ANALISIS SENTIMEN PENGGUNA TWITTER
PADA AKUN MAICIH
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
Ahmad Sopian
10110755
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
kehadirat Allah SWT yang telah memberikan rahmat dan karunia-Nya, shalawat serta salam semoga tercurah kepada Rasulullah SAW, sehingga penulis dapat menyelesaikan tugas akhir yang berjudul “ANALISIS SENTIMEN PENGGUNA TWITTER PADA AKUN MAICIH” untuk memenuhi salah satu syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika Universitas Komputer Indonesia.
Dengan keterbatasan ilmu dan pengetahuan serta pengalaman penulis, maka penulis mendapat banyak bantuan serta dukungan dari berbagai pihak. Oleh karena itu, penulis mengucapkan terimakasih yang sebesar –besarnya kepada:
1. Allah SWT karena dengan izin-Nya lah tugas akhir ini dapat terselesaikan. 2. Keluarga tercinta khususnya orang tua yang telah memberikan kasih sayang,
cinta, doa, dan dukungan baik moril maupun materi agar penulis dapat menyelesaikan tugas akhir ini tepat pada waktunya.
3. Bapak Iskandar Ikbal, S.T., M.Kom., selaku wali kelas IF-6/2010 yang selalu memberikan beberapa pengarahan kepada penulis.
4. Bapak Adam Mukharil Bachtiar S.Kom., M.T., selaku pembimbing yang selalu mengarahkan dan memberikan masukan dengan penuh kesabaran dalam menyelesaikan tugas akhir ini.
5. Ibu Nelly Indriani W, S.Si., M.T., selaku reviewer yang telah meluangkan waktu dan memberikan saran selama proses penyusunan tugas akhir ini. 6. Bapak dan Ibu dosen serta seluruh staf pegawai Program Studi Teknik
Informatika Universitas Komputer Indonesia yang telah banyak membantu penulis.
7. Ahmad, Artha, Rijal, Widi, Andri, Heni, Sigit dan Mongo selaku teman seperjuangan yang dibimbing oleh Pak Adam.
iv
kasih telah memberikan segala bentuk bantuan untuk menyelesaikan skripsi ini.
Penulis menyadari bahwa penulisan tugas akhir ini masih jauh dari sempurna. Untuk perbaikan dan pengembangan, penulis mengharapkan saran dan kritik yang bersifat membangun. Akhir kata, semoga penulisan tugas akhir ini dapat bermanfaat bagi penulis khususnya, dan semua yang membaca.
Bandung, 24 Februari 2015
v
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... xi
DAFTAR SIMBOL ... xiii
DAFTAR LAMPIRAN ... xvii
BAB I PENDAHULUAN ... 1
I.1 Latar Belakang Masalah ... 1
I.2 Perumusan Masalah ... 2
I.3 Maksud dan Tujuan... 2
I.4 Batasan Masalah ... 2
I.5 Metodologi Penelitian ... 3
I.5.1 Metode Pengumpulan Data ... 3
I.5.2 Metode Pembangunan Perangkat Lunak ... 4
I.5.3 Metode Penyelesaian Analisis Sentimen ... 5
I.6 Sistematika Penulisan ... 6
BAB II TINJAUAN PUSTAKA ... 9
II.1 Tinjauan Tempat Penelitian ... 9
II.1.1 Visi dan Misi ... 10
II.1.2 Struktur Organisasi ... 10
II.2 Landasan Teori... 12
II.2.1 Analisis Sentimen ... 12
II.2.2 Text Mining ... 12
II.2.3 Regular Expression ... 13
II.2.4 Text Preprocessing ... 14
III.1.5.1 Case Folding ... 15
vi
III.1.5.6 Tokenizer ... 18
III.1.5.7 Stemming ... 19
II.2.5 Machine Learning ... 19
II.2.6 Information Retrieval ... 20
II.2.7 Information Extraction ... 20
II.2.8 Term Weighting ... 21
II.2.9 Support Vector Machine ... 21
II.2.10 Naïve Bayes Classifier ... 25
II.2.11 K-Fold Cross Validation ... 27
BAB IIIANALISIS DAN PERANCANGAN SISTEM ... 29
III.1 Analisis Sistem... 29
III.1.1 Analisis Masalah ... 29
III.1.2 Analisis Sistem Berjalan ... 29
III.1.3 Analisis Data Masukan ... 30
III.1.4 Analisis Preprocessing ... 31
III.1.5 Analisis Metode / Algoritma ... 38
III.1.6 Spesifikasi Kebutuhan Perangkat Lunak ... 55
III.1.7 Analisis Kebutuhan Non Fungsional ... 56
III.1.7.1 Analisis Kebutuhan Perangkat Lunak ... 57
III.1.7.2 Analisis Kebutuhan Perangkat Keras ... 57
III.1.7.3 Analisis Kebutuhan Perangkat Pikir ... 57
III.1.8 Analisis Kebutuhan Fungsional ... 59
III.2 Perancangan Sistem ... 79
III.2.1 Perancangan Data... 79
III.2.2 Perancangan Arsitektural Menu ... 81
III.2.3 Perancangan Antarmuka ... 81
III.2.4 Perancangan Pesan ... 84
vii
IV.1.2 Implementasi Data ... 88
IV.1.3 Implementasi Antarmuka ... 89
IV.2 Pengujian Sistem ... 89
IV.2.1 Rencana Pengujian ... 89
IV.2.2 Skenario Pengujian ... 90
IV.2.3 Hasil Pengujian ... 92
IV.2.4 Evaluasi Pengujian ... 98
BAB V KESIMPULAN DAN SARAN... 99
V.1 Kesimpulan ... 99
V.2 Saran ... 99
101
L. Pakhpahan, “Social Media Untuk Promosi Bisnis,” [Online]. Available: http://latiefpakpahan.com/social-media-promosi-bisnis/. [Diakses 22 Oktober 2014].
[2] I. Sunni dan D. H. Widyantoro, “Analisis Sentimen dan Ekstraksi Topik Penentu Sentimen pada Opini Terhdap Tokoh Publik,” Jurnal Sarjana Institut Teknologi Bandung Bidang Elektro dan Informatika, vol. 1, pp. 200 - 206, 2012.
[3] Tan, P. N., Steinbach, M. & Kumar, V, Introduction to Data Mining, Boston: Pearson Addison Wesley, 2006.
[4] J. D. M. Rennie, L. Shih, J. Teevan dan D. R. Karger, “Tackling the Poor Assumptions of Naive BAyes Text Classifiers,” dalam Proceedings of the Twentieth International Conference on Machine Learning (ICML-2003), Washington DC, 2003.
[5] M. P. S. Dharma, Pendekatan, Jenis, dan Metode Penelitian Pendidikan, Jakarta: Direktorat Tenaga Kependidikan Departemen Pendidikan Nasional, 2008, p. 47.
[6] I. Sommerville, Software Engeneering, United States of America: Addision Wesley, 2011.
[7] I. H. Wltten, “Text Mining,” dalam Computer Science, University of Waikato, Hamilton, New Zealand, 2003.
[8] Haqqi, “Tutorial PHP: Pengenalan Dasar-Dasar Regex,” 14 Januari 2014. [Online]. Available: http://bisakomputer.com/tutorial-php-pengenalan-dasar-dasar-regex/. [Diakses 22 1 2015].
102 Indonesia,” pp. 1-3, 2012.
[11] T. M. Mitchell, Machine Learning, McGraw-Hill Science/Engineering/Math, 2005.
[12] A. Nugroho, A. Budi dan D. Handoko, “Support Vector Machine Teori dan Aplikasinya Pada Bioinformatika,” Kuliah Umum IlmuKomputer.Com, pp. 2-5, 2003.
[13] B. S. Tutorial Support Vector Machine, Surabaya.
[14] D. Anggraeni, “http://lontar.ui.ac.id/,” [Online]. Available: http://lontar.ui.ac.id/file?file=digital/123561-SK-739-Klasifikasi%20topik-Analisis.pdf. [Diakses 18 Oktober 2014].
[15] R. Kohavi, “A study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection,” 1995. [Online]. Available: http://frostiebek.free.fr/docs/Machine%20Learning/validation-1.pdf.
[Diakses 23 Desember 2014].
1
BAB I
PENDAHULUAN
I.1 Latar Belakang Masalah
Sosial media untuk promosi bisnis sudah wajar dilakukan karena merupakan salah satu sarana yang sangat penting bagi perusahaan di era digital marketing saat ini [1]. PT. Maicih Inti Sinergi (MIS) sebagai salah satu perusahaan asal Kota Bandung yang bergerak di bidang kuliner, dalam memasarkan produknya memanfaatkan media sosial seperti twitter, di mana strategi pemasaran seperti ini adalah hal yang unik pada saat itu. Melalui sosial media twitter inilah PT. MIS mempromosikan berbagai macam produk buatannya untuk menarik konsumen. Hingga saat ini akun twitter PT. MIS sudah memiliki 318.000 followers.
