PENERAPAN
BLOOM FILTER
PADA
CACHE
DENGAN TINGKAT
FALSE POSITIVE
YANG RENDAH
ANDRI HIDAYAT
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Penerapan Bloom Filter
pada Cache dengan Tingkat False Positive yang Rendah adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2016
Andri Hidayat
RINGKASAN
ANDRI HIDAYAT. Penerapan Bloom Filter pada Cache dengan Tingkat False
Positive yang Rendah. Dibimbing oleh FAHREN BUKHARI dan HERU
SUKOCO.
Objek/data merupakan bagian penting dalam suatu penyimpanan database. Objek/data adalah data secara umum yaitu dapat berupa dokumen, file, maupun gambar yang tersimpan didalam database. Setiap objek akan disimpan menggunakan alamat tertentu dalam ruang penyimpanan. Untuk mendapatkan suatu objek di dalam ruang penyimpanan memerlukan teknik pencarian yang baik sehingga objek yang dicari dapat ditemukan.
Pencarian suatu objek pada umumnya memerlukan kecepatan dan keakuratan terhadap objek yang ditemukan. Teknik pencarian berkaitan dengan pengecekan membership suatu objek dalam suatu set. Pencarian suatu objek, sederhananya dilakukan dengan mengecek satu per satu dari objek yang ada sampai objek tersebut ditemukan. Pencarian dengan cara seperti ini mempunyai akurasi yang tinggi tetapi memerlukan waktu yang lama untuk mendapatkan suatu objek terutama pada suatu set yang sangat besar.
Penerapan teknik Bloom filter untuk mendapatkan objek pada suatu set data yang besar merupakan hal yang tepat. Walaupun dalam penerapannya teknik
Bloom filter ini akan mengakibatkan adanya false positive, namun penggunaan
teknik ini lebih baik jika diterapkan pada suatu set dengan objek yang sangat besar. False positive yang dihasilkan dari teknik Bloom filter bisa diminimalisir dengan memvariasikan variabel-variabel yang dapat mempengaruhinya. Beberapa variabel yang berpengaruh pada false positive adalah jumlah objek, jumlah bit
yang disediakan, dan jumlah pemetaan objek (map bit).
Penelitian ini menguji keakuratan algoritme Bloom filter menggunakan algoritme sequential search untuk mendapatkan membership suatu objek pada suatu set yang besar yang di-cache. Selain itu untuk mendapatkan kombinasi yang tepat dari parameter-parameter yang bisa mempengaruhi adanya false positive
pada Bloom filter sehingga mendapatkan tingkat false positive yang rendah. Metode dalam penelitian ini diawali dengan merancang model Bloom filter
dan sequential search, kemudian dilanjutkan dengan membuat simulasi untuk
kedua model yang ada. Simulasi dengan membuat sekenario bahwa terdapat satu set objek dengan jumlah yang sangat besar. Kemudian ditetapkan sebagian kecil objek yang akan disimpan pada buffer. Tahapan dilanjutkan dengan memilih satu objek yang ada pada set secara acak untuk selanjutnya dibandingkan dengan objek pada buffer menggunakan Bloom filter dan menggunakan sequential search. Berikutnya yaitu tahapan menghitung false positive dan false negative serta menghitung perbedaan waktu antara hasil pencarian menggunakan Bloom filter
dan sequential search. Tahapan selanjutnya setelah tahapan simulasi secara
keseluruhan adalah analisis terhadap hasil, evaluasi, dan penarikan kesimpulan. Dalam penelitian ini didapatkan hasil bahwa kecepatan pencarian
membership suatu objek pada set yang sangat besar menggunakan metode Bloom
filter lebih cepat yaitu rata-rata 10µs dan cenderung lebih stabil bahkan lebih
iv
positive terendah dihasilkan oleh kombinasi parameter jumlah objek= 2000000
jumlah bit = 8, dan map bit = 7 dengan objek yang ada pada buffer sebesar 6%.
SUMMARY
ANDRI HIDAYAT. Bloom Filter Implementation in Cache with Low Level of False Positive. Supervised by FAHREN BUKHARI and HERU SUKOCO.
Object/data is an important part in a database storage . Object/data is data in general that can include documents, files , or images stored in the database. Each object will be stored using a particular address in the storage space . Getting an object until the object found. Searching in this way has high accuracy but requires a lot of time to find the object.
Applying Bloom filter technique to get the object in large data set is the right thing. Although practically Bloom filter will make false positives, the use of this technique is better when it is applied to a set with very large object. False positives resulted from Bloom Filter technique can be minimized by varying the variables affecting it. Some of the variables affecting false positive is the number of objects, the number of bits available, and the number of mapping objects (map bit).
This study examined the accuracy of the Bloom filter algorithm by using sequential search algorithm to obtain membership of an object on a large set cached. Correct combination of parameters that can affect false positive is able to generate low false positive level.
This study began by designing a model Bloom filter and Sequential Search and creating simulation for both models. Simulations were carried out by creating scenarios which had set of objects with enormous number. Then determining small set of objects to be stored in buffer. Furthermore, selecting an existing object on the set randomly which was compared to the objects in the buffer using Bloom filter and Sequential search. The next stage was counting false positive and false negative and calculatjng the time difference between the search results using Bloom filter and Sequential search. The next stages were the analysis of the results, evaluation, and conclusion.
The results of this study showed that the searching speed of object
membership in large set using Bloom filter was faster which was 10μs average and tended to be more stable and faster (0μs) than using Sequential search which could take up to 420μs to search the same number of objects. Lowest false
positives were generated by combination of parameters number of objects = 2000000, number of bits = 8, and map bit = 7 with the number of objects in the buffer is 6%.
vi
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis ini
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
PENERAPAN
BLOOM FILTER
PADA
CACHE
DENGAN TINGKAT
FALSE POSITIVE
YANG RENDAH
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
ii
iii
Judul Tesis : Penerapan Bloom Filter pada Cache dengan Tingkat False Positive
yang Rendah Nama : Andri Hidayat
NIM : G651120141
Disetujui oleh Komisi Pembimbing
Dr Ir Fahren Bukhari, MSc Ketua
DrEng Heru Sukoco, SSi MT Anggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
Dr Ir Sri Wahjuni, MT
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
v
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan April 2014 ini adalah
Bloom filter, dengan judul Penerapan Bloom Filter pada Cache dengan Tingkat
False Positive yang Rendah.
Terima kasih penulis ucapkan kepada Bapak Dr Ir Fahren Bukhari, MSc dan Bapak DrEng Heru Sukoco, SSi, MT selaku komisi pembimbing serta Ibu Dr Ir Sri Wahjuni, MT selaku penguji sekaligus ketua program studi Ilmu Komputer, yang telah banyak memberikan saran pada penelitian ini. Ungkapan terima kasih juga disampaikan kepada keluarga tercinta Ayahanda Muhammad Usman dan Ibunda Wadidah, Istri tercinta Irmawati dan anakku Tara Taseefa Fariza, serta saudara-saudaraku dan seluruh keluarga atas segala do'a, dukungan baik moril maupun materil serta kasih sayang dan motivasinya selama ini. Semoga Allah
Subhanahuwata’ala selalu merahmati.
Di samping itu, penghargaan penulis sampaikan kepada Direktur Politeknik Negeri Sambas atas kesempatan yang diberikan untuk melanjutkan studi ke jenjang S2, dan kepada Direktorat Jenderal Pendidikan Tinggi (DIKTI) melalui Beasiswa BPPDN 2013 atas pemberian fasilitas baik pembiayaan maupun sarana prasarana selama penyusunan studi dan karya ilmiah ini.
Terima kasih kepada pengelola pascasarjana, seluruh dosen dan staf akademik Fakultas Matematika dan Ilmu Pengetahuan Alam (MIPA) khususnya departemen Ilmu Komputer Institut Pertanian Bogor, Terima kasih juga penulis sampaikan kepada Sdr. Muhammad Fuad, Rake, Fahmi Amir, Ahmad Ridho sebagai teman diskusi penulis dalam menyelesaikan tesis ini, teman-teman di Lababoratorium Net Centric Computing (Lab. NCC) dan teman-teman MKom angkatan 14 dan 15 atas kebersamaan, dukungan dan bantuannya selama kuliah dan dalam penyelesaian penelitian ini.
