QUESTION ANSWERING
S
YSTEM
MENGGUNAKAN
N-GRAM
TERM WEIGHT MODEL
DEBBY PUSPA BAHRI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
QUESTION ANSWERING
S
YSTEM
MENGGUNAKAN
N-GRAM
TERM WEIGHT MODEL
DEBBY PUSPA BAHRI
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
i
ABSTRACT
DEBBY PUSPA BAHRI. Question Answering System Using N-Gram Term Weight Model. Supervised by SONY HARTONO WIJAYA.
Currently, search engine has been widely developed having question query feature known as the query answering system. The information provided by the system must fit a specific user requirement. This research will apply the passage selection method using n-gram term weighting model. The evaluation of the method is measured based on the set of questions and documents, and the accuracy for each answer. One thousand documents and 40 queries are used in this research. The result of the research indicates the accuracy for WHO questions is 90%, for WHEN questions is 80%, for WHERE questions is 80%, and for HOW MUCH/MANY questions is 40%.
Keywords: N-Gram, N-Gram Term Weight Model, QAS, Question Answering
vi Judul Skripsi : Question Answering System Menggunakan N-GramTerm Weight Model
Nama : Debby Puspa Bahri
NRP : G64096017
Menyetujui:
Pembimbing,
Sony Hartono Wijaya S.Kom., M.Kom NIP 198108092008121002
Mengetahui
Ketua Departemen Ilmu Komputer,
Dr. Ir. Agus Buono M.Si., M.Kom NIP 196607021993021001
vi
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah subhanahuwata’ala atas segala curahan rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul Question Answering System Menggunakan N-GramTerm Weight Model.
Penulis sadar bahwa tugas akhir ini tidak akan terselesaikan tanpa bantuan dari berbagai pihak. Pada kesempatan ini, penulis ingin mengucapkan terima kasih kepada:
1 Orang tua tercinta Bapak Syamsul Bahri dan Ibu Darmini Piliang atas segala doa, dukungan, dan kasih sayang yang tiada henti.
2 Bapak Sony Hartono Wijaya SKom MKom selaku dosen pembimbing tugas akhir. Terima kasih atas kesabaran dan dukungan dalam penyelesaian tugas akhir ini.
3 BapakFirman Ardiansyah SKom MSi dan Ahmad Ridha SKom MS selaku dosen penguji, Dr Ir Agus Buono MSi MKom selaku Ketua Departemen Ilmu Komputer IPB serta seluruh dosen dan staf Departemen Ilmu Komputer FMIPA IPB.
4 Mochammad Sudharmono atas segala bantuan, dukungan, dan doa.
5 Sahabat-sahabatku Mameto, Nina Maria, Anisah, Canma, Ai, dan seluruh teman-teman Ilmu Komputer angkatan IV. Terima kasih atas semangat dan kebersamaan selama penyelesaian tugas akhir ini.
6 Seluruh pihak yang turut membantu baik secara langsung maupun tidak langsung dalam pelaksanaan tugas akhir.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis berharap adanya masukan berupa saran dan kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini. Semoga tugas akhir ini bermanfaat.
Bogor, Juli 2013
Debby Puspa Bahri
vi
RIWAYAT HIDUP
Penulis dilahirkan di Kabanjahe pada tanggal 24 Agustus 1985. Penulis merupakan anak keenam dari enam bersaudara dari pasangan Bapak Syamsul Bahri dan Ibu Darmini Piliang. Penulis lulus dari SMU Negeri 1 Kabanjahe pada tahun 2003. Setahun kemudian, penulis melanjutkan pendidikannya di D3 Teknik Informatika, Departemen Ilmu Komputer, Institut Pertanian Bogor melalui program reguler. Tahun 2007 penulis lulus dari D3 Institut Pertanian Bogor. Penulis pernah melakukan praktik lapang di Biro Perencanaan dan Umum, Badan Koordinasi Survei dan Pemetaan Nasional (Bakosurtanal) dengan topik Sistem Informasi.
Pada tahun 2008 sampai 2011, penulis bekerja di sebuah perusahaan asing PT ExsaMap Asia sebagai 3D EditTechnician, Quality Control 3D Edit Technician, dan3D Road Technician. Pada tahun 2009, penulis melanjutkan pendidikan di Program Sarjana Alih Jenis Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
vi
DAFTAR ISI
Halaman
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA ... 1
Temu Kembali Informasi ... 1
Question Answering System ... 2
Pembobotan ... 2
Metode N-gram ... 2
Passage N-Gram Term Weight Model ... 3
METODE PENELITIAN ... 3
Pemrosesan Offline ... 3
Pemrosesan Online ... 4
Evaluasi Hasil Percobaan... 5
Lingkungan Pengembangan ... 5
HASIL DAN PEMBAHASAN ... 5
Koleksi Dokumen Pengujian... 5
Pemrosesan Dokumen ... 6
Indexing ... 6
Perhitungan tf-idf ... 6
Pembentukan Passages ... 6
Pemrosesan Query ... 6
Perolehan Dokumen Teratas ... 7
Perolehan Passages Top Documents ... 7
Ekstraksi dan Pembobotan N-gram pada Query ... 7
Pembobotan Passage ... 7
Ekstraksi Jawaban ... 7
Evaluasi Hasil Percobaan... 7
Hasil Percobaan Untuk Kata Tanya SIAPA ... 8
Hasil Percobaan Untuk Kata Tanya KAPAN ... 8
Hasil Percobaan Untuk Kata Tanya DI MANA ... 9
Hasil Percobaan Untuk Kata Tanya BERAPA ... 9
Hasil Percobaan Keseluruhan Kata Tanya Menggunakan Lima Dokumen Teratas ... 9
KESIMPULAN DAN SARAN ... 10
Kesimpulan ... 10
Saran ... 10
DAFTAR PUSTAKA ... 10
LAMPIRAN ... 12
vi
DAFTAR TABEL
Halaman
1 Ilustrasi matriks invertedindex ... 2
2 Rangkaian hasil n-gram ... 3
3 Daftar pasangan kata tanya dan namedentity ... 7
4 Perolehan bobot query n-gram ... 7
DAFTAR GAMBAR
Halaman 1 Kedekatan dokumen dalam ruang vektor (Manning 2008). ... 22 Alur pemrosesan offline... 3
3 Alur pemrosesan online. ... 4
4 Grafik hasil percobaan untuk kata tanya SIAPA... 8
5 Grafik hasil percobaan untuk kata tanya KAPAN. ... 8
6 Grafik hasil percobaan untuk kata tanya DI MANA. ... 9
7 Grafik hasil percobaan untuk kata tanya BERAPA... 9
8 Grafik hasil percobaan untuk semua kata tanya. ... 10
DAFTAR LAMPIRAN
Halaman 1 Antarmuka implementasi ... 132 Hasil percobaan untuk kata tanya „SIAPA‟ ... 14
3 Hasil percobaan untuk kata tanya „KAPAN‟ ... 15
4 Hasil percobaan untuk kata tanya „DIMANA‟ ... 16
PENDAHULUAN
Latar BelakangInformation Retrieval System (Sistem Temu Kembali Informasi) memiliki kaitan yang sangat erat dengan search engine (sistem pencarian). Saat ini sudah banyak dikembangkan search engine yang memiliki fitur query berupa pertanyaan atau yang sering dikenal dengan Question Answering System
misalnya www.ask.com. Pengguna memasukkan query berupa pertanyaan, bukan berupa kata atau kalimat saja. Informasi yang diperoleh pengguna diharapkan selain relevan juga lebih spesifik sesuai kebutuhan pengguna.
