungkinan penambahan, modifikasi, pencurian
dan gangguan-gangguan lain. Penyusunan basis data meliputi proses
memasukkan data kedalam media penyimpanan data, dan diatur dengan
menggunakan perangkat Sistem Manajemen Basis Data (Database
Management System / DBMS).
2.2.3 Pengenalan Pola, Data Mining, dan Machine Learning
Pengenalan pola adalah suatu disiplin ilmu yang mempelajari cara-cara
mengklasifikasikan obyek ke beberapa kelas atau kategori dan mengenali
kecenderungan data. Tergantung pada aplikasinya, obyek-obyek ini bisa berupa
pasien, mahasiswa, pemohon kredit, image atau signal atau pengukuran lain yang
perlu diklasifikasikan atau dicari fungsi regresinya (Santoso, 2007).
Data mining diartikan sebagai suatu proses ekstraksi informasi berguna
dan potensial dari sekumpulan data yang terdapat secara implisit dalam suatu
basis data. Pada dasarnya data mining berhubungan dengan analisa data dan
penggunaan teknik-teknik perangkat lunak untuk mencari pola dan keteraturan
Machine Learning adalah suatu area dalam artificial intelligence atau
kecerdasan buatan yang berhubungan dengan pengembangan teknik-teknik yang
bisa diprogramkan dan belajar dari data masa lalu. Pengenalan pola, data mining
dan machine learning sering dipakai untuk menyebut sesuatu yang sama. Bidang
ini bersinggungan dengan ilmu probabilitas dan statistik kadang juga optimasi.
Machine learning menjadi alat analisis dalam data mining (Santoso, 2007).
Dengan diperolehnya informasi-informasi yang berguna dari data-data
yang ada, hubungan antara item dalam transaksi, maupun informasi
informasi-yang potensial, selanjutnya dapat diekstrak dan dianalisa dan diteliti lebih lanjut
dari berbagai sudut pandang. Informasi yang ditemukan ini selanjutnya dapat
diaplikasikan untuk aplikasi manajemen, melakukan query processing,
pengambilan keputusan dan lain sebagainya. Dengan semakin berkembangnya
kebutuhan akan informasi, semakin banyak pula bidang-bidang yang rnenerapkan
konsep data mining.
2.2.3.1Tahapan Data Mining
Dalam proses data mining, data-data yang ada, tidak dapat langsung diolah
dengan menggunakan sistem data mining. Data-data tersebut harus dipersiapkan
terlebih dahulu agar hasil yang diperoleh dapat lebih maksimal, dan waktu
komputasinya lebih minimal. Proses persiapan data ini sendiri dapat mencapai
60% dari keseluruhan proses dalam data mining. Adapun tahapan-tahapan yang
Gambar 2.3 Tahapan Data Mining
1. Pembersihan Data (Data Cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang
tidak konsisten atau data tidak relevan. Pada umumnya data yang
diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen,
memiliki isian-isian yang tidak sempurna seperti data yang hilang, data
yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga
dimiliki. Data-data yang tidak relevan itu juga lebih baik dibuang.
Pembersihan data juga akan mempengaruhi performasi dari teknik data
mining karena data yang ditangani akan berkurang jumlah dan
kompleksitasnya.
2. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh
karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari
database.
3. Integrasi Data (Data Integration)
Integrasi data merupakan penggabungan data dari berbagai database ke
dalam satu database baru. Tidak jarang data yang diperlukan untuk data
mining tidak hanya berasal dari satu database tetapi juga berasal dari
beberapa database atau file teks. Integrasi data dilakukan pada
atribut-aribut yang mengidentifikasikan entitas-entitas yang unik seperti atribut
nama, jenis produk, nomor pelanggan dan lainnya. Integrasi data perlu
dilakukan secara cermat karena kesalahan pada integrasi data bisa
menghasilkan hasil yang menyimpang dan bahkan menyesatkan
pengambilan aksi nantinya.
Transformasi data melakukan peringkasan data dengan mengasumsikan
bahwa data telah tersimpan dalam tempat penyimpanan tunggal. Pada
langkah terakhir, data telah di ekstrak dari banyak basis data ke dalam
basis data tunggal. Tipe peringkasan yang dikerjakan dalam langkah ini
mirip dengan peringkasan yang dikerjakan selama tahap ekstraksi.
5. Proses Mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan
pengetahuan berharga dan tersembunyi dari data. Didalamnya termasuk
proses menjalankan algoritma, setelah semua proses sebelumnya
dikerjakan, maka algoritma data mining sudah siap untuk dijalankan.
6. Presentasi Pengetahuan
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang
digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.
Tahap terakhir dari proses data mining adalah bagaimana
memformulasikan keputusan atau aksi dari hasil analisis yang didapat.
Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami
data mining. Karenanya presentasi hasil data mining dalam bentuk
pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang
diperlukan dalam proses data mining. Dalam presentasi ini, visualisasi
juga bisa membantu mengkomunikasikan hasil data mining (Han, 2006).
Berikut beberapa jenis teknik Data Mining yang paling populer dikenal
dan digunakan:
1. Association Rule Mining
Association rule mining adalah teknik mining untuk menemukan aturan
assosiatif antara suatu kombinasi item. Penting tidaknya suatu aturan assosiatif
dapat diketahui dengan dua parameter, support yaitu persentase kombinasi item
tsb. dalam database dan confidence yaitu kuatnya hubungan antar item dalam
aturan assosiatif. Algoritma yang paling populer dikenal sebagai Apriori dengan
paradigma generate and test, yaitu pembuatan kandidat kombinasi item yang
mungkin berdasar aturan tertentu lalu diuji apakah kombinasi item tersebut
memenuhi syarat support minimum. Kombinasi item yang memenuhi syarat tsb.
disebut frequent itemset, yang nantinya dipakai untuk membuat aturan-aturan
yang memenuhi syarat confidence minimum. Algoritma baru yang lebih efisien
bernama FP-Tree.
