PENGENALAN SUARA BERDASARKAN USIA DAN JENIS
KELAMIN MENGGUNAKAN ALGORITME
SUPPORT
VECTOR MACHINE
(SVM)
IKRA DEWANTARA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa skripsi berjudul Pengenalan Suara Berdasarkan Usia dan Jenis Kelamin Menggunakan Algoritma Support Vector Machine (SVM) adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2013 IkraDewantara
ABSTRAK
IKRA DEWANTARA. Pengenalan Suara Berdasarkan Usia dan Jenis Kelamin Menggunakan Algoritma Support Vector Machine (SVM). Dibimbing oleh TOTO HARYANTO.
Pengenalan suara manusia dengan bantuan komputer dapat dilakukan karena masing-masing suara memiliki ciri serta frekuensi yang berbeda-beda. Pengelompokan ciri suara berdasarkan jenis kelamin, dapat dikelompokan menjadi laki-laki dan perempuan, sedangkan berdasarkan umur dapat dikelompokan menjadi anak-anak, remaja, dan dewasa. Penelitian ini bertujuan untuk mengenali suara yang dikelompokan ke dalam salah satu kelas berdasarkan usia dan jenis kelamin. Data yang digunakan berasal dari penelitian Fransiswa (2010). Data terdiri dari 6 penggolongan kelas, yaitu anak laki-laki (AL), anak perempuan (AP), remaja laki-laki (RL), remaja perempuan (RP), tua laki-laki (TL), dan tua perempuan (TP). Metode ekstraksi ciri yang digunakan adalah Mel Frequency Cepstrum Coefficient (MFCC), pengenalan pola menggunakan Support vector machine (SVM) dengan berbagai variasi kernel seperti linear, polynomial, dan Radial Basis Function (RBF). Parameter-parameter yang mempengaruhi dalam proses MFCC di antaranya: nilai koefisien, overlap, time frame, dan sampling rate. Hasil rata-rata akurasi tertinggi yaitu 98.24% diperoleh menggunakan kernel RBF.
Kata kunci: identifikasi suara, kernel RBF, MFCC, pengenalan suara, support vector machine (SVM).
ABSTRACT
IKRA DEWANTARA. Voice Recognition Based on Age and Gender Using Support Vector Machine (SVM) Algorithm. Supervised by TOTO HARYANTO.
Voice recognition using computers is made possible due to the unique characteristics and frequencies that each voice possesses. These vocal characteristics can be grouped according to gender (male or female) or age (child, teenager, or adult). The purpose of this research is to identify individual voices that have been placed within one of the groups based on age and gender. The data used comes from the research of Fransiswa (2010) and consists of six classes: boys (AL), girls (AP), teenage boys (RL), teenage girls (RP), men (TL), and women (TP). The method used to extract vocal characteristics was the Mel Frequency Cepstrum Coefficient (MFCC) and pattern recognition was performed using a Support Vector Machine (SVM) with several variations of the kernel such as Linear, Polynomial, and Radial Basis Function (RBF). The parameters affecting the MFCC process include: The value of the coefficients, overlap, time frame, and the rate of sampling. The average highest accuracy value of 98,24% was obtained using the RBF Kernel.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
PENGENALAN SUARA BERDASARKAN USIA DAN JENIS
KELAMIN MENGGUNAKAN ALGORITMA
SUPPORT
VECTOR MACHINE
(SVM)
IKRA DEWANTARA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
1 Mushthofa, SKom MSc
Judul Skripsi : Pengenalan Suara Berdasarkan Usia dan Jenis Kelamin Menggunakan Algoritme Support Vector Machine (SVM) Nama : Ikra Dewantara
NIM : G64104057
Disetujui oleh
Toto Haryanto, SKom MSi Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen Ilmu Komputer
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah subhanahu wata’ala, yang telah memberikan nikmat yang begitu banyak sehingga penulis dapat menyelesaikan penelitian dan tulisan ini. Shalawat serta salam penulis sampaikan kepada Nabi Muhammad shallallahu ‘alaihi wassalam, keluarga, sahabat, serta umatnya hingga akhir zaman. Tulisan ini merupakan hasil penelitian yang penulis lakukan sejak November 2012 hingga Juli 2013. Tulisan ini mengambil topik pengenalan pola suara untuk mengidentifikasi suara berdasarkan usia dan jenis kelamin.
Terima kasih penulis ucapkan kepada seluruh pihak yang telah berperan membantu dalam penelitian ini, yaitu:
1 Ayahanda Sudirah, Ibunda Titien Sulistyowati, serta Adik Maulana Husada dan Trias Prastyoningrum atas kasih sayang, doa, dan dorongan semangat yang telah diberikan kepada penulis agar penelitian ini cepat selesai.
2 Bapak Toto Haryanto, SKom MSi selaku pembimbing yang telah memberikan arahan dan saran selama penelitian ini berlangsung.
3 Bapak Mushthofa, SKom MSc dan Bapak Muhammad Asyhar Agmalaro, SSi MKom selaku dosen penguji yang telah bersedia menguji serta memberikan masukan-masukan dalam penelitian ini.
