APLIKASI PENGENALAN SUARA DIGITAL NADA DASAR PIANO
SKRIPSI
M. ARDIANSYAH
091402062
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
APLIKASI PENGENALAN SUARA DIGITAL NADA DASAR PIANO
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah
Sarjana Teknologi Informasi
M. ARDIANSYAH
091402062
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul : APLIKASI PENGENALAN SUARA DIGITAL
NADA DASAR PIANO
Kategori : SKRIPSI
Nama : MUHAMMAD ARDIANSYAH
Nomor Induk Mahasiswa : 091402062
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI
Diluluskan di
Medan, 23 Agustus 2014
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Marihat Situmorang, M.Kom NIP. 19631214 198903 1 001
Romi Fadillah Rahmat,B.Comp.Sc.,M.Sc. NIP. 19860303 201012 1 004
Diketahui/Disetujui oleh
Program Studi Teknologi Informasi Ketua,
PERNYATAAN
APLIKASI PENGENALAN SUARA DIGITAL NADA DASAR PIANO
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, 23 Agustus 2014
Muhammad Ardiansyah
PENGHARGAAN
Puji dan syukur penulis panjatkan kepada Allah SWT Yang Maha Pengasih dan Maha Penyayang, dengan segala rahmat dan karuniaNya lah penulis bisa menyelesaikan penyusunan tugas akhir ini.
Proses penyusunan skripsi ini tidak lepas dari dukungan dan bantuan dari pihak lain. Oleh karena itu penulis mengucapkan terima kasih banyak kepada :
1. Keluarga penulis, terutama kedua orang tua penulis. Ibunda, Adriaty Handayani dan Ayahanda, R. Epidaryanto yang selalu sabar dalam mendidik dan membesarkan penulis. Adik penulis Ananda Listiarini dan Kakak penulis Annisa Yunita yang selalu memberikan semangat kepada penulis.
2. Bapak Romi Fadillah Rahmat,B.Comp.Sc.,M.Sc. dan Bapak Drs. Marihat Situmorang, M.Kom selaku pembimbing yang telah banyak meluangkan waktu dan pikirannya, memotivasi dan memberikan kritik dan saran kepada penulis.
3. Bapak dan Ibu dosen pembanding.
4. Ketua dan Sekretaris Program Studi Teknologi Informasi Bapak M. Anggia Muchtar, ST.,MM.IT. dan Bapak M. Fadly Syahputra, B.Sc.,M.Sc.IT.
5. Dekan dan Pembantu Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara, semua dosen serta pegawai di Fakultas Ilmu Komputer dan Teknologi Informasi.
6. Kepada Melinda Agustien yang selalu memberikan motivasi, memberikan nasihat agar penulis dapat menyelesaikan penulisan tugas akhir ini dengan baik.
7. Kepada Nurul Khadijah, Ade Maulana yang selalu membantu penulis sehingga dapat menyelesaikan tugas akhir dengan baik.
8. Seluruh sahabat terbaik penulis yang selalu memberikan dukungan, Ade Tambunan, Ammar Adianshar, Ridzuan Ikram Fadjri, Julia Annisa, Yunisya Aulia Putri, Reza Elfandra, Ibnu setiawan, Raisha Ariani, Fanny sari wulandari, Yogi, Bora, Sheila, Septi, Aat, Ijal,Uti serta seluruh angkatan 09, serta teman-teman seluruh angkatan mahasiswa USU lainnya yang tidak dapat penulis sebutkan satu persatu, Semoga Allah SWT membalas kebaikan kalian dengan nikmat yang berlimpah.
ABSTRAK
Dalam bermain musik khususnya bermain piano, seorang pianist membutuhkan partitur dalam panduan untuk bermain musik. Partitur merupakan tulisan yang digunakan seorang pianist untuk menyimpan atau menyampaikan sebuah lagu. Banyak pianist yang tidak mempunyai keahlian dalam pembuatan partitur, khusunya dalam pembuatan musik yang spontan. Karena itu, diperlukan sebuah aplikasi yang dapat membantu dalam pembuatan partitur dari suara musik piano. Metode ekstraksi
Mel-Frequency Cepstral Coefficient dan metode pencocokan Learning Vector Quantization digunakan untuk membuat aplikasi tersebut. Metode MFCC digunakan untuk mengambil Vector – vector yang berada didalam sebuah lagu. Dan metode LVQ digunakan untuk mencocokkan data uji dengan data acuan yang telah disimpan terlebih dahulu. Output yang dihasilan dari sistem ini berupa partitur musik dari lagu yang telah diinput kedalam sistem.
VOICE RECOGNITION APPLICATIONS BASIC DIGITAL PIANO TONE
ABSTRACT
In playing music especially playing the piano, a pianist needs score to play music in the guide. Scores are writing who used by a pianist to store or deliver a song. Many pianists do not have expertise in the making of sheet music, especially in spontaneous music-making. Therefore, we need an application that can help in the making of the music scores. Methods for extracting is Mel - Frequency cepstral coefficient and Learning Vector Quantization matching method is used to create such applications. MFCC method is used to retrieve Vectors which resides in a song. And LVQ method is used to match test data with reference data that has been stored in advance. output of this system in the form of sheet music of a song that has been inputed into the system.
DAFTAR ISI
Persetujuan i
Pernyataan ii
Penghargaan iii
Abstrak iv
Abstract v
Daftar isi vi
Daftar tabel vii
Daftar gambar viii
Bab 1 Pendahuluan 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 3
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 3
1.7 Sistematika Penulisan 4
Bab 2 Landasan Teori 5
2.1 Latar Belakang Pengenalan Ucapan 6
2.2 Suara Musik 7
2.3 Pengolahan Audio 7
2.4 Mel-Frequency Cepstrum Coefficient ( MFCC ) 9
2.4.1 DC – Removal 9
2.4.2 Pre – Emphasize Filtering 10
2.4.4 Windowing 12
2.4.5 Analisis Fourier 13
a. Discrete Fourier Transform ( DFT ) 15
2.4.6 Fast Fourier Transform 16
2.4.7 Mel-Frequency Warping 18
2.4.8 DCT 19
2.5 Jaringan Syaraf Tiruan 19
2.5.1 Learning Vector Quantization ( LVQ ) 20
2.6 Penelitian Terdahulu 21
Bab 3 Analisis dan Perancangan 23
3.1 Analisis Sinyal Suara 24
3.2 Analisis Ekstraksi Fitur Suara Menggunakan MFCC 24
3.2.1 Input Suara 24
3.2.2 DC- Removal 25
3.2.3 Pre-Emphasize 26
3.2.4 Frame Blocking 27
3.2.5 Windowing 28
3.2.6 Analisis Fourier 28
3.2.7 Filter Bank 29
3.2.8 Discrete Cosine Transform ( DCT ) 29
3.3 Pencocokan dengan Metode Learning Vector Quantization 30
3.3.2 Algoritma LVQ 30
3.4 Database 34
3.5 Antarmuka Sistem 35
Bab 4 Impelemntasi dan Pengujian Sistem 38
4.2 Skenario Uji Coba Sistem 39
Bab 5 Kesimpulan dan Saran 50
5.1 Kesimpulan 50
5.2 Saran 52
DAFTAR TABEL
Hal
Tabel 2.1. Fungsi – fungsi window dan Formulanya 13
Tabel 2. 2 Penelitian Terdahulu 21
Tabel 4.1 Rencana Pengujian Sistem 45
Tabel 4.2 Pengujian Sistem ( input data acuan ) 46
Tabel 4.3 Pengujian Sistem ( pengenalan data ) 46
Tabel 4.4 Sampe data pengujian sistem 47
Tabel 4.5 Processing time 48
DAFTAR GAMBAR
Hal
Gambar 2.1 Tahapan dalam Speech Recognition 7
Gambar 2.2 Struktur WAV 8
Gambar 2.3 Contoh Dari Pre- Emphasize Pada Sebuah Frame 10
Gambar 2.4 Contoh Frame Blocking 11
Gambar 2.5 Contoh Dari Spectogram 14
Gambar 2.6 Tiga Gelombang Sinusoidal Dan Superposisinya 15
Gambar 2.7 Domain Waktu Menjadi Domain Frekuensi 16
Gambar 2.8 Grafik Perbandingan Kecepatan Direct Calculation Dengan
Algoritma FFT 17
Gambar 2.9 Pembagian Sinyal Suara Menjadi Dua Kelompok 17
Gambar 2.10 Arsitektur Jaringan LVQ 20
Gambar 3.1Arsitektur Umum Aplikasi 23
Gambar 3.2 Flowchart DC-Removal 25
Gambar 3.3 Flowchart Pre-Emphasize Filter 26
Gambar 3.4 Flowchart Frame Blocking 27
Gambar 3.5 Database Aplikasi 35
Gambar 3.6 Rancangan Halaman Awal 36
Gambar 3.7 Rancangan Halaman Pengenalan 36
Gambar 4.1 Tampilan Awal Aplikasi 40
Gambar 4.2 Tampilan Menu Pengenalan 40
Gambar 4.3 Tampilan Menu Pengenalan 41
Gambar 4.4 Tampilan Spectogram Untuk Suara Input 41
Gambar 4.5 Tampilan Spectogram Suara Potong 42
Gambar 4.6 Partitur Hasil 43
Gambar 4.7 Tampilan Menu Admin 44
ABSTRAK
Dalam bermain musik khususnya bermain piano, seorang pianist membutuhkan partitur dalam panduan untuk bermain musik. Partitur merupakan tulisan yang digunakan seorang pianist untuk menyimpan atau menyampaikan sebuah lagu. Banyak pianist yang tidak mempunyai keahlian dalam pembuatan partitur, khusunya dalam pembuatan musik yang spontan. Karena itu, diperlukan sebuah aplikasi yang dapat membantu dalam pembuatan partitur dari suara musik piano. Metode ekstraksi
Mel-Frequency Cepstral Coefficient dan metode pencocokan Learning Vector Quantization digunakan untuk membuat aplikasi tersebut. Metode MFCC digunakan untuk mengambil Vector – vector yang berada didalam sebuah lagu. Dan metode LVQ digunakan untuk mencocokkan data uji dengan data acuan yang telah disimpan terlebih dahulu. Output yang dihasilan dari sistem ini berupa partitur musik dari lagu yang telah diinput kedalam sistem.