2. Classification
Klasifikasi data adalah suatu proses yang menemukan properti-properti
yang sama pada sebuah himpunan obyek di dalarn sebuah basis data, dan
mengklasifikasikannya ke dalam kelas-kelas yang berbeda menurut model
klasifikasi yang ditetapkan (Badriyah, 2007).
Classification adalah proses untuk menemukan model atau fungsi yang
memperkirakan kelas dari suatu objek yang labelnya tidak diketahui. Model itu
sendiri bisa berupa aturan “jika-maka”, berupa decision tree, formula matematis
atau neural network. Decision tree adalah salah satu metode classification yang
paling populer karena mudah untuk diinterpretasi oleh manusia.
Decision tree merupakan struktur flowchart yang menyerupai tree
(pohon), dimana setiap simpul internal menandakan suatu tes pada atribut, setiap
cabang merepresentasikan hasil tes, dan simpul daun merepresentasikan kelas
atau distribusi kelas. Alur pada decision tree di telusuri dari simpul akar ke simpul
daun yang memegang prediksi kelas untuk contoh tersebut. Decision tree mudah
untuk dikonversi ke aturan klasifikasi (Kusnawi,2007).
Forward Chaining atau disebut juga penalaran maju adalah aturan-aturan
diuji satu demi satu dalam urutan tertentu. Inference Engine akan mencocokkan
fakta atau statement dalam Knowledge Base dengan situasi yang dinyatakan
dalam rule bagian IF. Jika fakta yang ada dalam Knowledge Base sudah sesuai
dengan kaidah IF, maka rule itu distimulasi dan rule berikutnya diuji. Proses
pengujian rule satu demi satu berlanjut sampai satu putaran lengkap melalui
seluruh perangkat rule (Andi, 2003). Untuk lebih jelasnya dapat kita lihat alur
Gambar 2.4 Metode forward chaining
3. Clustering
Berbeda dengan association rule mining dan classification dimana kelas
data telah ditentukan sebelumnya, clustering melakukan penge-lompokan data
tanpa berdasarkan kelas data tertentu. Bahkan clustering dapat dipakai untuk
memberikan label pada kelas data yang belum diketahui itu. Karena itu clustering
sering digolongkan sebagai metode unsupervised learning. Prinsip dari clustering
adalah memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan
kesamaan antar kelas/cluster. Clustering dapat dilakukan pada data yan memiliki
beberapa atribut yang dipetakan sebagai ruang multidimensi.
Banyak algoritma clustering memerlukan fungsi jarak untuk mengukur
kemiripan antar data, diperlukan juga metode untuk normalisasi bermacam atribut
yang dimiliki data. Beberapa kategori algoritma clustering yang banyak dikenal
adalah metode partisi dimana pemakai harus menentukan jumlah k partisi yang
diinginkan lalu setiap data dites untuk dimasukkan pada salah satu partisi, metode
bottom-up yang menggabungkan cluster kecil menjadi cluster lebih besar dan
top-down yang memecah cluster besar menjadi cluster yang lebih kecil. Kelemahan
metode ini adalah bila bila salah satu penggabungan/pemecahan dilakukan pada
tempat yang salah, tidak dapat didapatkan cluster yang optimal. Pendekatan yang
banyak diambil adalah menggabungkan metode hierarki dengan metode
clustering lainnya seperti yang dilakukan oleh Chameleon.
2.2.4 DBMS, MySQL dan SQL
2.2.4.1DBMS
Basis data atau database adalah kumpulan informasi yang disimpan di
dalam komputer secara sistematik sehingga dapat diperiksa menggunakan suatu
program komputer untuk memperoleh informasi dari basis data tersebut. Database
digunakan untuk menyimpan informasi atau data yang terintegrasi dengan baik di
dalam komputer.
Untuk mengelola database diperlukan suatu perangkat lunak yang disebut
DBMS atau Database Management System. DBMS merupakan suatu sistem
perangkat lunak yang memungkinkan pengguna untuk membuat, memelihara,
mengontrol, dan mengakses database secara praktis dan efisien. Dengan DBMS,
pengguna akan lebih mudah mengontrol dan memanipulasi data yang ada.
2.2.4.2MySQL
Sedangkan MySQL adalah Relational Database Management System
Public License). Dimana setiap orang bebas untuk menggunakan MySQL, namun
tidak boleh dijadikan produk turunan yang bersifat komersial. MySQL sebenarnya
merupakan turunan salah satu konsep utama dalam database sejak lama, yaitu
SQL (Structured Query Language). MySQL memiliki beberapa keistimewaan,
antara lain :
1. Portabilitas. MySQL dapat berjalan stabil pada berbagai sistem operasi
seperti Windows, Linux, FreeBSD, Mac Os X Server, Solaris, Amiga, dan
masih banyak lagi.
2. Open Source. MySQL didistribusikan secara open source, dibawah lisensi
GPL sehingga dapat digunakan secara cuma-cuma.
3. Multiuser. MySQL dapat digunakan oleh beberapa user dalam waktu yang
bersamaan tanpa mengalami masalah atau konflik.
4. Performance Tuning. MySQL memiliki kecepatan yang menakjubkan
dalam menangani query sederhana, dengan kata lain dapat memproses
lebih banyak SQL per satuan waktu.
