APLIKASI COX PROPORTIONAL HAZARD MODEL
DI ASURANSI JIWA
(Studi Kasus pada AJB Bumiputera)
AFIEF ARYADHANI
PROGRAM STUDI MATEMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI
SYARIF HIDAYATULLAH
APLIKASI COX PROPORTIONAL HAZARD MODEL
DI ASURANSI JIWA
(Studi Kasus pada AJB Bumiputera)
Skripsi
Sebagai Salah Satu Syarat Untuk Memperoleh Gelar Sarjana Sains
Fakultas Sains dan Teknologi
Universitas Islam Negeri Syarif Hidayatullah Jakarta
Oleh:
Afief Aryadhani 107094000260
PROGRAM STUDI MATEMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI
SYARIF HIDAYATULLAH
LEMBAR PENGESAHAN
Skripsi berjudul “Aplikasi Cox Proportional Hazard Model di Asuransi Jiwa” yang ditulis oleh Afief Aryadhani, NIM 107094000260 telah diuji dan dinyatakan lulus dalam Sidang Munaqosyah Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta pada tanggal 7 Juni 2011, skripsi ini telah diterima sebagai salah satu syarat untuk memperoleh gelar sarjana strata satu (S1) Program Studi Matematika.
Menyetujui,
Penguji 1 Penguji 2
Taufik Edy Sutanto, M.Sc.Tech Yanne Irene, M.Si
NIP. 19790530 200604 1 002 NIP. 19741231 200501 2 018
Pembimbing 1 Pembimbing 2
Hermawan Setiawan, M.TI Suma’inna, M.Si NIP. 19740623 199312 2 001 NIP. 150408699
Mengetahui,
Dekan Fakultas Sains dan Teknologi Ketua Prodi Matematika
Dr. Syopiansyah Jaya Putra, M.Sis Yanne Irene, M.Si
PERNYATAAN
DENGAN INI SAYA MENYATAKAN BAHWA SKRIPSI INI BENAR-BENAR HASIL KARYA SENDIRI YANG BELUM PERNAH DIAJUKAN SEBAGAI SKRIPSI PADA PERGURUAN TINGGI ATAU LEMBAGA MANAPUN.
Jakarta, Juni 2011
Afief Aryadhani
PERSEMBAHAN
Sebuah persembahan satu langkah menuju kesuksesan teruntuk
kedua orang tuaku tercinta yang telah bekerja keras, memberikan semangat dan dukungan, serta doa agar anak-anaknya mencapai kesuksesan.
MOTO
Setiap individu mempunyai lama waktu yang sama dalam seharinya
Sama-sama mempunyai kedua orang tua dengan kasih sayangnya
Menuntut ilmu dengan karakteristik yang sama di dalamnya
Sekolah dengan fasilitas yang sama,
Guru/Dosen dengan tujuan yang sama, serta
Buku yang digunakan pun sama
Tentunya hasil yang didapat toh harus sama
Namun …
Terdapat perbedaan hasil yang didapatkannya dengan segudang persamaan
Untuk itu jadikanlah semua itu motivasi
Karena jika individu lain bisa
ABSTRAK
Asuransi merupakan suatu istilah untuk pengalihan resiko. Fungsi utama asuransi adalah sebagai pengalihan resiko yang diderita tertanggung kepada penanggungnya. Karena fungsi tersebut, perusahaan asuransi diharuskan untuk mengetahui faktor-faktor yang mempengaruhinya dan mengetahui probabilitas
dimana pada waktu tertentu tertanggung akan banyak mengajukan klaim asuransi. Analisis yang tepat untuk permasalahan ini adalah analisis survival dengan metode Cox Proportional Hazard Model, karena analisis ini berhubungan dengan keadaan survive seseorang dan waktu sebagai faktor utamanya. Faktor-faktor yang digunakan dalam Cox Proportional Hazard Model, yaitu Survival Time merupakan waktu tertanggung dari start point sampai terjadi event atau end point, Status merupakan keadaan tertanggung apakah tertanggung terjadi event atau sampai end point tidak terjadi event, Age merupakan umur tertanggung, Sex merupakan jenis kelamin tertanggung, Smoking merupakan kebiasaan merokok tertanggung, dan
Medical Test merupakan keadaan kesehatan tertanggung.
Cox Proportional Hazard Model pada akhirnya akan memberikan informasi tentang faktor-faktor yang berpengaruh secara statistika, yaitu variabel Age, Smoking
dan Medical Test. Perbandingan probabilitas survival faktor yang sama antar karakteristik yang berbeda yang dihasilkan adalah resiko terjadi event tertanggung dengan usia t+1 adalah 1.168 kali dari tertanggung yang dengan usia t. Resiko terjadi
event tertanggung yang merokok adalah 2.407 kali dari tertanggung yang tidak merokok. Resiko terjadi event tertanggung dengan hasil medical test standard adalah 0.038 kali dari tertanggung dengan hasil medical test penyakit berat, resiko terjadi
event tertanggung dengan hasil medical test penyakit ringan adalah 0.122 kali dari tertanggung dengan hasil medical test penyakit berat, dan resiko terjadi event
tertanggung dengan hasil medical test penyakit sedang adalah 0.123 kali dari tertanggung dengan hasil medical test penyakit berat. Serta informasi tentang waktu-waktu di mana tertanggung akan banyak mengajukan klaim asuransi adalah pada waktu 2 t 6 bulan pertama.
ABSTRACT
Insurance is one of term for the transfer of risk. The main function of insurance is as a transfer of risk from the insured to the insurer. Because that function, insurance company are required to determine the factors influencing and know the probability where at a certain time the insured will be many taking insurance claim.
The right analysis for this problem is survival analysis by Cox Proportional Hazard Model method, because this analysis relates to someone survival situation and the time as main factor. Another factors are used in the Cox Proportional Hazard Model, that is Survival time is the time of the insured from start point until an event occurs or an end point, Status is insured condition whether the insured event occurs or until end point is not an event occurs, Age is age of the insured, Sex is sex of the
insured, Smoking is smoking habits of the insured, and Medical Test is insured’s
health condition.
Eventually, Cox Proportional Hazard Model will provide information about the factors that influence the survival time statistically, that is Age, Smoking, and Medical Test variable. Comparison of survival probabilities between the different characteristics in the same factors that produced are, the risk of the insured event occurs by age t+1 is 1.168 times from the insured by age t. The risk of the insured event occurs by smoking habits is 2.407 times from the insured by not smoking habits. The risk of the insured event occurs by standard medical test result is 0.038 times from the insured by severe disease medical test result, the risk of the insured event ocuurs by lightly disease medical test result is 0.122 times from the insured by severe disease medical test result, and the risk of the insured event occurs by medium disease medical test result is 0.123 from the insured by severe disease medical test result. As well as information about the times where the insured will be many taking insurance claims are filed at the time 2 t 6 of the first month.
KATA PENGANTAR
ميح رلا نمح رلا ها مسب
Seraya memanjatkan puji serta syukur hanya bagi Allah SWT. Tuhan semesta alam, yang mana dengan nikmat dan karunianya kita semua bisa merasakan nikmat dan indahnya kehidupan ini. Shalawat serta salam semoga selalu tercurahkan kepada junjungan kita, yaitu Nabi Muhammad SAW, beserta keluarga, sahabat, serta segenap
pengikutnya sampai akhir zaman. Alhamdulillah hirobbil a’lamin penulis ucapkan
karena berkat rahmat dan karunia-Nya penulis dapat menyelesaikan skripsi ini sebagai salah satu syarat untuk memperoleh gelar sarjana sains yang berjudul,
“Aplikasi Cox Proportional Hazard Model di Asuransi Jiwa”.
Dengan segala kerendahan hati, penulis menyadari bahwa dalam penulisan skripsi ini masih terdapat banyak kekurangan, dan penulis mencoba berikhtiar senantiasa memberikan semaksimal mungkin dengan harapan skripsi ini dapat memperoleh hasil yang lebih baik.
Dalam kesempatan yang baik ini, perkenankan penulis menghaturkan ucapan Terima Kasih kepada:
1. Dr.Syopiansyah Jaya Putra, M.Sis. selaku Dekan Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta.
2. Yanne Irene, M.Si. selaku Ketua Program Studi Matematika Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta dan selaku penguji II.
3. Hermawan Setiawan, M.TI. selaku dosen pembimbing I yang telah menyediakan waktu dan senantiasa membimbing penulis dengan penuh kesabaran dalam mengambil tema, dan menjelaskan dasar-dasar teori sampai selesainya skripsi ini. 4. Suma’inna, M.Si. selaku dosen pembimbing II yang telah membimbing dalam
5. Sarini Abdullah, M.Stat. yang telah memberikan waktu di tengah kesibukannya untuk membimbing penulis dalam mempelajari dasar teori Survival Analysis.
