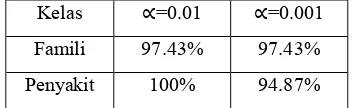ABSTRACT
PASKIANTI, KRISTINA. Document Classification using KNN Fuzzy Algorithm. Supervised by YENI HERDIYENI.
1 PENDAHULUAN
Latar Belakang
Indonesia adalah negara
$ yang kaya akan tumbuhan
obat potensial. Sampai tahun 2001,
Laboratorium Konservasi Tumbuhan,
Fakultas Kehutanan IPB telah mendata dari berbagai hasil riset bahwa tidak kurang dari 2.039 spesies tumbuhan obat berasal dari hutan Indonesia (Zuhud 2009). Fakta ini
mendorong para peneliti untuk terus
melakukan penelitian terutama di bidang pemanfaatan tumbuhan obat Indonesia. Banyak dokumen hasil riset yang sudah dihasilkan, namun dokumen tersebut belum memberikan manfaat yang optimal karena sulitnya mencari informasi. Oleh karena itu, diperlukan suatu teknik komputasi dalam
bentuk mesin pencari ( ) yang
mampu memberikan informasi tumbuhan obat secara lebih mudah dan cepat.
Kebutuhan informasi akan tumbuhan obat dapat dikelompokkan menjadi beberapa kategori, seperti famili, ramuan, kandungan
kimia serta penyakit yang dapat
disembuhkan. Hal ini menunjukkan perlunya suatu teknik klasifikasi untuk dokumen hasil riset sehingga pencarian melalui mesin pencari dapat dilakukan dengan efektif dan
efisien. Penerapan teknik klasifikasi
dokumen pada mesin pencari dilakukan untuk mengelompokkan informasi pada
dokumen. Klasifikasi dokumen secara
manual tidak memungkinkan untuk dokumen skala besar karena membutuhkan waktu yang lama. Solusi dari kelemahan klasifikasi
manual adalah membangun klasifikasi
dokumen secara automatis.
Ada banyak metode yang dapat
digunakan untuk klasifikasi dokumen secara
automatis, seperti -Nearest Neighbor
(KNN), Bayes, Decision Tree, Support Vector Machine, Rocchio dan lain-lain.
Shang et al (2006) mengembangkan
algoritma KNN Fuzzy untuk klasifikasi data Reuters-21578 dan data dari International Database Center di China. Algoritma KNN Fuzzy memiliki kemampuan untuk mengatasi persebaran dokumen yang tidak merata dan
karakteristik dokumen yang cenderung
seragam.
Penelitian ini akan menerapkan
algoritma KNN Fuzzy yang telah dilakukan Shang et al (2006) untuk klasifikasi dokumen tumbuhan obat. Penerapan algoritma ini
meliputi proses pemilihan fitur menggunakan
metode pengujian (Chi-Kuadrat).
Klasifikasi dilakukan untuk dua kelas target yaitu kelas famili dan kelas penyakit. Kedua kelas ini dianggap sebagai kelas yang
merepresentasikan kebutuhan informasi
pengguna.
Tujuan
Tujuan penelitian ini adalah menerapkan algoritma pengklasifikasi KNN Fuzzy pada dokumen tumbuhan obat Indonesia untuk sistem temu kembali informasi.
Ruang Lingkup
Ruang lingkup penelitian ini meliputi :
1. Dokumen terbatas pada 32 jenis
tumbuhan obat Indonesia
2. Dokumen berformat XML
Manfaat
Manfaat penelitian ini adalah memberi kemudahan kepada pengguna untuk mencari informasi tumbuhan obat Indonesia.
TINJAUAN PUSTAKA Temu Kembali Informasi
Temu kembali informasi atau
merupakan proses pencarian tidak terstruktur untuk memenuhi kebutuhan informasi dari sekumpulan koleksi yang besar (Manning 2008). Pengindeksan dalam temu kembali informasi adalah proses menentukan penciri dari suatu dokumen dalam sekumpulan koleksi yang besar. Penciri dari suatu dokumen dapat berupa kata, kalimat atau paragraf. Penciri dari suatu
dokumen disebut dengan % Setiap
dokumen akan melewati proses mendapatkan
pembobotan serta pembuatan
indeks.
Terdapat beberapa model dalam temu kembali informasi, salah satunya adalah
model ruang vektor atau & .
Pada model ini, setiap dokumen
direpresentasikan sebagai vektor dalam
ruang vektor. Representasi vektor dokumen
dengan elemen dinotasikan dengan
. Elemen yang dimaksud adalah
yang diperoleh dari proses
1 PENDAHULUAN
Latar Belakang
Indonesia adalah negara
$ yang kaya akan tumbuhan
obat potensial. Sampai tahun 2001,
Laboratorium Konservasi Tumbuhan,
Fakultas Kehutanan IPB telah mendata dari berbagai hasil riset bahwa tidak kurang dari 2.039 spesies tumbuhan obat berasal dari hutan Indonesia (Zuhud 2009). Fakta ini
mendorong para peneliti untuk terus
melakukan penelitian terutama di bidang pemanfaatan tumbuhan obat Indonesia. Banyak dokumen hasil riset yang sudah dihasilkan, namun dokumen tersebut belum memberikan manfaat yang optimal karena sulitnya mencari informasi. Oleh karena itu, diperlukan suatu teknik komputasi dalam
bentuk mesin pencari ( ) yang
mampu memberikan informasi tumbuhan obat secara lebih mudah dan cepat.
Kebutuhan informasi akan tumbuhan obat dapat dikelompokkan menjadi beberapa kategori, seperti famili, ramuan, kandungan
kimia serta penyakit yang dapat
disembuhkan. Hal ini menunjukkan perlunya suatu teknik klasifikasi untuk dokumen hasil riset sehingga pencarian melalui mesin pencari dapat dilakukan dengan efektif dan
efisien. Penerapan teknik klasifikasi
dokumen pada mesin pencari dilakukan untuk mengelompokkan informasi pada
dokumen. Klasifikasi dokumen secara
manual tidak memungkinkan untuk dokumen skala besar karena membutuhkan waktu yang lama. Solusi dari kelemahan klasifikasi
manual adalah membangun klasifikasi
dokumen secara automatis.
Ada banyak metode yang dapat
digunakan untuk klasifikasi dokumen secara
automatis, seperti -Nearest Neighbor
(KNN), Bayes, Decision Tree, Support Vector Machine, Rocchio dan lain-lain.
Shang et al (2006) mengembangkan
algoritma KNN Fuzzy untuk klasifikasi data Reuters-21578 dan data dari International Database Center di China. Algoritma KNN Fuzzy memiliki kemampuan untuk mengatasi persebaran dokumen yang tidak merata dan
karakteristik dokumen yang cenderung
seragam.
Penelitian ini akan menerapkan
algoritma KNN Fuzzy yang telah dilakukan Shang et al (2006) untuk klasifikasi dokumen tumbuhan obat. Penerapan algoritma ini
meliputi proses pemilihan fitur menggunakan
metode pengujian (Chi-Kuadrat).
Klasifikasi dilakukan untuk dua kelas target yaitu kelas famili dan kelas penyakit. Kedua kelas ini dianggap sebagai kelas yang
merepresentasikan kebutuhan informasi
pengguna.
Tujuan
Tujuan penelitian ini adalah menerapkan algoritma pengklasifikasi KNN Fuzzy pada dokumen tumbuhan obat Indonesia untuk sistem temu kembali informasi.
Ruang Lingkup
Ruang lingkup penelitian ini meliputi :
1. Dokumen terbatas pada 32 jenis
tumbuhan obat Indonesia
2. Dokumen berformat XML
Manfaat
Manfaat penelitian ini adalah memberi kemudahan kepada pengguna untuk mencari informasi tumbuhan obat Indonesia.
TINJAUAN PUSTAKA Temu Kembali Informasi
Temu kembali informasi atau
merupakan proses pencarian tidak terstruktur untuk memenuhi kebutuhan informasi dari sekumpulan koleksi yang besar (Manning 2008). Pengindeksan dalam temu kembali informasi adalah proses menentukan penciri dari suatu dokumen dalam sekumpulan koleksi yang besar. Penciri dari suatu dokumen dapat berupa kata, kalimat atau paragraf. Penciri dari suatu
dokumen disebut dengan % Setiap
dokumen akan melewati proses mendapatkan
pembobotan serta pembuatan
indeks.
Terdapat beberapa model dalam temu kembali informasi, salah satunya adalah
model ruang vektor atau & .
Pada model ini, setiap dokumen
direpresentasikan sebagai vektor dalam
ruang vektor. Representasi vektor dokumen
dengan elemen dinotasikan dengan
. Elemen yang dimaksud adalah
yang diperoleh dari proses
2 vektor dalam ruang vektor. Ilustrasi ini dapat
dilihat pada Gambar 1.
Gambar 1 Ilustrasi vektor dokumen dalam ruang vektor.
Pengukuran kesamaan atau kemiripan antara vektor dokumen dan dokumen dalam ruang vektor dilakukan dengan
menghitung nilai similaritas antara
dan . Nilai similaritas
dapat diperoleh dari Persamaan (1).
dengan pembilang menyatakan perkalian (
& ) antara vektor dan , sedangkan penyebut menyatakan perkalian antara panjang vektor.
Klasifikasi
Klasifikasi terbagi menjadi dua fase, yaitu pelatihan dan pengujian. Pada fase pelatihan, sebagian data yang telah diketahui kelasnya (data latih) digunakan untuk membentuk model. Pada fase pengujian, model yang sudah terbentuk diuji dengan sebagian data lainnya (data uji) untuk mengetahui akurasi dari model tersebut. Selanjutnya model dapat digunakan untuk memprediksi kelas data yang belum diketahui (Han & Kamber 2006).