VOICE RECOGNITION APPLICATIONS BASIC DIGITAL PIANO TONE
ABSTRACT
In playing music especially playing the piano, a pianist needs score to play music in the guide. Scores are writing who used by a pianist to store or deliver a song. Many pianists do not have expertise in the making of sheet music, especially in spontaneous music-making. Therefore, we need an application that can help in the making of the music scores. Methods for extracting is Mel - Frequency cepstral coefficient and Learning Vector Quantization matching method is used to create such applications. MFCC method is used to retrieve Vectors which resides in a song. And LVQ method is used to match test data with reference data that has been stored in advance. output of this system in the form of sheet music of a song that has been inputed into the system.
BAB 1
PENDAHULUAN
1.1Latar Belakang
Semua bangsa maju di dunia seperti Jerman, Amerika, Jepang, Inggris, Australia dan
negara Eropa pada umumnya adalah bangsa yang musical. Pengertian musical yang
dimaksud disini adalah pertama dapat memainkan instrument musik atau menyanyi
dengan baik, pengertian kedua tidak dapat bermain musik atau bernyanyi dengan baik.
Tapi dapat mengapresiasi musik Yuriandran (2008).
Musik adalah salah satu stimulus yang menyenangkan dan telah lama hadir dalam
kehidupan manusia. Rentfrom dan Gosling (2007) menemukan bahwa pertanyaan
mengenai jenis musik yang paling disukai adalah topik utama percakapan pada
individu yang berkenalan. Selain media hiburan, msuik mempunya fungsi yang amat
kompleks . Scripp dan Subotnik (2003) menjelaskan bahwa musik mewakili proses
kognitif pada bidang lain dan meliputi aktivitas mental. Musik merupakan instrumen
pendidikan yang sangat kuat. Musik mampu merangsang alam bawah sadar kreatif.
Kebiasaan mendengarkan musik menjadi konsep penting terkait musik dan
kecerdasan. Musik adalah hasil seni budaya yang terdiri dari unsur – unsur suara atau
bunyi yang teratur sehingga terjadi harmoni yang memuaskan pendengarnya. Musik
dapat berfungsi sebagai perangsang semangat kreatif dan alternatif untuk keluar dari
kejenuhan serta penyeimbang tugas linguistik dan logis. Gallahue (dalam Sudjito dkk,
2007) menyatakan bahwa mendengarkan musik mampu menstimulasi kemampuan
belajar melalui ritme. Melodi dan harmoni. Berbicara tentang musik tidak bisa
diabaikan penjelasan Gardner(1999) mengenai intelegensi. Intelegensi menunjukkan
kemahira dan keterampilan memecahkan kesulitan yang ditemukan, serta menciptkan
persoalan yang memungkinkan pengembangan pengetahuan. Hal menarik dari
penjelasan Gardner adalah intelegensi musik dapat mengorganisir cara berfikir dan
bekerja sehingga membantu pengembangan kemampuan matematika. Spasial dan
Kreativitas dalam bermusik memerupakan faktor yang sangat penting dihayati
perkembangannya karena sangat berpengaruh dalam kehidupan sehari – hari.
Kreativitas dalam musik dapat juga diaplikasikan pada kehidupabn sehari- hari oleh
siapa saja dan dimana saja. Karena ada potensi kreativitas dimasing – masing individu
tergantung cara mengembangkannya. Kreativitas merupakan fenomena yang melekat
dengan kehidupan manusia dan merupakan hasil interaksi antar manusia dengan
lingkungan atau kebudayaan dan sejarah dimana kreatifias dapat tumbuh dan
meningkat tergantung kepada kondusif kebudayaan dan orangnya (Munandar, 2009 )
Penelitian – penelitian membuktikan bahwa musik memberikan banyak manfaat
kepada manusia seperti merangsang pikiran. Memperbaiki konsentrasi dan ingatan,
meningkatkan aspek kognitif, membangun kecerdasan emosional dan lain – lain.
Musik juga dapat menyeimbangkan fungsi otak kanan dan otak kiri yang berarti
menyeimbangkan perkembangan aspek intelektual dan emosional . anak – anak yang
mendapatkan pendidikan musik jika kelak dewasa akan menjadi manusia yang
berpikiran logis sekaligus cerdas, kreatif dan mampu mengambil keputusan serta
mempunyai empati. Penting sekali untuk memperkuat musikalitas anak sejak dini
karena musikalitas itu sangat istimewa mencakup perkembangan intelektual bagi
anak, emosional, sosial dan kemauan yang bakal mempengaruhi anak di masa yang
akan datang. Musik pada anak – anak akan meningkatkan kemampuan intelegensi
spesialnya sebesar 46 persen dibandingkan anak – anak yang jarang bermusik. Mereka
membuktikan adanya kaitan erat antara kemahiran bermusik dengan penguasaan level
matematika yang tinggi dan kemampuan sains lainya Deporter (2000).
Dewasa kini penggunaan piano, keyboard maupun pianika sudah merupakan
barang yang tidak mahal , banyak orang dapat mencoba belajar musik dari alat musik
piano.
1.2Rumusan Masalah
Dalam bermain alat musik piano, seorang pianis yang baru mulai belajar bermain
Diperlukannya sebuah software yang dapat merubah suara instrumen piano menjadi
partitur.
1.3Batasan Masalah
Batasan masalah dalam penelitian ini adalah :
1. Aplikasi dijalankan di dekstop.
2. Nada yang digunakan adalah nada dasar mayor.
3. Format input nada suara yang dimasukkan adalah WAV.
4. Menggunakan not ¼
1.4Tujuan Penelitian
Penelitian ini bertujuan untuk mengunakan metode Learning Vector Quantization
dalam mengkonversi nada suara digital piano menjadi partitur, dimana ekstraksi
cirinya menggunakan Mel-Frequency Cepstral Coefficient ( MFCC ) untuk
memudahkan user dalam membuat partitur berdasarkan nada yang dimainkannya.
1.5Manfaat Penelitian
Manfaat penelitian ini adalah :
1. Dapat mengetahui nada dari sebuah lagu tanpa mempunyai partiturnya.
2. Menghemat waktu dalam membuat partitur.
3. Sebagai bahan referensi untuk penelitian selanjutnya yang berkenaan dengan
voice recognition.
1.6Metodologi Penelitian
Langkah – langkah yang ditempuh dalam menyelesaikan penelitian adalah sebagai
1. Studi Literatur
Studi Literatur dilakukan dengan mengumpulkan informasi lebih lanjut mengenai
permasalahan yang akan dibahas seperti penelitian terdahulu, pengumpulan musik
yang ingin digunakan didalam aplikasi, relasi data yang ingin dibuat dan metode –
metode yang akan digunakan untuk permasalahan ini.
2. Pengumpulan Data
Pada tahap ini dilakukan pengumpulan data yang mendukung dalam penyelesaian
masalah yang diteliti secara sistematis.
3. Analisa dan Perancangan Sistem
Pada tahapan ini dilakukan analisis terhadap materi dan data yang telah didapat
sebelumnya untuk kemudian digunakan dalam penyelesaian suatu masalah dan
dapat digunakan untuk merancang sebuah sistem yang akan diimplementasikan
nantinya.
4. Implementasi Sistem
Pada tahapan ini penulis mengimplementasikan metode ekstraksi ciri
Mel-frequency Cepstral Coefficient dan metode Learning Vector Quantization kedalam
sistem. Implementasi meliputi pembuatan program untuk digunakan sebagai
aplikasi dari metode diatas.
5. Pengujian Sistem
Pada tahapan ini, dilakukan pengujian terhadap metode MFCC dan LVQ yang
telah diimplementasikan kedalam sistem untuk mengetahui kehandalannya apakah
telah sesuai dengan yang diharapkan dalam penelitian ini.