Mohon maaf jika penulis banyak merepotkan ibu dan semoga ilmu ibu bermanfaat.
6. Taufik Edy Sutanto, M.Sc.Tech. selaku penguji I.
7. Seluruh staff AJB Bumiputera, khususnya mas Audi dan mas Didik yang telah membantu penulis dalam memperoleh data.
8. Seluruh dosen dan staff Program Studi Matematika Fakultas Sains dan Teknologi
UIN Syarif Hidayatullah Jakarta, khususnya ka’ Bambang Ruswandi, M.Stat.
yang telah banyak membantu dalam proses penyelesaian skripsi ini.
9. Kedua orang tuaku dan adik-adikku tercinta, yang senantiasa memberikan bantuan, dukungan dan doanya sehingga terselesaikannya skripsi ini.
10.Gadis ungilku, Anggraini yang telah banyak membantu, memberi dukungan dan mendoakan penulis. Susah, senang, panas, dan hujan kita lewati bersama agar terselesaikannya skripsi ini. Je t’aime.
11.Dan Seluruh teman-teman matematika, khsusunya matematika angakatan 2007, yang telah memberikan dukungan dan menerima saya selama 4 tahun ini sebagai teman kalian. Sukses semua.
Kritik dan saran konstruktif sangat penulis harapkan berkaitan dengan penyusunan skripsi ini yang masih jauh dari kesempurnaan. Semoga kita semua senantiasa diridhoi dan mendapatkan rahmat dan hidayah-Nya serta selalu berada di jalan yang lurus. Amin.
Jakarta, Juni 2011
DAFTAR ISI
HALAMAN JUDUL ………... i
LEMBAR PENGESAHAN ………... ii
PERNYATAAN ………. iii
PERSEMBAHAN DAN MOTO ………... iv
ABSTRAK ………. v
ABSTRACT ……… vi
KATA PENGANTAR ………... v ii DAFTAR ISI ……….. ix
DAFTAR TABEL .……….. xi
DAFTAR GAMBAR .……….. xii
DAFTAR LAMPIRAN ……….. xiii
BAB I. PENDAHULUAN 1.1. Latar Belakang ………..……… 1
1.2. Permasalahan ………. 3
1.3. Pembatasan Masalah .……….………... 3
1.4. Tujuan Penulisan ………...……… 4
1.5. Manfaat Penulisan ……...……….. 4
BAB II. LANDASAN TEORI 2.1. Definisi Asuransi .………….………….……….. 5
2.3. Survival Analysis .……… 10
2.4. Cluster Analysis .……….. 15
2.5. Penentuan Variabel ……….. 16
BAB III. METODE PENELITIAN 3.1. Metode Pengumpulan Data ……… 17
3.2. Metode Pengolahan Data ………... 19
3.3. Metode Analisis Data .………... 20
3.4. Alur Penelitian ………. 25
BAB IV. HASIL DAN PEMBAHASAN 4.1. Deskripsi ……….……….. 26
4.2. Pembuatan Persamaan ………... 28
4.3. Pengujian Kontribusi Peubah ………. 28
4.4. Model Terbaik ……… 31
4.5. Estimasi Fungsi Survival……… 33
4.6. Pengelompokkan Data………. 35
BAB V. KESIMPULAN DAN SARAN 5.1. Kesimpulan ……… 38
5.2. Saran ……….……….. 39 DAFTAR PUSTAKA
DAFTAR TABEL
Tabel 3.1. Nilai variabel dummy pada variabel Medical Test ……..……. 19 Tabel 4.1. Penyebaran pengamatan tiap karakteristik variabel …...…….. 26 Tabel 4.2. Penyebaran pengamatan yang tersensor tiap karakteristik
variabel ………...……….. 27
Tabel 4.3. Proses pemilihan variabel dalam uji peubah ganda
DAFTAR GAMBAR
Gambar 2.1. Contoh data sensor kanan …………..………...…… 12 Gambar 3.1. Alur Penelitian ………..………...……. 25 Gambar 4.1. Estimasi fungsi survival berdasarkan variabel kebiasaan
merokok ...………...…….. 33
DAFTAR LAMPIRAN
Lampiran 1. Iterasi Newton-Raphson .………. 41
Lampiran 2. Contoh Sebagian Data Analisis ..………. 42
Lampiran 3. Deskripsi Variabel Usia ……….. 43
Lampiran 4. Output Uji Kontribusi Peubah ………. 44
Lampiran 5. Estimasi Fungsi Survival dan Cumulative Hazard ………... 45
Lampiran 6. Dendogram ……….. 46
Lampiran 7. Anggota Masing-masing Cluster……… 47
BAB I
PENDAHULUAN
1.1. Latar Belakang
Asuransi merupakan suatu istilah yang dikenal sebagai pengalihan resiko. Sedangkan perusahaan asuransi merupakan suatu perusahaan yang bergerak dalam bidang mengatur pengelolaan resiko. Fungsi utama asuransi adalah sebagai pengalihan resiko yang diderita tertanggung kepada penanggungnya, tapi bukan berarti penanggung menanggung semua resiko tertanggung, melainkan sebagai imbalannya tertanggung harus membayarkan sejumlah uang yang disebut premi untuk biaya proteksi resiko yang mungkin akan menimpanya. Besar premi ditentukan pada saat perjanjian asuransi atau polis. Jenis-jenis asuransi beraneka ragam, salah satunya adalah asuransi jiwa, asuransi berkendaraan, asuransi kesehatan dan lain-lain. Walaupun banyak macam-macam asuransi, tetapi hanya terdapat sedikit perbedaan dalam jenis-jenis asuransi tersebut, tujuannya tetap satu yaitu sebagai pengalihan resiko.
Aktuaria merupakan salah satu bidang ilmu yang biasa memperhitungkan faktor-faktor dalam perhitungan asuransi, tetapi aktuaria tidak bisa memperkirakan seberapa besar resiko yang akan ditanggung perusahaan tersebut di masa yang akan datang, aktuaria hanya sebatas memperhitungkan faktor-faktor untuk menentukan berapa besar jumlah premi yang akan dibayarkan tertanggung.
Analisis yang dapat memprediksi waktu kedepannya diperlukan untuk menjawab pertanyaan ini. Terdapat beberapa analisis yang dapat digunakan untuk memprediksi, yaitu regresi dan time series. Time series memang analisis yang berhubungan dengan waktu, tetapi time series tidak menggunakan waktu sebagai faktor utamanya. Jadi regresi yang paling tepat digunakan untuk permasalahan ini, tetapi bukan regresi linier biasa yang digunakan, tetapi regresi yang menjadikan waktu sebagai faktor utamanya, yaitu Regresi Cox atau yang lebih dikenal dengan
Cox Proportional Hazard Model.
Cox Proportional Hazard Model banyak digunakan dalam survival analysis karena memiliki keuntungan bersifat semiparametrik, sehingga tidak dibutuhkan asumsi-asumsi tertentu dalam melakukan analisis tersebut. Keuntungan lainnya Cox Proportional Hazard Model tidak membutuhkan secara pasti dalam menentukan bentuk fungsi baseline hazard.
Cox Proportional Hazard Model sangat sensitif terhadap waktu, sehingga harus jelas dalam penentuan waktunya. Terdapat tiga kategori dalam penentuan waktu, pertama adalah waktu mulai penelitian (start point), kedua adalah waktu berakhir penelitian (end point) dan waktu kejadian/meninggal tertanggung (event).
sedangkan event adalah saat tertanggung meninggal (mengajukan klaim) dan end point adalah waktu selesai penelitian.
Faktor-faktor yang digunakan dalam Cox Proportional Hazard Model, yaitu survival time merupakan waktu tertanggung dari start point sampai terjadi
event atau end point, status merupakan keadaan tertanggung apakah tertanggung terjadi event atau sampai end point tidak terjadi event, age merupakan umur tertanggung, sex merupakan jenis kelamin tertanggung, smoking merupakan kebiasaan merokok tertanggung, dan medical test merupakan keadaan kesehatan tertanggung.
1.2. Permasalahan
Permasalahan yang diambil dalam penelitian ini adalah:
1. Faktor-faktor apa saja yang berpengaruh terhadap pengajuan klaim asuransi?
2. Berapakah perbandingan hazard terjadi pengajuan klaim antara variabel yang sama dengan kategori yang berbeda?
3. Pada selang waktu berapakah tertanggung-tertanggung akan mempunyai resiko terjadi pengajuan klaimpaling besar?
1.3. Pembatasan Masalah
Penelitian ini hanya akan membahas kasus asuransi jiwa kategori medical
1.4. Tujuan Penelitian
Tujuan penelitian adalah untuk mengetahui faktor-faktor apa saja yang berpengaruh dalam penentuan pengajuan klaim asuransi. Mulanya semua faktor yang dianggap penting dimasukkan dalam analisis, kemudian nantinya akan terlihat faktor-faktor apa saja yang berpengaruh secara statistik dalam penentuan klaim asuransi.