4 Rekan-rekan Ilkom Alih Jenis Angkatan 5.
Penulis menyadari bahwa masih terdapat kekurangan dalam penulisan skripsi ini. Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Tujuan 1
Manfaat 2
Ruang Lingkup 2
TINJAUAN PUSTAKA 2
Sinyal Suara 2
Transformasi Suara Analog ke dalam Suara Digital 2
Ekstraksi Ciri dengan MFCC 4
K-Fold Cross Validation 5
Pengenalan Pola dengan SVM 6
Multi Class SVM 8
METODE PENELITIAN 8
Kerangka Pemikiran 8
Pengambilan Data 9
Tahan Pra Proses 9
Ekstraksi Ciri Menggunakan MFCC 10
Standardisasi 10
Proporsi Data Latih dan Data Uji 10
K-Fold Cross Validation 10
Pemodelan SVM 12
Lingkungan Pengembangan 12
Pengujian 12
HASIL DAN PEMBAHASAN 12
Ekstraksi Ciri Menggunakan MFCC 12
Pemodelan dan Klasifikasi SVM 13
Perbandingan SVM dan PNN 15
Implementasi 17
SIMPULAN DAN SARAN 19
Simpulan 19
Saran 19
DAFTAR PUSTAKA 19
DAFTAR TABEL
1 Penggolongan kelas berdasarkan kisaran usia dan jenis kelamin 9
2 Proporsi data latih dan data uji 10
3 Pembagian data latih dan data uji berdasarkan subset untuk data latih 75% 11 4 Pembagian data latih dan data uji berdasarkan subset untuk data latih 50% 11 5 Pembagian data latih dan data uji berdasarkan subset untuk data latih 25% 11 6 Contoh tabel akurasi berdasarkan data latih, data uji, dan subset yang
digunakan 11
7 Parameter-parameter untuk masing-masing kernel SVM 12 8 Hasil perbandingan akurasi pengujian kernellinear (C = 2) 14 9 Hasil perbandingan akurasi pengujian kernelpolynomial (C = 2 dan d = 2) 14 10 Hasil perbandingan akurasi pengujian kernel RBF (C = 2 dan σ = 4) 14 11 Perbandingan rata-rata akurasi berdasarkan usia dan jenis kelamin
menggunakan SVM dengan kernel RBF 16
12 Perbandingan rata-rata akurasi berdasarkan usia dan jenis kelamin
menggunakan PNN 16
13 Akurasi tertinggi kernel RBF (koefisien 26 dengan subset 2) 17
DAFTAR GAMBAR
1 Tahapan transformasi sinyal menjadi informasi 3
2 Ilustrasi sampling 3
3 Blok diagram teknik MFCC 4
4 Ilustrasi SVM untuk linear separable data 6
5 Ilustrasi SVM untuk non-linear separable data 7 6 Proses pengambilan suara sampai mendapatkan informasi 9
7 Contoh hasil MFCC untuk koefisien 13 13
8 Pemodelan SVM 13
9 Perbandingan rata-rata akurasi berdasarkan jenis kelamin dan koefisien
menggunakan SVM dengan kernel RBF 17
10 Perbandingan rata-rata akurasi berdasarkan jenis kelamin dan koefisien
menggunakan PNN 17
DAFTAR LAMPIRAN
1 Akurasi pengenalan pola suara menggunakan kernel linear dilihat dari
pengaruh parameter C 21
2 Akurasi pengenalan pola suara menggunakan kernel polynomial dilihat
dari pengaruh parameter C 21
3 Akurasi pengenalan pola suara menggunakan kernel polynomial dilihat
dari pengaruh parameter d 22
4 Akurasi pengenalan pola suara menggunakan kernel RBFdilihat dari
pengaruh parameter C 22
5 Akurasi pengenalan pola suara menggunakan kernel RBFdilihat dari
pengaruh parameter σ 23
6 Akurasi kernel linear dengan C = 2 berdasarkan subset (S) yang
digunakan 24
7 Akurasi kernel polynomial dengan C = 2 dan d = 2 berdasarkan subset (S)
yang digunakan 24
8 Akurasi kernel RBF dengan C = 2 dan σ = 4 berdasarkan subset (S) yang
1
PENDAHULUAN
Latar Belakang
Pengenalan biometrik adalah salah satu metode pengenalan manusia yang dapat dilakukan oleh mesin. Pengenalan ini dilakukan untuk proses autentikasi dalam sistem. Sistem autentikasi yang berkembang saat ini di antaranya seperti pengenalan iris mata, pengenalan wajah, pengenalan sidik jari, dan pengenalan suara.
Pengenalan suara dapat diaplikasikan menjadi sistem autentikasi karena setiap pembicara memiliki gelombang suara yang bervariasi (Pelton 1993). Sebagai contoh jika seseorang mengucapkan sebuah kata, maka polanya akan berbeda dengan pola suara orang lain. Pola suara juga akan berbeda jika dilihat dari jenis kelamin maupun kisaran umur. Jika seseorang hanya mendengarkan suara saja tanpa tahu orangnya, untuk suara dengan pola yang mirip, sebagian besar orang akan sulit mengenali kisaran usianya.
Suara dalam bentuk analog harus dikonversi menjadi digital. Hasilnya adalah sebuah representasi vektor dalam ukuran besar dengan tidak menghilangkan ciri dari suara tersebut. Oleh karena itu, dibutuhkan sebuah teknik ekstraksi ciri untuk mengubah vektor suara menjadi vektor ciri tanpa mengurangi karakteristik suara tersebut. Menurut Buono et al. (2009), mel-frequency cepstrum coefficients (MFCC) dapat merepresentasikan ekstraksi ciri sinyal lebih baik dibandingkan dengan linear prediction ceptrum coefficient (LPCC) dan teknik ekstraksi ciri lainnya.
Penelitian pengenalan pola suara telah dilakukan oleh Fransiswa (2010) menggunakan MFCC sebagai ekstraksi ciri dan probabilistic neural network (PNN) sebagai pengenalan pola. Penelitian pola suara lainnya juga telah dilakukan oleh Ganapathiraju (2002) menggunakan SVM sebagai pengenalan pola suara. Menurut Ganapathiraju (2002) SVM telah banyak digunakan dan menghasilkan pengenalan pola suara yang sangat baik. SVM dapat menyelesaikan permasalahan pengelompokan 2 kelas secara sempurna menggunakan metode pembagian 2 wilayah linear. Adapun kendala yang dihadapi dalam pengenalan pola menggunakan SVM adalah dalam penyelesaian masalah pengelompokan kelas non-linear/banyak kelas.
Berdasarkan latar belakang tersebut, maka pada penelitian ini ditujukan untuk membandingkan hasil akurasi SVM untuk melakukan identifikasi suara terhadap PNN yang telah digunakan pada penelitian Fransiswa (2010). Adapun metode ekstraksi ciri yang digunakan adalah sama, yaitu MFCC.
Tujuan
Penelitian ini bertujuan untuk:
1 Menerapkan MFCC sebagai ekstraksi ciri.
2 Menerapkan SVM sebagai salah satu metode pengenalan suara berdasarkan kisaran usia dan jenis kelamin.
4 Membandingkan rata-rata akurasi antara pengenalan pola menggunakan SVM dengan kernel RBF dengan skripsi Fransiswa (2010) yang menggunakan PNN sebagai pengenalan suara berdasarkan usia dan jenis kelamin.
Manfaat
Penelitian ini diharapkan menghasilkan sistem yang cukup efektif dalam pengenalan suara suara berdasarkan kisaran usia dan jenis kelamin dengan MFCC sebagai ekstraksi ciri dan SVM sebagai algoritme klasifikasi.
Ruang Lingkup
Ruang lingkup penelitian ini dibatasi pada:
1 Data yang digunakan dalam penelitian ini menggunakan data penelitian Fransiswa (2010).
2 Kata yang direkam adalah “awas ada bom”. Kata ini dipilih karena tidak mengandung diftong sehingga susunan vokalnya berselingan. Diftong adalah 2 buah vokal yang berurutan, misal: buah, lauk, daun, dsb. Selain itu juga karena kata “awas ada bom” terdiri dari 3 kata, sehingga memiliki variasi warna suara.
