IMPLEMENTASI QUESTION ANSWERING SYSTEM PADA
DOKUMEN BAHASA INDONESIA MENGGUNAKAN
METODE N-GRAM
FANDI RAHMAWAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
IMPLEMENTASI QUESTION ANSWERING SYSTEM PADA
DOKUMEN BAHASA INDONESIA MENGGUNAKAN
METODE N-GRAM
FANDI RAHMAWAN
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
FANDI RAHMAWAN. Implementation of Question Answering System for Document in Bahasa Indonesia using N-Gram Method. Under direction of JULIO ADISANTOSO.
Recent development on Question Answering System (QAS) can accommodate language modeling mechanism for generating a better result. To develop the system, we use Indri Framework toolkit in order to obtain robust document structure andtext passages. Documents relevant to a question are first retrieved. The relevant documents are then divided into passages of 2 sentences each. In order to obtain candidate of answers, n-gram weighting is performed in the passage which is contained on the top document. The answer is identified based on matching annotations between the query and the document. One thousand documents and 40 queries are used in the experiment. The result of the experiment indicates 60% of correctness for who questions, 30% of correctness for how much/many questions, 90% of correctness for where question and 80% of correctness for when questions. Our results shows that we need to find ways to improve the effectiveness in finding correct answers, in particular, ways of reducing the number incorrect word tagging.
Judul Penelitian : Implementasi Question Answering System pada Dokumen Bahasa Indonesia Menggunakan Metode N-Gram
Nama : Fandi Rahmawan NRP : G64070043
Menyetujui:
Pembimbing
Ir. Julio Adisantoso, M.Kom NIP 19620714 198601 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP 19601126 198601 2 001
KATA PENGANTAR
Alhamdulilahirobbil’alamin, segala puji syukur penulis panjatkan kehadirat Allah SWT atas segala karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul Implementasi Question Answering System pada Dokumen Bahasa Indonesia dengan Menggunakan Metode N-Gram.
Penulis menyadari bahwa tugas akhir ini tidak akan terselesaikan tanpa bantuan dari berbagai pihak. Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada:
1. Orang tua tercinta, bapak Sumarsono dan ibu Tikke, kakak saya Rhino dan Rhini serta adik yang saya sayangi Fahri, yang selalu memberikan doa, nasihat, semangat, dukungan dan kasih sayang yang luar biasa kepada penulis sehingga dapat menyelesaikan tugas akhir ini.
2. Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing tugas akhir. Terima kasih atas kesabaran, bimbingan serta dukungan dalam penyelesaian tugas akhir ini.
3. Bapak Ahmad Ridha, S.Kom, M.S dan Ibu Karlina Khiyarin Nisa, S.Si, M.T. selaku dosen penguji tugas akhir.
4. Teman-teman satu bimbingan Aprilia Ramadhina, Devi Dian P, Agus Umriadi, Woro Indriani, Isna Mariam, Nova Maulizar, Nutri Rahayuni dan Ilkomerz 44 terima kasih atas kebersamaan dan semangatnya dalam menyelesaikan tugas akhir ini.
5. Dimpy Adira Ratu yang senantiasa memberikan semangat dan doa kepada penulis.
6. Seluruh staf Departemen Ilmu Komputer IPB yang telah banyak membantu baik selama penelitian maupun selama perkuliahan.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis berharap adanya masukan berupa saran atau kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini. Semoga tugas akhir ini bermanfaat.
RIWAYAT HIDUP
Fandi Rahmawan dilahirkan di kota Jakarta, pada tanggal 28 Juni 1989 dari pasangan Ibu Tikke Surtika dan Bapak Sumarsono. Pada tahun 2007 penulis lulus dari Sekolah Menengah Atas (SMA) Negeri 1 Bekasi.