Tujuan kedua adalah untuk merumuskan perhitungan secara matematika untuk memprediksi waktu kritis perusahaan dengan kata lain perusahaan akan menanggung banyak tanggungan karena tertanggung mengalami event, dan mengetahui pada waktu yang akan datang sebanyak apa probabilitas perusahaan akan memberikan kewajibannya menanggung resiko tertanggungnya.
1.5. Manfaat Penelitian
Secara praktis, manfaat yang diperoleh dalam penelitian ini adalah jika terdapat seseorang yang baru melakukan polis, perusahaan asuransi dapat mengetahui termasuk kelompok tertanggung yang mana berdasarkan faktor-faktor tersebut dan dapat mengetahui waktu di mana perusahaan akan banyak tertanggung yang mengajukan klaim asuransi.
BAB II
LANDASAN TEORI
2.1. Definisi Asuransi
Definisi asuransi menurut Pasal 246 Kitab Undang-undang Hukum Dagang (KUHD) Republik Indonesia, “Asuransi atau pertanggungan adalah suatu perjanjian, dengan mana seorang penanggung mengikatkan diri pada tertanggung dengan menerima suatu premi, untuk memberikan penggantian kepadanya karena suatu kerugian, kerusakan atau kehilangan keuntungan yang diharapkan, yang mungkin akan dideritanya karena suatu peristiwa yang tak tertentu.”
Berdasarkan definisi tersebut, maka dalam asuransi terkandung 4 unsur, yaitu:
Pihak tertanggung (insured) yang berjanji untuk membayar uang premi
kepada pihak penanggung, sekaligus atau pun bisa juga secara berangsur-angsur
Pihak penanggung (insure) yang berjanji akan membayar sejumlah uang
(santunan) kepada pihak tertanggung, sekaligus atau secara berangsur-angsur apabila terjadi sesuatu yang mengandung unsur tak tertentu (meninggal)
Suatu peristiwa (accident) yang tak tertentu (tidak diketahui
sebelumnya/tidak disengaja)
Kepentingan (interest) yang mungkin akan mengalami kerugian karena
2.2. Dasar Teori Analysis Survival
2.2.1. probability density function (pdf) dan cumulative density function (cdf)
Misal variabel acak kontinu T didefinisikan sebagai waktu survival dan misalkan ( )f t merupakan probability density function (pdf), didefinisikan sebagai
[2]:
1. f t( )0, tR.
2. f t dt( ) 1
.3. ( ) ( )
b
a
p a t b
f t dt.sehingga diberikan F t( ) merupakan cdf dari persamaan tersebut:
0
( ) ( ) ( )
t
F t P T t
f u du. (2.1)2.2.2. Fungsi Survival (Survival Function)
Fungsi survival menyatakan sebagai suatu peluang ketahanan observasi yang diamati selama waktu t. Misal S t( ) adalah fungsi survival, didefinisikan
sebagai berikut [4]:
( ) ( )
S t P T t . (2.2)
dari persamaan (2.2) di atas diperoleh:
( ) 1 ( )
S t P T t 1 F t( ) (2.3)
dan diperoleh hubungan: ( )
( ) dS t '( )
f t S t
dt
hal ini dapat ditunjukkan sebagai berikut [3]:
0
( ) ( ) ( )
( ) lim
t
dF t F t t F t
f t
dt t
0 0
( ) ( ) [1 ( )] [1 ( )]
lim lim
t t
P T t t P T t S t t S t
t t 0 [ ( ) ( )] ( )
lim '( )
t
S t t S t dS t
S t t dt .
2.2.3. Fungsi Hazard (Hazard Function)
Fungsi hazard menyatakan sebagai perbandingan rasio peluang kematian/kegagalan pada selang waktu antara t dan (t t). Misal h t( ) adalah
Fungsi hazard yang didefinisikan sebagai berikut [4]:
0
( )
( ) lim
t
P t T t t T t h t t 0
( ) 1
lim .
( )
t
P t T t t T t
t P T t
0
1 ( )
. lim
( ) t
P t T t t
P T t t
0
1 ( ) ( )
. lim
( ) t
P T t t P T t
P T t t
1 ( ) ( )
.
( ) ( )
dF t f t S t dt S t
. (2.5)
berdasarkan persamaan (2.5) dan (2.4) diperoleh hubungan: '( ) ( ) ( ) S t h t S t
( ln ( ))
d S t
dt
sehingga mempunyai fungsi cumulativehazard H t( ):
0
( ) ( )
t
H t
h u du
0
( ln ( ))
ln ( ) t
d S u
du S t du
. (2.7)jika persamaan (2.7) ditransformasi dalam bentuk exponensial diperoleh: ( ) exp( ( ))
S t H t . (2.8)
2.2.4. Maximum Likelihood Estimation (MLE)
Untuk menduga parameter model digunakan prosedur maximum likelihood estimation berdasarkan atas kemungkinan bersyarat dikenal dengan nama partial likelihood.
Misal Li adalah likelihood dari kegagalan pada suatu waktu dalam himpunan Ri, di mana himpunan resiko pada waktu ti berisi individu-individu
yang bertahan hidup hingga waktu t i disebut Ri { ( )}R ti dengan i adalah
spesifikasi waktu kegagalan sebanyak k waktu kegagalan. Perkalian peluang untuk setiap observasi waktu yang terjadi event membentuk persamaan kemungkinan L( ) yang hanya bergantung pada , sehingga didefinisikan sebagai berikut [5]:
1 2 1 ( ) . . ... . k k i i
L L L L L
dengan 0
0
( ) exp( ) ( ) exp( )
i
i i i
i l l R
h t X L
h t X
, sehingga diperoleh:0
1 0
( ) exp( ) ( )
( ) exp( )
i
k
i i
i i l
l R
h t X L
h t X
Persamaan (2.9) disebut partial likelihood. Persamaan ini tidak bergantung pada h t0( ), karena untuk menduga parameter-parameter i di dalam model regresi cox tidak perlu mengetahui h t0( ), sehingga diperoleh:
1 exp( ) ( ) exp( ) i k i i
i i l
l R X L X
. (2.10)Untuk mempermudah pencarian penduga kemungkinan maksimum L( ) ,
maka persamaan tersebut ditransformasi dalam bentuk ln menjadi ln L( ( )) .
Memaksimumkan ln L( ( )) dengan cara menurunkannya terhadap , yaitu:
( ) 0
d lnL
d . (2.11)
Untuk kasus sederhana, perhitungan dapat dilakukan secara eksak, namun jika kasus sudah meliputi multivariable dan mempunyai data dalam cakupan besar, maka dilakukan perhitungan secara numerik dengan bantuan software
dengan metode pemaksimuman yang digunakan adalah prosedur iterasi Newton-Raphson yang dapat dilihat pada lampiran 1.
2.2.5. Pengujian Kontribusi Peubah
A. Uji peubah tunggal
Uji peubah tunggal merupakan suatu uji yang dilakukan untuk mengetahui variabel-variabel apa saja yang berpengaruh terhadap model secara masing-masing terhadap model. Dengan mengasumsikan data berdistribusi normal baku atau Z-score, maka digunakan Uji Wald sebagai uji peubah tunggal dengan [5]:
( ) W SE
di mana: = koefisien penduga parameter
SE( ) = standard error penduga parameter .
B. Uji peubah ganda
Pengujian peubah ganda berkebalikkan dengan uji peubah tunggal, dalam pengujian peubah ganda dilakukan pengajuan kontribusi peubah secara bersama-sama. Uji statistik yang digunakan adalah likelihood ratio (LR) dengan menggunakan log likelihood statistik. LR dikenal juga dengan nama uji
Chi-Square (2) didefinisikan sebagai berikut [5]:
2
2lnLm r ( 2lnLm)
2(lnLm r lnLm). (2.13)
dengan: Lm = loglikelihood statistik dengan m variabel
m r
L = loglikelihood statistik dengan m variabel dan disisihkan sebanyak r
variabel.