3 Metode ekstraksi ciri yang digunakan adalah MFCC. MFCC dapat merepresentasikan sinyal lebih baik dibandingkan dengan LPCC dan teknik ekstraksi ciri lainnya (Buono et al. 2009).
4 Kelompok usia dibagi menjadi anak-anak memiliki kisaran usia antara 8 tahun sampai 11 tahun, remaja antara 12 tahun sampai 21 tahun dan dewasa antara 22 tahun sampai 50 tahun (IDAI 2009).
TINJAUAN PUSTAKA
Sinyal Suara
Sinyal suara merupakan gelombang analog yang merambat melalui medium (zat perantara). Suara manusia menghasilkan gelombang yang berasal dari paru-paru, kemudian diatur dan dibentuk oleh pita suara. Sinyal suara yang dapat didengar oleh manusia berkisar antara frekuensi 20 Hz sampai dengan 20 KHz. Adapun sinyal suara yang dapat didengar baik oleh manusia yang memiliki frekuensi di atas 10 KHz (Pelton 1993).
Transformasi Suara Analog ke dalam Suara Digital
3
ekstraksi ciri dan diakhiri dengan pengenalan pola untuk klasifikasi. Tahapan transformasi sinyal analog sampai menghasilkan informasi disajikan pada Gambar 1.
Gambar 1 Tahapan transformasi sinyal menjadi informasi (Buono et al. 2009)
Menurut Orfanidis (2010) pemrosesan sinyal analog menjadi sinyal digital harus melalui proses sampling dan kuantisasi. Sampling merepresentasikan sinyal analog x(t) yang diukur secara berkala setiap t detik sehingga waktu didiskritisasi dalam satuan sampling interval T. Ilustrasi sampling disajikan pada Gambar 2.
Gambar 2 Ilustrasi sampling (Orfanidis 2010)
Hasil dari sampling adalah representasi sebuah vektor yang terdiri atas nilai-nilai amplitudo terhadap waktu. Amplitudo merepresentasikan besar/kecilnya volume suara. Panjang suatu vektor ini ditentukan oleh durasi suara tersebut dan sampling rate yang digunakan. Sampling rate adalah banyaknya sampling yang diambil dalam waktu tertentu (t). Hubungan antara panjang vektor dan sampling rate dapat dinyatakan dalam Persamaan 1.
s t (1)
S = Panjang vektor
Tahapan selanjutnya ialah kuantisasi. Kuantisasi adalah pemetaan nilai-nilai amplitudo ke dalam representasi nilai-nilai 8 bit atau 16 bit.
Ekstraksi Ciri dengan MFCC
MFCC merupakan teknik ekstraksi ciri yang telah luas dipakai pada pemrosesan sinyal suara, terutama pada pengenalan pembicara. Penggunaan teknik ini pada sistem pemrosesan sinyal memberikan pengenalan yang lebih baik dibandingkan dengan metode lain yang sudah ada (Buono et al.2009).
Menurut Do (1994) MFCC adalah teknik ekstraksi ciri yang populer dan paling banyak digunakan. Blok diagram teknik MFCC disajikan pada Gambar 3.
Gambar 3 Blok diagram teknik MFCC
Frame blocking dan overlapping: Sinyal suara dibaca per blok (frame), terdiri dari sejumlah N titik samples, dan antara dua frame yang bersebelahan terdapat overlap. Overlap ini dipisahkan oleh M (M < N). Frame pertama diawali dengan titik sample N, sedangkan frame kedua diawali dengan Msamples setelah frame pertama. Overlap terjadi pada N - M atau frame pertama yang saling tumpang tindih terhadap frame kedua.
Windowing: Proses windowing dilakukan pada setiap frame dengan tujuan untuk meminimumkan diskontinuitas antar dua frame yang bersebelahan, khususnya pada bagian awal dan akhir. Jika window didefinisikan sebagai
1 0
),
(n nN
w , windowing dapat dihitung menggunakan perkalian vektor seperti pada Persamaan 2.
1
Fungsi Hamming window atau w(n)yang disajikan pada Persamaan 3. 1
N = banyaknya samples dalam setiap frame n = frame ke-n
yl (n) = fungsi windowing w(n) = fungsi Hamming window
FFT: Fast fourier transform (FFT) bertujuan melakukan konversi pada setiap frame yang terdiri atas N sampel dari domain waktu ke domain frekuensi. FFT adalah algoritma yang cepat untuk mengimplementasikan discrete fourier
5
Xk = nilai-nilai sampel yang akan di proses ke dalam domain frekuensi Xn = magnitudo frekuensi
N = jumlah data pada domain frekuensi j = bilangan imajiner
Secara umum Xk adalah bilangan kompleks dan hanya dilihat bilangan absolutnya saja. Hasil dari tahap FFT ini disebut dengan nama spektrum atau periodogram.
Mel-frequency wrapping: Tahap ini merupakan proses pemfilteran dari spektrum setiap frame yang diperoleh dari tahapan sebelumnya, menggunakan sejumlah M filter segitiga dengan tinggi satu. Filter ini dibuat dengan mengikuti persepsi telinga manusia dalam menerima suara. Persepsi ini dinyatakan dalam skala ’mel’ (berasal dari melody) yang mempunyai hubungan tidak linear dengan frekuensi suara, dalam hal ini skala mel-frequency adalah linear untuk frekuensi kurang dari 1000 Hz dan logaritmik untuk frekuensi di atas 1000 Hz. Hubungan antara skala mel dengan frekuensi (Hz) disajikan pada Persamaan 6.
mel . log z (6)
Cepstrum: Langkah terakhir yaitu mengubah spektrum log mel menjadi domain waktu. Hasilnya disebut dengan MFCC. Cepstral dari spektrum suara merepresentasikan sifat/ciri spektral lokal sinyal untuk analisis frame yang diketahui. Koefisien mel spectrum dapat dikonversi ke dalam domain waktu menggunakan discrete cosine transform (DCT) seperti ditunjukkan dalam Persamaan 7 dan 8.
mk ∑ - n n m kmel n (7)
cs n,m ∑ - k k . log mk cos n k , n , , , - (8)
dengan k = 0, 2, ..., K-1
K-Fold Cross Validation
Pengenalan Pola dengan SVM
Menurut Cortes dan Vapnik (1995) SVM adalah sistem pembelajaran untuk mengklasifikasikan data menjadi 2 kelompok menggunakan fungsi-fungsi linear dalam sebuah ruang fitur (feature space) berdimensi tinggi. Klasifikasi SVM dilakukan dengan cara menemukan hyperplane terbaik sehingga diperoleh ukuran
margin yang maksimal. Margin adalah jarak antara hyperplane tersebut dengan titik terdekat dari masing-masing kelas. Titik yang paling dekat ini disebut dengan support vector. Ilustrasi SVM untuk linear separable data disajikan pada Gambar 4.