Akhir kata semoga karya ilmiah ini bermanfaat bagi pembaca dan pengembangan ilmu pengetahuan pada umumnya.
Bogor, Agustus 2016
vii
DAFTAR ISI
DAFTAR TABEL xi
DAFTAR GAMBAR xi
DAFTAR LAMPIRAN xi
PENDAHULUAN 1
Latar Belakang 1
Rumusan Masalah 2
Tujuan Penelitian 2
Ruang Lingkup Penelitian 3
Manfaat Penelitian 3
TINJAUAN PUSTAKA 3
Bloom Filter 3
Probabilitas False Positive 6
Sequential Search 7
CRC32 8
METODE 9
Perancangan 10
Simulasi 10
Analisis Hasil 11
Evaluasi 11
HASIL DAN PEMBAHASAN 12
Perancangan 12
Perancangan Bloom Filter 12
Perancangan Sequential Search 13
Simulasi Pembangkitan Objek 13
Simpan Objek pada Buffer 14
Get Objek X 14
Periksa Objek X dengan Bloom Filter 14
Periksa Keberadaan Objek X dengan Sequential Search 15
Simulasi Menggunakan Bloom Filter 16
Simulasi Menggunakan Sequential Search 17
Analisis Hasil 17
Evaluasi 20
SIMPULAN DAN SARAN 21
Simpulan 21
Saran 22
DAFTAR PUSTAKA 23
LAMPIRAN 24
DAFTAR TABEL
1 Parameter utama pada Bloom filter 5
2 Variabel yang digunakan untuk pengujian 11
3 Perbandingan waktu akses Bloom filter dengan Sequential search 19
DAFTAR GAMBAR
1 Gambaran Bloom filter dengan 32 bit 4
2 Arsitektur Bloom filter 5
3 Ilustrasi register penampung hasil CRC sementara 8
4 Diagram Alir Tahapan penelitian 10
5 Proses Simulasi pada Bloom Filter dan Sequntial Search 16 6 Pengaruh jumlah objek terhadap False Positive 18
7 Pengaruh jumlah bit terhadap False Positive 18
8 Pengaruh Map bit terhadap False Positive 18
9 Grafik Perbandingan waktu akses Bloom filterVsSequential search 20
10 Tingkat false positive dari Bloom filter 21
DAFTAR LAMPIRAN
1 Garfik Pengaruh parameter utama terhadap false positive 25 2 Tabel-tabel perbandingan waktu pengaksesan objek antara Bloom
PENDAHULUAN
Latar Belakang
Jumlah pengguna internet/client yang semakin meningkat pada saat ini menyebabkan semakin tingginya akses pada suatu server. Pada tahun 2015 pengguna internet di seluruh dunia telah mencapai 3 miliyar orang, dan sepertiga dari pengguna internet di dunia tersebut mengakses internet melalui telepon seluler (https://www.emarketer.com/corporate/coverage#/results/1275/report). Peningkatan ini dapat dilihat dengan banyak masyarakat yang bergantung pada layanan internet untuk menunjang kegiatan dan aktifitasnya, bahkan untuk memenuhi kebutuhan sehari-hari mereka. Maraknya aplikasi sosial media dan bisnis online merupakan salah satu contoh yang banyak digunakan masyarakat untuk berinteraksi antara satu dengan yang lainnya serta untuk menunjang aktifitas keseharian mereka, sehingga terjadi peningkatan akses terhadap server.
Tingginya akses terhadap data/objek pada suatu server menyebabkan beban kerja server untuk melayani permintaan dari client juga meningkat sehingga mengakibatkan rendahnya respond time. Dalam hal ini data/objek yang dimaksud adalah data secara umum yaitu dapat berupa dokumen, file, maupun gambar yang tersimpan didalam database. Oleh karena itu diperlukan suatu cara untuk memenuhi permintaan client agar data yang diminta bisa didapat dengan baik. Salah satu upaya yang digunakan untuk meningkatkan respond time terhadap permintaan client yaitu dengan cara menempatkan objek lebih dekat pada client
yang dikenal dengan istilah cache (Tarkoma et al. 2012).
Ketika suatu objek diminta oleh client, maka objek tersebut akan disimpan pada cache terlebih dahulu. Cara ini memungkinkan untuk melayani permintaan terhadap suatu objek tanpa harus mengambil objek dari database sebagai sumber asli sehingga dapat mengurangi biaya komunikasi dan latency yang dihasilkan dari proses query database (Issa & Figueira 2012). Namun dengan keterbatasan jumlah objek yang ada pada cache, kemungkinan objek yang diminta client tidak berada pada cache. Untuk itu perlu mengambil kembali objek dari database untuk diberikan pada client. Hal ini akan memerlukan waktu yang lebih banyak ketika permintaan semakin tinggi dan objek yang diminta berada pada suatu set yang sangat besar.
Untuk mencari objek dalam suatu database/set yang sangat besar memerlukan teknik atau metode pencarian yang baik dan erat kaitannya dengan pengecekan membership suatu objek dalam suatu set (Broder & Mitzenmacher 2004). Teknik pencarian objek sangat menentukan kecepatan untuk mendapatkan objek yang dicari (Wei et al. 2011; Cheng & Ma 2013). Pengecekan membership
Cara lain yang dapat digunakan yaitu teknik pencarian membership suatu objek dengan mengutamakan kecepatan dan mentoleransi sedikit kesalahan. Kesalahan yang ditoleransi adalah kesalahan berupa objek yang bukan anggota tetapi dikatakan sebagai anggota dari set tersebut(false positive) (Guo et al. 2010). Teknik yang membolehkan adanya false positive dalam hal ini adalah teknik
Bloom filter. Bloom filter adalah struktur data yang digunakan untuk mengetahui
keanggotaan suatu objek pada suatu set (Is X ∈ S ?) (Bloom 1970). Performa dari suatu Bloom filter dipengaruhi oleh jumlah objek, jumlah bit, dan jumlah fungsi Hash (map bit) yang digunakan (Qiao et al. 2011; Qiao et al. 2014).
Kedua teknik pencarian menggunakan Bloom filter dan Sequential search
yang masing-masing mempunyai kelebihan yang berbeda dalam mendapatkan suatu objek dapat dijadikan sebagai bahan untuk menelusuri membership suatu objek pada suatu set dan mengurangi tingkat false positive. Oleh karenanya penelitian ini akan menggunakan teknik Bloom filter dengan teknik Sequential
search untuk mendapatkan membership suatu objek pada set yang besar dengan
tingkat false positive yang paling rendah sehingga objek cepat didapatkan. Selain itu teknik Sequential search juga digunakan untuk memverifikasi keakuratan dari teknik Bloom filter dalam mendapatkan suatu objek dalam suatu set yang sangat besar.
Agar penelitian ini mendapatkan hasil yang diharapkan maka akan dilakukan simulasi penerapan teknik Bloom filter dan Sequential search. Dalam simulasi ini akan diberikan data yang sama terhadap Bloom filter dan Sequential
search.
Rumusan Masalah
Berdasarkan latar belakang yang telah diungkapkan di atas dapat dibuat sebuah rumusan masalah. Permasalahan dalam penelitian ini adalah bagaimana mendapatkan suatu objek dengan menggunakan teknik Bloom filter yang mengedepankan kecepatan tetapi mentolerir adanya false positive, diuji dengan menggunakan teknik sequential search yang mengutamakan keakuratan namun memerlukan waktu yang lebih lama. Pengujian menggunakan teknik sequential
search ini akan mengetahui keakurasian dari teknik Bloom filter. Selain itu
diperlukan kombinasi parameter seperti apa yang tepat digunakan pada Bloom
filter untuk mendapatkan suatu objek pada suatu set yang besar.
Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk menguji keakuratan algoritme Bloom
filter menggunakan algoritme sequential search untuk mendapatkan membership
3 mempengaruhi adanya false positive pada Bloom filter sehingga mendapatkan tingkat false positive yang rendah.
Ruang Lingkup Penelitian
Agar dalam penelitian ini menjadi lebih terarah dan tidak menyimpang dari tujuan yang akan dicapai maka perlu ditetapkan batasan atau ruang lingkup penelitian. Adapun ruang lingkup dalam penelitian ini adalah:
1 Algoritme yang akan digunakan adalah Bloom filter dan sequential search. 2 Penelitian ini menggunakan model simulasi untuk menunjukkan kecepatan dan
keakuratan antara Bloom filter dan sequential search.
