ANALISIS AKURASI ALGORITMA
KLASIFIKASI DOKUMEN BERKATEGORI
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTASI ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
AKURASI ALGORITMA
NAÏVE BAYES
KLASIFIKASI DOKUMEN BERKATEGORI
TESIS
DEWI YANTI
117038006
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTASI ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
2013
NAÏVE BAYES
PADA
KLASIFIKASI DOKUMEN BERKATEGORI
PROGRAM STUDI S2 TEKNIK INFORMATIKA
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTASI ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah
Magister Teknik Informatika
DEWI YANTI
117038006
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTASI ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
2013
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah
PROGRAM STUDI S2 TEKNIK INFORMATIKA
ii
PERSETUJUAN
Judul : ANALISIS AKURASI ALGORITMA
NAÏVE BAYES
PADA KLASIFIKASI DOKUMEN BERKATEGORI
Kategori
: -
Nama
: Dewi Yanti
Nomor Induk Mahasiswa : 117038006
Program Studi
: S2 Teknik Informatika
Fakultas
: ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing
:
Pembimbing 2
Pembimbing 1
Dr. Marwan Ramli, M.Si
Prof. Dr. Herman Mawengkang
Diketahui/disetujui oleh
Program Studi S2 Teknik Informatika
Ketua,
PERNYATAAN
ANALISIS AKURASI ALGORITMA NAÏVE BAYES PADA KLASIFIKASI
DOKUMEN BERKATEGORI
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Agustus 2013
Dewi Yanti
iv
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di
bawah ini:
Nama
: Dewi Yanti
NIM
: 117038006
Program Studi
: Magister (S2) Teknik Informatika
Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada
Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (
N
on-Exclusive Royalty
Free Right) atas tesis saya yang berjudul:
ANALISIS AKURASI ALGORITMA NAÏVE BAYES PADA KLASIFIKASI
DOKUMEN BERKATEGORI
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti
Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media,
memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis
saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai
penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, Agustus 2013
Telah diuji pada
Tanggal : Agustus 2013
PANITIA PENGUJI TESIS
Ketua
: Prof. Dr. Muhammad Zarlis
Anggota
: 1. Dr. Marwan Ramli, M.Si
2. Prof. Dr. Herman Mawengkang
vi
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap
: Dewi Yanti, S.Kom
Tempat dan Tanggal Lahir
: Medan, 16 Maret 1986
Alamat Rumah
: Jl. Kertas Gg. Berdikari No. 86 Medan
Telepon/Faks/HP
: 085760888753
Instansi Tempat Bekerja
: KEMENPAREKRAF – UPT Akademi
Pariwisata Medan
Alamat Kantor
: Jl. R.S Haji No. 12 Medan
DATA PENDIDIKAN
KATA PENGANTAR
Puji dan Syukur penulis panjatkan kehadirat Allah SWT berkat limpahan rahmat dan
karunia–Nya lah penulis dapat menyelesaikan Tesis ini dengan bimbingan, arahan,
kritik dan saran serta bantuan dari pembimbing, pembanding, segenap dosen,
rekan-rekan mahasiswa Program Studi Magister (S2) Teknik Informatika Universitas
Sumatera Utara.
Tesis ini diajukan sebagai salah satu syarat untuk memperoleh gelar Magister
Komputer pada Program Studi Pascasarjana Magister Teknik Informatika pada
Fakultas Ilmu Komputer – Teknologi Informasi Universitas Sumatera Utara. Dengan
judul tesis
“Analisis Akurasi Algoritma
Naïve Bayes Pada Klasifikasi Dokumen
Berkategori”. Pada proses penulisan sampai dengan selesainya penulisan tesis ini,
penulis mengucapkan terima kasih yang sebesar-besarnya kepada :
1.
Prof. Dr. Muhammad Zarlis selaku Dekan Fakultas Ilmu Komputer dan
Teknologi Informasi sekaligus
Ketua Program Studi Magister (S2) Teknik
Informatika, dan M. Andri Budiman, ST, M.Comp.Sc, M.EM selaku
Sekretaris Program Studi Magister (S2) Teknik Informatika.
2.
Prof. Dr. Herman Mawengkang dan Dr. Marwan Ramli, M.Si selaku
pembimbing yang telah membimbing penulis dengan penuh kesabaran hingga
selesainya tesis ini dengan baik.
3.
Prof. Dr. Muhammad Zarlis, Prof. Dr. Drs. Iryanto, M.Sidan Prof. Dr. Tulus
selaku pembanding yang telah memberikan masukan dan arahan yang baik
demi selesainya tesis ini.
4.
Drs. Kosmas Harefa, M.Si selaku Direktur Akademi Pariwisata Medan dan
seluruh jajaran Manajemen yang telah memberikan izin studi S2 dan
memberikan dukungan baik moril maupun materil kepada penulis dalam
melanjutkan studi magister ini.
viii
pelayanan terbaik kepada penulis selama mengikuti perkuliahan hingga saat
ini.
6.
Rekan mahasiswa/i angkatan ketiga tahun 2011 pada Program Studi Magister
(S2) Teknik Informatika Program Pascasarjana Fakultas Ilmu Komputer dan
Teknologi Informasi Universitas Sumatera Utara yang telah bersama-sama
saling membantu selama mengikuti perkuliahan.
7.
Rekan-rekan dosen staf pengajar dan staf administrasi Akademi Pariwisata
Medanyang telah memberikan dukungan kepada penulis.
8.
Teristimewa untuk keluarga besar khususnya kedua orangtua yang telah
bersusah payah mendidik penulis dan memberikan semangat, bantuan moril
dan materil kepada penulis.
9.
Semua pihak yang tidak dapat penulis sebutkan satu persatu, terima kasih atas
bantuan yang telah diberikan kepada penulis selama ini.
Dengan segala kekurangan dan kerendahan hati, sekali lagi penulis mengucapkan
terimakasih. Semoga kiranya Allah SWT membalas segala bantuan dan kebaikan yang
telah diberikan.
Medan, Agustus 2013
Penulis
ABSTRAK
Saat ini penyebaran informasi berkembang sangat pesat dalam dokumen o
nline
dari ke
waktu waktu yang jumlahnya sangat besar. Diperlukan pengelolaan informasi yang
baik dari sekumpulan dokumen teks sehingga dapat mempermudah dalam pencarian
informasi yang relevan dengan kebutuhan. Metode yang dapat mengorganisir
dokumen teks secara otomatis diantaranya adalah klasifikasi. Klasifikasi dokumen
adalah proses pengelompokan dokumen sesuai dengan kategori yang dimilikinya.
Teknik yang banyak digunakan dalam klasifikasi dokumen diantaranya adalah
Naive
Bayes Classifier
(NBC) yang memiliki beberapa kelebihan antara lain, sederhana,
cepat dan berakurasi tinggi. Berdasarkan penelitian sebelumnya yang menggunakan
naive bayes
untuk klasifikasi dokumen. Penulis mencoba untuk melakukan penelitian
bagaimana mengklasifikasikan dokumen yang biasanya dilakukan dengan
menggunakan beberapa kategori tetapi pada penelitian kali ini kategori-kategori
tersebut dikelompokkan lagi ke dalam kategori-kategori yang lebih umum yang
memiliki domain yang sama yaitu
sub parent category
dan
parent category
. Diantara
kategori-kategori yang memiliki domain yang sama banyak terdapat kata-kata yang
muncul sama yang menunjukkan ciri dari
sub parent category
dan
parent category
-nya. Penggunaan
sub parent category
dan
parent category
pada algoritma
naïve bayes
diharapkan dapat menghasilkan akurasi yang lebih tinggi khususnya pada klasifikasi
dokumen karena banyaknya kata-kata yang muncul dari suatu dokumen yang saling
beririsan menyebabkan jumlah kesalahan klasifikasi antar kategori sangat besar.
Adapun hasil uji coba menunjukkan bahwa nilai akurasi 31,25% untuk klasifikasi
dokumen tanpa menggunakan sub
parent category
+
parent category
dan maksimal
34,37% untuk klasifikasi dokumen menggunakan sub
parent category
+
parent
category
x
ACCURACY ANALYSIS OF NAÏVE BAYES ALGORITHM ON CATEGORIZED
DOCUMENTS CLASSIFICATION
ABSTRACT
Nowadays, the growth and spread of information in online document sare very quick.
Thus, it requires a good management of information from a collection of text
documents to facilitate the search for relevant information needed. One kind of
methods that is able to organize the text documents automatically is classification.