Menurut Cortez dan Vapnik (1995) Gambar 4 di atas mengilustrasikan dua kelas yang dapat dipisahkan secara linier menggunakan sepasang bidang batas yang sejajar. Bidang batas pertama membatasi kelas pertama (yi = 1), dan bidang batas kedua membatasi kelas kedua (yi = 1). Persamaan bidang pembatas jika data terpisah secara linier dapat dihitung menggunakan perkalian vektor antara vektor bobot dengan data set seperti disajikan pada Persamaan 9.
w i b untuk kelas 1 = 1
w i b - untuk kelas 2 = 1 (9)
dengan: = data set = kelas dari data
w = vektor bobot yang tegak lurus terhadap hyperplane b = menentukan fungsi pemisah relatih terhadap titik asal
Bidang pemisah terbaik adalah bidang pemisah yang memiliki margin (jarak antara dua bidang pembatas) maksimal atau berada di tengah-tengah kedua kelas yang berbeda. Nilai margin antara dua bidang pembatas adalah m =
. Margin
maksimal diperoleh dengan menggunakan fungsi Lagrangian seperti pada Persamaan 10.
7
minw,b p w,b,a | w | -∑ ( li iyi w.x b - ) ∑li i (10)
Vektor w sering kali bernilai sangat besar bahkan tidak terhingga, tetapi untuk nilai terhingga. Persamaan Lagrange primal problem perlu diubah ke dalam Lagrange dual problem seperti Persamaan 11.
D ∑li i- ∑ ∑li lj i jyiyjxi.xj (11)
Karena minw,b Lp = max Ld. Sehingga solusi pencarian bidang pemisah terbaik disajikan dalam Persamaan 12.
max ∑li i- ∑ ∑li lj i jyiyjxi.xj (12)
s.t∑ iyi , l
i
Persamaan 12 akan menghasilkan nilai i untuk setiap data pemodelan. Nilai tersebut digunakan untuk menentukan bobot (w). Data yang memiliki nilai
i adalah support vector, sedangkan sisanya dianggap bukan support vector. Setelah i ditemukan, maka kelas dari data pengujian dapat ditentukan berdasarkan Persamaan 13.
f xd ∑ i iyixixd b (13)
dengan:
= support vector
NS = jumlah support vector
= data yang akan diklasifikasikan
Jika data terpisah secara non-linear, data terlebih dahulu diproyeksikan oleh fungsi kernel ke ruang vektor baru yang berdimensi tinggi sedemikian sehingga data itu dapat terpisah secara linear, seperti pada Gambar 5.
Selanjutnya di ruang vektor baru tersebut SVM mencari hyperplane terbaik untuk memisahkan dua kelas secara linear. Pencarian hyperplane bergantung kepada dot product dari data yang dipetakan pada ruang berdimensi tinggi, yaitu . Perhitungan transformasi ini sangat sulit, namun dapat digantikan dengan fungsi yang disebut dengan kernel sesuai pada Persamaan 14.
K u,v u . v (14)
Sehingga jika disubtitusi ke dalam persamaan Lagrangian menjadi seperti Persamaan 15 dengan fungsi yang dihasilkan pada Persamaan 16.
∑i l i- ∑ ∑i l lj i jyiyjK u.v (15)
f xd ∑ i iyiK u.v b (16)
Menurut Cortez dan Vapnik (1995) beberapa fungsi kernel yang umum digunakan adalah:
1 Linear kernel
K u,v u.v (17)
2 Polynomial kernel
K u,v u.v d (18)
3 Radial basis function (RBF) kernel
K u,v exp - |u-v| , (19)
dengan:
u = data latih
v = kelas pada data latih
d dan γ adalah parameter kernel
Pemodelan pada kernel linear dan polynomial merupakan perkalian vektor antara data latih dan kelas yang bersesuaian. Adapun data latih (u) harus ditranspose terlebih dahulu menjadi (uT)agar dimensi datanya sesuai.
Multi Class SVM
Matlab menyediakan fungsi SVM untuk melakukan pemodelan dan klasifikasi, namun memiliki keterbatasan yaitu hanya mampu melakukan pemodelan dan klasifikasi untuk 2 kelas. Adapun penelitian ini terdiri dari 6 kelas yang harus dibedakan. Oleh karena itu diperlukan sebuah metode untuk melakukan pemodelan dan klasifikasi untuk data yang memiliki lebih dari 2 kelas. Menurut Hsu dan Lin (2002) untuk mengklasifikasikan data yang lebih dari 2 kelas, terdapat suatu metode yaitu one-againts-all. Metode ini dibangun n buah model SVM (dimana n = jumlah kelas). Setiap model klasifikasi ke-i dilatih dengan menggunakan keseluruhan data.
METODE PENELITIAN
Kerangka Pemikiran
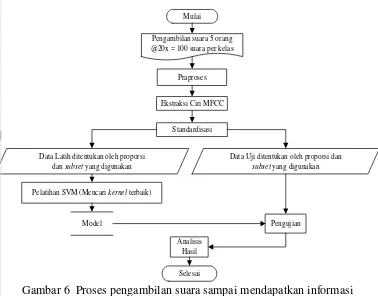
9
Mulai
Pengambilan suara 5 orang @20x = 100 suara per kelas
Ekstraksi Ciri MFCC
Pelatihan SVM (Mencari kernel terbaik)
Pengujian
Analisis Hasil
Selesai Praproses
Data Latih ditentukan oleh proporsi dan subset yang digunakan
Data Uji ditentukan oleh proporsi dan
subset yang digunakan
Model
Standardisasi
Gambar 6 Proses pengambilan suara sampai mendapatkan informasi
Pengambilan Data
Data suara yang digunakan dalam penelitian ini diambil dari penelitian Fransiswa (2010). Data tersebut terdiri atas 6 penggolongan kelas. Tabel 1 menunjukkan penggolongan kelas berdasarkan kisaran usia dan jenis kelamin.
Masing-masing kelas terdiri atas 5 orang. Masing-masing orang merekam “Awas Ada Bom”, diulang sebanyak 20 kali, sehingga total terdapat 600 suara.
