LEMBAGA ILMU PENGETAHUAN INDONESIA-LIPI
SKRIPSI
Diajukan Untuk Menempuh Ujian Sarjana
VALENTINUS SILALAHI
10109615
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
“PENERAPAN ANALISIS OUTLIER UNTUK PENGELOMPOKKAN JURNAL ILMIAH MENGGUNAKAN METODE HIERARCHICAL CLUSTERING DAN K-MEANS DI LEMBAGA ILMU PENGETAHUAN INDONESIA –LIPI”
Penyusunan skripsi ini tidak akan terwujud tanpa mendapat dukungan, bantuan dan masukan dari berbagai pihak. Untuk itu, penulis ingin menyampaikan
terimakasih yang sebesar-besarnya kepada :
1. Bapak Irawan afrianto, S.T.,M.T. sebagai ketua prodi Teknik informatika
2. Ibu Dian Dharmayanti, S.T.,M.Kom. Selaku pembimbing tugas akhir dalam memberikan ide, saran dan motivasi selama pengerjaan skripsi ini
3. Ibu Nelly Indriani W, S.Si.,M.T. Selaku reviewer tugas akhir dalam memberikan saran dan kritik dalam pengerjaan skripsi ini
4. Ibu Rani Susanto,S.Kom selaku penguji tugas akhir ini dalam memberikan masukan untuk penyempurnaan tugas akhir ini.
5. Lembaga Ilmu Pengetahuan Indonesia – LIPI atas ketersediaan data yang digunakan dalam penelitian ini
6. Ibu, Bapak dan segenap keluarga besar yang telah memberikan dukungan moril maupun material hingga terselesaikannya tugas akhir ini
7. Abang Farlin Sigiro dan Sudarsono Sihotang selaku pembimbing penulis diluar kampus dalam memberikan masukan dan saran untuk menyelesaikan skripsi ini. 8. Teman – teman di PMKRI, KMK, IKANMAS, Kost-an, yang tidak bisa penulis
sebut nama satu per satu dalam memberikan semangat dan motivasi dalam pengerjaan skripsi ini.
iv
Akhir kata semoga skripsi ini bermanfaat bagi pembaca
Bandung, Juli 2015
KATA PENGANTAR ... iii
DAFTAR ISI ... iv
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... x
DAFTAR SIMBOL ... xi
DAFTAR LAMPIRAN ... ivx
BAB I PENDAHULUAN ... 1
I.1. Latar Belakang Masalah ... 1
I.2. Identifikasi Masalah ... 2
I.3. Maksud dan Tujuan ... 3
I.4. Batasan Masalah ... 3
I.5. Metodologi Penelitian ... 4
I.6. Metode Pengumpulan Data ... 4
I.7. Metode Data Mining ... 4
I.8. Sistematika Penulisan ... 6
vi
II.1.3 VISI dan MISI Perusahaan ... 11
II.1.4 Struktur Organisasis Perusahaan ... 13
II.2 Landasan Teori ... 13
II.2.1 Data Mining ... 13
II.2.2 Clustering ... 17
II.2.3 Text Clustering ... 18
II.2.4 Hierarchical clustering... 20
II.2.5 K-Means Clustering... 21
II.2.6 Outlier analysis ... 22
II.2.6.1 Metode clustering based ... 23
II.2.6.2 Analisis cluster ... 24
II.2.7 UML ... 27
II.2.8 Java ... 34
BAB III ANALISIS DAN PERANCANGAN ... 37
III.1 Analisis Sistem ... 37
III.1.4.1 Analisis preprocessing ... 39
III.1.4.2 Pembobotan TF-IDF ... 49
III.1.4.3 Analisis Clustering ... 69
III.1.4.4 Analisis Outlier ... 103
III.1.5 Analisis Kebutuhan Non-Fungsional ... 105
III.1.5.1 Analisis Kebutuhan Perangkat Keras ... 105
III.1.5.2 Analisis Kebutuhan Perangkat Lunak ... 105
III.1.5.3 Analisis Kebutuhan Pengguna ... 107
III.1.6 Analisis Kebutuhan Fungsional ... 107
III.1.6.1 Use Case Diagram ... 108
III.1.6.2 Scenario Use Case ... 109
III.1.6.3 Activity Diagram ... 112
III.1.6.4 Sequence Diagram ... 117
III.2 Perancangan Sistem ... 120
III.2.1 Perancangan Struktur Menu ... 121
viii
IV.1.2 Perangkat Lunak ... 128
IV.2 Implementasi ... 128
IV.2.1 Implementasi GUI ... 128
IV.2.2 Implementasi Modul Program ... 129
IV.2.3 Implementasi Main Frame ... 130
IV.2.4 Implementasi Kelas Transformasi ... 130
IV.1.2.5 Implementasi Kelas Clustering ... 130
IV.3 Pengujian ... 131
IV.3.1 Fungsionalitas Transformasi ... 131
IV.3.2 Fungsionalitas Clustering... 133
IV.3.3 Fungsionalitas Analisis Outlier ... 136
IV.3.4 Evaluasi Pengujian ... 137
BAB V KESIMPULAN DAN SARAN ... 139
V.1 Kesimpulan ... 139
V.2 Saran ... 139
DAFTAR PUSTAKA
[1.] Ian Sommerville, Software Engineering, Eight Edition ed : Addison Wesley, 2007.
[2.] Pavel Berkhin dari accrue software, inc: “Survey of Clustering Data Mining Techniques”. Pavel Berkhin, Accrue Software, 1045 Forest Knoll Dr., San Jose, CA, 95129.
[3.] Chang Chia-Hui and Zhi-Kai Ding (2005). Data & Knowledge Engineering: Categorical Data Visualization and Clustering Using subjective Factors, vol 53, 243-262. Elsevier: www.elsevier.com/locate/datak [30 September 2004].
[4.] Han, J., Kamber, M., Data Mining Concept and Technique, 2nd Ed, Elsevier, 2006.
[5.] Michael, B., “Automatic Discovery of Similar Words,” Survey of Text Mining: Clustering, Classification and Retrieval, LLC, pp. 24-43, 2004.
[6.] Manning, Christopher D., Prabhakar Raghavan, Hinrich Schutze, 2009, An Introduction to Information Retrieval, Cambridge: Cambridge University
Presss.
[7.] Srivastava, Ashok., Mehran Sahami, 2009, Text Mining Classification,
Clustering, and
Applications, USA : Taylor and Francis Group, LLC.
[8.] Wu, Junjie, 2012, Advanced in K-means Clustering, London : Springer
[10.] putubuku, “Recall & Precision,” Ilmu Perpustakaan & Informasi – diskusi dan ulasan ringkas, 27-Mar-2008. [Online]. Available: http://iperpin.wordpress.com/2008/03/27/recall-precision/. [Accessed: 10-Agustus-2015].
[11.] “Precision and recall,” Wikipedia – The Free Encyclopedia. [Online]. Available: http://en.wikipedia.org/wiki/Precision_and_recall. [Accessed: 10-Agustus-2015].
[12.] J.Kowalski, G. (2000). Information Storage and Retrieval Systems: Theory and
Implementation. United States of America
BAB I PENDAHULUAN
I.1 Latar Belakang Masalah
Lembaga Ilmu Pengetahuan Indonesia(LIPI) merupakan salah satu lembaga yang bergerak dalam pengembangan ilmu pengetahuan. Pusat Penelitian Informatika merupakan salah satu lembaga yang berada dibawah koordinasi Lembaga Ilmu Pengetahuan Indonesia(LIPI). Pusat penelitian ini bertujuan untuk
penggunaan teknologi dalam pengumpulan, pengolahan, penyimpanan dan penyebarluasan data atau informasi kepada masyarakat dengan cepat, tepat waktu dan akurat. Sehingga akan terjadi percepatan peningkatan kemampuan masyarakat dalam pembangunan yang berkelanjutan.
Berdasarkan hasil wawancara dengan pihak Pusat Penelitian Informatika – LIPI. Menyadari semakin pesatnya perkembangan teknologi media penyimpanan digital telah mendorong terjadinya ledakan jumlah dokumen elektronik yang tersimpan dalam repository di lembaga tersebut. Berbagai artikel ilmiah dari berbagai peneliti dan kalangan masyarakat telah tersedia dalam versi digital. Namun, fenomena ini tidak disertai dengan pertumbuhan jumlah informasi atau pengetahuan yang dapat disarikan dari dokumen-dokumen elektronik tersebut, karena sistem yang berjalan sekarang ini hanya sebatas penyimpanan digital dan semua dokumen artikel ilmiah digabung dalam satu kelompok. Hal ini menjadi penghambat dalam mengakses informasi, mengkaji artikel ilmiah, memetakan, memonitoring, mengarahkan dan mengevaluasi informasi yang terkandung dalam tumpukan dokumen artikel ilmiah tersebut. Maka dari hambatan tersebut, pihak Pusat Penelitian Informatika – LIPI berencana untuk mengelompokkan dokumen menurut karakteristik yang dimiliki setiap artikel ilmiah supaya lebih cepat, tepat
waktu dan akurat dalam mendapatkan informasi atau pengetahuan.
