1
Layanan social media dan microblogging saat ini telah mengalami perkembangan yang cukup pesat. Salah satu layanan microblogging yang terkenal dan memiliki pengguna yang cukup besar adalah Twitter. Indonesia tercatat sebagai sumber pengguna Twitter terbanyak ketiga di dunia [1]. Pada Twitter terdapat istilah bernama tweet yang merupakan sebuah pesan atau status yang dibuat oleh penggunanya. Sebuah tweet dapat mengekspresikan sebuah perasaan atau keadaan dari pengguna Twiter. Tweet dapat mengandung sebuah opini dari penggunanya terhadap kejadian yang dialaminya. Opini tersebut dapat dimanfaatkan sebagai penilaian bagi sebuah perusahaan atau instansi.
Tujuan lain dari analisis sentimen adalah untuk mengetahui apakah sebuah objek yang diteliti, dalam hal ini tweet mengandung opini atau tidak [3]. Klasifikasi sentimen akan sangat membantu dalam memberikan input dan feedback dari pelanggan dengan cepat [4].
Salah satu proses yang penting dalam analisis sentimen adalah klasifikasi. Metode klasifikasi yang digunakan sangat menentukan hasil dari analisis sentimen itu sendiri. Naive bayes classifier adalah metode klasifikasi probabilistik sederhana berdasarkan penerapan teorema Bayes (dari statistik Bayesian) dengan asumsi independen (naif) yang kuat. Kelebihan dari naive bayes classifier adalah hanya memerlukan sejumlah kecil data pelatihan untuk mengestimasi parameter (rata-rata dan varian dari variabel) yang diperlukan untuk klasifikasi [5]. Metode ini memiliki algoritma yang sederhana sehingga mudah diimplementasikan [3].
Berdasarkan masalah yang telah diuraikan, maka penelitian ini bermaksud untuk membangun Analisis Sentimen Pada Akun Twitter Provider Telekomunikasi.
1.2 Rumusan Masalah
Berdasarkan uraian pada latar belakang dapat dirumuskan masalahnya adalah bagaimana melakukan klasifikasi opini positif dan negatif terhadap tweet yang ditujukan kepada akun twitter provider telekomunikasi?
1.3 Maksud dan Tujuan
Maksud dari penelitian yang dilakukan adalah untuk mengimplementasikan analisis sentimen dengan menggunakan metode klasifikasi naive bayes classifier.
1.4 Batasan Masalah
Batasan masalah pada penelitian yang akan dilakukan antara lain :
1. Data latih dan data uji yang digunakan pada penelitian menggunakan Bahasa Indonesia.
2. Akun twitter provider telekomunikasi yang digunakan pada penelitian adalah akun twitter XL123.
3. Data latih dan data uji diperoleh dari posting tweet yang ditujukan kepada akun twitter XL123.
4. Klasifikasi tweet relevan dan tidak relevan menggunakan metode Support Vector Machine.
5. Klasifikasi sentimen menggunakan metode Naive Bayes Classifier. 6. Terdapat dua kelas yang diklasifikasikan yaitu positif dan negatif.
7. Sistem harus terkoneksi internet untuk mengumpulkan data latih dan data uji.
8. Sistem bersifat simulator
1.5 Metodologi Penelitian
Metodologi yang digunakan pada penelitian ini adalah metode deskriptif. Metode deskriptif adalah suatu metode dalam meneliti status,suatu objek, suatu set kondisi, suatu kelas peristiwa pada masa sekarang. Metode ini memiliki tujuan untuk membuat deskripsi atau gambaran secara sistematis, faktual dan akurat mengenai fakta-fakta, sifat-sifat serta hubungan antar fenomena yang diselidiki.
1.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan pada penelitian ini adalah sebagai berikut :
1. Studi Literatur
2. Observasi
Teknik pengumpulan data secara langsung dengan melakukan peninjauan terhadap tweet-tweet yang ditujukan kepada akun twitter XL
1.5.2 Metode Pembangunan Perangkat Lunak
Model proses pembangunan perangkat lunak yang digunakan dalam penelitian ini adalah model prototype. Tahapan-tahapan pada model prototype menurut Roger S. Pressman adalah sebagai berikut :
Gambar 1.1. Skema Prototype [6]
1. Communication
Mendefinisikan objektif secara keseluruhan dan mengidentifikasi kebutuhan dari analisis sentimen.
2. Quick plan
Merupakan tahapan menentukan rencana yang akan dilakukan setelah mengetahui kebutuhan apa saja yang diperlukan.
3. Modeling Quick design
4. Construction of prototype
Merupakan tahap desain program yang diterjemahkan ke dalam kode-kode dengan menggunakan bahasa pemrograman yang sudah ditentukan dan testing yang disesuaikan dengan modeling yang telah selesai dibuat
5. Deployment Delivery & Feedback
Prototype dievaluasi oleh pengguna dan digunakan untuk memperbaiki persyaratan perangkat lunak yang akan dikembangkan. Apabila prototype sudah sesuai dengan kebutuhan, maka perangkat lunak dapat diterima dan penelitianpun selesai. Jika terdapat suatu revisi yang harus dilakukan ataupun tidak sesuai dengan kebutuhan, maka kembali lagi ke proses communication dan melakukan revisi yang dibutuhkan.
1.6 Sistematika Penulisan
Sistematika penulisan laporan akhir penelitian ini disusun untuk mendeskripsikan secara umum tentang penelitian yang dilakukan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB 1. PENDAHULUAN
Menjelaskan tentang latar belakang permasalahan, merumuskan inti permasalahan yang ada, menentukan tujuan dan kegunaan penelitian, yang kemudian diikuti dengan pembatasan masalah, asumsi, serta sistematika penulisan.