5. Jenis Kolom. MySQL memiliki tipe kolom yang sangat kompleks, seperti
signed / unsigned integer, float, double, char, text, date, timestamp, dan
lain-lain.
6. Perintah dan Fungsi. MySQL memiliki operator dan fungsi secara penuh
yang mendukung perintah Select dan Where dalam perintah (query).
7. Keamanan. MySQL memiliki beberapa lapisan sekuritas seperti level
subnetmask, nama host, dan izin akses user dengan sistem perizinan yang
8. Skalabilitas dan Pembatasan. MySQL mampu menangani basis data dalam
skala besar, dengan jumlah rekaman (records) lebih dari 50 juta dan 60
ribu tabel serta 5 milyar baris. Selain itu batas indeks yang dapat
ditampung mencapai 32 indeks pada tiap tabelnya.
9. Konektivitas. MySQL dapat melakukan koneksi dengan klien
menggunakan protokol TCP/IP, Unix soket (UNIX), atau Named Pipes
(NT).
10. Lokalisasi. MySQL dapat mendeteksi pesan kesalahan pada klien dengan
menggunakan lebih dari dua puluh bahasa. Meski pun demikian, bahasa
Indonesia belum termasuk di dalamnya.
11. Antar Muka. MySQL memiliki interface (antar muka) terhadap berbagai
aplikasi dan bahasa pemrograman dengan menggunakan fungsi API
(Application Programming Interface).
12. Klien dan Peralatan. MySQL dilengkapi dengan berbagai peralatan (toosl)
yang dapat digunakan untuk administrasi basis data, dan pada setiap
peralatan yang ada disertakan petunjuk online.
13. Struktur tabel. MySQL memiliki struktur tabel yang lebih fleksibel dalam
menangani ALTER TABLE, dibandingkan basis data lainnya semacam
PostgreSQL ataupun Oracle.
2.2.4.3SQL
SQL adalah sebuah konsep pengoperasian database, terutama untuk
data dikerjakan dengan mudah secara otomatis. Keandalan suatu sistem database
(DBMS) dapat diketahui dari cara kerja optimizer-nya dalam melakukan proses
perintah-perintah SQL, yang dibuat oleh user maupun program-program
aplikasinya. Sebagai database server, MySQL dapat dikatakan lebih unggul
dibandingkan database server lainnya dalam query data. Hal ini terbukti untuk
query yang dilakukan oleh single user, kecepatan query MySQL bisa sepuluh kali
lebih cepat dari PostgreSQL dan lima kali lebih cepat dibandingkan Interbases.
2.2.5 Bahasa Pemograman WEB
2.2.5.1HyperText Markup Language (HTML)
HyperText Markup Language (HTML) adalah sebuah bahasa markup yang
digunakan untuk membuat sebuah halaman web, menampilkan berbagai informasi
di dalam sebuah Penjelajah web Internet dan formating hypertext sederhana yang
ditulis kedalam berkas format ASCII agar dapat menghasilkan tampilan wujud
yang terintegerasi. Dengan kata lain, berkas yang dibuat dalam perangkat lunak
pengolah kata dan disimpan kedalam format ASCII normal sehingga menjadi
home page dengan perintah-perintah HTML. Bermula dari sebuah bahasa yang
sebelumnya banyak digunakan di dunia penerbitan dan percetakan yang disebut
dengan SGML (Standard Generalized Markup Language), HTML adalah sebuah
standar yang digunakan secara luas untuk menampilkan halaman web. HTML saat
ini merupakan standar Internet yang didefinisikan dan dikendalikan
penggunaannya oleh World Wide Web Consortium (W3C). HTML dibuat oleh
pada tahun 1989 (CERN adalah lembaga penelitian fisika energi tinggi di
Jenewa).
2.2.5.2JavaScript
JavaScript diperkenalkan pertama kali oleh Netscape pada tahun 1995.
Pada awalnya bahasa yang sekarang disebut JavaScript ini dulunya dinamai
LiveScrip” yang berfungsi sebagai bahasa sederhana untuk browser Netscape
Navigator 2 yang sangat populer pada saat itu. Kemudian sejalan dengan sedang
giatnya kerjasama antara Netscape dan Sun (pengembang bahasa pemrograman
Java) pada masa itu, maka Netscape memberikan nama JavaScript kepada bahasa
tersebut pada tanggal 4 desember 1995. Pada saat yang bersamaan Microsoft
sendiri mencoba untuk mengadaptasikan teknologi ini yang mereka sebut sebagai
Jscript di browser milik mereka yaitu Internet Explorer 3. JavaScript sendiri
merupakan modifikasi dari bahasa pemrograman C++ dengan pola penulisan yang
lebih sederhana dari bahasa pemrograman C++.