Dengan adanya akun twitter ini dan jumlah postingan tweet yang banyak setiap harinya ketersediaan sentimen untuk produk PT. MIS sangat melimpah sehingga dapat
dimanfaatkan untuk mengevaluasi produk-produk PT. MIS. Berdasarkan hasil
wawancara, PT. MIS ingin adanya sebuah aplikasi yang dapat mengetahui bagaimana
sentimen para konsumen terhadap produknya, karena selama ini pihak PT. MIS dalam
mengetahui sentimen para konsumen nya cukup hanya dengan melakukan pengecekan
tiap-tiap postingan konsumen nya secara manual. Hal ini dirasa kurang efektif, karena
mengingat banyaknya jumlah followers akun maicih.
salah satu metode yang menggunakan perhitungan probabilitas. Kelebihan Naïve Bayes Classifier selain menghasilkan akurasi yang baik adalah implementasinya yang relative lebih mudah [4].
Dari pemaparan di atas, pada penelitian ini studi kasus yang digunakan adalah analisis sentimen terhadap akun resmi PT. Maicih Inti Sinergi. Data analisis sentimen berasal dari postingan twitter akun resmi PT. Maicih Inti Sinergi dengan menggunakan metode Support Vector Machine dan Naïve Bayes.
I.2 Perumusan Masalah
Berdasarkan latar belakang tersebut, perumusan masalah dalam penulisan penelitian ini yaitu bagaimana membangun sebuah perangkat lunak yang dapat melakukan analisis sentimen terhadap akun Maicih Inti Sinergi.
I.3 Maksud dan Tujuan
Maksud dari penelitian ini adalah membangun sebuah perangkat lunak yang dapat mengklasifikasikan sentimen yang di dapat dari akun PT. MIS ke dalam beberapa kelas dengan menggunakan metode Support Vector Machine dan Naïve Bayes.
Sedangkan tujuan yang ingin dicapai dalam penelitian ini adalah untuk membantu pihak PT. MIS dalam mengetahui sentimen feedback yang diberikan oleh para konsumennya pada akun twitter milik PT. MIS.
I.4 Batasan Masalah
Batasan masalah dari penelitian yang dilakukan adalah:
1. Metode machine learning yang digunakan adalah Support Vector Machine dan Naïve Bayes.
2. Akun Twitter yang dianalisis adalah akun resmi PT. MIS “@maicih”.
3. Sistem yang dibangun menggunakan pendekatan Object Oriented Analysis and Design .
5. Jika nilai probabilitas tweet antara positif dan negatif sama, maka tweet tersebut dimasukkan kedalam tweet undefined (tidak akan di masukan ke kelas manapun).
I.5 Metodologi Penelitian
Metodologi penelitian yang digunakan dalam pelaksanaan penelitian ini adalah metode penelitian deskriptif. Metode ini digunakan dalam penelitian awal untuk menghimpun data tentang kondisi yang ada, faktor pendukung dan penghambat pengembangan, serta penggunaan produk dimana produk tersebut akan diterapkan [5].
Penelitian ini memiliki 3 metode dalam pelaksanaannya yaitu metode pengumpulan data, metode pembangunan perangkat lunak dan metode penyelesaian analisis sentimen. Berikut adalah pemaparannya
I.5.1 Metode Pengumpulan Data
Berikut adalah metode pengumpuan data dalam penelitian ini: 1. Studi Literatur
Pengumpulan data dilakukan dengan cara mempelajari, meneliti, dan menelaah berbagai literatur dari perpustakaan yang bersumber dari buku, situs internet, jurnal ilmiah, dan sumber-sumber lainnya yang berkaitan dengan penelitian yang dilakukan seperti analisis sentimen, klasifikasi teks, metode Support Vector Machine.
2. Pengumpulan Data Twitter
Data yang diperoleh, bila dilihat dari sumber datanya pengumpulan data menggunakan sumber data primer yang diambil secara langsung dari akun resmi twitter Maicih dengan memanfaatkan stream API (Application Programming Interface) yang disediakan oleh twitter.
3. Wawancara
solusi yang ditawarkan. Tahap kedua bertujuan untuk melakukan pengujian perangkat lunak yang telah dibangun.
4. Observasi
Obervasi yang dilakukan ialah mengamati data tweet yang akan di analisis yang terdapat pada akun resmi PT. MIS.
I.5.2 Metode Pembangunan Perangkat Lunak
Dalam pembangunan perangkat lunak ini menggunakan waterfall model sebagai tahapan pengembangan perangkat lunaknya. Berikut adalah prosesnya: a. Requirements analysis and definition
Tahap requirement analysis and definition dilakukan dalam pembangunan perangkat lunak ini adalah dengan melakukan pengumpulan data dengan cara studi literatur dan wawancara langsung dengan bagian Manager Sumber Daya Manusia PT. MIS. Dari hasil tersebut didapatkan masalah yang kemudian dicarikan solusinya.
b. System and software design
Tahap system and software design yang dilakukan dalam pembangunan perangkat lunak ini adalah dengan membuat perancangan data, perancangan arsitektural menu, perancangan antarmuka, perancangan pesan dan perancangan method.
c. Implementation and unit testing
Tahap implementation and unit testing yang dilakukan dalam pembangunan perangkat lunak ini adalahdengan membuat sebuah sistem berbasis web yang di implementasikan dengan bahasa pemrograman php.
d. Integration and system testing
Tahap integration and system testing yang dilakukan dalam pembangunan perangkat lunak ini adalah mengintegrasikan data testing dengan data training. e. Operation and maintenance
penggunaan perangkat lunak sehingga kedepannya jika ada perubahan dapat dilakukan update untuk optimalisasi pengoperasian.
Untuk lebih jelasnya tahapan-tahapan tersebut dapat dilihat pada Gambar I-1.
Gambar I-1 Model Proses Waterfall [6]
I.5.3 Metode Penyelesaian Analisis Sentimen
Berikut adalah gambaran penyelesaian masalah dalam penelitian ini dapat dilihat pada Gambar I-2
Gambar I-2 Gambaran Penyelesaian Analisis Sentimen
Berikut penjelasan dari gambaran penyelesaian analisis sentimen di atas: 1. Identifikasi Tweet
Identifikasi tweet merupakan tahapan awal yang dilakukan pada penelitian ini. Yang dilakukan pada tahapan ini adalah melakukan pengidentifikasian tweet yang akan di analisis yaitu pada akun twitter PT. MIS.
2. Penerapan Metode Algoritma Information Retrieval
dengan yang tidak, yang nantinya akan digunakan untuk perhitungan pada penerapan metode algoritma extraction.
3. Penerapan Metode Algoritma Extraction
Pada tahap ini tweet yang sudah di-retrieve kemudian diekstrak menggunakan algoritma extraction berupa klasifikasi, yaitu kelas positif dan kelas negatif. 4. Pengujian Tingkat Akurasi
Pada tahap ini tweet yang sudah memiliki kelas masing-masing diuji menggunakan metode pengujian, agar diketahui tingkat akurasi hasil yang di dapat.
I.6 Sistematika Penulisan
Sistematika penulisan penelitian ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan penelitian ini adalah:
BAB I PENDAHULUAN
Bab ini menerangkan secara umum mengenai latar belakang, perumusan masalah, menentukan maksud dan tujuan, batasan masalah, metodologi penelitian serta sistematika penulisan tugas akhir.
BAB II TINJAUAN PUSTAKA
Pada bab ini membahas profil instansi yang terkait (dalam kasus ini perusahaan Maicih Inti Sinergi) serta berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan. Landasan teori yang digunakan antara lain tentang twitter, analisis sentimen, teknik analisis sentimen menggunakan Machine Learning, pengklasifikasian menggunakan Support Vector Machine.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini menganalisis masalah dari objek penelitian untuk mengetahui hal atau masalah apa yang timbul dan mencoba memecahkan permasalahan tersebut dengan membangun sebuah perangkat lunak untuk mengimplementasikan metode-metode yang digunakan.
Bab ini membahas mengenai hasil pengujian dari analisis sistem yang ada pada Bab III kemudian melakukan analisis terhadap informasi dari hasil uji coba.
BAB V KESIMPULAN DAN SARAN
9
BAB II
TINJAUAN PUSTAKA
II.1Tinjauan Tempat Penelitian
Pertengahan 2010, nama Reza “Axl” Nurhilman mulai dikenal banyak orang. Axl, sapaan akrabnya, mendirikan Maicih, brand keripik pedas yang jadi pelopor makanan ringan pedas di Bandung, Jawa Barat. Tak membutuhkan waktu lama, keripik pedas Maicih milik Axl ini terpilih menjadi The Hot Snack 2011 oleh majalah Rolling Stone Indonesia.
Awalnya, Axl tidak memiliki strategi khusus pada saat memulai usaha ini. Fokusnya hanya menjual keripik pedas seunik dan sekreatif mungkin. Keripik singkong pedas yang jadi makanan favorit masa kecilnya pun, ia sulap menjadi produk berkelas yang siap bersaing dengan produk lainnya. Salah satu caranya adalah dengan memanfaatkan media sosial.
Keripik pedas Maicih dilambangkan oleh sosok nenek ramah yang bersahaja. Ia mulai di kenal banyak orang lewat media sosial Twitter dengan akun @maicih. Axl memang mengandalkan Twitter untuk mempromosikan keripik pedas Maicih nya. Lewat tagar #maicih yang begitu popular di microsite ini, distribusi dan promosi pun dilakukan. Akun @maicih yang resmi di buat bulan Oktober 2010 ini kemudian mengukuhkan konsep jualan keripik pedas ini. Sukses bergerilya jualan viaTwitter, kini keripik pedas maicih sudah bisa di nikmati semua penggemarnya di seluruh Indonesia.