Documents classification is the process of grouping documents according to its
category. The technique that is widely used in the documents classification such as
Naive Bayes Classifier (NBC), which has several advantages, among others. It is
simple, fast, and accurate. Based on the previous studies using the Naive Bayes for
classification of documents, the research ertries to classify documents that are usually
done using some categories, but in this study, these categories are grouped into more
common categories with the same domain, namely sub parent category and parent
category. Among the categories that have the same domain, there are many words that
appear showing the same characteristics of the sub parent category and its parent
category. The use of sub parent category and parent category in Naïve Bayes
algorithmis expected to gain a higher accuracy, especially in the documents
classification because the words that appear in a document that intersect each other
shave caused very large mis classification between the categories. The results showed
that the classification accuracy is 31,25% for the documents without sub parent
category + parent category and the maximum of accuracy is 34,37% for the
documents using sub parent category + parent category.
DAFTAR ISI
Halaman
HALAMAN JUDUL
i
PENGESAHAN
ii
PERNYATAAN ORISINALITAS
iii
PERSETUJUAN PUBLIKASI
iv
PANITIA PENGUJI
v
RIWAYAT HIDUP
vi
KATA PENGANTAR
vii
ABSTRAK
ix
ABSTRACT
x
DAFTAR ISI
xi
DAFTAR GAMBAR
xiii
DAFTAR TABEL
xiv
BAB 1 PENDAHULUAN
1.1 Latar Belakang
1
1.2 Perumusan Masalah
3
1.3 Batasan Masalah
3
1.4 Tujuan Penelitian
3
1.5 Manfaat Penelitian
3
BAB 2 TINJAUAN PUSTAKA
2.1
Text Mining
4
2.1.1
Text Preprocessing
7
2.1.2
Text Transformation
7
2.1.3
Pattern Discovery
8
2.2 Klasifikasi
9
2.3
Naive Bayes Classifier
12
2.4
Naive Bayes Classifier
untuk Klasifikasi Dokumen
13
2.5 Penelitian Terdahulu
16
xii
2.7 Kontribusi Riset
18
BAB 3 METODOLOGI PENELITIAN
3.1 Rancangan Penelitian
20
3.1.1 Perancangan
Text Preprocessing
20
3.1.2 Perancangan Text Transformation
21
3.1.3 Perancangan
Pattern Discovery
22
3.1.3.1
Learn naïve bayes
22
3.1.3.2
Classify naïve bayes
23
3.1.4 Perancangan
User Interface
24
3.2 Model Pengujian
26
3.3 Instrumen Penelitian
26
3.4 Analisis Proses
Naïve Bayes
26
BAB 4 HASIL DAN PEMBAHASAN
4.1 Hasil
28
4.1.1 Input Data
28
4.1.2 Hasil Pengujian
32
4.2 Pembahasan
34
BAB 5 KESIMPULAN DAN SARAN
5.1 Kesimpulan
37
5.2 Saran
37
DAFTAR PUSTAKA
39
LAMPIRAN PROSES
NAIVE BAYES CLASSIFICATION
DAFTAR GAMBAR
Gambar 2.1 Tahapan Proses Klasifikasi
9
Gambar 2.2 Klasifikasi sebagai pemetaan sebuah himpunan atribut x ke dalam
label class-nya 11
Gambar 2.3 Tahapan Proses Klasifikasi Dokumen dengan
Naïve Bayes
15
Gambar 3.1 Diagram Alir
Text Preprocessing
21
Gambar 3.2 Diagram Alir Penghilangan
Stopword
(
Filtering
)
22
Gambar 3.3 Diagram Alir Proses
Learn Naïve Bayes
23
Gambar 3.4 Diagram Alir Proses
Classify Naïve Bayes
24
Gambar 3.5 Rancangan Form Pembelajaran
25
Gambar 3.6 Rancangan Form Klasifikasi
25
Gambar 4.1 Form Pembelajaran
29
Gambar 4.2 Form Klasifikasi
30
Gambar 4.3 Form Dokumen Pembelajaran
31
Gambar 4.4 Form Dokumen Klasifikasi
32
xiv
DAFTAR TABEL
Tabel 3.1
Parent Category
,
Subparent Category
dan Kategori Dokumen
19
ABSTRAK
Saat ini penyebaran informasi berkembang sangat pesat dalam dokumen
online
dari ke
waktu waktu yang jumlahnya sangat besar. Diperlukan pengelolaan informasi yang
baik dari sekumpulan dokumen teks sehingga dapat mempermudah dalam pencarian
informasi yang relevan dengan kebutuhan. Metode yang dapat mengorganisir
dokumen teks secara otomatis diantaranya adalah klasifikasi. Klasifikasi dokumen
adalah proses pengelompokan dokumen sesuai dengan kategori yang dimilikinya.
Teknik yang banyak digunakan dalam klasifikasi dokumen diantaranya adalah
Naive
Bayes Classifier
(NBC) yang memiliki beberapa kelebihan antara lain, sederhana,
cepat dan berakurasi tinggi. Berdasarkan penelitian sebelumnya yang menggunakan
naive bayes
untuk klasifikasi dokumen. Penulis mencoba untuk melakukan penelitian
bagaimana mengklasifikasikan dokumen yang biasanya dilakukan dengan
menggunakan beberapa kategori tetapi pada penelitian kali ini kategori-kategori
tersebut dikelompokkan lagi ke dalam kategori-kategori yang lebih umum yang
memiliki domain yang sama yaitu
sub parent category
dan
parent category
. Diantara
kategori-kategori yang memiliki domain yang sama banyak terdapat kata-kata yang
muncul sama yang menunjukkan ciri dari
sub parent category
dan
parent category
-nya. Penggunaan
sub parent category
dan
parent category
pada algoritma
naïve bayes
diharapkan dapat menghasilkan akurasi yang lebih tinggi khususnya pada klasifikasi
dokumen karena banyaknya kata-kata yang muncul dari suatu dokumen yang saling
beririsan menyebabkan jumlah kesalahan klasifikasi antar kategori sangat besar.
Adapun hasil uji coba menunjukkan bahwa nilai akurasi 31,25% untuk klasifikasi
dokumen tanpa menggunakan sub
parent category
+
parent category
dan maksimal
34,37% untuk klasifikasi dokumen menggunakan sub
parent category
+
parent
category
x
ACCURACY ANALYSIS OF NAÏVE BAYES ALGORITHM ON CATEGORIZED
DOCUMENTS CLASSIFICATION
ABSTRACT
Nowadays, the growth and spread of information in online document sare very quick.
Thus, it requires a good management of information from a collection of text
documents to facilitate the search for relevant information needed. One kind of
methods that is able to organize the text documents automatically is classification.
Documents classification is the process of grouping documents according to its
category. The technique that is widely used in the documents classification such as
Naive Bayes Classifier (NBC), which has several advantages, among others. It is
simple, fast, and accurate. Based on the previous studies using the Naive Bayes for
classification of documents, the research ertries to classify documents that are usually
done using some categories, but in this study, these categories are grouped into more
common categories with the same domain, namely sub parent category and parent
category. Among the categories that have the same domain, there are many words that
appear showing the same characteristics of the sub parent category and its parent
category. The use of sub parent category and parent category in Naïve Bayes
algorithmis expected to gain a higher accuracy, especially in the documents
classification because the words that appear in a document that intersect each other
shave caused very large mis classification between the categories. The results showed
that the classification accuracy is 31,25% for the documents without sub parent
category + parent category and the maximum of accuracy is 34,37% for the
documents using sub parent category + parent category.
1.1
Latar Belakang
Penyebaran informasi berkembang sangat pesat dalam dokumen
online
dari setiap
waktu terus mengalami perkembangan dan jumlahnya semakin besar menyebabkan
semakin meningkat pula volume informasi yang berbentuk teks. Kondisi kebanjiran
informasi ini telah menimbulkan kesulitan manusia dalam mencerna informasi. Menurut
Bridge (2011), hal yang lebih menyulitkan dalam analisis adalah bahwa sekitar 80%
sampai 85% bentuk informasi tersebut dalam format tidak terstruktur (
unstructured
data
). Melimpahnya informasi teks tidak terstruktur telah mendorongnya munculnya
disiplin baru dalam analisis teks, yaitu
text
mining
yang mencoba menemukan pola-pola
informasi yang dapat digali dari suatu teks yang tidak terstruktur tersebut.
Text mining
merupakan sebuah proses pengetahuan intensif dimana pengguna
berinteraksi dan bekerja dengan sekumpulan dokumen dengan menggunakan beberapa
alat analisis (Feldman, R. & Sanger, J, 2007). Text mining mencoba untuk mengekstrak
informasi yang berguna dari sumber data melalui identifikasi dan eksplorasi dari suatu
pola menarik. Sumber data berupa sekumpulan dokumen dan pola menarik yang tidak
ditemukan dalam bentuk database record, tetapi dalam data teks yang tidak terstruktur.