2.3. Survival Analysis
2.3.1. Definisi Survival Analysis
individu. Kegagalan yang dimaksudkan antara lain adalah ketika tertanggung meninggal atau mengajukan klaim dikarenakan tertanggung terkena suatu musibah, seperti sakit, kecelakaan atau terkena bencana alam, sehingga pihak perusahaan asuransi harus menanggung biaya klaim yang diajukan itu. Maka waktu survival yang dicatat antara lain sebagai berikut [4]:
a. Selisih waktu mulai dilakukannya pengamatan sampai terjadinya pengajuan klaim, dengan kata lain tertanggung meninggal (event) dan data tersebut termasuk data tidak tersensor,
b. Jika waktu pengajuan klaim tidak diketahui (tertanggung survive), maka memakai selisih waktu mulai dilakukannya pengamatan sampai waktu terakhir penelitian dan data tersebut termasuk data tersensor (censored data).
Data tersensor merupakan data yang mendapatkan penyensoran karena sebab-sebab tertentu. Umumnya terdapat tiga alasan mengapa terjadi penyensoran, yaitu:
1.) Seseorang yang tidak terjadi event (meninggal) sampai end point,
2.) Seseorang yang informasinya tidak dapat diketahui kelanjutannya selama masa penelitian,
3.) Seseorang yang meninggal yang kematiannya karena alasan tertentu, karena narkoba, bunuh diri atau yang lainnya yang disengaja [5].
tertanggung tidak mengalami event. Dalam penelitian ini data termasuk data tersensor kanan, penyensoran pada data tersensor kanan dilakukan karena tertanggung diketahui sampai batas waktu penelitian tidak mengalami event.
Gambar 2.1. Contohdata sensor kanan
Sedangkan yang dinamakan data tersensor kiri adalah data yang mengalami penyensoran saat waktu kejadian kurang dari suatu nilai tertentu. Contohnya adalah penelitian balita yang mampu berjalan pada usia satu tahun, maka data tersensornya adalah balita yang mampu berjalan sebelum usia satu tahun [3].
2.3.2. Cox Proportional Hazard Model
Ada beberapa teori yang pernah membahas tentang survival analysis yaitu di antaranya adalah Kaplan-meier dan Cox. Pada mulanya permodelan dari teori ini digunakan pada cabang ilmu kedokteran, di mana mereka menganalisis kematian atau harapan hidup seseorang, namun permodelan ini semakin berkembang dan digunakan dalam bidang-bidang lain.
[image:26.595.143.527.183.398.2](0, i
t ~) adalah waktu seorang individu dapat bertahan dari penyakit hingga
kejadian, sedangkan wi bernilai 1 apabila individu tersebut mengalami event (meninggal) sehingga mengajukan klaim pada waktu ti dan bernilai 0 apabila
individu tersebut tersensor pada ti, Xi merupakan variabel dari individu ke-i
dimana Xi [X X1 2...Xip] dengan Xip berupa variabel dummy yang memiliki
nilai 0 atau 1.
Fungsi hazard yang bergantung pada variabel dapat ditulis sebagai berikut [5]:
0
1
( , ) ( ).exp( . )
p
i i i
h t X h t X
(2.14)dengan: h t X( , ) = resiko kematian individu pada waktu t dengan karakteristik X
h t0( ) = fungsi hazard baku
i = parameter variabel Xi
Jika variabel X1X2 ... Xp0, maka fungsi hazard tersebut
merupakan fungsi baseline hazard atau hazard baku yang hanya bergantung pada waktu, sehingga diperoleh [5]:
0
( , ) ( ).exp(0)
h t X h t
0( )
h t
Membandingkan persamaan hazard (2.14) dengan variabel sama dan kategori berbeda yang bebas terhadap waktu t, maka diperoleh hazard ratio.
Hazard ratio didefinisikan sebagai hazard untuk satu individu dibagi dengan
0 1
0
1
( ) exp( *)
( , *) ( , )
( ) exp( )
p i i i p i i i
h t X
h t X HR
h t X
h t X
1exp( ( * ))
p
i i i
i
X X
(2.15)2.3.3. Estimasi Fungsi Survival
Fungsi survival yang bergantung pada variabel adalah sebagai berikut [5]:
1
exp( . )
0 ( , ) ( ) p i i i X
S t X S t
(2.16)
dengan: S t X( , ) = kemungkinan survive individu pada waktu t dengan karakteristik X
S t0( ) = fungsi survival
i = parameter variabel Xi
Umumnya estimasi fungsi survival menggunakan estimasi Kaplan-Meier
yang disebut Product-Limit Estimator. Estimasi ini didefinisikan untuk semua nilai t pada data adalah sebagai berikut [6]:
1
0
1
,
, .
( )
{
ii i t ti
d Y i t t t t S t
(2.17)
dengan: ti = waktu terjadi event
di= jumlah kematian pada waktu ti
Yi= jumlah tertanggung yang beresiko terjadi event pada waktu ti.
Estimasi kumulatif hazard menggunakan estimasi Nelson-Aalen
didefinisikan sebagai berikut [6]:
1
0
,
, .
( )
{
ii i i t ti
2.4. Cluster Analysis
Cluster analysis adalah suatu teknik untuk menggabungkan observasi-observasi ke dalam beberapa grup atau kelompok dengan:
1. Setiap grup atau kelompok merupakan kelompok yang homogen atau padat dengan karakter yang sama,
2. Setiap grup atau kelompok akan dibedakan dari grup lainnya dengan karakternya masing-masing [7].
Penelitian ini menggunakan algoritma K-Means Cluster dengan menggunakan bantuan hierarchical clustering terlebih dahulu untuk mengetahui jumlah pengelompokkan yang sesuai dengan datanya. Langkah-langkah algoritma
K-Means Cluster adalah seperti dibawah ini [8]:
1) Tentukan q sebagai jumlah cluster yang ingin dibentuk
2) Bangkitkan q centroids sebagai titik pusat cluster awal secara acak
3) Hitung jarak setiap data ke centroids dengan jarak Euclidean seperti dibawah ini:
2
, 1 1
( )
p n
ij ik jk
i j k
D d d
(2.19)
dengan: Dij= jarak antara observasi i dan j
dik= observasi i pada variabel k
djk= observasi j pada variabel k
5) Tentukan posisi centroids baru dengan cara menghitung nilai rata-rata dari data yang mempunyai jarak centroids yang sama dengan:
1 1
1
( )
p n
q ik
i k q
C d
n
(2.20)dengan: nq= jumlah data cluster ke-q
2.5. Penentuan variabel
Umumnya faktor-faktor yang berperan dalam ilmu asuransi adalah [5]: 1. Usia
Usia seseorang mempunyai kaitan langsung terhadap kesehatan, semakin tua tertanggung, maka akan semakin tinggi resiko terkena penyakit.
2. Jenis kelamin
Jenis kelamin juga mempengaruhi kesehatan, karena pengalaman menunjukan, secara rata-rata kehidupan wanita lebih lama lima atau enam tahun dari pada kehidupan pria.
3. Kebiasaan
Kebiasaan hidup seseorang juga mempengaruhi kesehatannya. Misal kebiasaan merokok, makan berlebihan atau minum beralkohol akan mempunyai pengaruh besar terhadap kesehatan.
BAB III
METODE PENELITIAN
3.1. Metode Pengumpulan Data
Jenis data yang digunakan dalam penelitian ini adalah data sekunder tahun 2009 yang diperoleh dari Perusahaan Asuransi Bumiputera. Data yang dikumpulkan berupa hal-hal yang diperlukan dalam melakukan analisis, yaitu waktu klaim, umur, jenis kelamin, kebiasaan merokok, dan medical test.
Pendefinisian masing-masing variabel adalah sebagai berikut:
1. Waktu klaim
Data waktu klaim dihitung dalam skala bulan yang merupakan pengurangan antara waktu end point dengan waktu start point. Start point untuk data tersensor maupun event adalah waktu tertanggung terdaftar menjadi anggota asuransi, sedangkan untuk end point terdapat perbedaan antara data tersensor dan
event. Untuk data tersensor waktu end point adalah waktu selesai penelitian dengan kata lain sampai berakhir masa penelitian tertanggung tidak terjadi
event/meninggal, sebaliknya untuk data event waktu end point adalah waktu tertanggung terjadi event/meninggal.
2. Penyensoran
jika terdapat waktu pengajuan klaim diberi nilai 1, menyatakan bahwa data tersebut terjadi event, dengan kata lain tertanggung meninggal.
3. Usia
Data usia diukur dalam satuan tahun, dan diperoleh berdasarkan usia tertanggung pada saat masuk menjadi konsumen asuransi pada perusahaan tersebut.
4. Jenis kelamin
Data jenis kelamin diperoleh dengan memberikan nilai 0 untuk tertanggung berjenis kelamin perempuan, dan diberi nilai 1 untuk tertanggung berjenis kelamin laki-laki.