Gambar II-1 Logo maicih
II.1.1Visi dan Misi
Berikut adalah Visi Misi dari PT. Maicih Inti Sinergi: 1. Visi
Menjadi produk dan icon kota Bandung yang Nasional serta go international dalam bidang pangan, entertainment dan edukasi.
2. Misi
Memperkenalkan Maicih ke seluruh dunia, meningkatkan lagi jumlah produksi, serta mengikuti berbagai event untuk memberikan pengalaman dan sharing agar penduduk Indonesia bisa mengembangkan lagi cara-cara strategi berwirausaha.
II.1.2Struktur Organisasi
Gambar II-2 Struktur Organisasi
Berikut adalah pemaparan deskripsi kerja untuk tiap-tiap jabatan yang ada di PT. Maicih Inti Sinergi.
1. Presiden
a. Sebagai pengambil keputusan.
b. Sebagai koordinator semua kegiatan yang telah dilaksanakan. 2. Penasehat Presiden
a. Memberikan arahan nasehat kepada Presiden untuk melakukan jalan yang terbaik.
b. Melakukan tugas sementara yang tidak bisa dilakukan oleh Presiden. 3. Menteri Pangan
a. Melaporkan kepada Presiden tentang keadaan produk. b. Mengawasi dan melakukan pemeliharaan pada produk. c. Mengawasi penjualan produk yang dilakukan oleh Jendral. 4. Menteri Perhubungan
a. Melakukan koordinasi kepada para Jenderal di setiap daerah. b. Mengawasi dan mengatur pekerjaan yang dilakukan oleh Jenderal. 5. Menteri Keuangan
a. Melaporkan kepada Presiden tentang penjualan produk yang diperoleh. b. Bertanggung jawab penuh atas keuangan.
6. Jenderal
II.2Landasan Teori
Landasan Teori merupakan penejelasan berbagai konsep dasar dan teori-teori yang berkaitan dalam pembangunan perangkat lunak Analisis Sentimen ini. Berikut adalah beberapa teori terkait dengan pembangunan perangkat lunak ini:
II.2.1Analisis Sentimen
Analisis sentimen termasuk kedalam kategorisasi teks yang membagi ke dalam beberapa label atau kelas. Analisis sentimen merupakan sebuah permasalahan yang berfokus pada penentuan orientasi dari opini yang terkandung dalam sebuah kalimat atau dokumen. Orientasi atau dapat disebut juga dengan polaritas kalimat ini dapat berupa kalimat kalimat opini positif dan negatif. Polaritas positif dan negatif ini dapat berupa feedback sebuah produk, opini tentang suatu permasalahan atau orang atau kejadian, dan dapat juga berupa review sebuah film. Pada penelitian ini, penulis melakukan klasifikasi/kategori kedalam 2 sentimen, yaitu positif, dan negatif terhadap akun resmi PT. Maicih Inti Sinergi.
II.2.2Text Mining
Text mining merupakan varian baru hasil perkembangan dari data mining. Sesuai dengan namanya, text mining focus kepada data yang berbentuk dokumen atau teks, dengan menggali informasi yang terdapat pada teks, di mana sumber datanya berasal dari dokumen, dengan tujuan mencari kata-kata yang mewakili isi dokumen sehingga dapat melakukan analisa keterkaitan antar dokumen [7].
II.2.3Regular Expression
Regular expression atau yang biasa disingkat dengan regex adalah sebuah untaian teks untuk menggambarkan pencarian sebuah pola. Regex biasa digunakan untuk pencarian memanipulasi teks. Pola yang dibentuk oleh regex mungkin akan cocok sekali, beberapa kali, atau tidak sama sekali untuk teks yang diberikan. Regex didukung oleh banyak bahasa pemrograman termasuk PHP. Berikut adalah atura-aturan penulisan regular expression dalam bahasa pemrograman PHP [8].
1. Pencocokan simbol umum
Regular Expression menyediakan pola yang bisa digunakan untuk mencocokan simbol-simbol yang umum pada suatu teks. Untuk lebih jelasnya dapat dilihat pada
Tabel II-1
Tabel II-1 Regex
Regular Expression Deskripsi
. Mencocokan dengan karakter apapun
^regex Menentukan kata regex yang ada di awal baris Regex$ Menentukan kata regex yang ada di akhir baris
[abc] Tanda kurung siku digunakan untuk mencocokan salah satu huruf yang ada di dalamnya. Contoh digunakan untuk mencocokan dengan huruf a atau b atau c
[bcd][de] Mencocokan dengan huruf b atau c atau d kemudian di ikuti dengan huruf d atau e
[d-g4-7] Mencocokan dengan deretan huruf yang ada dari d hingga g dan 4 sampai 7
b|d Menemukan b atau d
2. Metacharacters
Metacharacter berikut memiliki arti yang ditentukan dan membuat pola umum yang lebih mudah digunakan. Berikut contohnya pada Tabel II-2
Tabel II-2 Metacharacter
Regular Expression Deskripsi
\d Mencocokan dengan angka, lebih sederhana dari [0-9] \D Mencocokan dengan bukan angka, lebih sederhana dari [^0-9] \s Mencocokan dengan spasi, lebih sederhana dari [\t\n\x0b\r\f] \S Mencocokan dengan bukan spasi, lebih sederhana dari [^\s]
\w Mencocokan dengan alphanumerik, lebih sederhana dari [a-zA-Z_0-9] \W Mencocokan dengan bukan alphanumerik, lebih sederhana dari [^\w] \i Mencocokan kata tanpa berpengaruh pada Case.
\b Mencocokan kata dengan mencegah pola yang dicari ada sebagai substring dari kata lainnya.
Quantifier mendefinisikan seberapa sering sebuah elemen dapat terjadi. Berikut contoh dan deskripsi pada
Tabel II-3 Quantifier Regex
Regular Expression
Deskripsi Contoh
* Terjadi kemunculan tidak sama seali atau berkali-kali. Lebih sederhana dari {0,}.
a* menemukan tidak sama sekali atau berkali-kali kemunculan huruf a
+ Terjadi kemunculan sekali atau berkali-kali. Lebih sederhana dari {1,}
a+ menemukan sekali atau berkali-kali kemunculan huruf a ? Terjadi kemunculan tidak sama sekali atau
sekali. Lebih sederhana dari {0,1}
A? menemukan tidak sama sekali atau tepat satu kali kemunculan huruf a
{x} Terjadi kemunculan sebanyak x \d{5} mencari untuk angka yang memiliki tiga digit
II.2.4Text Preprocessing
Pada text mining data yang di gunakan berasal dari dokumen atau teks yang tidak terstruktur. Oleh karena itu, dibutuhkan suatu proses yang dapat mengubah bentuk data yang sebelumnya tidak terstruktur menjadi data yang terstruktur. Proses ini bertujuan agar data yang akan digunakan nantinya bersih dari noise atau ciri-ciri yang tidak berpengaruh pada klasifikasi sentimen seperti link, “@”, “RT”, stopword. Proses preprosesing juga mempunyai tujuan agar data yang digunakan memiliki dimensi yang lebih kecil dan lebih terstruktur, sehingga dapat diolah lebih lanjut. Tahap preprocessing yang di gunakan dapat dilihat pada Gambar II-3
Gambar II-3 Proses Text Preprocessing
tokenizer dan stemming. Keseluruhan tahapan memiliki fungsi dan perannya masing-masing. Untuk mendapatkan dataset yang berdimensi lebih kecil dari data sebelumnya, terstruktur, serta bersih dari noise, maka kesemua tahap harus berkesinambungan.
III.1.5.1Case Folding
Case Folding merupakan proses text preprocessing yang dilakukan untuk menyeragamkan karakter pada data (dokumentasi/teks). Pada proses ini, semua huruf besar (uppercase) dijadikan huruf kecil (lowercase). Bila digambarkan, proses case folding dapat dilihat pada Gambar II-4
Gambar II-4 Gambaran proses case folding
III.1.5.2Cleansing
Gambar II-5 Gambaran proses Cleansing
III.1.5.3Stopword Removal
Stopword Removal merupakan tahap selanjutnya pada proses text preprocessing. Tahapan ini bertujuan untuk menghilangkan kata atau term yang dianggap tidak dapat memberikan pengaruh dalam menentukan suatu kategori tertentu dalam suatu dokumen. Proses ini dilakukan karena term tersebut sering muncul hampir disetiap dokumen sehingga dianggap tidak dapat menjadi pembeda yang baik dalam membedakan kategori yang satu dengan kategori yang lain [9].
Gambar II-6 gambaran proses stopword removal
Sebuah file akan didefinisikan sebagai sebuah string, kemudian sistem akan mengambil satu persatu term yang terdapat pada stoplist. Jika string terdapat substring stoplist, maka substring tersebut akan diganti dengan karakter blank. Proses stopword removal ini, besarnya ukuran atau dimensi data yang tereduksi bergantung pada banyaknya stopwords yang digunakan sebagai stoplist dan banyaknya term yang mengandung stopwords.