2
Teknik yang banyak digunakan dalam klasifikasi dokumen diantaranya adalah
Naive Bayes Classifier
(NBC) yang memiliki beberapa kelebihan antara lain, sederhana,
cepat dan berakurasi tinggi. Metode NBC untuk klasifikasi atau kategorisasi teks
menggunakan atribut kata yang muncul dalam satu dokumen sebagai dasar
klasifikasinya. Algoritma klasifikasi
Naïve Bayes
memanfaatkan teori probabilitas yang
dikemukan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di
masa depan berdasarkan pengalaman di masa sebelumya. Algoritma NBC yang
sederhana dan kecepatannya yang tinggi dalam proses pelatihan dan klasifikasi
membuat algoritma ini menarik untuk digunakan sebagai salah satu metode klasifikasi
(Wibisono, 2008). Proses klasifikasi
biasanya dibagi menjadi dua fase
learning
dan
test
.
Pada fase learning, sebagian data yang telah diketahui kelas datanya diumpankan untuk
membentuk model perkiraan. Kemudian pada fase
test
model yang sudah terbentuk
diuji dengan sebagian data lainnya untuk mengetahui
akurasi dari model tersebut.
Beberapa penelitian yang berkaitan dengan klasifikasi
naïve bayes
diantaranya
implementasi
naive bayes classifier
pada program bantu penentuan buku referensi
matakuliah menghasilkan nilai akurasi 69% (Nurani et al, 2007). Klasifikasi emosi
untuk teks bahasa Indonesia menggunakan metode naive bayes menghasilkan akurasi
nilai maksimum 60,45 dengan
precision
dan
recall
(Destuardi & Sumpeno, 2009).
Klasifikasi dokumen teks berbahasa Indonesia dengan menggunakan
naïve bayes
menghasilkan akurasi 83, 57% dan terus meningkat hingga 87,63% (Samodra et al,
2009). Klasifikasi dokumen menggunakan algoritma
naive bayes
dengan penambahan
parameter probabilitas
parent category
menghasilkan 61,77% untuk klasifikasi
menggunakan
naive bayes
dan
parent category
sedangkan 60,49% menggunakan
naive
bayes
saja (Trisedya & Jai, 2009). Klasifikasi
teks
dengan
Naïve Bayes Classifier (
Nbc)
untuk pengelompokan teks berita dan
abstract
akademis menghasilkan akurasi yang
lebih tinggi maksimal 91% dibandingkan dengan dokumen akademik maksimal 82%
(Hamzah, 2012).
Berdasarkan dari penelitian yang ada tersebut, penulis mencoba untuk melakukan
penelitian bagaimana mengklasifikasikan dokumen yang biasanya dilakukan dengan
menggunakan beberapa kategori tetapi pada penelitian kali ini kategori-kategori tersebut
dikelompokkan lagi ke dalam kategori-kategori yang lebih umum yang memiliki
kategori-kategori yang memiliki domain yang sama banyak terdapat kata-kata yang muncul sama
yang menunjukkan ciri dari
sub parent category
dan
parent category
-nya. Penggunaan
sub parent category
dan
parent category
pada algoritma
naïve bayes
diharapkan dapat
menghasilkan akurasi yang lebih tinggi khususnya pada klasifikasi dokumen karena
banyaknya kata-kata yang muncul dari suatu dokumen yang saling beririsan
menyebabkan jumlah kesalahan klasifikasi antar kategori sangat besar. Dari uraian
sebelumnya, penulis tertarik untuk mengambil judul “Analisis Akurasi Algoritma Naïve
Bayes Pada Klasifikasi Dokumen Berkategori”.
1.2 Perumusan Masalah
Berdasarkan latar belakang, maka penulis merumuskan masalah yaitu bagaimana
akurasi dari klasifikasi dokumen yang memiliki beberapa kategori dengan
menambahkan
sub parent category
dan
parent category
dengan pendekatan metode
naïve bayes
.
1.3
Batasan Masalah
Adapun batasan masalah dari penelitian ini adalah sebagai berikut :
1.
Data yang digunakan adalah dokumen
online
yang diambil dari situs berita.
2.
Teknik klasifikasi data yang digunakan adalah
naïve bayes classifier
.
1.4
Tujuan Penelitian
Tujuan yang ingin dicapai oleh penulis adalah untuk menganalisis akurasi dari
klasifikasi dokumen yang memiliki beberapa kategori dengan menambahkan
Sub
Parent Category
dan
parent category
dengan pendekatan metode
naïve bayes
.
1.5
Manfaat penelitian
Adapun manfaat dari penelitian ini sebagai berikut :
1.
Memberikan tambahan wawasan keilmuan serta memperdalam konsep dan teori
teknik pengklasifikasi data khususnya
naïve bayes
.
BAB
2
LANDASAN TEORI
2.1 Text Mining
Text
mining
dapat diartikan sebagai penemuan informasi yang baru dan tidak diketahui
sebelumnya oleh komputer, dengan secara otomatis mengekstrak informasi dari
sumber-sumber yang berbeda. Kunci dari proses ini adalah menggabungkan informasi
yang berhasil diekstraksi dari berbagai sumber (Hearst, 2003). Sedangkan menurut
(Harlian, 2006)
text mining
memiliki definisi menambang data yang berupa teks dimana
sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah mencari kata-kata
yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisa keterhubungan
antar dokumen.
Text mining
mengacu pada proses mengambil informasi berkualitas tinggi dari
teks. Informasi berkualitas tinggi biasanya diperoleh melalui peramalan pola dan
kecenderungan melalui sarana seperti pembelajaran pola statistik.
Text mining
biasanya
melibatkan proses penataan teks input (biasanya parsing, bersama dengan penambahan
beberapa fitur linguistik turunan dan penghilangan beberapa diantaranya, dan
penyisipan
subsequent
ke dalam
database
), menentukan pola dalam data terstruktur,
dan akhirnya mengevaluasi dan menginterpretasi output. Berkualitas tinggi di bidang
text mining
biasanya mengacu ke beberapa kombinasi relevansi, kebaruan, dan
interestingness
.
Menurut Saraswati (2011), saat ini
text
mining
telah mendapat perhatian dalam
berbagai bidang diantaranya :
1.
Aplikasi keamanan
Banyak paket perangkat lunak
text mining
dipasarkan terhadap aplikasi
keamanan, khususnya analisis
plain text
seperti berita internet. Hal ini juga
mencakup studi enkripsi teks.
2.
Aplikasi biomedis
Berbagai aplikasi
text mining
dalam literatur biomedis telah disusun. Salah satu
contohnya adalah PubGene yang mengkombinasikan
text mining
biomedis
dengan visualisasi jaringan sebagai sebuah layanan Internet. Contoh lain
text
mining
adalah GoPubMed.org. Kesamaan semantik juga telah digunakan oleh
sistem
text mining
, yaitu, GOAnnotator.
3.
Perangkat Lunak dan Aplikasi
Departemen riset dan pengembangan perusahaan besar, termasuk IBM dan
Microsoft, sedang meneliti teknik
text mining
dan mengembangkan program
untuk lebih mengotomatisasi proses pertambangan dan analisis. Perangkat lunak
text mining
juga sedang diteliti oleh perusahaan yang berbeda yang bekerja di
bidang pencarian dan pengindeksan secara umum sebagai cara untuk
meningkatkan performansinya.
4.
Aplikasi Media Online
Text mining sedang digunakan oleh perusahaan media besar, seperti perusahaan
Tribune, untuk menghilangkan ambigu informasi dan untuk memberikan
pembaca dengan pengalaman pencarian yang lebih baik, yang meningkatkan
loyalitas pada
site
dan pendapatan. Selain itu, editor diuntungkan dengan
mampu berbagi, mengasosiasi dan properti paket berita, secara signifikan
meningkatkan peluang untuk menguangkan konten.
5.
Aplikasi Pemasaran
6
6.
Sentiment Analysis
Sentiment Analysis
mungkin melibatkan analisis dari
review
film untuk
memperkirakan berapa baik review untuk sebuah film. Analisis semacam ini
mungkin memerlukan kumpulan data berlabel atau label dari efektifitas
kata-kata. Sebuah sumber daya untuk efektivitas kata-kata telah dibuat untuk
WordNet.
7.
Aplikasi Akademik
Masalah
text mining
penting bagi penerbit yang memiliki database besar untuk
mendapatkan informasi yang memerlukan pengindeksan untuk pencarian. Hal
ini terutama berlaku dalam ilmu sains, di mana informasi yang sangat spesifik
sering terkandung dalam teks tertulis. Oleh karena itu, inisiatif telah diambil
seperti
Nature’s proposal
untuk
Open Text Mining Interface
(OTMI) dan
Health’s
common Journal Publishing
untuk
Document Type Definition
(DTD)
yang akan memberikan isyarat semantik pada mesin untuk menjawab pertanyaan
spesifik yang terkandung dalam teks tanpa menghilangkan
barrier
penerbit
untuk akses publik.