5. Kebiasaan merokok
Data kebiasaan merokok diperoleh dengan memberi nilai 0 jika tertanggung mempunyai kebiasaan tidak merokok dan diberi nilai 1 jika tertanggung mempunyai kebiasaan merokok.
6. Medical test
Data medical test diperoleh dengan membentuk variabel dummy dengan variabel pembanding adalah tertanggung dengan kategori penyakit berat (SS5 & SS6). Kriterianya sebagai berikut, untuk dummy 1 bernilai 1 untuk kategori
dan bernilai 0 untuk kategori standard (STD), penyakit ringan (SS1 & SS2), maupun penyakit berat (SS5 & SS6). Untuk jelasnya dapat dilihat pada tabel 3.1. di bawah ini:
Tabel 3.1. Nilai variabel dummy pada variabel Medical_Test
MEDICAL_TEST
Variabel dummy
dummy 1 dummy 2 dummy 3
Standard 1 0 0
Penyakit Ringan 0 1 0
Penyakit Sedang 0 0 1
Penyakit Berat 0 0 0
3.2. Metode Pengolahan Data
Pengolahan data dalam penelitian ini menggunakan bantuan software
dengan variabel dependen adalah Waktu klaim (Survt(Y)), penyensoran (Status), dan variabel-variabel independennya adalah usia (Age(X1)), jenis kelamin
(Sex(X2)), kebiasaan merokok (Smoking(X3)), dummy 1 (X4.1), dummy 2 (X4.2),
dan dummy 3 (X4.3).
Uraian penelitian berupa, identifikasi variabel, pembuatan persamaan dengan mengasumsikan semua variabel berpengaruh terhadap model, uji kontribusi peubah untuk mengetahui variabel apa daja yang berpengaruh terhadap model dengan uji Wald dan uji Chi-Square, pembuatan model terbaik, estimasi fungsi survival dengan estimasi Kaplan-Meier dan fungsi kumulatif hazard
dengan estimasi Nelson-Aalen, dan terakhir adalah pengelompokkan dengan
3.3. Metode Analisis Data
Analisis data yang digunakan dalam penelitian ini adalah:
1. Deskripsi data
Mendeskripsikan data bertujuan untuk menampilkan jumlah keseluruhan data, jumlah data tersensor untuk semua variabel maupun berdasarkan masing-masing variabel dan mengertahui persentase data tersensor.
2. Pembuatan persamaan
Bentuk dasar cox proportional hazard model pada persamaan (2.14) adalah sebagai berikut:
1. 1 2. 2 ... .
0
( , ) ( ). X X pXp
h t X h t e
dengan menganggap semua variabel berpengaruh terhadap model, maka semua variabel dimasukkan ke dalam model, sehingga estimasi model menjadi:
1. 2. 3. 4.1. 1 4.2. 2 4.3. 3
0
( , ) ( ). AGE SEX SMOKING dummy dummy dummy
h t X h t e
3. Pengujian kontribusi peubah
Pengujian di sini berguna untuk mencari variabel yang berpengaruh terhadap model yang akan dibuat. Dalam hal ini terdapat dua analisis yang digunakan, yaitu analisis peubah tunggal dan analisis peubah ganda.
Mula-mula semua variabel diuji secara bersama-sama dengan menggunakan likelihood ratio (LR) atau dikenal dengan nama uji Chi-Square
2
bersama-sama terhadap model. Hipotesis dari pengujian tersebut adalah sebagai berikut [9]:
H0: 12 ... 430
H1: i 0, i1, 2,3, 4.1, 4.2, 4.3
dengan taraf nyata α = 5%, dan berdasarkan nilai signifikan, maka jika nilai signifikan > 0.05, maka terima H0, kesimpulannya semua variabel tidak
berpengaruh signifikan secara bersama-sama terhadap model. Dan jika nilai signifikan <0.05, maka tolak H0, kesimpulannya semua variabel berpengaruh
signifikan secara bersama-sama terhadap model.
Jika diketahui bahwa variabel-variabel tersebut tidak berpengaruh signifikan terhadap model, maka variabel-variabel tersebut tidak layak untuk dibentuk dalam model karena akan menghasilkan error yang besar dan tidak sesuai dengan keadaan data sebenarnya. Sebaliknya jika diketahui bahwa variabel tersebut berpengaruh signifikan terhadap model, maka variabel-variabel tersebut dilanjutkan dengan uji peubah tunggal. Analisis peubah tunggal menggunakan uji Wald dengan hipotesis sebagai berikut [9]:
a. Usia/Age (X1)
H0: 10 (variabel usia tidak berpengaruh signifikan terhadap model)
H1: 10 (variabel usia berpengaruh signifikan terhadap model)
dengan taraf nyata α = 5%, dan berdasarkan nilai signifikan, maka jika nilai signifikan > 0.05, maka terima H0, kesimpulannya variabel usia tidak berpengaruh
signifikan terhadap model. Sebaliknya jika nilai signifikan > 0.05, maka tolak H0,
b. Jenis kelamin/Sex (X2)
H0: 2 0 (variabel jenis kelamin tidak berpengaruh signifikan terhadap model)
H1: 2 0 (variabel jenis kelamin berpengaruh signifikan terhadap model)
Dengan taraf nyata α = 5%, dan berdasarkan nilai signifikan, maka jika nilai signifikan > 0.05, maka terima H0, kesimpulannya variabel jenis kelamin tidak
berpengaruh signifikan terhadap model. Sebaliknya jika nilai signifikan > 0.05, maka tolak H0, kesimpulannya variabel jenis kelamin berpengaruh signifikan
terhadap pembentukkan model.
c. Kebiasaan merokok/Smoking (X3)
H0: 30 (variabel merokok tidak berpengaruh signifikan terhadap model)
H1: 30 (variabel merokok berpengaruh signifikan terhadap model)
Dengan taraf nyata α = 5%, dan berdasarkan nilai signifikan, maka jika nilai signifikan > 0.05, maka terima H0, kesimpulannya variabel kebiasaan merokok
tidak berpengaruh signifikan terhadap model. Sebaliknya jika signifikan > 0.05, maka tolak H0, kesimpulannya variabel kebiasaan merokok berpengaruh
signifikan terhadap model.
d. Dummy1 (X4.1)
H0: 4.10 (variabel dummy 1 tidak berpengaruh signifikan terhadap model)
H1: 4.10 (variabel dummy 1 berpengaruh signifikan terhadap model)
Dengan taraf nyata α = 5%, dan berdasarkan nilai signifikan, maka jika nilai signifikan > 0.05, maka terima H0, kesimpulannya variabel dummy 1 tidak
maka tolak H0, kesimpulannya variabel dummy 1 berpengaruh signifikan terhadap
model.
e. Dummy2 (X4.2)
H0: 4.2 0 (variabel dummy 2 tidak berpengaruh signifikan terhadap model)
H1: 4.2 0 (variabel dummy 2 berpengaruh signifikan terhadap model)
Dengan taraf nyata α = 5%, dan berdasarkan nilai signifikan, maka jika nilai signifikan > 0.05, maka terima H0, kesimpulannya variabel dummy 2 tidak
berpengaruh signifikan terhadap model. Sebaliknya jika nilai signifikan > 0.05, maka tolak H0, kesimpulannya variabel dummy 2 berpengaruh signifikan terhadap
model.
f. Dummy3 (X4.3)
H0: 4.30 (variabel dummy 3 tidak berpengaruh signifikan terhadap model)
H1: 4.30 (variabel dummy 3 berpengaruh signifikan terhadap model)
Dengan taraf nyata α = 5%, dan berdasarkan nilai signifikan, maka jika nilai signifikan > 0.05, maka terima H0, kesimpulannya variabel dummy 3 tidak
berpengaruh signifikan terhadap model. Sebaliknya jika nilai signifikan > 0.05, maka tolak H0, kesimpulannya variabel dummy 3 berpengaruh signifikan terhadap
model.
4. Pembuatan model terbaik
Pembuatan model terbaik dapat dilakukan setelah pengujian kontribusi peubah dilakukan. Hasil pengujian kontribusi peubah akan dapat memperlihatkan variabel apa saja yang berpengaruh signifikan dan tidak berpengaruh signifikan terhadap model.
Dengan memasukkan variabel X1,...,Xp ke dalam model, di mana
1,..., p
X X merupakan variabel yang signifikan terhadap model. Dan membuang
variabel yang tidak signifikan terhadap model, sehingga diperoleh cox proportional hazardmodel terbaik.
5. Estimasi Fungsi Survival
Estimasi fungsi Survival tertanggung sampai waktu t dengan variabel X
adalah [5]:
0
exp( . )
0
( , ) ( )
p i i i
X
S t X S t
(3.1)
Dari persamaan (3.1) terlihat bahwa untuk menduga S t X( , ), maka S t0( )
harus diduga terlebih dahulu dengan Product-Limit Estimator pada persamaan (2.17).