JavaScript adalah bahasa pemrograman yang khusus untuk halaman web
agar halaman web menjadi lebih hidup. Kalau dilihat dari suku katanya terdiri dari
dua suku kata, yaitu Java dan Script. Java adalah bahasa pemrograman
berorientasi objek, sedangkan Script adalah serangkaian instruksi program. Ada
beberapa hal yang harus diperhatikan dalam pengelolaan pemrograman
JavaScript, diantaranya JavaScript adalah case sensitive, yang artinya JavaScript
membedakan huruf besar dan huruf kecil, dimana huruf T tidak sama dengan
2.2.5.3Asynchronous JavaScript and XMLHTTP (AJaX)
Asynchronous JavaScript and XMLHTTP, atau disingkat AJaX, adalah
suatu teknik pemrograman berbasis web untuk menciptakan aplikasi web
interaktif. Tujuannya adalah untuk memindahkan sebagian besar interaksi pada
komputer web surfer, melakukan pertukaran data dengan server di belakang layar,
sehingga halaman web tidak harus dibaca ulang secara keseluruhan setiap kali
seorang pengguna melakukan perubahan. Hal ini akan meningkatkan
interaktivitas, kecepatan, dan usability. Ajax merupakan kombinasi dari:
1. DOM yang diakses dengan client side scripting language, seperti VBScript
dan implementasi ECMAScript seperti JavaScript dan JScript, untuk
menampilkan secara dinamis dan berinteraksi dengan informasi yang
ditampilkan
2. Objek XMLHTTP dari Microsoft atau XMLHttpRequest yang lebih umum di
implementasikan pada beberapa browser. Objek ini berguna sebagai
kendaraan pertukaran data asinkronus dengan web server. Pada beberapa
framework AJAX, element HTML IFrame lebih dipilih daripada XMLHTTP
atau XMLHttpRequest untuk melakukan pertukaran data dengan web server.
3. XML umumnya digunakan sebagai dokumen transfer, walaupun format lain
juga memungkinkan, seperti HTML, plain text. XML dianjurkan dalam
pemakaian teknik AJaX karena kemudahan akses penanganannya dengan
4. JSON dapat menjadi pilihan alternatif sebagai dokumen transfer, mengingat
JSON adalah JavaScript itu sendiri sehingga penanganannya lebih mudah
Seperti halnya DHTML, LAMP, atau SPA, Ajax bukanlah teknologi spesifik,
melainkan merupakan gabungan dari teknologi yang dipakai bersamaan. Bahkan,
teknologi turunan/komposit yang berdasarkan Ajax, seperti AFLAX sudah mulai
bermunculan.
2.2.5.4Cascading Style Sheets (CSS)
Cascading Style Sheet (CSS) merupakan salah satu bahasa pemrograman
web untuk mengendalikan beberapa komponen dalam sebuah web sehingga akan
lebih terstruktur dan seragam.
Sama halnya styles dalam aplikasi pengolahan kata seperti Microsoft Word
yang dapat mengatur beberapa style, misalnya heading, subbab, bodytext, footer,
images, dan style lainnya untuk dapat digunakan bersama-sama dalam beberapa
berkas. Pada umumnya CSS dipakai untuk memformat tampilan halaman web
yang dibuat dengan bahasa HTML. CSS dapat mengendalikan ukuran gambar,
warna bagian tubuh pada teks, warna tabel, ukuran border, warna border, warna
hyperlink, warna mouse over, spasi antar paragraf, spasi antar teks, margin kiri,
kanan, atas, bawah, dan parameter lainnya.[1] CSS adalah bahasa style sheet yang
digunakan untuk mengatur tampilan dokumen. Dengan adanya CSS
memungkinkan kita untuk menampilkan halaman yang sama dengan format yang
2.2.5.5PHP
PHP (akronim dari PHP Hypertext Preprocessor) yang merupakan bahasa
pemrogramman berbasis web yang memiliki kemampuan untuk memproses data
dinamis. PHP dikatakan sebagai sebuah server-side embedded script language
artinya sintaks-sintaks dan perintah yang kita berikan akan sepenuhnya dijalankan
oleh server tetapi disertakan pada halaman HTML biasa. Aplikasi-aplikasi yang
dibangun oleh PHP pada umumnya akan memberikan hasil pada web browser,
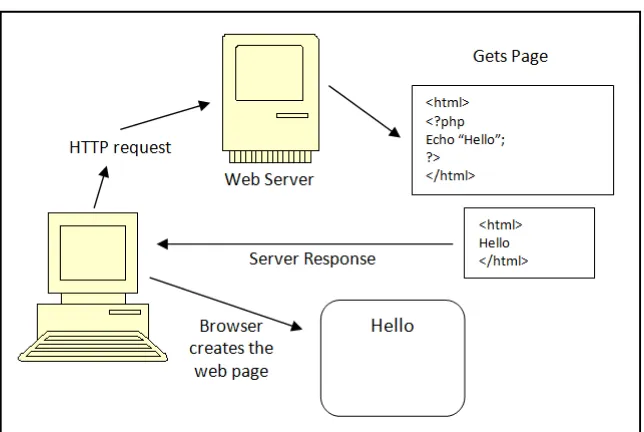
tetapi prosesnya secara keseluruhan dijalankan di server. Pada prinsipnya server
akan bekerja apabila ada permintaan dari client. Dalam hal ini client
menggunakan kode-kode PHP untuk mengirimkan permintaan ke server (dapat
dilihat pada gambar dibawah). Ketika menggunakan PHP sebagai server-side
embedded script language maka server akan melakukan hal-hal sebagai berikut :
• Membaca permintaan dari client/browser
• Mencari halaman/page di server
• Melakukan instruksi yang diberikan oleh PHP untuk melakukan
modifikasi pada halaman/page.
• Mengirim kembali halaman tersebut kepada client melalui internet atau
Gambar 2.5 Cara Kerja PHP
2.2.6 Web Server dan Apache
2.2.6.1Web Server
Web server adalah software yang menjadi tulang belakang dari world wide
web (www). Web server menunggu permintaan dari client yang menggunakan
browser seperti Netscape Navigator, Internet Explorer, Modzilla, dan program
browser lainnya. Jika ada permintaan dari browser, maka web server akan
memproses permintaan itu kemudian memberikan hasil prosesnya berupa data
yang diinginkan kembali ke browser. Data ini mempunyai format yang standar,
disebut dengan format SGML (standar general markup language). Data yang
berupa format ini kemudian akan ditampilkan oleh browser sesuai dengan
kemampuan browser tersebut. Contohnya, bila data yang dikirim berupa gambar,
menampilkan gambar tersebut, dan jika ada akan menampilkan alternatifnya saja.