Sebelumnya, website paling sering menggunakan pencarian berbasis teks, yang
hanya menemukan dokumen yang berisi kata-kata atau frase spesifik yang ditentukan
oleh pengguna. Sekarang, melalui penggunaan web semantik,
text
mining
dapat
menemukan konten berdasarkan makna dan konteks (daripada hanya dengan kata
tertentu).
Text mining
juga digunakan dalam beberapa filter email spam sebagai cara
untuk menentukan karakteristik pesan yang mungkin berupa iklan atau materi yang
tidak diinginkan lainnya.
Dengan
text mining
tugas-tugas yang berhubungan dengan penganalisaan teks
dengan jumlah yang besar, penemuan pola serta penggalian informasi yang mungkin
berguna dari suatu teks dapat dilakukan. Sebagai bentuk aplikasi dari
text mining
,
sistem klasifikasi berita menggunakan berita sebagai sumber informasi dan informasi
klasifikasi sebagai informasi yang akan diekstrak dari sumber informasi. Informasi
klasifikasi dapat berbentuk angkaangka probabilitas, set aturan atau bentuk lainnya.
(
text t
ransformation/feature generation
), dan penemuan pola (
pattern discovery
). (Even
dan Zohar, 2002). Masukan awal dari proses ini adalah suatu data teks dan
menghasilkan keluaran berupa pola sebagai hasil interpretasi.
2.1.1 Text Preprocessing
Tahapan awal dari
text mining
adalah
text preprocessing
yang bertujuan untuk
mempersiapkan teks menjadi data yang akan mengalami pengolahan pada tahapan
berikutnya. Beberapa contoh tindakan yang dapat dilakukan pada tahap ini, mulai dari
tindakan yang bersifat kompleks seperti
part of speech
(pos)
tagging
,
parse tree
, hingga
tindakan yang bersifat sederhana seperti proses parsing sederhana terhadap teks, yaitu
memecah suatu kalimat menjadi sekumpulan kata. Selain itu pada tahapan ini biasanya
juga dilakukan
case
folding
, yaitu pengubahan karakter huruf menjadi huruf kecil.
Proses
part of speech
melakukan parsing terhadap seluruh kalimat dalam
teks
kemudian memberikan peran kepada setiap kata, misalnya : petani (subyek)
pergi
(predikat) ke (kata hub) sawah (keterangan). Hasil dari
part of speech tagging
dapat
digunakan untuk
parse tree
, di mana masing-masing
kalimat berdiri
sebagai sebuah
pohon mandiri.
Untuk proses parsing sederhana tidak dibangun
parse tree
seperti cara
sebelumnya. Pada proses parsing sederhana sistem akan memecah teks menjadi
sekumpulan kata-kata,
yang kemudian akan dibawa sebagai input untuk tahap
berikutnya pada proses
text mining
.
2.1.2 Text Transformation (feature generation)
Pada tahap ini hasil yang diperoleh dari tahap
text preprocessing
akan melalui proses
tranformasi. Adapun proses transformasi ini dilakukan dengan mengurangi jumlah
kata-kata yang ada dengan penghilangan
stopword
dan juga dengan mengubah kata-kata ke
dalam bentuk dasarnya (
stemming
).
8
mengurangi beban kerja system. Dengan menghilangkan
stopword
dari suatu teks maka
sistem hanya akan memperhitungkan kata-kata yang dianggap penting.
Stemming
adalah contoh tindakan lain yang dapat dilakukan pada tahap
transformasi teks.
Stemming
adalah proses untuk mereduksi kata ke bentuk dasarnya
Sedangkan menurut Tala (2003)
Stemming
adalah suatu proses yang menyediakan suatu
pemetaan antara berbagai kata dengan morfologi yang berbeda menjadi satu bentuk
dasar (
stem
). Kata yang memiliki bentuk dasar sama walaupun imbuhannya berbeda
seharusnya memiliki kedekatan arti. Disamping itu juga, proses stemming akan sangat
mengurangi jumlah dan beban
database
. Jika setiap kata disimpan tanpa melalui proses
stemming
, maka satu macam kata dasar saja akan disimpan dengan berbagai macam
bentuk yang berbeda sesuai dengan imbuhan yang mungkin melekatinya. Hal ini sangat
berbeda jika kita menerapkan proses
stemming
pada tahap ini, satu kata dasar hanya
akan disimpan sekali walaupun mungkin kata dasar tersebut pada sumber data sudah
berubah dari bentuk aslinya dan mendapatkan berbagai macam imbuhan. Proses
stemming
dan penghilangan
stopword
dapat digunakan secara mandiri atau tergabung,
dimana dilakukan proses penghilangan
stopword
terlebih dahulu yang diikuti dengan
proses
stemming
. Hal ini dilakukan untuk menemukan pola dari teks dalam berita
tersebut.
2.1.3 Pattern Discovery
Tahap penemuan pola atau
pattern discovery
adalah tahap terpenting dari seluruh proses
text mining.
Tahap ini berusaha menemukan pola atau pengetahuan dari keseluruhan
teks. Seperti yang disebutkan dalam bab sebelumnya bahwa dalam data/
text
mining
terdapat dua teknik pembelajaran pada tahap
pattern discovery
ini, yaitu
unsupervised
dan
supervised learning.
Adapun perbedaan antara keduanya adalah pada
supervised
learning
terdapat label atau nama kelas pada data latih (supervisi) dan data baru
diklasifikasikan berdasarkan data latih. Sedangkan pada
unsupervised learning
tidak
terdapat label atau nama kelas pada data latih, data latih dikelompokkan berdasarkan
ukuran kemiripan pada suatu kelas.
atribut tujuan (tidak kontinyu). Tujuan dari
supervised learning
adalah untuk
memprediksi nilai dari fungsi untuk sebuah data masukan yang sah setelah melihat
sejumlah data latih.
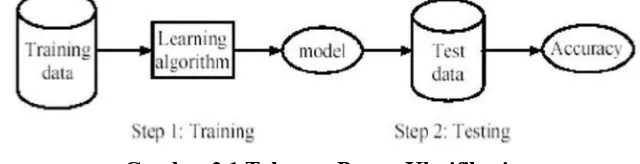
2.1 Klasifikasi
Klasifikasi adalah proses untuk menemukan model atau fungsi yang menjelaskan atau
membedakan konsep atau kelas data dengan tujuan untuk memperkirakan kelas yang
tidak diketahui dari suatu objek. Dalam pengklasifikasian data terdapat dua proses yang
dilakukan yaitu:
1.
Proses
training
Pada proses
training
digunakan
training set
yang telah diketahui label-labelnya
untuk membangun model atau fungsi.
2.
Proses
testing
Untuk mengetahui keakuratan model atau fungsi yang akan dibangun pada
proses
training
, maka digunakan data yang disebut dengan testing set untuk
memprediksi label-labelnya.
Gambar 2.1 Tahapan Proses Klasifikasi
Sumber: http://www.informatika.unsyiah.ac.id/tfa/dm/DM-Praktikum-Decision-Tree.pdf
10
Prediksi bisa dipandang sebagai pembentukan dan penggunaan model untuk
menguji kelas sampel yang tidak berlabel, atau menguji nilai atau rentang nilai dari
suatu atribut. Klasifikasi dan regresi adalah dua jenis masalah prediksi, dimana
klasifikasi digunakan untuk memprediksi nilai-nilai diskrit atau nominal, sedangkan
regresi digunakan untuk mempediksi nilai-nilai yang kontinyu. Untuk selanjutnya
penggunaan istilah
prediction
untuk memprediksi kelas yang berlabel disebut
classification
, dan penggunaan istilah prediksi untuk memprediksi nilai-nilai yang
kontinyu sebagai
prediction
.
Klasifikasi merupakan penempatan objek-objek ke salah satu dari beberapa
kategori yang telah ditetapkan sebelumnya. Klasifikasi telah banyak ditemui dalam
berbagai aplikasi. Sebagai contoh, pendeteksian pesan
,
spam
berdasarkan
header
dan isi atau mengklasifikasikan galaksi berdasarkan bentuk-bentuknya. Data input
untuk klasifikasi adalah koleksi
record
. Setiap
record
dikenal sebagai
instance
atau
contoh yang ditentukan oleh sebuah
tuple
(x,y). Dimana x adalah himpunan atribut dan
y adalah atribut tertentu, yang dinyatakan sebagai label
class
(juga dikenal sebagai
kategori atau atribut target).
Klasifikasi adalah tugas pembelajaran sebuah fungsi target f yang memetakan
setiap himpunan atribut x ke salah satu label kelas y yang telah di definisikan
sebelumnya. Fungsi target juga di kenal secara informal sebagai model klasifikasi.
Model klasifikasi berguna untuk keperluan sebagai berikut :
1.