6. Dokumentasi Sistem
Pada tahap dokumentasi sistem ini, penulis menyusun laporan terhadap metode
MFCC dan LVQ dari aplikasi yang telah dibuat.
1.7Sistematika Penulisan
Metodologi penelitian yang digunakan pada penelitian ini adalah :
Bab I Pendahuluan
Bab ini akan berisikan tentang latar belakang, rumusan masalah, tujuan
penelitian, batasan masalah, manfaat penelitian, metodologi penelitian,
Bab II Tinjauan Pustaka
Bab ini menguraikan tentang metode Mel-Frequency Cepstrum
Coefficient dan metode Learning Vector Quantization, hal- hal yang
mendukung metode tersebut dan penelitian terdahulu.
Bab III Analisis dan Perancangan Sistem
Pada bab ini akan dijelaskan beberapa hal seperti deksripsi umum
perangkat lunak yang dibangun, analisa data dan arsitektur perangkat
lunak, dan sampai kepada perancangan sistem antarmuka.
Bab IV Analisis dan Perancangan Sistem
Pembahasan pada bab ini diarahkan pada bagaimana hasil dari Metode
MFCC dan LVQ yang telah dibangun dan bagaimana pengujiannya
dengan menggunakan sistem yang dibuat.
Bab V Kesimpulan dan Saran
Bab ini berisi tentang kesimpulan hasil penelitian dan saran – saran
yang berkaitan dengan penelitian selanjutnya untuk pengembangan
BAB 2
LANDASAN TEORI
2.1 Latar Belakang Pengenalan Ucapan
Pengenalan ucapan atau pengenalan wicara dalam istilah bahasa inggirisnya automatic
speech recognition (ASR) adalah suatu pengembangan teknik dan sistem yang
memungkinkan komputer untuk menerima masukan berupa kata yang diucapkan.
Teknologi ini memungkinkan suatu perangkat untuk mengenali dan memahami kata –
kata yang diucapkan dengan cara digitalisasi kata dan mencocokkan sinyal digital
tersebut dengan suatu pola tertentu yang tersimpan dalam suatu perangkat. Kata – kata
yang diucapkan diubah bentuknya menjadi sinyal digital dengan cara mengubah
gelombang suara menjadi sekumpulan angka yang kemudian disesuaikan dengan kode – kode tertentu untuk mengidentifikasi kata – kata tersebut, Hasil dari identifikasi kata yang diucapkan dapat ditampilkan dalam bentuk tulisan atau dapat dibaca oleh
perangkat teknologi sebagai sebuah komando untuk melakukan suatu pekerjaan.
Misalnya penekanan tombol pada telelpon genggam yang dilakukan secara otomatis
dengan komando suara Lestary (2009).
Perkembangan teknologi dalam bidang speech recognition bertujuan untuk
mewujudkan keinginan manusia dalam memaksimalkan fungsi PC sebagai alat yang
mampu mempermudah pekerjaan manusia disegala aspek. Hal yang hendak dicapai
adalah menciptakan PC yang mampu berinteraksi dengan manusia secara langsung
menggunakan bahasa manusia sehari – hari sesuai tata bahasa yang berlaku, studi
tentang pengenalan ucapan sudah dilakukan selama bertahun – tahun untuk mencapai
sukses yang ideal. Tetapi hal tersebut belum juga dapat terpenuhi sampai saat ini.
Masih perlu dilakukan penelitian dan peningkatan lebih lanjut terhadap metode
pengenalan yang sudah ada.
Secara umum , proses pengenalan ucapan dimulai dengan meng-input-kan suara
melalui microphone, sinyal suara yang menjadi input bersifat continue, untuk itu
diperlukan pemrosesan awal ( pre-processing) untuk mengubah sinyal tersebut
melalui proses ekstraksi ciri ( feature extraction ) untuk mendapatkan parameter
khusus yang menjadi bahan pembanding dalam proses pencocokan pola. Pada tahap
selanjutnya yaitu pencocokan pola, maka program akan membandingkan sinyal
ucapan masukan dengan sinyal pembanding lalu program menentukan keputusan.
Tahapan dalam speech recognition dapat dilihat pada gambar 2.1 Rachman (2006).
Sumber : Rachman (2006)
Gambar 2.1. Tahapan dalam Speech Recognition.
2.2 Suara Musik
Kehadiran musik sebagai bagian dari kehidupan manusia bukanlah hal yang baru.
Setiap budaya di dunia memiliki musik yang khusus diperdengarkan atau dimainkan
berdasarkan peristiwa – peristiwa bersejarah dalam perjalanan hidup anggota
masyarakatnya. Ada musik yang dimainkan untuk mengungkapkan rasa syukur atas
kelahiran seorang anak. Ada juga musik yang khusus mengiringi upacara – upacara
tertentu seperti pernikahan dan kematian. Musik juga menjadi pendukung utama untuk
melengkapi dan menyempurnakan beragam bentuk kesenian dan berbagai budaya.
Musik adalah suara yang disusun demikian rupa sehingga mengandung irama.
Lagu, dan keharmonisan terutama suara yang dihasilkan dari alat- alat yang dapat
menghasilkan bunyi – bunyian, walaupun musik adalah sejenis fenomena intuisi,
untuk mencipta, memperbaiki dan mempersembahkannya adalah suatu bentuk seni ,
mendengar musik adalah sejenis hiburan. Musik adalah sebuah fenomena yang sangat
unik yang bisa dihasilkan oleh beberapa alat musik.
2.3 Pengolahan Audio
Suara adalah sebuah sinyal yang merambat melalui perantara, suara dapat dihantarkan
dengan media air, udara, maupun benda padat, Dengan kata lain, suara adalah
didengar manusia berkisar antara 20 Hz sampai dengan 20 KHz, dimana Hz adalah
satuan frekuensi yang artinya banyak getaran per-detik (cps / cycle per second)
Rabiner (1993).
Perlengkapan produksi suara pada piano konvensional terdapat palu pemukul (
Hammer ),tuts ( Keys ), senar piano ( Strings ). Secara garis besar terdiri atas tuts
ditekan oleh manusia, tuts ditekan menggerakan palu pemukul yang selanjutnya akan
memukul strings yang ada. Setiap tuts berbeda bunyinya.
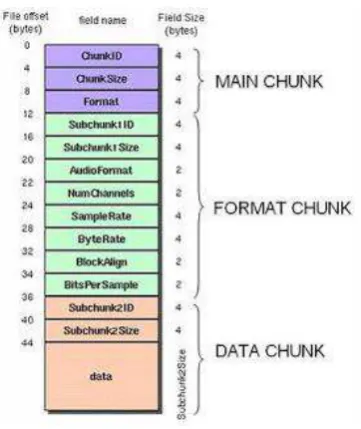
Format file “.WAV” merupakan bagian dari spesifikasi RIFF milik Microsoft
yang digunakan untuk penyimpanan file-file mulitimedia. File wav dimulai dengan
bagian header dan diikuti oleh rentetan data chunk. File wav terdiri dari 3 bagian,
yaitu main chunk, format chunk, dan data chunk.
Sinyal suara yang direpresentasikan file WAV dalam bentuk discrete, berupa deret
bilangan yang merepresentasikan amplitude dalam domain waktu. Pada bagian file
header terdapat informasi tentang file WAV tersebut, diantaranya menyatakan nilai
sample rate, jumlah channel, dan bit per sample. Dari keterangan pada file header
tersebut dapat diketahui berapa sampel yang dicuplik dari sinyal analog tiap detik
Wilson (2003). Struktur WAV dapat dilihatp ada gambar 2.2 :
Sumber: Wilson(2003)
2.4 Mel Frequency Cepstrum Coefficient ( MFCC )
Mel Frequency Cepstrum Coefficient ( MFCC ) merupakan salah satu metode yang
banyak digunakan dalam bidang speech recognition. Metode ini digunakan untuk
melakukan feature extraction, sebuah proses yang mengkonversikan sinyal suara
menjadi beberapa parameter. Keunggulan dari metode ini adalah :
Mampu menangkap karakteristik suara yang sangat penting bagi pengenalan suara atau dengan kata lain mampu menangkap informasi – informasi penting
yang terkandung dalam sinyal suara
Menghasilkan data seminimal mungkin tanpa menghilangkan informasi – informasi penting yang ada.
Mereplikasi organ pendengaran manusia dalam melakukan persepsi sinyal suara.
Perhitungan yang dilakukan dalam MFCC menggunakan dasar dasar perhitungan
short-term analysis. Hal ini dilakukan mengingat sinyal suara yang bersifat quasi
stationary. Pengujian yang dilakukan untuk periode waktu yang cukup pendek (sekitar
10 sampai 30 milidetik) akan menunjukkan karakteristik sinyal suara yang stationary.
Tetapi bila dilakukan dalam periode waktu yang lebih panjang, karakteristik sinyal
suara akan berubah sesuai dengan kata yang diucapkan.