Web server, untuk berkomunikasi dengan client-nya (web browser) mempunyai
protokol sendiri, yaitu HTTP (hypertext transfer protocol).
Dengan protokol ini, komunikasi antar web server dengan client-nya dapat
saling dimengerti dan lebih mudah. Seperti telah dijelaskan diatas, format data
pada world wide web adalah SGML. Tapi para pengguna internet saat ini lebih
banyak menggunakan format HTML (hypertext markup language) karena
penggunaannya lebih sederhana dan mudah dipelajari. Kata HyperText
mempunyai arti bahwa seorang pengguna internet dengan web browser-nya dapat
membuka dan membaca dokumen-dokumen yang ada dalam komputernya atau
bahkan jauh tempatnya sekalipun.
Hal ini memberikan cita rasa dari suatu proses yang tridimensional, artinya
pengguna internet dapat membaca dari satu dokumen ke dokumen yang lain
hanya dengan mengklik beberapa bagian dari halaman-halaman dokumen (web)
itu. Proses yang dimulai dari permintaan webclient (browser), diterima web
server, diproses, dan dikembalikan hasil prosesnya oleh web server ke web client
lagi dilakukan secara transparan. Setiap orang dapat dengan mudah mengetahui
apa yang terjadi pada tiap-tiap proses. Secara garis besarnya web server hanya
2.2.6.2Apache
Apache merupakan web server yang paling banyak dipergunakan di
Internet. Program ini pertama kali didesain untuk sistem operasi lingkungan
UNIX. Namun demikian, pada beberapa versi berikutnya Apache mengeluarkan
programnya yang dapat dijalankan di Windows NT. Apache mempunyai program
pendukung yang cukup banyak. Hal ini memberikan layanan yang cukup lengkap
bagi penggunanya. Beberapa dukungan Apache :
1. Kontrol Akses. Kontrol ini dapat dijalankan berdasarkan nama host atau
nomor IP.
2. CGI (Common Gateway Interface). Yang paling terkenal untuk digunakan
adalah perl (Practical Extraction and Report Language), didukung oleh
Apache dengan menempatkannya sebagai modul (mod_perl).
3. PHP (Personal Home Page/PHP Hypertext Processor). Program dengan
metode semacam CGI, yang memproses teks dan bekerja di server.
Apache mendukung PHP dengan menempatkannya sebagai salah satu
modulnya (mod_php). Hal ini membuat kinerja PHP menjadi lebih baik.
4. SSI (Server Side Includes).
Web server Apache mempunyai kelebihan dari beberapa pertimbangan di
atas, antara lain adalah :
2. Apache mudah sekali proses instalasinya jika dibanding web server
lainnya seperti NCSA, IIS, dan lain-lain.
3. Mampu beroperasi pada berbagai platform sistem operasi.
4. Mudah mengatur konfigurasinya. Apache mempunyai hanya empat file
konfigurasi.
5. Mudah dalam menambahkan peripheral lainnya ke dalam platform web
38
3.1 Analisis Sistem
Analisis sistem diperlukan untuk menganalisa sistem penelitian CIRAI
yang sudah berjalan, menganalisa permasalahan yang ada pada sistem penelitian
dan menganalisa kebutuhan yang diperlukan oleh penelitian saat ini.
3.1.1 Analisis Sistem Penelitian
Penelitian CIRAI yang merupakan kependekan dari Community-based and
Integrated Research of Influenza adalah salah satu kelompok kerja yang dilakukan
oleh Unit Penelitian Kesehatan (UPK) FK UNPAD - Rumah Sakit Hasan Sadikin
tentang penyakit influenza. Seperti penelitian kesehatan pada umumnya CIRAI
mempunyai kegiatan utama mengumpulkan data objek penelitian, dimana data
tersebut dikelola menjadi beberapa modul aplikasi yang terintregasi satu sama lain
dalam sebuah sistem berbasis web.
Dengan berkembangnya data penelitian, saat ini CIRAI melakukan
pengambilan data kematian didaerah penelitian dengan metode otopsi verbal,
tujuannya untuk mengidentifikasi penyebab kematian oleh symptoms influenza.
Dari kegiatan ini akan dihasilkan sebuah data otopsi verbal yang harus dikelola
oleh sistem untuk menghasilkan sebuah informasi berupa pendukung diagnosa
tentang identifikasi penyebab kematian oleh symptoms influenza, dengan acuan
Dimana pada modul aplikasi yang sudah ada, untuk membuat sebuah laporan
setiap modulnya, masih dilakukan secara manual oleh dokter penelitian. Manual
disini maksudnya, setelah data masuk ke database sistem, dokter akan
mendownloadnya dalam bentuk file excel, dan akan mengolahnya secara manual
untuk menghasilkan informasi yang dibutuhkan. Berikut ini adalah alur prosedur
dari sistem otopsi verbal yang sedang berjalan:
3.1.2 Analisis Masalah
Dari analisis sistem yang sedang berjalan, dapat dilihat bahwa
permasalahan dalam sistem penelitian CIRAI adalah dibutuhkan sebuah modul
aplikasi yang dapat mengelola data otopsi verbal dan menghasilkan informasi
berupa hasil identifikasi penyebab kematian oleh symptoms influenza untuk setiap
kasus otopsi verbal yang ada dengan acuan data korespondensi penyebab
kematian untuk otopsi verbal dengan kode ICD-10.