Pemodelan Deskriptif
Model klasifikasi dapat bertindak sebagai alat penjelas untuk membedakan
objek objek dari kelas kelas yang berbeda. Sebagai contoh untuk para ahli
Biologi, model deskriptif yang meringkas data.
2.
Pemodelan Prediktif
Input
Output
Attribut set (x)
Class
label (y)
Gambar 2.2 Klasifikasi sebagai pemetaan sebuah himpunan atribut input x
ke dalam label class-nya
Beberapa teknik klasifikasi yang digunakan adalah
decision tree classifier,
rule-based classifier, neural-network, support vector machine
, dan
naïve bayes classifier
,
Setiap teknik menggunakan algoritme pembelajaran untuk mengidentifikasi model
yang memberikan hubungan yang paling sesuai antara himpunan atribut dan label kelas
dari data input.
Pendekatan umum yang digunakan dalam masalah klasifikasi adalah,
pertama,training set berisi
record
yang mempunyai label kelas yang diketahui haruslah
tersedia . Training set digunakan untuk membangun model klasifikasi , yang kemudian
diaplikasikan ke
test
set, yang berisi
record-record
dengan label kelas yang tidak di
ketahui.
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh,
penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan
tinggi, pendapatan sedang, dan pendapatan rendah. Contoh lain klasifikasi dalam bisnis
dan penelitian adalah:
a. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang
curang atau bukan.
b. Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan
suatu kredit yang baik atau buruk.
c. Mendiagnosa penyakit seorang pasien untuk mendapatkan termasuk kategori
apa.
Klasifikasi dokumen adalah proses pengelompokan dokumen sesuai dengan
kategori yang dimilikinya. Klasifikasi dokumen merupakan masalah yang mendasar
namun sangat penting karena manfaatnya cukup besar mengingat jumlah dokumen yang
ada setiap hari semakin bertambah. Sebuah dokumen dapat dikelompokkan ke dalam
kategori tertentu berdasarkan kata-kata dan kalimat-kalimat yang ada di dalam dokumen
tersebut. Kata atau kalimat yang terdapat di dalam sebuah dokumen memiliki makna
12
tertentu dan dapat digunakan sebagai dasar untuk menentukan kategori dari dokumen
tersebut.
2.3 Naïve Bayes Classifier
Naïve bayes
klasifikasi merupakan metode terbaru yang digunakan untuk memprediksi
probabilitas.Algoritma ini memanfaatkan teori probabilitas yang dikemukakan oleh
ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di masa depan
berdasarkan pengalaman di masa sebelumnya. Dua kelompok peneliti, satu oleh pantel
dan Lin, dan yang lain oleh Microsoft Research memperkenalkan metode statistik
bayesian. Tetapi yang membuat naïve bayesian ini popular adalah pendekatan yang
dilakukan oleh Paul Graham.
Banyak aplikasi ini menghubungkan antara atribut set dan variabel kelas yang
non
deterministic
. Dengan kata lain, label kelas
test record
tidak dapat diprediksi
dengan peristiwa tertentu meski atribut set identik dengan beberapa contoh
training
.
Situasi ini makin meningkat karena
noisy
data atau kehadiran factor confouding
tertentu yang mempengaruhi klasifikasi tetapi tidak termasuk di dalam analisis. Sebagai
contoh, perhatikan tugas memprediksi apakah seseorang beresiko terkena penyakit hati
berdasarkan diet yang dilakukan dan olahraga teratur. Meski mempunyai pola makan
sehat dan melakukan olahraga teratur, tetapi masih beresiko terkena penyakit hati
karena faktor faktor lain seperti keturunan, merokok, dan penyalahgunaan alkohol.
Untuk menentukan apakah diet sehat dan olahraga teratur yang dilakukan sesorang
adalah cukup menjadi subyek interpretasi, yang akan memperkenalkan ketidakpastian
pada masalah pembelajaran.
diamati, maka P(X|H) adalah peluang data sampel
X
, bila diasumsikan bahwa hipotesa
H benar (valid). Karena asumsi atribut tidak saling terkait (
conditionally independent
),
maka P(X|C
i) dapat didekati dengan cara:
n
P (X|C
i) = ∏ P(X
k|C
i)
k=1Jika P(X|C
i) diketahui maka klas dari data sampel
X
dapat didekati dengan menghitungg
P(X|C
i)*P(C
i). Klas Ci dimana
P(X|C
i)*P(C
i) maksimum
adalah klas dari sampel
X
.
Naïve bayes classifier
memiliki asumsi bahwa hubungan antar atribut adalah
saling bebas.
Naïve bayes classifier
memiliki beberapa keuntungan dan kelemahan yaitu
diantaranya :
Keuntungan :
a.
Hasilnya cukup baik untuk sebagian besar kasus dan mudah diimplementasikan.
b.
Bila asumsi saling bebas terpenuhi, maka tingkat akurasinya sangat tinggi
Kelemahan :
a.
Adanya asumsi saling bebas antar atributnya terkadang akan menurunkan
tingkat akurasi.
b.
Biasanya dalam kehidupan nyata selalu ada hubungan antar atribut sehingga
asumsi saling bebas menjadi tidak terpenuhi dan keterkaitan tersebut tidak dapat
dimodelkan oleh
naïve bayes classifier
.
c.
Perkiraan kemungkinan class yang tidak akurat.
d.
Batasan atau
threshold
harus ditentukan secara manual bukan secara analitis.
2.4 Naïve Bayes Classifier untuk Klasifikasi Dokumen
14
pada P={p(C=c
i|D=d
j)} | c ε C dan d ε D}. Nilai probabilitas p(C=c
i|D=d
j) dapat
dihitung dengan persamaan :
p(C=c
i|D=d
j) =
( ( ⋂ ) )=
( | ) ( )( )
Dengan p(D=d
j|C=c
i) merupakan nilai probabilitas dari kemunculan dokumen dj jika
diketahui dokumen tersebut berkategori c
i, p(C=c
i) adalah nilai probabilitas kemunculan
kategori c
i, dan p(D=d
j) adalah nilai probabilitas kemunculan dokumen d
j.
Naïve Bayes
menganggap sebuah dokumen sebagai kumpulan dari kata-kata
yang menyusun dokumen tersebut, dan tidak memperhatikan urutan kemunculan kata
pada dokumen. Sehingga perhitungan probabilitas p(D=d
j|C=c
i) dapat dianggap sebagai
hasil perkalian dari probabilitas kemunculan kata-kata pada dokumen dj. Perhitungan
probabilitas p(C=c
i|D=d
j) dapat dituliskan sebagai berikut :
p(C=c
i|D=d
j) =
∏ (( , |, ,…) (,… ))dengan
∏ (wk |C = ci)
ada lah hasil perkalian dari probabilitas kemunculan semua
kata pada dokumen d
j.
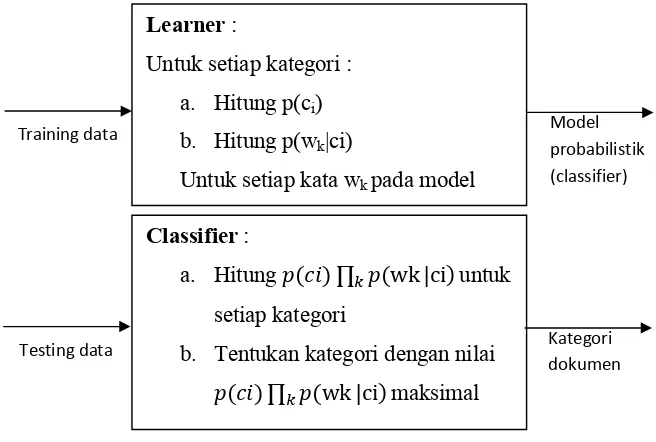
Proses klasifikasi dilakukan dengan membuat model probabilistic dari dokumen
training
, yaitu dengan menghitung nilai p(w
k|c). Untuk wkj diskritdengan w
kjε V =
{v
1,v
2,v
3,…,v
m} maka p(w
k|c) dicari untuk seluruh kemungkinan nilai w
kjdan
didapatkan dengan melakukan perhitungan :
P(w
k= w
kj|c) =
( ( ) . )dan
dengan D
b(w
k= w
kj.c) adalah fungsi yang mengembalikan jumlah dokumen b pada
kategori c yang memilki nilai kata w
k=w
kj, D
b(c) adalah fungsi yang mengembalikan
jumlah dokumen b yang memiliki kategori c, dan |D| adalah jumlah seluruh
t
raining
dokumen. Persamaan D
b(w
k= w
kj.c) sering dikombinasikan dengan
Laplacian
Smoothing
untuk mencegah persamaan mendapatkan nilai 0, yang dapat mengganggu
hasil klasifikasi secara keseluruhan. Sehingga persamaan D
b(w
k= w
kj.c) dituliskan
sebagai :
P(w
k= w
kj|c) =
( ( ) | |. )dengan |V| merupakan jumlah kemungkinan nilai dari wkj.