Data mining merupakan metode untuk mencari informasi baru yang berguna
akhir ini akan diterapkan metode clustering dengan penggabungan algoritma hierarchical-clustering dan algoritma k-means. Clustering merupakan teknik
mengelompokan data dengan melakukan pemisahan data ke dalam sejumlah kelompok menurut karakteristik tertentu, dimana label dari setiap data belum diketahui dan dengan pengelompokan tersebut diharapkan dapat mengetahui kelompok data untuk kemudian diberi label sesuai permasalahan yang dihadapi. Pada dataset yang memiliki banyak obyek dimungkinkan adanya beberapa obyek yang memiliki perbedaan karakteristik dengan yang lainnya, obyek ini disebut outlier. Jumlah outlier yang sedikit dari banyaknya objek menyebabkan outlier
sulit untuk terdeteksi. Sedangkan tidak jarang ada informasi penting yang dapat digunakan dari keanomalian tersebut. Clustering dapat digunakan untuk menganalisa keberadaa outlier.
Oleh sebab itu, Pusat Penelitian Informatika – LIPI memerlukan metode clustering untuk dapat menggunakan tumpukan artikel ilmiah tersebut, untuk mendapatkan suatu informasi yang digunakan sebagai acuan dalam mengakses informasi, mengkaji artikel ilmiah, memetakan, memonitoring, mengarahkan dan mengevaluasi informasi.
Dari permasalahan yang ada dan penjelasan yang telah dipaparkan diatas, maka dibutuhkan suatu aplikasi “Penerapan Analisis outlier untuk pengelompokkan artikel ilmiah menggunakan metode clustering”.
I.2 Rumusan Masalah
Berdasarkan latar belakang masalah maka diidentifikasi sebuah masalah yaitu bagaimana cara membangun sebuah sistem menggunakan data mining untuk membagi kelompok artikel ilmiah berdasarkan karakteristik yang dimiliki setiap artikel ilmiah untuk pemetaan, monitoring, arahan artikel ilmiah, evaluasi dan
I.3 Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dari penelitian ini adalah Membangun aplikasi data mining yang dapat mengelompokan artikel ilmiah dengan mengimplementasikan metode clustering.
Sedangkan tujuan yang akan dicapai dalam penelitian adalah :
1) Memudahkan Pusat Penelitian Informatika – LIPI dalam mengelompokkan artikel ilmiah yang memiliki kesamaan karakteristik khusus oleh setiap artikel ilmiah.
2) Membantu pihak Pusat Penelitian Informatika – LIPI dalam memetakan, monitoring, mengarahkan dan evaluasi.
I.4 Batasan Masalah
Berdasarkan latar belakang masalah yang telah diuraikan sebelumnya, maka dibuat batasan masalah agar penyajian lebih terarah dan mencapai sasaran yang ditentukan.
Adapun batasan masalah yang dibuat adalah sebagai berikut:
1) Data yang akan di analisis adalah artikel ilmiah yang ada di Pusat Penelitian Informatika – LIPI yang akan di transformasi dari *.PDF ke *.TXT.
2) Text/Data yang akan di cluster dari artikel ilmiah adalah bagaian abstrak. 3) Metode yang digunakan adalah waterfall model.
4) Sistem yang akan dibangun merupakan aplikasi yang berbasis desktop. 5) Bahasa pemrograman yang akan digunakan adalah Java.
I.5 Metodologi Penelitian
Perancangan dan pembangunan sistem ekstraksi data ke dalam bentuk terstruktur ini menggunakan teknik pengumpulan data sebagai berikut :
I.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan adalah sebagai berikut : 1. Studi Lapangan
Studi lapangan merupakan teknik pengumpulan data yang dilakukan dengan cara melakukan penelitian ke instansi yang terkait. Studi lapangan ini
dilakukan dengan menggunakan 2 cara, yaitu :
a. Observasi
Observasi merupakan kegiatan pengamatan langsung ditempat penelitian untuk mengumpulkan data yang dibutuhkan.
Pada penelitian ini pengamatan yang dilakukan ke Pusat Penelitian Informatika – LIPI.
b. Wawancara
Wawancara merupakan teknik pengumpulan data dengan mengadakan Tanya jawab secara langsung yang berkaitan dengan topik yang diambil.
Pada penelitian ini untuk mendapatkan data – data yang diolah sebagai bahan untuk tugas akhir mewawancarai pihak Pusat Penelitian Informatika – LIPI bagain editor yang bertanggungjawab dalam mengolah jurnal ilmiah.
2. Studi Literatur
I.5.2 Metode pembangunan perangkat lunak
Dalam pembuatan perangkat lunak ini menggunakan warterfall model sebagai tahapan pengembangan perangkat lunaknya. Berikut adalah tahapan beserta penjelasan dari waterfall model [1] :
1. Requirement Definition
Pada tahapan ini, segala kebutuhan di dalam pembangunan perangkat lunak akan didefinisikan secara lengkap. Kemudian kebutuhan-kebutuhan yang telah terdefinisi tersebut akan dianalisis dan selanjutnya akan
ditentukan kebutuhan-kebutuhan apa saja yang harus dipenuhi oleh perangkat lunak yang akan dibangun. Ini merupakan tahapan penting dan harus dikerjakan secara detail agar dapat menghasilkan design yang lengkap.
2. System and Software Design
Pada tahapan ini, setelah seluruh kebutuhan-kebutuhan di dalam pembangunan perangkat lunak telah terkumpul, kemudian perangkat lunak yang akan dibangun akan di desain terlebih dahulu. Desain perangkat lunak akan dibagi berdasarkan bagian-bagiannya dan aktivitas dari bagian-bagian tersebut yang telah dikumpulkan secara lengkap pada tahapan sebelumnya.
3. Implementation and Unit Testing
Pada tahapan ini, hasil dari desain yang telah dibuat akan diterjemahkan ke dalam kode-kode atau syntax-syntax pemrograman dengan menggunakan bahasa pemrograman yang telah ditentukan terlebih dahulu dan program yang dibangun akan langsung diuji berdasarkan unit-unitnya atau bagian-bagiannya, supaya tiap-tiap unit atau bagian pada perangkat lunak yang dibangun sesuai dengan tujuan yang ingin dicapai. 4. Integration and System Testing
dibuat akan diuji agar dapat berjalan sesuai dengan hasil analisis yang telah dilakukan sebelumnya.
5. Operation and Maintenance
Pada tahapan ini, perangkat lunak atau sistem yang telah dibuat akan dilakukan pemeliharaan program, seperti : penyesuaian atau perubahan sistem. Hal ini dilakukan supaya sistem yang telah dibangun dapat beradaptasi dengan situasi yang ada dan juga supaya program atau sistem yang telah dibangun tetap terjaga dari segi fungsionalitasnya. Dari
berbagai tahapan-tahapan tersebut, untuk lebih jelasnya bisa dilihat pada Gambar I.1.
I.6 Sistematika Penulisan
Sistematika penulisan disusun untuk memberikan gambaran secara umum mengenai permasalahan dan pemecahannya. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB 1 PENDAHULIAN
Bab ini membahas mengenai latar belakang masalah, identifikasi masalah, maksud dan tujuan, batasan masalah, metode penelitian, pengumpulan data dan metode data mining yang digunakan sebagai acuan dalam tahapan
penelitian yang akan dilakukan, serta sistematika penulisan untuk menjelaskan pokok – pokok pembahasannya.
BAB 2 LANDASAN TEORI
Pada bab ini akan menjelaskan mengenai objek dari penelitain, dan teori – teori pendukung yang berhubungan dengan pembangunan sistem.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Bab ini menganalisis masalah dari data hasil penelitian, kemudian dilakukan proses perancangan sistem yang akan dibangun sesuai dengan analisis yang telah dilakukan.
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi mengenai implementasi dan analisis dari perancangan sistem yang dilakukan, serta melakukan ujicoba terhadap sistem yang telah dibangun, dan hasil dari uji coba terhadap sistem tersebut.
BAB 5 KESIMPULAN DAN SARAN
II.1 Tinjauan Tempat Penelitian
Pada sub bab ini menjelaskan bahwa tempat penelitian yang telah dilakukan peninjauan adalah Pusat Penelitian Informatika – LIPI.
II.1.1 Sejarah Perusahaan
Pusat Penelitian Informatika didirikan dengan surat Keputusan Kepala LIPI No 1151/M/2001 tanggal 5 Juni 2001. Semula bernama Pusat Penelitian dan
Pengembangan Informatika dan Ilmu Pengetahuan Komputer didirikan pada tanggal 13 Januari 1986.
Berdirinya Pusat Penelitian Informatika tidak dapat dipisahkan dengan sejarah terbentuknya Lembaga Elektroteknika Nasional ( LEN ). Lembaga Elektroteknika Nasional sebagai lembaga penelitian dalam bidang elektronika diresmikan pada tanggal 10 Juni 1965. Bermula di kampus ITB dengan ruang seluas 30 meter persegi yang merupakan pinjaman dari ITB. Pada tahun 1967, berdasarkan Keputusan Presiden nomor 128 tahun 1967, Lembaga Elektroteknika Nasional (LEN) bernaung dibawah koordinasi Lembaga Ilmu Pengetahuan Indonesia. Pada tahun 1969, Prusahaan Negara Pertambangan Minyak dan Gas Bumi Nasional ( Pertamina ), memberikan pinjaman gedung seluas 1000 meter persegi di Jl. Sawunggaling No. 14 Bandung, sehingga ruangan dikomplek ITB ditinggalkan. Pada awal tahun 1978, komplek gedung perkantoran dan laboratorium LEN-LIPI sudah tersebar di 9 lokasi di kota Bandung, dengan luas lantai sekitar 2500 meter persegi.