Chi kuadrat (χ2)
Chi kuadrat (χ2) adalah suatu ukuran yang menyatakan perbedaan antara frekuensi observasi (oi) dengan frekuensi harapan (ei)
untuk setiap (i) yang dirumuskan
dengan
Pengaruh kedua frekuensi tersebut dapat diuji dengan suatu hipotesis H0. Hipotesis nol adalah hipotesis yang menyatakan tidak adanya perbedaan yang signifikan antara
frekuensi observasi dengan frekuensi
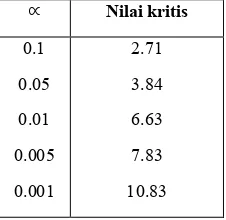
harapan. Pengujian hipotesis dilakukan pada taraf nyata α tertentu. Taraf nyata yang dimaksud adalah peluang salah menolak hipotesis yang seharusnya benar (Spiegel 2004).
Pada penelitian ini, nilai χ2 digunakan
untuk melihat pengaruh kemunculan
terhadap kelas (Yang&Pedersen 1997).
Nilai χ2 untuk setiap kemunculan
terhadap kelas dihitung menggunakan
Persamaan (2).
dengan adalah jumlah dokumen latih,
adalah jumlah dokumen pada kategori yang
memuat , adalah jumlah dokumen . Penentuan fitur dilakukan berdasarkan
nilai χ2 dari masing-masing . ' yang
memiliki nilai χ2 diatas nilai kritis pada taraf nyata α dan derajat bebas satu adalah yang akan terpilih sebagai fitur. Nilai kritis χ2 dengan derajat bebas satu dan taraf nyata α ditunjukkan oleh Tabel 1.
3 KNN Fuzzy
KNN Fuzzy adalah pengembangan
metode klasifikasi KNN klasik yang
dilakukan oleh Shang (2006).
Pengembangan ini dilakukan untuk
mengatasi masalah sebaran dokumen yang tidak merata pada suatu kelas. Metode ini
mengadopsi teori untuk
membangun fungsi keanggotaan yang baru berdasarkan nilai similaritas antar dokumen. Penghitungan derajat keanggotaan dokumen uji untuk setiap kelas dinyatakan dalam
keanggotaan bernilai 1 jika dokumen latih adalah anggota kelas dan bernilai 0 jika yang menyatakan jumlah data uji yang benar diklasifikasikan dan jumlah data uji yang
salah diklasifikasikan (Tan 2006).
Contoh " untuk klasifikasi
biner ditunjukkan pada Tabel 2.
Tabel 2 ! " untuk klasifikasi
Keterangan untuk tabel 2 dinyatakan sebagai berikut :
· ' (TP), yaitu jumlah
dokumen dari kelas 1 yang benar diklasifikasikan sebagai kelas 1.
· ' (TN), yaitu jumlah
dokumen dari kelas 0 yang benar diklasifikasikan sebagai kelas 0.
· (FP), yaitu jumlah
dokumen dari kelas 0 yang salah diklasifikasikan sebagai kelas 1.
· (FN), yaitu jumlah
dokumen dari kelas 1 yang salah diklasifikasikan sebagai kelas 0.
Perhitungan akurasi dinyatakan dalam
Persamaan (4).
(4)
dan
# dan adalah dua kriteria
yang digunakan untuk mengevaluasi tingkat efektifitas kinerja sistem temu kembali
informasi. # adalah rasio jumlah
dokumen relevan yang ditampilkan terhadap jumlah seluruh dokumen yang relevan. adalah rasio jumlah dokumen relevan yang ditampilkan terhadap jumlah seluruh dokumen yang ditampilkan (Manning
2008). Perhitungan dan &
dinyatakan pada Persamaan (5) dan (6).
() *++
Menurut Baeza-Yates dan Riberio-Neto (1999), algoritma temu kembali informasi yang dievaluasi menggunakan beberapa kueri
berbeda akan menghasilkan nilai dan
Perhitungan AVP dinyatakan dalam
4
yang memungkinkan untuk
melakukan pencarian dokumen atau $
di komputer. Sphinx menyediakan
fungsionalitas pencarian teks secara cepat dan relevan pada aplikasi klien. Sphinx telah dirancang khusus untuk berintegrasi
dengan $ SQL dan bahasa
pemrograman tertentu (STI 2008).
Pembobotan BM25
Pembobotan BM25 atau Okapi adalah pembobotan yang mengurutkan set dokumen
berdasarkan kueri yang muncul pada
setiap dokumen koleksi. Hubungan antara kueri dengan dokumen dipengaruhi oleh
parameter (parameter untuk kalibrasi skala
frekuensi ) dan parameter @ (parameter
untuk kalibrasi skala panjang dokumen).
Nilai parameter yang optimal untuk
pembobotan BM25 adalah =1.2 dan
@=0.75 (Manning 2008). Penghitungan bobot
suatu dokumen berdasarkan
dinyatakan dalam Persamaan (8).
(8)
dengan'A B " # @ 6 @ 8 C DC*0) E;
+.2 FGHI>J adalah ,
KL adalah frekuensi pada dokumen ,
CG dan CMNO adalah panjang dokumen dan
rata-rata panjang dokumen dalam koleksi,
dan @ adalah parameter pengskalaan terhadap
K dan panjang dokumen.
METODE PENELITIAN
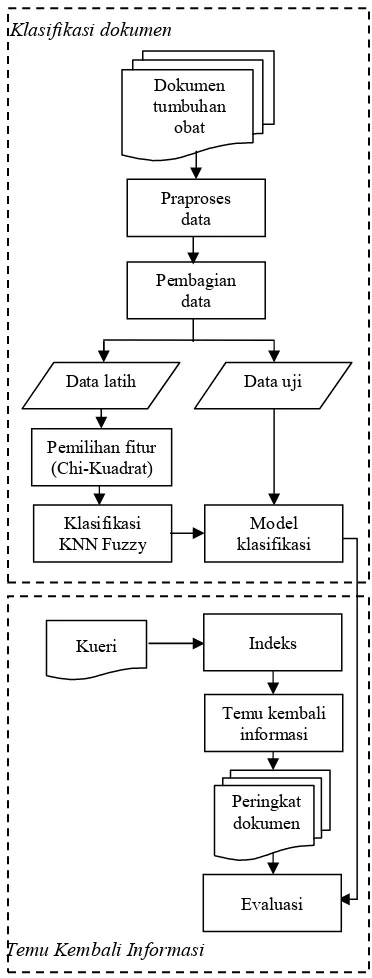
Penelitian ini dilaksanakan dalam dua bagian, yaitu klasifikasi dokumen dan temu kembali informasi. Klasifikasi dokumen meliputi tahap pengumpulan data, praproses data, pembagian data menjadi data latih dan data uji, pemilihan fitur dengan χ2, klasifikasi dokumen dengan KNN Fuzzy dan evaluasi. Temu kembali informasi meliputi tahap pencocokan kueri dengan dokumen dalam
koleksi, pembobotan dan evaluasi. Metode penelitian diilustrasikan pada Gambar 2.
' $ (
Gambar 2 Metode penelitian.
Dokumen tumbuhan obat
4
yang memungkinkan untuk
melakukan pencarian dokumen atau $
di komputer. Sphinx menyediakan
fungsionalitas pencarian teks secara cepat dan relevan pada aplikasi klien. Sphinx telah dirancang khusus untuk berintegrasi
dengan $ SQL dan bahasa
pemrograman tertentu (STI 2008).
Pembobotan BM25
Pembobotan BM25 atau Okapi adalah pembobotan yang mengurutkan set dokumen
berdasarkan kueri yang muncul pada
setiap dokumen koleksi. Hubungan antara kueri dengan dokumen dipengaruhi oleh
parameter (parameter untuk kalibrasi skala
frekuensi ) dan parameter @ (parameter
untuk kalibrasi skala panjang dokumen).
Nilai parameter yang optimal untuk
pembobotan BM25 adalah =1.2 dan
@=0.75 (Manning 2008). Penghitungan bobot
suatu dokumen berdasarkan
dinyatakan dalam Persamaan (8).
(8)
dengan'A B " # @ 6 @ 8 C DC*0) E;
+.2 FGHI>J adalah ,
KL adalah frekuensi pada dokumen ,
CG dan CMNO adalah panjang dokumen dan
rata-rata panjang dokumen dalam koleksi,
dan @ adalah parameter pengskalaan terhadap
K dan panjang dokumen.
METODE PENELITIAN
Penelitian ini dilaksanakan dalam dua bagian, yaitu klasifikasi dokumen dan temu kembali informasi. Klasifikasi dokumen meliputi tahap pengumpulan data, praproses data, pembagian data menjadi data latih dan data uji, pemilihan fitur dengan χ2, klasifikasi dokumen dengan KNN Fuzzy dan evaluasi. Temu kembali informasi meliputi tahap pencocokan kueri dengan dokumen dalam
koleksi, pembobotan dan evaluasi. Metode penelitian diilustrasikan pada Gambar 2.
' $ (
Gambar 2 Metode penelitian.
Dokumen tumbuhan obat
5 deskripsi, penyakit yang dapat disembuhkan
atau kandungan kimia yang dimiliki.
Dokumen terbatas pada 32 jenis tumbuhan obat Indonesia. Daftar 32 jenis tumbuhan obat yang digunakan dalam penelitian ini dapat dilihat pada Lampiran 1.
Dokumen tumbuhan obat melalui tahap
digitalisasi dan pemberian . Dokumen
ditulis dalam format XML. Berikut
-yang terdapat pada dokumen tumbuhan obat beserta contoh dokumen yang sudah ditulis dalam format XML :
· ini mewakili
keseluruhan dokumen tumbuhan obat.
· ini menunjukkan id
menunjukkan nama latin dari tumbuhan obat.
· ,
ini menunjukkan deskripsi dan manfaat dari tumbuhan obat.
· untuk kelas target
klasifikasi. ' ini menunjukkan famili
atau suku dari tumbuhan obat.