Pemberian kategori dari sebuah dokumen dilakukan dengan memilih nilai c yang
memilki nilai p(C=c
i|D=d
j) maksimum, dan dinyatakan dengan :
c* =arg max p
∏ (wk |C) x p(c)
cϵC
[image:32.595.163.491.461.682.2]Kategori c* merupakan kategori yang memiliki nilai p(C=c
i|D=d
j) maksimum. Nilai
p(D=d
j) tidak mempengaruhi perbandingan karena untuk setiap kategori nilainya akan
sama. Berikut ini gambaran proses klasifikasi dengan algoritma
Naïve Bayes
:
Gambar 2.3 Tahapan Proses Kalsifikasi Dokumen dengan Naïve Bayes
Learner
:
Untuk setiap kategori :
a.
Hitung p(c
i)
b.
Hitung p(w
k|ci)
Untuk setiap kata w
kpada model
Classifier
:
a.
Hitung
( ) ∏ (wk |ci)
untuk
setiap kategori
b.
Tentukan kategori dengan nilai
( ) ∏ (wk |ci)
maksimal
Training data Model
probabilistik (classifier)
Testing data Kategori
16
2.5 Penelitian Terdahulu
Terdapat beberapa riset yang telah dilakukan oleh banyak peneliti yang berkaitan
dengan penelitian yang penulis lakukan diantara penelitian tersebut yaitu :
Nurani et al (2007) menjelaskan implementasi
n
aive bayes classifier
pada
program bantu penentuan buku referensi matakuliah menghasilkan nilai akurasi 69%.
Dimana perpustakaan merupakan bagian yang penting dari suatu Universitas karena
menyediakan buku-buku referensi. Kesulitan yang terjadi adalah ketika perpustakaan
harus mengidentifikasi buku-buku referensi tersebut sesuai dengan matakuliahnya. Ada
beberapa buku yang sering dijadikan referensi bersama atas beberapa matakuliah. Ada
juga buku-buku yang dijadikan referensi tunggal suatu matakuliah, tetapi bahasan
materi matakuliah yang bersangkutan tidak dibahas secara optimal dalam buku referensi
tersebut. Setiap matakuliah memiliki silabus perkuliahan yang berisi materi-materi dan
disusun berdasarkan buku-buku referensi utama dan referensi pendukung dari
matakuliah tersebut. Proses klasifikasi akan dilakukan menggunakan metodeNaiue
BayesianClassifier (NBC). Dalammelaksanakan tugasnya untuk mengklasifikasikan
daftar isi buku referensi sistem dipengaruhi oleh berbagai faktor seperti pola data dan
jumlah data training.
Indranandita et al, (2008) menjelaskan sistem klasifikasi dan pencarian jurnal
dengan menggunakan metode
naive bayes
dan
vector space model
menghasilkan
akurasi sebesar 64%. Dimana kebutuhan konsumen terhadap informasi dalam bentuk
jurnal atau artikel ilmiah semakin meningkat, sehingga pengelompokan jurnal
dibutuhkan untuk mempermudah pencarian informasi. Topik jurnal diharapkan dapat
mewakili isi jurnal, tanpa harus membaca secara keseluruhan. Dalam kenyataannya,
pengelompokan jurnal yang mengacu topik/kategori tertentu sulit dilakukan jika hanya
mengandalkan query biasa. Sistem klasifikasi dan pencarian jurnal dengan metode
Naive Bayes dan Vector Space Model dengan pendekatan Cosine diharapkan membantu
pengguna dalam penentuan topik/kategori dan menghasilkan daftar jurnal berdasarkan
urutan tingkat kemiripan.
klaisifikasi teks. Pada proses klasifikasi itu akan digunakan data set yang telah diketahui
kelas emosinya yaitu jijik, malu, marah, sedih, senang, dan takut dengan menggunakan
metode
Naïve Bayes
dan
Naïve Bayes Multinomial
. Akan dilihat sejauh mana kedua
metode itu dapat mengklasifikasikan data emosi berbahasa indonesia. Dari hasil
percobaan yang dilakukan dapat ditarik kesimpulan bahwa Modifikasi data dapat
meningkatkan kemampuan mesin mengklasifikasi data teks emosi berbahasa indonesia.
Metode multinomial
naïve bayes
lebih baik dari metode
naïve bayes
untuk klasifikasi
teks berbahasa Indonesia. Dengan rasio 0,8 yang dihasilkan F-measure tinggi 62,15
untuk multinomial
naïve bayes
menggunakan data asli. Hasil klasifikasi mengggunakan
metode multinomial
naïve bayes
dan
naïve bayes
tidak memberikan perbaikan yang
signifikan saat rasio data 0,5 untuk percobaan DataNot.
Samodra et al, (2009) menjelaskan klasifikasi dokumen teks berbahasa
Indonesia dengan menggunakan
naïve bayes
. Dimana penyebaran informasi dalam
bentuk dokumen digital telah mengalami pertumbuhan yang sangat pesat. Dengan
menggunakan metode klasifikasi teks, maka kumpulan dokumen yang jumlahnya sangat
besar tersebut dapat diorganisir sedemikian rupa sehingga dapat mempermudah dan
mempercepat pencarian informasi yang dibutuhkan. Eksperimen ditujukan untuk
menghasilkan dokumen teks berbahasa Indonesia dengan menggunakan metode
Naïve
Bayes
. Uji coba dilakukan dengan menggunakan sampel dokumen teks yang dimabil
dari sebuah media massa elektonik berbasis web. Hasil eksperimen menunujukkan
bahwa metode
Naïve Bayes
dapat digunakan secara efektif untuk menghasilkan
dokumen teks berbahasa Indonesia. Hal ini terlihat dari hasil eksperimen yaitu dengan
porsi dokumen training yang kecil (20%) nilai akurasinya dapat mencapai 83,57 % dan
terus meningkat hingga 87,63 % sesuai dengan peningkatan porsi dokumen training.
18
Hamzah (2012) menjelaskan klasifikasi
teks
dengan
Naïve Bayes Classifier
(
Nbc) untuk pengelompokan teks berita dan
abstract
akademis menghasilkan akurasi
yang lebih tinggi maksimal 91% dibandingkan dengan dokumen akademik maksimal
82%. Dimana perkembangan informasi teks digital telah tumbuh sangat cepat. Saat ini
diperkirakan 80% teks digital dalam bentuk tidak terstruktur. Tingginya volume
dokumen teks ini dipicu oleh aktivitas dari berbagai sumber berita dan aktivitas
akademis dari kegiatan riset, konferensi dan pertemuan ilmiah yang makin meningkat.
Kebutuhan analisis
text mining
sangat diperlukan dalam menangani teks yang tidak
terstruktur tersebut. Salah satu kegiatan penting dalam text mining adalah klasifikasi
atau kategorisasi teks. Kategorisasi teks sendiri saat ini memiliki berbagai cara
pendekatan antara lain pendekatan
probabilistic
,
support vector machine
, dan
artificial
neural
network
, atau
decision tree classification.
Metode probabilistic
Naïve Bayes
Classifier
(NBC) memiliki beberapa kelebihan kesederhanaan dalam komputasinya.
Namun metode ini memiliki kelemahan dalam asumsi yang sulit dipenuhi, yaitu
independensi feature kata. Penelitian ini mengkaji kinerja NBC untuk kategorisasi teks
berita dan teks akademis. Penelitian menggunakan data 1000 dokumen berita dan 450
dokumen abstrak akademik. Seleksi kata dengan minimal muncul pada 4 atau 5
dokumen memberikan akurasi yang paling tinggi.
2.6 Perbedaan dengan Riset Lain
Dalam beberapa riset yang dilakukan peneliti sebelumnya, terdapat beberapa perbedaan
riset yang akan dilakukan oleh penulis. Riset yang dilakukan penulis dalam klasifikasi
naïve bayes
yaitu menggunakan
sub parent category
dan
parent category
dari suatu
kategori dalam proses
training
dan
testing
untuk menghasilkan nilai akurasi dari
klasifikasi dokumen.
2.7
Kontribusi Riset
Klasifikasi adalah proses untuk menemukan model atau fungsi yang menjelaskan atau
membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas
dari suatu objek yang labelnya tidak diketahui. Ada dua proses penting yang dilakukan
saat melakukan klasifikasi. Proses yang pertama adalah
learning (training)
yaitu proses
pembelajaran menggunakan data
training
. Proses yang kedua adalah proses
testing
yaitu
menguji model dengan menggunakan data
testing
. Penelitian ini dilakukan
menggunakan dokumen
online
yang diambil dari situs berita dan digunakan sebagai
objek penelitian.