BAB 2. TINJAUAN PUSTAKA
Membahas konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis permasalahan serta tinjauan terhadap penelitian.
BAB 3. ANALISIS DAN PERANCANGAN SISTEM
Bab ini membahas analisis sistem, analisis masalah, analisis pengumpulan data, analisis preprocessing, analisis support vector machine, analisis naive bayes classifier, analisis kebutuhan
non-fungsional, analisis kebutuhan non-fungsional, analisis perancangan antarmuka sistem dan jaringan semantik.
BAB I4. IMPLEMENTASI DAN PENGUJIAN SISTEM
Menjelaskan implementasi dan pengujian dari hasil analisis dan perancangan sistem yang dibangun, serta metode atau teknik analisis yang akan digunakan.
Bab ini menguraikan implementasi dari sistem, implementasi preprocessing, implementasi support vector machine, naive bayes classifier pada analisis sentimen, pengujian black box, pengujian confusion matrix.
BAB 5. KESIMPULAN DAN SARAN
7
Opini dan konsep terkait seperti sentimen, evaluasi, sikap, dan emosi adalah subyek dari studi analisis sentimen dan opinion mining. Sejak awal tahun 2000, analisis sentimen telah berkembang menjadi salah satu daerah penelitian yang paling aktif dalam pengolahan bahasa alami (natural language processing). Hal tersebut juga banyak dipengaruhi oleh perkembangan studi mengenai data mining, web mining, dan text mining. Beberapa tahun terakhir, kegiatan industri sekitar analisis sentimen juga berkembang. Sekarang analisis sentimen hampir dapat ditemukan pada setiap bisnis dan domain sosial [3].
Analisis sentimen atau biasa disebut juga opinion mining adalah bidang studi yang menganalisa opini , sentimen, evaluasi, sikap, dan emosi terhadap suatu entitas [7]. Entitas tersebut dapat berupa produk, jasa, organisasi, individu, masalah, peristiwa atau sebuah topik. Aplikasi analisis sentimen telah menyebar ke hampir setiap domain mulai dari produk, konsumen, jasa, kesehatan, dan jasa keuangan untuk kegiatan sosial dan politik.
Analisis sentimen berfokus pada opini yang menyatakan atau menyiratkan sentimen positif atau negatif. Secara garis besar analisis sentimen merupakan proses klasifikasi dokumen tekstual ke dalam dua kelas, yaitu kelas sentimen positif dan kelas sentimen negatif. Analisis sentimen dilakukan untuk melihat pendapat atau opini terhadap sebuah masalah atau dapat juga digunakan untuk identifikasi kecenderungan suatu hal pada lingkup tertentu. Menurut Liu, tujuan utama dari analisis sentimen adalah untuk melakukan ekstraksi atribut pada sebuah dokumen atau teks berisi komentar untuk mengetahui ekspresi-ekspresi yang ada di dalamnya sehingga komentar-komentar tersebut dapat bisa dikategorikan positif atau negatif.
2.2 Klasifikasi
luas, sehingga mencakup regresi dan ranking. Alasan bahwa klasifikasi sangat penting adalah bahwa banyak masalah yang menarik dapat dirumuskan sebagai penerapan klasifikasi / regresi / ranking ke unit tekstual [8]. Terdapat beberapa metode klasifikasi di antaranya seperti naive bayes classifier, k-nearest neighbour, decision trees, neural network, support vecor machine dan lain-lain [9].
2.3 Information Retrieval
Information Retrieval (IR) adalah proses untuk menemukan atau mencari suatu “material” (biasanya dokumen) yang bersifat tidak terstruktur (biasanya teks) yang memenuhi kebutuhan informasi dari dalam koleksi yang besar (biasanya disimpan di komputer) [8]. Information retrieval juga dapat mencakup jenis data lain.
Fokus dari information retrieval adalah bagaimana membuat representasi, mencari, dan memanipulasi koleksi dokumen digital agar pengguna mudah mencari informasi yang diperlukan. Informasi atau data yang dicari dapat berupa berupa teks, image, audio, video dan lain-lain. Koleksi data teks yang dapat dijadikan sumber pencarian juga dapat berupa pesan teks, seperti e-mail, fax, dan dokumen berita, bahkan dokumen yang beredar di internet. Dengan jumlah dokumen koleksi yang besar sebagai sumber pencarian, maka dibutuhkan suatu sistem yang dapat membantu user menemukan dokumen yang relevan dalam waktu yang singkat dan tepat.
Pada information retrieval terdapat tahapan preprocessing yang berguna untuk mengolah data sebelum dilakukan proses tertentu pada tahapan selanjutnya.
2.3.1 Preprocessing
1. Casefolding
Langkah awal dari preprocessing dimulai dengan melakukan casefolding terhadap tweet yang akan diproses. Casefolding merupakan proses mengubah semua teks pada tweet menjadi huruf kecil (lowercase).
2. Normalisasi Fitur
Merupakan proses menghilangkan atau menghapus komponen-komponen khas yang terdapat pada tweet seperti username, url, rt. Hal ini dilakukan karena komponen tersebut sama sekali tidak akan berpengaruh terhadap sentimen dari suatu tweet. Identifikasi komponen-komponen pada normalisasi fitur akan menggunakan regular expression.
Tabel 2.1. Normalisasi Fitur Krarakter
0 8 & ` : ?
1 9 * ~ ; /
2 ! ( [ “
3 @ ) ] ‘
4 # - \ <
5 $ _ | >
6 % + { ,
7 ^ = } .