3 Data yang digunakan adalah data acak yang dibangkitkan dengan pembangkit data, dan digunakan untuk kedua algoritme.
4 Parameter yang diukur adalah false positive ratio dan waktu.
Manfaat Penelitian
Penelitian ini diharapkan dapat memberikan suatu rekomendasi penggunaan algoritme Bloom filter yang dapat diterapkan untuk mendapatkan
membership terhadap suatu objek pada suatu set yang sangat besar, sehingga
pengaksesan terhadap objek semakin cepat dengan akurasi yang tinggi.
TINJAUAN PUSTAKA
Sebagai topik yang menjadi pembicaraan dalam penelitian ini, maka akan dibahas secara ringkas tentang apa dan bagaimana sebenarnya Bloom filter, probabilitas false positive, dan sequential search.
Bloom Filter
Bloom filter pertama kali dikenalkan oleh Burton H. Bloom pada tahun
tetapi sebenarnya bukan bagian dari set. Namun struktur ini tidak boleh menghasilkan false negative yaitu melaporkan sebuah objek sebagai bukan bagian dari set sedangkan objek tersebut ada pada set. Karena objek yang dicari semuanya berada pada suatu set, maka ketika Bloom filter menghasilkan false
negative hal ini berarti terdapat kesalahan pencarian objek dan hal ini dapat
mengakibatkan kekacauan pada suatu sistem.
Bloom filter telah digunakan untuk berbagai macam tugas yang melibatkan
lists dan set. Operasi dasarnya melibatkan penambahan objek pada set dan query
untuk merepresentasikan membership suatu objek dalam suatu set.
Pada dasarnya Bloom filter tidak mendukung penghapusan suatu elemen. Namun, sejumlah pengembangan yang telah dilakukan juga mendukung pemindahan. Keakuratan Bloom filter tergantung pada ukuran filter yaitu banyaknya bit yang digunakan untuk menampung objek, jumlah fungsi hash yang digunakan dalam filter yaitu banyaknya kombinasi bit untuk mengalamatkan objek pada filter, dan jumlah objek yang ada pada set (Tarkoma et al. 2012), sehingga semakin banyak objek yang dimasukkan ke Bloom filter, semakin tinggi kemungkinan operasi permintaan yang melaporkan adanya false positive. Adapun menurut Qiao et al. (2014), performa dari Bloom filter dinilai dengan tiga kriteria yaitu query overhead, space requirement, dan rasio false positive.
Bloom filter merupakan suatu array dari sejumlah m bit untuk
merepresentasikan satu set S = {x1, x2,. . . , xn} dari n objek. Awalnya semua bit
dalam filter akan bernilai nol. Dengan konsep utama yaitu menggunakan k fungsi hash, hi(x), 1 ≤i ≤k untuk memetakan objek x ∈ S ke nomor acak yang seragam
menggunakan fungsi hash dengan k = 3 yang berarti satu objek akan dialokasikan menempati 3 posisi bit dalam bit string tersebut. Bit yang telah ditempati oleh salah satu kombinasi alokasi objek tersebut akan bernilai 1, namun ketika sebuah
h1(x) h2(x)
h3(x)
h1(y) h2(y)
5 objek yang tidak terdapat di dalam set akan dicari, misalnya w maka objek w ini juga akan di-hashing menggunakan fungsi hash yang sama seperti objek x, y,dan
z sebelumnya yaitu dengan k = 3 ke posisi bit string. Dalam contoh ini, salah satu
bit dari objek w bernilai 0 sehingga laporan Bloom filter yang benar adalah objek
w tersebut tidak ada pada set. Namun kemungkinan terjadi bahwa semua posisi bit
dari sebuah objek dinyatakan bernilai satu. Ketika ini terjadi, Bloom filter secara keliru akan melaporkan bahwa elemen yang bukan anggota suatu set adalah anggota dari set tersebut. Laporan-laporan yang keliru inilah disebut false positive.
Tabel 1 memperlihatkan pengaruh tiga parameter utama ketika salah satu nilai menurun atau meningkat. Meningkatkan atau menurunkan jumlah fungsi hash terhadap kopt dapat menurunkan rasio false positive sambil meningkatkan
perhitungan dalam sisipan dan pencarian. Biaya akan berbanding lurus dengan jumlah fungsi hash. Besarnya ukuran filter dapat digunakan untuk menyempurnakan kebutuhan ruang dan false positive rate (FPR). Sebuah filter
yang lebih besar akan menghasilkan false positive yang lebih sedikit. Dengan demikian, ukuran dari set yang dimasukkan ke dalam filter menentukan false
positive rate (Tarkoma et al. 2012).
Tabel 1 Parameter utama pada Bloom filter
Parameter Jika Parameter Meningkat
Jumlah fungsi hash (k)
Ukuran filter (m)
Jumlah elemen dalam set (n)
Banyak penghitungan, mengurangi false positive rate sebagai k kopt
Lebih banyak ruang yang diperlukan, mengurangi false positive rate
False positive rate lebih tinggi
Gambar 2 menggambarkan proses terjadinya sebuah Bloom filter reguler dan menghitung empat objek R0, R1, R2 dan R3 untuk satu set. Saat di-hashing, objek R0 dialokasikan pada bit 0, 2, dan 4, untuk objek R1 dialokasikan pada alamat bit 0, 2, dan 5, untuk objek R2 dialokasikan pada bit 2, 6, dan 8, sedangkan objek R3 menempati alokasi bit 5, 8, dan 10. Bit-bit yang telah dialokasikan untuk keempat objek tersebut akan bernilai 1. Dapat dilihat bahwa ada beberapa bit yang ditempati oleh dua atau tiga kali dari bagian objek yang ada, hal inilah yang kemungkinan dapat menimbulkan adanya false positive.
Probabilitas False Positive
Seperti telah dijelaskan sebelumnya bahwa false positive yaitu menyatakan objek sebagai bagian dari set, tetapi sebenarnya bukan bagian dari set. Tingkat probabilitas false positive dari Bloom filter dan jumlah optimal dari fungsi hash untuk tingkat probabilitas false positive dapat dinyatakan dengan mengasumsikan bahwa fungsi hash memilih setiap posisi array dengan probabilitas yang sama, jumlah bit dalam Bloom filter dinyatakan dengan m (Tarkoma et al. 2012). Sehingga jika sebuah elemen dimasukkan ke dalam filter, probabilitas (P) bahwa
bit tertentu tidak dinyatakan bernilai satu oleh fungsi hash adalah:
P = 1 – (1)
m = jumlah bit
Ketika terdapat k fungsi hash yaitu jumlah alokasi bit (map bit) untuk suatu objek, dan kemungkinan salah satunya tidak memiliki set bit tertentu pada satu
yang diberikan masih nol adalah:
P = (3)
m = jumlah bit
k = jumlah map bit
n = jumlah objek
7 tersebut adalah termasuk bagian dari set. Kemungkinan ini terjadi ketika elemen yang bukan bagian dari set, diberikan oleh persamaan (Fan et al. 2000; Tarkoma
et al. 2012).
P = ≈ (5)
m = jumlah bit
k = jumlah map bit
n = jumlah objek
Untuk mendapatkan koptdapat menggunakan persamaan
kopt = ln2 (6)
m = jumlah bit
kopt = jumlah map bit optimal
n = jumlah objek
dan probabilitas false positive dapat dinyatakan dengan (Fan et al. 2000; Li
et al.2010; Tarkoma et al. 2012)
dahulu. Dalam pencarian ini proses dilakukan dengan cara mencocokan data yang akan dicari dengan semua data yang ada dalam kelompok data. Proses pencarian data dilakukan dengan mencocokan data yang dilakukan secara berurut satu demi satu dimulai dari data ke-1 hingga data pada urutan terakhir. Jika data yang dicari mempunyai nilai yang sama dengan data yang ada dalam kelompok data, berarti data telah ditemukan. Tetapi jika data yang dicari tidak ada yang cocok dengan data-data dalam sekelompok data, berarti data tersebut tidak ada dalam sekelompok data. Selanjutnya kita tinggal menampilkan hasil yang diperoleh tersebut.