Penelitian tentang Question Answering System dalam perkembangannya sudah diimplementasikan oleh Ballesteros dan Xiaoyan-Li (2007) berupa Question Answering yang digunakan untuk bahasa Inggris dan Mandarin. Penelitian tersebut menggunakan pembobotan heuristic dan
syntactic untuk mengidentifikasi kandidat kalimat yang relevan. Cidhy (2009) mengimplementasikan penggunaan pembobotan heuristic yang dilakukan Ballesteros dan Xiaoyan-Li (2007) ke dalam dokumen berbahasa Indonesia.
Pada umumnya, passage retrieval hanya mengambil kata kunci utama pada pertanyaan dengan menghilangkan stopwords,sedangkan pada N-gram Term Weight Model, pengembalian passage berdasarkan pencarian struktur pertanyaan tanpa menghilangkan
stopwords pada query yang diberikan, tetapi memberikan bobot terkecil pada stopwords
tersebut, yaitu sebesar 0.001 (Buscaldi et al.
2009).
Penelitian tentang Question Answering System yang menggunakan pembobotan n-gram dalam pemilihan passage telah diimplementasikan Buscaldi et al. (2009). Penelitian tersebut membahas mengenai
Question Answering System berdasarkan redudansi dan metode Passage Retrieval.
Penelitian terkait mengenai n-gram juga telah dilakukan oleh Najibullah (2011). Penelitian ini membahas pencarian teks dalam berbahasa Arab dengan memanfaatkan metode n-gram untuk pengambilan kata dasarnya.
Metode n-gram juga telah digunakan dalam penelitian Rahmawan (2012). Proses n-gram pada penelitian Rahmawan ialah dengan menghitung skor tiap passage dan menjumlahkan semua kemungkinan x-gram
yang cocok dengan query pertanyaan.
Penelitian ini akan menerapkan pemilihan
passage menggunakan metode N-gram Term Weight Model pada Question Answering System dan menjadi acuan untuk penelitian berikutnya.
Tujuan Penelitian
Penelitian ini bertujuan:
1 Menerapkan pemilihan passage dengan menggunakan metode N-gram Term Weight Model pada Question Answering System.
2 Melakukan evaluasi terhadap Question Answering System yang menggunakan N-gram Term Weight Model.
Ruang Lingkup
Ruang lingkup dalam penelitian ini ialah:
1 Korpus terdiri atas kumpulan dokumen berbahasa Indonesia dengan struktur tag
XML diambil dari Laboratorium Temu Kembali Informasi, Departemen Ilmu Komputer IPB.
2 Menggunakan kata tanya siapa, kapan, di mana, dan berapa.
3 Query pertanyaan yang dimasukkan dibatasi pada tipe factoid question, yaitu pertanyaan yang memiliki jawaban tunggal.
4 Query berkaitan dengan koleksi dokumen. 5 Metode N-gram Term Weight Model
diimplementasikan pada query dan
passage.
6 Pasangan pertanyaan diambil dari query
uji pada penelitian Sanur (2011).
7 Pembobotan dan pemilihan kandidat jawaban pada ekstraksi jawaban mengikuti penelitian Sanur (2011).
8 Hasil dari penelitian dievaluasi menggunakan persepsi manusia.
TINJAUAN PUSTAKA
Temu Kembali InformasiTemu kembali informasi berkaitan dengan merepresentasikan, menyimpan, meng-organisasi, dan mengakses informasi. Representasi dan organisasi suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Dalam pencarian informasi, pengguna harus menerjemahkan kebutuhan informasinya dalam bentuk query. Berdasarkan query
Question Answering System
Question Answering System adalah sebuah sistem yang memungkinkan penggunauntuk bertanya dalam bahasa alami (natural language) pada koleksi dokumen yang tidak terstruktur dalam rangka mendapatkan jawaban yang diinginkan. Question Answering System merupakan kombinasi antara
Information Retrieval (IR) dan Natural Language Processing (NLP). Question Answering System memiliki tujuan menampilkan jawaban berdasarkan query
dalam bentuk pertanyaan yang diajukan oleh pengguna. Perbedaan yang mendasar antara
Question Answering dengan IR terletak pada masukan (query) dan keluaran yang dihasilkan.
Pada IR, query yang dimasukkan berupa kata atau kalimat pertanyaan dan keluaran yang dihasilkan ialah dokumen yang dianggap relevan oleh sistem, sedangkan pada Question Answering System, query berupa kalimat tanya dan keluarannya berupa jawaban (entitas) yang dianggap sesuai oleh sistem sehingga memungkinkan sistem tidak mengembalikan jawaban apapun.
Pembobotan
Information Retrieval pada dasarnya adalah pembandingan kata yang ada pada
query dengan kata yang ada pada dokumen. Perolehan kata tertentu dalam dokumen yang mengandung informasi yang berkaitan dengan
query, dilakukan dengan cara menghitung kesamaan antara vektor dokumen dan vektor
query. Informasi yang diperlukan adalah term frequency (tf), document frequency (df), dan
invers document frequency (idf).