3.1.3 Solusi yang ditawarkan
Dari permasalahan yang telah dipaparkan dalam analisis masalah, maka
dapat disimpulkan bahwa saat ini pihak penelitian CIRAI membutuhkan sebuah
modul aplikasi otopsi verbal yang dapat mengelola data kematian dan
mengolahnya menjadi sebuah informasi dalam bentuk prediksi identifikasi
penyebab kematian dengan menggunakan acuan data korespondensi daftar
penyebab kematian untuk otopsi verbal dan hubungannya dengan kode ICD-10.
Untuk aplikasi otopsi verbalnya sendiri, berdasarkan bentuk form manual
otopsi verbal standar WHO yang komplek dengan pengkodean serta kondisi
disetiap pertanyaannya, penulis memberikan solusi sebuah aplikasi yang user
friendly dengan validasi disetiap pertanyaannya untuk meminimalisasi kesalahan
input data. Sedangkan untuk penyajian informasi dalam bentuk identifikasi
penyebab kematian, salah satu solusi yang dapat diterapkan adalah dengan data
mining, karena data mining dapat ‘menggali’ knowledge yang tersimpan dalam
verbal. Teknik mining yang akan digunakan adalah teknik Classification berupa
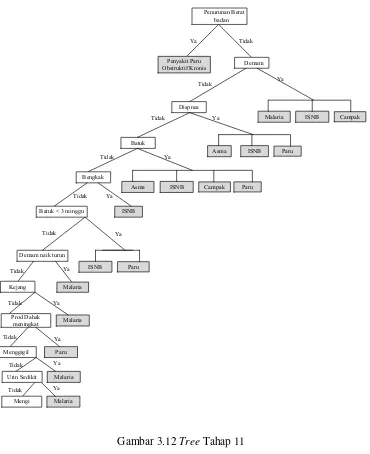
decision tree. Dan jenis tree yang akan diterapkan adalah forward chaining tree,
dimana algoritma forward chaining ini dapat menjawab kebutuhan penelitian,
karena menggunakan data symptoms influenza sebagai fakta dan data
korespondensi penyebab kematian untuk otopsi verbal dengan kode ICD-10
sebagai kaidah untuk memperoleh suatu kesimpulan.
3.1.4 Analisis Data
Dari analisa sistem yang akan dibangun, dapat diusulkan struktur data
yang akan digunakan oleh sistem. Dalam hal ini data dibagi menjadi dua kategori,
yaitu data pengolahan otopsi verbal, dan data siap mining dari data pengolahan
otopsi verbal tersebut. Usulan struktur data pengolahan otopsi verbal tersebut
terdiri dari tabel t_vo, t_vo_kematian, t_vo_observasi, t_vo11,t_vo12, t_vo12 ,
t_vo22, t_vo31, t_vo32 dan t_vo33. Pembagian tabel tersebut didasarkan pada
pola form dan design form aplikasi yang sesuai dengan form manual otopsi
verbal. Berikut tabel deskripsi dari pembagian tabel – tabel tersebut :
Tabel 3.1 Deskripsi masing – masing tabel otopsi verbal
No Tabel Deskripsi
1 t_vo Tabel utama, berisi informasi umum dari form otopsi verbal
2 t_vo_kematian Tabel yang berisi catatan riwayat kematian termasuk surat kematian 3 t_vo_observasi Tabel yang berisi informasi hasil
4 t_vo11 Tabel yang berisi informasi Penyakit atau kejadian yang mengarah pada kematian, untuk kategori umur 1 (usia kematian dibawah 4 minggu)
5 t_vo12 Tabel yang berisi informasi gejala sebelum kematian, untuk kategori umur 1 (usia kematian dibawah 4 minggu)
6 t_vo21 Tabel yang berisi informasi Penyakit atau kejadian yang mengarah pada kematian, untuk kategori umur 2 (usia kematian 4 minggu - 14 tahun)
7 t_vo22 Tabel yang berisi informasi gejala sebelum kematian, untuk kategori umur 2 (usia kematian 4 minggu - 14 tahun)
8 t_vo31 Tabel yang berisi informasi Penyakit atau kejadian yang mengarah pada kematian dan cidera/kecelakaan, untuk kategori umur 3 (usia kematian 15 tahun keatas)
9 t_vo32 Tabel yang berisi informasi gejala penyakit pada wanita dan gejala yang berkaitan dengan kehamilan sebelum kematian, untuk kategori umur 3 (usia kematian 15 tahun keatas)
10 t_vo33 Tabel yang berisi informasi
perawatan dan pelayanan kesehatan saat masa akhir hidup almarhum, untuk kategori umur 3(usia kematian 15 tahun keatas)
Sedangkan untuk aplikasi data miningnya sendiri akan membutuhkan tabel
3.1.5 Analisis Data Mining
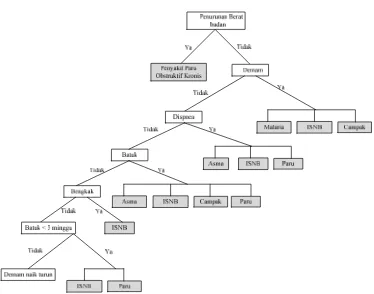