iv
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... v
DAFTAR TABEL ... v
DAFTAR LAMPIRAN ... v
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup Penelitian ... 1
TINJAUAN PUSTAKA ... 2
Temu Kembali Informasi ... 2
Question Answering System ... 2
Indri ... 2
Indri Query Language ... 3
N-gram ... 3
METODE PENELITIAN ... 3
Gambaran Umum Sistem ... 3
Evaluasi Sistem ... 4
Asumsi ... 4
Lingkungan Implementasi ... 4
HASIL DAN PEMBAHASAN ... 5
Koleksi Dokumen Pengujian (corpus) ... 5
Pemrosesan Kueri ... 5
Pemrosesan Dokumen ... 6
Perolehan Top Document ... 6
Pembentukan Passages ... 6
Pemrosesan Passages ... 6
Pembobotan Passages ... 6
Perolehan Kandidat Jawaban ... 7
Perolehan Entitas Jawaban ... 7
Evaluasi Question Answering System ... 7
KESIMPULAN DAN SARAN ... 8
Kesimpulan ... 8
Saran ... 8
DAFTAR PUSTAKA ... 9
v
DAFTAR GAMBAR
1 Proses penulisan MemoryIndex ke dalam disk (DiskIndex) secara bertahap... 2
2 Ilustrasi language modeling kueri. ... 3
3 Gambaran umum sistem. ... 4
4 Format dokumen TRECTEXT dengan struktur tag XML. ... 5
5 Kalimat yang sudah diberi tag. ... 5
6 Konfigurasi pada IndriBuildIndex. ... 6
7 Bentuk array kalimat. ... 6
8 Pembentukan passage. ... 6
DAFTAR TABEL 1 Daftar pasangan kata tanya dan named entity ... 5
2 Perolehan skor passage ... 7
3 Persentase perolehan jawaban ... 7
4 Contoh dokumentasi kueri ... 8
5 Perolehan index hasil wordmatch ... 8
6 Perolehan index kandidat jawaban ... 8
7 Hasil perhitungan kandidat jawaban ... 8
DAFTAR LAMPIRAN 1 Hasil pengujian untuk pertanyaan SIAPA ... 11
2 Hasil pengujian untuk pertanyaan DIMANA ... 12
3 Hasil pengujian untuk pertanyaan KAPAN ... 13
1
PENDAHULUAN
Latar Belakang
Sistem temu kembali informasi sangat erat kaitannya dengan sistem pencarian (search engine). Kadang kala, informasi yang ditemukembalikan kurang relevan dengan kebutuhan pengguna. Saat ini pengembangan sistem pencarian menggunakan pertanyaan sebagai kueri sudah banyak dikembangkan, mendampingi sistem pencarian konvensional. Sistem ini dikenal dengan Question Answering System (QAS). Dengan adanya fitur kueri berupa pertanyaan, informasi yang dikembalikan dapat lebih relevan dan spesifik sesuai dengan kebutuhan pengguna.
QAS telah diimplementasikan pada beberapa penelitian. Riloff & Thelen (2000) telah mengembangkan QAS untuk menemukan jawaban dari kueri pertanyaan dalam sebuah dokumen yang menggunakan bahasa baku. Sementara Sianturi (2008) telah mengimplementasikan QAS dengan metode rule-based pada dokumen berbahasa Indonesia.
Faktor yang sangat menentukan kinerja QAS adalah mendapatkan dokumen atau passage yang tepat untuk digunakan dalam menjawab pertanyaan atau kueri. Langkah ini sangat dipengaruhi oleh metode pengindeksan dokumen. Oleh karena itu, telah banyak dilakukan penelitian untuk menentukan metode dan sistem pengindeksan, salah satunya adalah pengindeksan menggunakan framework Indri oleh Herdi (2010).
Donald Metzler et al. (2004) pada TREC 2004 menggunakan mesin pencari Indri untuk mengindeks koleksi dokumen berukuran 426 GB (25 juta dokumen) selama 6 jam. Donald Metzler et al. (2005) melanjutkan penelitiannya untuk menentukan seberapa efisien dan efektif mesin pencari Indri dalam menemukembalikan named page pada koleksi dokumen web. Hasil yang diperoleh menunjukkan bahwa dengan menggunakan
pseudo-relevance feedback dan dependece
modeling, Indri akan lebih efektif dalam menemukembalikan named page. Berbeda dengan penelitian yang dilakukan sebelumnya, Xing Yi dan James Allan (2007) melakukan penelitian untuk menguji kinerja dari mesin pencari Indri dalam
menangani kueri dalam jumlah yang besar pada dokumen web.
Dalam beberapa tahun terakhir, telah banyak riset tentang metode language
modeling untuk berbagai macam
pemrosesan bahasa alami, seperti QAS. Penelitian terbaru pada QAS dapat mengakomodasi mekanisme probabilistic untuk mendapatkan hasil yang lebih baik.
Metode N-gram banyak digunakan dalam berbagai penelitian sebagai jembatan antara information retrieval dan natural
language processing. Majumder et al.
(2002) menggunakan pendekatan N-gram untuk membangun aplikasi pendeteksi bahasa India.
Pada penelitan ResPubliQA (2009), hasil yang didapatkan menunjukkan bahwa terdapat korelasi yang kuat antara kata-kata yang bersifat bahasa alami pada pertanyaan dan jawaban pada passage. Metode N-gram dapat digunakan untuk memanfaatkan korelasi ini untuk mendapatkan hasil yang lebih baik (Sabnani & Majumder 2010).
Pada penelitian ini akan diterapkan proses pengindeksan dokumen dengan
framework Indri ke dalam dokumen
berbahasa Indonesia, dan diintegrasikan ke dalam sebuah sistem pencarian berbasis pertanyaan, dengan melakukan pembobotan N-gram untuk memperoleh passage dengan tingkat relevansi yang tinggi.
Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan pengindeksan dan metode pembobotan language modeling dari
framework Indri pada dokumen bahasa
Indonesia, serta mengimplementasikan metode N-gram dalam pembobotan
passages pada sistem temu kembali
informasi dengan menggunakan kueri pertanyaan (Question Answering) untuk dokumen berbahasa Indonesia.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah: 1. Menggunakan korpus dokumen Bahasa
Indonesia dengan struktur tag XML. 2. Kata tanya yang digunakan yaitu siapa,
dimana, kapan, dan berapa.