Nilai tf menggambarkan frekuensi kemunculan suatu kata t dalam dokumen d, yang dilambangkan dengan tft,d. Nilai df
menggambarkan banyaknya dokumen di dalam koleksi yang mengandung kata tertentu. Nilai idf merupakan pembagian nilai dft dengan total dokumen yang ada dalam koleksi menghasilkan nilai idf untuk setiap kata sebagai berikut:
lo
N merupakan notasi untuk jumlah dokumen yang ada dalam koleksi. Melalui idf, dapat diketahui kata-kata tertentu yang merupakan penciri suatu dokumen. Dengan demikian, bobot untuk masing-masing kata dalam dokumen dapat diperoleh, yaitu wt,d
yang merupakan hasil perkalian antara tft,d dan
idft.
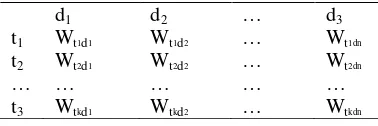
Tabel 1 menunjukkan ilustrasi matriks
inverted index, yang berisi bobot setiap kata t
dalam suatu dokumen d.
Tabel 1 Ilustrasi matriks invertedindex
d1 d2 … d3
t1 Wt1d1 Wt1d2 … Wt1dn
t2 Wt2d1 Wt2d2 … Wt2dn
… … … … …
t3 Wtkd1 Wtkd2 … Wtkdn
Ide untuk mengukur kesamaan dokumen dengan menggunakan kesamaan cosine adalah dokumen yang saling berdekatan dalam ruang vektor memiliki kecenderungan berisi informasi yang sama. Gambar 1 mengilustrasikan vektor dokumen yang terdapat dalam ruang vektor, yang diberi nilai oleh bobot kata.
Gambar 1 Kedekatan dokumen dalam ruang vektor (Manning et al. 2008).
Formula untuk memperoleh kesamaan
cosine untuk dj dan dk adalah:
sim | || |
Berdasarkan formula kesamaan cosine, dj dan dk adalah dokumen yang terdapat dalam ruang vektor M kata, dan M merupakan vektor bobot tiap dokumen. Dalam implementasi perolehan n dokumen teratas, hal serupa dilakukan untuk mengukur kesamaan antara vektor query dan dokumen. Dokumen diurutkan berdasarkan perolehan nilai cosine
dengan query. Kemudian dipilih n dokumen teratas dengan nilai cosine tertinggi.
Metode N-gram
diaplikasikan berupa kata. Metode n-gram ini digunakan untuk mengambil potongan kata sejumlah n dari sebuah kalimat yang secara kontinu dibaca dari teks awal hingga akhir dari dokumen. Tujuan utama dibalik pendekatan ini ialah menentukan kata-kata yang mirip dengan rangkaian n-gram secara umum (Majumder et al. 2002).
Seba ai contoh, “pen olahan sa u skala
industri berkemban ” menghasilkan rangkaian
n-gram yang dapat dilihat pada Tabel 2.
Tabel 2 Rangkaian hasil n-gram
N n-gram word(s) 2 pengolahan sagu 2 sagu skala 2 skala industri 2 industri berkembang 3 pengolahan sagu skala 3 sagu skala industri 3 skala industri berkembang 4 pengolahan sagu skala industri 4 sagu skala industri berkembang
5 pengolahan sagu skala industri berkembang
Passage N-Gram Term Weight Model
Kebanyakan dari sistem passage retrieval
terbaru tidak berorientasi pada masalah spesifik question answering karena question answering hanya mempertimbangkan kata kunci pertanyaan untuk mendapatkan bagian yang relevan, yaitu bagian yang memiliki jawaban yang benar.
Pada penelitian ini, passage akan digolongkan berdasarkan n-gram. Struktur n-gram dari setiap passage diekstraksi oleh fungsi ekstraksi n-gram. Hanya n-gram yang mengandung query yang diekstraksi.
Bobot dari tiap passage dihitung berdasarkan kesamaan antara query dan
passage n-gram term weight model. Nilai
similarity dari passage dengan query ialah lebih besar jika passage berbagi struktur n-gram lebih panjang dengan pertanyaan. Semakin besar nilai similarity, semakin tinggi
passage yang diperingkatkan oleh sistem. Berdasarkan penelitian Buscaldi et al. (2009), bagian penting dalam fungsi term
pada n-gram term weight model ada dua, yaitu:
1 Bobot dari term dari pertanyaan atau query
yang ditentukan oleh rumus:
w - lo lo n (1)
dengan nk adalah jumlah kalimat yang memiliki term K dan N adalah jumlah kalimat yang terdapat pada koleksi dokumen.
2 Fungsi h(x) mengukur bobot dari tiap n-gram dan didefinisikan sebagai:
h ∑w Penelitian ini dilakukan dalam tiga tahap, yaitu pemrosesan offline, pemrosesan online, dan evaluasi hasil percobaan.
Pemrosesan Offline
Pemrosesan offline terdiri atas tahap pengumpulan dokumen, praproses dokumen,
indexing dokumen, dan pembentukan
passages. Pemrosesan ini dilakukan untuk mendapatkan nilai tf-idf dan passage yang akan digunakan pada pemrosesan online. Hal ini dimaksudkan agar pemrosesan secara
online dapat dilakukan lebih cepat. Alur pemrosesan offline dapat dilihat pada Gambar 2.
Indexing
Praproses Dokumen
Pembentukan Passages Documents
Gambar 2 Alur pemrosesan offline.
Tahapan pemrosesan secara offline ialah:
1 Pengumpulan Dokumen
Koleksi dokumen uji dan daftar stopwords
diambil dari Laboratorium Temu Kembali Informasi, Departemen Ilmu Komputer IPB.
2 Praproses Dokumen
Pada tahap ini, dilakukan proses parsing
terhadap koleksi dokumen uji. Stopwords
pada koleksi dokumen uji tidak dihilangkan.
Proses indexing dokumen pada tahap ini menggunakan pembobotan tf-idf. Hasil
indexing berupa nilai idf dan tf-idf dari seluruh dokumen.