Kemungkinan terbaik (best case) dari algoritme ini adalah jika data yang dicari berada pada elemen array yang terdepan sehingga waktu yang dibutuhkan untuk pencarian data semakin singkat. Sebaliknya, kondisi terburuk (wors case) dari algoritme ini adalah jika data yang dicari berada pada elemen array terakhir.
CRC32
Salah satu fungsi hash yang dikembangkan untuk mendeteksi kerusakan data dalam proses transmisi maupun penyimpanan adalah Cyclic Redundancy
Check (CRC). Fungsi hash CRC akan menghasilkan suatu nilai yang dikenal
dengan checksum, nilai inilah yang digunakan untuk mendeteksi kesalahan atau kerusakan pada penyimpanan maupun transmisi data. Salah satu varian CRC yang banyak digunakan adalah CRC32.
CRC32 adalah suatu metode yang menggunakan polynomial 32 bit atau disebut 4 byte (karena 8 bit = 1 byte) untuk mendeteksi kesalahan (Wijayanto. 2007) Ilustrasi untuk menggambarkan register penampung hasil CRC sementara dapat dilihat seperti Gambar 3 berikut ini.
3 2 1 0 byte
+ - - + - - + - - + - - +
Pop! | | | | | bitstring
+ - - + - - + - - + - - +
1 < - - 32 bits - - > Poly 4 byte
Gambar 3 Ilustrasi register penampung hasil CRC sementara
Terdapat 4 ruang kosong pada Gambar 3 mengilustrasikan register yang digunakan untuk menampung hasil CRC sementara. Beberapa proses pada register tersebut yaitu:
1 Memasukkan bitstring (data) ke dalam register dari kanan ke kiri (shift per byte) untuk setiap register yang tidak terisi penuh
2 Ketika register telah penuh (4 byte), maka akan dilakukan pergeseran satu byte
ke kiri (ke luar) dan register paling kanan yang telah kosong akan diisi dengan 1 byte dari bitstring
9
bit tertinggi yang bernilai 1 dan nilai dari poly. Langkah ini terus diulangi sampai semua bit dari byte yang tergeser ke luar bernilai 0.
4 Ulangi langkah ke 2 dan ke 3 sampai semua proses bitstring (data input) selesai diproses.
Pada CRC32 untuk setiap byte yang digeser keluar dapat dihitung nilainya yang akan digunakan dalam operasi XOR dengan isi register. Nilai-nilai ini akan disimpan dan dikenal dengan tabel CRC.
METODE
Bab ini akan menjelaskan tahapan-tahapan dan teknik yang dilakukan secara sistematis sehingga penelitian berjalan pada arah yang telah ditentukan.
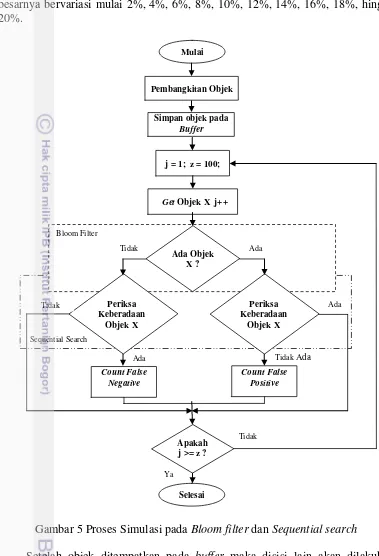
Penelitian ini diawali dengan perancangan untuk membuat model Bloom
filter dan sequential search. Tahap selanjutnya yaitu melakukan simulasi untuk
kedua rancangan Bloom filter dan sequential search tersebut. Simulasi dilakukan dengan membuat sekenario bahwa terdapat suatu set objek dengan jumlah yang sangat besar di dalamnya. Selanjutnya, masih dalam tahapan simulasi yaitu menetapkan sebagian objek yang ada pada set sebagai objek yang akan disimpan pada buffer dan diikuti dengan memilih satu objek secara acak (objek x) dari dalam set objek sebagai objek yang nantinya akan dicari pada buffer. Tahapan dalam simulasi ini dilanjutkan dengan memeriksa keberadaan objek x pada buffer
menggunakan Bloom filter dan memeriksa keberadaan objek x menggunakan
sequential search (sebagai informasi, bahwa objek x yang dicari menggunakan
Bloom filter adalah objek yang sama dengan objek x yang digunakan pada
sequential search). Berikutnya dalam tahapan simulasi ini adalah count false
positive dan count false negative yaitu menghitung perbedaan hasil pencarian
antara Bloom filter dengan sequential search. Tahapan selanjutnya setelah simulasi atau tahapan ketiga adalah analisis hasil, tahapan ini akan membahas hasil yang didapat dari proses simulasi. Tahapan keempat adalah evaluasi, pada tahapan ini dilakukan evaluasi terhadap hasil antara Bloom filter dan sequential
search. Pada tahapan ini juga dilakukan perhitungan probabilitas false positive
dari Bloom filter berdasarkan persamaan (7) sehingga tingkat false positive dari
Bloom filter dapat diketahui. Tahapan terakhir adalah penarikan kesimpulan, yaitu
menyimpulkan bagaimana teknik pencarian menggunakan Bloom filter yang telah diverifikasi menggunakan sequential search dapat menemukan membership suatu objek pada suatu set yang sangat besar serta kombinasi terbaik dari parameter yang mempengaruhi adanya false positive untuk memperoleh false positive
Gambar 4 Diagram alir tahapan penelitian
Perancangan
Perancangan bertujuan untuk menentukan bentuk rancangan yang akan dibuat untuk Bloom filter dan sequential search, serta menentukan parameter yang akan digunakan. Dalam penelitian ini dirancang algoritme Bloom filter dan
sequential search pada suatu bentuk bahasa pemrograman, model yang dirancang
yaitu model pencarian suatu objek pada suatu set, dengan objek yang digunakan adalah sama untuk kedua algorime ini.
Simulasi
Simulasi dalam hal ini akan dibedakan dalam beberapa tahap yaitu tahapan pembangkitan data/objek yang digunakan sebagai input utama, buffer sebagai media penampung data/objek yang di-cache, Get objek x yaitu pemilihan objek yang akan dicari membership-nya pada cache yang ada di buffer. Simulasi utama yaitu upaya pencarian objek menggunakan Bloom filter dan sequental search, serta penghitungan banyaknya false positive dan false negative dari Bloom filter
setelah melalui verifikasi menggunakan sequential search. Selain itu juga dilakukan perekaman waktu yang digunakan oleh Bloom filter dan squential
search untuk mendapatkan keanggotaan suatu objek pada suatu set.
Mulai
Simulasi
Selesai
PenarikanKesimpulan
Evaluasi Analisis Hasil
11
Analisis Hasil
Tahapan ini akan membahas tentang hasil yang didapat dari proses simulasi. Metode Bloom filter dan sequential search dalam hal ini akan mendapatkan input
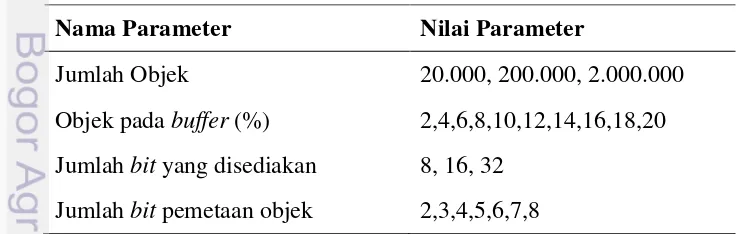
sejumlah objek yang sama. Kedua metode ini akan mencari keanggotaan objek yang akan dicari pada suatu set yang sama. Untuk menguji keanggotaan suatu objek pada suatu set menggunakan Bloom filter, objek yang dibangkitkan semuanya akan di-hasing menggunakan teknik hashing CRC32. Setelah semua objek di-hashing, objek tersebut akan mendapatkan alamat tersendiri untuk setiap objek. Pengalamatan ini bervariasi sesuai dengan jumlah map bit yang ditetapkan. Pada penelitian ini selain adanya variasi jumlah objek yang dibangkitkan juga menggunakan variabel jumlah bit yang disediakan untuk menampung objek, jumlah map bit untuk penempatan objek pada bit yang disediakan dan variasi terhadap jumlah objek yang ditempatkan pada buffer. Untuk lebih jelasnya, variabel-variabel tersebut dapat dilihat pada Tabel 2.