MFCC feature extraction sebenarnya merupakan adaptasi dari sistem pendengaran
manusia, dimana sinyal suara akan di-filter secara linear untuk frekuensi rendah (
dibawah 1000Hz ) dan secara logaritmik untuk frekuensi tinggi ( diatas 1000Hz),
berikut blok diagram untuk MFCC Manunggal(2005).
2.4.1 DC- Removal
Remove DC Components bertujuan untuk menghitung rata-rata dari data sampel
suara, dan mengurangkan nilai setiap sampel suara dengan nilai rata-rata tersebut.
Tujuannya adalah mendapat normalisasi dari data suara input Putra(2011).
– ……..(1)
= sampel signal asli
= nilai rata-rata sampel signal asli = panjang signal
2.4.2 Pre – Emphasize Filtering
Pre – empahsize filtering merupakan salah satu jenis filter yang sering digunakan
sebelum sebuah signal diproses lebih lanjut, Filter ini mempertahankan frekuensi –
frekuensi tinggi pada sebuah spektrum, yang umumnya tereleminasi pada saat proses
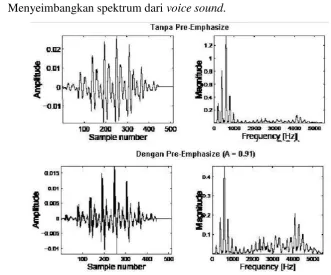
produksi suara. Tujuan dari Pre – emphasize Filtering ini adlaah ( Manunggal , 2005)
a. Mengurangi noise ratio pada signal, sehingga dapat meningkatkan kualitas
signal
b. Menyeimbangkan spektrum dari voice sound.
Sumber : Manunggal, 2005
Gambar 2.3 Contoh dari Pre-Emphasize pada sebuah frame
Pada gambar diatas terlihat bahwa distribusi energi pada setiap frekuensi terlihat
lebih seimbang setelah diimplementasikan pre-emphasize filter. Bentuk yang paling
umum digunakan dalam pre-emphasize filter adalah sebagai berikut.
dimana :
= signal hasil pre-emphasize filter
= signal sebelum pre-emphasize filter
2.4.3 Frame Blocking
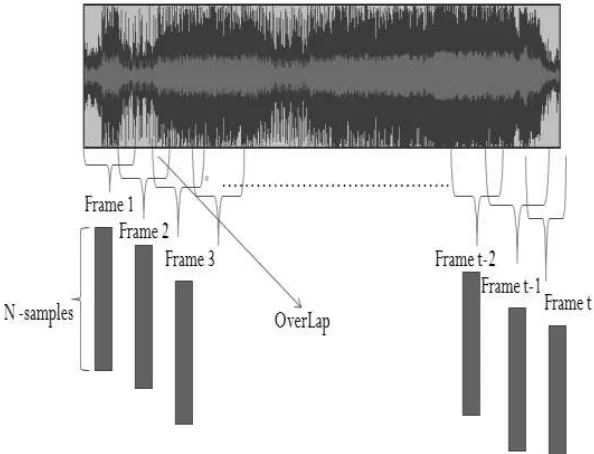
Karena sinyal suara terus mengalami perubahan akibat adanya pergeseran artikulasi
dari organ produksi suara, sinyal harus diproses secara short segments ( short frame ).
Panjang frame yang biasanya digunakan untuk pemrosesan sinyal adalah antara 10-30
milidetik. Panjang frame yang digunakan, sangat mempengaruhi keberhasilan dalam
analisa spektral, di satu sisi, ukuran frame harus diperpanjang sepanjang mungkin
untuk dapat menunjukkan resolusi frekuensi yang baik, tetapi dalam slain sisi, ukuran
frame juga harus cukup pendek untuk dapat menunjukkan resolusi waktu yang baik
Ridwan(2011).
Sumber : Ridwan(2011)
Gambar 2.4 Contoh Frame Blocking
Proses frame yang dilakukan terus sampai seluruh sinyal dapat terproses. Selain
Panjang daerah overlap yang umum digunakan adalah kurang lebih 30% sampai 50%
dari panjang frame.
2.4.4 Windowing
Proses framing dapat menyebabkan terjadinya kebocoran spektral ( Spectral leakage )
atau aliasing, aliasing adalah timbulnya sinyal baru dimana memiliki frekuensi yang
berbeda dengan sinyal aslinya. Efek ini dapat terjadi karena rendahnya jumlah
sampling rate, ataupun karena proses frame blocking dimana menyebablan sinyal
menjadi discontinue, Untuk mengurangi kemungkinan terjadinya kebocoran spektral
maka hasil dari proses framing harus melewati proses window.
Ada banyak fungsi window, w(n), seperti yang ditabel 2.1 sebuah fungsi window
yang baik harus menyempit pada bagian main lobe, dan melebar pada bagian side
lobe-nya.
Berikut ini adalah representasi fungsi window terhadap sinyal suara yang
di-inputkan.
………..(3)
=Nilai sampel sinyal
=Nilai sampel dari frame sinyal ke i =Fungsi window
=Frame size, merupakan kelipatan 2
Setiap fungsi windows mempunyai karakteristik masing-masing, diantara berbagai
fungsi window tersebut, Blackman windows menghasilkan sidelobe level yang paling
tinggi ( kurang dari -58 dB ). Tetapi fungsi ini juga menghasilkan noise paling besar (
kurang dari 1,73 BINS), Oleh karena itum fungsi ini jarang sekali digunakan baik
untuk speaker recognition maupun speech recognition.
Fungsi Rectangle window adalah fungsi window yang paling mudah untuk
diaplikasikan , Fungsi ini menghasilkan noise yang paling rendah yaitu sekitar 1.00
Sidelobe level yang rendah tersebut menyebabkan besarnya kebocoran spektral yang
terjadi dalam proses feature extraction.
Fungsi window yang paling sering digunakan dalam aplikasi speech recognition
adalah Hamming window. Fungsi window ini menghasilkan sidelobe level yang tidak
terlalu tinggi (kurang dari -43 dB), selain itu noise yang dihasilkan pun tidak terlalu
besar ( kurang lebih 1.36 BINS ) Darmawan (2011).
Tabel 2.1 Fungsi – fungsi window dan Formulanya
Nama
window
Sequence domain waktu
Rectangular 1
Bartlett
Hanning
Hamming
Blackman
Tukey
Sumber : Darmawan(2011)
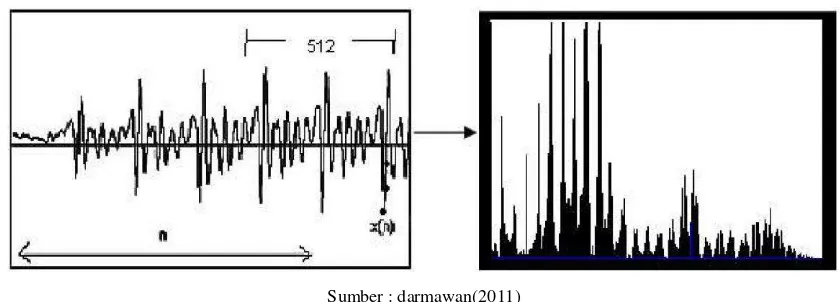
2.4.5 Analisis Fourier
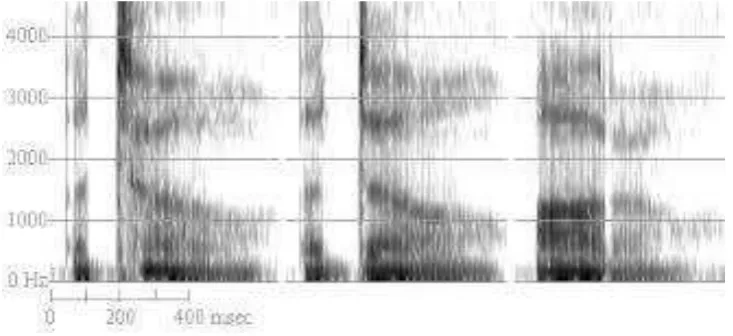
Analisis Fourier adalah sebuah bentuk yang memungkinkan untuk menganalisa
terhadap spectral propertis dari sinyal yang diinputkan. Representasi dari spectral
Dalam spectogram terhadap hubungan yang sangat erat antara waktu dan
frekuensi. Hubungan antara frekuensi dan waktu adalah hubungan berbanding
terbalik. Bila resolusi waktu yang digunakan tinggi. Maka resolusi frekuensi yang
digunakan akan semakin rendah. Kondisi seperti ini akan menghasilkan narrowband
spectogram, sedangkan wideband spectogram adalah kebalikan dari narrowband
spectogram
Sumber : Darmawan (2011)
Gambar 2.5 Contoh dari Spectogram
Inti dari transformasi fourier adalah menguraikan sinyal ke dalam komponen-
komponen bentuk sinus yang berbeda – beda frekuensinya. Gambar 2.11
menunjukkan tiga gelombang sinus dan superposisinya. Sinyal semula yang periodik
dapat diuraikan menjadi beberapa komponen bentuk sinus dengan frekuensi berbeda,
jika sinyal semula tidak periodik maka transformasi fourier-nya merupakan fungsi
frekuensi yang continue, artinya merupakan penjumlahan bentuk sinus dari segala
frekuensi, jadi dapat disimpulkan bahwa transformasi fourer merupakan representasi
domain frekuensi dari suatu sinyal. Representasi ini mengandung informasi yang tepat
Sumber : darmawan(2011)
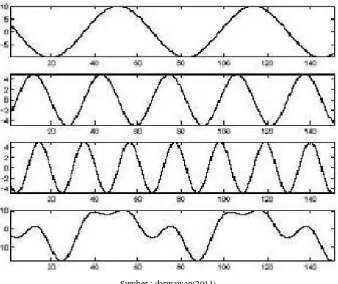
Gambar 2.6 Tiga Gelombang Sinusoidal dan Superposisinya
a. Discrete Fourier Transform ( DFT )
DFT merupakan perluasan dari transformasi fourier yang berlaku untuk sinyal – sinyal
diskrit dengan panjang yang terhingga. Semua sinyal periodik terbentuk dari
gabungan sinyal – sinyal sinusoidal yang menjadi satu dalam perumusanya dapat
ditulis:
∑
………(4)
= Jumlah sampel yang akan diproses = Nilai Sampel sinyal
= Variabel frekuensi discrete, dimana akan bernilai
Dengan rumus diatasa. Suatu sinyal suara dalam domain waktu dapat kita cari
frekuensi pembentuknya. Hal inilah tujuan dari penggunaan analisa Fourer pada data
domain frekuensi, Untuk pemrosesan sinyal suara, hal ini sangatlah menguntungkan
karena data pada frekuensi dapat diproses dengan lebih mudah dibandingkan data
pada domain waktu, karena pada domain frekuensi, keras lemahnya suara tidak
seberapa berpengaruh.