4 Pembentukan Passages
Sebelum passage dibentuk, terlebih dahulu dilakukan penamaan entitas pada koleksi dokumen pengujian. Penamaan entitas atau
tagging dilakukan secara otomatis menggunakan hasil penelitian dari Citrainingputra (2009). Entitas yang digunakan yaitu NAME, ORGANIZATION, DATE, LOCATION, NUMBER, dan CURRENCY. Pembentukan passage terdiri atas dua kalimat yang saling berdampingan.
Passage yang terbentuk akan digunakan pada pemrosesan secara online.
Pemrosesan Online
Alur pemrosesan online dapatdilihat pada Gambar 3.
Gambar 3 Alur pemrosesan online.
Tahapan pemrosesan secara online adalah:
1 InputQuery
Query berupa kalimat tanya yang diawali dengan kata tanya SIAPA, KAPAN, DI MANA, dan BERAPA.
2 Ekstraksi N-Gram dan Query N-Gram
Query yang dimasukkan akan dilakukan proses parsing terhadap kata tanya. Query
selain kata tanya kemudian diproses dengan menggunakan metode n-gram term weight model.
Pada tahap ini, dilakukan juga pemberian bobot terkecil pada stopwords sebesar 0.001 (Buscaldi et al. 2009). Hal ini dilakukan karena pada proses pembobotan n-gram, stopwords tidak dihilangkan untuk menjaga struktur dari query tersebut. Koleksi dokumen uji dan daftar stopwords diambil dari Laboratorium Temu Kembali Informasi, Departemen Ilmu Komputer IPB. Langkah selanjutnya ialah memberikan bobot per n-gram pada query yang diberikan. Pembobotan
n-gram pada query dihitung berdasarkan persamaan 1 dan 2.
3 Perolehan Lima Dokumen Teratas
Sistem akan mengembalikan lima dokumen teratas yang memiliki nilai kesamaan cosine tertinggi.
4 Passages
Kandidat passage diperoleh dari passages
yang terletak pada lima dokumen teratas.
5 N-Gram Comparison
Pada proses ini, akan dilakukan perhitungan terhadap nilai bobot kemiripan pada n-gram query dan n-gram passage yang dihasilkan oleh sistem. Passage yang diambil adalah passage yang memiliki nilai bobot kemiripan yang terbesar.
6 Ekstraksi N-Gram dan Passage N-Gram Term Weight Model
Perhitungan bobot pada passage terhadap
query akan dilakukan parsing terhadap
passage sesuai dengan jumlah n-gram pada
query. Mulai dari 1-gram hingga n-gram. Langkah selanjutnya ialah pembandingan antara kata pada query dan kata pada passage
yang dilakukan berdasarkan per n-gram
(1-gram query dibandingkan dengan 1-gram passage, dan seterusnya). Untuk tiap kesamaan kata yang diperoleh akan dijumlahkan nilai bobot per kata yang diperoleh pada bobot query sebelumnya yang ada pada passage sehingga masing-masing
passage akan memiliki bobot.
7 Re-ranked Passage
8 Ekstraksi Jawaban
Jawaban akhir diperoleh dengan menghitung jarak terdekat antara kandidat jawaban pada top passage dan kata-kata yang merupakan hasil pencocokkan dengan
keyword yang akan dihasilkan sebagai output.
Evaluasi Hasil Percobaan
Evaluasi Question Answering System
(QAS) ini dilakukan dengan melihat banyaknya kalimat jawaban yang ditemukembalikan dan banyaknya hasil yang bernilai benar maupun salah. Semakin banyak hasil yang benar, maka kinerja sistem semakin baik. Setiap query dapat memiliki satu atau lebih kandidat jawaban. Evaluasi dilakukan menurut persepsi manusia.
Pemberian nilai dilakukan berdasarkan empat kriteria, yaitu:
1 Wrong (W): jawaban tidak benar. 2 Right (R): jawaban dan dokumen benar. 3 Null: jawaban kosong karena tidak ada
kandidat jawaban yang memiliki format yang sesuai.
4 Unsupported: jawaban benar, tapi dokumen tidak mendukung.
Lingkungan Pengembangan
Perangkat keras notebook yang digunakan pada penelitian, yaitu:
1 Processor AMD X2 1.6 GHz. 2 RAM 2 GB.
3 Hard disk kapasitas 250 GB.
Perangkat lunak yang digunakan pada penelitian, yaitu:
1 Sistem operasi Windows 7 Ultimate. 2 Netbeans IDE 6.9
HASIL DAN PEMBAHASAN
Koleksi Dokumen PengujianDokumen uji yang digunakan ialah dokumen berbahasa Indonesia yang telah tersedia di Laboratorium Temu Kembali Informasi, Departemen Ilmu Komputer IPB. Secara umum, dokumen diberi nama berdasarkan sumber data dan tanggal data diterbitkan dengan ditambahkan nomor urut pada akhir, seperti gatra011102.txt yang berarti data berasal dari majalah Gatra dan diterbitkan pada tanggal 01 januari bulan
November 2002. Masing-masing dokumen uji berekstensi teks (*.txt) dan struktur XML di dalamnya. Dokumen memiliki tag dengan fungsi yang berbeda-beda. Pada baris pertama terdapat tag <DOC> yang berfungsi membedakan satu dokumen dengan dokumen lainnya. Tag <DOCNO> menunjukkan nama dokumen, tag <TITLE> menunjukkan judul dari dokumen, tag <AUTHOR> menunjukkan penulis dari dokumen dan tag <TEXT> yang menunjukkan isi dari dokumen. Berikut adalah contoh format struktur dokumen yang digunakan. <DATE> 1 November 2002 </DATE> <TEXT>
Selain industri kimia dan
parawisata, provinsi Banten juga
melirik agroindustri. Provinsi
pecahan Jawa Barat ini akan
mengembangkan `Agroindustrial
Park`, yaitu sebuah kawasan indutri
pengolahan hasil pertanian, di
Cilegon itu diungkapkan Gubernur
Banten, Dr Djoko Munandar, di
Serang, Jumat.