Evaluasi
Langkah ini dilakukan untuk mengevaluasi beberapa hasil pencarian objek yang telah diperoleh menggunakan teknik Bloom filter dan sequential search. Untuk mendapatkan hasil yang baik maka pada bagian ini akan membahas antara hasil pencarian keanggotaan suatu objek menggunakan Bloom filter dengan pencarian keanggotaan suatu objek menggunakan sequential search. Evaluasi ini difokuskan pada false positive yang dihasilkan oleh Bloom filter dan waktu yang diperlukan untuk mendapatkan keanggotaan suatu objek oleh kedua metode. Mengingat Bloom filter dapat memberikan hasil false positive sedangkan
sequential search tidak mengenal false positive, maka hasil akurasi dan kecepatan
kedua algoritme akan dapat dikombinasikan untuk mendapatkan hasil yang lebih baik. Dalam hal ini sequential search digunakan untuk menguji keakuratan dari
Bloom filter sehingga nilai optimal dari pencarian menggunakan Bloom filter bisa
didapatkan. Pada bagian ini juga dilakukan perhitungan probabilitas false positive
menggunakan persamaan (7) sehingga tingkat false positive dari Bloom filter
dapat diketahui.
Tabel 2 Variabel yang digunakan untuk pengujian
Nama Parameter Nilai Parameter
Jumlah Objek 20.000, 200.000, 2.000.000
Objek pada buffer (%) 2,4,6,8,10,12,14,16,18,20 Jumlah bit yang disediakan 8, 16, 32
HASIL DAN PEMBAHASAN
Pada bab ini akan mengemukakan dan mengulas hasil yang telah didapat dari penelitian yang dilakukan. Beberapa langkah dalam penelitian ini telah memberikan hasil seperti diulas pada tiap sub bab di bawah ini.
Perancangan
Langkah awal untuk memulai penelitian ini adalah perancangan, berdasarkan permasalahan yang telah diungkapkan sebelumnya bahwa pencarian suatu objek sangat berkaitan dengan pengecekan keanggotaan objek tersebut pada suatu set maka diperlukan suatu metode yang dapat mendukung kemudahan mendapatkan objek yang dicari. Dalam penelitian ini telah dibuat rancangan untuk mensimulasikan pencarian suatu objek pada suatu set yang besar menggunakan metode Bloom filter dan sequential search.
Perancangan Bloom filter
Perancangan menggunakan Bloom filter dilakukan dengan menerapkan teknik hashing pada semua objek yang ada pada suatu set. Di sisi lain, melakukan
hashing terhadap semua elemen dalam Bloom filter dengan memori tunggal akan
menghasilkan tingkat false positive yang tinggi (Kanizo et al. 2012). Keseluruhan objek yang telah di-hashing ditempatkan pada suatu array dengan penempatan secara acak namun dengan pengkodean menurut ketentuan yang telah ditetapkan. Dengan pengkodean ini setiap objek akan menempati kombinasi bit tertentu dalam suatu array sebagai alamat dari objek tersebut.
Dengan adanya pengalamatan terhadap setiap objek maka untuk mendapatkan kembali objek tersebut bukanlah suatu hal yang rumit, hal ini terjadi ketika objek yang dicari berada pada suatu set yang kecil. Sebaliknya ketika suatu objek berada pada suatu set yang sangat besar dan dengan ketersediaan bit yang disiapkan untuk menampung objek terbatas jumlahnya maka hal ini akan membuat kombinasi alamat pada bit penampung menjadi semakin rumit dan saling tumpang tindih. Dengan pengalamatan yang tumpang tindih ini kemungkinan dapat mengakibatkan terjadinya kesalahan yang diberikan oleh
Bloom filter ketika diminta mencari suatu objek, hal inilah yang dikenal dengan
false positive. Dengan adanya kemungkinan false positive maka keakuratan suatu
Bloom filter menjadi sesuatu yang dipertanyakan.
13 Dengan output yang bervariasi ini dapat dibandingkan hasil kombinasi variabel mana saja yang menghasilkan tigkat false positive yang lebih rendah. Tabel 2 memperlihatkan nilai-nilai dari variabel yang dijadikan sebagai input Bloom filter. Dalam proses pencarian suatu objek menggunakan Bloom filter ini, dilakukan dengan mencari 100 objek acak secara bergantian. Selain menghitung jumlah false positive yang dihasilkan oleh Bloom filter pada penelitian ini juga merekam waktu yang digunakan oleh Bloom filter untuk mendapatkan keanggotaan suatu objek dalam sebuah set. Gambar 5 memperlihatkan alur proses pencarian menggunakan Bloom filter yang dikombinasikan dengan pencarian
sequential search sebagai pembanding dan sekaligus sebagai verifikasi pencarian
objek pada suatu set.
Perancangan Sequential Search
Pencarian menggunakan sequential search lebih sederhana dibandingkan dengan Bloom filter. Pencarian menggunakan metode sequential search dilakukan dengan mencari objek secara berurutan dari bit awal sampai bit terakhir pada suatu set objek. Pencarian secara sequential search tidak memerlukan pengalamatan terhadap objek ataupun pengurutan objek terlebih dahulu. Dalam Gambar 5 juga diperlihatkan alur pencarian menggunakan sequential search. Ketika suatu objek yang akan dicari menggunakan sequential search, objek tersebut akan dibandingkan satu per satu dengan objek yang ada pada buffer. Dalam pencarian menggunakan sequential search, objek tercepat yang ditemukan adalah ketika objek yang dicari berada di awal ruang penyimpanan, dan objek terlama untuk ditemukan adalah ketika objek berada di akhir urutan ruang penyimpanan.
Simulasi Pembangkitan Objek
Simpan Objek pada Buffer
Buffer yang dimaksud dalam hal ini adalah penetapan jumlah objek yang
akan di-cache dan ditempatkan pada suatu wadah penampungan objek atau dinamakan dengan buffer. Tahapan ini diawali dengan menetapkan besaran jumlah objek yang akan di-cache dengan berbagai besaran yaitu bervariasi antara 2%, 4%, 6%, 8%, 10%, 12%, 14%, 16%, 18%, hingga 20%. Tiap besaran objek yang di-cache tersebut akan dijadikan sebagai masukan yang berbeda-beda dan dikombinasikan dengan variabel lain seperti yang telah dimuat pada Tabel 2. Objek yang disimpan pada buffer ini sebelumnya telah di-hashing dengan teknik dan ketentuan hashing CRC32.
Selain sebagai penyimpanan objek yang di-cache, pada buffer juga disediakan sejumlah bit yang digunakan untuk menampung objek yang telah
di-cache. Jumlah bit yang disediakan sebagai penampung objek yang di-cache juga
divariasikan dengan besaran 8 bit, 16 bit, dan 32 bit. Bit-bit yang disediakan ini digunakan untuk menyimpan alamat objek yang ada. Penyimpanan alamat objek ini dilakukan dengan menggunakan beberapa kombinasi bit (map bit) yaitu mulai dari kombinasi 2, 3, 4, 5, 6, 7, dan 8 bit untuk satu objek.
Get Objek X
Langkah selanjutnya yaitu Get objek x, langkah ini dimaksudkan untuk mendapatkan satu objek dari seluruh objek yang dibangkitkan. Objek x ini digunakan sebagai objek yang akan dicari, dan target pembanding untuk objek x
ini adalah objek yang telah tersimpan pada buffer. Untuk mencari objek x pada
buffer, objek x ini juga di-hashing menggunakan teknik dan ketentuan hashing
yang sama dengan teknik dan ketentuan yang digunakan terhadap objek pada
buffer. Objek x yang didapat pada tahapan ini digunakan untuk Bloom filter dan
sequential search. Dalam penelitian ini diambil sebanyak 100 kali objek yang
berbeda (acak) secara bergantian.