Lembaga Ilmu Pengetahuan Indonesia (LIPI) berdasarkan Keppres No. l tahun 1986 tanggal 13 Januari 1986, Lembaga Elektroteknika Nasional berkembang menjadi tiga Puslitbang dan satu Unit Pelaksana Teknis, yaitu:
a. Pusat Penelitian dan Pengembangan Telekomunikasi, Elektronika Strategis, Komponen dan Material (Puslitbang Telkoma-LIPI).
b. Pusat Penelitian dan Pengembangan Informatika dan Ilmu Pengetahuan Komputer (Puslitbang Inkom LIPI).
c. Pusat Penelitian dan Pengembangan Tenaga Listrik dan Mekatronika (Puslitbang
Telimek-LIPI)
d. UPT Pusat Laboratorium Enjiniring Nasional ( UPT Pusat LEN LIPI).
Dalam struktur organisasi LIPI, keempat Puslibang tersebut diatas berada dibawah koordinasi Deputi Bidang Ilmu Pengetahuan Teknik -LIPI.
Pada tanggal 8 Maret 1990 seluruh fasilitas UPT LEN-LIPI diserahkan ke BPIS. Kantor Puslitbang Inkom LIPI pindah ke Jl. Ranggamalela No.11 Bandung, sedangkan laboratoriumnya menempati salah satu bagian gedung di kompleks LIPI Jl. Cisitu 21/154D Bandung. Pada tahun 2001 dalam Reorganisasi baru Lembaga Ilmu Pengetahuan Indonesia, Pusat Penelitian dan Pengembangan Informatika dan Ilmu Pengetahuan Komputer berubah nama dan struktur organisasinya menjadi Pusat Penelitian Informatika LIPI.
II.1.2 Logo Perusahaan Makna Logo:
1. Bentuk bulatan merepresentasikan keselarasan dan melambangkan keutuhan. 2. Bentuk menyerupai huruf Q, direpresentasikan dengan lingkaran bergaris-garis
dan ada tonjolan di sebelah kanan bawah, melambangkan "Quality" (Mutu), sebagai salah satu dari bagian dari AMTeQ.
3. Bentuk menyerupai huruf T, direpresentasikan dengan satu batang berwarna putih mendatar dan batang putih miring atas ke bawah, melambangkan "Testing"
4. Garis-garis mendatar berselang-seling warna biru dan putih menunjukkan bahwa walaupun AMTeQ adalah bulat selaras dan utuh, tetapi terdapat spesialisasi/segmentasi dalam bidang mutu dan pengujian; garis-gari mendatar berselang-seling dari bawah ke atas juga melambangkan penjenjangan bahwa proses perbaikan berkelanjutan harus terus meningkat ke arah yang lebih baik
Gambar.II.1 Logo Perusahaan II.1.3 Visi dan Misi Perusahaan
Adapun visi dan misi dari Pusat Penelitian(PUSLIT) Informatika-LIPI adalah:
Visi :
pengolahan, penyimpanan dan penyebarluasan data atau informasi kepada masyarakat dengan cepat, tepat waktu dan akurat. Sehingga akan terjadi percepatan peningkatan kemampuan masyarakat dalam pembangunan yang berkelanjutan.
Misi :
Pusat Penelitian Informatika melaksanakan kegiatan penelitian, pengembangan, pelayanan jasa dan saran kebijaksanaan di bidang Informatika dan Ilmu Pengetahuan
Komputer. Informatika adalah suatu ilmu yang sifatnya problem solving, artinya, digunakan untuk menyelesaikan suatu masalah tertentu yang berhubungan dengan
II.1.4 Struktur Organisasi Perusahaan
Struktur organisasi dalam suatu institusi merupakan hal yang sangat penting, dengan adanya struktur organisasi ini memberikan pembagian tugas sesuai dengan bidangnya masing-masing.
Adapun struktur organisasi di Pusat Penelitian Informatika – LIPI adalah sebagai berikut :
Gambar.II.2 Struktur Organisasi Pusat Penelitian Informatika – LIPI II.2 Landasan Teori
Landasan teori ini akan menjelaskan teori – teori yang digunakan dalam pembangunan sistem ini.
II.2.1. Data Mining
Data mining diartikan sebagai suatu proses ekstraksi informasi berguna dan
potensial dari sekumpulan data yang terdapat secara implisit dalam suatu basis data. Banyak istilah lain dari data mining yang dikenal luas seperti knowledge mining from databases, knowledge extraction, data archeology, data dredging, data analysis dan lain sebagainya [2].
Data mining adalah proses yang menggunakan teknik statistic, perhitungan,
kecerdasan buatan dan machine learning untuk mengekstraksi dan mengidentifikasi
informasi yang bermanfaat dan pengetahuan terkait dari berbagai basis data besar [1].
Dari pengertian mengenai data mining di atas maka dapat disimpulkan bahwa data mining adalah salah satu ilmu yang digunakan untuk ekstraksi datasuatu pengetahuan dari tumupkan data tersebut dengan menggunakan sebuah metode yang berlaku pada data mining. Dengan konsep data mining dapat membantu dalam mengambil sebuah keputusan dan kebijakan suatu instansi.
Data mining adalah satu ilmu di bidang komputer yang cukup banyak
penerapanya, ditunjang kekayaan dan keanekaragaman berbagai bidang ilmu lainya seperti artificial intelligence, database, statistik, pemodelan matematika pengolahan citra, dan sebagainya, sehingga penerapan data mining menjadi kasus semakin luas.
statistik
Pada umumnya sistem data mining terdiri dari komponen – komponen berikut [4]:
a. Database, data warehouse
Media dalam ha ini bisa jadi berupa database, data warehouse, spreadsheet, atau jenis – jenis penampungan informasi lainnya. Data cleaning dan data integration dapat dilakukan pada data tersebut.
b. Database, atau data warehouse server
Database atau data warehouse server bertanggungjawab untuk menyediakan
data yang relevan berdasarkan permintaan dari user pengguna data mining.
c. Basis pengalaman (knowladge base)
Merupakan basis pengetahuan yang digunakan sebagai panduan dalam pencarian pola.
d. Data mining engine
Bagian dari software yang menjalankan program berdasarkan algoritma yang ada.
e. Pattern evaluation module
Bagian dari software yang berfungsi untuk menemukan paterrn atau pola –pola yang yang terdapat di dalam database yang diolah sehingga nantinya proses data mining dapat menentukan konwladge yang sesuai.
f. Graphical user interface
Gambar.II.4 Arsitektur data mining
Pada dasarnya data mining berhubungan dengan analisa data dan penggunaan teknik-teknik perangkat lunak untuk mencari pola dan keteraturan dalam himpunan data yang sifatnya tersembunyi. Data mining diartikan sebagai suatu proses ekstraksi informasi berguna dan potensial dari sekumpulan data yang terdapat secara implisit dalam suatu basis data. Tantangan-tantangan dalam Data Mining meliputi : penanganan berbagai tipe data, efisiensi dari algoritma data mining, kegunaan, kepastian dan keakuratan hasil, ekspresi terhadap berbagai jenis hasil dan data yang diambil dari berbagai sumber yang berbeda. Tahapan dalam Data Mining meliputi : proses seleksi, pembersihan data, tranformasi, implementasi teknik data mining dan
II.2.2. Clustering
Clustering termasuk ke dalam descriptive methods, dan juga termasuk unsupervised learning dimana tidak ada pendefinisian kelas objek sebelumnya. Sehingga clustering dapat digunakan untuk menentukan label kelas bagi data – data yang belum diketahui kelasnya. Konsep dasar dari clustering adalah mengelompokkan sejumlah objek ke dalam cluster dimana cluster yang baik adalah cluster yang memiliki tingkat kesamaan atau similarity yang tinggi antar objek di dalam satu cluster dan tingkat ketidaksamaan atau dissimilarity yang tinggi dengan
objek cluster yang lainnya. Aplikasi clustering bisa dibangun sebagai stand-alone tool atau sebagai preprocessing algoritma lainnya, misalnya untuk algoritma
pendeteksian outlier. Aplikasi clustering bisa dibangun sebagaistand-alone tool atau sebagai preprocessing algoritma lainnya, misalnya untuk algoritma pendeteksian outlier dalam pembahasan tugas akhir ini. Aplikasi clustering juga dapat di implementasikan untuk pattern recognition, spatial data analysis, image processing, klasifikasi dokumen dan market research. Terdapat banyak algoritma clustering yang dalam penggunaannya tergantung pada tipe data yang akan dikelompokkan dan apa tujuan dari pembuatan aplikasinya. Dalam pembahasan di sini, algoritma clustering digunakan untuk mengelompokkan objek ke dalam cluster – cluster, kemudian dari hasil clustering akan dideteksi keberadaan outlier dalam data tersebut.
Algoritma clustering diklasifikasikan ke dalam 5 kategori, yaitu : 1. Partitioning methods
Pengelompokkan objek dimana tiap objek terpartisi dengan tepat, yang berarti 1 objek dimiliki oleh 1 klaster. Yang termasuk ke dalam metode ini adalah algoritma k-means, k-medoid atau PAM, CLARA, dan CLARANS.
2. Hierarchical methods
Pengelompokan objek dapat dilakukan dengan 2 cara, agglomerative yang
yang lebih kecil. Yang termasuk ke dalam metode ini adalah algoritma CURE, BIRCH, dan Chameleon.
3. Density-based methods
Pengelompokkan objek berdasarkan tingkat kerapatan objek atau densitas.Yang termasuk ke dalam metode ini adalah algoritma DBSCAN, DENCLUE, dan OPTICS. 4. Grid-based methods
Pengelompokan objek dengan menggunakan struktur data grid multi resolusi. Mampu untuk menangani data berdimensi tinggi. Yang termasuk ke dalam metode ini adalah algoritma CLIQUE, Wave Cluster, dan STING.