Sumber : darmawan(2011)
Gambar 2.7 Domain waktu menjadi domain frekuensi
Untuk mendapatkan spektrum dari sebuah sinyal dengan DFT diperlukan N buah
sampel data berurutan pada domain waktu, yaitu data x[m] sampai dengan x[m+N-1].
Data tersebut dimasukkan dalam fungsi DFT maka akan menghasilkan N buah data,
Namun karena hasil DFT adalah simetris, maka hanya N/2 data yang diambil sebagai
spektrum Darmawan (2011).
2.4.6 Fast Fourier Transform
Perhitungan DFT secara langsung dalam komputerisasi dapat menyebabkan proses
perhitungan yang sangat lama. Hal itu disebabkan karena DFT, dibutuhkan N2
perkalian bilangan kompleks. Karena itu dibutuhkan cara lain untuk meghitung DFT
dengan cepat. Hal itu dilakukan dengan menggunakan algoritma Fast Fourier
Transform ( FFT ) dimana FFT menghilangkan proses perhitungan yang kembar
dalam DFT. Algoritma FFT hanya membutuhkan N log2 N perkalian kompleks.
Algoritma recombine (DFT) melakukan N perkalian kompleks, dan dengan
metode pembagian seperti ini. Maka terdapat log2(N) langkah perkalian kompleks.
Hal ini berarti jumlah perkalian kompleks berkurang dari N2 (pada DFT) menjadi N
log2(N).
Hasil dari proses FFT adalah simetris antara indek – dan Oleh karena itu , umumnya hanya blok pertama saja yang akan digunakan dalam proses-proses selanjutnya.
2.4.7 Mel Frequency Warping
Mel frequency Warping umumnya dilakukan dengan menggunakan filterbank.
Filterbank adalah salah satu bentuk dari filter yang dilakukan dengan tujuan untuk
mengetahui ukuran energi dari frequency band tertentu dalam sinyal suara. Filterbank
dapat diterapkan baik pada domain waktu maupun domain frekuensi, tetapi untuk
keperluan MFCC, filterbank harus diterapkan dalam domain frekuensi,
Filterbank menggunakan representasi konvolusi dalam melakukan filter terhadap
signal konvolusi dapat dilakukan dengan melakukan multiplikasi antara spektrum
signal dengan koefesien filterbank. Berikut ini adalah rumus yang digunakan dalam
perhitungan filterbanks.
∑ ………..(5)
= Jumlah magintude spectrum = Magnitude spectrum pada frekuensi
= koefesien filterbank pada frekuensi = Jumlah channel dalam filterbank
Persepsi manusia terhadap frekuensi dari signal suara tidak mengikuti linear scale
, frekuensi yang sebenarnya (dalam Hz) dalam sebuah signal akan diukur manusia
secara subyektif dengan menggunakan Mel scale, Mel frequency scale adalah linear
frekuensi scale pada frekuensi dibawah 1000 Hz, dan merupakan logarithmic scale
2.4.8 DCT
DCT merupakan langkah terakhir dari proses utama MFCC feature extraction.
Konsep dasar dari DCT adalah mendekorelasikan mel spectrum sehingga
menghasilkan representasi yang baik dari property spektral local. Pada dasarnya
konsep dari DCT sama dengan inverse fourier transform. Namun hasil dari DCT
mendekati PCA ( principle component analysis). PCA adalah metode static klasik
yang digunakan secara luas dalam analisa data dan kompresi. Hal inilah yang
menyebabkan seringkali DCT menggantikan inverse fourier transform dalam proses
MFCC Feature Extraction. Berikut adalah formula yang digunakan untuk menghitung
DCT.
∑ ………..(6) = Keluaran dari proses filterbank pada index K
= Jumlah koefesien yang diharapkan
Koefesien ke nol dari DCT pada umumnya akan dihilangkan, walaupun
sebenarnya mengindikasikan energi dari frame signal tersebut. Hal ini dilakukan
karena, berdasarkan penelitian – penelitian yang pernah dilakukan , koefesien ke nol
tidak reliable terhadap speaker recognition Putra(2011).
2.5 Jaringan Syaraf Tiruan
Semakin berkembangnya teknologi komputer menyebabkan pemanfaatan teknologi
jaringan syaraf untuk mempermudah manusia dalam memecahkan masalah tertentu
semakin banyak diterapkan. Tetapi banyak masalah yang kelihatan mudah bagi
manusia cukup sulit dilakukan oleh komputer, misalnya dalam pengenalan suatu tanda
tangan yang telah dikenal sebelumnya. Kemudahan yang dirasakan oleh manusia
tersebut disebabkan otak manusia memproses informasi yang didapat dengan
menggunakan elemen-elemen yang saling terkoneksi dalam suatu jaringan yang
disebut Neuron, sebaliknya jika masalah-masalah tersebut dipecahkan komputer,
maka menimbulkan berbagai kesulitan (marimin,2002)
Didasar pada kemudahan otak manusia melakukan hal-hal tersebut, para ahli
merancang suatu jaringan yang memiliki konsep menyerupai jaringan otak manusia
sehingga dapat berpikir dan mengambil keputusan seperti yang dilakukan oleh otak
manusia, jaringan tersebut disebut jaringan syaraf tiruan (JST).
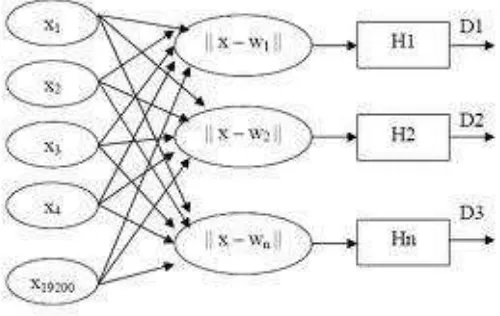
2.5.1 Learning Vector Quantization (LVQ)
Menurut Jang, et al.(1997) LVQ merupakan metode klasifikasi data adaptif
berdasarkan pada data pelatihan dengan informasi kelas yang diinginkan. Walaupun
merupakan suatu metoda pelatihan supervised tetapi LVQ menggunakan teknik data
clustering unsupervised untuk praproses set data dan penentuan cluster centernya.
Arsitektur jaringan LVQ hampir menyerupai suatu jaringan pelatihan kompetitif
kecuali pada masing-masing unit outputnya yang dihubungkan dengan suatu kelas
tertentu.
Kusumadewi dan hartai (2006) menyatakan LVQ merupakan metoda untuk
melakukan pelatihan terhadap lapisan-lapisan kompetitif supervised. Lapisan
kompetitif akan belajar secara otomatis untuk melakukan klasifikasi terhadap vektor
input yang diberikan. Apabila beberapa vektor input memiliki jarak yang sangat
berdekatan, maka vektor-vektor input tersebut akan dikelompokkan dalam kelas yang
sama.
Sumber : Ridwan(2011)
Gambar 2.10 Arsitektur Jaringan LVQ
Jaringan LVQ terdiri atas 2 lapis yaitu lapis kompetitif dan lapis linear, Lapis
kompetitif disebut juga Self Organizing Map (SOM). Disebut lapis kompetitif karena
neuron – neuron berkompetisi dengan algoritma kompetisi yang akan menghasilkan
1. Nilai error yang lebih kecil dibandingkan jaringan syaraf tiruan seperti
backpropagation.