2
TINJAUAN PUSTAKA
Temu Kembali Informasi
Temu kembali informasi merupakan suatu proses yang meliputi representasi, penyimpanan, pengorganisasian, dan pengaksesan informasi. Sistem temu kembali informasi menyediakan kemudahan akses informasi bagi pengguna. Dalam pencarian suatu informasi pengguna harus menerjemahkan kebutuhan informasinya dalam bentuk kueri. Dengan adanya kueri yang diberikan pengguna, tujuan utama dari sistem temu kembali informasi adalah mengembalikan informasi yang relevan dengan kueri (Baeza-Yates & Ribeiro-Neto 1999).
Question Answering System
Question Answering System (QAS) merupakan kombinasi dari Information
Retrieval (IR) dengan Natural Language
Processing (NLP). Tujuan utama dari QAS adalah menampilkan jawaban atas pertanyaan yang diberikan pengguna. Ide utama QAS adalah (Lin 2004) :
- Menentukan tipe semantik jawaban yang diharapkan.
- Menentukan dokumen-dokumen yang memiliki kata kunci seperti pertanyaan. - Mencari entitas dengan tipe yang sesuai
dengan pertanyaan, yang memiliki kedekatan tinggi dengan kueri.
QAS mengekstrak jawaban dari koleksi teks dengan cara mengklasifikasi tipe jawaban yang diharapkan, kemudian QAS menggunakan kata kunci dari pertanyaan untuk mengidentifikasi kandidat jawaban untuk menentukan passage mana yang mengandung jawaban yang paling tepat (Harabagiu & Narayan 2004).
Indri
Indri merupakan suatu Application
Programming Interface (API) yang
digunakan untuk melakukan pengindeksan dan pencarian teks yang dapat diintegrasikan ke dalam sebuah aplikasi. Indri merupakan bagian dari proyek Lemur, yaitu sebuah kerja sama antara University of
Massachusetts dan Carnegie Mellon
University dalam pengembangan sistem temu-kembali informasi (Herdi 2010).
Indri dapat mengolah dokumen dalam berbagai format, seperti dokumen TREC
dengan format text, XML, HTML, dan dokumen plain text (Strohman 2005). Indri memiliki dua tipe pengindeksan yaitu
MemoryIndex dan DiskIndex. MemoryIndex
melakukan pengindeksan di dalam RAM sedangkan DiskIndex di dalam disk. Pada saat pembentukan tempat penyimpanan dari suatu koleksi dokumen teks (inverted index), Indri menambahkan dokumen yang masuk
ke MemoryIndex yang aktif. Ketika
dokumen tersebut masuk ke dalam MemoryIndex, maka akan dilakukan proses tokenisasi terhadap dokumen. Proses tokenisasi ini akan dilakukan sampai semua isi dokumen telah ditokenisasi sebelum menambahkan dokumen baru ke dalam MemoryIndex.
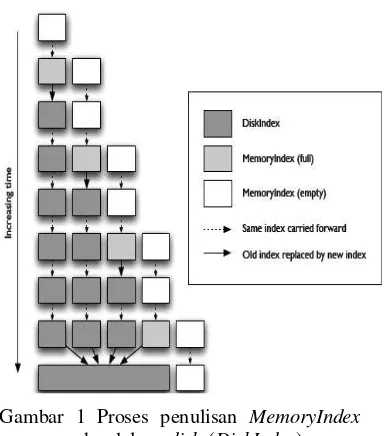
Untuk koleksi dokumen teks yang kecil, pengindeksan hanya dilakukan dalam MemoryIndex. Akan tetapi untuk koleksi yang besar MemoryIndex akan menuliskan hasil pengindeksannya ke dalam disk (DiskIndex) karena melebihi dari batas memori yang dimiliki. Pada saat penulisan ke dalam disk, MemoryIndex baru akan dibuat dan akan berfungsi sebagai active index yang siap melakukan pengindeksan terhadap dokumen selanjutnya. Proses penulisan ke dalam disk dapat dilihat pada Gambar 1.
Gambar 1 Proses penulisan MemoryIndex ke dalam disk (DiskIndex) secara bertahap.
3 keseluruhan informasi term (inverted index)
Indri menyimpannya dalam satu file yang terurut berdasarkan term tersebut (Strohman & Croft 2006).
Indri Query Language
Sistem temu kembali infromasi yang diimplementasikan di dalam mesin pencari Indri merupakan sebuah kombinasi dari metode language modeling dan inference network. Indri dilengkapi dengan Indri Query Language yang sangat berguna untuk memodelkan berbagai macam kebutuhan informasi. Indri Query Language dapat memodelkan kueri yang rumit, mencocokkan frase tertentu, mencari padanan suatu kata, membuat struktur indeks dokumen dan berbagai macam pemrosesan kata-kata yang bersifat bahasa alami lainnya (Strohman 2005).