5. Model-based methods.
Pengelompokan objek dengan memodelkan tiap cluster, dan mencoba mengoptimasikan kesesuaian data dengan model matematika. Yang termasuk ke dalam metode ini adalah algoritma COBWEB.
II.2.3. Text Mining
Text Clustering adalah proses unsupervised learning (proses pembelajaran sendiri) yang pengelompokkan kumpulan dokumen berdasarkan hubungan kemiripannya dan memisahkannya ke dalam beberapa kelompok. [5]
II.2.6.1. Preprocessing
Preprocessing merupakan pemrosesan awal dokumen agar diperoleh suatu nilai yang dapat dipelajari oleh sistem clustering.
II.2.6.2. Case Folding
II.2.6.3. Tokenization
Tokenization adalah proses pemotongan seluruh urutan karakter menjadi satu potongan kata[5].
II.2.6.4. Stopword Removal
Stopword removal merupakan proses penghapusan semua kata yang tidak memiliki makna[5].
II.2.6.5. Stemming
Stemming adalah proses membentuk suatu kata menjadi kata dasarnya. Algoritma
stemming yang digunakan dalam sistem pengelompokkan ini adalah algoritma Nazief – Adriani[4].
II.2.6.6. Term Weighting
Term weighting merupakan proses pemberian bobot suatu token dalam suatu term.
II.2.6.7. Term Frequency
Term Frequency (TF) adalah pembobotan yang menghitung frekuensi kemunculan sebuah token pada suatu dokumen
TF (t k , d j ) = f (t k , d j ) [1]………(5)
II.2.6.8. Document Frequency
Document Frequency (DF) adalah pembobotan yang menghitung frekuensi kemunculan sebuah token pada kumpulan dokumen
II.2.6.9. Pembobotan TF.IDF
TF • IDF (t k , d j ) = TF (t k , d j ) • IDF (t k ) [1]………..(5)
II.2.4. Hierarchical clustering
Pada algoritma clustering, data akan dikelompokkan menjadi cluster-cluster berdasarkan kemiripan satu data dengan yang lain. Prinsip dari clustering adalah memaksimalkan kesamaan antar anggota satu cluster dan meminimumkan kesamaan antar anggota cluster yang berbeda [4].
Kategori algoritma clustering yang banyak dikenal adalah Hierarchical Clustering. Hierarchical Clustering adalah salah satu algoritma clustering yang dapat
digunakan untuk meng-cluster dokumen (document clustering). Dari teknik
hierarchical clustering, dapat dihasilkan suatu kumpulan partisi yang berurutan,
dimana dalam kumpulan tersebut terdapat:
a. Cluster – cluster yang mempunyai poin – poin individu. Cluster – cluster ini berada di level yang paling bawah.
b. Sebuah cluster yang didalamnya terdapat poin – poin yang dipunyai semua cluster didalamnya. Single cluster ini berada di level yang paling atas.
Gambar.II.5 Dendogram
Metode ini menggunakan strategi disain Bottom-Up yang dimulai dengan meletakkan setiap obyek sebagai sebuah cluster tersendiri (atomic cluster) dan selanjutnya menggabungkan atomic cluster – atomic cluster tersebut menjadi cluster yang lebih besar dan lebih besar lagi sampai akhirnya semua obyek menyatu dalam sebuah cluster atau proses dapat pula berhenti jika telah mencapai batasan kondisi tertentu [6]. Metode Agglomerative Hierarchical Clustering yang digunakan pada penelitian ini adalah metode AGglomerative NESting (AGNES). Cara kerja AGNES dapat dilihat pada gambar 1.
Adapun ukuran jarak yang digunakan untuk menggabungkan dua buah obyek cluster adalah Minimum Distance [6], yang dapat dilihat pada persamaan 2.6.
min
( ,
i j)
min
p C p Ci, ' j- '
d
C C
p
p
...(1)Dimana |p –p’| jarak dua buah obyek p dan p’.
II.2.5. K-means Clustering
K-Means Clustering merupakan metode yang termasuk ke dalam golongan algoritma Partitioning Clustering.
Langkah-langkah dari metode K-Means adalah sebagi berikut : [4]
3. Hitung jarak setiap data ke masing-masing centroid menggunakan rumus korelasi antar dua objek ( Euclidean Distance ).
4. Kelompokkan setiap data berdasarkan jarak terdekat antara data dengan centroidnya.
5. Tentukan posisi centroid baru ( k C ) dengan cara menghitung nilai rata-rata dari data yang ada pada centroid yang sama.
∑ ………(4)
Dimana n k adalah jumlah dokumen dalam cluster k dan d i adalah dokumen dalam cluster k.
6. Kembali ke langkah 3 jika posisi centroid baru dengan centroid lama, tidak sama.
Gambar.II.6 langkah – langkah metode K-Means[4] II.2.6. Outliers Analysis
Sebuah sumber data atau dataset pada umumnya mempunyai nilai-nilai pada setiap obyek yang tidak terlalu berbeda jauh dengan obyek lain. Akan tetapi terkadang pada data tersebut juga ditemukan obyek - obyek yang mempunyai nilai
atau sifat atau karakteristik yang berbeda dibandingkan dengan obyek pada umumnya.
Teknik data mining dapat digunakan untuk mendeteksi adanya suatu outlier pada sebuah dataset. Teknik data mining yang diganakan adalah Clustering-based, Distance-based dan Density-based.
II.2.6.1. Metode Clustering-based
Clustering merupakan salah satu teknik analisis dalam Data Mining dimana clustering melakukan pengelompokan data berdasarkan kesamaan karakteristik data. Dengan kesamaan karakteristik pada sebuah kelompok ini dapat diambil suatu
informasi yang mempunyai arti dan berguna. 1. Algoritma CLAD
Pada CLAD terdapat dua fase utama yaitu pembuatan cluster dan meng-assign obyek – obyek data pada data set. Secara sederhana dapat dideskripsikan sebagai berikut:
1) inisialisasi cluster_outier = 0 2) fase_1
3) untuk setiap cluster_outlier hitung jarak centroid cluster dengan setiap obyek data 4) jika jarak obyek data dengan centroid cluster kurang dari lebar_cluster masukkan
obyek ke dalam cluster
5) jika jarak obyek data lebih dengan centroid lebih dari lebar_cluster dan obyek data belum menjadi anggota cluster_outlier lain maka buat cluster_outlier baru dengan obyek data sebagai centroid
6) fase_2
7) untuk setiap cluster_outlier hitung jarak centroid cluster dengan setiap obyek data 8) jika jarak centroid cluster_outlier dengan obyek data kurang dari lebar cluster dan
2. Lebar Cluster
Lebar cluster dideskripsikan sebagai jangkauan antara centroid cluster_outlier dengan obyek data. Perhitungan parameter lebar cluster_dilakukan dengan mengambil sampel data dari data set kemudian dihitung jarak rata-rata.
3. Fungsi Jarak
Perhitungan jarak antara dua obyek data dilakukan dengan menggunakan fungsi
Euclidan dimana fungsi ini dapat digunakan pada dimensi yang tinggi.
√ ∑
4. Analisis Cluster
Penentuan bahwa suatu cluster merupakan cluster outlier, CLAD menggunakan 2 attribut pada cluster yang telah terbentuk yaitu distance dan density dari cluster lain. Dikarenakan setiap cluster memiliki lebar cluster yang tetap maka kepadatan (density) dari setiap cluster dihitung berdasarkan jumlah obyek yang termasuk dalam cluster tersebut. Jarak (distance) antar cluster dihitung dengan menggunakan average intercluster distance (ICD)
∑
Standar deviasi yang digunakan adalah median absolute deviation (MAD) dikarenakan persebaran jumlah anggota cluster yang tidak merata.
Dengan menggunakan fungsi ICD dan MAD dapat diketahui apakah suatu
cluster dikatakan sebagai cluster outlier. Cluster dengan label sparse dikatakan sebagai local outlier, sedangkan cluster dengan label distant dikatakan sebagai global
Sebuah cluster diakatakan sebagai cluster_outlier jika memiliki status distant dan sparse.
II.2.6.2. Metode Distance-based
Sebuah metode pencarian outlier yang popular dengan menghitung jarak pada obyek tetangga terdekat (nearest neighbor). Dalam pendekatan ini, satu obyek melihat obyek-obyek local neighborhood yang dedefinisikan dengan k-nearest neighbor. Jika ketertetanggaan antar obyek relatif dekat maka dikatakan obyek
tersebut normal, akan tetapi jika ketertetanggaan antar obyek relatif sangat jauh maka dikatakan obyek tersebut tidak normal.
1. Algoritma Bay’s
Algoritma Bay’s mencari outlier dengan menghitung jarak antar obyek data pada dataset. Pencarian ini dilakukan dengan membandingkan jarak yang telah dihitung dengan jarak pada k tetangga terdekat (k-nearest neighbor), kemudian dipilih untuk menjadi tetangga terdekat menggantikan tetangga terdekat yang terjauh.
2. Analisis Obyek Data
Obyek data dikatakan sebagai outlier apabila obyek tersebut memiliki obyek tetangga yang sangat sedikit pada jarak tertentu dan memiliki jarak yang jauh dibandingkan dengan jarak rata-rata obyek-obyek data tetangga terdekat
II.2.6.3. Metode density-based
jumlah tetangga terdekat yang digunakan untuk mendefinisikan local neighborhood suatu obyek. MinPts diasumsikan sebagai jangkauan dari nilai MinPtsLB dan MinPtsUB Nilai MinPtsLB dan MinPtsUB disarankan bernilai 10 dan 20. Akhirnya semua obyek dalam dataset dihitung nilai LOFnya.