Untuk memperoleh ketepatan data dan mempermudah dalam pengujian
kebenaran dan keakuratan, maka data yang digunakan diambil dari dokumen yang telah
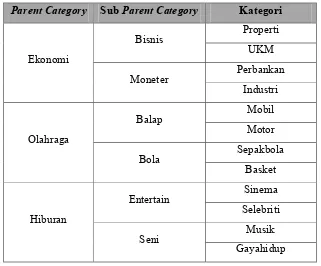
diklasifikasikan berdasarkan kategori dari situs berita. Terdapat 4
parent category
yang
digunakan dalam klasifikasi dokumen pada penelitian ini. Setiap
parent category
[image:36.595.159.480.448.714.2]memiliki sub
parent category
dan kategori sebagaimana disajikan pada tabel 3.1.
Tabel 3.1
Parent Category,
Sub
Parent Category
dan Kategori Dokumen
Parent Category
Sub
Parent Category
Kategori
Ekonomi
Bisnis
Properti
UKM
Moneter
Perbankan
Industri
Olahraga
Balap
Mobil
Motor
Bola
Sepakbola
Basket
Hiburan
Entertain
Sinema
Selebriti
Seni
Musik
20
Tekonolgi
Sains
Kedokteran
Umum
Komputer
Gadget
Internet
3.1 Rancangan Penelitian
Pada penelitian ini, data
text mining
untuk klasifikasi yang digunakan adalah dokumen
online
dimana dalam pengklasifikasian dokumen ada 2 tahapan. Tahap pertama adalah
proses pembelajaran atau pelatihan terhadap sekumpulan dokumen dan tahap kedua
adalah proses klasifikasi dokumen yang belum diketahui kategorinya. Pada perancangan
pengklasifikasian ini proses pembentukan pengetahuan maupun klasifikasi akan
melewati proses
text mining
yang memiliki 3 tahapan, yaitu
text preprocessing,
texttransformation,
dan
pattern discovery.
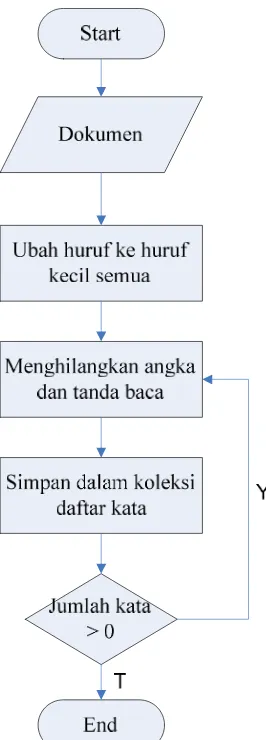
3.1.1 Perancangan
Text Preprocessing
Pada
preprocessing
, langkah-langkah yang akan dilakukan adalah
casefolding
, yaitu
mengubah semua huruf dalam teks menjadi huruf kecil. Kemudian dilakukan proses
parsing.
Parsing
yang digunakan adalah
parsin
g sederhana yaitu memecah sebuah teks
menjadi kumpulan kata-kata tanpa memperhatikan keterkaitan antar kata dan peran atau
kedudukannya dalam kalimat. Karakter yang diterima dalam pembentukan kata adalah
karakter huruf saja dan untuk angka dan tanda baca dihilangkan. Dengan demikian,
seperti kata ulang yang ada dalam kaidah bahasa Indonesia akan juga diurai menjadi
dua kata bukan satu kesatuan kata. Berikut diagram alir tentang proses
text
Gambar 3.1 Diagram Alir
Text Preprocessing
3.1.2 Perancangan
Text Transformation
22
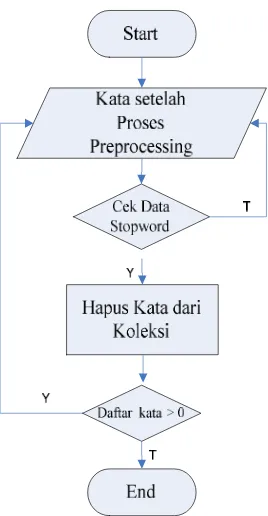
Gambar 3.2 Diagram Alir Penghilangan
Stopword
(
Filtering
)
3.1.3 Perancangan
Pattern Discovery
Pada penelitian ini, algoritma yang dipilih untuk digunakan dalam tahap
pattern
discovery
(pencarian pola) adalah algoritma
naïve bayes classifier
. Tahap ini terdiri dari
learn naïve bayes
dan
classify naïve bayes
.
Learn naïve bayes
berfungsi untuk
membentuk pengetahuan berupa probabilitas, sedangkan pada
classify naïve bayes
berfungsi untuk mengembalikan estimasi nilai target dari dokumen yang
diklasifikasikan.
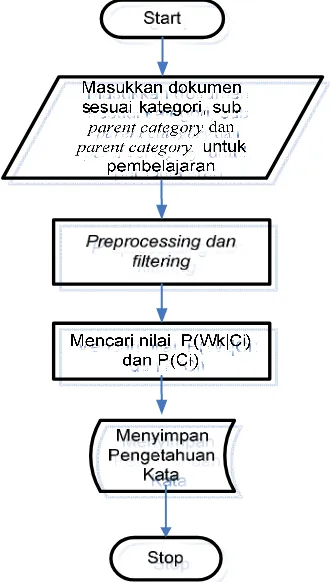
3.1.3.1
Learn Naïve Bayes
Pada tahap pembelajaran, serangkaian proses yang dilakukan adalah
1.
User
memasukkan teks dokumen yang akan dijadikan objek pembelajaran.
2.
User
menentukan kategori, sub
parent category
dan
parent category
dari teks
dokumen yang diinputkan.
4.
Untuk setiap kata yang dihasilkan, sistem akan mencari nilai (P(Wk|Ci)) dan
(P(Ci)).
[image:40.595.236.401.168.459.2]5.
Hasil penghitungan akan disimpan pada pengetahuan kata.
Berikut diagram alir dari pembelajaran sistem :
Gambar 3.3 Diagram Alir Proses
Learn Naïve Bayes
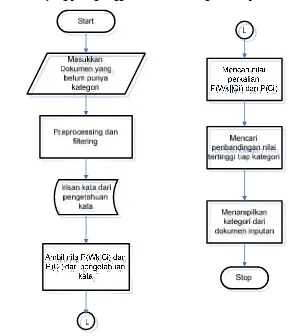
3.1.3.2
Classify Naïve Bayes
Selanjutnya pada tahap pengklasifikasian dokumen, proses yang dilakukan adalah:
1.
User
memasukkan teks dokumen yang ingin diklasifikasikan atau diketahui
kategorinya.
2.
Seperti pada tahap pembelajaran, sistem akan melakukan
processing
dan
filtering
pada teks dokumen untuk menghasilkan sekumpulan kata yang akan
diproses.
3.
Setiap kata yang dihasilkan disimpan dalam irisan kata dari pengetahuan kata.
4.
Sistem akan mengambil nilai (P(Wk|Ci)) dan (P(Ci)) dari pengetahuan kata.
24
6.
Kemudian membandingkan hasil probabilitas yang didapat antara kategori.
[image:41.595.163.452.138.474.2]7.
Kemudian sistem akan mengkategorikan dokumen tersebut berdasarkan nilai
probabilitas yang paling tinggi. Hasil akhir kategori di dapatkan.
Gambar 3.4 Diagram Alir Proses
Classify Naïve Bayes
3.1.4 Perancangan
User Interface
Sistem dibangun dengan desain
User interface
form atau antar muka yang memiliki dua
form inti, yang terdiri dari
interface
pembelajaran dan
interface
klasifikasi. Pada
interface
pembelajaran ini terdapat 4
parent category,
8 sub
parent category
dan 16
Gambar 3.
Interface
klasifikasi
mempunyai kategori. Melalui
perhitungan menggunakan algoritma
klasifikasi program.
Gambar 3.
Gambar 3.5 Rancangan Form Pembelajaran
klasifikasi juga terdapat area untuk menampilkan artikel yang belum
mempunyai kategori. Melalui
interface
ini
User
dapat mengetahui nilai hasil
perhitungan menggunakan algoritma
naïve bayes classification
dan kategori artikel hasil
Gambar 3.6 Rancangan Form Klasifikasi
26
3.2 Model Pengujian
Pengujian dilakukan untuk mengetahui akurasi dari klasifikasi yang dilakukan terhadap
dokumen. Pengujian dilakukan untuk dokumen yang bersumber dari situs berita yang
diambil sesuai dengan kategori terpilih. Di sini dokumen dibagi menjadi dua bagian.
Bagian pertama berperan sebagai data contoh yang akan digunakan dalam proses
pelatihan. Bagian kedua digunakan sebagai data pengujian untuk melihat tingkat
akurasi. Tingkat akurasi dihitung dengan menggunakan formula :
Akurasi =
100%
Hasil pengujian akan ditampilkan dalam bentuk grafik yang memperlihatkan hasil
eksperimen dengan berbagai proporsi data uji coba.