Pada penelitian ini, operator dari Indri Query Language yang digunakan adalah #combine(x1 x2). Operator tersebut melakukan pemeringkatan dokumen berdasarkan kemunculan kueri x1 dan x2 (Sabnani & Majumder 2010).
Ilustrasi language modeling dengan menggunakan operator #combine pada kueri
„menteri pertanian‟ dapat dilihat pada
Gambar 2.
Gambar 2 Ilustrasi language modeling kueri.
Pada Gambar 2, node „menteri‟ dan
„pertanian‟ merupakan bagian dokumen (ri) yang dapat direpresentasikan dengan Indri
Query Language. Persamaan (1)
menunjukkan bobot (b) pada node ri.
(1)
dengan µ sebagai parameter smoothing, |D| sebagai jumlah kata dalam dokumen, dan C sebagai jumlah kata dalam koleksi dokumen keseluruhan (Strohman. 2005).
Persamaan (2) menunjukkan scoring function dari operator #combine (Sabnani dan Majumder 2010), yaitu
b#combine = (2)
Sebagai contoh #combine(menteri pertanian) = 0.5 log (b(menteri)) + 0.5 log (b(pertanian)).
N-gram
N-gram (Markov Chain) adalah rangkaian karakter (alfabet) atau kata yang diekstrak dari dari sebuah teks. N-gram dapat dibedakan menjadi dua kategori, yaitu basis karakter dan basis kata. Sebuah karakter N-gram merupakan rangkaian dari n karakter yang berurutan. Tujuan utama dibalik pendekatan ini adalah menentukan kata-kata yang mirip dengan rangkaian N-gram secara umum (Majumder et al. 2002).
Pada umumnya N-gram mengekstrak dokumen atau kata-kata menjadi dua atau tiga rangkaian yang terurut (sering disebut bigrams dan trigrams). Sebagai contoh susunan bigrams dari kata „computer‟ adalah
„CO‟, „OM‟, „MP‟, „PU‟, „UT‟, „TE‟, dan
„ER‟.
Persamaan (3) menunjukkan proses penghitungan skor tiap passage yang dilakukan dengan menjumlahkan semua kemungkinan x-gram yang cocok, dimana x
≤ jumlah kata pada kueri pertanyaan
N-gram sum = (3) maksimum dari semua kemungkinan N-gram adalah (n*(n+1)/2) (Sabnani & Majumder 2010). Jadi skor yang diperoleh oleh tiap passage ditunjukkan oleh persamaan (4).
N-gram score =
(4)
METODE PENELITIAN
Gambaran Umum Sistem
4 Dalam tahapan offline atau indexing,
proses pengindeksan dimulai dengan mengambil koleksi dokumen yang terdapat pada satu direktori kemudian dilakukan indexing terhadap dokumen dengan aplikasi IndriBuildIndex yang terdapat pada framework Indri. Dari hasil pengindeksan dilakukan pembentukan inverted index oleh Indri.
Untuk melakukan pencarian, pada kueri dilakukan proses parsing terlebih dahulu. Dari kueri tersebut diperoleh kata tanya yang akan digunakan dalam proses pencarian jawaban. Setelah kueri di-parsing, kemudian diolah menjadi kueri yang sesuai dengan format Indri Structured Query.
Gambar 3 Gambaran umum sistem.
Kueri yang dimasukkan secara manual oleh pengguna berupa kalimat pertanyaan. Kueri ini dianalisis untuk mengidentifikasi tipe dari pertanyaan tersebut sehingga dapat ditentukan named entity yang akan dicari untuk dapat menentukan kandidat jawaban.
Langkah selanjutnya adalah proses tokenisasi dan pembentukan Indri Structured Query untuk mendapatkan token-token kata yang akan digunakan untuk memperoleh dokumen teratas. Dokumen teratas ditentukan berdasarkan jumlah kata pada kueri yang terdapat pada dokumen. Pada dokumen teratas ini dilakukan pemisahan terhadap dua kalimat yang saling berdampingan yang disebut passage.
Langkah selanjutnya adalah proses filtering passages, yaitu dilakukan pencarian passages yang mengandung entitas sesuai dengan kueri atau pertanyaan. Pada passages yang diseleksi dilakukan proses pembobotan passages dengan metode N-gram. Langkah terakhir adalah mencari kandidat jawaban yang terdekat dengan kata-kata kueri yang berada dalam passage.
Evaluasi Sistem
Evaluasi QAS ini dilakukan dengan menghitung banyaknya kalimat jawaban yang ditemukembalikan dan banyaknya hasil yang benar maupun yang salah. Kinerja sistem akan semakin tinggi apabila banyak hasil yang dianggap benar. Setiap kueri bisa memiliki satu atau lebih kandidat jawaban atau tidak sama sekali. Terdapat tiga jenis penilaian yang dilakukan, yaitu:
1. Right : jawaban dan dokumen benar
2. Wrong : jawaban salah
3. Empty Answer : jawaban kosong karena
tidak ada kandidat jawaban yang memiliki format sesuai.