·
untuk kelas target klasifikasi. ' ini
menunjukkan penyakit yang dapat
disembuhkan dengan tumbuhan obat.
Dokumen tumbuhan obat memiliki dua kelas target klasifikasi, yaitu kelas famili dan kelas penyakit. Persebaran jumlah dokumen untuk kelas famili ditunjukkan pada Tabel 3. Persebaran jumlah dokumen untuk kelas
penyakit ditunjukkan pada Tabel 4. Dari
kedua tabel tersebut terlihat bahwa
persebaran jumlah dokumen untuk setiap
kelas tidak merata. Misalnya kelas
Pencernaan memiliki dokumen sebanyak 26, sedangkan kelas Saluran Kemih hanya memiliki dokumen sebanyak 4. Jumlah dokumen yang banyak pada suatu kelas tertentu mengindikasikan bahwa banyak penelitian yang dilakukan terhadap kelas tersebut, sedangkan jumlah dokumen yang sedikit pada suatu kelas mengindikasikan bahwa belum banyak penelitian yang dilakukan terhadap kelas tersebut.
Tabel 3 Persebaran jumlah dokumen untuk
Praproses data hanya dilakukan pada deskripsi. Praproses data meliputi tahap
tokenisasi dan pembuangan & .
Tokenisasi adalah proses memotong teks menjadi bagian-bagian yang disebut dengan
!
! "
6
token. Selain pemotongan, tokenisasi
mungkin diikuti dengan proses pembuangan
karakter-karakter tertentu (Manning %
2008). Token yang dimaksud dalam
penelitian ini adalah kata atau % Proses
tokenisasi dilakukan sesuai dengan aturan berikut :
· Teks dipotong menjadi token. Karakter
yang dianggap sebagai karakter pemisah token didefinisikan dengan ekspresi regular berikut :
/[\s\-+\/*0-9%,.\"\];()\':=`?\[!@><]+/
· Token yang terdiri atas karakter numerik
saja tidak diikutsertakan
· Besar kecilnya karakter dari token
dipertahankan atau tidak dilakukan penyeragaman.
' yang tidak memiliki arti penting dan
memiliki frekuensi sangat besar ( & ),
seperti “yang”,”di”,”dan”,”atau”, “yakni”, “yaitu” tidak digunakan dalam proses klasifikasi.
Pembagian data
Dokumen tumbuhan obat yang telah melewati tahap praproses data kemudian dibagi menjadi dua, yaitu data latih dan data uji dengan persentasi 70%:30%. Data latih
digunakan sebagai & pelatihan
pengklasifikasi KNN Fuzzy, sedangkan data uji digunakan untuk menguji model hasil pelatihan pengklasifikasi KNN Fuzzy.
Pemilihan fitur dengan UV
Pemilihan fitur adalah proses memilih
subset kata ( ) yang dianggap telah
mewakili informasi penting dari suatu dokumen. Fitur inilah yang kemudian digunakan pada tahap klasifikasi dokumen. Pemilihan fitur memiliki dua tujuan, yaitu
mengurangi dimensi kata yang akan
digunakan dan meningkatkan akurasi
klasifikasi karena telah dihilangkan
(Manning 2008).
Pada penelitian ini, pemilihan fitur dilakukan dengan metode uji Chi-Kuadrat.
Penentuan fitur dilakukan dengan
menghitung nilai 'W antara dengan
kelas yang dinyatakan dalam Persamaan (2). Pemilihan fitur dilakukan pada dua taraf nyata , yaitu 0.01 dan 0.001 dengan derajat
bebas satu. ' yang terpilih pada taraf
nyata =0.01 adalah yang memiliki
nilai χ2 diatas nilai kritis 6.63, sedangkan yang terpilih pada taraf nyata 9S99"
adalah yang memiliki nilai χ2 diatas nilai
kritis 10.83. Fitur yang dihasilkan melalui uji Chi-Kuadrat kemudian digunakan untuk membangun model berbasis vektor . Model
terdiri atas beberapa dokumen yang
direpresentasikan sebagai vektor dari
frekuensi kemunculan fitur.
Klasifikasi KNN Fuzzy
Klasifikasi diawali dengan menghitung
panjang vektor setiap dokumen, baik
dokumen latih maupun dokumen uji. Setelah itu, vektor dokumen uji dikalikan dengan
setiap vektor dokumen latih untuk
mendapatkan ukuran kesamaan .
Ukuran kesamaan dihitung
menggunakan Persamaan (1). Nilai kesamaan antara dokumen uji dengan setiap
dokumen latih kemudian diurutkan secara
menurun.
Pengklasifikasi akan memilih vektor
dokumen X ! "!Y! Z [ yang memiliki
nilai kesamaan tertinggi sebagai
tetangga dari vektor dokumen uji . Nilai ditentukan secara manual dengan metode
$ % Derajat keanggotaan vektor
dokumen uji untuk setiap kelas dihitung menggunakan Persamaan (3). Kelas yang memiliki derajat keanggotaan tertinggi adalah kelas target dari dokumen uji .
Temu Kembali Informasi
Implementasi temu kembali informasi untuk dokumen tumbuhan obat Indonesia
dilakukan dengan Sphinx 1.10 beta.
Implementasi dilakukan dalam beberapa tahap, yaitu praproses data, pengindeksan dan pencarian teks. Praproses data adalah tahap untuk mempersiapkan data yang akan diindeks oleh Sphinx. Data yang digunakan
pada penelitian ini adalah $ SQL
yang memuat seluruh dokumen tumbuhan obat. Data yang akan diindeks memiliki atribut id, nama, nama latin, deskripsi, famili dan penyakit.
Tahap selanjutnya adalah pengindeksan. Pengindeksan dimulai dari membangun
koneksi ke $ , mengambil data yang
akan diindeks melalui perintah ,
tokenisasi, penentuan panjang minimal kata dan pembuatan indeks. Berikut perintah yang digunakan untuk mengambil data yang akan diindeks :
$ %$ & '()(*
7 Panjang minimal kata yang digunakan pada
penelitian ini adalah tiga karakter.
Tahap terakhir dari implementasi proses temu kembali informasi adalah pencarian
teks. Pencarian teks adalah proses
pencocokan kueri dengan indeks yang dihasilkan pada tahap sebelumnya. Pencarian
teks dilakukan pada kelas hasil
klasifikasi dokumen, tetapi dilakukan pada seluruh dokumen yang terdapat pada koleksi.
Kueri yang masuk diklasifikasikan
terlebih dahulu tetapi langsung diboboti dengan seluruh dokumen yang ada pada koleksi. Pembobotan yang digunakan adalah pembobotan BM25. Penghitungan bobot
dokumen terhadap kueri dinyatakan
dalam Persamaan (8). Dokumen yang paling relevan adalah dokumen yang memiliki bobot paling tinggi.
Evaluasi
Evaluasi yang dilakukan pada penelitian ini meliputi dua bagian, yaitu evaluasi untuk pengklasifikasi KNN Fuzzy dan evaluasi untuk sistem temu kembali informasi.
Evaluasi pengklasifikasi KNN Fuzzy
dilakukan dengan menghitung proporsi antara jumlah dokumen yang benar diklasifikasikan dengan seluruh jumlah dokumen pada koleksi. Nilai akurasi dihitung menggunakan Persamaan (4).
Evaluasi sistem temu kembali informasi dilakukan untuk melihat pengaruh dari klasifikasi dokumen terhadap kinerja sistem temu kembali informasi melainkan untuk melihat kinerja suatu sistem temu kembali
infomasi yang diimplementasikan pada
dokumen tumbuhan obat Indonesia. Evaluasi untuk sistem temu kembali informasi dimulai
dengan menghitung nilai dan &
dari 30 kueri uji. Penghitungan
& dinyatakan dalam Persamaan (5) dan (6). Proses selanjutnya adalah melakukan interpolasi maksimum untuk mendapatkan
nilai & (AVP) terhadap 11
titik standard. Perhitungan AVP
dinyatakan dalam Persamaan (7).
Kueri yang digunakan untuk
mengevaluasi sistem temu kembali informasi ditentukan sesuai dengan topik bahasan yang terdapat pada keseluruhan isi dokumen. Topik bahasan tersebut meliputi penyakit yang dapat disembuhkan oleh tumbuhan obat, deskripsi tumbuhan, kandungan kimia dan cara membuat ramuan dari tumbuhan obat. Pengujian juga dilakukan terhadap kueri
dengan panjang satu kata dan kueri dengan panjang dua kata. Kueri uji dengan panjang satu kata ditunjukkan oleh Tabel 5. Kueri uji dengan panjang dua kata ditunjukkan oleh Tabel 6.
Tabel 5 Kueri uji dengan panjang 1 kata Topik Bahasan Kueri Uji Penyakit yang dapat
Tabel 6 Kueri uji dengan panjang 2 kata Topik Bahasan Kueri Uji
Penyakit yang dapat
Lingkungan implementasi yang digunakan adalah :
1. Perangkat lunak:
a. Sistem operasi Windows 7 Starter
8
a. Processor Intel Atom 1.66 GHz
b. RAM 1 GB
c. Harddisk dengan sisa kapasitas 179
GB
HASIL DAN PEMBAHASAN Dokumen tumbuhan obat
Penelitian ini menggunakan 132
dokumen tumbuhan obat yang dibagi menjadi dua bagian, yaitu dokumen latih sebanyak 93 dokumen dan dokumen uji sebanyak 39
dokumen. Setiap dokumen uji akan
diklasifikasikan ke dalam dua kelas target yaitu kelas famili dan kelas penyakit.
Hasil praproses data
Praproses data hanya dilakukan pada
bagian deskripsi dari dokumen tumbuhan
obat. Hasil dari praproses data adalah daftar
Pemilihan fitur dengan metode pengujian W dilakukan pada dua taraf nyata , yaitu 0.01 dan 0.001. Fitur yang dihasilkan pada taraf nyata 0.01 adalah 2.942 fitur. Fitur yang dihasilkan pada taraf nyata 0.001 adalah 1.578 fitur.