2. Dapat meringkas data set yang besar menjadi vektor codebook berukuran kecil
untuk klasifikasi.
3. Dimensi dalam codebook tidak dibatasi seperti dalam teknol nearest
neighbour.
4. Model yang dihasilkan dapat diperbaharui secara bertahap.
Kekurangan dari LVQ adalah :
1. Dibutuhkan perhitungan jarak untuk seluruh atribut.
2. Akurasi model dengan bergantung pada inisialisasi model serta parameter
yang digunakan (learning rate, iterasi dan sebagainya ).
3. akurasi juga dipengaruhi distribusi kelas pada data training.
4. sulit untuk menentukan jumlah codebook vektor untuk masalah yang diberikan. Ridwan (2011).
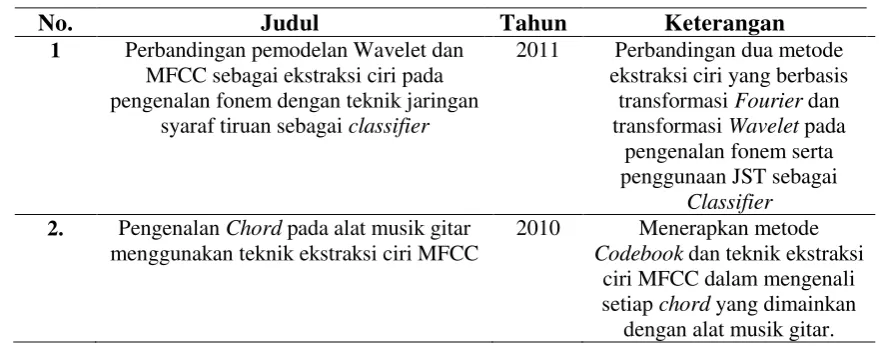
2.6 Penelitian Terdahulu
Dibagian ini akan dijabarkan beberapa penelitian terdahulu. Saat ini sudah banyak
penelitian yang berbasis pengenalan suara. Untuk lebih jelasnya. Pada table 2.2
berikut ini akan dijelaskan penelitian – penelitian yang telah dibuat sebelumnya.
Tabel 2.2 Penelitian terdahulu 2. Pengenalan Chord pada alat musik gitar
No. Judul Tahun Keterangan
3. Verifikasi biometrika suara menggunakan metode MFCC dan DTW
2011 Penggunaan metode MFCC
untuk proses ekstarksi ciri dari sinyal wicara dan metode
DTW ( Dynamic Time Warping ) untuk proses
pencocokan.
4. Pengenalan Suara Alat Musik Dengan
Metode Jaringan Saraf Tiruan ( JST )
Learning Vector Quantization Melalui ekstraksi Koefisien Cepstral
2011 Pengenalan suara alat musik dengan menggunakan metode
ekstraksi ciri Koeffisien Cepstral dan metode pencocokan adalah Learning
BAB 3
ANALISIS DAN PERANCANGAN
Pada bab ini , akan dibahas beberapa hal diantaranya yaitu analisa, design, dan
implementasi metode MFCC untuk extraksi fitur dan LVQ dalam pengenalan suara
piano.
Pre-Emphasis
Frame Blocking
Windowing
Fast Fourier Transform
LVQ
DCT Filterbank / Mel
Frequency Warping
DC-Removal Input Suara
Hasil Partitur
M F C C
3.1 Analisis sinyal suara
Suara yang dihasilkan piano adalah sinyal analog dengan amplitudo yang berubah
secara kontinyu terhadap waktu. pada manusia frekuensi suara yang dihasilkan adalah
50 Hz – 10 KHz. Sedangkan pada suara alat musik memliki frekuensi 20 Hz – 20 Khz.
Suara yang berada pada range pendengaran manusia disebut Audio dan
gelombangnya sebagai accoustic signal sedangkan suara diluar range pendengaran
manusia dapat dikatan sebagai noise ( getaran yang tidak teratur dan tidak berurutan
dalam berbagai frekuensi, tidak dapat didengar manusia ).
agar sinyal suara yang kontinyu dapat diproses. Maka harus digunakan teknik
sampling. Teknik sampling adalah proses mengubah gelombang bunyi ke dalam
interval waktu tertentu sehingga menghasilkan representasi digital dari suara.
3.2 Analisis Ekstraksi Fitur SuaraMenggunakan MFCC
Dalam ekstraksi fitur. Suara yang telah ada akan dilakukan proses untuk mendapatkan
ciri khusus dari sebuah suara. Dengan megubah suara menjadi parameter parameter.
Parameter tersebut akan digunakan ke metode selanjutnya untuk dilakukan
pencocokan ciri khusus. Didalam MFCC. Dilakukan beberapa tahap, yaitu :
1. Input suara
2. DC-Removal
3. Pre – Emphasis
4. Frame blocking
5. Windowing
6. Fast Fourier Transform
7. Filter bank / Mel-Frequency Warping
8. DCT
3.2.1 Input Suara
dengan memasukkan suara keprogram untuk memasukkan suara. Kali ini akan
menggunakan nada DO sebagai bahan uji.
3.2.2 DC-Removal
Remove DC Components bertujuan untuk menghitung rata-rata dari data sampel
suara, dan mengurangkan nilai setiap sampel suara dengan nilai rata-rata tersebut.
Tujuannya adalah mendapat normalisasi dari data suara input.
START
AVG = Ratarata(sig
nal)
I = 0
Hasil (i) = signal (i) - AVG I < signal
length END
No
Yes
Gambar 3.2 Flowchart DC-Removal
Contoh data dengan banyak vektor 10 : -0.9,0.9,-0.9,0.6,-0.4,0.9,0.9,0.2,-0.2,0.6
Rumus DC-removal telah dijelaskan pada bab 2 rumus 1.
Jadi : π =
= 0.17
menghasilkan =
3.2.3 Pre-Emphasis
Langkah kedua adalah untuk memmpertahankan frekuensi – frekuensi tinggi pada
sebuah spektrum , yang umumnya tereleminasi pada saat proses produksi suara.
START
AVG = Ratarata(sig
nal)
I = 0
Hasil (i) = signal (i) + signal (i-1) *
alpha I < signal
length No
Yes
Gambar 3.3 Flowchart Pre-Emphasis Filter
Merujuk pada bab sebelumnya di rumus poin ke 2. Dengan α = -0.97 menggunakan contoh vektor
jadi : – –
– –
menghasilkan :
3.2.4 Frame Blocking
Setelah digunakan pre-emphasize filter untuk mempertahankan suara suara tinggi.
Digunakan Frame Blocking untuk memetakan data – data yang akan diambil. Signal
akan diproses secara Short Segment ( Short Frame ).
START
MEMBAGI SIGNAL
WS = Sampling rate / framerate
I = 0 to cols -1
a = i*ws +1 b = a + ws =1
Simpan Blok
END NO
YES
3.2.5 Windowing
Proses framing dapat menyebabkan terjadinya kebocoran spektral atau aliasing.
Aliasing adalah signal baru dimana memiliki frekuensi yang berbeda dengan signal
aslinya. Efek ini dapat terjadi karena rendahnya jumlah sampling rate,ataupun karena
proses frame blocking dimana menyebabkan signal menjadi discontinue. Maka pada
tahap ini dilakukan proses window pada frame – frame yang telah dihasilkan oleh
tahap sebelumnya. Hal ini bertujuan untuk meminimalkan diskontinuitas pada bagian
awal dan akhir sinyal . Model window yang digunakan pada sistem ini adalah haming
window
3.2.6 Analisis Fourier
Analisa berdasarkan fourier transform sama artinya dengan analisa spektrum, karena
fourier transform merubah signal digital dari time domain ke domain frekuensi. FFT
dilakukan dengan membagi N buah titik pada transformasi dikrit menjadi 2, masing –
masing ( N/2 ) titik transformasi. Proses memecah menjadi (N/4) dan seterusnya
sehingga diperoleh titik minimum.
FFT ( Fast Fourier Transform ) adalah teknik perhitungan cepat dari DFT. FFT
adalah DFT dengan teknik perhitungan yang cepat dengan memanfaatkan sifat
periodical dari transformasi fourier. FFT yang digunakan pada tahap ini adalah FFT
Cooley-Tukey.. adapun algoritma FFT Cooley-Tukey adalah :
∑
Procedure filterbank
{ menghitung nilai Mel Spectrum i.s : Sinyal FFT
f.s : Sinyal Hasil Filterbank } kamus
H: double I,N : integer Algoritma For I = 0 to n do
Begin
H[i] ← ( 2595 * log ( 1 + 1000/700 )) / ( X[i] / 2 );
S[1] ← H[i] * X[i];
3.2.7 Filter Bank
Magnitude hasil dari proses FFT selanjutnya akan melalui tahap filterbank
∑
Dimana : = Jumlah magnitude Spectrum
= Magitude spectrum pada frekuensi j
= Koefesien filterbank pada frekuensi = Jumlah channel dalam filterbank
Untuk mendapatkan Hi digunakan rumus :
Berikut ini adalah Algoritma untuk proses Filterbank
3.2.8 Discrete Cosine Transform ( DCT )
Hasil dari DCT ini adalah fitur – fitur yang dibutuhkan oleh penulis untuk melakukan
proses analisa terhadap pengenalan suara tersebut. Menggunakan rumus :
= Keluaran dari proses filterbank pada indeks k = jumlah koefesien yang diharapkan
Berikut ini adalah algoritma untuk proses DCT.