Asumsi
Asumsi-asumsi yang digunakan dalam pembangunan sistem ini adalah:
1.Tidak ada kesalahan dalam pengetikan kueri.
2.Setiap kata pada kueri dipisahkan oleh whitespace atau spasi.
3.Setiap kueri diawali oleh kata tanya (siapa, berapa, dimana, dan kapan). 4.Kueri berkaitan dengan koleksi dokumen.
Lingkungan Implementasi
Lingkungan implementasi yang digunakan adalah sebagai berikut :
Perangkat Lunak :
Sistem operasi Ubuntu 10.10 Webserver Apache (PHP5) Indri lemur toolkit versi 4.12
5
Perangkat Keras :
Processor AMD Athlon X2
RAM 1,5 GB
Harddisk dengan kapasitas 110 GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen Pengujian (corpus)
Dokumen uji yang digunakan memiliki struktur yang sama. Format dokumen yang digunakan berupa TRECTEXT. Contoh dokumen dengan format TRECTEXT dapat dilihat pada Gambar 4. Dokumen memiliki tag dengan fungsi yang berbeda-beda. Pada baris pertama terdapat tag <DOC> yang berfungsi membedakan satu dokumen dengan dokumen lainnya. Tag <DOCNO> menunjukkan nama dokumen, tag <TITLE> menunjukkan judul dari dokumen, tag <AUTHOR> menunjukkan penulis dari dokumen dan tag <TEXT> yang menunjukkan isi dari dokumen.
<DOC>
<P>Penyiangan jalur untuk prapemupukan (Mangoensoekarjo, 1990)</P>
</TEXT></DOC>
Gambar 4 Format dokumen TRECTEXT dengan struktur tag XML.
Pada dokumen uji dilakukan penamaan entitas (named entity) pada dokumen dengan menggunakan Named Entity Tagger bahasa Indonesia yang merupakan aplikasi hasil penelitian dari Citraningputra (2009). Penamaan entitas dilakukan untuk proses perolehan kandidat jawaban sesuai dengan jenis pertanyaan. Named entity yang digunakan terdiri atas NAME,
ORGANIZATION, LOCATION,
CURRENCY, DATE, TIME dan NUMBER.
Contoh hasil tagging dapat dilihat pada Gambar 5.
Menperindag <NAME> Rini Soewandi </NAME> menolak menaikkan tarif impor gula, sebab sekarang tarif impor sudah tinggi.
Gambar 5 Kalimat yang sudah diberi tag.
Pada Gambar 5 kata “Rini Soewandi” diberi penamaan entitas <NAME> karena kata ini memiliki peranan sebagai keterangan entitas nama pada kalimat. Langkah selanjutnya adalah menggabungkan 1000 dokumen ke dalam satu file. File tersebut menjadi dokumen korpus yang siap diindeks dengan bantuan Indri.
Pemrosesan Kueri
Proses parsing pada kueri diawali dengan proses case folding, yaitu membuat huruf pada teks menjadi kecil. Setelah itu, kata pada kueri dibersihkan dari kata-kata yang terdapat pada koleksi kata-kata stopwords. Kueri tersebut juga dibersihkan dari tanda baca. Hasil dari proses parsing disimpan dalam struktur data array pertanyaan. Pada array tersebut diperoleh kata tanya (pada indeks ke-0) yang akan digunakan untuk menemukembalikan tipe jawaban.
Proses selanjutnya adalah memformat kueri berdasarkan format dari framework Indri. Operator kueri yang digunakan yaitu #combine.
Pada penelitian kali ini kata tanya yang digunakan dibatasi dalam empat jenis, yaitu siapa, kapan, dimana dan berapa. Tabel 1 menunjukkan daftar pasangan jenis kata tanya dan named entity yang menjadi penciri dari jawaban yang akan ditemukembalikan. Tabel 1 Daftar pasangan kata tanya dan
named entity
No Kata
Tanya Named Entity Tag
6
Pemrosesan Dokumen
Dokumen yang telah berformat TRECTEXT dan sudah di-tagging akan digunakan dalam proses indexing sesuai dengan konfigurasi pada Gambar 6. Proses
indexing ini dilakukan dengan aplikasi
IndriBuildIndex, dan hasilnya akan disimpan dalam hash file. File ini akan digunakan untuk proses pencarian dokumen teratas. <parameters>
<class>trectext</class> </corpus>
<stopper>
/home/fandirahmawan/stopwords </stopper>
</parameter>
Gambar 6Konfigurasi pada IndriBuildIndex.