Hasil evaluasi klasifikasi KNN Fuzzy 1. Pengaruh taraf nyata ( ) pada
pemilihan fitur terhadap tingkat akurasi
Pemilihan fitur dilakukan pada dua taraf nyata ( ) yang berbeda, yaitu 0.01 dan 0.001. Pengaruh kedua taraf nyata ( ) dengan derajat bebas satu terhadap tingkat akurasi dari pengklasifikasi KNN Fuzzy dapat dilihat pada Tabel 7. Tingkat akurasi yang dihasilkan untuk kelas famili memiliki nilai yang sama, baik untuk fitur pada taraf nyata
0.01 maupun fitur pada taraf nyata 0.001. Tingkat akurasi yang dihasilkan adalah 97.43%. Tidak adanya perbedaan dari tingkat akurasi yang dihasilkan menunjukkan bahwa peningkatan taraf nyata pada saat pemilihan fitur tidak berpengaruh terhadap tingkat akurasi dari pengklasifikasi untuk kelas target famili.
Tabel 7 Pengaruh taraf nyata ( pada
pemilihan fitur terhadap tingkat akurasi pengklasifikasi KNN Fuzzy
Kelas =0.01 =0.001
Famili 97.43% 97.43%
Penyakit 100% 94.87%
Kesalahan pelabelan kelas famili untuk kedua taraf nyata hanya terjadi pada dokumen uji yang berisi informasi tentang tumbuhan obat ‘remek daging’. Hal ini disebabkan kurangnya data latih mengenai
tumbuhan obat ‘remek daging’ dan
kurangnya fitur yang merepresentasikan kelas target ‘achantaceae’. Kesalahan pelabelan kelas dokumen ‘remek daging’ untuk kedua taraf nyata dapat dilihat pada Lampiran 2 dan 3.
Tingkat akurasi untuk kelas penyakit yang dihasilkan oleh fitur pada taraf nyata 0.01 adalah 100%, namun saat fitur yang digunakan adalah fitur pada taraf nyata 0.001, tingkat akurasi turun menjadi 94.87%. Penghitungan akurasi kelas penyakit untuk kedua taraf nyata dilakukan berdasarkan hasil
" yang terdapat pada Lampiran 4. Penurunan tingkat akurasi terjadi karena pemilihan fitur untuk kelas penyakit yang dilakukan pada taraf nyata 0.001 telah
menghilangkan beberapa yang
mempunyai informasi penting sehingga pengklasifikasi tidak mampu memberi label kelas yang benar untuk beberapa dokumen uji.
Hal ini selaras dengan perbedaan jumlah fitur yang dihasilkan oleh kedua taraf nyata. Jumlah fitur yang dihasilkan pada taraf nyata 0.01 (2.942 fitur) lebih banyak dibandingkan dengan jumlah fitur yang dihasilkan pada taraf nyata 0.001 (1.578 fitur) karena pemilihan fitur pada taraf nyata 0.01
menetapkan nilai kritis yang lebih rendah.
8
a. Processor Intel Atom 1.66 GHz
b. RAM 1 GB
c. Harddisk dengan sisa kapasitas 179
GB
HASIL DAN PEMBAHASAN Dokumen tumbuhan obat
Penelitian ini menggunakan 132
dokumen tumbuhan obat yang dibagi menjadi dua bagian, yaitu dokumen latih sebanyak 93 dokumen dan dokumen uji sebanyak 39
dokumen. Setiap dokumen uji akan
diklasifikasikan ke dalam dua kelas target yaitu kelas famili dan kelas penyakit.
Hasil praproses data
Praproses data hanya dilakukan pada
bagian deskripsi dari dokumen tumbuhan
obat. Hasil dari praproses data adalah daftar
Pemilihan fitur dengan metode pengujian W dilakukan pada dua taraf nyata , yaitu 0.01 dan 0.001. Fitur yang dihasilkan pada taraf nyata 0.01 adalah 2.942 fitur. Fitur yang dihasilkan pada taraf nyata 0.001 adalah 1.578 fitur.
Hasil evaluasi klasifikasi KNN Fuzzy 1. Pengaruh taraf nyata ( ) pada
pemilihan fitur terhadap tingkat akurasi
Pemilihan fitur dilakukan pada dua taraf nyata ( ) yang berbeda, yaitu 0.01 dan 0.001. Pengaruh kedua taraf nyata ( ) dengan derajat bebas satu terhadap tingkat akurasi dari pengklasifikasi KNN Fuzzy dapat dilihat pada Tabel 7. Tingkat akurasi yang dihasilkan untuk kelas famili memiliki nilai yang sama, baik untuk fitur pada taraf nyata
0.01 maupun fitur pada taraf nyata 0.001. Tingkat akurasi yang dihasilkan adalah 97.43%. Tidak adanya perbedaan dari tingkat akurasi yang dihasilkan menunjukkan bahwa peningkatan taraf nyata pada saat pemilihan fitur tidak berpengaruh terhadap tingkat akurasi dari pengklasifikasi untuk kelas target famili.
Tabel 7 Pengaruh taraf nyata ( pada
pemilihan fitur terhadap tingkat akurasi pengklasifikasi KNN Fuzzy
Kelas =0.01 =0.001
Famili 97.43% 97.43%
Penyakit 100% 94.87%
Kesalahan pelabelan kelas famili untuk kedua taraf nyata hanya terjadi pada dokumen uji yang berisi informasi tentang tumbuhan obat ‘remek daging’. Hal ini disebabkan kurangnya data latih mengenai
tumbuhan obat ‘remek daging’ dan
kurangnya fitur yang merepresentasikan kelas target ‘achantaceae’. Kesalahan pelabelan kelas dokumen ‘remek daging’ untuk kedua taraf nyata dapat dilihat pada Lampiran 2 dan 3.
Tingkat akurasi untuk kelas penyakit yang dihasilkan oleh fitur pada taraf nyata 0.01 adalah 100%, namun saat fitur yang digunakan adalah fitur pada taraf nyata 0.001, tingkat akurasi turun menjadi 94.87%. Penghitungan akurasi kelas penyakit untuk kedua taraf nyata dilakukan berdasarkan hasil
" yang terdapat pada Lampiran 4. Penurunan tingkat akurasi terjadi karena pemilihan fitur untuk kelas penyakit yang dilakukan pada taraf nyata 0.001 telah
menghilangkan beberapa yang
mempunyai informasi penting sehingga pengklasifikasi tidak mampu memberi label kelas yang benar untuk beberapa dokumen uji.
Hal ini selaras dengan perbedaan jumlah fitur yang dihasilkan oleh kedua taraf nyata. Jumlah fitur yang dihasilkan pada taraf nyata 0.01 (2.942 fitur) lebih banyak dibandingkan dengan jumlah fitur yang dihasilkan pada taraf nyata 0.001 (1.578 fitur) karena pemilihan fitur pada taraf nyata 0.01
menetapkan nilai kritis yang lebih rendah.
9 terhadap tingkat akurasi dari pengklasifikasi
untuk kelas target penyakit.
Dilihat dari waktu eksekusi, proses klasifikasi untuk fitur pada taraf nyata 0.01 membutuhkan waktu yang lebih lama dibandingkan dengan fitur pada taraf nyata 0.001. Waktu eksekusi rata-rata untuk fitur yang memiliki taraf nyata 0.01 adalah 13.47 detik, sedangkan waktu eksekusi rata-rata untuk fitur yang memiliki taraf nyata 0.001 adalah 7.56 detik. Pengaruh taraf nyata ( ) terhadap waktu eksekusi dapat dilihat pada Tabel 8.
Tabel 8 Pengaruh taraf nyata ( terhadap waktu eksekusi
Kelas Waktu ekseskusi
(detik)
= 0.01 13.47
'= 0.001 7.56
Perbedaan waktu eksekusi disebabkan oleh perbedaan jumlah fitur yang dihasilkan pada kedua taraf nyata. Jumlah fitur yang dihasilkan pada taraf nyata 0.01 lebih banyak dibandingkan dengan jumlah fitur yang dihasilkan pada taraf nyata 0.001. Jumlah fitur akan sangat berpengaruh pada saat
penghitungan nilai similaritas antara
dokumen uji dengan dokumen latih. Semakin banyak fitur yang digunakan, semakin banyak waktu yang dibutuhkan untuk menghitung similaritas antara dokumen uji dengan setiap dokumen latih.
Perbedaan waktu eksekusi yang tidak
signifikan antara kedua sistem
pengklasifikasi menunjukkan bahwa secara keseluruhan kinerja pengklasifikasi KNN Fuzzy saat menggunakan fitur pada taraf nyata 0.01 lebih baik dibandingkan saat menggunakan fitur pada taraf nyata 0.001 karena fitur yang dihasilkan pada taraf nyata 0.01 lebih informatif dibandingkan dengan fitur yang dihasilkan pada taraf nyata 0.001.
2. Pengaruh nilai \ (\-nearest neighbor) terhadap tingkat akurasi
Pada saat pengklasifikasi membentuk derajat keanggotaan untuk setiap kelas, pengklasifikasi terlebih dahulu menentukan -tetangga terdekat atau -dokumen latih yang memiliki nilai similaritas tertinggi terhadap dokumen uji.
Penentuan nilai dilakukan secara bertahap
dari =1 hingga =50 dengan interval
sebesar 5. Penentuan nilai secara bertahap
dilakukan untuk melihat nilai yang
optimum terhadap tingkat akurasi
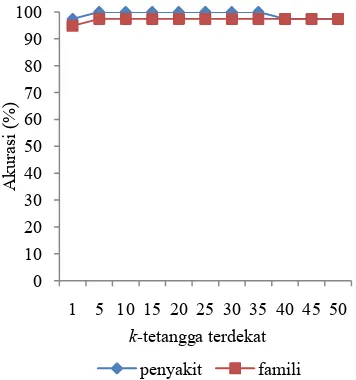
pengklasifikasi. Penentuan nilai dilakukan pada fitur dengan taraf nyata 0.01 dan derajat bebas satu. Pengaruh beberapa nilai terhadap tingkat akurasi pengklasifikasi KNN Fuzzy ditunjukkan pada Gambar 3.