3. Convert Emoticon
Emoticon yang sering digunakan oleh para pengguna twitter adalah sebagai berikut :
Tabel 2.2. Emoticon [12]
No Emoticon Jumlah Tweet Persentase
1 :) 32.115.789 33.36%
Emoticon yang digunakan pada penelitian ini adalah emoticon western style. Berikut ini adalah tabel konversi emoticon yang digunakan :
Tabel 2.3. Konversi Emoticon
Stopwords adalah kata umum yang biasanya muncul dalam jumlah besar dan dianggap tidak memiliki makna, sehingga tidak akan mempengaruhi sentimen. Stop words biasanya berupa kata ganti atau kata sambung.
5. Negation Handling
Negation handling atau penanganan negasi menjadi perhatian penting dalam analisis sentimen. Hal ini karena kata negasi dapat mengubah nilai positif atau negatif dari data yang dianalisis. Jika pada tweet terdapat kata negasi, maka kata negasi akan digabungkan dengan kata setelahnya sehingga menjadi satu kata baru.
6. Tokenization
Tokenization atau tokenisasi merupakan proses untuk memisah-misahkan atau memecah suatu kalimat menjadi kata-kata yang terpisah. Token adalah turunan dari urutan karakter dalam beberapa dokumen tertentu yang dikelompokkan bersama sebagai unit semantik yang berguna untuk diproses.
7. Stemming
Stemming merupakan salah satu proses yang digunakan untuk meningkatkan performa IR dengan cara mentransformasikan kata-kata dalam sebuah dokumen teks ke dalam bentuk kata dasarnya. Algoritma untuk proses stemming pada penelitian ini menggunakan algoritma Nazief & Adriani. Algoritma ini memiliki keakuratan yang baik dan presisi untuk teks berbahasa Indonesia [13].
Algoritma yang dibuat oleh Bobby Nazief dan Mirna Adriani ini memiliki tahap-tahap sebagai berikut [13]:
1. Cari kata yang akan distem dalam kamus. Jika ditemukan maka diasumsikan bahwa kata tesebut adalah root word.Maka algoritma berhenti.
maka langkah ini diulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”, atau “-nya”), jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”).Jika kata ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b. a. Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan.
Jika ditemukan maka algoritma berhenti, jika tidak pergi ke langkah 4b.
b. For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root word belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma berhenti. Catatan: jika awalan kedua sama dengan awalan pertama algoritma berhenti.
5. Melakukan Recoding.
(2.2)
(2.3) 2.4 Support Vector Machine
Support Vector Machine dikembangkan oleh Boser, Guyon, Vapnik dan dipertamakali dipresentasikan pada tahun 1992 di Annual Workshop on Computational Learning Theory. Konsep dasar SVM sebenarnya merupakan kombinasi dari teori-teori komputasi yang telah ada puluhan tahun sebelumnya. Prisip dasar SVM adalah pengklasifikasi linear (linear classifier), dan selanjutnya dikembangkan agar dapat bekerja pada masalah non-linear, dengan memasukkan kernel trick pada ruang kerja berdimensi tinggi. Fungsi kernel yang biasa digunakan biasanya yaitu linier, polynomial, radial basis function dan sigmoid. Teknik ini berusaha untuk menemukan fungsi pemisah (classifier) yang optimal yang bisa memisahkan dua set data dari dua kelas yang berbeda [14].
Pada kasus klasifikasi secara linier digunakan fungsi pemisah yang dapat didefinisikan sebagai berikut :
≔ ( ) (2.1)
= � + ,
Sedangkan pada kasus klasifikasi secara non linear untuk menemukan hyperplane pemisah yang akurat untuk mengkasifikasikan dua kelas, adalah dengan menggunakan fungsi pemisah nonlinear (yaitu, satu yang fungsinya pemetaan ∅ adalah pemetaan nonlinear dari ruang input ke dalam beberapa ruang fitur). Didefinisikan sebagai berikut :
ɸ ( ) = didasarkan pada persamaan linear berikut
�1 1̃ . ̃ + �1 1 1̃ . ̃ + �1 1 1̃ . ̃ = + 1
�1 1̃ . ̃ + �1 1 1̃ . ̃ + �1 1 1̃ . ̃ = + 1
(2.4) Setelah mendapatkan nilai � , maka langkah selanjutnya adalah mencari hyperplane untuk memisahkan kelas positif dan kelas negatif menggunakan persamaan (II.4) [15].
̃ = ∑ α ̃
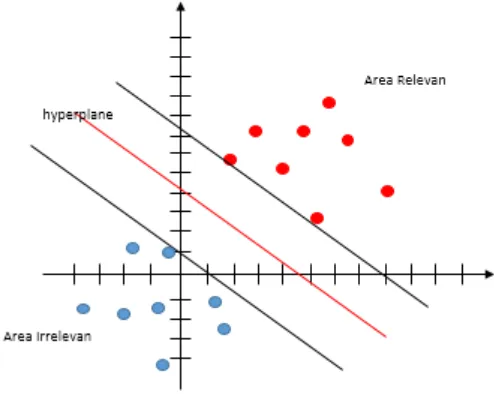
Berikut adalah gambaran dari penggunaan metode support vector machine pada pemisahan data relevan dan tidak relevan.
Gambar 2.1. Pemisah data relevan dan tidak relevan
2.5 Naive Bayes Classifier
klasifikasi. Karena variabel diasumsikan independen, hanya varian dari variabel-variabel untuk setiap kelas yang perlu ditentukan.