Perolehan Top Document
Proses ini dilakukan untuk mendapatkan dokumen dengan skor tertinggi yang akan digunakan untuk membentuk kalimat dan passage pada tahap selanjutnya. Kueri yang sudah diformat akan dijalankan terhadap indeks yang telah dibuat, kemudian dilakukan pembobotan dokumen oleh Indri dengan metode language modeling yang direpresentasikan dengan Indri Query Language. Dalam sistem ini, operator yang digunakan adalah #combine.
Kata pada kueri kecuali kata tanya akan dicocokkan dengan dokumen yang ada. Dokumen yang ditemukembalikan diurutkan dari dokumen dengan skor tertinggi sampai dengan skor terendah. Dokumen dengan skor tertinggi disimpan ke dalam array untuk proses selanjutnya.
Pembentukan Passages
Dokumen yang telah ditemukembalikan oleh Indri kemudian diproses menjadi kalimat. Kemudian pembentukan passages dilakukan dengan cara menggabungkan dua kalimat dari masing-masing dokumen, yaitu kalimat pada indeks sebelumnya dengan kalimat pada indeks sesudahnya. Dengan demikian, satu kalimat akan terdapat pada
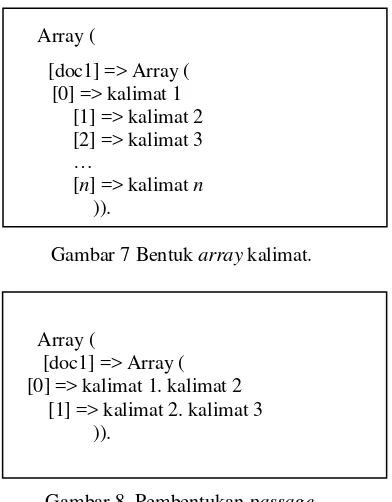
dua passages (hal ini tidak berlaku pada kalimat pertama dan terakhir). Gambar 7 adalah contoh dari arraykalimat yang selanjutnya dilakukan pembentukan passages pada sebuah dokumen (Gambar 8).
Array (
Gambar 7 Bentuk array kalimat.
Array (
[doc1] => Array ( [0] => kalimat 1. kalimat 2
[1] => kalimat 2. kalimat 3 )).
Gambar 8 Pembentukan passage.
Pemrosesan Passages
Passages yang diperoleh kemudian di-filter berdasarkan tag name entity yang sesuai dengan kata tanya. Misalnya kata
tanya “Siapa” maka passages yang diperoleh adalah yang mengandung tag ORGANIZATION atau PERSON. Kemudian passages yang telah diseleksi disimpan untuk proses selanjutnya.
Pembobotan Passages
Passages yang telah diseleksi kemudian diberi bobot atau skor dengan N-gram. Proses penghitungan skor tiap passage dilakukan dengan menjumlahkan semua kemungkinan x-gram yang cocok, dengan x
≤ jumlah kata pada kueri pertanyaan.
Kemudian hasil penjumlahan tersebut dibagi dengan jumlah atau skor maksimum dari kemungkinan N-gram.
7 Tabel 2 Perolehan skor passage
n n-gram word Ʃ
3 menteri pertanian indonesia 0
Total n-gram sum 3
n-gram score 3/6
Perolehan Kandidat Jawaban
Passage dengan bobot tertinggi akan dipilih sebagai Top Passage. Langkah selanjutnya adalah mencari kata-kata dalam tag yang sesuai dengan kata tanya. Semua daftar kandidat jawaban yang sesuai disimpan dalam suatu array untuk diproses pada tahap pengambilan entitas jawaban.
Perolehan Entitas Jawaban
Pada proses ini, hal yang pertama kali dilakukan adalah penyamaan format antara array kata tanya, array kata-kata dalam
passage, dan array kandidat jawaban.
Setelah itu, tiap kandidat jawaban dan pertanyaan yang terdapat dalam passage di simpan dalam array tersendiri dengan tetap mempertahankan indeks dari passage tersebut.
Langkah selanjutnya adalah menghitung jarak antara kata-kata pertanyaan yang terdapat pada passage dan kata-kata kandidat jawaban yang terdapat pada passage. Kandidat jawaban yang memiliki jarak terdekat dengan keseluruhan kata-kata pertanyaan, dipilih menjadi jawaban akhir dari sistem QAS ini.
Evaluasi Question Answering System Dalam tahapan evaluasi digunakan kueri berupa kalimat tanya. Kueri diuji merupakan kueri uji dari penelitian QAS Cidhy (2009). Kueri tersebut mewakili tipe pertanyaan siapa, kapan, dimana dan berapa. Dokumentasi keseluruhan kueri dapat dilihat pada Lampiran 1 sampai dengan Lampiran 4.
Tabel 3 Persentase perolehan jawaban
Kata perolehan untuk masing-masing jenis pertanyaan yang bersifat factoid. Pengambilan entitas jawaban dilakukan dengan penyamaan format antara kandidat jawaban dan kata-kata kandidat jawaban di dalam passage. Kata-kata yang mempunyai format dan isi sama akan menjadi kelompok kandidat jawaban yang akan diproses dalam penghitungan jarak untuk mencari jawaban akhir.