III.1.5.4Convert Emoticon
Sebuah emoticon merupakan salah satu cara untuk mengekspresikan ungkapan perasaan secara tekstual serta emoticon biasanya digunakan untuk mengekspresikan persetujuan atau pertidaksetujuan dalam suatu kalimat. Pada penelitian sebelumnya [2] convert emoticon dalam suatu kalimat dianggap penting dan memiliki kontribusi dalam menentukan nilai sentimen suatu kalimat. Maka dari itu dalam skripsi ini convert emoticon digunakan, meski hanya sebagian karena tidak semua emoticon yang sering digunakan pada suatu tweet, setiap emoticon akan dikonversikan kedalam string yang sesuai sesuai dengan ekspresi emoticon tersebut. Berikut daftar emoticon yang sering digunakan oleh pengguna twitter terdapat pada Tabel II-4.
Tabel II-4 Konversi Emoticon [2]
Emoticon Konversi
>:o >:O :-O :O o_O o.O 8-0 emotkaget >:\ >:/ :-/ :-. :/ :\ =/ =\ :S emotkesal
:| :-| emotdatar
Bila digambarkan, proses convertemoticon dapat dilihat pada Gambar II-7
Gambar II-7 gambaran proses convert emoticon
III.1.5.5Convert Negation
Beberapa kata yang bersifat negasi, akan merubah nilai sentimen suatu tweet. Ketika banyak kata negasi adalah ganjil, maka sentimen tweet tersebut akan dirubah. Kata yang bersifat negasi adalah “bukan”, “bkn”, “tidak”, “enggak”, “g”, “ga”, “jangan”, “nggak”, “tak”, “tdk”, dan “gak” [2]. Contohnya kata “enak” adalah kata kunci positif namun jika sebelumnya diikuti kata “ga” sehingga menjadi “ga enak” maka nilainya menjadi negatif.
III.1.5.6Tokenizer
Gambar II-8 Gambaran Tokenizer
III.1.5.7Stemming
Stemming digunakan untuk mencari kata dasar dari bentuk berimbuhan. Algoritma steamming untuk bahasa yang satu berbeda dengan algoritma stemming untuk bahasa lainnya. Bahasa Inggris memiliki morfologi yang berbeda dengan Bahasa Indonesia sehingga algoritma steamming yang digunakan pun berbeda [10]. Proses stemming pada teks berbahasa Indoensia lebih rumit karena terdapat variasi imbuhan yang harus dibuang untuk mendapatkan root word dari sebuah kata. Algoritma stemming yang digunakan pada penelitian ini adalah algoritma Nazief dan Andriani.
II.2.5Machine Learning
II.2.6Information Retrieval
Information Retrieval bertujuan menghasilkan dokumen yang paling relevan berdasarkan keyword pada query yang diberikan pengguna. Dokumen dianggap relevan jika suatu dokumen cocok dengan pertanyaan pengguna. Information Retrieval terdiri dari tiga komponen utama, yaitu masukan (Input), pemroses (processor) dan keluaran (output). Input harus berupa representasi yang tepat dari setiap dokumen dan query agar dapat diolah oleh pemroses. Pemroses (Processor) bertugas menstrukturkan informasi dalam bentuk yang tepat, misalnya dengan pengindeksan dan klasifikasi serta melakukan proses information retrieval, yaitu dengan menjalankan suatu strategi pencarian sebagai respon dari query. Output adalah keluaran yang diberikan oleh pemroses, biasanya berbentuk informasi tentang suatu dokumen, dokumen itu sendiri dan acuan ke dokumen lain (citation).
Didalam Information Retrieval juga terdapat Indexing atau pengindeksan yaitu proses membangun basis data indeks dari koleksi dokumen. Adapun tahapan dari pengindeksan adalah sebagai berikut:
1. Parsing dokumen yaitu proses pengambilan kata-kata dari kumpulan dokumen. 2. Stoplist yaitu proses pembuangan kata buang seperti: tetapi, yaitu, sedangkan
dan sebagainya.
3. Stemming yaitu proses penghilangan/ pemotongan dari suatu kata menjadi bentuk dasar.
4. Term Weighting dan Inverted File yaitu proses pemberian bobot pada istilah [10].
II.2.7Information Extraction
menggunakan Corpus Based Approach. Kelompok kedua adalah Information extraction dengan menggunakan Machine Learning. Pada penelitian ini, penulis menggunakan metode Machine Learning untuk melakukan Information Extraction.
II.2.8Term Weighting
Term weighting ialah proses memberikan bobot terhadap semua kata pada dokumen, metode Term weighting yang digunakan pada penelitian ini adalah TF-IDF.
Term Frequency adalah salah satu metode pembobotan yang paling sederhana. Pada metode ini, setiap term diasumsikan memiliki proporsi kepentingan sesuai dengan jumlah terjadinya (munculnya) term tersebut dalam dokumen. Persamaan TF adalah sebagai berikut:
, = �� , (II-1)
Dimana TF(d,t) adalah frekuensi kemunculan term t pada dokumen d.
Inverse Document Frequency memperhatikan kemunculan term pada kumpulan dokumen. Pada metode ini, term yang dianggap bernilai/berharga adalah term yang jarang muncul pada koleksi/ kumpulan dokumen. Persamaan IDF adalah sebagai berikut:
� � = � (II-2)
Dimana df(t) adalah banyak dokumen yang mengandung term t.
TF*IDF merupakan kombinasi metode TF dengan metode IDF. Sehingga persamaan TF*IDF adalah sebagai berikut:
�� ∗ � � , = �� , ∗ � � (II-3)
II.2.9Support Vector Machine
berfungsi sebagai pemisah dua buah class pada input space [12]. Gambaran SVM dalam berusaha mencari hyperplane terbaik dapat dilihat pada Gambar II-9
Gambar II-9 SVM berusaha menemukan hyperplane terbaik yang memisahkan kedua kelas y = -1 dan y = +1
Hyperplane pemisah terbaik antara kedua class dapat ditemukan dengan mengukur margin hyperplane tersebut dan mencari titik maksimalnya. Margin adalah jarak antara hyperplane tersebut dengan pattern terdekat masing-masing class. Pattern yang paling dekat ini disebut support vector. Garis solid pada Gambar II-9 –b menunjukkan hyperplane yang terbaik, yaitu yang terletak tepat pada tengah-tengah kedua class, sedangkan titik merah dan kuning yang berada dalam lingkungan hitam adalah support vector. Usaha untuk mencari lokasi hyperplane ini merupakan inti dari proses pembelajaran pada SVM. Klasifikasi pada SVM dibagi menjadi 2, yaitu linier dan nonlinier.
Dimulai dengan kasus klasifikasi secara linier, fungsi ini dapat didefinisikan sebagai.
∶= (II-4)
Dengan f = w + (II-5)
Atau = {+ , + +
Dimana x,w ℜn
dan b ℜ. Dalam teknik SVM berusaha menemukan fungsi
pemisah (klasifier/hyperplane) terbaik diantara fungsi yang tidak terbatas
jumlahnya untuk memisahkan dua macam objek. Hyperplane terbaik adalah
hyperplane yang terletak di tengah-tengah antara dua set objek dari dua kelas.
Mencari hyperplane terbaik ekuivalen dengan memaksimalkan margin atau jarak
antara dua set objek dari kelas yang berbeda. [13]
Input pada pelatihan SVM terdiri dari poin-poin yang merupakan vektor dari
angka-angka real Data yang tersedia dinotasikan sebagai xi ℜd
sedangkan label masing-masing dinotasikan sebagai yi {-1, +1} untuk i = 1,2,..,l dimana l adalah banyaknya data. Diasumsikan kedua kelas -1 (negatif) dan +1(positif) dapat terpisah secara sempurna oleh hyperplane berdimensi d, yang didefinisikan.
Dengan + = (II-7)
Sebuah pattern xi yang termasuk kelas -1 (sampel tidak relevan) dapat dirumuskan sebagai pattern yang memenuhi pertidaksamaan:
Dengan + − (II-8)
Sedangkan pattern xi yang termasuk kelas +1 (sampel relevan):
Dengan + + (II-9)
Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara hyperplane dan titik terdekatnya, yaitu
||�||. Hal ini dapat dirumuskan sebagai Quadratic Programming (QP) problem, yaitu mencari titik minimal persamaan dengan memperhatikan constraint persamaan (II.11)
|| || (II-10)
. + − (II-11)
Permasalahan ini dapat dipecahkan dengan berbagai teknik komputasi di antaranya Lagrangae Multiplier.
� , , � = || || − ∑ � [ � + − ]
=
αi adalah lagrange multiplier, yang bernilai nol atau positif. Nilai optimal dari persamaan di atas dapat dihitung dengan meminimalkan L terhadap w dan b, dan memaksimalkan L terhadap αi. Dengan memperhatikan sifat bahwa pada titik optimal gradient L=0, dari persamaan (II.12) dapat dimodifikasi sebagai maksimalisasi yang hanya mengandung αi saja, yaitu:
�a� ∑ � − ∑ � � �
, = =
Subject to ∑= � = ∝ , = , , . . ,
(II-13)
Dengan dot product xixj sering diganti dengan simbol K. K adalah matrik kernel.