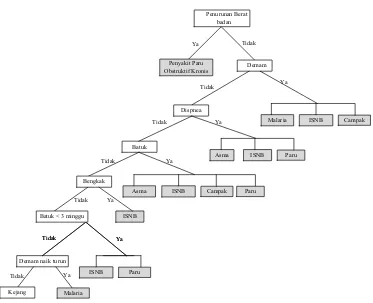
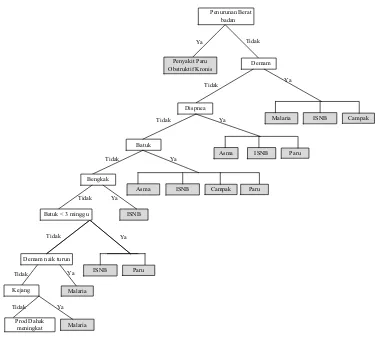
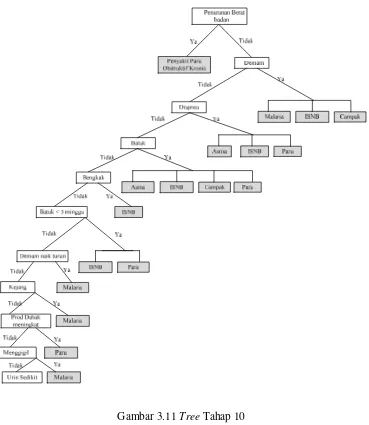
Metode yang digunakan dalam proses mining dalam melakukan pencarian
informasi mengenai identifikasi penyebab kematian disini menggunakan metode
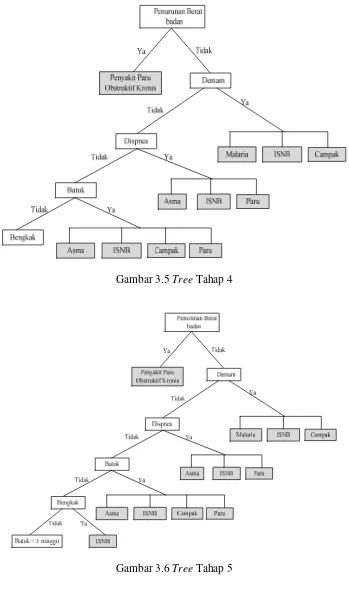
Decision Tree. Dimana jenis decision tree yang digunakan adalah forward
chaining tree. Dalam penulisan tugas akhir ini akan dilakukan proses pencarian
informasi dari sekumpulan data atau fakta berupa influenza symptoms, untuk
menemukan suatu kesimpulan yang menjadi solusi dari permasalahan yang
dihadapi yaitu jenis verbal autopsy themes sebagai hasil identifikasi penyebab
kematian. Proses akan mencari kaidah-kaidah dalam basis pengetahuan yang
premisnya sesuai dengan data-data tersebut, kemudian dari kaidah-kaidah tersebut
diperoleh suatu kesimpulan. Sesuai landasan teori data mining yang dijelaskan
pada bab sebelumnya, berikut tahapan proses mining identifikasi penyebab
kematian pada penelitian CIRAI:
1. Pembersihan Data (Data Cleaning)
Proses data mining dalam aplikasi ini terdiri dari dua sumber data, yaitu data
otopsi verbal hasil dari modul pengolahan otopsi verbal dalam aplikasi ini
sendiri dan data korespondensi hasil penyebab kematian dengan ICD – 10.
Kedua data tersebut mempunyai atribut-atribut data yang tidak relevan yang
perlu dibersihkan, berikut keterangan proses pembersihan data tersebut :
1.1Pembersihan Data Korespondensi Hasil Penyebab Kematian dengan
Dari batasan masalah yng ada, bahwa aplikasi ini dibatasi pada symptoms
influenza saja, maka proses pembersihan data dalam proses mining disini adalah
menghilangkan noise untuk field symptoms influenza. Data yang digunakan
untuk proses mining disini terdiri dari dua sumber data, yaitu data otopsi verbal
dan data korespondensi penyebab kematian untuk otopsi verbal dengan kode
ICD-10. Penghilangan noise pada data ICD-10, dilakukan dengan melakukan
pencocokan dengan symptoms influenza yang akan digunakan sesuai keterangan
pakar. Data ICD-10 dalam bentuk PDF, contohnya untuk kasus tema otopsi
verbal Campak, symptoms fotopobia dan tidak mendapat vaksin campak, tidak
terdapat pada data otopsi verbal, maka dihilangkang, seperti terlihat pada
gambar berikut:
1.2Pembersihan Data Otopsi Verbal
Data symptoms otopsi verbal menggunakan pengkodean disetiap
kontennya dimana pengkodean tersebut adalah sebagai berikut:
Tabel 3.3 Keterangan Pengkodean Data Symptoms Otopsi Verbal
No Kode Keterangan
1 1 Ya
2 2 Tidak
3 998 Tidak Tahu
Dari pengkodean tersebut, maka data symptoms yang akan dipakai hanya
data dengan isian 1 yang artinya Ya. Contohnya data symptoms dapat
dilihat pada isi tabel t_vo33 yang berisi symptoms untuk kematian kategori
umur diatas 15 tahun berikut ini:
Tabel 3.4 Contoh Data Symptoms Sebelum Dibersihkan
id_vo vo901 vo902 vo903 vo904 vo905 vo906 vo907 vo908 vo909 vo910
2. Seleksi Data (Data Selection)
Proses ini merupakan proses pemilihan data penelitian CIRAI yang akan
penentuan symptoms influenza yang telah dilakukan, maka hanya beberapa
field dari beberapa tabel yang akan digunakan, yaitu:
1. Tabel t_vo(id_vo, vo301)
2. Tabel t_vo12 (vo913, vo914,vo917,vo919,vo921,vo923)
3. Tabel t_vo22 (vo512,vo803, vo804, vo808, vo809, vo824)
4. Tabel t_vo33 (vo512,vo902, vo903,vo907,vo908,vo933)
Pemilihan atribut tersebut merupakan hasil analisis dari data korespondensi
penyebab kematian untuk otopsi verbal dengan kode ICD-10 dengan tabel
otopsi verbal terpilih. Dari data korespondensi penyebab kematian untuk