6. Pengelompokkan data
Cluster analysis berperan untuk mengelompokkan semua probabilitas
estimasi nilai survival untuk setiap kombinasi variabel yang digunakan. Jika semua variabel dimasukkan, maka akan menghasilkan kombinasi probabilitas
estimasi nilai survival yang relatif banyak. Sehingga digunakan cluster analysis
3.4. Alur Penelitian
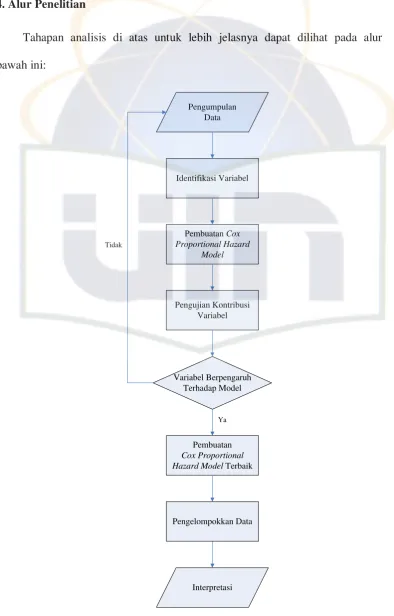
Tahapan analisis di atas untuk lebih jelasnya dapat dilihat pada alur dibawah ini:
Pengumpulan Data
Variabel Berpengaruh Terhadap Model
Pembuatan
Cox Proportional Hazard Model Terbaik
Interpretasi Identifikasi Variabel
Pembuatan Cox Proportional Hazard
Model
Pengelompokkan Data
Ya Tidak
Pengujian Kontribusi Variabel
[image:39.595.127.522.117.734.2]BAB IV
HASIL DAN PEMBAHASAN
4.1. Deskripsi
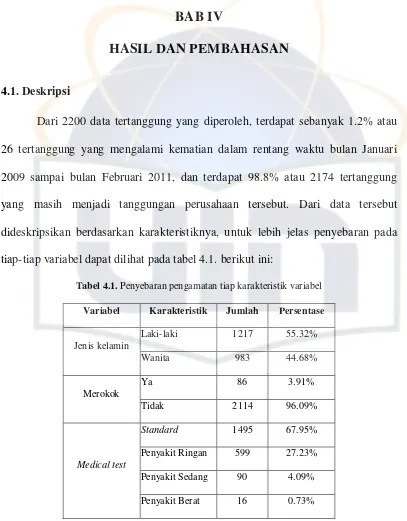
[image:40.595.113.520.106.627.2]Dari 2200 data tertanggung yang diperoleh, terdapat sebanyak 1.2% atau 26 tertanggung yang mengalami kematian dalam rentang waktu bulan Januari 2009 sampai bulan Februari 2011, dan terdapat 98.8% atau 2174 tertanggung yang masih menjadi tanggungan perusahaan tersebut. Dari data tersebut dideskripsikan berdasarkan karakteristiknya, untuk lebih jelas penyebaran pada tiap-tiap variabel dapat dilihat pada tabel 4.1. berikut ini:
Tabel 4.1. Penyebaran pengamatan tiap karakteristik variabel
Variabel Karakteristik Jumlah Persentase
Jenis kelamin
Laki-laki 1217 55.32%
Wanita 983 44.68%
Merokok
Ya 86 3.91%
Tidak 2114 96.09%
Medical test
Standard 1495 67.95%
Penyakit Ringan 599 27.23%
Penyakit Sedang 90 4.09%
Penyakit Berat 16 0.73%
Ket: Variabel lainnya terdapat pada lampiran 3
yang mempunyai kebiasaan tidak merokok. Tertanggung yang tidak mempunyai penyakit sebelumnya (Standard) adalah sebanyak 67.95%, tertanggung yang mempunyai penyakit kategori Penyakit Ringan sebanyak 27.23%, tertanggung yang mempunyai penyakit kategori Penyakit Sedang sebanyak 4.09% dan sisanya adalah tertanggung yang mempunyai penyakit Penyakit Berat sebanyak 0.73%.
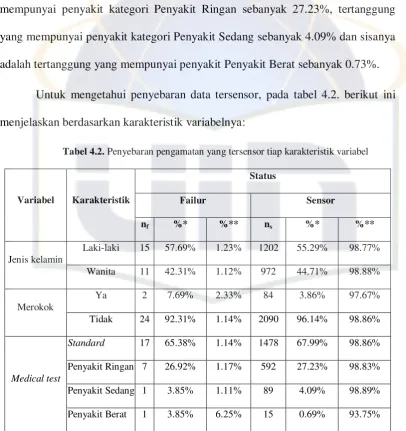
[image:41.595.114.521.167.599.2]Untuk mengetahui penyebaran data tersensor, pada tabel 4.2. berikut ini menjelaskan berdasarkan karakteristik variabelnya:
Tabel 4.2. Penyebaran pengamatan yang tersensor tiap karakteristik variabel
Variabel Karakteristik
Status
Failur Sensor
nf %* %** ns %* %**
Jenis kelamin
Laki-laki 15 57.69% 1.23% 1202 55.29% 98.77%
Wanita 11 42.31% 1.12% 972 44.71% 98.88%
Merokok
Ya 2 7.69% 2.33% 84 3.86% 97.67%
Tidak 24 92.31% 1.14% 2090 96.14% 98.86%
Medical test
Standard 17 65.38% 1.14% 1478 67.99% 98.86%
Penyakit Ringan 7 26.92% 1.17% 592 27.23% 98.83%
Penyakit Sedang 1 3.85% 1.11% 89 4.09% 98.89%
Penyakit Berat 1 3.85% 6.25% 15 0.69% 93.75%
Ket: *:Persentase dalam variabel dan status yang sama berdasarkan karakteristik yang berbeda
**: Persentase dalam variabel dan karakteristik yang sama berdasarkan status yang berbeda
resiko tertanggung berjenis kelamin wanita. Untuk variabel medical test, jika dilihat dalam bentuk persentase per karakteristik memang tidak menarik perhatian, tetapi jika dilihat dalam bentuk persentase antara failure dan sensor, maka akan terlihat bahwa tertanggung yang mempunyai kategori penyakit berat dan tertanggung yang merokok mempunyai persentase yang lebih besar dibandingkan yang lainnya, yaitu berturut-turut sebesar 6.25% dan 2.33%, sedangkan yang lainnya hanya sekitar 1%.
4.2. Pembuatan Persamaan
Pertama-tama dengan menganggap semua variabel berpengaruh terhadap model, maka semua variabel dimasukkan ke dalam persamaan (2.14), sehingga diperoleh estimasi coxproportional hazard model sebagai berikut:
0.155* 0.012* 0.875* 2.219* 1 2.1* 2 2.024 3
0
( ; ) ( ). AGE SEX SMOKING dummy dummy dummy
h t X h t e
persamaan tersebut mempunyai nilai sign 0.078 dan berdasarkan
likelihood ratio (LR) menghasilkan -2 log likelihood sebesar 377.668. Model ini mempunyai nilai signifikan > 0.05, berarti model ini tidak digunakan karena mempunyai nilai error lebih dari 5%.