Metode naive bayes classifier menempuh dua tahap dalam proses klasifikasi teks, yaitu tahap pelatihan dan tahap klasifikasi. Pada tahap pelatihan dilakukan proses analisis terhadap sampel dokumen berupa pemilihan vocabulary, yaitu kata yang mungkin muncul dalam koleksi dokumen sampel yang sedapat mungkin dapat menjadi representasi dokumen. Selanjutnya adalah penentuan probabilitas prior bagi tiap kategori berdasarkan sampel dokumen. Pada tahap klasifikasi ditentukan nilai kategori dari suatu dokumen berdasarkan term yang muncul dalam dokumen yang diklasifikasi [5]. Dengan menerapkan teorema bayes , maka persamaan untuk klasifikasi adalah sebagai berikut :
= max� ∈� � ∏ � |
Nilai � ditentukan pada saat pelatihan, yang nilainya diperoleh dengan :
�( ) =|�| |ℎ|
dimana adalah banyaknya keyword yang memiliki kategori j dalam pelatihan, sedangkan |� ℎ| banyaknya keyword dalam contoh yang digunakan untuk pelatihan.
Untuk nilai � | , yaitu probabilitas kata dalam kategori j ditentukan dengan :
�( | ) = + | + |
dimana adalah frekuensi kemunculan kata dalam dokumen yang berkategori , sedangkan nilai n adalah banyaknya seluruh kata dalam dokumen berkategori
dan | | adalah banyaknya kata dalam contoh pelatihan.
Tahapan pelatihan dan klasifikasi naive bayes classifier adalah sebagai berikut Pelatihan :
1. Bentuk vocabulary
2. Untuk setiap kategori hitung :
a. Tentukan (himpunan dok dalam kategori )
(2.5)
(2.6)
(2.8) b. Hitung �( ) dengan persamaan (2)
c. Hitung �( | ) dengan persamaan (3) untuk setiap dalam vocabulary
Klasifikasi :
1. Hitung � ∏ � | ) untuk setiap kategori 2. Tentukan nilai maksimumnya sebagai hasil kategorisasi.
2.6 Pembobotan Kata
Metode yang digunakan untuk pembobotan kata pada penelitian ini adalah metode TF-IDF (term frequency – inverse document frequency). Metode TF-IDF dapat dirumuskan sebagai berikut :
= ( )
dimana :
idf adalah invers dokumen frequency d adalah total dokumen
df adalah jumlah dokumen yang mengandung term (kata)
Bobot dari setiap term (kata) dapat dihitung dengan rumus = ∗
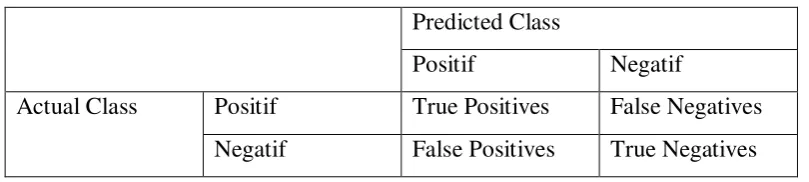
2.7 Confusion Matrix
Tabel 2.4. Confusion Matrix Predicted Class
Positif Negatif
Actual Class Positif True Positives False Negatives Negatif False Positives True Negatives
Keterangan :
True Positives : Jumlah record positif yang diklasifikasikan sebagai positif Flase Positives: Jumlah record positif yang diklasifikasikan sebagai negatif False Negatives : Jumlah record negatif yang diklasifikasikan sebagai positif True Negatives: Jumlah record negatif yang diklasifikasikan sebagai negatif.
Setiap kolom dari tabel confusion matrix merupakan contoh di kelas yang telah diprediksi, sedangkan setiap baris mewakili contoh di kelas yang sebenarnya. Setelah mendapatkan nilai untuk masing-masing kelas, selanjutnya adalah menghitung nilai precision dan akurasinya. Precision adalah ukuran terhadap suatu kelas yang telah diprediksi. Berikut ini adalah persamaannya :
� = � + �� + � + ��� − �
� = � + ���
dengan TP adalah true positives, FP False positives, TN True Negatives,dan FN adalah False Negatives. [16]
2.8 Object Oriented Programming
Object Oriented Programming (OOP) adalah sebuah pendekatan untuk pengembangan suatu software dimana dalam struktur software tersebut didasarkan kepada interaksi object dalam penyelesaian suatu proses tugas. Interaksi tersebut mengambil form dari pesan-pesan dan mengirimkannya kembali antar object tersebut. Object akan merespon pesan tersebut menjadi sebuah tindakan atau metode. Adapun konsep pada pemrograman berorientasi objek yaitu :
1. Object
Merupakah sebuah struktur yang menggabungkan data dan prosedur untuk bekerja bersama-sama
2. Abstraction
Ketika membangun objects dalam aplikasi OOP, penting untuk menggabungkan konsep abstraction ini.
3. Enkapsulasi
Sebuah proses dimana tidak ada akses langsung ke data yang diberikan, bahkan hidden. Jika ingin mendapat data, harus berinteraksi dengan object yang bertanggung jawab atas data tersebut
4. Polymorphisms
Kemampuan dua buah object yang berbeda untuk merespon pesan permintaan yang sama dalam suatu cara yang unik. Pada OOP, diterapkan tipe polymorphism melalui proses yang disebut overloading. Dapat dilakukan dalam implementasi metode yang berbeda pada sebuah object yang mempunyai nama yang sama.
5. Inheritance
Penggunaan inheritance dalam OOP adalah untuk mengklasifikasikan objects dalam program sesuai karakteristik umum fungsinya. Hal ini akan membuat pekerjaan bersama object lebih mudah dan lebih intuitif. Hal ini juga membuat programming lebih mudah karena memungkinkan untuk mengkombinasikan karakteristik umum ke dalam object parent dan mewariskan karakteristik ke child object.