Tahan Pra Proses
Suara yang sudah dalam bentuk digital, pada tahap ini akan dilakukan normalisasi. Proses normalisasi suara umunya dilakukan pada tinggi amplitudo yang berbeda-beda serta menghilangkan suara kosong (diam) pada awal dan akhir rekaman. Normalisasi amplitudo dilakukan dengan cara membagi setiap nilai
Tabel 1 Penggolongan kelas berdasarkan kisaran usia dan jenis kelamin
No. Usia Jenis kelamin Kisaran usia (tahun)
1 Anak Laki-laki 8 – 11
2 Anak Perempuan 8 – 11
3 Remaja Laki-laki 12 – 21
4 Remaja Perempuan 12 – 21
5 Tua Laki-laki 22 – 50
6 Tua Perempuan 22 – 50
dengan nilai maksimumnya sehingga diperoleh sebuah nilai yang sudah dinormalisasi.
Ekstraksi Ciri Menggunakan MFCC
Suara yang sudah dinormalisasi dan dihilangkan suara diamnya, kemudian diekstraksi ciri dengan menggunakan MFCC. Adapun parameter-parameter MFCC yang digunakan dalam penelitian ini di antaranya: time frame 40, sampling rate 11000 Hz, overlap 0.5, dan jumlah koefisien yang digunakan pada setiap frame yaitu 13, 20, dan 26.
Standardisasi
Standardisasi merupakan teknik mengambil nilai rata-rata ciri untuk semua frame dari matrix hasil MFCC. Jumlah baris menyatakan banyaknya ciri, sedangkan jumlah kolom menyatakan banyaknya frame. Sebagai contoh jika memiliki matriks dengan ukuran 13 × 33, maka matriks tersebut memiliki penciri sebanyak 13 dan jumlah frame sebanyak 33. Standardisasi diperlukan agar masing-masing data suara diwakilkan oleh sebuah kolom. Tahapan selanjutnya adalah melakukan transpose terhadap semua hasil standardisasi agar diperoleh matriks berukuran (jumlah data × koefisien).
Proporsi Data Latih dan Data Uji
Proporsi data latih dan data uji yang digunakan dalam penelitian ini sesuai dengan penelitian Fransiswa (2010) agar hasilnya bisa dibandingkan. Adapun proporsinya disajikan pada Tabel 2.
Tabel 2 Proporsi data latih dan data uji
Data latih Data uji
75% 25%
50% 50%
25% 75%
K-Fold Cross Validation
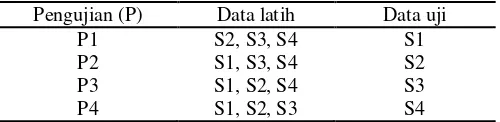
K-Fold Cross Validation digunakan untuk mencari akurasi terbaik di antara berbagai macam variasi data latih dan data uji yang digunakan. Pembagian data untuk proporsi data latih 75% menggunakan 4-fold cross validation dan untuk data latih 50% menggunakan 2-fold cross validation. Adapun pembagian data untuk proporsi data latih 25% tidak menggunakan metode k-fold.
11
Tabel 3 Pembagian data latih dan data uji berdasarkan subset untuk data latih 75%
Pengujian (P) Data latih Data uji
P1 S2, S3, S4 S1
P2 S1, S3, S4 S2
P3 S1, S2, S4 S3
P4 S1, S2, S3 S4
Data pada masing-masing subset (S), yaitu S1, S2, S3, dan S4 diperoleh dari total data suara masing-masing orang dibagi menjadi 4. Jika terdapat 6 kelas, masing-masing kelas terdiri dari 5 orang, dan masing-masing orang merekam 20 kali perulangan, maka setiap subset terdiri atas 6 ×5 × (20 / 4) = 150 data suara.
Pembagian data latih dan data uji jika dilihat berdasarkan subset (S) untuk data latih 50% disajikan pada Tabel 4.
Tabel 4 Pembagian data latih dan data uji
berdasarkan subset untuk data latih 50%
Pengujian (P) Data latih Data uji
P1 S1 S2
P2 S2 S1
Data pada masing-masing subset (S), yaitu S1 dan S2 diperoleh dari total data suara masing orang dibagi menjadi 2. Jika terdapat 6 kelas, masing-masing kelas terdiri atas 5 orang, dan masing-masing-masing-masing orang merekam 20 kali perulangan, maka setiap subset terdiri atas 6 × 5 × (20 / 2) = 300 data suara.
Pembagian data latih dan data uji jika dilihat berdasarkan subset (S) untuk data latih 25% disajikan pada Tabel 5.
Tabel 5 Pembagian data latih dan data uji
berdasarkan subset untuk data latih 25%
Pengujian (P) Data latih Data uji
P1 S1 S2, S3, S4
P2 S2 S1, S3, S4
P3 S3 S1, S2, S4
P4 S4 S1, S2, S3
Data pada masing-masing subset (S), yaitu S1, S2, S3, dan S4 diperoleh dari total data suara masing-masing orang dibagi menjadi 4. Jika terdapat 6 kelas, masing-masing kelas terdiri dari 5 orang, dan masing-masing orang merekam 20 kali perulangan, maka setiap subset terdiri atas 6 × 5 × (20 / 4) = 150 data suara.
Adapun hubungan proporsi data latih, data uji, dan subset yang digunakan disajikan pada Tabel 6.
Tabel 6 Contoh tabel akurasi berdasarkan data latih, data uji, dan subset yang digunakan
Data Latih Data Uji Subset 1 Subset 2 Subset 3 Subset 4
75% 25% Akurasi P1 Akurasi P2 Akurasi P3 Akurasi P4
50% 50% Akurasi P1 Akurasi P2
Pemodelan SVM
Pemodelan SVM dibentuk sesuai dengan kernel SVM yang akan digunakan. Masing-masing kernel memiliki parameter-parameter yang berbeda seperti disajikan pada Tabel 7.
Tabel 7 Parameter-parameter untuk masing-masing kernel SVM
Kernel Parameter
Linear C
Polynomial C d
RBF C σ
dengan:
C = besarnya nilai penalti akibat kesalahan klasifikasi d = derajat kernelpolynomial
=
Lingkungan Pengembangan
Spesifikasi perangkat keras yang digunakan untuk penelitian ini adalah prosesor AMD Phenom X6 2.8GHz, memori 4GB DDR3, hard disk 1TB, VGA ATi Radeon 4670 1GB, dan Standard Microphone/Headset. Adapun untuk perangkat lunak yang digunakan untuk penelitian ini adalah Windows 7 Ultimate 64bit, Matlab R2010b 64 bit, dan Microsoft Excel 2010.