otopsi verbal dengan kode ICD-10 dipelajari dan dipilih symptoms influenza
dan kemudian di cocokkan dengan attribute dari tabel t_vo12, t_vo22 dan
t_vo33. Setelah dianalisis, symptoms influenza tersebut tidak sama antara
masing - masing tabel t_vo12, t_vo22 dan t_vo33, karena symptoms untuk
masing – masing kategori umur akan berbeda. Dan berikut keterangan dari
setiap atribut tersebut:
Tabel 3.5 Keterangan Atribut
Tabel Atribut Keterangan
t_vo id_vo Id otopsi verbal t_vo vo301 Nama almarhum t_vo12 vo906 kejang
t_vo12 vo911 penurunan_kesadaran t_vo12 vo913 demam
t_vo22 vo803 demam
t_vo22 vo806 demam_turun_naik t_vo22 vo807 menggigil
t_vo22 vo808 batuk t_vo22 vo809 batuk_3mgg t_vo22 vo812 napas_cepat t_vo22 vo814 dispnea t_vo22 vo815 dispnea_3mgg t_vo22 vo818 mengi
t_vo22 vo841 penurunan_kesadaran t_vo22 vo844 kejang
t_vo22 vo851 urin_sedikit t_vo22 vo852 ruam t_vo22 vo856 mata_merah t_vo22 vo858 penurunan_berat t_vo22 vo863 bengkak
t_vo33 vo902 demam
t_vo33 vo905 demam_turun_naik t_vo33 vo907 batuk
t_vo33 vo908 batuk_3mgg t_vo33 vo989 penurunan_berat t_vo33 vo982 ruam
t_vo33 vo960 penurunan_kesadaran t_vo33 vo963 kejang
3. Integrasi Data (Data Integration)
Dalam penulisan tugas akhir kali ini diasumsikan bahwa data yang diambil
sudah berupa tabel-tabel dalam satu server. Dari sumber data yang sudah
dijabarkan sebelumnya, berikut integrasi data yang diusulkan untuk
penyelesaian mining identifikasi penyebab kematian, dari data korespondensi
penyebab kematian untuk otopsi verbal dengan kode ICD-10 terbentuk tabel
t_tema, dari tabel otopsi verbal terpilih terbentuk tabel t_symptoms dimana
hubungan keduanya adalah many to many, maka menghasilkan tabel
t_temasymp sebagai tabel referensi. Berikut struktur tabel – tabel tersebut :
Tabel 3.6 Struktur Tabel t_symptoms
Field Type Null Default
id_symp int(11) No
Symptoms varchar(50) No Keterangan varchar(100) Yes NULL
Tabel 3.7 Isi Tabel t_symptoms
id_symp symptoms keterangan
1 demam Demam
2 demam_turun_naik Demam Turun Naik
3 batuk Batuk
4 batuk_3mgg Batuk kurang dari 3 minggu 5 penurunan_berat Penurunan Berat Badan
6 ruam Ruam
7 penurunan_kesadaran Penurunan Kesadaran
8 kejang Kejang
11 dispnea Dispnea / Sesak Napas 12 dispnea_3mgg Dispnea kurang dari 3
minggu 13 nyeri dada Nyeri Dada
14 dahak Produksi dahak meningkat 15 mata_merah Matah merah
16 bengkak Pembengkakan / Edema
17 mengi Mengi
Tabel 3.8 Struktur Tabel t_tema
Field Type Null Default
id_va int(11) No
kode_va varchar(8) Yes NULL tema_va varchar(100) Yes NULL
Tabel 3.9 Isi Tabel t_symptoms
id_va kode_va tema_va
1 VA-01.07 Campak 2 VA-01.10 Malaria
3 VA-01.13
Infeksi Saluran Napas Bawah (termasuk pneumonia dan bronkitis akut)
4 VA-05.01 Penyakit Paru Obstruktif Kronis 5 VA-05.02 Asma
Tabel 3.10 Struktur Tabel t_temasymp
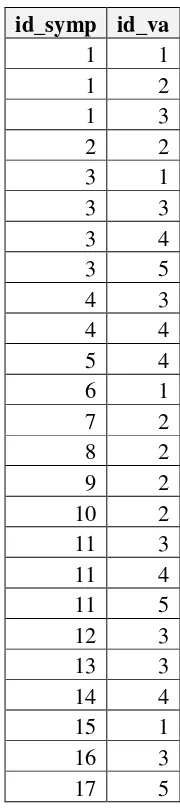
Field Type Null Default Links to
Tabel 3.11 Isi Tabel t_temasymp
4. Tranformasi Data (Data Transformation)
Dalam proses ini data akan ditransformasikan ke dalam data yang siap untuk
di mining, hasil dari transformasi data ini menghasilkan tabel t_kasus. Proses
tranformasi dimulai dari proses pembersihan tabel t_kasus untuk user sedang
semua kategori umur untuk setiap kematian pada data otopsi verbal dan
hasilnya akan disimpan dalam tabel t_kasus. Berikut struktur tabel t_kasus :
Tabel 3.12 Struktur Tabel t_kasus
Field Type Null Default Links to
id_vo int(11) No t_vo -> id_vo
id_symp int(11) No t_symptoms -> id_symp id_user int(11) No user -> id_user
Tabel 3.13 Isi Tabel t_kasus
id_vo id_symp id_user