2.8.1 Unified Modelling Language (UML)
1. Use Case Diagram
Use case diagram digunakan untuk memodelkan bisnis proses berdasarkan perspektif pengguna sistem. Terdiri atas diagram untuk use case dan actor. Actir merepresentasikan orang yang akan mengoperasikan atau orang yang berinteraksi dengan sistem aplikasi. Use case merepresentasikan operasi-operasi yang dilakukan oleh actor. Use case digambarkan berbentuk elips dengan nama operasi dituliskan didalamnya. Actor yang melaukan operasi dihubungkan dengan garis lurus ke use case.
2. Activity Diagram
Merupakan representasi grafis dari alur kerja tahapan aktivitas. Diagram ini mendukung pilihan tindakan, iterasi dan concurrency. Pada pemodalan UML, activity diagram dapat digunakan untuk menjelaskan bisnis dan alur kerja operasional secara step-by-sep dari komponen suatu sistem.
3. Sequence Diagram
Menjelaskan secara detil urutan proses yang dilakukan dalam sistem untuk mencapai tujuan dari use case. Interaksi yang terjadi antar class, operasi apa yang terlibat, urutan antar operasi dan informasi yang diperlukan oleh masing-masing operasi.
4. Class Diagram
73 4.1 Implementasi Sistem
Tahap implementasi sistem adalah tahapan yang dilakukan setelah perancangan sistem selesai dan selanjutnya diimplementasikan menggunakan bahasa pemrograman yang telah ditentukan. Pada tahapan ini juga terdapat pengujian sistem yang bertujuan untuk menilai dan menguji sistem yang dibuat agar dapat memberi masukan kepada pengembangan sistem selanjutnya.
4.1.1 Implementasi Perangkat Keras
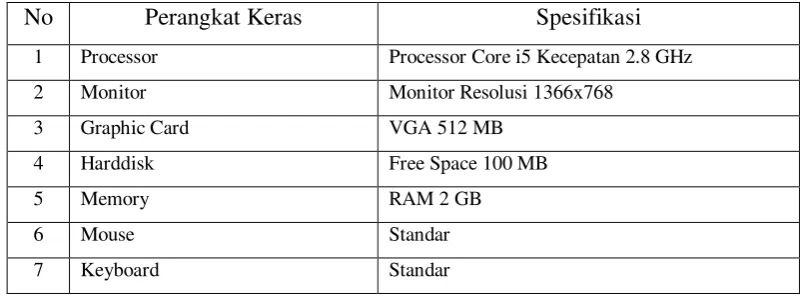
Spesifikasi perangkat keras (hardware) yang digunakan untuk membangun analisis sentimen terhadap tweet yang ditujukan kepada provider telekomunikasi menggunakan metode klasifikasi Naive Bayes dapat dilihat pada tabel berikut :
Tabel 4.1. Implementasi Perangkat Keras
No Perangkat Keras Spesifikasi
1 Processor Processor Core i5 Kecepatan 2.8 GHz
2 Monitor Monitor Resolusi 1366x768
3 Graphic Card VGA 512 MB
4 Harddisk Free Space 100 MB
5 Memory RAM 2 GB
6 Mouse Standar
7 Keyboard Standar
4.1.2 Implementasi Perangkat Lunak
Tabel 4.2. Implementasi Perangkat Lunak
No Perangkat Lunak Spesifikasi
1 Sistem Operasi Microsoft Windows 7
2 Aplikasi Compiler Microsoft Visual Studio 2012
3 DBMS MySQL
4.1.3 Implementasi Database
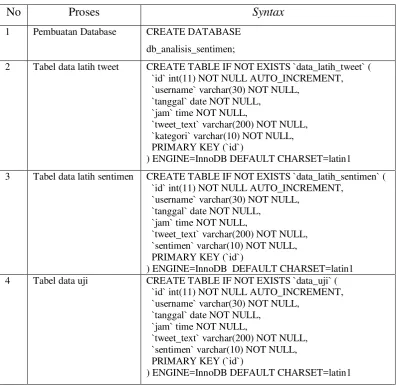
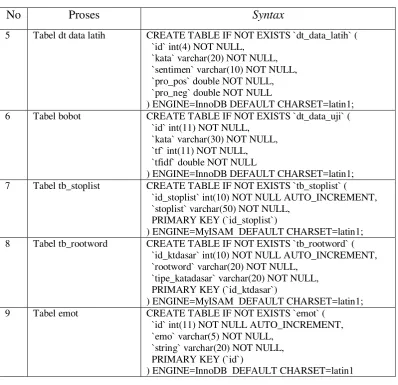
Implementasi database merupakan tahapan pembuatan basis data (database) menggunakan MySQL yang telah dirancang agar dapat menunjang kebutuhan sistem. Berikut adalah implementasi database yang digunakan :
Tabel 4.3. Implementasi Database
No Proses Syntax
1 Pembuatan Database CREATE DATABASE
db_analisis_sentimen;
2 Tabel data latih tweet CREATE TABLE IF NOT EXISTS `data_latih_tweet` (
`id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(30) NOT NULL,
`tanggal` date NOT NULL, `jam` time NOT NULL,
`tweet_text` varchar(200) NOT NULL, `kategori` varchar(10) NOT NULL, PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
3 Tabel data latih sentimen CREATE TABLE IF NOT EXISTS `data_latih_sentimen` (
`id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(30) NOT NULL,
`tanggal` date NOT NULL, `jam` time NOT NULL,
`tweet_text` varchar(200) NOT NULL, `sentimen` varchar(10) NOT NULL, PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
4 Tabel data uji CREATE TABLE IF NOT EXISTS `data_uji` (
`id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(30) NOT NULL,
`tanggal` date NOT NULL, `jam` time NOT NULL,
`tweet_text` varchar(200) NOT NULL, `sentimen` varchar(10) NOT NULL, PRIMARY KEY (`id`)
Tabel 4.4. Implementasi Database (Lanjutan)
No Proses Syntax
5 Tabel dt data latih CREATE TABLE IF NOT EXISTS `dt_data_latih` (
`id` int(4) NOT NULL, `kata` varchar(20) NOT NULL, `sentimen` varchar(10) NOT NULL, `pro_pos` double NOT NULL, `pro_neg` double NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
6 Tabel bobot CREATE TABLE IF NOT EXISTS `dt_data_uji` (