4.3. Pengujian Kontribusi Peubah
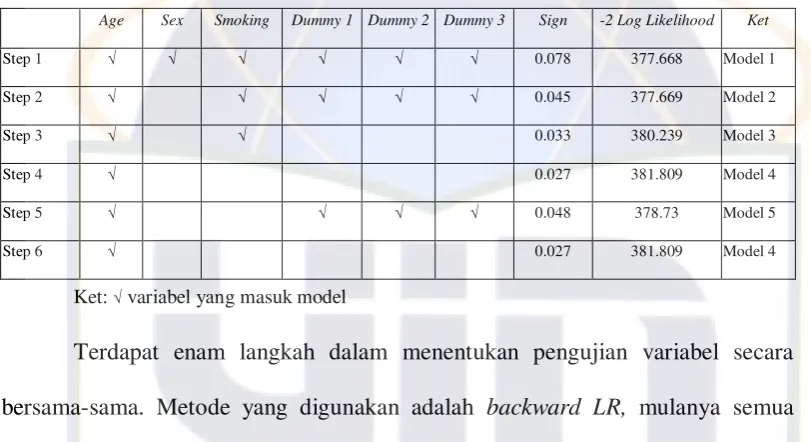
Tabel 4.3. di bawah ini memperlihatkan proses pemilihan variabel dalam uji peubah ganda:
Tabel 4.3. Proses pemilihan variabel dalam uji peubah ganda menggunakan metode backward LR
Age Sex Smoking Dummy 1 Dummy 2 Dummy 3 Sign -2 Log Likelihood Ket
Step 1 √ √ √ √ √ √ 0.078 377.668 Model 1
Step 2 √ √ √ √ √ 0.045 377.669 Model 2
Step 3 √ √ 0.033 380.239 Model 3
Step 4 √ 0.027 381.809 Model 4
Step 5 √ √ √ √ 0.048 378.73 Model 5
Step 6 √ 0.027 381.809 Model 4
Ket: √ variabel yang masuk model
Terdapat enam langkah dalam menentukan pengujian variabel secara bersama-sama. Metode yang digunakan adalah backward LR, mulanya semua variabel dimasukkan menghasilkan model 1 dengan nilai sign 0.078. Pada langkah ke-2 variabel jenis kelamin dikeluarkan dari model, sehingga menghasilkan model 2 dengan nilai sign 0.045. Pada langkah ke-3 variabel medical test dikeluarkan dari model, menghasilkan model 3 dengan nilai sign 0.033. Pada langkah ke-4 variabel kebiasaan merokok dikeluarkan dari model, menghasilkan model 4 dengan nilai sign 0.027. Pada langkah ke-5 memasukkan kembali variabel
medical test ke dalam model, menghasilkan model 5 dengan nilai sign 0.048. dan langkah terakhir kembali mengeluarkan variabel medical test dari model, menghasilkan model yang sama seperti langkah ke-4.
model 2 dengan tiga variabel di dalamnya yang berpengaruh bersama-sama terhadap model, model 3 dengan dua variabel yang berpengaruh bersama-sama terhadap model, model 4 dengan satu variabel yang berpengaruh bersama-sama terhadap model, dan model 5 dengan dua variabel yang berpengaruh bersama-sama terhadap model. Model yang paling signifikan dalam uji peubah ganda adalah model 4, tetapi hanya terdapat satu variabel yang berarti model ini hanya mewakili sebagian kecil variansi dari populasi data, dengan kata lain model ini banyak kehilangan informasi dari populasi data tersebut. Sedangkan model yang signifikan dan dianggap mewakili variansi populasi data adalah model 2 dengan tiga variabelnya, yaitu umur, kebiasaan merokok, dan medical test yang terdiri dari tiga variabel dummy menghasilkan -2 log likelihood 377.669.
Terdapat tiga variabel dalam model 2 yang berpengaruh bersama-sama terhadap model secara statistika. Untuk mengetahui variabel tersebut berpengaruh secara masing-masing, maka variabel-variabel tersebut diuji dengan uji peubah tunggal menggunakan uji Wald. Pada lampiran 4 memperlihatkan bahwa variabel
4.4. Pembuatan Model Terbaik
[image:45.595.114.513.327.560.2]Terdapat 5 model yang dibentuk dalam uji peubah ganda dan terdapat 4 model yang signifikan. Model yang paling signifikan dalam uji peubah ganda adalah model 4, tetapi hanya terdapat satu variabel yang berpengaruh signifikan terhadap model, mengakibatkan model banyak kehilangan variansi dari populasi data, sehingga dipilih model 2 dengan tiga variabel yang berpengaruh signifikan terhadap model. Namun, setelah diuji secara masing-masing dengan uji peubah tunggal, hanya dua dari tiga variabel yang berpengaruh signifikan terhadap model, sisanya tidak berpengaruh signifikan terhadap model. Untuk lebih jelasnya dapat dilihat pada tabel 4.4. di bawah ini:
Tabel 4.4. Nilai penduga parameter coxproportional hazard model
Variabel β exp(β) Sign
Age 0.155 1.168 0.023
Smoking 0.878 2.407 0.252
Dummy 1 -2.221 0.108 0.038
Dummy 2 -2.102 0.122 0.055
Dummy 3 -2.024 0.132 0.158
Model 2 tetap dipilih sebagai model terbaik yang mewakili populasi data, sehingga diperoleh coxproportional hazard model:
0.155* 0.878* 2.221* 1 2.102* 2 2.024* 3
0
( ;
)
( ).
AGE SMOKING dummy dummy dummyh t X
h t e
dengan variabel Age adalah umur, Smoking adalah kebiasaan merokok, dummy 1,
Nilai dugaan koefisien diperoleh variabel umur bernilai positif yang
berarti tertanggung dengan usia t+1 akan mempunyai resiko terjadi event yang lebih besar dibandingkan tertanggung dengan usia t. Demikian juga untuk variabel merokok yang bernilai positif, tertanggung yang merokok mempunyai resiko terjadi event lebih besar dibandingkan tertanggung yang tidak merokok. Untuk tiga variabel terakhir, yaitu variabel dummy 1, 2 dan 3 mempunyai nilai dugaan koefisien negatif yang berarti jika tertanggung dengan hasil medical test
standard, tertanggung kategori penyakit ringan dan tertanggung kategori penyakit sedang mempunyai resiko terjadi event lebih rendah dibandingkan tertanggung kategori penyakit berat.
Hal ini dipertegas dengan menginterpretasikan nilai exp( ) . Resiko terjadi event tertanggung dengan usia t+1 adalah 1.168 kali dari tertanggung yang dengan usia t, sesuai dengan tabel mortalita yang menyatakan bahwa usia t+1 mempunyai kemungkinan kematian yang lebih besar dibandingkan dengan usia t.
Untuk resiko terjadi event tertanggung yang merokok adalah 2.407 kali dari tertanggung yang tidak merokok, hal ini sesuai dengan yang kita ketahui bahwa merokok dapat merusak kesehatan paru-paru, jantung, dan penyakit lainnya.
mempunyai penyakit kategori penyakit berat akan mempunyai kemungkinan meninggal lebih cepat dibandingkan tertanggung yang sehat atau berpenyakit kategori penyakit ringan.
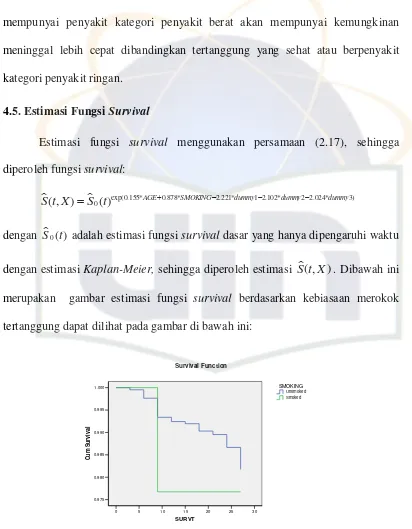
4.5. Estimasi Fungsi Survival
Estimasi fungsi survival menggunakan persamaan (2.17), sehingga diperoleh fungsi survival:
exp(0.155* 0.878* 2.221* 1 2.102* 2 2.024* 3)
0
( , ) ( ) AGE SMOKING dummy dummy dummy
S t X S t
dengan S t0( ) adalah estimasi fungsi survival dasar yang hanya dipengaruhi waktu
dengan estimasi Kaplan-Meier, sehingga diperoleh estimasi S t X( , ). Dibawah ini
merupakan gambar estimasi fungsi survival berdasarkan kebiasaan merokok tertanggung dapat dilihat pada gambar di bawah ini:
30 25 20 15 10 5 0
SURVT
1.000 0.995
0.990
0.985 0.980
0.975
C
um
S
urvi
val
Smoked Unsmoked
SMOKING
Survival Function
Gambar 4.1. Estimasi fungsi survival berdasarkan variabel kebiasaan merokok
[image:47.595.111.523.98.627.2]tertanggung yang merokok. Hal ini memperkuat pernyataan sebelumnya bahwa kemungkinan terjadi event tertanggung yang merokok adalah 2.407 kali dari tertanggung yang tidak merokok. Untuk melihat estimasi fungsi survival
berdasarkan medical test tertanggung dapat dilihat pada gambar di bawah ini:
30 25 20 15 10 5 0
SURVT
1.00 0.98 0.96 0.94 0.92 0.90 0.88 0.86
C
um
S
urvi
val
SS5&SS6 SS3&SS4 SS1&SS2 STD
MEDICAL_TEST
Survival Function
Gambar 4.2. Estimasi fungsi survival berdasarkan variabel medical test
[image:48.595.119.523.117.439.2]4.5. Pengelompokkan Data
Terdapat 384 (2x4x48) kombinasi estimasi nilai probabilitas survival
karena terdapat 3 variabel yang mempengaruhinya, yaitu variabel age dengan kategori usia antara 15-62 tahun, variabel smoking dengan kategori merokok dan tidak merokok, dan terakhir adalah variabel medical test dengan kategori tertanggung dengan hasil medical test penyakit ringan, penyakit sedang dan penyakit berat. Sehingga diperlukan pengelompokkan data untuk mempermudah interpretasi data.