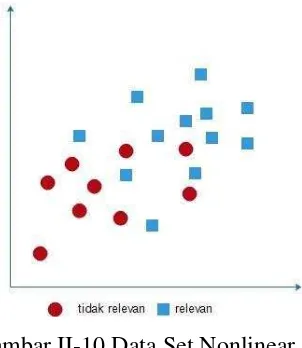
Matrik kernel ini digunakan untuk membuat data set yang bersifat non-linear menjadi linear. Contoh dataset yang bersifat non linear dapat dilihat pada Gambar II-10
Gambar II-10 Data Set Nonlinear
Oleh karena itu dalam SVM terdapat fungsi kernel yang dapat mengubah data set yang tidak linear menjadi linier dalam space baru.
Tabel II-5 Kernel Trik pada SVM
Kernel Type Value
Linear K(xi, xj) = xT x Polynomial K(xi,xj)= (xTx
Kernel Type Value
Gaussian K(xi,xj) = exp-||x1-x2||2/22
Pemilihan fungsi kernel yang tepat adalah hal yang sangat penting, karena fungsi kernel ini akan menentukan feature space di mana classifier akan dicari.
II.2.10 Naïve Bayes Classifier
Naïve Bayes merupakan salah satu metode machine learning yang menggunakan perhitungan probabilitas. Konsep dasar yang digunakan oleh Naïve bayes adalah Teorema Bayes, yaitu melakukan klasifikasi dengan melakukan perhitungan nilai probabilitas p(C = ci | D = dj), yaitu probabilitas kategori ci jika diketahui dokumen dj. Klasifikasi dilakukan untuk mementukan kategori c ϵC dari suatu dokumen d ϵ D dimana C = {c1, c2, c3, …, ci} dan D = {d1, d2, d3, …, dj}. Penentuan dari kategori sebuah dokumen dilakukan dengan mencari nilai maksimum dari p(C = ci | D = dj) pada P={ p(C = ci | D = dj)| c = C dan d = D}. Nilai probabilitas p(C = ci | D = dj) dapat dihitung dengan persamaan:
= | = = � ( = ⋂ = )
� ( = )
= � ( = | = ) × =
� ( = )
(II-14)
Dengan p(D = dj |C = ci) merupakan nilai probabilitas dari kemunculan dokumen dj jika diketahui dokemen tersebut berkategori ci, p(C = ci) adalah nilai probabilitas kemunculan kategori ci, dan p(D = dj) adalah nilai probabilitas kemunculan dokumen dj.
= | = = ∏ | = , , , … , × = �
(II-15)
Dengan ∏ | = adalah hasil perkalian dari probabilitas kemunculan semua kata pada dokumen dj.
Proses klasifikasi dilakukan dengan membuat model probabilistik dari dokumen training, yaitu dengan menghitung nilai p(wk | c) . Untuk wkj diskrit dengan wkj ε V = {v1, v2, v3, …, vm} maka p(wk | c) dicari untuk seluruh kemungkinan nilai wkj dan didapatkan dengan melakukan perhitungan:
= �
| | (II-16)
dimana
Db c adalah jumlah dokumen yang memiliki kategori ci. |D| adalah jumlah seluruh training dokumen.
Dan
( = | = � � = � .
�
(II-17)
dimana
Db ( � = � , c) adalah nilai kemunculan kata wkj pada kategori ci. Db c adalah jumlah keseluruhn kata pada kategori ci.
Persamaan Db(wk = wkj ,c) sering kali dikombinasikan dengan Laplacian Smoothing untuk mencegah persamaan mendapatkan nilai 0, yang dapat menggangu hasil klasifikasi secara keseluruhan. Sehingga persamaan Db(wk = wkj ,c) dituliskan sebagai:
( = | = ( = + | |, ) + (II-18)
dengan |V| merupakan jumlah kemungkinan nilai dari wkj.
Pemberian kategori dari sebuah dokumen dilakukan dengan memilih nilai c yang memiliki nilai p(C = ci | D = dj) maksimum, dan dinyatakan dengan:
∗ =
Kategori c* merupakan kategori yang memiliki nilai p(C = ci | D = dj) maksimum. Nilai p(D = dj) tidak mempengaruhi perbandingan karena untuk setiap k ategori nilainya akan sama. Berikut ini gambaran proses klasifikasi dengan algoritma Naïve Bayes dapa dilihat pada Gambar II-11:
II.2.11 K-Fold Cross Validation
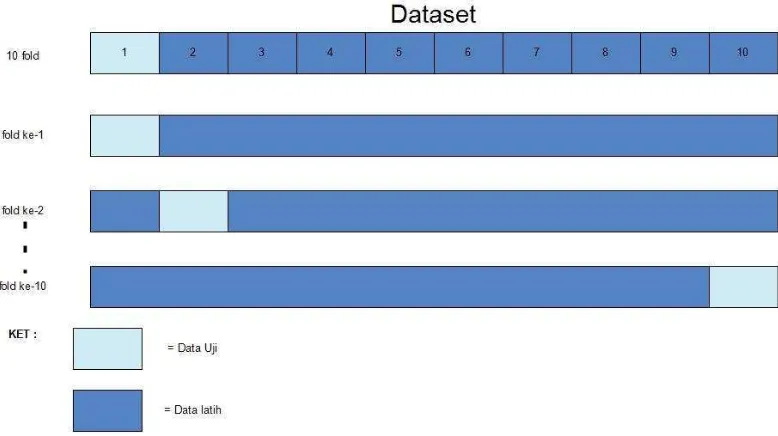
K-fold cross validation adalah salah satu metode untuk mengevaluasi kinerja classifier, metode ini dapat digunakan apabila memiliki jumlah data yang terbatas (jumlah instance tidak banyak) [14]. K-fold cross validation merupakan salah satu metode yang digunakan untuk mengetahui rata-rata keberhasilan dari suatu sistem dengan cara melakukan perulangan dengan mengacak atribut masukan sehingga sistem tersebut teruji untuk beberapa atribut input yang acak. K-fold cross validation diawali dengan membagi data sejumlah n-fold yang diinginkan. Dalam proses cross validationdata akan dibagi dalam n buah partisi dengan ukuran yang
Training:
Untuk setiap kategori: a. Hitung �
b. Hitung � � | untuk setiap kata pada model
Testing:
a. Hitung ∏ � � |c × � c Untuk setiap kategori
b. Tentukan kategori dengan nilai ∏ � � |c × � c maksimal
Training Data Model Probabilistik
(Classifier)
Testing Data Kategori Dokumen
sama D1, D2, D3 .. Dn selanjutnya proses uji dan latih dilakukan sebanyak n kali. Dalam iterasi ke-i partisi Di akan menjadi data uji dan sisanya akan menjadi data latih. Untuk penggunaan jumlah fold terbaik untuk uji validitas, dianjurkan menggunakan 10-fold cross validation dalam model [15]. Contoh pembagian dataset dalam proses 10-fold cross validation terlihat padaGambar II-12
Gambar II-12 Contoh iterasi data dengan k-fold cross validation Cara kerja K-fold cross validation adalah sebagai berikut:
1. Total instance dibagi menjadi N bagian.
2. Fold ke-1 adalah ketika bagian ke-1 menjadi data uji (testing data) dan sisanya menjadi data latih (training data). Selanjutnya, hitung akurasi berdasarkan porsi data tersebut. Perhitungan akurasi tersebut dengan menggunakan persamaan sebagai berikut [16]:
� = ∑ ∑ × % (II. 20)
3. Fold ke-2 adalah ketika bagian ke-2 menjadi data uji (testing data) dan sisanya menjadi data latih (training data). Selanjutnya, hitung akurasi berdasarkan porsi data tersebut.
29
BAB III
ANALISIS DAN PERANCANGAN SISTEM
III.1 Analisis Sistem
Analisis sistem bertujuan untuk mengidentifikasi permasalahan-permasalahan yang terdapat pada sistem serta menentukan kebutuhan-kebutuhan dari sistem yang akan dibangun. Analisis tersebut meliputi analisis masalah, analisis sistem yang sedang berjalan, analisis data masukan, analisis preprocessing, analisis metode/ algoritma, analisis kebutuhan non fungsional dan analisis kebutuhan fungsional.
III.1.1 Analisis Masalah
PT. Maicih Inti Sinergi (MIS) merupakan sebuah perusahaan yang menggunakan twitter sebagai salah satu sarana untuk mempromosikan produknya. Dengan adanya akun twitter PT. MIS dan jumlah postingan yang banyak setiap harinya memungkinkan feedback dari konsumen atau follower PT. MIS sebagai ketersediaan sentimen yang dapat dimanfaatkan untuk evaluasi produk PT.MIS.
Namun permasalahannya adalah bagaimana membangun sebuah perangkat lunak yang dapat melakukan pengklasifikasian sentimen pada data twitter yang nantinya dapat dimanfaatkan untuk evaluasi produk PT.MIS.
III.1.2 Analisis Sistem Berjalan
Pada penelitian ini, analisis sistem yang sedang berjalan dilakukan dengan metode wawancara untuk mendapatkan gambaran lengkap tentang bagaimana sistem yang sedang berjalan saat ini yang kemudian hasilnya akan digambarkan kedalam bentuk activity diagram sesuai dengan masalah yang sedang terjadi.