`id` int(11) NOT NULL, `kata` varchar(30) NOT NULL, `tf` int(11) NOT NULL, `tfidf` double NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
7 Tabel tb_stoplist CREATE TABLE IF NOT EXISTS `tb_stoplist` (
`id_stoplist` int(10) NOT NULL AUTO_INCREMENT, `stoplist` varchar(50) NOT NULL,
PRIMARY KEY (`id_stoplist`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
8 Tabel tb_rootword CREATE TABLE IF NOT EXISTS `tb_rootword` (
`id_ktdasar` int(10) NOT NULL AUTO_INCREMENT, `rootword` varchar(20) NOT NULL,
`tipe_katadasar` varchar(20) NOT NULL, PRIMARY KEY (`id_ktdasar`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
9 Tabel emot CREATE TABLE IF NOT EXISTS `emot` (
`id` int(11) NOT NULL AUTO_INCREMENT, `emo` varchar(5) NOT NULL,
`string` varchar(20) NOT NULL, PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
4.1.4 Implementasi Antarmuka
Implementasi antarmuka merupakan tahapan yang dihasilkan dari perancangan antarmuka pada tahap sebelumnya. Berikut adalah nama antarmuka, deskripsi, dan nama file yang digunakan pada implementasi antarmuka.
Tabel 4.5. Implementasi Antarmuka
No Nama Antarmuka Deskripsi Nama File
1 Menu Menampilkan halaman menu
utama
Menu.cs
2 Visualisasi Klasifikasi Menampilkan grafik hasil
klasifikasi dalam bentuk diagram pie
VisualisasiKlasifikasi.cs
3 Klasifikasi Menampilkan halaman proses
klasifikasi
Klasifikasi.cs
4 Pelatihan Menampilkan halaman proses
pelatihan
Tabel 4.6. Implementasi Antarmuka (Lanjutan)
No Nama Antarmuka Deskripsi Nama File
5 Crawling Menampilkan halaman
crawling tweet
Crawling.cs
4.2 Pengujian Sistem
Pengujian sistem bertujuan untuk menilai tingkat kesesuaian antara hasil klasifikasi terhadap data uji yang dilakukan oleh sistem dengan hasil klasifikasi secara manual. Pengujian terhadap hasil dari klasifikasi pada penelitian ini menggunakan metode confusion matrix.
4.2.1 Pengujian Black Box
Pengujian Black Box merupakan pengujian terhadap fungsionalitas dari perangkat lunak yang dibangun terhadap implementasi pengunannya. Skenario pengujian yang dilakukan adalah sebagai berikut :
Tabel 4.7. Skenario Pengujian No Komponen yang diuji Poin Pengujian
1 Proses Crawling Melakukan proses crawling tweet dan menyimpannya
ke dalam database
2 Proses Pelatihan Melakukan pelatihan untuk membuat data latih tweet
relevan, nonrelevan dan tweet sentimen.
3 Proses Klasifikasi Melakukan klasifikasi tweet relevan, nonrelevan dan
klasifikasi tweet sentimen.
4 Proses Visualisasi dari
klasifikasi
Menampilkan hasil klasifikasi dalam bentuk diagram pie pada rentang waktu yang telah ditentukan.
1. Pengujian Crawling
Tabel 4.8. Pengujian Crawling Kasus dan Hasil Uji (Terkoneksi Internet)
Masukan Prosedur Pengujian Hasil yang
diharapkan
Pengamatan Kesimpulan
Tidak ada Memastikan dapat
Tabel 4.9. Pengujian Crawling (Lanjutan) Kasus dan Hasil Uji (Tidak Terkoneksi Internet)
Tidak ada Memastikan dapat
mengakases internet
Tabel 4.10. Pengujian Pelatihan Kasus dan Hasil Uji (Data benar)
Masukan Prosedur Pengujian Hasil yang
diharapkan
Pengamatan Kesimpulan
Data tweet Menekan tombol
Pelatihan dan
Kasus dan Hasil Uji (Data Salah)
Data tweet Menekan tombol
Pelatihan dan
Tabel 4.11. Pengujian Klasifikasi Kasus dan Hasil Uji (Data Benar)
Masukan Prosedur Pengujian Hasil yang
diharapkan
Pengamatan Kesimpulan
Data Tweet Memastikan
menekan tombol
Kasus dan Hasil Uji (Data Salah)
Data Tweet Memastikan
4. Pengujain Visualisasi Klasifikasi
Tabel 4.12. Pengujian Visualisasi Klasifikasi Kasus dan Hasil Uji (Data benar)
Masukan Prosedur
Kasus dan Hasil Uji (Data salah) Data tweet
4.2.2 Pengujian Confusion Matrix
Pada pengujian klasifikasi terhadap tweet relevan dan non relevan digunakan data uji sebanyak 150 tweet relevan, 150 tweet non relevan. Sedangkan untuk tweet yang mengandung sentimen teridiri dari 150 tweet positif dan 150 negatif yang diperoleh pada periode bulan September 2014 sampai dengan bulan Januari 2015. Hasil klasifikasi dapat dilihat pada lampiran C.