Pada Tabel 4, diberikan contoh pertanyaan yang memperoleh nilai benar, ini berarti jawaban dan dokumen yang ditemukembalikan oleh sistem sesuai dengan pasangan jawaban dan dokumen yang ditentukan oleh penulis sebelumnya. Tabel 5 menunjukkan indeks kata-kata kueri yang berada dalam passage, sedangkan Tabel 6 menunjukkan indeks kandidat jawaban yang berada pada passage. Pada Tabel 7 berisi perolehan nilai untuk masing-masing kandidat jawaban. Jawaban yang diambil adalah rata-rata jarak terkecil antara kata hasil wordmatch dengan kandidat jawaban, yaitu US 190 Juta.
Dalam penelitian Cidhy (2009) telah dilakukan pembuatan QAS dengan metode
Heuristic. Akurasi jawaban untuk
pertanyaan siapa 60%, berapa 30%, dimana 90%, dan kapan 100%. Pada penelitian ini terdapat jawaban yang unsupported yaitu jawaban yang ditemukan benar, tetapi dokumen tidak mendukung.
8 Tabel 4 Contoh dokumentasi kueri
No. Query Kandidat Jawaban Ket.
1 Berapa nilai ekspor produk tanaman rempah
tidak lolos seleksi adalah karena terdapat kesalahan proses name entity tagging yang dilakukan pada awal proses sistem indexing. Tabel 5 Perolehan index hasil wordmatch
Value Index
Tabel 6 Perolehan index kandidat jawaban
Value Index
US 190 Juta 35
US 20 Juta 42
US 15 Juta 56
Tabel 7 Hasil perhitungan kandidat jawaban
Value AnswerRate
US 190 Juta 13.44
US 20 Juta 16.44
US 15 Juta 28.89
Kelebihan dan Kelemahan Sistem
Kelebihan dari Question Answering System yang telah dibangun adalah sistem dapat menemukembalikan jawaban dalam bentuk factoid dengan metode N-gram, sehingga passage yang memiliki tingkat relevansi tinggi dapat ditemukembalikan.
Sistem ini memiliki kelemahan berikut : Pemberian tag pada kandidat jawaban menggunakan aplikasi tagging, sehingga tag pada dokumen tidak sempurna.
Penghitungan N-gram similarity belum menggunakan Dice Coefficient untuk mendapatkan kesamaan antara kueri dan passage yang lebih akurat.
Tidak dilakukan pengkajian semantic dalam penelitian ini. Contohnya adalah makna yang terdapat dalam hubungan antar kata dan struktur kalimat dalam suatu passage.
Jawaban yang diperoleh bukan informasi terkini karena tidak ada waktu yang menunjukkan kapan informasi atau berita dibuat.
KESIMPULAN DAN SARAN
Kesimpulan
Berdasarkan penelitian yang dilakukan dapat disimpulkan bahwa metode N-gram dapat diimplementasikan dalam pembobotan passages dalam sistem QAS untuk temu kembali pada dokumen berbahasa Indonesia. Dengan menerapkan fungsi indexing dari
framework Indri, proses indexing dapat
berjalan cepat dan efektif. Dengan melihat akurasi jawaban akhir QAS, perlu proses
name entity tagging dan pembentukan
format dokumen/korpus yang lebih baik.
Saran
Melihat pencapaian dari sistem yang sudah dibuat, ada beberapa hal yang harus ditambahkan atau diperbaiki untuk penelitian ke depan, antara lain menambahkan metode SVM, Bayesian Filter atau Levensthein Distance sebagai penyempurnaan dari metode N-gram, melakukan pengkajian semantik terhadap kata tanya (kueri), dan melibatkan field
timestamp agar jawaban yang diperoleh
9
DAFTAR PUSTAKA
Baeza-Yates R, Ribeiro-Neto B. 1999. Modern Information Retrieval. Addison-Wesley.
Cidhy DATK. 2009. Implementasi Question Answering System dengan Pembobotan
Heuristic. Skripsi. Bogor: Fakultas
Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Herdi H. 2010. Pembobotan Dalam Proses Pengindeksan Dokumen Bahasa Indonesia Menggunakan Framework Indri . Skripsi. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Lin J, 2004. An Introduction to Information Retrieval and Question Answering.
College of Information Studies.
University of Maryland.
Majumder et al. 2002. N-gram: a language independent approach to IR and NLP. India.
Metzler et al. 2004. Indri at Trec 2004: Terabyte Track. USA.
Narayan, Srini dan Sanda Harabagiu. 2004. Question Answering System Based on Semantic Structures.
Riloff E, Thelen M. 2000. A Rule-Based Question Answering System for Reading Comprehension Tests. ANLP / NAACL - 2000 Workshop on Reading Comprehension Tests as Evaluation for Computer Based Language Understanding System.