1. Algoritma LOF (Local Outlier Factor)
Secara sederhana algoritma LOF dapat dideskripsikan sebagai berikut: 1. menghitung jumlah tetangga terdekat
2. menghitung kepadatan lokal dari setiap obyek 3. menghitung LOF untuk setiap obyek data
4. me-maintain obyek-obyek data dengan nilai LOF yang tinggi 2. Analisis Obyek Data
Obyek data akan dianggap memiliki nilai outlier yang tinggi jika pada jarak k tetangga terdekat memiliki kepadatan yang sangat kecil. Semakin banyak obyek – obyek tetangga dalam jarak k-tetangga terdekat obyek ini memiliki nilai LOF mendekati 1 dan tidak seharusnya diberi label sebagai outlier.
3. Pengaruh Nilai Parameter Minpts
II.2.7. Precission, Recall dan Accuracy
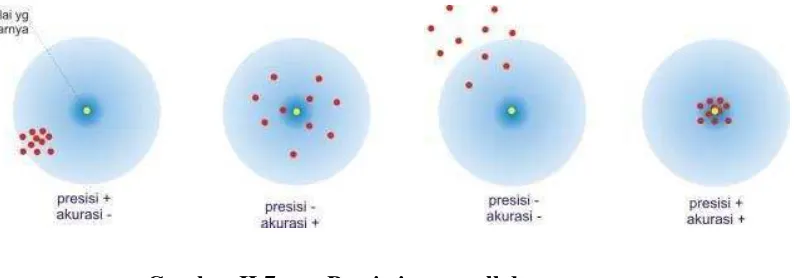
Dalam pengenalan pola (pattern recognition) dan temu kembali informasi (information retrieval), precision dan recall adalah dua perhitungan yang banyak digunakan untuk mengukur kinerja dari system yang digunakan. Precision adalah tingkat ketepatan antara informasi yang diminta oleh pengguna dengan jawaban yang diberikan oleh sistem. Sedangkan recall adalah tingkat keberhasilan sistem dalam
menemukan kembali sebuah informasi. Sedangkan di dalam statistika dikenal juga istilah accuray. Accuracy didefinisikan sebagai tingkat kedekatan antara nilai
prediksi dengan nilai aktual. Ilustrasi berikut ini memberikan gambaran perbedaan antara accuracy dan precision.
Gambar.II.7 Precission, recall dan accuracy
Salah satu penerapan prinsip relevansi yang sejak dahulu digunakan dalam pengembangan sistem IR adalah penggunaan ukuran recall and precision. Sejak teori tentang IR berkembang di tahun 1940an, para ilmuan selalu memeras otak, bagaimana caranya membuat sistem IR yang benar-benar handal. Bagaimana mengukur keefektifan sebuah sistem IR dalam memenuhi permintaan informasi? Bagaimana mengukur kemampuan sistem dalam menyediakan dokumen yang relevan dengan kebutuhan pemakai? Nah, recall and precision adalah upaya untuk menjawab persoalan itu.
Precision dapat diartikan sebagai kepersisan atau kecocokan (antara permintaan
informasi dengan jawaban terhadap permintaan itu). Jika seseorang mencari informasi di sebuah sistem, dan sistem menawarkan beberapa dokumen, maka kepersisan ini sebenarnya juga adalah relevansi. Artinya, seberapa persis atau cocok dokumen tersebut untuk keperluan pencari informasi, bergantung pada seberapa
Precision adalah rasio jumlah dokumen relevan yang ditemukan dengan total jumlah dokumen yang ditemukan oleh sistem, dengan rumus precision adalah sebagai berikut Error! Reference source not found.:
Precision =
Diketahui :
: jumlah dokumen relevan
b : jumlah dokumen yang diuji
Precision mengindikasikan kualitas himpunan jawaban, tetapi tidak memandang total jumlah dokumen yang relevan dalam kumpulan dokumen. Sedangkan
Recall adalah proporsi jumlah dokumen yang dapat ditemukan-kembali oleh sebuah proses pencarian di sistem IR. Rumusnya: Jumlah dokumen relevan yang ditemukan / Jumlah semua dokumen relevan di dalam koleksi. Lalu, precision adalah proporsi jumlah dokumen yang ditemukan dan dianggap relevan untuk kebutuhan si pencari informasi. Rumusnya: Jumlah dokumen relevan yang ditemukan / Jumlah semua dokumen yang ditemukan.[6]
Recall adalah rasio jumlah dokumen relevan yang ditemukan kembali dengan total jumlah dokumen dalam kumpulan dokumen yang dianggap relevan, dengan rumus recall adalah sebagai berikut :
Recall =
Diketahui :
: jumlah dokumen relevan b : jumlah dokumen yang diuji
(7)
Kedua ukuran di atas biasanya diberi nilai dalam bentuk persentase, 1 sampai 100%. Sebuah sistem informasi akan dianggap baik jika tingkat recall maupun precision-nya tinggi. Jika ada seseorang mencari dokumen tentang “Pangeran Diponegoro” pada sebuah sistem, dan jika sistem tersebut memiliki 100 buku tentang Pangeran Diponegoro, maka kinerja terbaik adalah jika sistem tersebut berhasil menemukan 100 dokumen tentang Pangeran Diponegoro.
Kalau sistem tersebut memberikan 100 temuan, dan di temuan tersebut ada 50 dokumen tentang “Pangeran Diponegoro”, maka nilai recall-nya adalah 0,5 (atau 50%) dan nilai precision-nya juga 0,5. Kalau sistem tersebut memberikan 1 dokumen saja, dan dokumen tersebut adalah tentang “Pangeran Diponegoro”, maka recall-nya bernilai 0,01 dan precision-nya bernilai 1. Perhatikan bahwa nilai precision yang tinggi ini sebenarnya terjadi karena sistem memberikan hanya 1 jawaban kepada si pencari informasi. Kalau sistem memberikan 100 dokumen, dan hanya 1 yang relevan, maka nilai recall-nya tetap 0,01 dan precision-nya pun ikut merosot ke 0,01.
II.2.8. Alat – Alat Pemodelan Sistem
Pemodelan sistem merupakan hal yang penting bagi kelangsungan sistem itu sendiri. Pemodelan sistem adalah suatu upaya untuk menjaga efektivitas sistem dalam memenuhi kebutuhan pengguna sistem. Pemodelan sistem dapat bererti menyusun sistem yang baru untuk menggantikan sistem yang lama secara keseluruhan atau memperbaiki sistem yang sudah ada [10].
II.2.8.1. UML
bukan hanya sekedar diagram, tetapi juga menceritakan konteksnya. Ketika pelanggan memesan sesuatu dari sistem, bagaimana transaksinya? Bagaimana sistem mengatasi error yang terjadi? Bagaimana keamanan terhadap sistem yang kita buat? Dan sebagainya dapat dijawab dengan UML. UML diaplikasikan untuk maksud tertentu, biasanya antara lain :
a. Merancang perangkat lunak.
b. Sarana komunikasi antara perangkat lunak dengan proses bisnis.
c. Menjabarkan sistem secara rinci untuk analisa dan mencari apa yang diperlukan
sistem.
d. Mendokumentasi sistem yang ada, proses-proses dan organisasinya.
Akan dijelaskan empat diagram yang paling sering digunakan dalam pemodelan UML, yaitu :
1. Use-Case Diagram
Salah satu kontributor terhadap diagram use-case dalam UML adalah Ivar Jacobsen. Use case menggambarkan external view dari sistem yang akan kita buat modelnya. Pooley mengatakan bahwa model use case dapat dijabarkan dalam diagram use case, tetapi yang perlu diingat, diagram tidak identik dengan model karena model lebih luas dari diagram.
Komponen pembentuk diagram use case adalah :
a. Aktor (actor), menggambarkan pihak-pihak yang berperan dalam sistem. b. Use case, aktivitas/sarana yang disiapkan oleh bisnis/sistem.
Gambar.II.8 UML Weekend Crash Course
Ada 6 elemen yang membangun use case diagram : actor, system, use case, association, dependencies, dan generalization.
a. Actor
Sebuah peran yang dimainkan oleh orang, sistem, atau perangkat yang memiliki saham dalam keberhasilan pengoperasian sistem.
b. System
Mengatur batas sistem dalam kaitannya dengan aktor yang menggunakannya (diluar sistem) dan fitur harus memberikan (dalam sistem).
c. Use case
Mengidentifikasi fitur kunci dari sistem. Tanpa fitur ini, sistem tidak akan memenuhi pengguna/aktor persyaratan. Setiap use case mengungkapkan bahwa tujuan sistem harus tercapai.
d. Association
dalam gilirannya memberikan seperangkat skenario yang berfungsi sebagai uji kasus ketika mengevaluasi analisis, desain, dan implementasi use case.
e. Dependencies
Mengindentifikasi hubungan komunikasi antara dua use case.
f. Generalization
Mendefinisikan sebuah hubungan antara dua aktor atau dua use case yang mana salah satu use case mewarisi dan menambah atau menggantikan sifat-sifat yang lain.
a. Class Diagram
Class adalah sebuah spesifikasi yang jika diinstansiasi akan menghasilkan
sebuah objek dan merupakan inti dari pengembangan dan desain berorientasi objek. Class menggambarkan keadaan (atribut/properti) suatu sistem, sekaligus menawarkan layanan untuk memanipulasi keadaan tersebut (metoda/fungsi).