Gambar 3 Pengaruh beberapa nilai \
terhadap tingkat akurasi pengklasifikasi KNN Fuzzy.
Tingkat akurasi optimum pengklasifikasi KNN Fuzzy untuk kelas famili dicapai pada
saat bernilai 5. Tingkat akurasi yang
dihasilkan sebesar 97.43%. Tingkat akurasi
tidak berubah hingga nilai =50. Hal ini
menunjukkan bahwa kinerja pengklasifikasi KNN Fuzzy untuk kelas famili relatif stabil terhadap penentuan nilai .
Tingkat akurasi optimum pengklasifikasi KNN Fuzzy untuk kelas penyakit dicapai pada saat bernilai 5. Tingkat akurasi yang dihasilkan sebesar 100%. Tingkat akurasi untuk kelas penyakit mengalami penurunan sebesar 2.57% pada saat nilai =40. Hal ini menunjukkan bahwa kinerja pengklasifikasi KNN Fuzzy untuk kelas penyakit tidak stabil
terhadap penentuan nilai . Nilai yang
10
Secara keseluruhan, kinerja
pengklasifikasi untuk kedua kelas target mencapai optimum saat nilai =5. Hal ini ditunjukkan dari tingkat akurasi yang dihasilkan untuk kedua kelas target. Tingkat akurasi yang dihasilkan untuk kelas famili dan kelas penyakit pada saat nilai =5 dapat dilihat pada Tabel 9.
Tabel 9 Tingkat akurasi yang dihasilkan untuk kelas famili dan kelas penyakit pada saat nilai \=5
Kelas Famili Penyakit
Tingkat
akurasi 97.43% 100%
Penentuan nilai diperlukan untuk
mengetahui kinerja pengklasifikasi KNN Fuzzy yang optimum. Penentuan nilai yang ‘baik’ dapat dilakukan dengan teknik optimisasi parameter.
3. Pengaruh fuzzy terhadap distibusi dokumen yang tidak merata
Penggunaan fuzzy pada pengklasifikasi merupakan adaptasi dari algoritma Fuzzy C-means. Algoritma ini memungkinkan suatu
dokumen untuk memiliki tingkat
keanggotaan terhadap semua kelas yang ada sehingga suatu dokumen tidak mutlak dikatakan sebagai anggota dari satu kelas tertentu. Persebaran dokumen yang tidak merata pada setiap kelas menyebabkan dokumen uji cenderung diberi label kelas
yang dominan. Kelas dominan yang
dimaksud adalah kelas yang memiliki jumlah dokumen lebih banyak (secara kuantitas) dibandingkan dengan kelas lainnya. Kelas yang dominan akan memiliki lebih banyak
sampel pada saat pengambilan tetangga
terdekat sehingga dokumen uji berpeluang lebih besar untuk masuk ke dalam kelas yang dominan. Hal ini dapat diatasi dengan menggunakan fuzzy. Penggunaan fuzzy pada
pengklasifikasi digunakan untuk
menghilangkan efek dari kelas dominan dengan cara memberi derajat keanggotaan untuk setiap kelas yang ada.
Pengaruh fuzzy pada algoritma
pengklasifikasi dalam mengatasi masalah persebaran dokumen yang tidak merata
ditunjukkan dari tingkat akurasi yang
dihasilkan. Pada penggunaan fitur dengan taraf nyata 0.01, nilai =5 untuk kelas famili dan =5 untuk kelas penyakit, tingkat akurasi yang dihasilkan untuk kelas famili sebesar
97.43% dan untuk kelas penyakit sebesar
100%. Hasil ini menunjukkan bahwa
penerapan fuzzy pada algoritma
pengklasifikasi mampu mengatasi persebaran dokumen yang tidak merata pada suatu kelas.
4. Pengaruh fuzzy dalam mengatasi karakteristik dokumen tumbuhan obat yang seragam
Dokumen tumbuhan obat yang
digunakan pada penelitian ini memiliki
karakteristik yang seragam sehingga
pengelompokan dokumen sulit untuk
dilakukan. Pengaruh fuzzy dalam mengatasi karakteristik dokumen yang seragam dapat dilihat melalui pengujian terhadap dua contoh dokumen. Dokumen uji yang pertama adalah dokumen tentang tumbuhan obat ‘landik’
yang diklasifikasikan sebagai kelas
11 Tiga kelas famili yang memiliki derajat
keanggotaan tertinggi untuk dokumen uji pertama adalah ‘achantaceae’, ‘rutaceae’ dan
‘euphorbiacae’, sedangkan tiga kelas
penyakit yang memiliki derajat keanggotaan tertinggi untuk dokumen uji pertama adalah
‘kulit’, ‘nyeri-radang-demam’ dan
‘perawatan’. Derajat keanggotaan yang
dihasilkan oleh dokumen uji pertama dapat dilihat pada Tabel 10.
Tabel 10 Derajat keanggotaan yang
dihasilkan oleh dokumen uji pertama dengan taraf nyata 0.01, \=5 untuk kelas famili dan
\=5 untuk kelas penyakit
Kelas Nilai keanggotaan tertinggi untuk dokumen uji kedua adalah ‘rutaceae’, ‘euphorbiaceae’ dan
‘menispermacae’, sedangkan tiga kelas
penyakit yang memiliki derajat keanggotaan tertinggi untuk dokumen uji kedua adalah
‘nyeri-radang-demam’, ‘kulit’ dan
‘pencernaan’. Derajat keanggotaan yang dihasilkan oleh dokumen uji kedua dapat dilihat pada Tabel 11.
Hasil klasifikasi terhadap dokumen uji
menunjukkan bahwa fuzzy mampu
mengelompokkan kedua dokumen uji ke dalam kelas yang berbeda meskipun kedua
dokumen memiliki karakteristik yang
seragam. Kedekatan karakteristik antara dua dokumen uji dapat dilihat dari derajat keanggotaan yang dihasilkan.
Tabel 11 Derajat keanggotaan yang
dihasilkan oleh dokumen uji kedua dengan taraf nyata 0.01, \=5 untuk kelas famili dan
\=5 untuk kelas penyakit
Kelas Nilai
Hasil evaluasi temu kembali informasi Evaluasi temu kembali informasi yang
dilakukan dalam penelitian ini
menunjukkan pengaruh klasifikasi dokumen terhadap hasil pencarian dokumen relevan karena kueri tidak melalui tahap klasifikasi terlebih dahulu. Hal ini terjadi akibat waktu eksekusi untuk kedua model klasifikasi yang tidak efisien untuk melakukan pencarian berdasarkan hasil klasifikasi kueri. Oleh karena itu, hasil evaluasi temu kembali informasi tidak merepresentasikan kinerja sistem akibat klasifikasi dokumen.
12 panjang 1 kata dan kueri uji dengan panjang
2 kata. Detail dari kueri uji yang digunakan untuk mengevaluasi sistem temu kembali informasi dapat dilihat pada Tabel 5 dan Tabel 6.
Sebagian besar dokumen yang
ditemukembalikan oleh sistem dengan kueri uji 1 kata adalah dokumen yang relevan. Dokumen yang tidak relevan namun ikut ditemukembalikan hanya terjadi pada kueri uji ‘vitamin’ dan kueri uji ‘kalsium’. Hal ini disebabkan sistem tidak mengetahui makna dari kueri yang diinginkan oleh pengguna.
Misalnya informasi yang diinginkan
pengguna adalah informasi mengenai
kandungan vitamin dalam tumbuhan obat
(kueri ‘vitamin’), namun sistem
menemukembalikan informasi mengenai
penyakit yang terjadi akibat kekurangan vitamin (kueri ‘vitamin’).
Pada saat sistem dievaluasi dengan kueri uji 2 kata, terdapat beberapa dokumen tidak relevan yang ikut ditemukembalikan. Hal ini terjadi pada saat sistem dievaluasi dengan kueri ‘gatal-gatal’, ‘vitamin c’, ‘zat warna’ dan ‘buah diperas’. Kesalahan sistem dalam menemukembalikan dokumen disebabkan
sistem melakukan pencarian dokumen
(berdasarkan pembobotan BM25) secara terpisah untuk masing-masing kata. Misalnya untuk kueri ‘zat warna’, sistem akan melakukan pembobotan terhadap kata ‘zat’ dan kata ‘warna’. Hal ini sejalan dengan metode pembobotan BM25 yang hanya memperhatikan kemunculan satu kata tanpa
memperhatikan kedekatan kata yang
digunakan pada kueri.
Pada saat sistem dievaluasi dengan kueri uji 2 kata, sistem akan melakukan pencarian secara terpisah terhadap masing-masing kata dan hal ini menyebabkan dokumen yang tidak relevan ikut terambil, namun ada beberapa kueri dengan panjang 2 kata yang
berhasil menemukembalikan seluruh
dokumen relevan, yaitu kueri ‘batuk pilek’, ‘datang bulan’, ‘sesak napas’, ‘tumbuhan merambat’, ‘tanaman hias’, ‘daun lebar’, ‘buah buni’ dan ‘kalsium oksalat’. Hal ini terjadi karena kata pertama dan kata kedua dalam kueri tersebut memiliki frekuensi kemunculan yang cenderung sama. Frekuensi kemunculan dua kata secara bersamaan sangat dipengaruhi oleh makna dari kata tersebut. Misalnya untuk kata “buah buni”, kata “buni” tidak ditemukan berdiri sendiri dalam seluruh koleksi dokumen tumbuhan
obat karena kemuculan kata “buni” akan selalu diikuti oleh kemunculan kata “buah”. Namun demikian hal ini sangat mungkin dipengaruhi oleh koleksi dokumen yang digunakan.