Periksa Objek X dengan Bloom Filter
Objek x yang telah didapat pada tahapan sebelumnya selanjutnya dibandingkan dengan objek yang ada pada buffer menggunakan teknik Bloom
filter. Objek x tersebut akan di-hashing menggunakan teknik dan ketentuan yang
sama dengan teknik dan ketentuan yang digunakan pada objek yang tersimpan pada buffer, yaitu hashing menggunakan CRC32. Nilai hash dari objek x ini akan dibandingkan dengan nilai-nilai hashing dari objek yang ada pada buffer oleh
Bloom filter. Jika nilai hash objek x sama dengan nilai hash objek pada buffer
15 Sebaliknya jika nilai hash dari objek x berbeda dengan nilai hash objek yang ada pada buffer maka Bloom filter akan menyatakan objek x tersebut tidak ada pada
buffer atau bukan bagian dari set. Hal ini akan terus dilakukan hingga sebanyak
objek x yang akan dicari pada suatu set objek yang ada pada buffer.
Periksa Keberadaan Objek X dengan Sequential Search
Untuk memastikan Objek x yang telah dinyatakan oleh Bloom filter ada atau tidak pada buffer, maka diperlukan pencarian menggunakan teknik lain yaitu
sequential search. Pada tahapan ini ketika hasil pencarian menggunakan Bloom
filter menyatakan objek x ada pada buffer maka akan dilakukan verfikasi
menggunakan sequential search terhadap objek x. Apabila hasil pencarian menggunakan sequential search sama dengan hasil yang dinyatakan oleh Bloom
filter maka dapat dipastikan objek x benar-benar ada pada buffer dan akan
dilanjutkan dengan objek x yang lainnya sampai sebanyak objek x yang akan diperiksa, tetapi bila hasilnya menyatakan objek x tidak ada pada buffer maka hal ini akan dihitung sebagai false positive dari Bloom filter.
Sebaliknya jika hasil pencarian menggunakan Bloom filter menyatakan objek x tidak ada pada buffer maka verifikasi menggunakan sequential search
juga tetap dilakukan. Apabila hasil pencarian objek menggunakan sequential
search sama dengan hasil pernyataan dari Bloom filter maka dapat dipastikan
bahwa objek x benar-benar tidak ada pada buffer dan dilanjutkan pada objek x
berikutnya sampai sejumlah objek x yang akan diperiksa, namun ketika hasil pencarian menggunakan sequential search menyatakan objek x ada pada buffer
maka hal ini akan menunjukkan bahwa Bloom filter memberikan jawaban yang keliru atau disebut dengan false negative.
Simulasi Menggunakan Bloom Filter
Seperti dijelaskan pada sub bahasan sebelumnya bahwa objek yang digunakan adalah objek yang dibangkitkan secara acak menggunakan generator pembangkitan objek yang membangkitkan objek secara unik atau tanpa adanya duplikasi objek. Pembangkitan objek pada simulasi ini bervariasi yaitu 20000, 200000, dan 2000000 objek. Objek tersebut kemudian di-hashing menggunakan
hashing CRC32.
CRC32 adalah metode yang digunakan untuk mendeteksi kesalahan dengan menggunakan polynomial 32 bit atau dengan kata lain polynomial 4 byte. Pada
algoritme ini yang pertama dilakukan adalah inisialisasi variabel pada register dengan suatu nilai, dengan kata lain inisialisasi CRC umumnya menggunakan bilangan hexadesimal yaitu FFFFFFFF.
bervariasi dari kombinasi 2, 3, 4, 5, 6, 7, dan 8 bit. Selanjutnya objek tersebut dipilih secara acak dengan jumlah persentase objek yang ditempatkan pada buffer
besarnya bervariasi mulai 2%, 4%, 6%, 8%, 10%, 12%, 14%, 16%, 18%, hingga 20%.
Gambar 5 Proses Simulasi pada Bloom filter dan Sequential search
Setelah objek ditempatkan pada buffer maka disisi lain akan dilakukan pemilihan satu objek secara acak untuk dijadikan objek yang nantinya akan dibandingkan dengan objek yang ada pada buffer. Objek ini juga akan di-hashing
menggunakan teknik hashing yang sama dengan objek yang ada pada buffer yaitu CRC32 sehingga nilai hasing dari objek ini akan dibandingkan dengan nilai
hashing dari objek yang ada pada buffer.
17 Ketika nilai hashing objek yang dicari sama dengan nilai hashing objek yang ada pada buffer maka Bloom filter akan menyatakan bahwa objek tersebut berada pada set (dalam hal ini buffer). Namun ketika nilai hashing dari objek yang dicari tidak sama dengan nilai hashing objek yang ada pada buffer, maka Bloom
filter akan menyatakan objek tersebut tidak ada pada set (buffer).
Pencarian objek dapat dilakukan beberapa kali tergantung dengan kebutuhan seberapa banyak objek yang akan dicari, dalam simulasi ini dilakukan pencarian terhadap 100 objek untuk setiap kombinasi parameter. Selain itu setiap pencarian terhadap objek yang dicari pada simulasi ini juga dilakukan pencatatan waktu yang diperlukan oleh Bloom filter untuk mendapatkan objek tersebut. Gambar 5 memperlihatkan proses simulasi pencarian terhadap suatu objek hingga objek tersebut dinyatakan ada atau tidak ada pada suatu set objek.
Simulasi Menggunakan Sequential Search
Pencarian menggunakan sequential search dalam hal ini dilakukan menggunakan objek yang sama dengan objek yang digunakan pada Bloom filter. Objek x telah ditetapkan untuk dicari akan dibandingkan satu per satu dengan objek yang ada pada buffer. Hasil dari pencarian menggunakan sequential search
ini digunakan sebagai pembanding dari pencarian menggunakan Bloom filter. Pencarian menggunakan sequential search ini juga sebagai verifikasi keakuratan hasil pencarian dengan Bloom filter.
Analisis Hasil
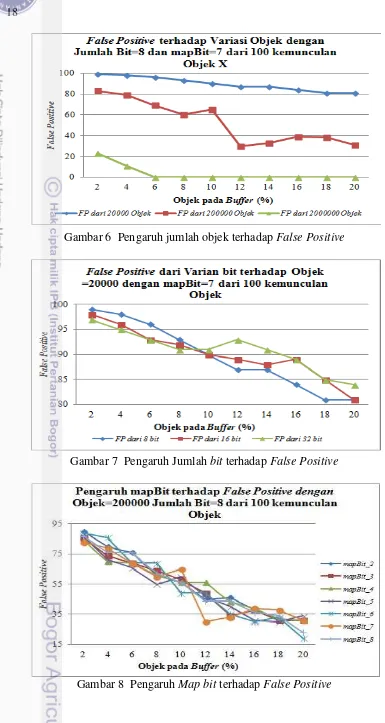
Hasil simulasi yang telah dilakukan memperlihatkan pengaruh nilai variabel pada Tabel 2 terhadap adanya false positive (FP). Hal ini dapat dilihat pada Gambar 6 yang memperlihatkan perubahan yang signifikan terhadap false positive
pada saat jumlah objek divariasikan. Pada Gambar 6 juga ditampilkan bahwa tingkat false positive menjadi 0 ketika jumlah objek pada buffer sebesar 6% dari 2000000 objek yang sebenarnya dan terus stabil hingga objek pada buffer sebesar 20%.
Sedangkan variasi terhadap jumlah bit dan map bit walaupun dapat menyebabkan perubahan terhadap false positive tetapi tidak begitu besar pengaruhnya terhadap false positive. Pengaruh map bit hanya dapat menurunkan
false positive dalam ukuran yang kecil atau tidak signifikan hal ini dapat dilihat
pada Gambar 7 dan Gambar 8. Untuk data lebih lengkap berkaitan dengan false
positive akibat kombinasi variabel-variabel yang ada pada Tabel 2 dapat dilihat
Gambar 6 Pengaruh jumlah objek terhadap False Positive
Gambar 7 Pengaruh Jumlah bit terhadap False Positive
19 Jika dilihat dari sisi waktu, pengaksesan suatu objek/data menggunakan
Bloom filter lebih cepat jika dibanding dengan menggunakan sequential search.
Hasil dari Bloom filter ini akan dibandingkan dengan hasil dari sequential search
dari segi akurasi dan kecepatan. Tabel 3 memperlihatkan perbandingan kecepatan akses antara Bloom filter dengan sequential search.