"Nantinya kawasan ini akan menjadi pusat pengolahan berbagai produk pertanian, walaupun bahan bakunya tidak hanya dipasok dari Banten, tetapi akan makin memacu kemajuan
pertanian di propinsi ini,"
katanya, seusai acara gelar wicara tentang upaya peningkatan produk
olahan dan pemasaran hasil
pertanian, di Aula Kantor
Gubernuran. </TEXT> </DOC>
Pada tahap indexing, pemrosesan dokumen hanya diambil bagian yang diapit oleh tag
<TITLE> dan <TEXT>, sedangkan untuk pembentukan passages, yang digunakan hanya bagian dokumen yang diapit oleh tag
<TEXT>. Berikut adalah menunjukkan ilustrasi bagian dokumen yang diproses.
<DOC>
<DOCNO> --- </DOCNO>
<TITLE> --- </TITLE>
<AUTHOR> --- </AUTHOR>
<DATE> --- </DATE>
<TEXT> --- </TEXT>
Pemrosesan Dokumen
Langkah pertama pada pemrosesan dokumen ialah penamaan entitas (named entity) yang disebut tagging pada dokumen uji dengan menggunakan hasil penelitian dari Citrainingputra (2009). Penamaan entitas dilakukan untuk proses perolehan kandidat jawaban sesuai dengan jenis pertanyaan. Penamaan entitas yang digunakan terdiri atas NAME, ORGANIZATION, LOCATION ,NUMBER, CURRENCY, DATE, dan TIME. Pada tahap ini, dilakukan dengan memasukkan satu per satu bagian dokumen yang diapit tag <TEXT> ke dalam sistem
name entity tagging (Citraningputra 2009). Selanjutnya, semua dokumen hasil tagging
kemudian disimpan dalam korpus. Berikut adalah contoh penggunaan tagging.
<ORGANIZATION>Ketua Umum Himpunan Kerukunan Tani Indonesia
(HKTI</ORGANIZATION>) <NAME>Siswono Yudo Husodo</NAME> menyatakan, jika bangsa
<LOCATION>Indonesia</LOCATION> tidak mampu mengelola daya saing pertanian dalam era pasar bebas <ORGANIZATION>ASEAN</ORGANIZATION> (<ORGANIZATION>AFTA</ORGANIZATION>) yang sudah berlaku per <DATE>1 Januari 2003</DATE> maka pertanian akan mengalami kehancuran bahkan jutaan petani juga kehilangan pekerjaan.
Langkah kedua ialah pembacaan terhadap isi file dari korpus. Pembacaan hanya berlaku pada isi file yang berada pada tag <TITLE> dan <TEXT>. Kemudian pada isi file tersebut dilakukan parsing dengan pemisah kata yang
terdiri atas tanda baca
[+\/%,.\"\];()\':=`?\[!@].\
Indexing
Proses indexing dilakukan dengan melakukan perhitungan tf-idf dengan mendapatkan nilai term frequency dengan memanfaatkan hasil pada tahap pemrosesan dokumen. Term frequency diperoleh dari pasangan dokumen dan hasil parsing dari masing-masing file disimpan dalam suatu
array pada variabel tf.Variabel ini digunakan untuk menghitung nilai df, idf, dan tf-idf setiap kata.
Perhitungan tf-idf
Langkah pertama melakukan perhitungan
tf-idf ialah mendapatkan nilai term frequency, dengan memanfaatkan hasil pada tahap pemrosesan dokumen. Term frequency
diperoleh dari pasangan dokumen dan hasil
parsing (token-token) dari masing-masing file
disimpan dalam suatu array pada variabel tf. Variabel ini digunakan untuk menghitung nilai df, idf, dan tf-idf setiap kata.
Langkah selanjutnya ialah mendapatkan
document frequency (df). Document frequency
adalah jumlah dokumen yang mengandung kata tertentu. Kemudian dari hasil tersebut dapat dihitung nilai invers document frequency (idf). Tujuan dari idf ialah untuk menentukan kata-kata (term) yang merupakan penciri dari suatu dokumen. Oleh karena itu, dalam penelitian ini hanya kata dengan nilai
idf lebih besar sama dengan 0.3 yang disimpan (Sanur 2011). Hal ini bertujuan menghapus kata-kata yang tidak termasuk dalam stopwords namun bukan penciri dari
Tahap awal pembentukan passage
dilakukan pembentukan kalimat untuk setiap dokumen dengan menggunakan tanda pemisah antar kalimat yaitu [.?!]. Setiap
passage dibentuk dari dua kalimat yang berurutan sehingga passage yang posisinya berdekatan saling overlap.
Pemrosesan Query memiliki kata stopwords akan diberikan bobot 0.001 (Buscaldi et al. 2009). Query tersebut juga dibersihkan dari tanda baca. Hasil dari proses parsing disimpan dalam struktur data
array pertanyaan. Pada array tersebut, diperoleh kata tanya (pada indeks ke-0) yang akan digunakan untuk menentukan tipe jawaban yang akan dikembalikan oleh sistem. Proses selanjutnya adalah parsing terhadap kalimat tanya dengan pemisah kata yang
terdiri atas tanda baca
[+\/%,.\"\];()\':=`?\[!@].
kata tanya dan named entity yang menjadi
1 Siapa NAME, ORGANIZATION 2 Kapan DATE
3 Di mana LOCATION
4 Berapa NUMBER, CURRENCY
Perolehan Dokumen Teratas
Dokumen yang digunakan untuk proses perolehan jawaban ialah lima dokumen dengan bobot kesamaan cosine tertinggi. Dengan memanfaatkan nilai idf dan tf-idf, dilakukan perolehan norm dari query dan dokumen. Query dimasukkan secara manual kemudian dilakukan perhitungan terhadap
norm query, tf-idf query, dan norm untuk setiap dokumen. Langkah selanjutnya ialah memasangkan nilai norm query dengan query
setiap dokumen untuk menghasilkan nilai dot product dan cosine. Setelah nilai cosine
diperoleh, dilakukan pengurutan nilai cosine. Dokumen yang diambil untuk memasuki langkah selanjutnya ialah lima dokumen dengan nilai cosine tertinggi.
Selanjutnya dilakukan pemilihan passage
pada kamus passage yang termasuk dalam lima dokumen teratas. Hasil pemilihan
passage ini disimpan akan digunakan pada tahap perolehan top passage.
Perolehan Passages Top Documents
Passage yang digunakan dalam proses pembobotan ialah passage yang mengandung
tag named entity yang dibutuhkan. Misalnya
“Siapa” yan men acu pada NAME dan
ORGANIZATION, “Dimana” yan men acu
pada LOCATION.