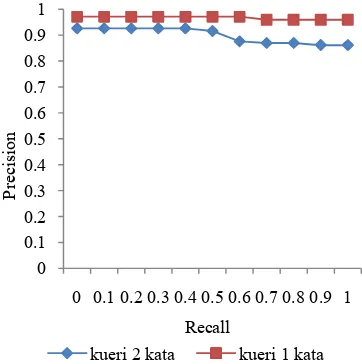
Nilai AVP yang dihasilkan saat sistem dievaluasi dengan kueri uji 1 kata adalah 0.96, sedangkan nilai AVP yang dihasilkan saat sistem dievaluasi dengan kueri uji 2 kata adalah 0.89. Penurunan nilai AVP sebesar 0.06 menunjukkan bahwa kinerja sistem temu kembali informasi lebih baik pada saat sistem dievaluasi dengan kueri uji yang memiliki panjang 1 kata. Secara keseluruhan kinerja sistem temu kembali informasi sudah baik. Hal ini ditunjukkan dari nilai
& (AVP) yang dihasilkan. Perbandingan nilai AVP untuk kedua kategori kueri uji dapat dilihat pada Gambar 3.
Gambar 4 Perbandingan AVP untuk kueri uji 1 kata dan kueri uji 2 kata.
KESIMPULAN DAN SARAN Kesimpulan
Penelitian ini menerapkan metode W
untuk pemilihan fitur dan metode KNN Fuzzy untuk klasifikasi dokumen tumbuhan obat. Pemilihan fitur dilakukan pada dua taraf nyata, yaitu 0.01 dan 0.001. Jumlah fitur yang dihasilkan pada taraf nyata 0.01 lebih banyak dibandingkan dengan jumlah fitur yang dihasilkan pada taraf nyata 0.001 sehingga tingkat akurasi yang dihasilkan oleh
pengklasifikasi saat menggunakan fitur
dengan taraf nyata 0.01 lebih tinggi dibandingkan saat menggunakan fitur dengan
0
12 panjang 1 kata dan kueri uji dengan panjang
2 kata. Detail dari kueri uji yang digunakan untuk mengevaluasi sistem temu kembali informasi dapat dilihat pada Tabel 5 dan Tabel 6.
Sebagian besar dokumen yang
ditemukembalikan oleh sistem dengan kueri uji 1 kata adalah dokumen yang relevan. Dokumen yang tidak relevan namun ikut ditemukembalikan hanya terjadi pada kueri uji ‘vitamin’ dan kueri uji ‘kalsium’. Hal ini disebabkan sistem tidak mengetahui makna dari kueri yang diinginkan oleh pengguna.
Misalnya informasi yang diinginkan
pengguna adalah informasi mengenai
kandungan vitamin dalam tumbuhan obat
(kueri ‘vitamin’), namun sistem
menemukembalikan informasi mengenai
penyakit yang terjadi akibat kekurangan vitamin (kueri ‘vitamin’).
Pada saat sistem dievaluasi dengan kueri uji 2 kata, terdapat beberapa dokumen tidak relevan yang ikut ditemukembalikan. Hal ini terjadi pada saat sistem dievaluasi dengan kueri ‘gatal-gatal’, ‘vitamin c’, ‘zat warna’ dan ‘buah diperas’. Kesalahan sistem dalam menemukembalikan dokumen disebabkan
sistem melakukan pencarian dokumen
(berdasarkan pembobotan BM25) secara terpisah untuk masing-masing kata. Misalnya untuk kueri ‘zat warna’, sistem akan melakukan pembobotan terhadap kata ‘zat’ dan kata ‘warna’. Hal ini sejalan dengan metode pembobotan BM25 yang hanya memperhatikan kemunculan satu kata tanpa
memperhatikan kedekatan kata yang
digunakan pada kueri.
Pada saat sistem dievaluasi dengan kueri uji 2 kata, sistem akan melakukan pencarian secara terpisah terhadap masing-masing kata dan hal ini menyebabkan dokumen yang tidak relevan ikut terambil, namun ada beberapa kueri dengan panjang 2 kata yang
berhasil menemukembalikan seluruh
dokumen relevan, yaitu kueri ‘batuk pilek’, ‘datang bulan’, ‘sesak napas’, ‘tumbuhan merambat’, ‘tanaman hias’, ‘daun lebar’, ‘buah buni’ dan ‘kalsium oksalat’. Hal ini terjadi karena kata pertama dan kata kedua dalam kueri tersebut memiliki frekuensi kemunculan yang cenderung sama. Frekuensi kemunculan dua kata secara bersamaan sangat dipengaruhi oleh makna dari kata tersebut. Misalnya untuk kata “buah buni”, kata “buni” tidak ditemukan berdiri sendiri dalam seluruh koleksi dokumen tumbuhan
obat karena kemuculan kata “buni” akan selalu diikuti oleh kemunculan kata “buah”. Namun demikian hal ini sangat mungkin dipengaruhi oleh koleksi dokumen yang digunakan.
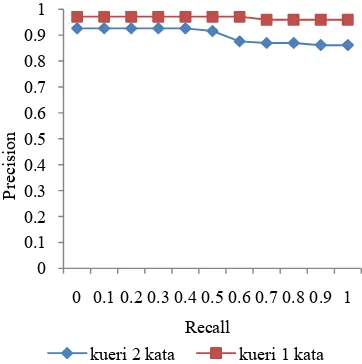
Nilai AVP yang dihasilkan saat sistem dievaluasi dengan kueri uji 1 kata adalah 0.96, sedangkan nilai AVP yang dihasilkan saat sistem dievaluasi dengan kueri uji 2 kata adalah 0.89. Penurunan nilai AVP sebesar 0.06 menunjukkan bahwa kinerja sistem temu kembali informasi lebih baik pada saat sistem dievaluasi dengan kueri uji yang memiliki panjang 1 kata. Secara keseluruhan kinerja sistem temu kembali informasi sudah baik. Hal ini ditunjukkan dari nilai
& (AVP) yang dihasilkan. Perbandingan nilai AVP untuk kedua kategori kueri uji dapat dilihat pada Gambar 3.
Gambar 4 Perbandingan AVP untuk kueri uji 1 kata dan kueri uji 2 kata.
KESIMPULAN DAN SARAN Kesimpulan
Penelitian ini menerapkan metode W
untuk pemilihan fitur dan metode KNN Fuzzy untuk klasifikasi dokumen tumbuhan obat. Pemilihan fitur dilakukan pada dua taraf nyata, yaitu 0.01 dan 0.001. Jumlah fitur yang dihasilkan pada taraf nyata 0.01 lebih banyak dibandingkan dengan jumlah fitur yang dihasilkan pada taraf nyata 0.001 sehingga tingkat akurasi yang dihasilkan oleh
pengklasifikasi saat menggunakan fitur
dengan taraf nyata 0.01 lebih tinggi dibandingkan saat menggunakan fitur dengan
0
13 taraf nyata 0.001. Penentuan nilai tetangga
terdekat yang besar menyebabkan batasan antar kelas menjadi lebih kabur. Tingkat akurasi optimum dari pengklasifikasi KNN Fuzzy untuk kedua kelas target dicapai pada saat nilai =5.
Secara keseluruhan, kinerja sistem temu kembali informasi sudah baik. Hal ini
ditunjukkan dari nilai &
(AVP) yang dihasilkan. Nilai AVP yang dihasilkan untuk kueri dengan panjang 1 kata adalah 0.96. Nilai AVP yang dihasilkan untuk kueri dengan panjang 2 kata adalah 0.89. Kinerja sistem temu kembali informasi lebih baik saat pencarian dokumen dilakukan dengan kueri yang memiliki panjang 1 kata.
Saran
Berikut ini penelitian lanjutan yang dapat
dilakukan berkaitan dengan klasifikasi
dokumen menggunakan KNN Fuzzy:
1. Penggunaan jumlah dokumen tumbuhan
obat yang lebih besar dan jenis tumbuhan obat yang lebih bervariasi.
2. Pengaruh teknik optimisasi parameter
dalam menentukan nilai tetangga
terdekat terhadap tingkat akurasi
pengklasifikasi.
DAFTAR PUSTAKA
Baeza-Yates R, Riberio-Neto B. 1999.
! ( # %
England: Addison Wesley.
Han J, Kamber M. 2006% ) !
& ' . USA : Morgan Kaufman Publishers.
Manning CD, Raghavan P, Schutze H. 2008.
( ( # %
New York : Cambridge University Press.
Spiegel M. 2004. * + , .
Jakarta: Erlangga.
Shang % 2006. An Adaptive Fuzzy kNN
Text Classifier. ( -../. Part III. Hal
: 216-223.
[STI] Sphinx Technologies Inc. 2008. & "
0%0. $ %
http://sphinxsearch.com [9 Maret 2011].
Tan % 2006. ( ) ! %
USA: Addison Weasley.
Wang J % 2000. Research on web text
mining. 1 & #
) & . Vol 37. Hal : 518-519. Yang Y, Pedersen J. 1997. A Comparative Study on Feature Selection in Text Categorization. (
! 2 0334%
Zuhud, E.A.M. 2009. Potensi Hutan Tropika Indonesia sebagai Penyangga Bahan Obat Alam untuk Kesehatan Bangsa.
1 5 6 ( . Vol VI
KLASIFIKASI DO
D
FAKULTAS MAT
SI DOKUMEN TUMBUHAN OBAT MENGG
ALGORITMA KNN FUZZY
KRISTINA PASKIANTI
DEPARTEMEN ILMU KOMPUTER
S MATEMATIKA DAN ILMU PENGETAHUA
INSTITUT PERTANIAN BOGOR
BOGOR
2011
NGGUNAKAN
13 taraf nyata 0.001. Penentuan nilai tetangga
terdekat yang besar menyebabkan batasan antar kelas menjadi lebih kabur. Tingkat akurasi optimum dari pengklasifikasi KNN Fuzzy untuk kedua kelas target dicapai pada saat nilai =5.