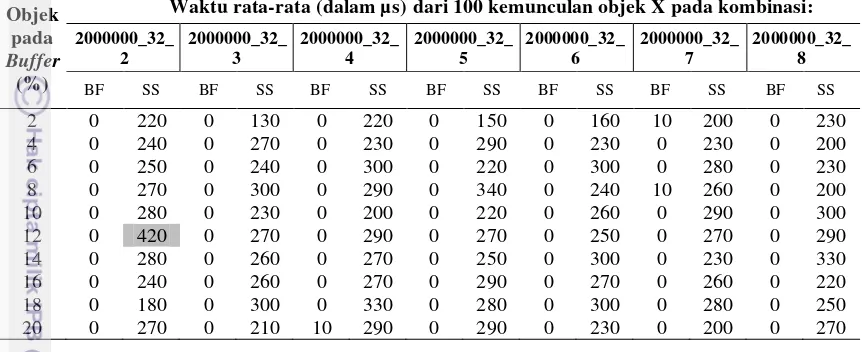
Tabel 3 Perbandingan waktu akses Bloom filter dengan sequential search Objek
pada
Buffer
(%)
Waktu rata-rata (dalam µs)dari 100 kemunculan objek X pada kombinasi:
2000000_32_
Perbandingan waktu antara Bloom filter dengan sequential search dapat dilihat pada Tabel 3. Secara umum pencarian menggunakan Bloom filter lebih cepat dibanding pencarian menggunakan sequential search, hal ini dapat dilihat dari hasil penelitian yang mengkombinasikan masing-masing parameter yang dapat mempengaruhi false positive. Pencarian menggunakan Bloom filter lebih cepat dari pada sequential search karena pada Bloom filter ruang pencarian suatu objek menjadi lebih kecil. Hal ini akibat dari penggunaan buffer sebagai tempat penampungan data sementara yang ditentukan hanya sebesar beberapa persen dari data set yang ada. Sementara itu pada sequential search, ruang pencarian adalah sebesar set yang ada. Namun karena kemungkinan adanya false positive pada
Bloom filter maka perlu adanya pembanding yang dapat menguatkan hasil akurasi
dari Bloom filter. Untuk hasil perbandingan waktu antara Bloom filter dan
sequential search secara lengkap dapat dilihat pada Lampiran 2.
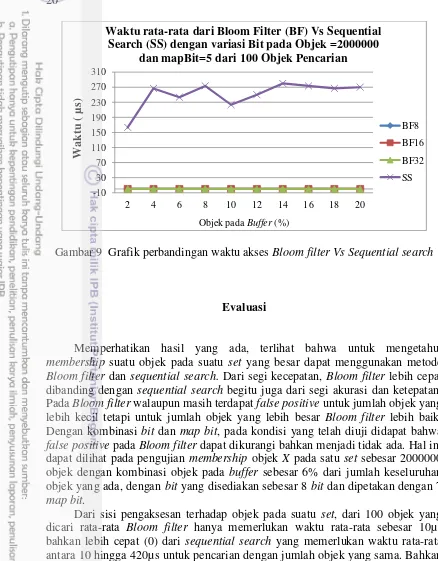
Gambar 9 memperlihatkan perbandingan waktu rata-rata pengaksesan antara Bloom filter dengan sequential search. Dapat dilihat bahwa waktu yang digunakan oleh Bloom filter untuk mendapatkan membership suatu objek lebih cepat (0µs) dan konstan walaupun jumlah objek pada suatu set terus meningkat. Sedangkan dengan menggunakan sequential search, waktu yang diperlukan jauh lebih lama dan tidak konstan.
Dengan hasil yang ditampilkan pada Lampiran 2, secara keseluruhan dapat dilihat bahwa hasil terbaik perbandingan waktu pengaksesan objek antara Bloom
filter dengan sequential search adalah pada jumlah objek sebesar 2000000 dengan
Gambar 9 Grafik perbandingan waktu akses Bloom filter Vs Sequential search
Evaluasi
Memperhatikan hasil yang ada, terlihat bahwa untuk mengetahui
membership suatu objek pada suatu set yang besar dapat menggunakan metode
Bloom filter dan sequential search. Dari segi kecepatan, Bloom filter lebih cepat
dibanding dengan sequential search begitu juga dari segi akurasi dan ketepatan. Pada Bloom filter walaupun masih terdapat false positive untuk jumlah objek yang lebih kecil tetapi untuk jumlah objek yang lebih besar Bloom filter lebih baik. Dengan kombinasi bit dan map bit, pada kondisi yang telah diuji didapat bahwa
false positive pada Bloom filter dapat dikurangi bahkan menjadi tidak ada. Hal ini
dapat dilihat pada pengujian membership objek X pada satu set sebesar 2000000 objek dengan kombinasi objek pada buffer sebesar 6% dari jumlah keseluruhan objek yang ada, dengan bit yang disediakan sebesar 8 bit dan dipetakan dengan 7
map bit.
Dari sisi pengaksesan terhadap objek pada suatu set, dari 100 objek yang dicari rata-rata Bloom filter hanya memerlukan waktu rata-rata sebesar 10µs bahkan lebih cepat (0) dari sequential search yang memerlukan waktu rata-rata antara 10 hingga 420µs untuk pencarian dengan jumlah objek yang sama. Bahkan untuk jumlah objek yang semakin besar, waktu yang diperlukan oleh sequential
search semakin besar pula. Berbeda dengan Bloom filter yang lebih stabil pada
10µs dan bahkan lebih cepat (0) pada pencarian objek yang lebih besar seperti tersaji pada Tabel 3.
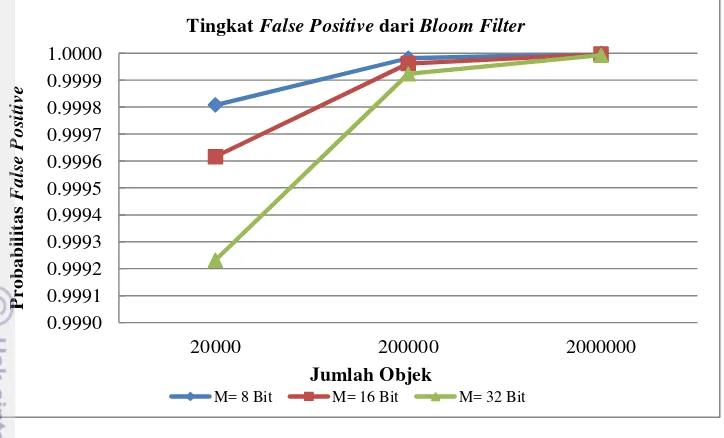
Berdasarkan persamaan (7), dengan jumlah objek yang ada dan jumlah bit
yang disediakan didapat tingkat false positive dari Bloom filter seperti ditunjukkan pada Gambar 10. Sehingga dapat dilihat besarnya probabilitas false positive (Pfp)
yang muncul berdasarkan hubungan jumlah objek dan jumlah bit yang disediakan.
-10
Waktu rata-rata dari Bloom Filter (BF) Vs Sequential Search (SS) dengan variasi Bit pada Objek =2000000
dan mapBit=5 dari 100 Objek Pencarian
BF8
BF16
BF32
21
Gambar 10 Tingkat false positive dari Bloom filter
SIMPULAN DAN SARAN
Simpulan
Berdasarkan hasil dan analisa yang telah dilakukan, penelitian ini memiliki beberapa kesimpulan diantaranya yaitu false positive yang dihasilkan dari penggunaan metode Bloom filter dapat diminimalisir dengan melakukan kombinasi yang tepat terhadap jumlah objek, jumlah bit dan jumlah pemetaan terhadap objek (map bit). Dari ketiga parameter yang dapat mempengaruhi false
positive pada metode Bloom filter maka jumlah objek adalah parameter yang
paling berpengaruh terhadap kemunculan false positive. False positive terendah didapat dengan kombinasi dari parameter yang digunakan adalah pada jumlah objek sebesar 2000000, jumlah bit = 8, dan jumlah map bit = 7. Semakin besar jumlah objek pada suatu set, tingkat false positive yang didapat akan semakin kecil. Jumlah terbaik untuk ketersediaan jumlah objek yang di-cache pada buffer
yaitu sebesar 6-8 % dari seluruh objek. Kecepatan pencarian membership suatu objek pada satu set yang besar menggunakan Bloom filter jauh lebih cepat yaitu rata-rata 10µs dan cenderung stabil walaupun pada jumlah objek yang sangat besar. Oleh karena itu penggunaan Bloom filter sangat direkomendasikan untuk mencari membership objek pada suatu set yang sangat besar.