Selanjutnya passage yang disimpan akan disaring untuk diambil passage yang memiliki TAG sesuai kata tanya pada query pertanyaan. Selanjutnya dilakukan pembobotan n-gram
pada passage tersebut.
Ekstraksi dan Pembobotan N-gram pada
Query
Langkah pertama yang dilakukan pada ekstraksi n-gram ialah dengan mencari bobot masing-masing perkata (W) pada query
menggunakan pembobotan n-gram term weight model berdasarkan persamaan 1. Pembobotan n-gram pada query dihitung terhadap lima dokumen teratas yang telah
ditemukembalikan. Seba ai contoh, “Siapa
menteri pertanian Indonesia?”.
Langkah selanjutnya ialah menjumlahkan keseluruhan bobot tiap n-gram (h) berdasarkan persamaan 2. Sebagai contoh hasil perolehan bobot query n-gram dapat dilihat pada Tabel 4.
Tabel 4 Perolehan bobot query n-gram
n n-gram word(s) W
1 Menteri 0.679
1 Pertanian 0.541
1 Indonesia 0.569
2 Menteri pertanian 1.220 2 Pertanian Indonesia 1.110 3 Menteri pertanian Indonesia 1.789
H 6.143
Pembobotan Passage
Pembobotan terhadap passage
menggunakan metode n-gram term weight model, sama seperti pencarian bobot pada n-gram query. Langkah yang dilakukan ialah perhitungan perhitungan bobot kemiripan antara n-gram query dan n-gram passage
yang dihasilkan oleh sistem. Passage yang diambil ialah passage yang memiliki nilai bobot kemiripan yang terbesar. Passage yang mendapatkan nilai tertinggi akan dikembalikan sebagai top passage dari query
pertanyaan yang diberikan. Passage yang diambil ialah passage yang memiliki nilai bobot kemiripan yang terbesar.
Ekstraksi Jawaban
Proses selanjutnya ialah ekstraksi jawaban dari top passages yang diperoleh. Passage
yang memiliki bobot tertinggi pada pembobotan passage menjadi top passage. Kata yang menjadi kandidat jawaban ialah kata yang memiliki entitas sesuai dengan kata tanya pada query pertanyaan. Dalam perolehan entitas jawaban, yang perlu diperhatikan ialah top passage dapat terdiri atas dua passage dan passage dapat memiliki satu atau lebih kandidat jawaban.
Jawaban akhir setiap passage diperoleh dengan cara menghitung jarak antara setiap kandidat jawaban pada setiap passage dan masing-masing kata. Kandidat jawaban yang memiliki jarak terpendek dianggap sebagai jawaban yang paling tepat.
Evaluasi Hasil Percobaan
1 Pasangan jawaban dan dokumen (Responsiveness).
2 Ketepatan untuk setiap jawaban dari pertanyaan yang diberikan.
Berikut pembahasan untuk masing-masing percobaan:
Hasil Percobaan Untuk Kata Tanya SIAPA
Tampilan antarmuka dapat dilihat pada Lampiran 1. Berdasarkan sepuluh query
pertanyaan yang diuji, diambil contoh query
Siapa Asisten Sekretaris Daerah
(Assekda) Bidang Kesejahteraan Rakyat
Provinsi DIY? Top passage yang diperoleh
pada penelitian ini:
NUSANTARA YOGYAKARTA (Media):
Pertanian di <LOCATION> Daerah
Istimewa Yogyakarta (DIY)
</LOCATION> sama sekali tidak
terpengaruh oleh kekeringan.
<ORGANIZATION> Asisten Sekretaris
Daerah (Assekda) Bidang
Kesejahteraan Rakyat
</ORGANIZATION> Provinsi <LOCATION>
DIY </LOCATION> <NAME> Bambang
Purnomo </NAME> mengatakan hal
tersebut kepada Media di <LOCATION> Yogyakarta </LOCATION>, kemarin.
Top passage di atas diperoleh dari dokumen mediaindonesia270803.txt. Jawaban yang diperoleh dengan menggunakan pembobotan n-gram adalah Bambang Purnomo
dengan kriteria right.
Pembobotan n-gram term weight model
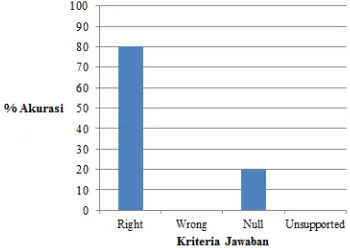
untuk kata tanya SIAPA menghasilkan persentase ketepatan jawaban untuk kriteria
right sebesar 90%, wrong 0%, null 10%,
unsupported 0%. Untuk kriteria null, disebabkan karena tidak ditemukannya kandidat jawaban pada passage.Daftar query
pertanyaan dan evaluasi untuk kata tanya SIAPA dapat dilihat pada Lampiran 2. Grafik hasil percobaan untuk kata tanya SIAPA dapat dilihat pada Gambar 4.
Gambar 4 Grafik hasil percobaan untuk kata tanya SIAPA.
Hasil Percobaan Untuk Kata Tanya KAPAN
Pada percobaan untuk kata tanya KAPAN, diambil contoh query Kapan dilakukan
penelitian di rumah kaca Balittro?Top
passage yang dikembalikan ialah sebagai berikut:
Untuk itu telah dilakukan penelitian di <LOCATION> rumah kaca Balittro Bogor </LOCATION> pada tahun <DATE> 1997/1998 </DATE> dan di lanjutkan penelitian di lapang di <LOCATION> IP Sukamulya (Sukabumi) </LOCATION> pada tahun <DATE> 1998/1999 </DATE>. Pada percobaan rumah kaca, tujuh jenis bakteri antagonis baik secara sendiri-sendiri maupun gabungan yang diformulasikan dalam suatu pembawa,
yaitu bakteri antagonis P~
Top passage tersebut diperoleh dari dokumen balaipenelitian000000-009. Jawaban yang diperoleh dengan menggunakan pembobotan n-gram adalah 1997/1998
dengan kriteria right.