Pengujian
Pengujian dapat dilakukan dengan cara mencocokan hasil dari data uji dengan data pada kelas sebenarnya. Data yang sama dijumlahkan dan hasilnya dibagi dengan keseluruhan data uji. Secara matematis rumus untuk menghitung akurasi dapat dilihat seperti rumus di bawah ini:
asil akurasi suara uji teridentifikasi benar suara pada kelas sebenarnya (20)
HASIL DAN PEMBAHASAN
Ekstraksi Ciri Menggunakan MFCC
13
Setiap suara memiliki ciri yang berbeda-beda. Ciri ini diperoleh dari hasil ekstraksi MFCC. Hasil ekstraksi menghasilkan matriks berukuran n × koefisien MFCC, dengan n adalah jumlah data. Beberapa penelitian yang sudah dilakukan untuk melakukan ekstraksi ciri di antaranya:
1 Menggunakan koefisien 13 Suhartono (2007). 2 Menggunakan koefisien 20 Do (1994).
3 Menggunakan koefisien 26 Buono (2009).
Penelitian ini menggunakan fungsi MFCC yang diperoleh dari penelitian Buono et al. (2009). Fungsi tersebut memiliki fitur dinamis yang berarti koefisiennya dapat diubah-ubah menjadi 13, 20, atau 26. Parameter-parameter yang digunakan untuk ekstraksi ciri di antaranya: sampling rate 11000 Hz, time frame 40 ms, jumlah koefisien (13, 20, dan 26), dan overlap 0,5. Contoh hasil MFCC untuk koefisien 13 dengan jumlah data sebanyak 600 disajikan pada Gambar 7.
Gambar 7 Contoh hasil MFCC untuk koefisien 13
Pemodelan dan Klasifikasi SVM
Data hasil MFCC yang sudah distandaridsasi, kemudian dipilah sesuai dengan proporsi data latih dan data uji yang digunakan. Berbagai macam variasi data juga diujikan untuk mendapatkan akurasi yang terbaik, dalam hal ini menggunakan teknik k-fold. Pemodelan dilakukan dengan cara melatih data sesuai dengan kelasnya, sisa data dianggap bukan kelasnya (konsep one against all) sehingga menghasilkan sebuah model untuk masing-masing kelas. Proses pemodelan dilakukan dengan bantuan aplikasi Matlab menggunakan perintah
svmtrain dengan berbagai macam variasi parameter-parameter kernel. Hasilnya
adalah dalam masing-masing subset terdiri dari 6 buah model, yaitu model AL, model AP, model RL, model RP, model TL, dan model TP. Pemodelan SVM disajikan pada Gambar 8.
Gambar 8 Pemodelan SVM
Fungsi dari model itu sendiri adalah untuk melakukan klasifikasi terhadap data baru yang diujikan. Klasifikasi dilakukan dengan cara menguji data baru dengan model-model yang telah diperoleh dari pemodelan SVM.
Perbandingan Kernel-Kernel SVM
Matlab menyediakan beberapa kernel yang dapat digunakan dalam pemodelan SVM. Beberapa kernel yang umum digunakan yaitu linear, polynomial, dan RBF. Masing-masing kernel memiliki waktu pemodelan, parameter serta tingkat akurasi yang berbeda-beda. Hasil akurasi terbaik masing-masing kernel disajikan pada Tabel 8, 9, dan 10.
Tabel 8 Hasil perbandingan akurasi pengujian kernellinear (C = 2)
Data
Tabel 9 Hasil perbandingan akurasi pengujian kernelpolynomial (C = 2 dan d = 2) semakin cepat untuk mendapatkan model. Waktu pemodelan tercepat diperoleh dengan menggunakan kernel RBF (Tabel 10).
Akurasi
15
Oleh karena itu penelitian ini menggunakan SVM dengan kernel RBF untuk mencapai akurasi tertinggi.
Kernel Linear
Berdasarkan Lampiran 1, terlihat bahwa pada kernel linear semakin kecil nilai C (yaitu 21), semakin tinggi akurasi yang dihasilkan. Akurasi tertinggi yang diperoleh oleh kernel linear sebesar 92.81% pada koefisien 26 dengan waktu pemodelan terlama yaitu 2201 detik. Jika ditarik kesimpulan, jumlah koefisien, dan lama pemodelan berbanding lurus dengan akurasi yang dihasilkan.
KernelPolynomial
Berdasarkan Lampiran 2, terlihat bahwa parameter C tidak mempengaruhi akurasi, melainkan mempengaruhi waktu pemodelan. Semakin besar nilai C, maka waktu pemodelan akan semakin lama. Jika dilihat dari sisi koefisien, akurasi relatif stabil hanya selisih 1%.
Berdasarkan Lampiran 3, terlihat bahwa akurasi kernel polynomial sangat bergantung kepada nilai d (derajat kernel). Semakin kecil nilai d (yaitu 2), semakin tinggi akurasi yang dihasilkan. Jika dilihat dari sisi waktu pemodelan, semakin besar nilai d yang digunakan, semakin cepat pemodelannya, namun semakin kecil akurasi yang diperoleh. Adapun polynomial dengan derajat d=2 disebut juga sebagai kernelquadratic.
Kernel RBF
Berdasarkan Lampiran 4, terlihat bahwa akurasi tidak terlalu dipengaruhi parameter C pada nilai C = 21 sampai dengan C = 24 memiliki akurasi antara 92.44% sampai dengan 97.20%. Namun pada nilai C = 25 untuk semua koefisien (13, 20, dan 26) akurasinya turun drastis hingga 76.46% pada koefisien 26. Akurasi tertinggi diperoleh dengan menggunakan nilai C sekecil mungkin, dalam penelitian ini C = 21.
Berdasarkan Lampiran 5 jika dilihat dari parameter σ akurasinya relatif stabil (baik dari koefisien 13, 20, dan 26) berkisar antara 93.04% sampai dengan 98.41%. Akurasi tertinggi diperoleh dengan menggunakan koefisien 20 (yaitu 98.41%), dan akurasi terendah diperoleh dengan menggunakan koefisien 26 (yaitu 93.04%).
Perbandingan SVM dan PNN
Perbandingan SVM dan PNN ini dilakukan dengan cara membandingkan hasil rata-rata akurasi berdasarkan koefisien dan data latih menggunakan data hasil ekstraksi ciri yang sama.