3.3 Pencocokan dengan metode Learning Vector Quantization ( LVQ )
LVQ merupakan salah satu jaringan saraf tiruan yang melakukan pemebelajaran
secara terawasi. LVQ mengklasifikasikan input secara berkelompok ke dalam kelas
yang sudah didefenisikan melalui jaringan yang telah dilatih. Dengan kata lain LVQ
mendapatkan n input dan mengkelompokkan ke dalam m output. Arsitektur jaringan
LVQ ini terdiri dari input, lapisan kohonen, dan lapisan output.
Pada proses pelatihan, LVQ menggunakan lapisan kohonen, dimana pada proses
pelatihan jaringan ini akan dibandingkan dengan nilai dari vektor yang dilatih dengan
semua elemen pemroses. Jarak terkecil antara vektor yang dilatih dengan elemen
pemroses akan menentukan kelas dari data yang dilatih.
3.3.2 Algoritma LVQ
Pada beberapa literature mungkin ditemui beberapa algoritma tentang LVQ yang
berbeda. Secara garis besar, algoritma LVQ adalah sebagai berikut. Procedure DCT ( k : integer, dct : float )
Kamus
K : integer Fbank : float ; Algoritma
For ( int n = 0 ; N <= k ; N++ ) Begin
Sum = 0.0;
Sum += fbank[k-1]*cos(n*(k-0,5) * ( PI/ Fiternum));
K+1;
1. Langkah pertama adalah menentukan masing masing kelas output,
menentukan bobot, dan menenetapkan learning rateα
2. Bandingkan masing – masing input dengan masing – masing output bobot
yang telah ditetapkan dengan melakukan pengukuran jarak antara masing –
masing bobot wodan input xp. persamaannya adalah sebagai berikut
–
3. Nilai minimum dari hasil perbandingan itu akan menentukan kelas dari vektor
input dan perubahan bobot dari kelas tersebut. Perubahan untuk bobot baru (
wo’ ) dapat dihitung dengan perasamaan berikut.
Untuk input dan bobot yang memiliki kelas yang sama :
Untuk input dan bobot yang memiliki kelas yang berbeda : –
Berikut contoh vektor fitur :
Nada yang akan diuji =
Nada latih =
=
=
Dengan Epoch = 5 , Learning Rate ( ) = 0.05 dan pengurangan Learning Rate (LR)
= 0.002. Proses pelatihan yang terjadi adalah sebagai berikut :
1. Proses Pelatihan
Data uji di hitung bobotnya dibandingkan dengan nada latih
yang ada.
=√
Bobot data latih kedua
√
Bobot data latih ketiga
=√
Jarak terpendek adalah pada data latih pertama, sehingga bobot ke -1 yang baru adalah
:
Iterasi 1:
– – ( – )
– – ( – )
Didapatlah vektor baru w1
Pengurangan learning Rate
LR =
Iterasi 2 :
– –
( – )
– – ( – )
Didapat
Pengurangan learning Rate
LR =
Iterasi 3:
Didapat vektor sementara hasil iterasi kedua
– –
( – )
– –
( – )
Sehingga didapatlah hasil vektor yang baru
2. Proses Pengenalan
Pengenalan nada terhadapat bobot yang sudah didapat, dilakukan dengan mencari
jarak antara bobot nada uji dan nada acuan. Jarak bobot terpendek dengan nada acuan
merupakan kelas dari nada uji. Berikut merupakan satu nada untuk menguji metode
LVQ :
Dari nada uji tersebut, nilai fitur adalah Selanjutnya nilai
tersebut akan diproses dengan nada acuan untuk mencari jaraknya, seperti berikut :
Bobot data latih pertama
=√
Bobot data latih kedua
√
Bobot data latih ketiga
=√
Bobot terkecil terletak pada kelas data pertama. Maka nada uji merupakan kelas yang
sama dengan data latih pertama.
3.4 Database
Pada database applkasi ini teradapat 2 tabel, tabel pertama adalah tabel jenis nada
yaitu database untuk menyimpan jenis nada apa yang akan tersimpan kedalam
database. Dan satu tabel lagi adalah tabel vektor. Dimana tabel vektor berguna untuk
menyimpan data acuan yang akan digunakan untuk mencocokkan dengan data
Gambar 3.5 Database Aplikasi
3.5 Antarmuka Sistem
Interface ( antarmuka sistem ) diperlukan untuk mempermudah seorang user dalam
menggunakan atau mengakses sebuah applikasi. Antarmuka sistem merupakan sebuah
alur komunikasi anatar user dengan sistem
Dengan kata lain antarmuka sistem digunakan sebagai media antara user dan
komputer agar dapat berinteraksi satu sama lain. Sehingga user dapat lebih mudah
mengerti dan menggunakan sistem tersebut.
Disini akan dijabarkan tentang rancangan halaman dan menu sistem yang akan
dibuat. Berikut adalah gambar rancangan dasar antarmuka dari aplikasi :
1. Rancangan Halaman Awal ( Home )
Rancanngan awal berisi tombol input dari lagu yang ingin masukkan. Partitur
gambar jadi yang akan dihasilkan dari pengenalan suara. Terdapat juga tombol
3. Rancangan halaman pelatihan
BAB 4
IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab ini akan dijelaskan implementasi ekstraksi ciri MFCC dan metode LVQ
pada sistem sesuai dengan perancangan sistem yang telah dijabarkan pada bab 3.
Kemudian dilakukannya pengujian pada sistem yang telah dibangun.
4.1 Implementasi Sistem
Implementasi sistem adalah prosedur yang dilakukan untuk menyelesaikan desain
sistem yang telah dibuat untuk memenuhi syarat yang telah dirancang.. komponen
yang dibutuhkan dalam implementasi sistem adalah :
a. Hardware ( Perangkat keras )
Hardware adalah komponen komponen / peralatan yang merupakan dasar dari
sebuah sistem komputer dalam menjalankan sistem. Adapun hardware
yang digunakan:
1. Processor Intel Core 2 Duo `2.7 Ghz.
2. 2 GB RAM DDR3 ( Memory )
3. Mouse
4. Keyboard
5. Hard Disk 320 GB
b. Software ( Perangkat Lunak )
Software adalah sekumpulan instruksi yang telah diprogram yang digunakan
untuk Memproses, mengendalikan dan mengkoordinasikan kerja pada elemen – elemen Perangkat keras komputer didalam sebuah sistem informasi. Adapun software yang digunakan adalah :
1. Operating Sistem Windows 7 Ultimate
3. MySql Versi 5.1.30
4.2 Skenario Uji Coba Sistem
Pada sub-bab skenario uji coba ini akan dilakukan pengujian berdasarkan 2 langkah
penggunaan sistem. Langkah pertama adalah langkah pelatihan nada. Dan langkah
kedua adalah pengenalan nada.
4.2.1 tampilan awal applikasi
Gambar 4.1 Tampilan awal applikasi
Pada tampilan awal tersebut. disediakan tiga buah tombol. yang pertama adalah
tombol pengenalan. Kedua adalah tombol menu admin. Yaitu menu untuk melakukan
pelatihan. Yang ketiga adalah tombol tentang. Yang berisi perancang sistem
Gambar 4.2 Tampilan Menu Pengenalan
Pada menu pengenalan. Disediakan tombol untuk pilih file yang akan menginput file dengan filter format “.WAV”. apabila file telah diinput dan di pilih tombol kenali. Maka not yang ada didalam file akan dikenali dan ditulis satu persatu di text box jenis
not. Dan ada 2 opsi untuk menampilkan spectogram. Yaitu tamplan spectogram suara
input. Dan tampilan spectogram suara hasil potong . dimana suara hasil potong adalah
Gambar 4.3 Tampilan menu pengenalan
Pada tampilan form diatas. Setelah nada diinput, maka tombol kenali ditekan. Dalam proses penampilan partiturnya. Jenis not akan ditampilkan satu persatu kedalam form. Yang merupakan not dari musik yang diinput terlebih dahulu
Gambar 4.4 Tampilan Spectogram untuk suara input
potong. Pada spectogram tersebut terlihat bagian dari lagu yang mana yang akan diproses untuk diambil ekstraksinya.