Pembobotan n-gram term weight model
untuk kata tanya KAPAN menghasilkan persentase ketepatan jawaban untuk kriteria
right sebesar 80%, wrong 0%, null 20%, dan
unsupported 0%. Untuk kriteria null, dikarenakan tidak ditemukannya passage
yang sesuai. Daftar query pertanyaan dan evaluasi untuk kata tanya KAPAN dapat dilihat pada Lampiran 3. Grafik hasil percobaan untuk kata tanya KAPAN dapat dilihat pada Gambar 5.
Hasil Percobaan Untuk Kata Tanya DI MANA
Berdasarkan sepuluh query pertanyaan yang diuji, diambil contoh query pertanyaan
Di mana terjadi kekeringan dengan
jumlah terbanyak?. Hasil penelitian ini
mengembalikan top passage sebagai berikut:
Mereka yang terkena dampak
kekeringan khususnya pada
kebutuhan rumah tangga itu
terdapat di wilayah <LOCATION>
Kabupaten Gunungkidul
</LOCATION>, <LOCATION> Sleman,
dan Kulonprogo </LOCATION>.
Jumlah yang terkena kekeringan terbanyak di wilayah <LOCATION>
Kabupaten Gunungkidul
</LOCATION> yang mencapai lebih dari <NUMBER> 100 ribu jiwa </NUMBER>.
Top passage tersebut diperoleh dari dokumen mediaindonesia270803.txt. Jawaban yang diperoleh dengan menggunakan pembobotan n-gram adalah Sleman dan
Kulonprogo dengan kriteria wrong. Top
passage yang dikembalikan sudah benar tetapi kesalahan terjadi pada pemillihan kandidat jawaban. Kandidat yang dipilih ialah kandidat yang memiliki jarak terdekat.
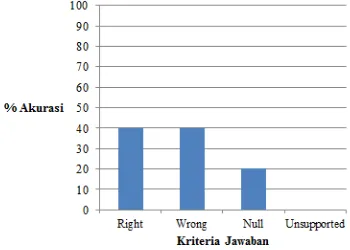
Pembobotan n-gram term weight model
untuk kata tanya DI MANA menghasilkan persentase ketepatan jawaban untuk kriteria
right sebesar 80%, wrong 20%, null 0%, dan
unsupported 0%. Kriteria wrong disebabkan oleh kandidat yang dipilih tidak sesuai dengan jawaban yang benar. Kandidat yang dipilih adalah kandidat dengan jarak terdekat dengan
query pada passage. Daftar query pertanyaan dan evaluasi untuk kata tanya DI MANA dapat dilihat pada Lampiran 4. Grafik hasil percobaan untuk kata tanya DI MANA dapat dilihat pada Gambar 6.
Gambar 6 Grafik hasil percobaan untuk kata tanya DI MANA.
Hasil Percobaan Untuk Kata Tanya BERAPA
Pada percobaan untuk kata tanya BERAPA, diambil contoh query pertanyan
Berapa harga jual untuk sapi dengan
berat 250 kg?. Top passage yang
dikembalikan adalah sebagai berikut:
Menurutnya, dengan berat sapi yang
dikembangkan hingga rata-rata
<NUMBER> 250 kg </NUMBER>, petani bisa menjualnya seharga <CURRENCY> Rp 3 juta-Rp 4 juta </CURRENCY>.
"Sementara harga standar yang
ditetapkan <ORGANIZATION> Dinas
Pertanian </ORGANIZATION>, untuk
pengembalian bantuan dana,
ditetapkan sebesar <CURRENCY> Rp 2,3 juta </CURRENCY>.
Top passage tersebut diperoleh dari dokumen gatra230103-002.txt. Jawaban yang diperoleh dengan menggunakan pembobotan n-gram adalah Rp 3 juta-Rp 4
juta dengan kriteria right.
Pembobotan n-gram term weight model
untuk kata tanya BERAPA menghasilkan persentase ketepatan jawaban untuk kriteria
right sebesar 40%, wrong 40%, null 20%, dan
unsupported 0%. Kriteria wrong disebabkan karena kandidat yang dipilih tidak sesuai dengan jawaban yang benar. Kandidat yang dipilih adalah kandidat dengan jarak terdekat dengan query pada passage,sedangkan untuk kriteria null, dikarenakan tidak ditemukannya
passage yang sesuai. Daftar query pertanyaan dan evaluasi untuk kata tanya BERAPA dapat dilihat pada Lampiran 5. Grafik hasil percobaan untuk kata tanya BERAPA dapat dilihat pada Gambar 7.
Gambar 7 Grafik hasil percobaan untuk kata tanya BERAPA.
Hasil Percobaan Keseluruhan Kata Tanya Menggunakan Lima Dokumen Teratas
MANA, dan BERAPA dapat dilihat pada Gambar 8. Hasil penelitian dengan pembobotan n-gram term weight model ini menghasilkan ketepatan jawaban untuk masing-masing kata tanya dengan kriteria
right sebesar 72.5%, wrong 15%, null 12.5%, dan unsupported 0%.
Gambar 8 Grafik hasil percobaan untuk semua kata tanya.
KESIMPULAN DAN SARAN
KesimpulanHasil penelitian menunjukkan metode n-gram Term Weight Model dapat diimplementasikan dalam pembobotan
passage dalam QAS dan dapat menemukembalikan passage yang mengandung kandidat jawaban benar dengan akurasi yang cukup tinggi, yaitu 72.5% secara keseluruhan dari semua kata tanya SIAPA, KAPAN, DI MANA, dan BERAPA. Semakin mirip struktur query dengan kalimat yang ada pada passage maka kemungkinan jawaban yang benar diperoleh dari passage tersebut akan semakin besar. Pemilihan kandidat jawaban menggunakan rataan jarak terpendek namun kandidat jawaban dengan rataan jarak terpendek belum tentu memiliki jawaban yang benar.
Saran
Untuk penelitian selanjutnya yang terkait dengan question answering system dengan metode n-gram term weight model disarankan untuk melakukan penelitian dengan:
1 Perbaikan pada proses ekstraksi jawaban dengan menggunakan metode ekstraksi jawaban yang lain misalnya metode yang digunakan oleh Murata et al. (2005). 2 Menggunakan metode lain dalam proses
indexing agar kinerja pencarian diperoleh lebih cepat.
3 Melengkapi n-gram term weight model
dengan penambahan Distance Model pada pembobotan passage.