0.9990
20000 200000 2000000
P
Tingkat False Positive dari Bloom Filter
Saran
Diharapkan metode Bloom filter ini dapat diimplementasikan sebagai mesin pencarian pada umumnya, dan khususnya pada sistem informasi IPB sesuai dengan kebutuhan yang ada. Selain itu penerapan metode Bloom filter akan lebih menampakkan hasil yang baik ketika objek yang akan dicari berada pada suatu set
23
DAFTAR PUSTAKA
Bloom BH. 1970. Space/time trade-offs in hash coding with allowable errors.
Communications of the ACM, 13(7): 422–426.
Broder A, Mitzenmacher M. 2004. Network applications of bloom filters: A survey. Internet Mathematics.1(4): 485–509.
Cheng HY, Ma H. 2013. Membership classification using integer bloom filter.
IEEE. : 385 – 390.
Fan L, Cao P, Almeida J, Broder AZ. 2000. Summary cache: a scalable wide-area Web cache sharing protocol. IEEE/ACM Transactions on Networking. 8(3):281-293.
Guo D, Liu Y, Li X, Yang P. 2010. False negative problem of counting bloom filter. IEEE Transactions On Knowledge And Data Engineering. 22(5): 651-664.
Issa J, Figueira S. 2012. Hadoop and memcached: Performance and power characterization and analysis. Journal of Cloud Computing a springer open
journal.
Kanizo Y, Hay D, Keslassy I. 2012. Access-efficient balanced bloom filters. IEEE
ICC 2012 - Next-Generation Networking Symposium: 2723-2728.
Li L,Wang B, Lan J. 2010. A variable length counting bloom filter. IEEE 2nd International Conference on Computer Engineering and Technology.
3(-) :504-508.
Qiao Y, Li T, Chen S. 2011. One memory access bloom filters and their generalization. IEEE INFOCOM. :1745-1753.
Qiao Y, Li T, Chen S. 2014. Fast bloom filters and their generalization. IEEE
Transactions On Parallel And Distributed Systems.
25(1):93-103.doi:10.1109/TPDS.2013.46.
Tarkoma S, Rothenberg CE, Lagerspetz E. 2012. Theory and practice of bloom filters for distributed systems. IEEE.Commun. Surveys Tuts 14(1): 131 –155. doi:10.1109/SURV.2011.031611.00024.
Wei J, Jiang H, Zhou K, Feng D. 2011. DBA: A dynamic bloom filter array for scalable membership representation of variable large data sets. IEEE International Symposium on Modelling, Analysis, and Simulation of
Computer and Telecommunication System. :466-468.
doi:10.1109/MASCOTS.2011.36
Wijayanto IS. 2007. Penggunaan CRC32 dalam integritas data.[Internet].[diunduh
18 Agustus 2016]. Tersedia pada
25 Lampiran 1 Garfik Pengaruh parameter utama terhadap false positive
Pengaruh mapBit terhadap False Positive dengan
Objek =20000, Jumlah Bit=8 dari 100 kemunculan Objek
Pengaruh mapBit terhadap False Positive dengan
Objek =20000, Jumlah Bit=16 dari 100 kemunculan Objek
Pengaruh mapBit terhadap False Positive dengan
Lanjutan
Pengaruh mapBit terhadap False Positive dengan
Objek=200000 Jumlah Bit=8 dari 100 kemunculan Objek
Pengaruh mapBit terhadap False Positive dengan
Objek=200000 Jumlah Bit=16 dari 100 kemunculan Objek
Pengaruh mapBit terhadap False Positive dengan
27
Pengaruh mapBit terhadap False Positive dengan
Objek=2000000 Jumlah Bit=8 dari 100 kemunculan Objek
Pengaruh mapBit terhadap False Positive dengan
Objek=2000000 Jumlah Bit=16 dari 100 kemunculan Objek
Pengaruh mapBit terhadap False Positive dengan Objek=2000000 Jumlah Bit=32 dari 100
Lanjutan
False Positive terhadap Variasi Objek dengan Jumlah Bit=8 dan mapBit=2 dari 100
kemunculan Objek X
FP dari 20000 objek FP dari 200000 objek FP dari 2000000 objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=8 dan mapBit=3 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=8 dan mapBit=4 dari 100
kemunculan Objek X
29
False Positive terhadap Variasi Objek dengan Jumlah Bit=8 dan mapBit=5 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=8 dan mapBit=6 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=8 dan mapBit=7 dari 100
kemunculan Objek X
Lanjutan
False Positive terhadap Variasi Objek dengan Jumlah Bit=8 dan mapBit=8 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=16 dan mapBit=2 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=16 dan mapBit=3 dari 100
kemunculan Objek X
31
False Positive terhadap Variasi Objek dengan Jumlah Bit=16 dan mapBit=4 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=16 dan mapBit=5 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=16 dan mapBit=6 dari 100
kemunculan Objek X
Lanjutan
False Positive terhadap Variasi Objek dengan Jumlah Bit=16 dan mapBit=7 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=16 dan mapBit=8 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=32 dan mapBit=2 dari 100
kemunculan Objek X
33
False Positive terhadap Variasi Objek dengan Jumlah Bit=32 dan mapBit=3 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=32 dan mapBit=4 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=32 dan mapBit=5 dari 100
kemunculan Objek X
Lanjutan
False Positive terhadap Variasi Objek dengan Jumlah Bit=32 dan mapBit=6 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
False Positive terhadap Variasi Objek dengan Jumlah Bit=32 dan mapBit=7 dari 100
kemunculan Objek X
FP dari 20000 Objek FP dari 200000 Objek FP dari 2000000 Objek
0
Objek pada Buffer (%)
False Positive terhadap Variasi Objek dengan Jumlah Bit=32 dan mapBit=8 dari 100
kemunculan Objek X
35
False Positive dari Varian bit terhadap Objek =20000 dengan mapBit=2 dari 100 kemunculan
Objek
False Positive dari Varian bit terhadap Objek =20000 dengan mapBit=3 dari 100 kemunculan
Objek
False Positive dari Varian bit terhadap Objek =20000 dengan mapBit=4 dari 100 kemunculan
Objek
Lanjutan
False Positive dari Varian bit terhadap Objek =20000 dengan mapBit=5 dari 100 kemunculan
Objek
False Positive dari Varian bit terhadap Objek =20000 dengan mapBit=6 dari 100 kemunculan
Objek
False Positive dari Varian bit terhadap Objek =20000 dengan mapBit=7 dari 100 kemunculan
Objek
37
False Positive dari Varian bit terhadap Objek =20000 dengan mapBit=8 dari 100 kemunculan
Objek
False Positive dari Varian bit terhadap Objek =200000 dengan mapBit=2 dari 100 kemunculan
Objek
False Positive dari Varian bit terhadap Objek =200000 dengan mapBit=3 dari 100 kemunculan
Objek
Lanjutan
False Positive dari Varian bit terhadap Objek =200000 dengan mapBit=4 dari 100 kemunculan
Objek
False Positive dari Varian bit terhadap Objek =200000 dengan mapBit=5 dari 100 kemunculan
Objek
False Positive dari Varian bit terhadap Objek =200000 dengan mapBit=6 dari 100 kemunculan
Objek
39
False Positive dari Varian bit terhadap Objek =200000 dengan mapBit=7 dari 100 kemunculan
Objek
False Positive dari Varian bit terhadap Objek =200000 dengan mapBit=8 dari 100 kemunculan
Objek
False Positive dari Varian bit terhadap Objek =2000000 dengan mapBit=2 dari 100
kemunculan Objek
Lanjutan
False Positive dari Varian bit terhadap Objek =2000000 dengan mapBit=3 dari 100
kemunculan Objek
False Positive dari Varian bit terhadap Objek =2000000 dengan mapBit=4 dari 100
kemunculan Objek
False Positive dari Varian bit terhadap Objek =2000000 dengan mapBit=5 dari 100
kemunculan Objek