Gambar 4.5 Tampilan spectogram suara potong
Setelah dilakukan perkenalan. Maka hasil akhir dari pengenalan adalah gambar
Gambar 4.6 Partitur hasil not
4.2.3Tampilan menu admin
Gambar 4.7 Tampilan menu admin
Pada menu admin terdapat 2 cara dalam menyimpan data acuan. Yang pertama adalah
dengan menggunakan MFCC saja langsung diproses dan disimpan ke database.
Atapun menggunakan LVQ dalam memproses data acuannya. Hal ini dimaksudkan
agar range data acuan lebar. Sehingga dapat menggenali suara not yang akan dikenal.
4.2.4 Tampilan Tentang
Berisi nama dan nim dari pembuat applikasi
Gambar 4.8 Tampilan menu tentang
Pengujian sistem penting dilakukan untuk menguhu dan memastikan bahwa hal – hal
yang terdapat didalam sistem telah sesuai dengan apa yang ingin diselesaikan.
Metode pengujian yang diterapkan pada penelitian ini adalah metode ekstraksi ciri
Mel-Frequency Cepstrum Coefficient Dengan metode pencocokannya adalah metode
Learning Vector Quantization
4.3.1 Rencana Pengujian Sistem
Rancangan pengujian sistem yang akan diuji dengan metode pengujian black box
dapat dilihat pada tabel 4.1 berikut.
Tabel 4.1 Rencana Pengujian Sistem
No. Komponen sistem yang diuji Butir Uji
1. Halaman Awal Mencoba semua menu
2. Halaman pengenalan Tombol Pilih data
Tombol mainkan data
Tombol Tampilkan
Spectogram
Tombol tampilkan
spectogram data uji
Tombol Buka Gambar
3. Halaman Pilih File Memilih file yang akan
diuji dengan format “.Wav’
4. Halaman Menu Admin Tombol Pilih File
Tabel Isi database
Tombol Pelatihan data
Tabel 4.1 Rencana Pengujian Sistem
4.3.2 Kasus dan hasil Pengujian Sistem
4.3.2.1 Pengujian Input data
1. Input data acuan
Pada tabel 4.2 Berikut ini akan dilakukan pengujian sistem untuk input data acuan .
input data acuan dilakukan oleh admin yang akan mengisi data acuan.:
Tabel 4.2 Pengujian sistem ( input data acuan )
No. Skenario Uji Hasil yang diharapkan Hasil pengujian
Tabel 4.2 Pengujian sistem ( input data acuan ) ( lanjutan )
No. Skenario Uji Hasil yang diharapkan Hasil Pengujian
Pada tabel 4.4. Dilakukan pengujian sistem untuk pengenalan suara. Pengenalan suara
dilakukan oleh user. Data yang diinput berupa file musik yang akan dirubah menjadi
partitur.
5. Halaman Tentang Menampilan data pembuat
Tabel 4.3 Pengujian Sistem ( Pengenalan Data )
No. Skenario Uji Hasil yang diharapkan Hasil pengujian
3. Memilih tombol kenali Sistem akan mengenali data yang dipilih dan mencocokannya
Berisi file partitur berupa images Berhasil
4.3.3 Pengujian kinerja Sistem
Pengujian kinerja sistem dilakukan dengan memasukkan sampel data sebanyak 4 buah
lagu. Beriut adalah sampel data pengujian data :
Tabel 4.4 Sampel data pengujian sistem
No. Nama lagu Banyak not Format
1. Balonku. 57 .wav
2. Cicak 27 .wav
3. Kartini 23 .wav
4. Doremi 3 .wav
Pengujian sistem ini dilakukan agar penulis dapat mengetahui akurasi dari sistem yang
telah dibangun. Adapun langkah – langkahnya adalah :
1. User mengisi data acuang dari nada yang akan digunakan untuk melakukan
pengenalan kedalam sistem
2. User memilih lagu apa yang akan dikenalkan ke dalam sistem
Pelatihan sistem dilakukan dengan memasukkan 20 data latih nada mayor dengan
epoch 5, Learning Rate = 0.02 dan pengurangan Learning Rate = 0.00005. Semakin
rendah nilai Learning Rate maka persentase pengenalan makin lebih besar.
Pengujian yang dilakukan selanjutnya adalah pengujian terhadap data unuk
mengetahui running time dari sistem yang telah dibuat. Tabel 4.6. Berikut adalah hasil
pengujian running time terhadap 4 data pada sampel data
Tabel 4.5 Processing time
Dengan menganalisa data dari tabel diatas. Maka dapat ditarik kesimpulan bahwa
proses dalam sistem rata – rata mengkonsumsi waktu sekitar 10 detik untuk mengolah
data sebanyak 25 not.
Pengujian selanjutnya dilakukan pengujian untuk menguji ketepatan sistem apabila
4. Cicak – Cicak 27 Lambat 27 27 100%
5. Cicak – Cicak 27 Sedang 25 5 20%
6. Cicak – Cicak 27 Cepat 17 0 0%
7. Balonku 57 Lambat 57 57 100%
8. Balonku 57 Sedang 52 3 5%
9. Balonku 57 Cepat 36 0 0%
Total persentase kecocokan didapat dengan
% pengenalan =
Persentase diatas didapat bahwa tempo yang lambat merupakan tempo yang paling
pas untuk digunakan dalam aplikasi ini. Hal ini terjadi karena terjadi pemotongan
suara yang tidak tepat apabila tempo yang digunakan menjadi sedang dan cepat.
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan pembahasan implementasi dan pengujian yang telah dilakukan maka dapat
diperoleh beberapa kesimpulan :
1. Semakin rendah nilai Learning Rate pada LVQ maka persentase pengenalan makin
lebih besar.
2. Pemotongan nada untuk pemprosesan nada yang masi statis. Sehingga pemotongan
nada yang berdekatan menjadi tidak tepat.
3. Nilai Learning Rate yang paling optimal pada masalah ini yaitu 0.02.
4. Penggunaan metode Mel-Frequency Cepstrum Coefficient ( MFCC ) dengan metode
pencocokan Learning Vector Quantization ( LVQ ) dapat diimplementasikan pada
aplikasi pengenalan nada suara piano untuk dibuat menjadi partitur.
5. Dengan adanya aplikasi, maka user dapat membuat partitur tanpa harus menulisnya
satu persatu apa nada yang dimainkan, sehingga lebih mudah dalam pembuatan
5.2 Saran
Sistem ini dirancang dan dibangun berdasarkan ide dan alur pemikiran dari penulis, maka
untuk menghasilkan sistem yang lebih baik dan maksimal diperlukan saran dari pihak
manapun untuk melengkapi kekurangan yang ada pada sistem ini. Saran dari penulis
yaitu:
1. Sistem ini dapat dikembangkan untuk menambah tempo pada lagu. Sehingga
pemotongan nada suara pada data uji dapat dikenalkan berapa lama tempo yang lagi
dimainkan.
2. Sistem ini dapat dikembangkan untuk menambah data acuan yang lebih kompleks
lagi. Tidak Cuma nada dasar saja yang menjadi data acuan.
3. Sistem ini juga dapat dilakukan dengan metode dan algoritma pada sistem
DAFTAR PUSTAKA
Andriana, A.D dan Irfan Maliki., 2011. Perangkat lunak untuk membuka applikasi pada
komputer dengan perintah suara menggunakan metode Mel Frequency Coefficient (
MFCC ). Skripsi. Universitas Komputer indonesia.
Ayunisa, Y. Dian,. 2012. Perancangan Sistem pengenalan suara untuk pengamanan dan
pemantauan fasilitas PLTA. Skripsi. Institut Teknologi Surabaya.
Darmawan, Yudi. 2011. Speech recognition Menggunakan Metode Mel-Frequency Cepstrum
Coefficient dan Algoritma Dynamic Time Warping. Skripsi. Universitas Sumatera
Utara.
DePorter B. et. Al. 2000. Quantum Teaching : Mempraktikkan Quantum Learning Di Ruang-
Ruang Kelas. Kaifa. Bandung.
Gardner. H. 1999. Intelegence Reframed: Multiple Intelligence for 21st Century. New York:
Basic Books.
Lestary, J. 2009. Aplikasi Pengenalan Ucapan Kata Bahasa Inggris Menggunakan Linear
Predictive Coding ( LPC ) dan Hidden Markov Model ( HMM ). Tesis. Universitas
Gunadharma.
Manunggal, H.S. 2005. Perancangan Dan Pembuatan Perangkat Lunak Pengenalan Suara
Pembicara dengan Menggunakan Analisa MFCC Feature Extraction. Skripsi.
Surabaya. Universitas Kristen Petra.
Masitah. 2008. Tingkat Pemrosesan Informasi pada mahasiswa yang memiliki kebiasaan
mendengarkan musik rap. Skripsi. Universitas Sumatera Utara.
Munandar, S.C.U. 2009. Pengembangan Kreativitas Anak Berbakat. Jakarta: PT Rineka
Cipta dan Dep. Pendidikan dan Kebudayaan.
Mustofa, Ali. 2007. Sistem Pengenalan Penutur Dengan Metode Mel-Frequency Wrapping.