Berikut adalah grafik dari hasil klasifikasi sentimen pada periode bulan September 2014 sampai bulan Januari 2015.
Tabel 4.13. ConfusionMatrix Hasil Klasifikasi Tweet
Precision Kelas Relevan = 111
111+ 9= 0. 4
Precision Kelas Non Relevan = 1
1 +1 = 0. 0
Tabel 4.14. ConfusionMatrix Hasil Klasifikasi Sentimen Predicted Class
Precision Kelas Positif = 1
1 + = 0. 6
Precision Kelas Negatif = 1
1 + = 0. 7
4.3 Kesimpulan Pengujian
Berdasarkan dari pengujian yang telah dilakukan terhadap kasus uji, maka dapat disimpulkan :
Jika terkoneksi internet dengan baik dan data tweet latih serta tweet uji tersedia maka sistem secara fungsional akan mengeluarkan keluaran sesuai dengan harapan.
81
Pada bab ini akan dikemukakan kesimpulan yang dapat diperoleh dari pembahasan pada bab-bab sebelumnya serta saran untuk perbaikan dan pengembangan lebih lanjut.
5.1 Kesimpulan
Berdasarkan hasil yang diperoleh dari penelitian dan penyusunan skripsi ini , serta disesuaikan dengan tujuannya, maka diperoleh kesimpulan bahwa sistem analisis sentimen yang dibangun dengan menggunakan metode Naive Bayes Classifier dapat melakukan klasifikasi opini positif dan negatif terhadap tweet yang ditujukan kepada akun twitter provider telekomunikasi dengan tingkat akurasi mencapai 96%.
5.2 Saran
Saran untuk pengembangan lebih lanjut adalah dengan perbaikan atau penambahan fitur sebagai berikut :
1. Penambahan jumlah data latih tweet relevan, non relevan dan tweet sentimen sehingga hasil klasifikasi diharapkan menjadi lebih baik dan akurasinya meningkat.
NIM : 10110433
Tempat/Tanggal Lahir : Bandung/03 Februari 1992 Jenis Kelamin : Laki-laki
Agama : Islam
Alamat : Jalan Babakan Sukaresik No.05 RT.01, RW.02 Kelurahan Sukagalih, Kecamatan Sukajadi
Kota : Bandung Kode POS: 40163
Telepon : 089696117693
PENDIDIKAN
1.1998 – 2004 : SD Negeri Caringin 1 2.2004 – 2007 : SMP Negeri 26 Bandung 3.2007 – 2010 : SMK TI Pembangunan Cimahi
4.2010 – 2015 : Program Studi S1 Jurusan Teknik Informatika Fakultas Teknik dan Ilmu Komputer
Universitas Komputer Indonesia, Bandung
Dengan ini Penulis menyatakan bahwa semua informasi yang diberikan dalam dokumen ini adalah benar
Bandung, 21 Februari 2015 Penulis
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
SOLAHUDIN ANWAR
10110433
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA
v
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... x
DAFTAR SIMBOL ... xii
DAFTAR LAMPIRAN ... xv
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah... 1
1.2 Rumusan Masalah ... 2
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah ... 3
1.5 Metodologi Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 3
1.5.2 Metode Pembangunan Perangkat Lunak... 4
1.6 Sistematika Penulisan ... 5
BAB 2 TINJAUAN PUSTAKA ... 7
2.1 Analisis Sentimen ... 7
2.2 Klasifikasi ... 8
2.3 Information Retrieval ... 8
2.3.1 Preprocessing ... 8
2.4 Support Vector Machine ... 13
2.5 Naive Bayes Classifier ... 14
2.6 Pembobotan Kata ... 16
2.7 Confusion Matrix ... 16
2.8 Object Oriented Programming ... 17
2.8.1 Unified Modelling Language (UML) ... 18
vi
3.1.3 Analisis Preprocessing ... 25
3.1.4 Analisis Pembobotan Kata ... 29
3.1.5 Analisis Support Vector Machine... 30
3.1.6 Analisis Naive Bayes Classifier ... 36
3.2 Spesifikasi Kebutuhan Perangkat Lunak ... 39
3.2.1 Analisis Kebutuhan Non-Fungsional ... 40
3.2.2 Analisis Kebutuhan Perangkat Keras ... 41
3.2.3 Analisis Kebutuhan Perangkat Lunak ... 42
3.3 Analisis Kebutuhan Fungsional ... 42
3.3.1 Identifikasi Aktor ... 42
3.3.2 Use Case Diagram ... 42
3.3.3 Activity Diagram ... 54
3.3.4 Sequence Diagram ... 60
3.3.5 Class Diagram ... 66
3.4 Perancangan Arsitektur Sistem... 67
3.4.1 Perancangan Database ... 67
3.4.2 Perancangan Struktur Menu ... 68
3.4.3 Perancangan Antarmuka ... 68
3.4.4 Jaringan Semantik ... 71
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... 73
4.1 Implementasi Sistem ... 73
4.1.1 Implementasi Perangkat Keras ... 73
4.1.2 Implementasi Perangkat Lunak ... 73
4.1.3 Implementasi Database ... 74
4.1.4 Implementasi Antarmuka ... 75
4.2 Pengujian Sistem ... 76
4.2.1 Pengujian Black Box ... 76
vii
83
DAFTAR PUSTAKA
[1] I. A. Tarigan, “Pengguna Twitter Indonesia Teraktif Ketiga di Dunia,” CHIP ONLINE, 21 11 2013. [Online]. Available: http://chip.co.id/news/apps-social_media/9030/pengguna_twitter_indonesia_teraktif_ketiga_di_dunia. [Diakses 20 8 2014].