Class diagram menggambarkan struktur dan deskripsi class, package dan
objek beserta hubungan satu sama lain seperti containment, pewarisan, asosiasi, dan lain-lain. Class memiliki tiga area pokok yaitu :
a. Nama (dan stereotype) b. Atribut
c. Metoda
Atribut dan metoda memiliki salah satu dari sifat berikut :
a. Private, tidak dapat dipanggil dari luar class yang bersangkutan.
b. Protected, hanya dapat dipanggil oleh class yang bersangkutan dan anak-anak yang mewarisinya.
Class dapat merupakan implementasi dari sebuah interface, yaitu class abstrak
yang hanya memiliki metoda. Interface tidak dapat langsung diinstansiasikan, tetapi harus diimplementasikan dahulu menjadi sebuah class. Dengan demikian interface mendukung resolusi metoda pada saat run-time. Hubungan antar class
antara lain :
a. Asosiasi, yaitu hubungan statis antar class. Umumnya menggambarkan class yang memiliki atribut berupa class lain, atau class yang harus
mengetahui eksistensi lain. Panah navigability menunjukkan arah query
antar class.
b. Agregasi, yaitu hubungan yang menyatakan bagian (“terdiri atas..”).
c. Pewarisan, yaitu hubungan hierarki antar class. Class dapat diturunkan dari class lain dan mewarisi semua atribut dan metoda class asalnya dan menambahkan fungsionalitas baru, sehingga ia disebut anak dari class yang diwarisinya. Kebalikan dari pewarisan adalah generalisasi.
Berdasarkan gambar 3.3 di atas, maka dapat dijelaskan sebagai berikut:
1. Pelanggan menempatkan pesanan untuk satu atau lebih item tidak peduli apakah mereka telah membeli atau belum.
2. Pelanggan menempatkan pesanan untuk satu atau lebih item. Pelanggan dapat menanyakan tentang status pesanannya dengan menggunakan nomor urut.
3. Pelanggan memesan untuk satu atau lebih item.
4. Setiap item sesuai dengan produk. Produk diidentifikasikan dengan menggunakan nomor seri yang unik.
5. Setiap item yang belum dikirim ditempatkan ada backorder dengan referensi untuk urutan asli.
6. Pelanggan pesanan dikirimkan sebagai produk yang sudah tersedia, sehingga mungkin ada lebih dari satu pengiriman untuk memenuhi pesanan pelanggan tunggal.
7. Pengiriman produk dari vendor yang diterima dan ditempatkan ke saham.
8. Setiap produk ditugaskan untuk lokasi sehingga nanti kita dapat dengan mudah menemukan ketika mengisi perintah. Setiap lokasi memiliki pengenal lokasi yang unik.
9. Produk ini dapat dibeli langsung dari vendor dan dijual kembali.
10.Kita dapat membuat paket produk vendor bersama-sama untuk membuat produk sendiri.
2. Activity Diagram
Activity diagram menggambarkan berbagai alir aktivitas dalam sistem yang
1. Sequence Diagram
Sequence diagram menggambarkan interaksi antar objek di dalam dan di
sekitar sistem (termasuk pengguna, display, dan sebagainya) berupa message yang digambarkan terhadap waktu. Sequence diagram terdiri atas dimensi vertikal (waktu) dan dimensi horizontal (objek-objek yang terkait). Sequence diagram biasa digunakan untuk menggambarkan skenario atau rangkaian langkah-langkah yang dilakukan
II.2.11.1. Java
Java adalah bahasa pemrograman tingkat tinggi yang berorientasi objek dan program java tersusun dari bagian yang disebut kelas. Kelas terdiri atas
metode-metode yang melakukan pekerjaan dan mengembalikan informasi setelah melakukan tugasnya. Para pemrograman Java banyak mengambil keuntungan dari kumpulan kelas di pustaka kelas Java, yang disebut dengan Java Application Programming Interface (API). Kelas-kelas ini diorganisasikan menjadi sekelompok yang disebut
Interpreter merupakan modul utama sistem Java yang digunakan aplikasi Java dan menjalankan program bytecode Java.
Java merupakan bahasa berorientasi objek (OOP) yaitu cara ampuh dalam pengorganisasian dan pengembangan perangkat lunak. Pada OOP, program komputer sebagai kelompok objek yang saling berinteraksi. Deskripsi ringkas OOP adalah mengorganisasikan program sebagai kumpulan komponen, disebut objek. Objek-objek ini ada secara independen, mempunyai aturan-aturan berkomunikasi dengan
objek lain dan untuk memerintahkan objek lain guna meminta informasi tertentu atau meminta objek lain mengerjakan sesuatu. Kelas bertindak sebagai modul sekaligus tipe. Sebagai tipe maka pada saat jalan, program menciptakan objek-objek yang merupakan instan-instan kelas. Kelas dapat mewarisi kelas lain. Java tidak mengijinkan pewarisan jamak namun menyelesaikan kebutuhan pewarisan jamak dengan fasilitas antarmuka yang lebih elegan.
Seluruh objek diprogram harus dideklarasikan lebih dulu sebelum digunakan. Ini merupakan keunggulan Java yaitu Statically Typed. Pemaksaan ini memungkinkan kompilator Java menentukan dan melaporkan terjadinya pertentangan (ketidakkompatibelan) tipe yang merupakan barikade awal untuk mencegah kesalahan yang tidak perlu (seperti mengurangkan variabel bertipe integer dengan variabel bertipe string). Pencegahan sedini mungkin diharapkan menghasilkan program yang bersih. Kebaikan lain fitur ini adalah kode program lebih dapat dioptimasi untuk menghasilkan program berkinerja tinggi.
dengan mengendalikan apakah program berhak mengakses sumber daya seperti sistem file, port jaringan, proses eksternal dan sistem window.
Java termasuk bahasa Multithreading. Thread adalah untuk menyatakan program komputer melakukan lebih dari satu tugas di satu waktu yang sama. Java menyediakan kelas untuk menulis program multithreaded, program mempunyai lebih dari satu thread eksekusi pada saat yang sama sehingga memungkinkan program menangani beberapa tugas secara konkuren.
Program Java melakukan garbage collection yang berarti program tidak perlu
37
BAB III
ANALISIS DAN PERANCANGAN
III.1 Analisis Sistem
Analisis sistem adalah penelitian atas sistem yang telah ada de ngan tujuan untuk perancang system yang baru atau diperbarui. Tahap analisis sistem ini merupakan tahap yang sangat kritis dan sangat penting, karena kesalahan di dalam tahap ini akan menyebabkan juga kesalahan di tahap selanjutnya. Tugas utama analis sistem dalam tahap ini adalah menemukan kelemahan-kelemahan dari sistem yang berjalan
sehingga dapat diusulkan perbaikannya. Dalam membangun perangkat lunak ini dilakukan beberapa tahap analisis yaitu :
1) Analisis Masalah
2) Analisis Sistem yang Sedang Berjalan 3) Analisis Text Mining
4) Analisis Kebutuhan Non-Fungsional 5) Analisis Kebutuhan Fungsional
III.1.1.Analisis Masalah
Analisis masalah merupakan tahapan awal yang dilakukan dalam tahap analisis sistem. Masalah dapat didefinisikan sebagai sesuatu hal yang yang ingin dipecahkan, masalah inilah yang menyebabkan tujuan suatu sistem tidak dapat dicapai. Oleh karena itu perlu didefinisikan terlebih dahulu masalah yang terjadi pada sistem saat ini.
1) Pengelompokan dokumen artikel ilmiah yang dilakukan pihak Pusat Penelitian Informatika – LIPI masih digabung dalam satu kelompok penyimpanan digital. 2) Pihak Pusat Penelitian Informatika – LIPI kesulitan dalam mengakses informasi,
mengkaji artikel ilmiah, memetakan, memonitoring, mengarahkan dan mengevaluasi informasi yang terkandung di dalam tumpukan dokumen artikel ilmiah tersebut disebabkan karena belum adanya sistem untuk memfilter artikel ilmiah berdasarkan karakteristik masing – masing dokumen.
III.1.2.Analisis Sistem yang Sedang Berjalan
Analisis sistem yang sedang berjalan adalah salah satu proses yang ada pada analisis sistem yang bertujuan untuk memberikan gambaran tentang bagaimana cara kerja dari sistem yang berjalan.
Proses pengelompokan yang dilakukan pihak Pusat Penelitian Informatika – LIPI dilihat pada prosedur sebagai berikut:
1. Pusat Penelitian Informatika – LIPI menerima artikel – artikel ilmiah dari kalangan masyarakat dan tim riset yang ada di Pusat Penelitian Informatika – LIPI.
2. Pusat Penelitian Informatika – LIPI mempublikasikan artikel ilmiah melalui versi cetak.
3. Untuk arsip Pusat Penelitian Informatika – LIPI, artikel ilmiah disimpan dalam satu penyimpanan digital dalam format *.Pdf.