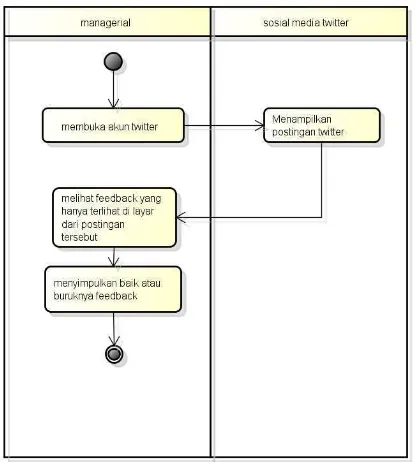
Berikut adaah sistem yang berjalan di PT. Maicih Inti Sinergi dalam mengetahui bagaimana sentimen para konsumen terhadap produknya.
1. Managerial membuka akun twitter PT. MIS (@maicih) 2. Managerial melihat feedback yang hanya terlihat dilayar.
Activity diagram sistem yang sedang berjalan di PT. Maicih Inti Sinergi dapat dilihat pada Gambar III-1
Gambar III-1 sistem yang sedang berjalan
III.1.3 Analisis Data Masukan
Data masukan yang digunakan adalah data tweet dari akun twitter PT. Maicih Inti Sinergi (@maicih). Data tweet tersebut didapat dengan memanfaatkan fitur API (Aplication Interface) yang telah disediakan oleh twitter. Data yang diambil adalah data tweet yang mengandung kata “maicih” atau data tweet yang terdapat pada akun PT. Maicih Inti Sinergi “@maicih”. Data yang didapat berupa sebuah kalimat dengan panjang maksimal 140 karakter. Contoh data tweet yang didapat dari twitter dapat dilihat pada Gambar III-2 dan Gambar III-3
Gambar III-3 Contoh tweet negatif
III.1.4 Analisis Preprocessing
Agar data tweets tersebut dapat dimanfaatkan dengan baik untuk mengklasifikasikan sentimen, maka diperlukan proses preprocessing. Pada proses ini data tweet yang digunakan untuk data training dan data testing dibersihkan dari noise seperti link, “RT”, “@”, stopword dan lain sebagainya. Gambaran proses preprocessing dapat dilihat pada Gambar III-4
Gambar III-4 Gambaran Tahapan Preprocessing
Proses preprocessing terdiri dari beberapa tahapan yaitu case folding, cleansing, stopword removal, convert emoticon, convert negation, tokenizer dan stemming. Berikut adalah penjelasan dari masing-masing tahapan:
1. Case Folding
Gambar III-5 Gambaran Proses Case Folding
2. Tokenizing
Pada proses tokenizing setiap kata pada tweet dipisahkan, pada proses ini tahap yang dilakukan adalah memisahkan setiap kata yang dipisahkan oleh spasi. Hal ini dilakukan agar tahap preproses selanjutnya dapat berjalan. Gambaran proses dari tahap tokenizing dapat dilihat pada Gambar III-6
Gambar III-6 Gambaran Proses Tokenizer
@maicih Maicih level 10 pedasss #kebakaranmulut ga kuat lagi makannya :’(
@maicih Kabar menggembirakan Untuk kita semua. Maicih kini ada Level 0 :)
RT @maicih Maicih kayaknya Enak YES. :) :)
@maicih maicih level 10 pedasss #kebakaranmulut ga kuat lagi makannya :’(
@maicih kabar menggembirakan untuk kita semua. maicih kini ada level 0 :)
rt @maicih maicih kayaknya enak yes. :) :)
maicih level 10 pedasss gakuat makannya emotsedih kabar menggembirakan. maicih level 0 emotsenang maicih kayaknya enak yes. emotsenang emotsenang
maicih level pedasss gakuat makannya emotsedih
kabar menggembirakan maicih level emotsenang
3. Cleansing
Tweet yang terdapat pada akun PT. Maicih Inti Sinergi memiliki berbagai komponen atau karateristik tweet yang khas seperti “@”, link, “#” dan RT. Komponen-komponen tersebut tidak memiliki pengaruh apapun terhadap sentimen, maka akan dibuang. Gambaran proses dari tahap cleansing dapat dilihat pada Gambar III-7
Gambar III-7 Gambaran Proses Cleansing
Berikut aturan produksi regular expression yang digunakan pada proses cleansing :
// untuk menghilangkan mention
$tweet = preg_replace('/@[-A-Z0-9+&@#\/%?=~_|$!:,.;]*[A-Z0-9+&@#\/%=~_|$]/i','', $tweet);
//untuk menghilangkan hashtag
$tweet= preg_replace('/#[-A-Z0-9+&@#\/%?=~_|$!:,.;]*[A-Z0-9+&@#\/%=~_|$]/i','', $tweet);
// untuk menghilangkan link
$tweet = preg_replace('/\b(https?|ftp|file|http):\/\/[-A-Z0-9+&@#\/%?=~_|$!:,.;]*[A-Z0-9+&@#\/%=~_|$]/i','', $tweet);
4. Stopword Removal
Pada tahap ini tweet masih mengandung kata yang dianggap tidak dapat memerikan pengaruh dalam menentukan suatu kategori sentimen. Kata-kata tersebut dimasukkan ke dalam daftar stopword yang biasa berupa kata ganti orang, kata ganti penghubung, paranomial petunjuk dan lain sebagainya. Jika pada tweet
@maicih maicih level 10 pedasss #kebakaranmulut ga kuat lagi makannya :’(
@maicih kabar menggembirakan untuk kita semua. maicih kini ada level 0 :)
rt @maicih maicih kayaknya enak yes. :) :)
maicih level 10 pedasss ga kuat lagi makannya :’(
yang sudah melalui proses cleansing masih terdapat kata yang tercantum pada daftar stopword maka kata tersebut dihilangkan. Untuk list lengkap stopword yang digunakan dapat dilihat pada Lampiran A. Gambaran proses dari tahap stopword removal dapat dilihat pada Gambar III-8
Gambar III-8 Gambaran Proses Stopword Removal
Berikut aturan produksi regular expression yang digunakan pada proses stopword Removal :
1
$tweet = preg_replace(array_map( function($stopword){ return'/\b'.$stopword.'\b/';
}, $stoplist), '',$tweet);
5. Convert Emoticon
Convert Emoticon adalah proses mengkonversikan emoticon kedalam string yang sesuai dengan ekspresi emoticon itu sendiri. Convert emoticon dilakukan karena pada tweet yang diambil terdapat emoticon yang merupakan salah satu cara follower mengekspresikan persetujuan atau pertidaksetujuan dalam suatu tweet. Hal ini dirasa mempunyai pengaruh terhadap pengklasifikasian sentimen, oleh karena itu convert emoticon digunakan. Gambaran proses dari tahap convert emoticon dapat dilihat pada Gambar III-9
maicih level 10 pedasss ga kuat lagi makannya :’(
kabar menggembirakan untuk kita semua. maicih kini ada level 0 :)
maicih kayaknya enak yes. :) :)
Gambar III-9 Gambaran Proses Convert Emoticon
Untuk standard emoticon yang digunakan dalam penelitian ini dapat dilihat pada Tabel III-1
Tabel III-1 standard emoticon
Emoticon Konversi
>:]:-):):o):]:3:c):>=]8)=):}:>) emotsenang >:[:-(:(:'(:-c:c:-<:-[:[:{>.><.<>.< emotsedih
Berikut aturan produksi regular expression yang digunakan pada proses convert emoticon :
1
$esedih = array(">:[",":-(",":(",":'(",":-c",":c",":-<",":-[",":[",":{",">.>","<.<",">.<","t_t");
//regex senang
foreach ($esenang as $item) {
$quotedSenang[] = preg_quote($item,'#'); }
$regexSenang = implode('|', $quotedSenang);
$fullSenang = '#(^|\W)('.$regexSenang.')($|\W)#';
//regex sedih
foreach ($esedih as $item) {
$quotedSedih[] = preg_quote($item,'#'); }
$regexSedih = implode('|', $quotedSedih);
$fullSedih = '#(^|\W)('.$regexSedih.')($|\W)#';
$tweet = preg_replace($fullSenang, ' emotsenang ', $tweet); $tweet = preg_replace($fullSedih, ' emotsedih ', $tweet);
6. Convert Negation
maicih level 10 pedasss ga kuat makannya :’( kabar menggembirakan. maicih level 0 :) maicih kayaknya enak yes. :) :)
Convert Negation merupakan proses konversi kata-kata negasi yang terdapat pada suatu tweet, karena kata negasi mempunyai pengaruh dalam merubah nilai sentimen pada suatu tweet. Jika terdapat kata negasi pada suatu tweet makan kata tersebut akan disatukan dengan kata setelahnya. Kata-kata negasi tersebut meliputi “bukan”, “bkn”, “tidak”, “enggak”, “g”, “ga”, “jangan”, “nggak”, “tak”, “tdk”, dan “gak”. Gambaran proses dari tahap convert negation dapat dilihat pada Gambar III-10
Gambar III-10 Gambaran Proses Convert Negation
Berikut aturan produksi regular expression yang digunakan pada proses convert negation :
1
foreach ($list as $from => $to)
maicih level 10 pedasss ga kuat makannya emotsedih kabar menggembirakan. maicih level 0 emotsenang maicih kayaknya enak yes. emotsenang emotsenang
23 24 25 26 27 28
{
$from = '/\b' . $from . '\b/'; $patterns[] = $from;
$replacement[] = $to; }
$tweet = preg_replace($patterns, $replacement, $tweet);
7. Stemming
Stemming adalah proses mengubah kata berimbuhan kebentuk asalnya (kata dasar). Algoritma yang digunakan untuk proses stemming berbahasa Indonesia adalah Nazief dan Andriani. Proses Stemming juga termasuk salah satu proses dalam Information Retrieval. Gambaran proses dari tahap stemming dapat dilihat pada Gambar III-11
Gambar III-11 Gambaran Proses Stemming
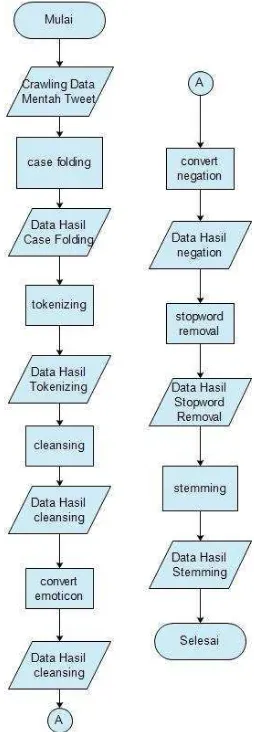
Berikut adalah diagram alir dari proses preprocessing dapat dilihat pada Gambar III-12
maicih level pedasss gakuat makannya emotsedih kabar menggembirakan maicih level emotsenang maicih kayaknya enak yes emotsenang emotsenang
maicih level pedasss gakuat makan emotsedih kabar gembira maicih level emotsenang
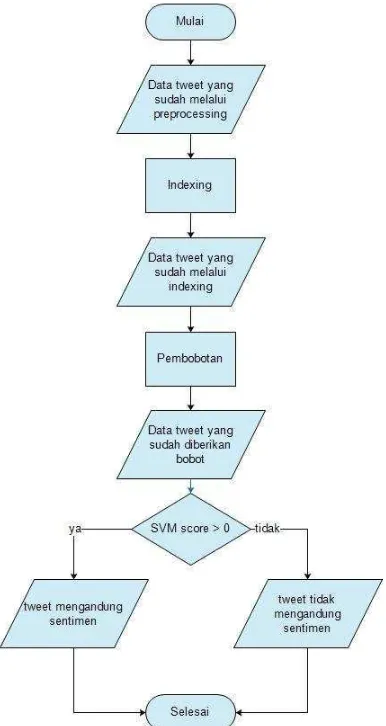
Gambar III-12 Flowchart Preprocessing
III.1.5 Analisis Metode / Algoritma
Analisis Metode yang dilakukan pada penelitian ini memiliki 2 tahap diantaranya Support Vector Machine sebagai metode untuk retrieval dan Naïve Bayes sebagai metode untuk extraction berupa klasifikasi.