4 Perlu dilakukan perbaikan metode perolehan jawaban secara semantik dengan POS-Tagging untuk mengidentifikasi jenis kata.
DAFTAR PUSTAKA
Baeza-Yates R, Ribeiro-Neto B. 1999.
Modern Information Retrieval. New York. ACM Press. Departement, Mount Holyoke College. hlm 230-233.
Buscaldi D, Sanchis E, Gómez JM, Rosso P, Soriano. 2009. Answering question with n-gram based passage retrieval engine. Intelligent Information System 34:113-134.
Chaudhuri BB, Mitra M, Majumder P. 2002. N-gram: a language independent approach to IR and NLP. Di dalam: International conference on universal knowledge and language. Goa, India. 25-29 November 2002.
Cidhy DATK. 2009. Implementasi question answering system dengan pembobotan heuristic [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Citraningputra P. 2009. Entitas tagging untuk dokumen berbahasa indonesia menggunakan metode berbasis aturan [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Manning CD, Raghavan P, Schütze H. 2008.
Introduction to Information Retrieval. Cambridge: Cambridge University Press.
Najibullah A. 2011. Implementasi n-gram
dalam pencarian teks sebagai penunjang aplikasi perpustakaan kitab berbahasa Arab [skripsi]. Surabaya: Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember.
Rahmawan F. 2012. Implementasi question answering system pada dokumen berbahasa indonesia menggunakan n-gram
[skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Sanur SA. 2011. Pemilihan passage dalam
Lampiran 2 Hasil percobaan untuk kata tanya „SIAPA‟
No Query Jawaban Keterangan
1 Siapa Asisten Sekretaris Daerah (Assekda) Bidang Kesejahteraan Rakyat Provinsi DIY?
Bambang Purnomo R
2 Siapa Bambang Purnomo? Asisten Sekretaris Daerah Assekda
Bidang Kesejahteraan Rakyat R
3 Siapa Juru Bicara Departemen Luar Negeri
Republik Indonesia? Marty Natalegawa R
4 Siapa Marty Natalegawa? Juru Bicara Departemen Luar
Negeri Republik Indonesia R
5 Siapa menteri pertanian? Bungaran Saragih R
6 Siapa yang bekerja sama dengan Unibraw
untuk menangani pasca panen ikan? lembaga kimia nasional R
7 Siapa Ketua Umum Dewan Pimpinan Pusat
Himpunan Alumni Institut Pertanian Bogor? Muwardi P Simatupang R
8 Siapa Prof. Dr Ir Naik Sinukaban MSc Null N
9 Siapa Bungaran Saragih? Menteri Pertanian R
10 Siapa menghasilkan penelitian tentang budi
daya pisang dengan kultur jaringan? Unibraw R
Lampiran 3 Hasil percobaan untuk kata tanya „KAPAN‟
No Query Jawaban Keterangan
1 Kapan dilakukan penelitian di rumah kaca Balittro? 1997/1998 R
2 Kapan Malaysia menyatakan akan menindak tegas para
pekerja asing? Null N
3
Kapan Bungaran Saragih menyatakan kelangkaan pupuk diakibatkan adanya penyebaran yang terjadi secara sporadic?
Null N
4 Kapan diadakan semiloka pengelolaan ekosistem pesisir? 31 Juli 2002 R
5
Kapan dilakukan Penelitian secara on-farm adaptif pada dua lokasi di desa Nepo Kecamatan Mallusetasi, kabupaten Barru?
Agustus sampai
nopember 2000 R
6 Kapan pengaruh isu pertanian, kenaikan harga pangan,
mempengaruhi sejarah Indonesia? 1965 R
7 Kapan perkenalan Warno dengan cacing? 1998 R
8 Kapan WTO RIO DE JANERIO 20 negara dilaksanakan? 10-14 September
2003 R
9 Kapan diadakan semiloka Pengembangan Kawasan Pantai
sebagai alternative akselerator pembangunan daerah? 31-Jul-02 R
10 Kapan dilaksanakan Konpernas Ekonomi Pertanian XIV
dan Kongres XIII? senin 17/5 R
Lampiran 4 Hasil percobaan untuk kata tanya „DIMANA‟
No Query Jawaban Keterangan
1 Di mana terjadi kekeringan dengan jumlah terbanyak? Kulonprogo W
2 Di mana dilakukan pengembangan tanaman jahe gajah secara besar-besaran?
Kabupaten Rejang
Lebong R
3 Di mana dilakukan peresmian Pencanangan Gerakan Tambahan Dua Juta Ton Jagung (Gentataton)?
Dunggalan,Tibawa,
Gorontalo R
4 Di mana Bureau of Animal and Plant Health
Inspection and Quarantine (BAPHIQ)? Taiwan R
5 Di mana Peter Allgeire menjadi deputi perwakilan
dagang? AS R
6 Di mana kegiatan bongkar muat beras import dilakukan?
Pelabuhan Tanjung
Perak Surabaya R
7 Di mana pengolahan sagu skala industry berkembang? Maluku R
8 Di mana unsure N diyakini sebagai kunci utama
peningkatan produksi padi? Sulawesi Selatan R
9
Di mana terjadi masalah sempitnya lahan pertanian, inefisiensi, produktivitas rendah, dan fluktuasi harga produk pertanian?
Indonesia R
10 Di mana terjadi penurunan produksi tanaman
tembakau? Perkebunan Inti Rakyat W
Lampiran 5 Hasil percobaan untuk kata tanya „BERAPA‟
No Query Jawaban Keterangan
1 Berapa harga jual untuk sapi dengan berat 250 kg? Rp 3 juta-Rp 4
juta R
2 Berapa harga pemesanan kursi Rafles? Rp 275 ribu/unit R
3 Berapa luas Kalimantan Timur? 24.5 juta hektar R
4 Berapa luas areal sagu Malaysia? 51.3% W
5 Berapa usia panen pertama kali lengkeng? Null N
6 Berapa luas areal sagu dunia? 51.3% W
7 Berapa harga beras dalam negri antara bulan Juni-Juli? Null N
8 Berapa luas areal sagu Indonesia? 1 128 juta ha R
9 Berapa jumlah penduduk China? 210 juta W
10 Berapa luas wilayah yang ditanami tanaman padi di Kalimantan Timur?
24.5 juta hektar
W