Tabel 11 Perbandingan rata-rata akurasi berdasarkan usia dan jenis kelamin menggunakan SVM dengan kernel RBF
Kelas Koefisien 13
(%)
Hasil rata-rata akurasi menggunakan PNN dari keenam kelas yang diujikan jika dilihat dari kelas dan koefisien dapat dilihat pada Tabel 12.
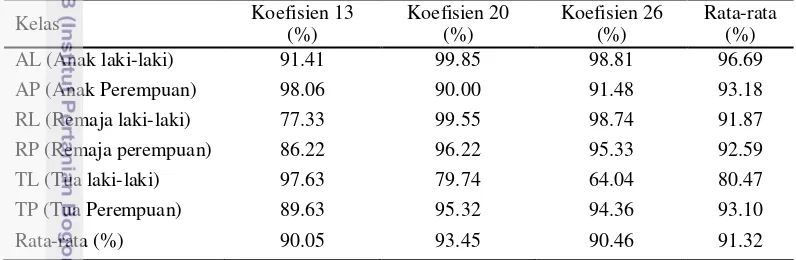
Tabel 12 Perbandingan rata-rata akurasi berdasarkan usia dan jenis kelamin menggunakan PNN (Fransiswa 2010)
Kelas Koefisien 13
(%)
Berdasarkan Tabel 11 jika dilihat dari sisi koefisien, rata-rata akurasi yang diperoleh menggunakan koefisien 13, 20, dan 26 sangat stabil dan sangat tinggi. Rata-rata akurasi tertinggi diperoleh dengan menggunakan koefisien 26 yaitu 98,13%. Adapun jika dilihat dari sisi usia dan jenis kelamin, data dengan akurasi tertinggi berasal dari kelas TP (tua perempuan) yaitu sebesar 99.32%. Hasil rata-rata akurasi berdasarkan usia dan jenis kelamin menggunakan PNN disajikan pada Tabel 12.
Berdasarkan Tabel 12 di atas, penggunaan koefisien 20 pada pengenalan pola menggunakan PNN menghasilkan akurasi rata-rata yang paling tinggi dibandingkan dengan penggunaan koefisien 13 dan koefisien 26. Hal ini menunjukkan banyaknya jumlah koefisien belum tentu mempengaruhi akurasi.
17
Gambar 9 Perbandingan rata-rata akurasi berdasarkan jenis kelamin dan koefisien menggunakan SVM dengan kernel RBF
Gambar 10 Perbandingan rata-rata akurasi berdasarkan jenis kelamin dan koefisien menggunakan PNN (Fransiswa 2010)
Implementasi
Tahapan-tahapan implementasi terdiri atas beberapa tahap, dimulai dari pemilihan model terbaik berdasarkan subset fold (Lampiran 1), pemilihan data latih, dan pemilihan koefisien yang digunakan.
Berdasarkan Lampiran 8, model dengan akurasi tertinggi diperoleh pada kernel RBF dengan koefisien 26 subset 2 sebesar 98.67% disajikan pada Tabel 13.
Tabel 13 Akurasi tertinggi kernel RBF (koefisien 26 dengan subset 2)
Data
Berdasarkan Tabel 14 disarankan menggunakan koefisien 26 dengan data latih 75% karena menghasilkan akurasi yang paling tinggi.
0
koefisien 13 (%) koefisien 20 (%) koefisien 26 (%)
akura
koefisien 13 (%) koefisien 20 (%) koefisien 26 (%)
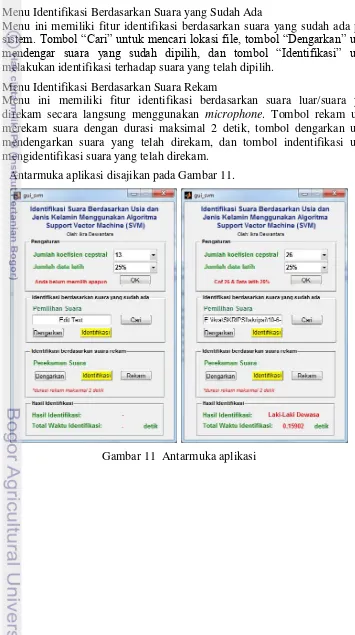
Antarmuka Aplikasi
Aplikasi yang dikembangkan memiliki tiga menu, di antaranya: 1 Menu Pengaturan
Menu ini pengguna dihadapkan kepada pilihan option box yaitu pemilihan koefisien (13, 20, 26) dan jumlah data latih (25%, 50%, 75%).
2 Menu Identifikasi Berdasarkan Suara yang Sudah Ada
Menu ini memiliki fitur identifikasi berdasarkan suara yang sudah ada pada sistem. Tombol “Cari” untuk mencari lokasi file, tombol “Dengarkan” untuk mendengar suara yang sudah dipilih, dan tombol “Identifikasi” untuk melakukan identifikasi terhadap suara yang telah dipilih.
3 Menu Identifikasi Berdasarkan Suara Rekam
Menu ini memiliki fitur identifikasi berdasarkan suara luar/suara yang direkam secara langsung menggunakan microphone. Tombol rekam untuk merekam suara dengan durasi maksimal 2 detik, tombol dengarkan untuk mendengarkan suara yang telah direkam, dan tombol indentifikasi untuk mengidentifikasi suara yang telah direkam.
Antarmuka aplikasi disajikan pada Gambar 11.
19
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelititan yang sudah dilakukan, dapat ditarik kesimpulan sebagai berikut:
1 MFCC dapat diterapkan sebagai salah satu teknik ekstraksi ciri suara. MFCC menghasilkan representasi vektor ciri tanpa mengurangi karakteristik suara. 2 SVM dapat diterapkan sebagai pengenalan suara berdasarkan kisaran usia
dan jenis kelamin. SVM menghasilkan akurasi yang bervariasi sesuai dengan parameter-parameter yang digunakan, seperti jumlah data latih, jumlah koefisien, dan kernel yang digunakan.
3 Pengujian kernel-kernel menghasilkan tingkat akurasi yang berbeda-beda. Pemodelan tercepat diperoleh menggunakan kernel RBF yaitu 662 detik dengan rata-rata akurasi tertinggi yaitu 98.24%.
4 Hasil rata-rata akurasi yang diperoleh dari penelitian Fransiswa (2010) yaitu 91.32%, sedangkan pengenalan pola menggunakan SVM dengan kernel RBF menghasilkan rata-rata akurasi 98.24%. Akurasi kernel RBF lebih tinggi 6.92%.
Saran
Penelitian ini memungkinkan untuk dikembangkan menjadi yang lebih baik lagi. Beberapa saran untuk penelitian selanjutnya adalah:
1 Menambahkan data pembicara pada setiap kelompok, sehingga sesuai dengan standar jumlah data statistik, yang berjumlah 30 orang pada setiap kelompoknya (Mattjik 2006).