Gambar III-13 flowchart retrieval menggunakan SVM
Dikarenakan SVM merupakan metode machine learning yang hanya peduli tentang titik dalam ruang daripada email atau dokumen. Maka dalam penelitian ini untuk format representasi data SVM adalah sebagai berikut.
Relevan : “maicih enak pisan” menjadi
1 1:0.764 2:0.847 3:0.173
1. Menghitung Data Training
Pada tahap ini data tweet training yang sudah melalui tahap preprocessing selanjutnya di index dan dihitung masing-masing bobot per katanya menggunakan persamaan (II.3).
Tabel III-2 Contoh kasus
Tweet Kategori Fitur
Tweet1 Relevan maicih level pedasss gakuat makan emotsedih Tweet2 Relevan kabar gembira maicih level emotsenang Tweet3 Relevan maicih kayak enak yes emotsenang emotsenang Tweet4 Tidak relevan jual produk
Kemudian dihitung bobot masing-masing kata menggunakan TF-IDF.
Tabel III-3 Pembobotan TF-IDF
term TF df idf TF-IDF
Dari Tabel III-3 diketahui bobot masing-masing kata pada semua data tweet training. Selanjutnya data tweet tersebut diubah format nya kedalam format SVM. Untuk dokumen relevan di beri nilai 1 dan dokumen tidak relevan di beri label -1.
Tabel III-4 format data svm
term tweet1 (x1) tweet2 (x2) tweet3 (x3) tweet4 (x4)
maicih 0.1249387 0.1249387 0.1249387 0 level 0.30103 0.30103 0 0 pedasss 0.60206 0 0 0
term tweet1 (x1) tweet2 (x2) tweet3 (x3) tweet4 (x4)
Kemudian tahap selanjutnya adalah melakukan kernelisasi menggunakan fungsi polynomial kernel pangkat 2 yang didefiniskan sebagai �( , ) =
+ � + . Matriks kernel K dihitung dengan dimensi l x l, dimana l adalah
=
� = [ . , . , , , , , . , . , . , , , , , ]
[ . , . , . , . , . , . , , , , , , , , ]T
= . + .
= 0.107
� = [ . , . , , , , , . , . , . , , , , , ]
[ . , . , , , , , . , . , . , , , , , ]T
= . + . + . + . + .
= 0.922
� = [ . , . , , , , , . , . , . , , , , , ]
[ . , , , , , , , , . , . , . , . , , ]T
= . + .
= 0.197
� = [ . , . , , , , , . , . , . , , , , , ]
[ , , , , , , , , , , , , . , . ]T
=
� = [ . , , , , , , , , . , . , . , . , , ]
[ . , . , . , . , . , . , , , , , , , , ]T
= . = 0.016
� = [ . , , , , , , , , . , . , . , . , , ]
[ . , . , , , , , . , . , . , , , , , ]T
= . + .
= 0.197
� = [ . , , , , , , , , . , . , . , . , , ]
[ . , , , , , , , , . , . , . , . , , ]T
= . + . + . + . + .
= 1.826
� = [ . , , , , , , , , . , . , . , . , , ]
=
� = [ , , , , , , , , , , , , . , . ]
[ . , . , . , . , . , . , , , , , , , , ]T
= 0
� = [ , , , , , , , , , , , , . , . ]
[ . , . , , , , , . , . , . , , , , , ]T = 0
� = [ , , , , , , , , , , , , . , . ]
[ . , , , , , , , , . , . , . , . , , ]T = 0
� = [ , , , , , , , , , , , , . , . ]
[ , , , , , , , , , , , , . , . ]T
= . + .
= 0.725
Maka matriks K yang terbentuk adalah sebagai berikut:
[
. .
. . ..
. . .
. ]
Selanjutnya hasil kernelisasi disubtitusikan ke persamaan (II-13), untuk setiap
� + � − � = dimana � ≥ .
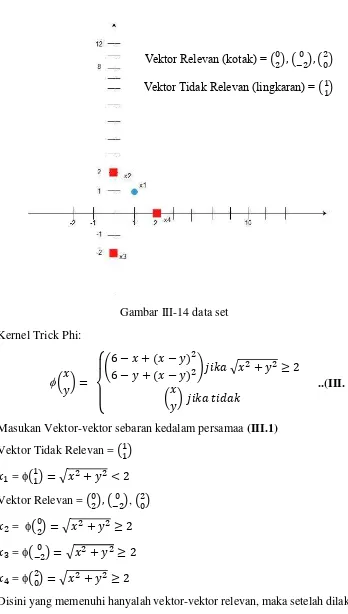
Gambar III-14 data set Kernel Trick Phi:
( ) =
{
− + −
− + − �√ + ≥
( ) � �
Masukan Vektor-vektor sebaran kedalam persamaa (III.1) Vektor Tidak Relevan = ( )
= ( ) = √ + <
Vektor Relevan = ( ),(− ), ( ) = ( ) = √ + ≥
= (− ) = √ + ≥
= ( ) = √ + ≥
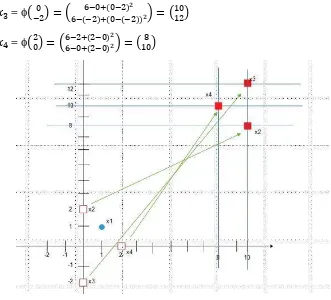
Disini yang memenuhi hanyalah vektor-vektor relevan, maka setelah dilakukan kernel trick, akan didapatkan data set baru seperti berikut:
= ( ) = − + −− + − 22 = (8)
Vektor Relevan (kotak) = ( ),(− ), ( )
Vektor Tidak Relevan (lingkaran) = ( )
= (− ) = − − + − −− + − 2 2 = ( ) = ( ) = − + −− + − 22 = (8)
Gambar III-15 data set baru
Setelah Data set terpisah secara linier, barulah kita dapat menentukan support vector pada data set tersebut:
= (8), = (8), = ( )
Setelah itu masing-masing support vector diberi nilai bias 1, menjadi:
= ( ) => ̃ = ( )
= ( ) => ̃ = ( )
= ( ) => ̃ = ( )
Sekarang cari 3 parameter α1, α2 dan α3 menggunakan persamaan linear:
α ̃ . ̃ + α ̃ . ̃ + α ̃ . ̃ = + �
α ̃ . ̃ + α ̃ . ̃ + α ̃ . ̃ = + �
α ̃ . ̃ + α ̃ . ̃ + α ̃ . ̃ = − � �
Subtitusikan menjadi:
α ( ) . ( ) + α ( ) . ( ) + α ( ) . ( ) = +
α ( ) . ( ) + α ( ) . ( ) + α ( ) . ( ) = +
α ( ) . ( ) + α ( ) . ( ) + α ( ) . ( ) = −
Setelah dikalikan
α + α + α = +
α + + α = +
α + α + α = −
Didapatlah:
α = 0.859, α = 0.859, α = -1.4219
Setelah didapatkan nilai α masukan persamaan:
̃ = α (8) + α (8) +α ( )
̃ = . ( ) + . ( ) + − . ( ) = ( ..