3.3 Instrumen Penelitian
Pada penelitian ini digunakan perangkat keras dan perangkat lunak sebagai berikut:
a.
Hardware (Core I3, memory 2 GB, Harddisk 640 GB, etc)
b.
Software bahasa pemrograman (Borland Delphi)
c.
Software
database
(MySQL)
3.4 Analisis Proses
Naive Bayes
[image:43.595.135.503.604.708.2]Pada penelitian ini, untuk mengetahui suatu dokumen bagian dari suatu kategori
dilakukan proses klasifikasi. Kemudian untuk menghasilkan kategori yang lebih tepat
proses ditambahkan dengan sub
parent category
dan
parent category
, sebagaimana
disajikan pada Tabel 3.2.
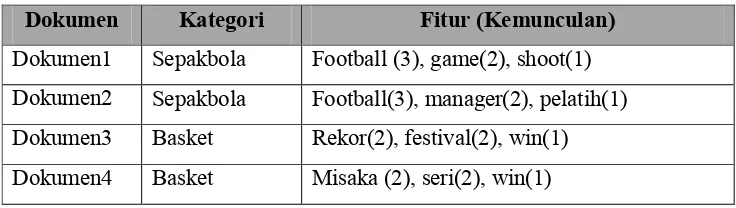
D
okumen5
Mobil
Suzuki(2), game(1), jepang(1)
Dokumen6
Mobil
Bus(2), Mercy(1), Rally(1)
Dokumen7
Motor
Rossy(2), sirkuit(1), win(1)
Dokumen8
Motor
Honda(2), sepang(1), malaysia(1)
Dokumen9
Gadget
Football(3), cyber(2), game(1)
Dokumen10
Gadget
Fitur(3), cyber(2), game(1)
Dokumen11
Komputer
World(2), cyber(2), media(1)
Dokumen12
Komputer
Line(2), cyber(2), dashboard(1)
Dokumen13 Kedokteran
Caesar(2), operasi(2), bayi(1)
Dokumen14
Kedokteran
Kanker(2), virus(2), penyakit(1)
Dokumen15
Umum
Galaxy(1), komet(1), planet(1)
Dokumen16
Umum
Arkeolog(1), fosil(1), ilmu(1)
Dokumen17
?
Football(1), media(1), manager(1), cyber(1)
Proses untuk mengetahui dokumen17 kategorinya berada dimana, maka
sebelumnya harus dipilih prediksi kategori untuk dokumen17 tersebut. Pada contoh
dimisalkan prediksi kategori dokumen17 adalah komputer. Untuk mencari kategori dari
dokumen17 dengan menggunakan
naive bayes
digunakan persamaan :
P(w
kj|c
i) =
(( ) | |. ),
denganf(w
kj.c
i) adalah nilai kemunculan kata w
kjpada kategori c
i, f(c
i) adalah jumlah
keseluruhan kata pada kategori c
idan |W| adalah jumlah keseluruhan kata/fitur yang
digunakan. Probabiltas kategori c
idihitung dengan menggunakan formula :
p(c
i) = | |( ),28
BAB 4
HASIL DAN PEMBAHASAN
Pada bab ini akan dijelaskan mengenai hasil penelitian yang dilakukan penulis terhadap
akurasi dari klasifikasi
naive bayes
dengan objek penelitian sebanyak 16 dokumen.
Pada sistem ini hanya terdapat satu aktor yaitu
user
. Ketika pertama kali menjalankan
sistem,
user
diharuskan melakukan pembelajaran sistem terlebih dahulu sesuai dengan
kebutuhan sistem,
user
dapat menginputkan dokumen yang telah diketahui kategorinya
dan melakukan proses pembelajaran. Selanjutnya
user
dapat melakukan klasifikasi
dokumen dengan meng-
input
-kan dokumen yang belum diketahui kategorinya dan
sistem mengklasifikasikan secara otomatis berdasarkan kategori yang ada.
User
interface
pada klasifikasi
naive bayes
ini terdiri dari beberapa
form
diantaranya
form
pembelajaran,
form
klasifikasi,
form
dokumen pembelajaran,
form
dokumen klasifikasi,
form
reset pembelajaran dan
form
reset klasifikasi.
4.1 Hasil Penelitian
Pada penelitian ini klasifikasi dokumen terdiri dari 4
parent category,
8 sub
parent
category
dan 16 kategori. Keempat
parent category
tersebut adalah ekonomi, olah raga,
hiburan dan teknologi. Untuk
parent category
ekonomi memuat sub
parent category
moneter dan bisnis dengan kategori properti, UKM, perbankan, industri.
Parent
category
olahraga memuat sub
parent category
bola dan balap dengan kategori
sepakbola, basket, mobil motor.
Parent category
hiburan memuat sub
parent category
entertain dan seni dengan kategori iinema, selebriti, musik, gaya hidup. Serta
parent
category
teknologi memuat sub
parent category
sains dan komputer dengan kategori
kedokteran, umum, komputer,
gadget
.
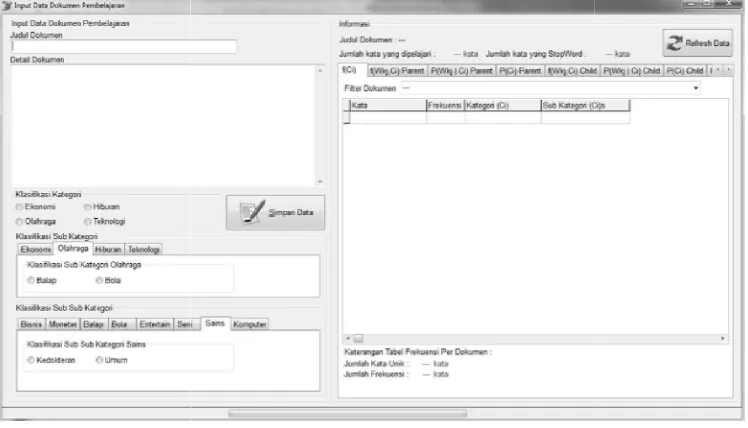
4.1.1 Input Data
Proses diawali dengan input data sebagai proses pembelajaran dengan memasukkan
dokumen pada form pembelajaran yang memiliki komponen-komponen yaitu :
2.
Teks Area detail dokumen berfungsi untuk menampilkan dokumen.
3.
Radio Button kategori dan sub kategori berfungsi untuk pemilihan kategori
berdasarkan kesesuaian file data latih.
4.
Tombol kalkulasi ulang berfungsi untuk memulai pemrosesan data untuk
pembelajaran yaitu
text preprocessing
,
text transformation, filtering, dan pattern
discovery
dengan menyimpan file pembelajaran di dalam folder di
direktory
.
5.
Tombol Simpan data berfungsi sama seperti tombol kalkulasi hanya tempat
penyimpanan file pembelajaran
user
yang memilih.
6.
Teks informasi berfungsi untuk menampilkan judul dokumen, jumlah kata yang
dipelajari, dan jumlah kata
stopword
.
[image:46.612.132.506.379.593.2]7.
Tabel berfungsi untuk menampilkan frekuensi perdokumen, frekuensi kata
perkategori, probabilitas kata perkategori, probabilitas dokumen perkategori,
frekuensi kata persubkategori, probabilitas kata persubkategori, dan probabilitas
dokumen persubkategori.
Gambar 4.1 Form Pembelajaran
Pada form klasifikasi terdapat komponen-komponen yaitu :
30
3.
Radio Button kategori dan sub kategori berfungsi untuk pemilihan kategori
berdasarkan kesesuaian file data latih.
4.
Tombol Simpan data berfungsi untuk memulai pemrosesan data untuk
pembelajaran yaitu
text preprocessing
,
text transformation, filtering, dan pattern
discovery
.
5.
Teks informasi berfungsi untuk menampilkan judul dokumen, jumlah kata yang
dipelajari, dan jumlah kata stopword.
[image:47.612.133.507.301.517.2]6.
Tabel berfungsi untuk menampilkan frekuensi perdokumen, probabilitas kata
perkategori, probabilitas dokumen perkategori, probabilitas kata persubkategori,
probabilitas dokumen persubkategori, hasil klasifikasi dan rincian proses.
Gambar 4.2 Form Klasifikasi
Pada form dokumen pembelajaran terdapat komponen-komponen sebagai berikut :
1.
Komponen filter kategori dan sub kategori
berfungsi untuk mempermudah
pemilihan kategori dan subkategori yang telah melakukan pembelajaran.
2.
Tabel daftar dokumen pembelajaran berfungsi untuk menampilkan judul
dokumen sesuai dengan kategori dan subkategori.
frekuensi kata persubkategori, probabilitas kata persubkateg