4. Artikel ilmiah terbit dua kali dalam setahun yaitu dibulan Mei dan November 5. Artikel ilmiah mengkaji masalah yang berhubungan dengan Informatika, Sistem
III.1.3.Analisis Karakteristik Sumber Data
Analisis karakteristik sumber data merupakan kegiatan yang dilakukan dalam menganalisis seluruh data yang akan digunakan. Dokumen yang akan digunakan sebagai data inputan dalam perangkat lunak pada pengelompokan artikel ilmiah di Pusat Penelitian Informatika – LIPI adalah arsip artikel ilmiah yang berformat *.pdf
Datasets dalam tahapan analisis ini berjumlah lima dokumen berformat *.pdf sebagai contoh perhitungan yang diambil dari jurnal ilmiah di Pusat Penelitian
Informatika – LIPI. Dokumen artikel ilmiah yang berformat *.pdf akan ditransformasikan kedalam format *.txt dan selanjutnya subjudul abstrak yang ada di setiap dokumen artikel ilmiah berformat *.txt akan di ekstrak untuk memudahkan dalam tahapan selanjutnya. Mengingat bahwa abstrak adalah rangkuman yang terkandung disetiap artikel ilmiah tersebut.
Tahapan dalam pengambilan abstrak pada artikel ilmiah adalah sebagai berikut:
1. Dokumen dalam format *.Pdf ditransformasikan ke format *.Txt.
2. Dalam format *.Pdf, artikel ilmiah mempunyai bagian judul artikel ilmiah dan beberapa subjudul seperti abstrak.
3. Pada format *.Txt bagian subjudul abstrak artikel ilmiah akan diekstrak.
4. Semua kata yang ada pada isi subjudul abstrak akan di ekstrak sampai ketemu subjudul baru yaitu Kata Kunci.
III.1.4.Analisis Text Mining
Text Clustering adalah proses unsupervised learning (proses pembelajaran sendiri) yang mengelompokkan kumpulan dokumen berdasarkan hubungan kemiripannya dan memisahkannya ke dalam beberapa kelompok[5].
III.1.4.1. Analisis Preprocessing
Tahapan preprocessing adalah tahapan awal sebelum dilakukan proses clustering, tahapan ini dilakukan untuk mengubah suatu dokumen kedalam format yang sesuai
agar dapat diproses dalam bentuk yang tepat dan dapat diproses pada tahapan selanjutnya. Penelitian ini menggunakan tiga tahap untuk preprocessing, yaitu: tokenization, stopword, dan stemming.
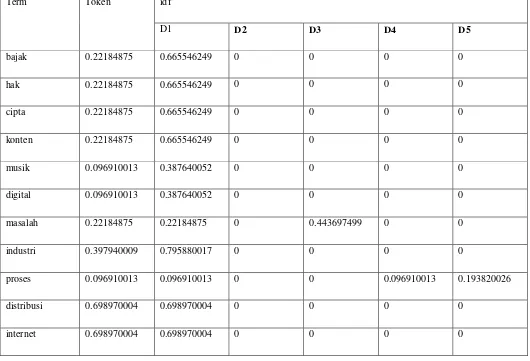
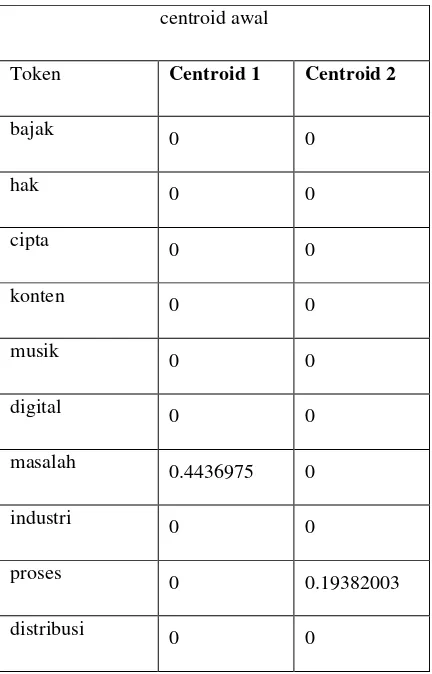
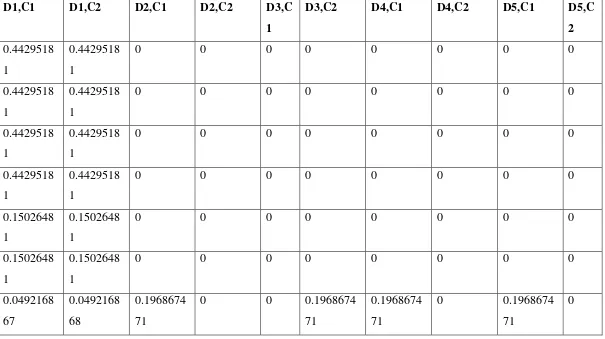
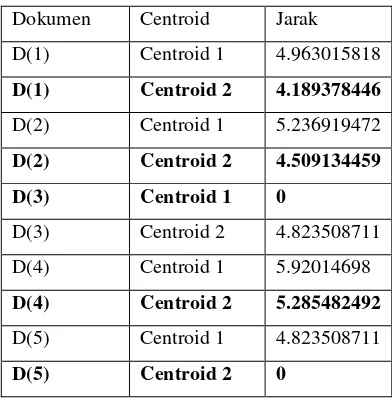
Berikut contoh setiap tahapan yang diambil dari abstrak setiap dokumen.
1. Tokenization, merupakan tahapan penguraian string teks menjadi term atau kata.
Abstrak Dokumen1: “Pembajakan hak cipta terhadap konten musik digital masih menjadi masalah besar dalam industry musik. Hal tersebut dikarenakan mudahnya proses pembajakan dan kemudahan distribusi konten digital melalui internet. Isu perlindungan hak cipta menjadi hal sangat penting untuk diterapkan dalam industri musik. Digital right management (DRM) dan audio watermarking adalah cara yang bisa diterapkan untuk melindungi properti intelektual hak cipta pada konten musik digital melawan pembajakan.”
Abstrak Dokumen2: “Telah dilakukan pembuatan suatu aplikasi kontrol switch menggunakan Silicon Controlled Rectifier (SCR) melalui parallel port. Menggunakan parallel port sebagai media antarmuka, SCR sebagai switch elektronis, optocoupler sebagai pengisolasi elektris dan bahasa pemograman yang digunakan Ezy Pascal. Dilakukan pengujian pada bagian output parallel port, bagian tegangan input, penggerak SCR dan bagian beban. Sistim yang dibuat membuktikan bahwa media parallel port dapat berfungsi sebagai media pengontrol SCR untuk mengaktifkan atau menonaktifkan beban.”
Hasil Token Dokumen2 : “telah dilakukan pembuatan suatu aplikasi kontrol switch menggunakan silicon controlled rectifier (scr) melalui parallel port. menggunakan parallel port sebagai media antarmuka, scr sebagai switch elektronis, optocoupler sebagai pengisolasi elektris dan bahasa pemograman yang digunakan ezy pascal. dilakukan pengujian pada bagian output parallel port, bagian tegangan input, penggerak scr dan bagian beban. sistim yang dibuat membuktikan bahwa media parallel port dapat berfungsi sebagai media pengontrol scr untuk mengaktifkan atau menonaktifkan beban.”
Abstrak Dokumen3: “Makalah ini mendeskripsikan model formal dari sistem interaktif berdasarkan sebuah studi kasus pada sistem kesehatan bergerak. Model ini mendeskripsikan sebuah session interaktif melibatkan professional medis yang menggunakan PDA untuk mengakses rekam medis pasien, dan terhubung pada server basis data dalam jaringan komunikasi nirkabel. Perilaku sistem dapat memunculkan masalah keselamatan bila dikaitkan dengan perilaku pemakai dalam pelayanan kesehatan. Akhirnya model sistem telah diverifikasi untuk menghindari masalah tersebut.”
Hasil Token Dokumen3: ”makalah ini mendeskripsikan model formal dari sistem interaktif berdasarkan sebuah studi kasus pada sistem kesehatan bergerak.
yang menggunakan pda untuk mengakses rekam medis pasien, dan terhubung pada server basis data dalam jaringan komunikasi nirkabel. perilaku sistem dapat memunculkan masalah keselamatan bila dikaitkan dengan perilaku pemakai dalam pelayanan kesehatan. akhirnya model sistem telah diverifikasi untuk menghindari masalah tersebut.”
Abstrak Dokumen4: “Sebuah simulator helikopter perlu dibuat agar benar-benar mirip dengan lingkungan cockpit sebenar-benarnya termasuk instrumentasinya.
Sebuah instrumen tersimulasi menggunakan teknologi mekatronika dimana sebuah sistem mekanik dikontrol secara elektronik untuk menunjukkan variabel terbang tertentu. Makalah ini menjelaskan proses rancang bangun sebuah indikator ketinggian tersimulasi yang digunakan pada sebuah simulator helikopter super puma. Indikator ini memiliki sebuah jarum utama yang dapat berputar 100 kali, sebuah jarum kecil yang dapat berputar 10 kali, dan sebuah jarum segi tiga yang dapat berputar sekali. Fitur keterbaruan makalah ini adalah bahwa jarum utama dan jarum kecil digerakkan oleh motor stepper sebagai pengganti syncro yang umumnya digunakan. Sebuah teknik kendali diusulkan untuk menggerakkan motor, dan kesalahan posisi diminimalkan memakai kompensator peranti lunak. Dari hasil eksperimen tingkat presisi berulang-ulang diperoleh kesimpulan bahwa indikator ketinggian tersimulasi yang dirancang bangun dapat bekerja dengan baik dengan tingkat ketelitian 0,03 (dial memory) untuk jarum utama dan 0,22 (dial memory) untuk jarum kecil.”