− . )
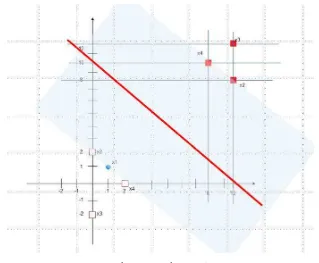
y = w x + b dengan w = .. / ./ = ( ) Dan dengan offset b = - .
. = − .
Didapatkan lah nilai hyperplane untuk mengklasifikasikan kedau kelas, yaitu 10.057
Gambar III-17 hyperplane 2. Menghitung Data Testing
Masukan vektor tersebut kedalam persamaan (III.1) = (− ) = + + − − 2
− + − − 2 = ( ) w . =( ). ( ) = >
Gambar III-18 hasil retrieval
Didalam aplikasi yang dibuat untuk menghitung nilai-nilai di atas dalam penelitian ini menggunakan sebuah library bernama LibSVM yang di buat oleh IanBarber yang selanjutnya di modifikasi sesuai dengan kebutuhan. Function yang digunakan adalah sebagai berikut:
1. Function Train
Function ini berfungsi untuk membuat data latih pada metode SVM. 1
public function train($dataFile, $modelFile, $testDataFile = null) {
$this->recordCount = $this->loadData($dataFile); one for each example
for($i = 0; $i < $this->recordCount; $i++) {
if(isset($modelFile) && is_string($modelFile)) { $this->writeSVM($modelFile);
}
46
if(isset($testDataFile) && is_string($testDataFile)) {
$this->test($testDataFile, null, null); }
}
2. Function Predict
Function ini berfungsi untuk mendapatkan hasil klasifikasi dengan nilai -1 atau 1.
public function predict($dataFile, $modelFile = null, $outputFile = null)
{
$right = $wrong = 0;
// If we're already in a valid SVM, we don't need the model if($modelFile) {
$vectorCount = $this->readSVM($modelFile); } else if(!count($this->lagrangeMults)) {
$this->recordCount = $this->loadData($dataFile, $vectorCount);
39 over " . ($right+$wrong) . " examples.\n";
} }
Setelah di modifikasi kedua fungsi di atas diubah menjadi: 1. Function Train
public function train($data) {
34
public function predict($data) { $right = $wrong = 0;
$this->recordCount=$this->loadData($data, $vectorCount);
// Klasifikasian
for($i = $vectorCount; $i < $this->recordCount; $i++){ $classification = $this->classify($i);
}
return $classification; }
Gambar III-19 flowchart klasifikasi Naive Bayes (a) Proses Training (b) Proses Testing
1. Menghitung Data Training
Tabel III-5 Tabel contoh Data Training
Tweet Kategori Fitur
Tweet1 negatif maicih level pedasss gakuat makan emotsedih Tweet2 Positif kabar gembira maicih level emotsenang Tweet3 Positif maicih kayak enak yes emotsenang emotsenang
Dibentuk sebuah model probabilistik, dengan mengacu pada persamaan (II.18) dan persamaan (II.19):
� ℎ| = # # ℎ, + | |+ = +
� ℎ| =
# , +
# + | | =
+
+ =
Jika dibentuk sebuah tabel, maka hasil dari perhitungan probabilistik setiap kata pada data training terdapat pada Tabel III-6 dan Tabel III-7
Tabel III-6 Hasil perhitungan probabilitas data training (1)
Kategori � � | c)
maicih level pedasss gakuat makan emotsedih kabar gembira Positif
Negatif
Tabel III-7 hasil perhitungan probabilitas data training (2)
Kategori � � | c)
emotsenang kayak enak yes Positif
Negatif
Hasil perhitungan probabilitas tersebut digunakan sebagai model probabilistik yang nantinya digunakan sebagai penentuan kategori data testing. Contoh kasus data testing yang sudah melalui tahap preprocessing adalah sebagai berikut:
Tweet1 = pedasss emotsenang emotsenang Tweet2 = gakuat makan maicih emotsedih
2. Menghitung Data Testing
Gunakan persamaan (II.16) untuk mengetahui kedalam kategori apa kedua data testing tersebut masuk.
�(Tweet |� )
= �( |� ) × �( |� ) × �( |� )
= × × ×
= .
= �( |� ) × �( |� ) × �( |� ) = 8 × 8 × 8 ×
= .
Sedangkan untuk perhitungan tweet2 adalah sebagai berikut:
�(Tweet |� )
= �( |� ) × �( |� ) × �( ℎ|� ) ×
�( ℎ|� )
= × × × ×
= .
�(Tweet |� )
= �( |� ) × �( |� ) × �( ℎ|� ) ×
�( ℎ|� )
= 8 × 8 × 8× 8 × = .
Setelah menghitung probabilitas dari setiap tweet yang digunakan sebagai data testing didapatkan hasil yang terdapat pada Tabel III-8
Tabel III-8 Nilai probabilitas pada data testing Tweet Positif Negatif
Tweet1 . .
Tweet2 . .
Dapat disimpulkan bawah tweet1 masuk kedalam kategori positif dikarenakan nilai probabilitas positifnya lebih besar, sedangkan tweet2 masuk kedalam kategori negatif karena porbabilitas negatif nya lebih besar.
III.1.6 Spesifikasi Kebutuhan Perangkat Lunak
nonfungsional dapat dilihat pada Tabel III-9 sedangkan spesifikasi kebutuhan
fungsional dapat dilihat pada Tabel III-10.
Tabel III-9 Spesifikasi Kebutuhan Non Fungsional
Nomor Spesifikasi Kebutuhan NonFungsional
SKPL-NF-001 Sistem yang dibangun berbasis web.
SKPL-NF-002 Aplikasi yang dibangun dapat berjalan optimal di browser google chrome dan mozilla firefox.
SKPL-NF-003 Aplikasi ini dibangun dengan spesifikasi hardware yang memenuhi standar minimum kebutuhan.
SKPL-NF-004 Aplikasi ini dapat berjalan jika ada koneksi internet.
SKPL-NF-005 Pengguna yang akan menggunakan aplikasi ini harus memenuhi lima kategori yaitu user knowledge and experience, user jobs and tasks, user physical characteristic dan user tools.
SKPL-NF-006 Data yang dipakai untuk di klasifikasi adalah data yang diambil langsung dari twitter.
Tabel III-10 Spesifikasi Kebuthan Fungsional
Nomor Spesifikasi Kebutuhan Fungsional
SKPL-F-001 Aplikasi ini dapat membantu Mangerial melakukan crawling data tweet yang didapatkan langsung dari twitter menggunakan API yang disediakan twitter. SKPL-F-002 Aplikasi ini dapat melakukan preprocessing untuk mengubah data mentah
menjadi data siap pakai.
SKPL-F-003 Aplikasi ini dapat membantu Mangerial melakukan retrieval terhadap tweet yang di crawling. Sehingga data yang diklasifikasi benar-benar tweet yang mengandung sentimen.
SKPL-F-004 Aplikasi ini dapat membantu Mangerial melakukan klasifikasi terhadap sentimen yang diberikan konsumen
SKPL-F-005 Aplikasi ini dapat melakukan pengujian untuk menguji akurasi klasifikasi. SKPL-F-006 Aplikasi ini dapat membantu Mangerial melihat hasil klasifikasi yang di
visualisasikan berupa grafik
III.1.7 Analisis Kebutuhan Non Fungsional
III.1.7.1 Analisis Kebutuhan Perangkat Lunak
Analisis kebutuhan perangkat lunak (software) pada penelitian ini merupakan kebutuhan perangkat lunak yang digunakan dalam pembangunan perangkat lunak ini. Adapun perangkat lunak yang digunakan sebagai berikut:
1. Sistem Operasi Window 8.1 Profesional 64 bit. 2. Bahasa Pemrograman PHP
3. Web server XAMPP v3.2.1 4. Code Editor SublimeText 3 5. DBMS : MongoDB
6. Adobe Photoshop CS6
7. Web Browser Google Chrome 38.0.2125.101 m
III.1.7.2 Analisis Kebutuhan Perangkat Keras
Analisis kebutuhan perangkat keras (hardware) pada penelitian ini merupakan kebutuhan perangkat keras yang digunakan dalam pembangunan perangkat lunak ini. Adapun perangkat keras yang digunakan sebagai berikut:
1. Processor intel i3-2305 2.3GHz 2. Hardisk 340GB
3. Memory 6GB (RAM)
4. Monitor dengan resolusi 1366x768 pixels 5. QWERTY Creative
6. Mouse Wireless Logitec
7. VGA intel(R) HD graphics 3000 1696MB
III.1.7.3 Analisis Kebutuhan Perangkat Pikir
Analisis kebutuhan perangkat pikir (brainware) yang dilakukan pada penelitian ini dikelompokkan menjadi empat kategori yaitu user knowledge and experience, user jobs and tasks, user physical characteristic dan user tools. Perangkat pikir yang terlibat dalam pembangunan perangkat lunak pada penelitian ini adalah bagian managerial dari PT. Maicih Inti Sinergi.