Pertama-tama dilakukan hierarchical clustering untuk memperoleh pengelompokkan yang sesuai dengan data, pada dendogram lampiran 6 menunjukkan bahwa pengelompokkan 2 cluster merupakan pengelompokkan terbaik karena mempunyai jarak pengelompokkan terjauh dibandingkan kelompok
cluster lainnya, jarak terjauh kedua adalah pada pengelompokkan 3 cluster.
Sehingga dibentuk pengelompokkan 2 cluster dengan metode K-Means Cluster, namun setelah dibentuk 2 cluster terdapat kesulitan untuk memberi nama cluster
karena dilihat dari cluster membership pengelompokkan yang dihasilkan masih belum spesifik. Sehingga dilakukan percobaan kedua dengan membentuk pengelompokkan menjadi 3 cluster, diperoleh pengelompokkan data dengan spesifikasi yang lebih jelas dibandingkan 2 cluster. Pada akhirnya dibentuklah 3
cluster dengan cluster 1 adalah tertanggung dengan nilai survival rata-rata yang tertinggi kedua pada setiap t, cluster 2 adalah tertanggung dengan nilai survival
Cluster 1 diberi nama kelompok dengan pengajuan waktu klaim sedang,
cluster 2 diberi nama kelompok tertanggung dengan pengajuan waktu klaim terpanjang, dan cluster 3 diberi nama kelompok tertanggung dengan pengajuan waktu klaim terpendek. Keanggotaan masing-masing cluster dapat dilihat pada lampiran 7.
Kelompok tertanggung dengan pengajuan waktu klaim terpanjang mempunyai nilai probabilitas survival 90.32% untuk waktu satu tahun pertama, artinya sampai waktu satu tahun pertama terdapat kemungkinan 9.68% dari jumlah tertanggung yang terjadi event, sehingga jika terdapat 100 tertanggung, hanya 10 tertanggung yang berkemungkinan mengajukkan klaim asuransi. Dan sampai waktu dua tahun pertama terdapat 85.26% tertanggung yang survive atau tidak terjadi event. Sehingga jika pada tahun pertama sudah terjadi 10 tertanggung yang terjadi event, tahun ke dua hanya terdapat 5 tertanggung yang berkemungkinan terjadi event.
Dan untuk kelompok tertanggung dengan pengajuan waktu klaim terpendek mempunyai nilai probabilitas survival 50.35% dalam waktu tiga bulan pertama, artinya sampai waktu tiga bulan pertama sudah terdapat kemungkinan 50% atau tepatnya 49.65% dari jumlah tertanggung yang akan mengajukan klaim, sehingga jika terdapat 100 tertanggung, ada 50 tertanggung yang berkemungkinan mengajukkan klaim asuransi. Dan sampai waktu satu tahun pertama hanya mencapai kemungkinan sekitar 1% tertanggung yang survive atau tidak terjadi
BAB V
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Terdapat tiga faktor yang berpengaruh signifikan terhadap model dengan taraf nyata 5%, yaitu usia, kebiasaan merokok dan tiga variabel dummy medical test, yaitu dummy 1 Standard, dummy 2 adalah penyakit ringan, dan dummy 3
adalah penyakit sedang.
Perbandingan hazard faktor-faktor antar karakteristik yang berbeda yang dihasilkan adalah sebagai berikut:
1. Usia t+1 adalah 1.168 kali usia t,
2. Smoking adalah 2.407 kali unsmoking,
3. a. dummy1 (Standard) adalah 0.038 kali penyakit berat,
b. dummy 2 (penyakti ringan) adalah 0.122 kali penyakit berat, dan
c. dummy 3 (penyakti ringan) adalah 0.123 kali penyakit berat.
Pada grafik fungsi survival pada lampiran 8 terlihat bahwa ke tiga cluster
5.2. Saran
DAFTAR PUSTAKA
[1] Morton, G. Principles of Life and Health Insurance. LOMA. 1999.
[2] Walpole, R. E. Pengantar Statistik. Jakarta: Gramedia Pustaka Utama. 1995.
[3] Muthma’inna. Perbandingan Model Cox Proportional Hazard
Berdasarkan Analisis Residual (Studi Kasus pada Data Kanker Paru-paru yang Diperoleh dari Contoh Data pada Software S-PLUS 2000 dan Stimulasi untuk Distribusi Eksponensial dan Weibull). Jakarta: Skripsi UIN Syarif Hidayatullah Jakarta. 2007.
[4] Dobson, Annette. J. An introduction to generalized linear models. CRC. New York. 2002.
[5] Kleinbaum, D. G. dan Klein, M. Survival analysis a self-learning text.
Spinger. New York. 2005.
[6] Klein, J. P. dan Moeschberger, M. L. Survival Analysis Techniques for Censored and Truncated Data. Spinger. New York. 1997.
[7] Sharma Subhash. Applied Multivariate Techniques. John Wiley & Sons, Inc. USA. 1996.
[8] Richard, A. Johnson. Applied Multivariate Statistical Analysis. New Jersey.
[9] Agresti, A. An Introduction to Categorical Data Analysis. John Wiley & Sons, Inc. New York. 1996.
---
Nama : Afief Aryadhani
NIM : 107094000260
Tempat Tanggal Lahir : Jakarta, 30 Maret 1989
Alamat Rumah : Jl. K.H. Dewantoro. Komp Depkes Blok C2/2. Ciputat. Tangsel
Hp : 081514170930
Email : [email protected]
Jenis Kelamin : Laki-laki
---
1. S1 : Program Studi Matematika Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta, Tahun 2007-2011
2. SMA : SMA Negeri 1 Ciputat, Tahun 2004-2007 3. SMP : SMP Negeri 2 Ciputat, Tahun 2001-2004 4. SD : SD Negeri 4 Ciputat, Tahun 1995-2001 5. TK : TK An-Nur, Tahun 1994-1995
Data Pribadi
Riwayat Pendidikan
Lampiran 1
Iterasi Newton-Raphson
Untuk fungsi kemungkinan L( , 1 2,...,i)L( ) , di mana L( ) atau logL( ) mencapai maksimum dan memenuhi persamaan:
log ( )
( ) 0
i
i
L
U
, i1, 2,...,k
Misal U( ) merupakan turunan pertama dari fungsi log-likelihood untuk menduga
parameter . Misalkan 0 merupakan dugaan untuk , kemudian dilakukan ekspansi deret Taylor pada 0, menghasilkan:
0 0 0
( ) ( ) ( )( )
U U G
Dengan G( ) merupakanturunan kedua dari fungsi log-likelihood, yaitu:
2
log ( ) ( )
ij
i j
L
G
Karena memenuhi U( ) 0, sehingga parameter pada iterasi ke (i+1) adalah:
1
1 ( ) ( )
i i G i u i
, i1, 2,...,k
Prosedur iterasi dimulai dengan memperoleh dugaan awal 0 0, kemudian menghitung U(0) dan G(0) untuk memperoleh dugaan 1 dari
1
1 0 G ( 0) (u 0)
, dan berhenti ketika perubahan fungsi log-likelihood relatif
Lampiran 2
Contoh Sebagian Data Analisis
No Usia Th 2009 Jumlah Rokok/Hari Jenis Kelamin Cek Medical Polis Data Klaim
1 15 0 L STD 5/12/2009 -
2 16 0 L STD 11/11/2009 -
3 16 0 L STD 8/19/2009 -
4 16 0 L STD 2/24/2009 -
5 17 0 L SS1 5/29/2009 -
6 17 0 P STD 1/30/2009 -
7 18 0 L STD 5/25/2009 -
8 18 0 L SS2 7/31/2009 -
9 19 0 P STD 3/6/2009 -
10 19 0 L STD 1/12/2009 -
11 19 0 P STD 6/18/2009 -
12 19 0 L STD 10/23/2009 -
13 19 0 L STD 8/31/2009 -
14 20 0 L STD 12/22/2009 -
15 20 0 L STD 1/5/2009 -
16 21 0 L STD 3/31/2009 -
17 21 8 L SS1 5/26/2009 -
18 21 0 L STD 1/21/2009 -
19 21 0 P STD 3/30/2009 -
20 21 0 P STD 3/30/2009 -
21 22 0 L SS1 5/24/2009 -
22 22 0 P STD 4/15/2009 -
23 22 0 L SS1 9/10/2009 -
24 23 0 P SS1 4/1/2009 -
25 23 0 P STD 7/27/2009 -
26 23 0 L SS1 6/29/2009 -
27 23 0 P