2 Menguji kernel RBF dengan menggunakan noise cancelling (sinyal suara ditambahkan noise). Tujuannya adalah ingin mengetahui apakah kernel RBF selain cepat dalam pemodelan, juga tahan terhadap noise.
DAFTAR PUSTAKA
Buono A, Jatmiko W, Kusumo P. 2009. Perluasan metode MFCC 1D ke 2D sebagai esktraksi ciri pada sistem identifikasi pembicara menggunakan hidden markov model (HMM). Jurnal Makara Sains 13(1):87-93.
Cortes C, Vapnik V. 1995. Support vector networks [Internet]. [diunduh 2013 Mar 22]. Tersedia pada http://www.springerlink.com/index/ K238JX04HM87J80G.pdf
Do MN. 1994. DSP mini-project: an automatic speaker recoginiton system.
Fransiswa R. 2010. Pengembangan PNN pada pengenalan kisaran usia dan jenis kelamin berbasis suara [skripsi]. Bogor (ID): Institut Pertanian Bogor. Ganapathiraju A. 2002. Application of support vector machine to speech
Hsu C, Lin C. 2002. A comparison of methods for multiclass support vector machines. IEEE Transaction on Neural Networks. 13(2):415-425.
[IDAI] Ikatan Dokter Anak Indonesia. 2009. Overview adolescent health problems and services [Internet]. [diunduh 2010 Januari 26]. Tersedia pada: http://www.idai.or.id/remaja/artike.asp?q= 200994155149.
Kohavi R. 1995. A study of cross validation and bootstrap for accuracy estimation and modem selection. Di dalam: Proceedings of the 14th International Joint Conference on Artificial Intelligence. Quebec, Kanada. hlm 1137-1193. Mattjik AA. 2006. Perancangan Percobaan dengan Aplikasi SAS dan Minitab.
Bogor (ID): Institut Pertanian Bogor.
Orfanidis SJ. 2010. Introduction to Signal Processing. New Jersey (US): Rutgers Univ.
Pelton GE. 1993. Voice Processing. Singapura (SG): McGraw Hill.
Suhartono MN. 2007. Pengembangan model identifikasi pembicara dengan probabilistic neural network[skripsi]. Bogor (ID): Institut Pertanian Bogor. Wang S, Mathew A, Chen Y, Ci L, Ma L, Lee J. 2009. Empirical analysis of
21
Lampiran 1 Akurasi pengenalan pola suara menggunakan kernel linear dilihat dari pengaruh parameter C
Kernel Cepstral Parameter
Total: 1305 Rata-Rata: 89.55
20
Total: 1717 Rata-Rata: 90.72
26
Total: 2201 Rata-Rata: 91.50 Total: 5223 Rata-Rata: 90.60
Lampiran 2 Akurasi pengenalan pola suara menggunakan kernel polynomial dilihat dari pengaruh parameter C
Kernel Cepstral Parameter
Total: 1317 Rata-Rata: 95.96
20
Total: 1340 Rata-Rata: 96.37
Lampiran 3 Akurasi pengenalan pola suara menggunakan kernel polynomial dilihat dari pengaruh parameter d
Kernel Cepstral Parameter Total: 1507 Rata-Rata: 94.62
20 Total: 1509 Rata-Rata: 94.87
26 Total: 1469 Rata-Rata: 91.34
Total:4485 Rata-Rata: 93.61
Lampiran 4 Akurasi pengenalan pola suara menggunakan kernel RBFdilihat dari pengaruh parameter C
Total: 1119 Rata-Rata: 92.65
20 Total: 1077 Rata-Rata: 91.56
23
Lampiran 5 Akurasi pengenalan pola suara menggunakan kernel RBFdilihat dari pengaruh parameter σ Total: 758 Rata-Rata: 97.26
20 Total: 851 Rata-Rata: 97.23
Lampiran 6 Akurasi kernel linear dengan C = 2 berdasarkan subset (S) yang digunakan
Data latih Data uji Koefisien 13
Rata-Rata
Koefisien 20
Rata-Rata
Koefisien 26
Rata-Rata
S1 S2 S3 S4 S1 S2 S3 S4 S1 S2 S3 S4
75% 25% 94.00 96.67 86.67 92.00 92.33 97.33 94.00 90.00 92.00 93.33 96.67 96.00 90.00 94.00 94.17
50% 50% 88.00 94.00 91.00 90.00 96.00 93.00 90.00 96.00 93.00
25% 75% 89.78 90.00 85.33 92.44 89.39 89.56 91.11 88.44 92.44 90.39 90.00 91.11 91.11 92.89 91.28
90.59 93.56 86.00 92.22 90.91 92.30 93.70 89.22 92.22 92.24 92.22 94.37 90.56 93.44 92.81
Lampiran 7 Akurasi kernel polynomial dengan C = 2 dan d = 2 berdasarkan subset (S) yang digunakan
Data latih Data uji Koefisien 13
Rata-Rata
Koefisien 20
Rata-Rata
Koefisien 26
Rata-Rata
S1 S2 S3 S4 S1 S2 S3 S4 S1 S2 S3 S4
75% 25% 98.00 96.67 98.00 97.33 97.50 96.67 98.00 96.67 96.00 96.83 96.67 98.00 98.00 96.67 97.33
50% 50% 98.00 97.67 97.83 97.33 96.67 97.00 97.00 96.67 96.83
25% 75% 91.11 95.56 90.89 93.78 92.83 94.22 96.44 95.11 95.78 95.39 93.56 95.11 94.44 94.67 94.44 95.70 96.63 94.44 95.56 96.06 96.07 97.04 95.89 95.89 96.41 95.74 96.59 96.22 95.67 96.20
Lampiran 8 Akurasi kernel RBF dengan C = 2 dan σ = 4 berdasarkan subset (S) yang digunakan
Data latih Data uji Koefisien 13
Rata-Rata
Koefisien 20
Rata-Rata
Koefisien 26
Rata-Rata
S1 S2 S3 S4 S1 S2 S3 S4 S1 S2 S3 S4
75% 25% 99.33 98.67 98.00 97.33 98.33 98.67 99.33 99.33 98.67 99.00 100,00 99.33 98.67 97.33 98.83
50% 50% 97.67 99.00 98.33 98.33 99.00 98.67 98.00 99.33 98.67
25% 75% 97.11 96.44 97.78 99.11 97.61 97.11 97.33 97.56 98.22 97.56 97.33 97.33 96.67 97.33 97.17
25