Sabnani H, Majmumder P. 2010. Question Answering System: Retrieving relevant passages. India
Sianturi RD. 2008. Implementasi Question
Answering System dengan Metode
Rule-Based pada Banyak Dokumen Berbahasa Indonesia. Skripsi. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Strohman T. 2005. Dynamic Collection in Indri. USA.
Strohman T, W. Bruce C. 2006. Low Latency Index Maintenance in Indri. USA.
11 Lampiran 1 Hasil pengujian untuk pertanyaan SIAPA
No Query Jawaban Keterangan
1 Siapa Asisten Sekretaris Daerah (Assekda) Bidang Kesejahteraan Rakyat Provinsi DIY?
Bambang Purnomo Right
2 Siapa Bambang Purnomo? Bambang Purnomo Wrong
3 Siapa Juru Bicara Departemen Luar Negeri Republik Indonesia?
Null Empty
Answer
4 Siapa Marty Natalegawa? Null Empty
Answer
5 Siapa menteri pertanian? Bungaran Saragih Right
6 Siapa yang bekerja sama dengan Unibraw untuk menangani pasca panen ikan?
Lembaga Kimia Nasional Right
7 Siapa Ketua Umum Dewan Pimpinan Pusat Himpunan Alumni Institut Pertanian Bogor?
Muwardi P Simatupang Right
8 Siapa gubernur DKI? Sutiyoso Right
9 Siapa Bungaran Saragih? Bungaran Saragih Wrong
10 Siapa menghasilkan penelitian tentang budi daya pisang dengan kultur jaringan?
12 Lampiran 2 Hasil pengujian untuk pertanyaan DIMANA
No Query Jawaban Keterangan
1 Dimana terjadi kekeringan dengan jumlah terbanyak?
Kulonprogo Wrong
2 Dimana dilakukan pengembangan tanaman jahe gajah secara besar-besaran?
Bengkulu Selatan Right
3 Dimana dilakukan peresmian Pencanangan Gerakan Tambahan Dua Juta Ton Jagung (Gentataton)?
Gorontalo Right
4 Dimana Bureau of Animal and Plant Health Inspection and Quarantine (BAPHIQ)?
Taiwan Right
5 Dimana Peter Allgeire menjadi deputi perwakilan dagang?
AS Right
6 Dimana kegiatan bongkar muat beras import dilakukan?
Pelabuhan Tanjung Perak Surabaya
Right
7 Dimana pengolahan sagu skala industri berkembang?
Maluku Right
8 Dimana unsur N diyakini sebagai kunci utama peningkatan produksi padi?
Kabupaten Barru Right
9 Dimana terjadi masalah sempitnya lahan pertanian, inefisiensi, produktivitas rendah, dan fluktuasi harga produk pertanian?
Indonesia Right
10 Dimana terjadi penurunan produksi tanaman tembakau?
13 Lampiran 3 Hasil pengujian untuk pertanyaan KAPAN
No Query Jawaban Keterangan
1 Kapan dilakukan penelitian di rumah kaca Balitro?
Null Empty
Answer
2 Kapan Malaysia menyatakan akan menindak tegas para pekerja asing?
Senin Right
3 Kapan Bungaran Saragih menyatakan kelangkaan pupuk diakibatkan adanya penyebaran yang terjadi secara sporadic?
Rabu Right
4 Kapan diadakan semiloka pengelolaan ekosistem pesisir?
31 Juli 2002 Right
5 Kapan dilakukan Penelitian secara on-farm adaptif pada dua lokasi di desa Nepo Kecamatan Mallusetasi, kabupaten Barru?
Agustus Right
6 Kapan pengaruh isu pertanian, kenaikan harga pangan,
mempengaruhi sejarah Indonesia?
1965 Right
7 Kapan perkenalan Warno dengan cacing?
1998 Right
8 Kapan WTO RIO DE JANERIO 20 negara dilaksanakan?
Null Empty
Answer
9 Kapan diadakan semiloka Pengembangan Kawasan Pantai sebagai alternatif akselerator pembangunan daerah?
31 Juli 2002 Right
10 Kapan dilaksanakan Konpernas Ekonomi Pertanian XIV dan Kongres XIII?
14 Lampiran 4 Hasil pengujian untuk pertanyaan BERAPA
No Query Jawaban Keterangan
1 Berapa harga jual untuk sapi dengan berat 250 kg?
Rp 3 juta Right
2 Berapa harga pemesanan kursi Rafles?
Null Empty
Answer
3 Berapa luas Kalimantan Timur? 330000 Wrong
4 Berapa luas areal sagu Malaysia? 5 Wrong
5 Berapa usia panen pertama kali lengkeng?
3 Wrong
6 Berapa luas areal sagu dunia? 6 Wrong
7 Berapa harga beras dalam negeri antara bulan Juni-Juli?
Rp 4000 Right
8 Berapa baku mutu COD sungai? 300 mg per liter Right
9 Berapa jumlah penduduk China? 5 Wrong
10 Berapa luas wilayah yang ditanami tanaman padi di Kalimantan Timur?