Hasil Token Dokumen4: ”sebuah simulator helikopter perlu dibuat agar benar-benar mirip dengan lingkungan cockpit sebenarnya termasuk instrumentasinya. sebuah instrumen tersimulasi menggunakan teknologi mekatronika dimana sebuah sistem mekanik dikontrol secara elektronik untuk menunjukkan variabel terbang tertentu. makalah ini menjelaskan proses rancang bangun sebuah indikator ketinggian tersimulasi yang digunakan pada sebuah simulator helikopter super puma. indikator ini memiliki sebuah jarum utama yang dapat berputar 100 kali, sebuah jarum kecil
fitur keterbaruan makalah ini adalah bahwa jarum utama dan jarum kecil digerakkan oleh motor stepper sebagai pengganti syncro yang umumnya digunakan. sebuah teknik kendali diusulkan untuk menggerakkan motor, dan kesalahan posisi diminimalkan memakai kompensator peranti lunak. dari hasil eksperimen tingkat presisi berulang-ulang diperoleh kesimpulan bahwa indikator ketinggian tersimulasi yang dirancang bangun dapat bekerja dengan baik dengan tingkat ketelitian 0,03 (dial memory) untuk jarum utama dan 0,22 (dial memory) untuk jarum kecil.“
Abstrak dokumen 5: “Kualitas layanan jaringan merupakan hal yang sangat penting untuk terus ditingkatkan. Oleh karena itu, perlu dilakukan layanan optimasi BTS yang bertujuan untuk pengoptimalan jaringan. Kegiatan optimasi jaringan dengan dilakukannya drive test. Begitu data telah terkumpul dari suatu area cakupan tertentu, data akan diproses lebih lanjut dengan software tool terpisah. Maintenance engineer dapat menggunakan data yang telah diproses untuk menganalisa unjuk kerja sistem di daerah tersebut. Layanan optimasi BTS diharapkan dapat mencapai target yang telah ditentukan untuk pengoptimalan seluruh sel disemua BTS.”
Hasil token Dokumen5 : “kualitas layanan jaringan merupakan hal yang sangat penting untuk terus ditingkatkan. oleh karena itu, perlu dilakukan layanan optimasi bts yang bertujuan untuk pengoptimalan jaringan. kegiatan optimasi jaringan dengan dilakukannya drive test. begitu data telah terkumpul dari suatu area cakupan tertentu, data akan diproses lebih lanjut dengan software tool terpisah. maintenance engineer dapat menggunakan data yang telah diproses untuk menganalisa unjuk kerja sistem di daerah tersebut. layanan optimasi bts diharapkan dapat mencapai target yang telah ditentukan untuk pengoptimalan seluruh sel disemua bts.”
2. Stopword, merupakan tahapan penghapusan kata-kata yang tidak relevan dalam
penentuan topik sebuah dokumen dan yang sering muncul pada sebuah dokumen
Ada; akan; antara; apa; atas; atau; bagi; baik; banyak; belum; demikian; kembali; berapa; bisa; buat; bukan; missal; secara; butuh; cukup; dalam; dan; dapat; dari; dengan; depan; di; dulu; tetapi; yaitu; bahkan; hanya; harus; ia; ini; itu; juga; kala; kami; jika; tahu; karena ke; kenapa; kendati; kira; ketika; kini; diri; mulai; kita; lagi; lain; lalu; lantas; mengerti; pilih; lebih; kata; maka; maksud; masing; kapan; masih; sementara; justru; mau; menjadi; mereka; namun; nanti; oleh; orang; pada; perlu; pernah; pula; seperti; sebagai; sedang; menjadi; agar; punya; memang; rendah; meski; terhadap; bahwa; saat; saja; bagai; sangat; saya; sejak; sejenak; semua; seusai;
sekarang; menurut; meskipun; paling; siapa; sudah; tahun; tambah; mungkin; tanpa; mana; dahulu; telah; ternyata; tersebut; tidaktinggi; turun; untuk; walau; yang.
Hasil Stopword Dokumen1 :
Pembajakan; hak; cipta; konten; music; digital; masalah; industry; proses; distribusi; internet; isu; perlindungan; diterapkan; right; management; drm; audio; watermarking; diterapkan; property; intelektual; melawan.
Hasil Stopword Dokumen2 :
pembuatan; aplikasi; control; switch; silicon; controlled; rectifier; scr; parallel; port; parallel; port; media; antarmuka; scr; switch; elektronis; optocoupler; pengisolasi; elektris; bahasa; pemograman; ezy; pascal; pengujian; output; parallel; port; tegangan; input; penggerak; scr; beban; sistim; membuktikan; media; parallel; port; berfungsi; media; pengontrol; scr; mengaktifkan; menonaktifkan; beban.
Hasil Stopword Dokumen3 :
system; memunculkan; masalah; keselamatan; dikaitkan; perilaku; pemakai; pelayanan; kesehatan; model; system; diverifikasi; menghindari; masalah.
Hasil Stopword Dokumen4 :
simulator; helicopter; perlu; dibuat; mirip; lingkungan; cockpit; instrumentasinya; instrument; tersimulasi; menggunakan; teknologi; mekatronika; system; mekanik; dikontrol; elektronik; menunjukkan; variable; terbang; makalah; menjelaskan; proses;
rancang; bangun; sebuah; indicator; ketinggian; tersimulasi; digunakan; sebuah; simulator; helicopter; super; puma; indicator; sebuah; jarum; utama; berputar; 100;
kali; sebuah; jarum; kecil; berputar; 10; kali; sebuah; jarum; segitiga; berputar; sekali; fitur; keterbaruan; makalah; jarum; utama; jarum; kecil; digerakkan; motor; stepper; pengganti; syncro; umumnya; digunakan; sebuah; teknik; kendali; diusulkan; menggerakkan; motor; kesalahan; posisi; diminimalkan; kompensator; peranti; lunak; hasil; eksperimen; tingkat; presisi; berulangulang; indicator; ketinggian; tersimulasi; dirancang; bangun; bekerja; tingkat; ketelitian; 0,03; dialmemory; jarum; utama; 0,22; dialmemory; jarum; kecil.
Hasil Stopword Dokumen5 :
kualitas; layanan; jaringan; hal; ditingkatkan; dilakukan; layanan; optimasi; bts; pengoptimalan; jaringan; optimasi; jaringan; dilakukannya; drive; test; data; terkumpul; area; cakupan; data; diproses; software; tool; maintenance; engineer; data; diproses; menganalisa unjuk; kerja; system; daerah; layanan; optimasi; bts; mencapai; target; ditentukan; pengoptimalan; sel; disemua; bts.
3. Stemming, merupakan tahapan pengubahan suatu kata menjadi akar kata nya
dengan menghilangkan imbuhan awal atau akhir pada kata tersebut
Hasil Stemming Dokumen2 : buat; aplikasi; control; switch; silicon; rectifier; scr; port; parallel; media; antarmuka; elektronis; optocoupler; isolasi; elektris; bahasa; program; ezy; pascal; uji; output; tegang; input; gerak; beban; sistim; bukti; fungsi; aktif.
Hasil Stemming Dokumen3 : Makalah; deskripsi; model; formal; sistem; interaktif; studi; kasus; sehat; gerak; sebuah; session; libat; professional; medis; guna; pda; akses; rekam; pasien; hubung; server; basis; data; jaringan; komunikasi;
nirkabel; perilaku; muncul; masalah; selamat; kait; pemakai; layan; verifikasi; hindari.
Hasil Stemming Dokumen4 : Simulator; helicopter; lingkungan; cockpit; instrument; simulasi; teknologi; mekatronika; sistem; mekanik; kontrol; elektronik; variable; terbang; proses; rancang; bangun; indikator; tinggi; super; puma; jarum; utama; kecil; segitiga; fitur; gerak; motor; stepper; syncro; teknik; kendali; posisi kompensator; peranti; lunak; eksperimen; tingkat; presisi; berulangulang; tinggi; dial; memory.
Hasil Stemming Dokumen5 : kualitas; layanan; jaringan; tingkat; optimasi; bts; optimal; drive; test; data; kumpul; area; proses; software; tool; maintenance; engineer; analisa; sistem; daerah; sel.
Berikut adalah tabel hasil dari preprosesing data untuk digunakan ke tahapan penentuan bobot setiap kata didalam sebuah dokumen.
Tabel III.1. Stemming Dokumen 1
isu; 1
Tabel III.2. Stemming dokumen 2
Kata Jumlah kata
Tabel III.3. Stemming Dokumen 3
akses; 1
Tabel III.4. Stemming Dokumen 4
Tabel III.5. Stemming Dokumen 5
Setelah tahapan ini selesai hasil dari stemming digunakan sebagai data inputan untuk menghitung bobot setiap kata yang ada didokumen dengan menggunakan Pembobotan TF-IDF
III.1.4.2. Pembobotan TF-IDF
Pada tahap pembobotan digunakan sebuah rumus TF-IDF untuk menentukan tingkat similaritas antar dokumen. TF (Term Frequency) adalah frekuensi dari kemunculan sebuah term dalam dokumen yang bersangkutan. Oleh sebab itu, TF memiliki nilai yang bervariasi dari satu dokumen ke dokumen yang lain bergantung pada sebuah term dalam sebuah dokumen yang tersedia.
Sedangkan IDF (Inverse Document Frequency) adalah sebuah statistik global yang mengkarakteristikkan sebuah term dalam keseluruhan korelasi dokumen. IDF merupakan sebuah perhitungan dari bagaimana term didistribusikan secara luas pada kalimat-kalimat.
Perhitungan bobot dari term tertentu dalam sebuah kalimat dengan menggunakan