Secara keseluruhan, kinerja sistem temu kembali informasi sudah baik. Hal ini
ditunjukkan dari nilai &
(AVP) yang dihasilkan. Nilai AVP yang dihasilkan untuk kueri dengan panjang 1 kata adalah 0.96. Nilai AVP yang dihasilkan untuk kueri dengan panjang 2 kata adalah 0.89. Kinerja sistem temu kembali informasi lebih baik saat pencarian dokumen dilakukan dengan kueri yang memiliki panjang 1 kata.
Saran
Berikut ini penelitian lanjutan yang dapat
dilakukan berkaitan dengan klasifikasi
dokumen menggunakan KNN Fuzzy:
1. Penggunaan jumlah dokumen tumbuhan
obat yang lebih besar dan jenis tumbuhan obat yang lebih bervariasi.
2. Pengaruh teknik optimisasi parameter
dalam menentukan nilai tetangga
terdekat terhadap tingkat akurasi
pengklasifikasi.
DAFTAR PUSTAKA
Baeza-Yates R, Riberio-Neto B. 1999.
! ( # %
England: Addison Wesley.
Han J, Kamber M. 2006% ) !
& ' . USA : Morgan Kaufman Publishers.
Manning CD, Raghavan P, Schutze H. 2008.
( ( # %
New York : Cambridge University Press.
Spiegel M. 2004. * + , .
Jakarta: Erlangga.
Shang % 2006. An Adaptive Fuzzy kNN
Text Classifier. ( -../. Part III. Hal
: 216-223.
[STI] Sphinx Technologies Inc. 2008. & "
0%0. $ %
http://sphinxsearch.com [9 Maret 2011].
Tan % 2006. ( ) ! %
USA: Addison Weasley.
Wang J % 2000. Research on web text
mining. 1 & #
) & . Vol 37. Hal : 518-519. Yang Y, Pedersen J. 1997. A Comparative Study on Feature Selection in Text Categorization. (
! 2 0334%
Zuhud, E.A.M. 2009. Potensi Hutan Tropika Indonesia sebagai Penyangga Bahan Obat Alam untuk Kesehatan Bangsa.
1 5 6 ( . Vol VI
KLASIFIKASI DO
D
FAKULTAS MAT
SI DOKUMEN TUMBUHAN OBAT MENGG
ALGORITMA KNN FUZZY
KRISTINA PASKIANTI
DEPARTEMEN ILMU KOMPUTER
S MATEMATIKA DAN ILMU PENGETAHUA
INSTITUT PERTANIAN BOGOR
BOGOR
2011
NGGUNAKAN
ABSTRACT
PASKIANTI, KRISTINA. Document Classification using KNN Fuzzy Algorithm. Supervised by YENI HERDIYENI.
KLASIFIKASI DOKUMEN TUMBUHAN OBAT MENGGUNAKAN
ALGORITMA KNN FUZZY
KRISTINA PASKIANTI
Skripsi
Sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Klasifikasi Dokumen Tumbuhan Obat menggunakan Algoritma KNN Fuzzy
Nama : Kristina Paskianti
NIM : G64070113
Menyetujui: Pembimbing,
Dr. Yeni Herdiyeni, S.Si, M.Kom. NIP. 19750923 200012 2 001
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Tuhan Yang Maha Esa atas limpahan berkat dan karunia-Nya sehingga skripsi yang berjudul “Klasifikasi Dokumen Tumbuhan Obat menggunakan Algoritma KNN Fuzzy” dapat penulis selesaikan dengan baik. Penelitian ini dilaksanakan di departemen Ilmu Komputer Institut Pertanian Bogor selama periode Januari 2011 sampai dengan Juli 2011.
Selama penulis melakukan penelitian, penulis menyadari bahwa banyak pihak yang ikut membantu dalam penyelesaian skripsi ini. Oleh karena itu, penulis ingin menyampaikan ucapan terima kasih yang sebesar-besarnya kepada :
1. Orang tua terkasih, kakak dan keponakan atas doa dan dukungan yang diberikan.
2. Ibu Dr. Yeni Herdiyeni selaku pembimbing tugas akhir yang telah banyak memberikan ilmu,
pengalaman dan nasehat kepada penulis.
3. Bapak Ir. Julio Adisantoso M.Kom dan Bapak Musthofa S.Kom, M.Sc. selaku dosen penguji
atas kemudahan yang diberikan.
4. Yayasan Beasiswa Oikoumene atas bantuan yang diberikan selama periode 2009-2011.
5. Sahabat terbaik di Ilkomerz 44, Ria, Inne, Fani R., Manda, Jilly, Faza, Ade, Gamma, Fai dan
Yoga H. yang telah berbagi cerita suka dan duka bersama selama penulis menjadi mahasiswa.
6. Teman-teman satu bimbingan Yoga H., Fani R., Fani V., Iyos, Ella, Dimpy, Wido, Mba Vira
dan Mba Putri atas semangat, bantuan dan nasehat yang diberikan kepada penulis.
7. Ricky untuk semangat dan dukungan yang telah diberikan selama penulis menyelesaikan
tugas akhir.
Penulis menyadari bahwa masih banyak kekurangan yang ditemukan dalam tugas akhir ini. Penulis berharap adanya saran dan kritik yang membangun dari pihak yang membaca tulisan ini. Akhir kata, semoga tulisan ini dapat membawa manfaat.
Bogor, Juli 2011
RIWAYAT HIDUP
v
DAFTAR ISI
Halaman DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN ... 1 Latar Belakang ... 1 Tujuan ... 1 Ruang Lingkup ... 1 Manfaat ... 1
TINJAUAN PUSTAKA ... 1 Temu Kembali Informasi ... 1 Klasifikasi ... 2 Chi kuadrat (χ2) ... 2 KNN Fuzzy ... 3
! " ... 3
# dan ... 3 Sphinx ... 4 Pembobotan BM25... 4
METODE PENELITIAN ... 4 Dokumen tumbuhan obat ... 4 Praproses data ... 5 Pembagian data ... 6 Pemilihan fitur dengan χ ... 6 Klasifikasi KNN Fuzzy ... 6 Temu Kembali Informasi ... 6 Evaluasi ... 7 Lingkungan Implementasi ... 7
HASIL DAN PEMBAHASAN ... 8 Dokumen tumbuhan obat ... 8 Hasil praproses data ... 8 Hasil pemilihan fitur ... 8 Hasil evaluasi klasifikasi KNN Fuzzy ... 8 1. Pengaruh taraf nyata pada pemilihan fitur terhadap tingkat akurasi. ... 8 2. Pengaruh nilai ( -nearest neighbor) terhadap tingkat akurasi ... 9 3. Pengaruh fuzzy terhadap distibusi dokumen yang tidak merata... 10 4. Pengaruh fuzzy dalam mengatasi karakteristik dokumen tumbuhan obat yang seragam .. 10 Hasil evaluasi temu kembali informasi ...11
KESIMPULAN DAN SARAN ... 12 Kesimpulan ...12 Saran ...13
vi
DAFTAR GAMBAR
Halaman 1 Ilustrasi vektor dokumen dalam ruang vektor. ... 2 2 Metode penelitian. ... 4 3 Pengaruh beberapa nilai terhadap tingkat akurasi pengklasifikasi KNN Fuzzy. ... 9 4 Perbandingan AVP untuk kueri uji 1 kata dan kueri uji 2 kata. ...12
DAFTAR TABEL
Halaman 1 Nilai kritis χ2 dengan derajat bebas satu dan taraf nyata α ... 2 2 ! " untuk klasifikasi biner ... 3 3 Persebaran jumlah dokumen untuk kelas famili ... 5 4 Persebaran jumlah dokumen untuk kelas penyakit... 5 5 Kueri uji dengan panjang 1 kata ... 7 6 Kueri uji dengan panjang 2 kata ... 7 7 Pengaruh taraf nyata ( ) pada pemilihan fitur terhadap tingkat akurasi pengklasifikasi KNN
Fuzzy ... 8 8 Pengaruh taraf nyata ( ) terhadap waktu eksekusi ... 9 9 Tingkat akurasi yang dihasilkan untuk kelas famili dan kelas penyakit pada saat nilai =5 ...10 10 Derajat keanggotaan yang dihasilkan oleh dokumen uji pertama dengan taraf nyata 0.01, =5
untuk kelas famili dan =5 untuk kelas penyakit ...11 11 Derajat keanggotaan yang dihasilkan oleh dokumen uji kedua dengan taraf nyata 0.01, =5
untuk kelas famili dan =5 untuk kelas penyakit ...11
DAFTAR LAMPIRAN
1 PENDAHULUAN
Latar Belakang
Indonesia adalah negara
$ yang kaya akan tumbuhan
obat potensial. Sampai tahun 2001,
Laboratorium Konservasi Tumbuhan,
Fakultas Kehutanan IPB telah mendata dari berbagai hasil riset bahwa tidak kurang dari 2.039 spesies tumbuhan obat berasal dari hutan Indonesia (Zuhud 2009). Fakta ini
mendorong para peneliti untuk terus
melakukan penelitian terutama di bidang pemanfaatan tumbuhan obat Indonesia. Banyak dokumen hasil riset yang sudah dihasilkan, namun dokumen tersebut belum memberikan manfaat yang optimal karena sulitnya mencari informasi. Oleh karena itu, diperlukan suatu teknik komputasi dalam
bentuk mesin pencari ( ) yang
mampu memberikan informasi tumbuhan obat secara lebih mudah dan cepat.