[2] A. Kumar dan T. M. Sebastian, “Sentiment Analysis on Twitter,” IJCSI International Journal of Computer Science Issues,, vol. 9, no. 4, p. 372, 2012.
[3] Herlili dan Y. Wibisono, “Sistem Analisis Opini Microblogging Berbahasa
Indonesia”.
[4] B. Pang, L. Lee dan S. Waithanathan, “Thumbs up? Sentiment Classification
using Machine Learning Techniques,” dalam Proceedings of EMNLP, 2002.
[5] A. Hamzah, “Klasifikasi Teks Dengan Naive Bayes Classifier (NBC) untuk Pengelompokan Teks Berita dan Abstract Akademis,” dalam Prosiding Seminar Nasional Aplikasi Sains & Teknologi (SNAST) Periode III, Yogyakarta, 2012.
[6] R. S. Pressman, Software Engineering A Practitioner’s Approach Seventh Edition, McGraw-Hill,, 2010.
[7] B. Liu, Sentiment Analysis and Opinion Mining, Morgan & Claypool Publishers, 2012.
[8] C. D. Manning, P. Raghavan dan H. Schütze, Introduction to Information Retrieval, Cambridge, England: Cambridge University Press, 2009.
[9] B. Pang dan L. Lee, “Opinion Mining and Sentiment Analysis,” dalam Foundations and Trends in Information Retrieval Vol. 2,Nos.1–2(2008)1– 135, 2008.
[10] E. Haddi, X. Liu dan Y. Shi, “The Role of Text Pre-processing in Sentiment
Analysis,” dalam Information Technology and Quantitative Management
84 1, no. 1, pp. 200-206, 2012.
[12] N. Berry, “Emoticon Analysis in Twitter,” DataGenetics, 5 October 2012. [Online].Available:
http://www.datagenetics.com/blog/october52012/index.html. [Diakses 17 October 2014].
[13] L. Agusta, “Perbandingan Algoritma Stemming Porter dengan Algoritma
Nazief & Adriani untuk Stemming Dokumen Teks Bahasa Indonesia,”
Konferensi Nasional Sistem dan Informatika, vol. KNS&I09, p. 36, 2009.
[14] B. Santosa, “Tutorial Support Vector Machine,” [Online]. Available: http://oc.its.ac.id/ambilfile.php?idp=1223. [Diakses 3 October 2014].
[15] D. Ventura, “SVM Example,” 16 April 2009. [Online]. Available: http://axon.cs.byu.edu/Dan/478/misc/SVM.example.pdf. [Diakses 1 Oktober 2014].
[16] S. Visa, B. Ramsay, A. Ralescu dan E. v. d. Knaap, “Confusion Matrix-based
Feature Selection,” Midwest Artificial Intelligence and Cognitive Science
Conference 2011, vol. 710, pp. 120-127, 2011.
[17] A. Jose, “2014, XL Capai 68 Juta Pelanggan,” Okezone, 12 Juni 2014. [Online].Available:
iii
atas semua nikmatnya penulis dapat menyelesaikan penulisan skripsi yang berjudul “Analisis Sentimen Pada Akun Twitter Provider Telekomunikasi”.
Penyusunan skripsi ini banyak menemui hambatan dan kesulitan. Namun berkat dorongan, bantuan dan bimbingan baik secara moril ataupun materil dari berbagai pihak hingga dapat mengatasinya. Oleh karena itu kepada semua pihak yang telah membantu dalam penyelesaian skripsi ini disampaikan penghargaan dan ucapan terima kasih khususnya kepada yang terhormat:
1. Allah SWT yang telah melimpahkan rahmat, berkah dan karunia-Nya.
2. Kedua orang tua, kakak, dan nenek yang tidak kenal lelah memberikan doa, dukungan, dan semangat yang yang menjadi kekuatan bagi penulis untuk menyelesaikan penelitian ini.
3. Ibu Nelly Indriani W, S.Si., M.T., selaku dosen pembimbing yang telah bersedia meluangkan waktu, tenaga dan pikirannya serta memberikan pengarahan dan masukan dalam penyusunan penelitian ini.
4. Bapak Eko Budi Setiawan, S.Kom., M.T. selaku dosen penguji seminar dan penguji satu sidang yang telah banyak memberi masukan dan arahan berarti bagi penelitian ini.
5. Ibu Riani Lubis, S.T., M.T. selaku dosen penguji tiga sidang yang telah menguji dan memberikan masukan serta arahan terhadap penulis.
6. Ibu Sufaatin, S.T., M.Kom., selaku dosen wali yang telah memberikan bimbingan, dukungan dan arahan selama penulis kuliah di Program Studi Teknik Informatika Universitas Komputer Indonesia.
7. Teman-teman IF-10 angkatan 2010 atas dukungan ,semangat dan kebersamaan yang telah terjalin selama ini, terutama untuk Iwan, Rio, dan Aprisal yang telah membagikan ilmu dan sarannya terhadap pengerjaan penelitian ini.
iv
Bandung, 21 Februari 2015
![Gambar 1.1. Skema Prototype [6]](https://thumb-ap.123doks.com/thumbv2/123dok/1267520.788078/4.595.200.427.287.505/gambar-skema-prototype.webp)
![Tabel 2.2. Emoticon [12]](https://thumb-ap.123doks.com/thumbv2/123dok/1267520.788078/10.595.149.512.559.678/tabel-emoticon.webp)