Kebutuhan informasi akan tumbuhan obat dapat dikelompokkan menjadi beberapa kategori, seperti famili, ramuan, kandungan
kimia serta penyakit yang dapat
disembuhkan. Hal ini menunjukkan perlunya suatu teknik klasifikasi untuk dokumen hasil riset sehingga pencarian melalui mesin pencari dapat dilakukan dengan efektif dan
efisien. Penerapan teknik klasifikasi
dokumen pada mesin pencari dilakukan untuk mengelompokkan informasi pada
dokumen. Klasifikasi dokumen secara
manual tidak memungkinkan untuk dokumen skala besar karena membutuhkan waktu yang lama. Solusi dari kelemahan klasifikasi
manual adalah membangun klasifikasi
dokumen secara automatis.
Ada banyak metode yang dapat
digunakan untuk klasifikasi dokumen secara
automatis, seperti -Nearest Neighbor
(KNN), Bayes, Decision Tree, Support Vector Machine, Rocchio dan lain-lain.
Shang et al (2006) mengembangkan
algoritma KNN Fuzzy untuk klasifikasi data Reuters-21578 dan data dari International Database Center di China. Algoritma KNN Fuzzy memiliki kemampuan untuk mengatasi persebaran dokumen yang tidak merata dan
karakteristik dokumen yang cenderung
seragam.
Penelitian ini akan menerapkan
algoritma KNN Fuzzy yang telah dilakukan Shang et al (2006) untuk klasifikasi dokumen tumbuhan obat. Penerapan algoritma ini
meliputi proses pemilihan fitur menggunakan
metode pengujian (Chi-Kuadrat).
Klasifikasi dilakukan untuk dua kelas target yaitu kelas famili dan kelas penyakit. Kedua kelas ini dianggap sebagai kelas yang
merepresentasikan kebutuhan informasi
pengguna.
Tujuan
Tujuan penelitian ini adalah menerapkan algoritma pengklasifikasi KNN Fuzzy pada dokumen tumbuhan obat Indonesia untuk sistem temu kembali informasi.
Ruang Lingkup
Ruang lingkup penelitian ini meliputi :
1. Dokumen terbatas pada 32 jenis
tumbuhan obat Indonesia
2. Dokumen berformat XML
Manfaat
Manfaat penelitian ini adalah memberi kemudahan kepada pengguna untuk mencari informasi tumbuhan obat Indonesia.
TINJAUAN PUSTAKA Temu Kembali Informasi
Temu kembali informasi atau
merupakan proses pencarian tidak terstruktur untuk memenuhi kebutuhan informasi dari sekumpulan koleksi yang besar (Manning 2008). Pengindeksan dalam temu kembali informasi adalah proses menentukan penciri dari suatu dokumen dalam sekumpulan koleksi yang besar. Penciri dari suatu dokumen dapat berupa kata, kalimat atau paragraf. Penciri dari suatu
dokumen disebut dengan % Setiap
dokumen akan melewati proses mendapatkan
pembobotan serta pembuatan
indeks.
Terdapat beberapa model dalam temu kembali informasi, salah satunya adalah
model ruang vektor atau & .
Pada model ini, setiap dokumen
direpresentasikan sebagai vektor dalam
ruang vektor. Representasi vektor dokumen
dengan elemen dinotasikan dengan
. Elemen yang dimaksud adalah
yang diperoleh dari proses
2 vektor dalam ruang vektor. Ilustrasi ini dapat
dilihat pada Gambar 1.
Gambar 1 Ilustrasi vektor dokumen dalam ruang vektor.
Pengukuran kesamaan atau kemiripan antara vektor dokumen dan dokumen dalam ruang vektor dilakukan dengan
menghitung nilai similaritas antara
dan . Nilai similaritas
dapat diperoleh dari Persamaan (1).
dengan pembilang menyatakan perkalian (
& ) antara vektor dan , sedangkan penyebut menyatakan perkalian antara panjang vektor.
Klasifikasi
Klasifikasi terbagi menjadi dua fase, yaitu pelatihan dan pengujian. Pada fase pelatihan, sebagian data yang telah diketahui kelasnya (data latih) digunakan untuk membentuk model. Pada fase pengujian, model yang sudah terbentuk diuji dengan sebagian data lainnya (data uji) untuk mengetahui akurasi dari model tersebut. Selanjutnya model dapat digunakan untuk memprediksi kelas data yang belum diketahui (Han & Kamber 2006).
Chi kuadrat (χ2)
Chi kuadrat (χ2) adalah suatu ukuran yang menyatakan perbedaan antara frekuensi observasi (oi) dengan frekuensi harapan (ei)
untuk setiap (i) yang dirumuskan
dengan
Pengaruh kedua frekuensi tersebut dapat diuji dengan suatu hipotesis H0. Hipotesis nol adalah hipotesis yang menyatakan tidak adanya perbedaan yang signifikan antara
frekuensi observasi dengan frekuensi
harapan. Pengujian hipotesis dilakukan pada taraf nyata α tertentu. Taraf nyata yang dimaksud adalah peluang salah menolak hipotesis yang seharusnya benar (Spiegel 2004).
Pada penelitian ini, nilai χ2 digunakan
untuk melihat pengaruh kemunculan
terhadap kelas (Yang&Pedersen 1997).
Nilai χ2 untuk setiap kemunculan
terhadap kelas dihitung menggunakan
Persamaan (2).
dengan adalah jumlah dokumen latih,
adalah jumlah dokumen pada kategori yang
memuat , adalah jumlah dokumen . Penentuan fitur dilakukan berdasarkan
nilai χ2 dari masing-masing . ' yang
memiliki nilai χ2 diatas nilai kritis pada taraf nyata α dan derajat bebas satu adalah yang akan terpilih sebagai fitur. Nilai kritis χ2 dengan derajat bebas satu dan taraf nyata α ditunjukkan oleh Tabel 1.
3 KNN Fuzzy
KNN Fuzzy adalah pengembangan
metode klasifikasi KNN klasik yang
dilakukan oleh Shang (2006).
Pengembangan ini dilakukan untuk
mengatasi masalah sebaran dokumen yang tidak merata pada suatu kelas. Metode ini
mengadopsi teori untuk
membangun fungsi keanggotaan yang baru berdasarkan nilai similaritas antar dokumen. Penghitungan derajat keanggotaan dokumen uji untuk setiap kelas dinyatakan dalam
keanggotaan bernilai 1 jika dokumen latih adalah anggota kelas dan bernilai 0 jika yang menyatakan jumlah data uji yang benar diklasifikasikan dan jumlah data uji yang
salah diklasifikasikan (Tan 2006).
Contoh " untuk klasifikasi
biner ditunjukkan pada Tabel 2.
Tabel 2 ! " untuk klasifikasi
Keterangan untuk tabel 2 dinyatakan sebagai berikut :
· ' (TP), yaitu jumlah
dokumen dari kelas 1 yang benar diklasifikasikan sebagai kelas 1.
· ' (TN), yaitu jumlah
dokumen dari kelas 0 yang benar diklasifikasikan sebagai kelas 0.
· (FP), yaitu jumlah
dokumen dari kelas 0 yang salah diklasifikasikan sebagai kelas 1.
· (FN), yaitu jumlah
dokumen dari kelas 1 yang salah diklasifikasikan sebagai kelas 0.
Perhitungan akurasi dinyatakan dalam
Persamaan (4).
(4)
dan
# dan adalah dua kriteria
yang digunakan untuk mengevaluasi tingkat efektifitas kinerja sistem temu kembali
informasi. # adalah rasio jumlah
dokumen relevan yang ditampilkan terhadap jumlah seluruh dokumen yang relevan. adalah rasio jumlah dokumen relevan yang ditampilkan terhadap jumlah seluruh dokumen yang ditampilkan (Manning
2008). Perhitungan dan &
dinyatakan pada Persamaan (5) dan (6).
() *++
Menurut Baeza-Yates dan Riberio-Neto (1999), algoritma temu kembali informasi yang dievaluasi menggunakan beberapa kueri
berbeda akan menghasilkan nilai dan
Perhitungan AVP dinyatakan dalam
4
yang memungkinkan untuk
melakukan pencarian dokumen atau $
di komputer. Sphinx menyediakan
fungsionalitas pencarian teks secara cepat dan relevan pada aplikasi klien. Sphinx telah dirancang khusus untuk berintegrasi
dengan $ SQL dan bahasa
pemrograman tertentu (STI 2008).
Pembobotan BM25
Pembobotan BM25 atau Okapi adalah pembobotan yang mengurutkan set dokumen
berdasarkan kueri yang muncul pada
setiap dokumen koleksi. Hubungan antara kueri dengan dokumen dipengaruhi oleh
parameter (parameter untuk kalibrasi skala
frekuensi ) dan parameter @ (parameter
untuk kalibrasi skala panjang dokumen).
Nilai parameter yang optimal untuk
pembobotan BM25 adalah =1.2 dan
@=0.75 (Manning 2008). Penghitungan bobot
suatu dokumen berdasarkan
dinyatakan dalam Persamaan (8).
(8)
dengan'A B " # @ 6 @ 8 C DC*0) E;
+.2 FGHI>J adalah ,
KL adalah frekuensi pada dokumen ,
CG dan CMNO adalah panjang dokumen dan
rata-rata panjang dokumen dalam koleksi,
dan @ adalah parameter pengskalaan terhadap
K dan panjang dokumen.
METODE PENELITIAN
Penelitian ini dilaksanakan dalam dua bagian, yaitu klasifikasi dokumen dan temu kembali informasi. Klasifikasi dokumen meliputi tahap pengumpulan data, praproses data, pembagian data menjadi data latih dan data uji, pemilihan fitur dengan χ2, klasifikasi dokumen dengan KNN Fuzzy dan evaluasi. Temu kembali informasi meliputi tahap pencocokan kueri dengan dokumen dalam
koleksi, pembobotan dan evaluasi. Metode penelitian diilustrasikan pada Gambar 2.
' $ (
Gambar 2 Metode penelitian.
Dokumen tumbuhan obat